对于想了解Tensorflow,在RNN中保存状态的最佳方法?的读者,本文将提供新的信息,我们将详细介绍tensorflow保存模型方法,并且为您提供关于Centos6安装TensorFlow及Ten
对于想了解Tensorflow,在RNN中保存状态的最佳方法?的读者,本文将提供新的信息,我们将详细介绍tensorflow保存模型方法,并且为您提供关于Centos6安装TensorFlow及TensorFlowOnSpark、hello tensorflow,我的第一个tensorflow程序、RNN 的 Tensorflow NAN 损失结果、RNN-LSTM 讲解 - 基于 tensorflow 实现的有价值信息。
本文目录一览:- Tensorflow,在RNN中保存状态的最佳方法?(tensorflow保存模型方法)
- Centos6安装TensorFlow及TensorFlowOnSpark
- hello tensorflow,我的第一个tensorflow程序
- RNN 的 Tensorflow NAN 损失结果
- RNN-LSTM 讲解 - 基于 tensorflow 实现
")
Tensorflow,在RNN中保存状态的最佳方法?(tensorflow保存模型方法)
我目前在tensorflow中具有一系列链接在一起的RNN的以下代码。我不使用MultiRNN,因为稍后我将对每个图层的输出进行处理。
for r in range(RNNS): with tf.variable_scope(''recurent_%d'' % r) as scope: state = [tf.zeros((BATCH_SIZE, sz)) for sz in rnn_func.state_size] time_outputs = [None] * TIME_STEPS for t in range(TIME_STEPS): rnn_input = getTimeStep(rnn_outputs[r - 1], t) time_outputs[t], state = rnn_func(rnn_input, state) time_outputs[t] = tf.reshape(time_outputs[t], (-1, 1, RNN_SIZE)) scope.reuse_variables() rnn_outputs[r] = tf.concat(1, time_outputs)目前,我有固定的时间步数。但是,我想将其更改为只有一个时间步长,但要记住批次之间的状态。因此,我需要为每个层创建一个状态变量,并将其分配给每个层的最终状态。这样的事情。
for r in range(RNNS): with tf.variable_scope(''recurent_%d'' % r) as scope: saved_state = tf.get_variable(''saved_state'', ...) rnn_outputs[r], state = rnn_func(rnn_outputs[r - 1], saved_state) saved_state = tf.assign(saved_state, state)然后,对于每一层,我都需要评估sess.run函数中的保存状态以及调用训练函数。我需要为每个rnn层执行此操作。这似乎有点麻烦。我需要跟踪每个保存的状态并在运行中对其进行评估。同样,然后运行将需要将状态从我的GPU复制到主机内存,这会造成效率低下和不必要的情况。有更好的方法吗?
答案1
小编典典这是state_is_tuple=True通过定义状态变量来更新LSTM初始状态的代码。它还支持多层。
我们定义了两个函数-
一个用于获取具有初始零状态的状态变量,另一个用于返回操作的函数,可以传递给该函数以session.run用LSTM的最后一个隐藏状态更新状态变量。
def get_state_variables(batch_size, cell): # For each layer, get the initial state and make a variable out of it # to enable updating its value. state_variables = [] for state_c, state_h in cell.zero_state(batch_size, tf.float32): state_variables.append(tf.contrib.rnn.LSTMStateTuple( tf.Variable(state_c, trainable=False), tf.Variable(state_h, trainable=False))) # Return as a tuple, so that it can be fed to dynamic_rnn as an initial state return tuple(state_variables)def get_state_update_op(state_variables, new_states): # Add an operation to update the train states with the last state tensors update_ops = [] for state_variable, new_state in zip(state_variables, new_states): # Assign the new state to the state variables on this layer update_ops.extend([state_variable[0].assign(new_state[0]), state_variable[1].assign(new_state[1])]) # Return a tuple in order to combine all update_ops into a single operation. # The tuple''s actual value should not be used. return tf.tuple(update_ops)我们可以用它来更新每批LSTM的状态。请注意,我tf.nn.dynamic_rnn用于展开:
data = tf.placeholder(tf.float32, (batch_size, max_length, frame_size))cell_layer = tf.contrib.rnn.GRUCell(256)cell = tf.contrib.rnn.MultiRNNCell([cell] * num_layers)# For each layer, get the initial state. states will be a tuple of LSTMStateTuples.states = get_state_variables(batch_size, cell)# Unroll the LSTMoutputs, new_states = tf.nn.dynamic_rnn(cell, data, initial_state=states)# Add an operation to update the train states with the last state tensors.update_op = get_state_update_op(states, new_states)sess = tf.Session()sess.run(tf.global_variables_initializer())sess.run([outputs, update_op], {data: ...})该答案的主要区别在于,state_is_tuple=True使LSTM的状态成为包含两个变量(单元状态和隐藏状态)而不是单个变量的LSTMStateTuple。然后,使用多层可以使LSTM的状态成为LSTMStateTuples的元组-
每层一个。
重置为零
使用训练有素的模型进行预测/解码时,您可能需要将状态重置为零。然后,您可以使用此功能:
def get_state_reset_op(state_variables, cell, batch_size): # Return an operation to set each variable in a list of LSTMStateTuples to zero zero_states = cell.zero_state(batch_size, tf.float32) return get_state_update_op(state_variables, zero_states)例如上面的例子:
reset_state_op = get_state_reset_op(state, cell, max_batch_size)# Reset the state to zero before feeding inputsess.run([reset_state_op])sess.run([outputs, update_op], {data: ...})
Centos6安装TensorFlow及TensorFlowOnSpark
1. 需求描述
在Centos6系统上安装Hadoop、Spark集群,并使用TensorFlowOnSpark的 YARN运行模式下执行TensorFlow的代码。(最好可以在不联网的集群中进行配置并运行)
2. 系统环境(拓扑)
操作系统:Centos6.5 Final ; Hadoop:2.7.4 ; Spark:1.5.1-Hadoop2.6; TensorFlow 1.3.0;TensorFlowOnSpark (github最新下载);Python:2.7.12;
s0.centos.com: memory:1.5G namenode/resourcemanager ; 1核<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>2</value>
</property>
3. 参考
https://blog.abysm.org/2016/06/building-tensorflow-centos-6/: Centos6 build TensorFlow
TensorFlow github wiki :https://github.com/yahoo/TensorFlowOnSpark/wiki/GetStarted_YARN ; installTensorFlowOnSpark ;
TensorFlow github wiki: https://github.com/yahoo/TensorFlowOnSpark/wiki/Conversion-Guide ;conversionTensorFlow code ;
4. 步骤
1.安装devtoolset-6 及Python:
安装repo库: yum install -y centos-release-scl 安装 devtoolset: yum install -y devtoolset-6
安装Python:
yum install python27 python27-numpy python27-python-devel python27-python-wheel安装一些常用包:
yum install –y vim zip unzip openssh-clients
2.下载bazel,这里下载的是0.5.1(虽然也下载了0.4.X的版本,下载包难下)
先执行: export CC=/opt/rh/devtoolset-6/root/usr/bin/gcc 接着进入编译环境: scl enable devtoolset-6 python27 bash 接着以此执行: unzip bazel-0.5.1-dist.zip -d bazel-0.5.1-dist cd bazel-0.5.1-dist # compile ./compile.sh # install mkdir -p ~/bin cp output/bazel ~/bin/ exit //退出scl环境 // 耗时较久
3.下载TensorFlow1.3.0源码并解压
4.进入tensorflow-1.3.0 ,修改tensorflow/tensorflow.bzl文件中的tf_extension_linkopts函数如下形式:(添加一个-lrt)
def tf_extension_linkopts(): return ["-lrt"] # No extension link opts
5.编译安装TensorFlow:
安装基本软件: yum install –y patch 接着,进入编译环境: scl enable devtoolset-6 python27 bash cd tensorflow-1.3.0 ./configure # build ~/bin/bazel build --config=opt //tensorflow/tools/pip_package:build_pip_package bazel-bin/tensorflow/tools/pip_package/build_pip_package /tmp/tensorflow_pkg exit // 退出编译环境 // 耗时同样很久,同样使用bazel0.4.X的版本编译TensorFlow1.3提示版本过低
