对于想了解流计算框架Flink与Storm的性能对比的读者,本文将是一篇不可错过的文章,我们将详细介绍flink流式计算框架,并且为您提供关于ApacheFlink,流计算?不仅仅是流计算!、Apac
对于想了解流计算框架 Flink 与 Storm 的性能对比的读者,本文将是一篇不可错过的文章,我们将详细介绍flink流式计算框架,并且为您提供关于Apache Flink,流计算?不仅仅是流计算!、Apache 流框架 Flink,Spark Streaming,Storm 对比分析、Apache 流框架 Flink,Spark Streaming,Storm 对比分析(一)、Apache流计算框架详细对比的有价值信息。
本文目录一览:- 流计算框架 Flink 与 Storm 的性能对比(flink流式计算框架)
- Apache Flink,流计算?不仅仅是流计算!
- Apache 流框架 Flink,Spark Streaming,Storm 对比分析
- Apache 流框架 Flink,Spark Streaming,Storm 对比分析(一)
- Apache流计算框架详细对比
")
流计算框架 Flink 与 Storm 的性能对比(flink流式计算框架)
1. 背景
Apache Flink 和 Apache Storm 是当前业界广泛使用的两个分布式实时计算框架。其中 Apache Storm(以下简称“Storm”)在美团点评实时计算业务中已有较为成熟的运用(可参考 Storm 的可靠性保证测试:https://tech.meituan.com/test-of-storms-reliability.html),有管理平台、常用 API 和相应的文档,大量实时作业基于 Storm 构建。而 Apache Flink(以下简称“Flink”)在近期倍受关注,具有高吞吐、低延迟、高可靠和精确计算等特性,对事件窗口有很好的支持,目前在美团点评实时计算业务中也已有一定应用。
为深入熟悉了解 Flink 框架,验证其稳定性和可靠性,评估其实时处理性能,识别该体系中的缺点,找到其性能瓶颈并进行优化,给用户提供最适合的实时计算引擎,我们以实践经验丰富的 Storm 框架作为对照,进行了一系列实验测试 Flink 框架的性能,计算 Flink 作为确保“至少一次”和“恰好一次”语义的实时计算框架时对资源的消耗,为实时计算平台资源规划、框架选择、性能调优等决策及 Flink 平台的建设提出建议并提供数据支持,为后续的 SLA 建设提供一定参考。
Flink 与 Storm 两个框架对比:
| Storm | Flink | |
|---|---|---|
| 状态管理 | 无状态,需用户自行进行状态管理 | 有状态 |
| 窗口支持 | 对事件窗口支持较弱,缓存整个窗口的所有数据,窗口结束时一起计算 | 窗口支持较为完善,自带一些窗口聚合方法,并且会自动管理窗口状态。 |
| 消息投递 | At Most Once At Least Once |
At Most Once At Least Once Exactly Once |
| 容错方式 | ACK机制 :对每个消息进行全链路跟踪,失败或超时进行重发。 | 检查点机制 :通过分布式一致性快照机制,对数据流和算子状态进行保存。在发生错误时,使系统能够进行回滚。 |
| 应用现状 | 在美团点评实时计算业务中已有较为成熟的运用,有管理平台、常用 API 和相应的文档,大量实时作业基于 Storm 构建。 | 在美团点评实时计算业务中已有一定应用,但是管理平台、API 及文档等仍需进一步完善。 |
2. 测试目标
评估不同场景、不同数据压力下 Flink 和 Storm 两个实时计算框架目前的性能表现,获取其详细性能数据并找到处理性能的极限;了解不同配置对 Flink 性能影响的程度,分析各种配置的适用场景,从而得出调优建议。
2.1 测试场景
“输入-输出”简单处理场景
通过对“输入-输出”这样简单处理逻辑场景的测试,尽可能减少其它因素的干扰,反映两个框架本身的性能。
同时测算框架处理能力的极限,处理更加复杂的逻辑的性能不会比纯粹“输入-输出”更高。
用户作业耗时较长的场景
如果用户的处理逻辑较为复杂,或是访问了数据库等外部组件,其执行时间会增大,作业的性能会受到影响。因此,我们测试了用户作业耗时较长的场景下两个框架的调度性能。
窗口统计场景
实时计算中常有对时间窗口或计数窗口进行统计的需求,例如一天中每五分钟的访问量,每 100 个订单中有多少个使用了优惠等。Flink 在窗口支持上的功能比 Storm 更加强大,API 更加完善,但是我们同时也想了解在窗口统计这个常用场景下两个框架的性能。
精确计算场景(即消息投递语义为“恰好一次”)
Storm 仅能保证“至多一次” (At Most Once) 和“至少一次” (At Least Once) 的消息投递语义,即可能存在重复发送的情况。有很多业务场景对数据的精确性要求较高,希望消息投递不重不漏。Flink 支持“恰好一次” (Exactly Once) 的语义,但是在限定的资源条件下,更加严格的精确度要求可能带来更高的代价,从而影响性能。因此,我们测试了在不同消息投递语义下两个框架的性能,希望为精确计算场景的资源规划提供数据参考。
2.2 性能指标
吞吐量(Throughput)
-
单位时间内由计算框架成功地传送数据的数量,本次测试吞吐量的单位为:条/秒。
-
反映了系统的负载能力,在相应的资源条件下,单位时间内系统能处理多少数据。
-
吞吐量常用于资源规划,同时也用于协助分析系统性能瓶颈,从而进行相应的资源调整以保证系统能达到用户所要求的处理能力。假设商家每小时能做二十份午餐(吞吐量 20 份/小时),一个外卖小哥每小时只能送两份(吞吐量 2 份/小时),这个系统的瓶颈就在小哥配送这个环节,可以给该商家安排十个外卖小哥配送。
延迟(Latency)
-
数据从进入系统到流出系统所用的时间,本次测试延迟的单位为:毫秒。
-
反映了系统处理的实时性。
-
金融交易分析等大量实时计算业务对延迟有较高要求,延迟越低,数据实时性越强。
-
假设商家做一份午餐需要 5 分钟,小哥配送需要 25 分钟,这个流程中用户感受到了 30 分钟的延迟。如果更换配送方案后延迟变成了 60 分钟,等送到了饭菜都凉了,这个新的方案就是无法接受的。
3. 测试环境
为 Storm 和 Flink 分别搭建由 1 台主节点和 2 台从节点构成的 Standalone 集群进行本次测试。其中为了观察 Flink 在实际生产环境中的性能,对于部分测内容也进行了 on Yarn 环境的测试。
3.1 集群参数
| 参数项 | 参数值 |
|---|---|
| CPU | QEMU Virtual CPU version 1.1.2 2.6GHz |
| Core | 8 |
| Memory | 16GB |
| Disk | 500G |
| OS | CentOS release 6.5 (Final) |
3.2 框架参数
| 参数项 | Storm 配置 | Flink 配置 |
|---|---|---|
| Version | Storm 1.1.0-mt002 | Flink 1.3.0 |
| Master Memory | 2600M | 2600M |
| Slave Memory | 1600M * 16 | 12800M * 2 |
| Parallelism | 2 supervisor 16 worker |
2 Task Manager 16 Task slots |
4. 测试方法
4.1 测试流程
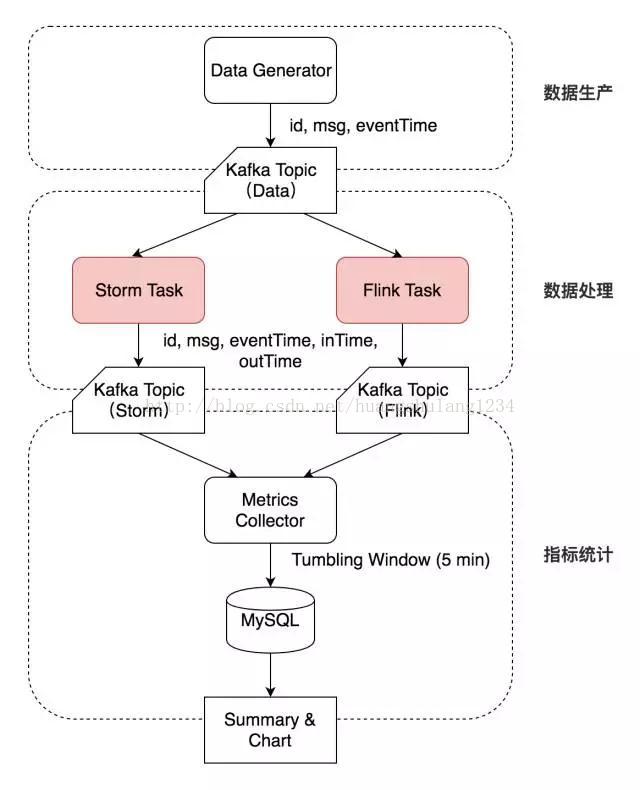
数据生产
Data Generator 按特定速率生成数据,带上自增的 id 和 eventTime 时间戳写入 Kafka 的一个 Topic(Topic Data)。
数据处理
Storm Task 和 Flink Task (每个测试用例不同)从 Kafka Topic Data 相同的 Offset 开始消费,并将结果及相应 inTime、outTime 时间戳分别写入两个 Topic(Topic Storm 和 Topic Flink)中。
指标统计
Metrics Collector 按 outTime 的时间窗口从这两个 Topic 中统计测试指标,每五分钟将相应的指标写入 MySQL 表中。
Metrics Collector 按 outTime 取五分钟的滚动时间窗口,计算五分钟的平均吞吐(输出数据的条数)、五分钟内的延迟(outTime - eventTime 或 outTime - inTime)的中位数及 99 线等指标,写入 MySQL 相应的数据表中。最后对 MySQL 表中的吞吐计算均值,延迟中位数及延迟 99 线选取中位数,绘制图像并分析。
4.2 默认参数
-
Storm 和 Flink 默认均为 At Least Once 语义。
-
Storm 开启 ACK,ACKer 数量为 1。
-
Flink 的 Checkpoint 时间间隔为 30 秒,默认 StateBackend 为 Memory。
-
-
保证 Kafka 不是性能瓶颈,尽可能排除 Kafka 对测试结果的影响。
-
测试延迟时数据生产速率小于数据处理能力,假设数据被写入 Kafka 后立刻被读取,即 eventTime 等于数据进入系统的时间。
-
测试吞吐量时从 Kafka Topic 的最旧开始读取,假设该 Topic 中的测试数据量充足。
4.3 测试用例
Identity
-
Identity 用例主要模拟“输入-输出”简单处理场景,反映两个框架本身的性能。
-
输入数据为“msgId, eventTime”,其中 eventTime 视为数据生成时间。单条输入数据约 20 B。
-
进入作业处理流程时记录 inTime,作业处理完成后(准备输出时)记录 outTime。
-
作业从 Kafka Topic Data 中读取数据后,在字符串末尾追加时间戳,然后直接输出到 Kafka。
-
输出数据为“msgId, eventTime, inTime, outTime”。单条输出数据约 50 B。

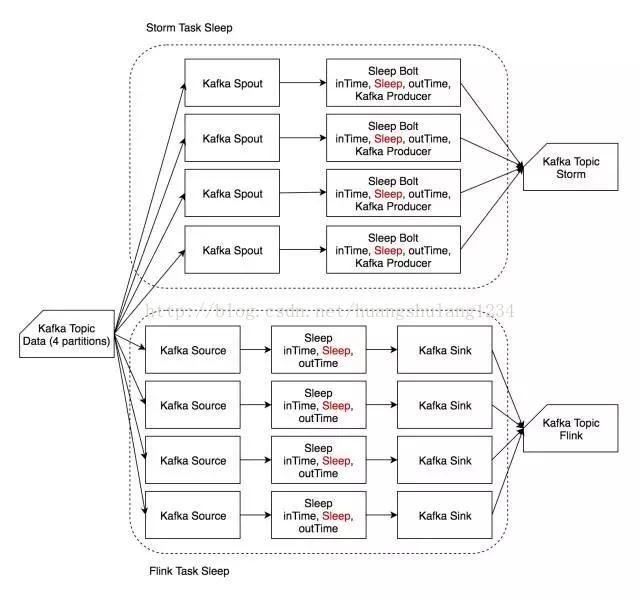
Sleep
-
Sleep 用例主要模拟用户作业耗时较长的场景,反映复杂用户逻辑对框架差异的削弱,比较两个框架的调度性能。
-
输入数据和输出数据均与 Identity 相同。
-
读入数据后,等待一定时长(1 ms)后在字符串末尾追加时间戳后输出
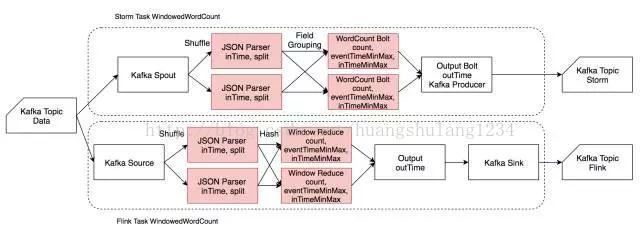
Windowed Word Count
-
Windowed Word Count 用例主要模拟窗口统计场景,反映两个框架在进行窗口统计时性能的差异。
-
此外,还用其进行了精确计算场景的测试,反映 Flink 恰好一次投递的性能。
-
输入为 JSON 格式,包含 msgId、eventTime 和一个由若干单词组成的句子,单词之间由空格分隔。单条输入数据约 150 B。
-
读入数据后解析 JSON,然后将句子分割为相应单词,带 eventTime 和 inTime 时间戳发给 CountWindow 进行单词计数,同时记录一个窗口中最大最小的 eventTime 和 inTime,最后带 outTime 时间戳输出到 Kafka 相应的 Topic。
-
Spout/Source 及 OutputBolt/Output/Sink 并发度恒为 1,增大并发度时仅增大 JSONParser、CountWindow 的并发度。
-
由于 Storm 对 window 的支持较弱,CountWindow 使用一个 HashMap 手动实现,Flink 用了原生的 CountWindow 和相应的 Reduce 函数。
5. 测试结果
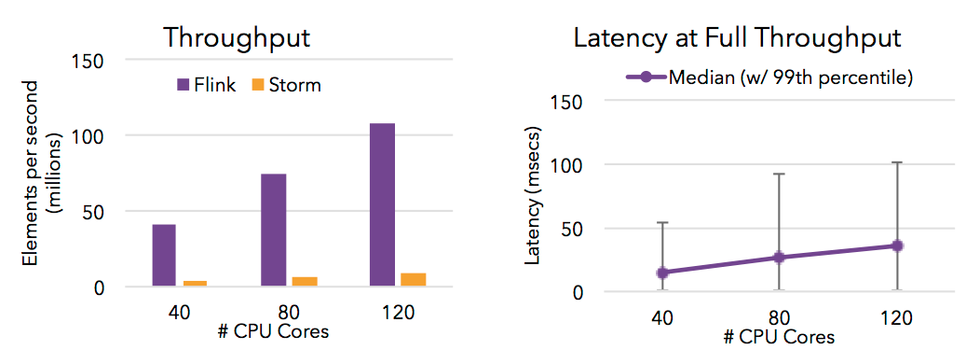
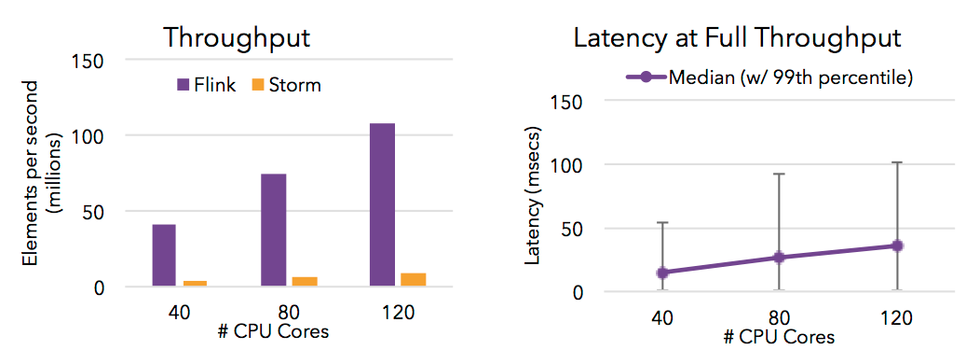
5.1 Identity 单线程吞吐量

-
上图中蓝色柱形为单线程 Storm 作业的吞吐,橙色柱形为单线程 Flink 作业的吞吐。
-
Identity 逻辑下,Storm 单线程吞吐为 8.7 万条/秒,Flink 单线程吞吐可达 35 万条/秒。
-
当 Kafka Data 的 Partition 数为 1 时,Flink 的吞吐约为 Storm 的 3.2 倍;当其 Partition 数为 8 时,Flink 的吞吐约为 Storm 的 4.6 倍。
-
由此可以看出,Flink 吞吐约为 Storm 的 3-5 倍。
5.2 Identity 单线程作业延迟
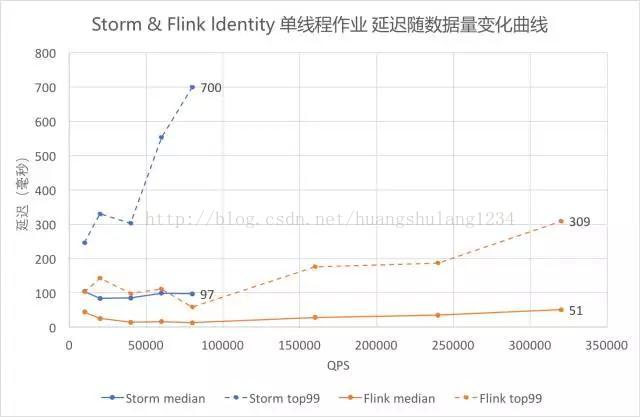
-
采用 outTime - eventTime 作为延迟,图中蓝色折线为 Storm,橙色折线为 Flink。虚线为 99 线,实线为中位数。
-
从图中可以看出随着数据量逐渐增大,Identity 的延迟逐渐增大。其中 99 线的增大速度比中位数快,Storm 的 增大速度比 Flink 快。
-
其中 QPS 在 80000 以上的测试数据超过了 Storm 单线程的吞吐能力,无法对 Storm 进行测试,只有 Flink 的曲线。
-
对比折线最右端的数据可以看出,Storm QPS 接近吞吐时延迟中位数约 100 毫秒,99 线约 700 毫秒,Flink 中位数约 50 毫秒,99 线约 300 毫秒。Flink 在满吞吐时的延迟约为 Storm 的一半。
5.3 Sleep 吞吐量

