对于想了解Python:Seleniumxpath查找不区分大小写字符的元素吗?的读者,本文将提供新的信息,我们将详细介绍python查找大写字母,并且为您提供关于PythonSeleniumdriv
对于想了解Python:Selenium xpath查找不区分大小写字符的元素吗?的读者,本文将提供新的信息,我们将详细介绍python查找大写字母,并且为您提供关于Python Selenium driver.find_element_by_xpath 在 iframe 中找不到元素、Python selenium PO By.XPATH 定位元素报错、python selenium xpath 定位方式、Python selenium 使用 xpath 和 for 循环提取元素的有价值信息。
本文目录一览:- Python:Selenium xpath查找不区分大小写字符的元素吗?(python查找大写字母)
- Python Selenium driver.find_element_by_xpath 在 iframe 中找不到元素
- Python selenium PO By.XPATH 定位元素报错
- python selenium xpath 定位方式
- Python selenium 使用 xpath 和 for 循环提取元素
")
Python:Selenium xpath查找不区分大小写字符的元素吗?(python查找大写字母)
我能够做到这一点
search = "View List"driver.find_elements_by_xpath("//*/text()[normalize-space(.)=''%s'']/parent::*" % search)但是我需要它忽略和匹配所有元素,例如“ VieW LiSt”或“ view LIST”
search = "View List"driver.find_elements_by_xpath("//*/lower-case(text())[normalize-space(.)=''%s'']/parent::*" % search.lower())以上似乎不起作用。lower-case()在XPATH 1.0中
答案1
小编典典lower-case()仅XPath 2.0支持此功能。对于XPath 1.0,您必须使用translate()。
编辑:Selenium python绑定站点有一个常见问题解答-Selenium 2是否支持XPath
2.0?:
参考:http : //seleniumhq.org/docs/03_webdriver.html#how-xpath-works-in-
webdriverSelenium委托XPath向下查询到浏览器自己的XPath引擎,因此Selenium支持XPath支持浏览器支持的任何内容。在没有本地XPath引擎(IE 6,7,8)的浏览器中,Selenium仅支持XPath 1.0。

Python Selenium driver.find_element_by_xpath 在 iframe 中找不到元素
试试这样使用:
driver = webdriver.Chrome()
driver.get(URL)
driver.implicitly_wait(5)
driver.switch_to.frame(driver.find_element(By.TAG_NAME,'iframe'))
element = driver.find_element(By.XPATH,'//div[@]')
driver.quit()
如果它与您在代码中所做的相同,请提供更多信息以查看页面
试试这个,它会移动到第一类游戏的第一个游戏并获取所有的分数并打印出来:
import time
from selenium import webdriver
driver = webdriver.Chrome()
driver.get('https://campobet.se/en/sport/prelive?sportids=66')
time.sleep(5)
driver.switch_to.frame(
driver.find_element_by_xpath("//iframe[contains(@src,'https://sb1client-altenar.biahosted.com')]"))
time.sleep(1)
game_types = driver.find_elements_by_xpath("//div[@name='leagues-selector']")
time.sleep(1)
game_types[0].click()
time.sleep(1)
games = driver.find_elements_by_xpath(
"//div[@]")
games[0].click()
time.sleep(1)
scores = driver.find_elements_by_xpath("//div[@]/span")
time.sleep(1)
scores_values = [el.text for el in scores]
time.sleep(1)
print(scores_values)
driver.quit()

Python selenium PO By.XPATH 定位元素报错
Python selenium PO By.XPATH 定位元素报错
如下代码经常报错:
# 首页的“新建投放计划”按钮
new_ads_plan = (By.XPATH, "//*[text()=''百度新闻'']/..")
