想了解SQL技巧:B树和B+树原理及在索引中的应用的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于数据库b树和b+树的相关问题,此外,我们还将为您介绍关于2020-06-25:B+树和B树有
想了解SQL 技巧:B树和B+树原理及在索引中的应用的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于数据库b树和b+树的相关问题,此外,我们还将为您介绍关于2020-06-25:B+树和B树有什么区别?、b-树和b+树以及mysql索引、B-树和B+树的应用:数据搜索和数据库索引、B树和B+树的新知识。
本文目录一览:- SQL 技巧:B树和B+树原理及在索引中的应用(数据库b树和b+树)
- 2020-06-25:B+树和B树有什么区别?
- b-树和b+树以及mysql索引
- B-树和B+树的应用:数据搜索和数据库索引
- B树和B+树
")
SQL 技巧:B树和B+树原理及在索引中的应用(数据库b树和b+树)
https://blog.csdn.net/du5006150054/article/details/82379210
B+树索引是B+树在数据库中的一种实现,是最常见也是数据库中使用最为频繁的一种索引。B+树中的B代表平衡(balance),而不是二叉(binary),因为B+树是从最早的平衡二叉树演化而来的。在讲B+树之前必须先了解二叉查找树、平衡二叉树(AVLTree)和平衡多路查找树(B-Tree),B+树即由这些树逐步优化而来。
二叉查找树
二叉树具有以下性质:左子树的键值小于根的键值,右子树的键值大于根的键值。
如下图所示就是一棵二叉查找树,
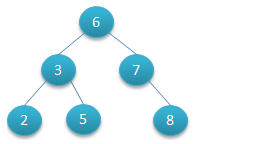
对该二叉树的节点进行查找发现深度为1的节点的查找次数为1,深度为2的查找次数为2,深度为n的节点的查找次数为n,因此其平均查找次数为 (1+2+2+3+3+3) / 6 = 2.3次
二叉查找树可以任意地构造,同样是2,3,5,6,7,8这六个数字,也可以按照下图的方式来构造:
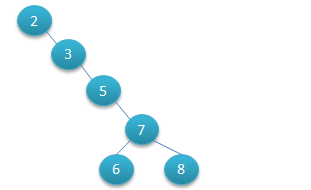
但是这棵二叉树的查询效率就低了。因此若想二叉树的查询效率尽可能高,需要这棵二叉树是平衡的,从而引出新的定义——平衡二叉树,或称AVL树。
平衡二叉树(AVL Tree)
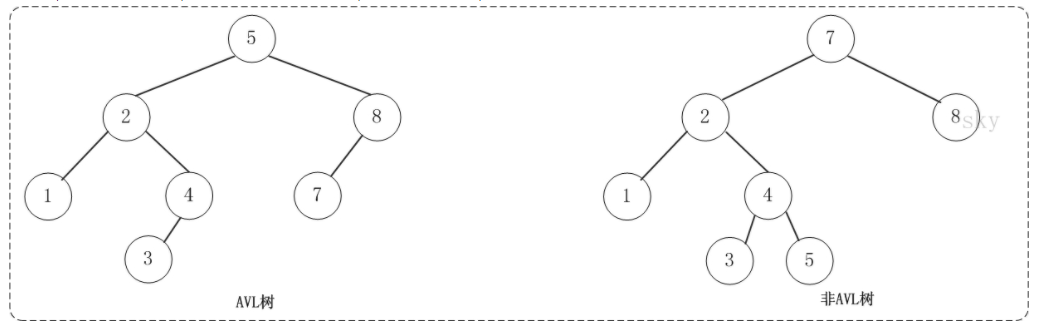
平衡二叉树(AVL树)在符合二叉查找树的条件下,还满足任何节点的两个子树的高度最大差为1。下面的两张图片,左边是AVL树,它的任何节点的两个子树的高度差<=1;右边的不是AVL树,其根节点的左子树高度为3,而右子树高度为1;
如果在AVL树中进行插入或删除节点,可能导致AVL树失去平衡,这种失去平衡的二叉树可以概括为四种姿态:LL(左左)、RR(右右)、LR(左右)、RL(右左)。它们的示意图如下:

这四种失去平衡的姿态都有各自的定义:
LL:LeftLeft,也称“左左”。插入或删除一个节点后,根节点的左孩子(Left Child)的左孩子(Left Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
RR:RightRight,也称“右右”。插入或删除一个节点后,根节点的右孩子(Right Child)的右孩子(Right Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
LR:LeftRight,也称“左右”。插入或删除一个节点后,根节点的左孩子(Left Child)的右孩子(Right Child)还有非空节点,导致根节点的左子树高度比右子树高度高2,AVL树失去平衡。
RL:RightLeft,也称“右左”。插入或删除一个节点后,根节点的右孩子(Right Child)的左孩子(Left Child)还有非空节点,导致根节点的右子树高度比左子树高度高2,AVL树失去平衡。
AVL树失去平衡之后,可以通过旋转使其恢复平衡。下面分别介绍四种失去平衡的情况下对应的旋转方法。
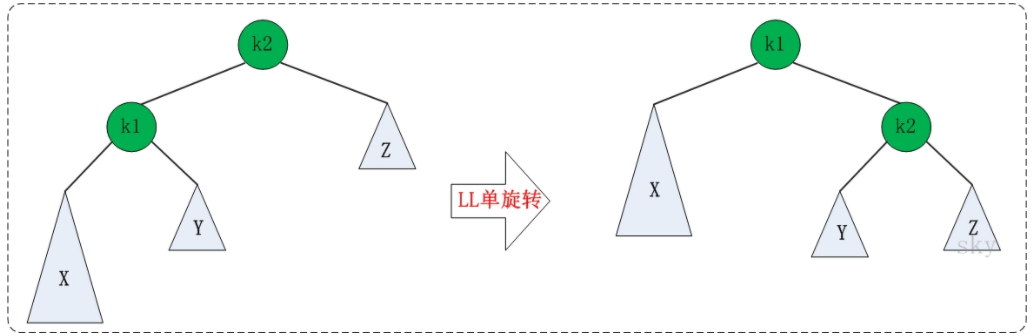
LL的旋转。LL失去平衡的情况下,可以通过一次旋转让AVL树恢复平衡。步骤如下:
- 将根节点的左孩子作为新根节点。
- 将新根节点的右孩子作为原根节点的左孩子。
- 将原根节点作为新根节点的右孩子。
LL旋转示意图如下:
RR的旋转:RR失去平衡的情况下,旋转方法与LL旋转对称,步骤如下:
- 将根节点的右孩子作为新根节点。
- 将新根节点的左孩子作为原根节点的右孩子。
- 将原根节点作为新根节点的左孩子。
RR旋转示意图如下:
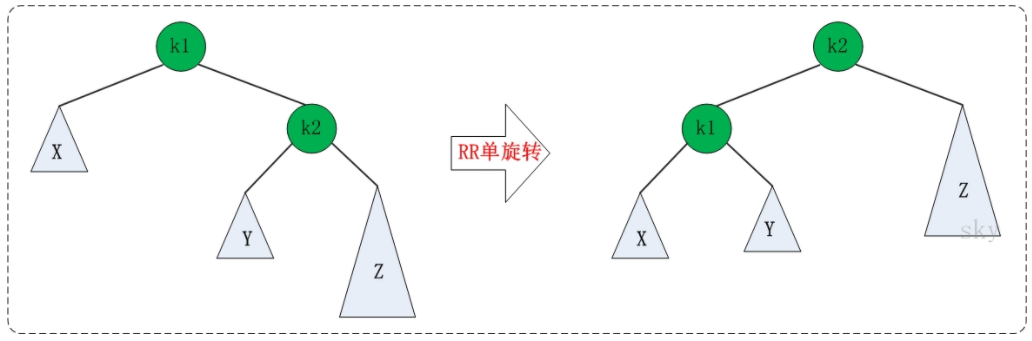
LR的旋转:LR失去平衡的情况下,需要进行两次旋转,步骤如下:
- 围绕根节点的左孩子进行RR旋转。
- 围绕根节点进行LL旋转。
LR的旋转示意图如下:
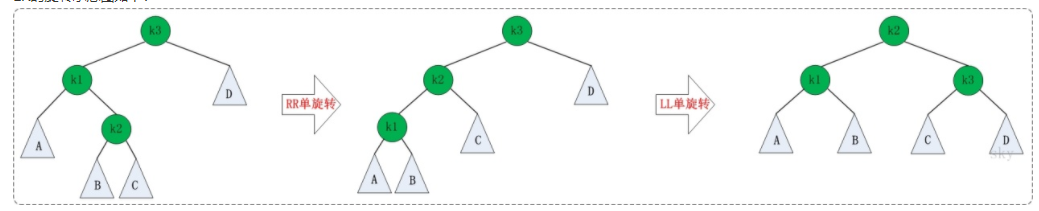
RL的旋转:RL失去平衡的情况下也需要进行两次旋转,旋转方法与LR旋转对称,步骤如下:
- 围绕根节点的右孩子进行LL旋转。
- 围绕根节点进行RR旋转。
RL的旋转示意图如下:

平衡多路查找树(B-Tree)
B-Tree是为磁盘等外存储设备设计的一种平衡查找树。因此在讲B-Tree之前先了解下磁盘的相关知识。
系统从磁盘读取数据到内存时是以磁盘块(block)为基本单位的,位于同一个磁盘块中的数据会被一次性读取出来,而不是需要什么取什么。
InnoDB存储引擎中有页(Page)的概念,页是其磁盘管理的最小单位。InnoDB存储引擎中默认每个页的大小为16KB,可通过参数innodb_page_size将页的大小设置为4K、8K、16K,在MySQL中可通过如下命令查看页的大小:
mysql> show variables like ''innodb_page_size'';1- 1
而系统一个磁盘块的存储空间往往没有这么大,因此InnoDB每次申请磁盘空间时都会是若干地址连续磁盘块来达到页的大小16KB。InnoDB在把磁盘数据读入到磁盘时会以页为基本单位,在查询数据时如果一个页中的每条数据都能有助于定位数据记录的位置,这将会减少磁盘I/O次数,提高查询效率。
B-Tree结构的数据可以让系统高效的找到数据所在的磁盘块。为了描述B-Tree,首先定义一条记录为一个二元组[key, data] ,key为记录的键值,对应表中的主键值,data为一行记录中除主键外的数据。对于不同的记录,key值互不相同。
一棵m阶的B-Tree有如下特性:
\1. 每个节点最多有m个孩子。
\2. 除了根节点和叶子节点外,其它每个节点至少有Ceil(m/2)个孩子。
\3. 若根节点不是叶子节点,则至少有2个孩子
\4. 所有叶子节点都在同一层,且不包含其它关键字信息
\5. 每个非终端节点包含n个关键字信息(P0,P1,…Pn, k1,…kn)
\6. 关键字的个数n满足:ceil(m/2)-1 <= n <= m-1
\7. ki(i=1,…n)为关键字,且关键字升序排序。
\8. Pi(i=1,…n)为指向子树根节点的指针。P(i-1)指向的子树的所有节点关键字均小于ki,但都大于k(i-1)
B-Tree中的每个节点根据实际情况可以包含大量的关键字信息和分支,如下图所示为一个3阶的B-Tree:
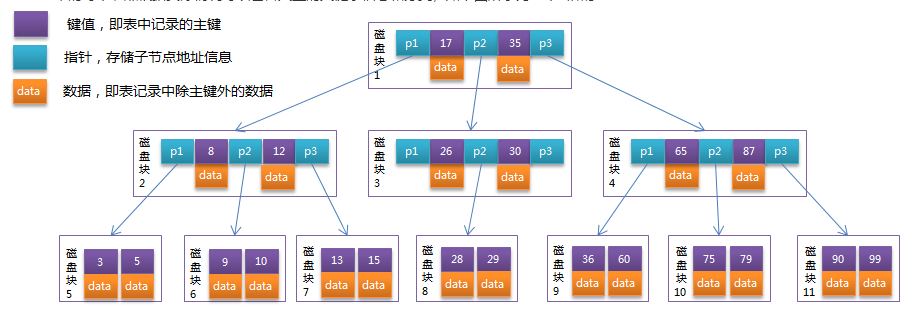
每个节点占用一个盘块的磁盘空间,一个节点上有两个升序排序的关键字和三个指向子树根节点的指针,指针存储的是子节点所在磁盘块的地址。两个关键词划分成的三个范围域对应三个指针指向的子树的数据的范围域。以根节点为例,关键字为17和35,P1指针指向的子树的数据范围为小于17,P2指针指向的子树的数据范围为17~35,P3指针指向的子树的数据范围为大于35。
模拟查找关键字29的过程:
- 根据根节点找到磁盘块1,读入内存。【磁盘I/O操作第1次】
- 比较关键字29在区间(17,35),找到磁盘块1的指针P2。
- 根据P2指针找到磁盘块3,读入内存。【磁盘I/O操作第2次】
- 比较关键字29在区间(26,30),找到磁盘块3的指针P2。
- 根据P2指针找到磁盘块8,读入内存。【磁盘I/O操作第3次】
- 在磁盘块8中的关键字列表中找到关键字29。
分析上面过程,发现需要3次磁盘I/O操作,和3次内存查找操作。由于内存中的关键字是一个有序表结构,可以利用二分法查找提高效率。而3次磁盘I/O操作是影响整个B-Tree查找效率的决定因素。B-Tree相对于AVLTree缩减了节点个数,使每次磁盘I/O取到内存的数据都发挥了作用,从而提高了查询效率。
B+Tree
B+Tree是在B-Tree基础上的一种优化,使其更适合实现外存储索引结构,InnoDB存储引擎就是用B+Tree实现其索引结构。
从上一节中的B-Tree结构图中可以看到每个节点中不仅包含数据的key值,还有data值。而每一个页的存储空间是有限的,如果data数据较大时将会导致每个节点(即一个页)能存储的key的数量很小,当存储的数据量很大时同样会导致B-Tree的深度较大,增大查询时的磁盘I/O次数,进而影响查询效率。在B+Tree中,所有数据记录节点都是按照键值大小顺序存放在同一层的叶子节点上,而非叶子节点上只存储key值信息,这样可以大大加大每个节点存储的key值数量,降低B+Tree的高度。
B+Tree相对于B-Tree有几点不同:
- 非叶子节点只存储键值信息。
- 所有叶子节点之间都有一个链指针。
- 数据记录都存放在叶子节点中。
将上一节中的B-Tree优化,由于B+Tree的非叶子节点只存储键值信息,假设每个磁盘块能存储4个键值及指针信息,则变成B+Tree后其结构如下图所示:
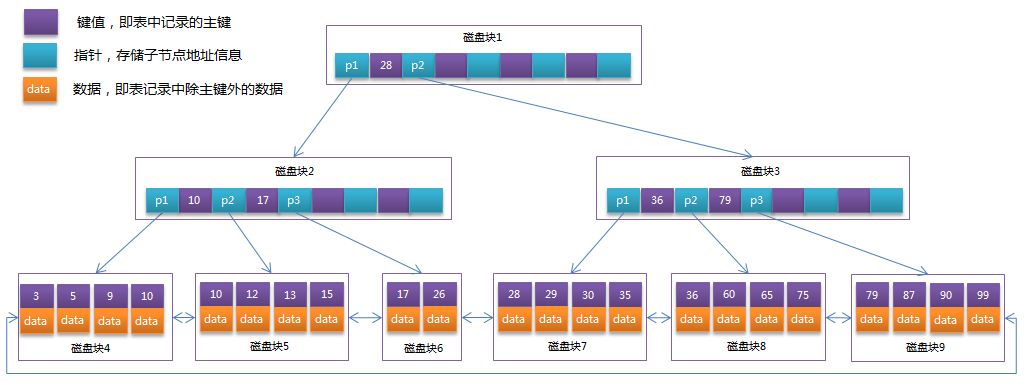
通常在B+Tree上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点,而且所有叶子节点(即数据节点)之间是一种链式环结构。因此可以对B+Tree进行两种查找运算:一种是对于主键的范围查找和分页查找,另一种是从根节点开始,进行随机查找。
可能上面例子中只有22条数据记录,看不出B+Tree的优点,下面做一个推算:
InnoDB存储引擎中页的大小为16KB,一般表的主键类型为INT(占用4个字节)或BIGINT(占用8个字节),指针类型也一般为4或8个字节,也就是说一个页(B+Tree中的一个节点)中大概存储16KB/(8B+8B)=1K个键值(因为是估值,为方便计算,这里的K取值为〖10〗^3)。也就是说一个深度为3的B+Tree索引可以维护10^3 * 10^3 * 10^3 = 10亿 条记录。
实际情况中每个节点可能不能填充满,因此在数据库中,B+Tree的高度一般都在2~4层。MySQL的InnoDB存储引擎在设计时是将根节点常驻内存的,也就是说查找某一键值的行记录时最多只需要1~3次磁盘I/O操作。
数据库中的B+Tree索引可以分为聚集索引(clustered index)和辅助索引(secondary index)。上面的B+Tree示例图在数据库中的实现即为聚集索引,聚集索引的B+Tree中的叶子节点存放的是整张表的行记录数据。辅助索引与聚集索引的区别在于辅助索引的叶子节点并不包含行记录的全部数据,而是存储相应行数据的聚集索引键,即主键。当通过辅助索引来查询数据时,InnoDB存储引擎会遍历辅助索引找到主键,然后再通过主键在聚集索引中找到完整的行记录数据

2020-06-25:B+树和B树有什么区别?
参考答案如下:
B树:1.叶子节点和非叶子节点都存数据。2.数据无链指针。
B+树:1.只有叶子节点存数据。2.数据有链指针。
B树优势:1.靠近根节点的数据,访问速度快。
B+树优势:1.一页内存可以容纳更多的键,访问数据需要更少的缓存未命中。2.全面扫描只需要扫描叶子节点。
评论