-
从图中可以看出,Sleep 1 毫秒时,Storm 和 Flink 单线程的吞吐均在 900 条/秒左右,且随着并发增大基本呈线性增大。
-
对比蓝色和橙色的柱形可以发现,此时两个框架的吞吐能力基本一致。
5.4 Sleep 单线程作业延迟(中位数)

-
依然采用 outTime - eventTime 作为延迟,从图中可以看出,Sleep 1 毫秒时,Flink 的延迟仍低于 Storm。
5.5 Windowed Word Count 单线程吞吐量

-
单线程执行大小为 10 的计数窗口,吞吐量统计如图。
-
从图中可以看出,Storm 吞吐约为 1.2 万条/秒,Flink Standalone 约为 4.3 万条/秒。Flink 吞吐依然为 Storm 的 3 倍以上。
5.6 Windowed Word Count Flink At Least Once 与 Exactly Once 吞吐量对比
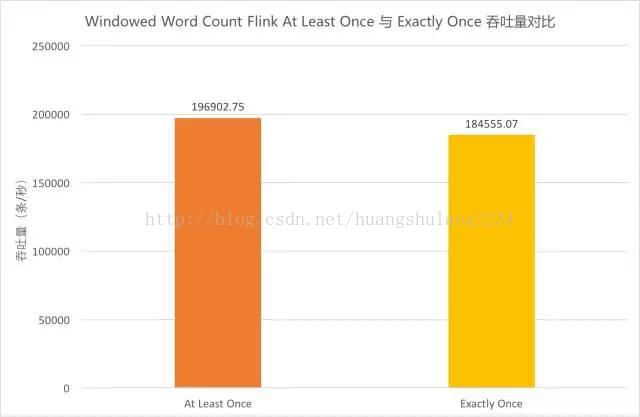
-
由于同一算子的多个并行任务处理速度可能不同,在上游算子中不同快照里的内容,经过中间并行算子的处理,到达下游算子时可能被计入同一个快照中。这样一来,这部分数据会被重复处理。因此,Flink 在 Exactly Once 语义下需要进行对齐,即当前最早的快照中所有数据处理完之前,属于下一个快照的数据不进行处理,而是在缓存区等待。当前测试用例中,在 JSON Parser 和 CountWindow、CountWindow 和 Output 之间均需要进行对齐,有一定消耗。为体现出对齐场景,Source/Output/Sink 并发度的并发度仍为 1,提高了 JSONParser/CountWindow 的并发度。具体流程细节参见前文 Windowed Word Count 流程图。
-
上图中橙色柱形为 At Least Once 的吞吐量,黄色柱形为 Exactly Once 的吞吐量。对比两者可以看出,在当前并发条件下,Exactly Once 的吞吐较 At Least Once 而言下降了 6.3%
5.7 Windowed Word Count Storm At Least Once 与 At Most Once 吞吐量对比

-
Storm 将 ACKer 数量设置为零后,每条消息在发送时就自动 ACK,不再等待 Bolt 的 ACK,也不再重发消息,为 At Most Once 语义。
-
上图中蓝色柱形为 At Least Once 的吞吐量,浅蓝色柱形为 At Most Once 的吞吐量。对比两者可以看出,在当前并发条件下,At Most Once 语义下的吞吐较 At Least Once 而言提高了 16.8%
5.8 Windowed Word Count 单线程作业延迟
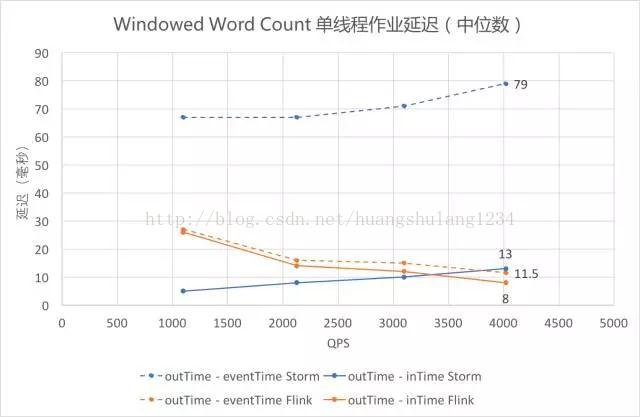
-
Identity 和 Sleep 观测的都是 outTime - eventTime,因为作业处理时间较短或 Thread.sleep() 精度不高,outTime - inTime 为零或没有比较意义;Windowed Word Count 中可以有效测得 outTime - inTime 的数值,将其与 outTime - eventTime 画在同一张图上,其中 outTime - eventTime 为虚线,outTime - InTime 为实线。
-
观察橙色的两条折线可以发现,Flink 用两种方式统计的延迟都维持在较低水平;观察两条蓝色的曲线可以发现,Storm 的 outTime - inTime 较低,outTime - eventTime 一直较高,即 inTime 和 eventTime 之间的差值一直较大,可能与 Storm 和 Flink 的数据读入方式有关。
-
蓝色折线表明 Storm 的延迟随数据量的增大而增大,而橙色折线表明 Flink 的延迟随着数据量的增大而减小(此处未测至 Flink 吞吐量,接近吞吐时 Flink 延迟依然会上升)。
-
即使仅关注 outTime - inTime(即图中实线部分),依然可以发现,当 QPS 逐渐增大的时候,Flink 在延迟上的优势开始体现出来。
5.9 Windowed Word Count Flink At Least Once 与 Exactly Once 延迟对比
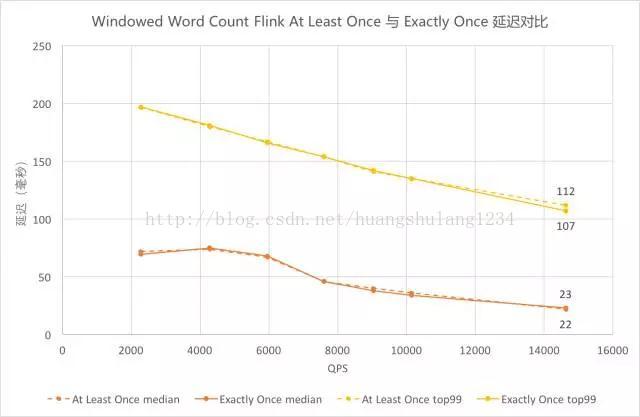
-
图中黄色为 99 线,橙色为中位数,虚线为 At Least Once,实线为 Exactly Once。图中相应颜色的虚实曲线都基本重合,可以看出 Flink Exactly Once 的延迟中位数曲线与 At Least Once 基本贴合,在延迟上性能没有太大差异。
5.10 Windowed Word Count Storm At Least Once 与 At Most Once 延迟对比

-
图中蓝色为 99 线,浅蓝色为中位数,虚线为 At Least Once,实线为 At Most Once。QPS 在 4000 及以前的时候,虚线实线基本重合;QPS 在 6000 时两者已有差异,虚线略高;QPS 接近 8000 时,已超过 At Least Once 语义下 Storm 的吞吐,因此只有实线上的点。
-
可以看出,QPS 较低时 Storm At Most Once 与 At Least Once 的延迟观察不到差异,随着 QPS 增大差异开始增大,At Most Once 的延迟较低。
5.11 Windowed Word Count Flink 不同 StateBackends 吞吐量对比

-
Flink 支持 Standalone 和 on Yarn 的集群部署模式,同时支持 Memory、FileSystem、RocksDB 三种状态存储后端(StateBackends)。由于线上作业需要,测试了这三种 StateBackends 在两种集群部署模式上的性能差异。其中,Standalone 时的存储路径为 JobManager 上的一个文件目录,on Yarn 时存储路径为 HDFS 上一个文件目录。
-
对比三组柱形可以发现,使用 FileSystem 和 Memory 的吞吐差异不大,使用 RocksDB 的吞吐仅其余两者的十分之一左右。
-
对比两种颜色可以发现,Standalone 和 on Yarn 的总体差异不大,使用 FileSystem 和 Memory 时 on Yarn 模式下吞吐稍高,使用 RocksDB 时 Standalone 模式下的吞吐稍高。
5.12 Windowed Word Count Flink 不同 StateBackends 延迟对比
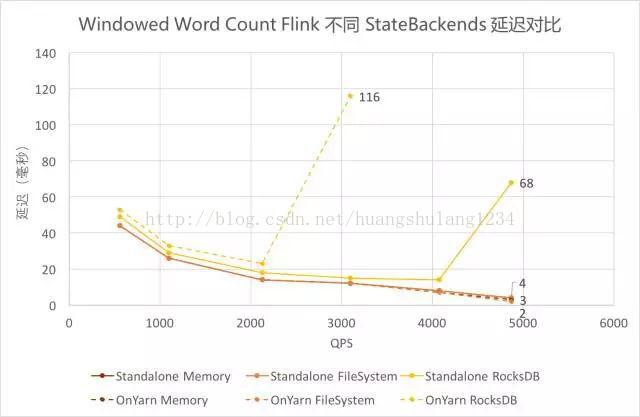
-
使用 FileSystem 和 Memory 作为 Backends 时,延迟基本一致且较低。
-
使用 RocksDB 作为 Backends 时,延迟稍高,且由于吞吐较低,在达到吞吐瓶颈前的延迟陡增。其中 on Yarn 模式下吞吐更低,接近吞吐时的延迟更高。
6. 结论及建议
6.1 框架本身性能
-
由 5.1、5.5 的测试结果可以看出,Storm 单线程吞吐约为 8.7 万条/秒,Flink 单线程吞吐可达 35 万条/秒。Flink 吞吐约为 Storm 的 3-5 倍。
-
由 5.2、5.8 的测试结果可以看出,Storm QPS 接近吞吐时延迟(含 Kafka 读写时间)中位数约 100 毫秒,99 线约 700 毫秒,Flink 中位数约 50 毫秒,99 线约 300 毫秒。Flink 在满吞吐时的延迟约为 Storm 的一半,且随着 QPS 逐渐增大,Flink 在延迟上的优势开始体现出来。
-
综上可得,Flink 框架本身性能优于 Storm。
6.2 复杂用户逻辑对框架差异的削弱
-
对比 5.1 和 5.3、5.2 和 5.4 的测试结果可以发现,单个 Bolt Sleep 时长达到 1 毫秒时,Flink 的延迟仍低于 Storm,但吞吐优势已基本无法体现。
-
因此,用户逻辑越复杂,本身耗时越长,针对该逻辑的测试体现出来的框架的差异越小。
6.3 不同消息投递语义的差异
-
由 5.6、5.7、5.9、5.10 的测试结果可以看出,Flink Exactly Once 的吞吐较 At Least Once 而言下降 6.3%,延迟差异不大;Storm At Most Once 语义下的吞吐较 At Least Once 提升 16.8%,延迟稍有下降。
-
由于 Storm 会对每条消息进行 ACK,Flink 是基于一批消息做的检查点,不同的实现原理导致两者在 At Least Once 语义的花费差异较大,从而影响了性能。而 Flink 实现 Exactly Once 语义仅增加了对齐操作,因此在算子并发量不大、没有出现慢节点的情况下对 Flink 性能的影响不大。Storm At Most Once 语义下的性能仍然低于 Flink。
6.4 Flink 状态存储后端选择
-
Flink 提供了内存、文件系统、RocksDB 三种 StateBackends,结合 5.11、5.12 的测试结果,三者的对比如下:
| StateBackend | 过程状态存储 | 检查点存储 | 吞吐 | 推荐使用场景 |
|---|---|---|---|---|
| Memory | TM Memory | JM Memory | 高(3-5 倍 Storm) | 调试、无状态或对数据是否丢失重复无要求 |
| FileSystem | TM Memory | FS/HDFS | 高(3-5 倍 Storm) | 普通状态、窗口、KV 结构(建议作为默认 Backend) |
| RocksDB | RocksDB on TM | FS/HDFS | 低(0.3-0.5 倍 Storm) | 超大状态、超长窗口、大型 KV 结构 |
6.5 推荐使用 Flink 的场景
综合上述测试结果,以下实时计算场景建议考虑使用 Flink 框架进行计算:
-
要求消息投递语义为 Exactly Once 的场景;
-
数据量较大,要求高吞吐低延迟的场景;
-
需要进行状态管理或窗口统计的场景。
7. 展望
-
本次测试中尚有一些内容没有进行更加深入的测试,有待后续测试补充。例如:
-
Exactly Once 在并发量增大的时候是否吞吐会明显下降?
-
用户耗时到 1ms 时框架的差异已经不再明显(Thread.sleep() 的精度只能到毫秒),用户耗时在什么范围内 Flink 的优势依然能体现出来?
-
-
本次测试仅观察了吞吐量和延迟两项指标,对于系统的可靠性、可扩展性等重要的性能指标没有在统计数据层面进行关注,有待后续补充。
-
Flink 使用 RocksDBStateBackend 时的吞吐较低,有待进一步探索和优化。
-
关于 Flink 的更高级 API,如 Table API & SQL 及 CEP 等,需要进一步了解和完善。
8. 参考内容
-
分布式流处理框架——功能对比和性能评估:
-
intel-hadoop/HiBench: HiBench is a big data benchmark suite.
-
Yahoo的流计算引擎基准测试.
-
Extending the Yahoo! Streaming Benchmark.
出处:https://tech.meituan.com/Flink_Benchmark.html

Apache Flink,流计算?不仅仅是流计算!
阿里妹导读:2018年12月下旬,由阿里巴巴集团主办的Flink Forward China在北京国家会议中心举行。Flink Forward是由Apache软件基金会授权的全球范围内的Flink技术大会,2015年开始在德国柏林举办,今年第一次进入中国。
今天,计算平台事业部的资深技术专家莫问,将带领我们重温这场大数据技术的饕餮盛宴,感受Apache Flink 作为下一代大数据计算引擎的繁荣生态。
Flink Forward China 大会邀请到了来自阿里巴巴、腾讯、华为、滴滴、美团点评、字节跳动、爱奇艺、去哪儿、Uber、DellEMC、DA(Flink 创始公司)等国内外知名企业以及Apache软件基金会的嘉宾为大家分享了Apache Flink的成长历程、应用场景和发展趋势。
Flink Forward China 2018 嘉宾PPT及演讲视频:
https://github.com/flink-china/flink-forward-china-2018
参与有道,如何更“好”地贡献 Apache 项目
上午大会由Apache软件基金会的秘书长Craig Russell开场,Craig首先分享了Apache开源之道,以及开源社区的精神和体制,然后以Apache Flink项目的成长经历为背景,向大家介绍了如何创建以及管理一个Apache开源项目,如何为Apache开源项目做贡献,并跟随开源项目一起成长和收获。

通过Craig的分享,我们也更详细地了解到了Apache Flink的发展经历。Flink早期起源于德国柏林工业大学的一个研究项目Stratosphere,并于2014年4月捐献给Apache软件基金会,同时重新定位品牌为Flink,经过8个月孵化期,在2014年12月成功从Apache软件基金会毕业,成为Apache顶级项目,从此开始在大数据领域航行。经过最近4年的持续快速发展,Apache Flink社区已经培养出了42名Committer和19名PMC Member,不断加入的新鲜血液为Apache Flink社区持续贡献代码,并推动社区健康快速的发展。

云上计算普惠科技

在Craig分享后,阿里巴巴集团副总裁、搜索事业部与计算平台事业部负责人周靖人进行了主题演讲。靖人首先向大家介绍了阿里巴巴大数据云上计算的现状和趋势,让大家看到了阿里巴巴大数据业务场景的超大规模,以及未来更大的挑战。

为了更好地支持阿里巴巴未来大数据的发展,阿里大数据发展策略一方面要进一步提升计算力和智能化,增强企业级服务能力。同时也要加强技术的生态化建设,大力支持并推动开源技术社区的发展,兼容行业生态标准,发展生态伙伴联盟,推动生态建设。

目前阿里巴巴已经参与贡献230+开源项目,具备8000+合作伙伴和2000+ ISV,云上生态也已经突破1000,000开发人员。在大数据领域,阿里巴巴最近几年对Apache Flink社区进行了持续大力的投入,贡献超过15w行代码,主导建立了Flink China中文社区,加速Flink在国内的生态建设,并于今年开始在北京、杭州、上海、深圳等地多次组织Flink Meetup,促进国内Flink技术人员更方便的分享交流。

靖人在分享的最后宣布了阿里巴巴内部Flink版本(Blink)将于2019年1月正式开源,本次开源内部版本的目标主要是希望让广大Flink用户能提前享受到阿里巴巴对Flink的改进和贡献。阿里巴巴同时会尽快将Blink中对Flink的各项改进和优化贡献给Flink社区,坚持对Apache Flink一个社区的拥抱和支持。

Apache Flink,如何重新定义计算?
在靖人宣布阿里巴巴开源内部Flink版本(Blink)后,阿里巴巴集团研究员蒋晓伟分享了Apache Flink在阿里巴巴内部的成长路线以及技术演进之路。
阿里巴巴从2015年开始调研Flink,并于2016年第一次在搜索场景中上线Flink,在经过搜索大数据场景的检验后,2017年Flink开始在阿里巴巴集团范围内支持各项实时计算业务, 到目前为止阿里巴巴基于Flink打造的实时计算平台,已经支持了包括淘宝、天猫、支付宝、高德、飞猪、优酷、菜鸟、饿了么等所有阿里巴巴集团下的所有子公司的数据业务,并通过阿里云向中小企业提供一站式实时计算服务。在2018年的双11中,阿里实时计算平台已经实现了峰值每秒17亿次,当天万亿级的消息处理能力。

Apache Flink目前在阿里巴巴内部最典型的业务场景是实时BI,阿里巴巴内部有着海量的在线交易以及用户数据,实时看到各个维度的数据统计可以及时地感知并指导阿里巴巴的运营。下图是一个典型的阿里实时BI流程,阿里的在线服务系统和数据库会实时产生大量日志数据并进入消息队列,FlinkJob会从消息队列中实时读取处理这些数据,然后将各种统计分析结果实时更新到KV/Table存储系统中,例如:HBase,终端用户可以通过Dashboard实时看到各种维度的数据统计分析结果。

在双11当天,各种维度的实时数据报表是指导双11决策的依据,其中最为关键的就是全球直播的实时GMV成交额。Flink已经连续两年支持阿里巴巴双11实时GMV大屏,一个看似简单的数字,其背后实际上需要大量Flink计算任务平稳、精准地运行支撑。

Flink在阿里巴巴另一个典型的应用场景是在线机器学习,传统的离线机器学习方法需要T+1的分析用户历史行为,训练出模型,当第二天模型上线后就已经是过去式,用户当前的需求和预期可能已经完全改变。为了给用户更好的购物消费体验,阿里巴巴的机器学习系统早已经进化到在线学习时代,例如:当一个用户在搜索完一个Query,浏览结果页时,或者点击查看部分商品时,阿里巴巴的在线学习系统已经可以利用这个间隙了解到这个用户当时的意图和偏好,并在下次用户Query时给出更好的排序,并向用户推荐更合适的商品,这种方式不仅可以进一步提升业务效率,同时也能为用户带来更好的产品体验,尤其是在双11这种大促场景,用户的行为时效性都是很短的,只有通过实时在线学习方式,才能做出更加精确的个性化预测和推荐。
在线学习系统的优势在于可以实时收集并处理用户的行为数据,从而进行实时流式的特征计算和在线训练,并将模型的增量更新实时同步回在线系统,形成数据闭环,通过不断迭代自动优化系统效率和用户体验。在阿里的业务规模下,整个在线学习流程将会面对海量的用户数据规模、和极其复杂的计算挑战,但在Flink的驱动下,整个流程可以在秒级完成。

通过以上两种经典场景可以看出阿里巴巴实时业务场景在各方面的挑战都很大,直接将Flink社区版本在阿里上线使用是不现实的,因此阿里巴巴实时计算团队这两年也对Flink进行了全面的优化、改进和功能扩展,其中有些功能和改进已经推回到了Flink社区。
在Flink Runtime领域,阿里巴巴贡献了:
全新的分布式系统架构:一方面对Flink的Job调度和资源管理进行了解耦,使得Flink可以原生运行在YARN,K8S之上;另一方面将Flink的Job调度从集中式转为了分布式,使得Flink集群规模可以更大的扩展。
完善的容错机制:Flink默认在任何task和master失败后,都会整个Job 重启,阿里巴巴提出的region-based failover策略以及job manager failover/ha机制,让Flink可以运行地更加可靠稳定;
大量的性能优化:Flink早期只提供全量Checkpoint机制,这在阿里巴巴大规模State场景下无法正常运行,阿里巴巴提出了增量Checkpoint机制,让Flink即使在TB级State场景下也可以高效运行;Flink Job经常在内部算子或者UDF中访问外部存储系统,例如:mysql,hbase,redis等,一旦出现个别query被卡住,整个task就被卡住,并通过反压影响到整个job,阿里巴巴提出了async IO机制,大幅降低了同步IO访问带来的影响。 此外,阿里巴巴贡献了credit-based的全新网络流控机制,使得Flink网络数据传输性能得到了显著提升。
在Flink SQL领域,阿里巴巴贡献了全新的Streaming SQL语义和功能。例如:Agg Retraction,UDX支持,DDL支持和大量的Connector适配。

在阿里巴巴,我们发现很多经典的业务场景都是同时具备实时流处理和离线批处理两种需求,而且流处理和批处理中的业务逻辑几乎是一样的,但用户需要开发两套代码,两套集群资源部署,导致额外的成本。例如阿里巴巴的商品搜索索引构建流程,白天需要将商品的更新信息流式同步到搜索引擎中,让用户可以在搜索引擎中看到实时的商品信息,晚上需要将全量的阿里巴巴商品进行批处理构建全量索引,这就是传统的Lambda架构。

阿里巴巴的解法是希望提供一套批流融合计算引擎,让用户只需开发一套业务代码,就可以在实时和离线两种场景下复用,这也是在2015年阿里巴巴选择Flink作为未来大数据引擎的初衷。 Flink基于流处理机制实现批流融合相对Spark基于批处理机制实现批流融合的思想更自然,更合理,也更有优势,因此阿里巴巴在基于Flink支持大量核心实时计算场景的同时,也在不断改进Flink的架构,使其朝着真正批流融合的统一计算引擎方向前进。
在Flink Runtime领域,阿里巴巴提出了全新的Operator Framework/API设计,使其能够同时适应批流两种算子特性;同时在Job调度和网络Shuffle两种核心机制上,都实现了灵活的插件化机制,使其能够适应批流不同场景的需求。
在Flink SQL领域,阿里巴巴提出了全新的Query Execution和Optimizer架构,利用高效的二级制数据结构,更加合理的内存利用方式,更细粒度的Codegen机制以及更加丰富的优化器策略,使得Streaming 和Batch SQL都有了非常大的性能提升。

经过大量架构改进和性能优化后,阿里巴巴内部Flink版本(Blink)在批处理上也实现了重大成果突破,在1T,10T和30T的TPC-DS的Benchmark中,Blink的性能数据均明显超出Spark,并且性能优势在数据量不断增加的趋势下越来越明显,这也从结果上验证了Flink基于流做批的架构优势。

目前,阿里巴巴的内部Flink版本(Blink)已经开始支持内部批流融合的应用场景,例如阿里巴巴的搜索推荐算法平台,流式和批量的特征以及训练流程都已经统一基于Flink在运行。

蒋晓伟在分享的最后给出了对Flink未来的一些展望,他认为Flink除了批流融合,还有很多新的方向值得去扩展,例如:Flink可以进一步加强在机器学习和图计算生态上的投入,从而在AI浪潮中实现新的突破。
此外,Flink天然具备基于事件驱动的处理思想,天然的反压和流控机制,以及自带状态管理和弹性扩缩容的能力,这些优势都在促使基于Flink构建微服务框架成为一种新的思想和解决方案。

总结蒋晓伟老师的分享,Apache Flink过去虽然在流计算领域已经获得很大的成功,但Flink并没有停滞,而是正在不断在突破自己的边界,Flink不仅仅是Streaming Engine,也不仅仅是Bigdata Engine,未来更希望努力成为Application Engine。

流处理即未来
接下来来自DA(Flink创始公司)的CTO - Stephan Ewen也对Flink的发展趋势给出类似的观点。Stephan认为“Streaming Takes on Everything”即流处理是一切计算的基础, Flink一方面需要朝着离线方向发展,实现批流融合大数据计算能力,另一方面也需要朝着更加实时在线方向发展,支持Event-Driven Application。前面已经重点阐述了Flink在批流融合计算方面的进展,接下来我们重点介绍下Flink在Event-Driven Application方向的思路。

传统的应用服务架构一般是Online App +Database的架构,Online App负责接收用户Request,然后进行内部计算,最后将Result返回给用户,Application的内部状态数据存储在Database中;在Flink的event-drivenApplication架构中,可以认为Flink Source接收Request, Sink返回Result,JobGraph进行内部计算,状态数据都存储在State中。

传统应用服务架构需要自己负责分布式和弹性管理,并由Database负责数据一致性管理;而Flink在这两方面是存在天然优势的,因为Flink天然是分布式系统,可以自己管理弹性伸缩,此外Flink内置了状态管理和exactly once一致性语义,因此基于Flink可以更方便、高效实现Transactional Application。
城市级实时计算的力量
在Apache Flink社区大神Stephan Ewen的分享后,来自阿里云的AI首席科学家闵万里向大家分享了实时计算在阿里云智慧城市中发挥的力量,通过分享多个真实应用案例,让大家对实时技术有了更多的体感和认识。
在城市大脑的业务场景中,不仅要能实时处理来自各种传感器收集到的信息,对现实世界发生的事情进行响应,同时也要对未来将要发生的事情进行预测,例如:接下来那里可能要发生交通拥堵,从而提前做出干预,这才是更大的价值。整个城市大脑的架构都运行在阿里云基础设施之上,Apache Flink承担了核心实时计算引擎的角色,负责处理各种结构化和非结构化数据。

在2018年9月的云栖大会上,阿里云发布了杭州城市大脑2.0,覆盖杭州420平方公里,可以监控到超过150万辆在途行驶机动车的实况信息,这个看似简单的事情在过去是很难做到的,现在我们通过1300多个路口的摄像头、传感器以及高德App的实时信息,通过Flink进行三流合一的处理,就可以实时感知到整个城市交通的脉搏信息,并通过进一步分析可以得出延误、安全等交通指数,预测感知城市的态势发展。

在杭州,城市大脑通过实时分析4000多个交通摄像头采集的视频流,可以实时监控路上车辆的异常事件,例如:车辆超速、逆行和擦碰等,并将这些异常事件实时同步到交警指挥中心进行实时报警,目前杭州的交通事件报警已经有95%来自城市大脑自动通报的,这背后都是通过Flink进行各种复杂的计算逻辑实时算出来的。实时计算让交警处理交通故障的方式从过去的被动等待变成了主动处理,从而大幅提升城市交通的效率,为老百姓带来实实在在的好处。

这50%,关乎生死
2018年,城市大脑第一次走出国门,来到马来西亚吉隆坡,基于实时大数据对交通进行智能调度,它可以根据救护车的行驶信息,以及沿途路况信息,智能调整红绿灯,为救护车开辟绿色快速通道,这项技术为救护车节省了近50%的时间到达医院,这50%的时间可能意味着人的生和死,在这里技术显得不再骨感,实时计算的力量也许可以挽救生命。

在工业生产IOT场景中,大量设备的传感器都收集了海量的指标数据,这些信息过去都被暂存2个月后丢弃了,唯一的用途就是在出现生产故障时拿来分析用,在有了大数据实时计算能力后,这些指标都可以被实时监控起来,作为及时调控生产流程的依据。协鑫光伏是全球最大的光伏切片企业,阿里云利用实时设备监控,帮助其提高了1%的良品率,每年可以增加上亿元的收入。

滴滴实时计算平台架构与实践
Keynote最后一位嘉宾是来自滴滴出行的研究员罗李,大家都知道滴滴出行是一个实时出行平台和交易引擎,它的数据和场景天然是实时的,各种网约车服务产生的数据都需要实时处理和分析。

滴滴的实时业务场景主要包括实时风控、实时发券、实时异常检测,实时交易、服务和工单监控,以及实时乘客、司机和订单特征处理等。
滴滴实时计算平台发展已经经历了三个阶段,第一阶段是各个业务方自建小集群,造成集群和资源碎片化问题;第二阶段由公司统一建立了大集群,提供统一的平台化服务,降低了集群资源和维护成本;第三阶段是通过Flink SQL方式提供平台化服务,通过SQL语言优势进一步降低业务开发成本,提升开发效率。
滴滴现阶段基于Apache Flink引擎建设的实时计算平台以开源的Hadoop技术体系作为平台底座,并通过DataStream, SQL和CEP三种API向滴滴内部业务提供实时计算服务,同时在平台层也已经具备相对完善的WebIDE、数据血缘管理、监控报警和多组合隔离等机制。

在滴滴实时业务的快速发展推动下,其实时计算集群已经达到千台规模,每天运行2000+流计算任务,可以处理PB级的数据。
滴滴在搭建Flink实时计算平台的过程中,在内部也对Flink做了一些改进,例如在 Stream SQL领域扩展了DDL,丰富了 UDF,支持了TTL的双流Join和维表Join等;在CEP领域,增加了更多算子支持和规则动态修改能力等,其中部分优化已经推回了社区。

最后,罗李介绍了滴滴实时计算平台的未来规划,主要方向在于进一步推广Stream SQL提升业务开发效率,推动CEP在更多业务场景落地,同时完成公司内部原有Spark Streaming向Flink的迁移,并发力IOT领域。
在下午的几个分会场中,来自阿里巴巴、腾讯、华为、滴滴、美团点评、字节跳动、爱奇艺、去哪儿、Uber、EMC、DA(Flink 创始公司)的多位嘉宾和讲师都围绕Flink技术生态和应用场景进行了分享和交流。从分享的内容上可以看出,BAT三家中阿里巴巴和腾讯都已经完全拥抱了Flink;美团、滴滴和字节跳动(TMD)三家新兴互联网企业在实时计算场景也都已经以Flink作为主流技术方向开始建设,滴滴在Keynote上分享已经令人印象深刻,美团的实时计算集群也已经突破4000台规模,字节跳动(头条和抖音的母公司)的Flink生产集群规模更是超过了1w台的惊人规模 。

由此可见Apache Flink的技术理念已经在业界得到了大量认可,基于Flink的实时计算解决方案开始在国内占据主流趋势。下一步Flink需要一方面继续完善流计算能力,争取在IOT等更多场景落地,与此同时进一步加强在批流融合能力上的全面突破,并完善在机器学习和AI生态上的建设,以及在event-driven的application和微服务场景上进行更长远的探索。
本文作者: 莫问
阅读原文
本文来自云栖社区合作伙伴“阿里技术”,如需转载请联系原作者。

Apache 流框架 Flink,Spark Streaming,Storm 对比分析
1.Flink 架构及特性分析
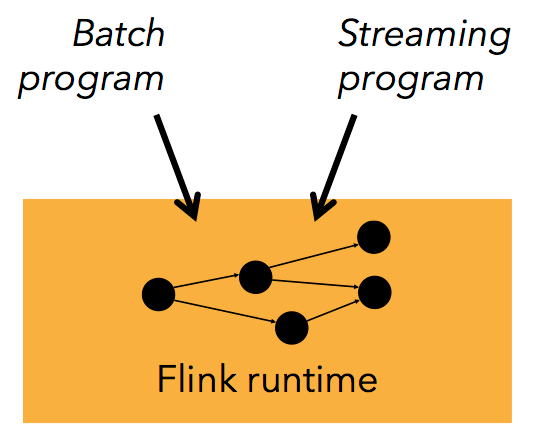
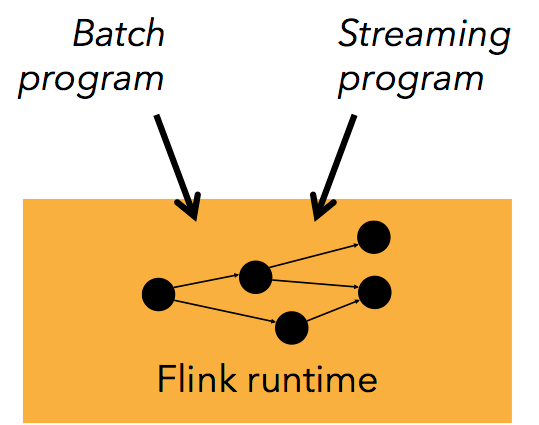
Flink 是个相当早的项目,开始于 2008 年,但只在最近才得到注意。Flink 是原生的流处理系统,提供 high level 的 API。Flink 也提供 API 来像 Spark 一样进行批处理,但两者处理的基础是完全不同的。Flink 把批处理当作流处理中的一种特殊情况。在 Flink 中,所有 的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
1.1 基本架构
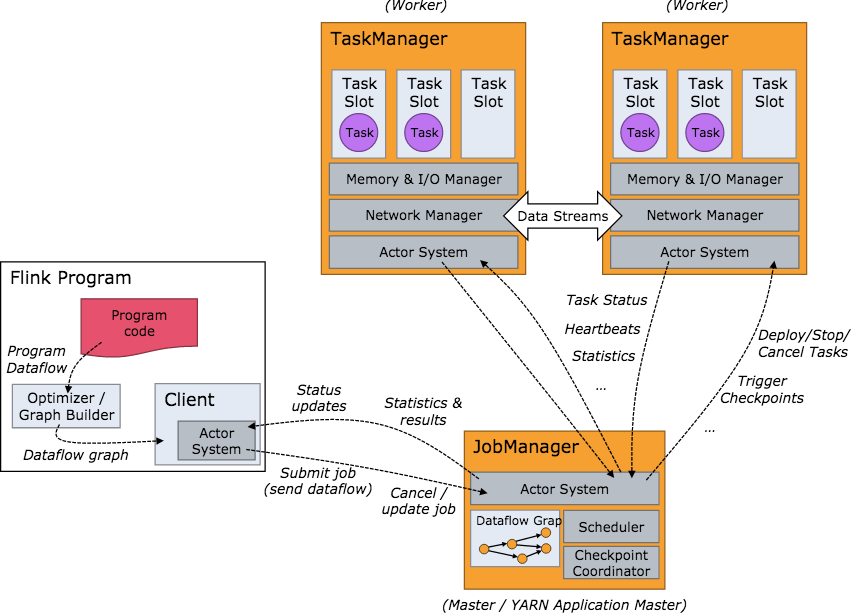
下面我们介绍下 Flink 的基本架构,Flink 系统的架构与 Spark 类似,是一个基于 Master-Slave 风格的架构。