print(type(self.new_ads_plan))
self.driver.find_element(self.new_ads_plan).click()
运行经常报错:
selenium.common.exceptions.WebDriverException: Message: invalid argument: ''using'' must be a string
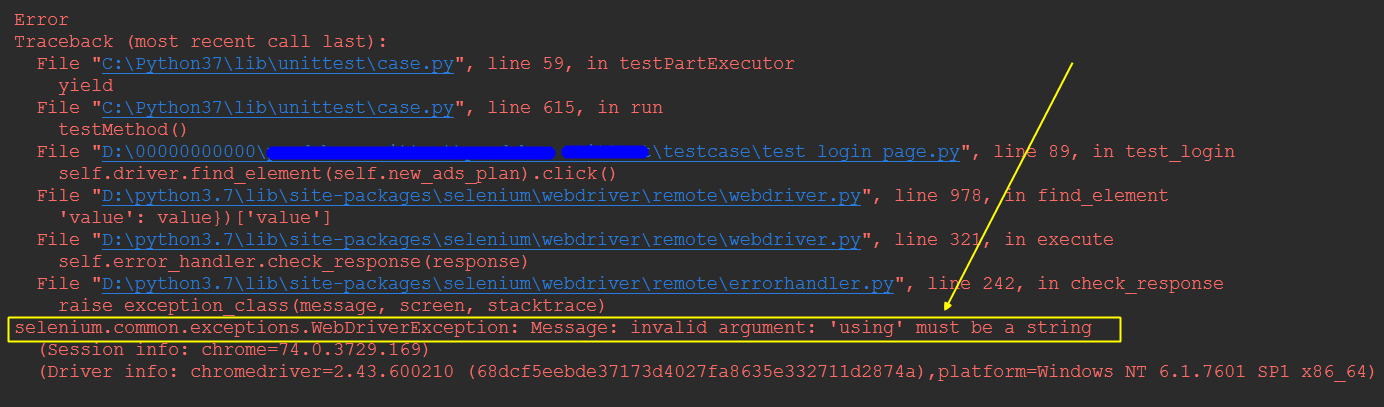
解决办法:
self.driver.find_element(*self.new_ads_plan).click()在参数里面的元素定位 self 前加一个星号 *
=============================================================================================================================================================================================================================
new_ads_plan = (By.XPATH, "//*[text()=''百度新闻'']")
shouye = (By.XPATH, "//a[text()= ''首页'']")
zanTing = (By.XPATH, "//span[text()= ''删 除'']")
bianji = (By.XPATH, "//span[text()= ''编 辑'']")
addSuCai = (By.XPATH, "//span[text()= ''添加'']")
def isElementExists(self, *loc):
flag = True
try:
for num in range(0, len(loc)):
print(str(loc[num]))
self.driver.find_element(*loc[num])
return flag
except:
flag = False
return flag
# 判断元素是否显示
def is_ElementExists(self):
return self.isElementExists((self.new_ads_plan),
(self.shouye),
(self.zanTing),
(self.bianji),
(self.addSuCai))
# 此处必须将多个定位元素的入参以元祖的形式填入,每一个元素的定位参数都是一个数组。

python selenium xpath 定位方式
xpath 是一种在 xm 文档中定位的语言,详细简介,请自行参照百度百科,本文主要总结一下 xpath 的使用方法,个人看法,如有不足和错误,敬请指出。
注意:xpath 的定位 同一级别的多个标签 索引从 1 开始 而不是 0
1. 绝对定位:
此方法最为简单,具体格式为
xxx.find_element_by_xpath ("绝对路径")
具体例子:
xxx.find_element_by_xpath ("/html/body/div [x]/form/input") x 代表第 x 个 div 标签,注意,索引从 1 开始而不是 0
此方法缺点显而易见,当页面元素位置发生改变时,都需要修改,因此,并不推荐使用。
2. 相对路径:
相对路径,以‘//’开头,具体格式为
xxx.find_element_by_xpath ("// 标签")
具体例子:
xxx.find_element_by_xpath ("//input [x]") 定位第 x 个 input 标签,[x] 可以省略,默认为第一个
相对路径的长度和开始位置并不受限制,也可以采取以下方法