b-树和b+树以及mysql索引
b-树(m阶):
1.根节点至少有2个子节点;
2.中间节点包含k个子节点和k-1个元素,m/2 <= k <= m;
3.每个节点中的元素从小到大排列,节点当中k-1个元素正好是k个孩子包含的元素的值域分划;
4.每一个叶子节点都包含k-1个元素,其中 m/2 <= k <= m;
5.所有叶子节点都在同一层。
b+树(m阶):
在b-树的基础上添加了新的特性:
1.有k个子树的中间节点包含有k个元素(B树中是k-1个元素),每个元素不保存数据,只存储索引,所有数据都保存在叶子节点。
2.所有的叶子结点中包含了全部元素的信息,及指向含这些元素记录的指针,且叶子结点本身依关键字的大小自小而大顺序链接。
3.所有的中间节点元素都同时存在于子节点,在子节点元素中是最大(或最小)元素。
b+树相比b-树优点:
1.io次数少:b+树中间节点只存索引,不存在实际的数据,所以可以存储更多的数据。索引树更加的矮胖,io次数更少。
2.性能稳定:b+树数据只存在于叶子节点,查询性能稳定
3.范围查询简单:b+树不需要中序遍历,遍历链表即可
mysql索引:
索引字段要尽量小:通过上面的分析,我们知道IO次数取决于b+数的高度h,假设当前数据表的数据为N,每个磁盘块的数据项的数量是m,则有h=㏒(m+1)N,当数据量N一定的情况下,m越大,h越小;而m = 磁盘块的大小 / 数据项的大小,磁盘块的大小也就是一个数据页的大小,是固定的,如果数据项占的空间越小,数据项的数量越多,树的高度越低。这就是为什么每个数据项,即索引字段要尽量的小,比如int占4字节,要比bigint8字节少一半。这也是为什么b+树要求把真实的数据放到叶子节点而不是内层节点,一旦放到内层节点,磁盘块的数据项会大幅度下降,导致树增高。当数据项等于1时将会退化成线性表。
最左匹配特性:当b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+数是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道下一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。
过度使用索引的缺点:
1.在创建索引和维护索引 会耗费时间,随着数据量的增加而增加
2.索引文件会占用物理空间,除了数据表需要占用物理空间之外,每一个索引还会占用一定的物理空间
3.当对表的数据进行 INSERT,UPDATE,DELETE 的时候,索引也要动态的维护,这样就会降低数据的维护速度,(建立索引会占用磁盘空间的索引文件。一般情况这个问题不太严重,但如果你在一个大表上创建了多种组合索引,索引文件的会膨胀很快)

B-树和B+树的应用:数据搜索和数据库索引
B-树
1 .B-树定义
B-树是一种平衡的多路查找树,它在文件系统中很有用。
定义:一棵m 阶的B-树,或者为空树,或为满足下列特性的m 叉树:
⑴树中每个结点至多有m 棵子树;
⑵若根结点不是叶子结点,则至少有两棵子树;
⑶除根结点之外的所有非终端结点至少有[m/2] 棵子树;
⑷所有的非终端结点中包含以下信息数据:
(n,A0,K1,A1,K2,…,Kn,An)
其中:Ki(i=1,2,…,n)为关键码,且Ki<Ki+1,
Ai 为指向子树根结点的指针(i=0,1,…,n),且指针Ai-1 所指子树中所有结点的关键码均小于Ki (i=1,2,…,n),An 所指子树中所有结点的关键码均大于Kn.
n 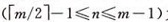 为关键码的个数。
为关键码的个数。
⑸所有的叶子结点都出现在同一层次上,并且不带信息(可以看作是外部结点或查找失败的结点,实际上这些结点不存在,指向这些结点的指针为空)。
即所有叶节点具有相同的深度,等于树高度。
如一棵四阶B-树,其深度为4.
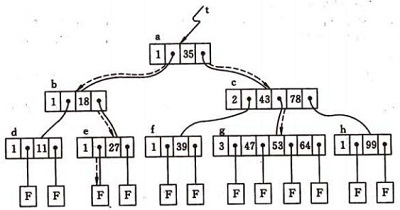
B-树的查找类似二叉排序树的查找,所不同的是B-树每个结点上是多关键码的有序表,在到达某个结点时,先在有序表中查找,若找到,则查找成功;否则,到按照对应的指针信息指向的子树中去查找,当到达叶子结点时,则说明树中没有对应的关键码。
在上图的B-树上查找关键字47的过程如下:
1)首先从更开始,根据根节点指针找到 *节点,因为 *a 节点中只有一个关键字,且给定值47 > 关键字35,则若存在必在指针A1所指的子树内。
2)顺指针找到 *c节点,该节点有两个关键字(43和 78),而43 < 47 < 78,若存在比在指针A1所指的子树中。
3)同样,顺指针找到 *g节点,在该节点找到关键字47,查找成功。
2. 查找算法
typedef int KeyType ;
#define m 5 /*B 树的阶,暂设为5*/
typedef struct Node{
int keynum; /* 结点中关键码的个数,即结点的大小*/
struct Node *parent; /*指向双亲结点*/
KeyType key[m+1]; /*关键码向量,0 号单元未用*/
struct Node *ptr[m+1]; /*子树指针向量*/
Record *recptr[m+1]; /*记录指针向量*/
}NodeType; /*B 树结点类型*/
typedef struct{
NodeType *pt; /*指向找到的结点*/
int i; /*在结点中的关键码序号,结点序号区间[1…m]*/
int tag; /* 1:查找成功,0:查找失败*/
}Result; /*B 树的查找结果类型*/
Result SearchBTree(NodeType *t,KeyType kx)
{
/*在m 阶B 树t 上查找关键码kx,反回(pt,i,tag)。若查找成功,则特征值tag=1,*/
/*指针pt 所指结点中第i 个关键码等于kx;否则,特征值tag=0,等于kx 的关键码记录*/
/*应插入在指针pt 所指结点中第i 个和第i+1 个关键码之间*/
p=t;q=NULL;found=FALSE;i=0; /*初始化,p 指向待查结点,q 指向p 的双亲*/
while(p&&!found)
{ n=p->keynum;i=Search(p,kx); /*在p-->key[1…keynum]中查找*/
if(i>0&&p->key[i]= =kx) found=TRUE; /*找到*/
else {q=p;p=p->ptr[i];}
}
if(found) return (p,i,1); /*查找成功*/
else return (q,i,0); /*查找不成功,反回kx 的插入位置信息*/
}
B- 树查找算法分析
从查找算法中可以看出, 在B- 树中进行查找包含两种基本操作:
( 1) 在B- 树中查找结点;
( 2) 在结点中查找关键字。
由于B- 树通常存储在磁盘上, 则前一查找操作是在磁盘上进行的, 而后一查找操作是在内存中进行的, 即在磁盘上找到指针p 所指结点后, 先将结点中的信息读入内存, 然后再利用顺序查找或折半查找查询等于K 的关键字。显然, 在磁盘上进行一次查找比在内存中进行一次查找的时间消耗多得多.
因此, 在磁盘上进行查找的次数、即待查找关键字所在结点在B- 树上的层次树, 是决定B树查找效率的首要因素
那么,对含有n 个关键码的m 阶B-树,最坏情况下达到多深呢?可按二叉平衡树进行类似分析。首先,讨论m 阶B-数各层上的最少结点数。
由B树定义:B树包含n个关键字。因此有n+1个树叶都在第J+1 层。
1)第一层为根,至少一个结点,根至少有两个孩子,因此在第二层至少有两个结点。
2)除根和树叶外,其它结点至少有[m/2]个孩子,因此第三层至少有2*[m/2]个结点,在第四层至少有2*[m/2]2 个结点…
3)那么在第J+1层至少有2*[m/2]J-1个结点,而J+1层的结点为叶子结点,于是叶子结点的个数n+1。有:

也就是说在n个关键字的B树查找,从根节点到关键字所在的节点所涉及的节点数不超过:
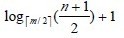
3.B-树的插入
B-树的生成也是从空树起,逐个插入关键字而得。但由于B-树结点中的关键字个数必须≥ceil(m/2)-1,因此,每次插入一个关键字不是在树中添加一个叶子结点,而是首先在最低层的某个非终端结点中添加一个关键字,若该结点的关键字个数不超过m-1,则插入完成,否则要产生结点的“分裂”,
如图(a) 为3阶的B-树(图中略去F结点(即叶子结点)),假设需依次插入关键字30,26,85。

1) 首先通过查找确定插入的位置。由根*a 起进行查找,确定30应插入的在*d 节点中。由于*d 中关键字数目不超过2(即m-1),故第一个关键字插入完成:如(b)

2) 同样,通过查找确定关键字26亦应插入 *d. 由于*d节点关键字数目超过2,此时需要将 *d分裂成两个节点,关键字26及其前、后两个指针仍保留在 *d 节点中,而关键字37 及其前、后两个指针存储到新的产生的节点 *d` 中。同时将关键字30 和指示节点 *d `的指针插入到其双亲的节点中。由于 *b节点中的关键字数目没有超过2,则插入完成.如(c)(d)


3) (e) -(g) 为插入85后;


插入算法:
int InserBTree(NodeType **t,KeyType kx,NodeType *q,int i){
/* 在m 阶B 树*t 上结点*q 的key[i],key[i+1]之间插入关键码kx*/
/*若引起结点过大,则沿双亲链进行必要的结点分裂调整,使*t仍为m 阶B 树*/
x=kx;ap=NULL;finished=FALSE;
while(q&&!finished)
{
Insert(q,i,x,ap); /*将x 和ap 分别插入到q->key[i+1]和q->ptr[i+1]*/
if(q->keynum<m) finished=TRUE; /*插入完成*/
else
{ /*分裂结点*p*/
s=m/2;split(q,ap);x=q->key[s];
/*将q->key[s+1…m],q->ptr[s…m]和q->recptr[s+1…m]移入新结点*ap*/
q=q->parent;
if(q) i=Search(q,kx); /*在双亲结点*q 中查找kx 的插入位置*/
}
}
if(!finished) /*(*t)是空树或根结点已分裂为*q*和ap*/
NewRoot(t,q,x,ap); /*生成含信息(t,x,ap)的新的根结点*t,原*t 和ap 为子树指针*/
}
4. B-树的删除
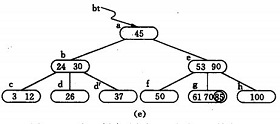
反之,若在B-树上删除一个关键字,则首先应找到该关键字所在结点,并从中删除之,若该结点为最下层的非终端结点,且其中的关键字数目不少于ceil(m/2),则删除完成,否则要进行“合并”结点的操作。假若所删关键字为非终端结点中的Ki,则可以指针Ai所指子树中的最小关键字Y替代Ki,然后在相应的结点中删去Y。例如,在下图 图4.1( a)的B-树上删去45,可以*f结点中的50替代45,然后在*f结点中删去50。
图4.1( a)
因此,下面我们可以只需讨论删除最下层非终端结点中的关键字的情形。有下列三种可能:
(1)被删关键字所在结点中的关键字数目不小于ceil(m/2),则只需从该结点中删去该关键字Ki和相应指针Ai,树的其它部分不变,例如,从图 图4.1( a)所示B-树中删去关键字12,删除后的B-树如图 图4.2( a)所示:

图4.2( a)
(2)被删关键字所在结点中的关键字数目等于ceil(m/2)-1,而与该结点相邻的右兄弟(或左兄弟)结点中的关键字数目大于ceil(m/2)-1,则需将其兄弟结点中的最小(或最大)的关键字上移至双亲结点中,而将双亲结点中小于(或大于)且紧靠该上移关键字的关键字下移至被删关键字所在结点中。
[例如],从图图4.2( a)中删去50,需将其右兄弟结点中的61上移至*e结点中,而将*e结点中的53移至*f,从而使*f和*g中关键字数目均不小于ceil(m-1)-1,而双亲结点中的关键字数目不变,如图图4.2(b)所示。

图4.2(b)
(3)被删关键字所在结点和其相邻的兄弟结点中的关键字数目均等于ceil(m/2)-1。假设该结点有右兄弟,且其右兄弟结点地址由双亲结点中的指针Ai所指,则在删去关键字之后,它所在结点中剩余的关键字和指针,加上双亲结点中的关键字Ki一起,合并到 Ai所指兄弟结点中(若没有右兄弟,则合并至左兄弟结点中)。
[例如],从图4.2(b)所示 B-树中删去53,则应删去*f结点,并将*f中的剩余信息(指针“空”)和双亲*e结点中的 61一起合并到右兄弟结点*g中。删除后的树如图4.2(c)所示。

图4.2(c)
如果因此使双亲结点中的关键字数目小于ceil(m/2)-1,则依次类推。
[例如],在 图4.2(c)的B-树中删去关键字37之后,双亲b结点中剩余信息(“指针c”)应和其双亲*a结点中关键字45一起合并至右兄弟结点*e中,删除后的B-树如图 4.2(d)所示。 
图 4.2(d)
B-树主要应用在文件系统
为了将大型数据库文件存储在硬盘上 以减少访问硬盘次数为目的 在此提出了一种平衡多路查找树——B-树结构 由其性能分析可知它的检索效率是相当高的 为了提高 B-树性能’还有很多种B-树的变型,力图对B-树进行改进
B+树
B+树是应文件系统所需而产生的一种B-树的变形树。一棵m 阶的B+树和m 阶的B-
树的差异在于:
⑴有n 棵子树的结点中含有n 个关键码;
⑵所有的叶子结点中包含了全部关键码的信息,及指向含有这些关键码记录的指针,且
叶子结点本身依关键码的大小自小而大的顺序链接。
⑶所有的非终端结点可以看成是索引部分,结点中仅含有其子树根结点中最大(或最小)关键码。
如图一棵3阶的B+树:

通常在B+树上有两个头指针,一个指向根节点,另一个指向关键字最小的叶子节点。因此可以对B+树进行两种查找运算:一种是从最小关键字起顺序查找,另一种是从根节点开始,进行随机查找。
在B+树上进行随机查找、插入和删除的过程基本上与B-树类似。只是在查找时,若非终端结点上的关键码等于给定值,并不终止,而是继续向下直到叶子结点。因此,在B+
树,不管查找成功与否,每次查找都是走了一条从根到叶子结点的路径。
B+树在数据库中的应用
1. 索引在数据库中的作用
在数据库系统的使用过程当中,数据的查询是使用最频繁的一种数据操作。
最基本的查询算法当然是顺序查找(linear search),遍历表然后逐行匹配行值是否等于待查找的关键字,其时间复杂度为O(n)。但时间复杂度为O(n)的算法规模小的表,负载轻的数据库,也能有好的性能。 但是数据增大的时候,时间复杂度为O(n)的算法显然是糟糕的,性能就很快下降了。
好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
索引是对数据库表 中一个或多个列的值进行排序的结构。与在表 中搜索所有的行相比,索引用指针 指向存储在表中指定列的数据值,然后根据指定的次序排列这些指针,有助于更快地获取信息。通常情 况下 ,只有当经常查询索引列中的数据时 ,才需要在表上创建索引。索引将占用磁盘空间,并且影响数 据更新的速度。但是在多数情况下 ,索引所带来的数据检索速度优势大大超过它的不足之处。
2. B+树在数据库索引中的应用
目前大部分数据库系统及文件系统都采用B-Tree或其变种B+Tree作为索引结构
1)在数据库索引的应用
在数据库索引的应用中,B+树按照下列方式进行组织 :
① 叶结点的组织方式 。B+树的查找键 是数据文件的主键 ,且索引是稠密的。也就是说 ,叶结点 中为数据文件的第一个记录设有一个键、指针对 ,该数据文件可以按主键排序,也可以不按主键排序 ;数据文件按主键排序,且 B +树是稀疏索引 , 在叶结点中为数据文件的每一个块设有一个键、指针对 ;数据文件不按键属性排序 ,且该属性是 B +树 的查找键 , 叶结点中为数据文件里出现的每个属性K设有一个键 、 指针对 , 其中指针执行排序键值为 K的 记录中的第一个。
② 非叶结点 的组织方式。B+树 中的非叶结点形成 了叶结点上的一个多级稀疏索引。 每个非叶结点中至少有ceil( m/2 ) 个指针 , 至多有 m 个指针 。
2)B+树索引的插入和删除
①在向数据库中插入新的数据时,同时也需要向数据库索引中插入相应的索引键值 ,则需要向 B+树 中插入新的键值。即上面我们提到的B-树插入算法。
②当从数据库中删除数据时,同时也需要从数据库索引中删除相应的索引键值 ,则需要从 B+树 中删 除该键值 。即B-树删除算法
为什么使用B-Tree(B+Tree)
二叉查找树进化品种的红黑树等数据结构也可以用来实现索引,但是文件系统及数据库系统普遍采用B-/+Tree作为索引结构。
一般来说,索引本身也很大,不可能全部存储在内存中,因此索引往往以索引文件的形式存储的磁盘上。这样的话,索引查找过程中就要产生磁盘I/O消耗,相对于内存存取,I/O存取的消耗要高几个数量级,所以评价一个数据结构作为索引的优劣最重要的指标就是在查找过程中磁盘I/O操作次数的渐进复杂度。换句话说,索引的结构组织要尽量减少查找过程中磁盘I/O的存取次数。为什么使用B-/+Tree,还跟磁盘存取原理有关。
局部性原理与磁盘预读
由于存储介质的特性,磁盘本身存取就比主存慢很多,再加上机械运动耗费,磁盘的存取速度往往是主存的几百分分之一,因此为了提高效率,要尽量减少磁盘I/O。为了达到这个目的,磁盘往往不是严格按需读取,而是每次都会预读,即使只需要一个字节,磁盘也会从这个位置开始,顺序向后读取一定长度的数据放入内存。这样做的理论依据是计算机科学中著名的局部性原理:
当一个数据被用到时,其附近的数据也通常会马上被使用。
程序运行期间所需要的数据通常比较集中。
由于磁盘顺序读取的效率很高(不需要寻道时间,只需很少的旋转时间),因此对于具有局部性的程序来说,预读可以提高I/O效率。
预读的长度一般为页(page)的整倍数。页是计算机管理存储器的逻辑块,硬件及操作系统往往将主存和磁盘存储区分割为连续的大小相等的块,每个存储块称为一页(在许多操作系统中,页得大小通常为4k),主存和磁盘以页为单位交换数据。当程序要读取的数据不在主存中时,会触发一个缺页异常,此时系统会向磁盘发出读盘信号,磁盘会找到数据的起始位置并向后连续读取一页或几页载入内存中,然后异常返回,程序继续运行。
我们上面分析B-/+Tree检索一次最多需要访问节点:
h =
![]()
数据库系统巧妙利用了磁盘预读原理,将一个节点的大小设为等于一个页,这样每个节点只需要一次I/O就可以完全载入。为了达到这个目的,在实际实现B- Tree还需要使用如下技巧:
每次新建节点时,直接申请一个页的空间,这样就保证一个节点物理上也存储在一个页里,加之计算机存储分配都是按页对齐的,就实现了一个node只需一次I/O。
B-Tree中一次检索最多需要h-1次I/O(根节点常驻内存),渐进复杂度为O(h)=O(logmN)。一般实际应用中,m是非常大的数字,通常超过100,因此h非常小(通常不超过3)。
综上所述,用B-Tree作为索引结构效率是非常高的。
而红黑树这种结构,h明显要深的多。由于逻辑上很近的节点(父子)物理上可能很远,无法利用局部性,所以红黑树的I/O渐进复杂度也为O(h),效率明显比B-Tree差很多。
MySQL的B-Tree索引(技术上说B+Tree)
在 MySQL 中,主要有四种类型的索引,分别为: B-Tree 索引, Hash 索引, Fulltext 索引和 R-Tree 索引。我们主要分析B-Tree 索引。
B-Tree 索引是 MySQL 数据库中使用最为频繁的索引类型,除了 Archive 存储引擎之外的其他所有的存储引擎都支持 B-Tree 索引。Archive 引擎直到 MySQL 5.1 才支持索引,而且只支持索引单个 AUTO_INCREMENT 列。
不仅仅在 MySQL 中是如此,实际上在其他的很多数据库管理系统中B-Tree 索引也同样是作为最主要的索引类型,这主要是因为 B-Tree 索引的存储结构在数据库的数据检索中有非常优异的表现。
一般来说, MySQL 中的 B-Tree 索引的物理文件大多都是以 Balance Tree 的结构来存储的,也就是所有实际需要的数据都存放于 Tree 的 Leaf Node(叶子节点) ,而且到任何一个 Leaf Node 的最短路径的长度都是完全相同的,所以我们大家都称之为 B-Tree 索引。当然,可能各种数据库(或 MySQL 的各种存储引擎)在存放自己的 B-Tree 索引的时候会对存储结构稍作改造。如 Innodb 存储引擎的 B-Tree 索引实际使用的存储结构实际上是 B+Tree,也就是在 B-Tree 数据结构的基础上做了很小的改造,在每一个Leaf Node 上面出了存放索引键的相关信息之外,还存储了指向与该 Leaf Node 相邻的后一个 LeafNode 的指针信息(增加了顺序访问指针),这主要是为了加快检索多个相邻 Leaf Node 的效率考虑。
下面主要讨论MyISAM和InnoDB两个存储引擎的索引实现方式:
1. MyISAM索引实现:
1)主键索引:
MyISAM引擎使用B+Tree作为索引结构,叶节点的data域存放的是数据记录的地址。下图是MyISAM主键索引的原理图:

(图myisam1)
这里设表一共有三列,假设我们以Col1为主键,图myisam1是一个MyISAM表的主索引(Primary key)示意。可以看出MyISAM的索引文件仅仅保存数据记录的地址。
2)辅助索引(Secondary key)
在MyISAM中,主索引和辅助索引(Secondary key)在结构上没有任何区别,只是主索引要求key是唯一的,而辅助索引的key可以重复。如果我们在Col2上建立一个辅助索引,则此索引的结构如下图所示:

同样也是一颗B+Tree,data域保存数据记录的地址。因此,MyISAM中索引检索的算法为首先按照B+Tree搜索算法搜索索引,如果指定的Key存在,则取出其data域的值,然后以data域的值为地址,读取相应数据记录。
MyISAM的索引方式也叫做“非聚集”的,之所以这么称呼是为了与InnoDB的聚集索引区分。
2. InnoDB索引实现
然InnoDB也使用B+Tree作为索引结构,但具体实现方式却与MyISAM截然不同.
1)主键索引:
MyISAM索引文件和数据文件是分离的,索引文件仅保存数据记录的地址。而在InnoDB中,表数据文件本身就是按B+Tree组织的一个索引结构,这棵树的叶节点data域保存了完整的数据记录。这个索引的key是数据表的主键,因此InnoDB表数据文件本身就是主索引。
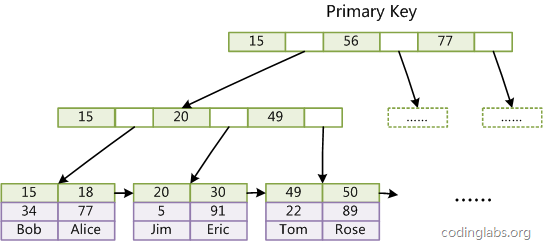
(图inndb主键索引)
(图inndb主键索引)是InnoDB主索引(同时也是数据文件)的示意图,可以看到叶节点包含了完整的数据记录。这种索引叫做聚集索引。因为InnoDB的数据文件本身要按主键聚集,所以InnoDB要求表必须有主键(MyISAM可以没有),如果没有显式指定,则MySQL系统会自动选择一个可以唯一标识数据记录的列作为主键,如果不存在这种列,则MySQL自动为InnoDB表生成一个隐含字段作为主键,这个字段长度为6个字节,类型为长整形。
2). InnoDB的辅助索引
InnoDB的所有辅助索引都引用主键作为data域。例如,下图为定义在Col3上的一个辅助索引:

InnoDB 表是基于聚簇索引建立的。因此InnoDB 的索引能提供一种非常快速的主键查找性能。不过,它的辅助索引(Secondary Index, 也就是非主键索引)也会包含主键列,所以,如果主键定义的比较大,其他索引也将很大。如果想在表上定义 、很多索引,则争取尽量把主键定义得小一些。InnoDB 不会压缩索引。
文字符的ASCII码作为比较准则。聚集索引这种实现方式使得按主键的搜索十分高效,但是辅助索引搜索需要检索两遍索引:首先检索辅助索引获得主键,然后用主键到主索引中检索获得记录。
不同存储引擎的索引实现方式对于正确使用和优化索引都非常有帮助,例如知道了InnoDB的索引实现后,就很容易明白为什么不建议使用过长的字段作为主键,因为所有辅助索引都引用主索引,过长的主索引会令辅助索引变得过大。再例如,用非单调的字段作为主键在InnoDB中不是个好主意,因为InnoDB数据文件本身是一颗B+Tree,非单调的主键会造成在插入新记录时数据文件为了维持B+Tree的特性而频繁的分裂调整,十分低效,而使用自增字段作为主键则是一个很好的选择。
InnoDB索引和MyISAM索引的区别:
一是主索引的区别,InnoDB的数据文件本身就是索引文件。而MyISAM的索引和数据是分开的。
二是辅助索引的区别:InnoDB的辅助索引data域存储相应记录主键的值而不是地址。而MyISAM的辅助索引和主索引没有多大区别。

B树和B+树
简介
在计算机科学中,B树(英语:B-tree)是一种自平衡的树,能够保持数据有序。这种数据结构能够让查找数据、顺序访问、插入数据及删除的动作,都在对数时间内完成。B树,概括来说是一个一般化的二叉查找树(binary search tree),可以拥有多于2个子节点。与自平衡二叉查找树不同,B树为系统大块数据的读写操作做了优化。B树减少定位记录时所经历的中间过程,从而加快存取速度。B树这种数据结构可以用来描述外部存储。这种数据结构常被应用在数据库和文件系统的实现上。
定义
B-Tree is a self-balanced search tree with multiple keys in every node and more than two children for every node.B树是一种自平衡的搜索树,每一个节点node都有多个keys,并且每个节点有2个子节点或者多于2个子节点。
A B+ tree is an N-ary tree with a variable but often large number of children per node. A B+ tree consists of a root, internal nodes and leaves.The root may be either a leaf or a node with two or more childrenB+树是一个n叉排序树,通常每个节点有多个孩子,一棵B+树包含一个根节点、多个内部节点和叶子节点。根节点可能是一个叶子节点,也可能是一个包含两个或两个以上孩子节点的节点。
特征
B-Tree of Order m has the following properties...
-
Property #1- All the leaf nodes must be at same level. -
Property #2- All nodes except root must have at least [m/2]-1 keys and maximum of m-1 keys. -
Property #3- All non leaf nodes except root (i.e. all internal nodes) must have at least m/2 children. -
Property #4- If the root node is a non leaf node, then it must have at least 2 children. -
Property #5- A non leaf node with n-1 keys must have n number of children. -
Property #6- All the key values within a node must be in Ascending Order.
搜寻方法
In a B-Ttree, the search operation is similar to that of Binary Search Tree. In a Binary search tree, the search process starts from the root node and every time we make a 2-way decision (we go to either left subtree or right subtree). In B-Tree also search process starts from the root node but every time we make n-way decision where n is the total number of children that node has. In a B-Ttree, the search operation is performed with O(log n) time complexity. The search operation is performed as follows...
- Step 1: Read the search element from the user
- Step 2: Compare, the search element with first key value of root node in the tree.
- Step 3: If both are matching, then display "Given node found!!!" and terminate the function
- Step 4: If both are not matching, then check whether search element is smaller or larger than that key value.
- Step 5: If search element is smaller, then continue the search process in left subtree.
- Step 6: If search element is larger, then compare with next key value in the same node and repeate step 3, 4, 5 and 6 until we found exact match or comparision completed with last key value in a leaf node.
- Step 7: If we completed with last key value in a leaf node, then display "Element is not found" and terminate the function.
大致的意思就是查询的条件A,和root节点值比较,如果相等则success,不相等则判断是否小于该节点,小于则查询左子树,大于则查询此时节点的下一个值,以此类推,直到此时节点最后一个值还是小于A,则查询右子树,直到找到或者结束查找。
插入方法
Insertion Operation in B-Tree
In a B-Tree, the new element must be added only at leaf node. That means, always the new keyValue is attached to leaf node only. The insertion operation is performed as follows...
- Step 1: Check whether tree is Empty.
- Step 2: If tree is Empty, then create a new node with new key value and insert into the tree as a root node.
- Step 3: If tree is Not Empty, then find a leaf node to which the new key value cab be added using Binary Search Tree logic.
- Step 4: If that leaf node has an empty position, then add the new key value to that leaf node by maintaining ascending order of key value within the node.
- Step 5: If that leaf node is already full, then split that leaf node by sending middle value to its parent node. Repeat tha same until sending value is fixed into a node.
- Step 6: If the spilting is occuring to the root node, then the middle value becomes new root node for the tree and the height of the tree is increased by one.


删除方法
参考8的链接,有图有真相,这里就摘录一些重点文字条件吧。
k:删除的值
x: k所在的节点
x.n: k所在节点的长度
t: k所在节点的层级- If k is in the node x which is a leaf and x.n>=t,
Here you can straightaway delete k from x.
-
If k is in the node x which is a leaf and x.n == (t-1)
Find the immediate sibling y of x, the extreme key m of y, the parent p of x and the parent key l of k If y.n >= t: Move l into x Move m into p Delete k from xFind the immediate sibling y of x, the extreme key m of y, the parent p of x and the parent key l of k If y.n == t-1: Merge x and y Move down l to the new node as the median key Delete k from the new node -
If k is in the node x and x is an internal node (not a leaf)
Find the child node y that precedes k (the node which is on the left side of k) If y.n >= t: Find the key k’ in y which is the predecessor of k Delete k’ recursively. (Here k’ can be another internal node as well. So we have to delete it recursively in the same way) Replace k with k’ in xFind the child node y that precedes k If y.n < t (or y.n == (t-1)): Find the child node z that follows k (the node which is on the right side of k) If z.n >= t: Find k’’ in z which is the successor of k Delete k’’ recursively Replace k with k’’ in xFind the child node y that precedes k and the child node z that follows k If y.n == (t-1) AND z.n == (t-1): Merge k and z to y Free memory of node z Recursively delete k from y
B-树和B+树区别
B和B+树的区别在于,B+树的非叶子结点只包含key信息,不包含data,每个节点的指针上限为2t而不是2t+1.所有的叶子结点和相连的节点使用链表相连,便于区间查找和遍历。

综述
磁盘存储和mysql的索引这一块用的比较多,以空间换时间来提升查找速度。(图片基本是从参考链接那边拿过来的,站在前人的肩膀上。)
参考
- https://zh.wikipedia.org/wiki/B%E6%A0%91
- http://blog.codinglabs.org/articles/theory-of-mysql-index.html
- http://btechsmartclass.com/DS/U5_T3.html
- http://www.cnblogs.com/yangecnu/p/Introduce-B-Tree-and-B-Plus-Tree.html
- https://www.geeksforgeeks.org/b-tree-set-1-introduction-2/
- https://www.geeksforgeeks.org/b-tree-set-1-insert-2/
- https://www.geeksforgeeks.org/b-tree-set-3delete/
- https://medium.com/@vijinimallawaarachchi/all-you-need-to-know-about-deleting-keys-from-b-trees-9090f3334b5c
今天的关于SQL 技巧:B树和B+树原理及在索引中的应用和数据库b树和b+树的分享已经结束,谢谢您的关注,如果想了解更多关于2020-06-25:B+树和B树有什么区别?、b-树和b+树以及mysql索引、B-树和B+树的应用:数据搜索和数据库索引、B树和B+树的相关知识,请在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