编译后在/tmp/tensorflow_pkg则会生成一个TensorFlow的 安装包 ,并且是属于当前系统也就是Centos系统的安装包;
6.安装Python自定义包(保持在联网状态下);
由于想在未联网的情况下使用TensorFlow以及TensorFlowOnSpark,所以参考TensorFlowOnSpark github WIKI,直接编译一个Python包,并且把TensorFlow、TensorFlowOnSpark及其他常用module安装在这个Python包中,后面就可以直接把这个包上传到HDFS,使得各个子节点都可以共享共同一个Python.zip包的环境变量。
export PYTHON_ROOT=~/Python // 设置环境变量,并下载Python curl -O https://www.python.org/ftp/python/2.7.12/Python-2.7.12.tgz tar -xvf Python-2.7.12.tgz
编译并安装Python:
pushd Python-2.7.12
./configure --prefix="${PYTHON_ROOT}" --enable-unicode=ucs4
make
make install
popd
安装Pip:
pushd "${PYTHON_ROOT}"
curl -O https://bootstrap.pypa.io/get-pip.py
bin/python get-pip.py
popd
安装TensorFlow:
pushd "${PYTHON_ROOT}"
bin/pip install /tmp/tensorflow_pkg/tensorflow-1.3.0-cp27-none-linux_x86_64.whl
popd在安装TensorFlow的时候会自动安装诸如 numpy等常用Python包;
安装TensorFlowOnSpark:pushd "${PYTHON_ROOT}"
bin/pip install tensorflowonspark
popd
把“武装”好的Python打包并上传到HDFS:
pushd "${PYTHON_ROOT}"
zip -r Python.zip *
popd
hadoop fs -put ${PYTHON_ROOT}/Python.zip
现在就可以使用TensorFlow了;
7. 修改TensorFlow代码,比如下面的TensorFlow代码是可以在TensorFlow环境中运行的:
# from __future__ import absolute_import
# from __future__ import division
# from __future__ import print_function
import numpy as np
import tensorflow as tf
X_FEATURE = 'x' # Name of the input feature.
train_percent = 0.8
def load_data(data_file_name):
data = np.loadtxt(open(data_file_name),delimiter=",",skiprows=0)
return data
def data_selection(iris,train_per):
data,target = np.hsplit(iris[np.random.permutation(iris.shape[0])],np.array([-1]))
row_split_index = int(data.shape[0] * train_per)
x_train,x_test = (data[1:row_split_index],data[row_split_index:])
y_train,y_test = (target[1:row_split_index],target[row_split_index:])
return x_train,x_test,y_train.astype(int),y_test.astype(int)
def run():
# Load dataset.
data_file = 'iris01.csv'
iris = load_data(data_file)
# x_train,y_train,y_test = model_selection.train_test_split(
# iris.data,iris.target,test_size=0.2,random_state=42)
x_train,y_test = data_selection(iris,train_percent)
# print(x_test)
# print(y_test)
#
# # Build 3 layer DNN with 10,20,10 units respectively.
feature_columns = [
tf.feature_column.numeric_column(
X_FEATURE,shape=np.array(x_train).shape[1:])]
classifier = tf.estimator.DNNClassifier(
feature_columns=feature_columns,hidden_units=[10,10],n_classes=3)
#
# # Train.
train_input_fn = tf.estimator.inputs.numpy_input_fn(
x={X_FEATURE: x_train},y=y_train,num_epochs=None,shuffle=True)
classifier.train(input_fn=train_input_fn,steps=200)
#
# # Predict.
test_input_fn = tf.estimator.inputs.numpy_input_fn(
x={X_FEATURE: x_test},y=y_test,num_epochs=1,shuffle=False)
predictions = classifier.predict(input_fn=test_input_fn)
y_predicted = np.array(list(p['class_ids'] for p in predictions))
y_predicted = y_predicted.reshape(np.array(y_test).shape)