xxx.find_element_by_xpath ("//div [x]/form [x]/input [x]"), [x] 依然是可以省略的

("//*[@id=''J_login_form'']/dl/dt/input[@id=''J_password'']"
3. 标签属性定位:
3.1 标签属性定位,相对比较简单,也要求属性能够定位到唯一一个元素,如果存在多个相同条件的标签,默认只是第一个,具体格式
xxx.find_element_by_xpath ("// 标签 [@属性 ==‘属性值’]")
属性判断条件:最常见为 id,name,class 等等,目前属性的类别没有特殊限制,只要能够唯一标识一个元素都是可以的
具体例子
xxx.find_element_by_xpath("//a[@href=''/industryMall/hall/industryIndex.ht'']")
xxx.find_element_by_xpath ("//input [@value='' 确定 '']")
xxx.find_element_by_xpath("//div[@submit'']/input")
当某个属性不足以唯一区别某一个元素时,也可以采取多个条件组合的方式,具体例子
xxx..find_element_by_xpath("//input[@type=''name'' and @name=''kw1'']")
3.2 当标签属性很少,不足以唯一区别元素时,但是标签中间中间存在唯一的文本值,也可以定位,其具体格式
xxx.find_element_by_xpath ("// 标签 [contains (text (),'' 文本值 '')]")
具体例子:
xxx.find_element_by_xpath ("//iunpt [contains (text (),'' 型号:'')]")
注意:尽量在 html 中复制此段文本,避免因为肉眼无法分辨的字符导致定位失败
3.3 其他的属性值如果太长,也可以采取模糊方法定位,直接上示例
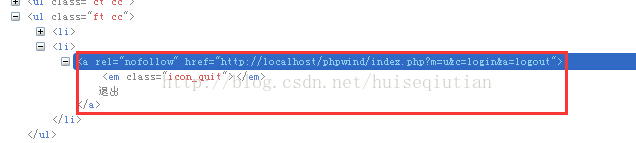
xxx.find_element_by_xpath(“//a[contains(@href, ‘logout’)]”)
3.4 XPath 关于网页中的动态属性的定位,例如,ASP.NET 应用程序中动态生成 id 属性值,可以有以下四种方法:
a.starts-with 例子: input [starts-with (@id,''ctrl'')] 解析:匹配以 ctrl 开始的属性值
b.ends-with 例子:input [ends-with (@id,''_userName'')] 解析:匹配以 userName 结尾的属性值
c.contains () 例子:Input [contains (@id,''userName'')] 解析:匹配含有 userName 属性值
当然,如果上面的单一方法不能完成定位,也可以采取组合式定位 类似 ("//input [@id=''kw1'']//input [start-with (@id,''nice'']/div [1]/form [3])
以上是普通的情况,存在可以定位的属性,当某个元素的各个属性及其组合都不足以定位时,我们可以利用其兄弟节点或者父节点等各种可以定位的元素进行定位,先看看 xpath 中支持的方法:
1、child 选取当前节点的所有子元素
2、parent 选取当前节点的父节点
3、descendant 选取当前节点的所有后代元素(子、孙等)
4、ancestor 选取当前节点的所有先辈(父、祖父等)
5、descendant-or-self 选取当前节点的所有后代元素(子、孙等)以及当前节点本身
6、ancestor-or-self 选取当前节点的所有先辈(父、祖父等)以及当前节点本身