当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager, JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。 TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程 (Streaming 的任务),也可以不结束并等待结果返回。
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包 等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要 部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
JobManager
JobManager 是 Flink 系统的协调者,它负责接收 Flink Job,调度组成 Job 的多个 Task 的执行。同时,JobManager 还负责收集 Job 的状态信息,并管理 Flink 集群中从节点 TaskManager。JobManager 所负责的各项管理功能,它接收到并处理的事件主要包括:
RegisterTaskManager
在 Flink 集群启动的时候,TaskManager 会向 JobManager 注册,如果注册成功,则 JobManager 会向 TaskManager 回复消息 AcknowledgeRegistration。
SubmitJob
Flink 程序内部通过 Client 向 JobManager 提交 Flink Job,其中在消息 SubmitJob 中以 JobGraph 形式描述了 Job 的基本信息。
CancelJob
请求取消一个 Flink Job 的执行,CancelJob 消息中包含了 Job 的 ID,如果成功则返回消息 CancellationSuccess,失败则返回消息 CancellationFailure。
UpdateTaskExecutionState
TaskManager 会向 JobManager 请求更新 ExecutionGraph 中的 ExecutionVertex 的状态信息,更新成功则返回 true。
RequestNextInputSplit
运行在 TaskManager 上面的 Task,请求获取下一个要处理的输入 Split,成功则返回 NextInputSplit。
JobStatusChanged
ExecutionGraph 向 JobManager 发送该消息,用来表示 Flink Job 的状态发生的变化,例如:RUNNING、CANCELING、 FINISHED 等。
TaskManager
TaskManager 也是一个 Actor,它是实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task。每个 TaskManager 负责管理 其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向 JobManager 汇报。TaskManager 端可以分成两个 阶段:
注册阶段
TaskManager 会向 JobManager 注册,发送 RegisterTaskManager 消息,等待 JobManager 返回 AcknowledgeRegistration,然 后 TaskManager 就可以进行初始化过程。
可操作阶段
该阶段 TaskManager 可以接收并处理与 Task 有关的消息,如 SubmitTask、CancelTask、FailTask。如果 TaskManager 无法连接 到 JobManager,这是 TaskManager 就失去了与 JobManager 的联系,会自动进入 “注册阶段”,只有完成注册才能继续处理 Task 相关的消息。
Client
当用户提交一个 Flink 程序时,会首先创建一个 Client,该 Client 首先会对用户提交的 Flink 程序进行预处理,并提交到 Flink 集群中处 理,所以 Client 需要从用户提交的 Flink 程序配置中获取 JobManager 的地址,并建立到 JobManager 的连接,将 Flink Job 提交给 JobManager。Client 会将用户提交的 Flink 程序组装一个 JobGraph, 并且是以 JobGraph 的形式提交的。一个 JobGraph 是一个 Flink Dataflow,它由多个 JobVertex 组成的 DAG。其中,一个 JobGraph 包含了一个 Flink 程序的如下信息:JobID、Job 名称、配 置信息、一组 JobVertex 等。
1.2 基于 Yarn 层面的架构
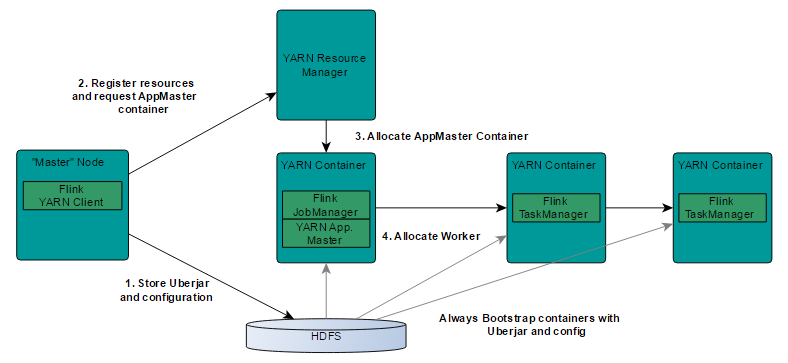
基于 yarn 层面的架构类似 spark on yarn 模式,都是由 Client 提交 App 到 RM 上面去运行,然后 RM 分配第一个 container 去运行 AM,然后由 AM 去负责资源的监督和管理。需要说明的是,Flink 的 yarn 模式更加类似 spark on yarn 的 cluster 模式,在 cluster 模式 中,dirver 将作为 AM 中的一个线程去运行,在 Flink on yarn 模式也是会将 JobManager 启动在 container 里面,去做个 driver 类似 的 task 调度和分配,YARN AM 与 Flink JobManager 在同一个 Container 中,这样 AM 可以知道 Flink JobManager 的地址,从而 AM 可以申请 Container 去启动 Flink TaskManager。待 Flink 成功运行在 YARN 集群上,Flink YARN Client 就可以提交 Flink Job 到 Flink JobManager,并进行后续的映射、调度和计算处理。
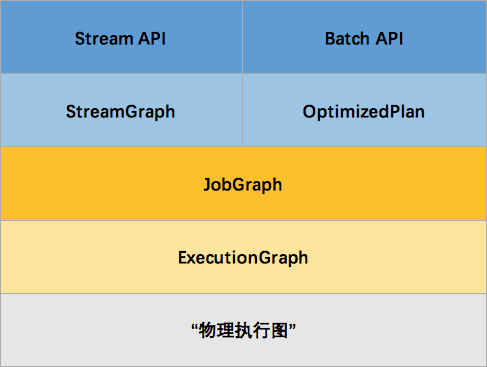
1.3 组件栈
Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。
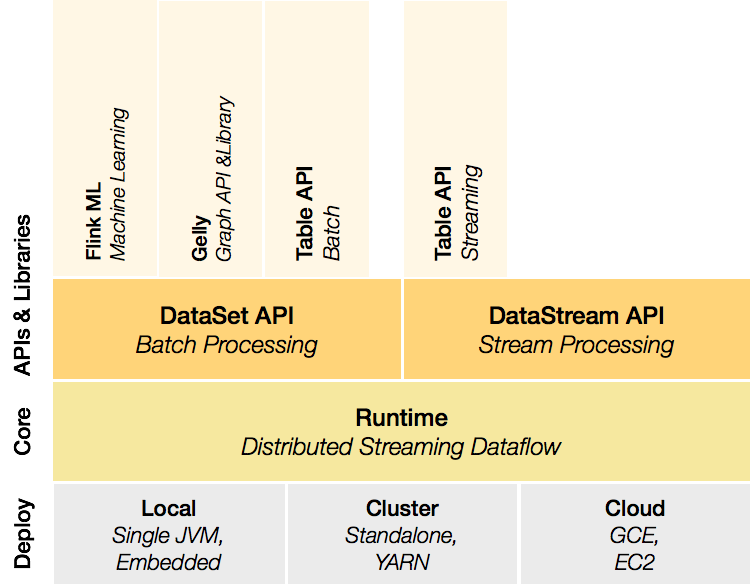
Deployment 层
该层主要涉及了 Flink 的部署模式,Flink 支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone 部署模式与 Spark 类似,这里,我们看一下 Flink on YARN 的部署模式
Runtime 层
Runtime 层提供了支持 Flink 计算的全部核心实现,比如:支持分布式 Stream 处理、JobGraph 到 ExecutionGraph 的映射、调度等 等,为上层 API 层提供基础服务。
API 层
API 层主要实现了面向无界 Stream 的流处理和面向 Batch 的批处理 API,其中面向流处理对应 DataStream API,面向批处理对应 DataSet API。
Libraries 层
该层也可以称为 Flink 应用框架层,根据 API 层的划分,在 API 层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理 和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于 SQL-like 的操作(基于 Table 的关系操作);面向批处理支持: FlinkML(机器学习库)、Gelly(图处理)。
从官网中我们可以看到,对于 Flink 一个最重要的设计就是 Batch 和 Streaming 共同使用同一个处理引擎,批处理应用可以以一种特 殊的流处理应用高效地运行。
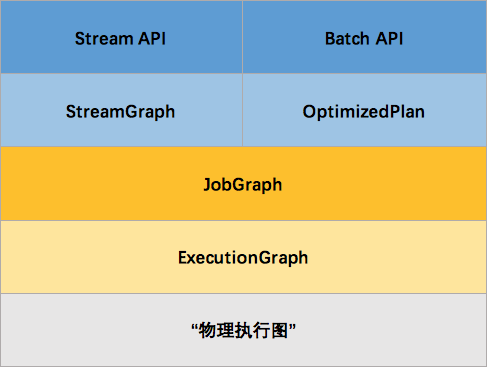
这里面会有一个问题,就是 Batch 和 Streaming 是如何使用同一个处理引擎进行处理的。
1.4 Batch 和 Streaming 是如何使用同一个处理引擎。
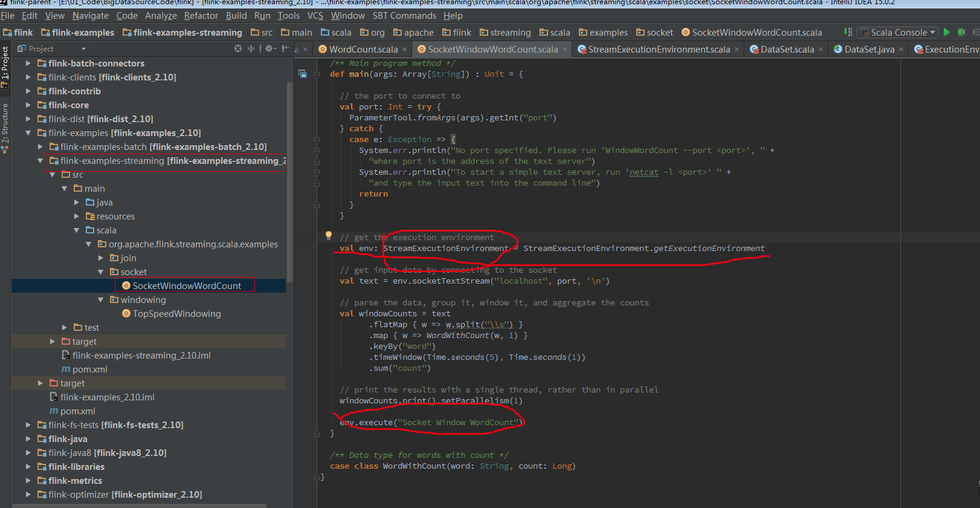
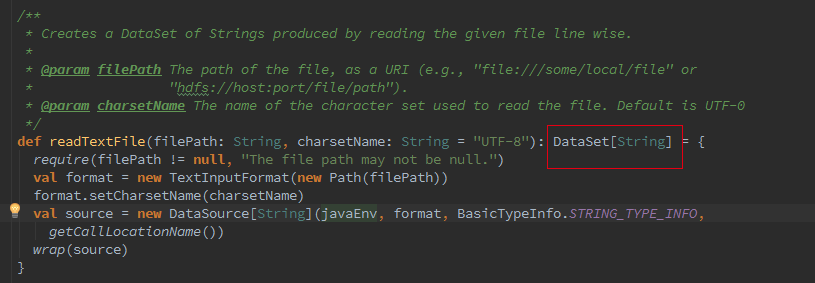
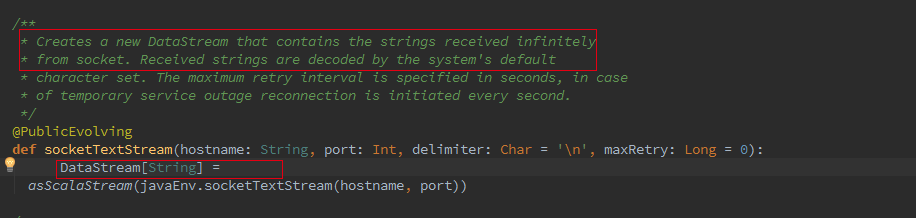
下面将从代码的角度去解释 Batch 和 Streaming 是如何使用同一处理引擎的。首先从 Flink 测试用例来区分两者的区别。
Batch WordCount Examples
Streaming WordCount Examples
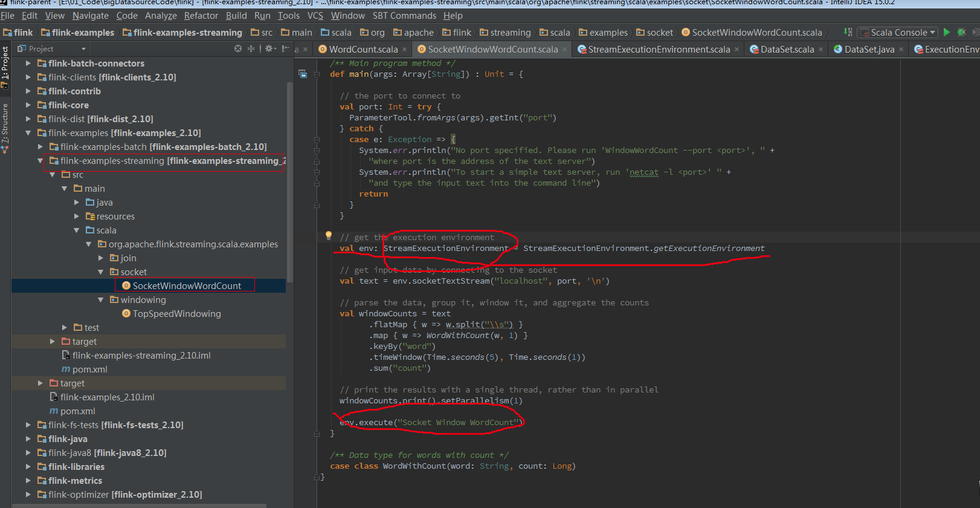
Batch 和 Streaming 采用的不同的 ExecutionEnviroment,对于 ExecutionEnviroment 来说读到的源数据是一个 DataSet, 而 StreamExecutionEnviroment 的源数据来说则是一个 DataStream。

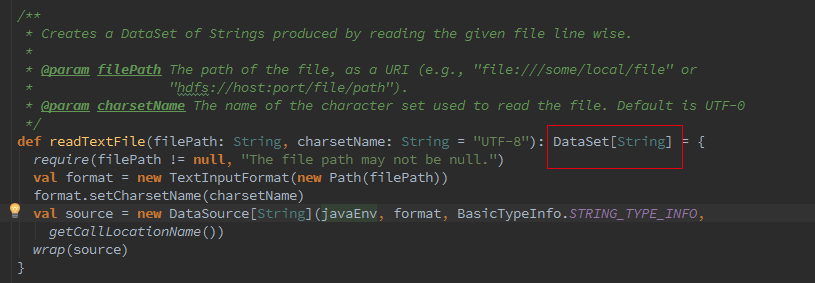

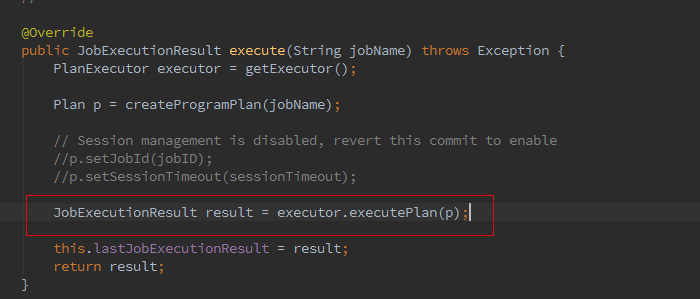
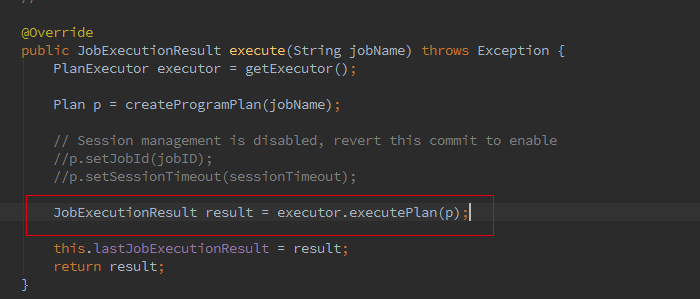
接着我们追踪下 Batch 的从 Optimzer 到 JobGgraph 的流程,这里如果是 Local 模式构造的是 LocalPlanExecutor,这里我们只介绍 Remote 模式,此处的 executor 为 RemotePlanExecutor

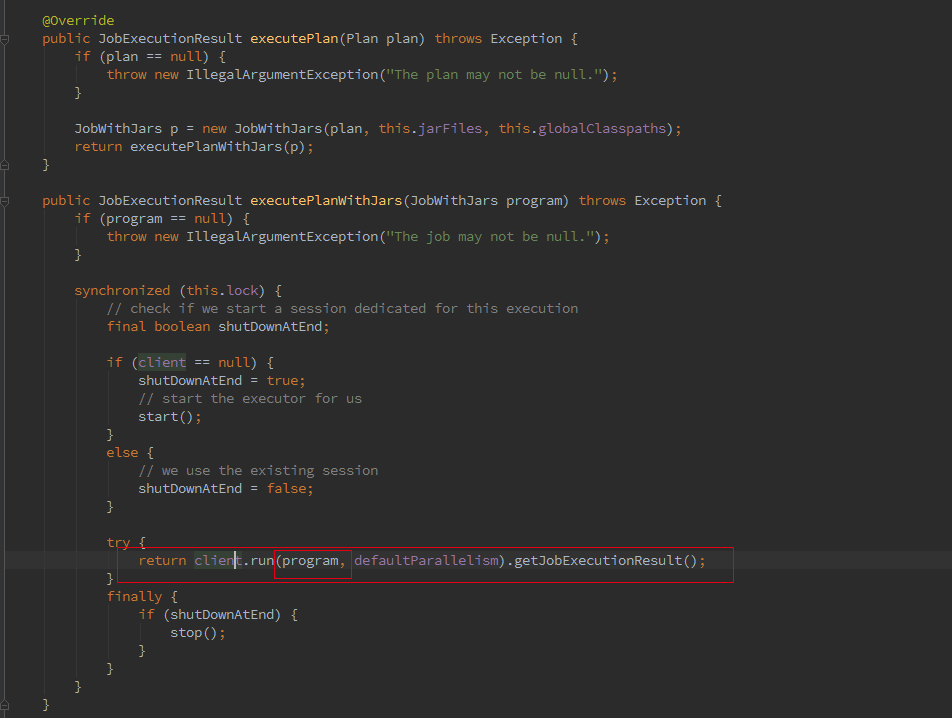
最终会调用 ClusterClient 的 run 方法将我们的应用提交上去,run 方法的第一步就是获取 jobGraph,这个是 client 端的操作,client 会将 jobGraph 提交给 JobManager 转化为 ExecutionGraph。Batch 和 streaming 不同之处就是在获取 JobGraph 上面。
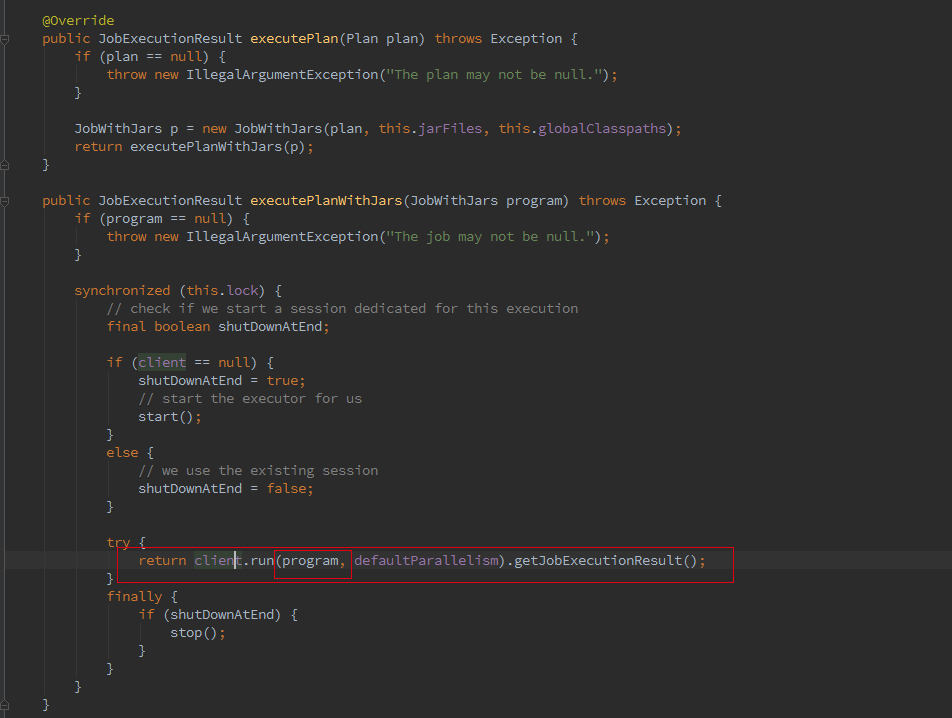

如果我们初始化的 FlinkPlan 是 StreamingPlan,则首先构造 Streaming 的 StreamingJobGraphGenerator 去将 optPlan 转为 JobGraph,Batch 则直接采用另一种的转化方式。

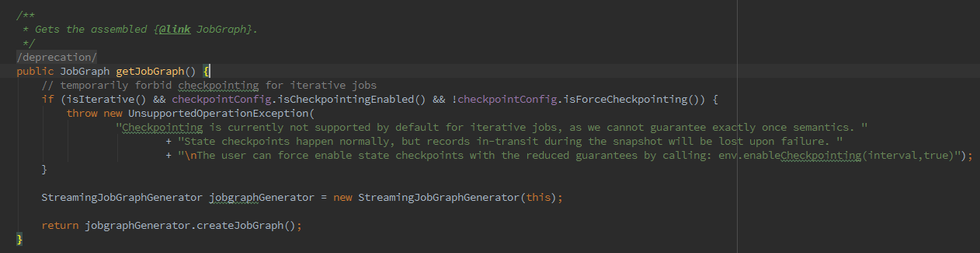
简而言之,Batch 和 streaming 会有两个不同的 ExecutionEnvironment,不同的 ExecutionEnvironment 会将不同的 API 翻译成不同 的 JobGgrah,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。 StreamGraph 是由 Stream API 转换而来的,JobGraph 的责任就是统一 Batch 和 Stream 的图。
1.5 特性分析
高吞吐 & 低延迟
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。下图展示了一个分布式计数的任务的性能,包括了流数据 shuffle 过程。

支持 Event Time 和乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。
Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单。
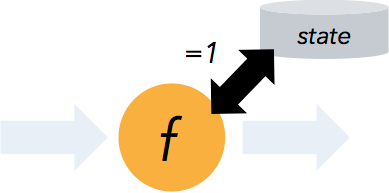
状态计算的 exactly-once 语义
流程序可以在计算过程中维护自定义状态。
Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。

高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口
窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
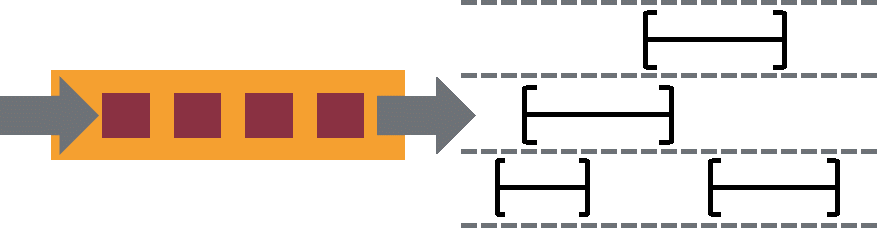
带反压的连续流模型
数据流应用执行的是不间断的(常驻)operators。
Flink streaming 在运行时有着天然的流控:慢的数据 sink 节点会反压(backpressure)快的数据源(sources)。
容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。
这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
Batch 和 Streaming 一个系统流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。

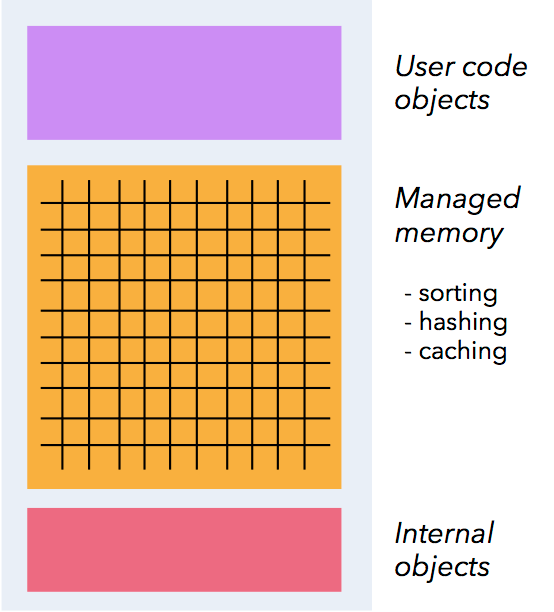
内存管理
Flink 在 JVM 中实现了自己的内存管理。
应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
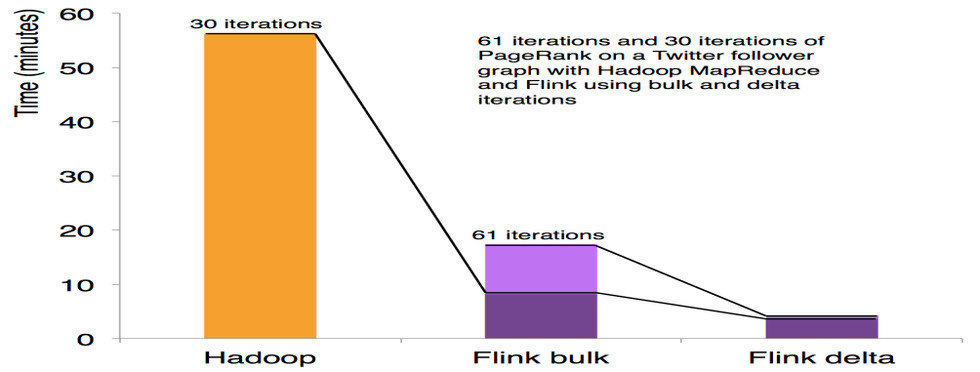
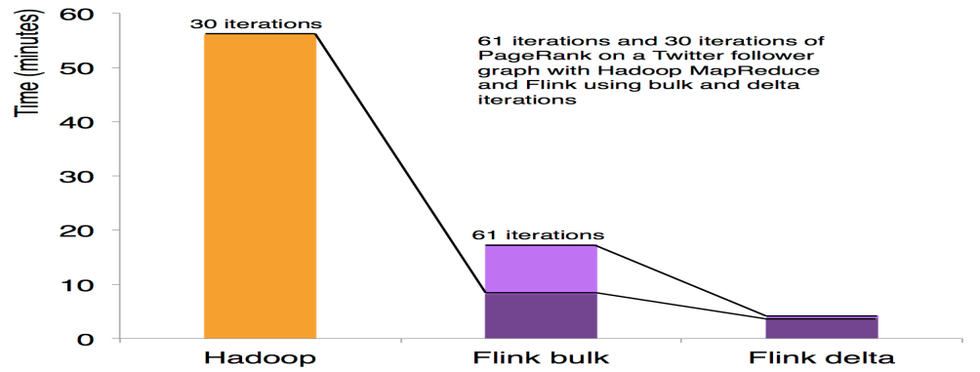
迭代和增量迭代
Flink 具有迭代计算的专门支持(比如在机器学习和图计算中)。
增量迭代可以利用依赖计算来更快地收敛。

程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
API 和 类库
流处理应用
DataStream API 支持了数据流上的函数式转换,可以使用自定义的状态和灵活的窗口。
右侧的示例展示了如何以滑动窗口的方式统计文本数据流中单词出现的次数。
val texts:DataStream[String] = ...
val counts = text .flatMap { line => line.split("\\W+") } .map { token => Word(token, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("freq")
批处理应用
Flink 的 DataSet API 可以使你用 Java 或 Scala 写出漂亮的、类型安全的、可维护的代码。它支持广泛的数据类型,不仅仅是 key/value 对,以及丰富的 operators。
右侧的示例展示了图计算中 PageRank 算法的一个核心循环。
case class Page( pageId: Long, rank:Double) case class Adjacency( id: Long, neighbors:Array[Long])
val result = initialRanks.iterate(30) { pages => pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => { out.collect(Page(page.id, 0.15 / numPages)) for (n <- adj.neighbors) { out.collect(Page(n, 0.85*page.rank/adj.neighbors.length)) } } } .groupBy("pageId").sum("rank") }
类库生态
Flink 栈中提供了提供了很多具有高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理。当前类库还在 beta 状 态,并且在大力发展。

广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。
Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储 系统。

部署
Flink 可以单独脱离 Hadoop 进行部署,部署只依赖 Java 环境,相对简单。
2.Spark Streaming 架构及特性分析
2.1 基本架构

基于是 spark core 的 spark streaming 架构。
Spark Streaming 是将流式计算分解成一系列短小的批处理作业。这里的批处理引擎是 Spark,也就是把 Spark Streaming 的输入数 据按照 batch size(如 1 秒)分成一段一段的数据(Discretized Stream),每一段数据都转换成 Spark 中的 RDD(Resilient Distributed Dataset ) , 然 后 将 Spark Streaming 中 对 DStream 的 Transformation 操 作 变 为 针 对 Spark 中 对 RDD 的 Transformation 操作,将 RDD 经 过操作变成中间结果保存在内存中。整个流式计算根据业务的需求可以对中间的结果进行叠加, 或者存储到外部设备。

简而言之,Spark Streaming 把实时输入数据流以时间片 Δt (如 1 秒)为单位切分成块,Spark Streaming 会把每块数据作为一个 RDD,并使用 RDD 操作处理每一小块数据。每个块都会生成一个 Spark Job 处理,然后分批次提交 job 到集群中去运行,运行每个 job 的过程和真正的 spark 任务没有任何区别。
JobScheduler
负责 job 的调度
JobScheduler 是 SparkStreaming 所有 Job 调度的中心, JobScheduler 的启动会导致 ReceiverTracker 和 JobGenerator 的启动。 ReceiverTracker 的启动导致运行在 Executor 端的 Receiver 启动并且接收数据,ReceiverTracker 会记录 Receiver 接收到的数据 meta 信息。JobGenerator 的启动导致每隔 BatchDuration,就调用 DStreamGraph 生成 RDD Graph,并生成 Job。JobScheduler 中的线程池来提交封装的 JobSet 对象 (时间值,Job,数据源的 meta)。Job 中封装了业务逻辑,导致最后一个 RDD 的 action 被触 发,被 DAGScheduler 真正调度在 Spark 集群上执行该 Job。
JobGenerator
负责 Job 的生成
通过定时器每隔一段时间根据 Dstream 的依赖关系生一个一个 DAG 图。
ReceiverTracker
负责数据的接收,管理和分配
ReceiverTracker 在启动 Receiver 的时候他有 ReceiverSupervisor, 其实现是 ReceiverSupervisorImpl, ReceiverSupervisor 本身启 动的时候会启动 Receiver,Receiver 不断的接收数据,通过 BlockGenerator 将数据转换成 Block。定时器会不断的把 Block 数据通会不断的把 Block 数据通过 BlockManager 或者 WAL 进行存储,数据存储之后 ReceiverSupervisorlmpl 会把存储后的数据的元数据 Metadate 汇报给 ReceiverTracker,其实是汇报给 ReceiverTracker 中的 RPC 实体 ReceiverTrackerEndpoint,主要。
2.2 基于 Yarn 层面的架构分析

上图为 spark on yarn 的 cluster 模式,Spark on Yarn 启动后,由 Spark AppMaster 中的 driver(在 AM 的里面会启动 driver,主要 是 StreamingContext 对象)把 Receiver 作为一个 Task 提交给某一个 Spark Executor;Receive 启动后输入数据,生成数据块,然 后通知 Spark AppMaster;Spark AppMaster 会根据数据块生成相应的 Job,并把 Job 的 Task 提交给空闲 Spark Executor 执行。图 中蓝色的粗箭头显示被处理的数据流,输入数据流可以是磁盘、网络和 HDFS 等,输出可以是 HDFS,数据库等。对比 Flink 和 spark streaming 的 cluster 模式可以发现,都是 AM 里面的组件(Flink 是 JM,spark streaming 是 Driver)承载了 task 的分配和调度,其他 container 承载了任务的执行(Flink 是 TM,spark streaming 是 Executor),不同的是 spark streaming 每个批次都要与 driver 进行 通信来进行重新调度,这样延迟性远低于 Flink。
具体实现
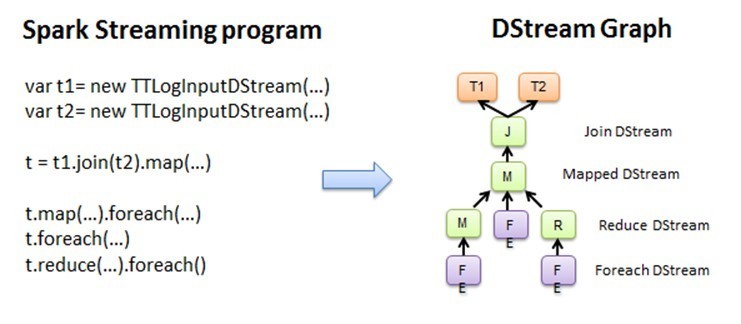
图 2.1 Spark Streaming 程序转换为 DStream Graph
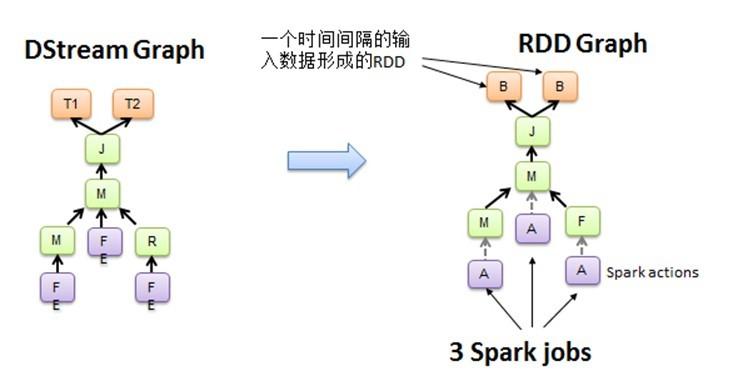
图 2.2 DStream Graph 转换为 RDD 的 Graph
Spark Core 处理的每一步都是基于 RDD 的,RDD 之间有依赖关系。下图中的 RDD 的 DAG 显示的是有 3 个 Action,会触发 3 个 job, RDD 自下向上依 赖,RDD 产生 job 就会具体的执行。从 DSteam Graph 中可以看到,DStream 的逻辑与 RDD 基本一致,它就是在 RDD 的基础上加上了时间的依赖。RDD 的 DAG 又可以叫空间维度,也就是说整个 Spark Streaming 多了一个时间维度,也可以成 为时空维度,使用 Spark Streaming 编写的程序与编写 Spark 程序非常相似,在 Spark 程序中,主要通过操作 RDD(Resilient Distributed Datasets 弹性分布式数据集)提供的接口,如 map、reduce、filter 等,实现数据的批处理。而在 Spark Streaming 中,则通过操作 DStream(表示数据流的 RDD 序列)提供的接口,这些接口和 RDD 提供的接口类似。
Spark Streaming 把程序中对 DStream 的操作转换为 DStream Graph,图 2.1 中,对于每个时间片,DStream Graph 都会产生一个 RDD Graph;针对每个输出 操作(如 print、foreach 等),Spark Streaming 都会创建一个 Spark action;对于每个 Spark action,Spark Streaming 都会产生 一个相应的 Spark job,并交给 JobScheduler。JobScheduler 中维护着一个 Jobs 队列,Spark job 存储在这个队列中, JobScheduler 把 Spark job 提交给 Spark Scheduler,Spark Scheduler 负责调度 Task 到相应的 Spark Executor 上执行,最后形成 spark 的 job。
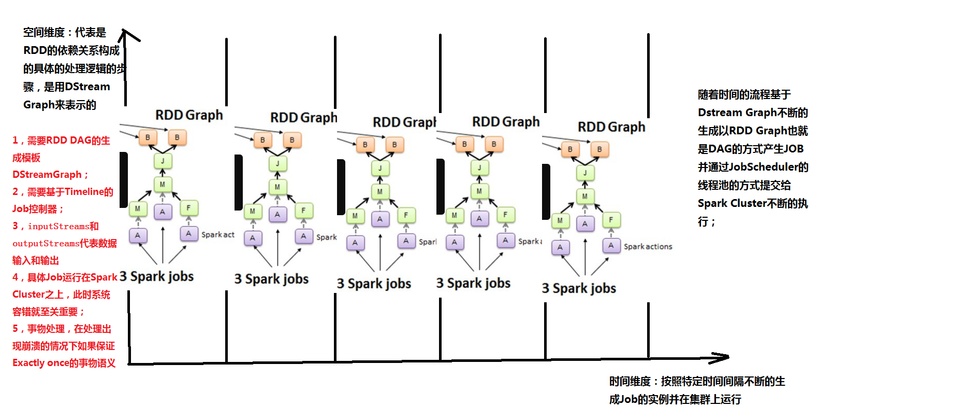
图 2.3 时间维度生成 RDD 的 DAG
Y 轴就是对 RDD 的操作,RDD 的依赖关系构成了整个 job 的逻辑,而 X 轴就是时间。随着时间的流逝,固定的时间间隔(Batch Interval)就会生成一个 job 实例,进而在集群中运行。
代码实现
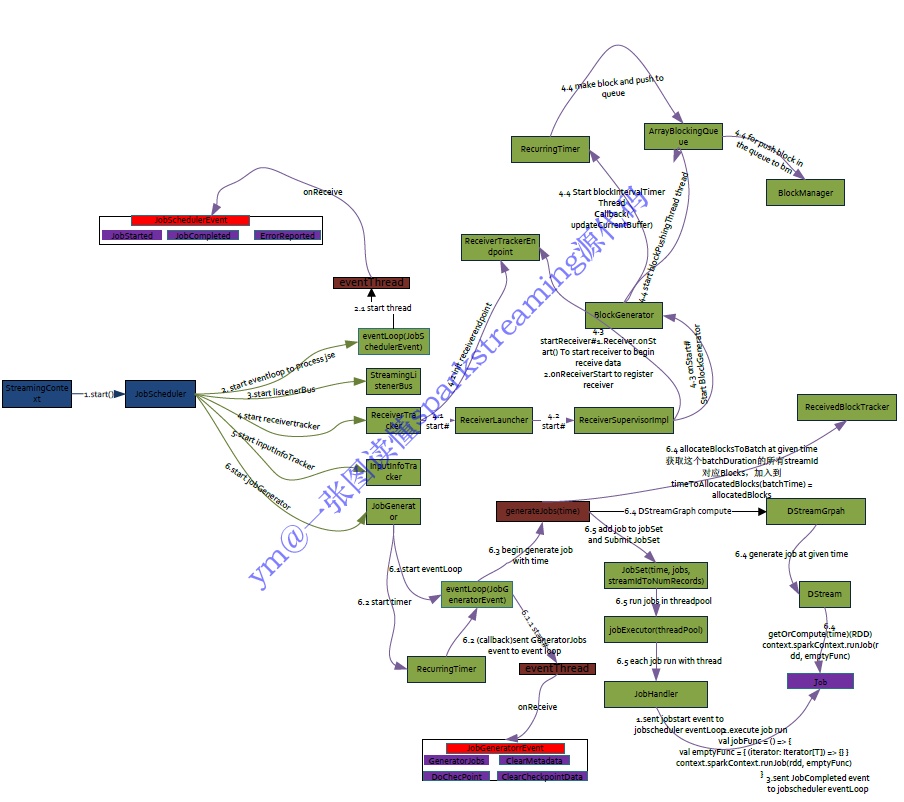
基于 spark 1.5 的 spark streaming 源代码解读,基本架构是没怎么变化的。
2.3 组件栈

支持从多种数据源获取数据,包括 Kafk、Flume、Twitter、ZeroMQ、Kinesis 以及 TCP sockets,从数据源获取数据之后,可以 使用诸如 map、reduce、join 和 window 等高级函数进行复杂算法的处理。最后还可以将处理结果 存储到文件系统,数据库和现场 仪表盘。在 “One Stack rule them all” 的基础上,还可以使用 Spark 的其他子框架,如集群学习、图计算等,对流数据进行处 理。
2.4 特性分析
吞吐量与延迟性
Spark 目前在 EC2 上已能够线性扩展到 100 个节点(每个节点 4Core),可以以数秒的延迟处理 6GB/s 的数据量(60M records/s),其吞吐量也比流行的 Storm 高 2~5 倍,图 4 是 Berkeley 利用 WordCount 和 Grep 两个用例所做的测试,在 Grep 这个 测试中,Spark Streaming 中的每个节点的吞吐量是 670k records/s,而 Storm 是 115k records/s。
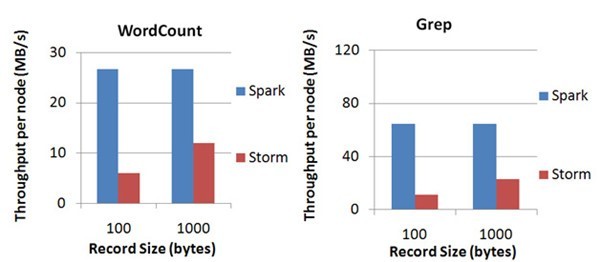
Spark Streaming 将流式计算分解成多个 Spark Job,对于每一段数据的处理都会经过 Spark DAG 图分解,以及 Spark 的任务集的调 度过程,其最小的 Batch Size 的选取在 0.5~2 秒钟之间(Storm 目前最小的延迟是 100ms 左右),所以 Spark Streaming 能够满足 除对实时性要求非常高(如高频实时交易)之外的所有流式准实时计算场景。
exactly-once 语义
更加稳定的 exactly-once 语义支持。
反压能力的支持
Spark Streaming 从 v1.5 开始引入反压机制(back-pressure), 通过动态控制数据接收速率来适配集群数据处理能力.
Sparkstreaming 如何反压?
简单来说,反压机制需要调节系统接受数据速率或处理数据速率,然而系统处理数据的速率是没法简单的调节。因此,只能估计当 前系统处理数据的速率,调节系统接受数据的速率来与之相匹配。
Flink 如何反压?
严格来说,Flink 无需进行反压,因为系统接收数据的速率和处理数据的速率是自然匹配的。系统接收数据的前提是接收数据的 Task 必须有空闲可用的 Buffer,该数据被继续处理的前提是下游 Task 也有空闲可用的 Buffer。因此,不存在系统接受了过多的数据,导 致超过了系统处理的能力。
由此看出,Spark 的 micro-batch 模型导致了它需要单独引入反压机制。
反压与高负载
反压通常产生于这样的场景:短时负载高峰导致系统接收数据的速率远高于它处理数据的速率。
但是,系统能够承受多高的负载是系统数据处理能力决定的,反压机制并不是提高系统处理数据的能力,而是系统所面临负载高于 承受能力时如何调节系统接收数据的速率。
容错
Driver 和 executor 采用预写日志(WAL)方式去保存状态,同时结合 RDD 本身的血统的容错机制。
API 和 类库
Spark 2.0 中引入了结构化数据流,统一了 SQL 和 Streaming 的 API,采用 DataFrame 作为统一入口,能够像编写普通 Batch 程序或 者直接像操作 SQL 一样操作 Streaming,易于编程。

广泛集成
除了可以读取 HDFS, Flume, Kafka, Twitter andZeroMQ 数据源以外,我们自己也可以定义数据源,支持运行在 Yarn, Standalone 及 EC2 上,能够通过 Zookeeper,HDFS 保证高可用性,处理结果可以直接写到 HDFS
部署性
依赖 java 环境,只要应用能够加载到 spark 相关的 jar 包即可。
3.Storm 架构及特性分析
3.1 基本架构
Storm 集群采用主从架构方式,主节点是 Nimbus,从节点是 Supervisor,有关调度相关的信息存储到 ZooKeeper 集群中。架构如下:

Nimbus
Storm 集群的 Master 节点,负责分发用户代码,指派给具体的 Supervisor 节点上的 Worker 节点,去运行 Topology 对应的组件 (Spout/Bolt)的 Task。
Supervisor
Storm 集群的从节点,负责管理运行在 Supervisor 节点上的每一个 Worker 进程的启动和终止。通过 Storm 的配置文件中的 supervisor.slots.ports 配置项,可以指定在一个 Supervisor 上最大允许多少个 Slot,每个 Slot 通过端口号来唯一标识,一个端口号 对应一个 Worker 进程(如果该 Worker 进程被启动)。
ZooKeeper
用来协调 Nimbus 和 Supervisor,如果 Supervisor 因故障出现问题而无法运行 Topology,Nimbus 会第一时间感知到,并重新分配 Topology 到其它可用的 Supervisor 上运行。
运行架构
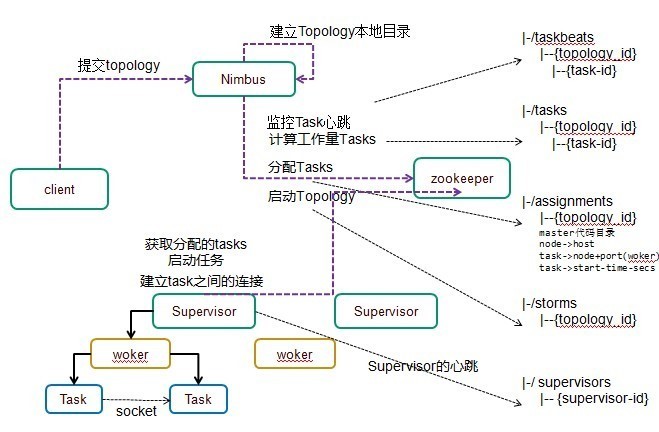
运行流程
1)户端提交拓扑到 nimbus。
2) Nimbus 针对该拓扑建立本地的目录根据 topology 的配置计算 task,分配 task,在 zookeeper 上建立 assignments 节点存储 task 和 supervisor 机器节点中 woker 的对应关系;
在 zookeeper 上创建 taskbeats 节点来监控 task 的心跳;启动 topology。
3) Supervisor 去 zookeeper 上获取分配的 tasks,启动多个 woker 进行,每个 woker 生成 task,一个 task 一个线程;根据 topology 信息初始化建立 task 之间的连接;Task 和 Task 之间是通过 zeroMQ 管理的;后整个拓扑运行起来。
3.2 基于 Yarn 层面的架构
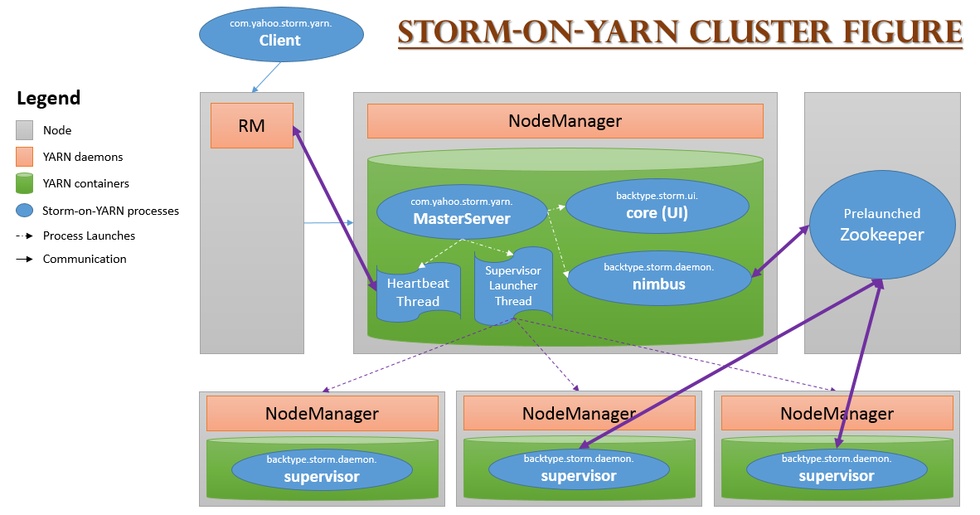
在 YARN 上开发一个应用程序,通常只需要开发两个组件,分别是客户端和 ApplicationMaster,其中客户端主要作用是提交应用程 序到 YARN 上,并和 YARN 和 ApplicationMaster 进行交互,完成用户发送的一些指令;而 ApplicationMaster 则负责向 YARN 申请 资源,并与 NodeManager 通信,启动任务。
不修改任何 Storm 源代码即可将其运行在 YARN 之上,最简单的实现方法是将 Storm 的各个服务组件(包括 Nimbus 和 Supervisor) 作为单独的任务运行在 YARN 上,而 Zookeeper 作为一个公共的服务运行在 YARN 集群之外的几个节点上。
1)通过 YARN-Storm Client 将 Storm Application 提交到 YARN 的 RM 上;
2)RM 为 YARN-Storm ApplicationMaster 申请资源,并将其运行在一个节点上(Nimbus);
3)YARN-Storm ApplicationMaster 在自己内部启动 Nimbus 和 UI 服务;
4) YARN-Storm ApplicationMaster 根据用户配置向 RM 申请资源,并在申请到的 Container 中启动 Supervisor 服务;
3.3 组件栈
3.4 特性分析
简单的编程模型。
类似于 MapReduce 降低了并行批处理复杂性,Storm 降低了进行实时处理的复杂性。
服务化
一个服务框架,支持热部署,即时上线或下线 App.
可以使用各种编程语言
你可以在 Storm 之上使用各种编程语言。默认支持 Clojure、Java、Ruby 和 Python。要增加对其他语言的支持,只需实现一个简单 的 Storm 通信协议即可。
容错性
Storm 会管理工作进程和节点的故障。
水平扩展
计算是在多个线程、进程和服务器之间并行进行的。
可靠的消息处理
Storm 保证每个消息至少能得到一次完整处理。任务失败时,它会负责从消息源重试消息。
快速
系统的设计保证了消息能得到快速的处理,使用 ZeroMQ 作为其底层消息队列。
本地模式
Storm 有一个 “本地模式”,可以在处理过程中完全模拟 Storm 集群。这让你可以快速进行开发和单元测试。
部署性
依赖于 Zookeeper 进行任务状态的维护,必须首先部署 Zookeeper。
4.三种框架的对比分析

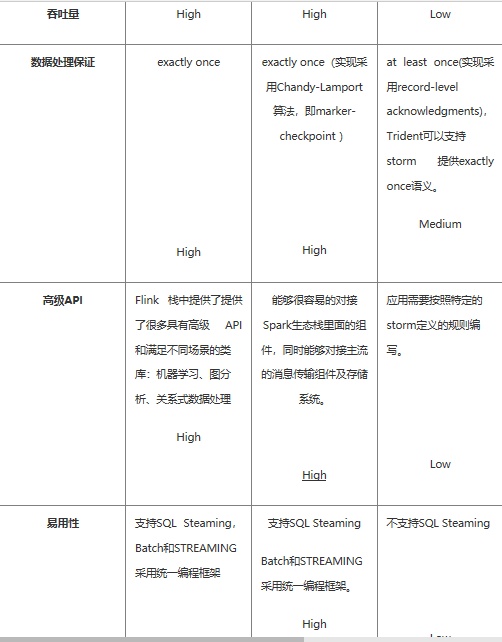
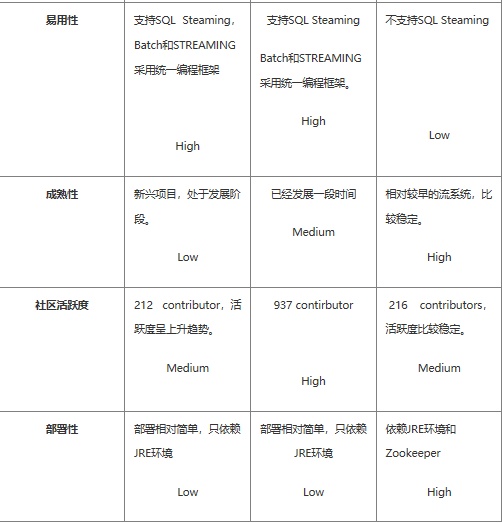
对比分析
如果对延迟要求不高的情况下,建议使用 Spark Streaming,丰富的高级 API,使用简单,天然对接 Spark 生态栈中的其他组 件,吞吐量大,部署简单,UI 界面也做的更加智能,社区活跃度较高,有问题响应速度也是比较快的,比较适合做流式的 ETL,而 且 Spark 的发展势头也是有目共睹的,相信未来性能和功能将会更加完善。
如果对延迟性要求比较高的话,建议可以尝试下 Flink,Flink 是目前发展比较火的一个流系统,采用原生的流处理系统,保证了低延迟性,在 API 和容错性上也是做的比较完善,使用起来相对来说也是比较简单的,部署容易,而且发展势头也越来越好,相信后面社区问题的响应速度应该也是比较快的。
个人对 Flink 是比较看好的,因为原生的流处理理念,在保证了低延迟的前提下,性能还是比较好的,且越来越易用,社区也在不断 发展。
")
Apache 流框架 Flink,Spark Streaming,Storm 对比分析(一)
本文由 网易云 发布。
1.Flink 架构及特性分析
Flink 是个相当早的项目,开始于 2008 年,但只在最近才得到注意。Flink 是原生的流处理系统,提供 high level 的 API。Flink 也提供 API 来像 Spark 一样进行批处理,但两者处理的基础是完全不同的。Flink 把批处理当作流处理中的一种特殊情况。在 Flink 中,所有 的数据都看作流,是一种很好的抽象,因为这更接近于现实世界。
1.1 基本架构
下面我们介绍下 Flink 的基本架构,Flink 系统的架构与 Spark 类似,是一个基于 Master-Slave 风格的架构。
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager, JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。 TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程 (Streaming 的任务),也可以不结束并等待结果返回。
JobManager 主要负责调度 Job 并协调 Task 做 checkpoint,职责上很像 Storm 的 Nimbus。从 Client 处接收到 Job 和 JAR 包 等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要 部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
JobManager
JobManager 是 Flink 系统的协调者,它负责接收 Flink Job,调度组成 Job 的多个 Task 的执行。同时,JobManager 还负责收集 Job 的状态信息,并管理 Flink 集群中从节点 TaskManager。JobManager 所负责的各项管理功能,它接收到并处理的事件主要包括:
RegisterTaskManager
在 Flink 集群启动的时候,TaskManager 会向 JobManager 注册,如果注册成功,则 JobManager 会向 TaskManager 回复消息 AcknowledgeRegistration。
SubmitJob
Flink 程序内部通过 Client 向 JobManager 提交 Flink Job,其中在消息 SubmitJob 中以 JobGraph 形式描述了 Job 的基本信息。
CancelJob
请求取消一个 Flink Job 的执行,CancelJob 消息中包含了 Job 的 ID,如果成功则返回消息 CancellationSuccess,失败则返回消息 CancellationFailure。
UpdateTaskExecutionState
TaskManager 会向 JobManager 请求更新 ExecutionGraph 中的 ExecutionVertex 的状态信息,更新成功则返回 true。
RequestNextInputSplit
运行在 TaskManager 上面的 Task,请求获取下一个要处理的输入 Split,成功则返回 NextInputSplit。
JobStatusChanged
ExecutionGraph 向 JobManager 发送该消息,用来表示 Flink Job 的状态发生的变化,例如:RUNNING、CANCELING、 FINISHED 等。
TaskManager
TaskManager 也是一个 Actor,它是实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task。每个 TaskManager 负责管理 其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向 JobManager 汇报。TaskManager 端可以分成两个 阶段:
注册阶段
TaskManager 会向 JobManager 注册,发送 RegisterTaskManager 消息,等待 JobManager 返回 AcknowledgeRegistration,然 后 TaskManager 就可以进行初始化过程。
可操作阶段
该阶段 TaskManager 可以接收并处理与 Task 有关的消息,如 SubmitTask、CancelTask、FailTask。如果 TaskManager 无法连接 到 JobManager,这是 TaskManager 就失去了与 JobManager 的联系,会自动进入 “注册阶段”,只有完成注册才能继续处理 Task 相关的消息。
Client
当用户提交一个 Flink 程序时,会首先创建一个 Client,该 Client 首先会对用户提交的 Flink 程序进行预处理,并提交到 Flink 集群中处 理,所以 Client 需要从用户提交的 Flink 程序配置中获取 JobManager 的地址,并建立到 JobManager 的连接,将 Flink Job 提交给 JobManager。Client 会将用户提交的 Flink 程序组装一个 JobGraph, 并且是以 JobGraph 的形式提交的。一个 JobGraph 是一个 Flink Dataflow,它由多个 JobVertex 组成的 DAG。其中,一个 JobGraph 包含了一个 Flink 程序的如下信息:JobID、Job 名称、配 置信息、一组 JobVertex 等。
1.2 基于 Yarn 层面的架构
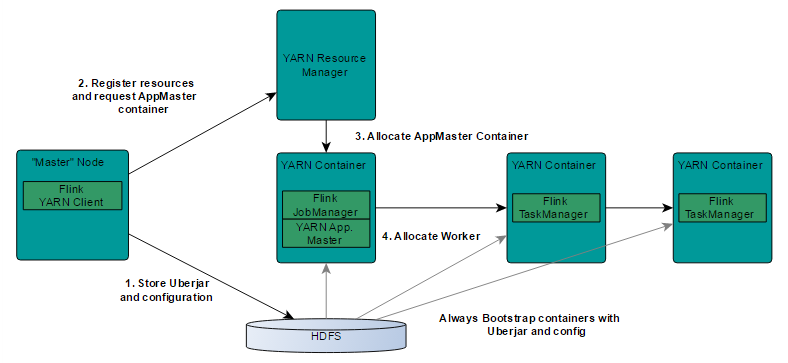
基于 yarn 层面的架构类似 spark on yarn 模式,都是由 Client 提交 App 到 RM 上面去运行,然后 RM 分配第一个 container 去运行 AM,然后由 AM 去负责资源的监督和管理。需要说明的是,Flink 的 yarn 模式更加类似 spark on yarn 的 cluster 模式,在 cluster 模式 中,dirver 将作为 AM 中的一个线程去运行,在 Flink on yarn 模式也是会将 JobManager 启动在 container 里面,去做个 driver 类似 的 task 调度和分配,YARN AM 与 Flink JobManager 在同一个 Container 中,这样 AM 可以知道 Flink JobManager 的地址,从而 AM 可以申请 Container 去启动 Flink TaskManager。待 Flink 成功运行在 YARN 集群上,Flink YARN Client 就可以提交 Flink Job 到 Flink JobManager,并进行后续的映射、调度和计算处理。
1.3 组件栈
Flink 是一个分层架构的系统,每一层所包含的组件都提供了特定的抽象,用来服务于上层组件。

Deployment 层
该层主要涉及了 Flink 的部署模式,Flink 支持多种部署模式:本地、集群(Standalone/YARN)、云(GCE/EC2)。Standalone 部署模式与 Spark 类似,这里,我们看一下 Flink on YARN 的部署模式
Runtime 层
Runtime 层提供了支持 Flink 计算的全部核心实现,比如:支持分布式 Stream 处理、JobGraph 到 ExecutionGraph 的映射、调度等 等,为上层 API 层提供基础服务。
API 层
API 层主要实现了面向无界 Stream 的流处理和面向 Batch 的批处理 API,其中面向流处理对应 DataStream API,面向批处理对应 DataSet API。
Libraries 层
该层也可以称为 Flink 应用框架层,根据 API 层的划分,在 API 层之上构建的满足特定应用的实现计算框架,也分别对应于面向流处理 和面向批处理两类。面向流处理支持:CEP(复杂事件处理)、基于 SQL-like 的操作(基于 Table 的关系操作);面向批处理支持: FlinkML(机器学习库)、Gelly(图处理)。
从官网中我们可以看到,对于 Flink 一个最重要的设计就是 Batch 和 Streaming 共同使用同一个处理引擎,批处理应用可以以一种特 殊的流处理应用高效地运行。
这里面会有一个问题,就是 Batch 和 Streaming 是如何使用同一个处理引擎进行处理的。
1.4 Batch 和 Streaming 是如何使用同一个处理引擎。
下面将从代码的角度去解释 Batch 和 Streaming 是如何使用同一处理引擎的。首先从 Flink 测试用例来区分两者的区别。
Batch WordCount Examples

Streaming WordCount Examples
Batch 和 Streaming 采用的不同的 ExecutionEnviroment,对于 ExecutionEnviroment 来说读到的源数据是一个 DataSet, 而 StreamExecutionEnviroment 的源数据来说则是一个 DataStream。
接着我们追踪下 Batch 的从 Optimzer 到 JobGgraph 的流程,这里如果是 Local 模式构造的是 LocalPlanExecutor,这里我们只介绍 Remote 模式,此处的 executor 为 RemotePlanExecutor
最终会调用 ClusterClient 的 run 方法将我们的应用提交上去,run 方法的第一步就是获取 jobGraph,这个是 client 端的操作,client 会将 jobGraph 提交给 JobManager 转化为 ExecutionGraph。Batch 和 streaming 不同之处就是在获取 JobGraph 上面。
如果我们初始化的 FlinkPlan 是 StreamingPlan,则首先构造 Streaming 的 StreamingJobGraphGenerator 去将 optPlan 转为 JobGraph,Batch 则直接采用另一种的转化方式。
简而言之,Batch 和 streaming 会有两个不同的 ExecutionEnvironment,不同的 ExecutionEnvironment 会将不同的 API 翻译成不同 的 JobGgrah,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。 StreamGraph 是由 Stream API 转换而来的,JobGraph 的责任就是统一 Batch 和 Stream 的图。
1.5 特性分析
高吞吐 & 低延迟
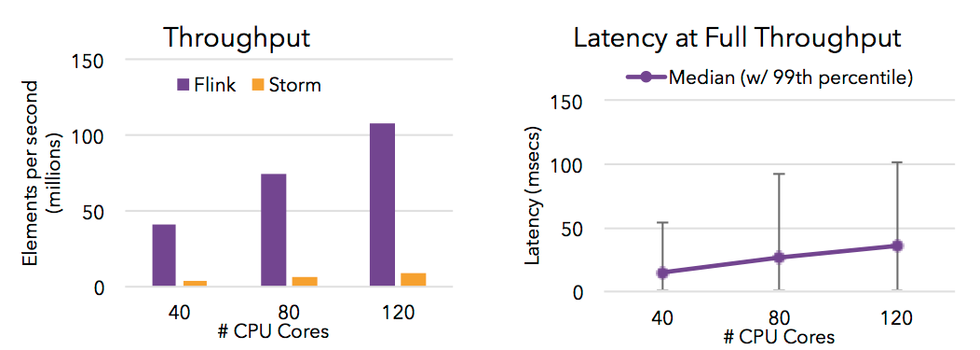
Flink 的流处理引擎只需要很少配置就能实现高吞吐率和低延迟。下图展示了一个分布式计数的任务的性能,包括了流数据 shuffle 过程。
支持 Event Time 和乱序事件
Flink 支持了流处理和 Event Time 语义的窗口机制。
Event time 使得计算乱序到达的事件或可能延迟到达的事件更加简单。
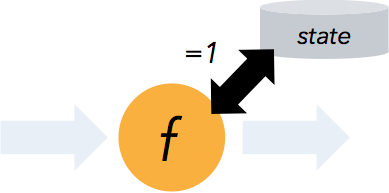
状态计算的 exactly-once 语义
流程序可以在计算过程中维护自定义状态。
Flink 的 checkpointing 机制保证了即时在故障发生下也能保障状态的 exactly once 语义。

高度灵活的流式窗口
Flink 支持在时间窗口,统计窗口,session 窗口,以及数据驱动的窗口
窗口可以通过灵活的触发条件来定制,以支持复杂的流计算模式。
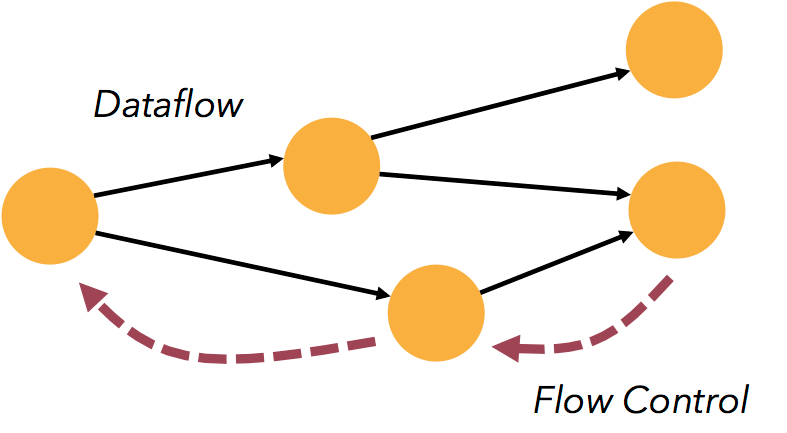
带反压的连续流模型
数据流应用执行的是不间断的(常驻)operators。
Flink streaming 在运行时有着天然的流控:慢的数据 sink 节点会反压(backpressure)快的数据源(sources)。
容错性
Flink 的容错机制是基于 Chandy-Lamport distributed snapshots 来实现的。
这种机制是非常轻量级的,允许系统拥有高吞吐率的同时还能提供强一致性的保障。
Batch 和 Streaming 一个系统流处理和批处理共用一个引擎
Flink 为流处理和批处理应用公用一个通用的引擎。批处理应用可以以一种特殊的流处理应用高效地运行。
内存管理
Flink 在 JVM 中实现了自己的内存管理。
应用可以超出主内存的大小限制,并且承受更少的垃圾收集的开销。
迭代和增量迭代
Flink 具有迭代计算的专门支持(比如在机器学习和图计算中)。
增量迭代可以利用依赖计算来更快地收敛。
程序调优
批处理程序会自动地优化一些场景,比如避免一些昂贵的操作(如 shuffles 和 sorts),还有缓存一些中间数据。
API 和 类库
流处理应用
DataStream API 支持了数据流上的函数式转换,可以使用自定义的状态和灵活的窗口。
右侧的示例展示了如何以滑动窗口的方式统计文本数据流中单词出现的次数。
val texts:DataStream[String] = ...
val counts = text .flatMap { line => line.split("\\W+") } .map { token => Word(token, 1) } .keyBy("word") .timeWindow(Time.seconds(5), Time.seconds(1)) .sum("freq")
批处理应用
Flink 的 DataSet API 可以使你用 Java 或 Scala 写出漂亮的、类型安全的、可维护的代码。它支持广泛的数据类型,不仅仅是 key/value 对,以及丰富的 operators。
右侧的示例展示了图计算中 PageRank 算法的一个核心循环。
case class Page( pageId: Long, rank:Double) case class Adjacency( id: Long, neighbors:Array[Long])
val result = initialRanks.iterate(30) { pages => pages.join(adjacency).where("pageId").equalTo("pageId") { (page, adj, out : Collector[Page]) => { out.collect(Page(page.id, 0.15 / numPages)) for (n <- adj.neighbors) { out.collect(Page(n, 0.85*page.rank/adj.neighbors.length)) } } } .groupBy("pageId").sum("rank") }
类库生态
Flink 栈中提供了提供了很多具有高级 API 和满足不同场景的类库:机器学习、图分析、关系式数据处理。当前类库还在 beta 状 态,并且在大力发展。

广泛集成
Flink 与开源大数据处理生态系统中的许多项目都有集成。
Flink 可以运行在 YARN 上,与 HDFS 协同工作,从 Kafka 中读取流数据,可以执行 Hadoop 程序代码,可以连接多种数据存储 系统。

部署
Flink 可以单独脱离 Hadoop 进行部署,部署只依赖 Java 环境,相对简单。
本文未结束,余下内容请见 --Apache 流框架 Flink,Spark Streaming,Storm 对比分析 (二)
网易有数
企业级大数据可视化分析平台。面向业务人员的自助式敏捷分析平台,采用 PPT 模式的报告制作,更加易学易用,具备强大的探索分析功能,真正帮助用户洞察数据发现价值。
点击这里 --- 免费试用。
了解 网易云 :
网易云官网:https://www.163yun.com/
新用户大礼包:https://www.163yun.com/gift
网易云社区:https://sq.163yun.com/

Apache流计算框架详细对比
原文
几个月之前我们在这里讨论过[](http://www.cakesolutions.net/teamblogs/introduction-into-distributed-real-time-stream-processing)目前对于这种日渐增加的分布式流计算的需求的原因。当然,目前也有很多的各式各样的框架被用于处理这一些问题。现在我们会在这篇文章中进行回顾,来讨论下各种框架之间的相似点以及区别在哪里,还有就是从我的角度分析的,推荐的适用的用户场景。
如你所想,分布式的流处理也就是通常意义上的持续处理、数据富集以及对于无界数据的分析过程的组合。它是一个类似于MapReduce这样的通用计算模型,但是我们希望它能够在毫秒级别或者秒级别完成响应。这些系统经常被有向非循环图(Directed ACyclic Graphs,DAGs)来表示。
DAG主要功能即是用图来表示链式的任务组合,而在流处理系统中,我们便常常用DAG来描述一个流工作的拓扑。笔者自己是从Akka的Stream中的术语得到了启发。如下图所示,数据流经过一系列的处理器从源点流动到了终点,也就是用来描述这流工作。谈到Akka的Streams,我觉得要着重强调下分布式这个概念,因为即使也有一些单机的解决方案可以创建并且运行DAG,但是我们仍然着眼于那些可以运行在多机上的解决方案。

Points of Interest
在不同的系统之间进行选择的时候,我们主要关注到以下几点。
Runtime and Programming model(运行与编程模型)
一个平台提供的编程模型往往会决定很多它的特性,并且这个编程模型应该足够处理所有可能的用户案例。这是一个决定性的因素,我也会在下文中多次讨论。
Functional Primitives(函数式单元)
一个合格的处理平台应该能够提供丰富的能够在独立信息级别进行处理的函数,像map、filter这样易于实现与扩展的一些函数。同样也应提供像aggregation这样的跨信息处理函数以及像join这样的跨流进行操作的函数,虽然这样的操作会难以扩展。
State Management(状态管理)
大部分这些应用都有状态性的逻辑处理过程,因此,框架本身应该允许开发者去维护、访问以及更新这些状态信息。
Message Delivery Guarantees(消息投递的可达性保证)
一般来说,对于消息投递而言,我们有至多一次(at most once)、至少一次(at least once)以及恰好一次(exactly once)这三种方案。
at most once
At most once投递保证每个消息会被投递0次或者1次,在这种机制下消息很有可能会丢失。
at least once
At least once投递保证了每个消息会被默认投递多次,至少保证有一次被成功接收,信息可能有重复,但是不会丢失。
exactly once
exactly once意味着每个消息对于接收者而言正好被接收一次,保证即不会丢失也不会重复。
Failures Handling
在一个流处理系统中,错误可能经常在不同的层级发生,譬如网络分割、磁盘错误或者某个节点莫名其妙挂掉了。平台要能够从这些故障中顺利恢复,并且能够从最后一个正常的状态继续处理而不会损害结果。
除此之外,我们也应该考虑到平台的生态系统、社区的完备程度,以及是否易于开发或者是否易于运维等等。
RunTime and Programming Model
运行环境与编程模型可能是某个系统的最重要的特性,因为它定义了整个系统的呈现特性、可能支持的操作以及未来的一些限制等等。因此,运行环境与编程模型就确定了系统的能力与适用的用户案例。目前,主要有两种不同的方法来构建流处理系统,其中一个叫Native Streaming,意味着所有输入的记录或者事件都会根据它们进入的顺序一个接着一个的处理。

另一种方法叫做Micro-Batching。大量短的Batches会从输入的记录中创建出然后经过整个系统的处理,这些Batches会根据预设好的时间常量进行创建,通常是每隔几秒创建一批。

两种方法都有一些内在的优势与不足,首先来谈谈Native Streaming。好的一方面呢是Native Streaming的表现性会更好一点,因为它是直接处理输入的流本身的,并没有被一些不自然的抽象方法所限制住。同时,因为所有的记录都是在输入之后立马被处理,这样对于请求方而言响应的延迟就会优于那种Micro-Batching系统。处理这些,有状态的操作符也会更容易被实现,我们在下文中也会描述这个特点。不过Native Streaming系统往往吞吐量会比较低,并且因为它需要去持久化或者重放几乎每一条请求,它的容错的代价也会更高一些。并且负载均衡也是一个不可忽视的问题,举例而言,我们根据键对数据进行了分割并且想做进一步地处理。如果某些键对应的分区因为某些原因需要更多地资源去处理,那么这个分区往往就会变成整个系统的瓶颈。
而对于Micro-Batching而言,将流切分为小的Batches不可避免地会降低整个系统的变现性,也就是可读性。而一些类似于状态管理的或者joins、splits这些操作也会更加难以实现,因为系统必须去处理整个Batch。另外,每个Batch本身也将架构属性与逻辑这两个本来不应该被糅合在一起的部分相连接了起来。而Micro-Batching的优势在于它的容错与负载均衡会更加易于实现,它只要简单地在某个节点上处理失败之后转发给另一个节点即可。最后,值得一提的是,我们可以在Native Streaming的基础上快速地构建Micro-Batching的系统。
而对于编程模型而言,又可以分为Compositional(组合式)与Declarative(声明式)。组合式会提供一系列的基础构件,类似于源读取与操作符等等,开发人员需要将这些基础构件组合在一起然后形成一个期望的拓扑结构。新的构件往往可以通过继承与实现某个接口来创建。另一方面,声明式API中的操作符往往会被定义为高阶函数。声明式编程模型允许我们利用抽象类型和所有其他的精选的材料来编写函数式的代码以及优化整个拓扑图。同时,声明式API也提供了一些开箱即用的高等级的类似于窗口管理、状态管理这样的操作符。下文中我们也会提供一些代码示例。
Apache Streaming Landscape
目前已经有了各种各样的流处理框架,自然也无法在本文中全部攘括。所以我必须将讨论限定在某些范围内,本文中是选择了所有Apache旗下的流处理的框架进行讨论,并且这些框架都已经提供了Scala的语法接口。主要的话就是Storm以及它的一个改进Trident Storm,还有就是当下正火的Spark。最后还会讨论下来自LinkedIn的Samza以及比较有希望的Apache Flink。笔者个人觉得这是一个非常不错的选择,因为虽然这些框架都是出于流处理的范畴,但是他们的实现手段千差万别。

