本文将介绍在ApacheIgnite中,如何控制在哪个节点上创建缓存的详细情况,特别是关于在apache中可以采用修改http的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个
本文将介绍在 Apache Ignite 中,如何控制在哪个节点上创建缓存的详细情况,特别是关于在apache中可以采用修改http的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Apache Cassandra 和 Apache Ignite: 架构简化思考、Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL、Apache Cassandra 和 Apache Ignite:分布式数据库的明智之选、Apache Cassandra和Apache Ignite:强一致和事务的知识。
本文目录一览:- 在 Apache Ignite 中,如何控制在哪个节点上创建缓存(在apache中可以采用修改http)
- Apache Cassandra 和 Apache Ignite: 架构简化思考
- Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL
- Apache Cassandra 和 Apache Ignite:分布式数据库的明智之选
- Apache Cassandra和Apache Ignite:强一致和事务
")
在 Apache Ignite 中,如何控制在哪个节点上创建缓存(在apache中可以采用修改http)
如何解决在 Apache Ignite 中,如何控制在哪个节点上创建缓存?
在 ignite 中,我如何控制在哪个节点上创建缓存?如果我需要保证在所有节点上创建一个缓存,我该怎么做?
以下代码会在所有节点上创建缓存还是仅在其中一些节点上创建缓存?
ignite.cluster().forServers().ignite().createCache("myCache")
谢谢。
解决方法
简而言之,要在所有节点上都有缓存,您需要配置 REPLICATED 缓存模式。默认模式是 PARTITIONED 一种,这意味着数据将在集群节点之间平均分布。
我认为配置 nodeFilters 是调整默认行为的最简单方法,您可以根据某些用户定义的节点属性告诉 Ignite 哪些节点不应保留数据。请注意,您应该有一个很好的理由来更改默认发行版并了解权衡。
,默认情况下,Ignite 在整个服务器节点集上创建缓存。 但是,可以控制这种行为。有一种称为 node filter 的机制可以选择节点子集来存储缓存数据。 我在这里想说的是,即使通过调用,也会在任何地方创建缓存:
ignite.getOrCreateCache("myCache")
为了让您计算呼叫并置,您可以使用 affinityCall。可以在 here 找到更详细的信息。示例(此 lambda 将在存储 myKey 键的节点上执行):
ignite.compute().affinityCall("myCache",myKey,() -> {
// do something
return "something";
})
另一种选择是 specify 节点的子集(甚至可能只有一个节点)用于您的计算。类似的东西(此 lambda 将在具有 nodeId id 的节点上执行):
ignite.compute(ignite.cluster().forNodeId(nodeId)).call(() -> {
// do something
return "something";
})

Apache Cassandra 和 Apache Ignite: 架构简化思考
Apache Cassandra 在软件架构师和工程师当中,正在成为日益流行的数据库,很多人愿意将数据交给它。目前,这个著名的 NoSQL 数据库已经有了大量的部署。毋庸置疑,Cassandra 实至名归,他用简单的方法达到了目标:保证快速写入的前提下实现了无限扩展和高可用。
这两个基本功能帮助 Cassandra 快速崛起,它解决了传统关系型数据库无法解决的问题。这些问题需要水平扩展、高可用、容错以及 7*24 小时无故障运行,传统关系型数据库至少现在还无法全面满足这些条件(除了可能的分布式关系型数据库,比如 Google Spanner 以及 CockroachDB)。
但是,扩展性和高可用不是没有代价的,被简化的设计原则和关系数据库特性宠坏的我们,不得不去学习如何正确地使用 Cassandra,如何正确地进行数据建模,以及如何在没有高级 SQL 特性的情况下解决问题。
在本文中,会展示 Cassandra 数据建模概念中不为人知的一面,这是 Cassandra 架构的总览,然后通过学习 Cassandra 给我们带来的丰富现代数据库特性,给出如何使架构简化的建议。
正确地进行数据建模
当然,掌握 Cassandra 的数据建模思想需要一定的时间(这不是个大问题),这方面的资源也有很多。这个思想基于一个非常规策略,需要我们事先去猜数据库上执行的所有查询。坦白说,这也是可行的,设想有一组查询,使 Cassandra 的表针对这些查询进行优化,然后进入生产。
这个方法叫做查询驱动方法,这意味着应用的开发由查询驱动,不能在还不知道查询是什么样的情况下,就 进行一个应用的开发。这个模式有些棘手,但是它在 Cassandra 环境中带来了更快和更廉价的写入。
比如,假定一个应用要跟踪一个厂商生产的所有车辆,然后评估每个厂商的生产能力,在关系型世界中,数据模型可能如下:
从技术上来说,在 Cassandra 中使用同样的模式也不是不行,但是从架构的视角来看,该模型不可行,因为 Cassandra 无法对不同的表进行关联 -- 我们肯定需要将车辆、厂商以及产量的数据聚合成一个结果集。如果要做到这一点,就需要放弃关系模型,发挥非常规策略的优势。
该策略会引导我们形成一个应用需要的查询操作的列表,然后围绕它们设计模型。实际上,这很简单。下面会针对不熟悉 Cassandra 的举例说明这个策略。
假定应用需要支持如下的查询:
Q1:获得一个厂商在特定时间窗口内生产的车型(最新,第一)
如果要在 Cassandra 中高效地执行该查询,下面会创建一张表,通过 vendor_name 进行分区,然后将 production_year 和 car_model 作为聚类列:
CREATE TABLE cars_by_vendor_year_model (
vendor_name text,
production_year int,
car_model text,
total int,
PRIMARY KEY ((vendor_name), production_year, car_model)
) WITH CLUSTERING ORDER BY (production_year DESC, car_model ASC);
之后,就可以根据之前定义的 Q1 执行一个 Cassandra 查询了:
select car_model, production_year, total from cars_by_vendor_year_model where vendor_name = ''Ford Motors'' and production_year >= 2017
在这基础上,该表还可以满足下面的操作:
- 获取一个厂商生产的车型:
select * from cars_by_vendor_year_model where vendor_name = ''Ford Motors''
- 获取某一年一个特定车型的产量:
select * where vendor_name = ''Ford Motors'' and production_year = 2016 and car_model = ''Explorer''
接下来,需要为应用需要支持的每个查询都进行这样的练习,所有的工作完成后,就可以将应用部署到生产环境了。好了,工作完成了!准备拿奖金吧!
缺点
好,还有一个可能拿不到奖金。
在生产环境中的应用,经常会面对基于 Cassandra 架构的不足,如果有人跳出我们划定的框框,希望快速地增加一个新的操作来增强应用时,这样的事就会经常发生,这就是 Cassandra 的不足。
如果数据模型是关系型的,那么可以准备一个 SQL 查询,创建一个索引(如果必要),然后给生产环境打个补丁就可以了,但是 Cassandra 不是这么简单。如果由于架构所限查询无法执行或者无法高效地执行,那么就需要创建一个全新的 Cassandra 表,配置主键和聚类键来满足特定查询的需求,还需要从已有的表中拷贝必要的数据。
下面回到之前的车辆和厂商的应用,它已被大量用户使用,然后要满足新的需求:
Q2:获取一个厂商某特定车型的产量。
考虑一会之后,可能会得出结论,基于之前创建的 cars_by_vendor_year_model 表,构造一个新的查询,好吧,查询已经准备好然后执行:
select production_year, total from cars_by_vendor_year_model where vendor_name = ''Ford Motors'' and car_model = ''Edge''
但是,查询出错了,异常如下:
InvalidRequest: code=2200 [Invalid query] message="PRIMARY KEY column "car_model" cannot be restricted (preceding column "production_year" is not restricted)"
异常大概是说,在通过 car_model 过滤数据之前,需要指定生产年份!但是年份未知啊,之后就需要创建一个不同的新表来满足 Q2:
CREATE TABLE cars_by_vendor_model (
vendor_name text,
car_model text,
production_year int,
total int,
PRIMARY KEY ((vendor_name), car_model, production_year)
);
最后,满足 Q2 的查询执行成功了:
select production_year, total from cars_by_vendor_model where vendor_name = ''Ford Motors'' and car_model = ''Edge''
现在退一步,看看 cars_by_vendor_year_model 和 cars_by_vendor_model 的结构,看看能发现多少不同。好吧,只有一点,主要是调整了聚类键!这样,只是为了满足 Q2,做了如下的工作:
- 创建了一个新表,将之前的数据复制过来;
- 在应用中嵌入了批处理后,注意两者的原子更新;
- 应用架构变得复杂;
这个故事会一次又一次地发生,除非应用停止演进。实际上至少是头几年,这是不可能的。这意味着要准备好投入无限复杂的架构中。有办法避免么?绝对的,在现有的 Cassandra 功能中,能发生奇迹么?不能。
Apache Ignite 能解决么?
带关联的 SQL 查询代价并不低,即使运行在单机上的关系型数据库,随着工作负载的增加也可能发生 “阻塞”,这也是为什么很多人即便要忍受 Cassandra 数据模型技术的缺点也要转向它的原因,但是这导致了架构的复杂化。
分布式的存储、数据库以及平台的市场正在经历大幅度的增长,既有可扩展性,同时又有 Cassandra 的高可用性,但是同时应用还可以构建在关系模型上,目前来说找到一个这样的数据库是可行的。
在 Apache 软件基金会(ASF)的项目中找一下,我们发现了 Apache Ignite,这是一个以内存为中心的数据存储,它是一个分布式的缓存或者数据库,内建了 SQL、键 - 值还有计算 API。 Ignite 仍然处于 Cassandra 这个 ASF 老朋友的阴影下,虽然仍然有人因为可扩展、高可用以及持久化的原因选择它,但是已经有人确认 Ignite 在 SQL、分布式事务以及内存存储上是无敌的。此外,那些在生产环境非常信任 Cassandra 的,也可以将 Ignite 作为缓存层对其进行加速 -- 这可以作为将 Cassandra 替换为 Ignite 自身存储的一个中间步骤。
你是否和我一样已经加入了 Ignite 社区?那么可以期待下一篇文章,届时会使用 Ignite 构建一个基于简单关系模型的架构,它会使用关系并置、分区概念、高效的并置 SQL 关联以及其它的技术,为厂商和车辆的应用创建一个示例。如果你等不及或者想自己搞定这个问题,可以看下第一部分和第二部分,了解一下 Ignite 的主要功能和概念。
本文译自 Denis Magda 的博客。

Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL
在上一篇文章中,回顾和总结了 Cassandra 中使用的查询驱动数据模型(或者说非常规数据模型)方法论的缺陷。事实证明,如果不对查询有深入的了解,通过该方法论将无法开发高效的应用。实际上,这种场景的应用架构上会变得更加的复杂,难于维护,并且会造成很大的数据冗余。
此外,这个问题通常会被这样的观点掩盖:“如果想要扩展性、速度以及高可用性,那么就得准备存储多份数据,并且牺牲 SQL 和强一致性。”,这个论调十年前可能是正确的,但是现在完全错误!
没那么夸张,我们选择了另一个 ASF 成员,Apache Ignite。在本文中,会讲解基于 Ignite 的应用架构,然后衡量它的维护成本。
我们选择的应用仍然是跟踪所有厂商生产的车辆,然后了解每个单一厂商的产能,如果看过第一篇文章,那么应该知道关系模型如下:
下一步,可以使用 Ignite 的 CREATE TABLE 命令创建这三个表,然后运行由 SQL 驱动的应用了么?不一定,如果不需要对存储于不同表中的数据进行关联操作,那么是可以的。但是根据前文,前提是应用需要支持两种关联的查询:
- Q1:获取一个厂商在特定的时间段内生产的车型。
- Q2:获取一个厂商特定车型的产量。
在 Cassandra 的案例中,我们为每个查询创建了一张表规避了关联的问题,那么用 Ignite,是不是还要经历同样的过程?完全不用。事实上,Ignite 的非并置的关联已经完全可用,如果三个表已经建好了,那么不需要什么额外的工作。但是,这没有比并置的高效和快速。因此,首先要多学习一下关系并置,然后了解这个概念在 Ignite 中是如何使用的。
基于并置关联的数据模型
关系并置在 Ignite(还有其他的分布式数据库,比如 Google Spanner 以及 MemSQL)中是一个强大的概念,它可以在以一个集群节点上存储相关的数据。那么哪些数据是相关的呢?尤其是在关系数据库的背景下,这非常简单,只需要在业务对象之间标示一个父子关系,在 CREATE TABLE 语句中指定一个关系键就可以了,剩下的就交给 Ignite 了!