7、preceding-sibling 选取当前节点之前的所有同级节点
8、following-sibling 选取当前节点之后的所有同级节点
9、preceding 选取文档中当前节点的开始标签之前的所有节点
10、following 选取文档中当前节点的结束标签之后的所有节点
11、self 选取当前节点
12、attribute 选取当前节点的所有属性
13、namespace 选取当前节点的所有命名空间节点
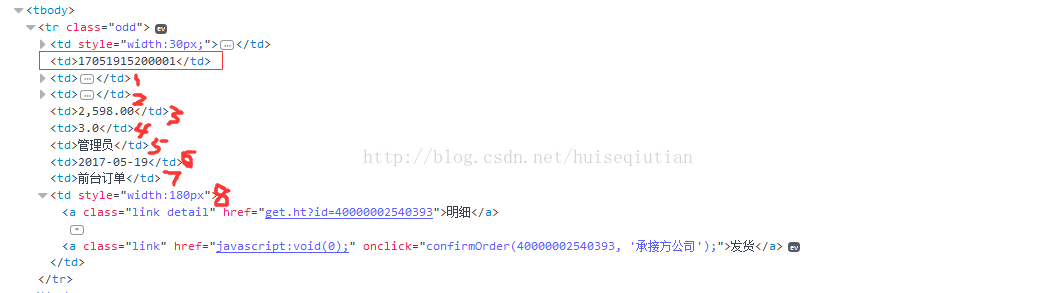
上图实例,需要点击订单号为 17051915200001 的发货按钮,这时候不能直接定位到发货按钮,而是先要定位到订单号元素,再定位他的兄弟节点。参照上图,我们首先定位到 td 标签中包含订单号的 td 元素,然后选择其之后的同级节点,following-sibling,我们要找的元素在后面的第 8 个 td 标签下,因此定位可以写名为下面的格式
Xxx.find_element_by_xpath("//td[contains(text(),’17051915200001’)]/following-sibling::td[8]/a[@link'']")
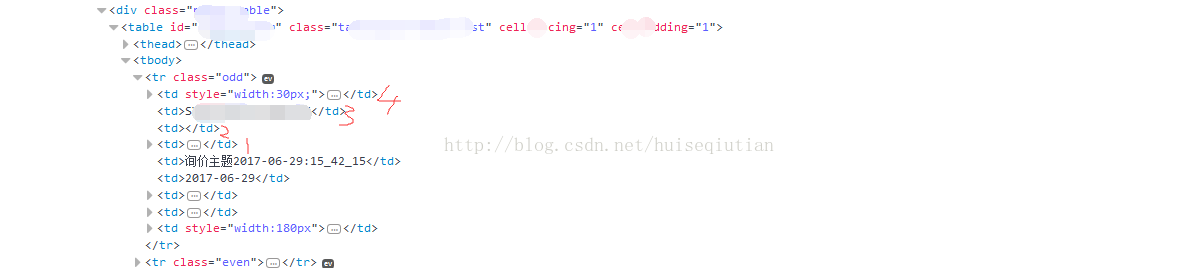
preceding-sibling 情况类似,但是所有元素的排列顺序是相反的(和 following-sibling 相反),如图:
其他方法的使用方式相同, 11-13 目前没有使用过,也没有搜索到实际使用的案例,如果有人知道,希望不吝赐教。
---------------------
作者:辉色秋天
来源:CSDN
原文:https://blog.csdn.net/huiseqiutian/article/details/73739707
版权声明:本文为博主原创文章,转载请附上博文链接!

Python selenium 使用 xpath 和 for 循环提取元素
试试这个方法:
headers = [h.text for h in driver.find_elements(By.XPATH,"//tr[@]/td/h5")]
这是一个用于提取元素并将文本值提取到列表的单行程序。
,你快到了。 xpath 中的 / 表示第一个孩子。但 <h5> 不是 //tr[@] 的第一个孩子。
解决方案
您需要将单个正斜杠(即 /)替换为双正斜杠,即 //,这将指示后代。因此,您的有效代码行将是:
print([my_elem.text for my_elem in driver.find_elements(By.XPATH,"//tr[@]//h5")])
理想情况下,您需要为 visibility_of_all_elements_located() 引入 WebDriverWait,您可以使用以下 Locator Strategy:
print([my_elem.text for my_elem in WebDriverWait(driver,20).until(EC.visibility_of_all_elements_located((By.XPATH,"//tr[@]//h5")))])
我们今天的关于Python:Selenium xpath查找不区分大小写字符的元素吗?和python查找大写字母的分享就到这里,谢谢您的阅读,如果想了解更多关于Python Selenium driver.find_element_by_xpath 在 iframe 中找不到元素、Python selenium PO By.XPATH 定位元素报错、python selenium xpath 定位方式、Python selenium 使用 xpath 和 for 循环提取元素的相关信息,可以在本站进行搜索。
本文标签:




