对于python-threading多线程setDaemon和join的区别感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python多线程join函数,并为您提供关于Thread.setDa
对于python - threading 多线程 setDaemon 和 join 的区别感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍python 多线程join函数,并为您提供关于 Thread.setDaemon 详解、Java中User Thread和Daemon Thread的区别、Python (多线程 threading 模块)、python threading queue模块中join setDaemon及task_done的使用方法及示例的有用信息。
本文目录一览:- python - threading 多线程 setDaemon 和 join 的区别(python 多线程join函数)
- Thread.setDaemon 详解
- Java中User Thread和Daemon Thread的区别
- Python (多线程 threading 模块)
- python threading queue模块中join setDaemon及task_done的使用方法及示例
")
python - threading 多线程 setDaemon 和 join 的区别(python 多线程join函数)
#! /usr/bin/env python
"""
python 多线程的管理机制
"""
__author__ = ''sallency''
import threading
import time
#封装一个线程包的类
class MyThread(threading.Thread):
def __init__(self, name, count, interval):
threading.Thread.__init__(self)
self.name = name
self.count = count
self.interval = interval
self.stop = False
def run(self):
while not self.stop:
print "thread: %s count %d time %s" % (self.name, self.count, time.ctime())
time.sleep(self.interval)
self.count += 1
def stop(self):
self.stop = True
#任务
def task():
thr_1 = MyThread(''thread_1'', 10, 3)
thr_2 = MyThread(''thread_2'', 5, 3)
#如果这里设为true的话 则主线程执行完毕后会将子线程回收掉
#默认是 false 则主进程执行结束时不会回收子线程
thr_1.setDaemon(True)
thr_2.setDaemon(True)
thr_1.start()
thr_2.start()
#join则是阻塞主线程 让其在子线程执行完毕后方可继续执行
#这就保证了当主线程执行完毕前,所有的子线程一定执行完毕了
#thr_1.join()
#thr_2.join()
return True
if __name__ == "__main__":
print "main threading start: %s" % (time.ctime())
task()
print "main threading end: %s" % (time.ctime())python 可以方便的使用 threading 包来实现多线程
线程对象有两个用来管理线程机制的方法: setDaemon 和 join
主线程启动若干个子线程后,可以继续执行主线程的代码,也可以等待所有的子线程执行完毕后继续执行主线程,这里需要用到的就是 join 方法,子线程通过调用 join 可以告诉主线程,你必须等着我,我完事了你才可以再往下执行。
这里要理解,比如 子线程1 花费 10秒,子线程2 花费 5秒,如果子线程 2 调用了 join,那么 主线程只会等待用时 5秒 的子线程2 执行完毕,会继续向下执行,而不会等待还需要5秒才能执行完毕的子线程1
所以如果需要所有的子线程都能在主线程结束前被执行完毕,则必须为每一个子线程都注册 join
如果没有为子线程注册 join,则可能会出现在主线程执行完毕之前,还有很多子线程没有执行完毕,这时如果你为子线程注册了 setDaemon(True) 的话,主线程会回收此子线程;否则,主线程就不管他了,自己结束了,子线程依旧在那执行。默认是 False,也就说主线程不会回收子线程
setDaemon
setDaemon() : 设置此线程是否被主线程守护回收。默认False不回收,需要在 start 方法前调用;设为True相当于像主线程中注册守护,主线程结束时会将其一并回收
join
join(): 设置主线程是否同步阻塞自己来待此线程执行完毕。如果不设置的话则主进程会继续执行自己的,在结束时根据 setDaemon 有无注册为守护模式的子进程,有的话将其回收,没有的话就结束自己,某些子线程可以仍在执行

Thread.setDaemon 详解
java 中线程分为两种类型:用户线程和守护线程。通过 Thread.setDaemon (false) 设置为用户线程;通过 Thread.setDaemon (true) 设置为守护线程。如果不设置次属性,默认为用户线程。
用户线程和守护线程的区别:
1. 主线程结束后用户线程还会继续运行,JVM 存活;主线程结束后守护线程和 JVM 的状态又下面第 2 条确定。
2. 如果没有用户线程,都是守护线程,那么 JVM 结束(随之而来的是所有的一切烟消云散,包括所有的守护线程)。
补充说明:
定义:守护线程 -- 也称 “服务线程”,在没有用户线程可服务时会自动离开。
优先级:守护线程的优先级比较低,用于为系统中的其它对象和线程提供服务。
设置:通过 setDaemon (true) 来设置线程为 “守护线程”;将一个用户线程设置为守护线程的方式是在线程启动用线程对象的 setDaemon 方法。
example: 垃圾回收线程就是一个经典的守护线程,当我们的程序中不再有任何运行的 Thread, 程序就不会再产生垃圾,垃圾回收器也就无事可做,所以当垃圾回收线程是 JVM 上仅剩的线程时,垃圾回收线程会自动离开。它始终在低级别的状态中运行,用于实时监控和管理系统中的可回收资源。
生命周期:守护进程(Daemon)是运行在后台的一种特殊进程。它独立于控制终端并且周期性地执行某种任务或等待处理某些发生的事件。也就是说守护线程不依赖于终端,但是依赖于系统,与系统 “同生共死”。那 Java 的守护线程是什么样子的呢。当 JVM 中所有的线程都是守护线程的时候,JVM 就可以退出了;如果还有一个或以上的非守护线程则 JVM 不会退出。
例子代码:
import java.io.IOException; class TestMain4 extends Thread { public void run() { //永真循环线程 for(int i=0;;i++){ try { Thread.sleep(1000); } catch (InterruptedException ex) { } System.out.println(i); } } public static void main(String [] args){ TestMain4 test = new TestMain4(); test.setDaemon(true); //调试时可以设置为false,那么这个程序是个死循环,没有退出条件。设置为true,即可主线程结束,test线程也结束。 test.start(); System.out.println("isDaemon = " + test.isDaemon()); try { System.in.read(); // 接受输入,使程序在此停顿,一旦接收到用户输入,main线程结束,守护线程自动结束 } catch (IOException ex) {} } }

Java中User Thread和Daemon Thread的区别
Java将线程分为User线程和Daemon线程两种。通常Daemon线程用来为User线程提供某些服务。程序的main()方法线程是一个User进程。User进程创建的进程为User进程。当所有的User线程结束后,JVM才会结束。
通过在一个线程对象上调用setDaemon(true),可以将user线程创建的线程明确地设置成Daemon线程。例如,时钟处理线程、idle线程、垃圾回收线程、屏幕更新线程等,都是Daemon线程。通常新创建的线程会从创建它的进程哪里继承daemon状态,除非明确地在线程对象上调用setDaemon方法来改变daemon状态。
需要注意的是,setDaemon()方法必须在调用线程的start()方法之前调用。一旦一个线程开始执行(如,调用了start()方法),它的daemon状态不能再修改。通过方法isDaemon()可以知道一个线程是否Daemon线程。
通过执行下面的代码,可以很清楚地说明daemon的作用。当设置线程t为Daemon线程时,只要User线程(main线程)一结束,程序立即退出,也就是说Daemon线程没有时间从10数到1。但是,如果将线程t设成非daemon,即User线程,则该线程可以完成自己的工作(从10数到1)。
import static java.util.concurrent.TimeUnit.*;
public class DaemonTest {
public static void main(String[] args) throws InterruptedException {
Runnable r = new Runnable() {
public void run() {
for (int time = 10; time > 0; --time) {
System.out.println("Time #" + time);
try {
SECONDS.sleep(2);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
};
Thread t = new Thread(r);
t.setDaemon(true); // try to set this to "false" and see what happens
t.start();
System.out.println("Main thread waiting...");
SECONDS.sleep(6);
System.out.println("Main thread exited.");
}
}t为Daemon线程的输出:
Main thread waiting...
Time #10
Time #9
Time #8
Main thread exited.
Time #7
t为User线程的输出:
Main thread waiting...
Time #10
Time #9
Time #8
Main thread exited.
Time #7
Time #6
Time #5
Time #4
Time #3
Time #2
Time #1
")
Python (多线程 threading 模块)
day27
参考:http://www.cnblogs.com/yuanchenqi/articles/5733873.html
CPU 像一本书,你不阅读的时候,你室友马上阅读,你准备阅读的时候,你室友记下他当时页码,等下次你不读的时候开始读。
多个线程竞争执行。
进程:A process can have one or many threads. 一个进程有多个线程。