# #
# # # score with sklearn.
# score = metrics.accuracy_score(y_test,y_predicted)
# print('Accuracy (sklearn): {0:f}'.format(score))
print(np.concatenate(( y_predicted,y_test),axis= 1))
# score with tensorflow.
scores = classifier.evaluate(input_fn=test_input_fn)
print('Accuracy (tensorflow): {0:f}'.format(scores['accuracy']))
print(classifier.params)
if __name__ == '__main__':
run()
其中iris01.csv 数据如下:
5.1,3.5,1.4,0.2,0 4.9,3.0,0 4.7,3.2,1.3,0 4.6,3.1,1.5,0 5.0,3.6,0 5.4,3.9,1.7,0.4,3.4,0.3,0 4.4,2.9,0.1,3.7,0 4.8,1.6,0 4.3,1.1,0 5.8,4.0,1.2,0 5.7,4.4,0 5.1,3.8,1.0,3.3,0.5,1.9,0 5.2,4.1,0 5.5,4.2,0 4.5,2.3,0.6,0 5.3,0 7.0,4.7,1 6.4,4.5,1 6.9,4.9,1 5.5,1 6.5,2.8,4.6,1 5.7,1 6.3,1 4.9,2.4,1 6.6,1 5.2,2.7,1 5.0,2.0,1 5.9,1 6.0,2.2,1 6.1,1 5.6,1 6.7,1 5.8,1 6.2,2.5,4.8,1.8,4.3,1 6.8,5.0,2.6,5.1,1 5.4,1 5.1,6.0,2 5.8,2 7.1,5.9,2.1,2 6.3,5.6,2 6.5,5.8,2 7.6,6.6,2 4.9,2 7.3,6.3,2 6.7,2 7.2,6.1,2 6.4,5.3,2 6.8,5.5,2 5.7,2 7.7,6.7,6.9,2 6.0,2 6.9,5.7,2 5.6,2 6.2,2 6.1,2 7.4,2 7.9,6.4,5.4,5.2,2 5.9,2
那代码怎么修改呢?
1). 导入必要的包:
from pyspark.context import SparkContext from pyspark.conf import SparkConf from tensorflowonspark import TFCluster,TFNode #from com.yahoo.ml.tf import TFCluster,TFNode from datetime import datetime
这里要注意,导入TFCluster的时候,不要参考官网的导入方式,而应该从tensorflowonspark导入;
2.) 修改main函数,比如我这里的函数run,只需要添加两个参数即可:(argv,cxt)
3) 把原来的main函数调用,替换成下面的调用方式 ,比如我这里原来只需要在main函数执行run即可,这里需要调用TFCluster.run,并且把我的run函数传递给第二个参数值:
sc = SparkContext(conf=SparkConf().setAppName("your_app_name"))
num_executors = int(sc._conf.get("spark.executor.instances"))
num_ps = 1
tensorboard = True
cluster = TFCluster.run(sc,run,sys.argv,num_executors,num_ps,tensorboard,TFCluster.InputMode.TENSORFLOW)
cluster.shutdown()
然后就可以运行了,修改后的代码如下:
# from __future__ import absolute_import
# from __future__ import division
# from __future__ import print_function
from pyspark.context import SparkContext
from pyspark.conf import SparkConf
from tensorflowonspark import TFCluster,TFNode
from datetime import datetime
import numpy as np
import sys
# from sklearn import metrics
# from sklearn import model_selection
import tensorflow as tf
X_FEATURE = 'x' # Name of the input feature.
train_percent = 0.8
def load_data(data_file_name):
data = np.loadtxt(open(data_file_name),y_test.astype(int)
def map_run(argv,ctx):
# Load dataset.
data_file = 'iris01.csv'
iris = load_data(data_file)
# x_train,axis= 1))
# score with tensorflow.
scores = classifier.evaluate(input_fn=test_input_fn)
print('Accuracy (tensorflow): {0:f}'.format(scores['accuracy']))
print(classifier.params)
if __name__ == '__main__':
import tensorflow as tf
import sys
sc = SparkContext(conf=SparkConf().setAppName("your_app_name"))
num_executors = int(sc._conf.get("spark.executor.instances"))
num_ps = 1
tensorboard = False
cluster = TFCluster.run(sc,map_run,TFCluster.InputMode.TENSORFLOW)
cluster.shutdown()
7. 设置环境变量,并运行:
1)上传iris01.csv到HDFS: hdfs dfs -put iris01.csv
2) 设置环境变量:
export PYTHON_ROOT=./Python
export LD_LIBRARY_PATH=${PATH}
export PYSPARK_PYTHON=${PYTHON_ROOT}/bin/python
export SPARK_YARN_USER_ENV="PYSPARK_PYTHON=Python/bin/python"
export PATH=${PYTHON_ROOT}/bin/:$PATH
#export QUEUE=gpu
# set paths to libjvm.so,libhdfs.so,and libcuda*.so
#export LIB_HDFS=/opt/cloudera/parcels/CDH/lib64 # for CDH (per @wangyum)
export LIB_HDFS=$HADOOP_PREFIX/lib/native
export LIB_JVM=$JAVA_HOME/jre/lib/amd64/server
#export LIB_CUDA=/usr/local/cuda-7.5/lib64
# for cpu mode:
export QUEUE=default
3) 调用代码:
/usr/local/spark-1.5.1-bin-hadoop2.6/bin/spark-submit --master yarn --deploy-mode cluster --num-executors 3 --executor-memory 1024m --archives hdfs://s0:8020/user/root/Python.zip#Python,/root/iris01.csv /root/iris_c.py
4) 查看yarn日志,可以看到执行成功;
5. 问题及解决
File "iris_c.py",line 6,in <module>
from com.yahoo.ml.tf import TFCluster,TFNode
ImportError: No module named com.yahoo.ml.tf
from com.yahoo.ml.tf import TFCluster,TFNode
=》
from tensorflowonspark import TFCluster,TFNode
6. 总结

hello tensorflow,我的第一个tensorflow程序
上代码:
import tensorflow as tf
if __name__==''__main__'':
g = tf.Graph()
# add ops to the user created graph
with g.as_default():
hello = tf.constant(''Hello Tensorflow'')
sess = tf.compat.v1.Session(graph=g)
print(sess.run(hello)) 输出如下图右侧:
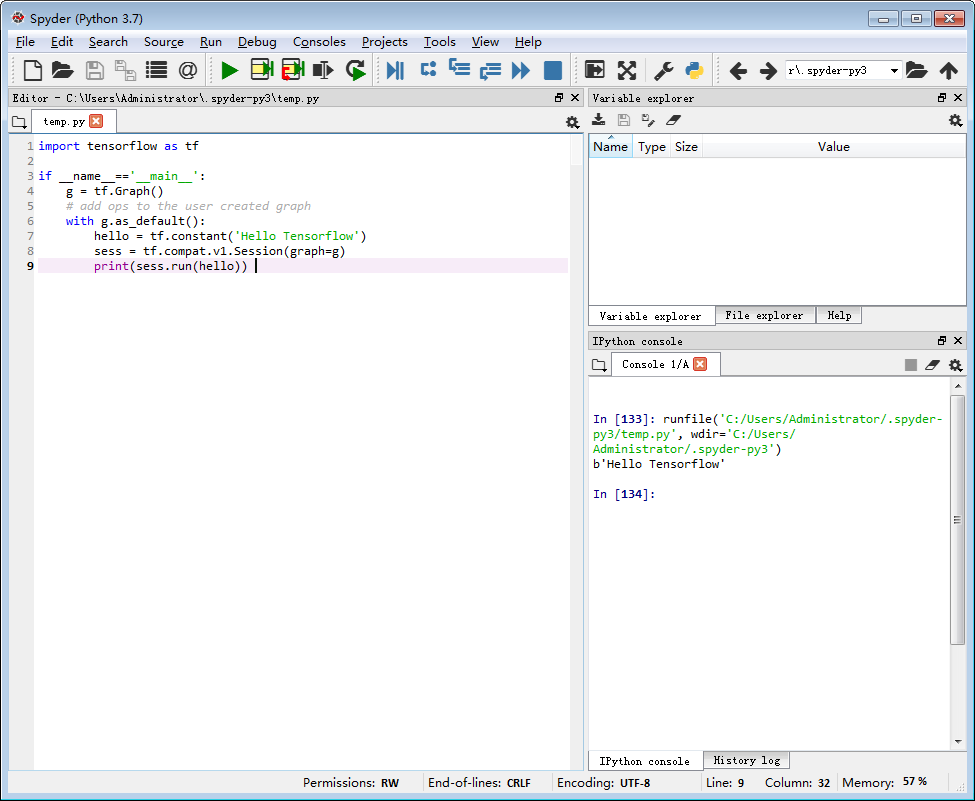
说明:python3.7.4 ,tensorflow2.0
若对您有用,请赞助个棒棒糖~


RNN 的 Tensorflow NAN 损失结果
如何解决RNN 的 Tensorflow NAN 损失结果?
我在 Windows 10 中使用 Anaconda 环境。我使用的是 python 3.6.13、numpy 1.19.5 和 tensorflow 2.1.0
我正在尝试为时间序列预测创建 RNN,但我一直将 nan 作为损失值。我使用以下函数作为损失函数:
warmup_steps = 50
def loss_mse_warmup(y_true,y_pred):
"""
Calculate the Mean Squared Error between y_true and y_pred,but ignore the beginning "warmup" part of the sequences.
y_true is the desired output.
y_pred is the model''s output.
"""
# The shape of both input tensors are:
# [batch_size,sequence_length,num_y_signals].
# Ignore the "warmup" parts of the sequences
# by taking slices of the tensors.
y_true_slice = y_true[:,warmup_steps:,:]
y_pred_slice = y_pred[:,:]
# These sliced tensors both have this shape:
# [batch_size,sequence_length - warmup_steps,num_y_signals]
# Calculat the Mean Squared Error and use it as loss.
mse = mean(square(y_true_slice - y_pred_slice))
return mse
另外,在格式化数据时,我用 df.dropna()
这是我的模型
model = Sequential()
model.add(GRU(units=128,return_sequences=True,input_shape=(None,num_x_signals)))
model.add(Dense(num_y_signals,activation=''sigmoid''))
optimizer = Adam(clipvalue=1)
model.compile(loss=loss_mse_warmup,optimizer=optimizer)
我的模型只返回 nan 作为损失结果,有谁知道为什么会发生这种情况以及我该如何解决?