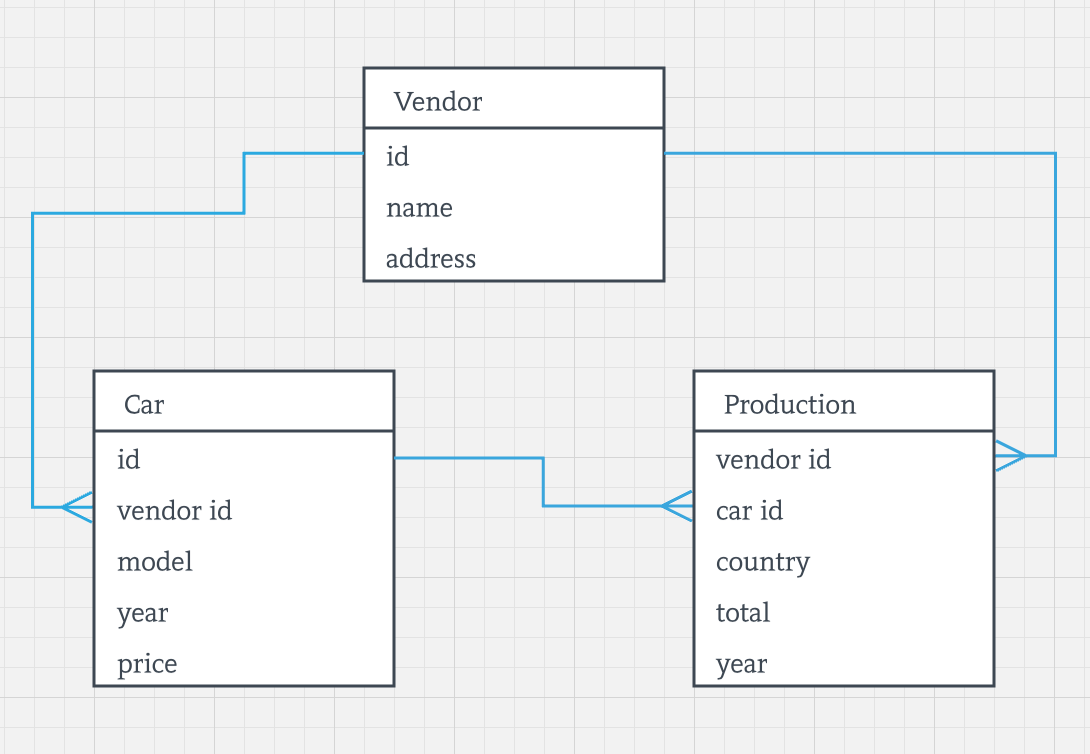
还是拿车辆和厂商的应用举例,使用厂商作为父实体,车辆作为子实体是合理的。比如,按照这样配置好之后,某个厂商生产的所有车辆数据都会存储于同一个节点上,如下图所示:
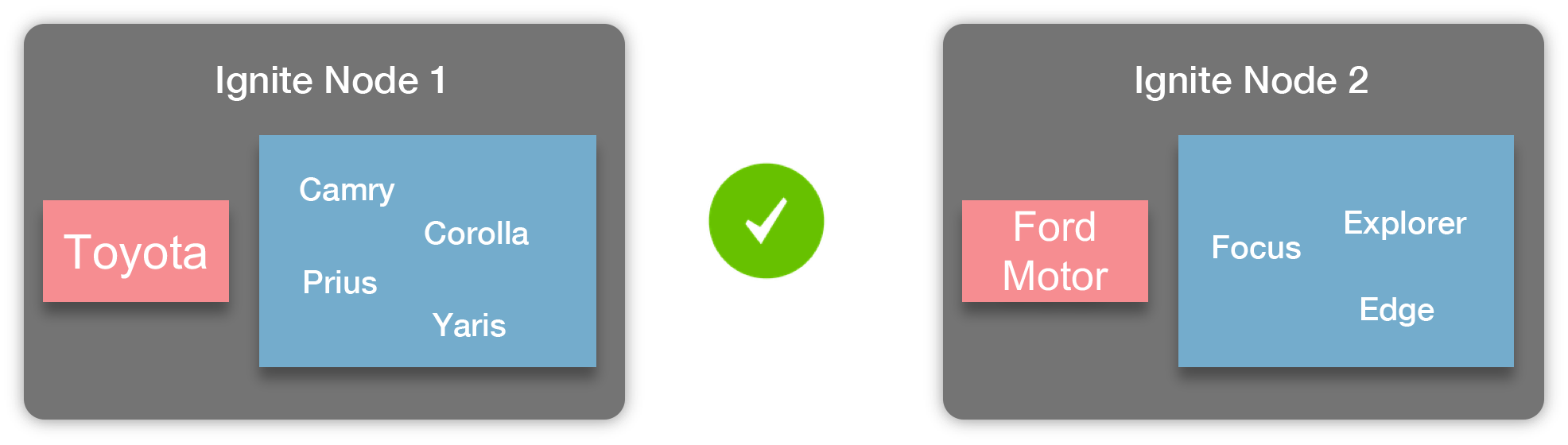
如图所示,丰田生产的车辆都存储于节点 1,而福特生产的车辆都存储于节点 2,这就是关系并置,车辆都会存储于对应的厂商所在的节点上。
要做到这样的数据分布,Vendor 表的 SQL 定义如下:
CREATE TABLE Vendor (
id INT PRIMARY KEY,
name VARCHAR,
address VARCHAR
);
厂商数据会在整个集群中随机地分布,Ignite 会使用主键列计算厂商数据所在的节点。 下一个是 Car 表:
CREATE TABLE Car (
id INT,
vendor_id INT,
model VARCHAR,
year INT,
price float,
PRIMARY KEY(id, vendor_id)
) WITH "affinityKey=vendor_id";
车辆表有一个 affinityKey 参数,配置为 vendor_id 列,它告诉 Ignite,车辆存储于 vendor_id 对应的集群节点。
在 Production 表上重复同样的过程,它的数据也是存储于 vendor_id 对应的集群节点上,如下:
CREATE TABLE Production (
id INT,
car_id INT,
vendor_id INT,
country VARCHAR,
total INT,
year INT,
PRIMARY KEY(id, car_id, vendor_id)
) WITH "affinityKey=vendor_id";
这样数据模型就建完了,下一步就进入应用的代码,然后开发必要的查询。
带关联的 SQL 查询
Ignite 集群可以使用我们熟悉的 SQL 进行查询,它支持分布式的 SQL 关联以及二级索引。 Ignite 支持两种类型的关联:并置和非并置。假定要关联的表已经并置,并且本地数据全部可用,那么并置的关联会避免数据 (关联所需的)的移动,这是在分布式数据库中效率最高、性能最好的。如果部分表无法实现关系并置,但是还需要进行关联,那么非并置的关联就是一个备份计划。这种类型的关联速度较慢,因为在关联时它需要在集群节点间进行数据的移动。
之前,已经配置好了 Vendor、Car 和 Production 表,下一步就是利用并置关联的优势,为 Q1 写一个 SQL:
SELECT c.model, p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = ''Ford Motor'' and p.year >= 2017
ORDER BY p.year;
还能更快么?当然能。下面为 Vendor.name 和 Production.year 列定义二级索引:
CREATE INDEX vendor_name_id ON Vendor (name);
CREATE INDEX prod_year_id ON Production (year);
针对 Q2 的查询也不需要额外的工作:
SELECT p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = ''Ford Motor'' and c.model = ''Explorer'';
现在,如果老板要求增加一个新特性时,很快就能构造出一套新的 SQL 满足他。 完成!作为比较,如果要支持 Q2,可以看看基于 Cassandra 的架构是怎么搞的。
架构简化:任务完成!
Ignite 的基于关系并置的数据模型,针对 Cassandra 的基于查询驱动的模型有如下的优点:
- 应用的数据层基于熟悉的关系模型进行建模,易于维护;
- 数据使用标准的 SQL 语法进行访问;
- 关系并置提供了现代分布式数据库的更多好处:
- 高效和高性能的分布式关联;
- 并置计算 ;
使用 Ignite 替代 Cassandra,简化的软件架构并不是唯一的好处,过段时间,还会有关于强一致性和内存极性能方面的想法。
本文译自 Denis Magda 的博客。

Apache Cassandra 和 Apache Ignite:分布式数据库的明智之选
Apache Cassandra 应用广泛,是一个开源的、分布式的、键值存储列模式 NoSQL 数据库,支撑了很多大公司的关键业务,比如 Netflix、eBay 以及 Expedia,对于 Cassandra 的用户来说,如果他对 Cassandra 很满意,但是又需要高级的 SQL 查询功能,那么 Ignite 对于 Cassandra 来说,是一个增强,如果他对 Cassandra 的速度不满意,或者希望在分布式键值存储数据库中执行 SQL,那么 Ignite 会是 Cassandra 的一个强有力替代者。
Cassandra 的优势和限制
Cassandra 的优势包括:
- 全分布式、对等架构:Cassandra 无单点故障,因此适用于高可用场景。它支持多数据中心复制,比如,可以将数据存储于多个 AWS 可用区域中,以获得更大的弹性;
- 大规模和线性扩展:在任意数据中心的任意 Cassandra 集群中,可以添加 / 删除任意数量的节点,使得用户可以可靠地存储不断增长的结构化和非结构化数据;
- 柔性建模:Cassandra 的分布式系统技术来源于亚马逊的 Dynamo 键值存储以及 Google 的 BigTable 列数据模型,使其可以对相对于传统关系型数据库更复杂的数据结构进行建模;
- 可调一致性:用户可以配置复制来平衡速度和可靠性;
- 开源社区:Cassandra 用户受益于一个庞大而活跃的社区,社区对 Cassandra 进行持续地改进,并且通过一些网站提供技术支持。
Cassandra 的常规用途包括从应用日志和传感器获得大量数据,然后进行存储和分析,还有就是高可用地存储键值数据,这对于面向 Web 的应用,或者 IT 监控非常有用,他们需要对大量数据进行高速的统计。
虽然强大,但是 Cassandra 也有一些限制:
- 基于磁盘,因此限制了某些操作的速度,因为需要对磁盘进行读写;
- 不支持 ANSI-99 SQL,因此无法执行特定的 SQL 查询;
- Cassandra 是最终一致的,因此事务数据可能丢失,这对于事务敏感的应用来说,是个挑战。
Cassandra 和 Ignite 一起使用的好处
在已有的数据层和应用层之间,Ignite 可以充当一个内存计算层,在 Cassandra 和已有的应用层之间,可以插入一个 Ignite 集群,这样在 Ignite 集群保持的数据中可以提供 ANSI-99 SQL 支持以及 ACID 事务支持。
SQL 查询
Ignite 包含了一个兼容 ANSI-99 SQL 的引擎,它可以在 Ignite 集群持有的数据中,执行 SQL 以及对数据进行索引,使用 Ignite 的 ODBC/JDBC API,可以向 Ignite 发送标准的 SQL 命令,对于 Ignite 持有的 Cassandra 数据,也可以执行 SQL 查询,从而为 Cassandra 中存储的数据提供高性能和高灵活性的 SQL 支持。
ACID 事务
Ignite 为分布式事务提供了用户可定义的事务保证,可以从最终一致调整为强一致,Ignite 会将任何变化写入内存数据集以及后面的 Cassandra,保证两者间的数据一致性。
数据无需重建模
加入 Ignite,不需要修改 Cassandra 中已有的数据,和处理传统关系型数据库一样,Ignite 可以从 Cassandra 及其他的 NoSQL 数据库中读取数据。也不需要修改模型,这些都会被直接迁移到 Ignite 中。
Ignite 不需要推倒重来,因此如果希望从关系型数据库迁移到 Cassandra,这会是一个捷径,因为无需为了匹配 Cassandra 的约束而对数据重新建模。为了解决移植需要对数据重新建模的问题,可以在关系型数据库上使用 Ignite,然后将编程接口切换为 Ignite,然后将关系型数据库移植到 Cassandra,通过 Ignite,应用无法感知到前后有什么不同。
Ignite 可以很好地与 NoSQL、RDBMS 以及 Hadoop 存储协同,因此 Ignite 可以用于对它们进行加速和扩展。Ignite 也可以与 Spark 一起工作,Ignite 文件系统还可以用于将弹性分布式数据集(RDD)或者 DataFrames 移入内存,使 SparkRDD 可变,并且可以在多个 Spark 作业间共享状态。
成熟的代码库
虽然 Ignite 对于 Apache 基金会(ASF)来说非常新,但是它有一个很成熟的代码库。它以前在 2007 年时,是一个私有的项目,在 2014 年捐赠给 ASF。然后一年后毕业成为 ASF 的顶级项目,毕业速度在 Apache 项目中第二快(在 Spark 之后)。Ignite 有一个活跃的全球社区,有超过 100 万行代码,有健壮的特性集。
方案集成
从架构上来说,Ignite 与 Cassandra 的集成是非常简单的。Cassandra 的用户,通常来说需要对 Cassandra 集群进行读写(可能使用 Kafka 或者其他的客户端)。Ignite 会嵌入应用和 Cassandra 之间,使用 Ignite 的 Cassandra 连接器进行集成。应用以后就不需要对 Cassandra 进行读写,而是对 Ignite 进行读写,因此他就会访问内存而不是磁盘中的数据,而 Ignite 会对 Cassandra 进行读写。
单一的选择可能更好
虽然将 Ignite 和 Cassandra 整合可以创建一个强大的方案,但是对于某些场景来说,未必是最佳的。比如,对于新的应用来说,需要执行 SQL 查询的功能,Ignite 包含了一个内存数据库,它可以作为一个独立的、分布式的内存 RDBMS,支持 ACID 事务以及 ANSI-99 SQL,包括 DML 和 DDL。兼容 ANSI-99 的 SQL 引擎支持带索引的内存级 SQL,可以以内存计算的速度执行 SQL 查询。Ignite 还支持 ACID 事务的强一致,可以满足对事务有强需求的应用。
对于受限于 Cassandra 的 SQL 能力和最终一致性的用户,会发现迁移到 Ignite(而不是添加)后有了他们需要的数据库功能和内存级的性能,而只需要维护一个简单的应用 / 数据库两层架构。
对于读密集型应用来说,Ignite 会比 Cassandra 快 3-6 倍,而 Cassandra 会有更好的写入性能。因此如果一个应用写入负载很重,而对 SQL 查询以及 ACID 事务要求不高,那么 Cassandra 仍然是独立方案的最佳选择。然而,对于任何需要高速读或者混合性能的关键应用,独立的 Ignite 部署会是最佳选择。
下一步
对于正在使用或者考虑使用 Cassandra 的用户,面对当前的面向 Web 的应用,也会关心极限 OLTP 和 OLAP 负载下的性能需求,应该考虑利用 Ignite 内存计算平台的优势,将两个方案结合,会使应用在内存中而不是磁盘上访问数据,这是一个比磁盘快 1000 倍的方法。在 Cassandra 之上加入 Ignite,在维持 Cassandra 的高可用和水平扩展之外,还提供了其他的好处,包括更灵活的兼容 ANSI-99 的 SQL 查询,以及更健壮的一致性,这些都不需要对数据进行重新建模。但是,如果对 SQL 查询、强一致、或者要求主要是读或者混合读写的性能最大化,那么会发现将 Cassandra 替换成 Ignite 或者最初就选择 Ignite 可能会更好。
如果要入门,可以访问 Apache Ignite 的官方网站了解更多信息,社区也会通过 Apache Ignite 用户列表提供技术支持。
本文译自 GridGain 公司创始人和 CTO 尼基塔 伊万诺夫的博客。

Apache Cassandra和Apache Ignite:强一致和事务
NoSQL数据库,比如Apache Cassandra,是最终一致性系统的典型案例,这种系统的机制比较简单:如果应用在一台主机上触发了数据的变更,那么在某个时间点更新会被传播到所有的副本,换言之,最终一致。
在变更完全同步之前,系统作为一个整体会处于一个不一致的状态。如果从一个未同步的副本中读取变更的数据,更甚者,同时更新数据,谁知道会发生什么呢?
NoSQL的厂商和用户接受了这个机制和行为,因为最终一致给分布式系统带来了高可扩展和高性能,这是事实,如果需要强一致和事务,那么就得考虑传统RDBMS了,但是现在不是这样了!
在前面的文章中,提到即使在分布式数据库中,SQL也可以高效地执行。比如Apache Ignite,不仅仅可以执行简单的SQL操作,还可以容易地对存储于不同主机的数据进行关联,这在十年前是不可能的,但是目前已经成为现代分布式数据库的标配。
再次回到一致性和事务的话题,Ignite可以混合匹配NoSQL的水平扩展和高性能以及RDBMS领域的功能,下面会以Apache Cassandra作为NoSQL数据库的代表,与Ignite作为现代分布式数据库的代表进行比较。
可调一致性和轻量级事务
Cassandra关注于高数据一致性和事务,这不是秘密,因为这是用户的需求。 首先,如果将读写一致性级别配置为ALL,这就获得了最高的一致性。这个模式中,Cassandra会在完成提交日志和所有副本节点内存表的写入之后完成写入操作,相对应的对于读,会在所有副本认可的情况下,才会返回值。这个功能很方便,但是它在保证一致性的前提下,降低了性能,如果需要,可以启用。
其次,这个读写ALL模式没有解决并发更新的问题。如果要更新一个用户账户,如何确保没有其他人干扰呢?事务通常用于解决这样的问题,这时用户可以使用Cassandra的叫做轻量级事务(LWT)的功能。
轻量级事务是为避免单条记录的并发更新而特别设计的。比如,如果两个不同的应用都试图更新一个用户账户,那么LWT会确保只有一个应用成功,而其他的失败。假定第一个应用更早地发起了一个事务,那么就可以像下面这样安全而原子地对年龄进行修改:
UPDATE user_account
SET user_age=35
IF user_id=’Bob Smith’;
但是对于更复杂的操作,比如不同账户间的转账,会怎么样呢?
不幸的是,这超出了Cassandra及其LWT的范围,因为后者限定在单一分区内,而银行账户是可以存储在不同的集群节点上的。
强一致和ACID事务
虽然转账在Cassandra中是个大问题,但是在Ignite中却是个常规操作。 首先,在Ignite中要做到强一致性,需要配置FULL_SYNC同步模式以及为缓存(或者表)开启事务模式,甚至开启FSYNC模式的预写日志来避免整个集群的电源故障。
其次,使用Ignite的事务API,可以对可能存储在不同节点上的账户间进行转账操作:
try (Transaction tx = Ignition.ignite().transactions().txStart(PESSIMISTIC, REPEATABLE_READ)) {
Account acctA = accounts.get(acctAid);
Account acctB = accounts.get(acctBid);
// Withdraw from accountB.
acctB.update(amount);
// Deposit into accountA.
acctA.update(amount);
// Store updated accounts in the cluster.
accounts.put(acctAid, acctA);
accounts.put(acctBid, acctB);
tx.commit();
}
就是这些,Ignite的ACID事务基于2阶段提交(2PC)的高级版,即使故障,也能保证数据的一致性,参考这个系列文章,可以学习Ignite事务子系统实现的更多细节。
总结
Ignite证明了分布式的ACID事务和强一致是可行的,并且被可以水平扩展和高可用的现代数据库广泛采用,它完全可以根据需要进行配置。看一下有多少金融机构信任Ignite,将其部署进核心应用,你就知道ASF的项目不是徒有虚名。
本文译自Denis Magda的博客。
今天关于在 Apache Ignite 中,如何控制在哪个节点上创建缓存和在apache中可以采用修改http的讲解已经结束,谢谢您的阅读,如果想了解更多关于Apache Cassandra 和 Apache Ignite: 架构简化思考、Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL、Apache Cassandra 和 Apache Ignite:分布式数据库的明智之选、Apache Cassandra和Apache Ignite:强一致和事务的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