Apache Storm 最初由Nathan Marz以及他的BackType的团队在2010年创建。后来它被Twitter收购并且开源出来,并且在2014年变成了Apache的顶层项目。毫无疑问,Storm是大规模流处理中的先行者并且逐渐成为了行业标准。Storm是一个典型的Native Streaming系统并且提供了大量底层的操作接口。另外,Storm使用了Thrift来进行拓扑的定义,并且提供了大量其他语言的接口。
Trident 是一个基于Storm构建的上层的Micro-Batching系统,它简化了Storm的拓扑构建过程并且提供了类似于窗口、聚合以及状态管理等等没有被Storm原生支持的功能。另外,Storm是实现了至多一次的投递原则,而Trident实现了恰巧一次的投递原则。Trident 提供了 Java, Clojure 以及 Scala 接口。
众所周知,Spark是一个非常流行的提供了类似于SparkSQL、Mlib这样内建的批处理框架的库,并且它也提供了Spark Streaming这样优秀地流处理框架。Spark的运行环境提供了批处理功能,因此,Spark Streaming毫无疑问是实现了Micro-Batching机制。输入的数据流会被接收者分割创建为Micro-Batches,然后像其他Spark任务一样进行处理。Spark 提供了 Java, Python 以及 Scala 接口。
Samza最早是由LinkedIn提出的与Kafka协同工作的优秀地流解决方案,Samza已经是LinkedIn内部关键的基础设施之一。Samza重负依赖于Kafaka的基于日志的机制,二者结合地非常好。Samza提供了Compositional接口,并且也支持Scala。
最后聊聊Flink. Flink可谓一个非常老的项目了,最早在2008年就启动了,不过目前正在吸引越来越多的关注。Flink也是一个Native Streaming的系统,并且提供了大量高级别的API。Flink也像Spark一样提供了批处理的功能,可以作为流处理的一个特殊案例来看。Flink强调万物皆流,这是一个绝对的更好地抽象,毕竟确实是这样。
下表就简单列举了上述几个框架之间的特性:

Counting Words
Wordcount就好比流处理领域的HelloWorld,它能够很好地描述不同框架间的差异性。首先看看Storm是如何编写WordCount程序的:
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("spout", new RandomSentenceSpout(), 5);
builder.setBolt("split", new Split(), 8).shuffleGrouping("spout");
builder.setBolt("count", new WordCount(), 12).fieldsGrouping("split", new Fields("word"));
...
Map<String, Integer> counts = new HashMap<String, Integer>();
public void execute(Tuple tuple, BasicOutputCollector collector) {
String word = tuple.getString(0);
Integer count = counts.containsKey(word) ? counts.get(word) + 1 : 1;
counts.put(word, count);
collector.emit(new Values(word, count));
}首先来看看它的拓扑定义,在第2行那边是定义了一个Spout,也就是一个输入源。然后定义了一个Bold,也就是一个处理的组件,用于将某个句子分割成词序列。然后还定义了另一个Bolt用来负责真实的词计算。5,8到12行省略的过程用于定义集群中使用了多少个线程来供每一个组件使用。如你所见,所有的定义都是比较底层的与手动的。接下来继续看看这个8-15行,也就是真正用于WordCount的部分代码。因为Storm没有内建的状态处理的支持,所以我必须自定义这样一个本地状态,和理想的相差甚远啊。下面我们继续看看Trident。
正如我上文中提及的,Trident是一个基于Storm的Micro-Batching的扩展,它提供了状态管理等等功能。
public static StormTopology buildTopology(LocalDRPC drpc) {
FixedBatchSpout spout = ...
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout)
.each(new Fields("sentence"),new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(),
new Count(), new Fields("count"));
...
}从代码中就可以看出,在Trident中就可以使用一些上层的譬如each、groupBy这样的操作符,并且可以在Trident中内建的进行状态管理了。接下来我们再看看Spark提供的声明式的接口,要记住,与前几个例子不同的是,基于Spark的代码已经相当简化了,下面基本上就是要用到的全部的代码了:
val conf = new SparkConf().setAppName("wordcount")
val ssc = new StreamingContext(conf, Seconds(1))
val text = ...
val counts = text.flatMap(line => line.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
counts.print()
ssc.start()
ssc.awaitTermination()每个Spark的流任务都需要一个StreamingContext用来指定整个流处理的入口。StreamingContext定义了Batch的间隔,上面是设置到了1秒。在6-8行即是全部的词统计的计算过程,非常不一样啊。下面再看看Apache Samza,另一个代表性的组合式的API:
class WordCountTask extends StreamTask {
override def process(envelope: IncomingMessageEnvelope, collector: MessageCollector,
coordinator: TaskCoordinator) {
val text = envelope.getMessage.asInstanceOf[String]
val counts = text.split(" ").foldLeft(Map.empty[String, Int]) {
(count, word) => count + (word -> (count.getOrElse(word, 0) + 1))
}
collector.send(new OutgoingMessageEnvelope(new SystemStream("kafka", "wordcount"), counts))
}Topology定义在了Samza的属性配置文件里,为了明晰起见,这里没有列出来。下面再看看Fink,可以看出它的接口风格非常类似于Spark Streaming,不过我们没有设置时间间隔:
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(...)
val counts = text.flatMap ( _.split(" ") )
.map ( (_, 1) )
.groupBy(0)
.sum(1)
counts.print()
env.execute("wordcount")Fault Tolerance
与批处理系统相比,流处理系统中的容错机制固然的会比批处理中的要难一点。在批处理系统中,如果碰到了什么错误,只要将计算中与该部分错误关联的重新启动就好了。不过在流计算的场景下,容错处理会更加困难,因为会不断地有数据进来,并且有些任务可能需要7*24地运行着。另一个我们碰到的挑战就是如何保证状态的一致性,在每天结束的时候我们会开始事件重放,当然不可能所有的状态操作都会保证幂等性。下面我们就看看其他的系统是怎么处理的:
Storm
Storm使用了所谓的逆流备份与记录确认的机制来保证消息会在某个错误之后被重新处理。记录确认这一个操作工作如下:一个操作器会在处理完成一个记录之后向它的上游发送一个确认消息。而一个拓扑的源会保存有所有其创建好的记录的备份。一旦受到了从Sinks发来的包含有所有记录的确认消息,就会把这些确认消息安全地删除掉。当发生错误时,如果还没有接收到全部的确认消息,就会从拓扑的源开始重放这些记录。这就确保了没有数据丢失,不过会导致重复的Records处理过程,这就属于At-Least投送原则。
Storm用一套非常巧妙的机制来保证了只用很少的字节就能保存并且追踪确认消息,但是并没有太多关注于这套机制的性能,从而使得Storm有较低地吞吐量,并且在流控制上存在一些问题,譬如这种确认机制往往在存在背压的时候错误地认为发生了故障。

Spark Streaming

Spark Streaming以及它的Micro-Batching机制则使用了另一套方案,道理很简单,Spark将Micro-Batches分配到多个节点运行,每个Micro-Batch可以成功运行或者发生故障,当发生故障时,那个对应的Micro-Batch只要简单地重新计算即可,因为它是持久化并且无状态的,所以要保证Exactly-Once这种投递方式也是很简单的。
Samza
Samza的实现手段又不一样了,它利用了一套可靠地、基于Offset的消息系统,在很多情况下指的就是Kafka。Samza会监控每个任务的偏移量,然后在接收到消息的时候修正这些偏移量。Offset可以是存储在持久化介质中的一个检查点,然后在发生故障时可以进行恢复。不过问题在于你并不知道恢复到上一个CheckPoint之后到底哪个消息是处理过的,有时候会导致某些消息多次处理,这也是At-Least的投递原则。

Flink
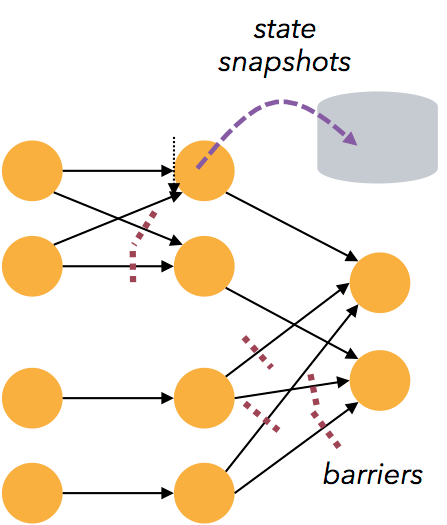
Flink主要是基于分布式快照,每个快照会保存流任务的状态。链路中运送着大量的CheckPoint Barrier(检查点障碍,就是分隔符、标识器之类的),当这些Barrier到达某个Operator的时候,Operator将自身的检查点与流相关联。与Storm相比,这种方式会更加高效,毕竟不用对每个Record进行确认操作。不过要注意的是,Flink还是Native Streaming,概念上和Spark还是相去甚远的。Flink也是达成了Exactly-Once投递原则。

Managing State
大部分重要的流处理应用都会保有状态,与无状态的操作符相比,这些应用中需要一个输入和一个状态变量,然后进行处理最终输出一个改变了的状态。我们需要去管理、存储这些状态,要保证在发生故障的时候能够重现这些状态。状态的重造可能会比较困难,毕竟上面提到的不少框架都不能保证Exactly-Once,有些Record可能被重放多次。
Storm
Storm是实践了At-Least投递原则,而怎么利用Trident来保证Exactly-Once呢?概念上还是很简单的,只需要使用事务进行提交Records,不过很明显这种方式及其低效。所以呢,还是可以构建一些小的Batches,并且进行一些优化。Trident是提供了一些抽象的接口来保证实现Exactly-Once,如下图所示,还有很多东西等着你去挖掘。

Spark Streaming
当想要在流处理系统中实现有状态的操作时,我们往往想到的是一个长时间运行的Operator,然后输入一个状态以及一系列的Records。不过Spark Streaming是以另外一种方式进行处理的,Spark Streaming将状态作为一个单独地Micro-Batching流进行处理,所以在对每个小的Micro-Spark任务进行处理时会输入一个当前的状态和一个代表当前操作的函数,最后输出一个经过处理的Micro-Batch以及一个更新好的状态。
Samza
Samza的处理方式更加简单明了,就是把它们放到Kafka中,然后问题就解决了。Samza提供了真正意义上的有状态的Operators,这样每个任务都能保有状态,然后所有状态的变化都会被提交到Kafka中。在有需要的情况下某个状态可以很方便地从Kafka的Topic中完成重造。为了提高效率,Samza允许使用插件化的键值本地存储来避免所有的消息全部提交到Kafka。这种思路如下图所示,不过Samza只是提高了At-Least这种机制,未来可能会提供Exactly-Once。

Flink
Flink提供了类似于Samza的有状态的Operator的概念,在Flink中,我们可以使用两种不同的状态。第一种是本地的或者叫做任务状态,它是某个特定的Operator实例的当前状态,并且这种状态不会与其他进行交互。另一种呢就是维护了整个分区的状态。

Counting Words with State
Trident
public static StormTopology buildTopology(LocalDRPC drpc) {
FixedBatchSpout spout = ...
TridentTopology topology = new TridentTopology();
TridentState wordCounts = topology.newStream("spout1", spout)
.each(new Fields("sentence"),new Split(), new Fields("word"))
.groupBy(new Fields("word"))
.persistentAggregate(new MemoryMapState.Factory(), new Count(), new Fields("count"));
...
}在第9行中,我们可以通过调用一个持久化的聚合函数来创建一个状态。
Spark Streaming
// Initial RDD input to updateStateByKey
val initialRDD = ssc.sparkContext.parallelize(List.empty[(String, Int)])
val lines = ...
val words = lines.flatMap(_.split(" "))
val wordDstream = words.map(x => (x, 1))
val trackStateFunc = (batchTime: Time, word: String, one: Option[Int],
state: State[Int]) => {
val sum = one.getOrElse(0) + state.getOption.getOrElse(0)
val output = (word, sum)
state.update(sum)
Some(output)
}
val stateDstream = wordDstream.trackStateByKey(
StateSpec.function(trackStateFunc).initialState(initialRDD))在第2行中,我们创建了一个RDD用来保存初始状态。然后在5,6行中进行一些转换,接下来可以看出,在8-14行中,我们定义了具体的转换方程,即输入时一个单词、它的统计数量和它的当前状态。函数用来计算、更新状态以及返回结果,最后我们将所有的Bits一起聚合。
Samza
class WordCountTask extends StreamTask with InitableTask {
private var store: CountStore = _
def init(config: Config, context: TaskContext) {
this.store = context.getStore("wordcount-store")
.asInstanceOf[KeyValueStore[String, Integer]]
}
override def process(envelope: IncomingMessageEnvelope,
collector: MessageCollector, coordinator: TaskCoordinator) {
val words = envelope.getMessage.asInstanceOf[String].split(" ")
words.foreach { key =>
val count: Integer = Option(store.get(key)).getOrElse(0)
store.put(key, count + 1)
collector.send(new OutgoingMessageEnvelope(new SystemStream("kafka", "wordcount"),
(key, count)))
}
}在上述代码中第3行定义了全局的状态,这里是使用了键值存储方式,并且在5~6行中定义了如何初始化。然后,在整个计算过程中我们都使用了该状态。
Flink
val env = ExecutionEnvironment.getExecutionEnvironment
val text = env.fromElements(...)
val words = text.flatMap ( _.split(" ") )
words.keyBy(x => x).mapWithState {
(word, count: Option[Int]) =>
{
val newCount = count.getOrElse(0) + 1
val output = (word, newCount)
(output, Some(newCount))
}
}在第6行中使用了mapWithState函数,第一个参数是即将需要处理的单次,第二个参数是一个全局的状态。
Performance
合理的性能比较也是本文的一个重要主题之一。不同的系统的解决方案差异很大,因此也是很难设置一个无偏的测试。通常而言,在一个流处理系统中,我们常说的性能就是指延迟与吞吐量。这取决于很多的变量,但是总体而言标准为如果单节点每秒能处理500K的Records就是个合格的,如果能达到100万次以上就已经不错了。每个节点一般就是指24核附带上24或者48GB的内存。
对于延迟而言,如果是Micro-Batch的话往往希望能在秒级别处理。如果是Native Streaming的话,希望能有百倍的减少,调优之后的Storm可以很轻易达到几十毫秒。
另一方面,消息的可达性保证、容错以及状态管理都是需要考虑进去的。譬如如果你开启了容错机制,那么会增加10%到15%的额外消耗。除此之外,以文章中两个WordCount为例,第一个是无状态的WordCount,第二个是有状态的WordCount,后者在Flink中可能会有25%额外的消耗,而在Spark中可能有50%的额外消耗。当然,我们肯定可以通过调优来减少这种损耗,并且不同的系统都提供了很多的可调优的选项。
还有就是一定要记住,在分布式环境下进行大数据传输也是一件非常昂贵的消耗,因此我们要利用好数据本地化以及整个应用的序列化的调优。
Project Maturity(项目成熟度)
在为你的应用选择一个合适的框架的时候,框架本身的成熟度与社区的完备度也是一个不可忽略的部分。Storm是第一个正式提出的流处理框架,它已经成为了业界的标准并且被应用到了像Twitter、Yahoo、Spotify等等很多公司的生产环境下。Spark则是目前最流行的Scala的库之一,并且Spark正逐步被更多的人采纳,它已经成功应用在了像Netflix、Cisco、DataStax、Indel、IBM等等很多公司内。而Samza最早由LinkedIn提出,并且正在运行在几十个公司内。Flink则是一个正在开发中的项目,不过我相信它发展的会非常迅速。
Summary
在我们进最后的框架推荐之前,我们再看一下上面那张图:
Framework Recommendations
这个问题的回答呢,也很俗套,具体情况具体分析。总的来说,你首先呢要仔细评估下你应用的需求并且完全理解各个框架之间的优劣比较。同时我建议是使用一个提供了上层接口的框架,这样会更加的开发友好,并且能够更快地投入生产环境。不过别忘了,绝大部分流应用都是有状态的,因此状态管理也是不可忽略地一个部分。同时,我也是推荐那些遵循Exactly-Once原则的框架,这样也会让开发和维护更加简单。不过不能教条主义,毕竟还是有很多应用会需要At-Least-Once与At-Most-Once这些投递模式的。最后,一定要保证你的系统可以在故障情况下很快恢复,可以使用Chaos Monkey或者其他类似的工具进行测试。在我们之前的讨论中也发现这个快速恢复的能力至关重要。
对于小型与需要快速响应地项目,Storm依旧是一个非常好的选择,特别是在你非常关注延迟度的情况下。不过还是要谨记容错机制和Trident的状态管理会严重影响性能。Twitter目前正在设计新的流计算系统Heron用来替代Storm,它可以在单个项目中有很好地表现。不过Twitter可不一定会开源它。
对于Spark Streaming而言,如果你的系统的基础架构中已经使用了Spark,那还是很推荐你试试的。另一方面,如果你想使用Lambda架构,那Spark也是个不错的选择。不过你一定要记住,Micro-Batching本身的限制和延迟对于你而言不是一个关键因素。
如果你想用Samza的话,那最好Kafka已经是你的基础设施的一员了。虽然在Samza中Kafka只是个可插拔的组件,不过基本上所有人都会使用Kafka。正如上文所说,Samza提供了强大的本地存储功能,能够轻松管理数十G的状态数据。不过它的At-Least-Once的投递限制也是很大一个瓶颈。
Flink目前在概念上是一个非常优秀的流处理系统,它能够满足大部分的用户场景并且提供了很多先进的功能,譬如窗口管理或者时间控制。所以当你发现你需要的功能在Spark当中无法很好地实现的时候,你可以考虑下Flink。另外,Flink也提供了很好地通用的批处理的接口,只不过你需要很大的勇气来将你的项目结合到Flink中,并且别忘了多关注关注它的路线图。
Dataflow与开源
我最后一个要提到的就是Dataflow和它的开源计划。Dataflow是Google云平台的一个组成部分,是目前在Google内部提供了统一的用于批处理与流计算的服务接口。譬如用于批处理的MapReduce,用于编程模型定义的FlumeJava以及用于流计算的MillWheel。Google最近打算开源这货的SDK了,Spark与Flink都可以成为它的一个运行驱动。

Conclusion
本文我们过了一遍常用的流计算框架,它们的特性与优劣对比,希望能对你有用吧。
关于流计算框架 Flink 与 Storm 的性能对比和flink流式计算框架的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于Apache Flink,流计算?不仅仅是流计算!、Apache 流框架 Flink,Spark Streaming,Storm 对比分析、Apache 流框架 Flink,Spark Streaming,Storm 对比分析(一)、Apache流计算框架详细对比等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