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

RNN-LSTM 讲解 - 基于 tensorflow 实现
cnn 卷积神经网络在前面已经有所了解了,目前博主也使用它进行了一个图像分类问题,基于 kaggle 里面的 food-101 进行的图像识别,识别率有点感人,基于数据集的关系,大致来说还可行。
下面我就继续学习 rnn 神经网络。
rnn 神经网络(递归 / 循环神经网络)模式如下:
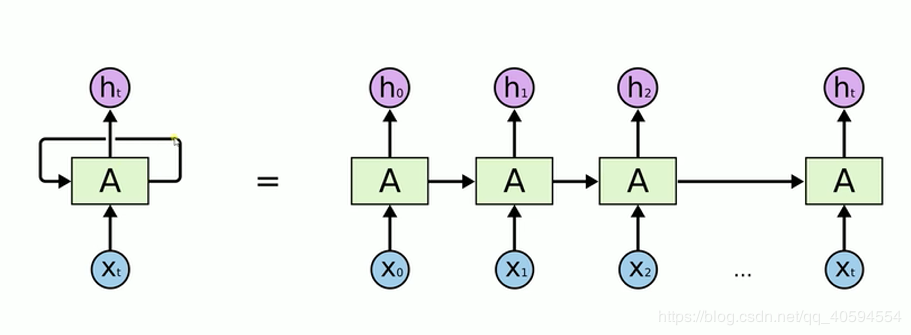
我们在处理文字等问题的时候,我们的输入会把上一个时间输出的数据作为下一个时间的输入数据进行处理。
例如:我们有一段话,我们将其分词,得到 t 个数据,我们分别将每一个词传入到 x0,x1....xt 里面,当 x0 传入后,会得到一个结果 h0,同时我们会将处理后的数据传入到下个时间,到下个时间的时候,我们会再传入一个数据 x1,同时还有上一个时间处理后的数据,将这两个数据进行整合计算,然后再向下传输,一直到结束。
rnn 本质来说还是一个 bp 回路,不过他只是比 bp 网络多一个环节,即它可以反馈上一时间点处理后的数据。
上图细化如下:
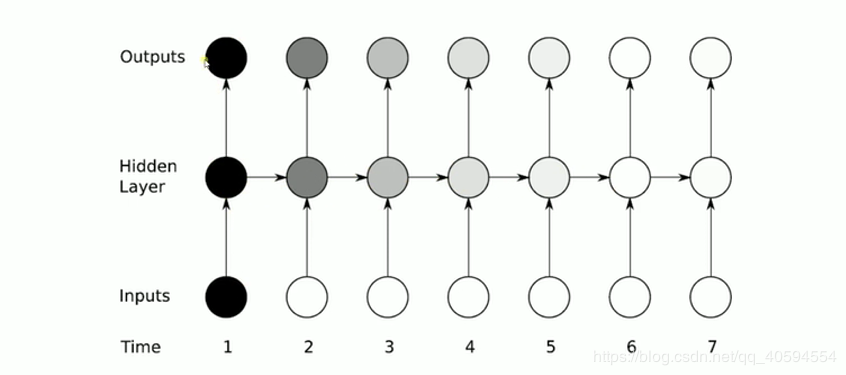
rnn 实际上还是存在梯度消失的问题,因此如上图所示,当我们在第一个时间输入的数据,可能在很久之后他就已经梯度消失了(影响很小),因此我们使用 lstm (long short trem memory)
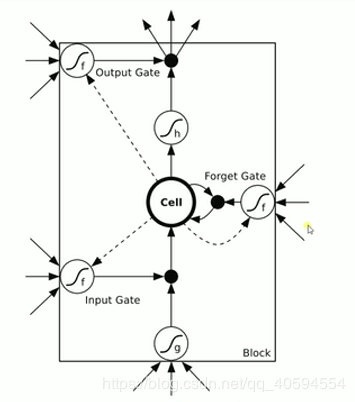
上图有三个门:输入门 忘记门 输出门
1. 输入门:通过 input * g 来判断是否输入,如果不输入就为 0,输入就是 0,以此判断信号是否输入
2. 忘记门:这个信号是否需要衰减多少,可能为 50%,衰减是根据信号来判断。
3. 输入门:通过判断是否输出,或者输出多少,例如输出 50%。
因此上述图可化为:

可以看出,这三个门,所有得影响都是关于输入和上一个数据得输出来进行计算的。
可以看下图:
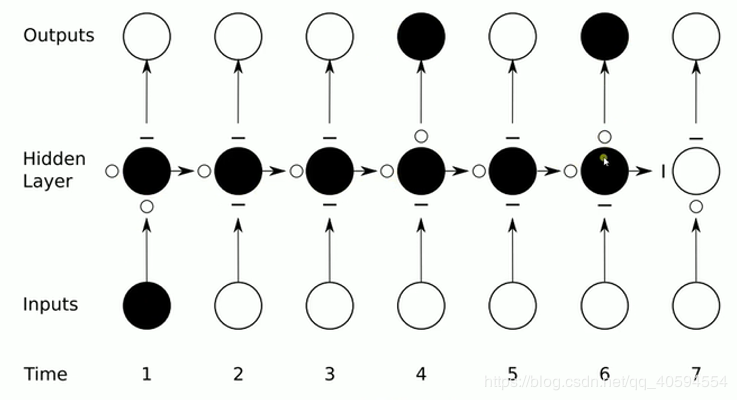
我们使用 lstm 得话,通过三个门决定信号是否向下传输,传输多少都可以控制,是否传入信号,输出信息都进行控制。
下面我们还是用 tensorflow 实现,数据集还是手写数字,虽然 rnn 主要是用在文字和语言上,但是它依旧可以用在图片上。
下面给出代码:
```python
import tensorflow as tf
from tensorflow.contrib import rnn
from tensorflow.examples.tutorials.mnist import input_data
mnist=input_data.read_data_sets("MNNIST_data",one_hot=True)
#输入图片为 28*28
n_inputs=28#输入一行,一行有28个像素
max_time=28#一共28行,所以为28*28
lstm_size=100#100个隐藏单元
batch_size=50
n_classes=10
n_batch=mnist.train.num_examples//batch_size#计算一共多少批次
#这里none表示第一个维度可以是任意长度
x=tf.placeholder(tf.float32,[None,784])