一个线程就是一堆指令集合。
线程和进程是同样的东西。
线程是操作系统能够进行运算调度的最小单位。它被包含在进程之中,是进程中的实际运作单位。
1 import time
2 import threading
3
4 begin = time.time()
5 def foo(n):
6 print(''foo%s''%n)
7 time.sleep(1)
8
9 def bar(n):
10 print(''bar%s''%n)
11 time.sleep(2)
12
13
14 # foo()
15 # bar()
16 # end = time.time()
17
18 #并发,两个线程竞争执行
19 t1 = threading.Thread(target = foo, args =(1,) )
20 t2 = threading.Thread(target = bar, args =(2,) )
21 t1.start()
22 t2.start()
23
24 t1.join()#t1,t2执行完再往下执行
25 t2.join()
26 #t1,t2同时执行
27 end = time.time()
28
29
30 print(end - begin)并发,两个线程竞争执行执行结果:
foo1
bar2
2.002244710922241
Process finished with exit code 0
IO 密集型任务函数(以上为 IO 密集型)计算效率会被提高,可用多线程
计算密集型任务函数(以下为计算密集型)改成 C 语言
1 import time
2 import threading
3 begin = time.time()
4
5 def add(n):
6 sum = 0
7 for i in range(n):
8 sum += i
9 print(sum)
10
11 # add(50000000)
12 # add(80000000)
13
14 #并发,两个线程竞争执行
15 t1 = threading.Thread(target = add, args =(50000000,) )
16 t2 = threading.Thread(target = add, args =(80000000,) )
17 t1.start()
18 t2.start()
19
20 t1.join()#t1,t2执行完再往下执行
21 t2.join()
22 end = time.time()
23
24 print(end - begin)计算密集型中用并发计算效率并没有提高。
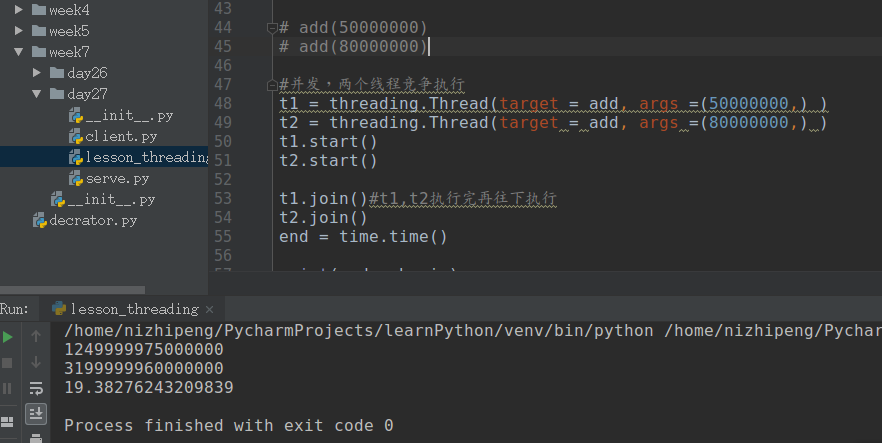
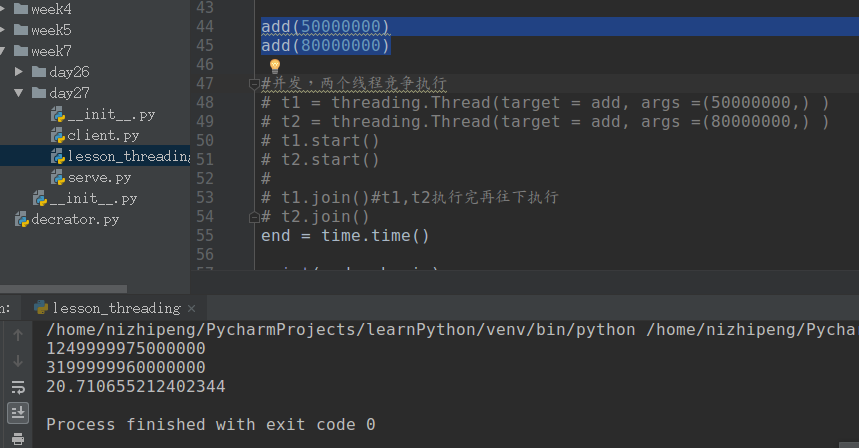
计算效率并没有提高。
GIL
In CPython, due to the Global Interpreter Lock, only one thread can execute Python code at once.
在同一时刻,只能有一个线程。
使之有多个进程就可以解决(如果三个线程无法同时进行,那么把它们分到三个进程里面去,用于解决 GIL 问题,实现并发)。
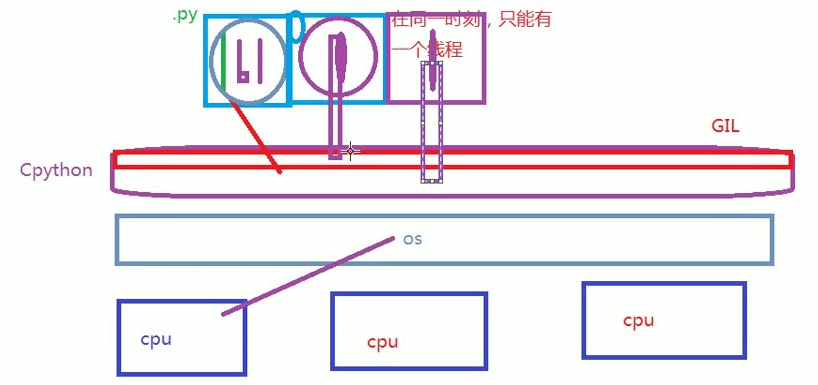
线程与进程的区别:
- Threads share the address space of the process that created it; processes have their own address space.
- Threads have direct access to the data segment of its process; processes have their own copy of the data segment of the parent process.
- Threads can directly communicate with other threads of its process; processes must use interprocess communication to communicate with sibling processes.
- New threads are easily created; new processes require duplication of the parent process.
- Threads can exercise considerable control over threads of the same process; processes can only exercise control over child processes.
- Changes to the main thread (cancellation, priority change, etc.) may affect the behavior of the other threads of the process; changes to the parent process does not affect child processes.
threading_test.py
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(1)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(5)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 for t in threads:#线程加到了列表中
26 # t.setDaemon(True)
27 t.start()
28 # t.join()
29 # t1.join()
30 #t2.join()########考虑这三种join位置下的结果?
31 print ("all over %s" %ctime())
32
33 #一共执行10秒一共只执行 10 秒,因为是同时执行,看哪个时间长。2*5s
执行结果:
Begin listening to 七里香. Fri Nov 2 16:43:09 2018
all over Fri Nov 2 16:43:09 2018
Begin watching at the 阿甘正传! Fri Nov 2 16:43:09 2018
end listening Fri Nov 2 16:43:10 2018
Begin listening to 七里香. Fri Nov 2 16:43:10 2018
end listening Fri Nov 2 16:43:11 2018
end watching Fri Nov 2 16:43:14 2018
Begin watching at the 阿甘正传! Fri Nov 2 16:43:14 2018
end watching Fri Nov 2 16:43:20 2018
Process finished with exit code 0
join
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(2)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(3)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 for t in threads:#线程加到了列表中
26 # t.setDaemon(True)
27 t.start()
28 #t.join() #变成了串行 t1已经执行完了,但是t2阻塞了,其中t为t2
29 t1.join() #all over在第四秒就会被打印,因为t1四秒执行完,不再阻塞,而t2还在执行
30 #t2.join()########考虑这三种join位置下的结果?
31 print ("all over %s" %ctime())
32
33 #一共执行6秒
t1.join,t1 执行完才能到下一步,所以 4 秒后才能 print ("all over %s" %ctime())
t2.join,t2 执行结束才能到下一步,所以 6 秒后才能 print ("all over %s" %ctime())
如果将 t.join () 放到 for 循环中,即和串行一样先执行 t1, 再执行 t2。
setDeamon
1 import threading
2 from time import ctime,sleep
3 import time
4
5 def music(func):
6 for i in range(2):
7 print ("Begin listening to %s. %s" %(func,ctime()))
8 sleep(2)
9 print("end listening %s"%ctime())
10
11 def move(func):
12 for i in range(2):
13 print ("Begin watching at the %s! %s" %(func,ctime()))
14 sleep(3)
15 print(''end watching %s''%ctime())
16
17 threads = []
18 t1 = threading.Thread(target=music,args=(''七里香'',))
19 threads.append(t1)
20 t2 = threading.Thread(target=move,args=(''阿甘正传'',))
21 threads.append(t2)
22
23 if __name__ == ''__main__'':
24
25 t2.setDaemon(True)
26 for t in threads:#线程加到了列表中
27 #t.setDaemon(True)
28 t.start()
29
30 print ("all over %s" %ctime())
31
32 #主线程只会等待没设定的子线程t1,t2被设定setDaemon
33 #t1已经执行完(4s),但是t2还没执行完,和主线程一起退出32 #主线程只会等待没设定的子线程t1,t2被设定setDaemon
33 #t1已经执行完(4s),但是t2还没执行完,和主线程一起退出
执行结果:Begin listening to 七里香. Fri Nov 2 17:33:29 2018
Begin watching at the 阿甘正传! Fri Nov 2 17:33:29 2018
all over Fri Nov 2 17:33:29 2018
end listening Fri Nov 2 17:33:31 2018
Begin listening to 七里香. Fri Nov 2 17:33:31 2018
end watching Fri Nov 2 17:33:32 2018
Begin watching at the 阿甘正传! Fri Nov 2 17:33:32 2018
end listening Fri Nov 2 17:33:33 2018
Process finished with exit code 04 秒就结束。
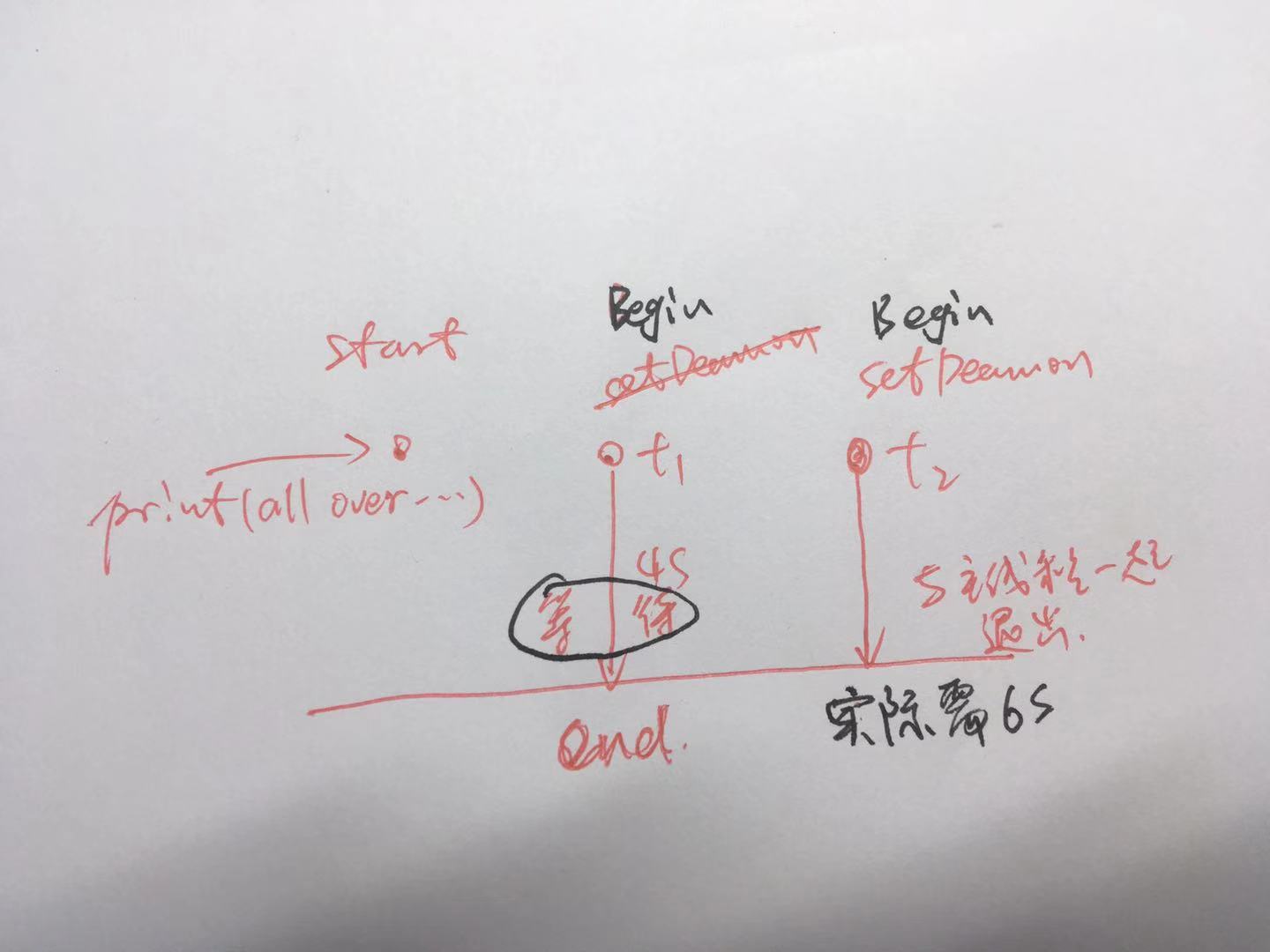
print属于主线程!
继承式调用
1 import threading
2 import time
3
4
5 class MyThread(threading.Thread):#继承
6 def __init__(self, num):
7 threading.Thread.__init__(self)
8 self.num = num
9
10 def run(self): # 定义每个线程要运行的函数
11
12 print("running on number:%s" % self.num)
13
14 time.sleep(3)
15 if __name__ == ''__main__'':
16 t1 = MyThread(1)
17 t2 = MyThread(2)
18 t1.start()
19 t2.start()
同步锁
1 import time
2 import threading
3
4 def addNum():
5 global num #在每个线程中都获取这个全局变量
6
7 temp = num
8
9 time.sleep(0.0001)#在前一次还没执行完,就开始减1
10 num =temp-1 #对此公共变量进行-1操作
14
15 num = 100 #设定一个共享变量
16 thread_list = []
17 r = threading.Lock()#同步锁
18 for i in range(100):
19
20 t = threading.Thread(target=addNum)
21 t.start()
22 thread_list.append(t)
23
24 for t in thread_list: #等待所有线程执行完毕
25 t.join()
26
27 print(''final num:'', num )#有join所有执行完再输出执行结果:
final num: 47
Process finished with exit code 0最终结果不是 0 的原因:由于有 sleep 的原因,100 个减一操作几乎同时进行,前一次还在 sleep 没进行减法运算,全局变量就被后一次线程进行减法运算。
正常情况:100-1=99,99-1=98........1-1 = 0。
有 sleep:100-1=99 (还没减),全局变量 100 被拿走,进行下一线程的运算 100-1=99,造成最后结果不为 0;
解决方法:同步锁,使数据运算部分变成了串行。
1 import time
2 import threading
3
4 def addNum():
5 global num #在每个线程中都获取这个全局变量
6 #num -= 1
7
8 r.acquire()#同步锁,又变成串行
9 temp = num
10 #print(''--get num:'',num )
11 time.sleep(0.0001)#在前一次还没执行完,就开始减1
12 num =temp-1 #对此公共变量进行-1操作
13 r.release()
14 #只是将以上的部分变成了串行
15
16 print(''ok'')
17 #将不是数据的部分内容不放到锁中,100个线程同时拿到ok,这部分将不是串行,而是并发
18
19
20 num = 100 #设定一个共享变量
21 thread_list = []
22 r = threading.Lock()#同步锁
23 for i in range(100):
24
25 t = threading.Thread(target=addNum)
26 t.start()
27 thread_list.append(t)
28
29 for t in thread_list: #等待所有线程执行完毕
30 t.join()
31
32 print(''final num:'', num )#有join所有执锁中的部分变成了串行,只有运行结束才进入下一线程。
但是锁外面的部分 print (''ok'') 还是并发的,100 个线程同时拿到 ok。
死锁和递归锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁,因为系统判断这部分资源都正在使用,所有这两个线程在无外力作用下将一直等待下去。
1 import threading,time
2
3 class myThread(threading.Thread):
4 def doA(self):
5 lockA.acquire()
6 print(self.name,"gotlockA",time.ctime())
7 time.sleep(3)#以上部分被A锁住
8
9 lockB.acquire()#下面的也锁住
10 print(self.name,"gotlockB",time.ctime())
11
12 lockB.release()#释放后,执行doB
13 lockA.release()
14
15 def doB(self):
16 #在此过程中,第二个线程进入,因为A,B已经被释放
17 lockB.acquire()#有锁,正常输出,由于第二个进入,所以A(第二个线程),B(第一个线程)几乎同时获取
18 #但是之后第一个线程想要获取A锁的时候,A锁已经被第二个线程占着,造成死锁.
19 print(self.name,"gotlockB",time.ctime())
20 time.sleep(2)
21
22 lockA.acquire()
23 print(self.name,"gotlockA",time.ctime())#没有被打印,反而第二个线程的被打印了
24
25 lockA.release()
26 lockB.release()
27
28 def run(self):
29 self.doA()
30 self.doB()
31
32 if __name__=="__main__":
33
34 lockA=threading.Lock()#两个锁
35 lockB=threading.Lock()
36
37 #lock = threading.RLock()#该锁可以多次获取,多次acquire和release
38 threads=[]
39 for i in range(5):#5个线程
40 threads.append(myThread())
41 for t in threads:
42 t.start()
43 for t in threads:
44 t.join()#等待线程结束,后面再讲。执行结果:
Thread-1 gotlockA Sat Nov 3 13:40:48 2018
Thread-1 gotlockB Sat Nov 3 13:40:51 2018
Thread-1 gotlockB Sat Nov 3 13:40:51 2018
Thread-2 gotlockA Sat Nov 3 13:40:51 2018以上程序卡住不能运行,doA 运行完锁 A 锁 B 都释放,准备运行 doB,休眠 2 秒后,获取锁 A,此时由于线程锁都被释放,可以进入其他线程,如进入线程二,同时也获取锁 A,两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁。
解决方法:
1 import threading,time
2
3 class myThread(threading.Thread):
4 def doA(self):
5 lock.acquire()
6 print(self.name,"gotlockA",time.ctime())
7 time.sleep(3)#以上部分被A锁住
8
9 lock.acquire()#下面的也锁住
10 print(self.name,"gotlockB",time.ctime())
11
12 lock.release()#释放后,执行doB
13 lock.release()
14
15 def doB(self):
16 #在此过程中,第二个线程进入,因为A,B已经被释放
17 lock.acquire()#有锁,正常输出,由于第二个进入,所以A(第二个线程),B(第一个线程)几乎同时获取
18 #但是之后第一个线程想要获取A锁的时候,A锁已经被第二个线程占着,造成死锁.
19 print(self.name,"gotlockB",time.ctime())
20 time.sleep(2)
21
22 lock.acquire()
23 print(self.name,"gotlockA",time.ctime())#没有被打印,反而第二个线程的被打印了
24
25 lock.release()
26 lock.release()
27
28 def run(self):
29 self.doA()
30 self.doB()
31
32 if __name__=="__main__":
33
34 # lockA=threading.Lock()#两个锁
35 # lockB=threading.Lock()
36
37 lock = threading.RLock()#该锁可以多次获取,多次acquire和release
38 threads=[]
39 for i in range(5):#5个线程
40 threads.append(myThread())
41 for t in threads:
42 t.start()
43 for t in threads:
44 t.join()#等待线程结束,后lock = threading.RLock (),该锁可以重用,只用 lock。不用 lockA,lockB。
执行结果:
Thread-1 gotlockA Sat Nov 3 13:48:04 2018
Thread-1 gotlockB Sat Nov 3 13:48:07 2018
Thread-1 gotlockB Sat Nov 3 13:48:07 2018
Thread-1 gotlockA Sat Nov 3 13:48:09 2018
Thread-3 gotlockA Sat Nov 3 13:48:09 2018
Thread-3 gotlockB Sat Nov 3 13:48:12 2018
Thread-4 gotlockA Sat Nov 3 13:48:12 2018
Thread-4 gotlockB Sat Nov 3 13:48:15 2018
Thread-4 gotlockB Sat Nov 3 13:48:15 2018
Thread-4 gotlockA Sat Nov 3 13:48:17 2018
Thread-2 gotlockA Sat Nov 3 13:48:17 2018
Thread-2 gotlockB Sat Nov 3 13:48:20 2018
Thread-2 gotlockB Sat Nov 3 13:48:20 2018
Thread-2 gotlockA Sat Nov 3 13:48:22 2018
Thread-5 gotlockA Sat Nov 3 13:48:22 2018
Thread-5 gotlockB Sat Nov 3 13:48:25 2018
Thread-3 gotlockB Sat Nov 3 13:48:25 2018
Thread-3 gotlockA Sat Nov 3 13:48:27 2018
Thread-5 gotlockB Sat Nov 3 13:48:27 2018
Thread-5 gotlockA Sat Nov 3 13:48:29 2018
信号量 (Semaphore)
信号量用来控制线程并发数的,BoundedSemaphore 或 Semaphore 管理一个内置的计数 器,每当调用 acquire () 时 - 1,调用 release () 时 + 1。
计数器不能小于 0,当计数器为 0 时,acquire () 将阻塞线程至同步锁定状态,直到其他线程调用 release ()。(类似于停车位的概念)
BoundedSemaphore 与 Semaphore 的唯一区别在于前者将在调用 release () 时检查计数 器的值是否超过了计数器的初始值,如果超过了将抛出一个异常。
1 import threading,time
2 class myThread(threading.Thread):
3 def run(self):
4 if semaphore.acquire():
5 print(self.name)
6 time.sleep(3)
7 semaphore.release()
8 if __name__=="__main__":
9 semaphore=threading.Semaphore(5)
10 thrs=[]
11 for i in range(23):
12 thrs.append(myThread())
13 for t in thrs:
14 t.start()执行结果:
Thread-1
Thread-2
Thread-3
Thread-4
Thread-5
Thread-6
Thread-7
Thread-8
Thread-9
Thread-10
Thread-11
Thread-12
Thread-13
Thread-14
Thread-15
Thread-16
Thread-17
Thread-18
Thread-19
Thread-20
Thread-21
Thread-22
Thread-23
Process finished with exit code 0一次同时输出五个,最后一次输出三个。
条件变量同步 (Condition)
线程间通信的作用
1 import threading,time
2 from random import randint
3 class Producer(threading.Thread):
4 def run(self):
5 global L#一屉
6 while True:
7 val=randint(0,100)
8 print(''生产者'',self.name,":Append"+str(val),L)
9
10 if lock_con.acquire():#锁 ,与lock_con.acquire()一样
11 L.append(val)#做包子,从后面加
12 lock_con.notify()#通知wait,激活wait
13 lock_con.release()
14 time.sleep(3)
15 class Consumer(threading.Thread):
16 def run(self):
17 global L
18 while True:
19 lock_con.acquire()
20 if len(L)==0:#没包子
21 lock_con.wait()#wait阻塞
22
23 print(''消费者'',self.name,":Delete"+str(L[0]),L)
24 del L[0]#从前面吃
25 lock_con.release()
26 time.sleep(0.1)
27
28 if __name__=="__main__":
29
30 L=[]
31 lock_con=threading.Condition()#条件变量的锁
32 threads=[]
33 for i in range(5):#启动五个人在做包子,5个线程
34 threads.append(Producer())
35 threads.append(Consumer())#
36 for t in threads:
37 t.start()
38 for t in threads:
39 t.join()当一屉中有包子的时候,notify 激活 waiting,添加包子,和吃包子时有线程锁。
同步条件 (Event)
1 import threading,time
2
3 class Boss(threading.Thread):
4 def run(self):
5 print("BOSS:今晚大家都要加班到22:00。")
6 event.isSet() or event.set()#set()设为true
7 time.sleep(5)
8 print("BOSS:<22:00>可以下班了。")
9 event.isSet() or event.set()
10
11 class Worker(threading.Thread):
12 def run(self):
13 event.wait()#等待老板决定,阻塞
14 print("Worker:哎……命苦啊!")
15 #event.clear() # 标志位 False 等老板说可以下班, 设为true
16 time.sleep(1)
17 event.clear()#标志位 False 等老板说可以下班, 设为true
18 event.wait()#等老板说别的 ,设为true后
19 print("Worker:OhYeah!") #print Oh,Yeah
20
21 if __name__=="__main__":
22 event=threading.Event()
23 threads=[]
24 for i in range(5):#五个worker
25 threads.append(Worker())
26 threads.append(Boss())#一个老板
27 for t in threads:
28 t.start()
29 for t in threads:
30 t.join()boss 说完后,5 个 worker 马上能有反应。boss 输出后,even.set (),标志位变为 True,worker 中的 event.wait () 才能停止阻塞。之后还需将标志位设为 False,即 event.clear ()。
再次等待 boss 说完话后 even.set () 将标志位变为 True,worker 再次发言。
执行结果:
BOSS:今晚大家都要加班到22:00。
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
Worker:哎……命苦啊!
BOSS:<22:00>可以下班了。
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Worker:OhYeah!
Process finished with exit code 0

python threading queue模块中join setDaemon及task_done的使用方法及示例
threading:
t.setDaemon(True) 将线程设置成守护线程,主进行结束后,此线程也会被强制结束。如果线程没有设置此值,则主线程执行完毕后还会等待此线程执行。
t.join() 线程阻塞,只有当线程运行结束后才会继续执行后续语句
示例:
#coding: utf-8
import threading
import time
def foo(name):
time.sleep(2)
print ''this is %s \n'' % (name,)
if __name__ == ''__main__'':
mythread = []
for i in range(5):
t = threading.Thread(target=foo, args=(i, ))
# t.setDaemon(True)
t.start()
mythread.append(t)
# for t in mythread:
# t.join()
print ''-- end --''
运行结果(注意,print为非线程安全,所以打印内容有时会比较乱):
-- end --
this is 1
this is 2
this is 4
this is 0
this is 3
Process finished with exit code 0
可以看到,主线程和子线程是独立运行的(最后一行先被打印),主线程运行结束后依旧等待子线程结束。
把上面的t.setDaemon(True)取消注释,再运行一遍,发现只打印了如下内容:
-- end --
Process finished with exit code 0
即主线程运行结束后,会强制结束掉子线程
我们继续再把下面的注释去掉
# for t in mythread:
# t.join()
再运行一遍,输出如下:
this is 1
this is 0
this is 3
this is 4
this is 2
-- end --
Process finished with exit code 0
注意:end在最后才被输出,说明在join那里阻塞了主线程的运行,在等待子线程运行完成。
queue:
q.put(item) 将item放入队列中。
q.get() 从队列中取出数据。
q.task_done() 每次从queue中get一个数据之后,当处理好相关问题,最后调用该方法,以提示q.join()是否停止阻塞,让线程向前执行或者退出;
q.join() 阻塞,直到queue中的数据已经每项已经task_done处理到空。
如果不使用task_done也可以,可以通过q.full() q.empty()等来判断
q.join()隐藏的问题:
对于生产者-消费者模型,这种阻塞方式是有漏洞的,因为如果queue初始为空,q.join()会直接停止阻塞,继续执行后续语句。
还有另一种情况,就是生产者生产速度比较慢,而消费者消费速度比较快,也有可能停止阻塞,继续执行后续语句
如果有多个消费者,没有生产者,且queue始初化为一定的数据量,则可以正常执行。
示例:
#coding: utf-8
import Queue
import threading
import time
queue = Queue.Queue(maxsize=3)
def produce():
for i in range(5):
item = "item" + str(i)
queue.put(item)
print "%s produce" % (item, )
# time.sleep(4)
def customer():
while True:
time.sleep(2)
item = queue.get()
print "process %s finished" % (item, )
queue.task_done()
if __name__ == ''__main__'':
t = threading.Thread(target=produce)
t.setDaemon(True)
t.start()
for i in range(3):
c = threading.Thread(target=customer)
c.setDaemon(True)
c.start()
queue.join()
print ''-- end --''
运行输出如下:
item0 produce
item1 produce
item2 produce
process item0 finished
process item2 finishedprocess item1 finished
item3 produce
item4 produce
process item3 finished
process item4 finished
-- end --
Process finished with exit code 0
可以看到程序正常结束,end字符也在最后在打印出来。
我们把produce函数中注释掉如下语句,
queue.put(item)
print "%s produce" % (item, )
运行得到:
-- end --
Process finished with exit code 0
即queue为空,join()方法并不阻塞线程。
我们在produce函数中加上sleep,让生产慢一点,去掉time.sleep(4)前面的注释,运行得到:
item0 produce
process item0 finished
-- end --
Process finished with exit code 0
有时运行有可能会得到这样的错误信息:
Exception in thread Thread-3 (most likely raised during interpreter shutdown)
报错信息表明主线程不等待子线程就结束了。
可以发现,其实produce函数中应该还有任务要生成,但因为太慢,在join语句那里检测到队列为已经全部被设置task_done,就会继续往后执行,这有可能有时并不我们需要的,针对这样的情况,我们可以在queue.join()前加多一个子句t.join()即可达成目的。
如果我们再把customer函数中的queue.task_done()函数去掉,运行得到
item0 produce
process item0 finished
item1 produce
process item1 finished
item2 produce
process item2 finished
item3 produce
process item3 finished
item4 produce
process item4 finished
注意程序一直没有结束,而最后一行end语句也没有出现。因为在join那里,虽然队列已经全部为消费完,已经为0,但是由于它不是调用task_done函数而让其计数为0,所以此时,函数会一直阻塞在这里。
今天关于python - threading 多线程 setDaemon 和 join 的区别和python 多线程join函数的讲解已经结束,谢谢您的阅读,如果想了解更多关于 Thread.setDaemon 详解、Java中User Thread和Daemon Thread的区别、Python (多线程 threading 模块)、python threading queue模块中join setDaemon及task_done的使用方法及示例的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