y=tf.placeholder(tf.float32,[None,10])
#初始化权值
weights=tf.Variable(tf.truncated_normal([lstm_size,n_classes],stddev=0.1))
#初始化偏置值
biases=tf.Variable(tf.constant(0.1,shape=[n_classes]))
##定义Rnn 网络
def RNN(X,weights,biases):
inputs=tf.reshape(X,[-1,max_time,n_inputs])
#定义lstm基本cell
lstm_cell = rnn.BasicLSTMCell(lstm_size)
#lstm_cell=tf.contrib.rnn.core_rnn_cell.BasicLSTMCell(lstm_size)
outputs,final_state=tf.nn.dynamic_rnn(lstm_cell,inputs,dtype=tf.float32)
results=tf.nn.softmax(tf.matmul(final_state[1],weights)+biases)
return results
prediction=RNN(x,weights,biases)
#损失函数
cross_entropy=tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=prediction,labels=y))
#优化器
train_step=tf.train.AdamOptimizer(1e-4).minimize(cross_entropy)
#保存结果
correct_prediction=tf.equal(tf.argmax(y,1),tf.argmax(prediction,1))
accuracy=tf.reduce_mean(tf.cast(correct_prediction,tf.float32))
init=tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
for epoch in range(6):
for batch in range(n_batch):
batch_xs,batch_ys=mnist.train.next_batch(batch_size)
sess.run(train_step,feed_dict={x:batch_xs,y:batch_ys})
acc=sess.run(accuracy,feed_dict={x:mnist.test.images,y:mnist.test.labels})
print("iter:"+str(epoch)+"testing accuracy"+str(acc))
```
运行结果如下:
原文出处:https://www.cnblogs.com/lh9527/p/9527-11.html
今天关于Tensorflow,在RNN中保存状态的最佳方法?和tensorflow保存模型方法的讲解已经结束,谢谢您的阅读,如果想了解更多关于Centos6安装TensorFlow及TensorFlowOnSpark、hello tensorflow,我的第一个tensorflow程序、RNN 的 Tensorflow NAN 损失结果、RNN-LSTM 讲解 - 基于 tensorflow 实现的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

