在本文中,我们将详细介绍如何计算数组的中位数?的各个方面,并为您提供关于如何计算数组的中位数值的相关解答,同时,我们也将为您带来关于004.寻找两个有序数组的中位数、2021-11-03:数据流的中位
在本文中,我们将详细介绍如何计算数组的中位数?的各个方面,并为您提供关于如何计算数组的中位数值的相关解答,同时,我们也将为您带来关于004.寻找两个有序数组的中位数、2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2、4.寻找两个正序数组的中位数、5个排序数组的中位数的有用知识。
本文目录一览:- 如何计算数组的中位数?(如何计算数组的中位数值)
- 004.寻找两个有序数组的中位数
- 2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2
- 4.寻找两个正序数组的中位数
- 5个排序数组的中位数
")
如何计算数组的中位数?(如何计算数组的中位数值)
我正在尝试计算由文本字段接收的输入填充的数组的总数,均值和中位数。我设法算出了总数和均值,但我只是无法获得中位数。我认为在执行此操作之前需要对数组进行排序,但是我不确定如何执行此操作。这是问题吗,还是我没有找到另一个问题?这是我的代码:
import java.applet.Applet;import java.awt.Graphics;import java.awt.*;import java.awt.event.*;public class whileloopq extends Applet implements ActionListener{ Label label; TextField input; int num; int index; int[] numArray = new int[20]; int sum; int total; double avg; int median; public void init () { label = new Label("Enter numbers"); input = new TextField(5); add(label); add(input); input.addActionListener(this); index = 0; } public void actionPerformed (ActionEvent ev) { int num = Integer.parseInt(input.getText()); numArray[index] = num; index++; if (index == 20) input.setEnabled(false); input.setText(""); sum = 0; for (int i = 0; i < numArray.length; i++) { sum += numArray[i]; } total = sum; avg = total / index; median = numArray[numArray.length/2]; repaint(); } public void paint (Graphics graf) { graf.drawString("Total = " + Integer.toString(total), 25, 85); graf.drawString("Average = " + Double.toString(avg), 25, 100); graf.drawString("Median = " + Integer.toString(median), 25, 115); }}答案1
小编典典Java中的Arrays类具有静态的排序功能,您可以使用调用该功能Arrays.sort(numArray)。
Arrays.sort(numArray);double median;if (numArray.length % 2 == 0) median = ((double)numArray[numArray.length/2] + (double)numArray[numArray.length/2 - 1])/2;else median = (double) numArray[numArray.length/2];
004.寻找两个有序数组的中位数
There are two sorted arrays nums1 and nums2 of size m and n respectively.
Find the median of the two sorted arrays. The overall run time complexity should be O(log (m+n)).
Example 1:
nums1 = [1, 3] nums2 = [2]
The median is 2.0
Example 2:
nums1 = [1, 2] nums2 = [3, 4]
The median is (2 + 3)/2 = 2.5
给定两个大小为 m 和 n 的有序数组 nums1 和 nums2 。
请找出这两个有序数组的中位数。要求算法的时间复杂度为 O(log (m+n)) 。
1.自己的想法是 一共m + n 个,我们可以新建一个List 然后每把最小的数放进去,代码如下:
class Solution:
def findMedianSortedArrays(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: float
"""
leng = len(nums1) + len(nums2)
tmpLen = leng//2 + 1
newList = [0]*tmpLen
i = 0
j = 0
for k in range(tmpLen):
if i == len(nums1):
newList[k] = nums2[j]
j += 1
elif j == len(nums2):
newList[k] = nums1[i]
i += 1
else:
if nums1[i] < nums2[j]:
newList[k] = nums1[i]
i += 1
else:
newList[k] = nums2[j]
j += 1
if leng %2 == 0:
return (newList[tmpLen - 2] + newList[tmpLen - 1])/2
else:
return newList[tmpLen - 1]2.类似与折半查找的思路,
由于题目要求的时间复杂度是(log(m+n)),如果我们直接把两个数组整合一起,那么时间复杂度肯定超过(log(m+n))。所以整理肯定是不行的。那么还有什么方法吗?答案是肯定的。
首先我们要先了解中位数的概念,中位数就是有序数组的中间那个数。那么如果我们将比中位数小的数和比中位数大的数去掉同样的个数,中位数的值也不会变化(数组的个数为偶数的时候另外讨论,因为那时候中位数是中间两个数的平均值,所以中位数旁边两个数不能去掉)。
所以我们不妨试着将数组长度不断缩短。这里不妨提出一个引理。假设有两个有序数组am,bn,他们整合后的有序数组为cn+m。他们的中位数分别是Am/2,Bn/2,C(m+n)/2。如果Am/2 < Bn/2,则 A0…m/2 <= C(m+n)/2 <= Bn/2…n 。
引理证明:
假设 Am/2 > C(m+n)/2 ,那么 Bn/2 > C(m+n)/2,所以在数组Am里有大于m/2个数大于C(m+n)/2,在数组Bn里也有n/2个数大于C(m+n)/2
也就是说在Cn+m里有(m+n)/2个数大于C(m+n)/2,此时就C(m+n)/2不再是数组Cn+m的中位数。
所以A0…m/2 <= C(m+n)/2。
同理可得C(m+n)/2 <= Cn/2…n 。
根据上述引理,我们不妨设m>n,那么我们根据判断两个数组的中位数大小,每个数组每次减少n/2长度,直到n为1。如此,我们通过减少log(n)次可以得到答案。这种方法的时间复杂度是(log(min(m,n)))。
class Solution:
def getMedian(self,nums):
size = len(nums)
if size == 0:
return [0,0]
if size % 2 == 1:
return [nums[size//2],size//2]
else:
return [(nums[size//2 - 1] + nums[size//2])/2,size//2]
def findMedianSortedArrays(self, nums1, nums2):
"""
:type nums1: List[int]
:type nums2: List[int]
:rtype: float
"""
size1 = len(nums1) # ig longer
size2 = len(nums2)
if size1 < size2:
return self.findMedianSortedArrays(nums2,nums1)
m1 = self.getMedian(nums1)
m2 = self.getMedian(nums2)
if size2 == 0:
return m1[0]
if size2 == 1:
if size1 == 1:
return (m1[0] + m2[0])/2
if size1 % 2 == 0:
if nums2[0] < nums1[size1//2 - 1]:
return nums1[size1//2 -1]
if nums2[0] > nums1[size1//2]:
return nums1[size1//2]
else:
return nums2[0]
else:
if nums2[0] < nums1[size1//2 - 1]:
return (nums1[size1//2 - 1] + nums1[size1//2])/2
if nums2[0] > nums1[size1//2 + 1]:
return (nums1[size1//2 + 1] + nums1[size1//2])/2
else:
return (nums2[0] + nums1[size1//2])/2
if size1 % 2 == 0:
if size2 % 2 == 0:
if nums1[size1//2 - 1] > nums2[size2//2 - 1] and nums2[size2//2] > nums1[size1//2]:
return m1[0]
if nums1[size1//2 - 1] < nums2[size2//2 - 1] and nums2[size2//2] < nums1[size1//2]:
return m2[0]
if m1[0] < m2[0]:
return self.findMedianSortedArrays(nums1[m2[1]:],nums2[:size2 - m2[1]])
if m1[0] > m2[0]:
return self.findMedianSortedArrays(nums1[:size1 - m2[1]],nums2[m2[1]:])
else:
return m1[0]
![2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2](http://www.gvkun.com/zb_users/upload/2025/02/a2af6bf8-20de-49c0-b803-fcc155e8d1761739595520825.jpg "2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2")
2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2
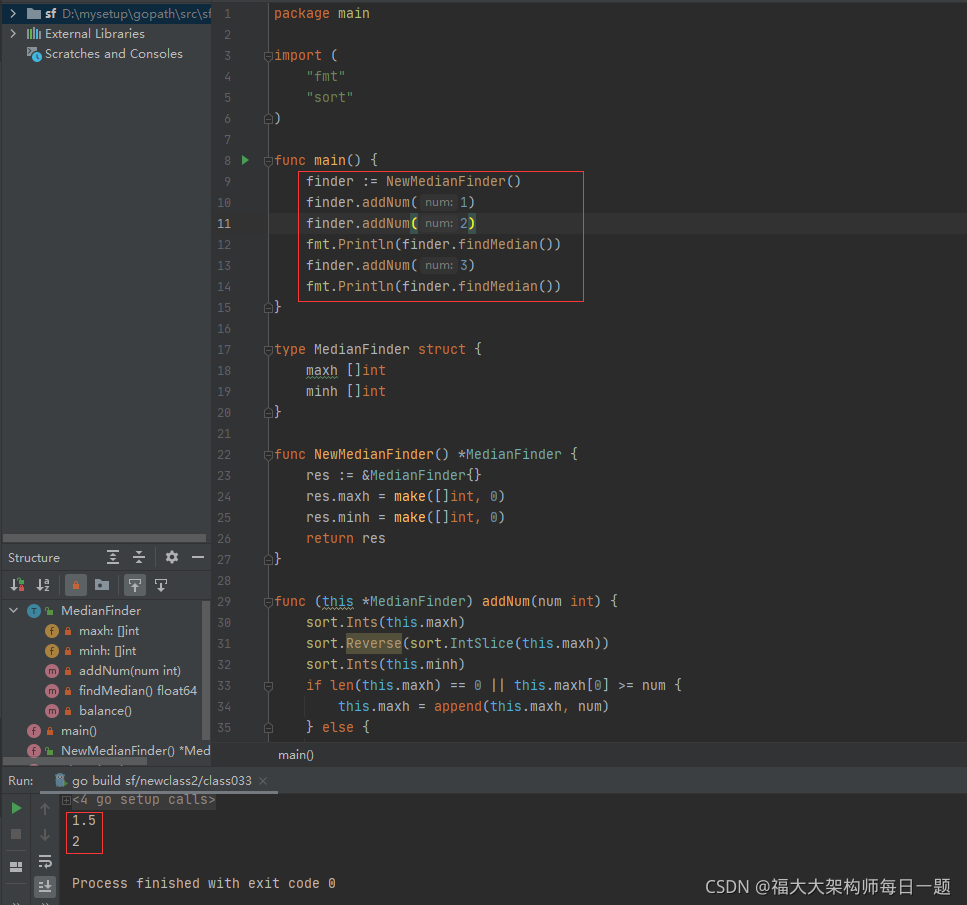
2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2 = 2.5。设计一个支持以下两种操作的数据结构:void addNum(int num) - 从数据流中添加一个整数到数据结构中。double findMedian() - 返回目前所有元素的中位数。示例:addNum(1),addNum(2),findMedian() -> 1.5,addNum(3) ,findMedian() -> 2。进阶:如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法?如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法?力扣295。
答案2021-11-03:
大根堆和小根堆。
addNum方法时间复杂度:O(logN)。
findMedian方法时间复杂度:O(logN)。
代码用golang编写。代码如下:
package main
import (
"fmt"
"sort"
)
func main() {
finder := NewMedianFinder()
finder.addNum(1)
finder.addNum(2)
fmt.Println(finder.findMedian())
finder.addNum(3)
fmt.Println(finder.findMedian())
}
type MedianFinder struct {
maxh []int
minh []int
}
func NewMedianFinder() *MedianFinder {
res := &MedianFinder{
}
res.maxh = make([]int, 0)
res.minh = make([]int, 0)
return res
}
func (this *MedianFinder) addNum(num int) {
sort.Ints(this.maxh)
sort.Reverse(sort.IntSlice(this.maxh))
sort.Ints(this.minh)
if len(this.maxh) == 0 || this.maxh[0] >= num {
this.maxh = append(this.maxh, num)
} else {
this.minh = append(this.minh, num)
}
this.balance()
}
func (this *MedianFinder) findMedian() float64 {
sort.Ints(this.maxh)
sort.Reverse(sort.IntSlice(this.maxh))
sort.Ints(this.minh)
if len(this.maxh) == len(this.minh) {
return float64(this.maxh[0]+this.minh[0]) / float64(2)
} else {
if len(this.maxh) > len(this.minh) {
return float64(this.maxh[0])
} else {
return float64(this.minh[0])
}
}
}
func (this *MedianFinder) balance() {
sort.Ints(this.maxh)
sort.Reverse(sort.IntSlice(this.maxh))
sort.Ints(this.minh)
if Abs(len(this.maxh)-len(this.minh)) == 2 {
if len(this.maxh) > len(this.minh) {
this.minh = append(this.minh, this.maxh[0])
} else {
this.maxh = append(this.maxh, this.minh[0])
}
}
}
func Abs(a int) int {
if a < 0 {
return -a
} else {
return a
}
}执行结果如下:
左神java代码

4.寻找两个正序数组的中位数
/**
* 4.寻找两个正序数组的中位数
* 给定两个大小分别为 m 和 n 的正序(从小到大)数组nums1 和nums2。请你找出并返回这两个正序数组的 中位数 。
*
* 算法的时间复杂度应该为 O(log (m+n))
*
*/
public class Median {
public static double findMedianElement(int[] numArray1, int[] numArray2) {
int length1 = numArray1.length, length2 = numArray2.length;
int totalLength = length1 + length2;
//奇数
if (totalLength % 2 == 1) {
int midIndex = totalLength / 2;
double median = getElement(numArray1, numArray2, midIndex + 1);
return median;
} else {
//偶数
int midIndex1 = totalLength / 2 - 1, midIndex2 = totalLength / 2;
int k1 = getElement(numArray1, numArray2, midIndex1 + 1);
int k2 = getElement(numArray1, numArray2, midIndex2 + 1);
double median = ( k1 + k2 ) / 2.0;
return median;
}
}
public static int getElement(int[] numArray1, int[] numArray2, int k) {
int length1 = numArray1.length, length2 = numArray2.length;
int index1 = 0, index2 = 0;
//临时存储K
int kTemp = k;
//记录遍历次数
int count = 0;
while (true) {
//特殊情况,取第一个元素
if (k == 1) {
if (length1 == 0){
return numArray2[index2];
}
if (length2 == 0){
return numArray1[index1];
}
return Math.min(numArray1[index1], numArray2[index2]);
}
//元素初始值
int pivot1 = -99999, pivot2 = -99999;
//数组1,下标没有越界,且数组个数大于0
if (index1 <= length1 -1 && length1 > 0){
pivot1 = numArray1[index1];
}
//数组2,下标没有越界,且数组个数大于0
if (index2 <= length2 -1 && length2 > 0){
pivot2 = numArray2[index2];
}
//已经遍历了 k-1次 等同于 已经找到了目标元素
if(count == (kTemp-1)){
if (index1 > length1 - 1) {
return pivot2;
}
if (index2 > length2 - 1) {
return pivot1;
}
return Math.min(pivot1,pivot2);
}
//谁的元素小,谁移动指针
if ((pivot1 != -99999 && pivot2 != -99999 && pivot1 <= pivot2) ||
pivot2 == -99999
) {
//右移 nums1 指针
index1 += 1;
//记录遍历次数
count += 1;
} else {
//右移 nums2 指针
index2 += 1;
//记录遍历次数
count += 1;
}
}
}
5个排序数组的中位数
我试图找到5个排序数组中位数的解决方案。这是一次面试的问题。
我能想到的解决方案是合并5个数组,然后找到中位数[O(l + m + n + o + p)]。
我知道对于相同大小的2个排序数组,我们可以在log(2n)中进行。[通过比较两个数组的中位数,然后扔掉每个数组的一半并重复该过程]。..在排序数组中查找中位数可以是恒定时间..所以我认为这不是log(n)吗?..这的时间复杂度是多少?
1]是否有针对5个数组的类似解决方案。如果数组大小相同怎么办,有没有更好的解决方案呢?
2]我假设既然要求5,那么对N个排序的数组会有一些解决方案吗?
感谢您的指导。
我向面试官问了一些澄清/问题:
数组的长度是否相同
=>否,
我想数组的值会重叠
=>是
作为练习,我认为2个数组的逻辑不会扩展。尝试一下:
将上述2个数组的逻辑应用于3个数组:[3,7,9] [4,8,15] [2,3,9] …中位数7,3
抛出元素[ 3,8] [3,9] ..中位数7,6,6
抛出元素[3,7] [8] [9] ..中位数5,9 …
抛出元素[7] [8] [9] ..中位数= 8 …这似乎不正确吗?
已排序元素的合并=> [2,4,9,15] =>预期中位数= 7
今天关于如何计算数组的中位数?和如何计算数组的中位数值的讲解已经结束,谢谢您的阅读,如果想了解更多关于004.寻找两个有序数组的中位数、2021-11-03:数据流的中位数。中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。例如,[2,3,4] 的中位数是 3,[2,3] 的中位数是 (2 + 3) / 2、4.寻找两个正序数组的中位数、5个排序数组的中位数的相关知识,请在本站搜索。
本文的目的是介绍计算RDD中的行数的详细情况,特别关注rdd求和的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解计算RDD中的行数的机会,同时也不会遗漏关于bash – 如何计算源代码中的行数、Django 计算子查询中的行数、java – 如何计算JTextArea中的行数,包括由包装引起的行数?、jQuery:计算表中的行数的知识。
本文目录一览:- 计算RDD中的行数(rdd求和)
- bash – 如何计算源代码中的行数
- Django 计算子查询中的行数
- java – 如何计算JTextArea中的行数,包括由包装引起的行数?
- jQuery:计算表中的行数
")
计算RDD中的行数(rdd求和)
我在Java中使用spark,并且具有500万行的RDD。有没有一种解决方案可以让我计算RDD的行数。我已经尝试过,RDD.count()但是要花很多时间。我已经知道我可以使用该功能fold。但是我没有找到此功能的Java文档。您能否请教我如何使用它,或给我另一个解决方案以获取RDD的行数。
这是我的代码:
JavaPairRDD<String, String> lines = getAllCustomers(sc).cache();JavaPairRDD<String,String> CFIDNotNull = lines.filter(notNull()).cache();JavaPairRDD<String, Tuple2<String, String>> join =lines.join(CFIDNotNull).cache();double count_ctid = (double)join.count(); // i want to get the count of these three RDDdouble all = (double)lines.count();double count_cfid = all - CFIDNotNull.count();System.out.println("********** :"+count_cfid*100/all +"% and now : "+ count_ctid*100/all+"%");谢谢。
答案1
小编典典您有一个正确的想法:用于rdd.count()计算行数。没有更快的方法。
我认为您应该问的问题是 为什么rdd.count()这么慢?
答案是rdd.count()“动作”,这是一个急切的操作,因为它必须返回实际的数字。您之前执行的RDD操作count()是“转换”-他们将RDD延迟地转换为另一个。实际上,转换实际上并没有执行,只是排队。调用时count(),您将强制执行所有先前的惰性操作。输入的文件需要立即加载,执行map()s和filter()s,执行随机播放等,直到最后我们有了数据并可以说出它有多少行。
请注意,如果您拨打count()两次,所有这些都会发生两次。返回计数后,所有数据都将被丢弃!如果要避免这种情况,请调用cache()RDD。然后,对的第二次调用count()将很快,并且派生的RDD也会更快地计算出来。但是,在这种情况下,RDD必须存储在内存(或磁盘)中。

bash – 如何计算源代码中的行数
sloccount

Django 计算子查询中的行数
这是在 Django 中计算子查询中行数的正确方法
subquery = Subquery(Child.objects.filter(parent_id=OuterRef('id')).order_by()
.values('parent').annotate(count=Count('pk'))
.values('count'),output_field=IntegerField())
Parent.objects.annotate(child_count=Coalesce(subquery,0))
-
.order_by()将取消订单(如有) - 第一个值
.values('parent')将引入正确的分组 -
.annotate(count=Count('pk'))将注释(每行广告)我们正在寻找的答案 - 第二个值
.values('count')将行限制在count中 -
Coalesce将首先返回非空值或零
这在 Django 中很棘手,但非常有效。

java – 如何计算JTextArea中的行数,包括由包装引起的行数?
为了做到这一点,我计划使用…来计算字体的高度
Font font = jTextArea.getFont(); FontMetrics fontMetrics = jTextArea.getFontMetrics(font); int lineHeight = fontMetrics.getAscent() + fontMetrics.getDescent();
…然后将其乘以JTextArea中使用的行数.问题是JTextArea.getLineCount()计算忽略包装线的行返回数.
如何计算JTextArea中使用的行数,包括由word wrap引起的行数?
这里有一些演示代码让这个问题变得更容易.我有一个监听器,每次窗口调整大小时打印出行数.目前,它总是打印1,但是我想要补偿单词包装,并打印出实际使用了多少行.
编辑:我在下面的代码中包含了问题的解决方案.静态countLines方法给出了解决方案.
package components;
import java.awt.*;
import java.awt.event.*;
import java.awt.font.*;
import java.text.*;
import javax.swing.*;
public class JTextAreaLineCountDemo extends JPanel {
JTextArea textArea;
public JTextAreaLineCountDemo() {
super(new GridBagLayout());
String inputStr = "Lorem ipsum dolor sit amet,consectetur adipisicing elit,sed do eiusmo";
textArea = new JTextArea(inputStr);
textArea.setEditable(false);
textArea.setLineWrap(true);
textArea.setWrapStyleWord(true);
// Add Components to this panel.
GridBagConstraints c = new GridBagConstraints();
c.gridwidth = GridBagConstraints.REMAINDER;
c.fill = GridBagConstraints.BOTH;
c.weightx = 1.0;
c.weighty = 1.0;
add(textArea,c);
addComponentListener(new ComponentAdapter() {
@Override
public void componentResized(ComponentEvent ce) {
System.out.println("Line count: " + countLines(textArea));
}
});
}
private static int countLines(JTextArea textArea) {
AttributedString text = new AttributedString(textArea.getText());
FontRenderContext frc = textArea.getFontMetrics(textArea.getFont())
.getFontRenderContext();
AttributedCharacterIterator charIt = text.getIterator();
LineBreakMeasurer lineMeasurer = new LineBreakMeasurer(charIt,frc);
float formatWidth = (float) textArea.getSize().width;
lineMeasurer.setPosition(charIt.getBeginIndex());
int noLines = 0;
while (lineMeasurer.getPosition() < charIt.getEndindex()) {
lineMeasurer.nextLayout(formatWidth);
noLines++;
}
return noLines;
}
private static void createAndShowGUI() {
JFrame frame = new JFrame("JTextAreaLineCountDemo");
frame.setDefaultCloSEOperation(JFrame.EXIT_ON_CLOSE);
frame.add(new JTextAreaLineCountDemo());
frame.pack();
frame.setVisible(true);
}
public static void main(String[] args) {
javax.swing.SwingUtilities.invokelater(new Runnable() {
public void run() {
createAndShowGUI();
}
});
}
}
解决方法
LineBreakMeasurer类.
The LineBreakMeasurer class allows styled text to be broken into lines (or segments) that fit within a particular visual advance. This is useful for clients who wish to display a paragraph of text that fits within a specific width,called the wrapping width.LineBreakMeasurer implements the most commonly used line-breaking policy: Every word that fits within the wrapping width is placed on the line. If the first word does not fit,then all of the characters that fit within the wrapping width are placed on the line. At least one character is placed on each line.

jQuery:计算表中的行数
如何使用 jQuery 计算表中 tr 元素的数量?
我们今天的关于计算RDD中的行数和rdd求和的分享已经告一段落,感谢您的关注,如果您想了解更多关于bash – 如何计算源代码中的行数、Django 计算子查询中的行数、java – 如何计算JTextArea中的行数,包括由包装引起的行数?、jQuery:计算表中的行数的相关信息,请在本站查询。
在本文中,我们将详细介绍计算字符串中的单词的各个方面,并为您提供关于计算字符串中的单词数量的相关解答,同时,我们也将为您带来关于434. 字符串中的单词数、C ++程序使用递归和结构来计算字符串中的冗余单词、c# – 如何计算字符串中的唯一字符、c# – 计算字符串中的零个数的有用知识。
本文目录一览:")
计算字符串中的单词(计算字符串中的单词数量)
function WordCount(str) { var totalSoFar = 0; for (var i = 0; i < WordCount.length; i++) if (str(i) === " ") { // if a space is found in str totalSoFar = +1; // add 1 to total so far } totalsoFar += 1; // add 1 to totalsoFar to account for extra space since 1 space = 2 words}console.log(WordCount("Random String"));我认为我已经很好地理解了这一点,但我认为该if陈述是错误的。怎么说if(str(i)包含空格,加1。
编辑:
我发现(感谢Blender)可以用更少的代码来做到这一点:
function WordCount(str) { return str.split(" ").length;}console.log(WordCount("hello world"));答案1
小编典典使用方括号,而不是括号:
str[i] === " "或charAt:
str.charAt(i) === " "您也可以使用.split():
return str.split('' '').length;
434. 字符串中的单词数
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
请注意,你可以假定字符串里不包括任何不可打印的字符。
示例:
输入: "Hello, my name is John"
输出: 5
思路详见注释。 1 class Solution(object):
2 def countSegments(self, s):
3 """
4 :type s: str
5 :rtype: int
6 """
7 if len(s.split()) == 0:
8 return 0
9 # 设置计数器,初始值为1
10 index = 0
11 # 遍历字符串,如果当前遇到的字符是字母前一个字符是空格时,计数器增1
12 # 当然,字符串第一个字符单独考虑
13 for i in range(len(s)):
14 if (i == 0 or s[i - 1] == '' '') and s[i].isalnum():
15 index += 1
16 return index
17
18 def countSegments2(self, s):
19 """
20 :type s: str
21 :rtype: int
22 """
23 # 设置计数器,初始值为1
24 index = 1
25 # 遍历字符串,如果当前遇到的字符不是字母,那么在遇到下一个字母时,计数器增1
26 for i in range(len(s)):
27 if not s[i - 1].isalnum() and s[i].isalnum():
28 index += 1
29 return index
30
31 def countSegments3(self, s):
32 """
33 :type s: str
34 :rtype: int
35 """
36 # 测试用例每个单词后都会有一个空格
37 return len(s.split())
38
39
40 if __name__ == ''__main__'':
41 solution = Solution()
42 print(solution.countSegments(", , , , a, eaefa"))
43 print(solution.countSegments("Of all the gin joints in all the towns in all the world, "))
44 print(solution.countSegments("Hello, my, name, is, John"))
45 print(solution.countSegments("love live! mu''sic forever"))

C ++程序使用递归和结构来计算字符串中的冗余单词
使用std::unordered_map,将单词存储为键,并将每个单词的计数存储为值。
一旦您遍历了输入句子的长度,存储/增加了当前单词的值,那么您就可以从哈希表的开头到结尾进行迭代,将所有大于1的值相加。 / p>

c# – 如何计算字符串中的唯一字符
假设我们有变量myString =“blabla”或mystring = 998769
myString.Length; //will get you your result myString.Count(char.IsLetter); //if you only want the count of letters:
如何获得,独特的字符数?我的意思是“blabla”结果必须是3,doe“998769”它将是4.是否准备好了功能?有什么建议?
解决方法
var count = myString.distinct().Count();
它使用一个事实,该字符串实现IEnumerable< char>.
如果没有LINQ,你可以在内部做与distinct相同的东西并使用HashSet< char>:
var count = (new HashSet<char>(myString)).Count;

c# – 计算字符串中的零个数
此字符串不固定.它将附加取决于板的数量.如果有两个板,则字符串将如下512000000000000000000000000000000052200000000000000000000000000000
我想知道如何计算字符串中的零数.
我使用以下代码,但如果有两个以上的板,则不灵活.
string str = "51200000000000000000000000000000";
string zeros = "00000000000000000000000000000";
if (str.Contains(zeros))
{
Console.WriteLine("true");
}
else
{
Console.WriteLine("false");
}
解决方法
char matchChar='0'; string strInput = "51200000000000000000000000000000"; int zeroCount = strInput.Count(x => x == matchChar); // will be 29
您可以通过迭代每个字符并检查它是否是必需字符(比如0)然后计算它来做同样的事情.
今天的关于计算字符串中的单词和计算字符串中的单词数量的分享已经结束,谢谢您的关注,如果想了解更多关于434. 字符串中的单词数、C ++程序使用递归和结构来计算字符串中的冗余单词、c# – 如何计算字符串中的唯一字符、c# – 计算字符串中的零个数的相关知识,请在本站进行查询。
如果您想了解给定两个日期的相关知识,那么本文是一篇不可错过的文章,我们将对不包括周末计算日期进行全面详尽的解释,并且为您提供关于Google表格:如何在数据表中查找和计算日期在两个日期之间的值、java – 在两个日期之间迭代,包括开始日期?、java 获取两个日期之间的所有日期(年月日)、java获取给定月份和给定年份的第一个日期和最后一个日期的有价值的信息。
本文目录一览:- 给定两个日期(不包括周末)计算日期(给定两个日期计算天数)
- Google表格:如何在数据表中查找和计算日期在两个日期之间的值
- java – 在两个日期之间迭代,包括开始日期?
- java 获取两个日期之间的所有日期(年月日)
- java获取给定月份和给定年份的第一个日期和最后一个日期
计算日期(给定两个日期计算天数)")
给定两个日期(不包括周末)计算日期(给定两个日期计算天数)
我在Spring 3.0项目中使用Joda time
api计算日期。现在我有一个开始日期和结束日期,我想在这两个日期之间得到每天的周末,星期六或星期日。我该如何实现?
我看了这篇Joda的时间-两个日期之间的所有星期一。它提供了一些指导,但在如何排除两个日期方面仍然含糊。
答案1
小编典典我想你的问题是如何
在两个日期之间的周末,星期六或星期日除外的每一天获取。
解决方案 :
public static void main(String[] args) { final LocalDate start = LocalDate.now(); final LocalDate end = new LocalDate(2012, 1, 14); LocalDate weekday = start; if (start.getDayOfWeek() == DateTimeConstants.SATURDAY || start.getDayOfWeek() == DateTimeConstants.SUNDAY) { weekday = weekday.plusWeeks(1).withDayOfWeek(DateTimeConstants.MONDAY); } while (weekday.isBefore(end)) { System.out.println(weekday); if (weekday.getDayOfWeek() == DateTimeConstants.FRIDAY) weekday = weekday.plusDays(3); else weekday = weekday.plusDays(1); }}
Google表格:如何在数据表中查找和计算日期在两个日期之间的值
如何解决Google表格:如何在数据表中查找和计算日期在两个日期之间的值?
我正在尝试从汇率不同的海外订购产品来支付我的帐户费用。
我有两个单独的电子表格 1.Currency EXC,我用来添加我的汇率和金额数据。
Date Amount EXC Rate
07/01/2021 ₩ 200,000 0.0276
12/01/2021 ₩ 400,000 0.0275
15/01/2021 ₩ 103,600 0.0274
16/01/2021 ₩ 200,000 0.0274
22/01/2021 ₩ 100,000 0.0273
2.Purchase Order 用于记录我购买的商品。
Date Product Item Price QTY
03/01/2021 item1 ₩ 14,900 10
12/01/2021 item2 ₩ 14,900 5
15/01/2021 item3 ₩ 33,000 3
我想知道我在兑换货币的日期以当地货币购买的价格。 例如:我在 1 月 3 日购买了第 1 件商品,我以每 ₩ 200,000 0.0276 的价格兑换了货币。这意味着我以 411.24 x 10 = 4112.40 的价格购买了商品 1。 我口袋里的总钱 = 200,000 - 149,000 = 51,000 然后我在 1 月 12 日又买了一件东西,但我还剩下 51,000 美元。 item2 的总费用为 74,500,这意味着 51,000 x 0.0276 = 1407.60 和 23,500 x 0.0275 = 646.25
我想在另一个谷歌电子表格中自动计算这些数据,但我不知道如何为此制定公式。
谢谢。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

java – 在两个日期之间迭代,包括开始日期?
public static void main(String[] args)throws Exception {
GregorianCalendar gcal = new GregorianCalendar();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy.MM");
Date start = sdf.parse("2010.01");
Date end = sdf.parse("2010.04");
gcal.setTime(start);
while (gcal.getTime().before(end)) {
gcal.add(Calendar.MONTH,1);
Date d = gcal.getTime();
System.out.println(d);
}
}
在上面的代码打印日期之间,但我需要打印开始日期也..
上面的代码输出是
Mon Feb 01 00:00:00 IST 2010 Mon Mar 01 00:00:00 IST 2010 Thu Apr 01 00:00:00 IST 2010
但我还需要在输出上开始约会..
请帮我解决这个问题
提前致谢..
解决方法
SimpleDateFormat sdf = new SimpleDateFormat("yyyy.MM");
Date start = sdf.parse("2010.01");
Date end = sdf.parse("2010.04");
GregorianCalendar gcal = new GregorianCalendar();
gcal.setTime(start);
while (!gcal.getTime().after(end)) {
Date d = gcal.getTime();
System.out.println(d);
gcal.add(Calendar.MONTH,1);
}
输出:
Fri Jan 01 00:00:00 WST 2010 Mon Feb 01 00:00:00 WST 2010 Mon Mar 01 00:00:00 WST 2010 Thu Apr 01 00:00:00 WST 2010
我们所做的就是在递增之前打印日期,然后如果日期不在结束日期之后再重复.
另一个选择是在while(yuck)之前复制打印代码或者使用do … while(也是yuck).
")
java 获取两个日期之间的所有日期(年月日)
前言:直接上代码
java 获取两个日期之间的所有日期(年月日)
/**
* 获取两个日期之间的日期,包括开始结束日期
* @param start 开始日期
* @param end 结束日期
* @return 日期集合
*/
private List<Date> getBetweenDates(Date start, Date end) {
List<Date> result = new ArrayList<Date>();
Calendar tempStart = Calendar.getInstance();
tempStart.setTime(start);
tempStart.add(Calendar.DAY_OF_YEAR, 1);
Calendar tempEnd = Calendar.getInstance();
tempEnd.setTime(end);
result.add(start);
while (tempStart.before(tempEnd)) {
result.add(tempStart.getTime());
tempStart.add(Calendar.DAY_OF_YEAR, 1);
}
return result;
}

java获取给定月份和给定年份的第一个日期和最后一个日期
我试图获取给定月份和年份的第一个日期和最后一个日期。我使用以下代码以yyyyMMdd格式获取最后日期。但是无法获得这种格式。另外,我希望开始日期采用相同的格式。我仍在努力。任何人都可以帮助我修复以下代码。
public static java.util.Date calculateMonthEndDate(int month, int year) { int[] daysInAMonth = { 29, 31, 28, 31, 30, 31, 30, 31, 31, 30, 31, 30, 31 }; int day = daysInAMonth[month]; boolean isLeapYear = new GregorianCalendar().isLeapYear(year); if (isLeapYear && month == 2) { day++; } GregorianCalendar gc = new GregorianCalendar(year, month - 1, day); java.util.Date monthEndDate = new java.util.Date(gc.getTime().getTime()); return monthEndDate;}public static void main(String[] args) { int month = 3; int year = 2076; final java.util.Date calculatedDate = calculateMonthEndDate(month, year); SimpleDateFormat format = new SimpleDateFormat("yyyyMMdd"); format.format(calculatedDate); System.out.println("Calculated month end date : " + calculatedDate);}答案1
小编典典获取 开始日期
GregorianCalendar gc = new GregorianCalendar(year, month-1, 1); java.util.Date monthEndDate = new java.util.Date(gc.getTime().getTime()); System.out.println(monthEndDate);( 注意 :在开始日期中, 日期 = 1)
对于格式化
SimpleDateFormat format = new SimpleDateFormat(/////////add your format here);System.out.println("Calculated month end date : " + format.format(calculatedDate));关于给定两个日期和不包括周末计算日期的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Google表格:如何在数据表中查找和计算日期在两个日期之间的值、java – 在两个日期之间迭代,包括开始日期?、java 获取两个日期之间的所有日期(年月日)、java获取给定月份和给定年份的第一个日期和最后一个日期等相关知识的信息别忘了在本站进行查找喔。
这篇文章主要围绕javascript根据周数计算日期和js根据日期计算星期展开,旨在为您提供一份详细的参考资料。我们将全面介绍javascript根据周数计算日期的优缺点,解答js根据日期计算星期的相关问题,同时也会为您带来javascript - 关于计算日期差。、javascript – jQuery计算日期、javascript – 如何从周数和年份获得一周的第一个日期和最后日期?、javascript – 根据质量和弹跳系数计算球与球碰撞的速度和方向的实用方法。
本文目录一览:- javascript根据周数计算日期(js根据日期计算星期)
- javascript - 关于计算日期差。
- javascript – jQuery计算日期
- javascript – 如何从周数和年份获得一周的第一个日期和最后日期?
- javascript – 根据质量和弹跳系数计算球与球碰撞的速度和方向
")
javascript根据周数计算日期(js根据日期计算星期)
我如何知道JavaScript的周数和年份来计算日期?对于第20周和2013年以获得5/16/2013,我正在尝试这样做:
Date.prototype.dayofYear = function() { var d = new Date(this.getFullYear(), 0, 0); return Math.floor((enter code here this - d) / 8.64e + 7); }答案1
小编典典function getDateOfWeek(w, y) {
var d = (1 + (w - 1) * 7); // 1st of January + 7 days for each week
return new Date(y, 0, d);}这使用简单的周定义,即2013年的第20周是5月14日。
计算给定ISO8601周的开始日期(始终为星期一)
function getDateOfISOWeek(w, y) { var simple = new Date(y, 0, 1 + (w - 1) * 7); var dow = simple.getDay(); var ISOweekStart = simple; if (dow <= 4) ISOweekStart.setDate(simple.getDate() - simple.getDay() + 1); else ISOweekStart.setDate(simple.getDate() + 8 - simple.getDay()); return ISOweekStart;}
javascript - 关于计算日期差。
背景:我用php计算从今天起,推迟三个月(三个月不一定是90天,比如从今天的11月30号,推迟三个月就是2月的28号)的日期。java端说他们很好得到这三个月的日期。
疑惑:计算两个时间之间的日期差我知道,但是计算三个月的我不会。我现在的做法是这样:
立即学习“Java免费学习笔记(深入)”;
echo floor((strtotime(''+3 month'') - strtotime(date(''Y-m-d'')))/86400);
求解:如何用PHP和javascript计算真实日期差。
回复内容:
背景:我用php计算从今天起,推迟三个月(三个月不一定是90天,比如从今天的11月30号,推迟三个月就是2月的28号)的日期。java端说他们很好得到这三个月的日期。
疑惑:计算两个时间之间的日期差我知道,但是计算三个月的我不会。我现在的做法是这样:
立即学习“Java免费学习笔记(深入)”;
echo floor((strtotime(''+3 month'') - strtotime(date(''Y-m-d'')))/86400);
求解:如何用PHP和javascript计算真实日期差。
Moment ( 一款js时间框架 )
文档地址:http://momentjs.com/#relative-time
jsmoment("20111031", "YYYYMMDD").fromNow(); // 4 years ago
moment("20120620", "YYYYMMDD").fromNow(); // 3 years ago
moment().startOf(''day'').fromNow(); // 15 hours ago
moment().endOf(''day'').fromNow(); // in 9 hours
moment().startOf(''hour''
其他使用方式
jsvar date1 = moment(''2015-01-01'')
var date2 = moment(''2000-01-01'')
date1.diff(date2) // 473385600000
date1.from(date2) // "in 15 years"
Carbon 可能是 PHP 中时间处理最好的轮子了:http://carbon.nesbot.com/docs/#api-difference
javascript// 之前项目里用到的实现方式
var f = function (date, diff) {
var day;
if (typeof date == ''string'') {
// yyyy-mm-dd 不是合法的格式
date = date.replace(/-/g, ''/'');
}
date = new Date(date);
day = date.getDate();
diff = ~~diff || 0;
date.setMonth(date.getMonth() + diff);
// 天数超出目标月的最大天数时,会顺延到下个月
// 然后设置下个月的第零天,重置到目标月的最后一天
if (date.getDate() != day) {
date.setDate(0);
}
return date;
}
f(''2014/11/30'', 3);
js 版本,
var d = new Date(); d.setMonth(d.getMonth() + 3);
我记得php里面有一个很好用的时间函数,可以直接加月份的,php操作时间最为简单的,普通地加3 month就好
SimpleDateFormat sdf=new SimpleDateFormat("yyyy-MM-dd");
Date date=new Date();
String dateString=sdf.format(date);
date.setMonth(date.getMonth()+10);
String dateString1=sdf.format(date);
======结果=====
2015-06-10 :2016-04-10
这个就要对比php和java的算法了,php端是这样理解+n month的
/**
* @var $days int 总计天数
* @var $year int 当前年
* @var $month int 当前月
*/
$days = 0; $year = 2015; $month = 3;
/**
* @var $n int 几个月
*/
for ($i = 0; $i
<p>但是我不知道java是不是这样算的,不过逻辑一分析明白了楼主应该理解js端怎么搞了吧。</p>
<p>例 date(''Y-m-d'', strtotime(''2015-01-30 +1 month'') === date(''Y-m-d'', strtotime(''2015-01-30 +31 days'') 是3月2号</p>
<pdata-id="1020000002898361">
</p><p>你的代码改良一下,话说这样还不够简单吗?</p>
<pre>echo floor((strtotime(''+3 month'') - time())/86400);
这个有点扯蛋吧,如果今天是2月28日,java能计算出三个月以后的今天是5月30日,那5月28号怎么办?没有那个语言这么智能。
你想要这种结果(基于当前日期离下一个月1号的距离) ,php也是可以做到的。
echo date(''Y-m-d'',strtotime(''last day of +3 month'')-(strtotime(''last day of this month'')-strtotime(''today'')));
先计算这个月离下个月1号的距离,然后在当前月底加上3个月,减去这个距离。
显然这个是任何语言都能实现的。
phpdate(''Y-m-d'',strtotime(''-3 months''));
问题没看明白,是要「今天」推迟3个月的时间吗?
如果只要是推迟3个月是几号:
phpdate(''d'',strtotime(''-3 months''));

javascript – jQuery计算日期
http://jsfiddle.net/SparrwHawk/MH5wP/
我已经编写了下面的代码供参考,但在jsfiddle上显然更清晰
<p>Sun / Closed</p>
<p>Mon / Closed</p>
<p>Tues / 9am – 5pm</p>
<p>Wed / 9am – 5pm</p>
<p>Thurs / 9am – 8pm</p>
<p>Fri / 9.30pm – 6.30pm</p>
<p>Sat / 8.30am – 4.30pm</p>
<script>
// Day where 0 is Sunday
var date = new Date();
var d = (date.getDay());
$(function(){
if (d = 1) {
$('p:contains("Mon")').addClass('today');
} else if (d = 2) {
$('p:contains("Tues")').addClass('today');
} else if (d = 3) {
$('p:contains("Wed")').addClass('today');
} else if (d = 4) {
$('p:contains("Thurs")').addClass('today');
} else if (d = 5) {
$('p:contains("Fri")').addClass('today');
} else if (d = 6) {
$('p:contains("Sat")').addClass('today');
} else {
$('p:contains("Sun")').addClass('today');
}
});
</script>
解决方法
所以你要做的是if((d = 1)=== true)又如果你可以给1分配1.这是有效的,所以代码输入你的第一个if并且elses永远不会被触及.
确保不会出现这种错误的一种简单方法是在检查硬编码值时反转操作数的顺序:
$(function(){
if (1 == d) {
// do something ...
这样,如果您错误地使用=,则分配失败并且您收到错误.

javascript – 如何从周数和年份获得一周的第一个日期和最后日期?
例如,如果我输入的是:
2(周),2012
然后我的输出应该是:
2012-01-08和2012-01-14
解决方法
var year = 2012;
var week = 2;
var d = new Date("Jan 01," + year + " 01:00:00");
var w = d.getTime() + 604800000 * (week - 1);
var n1 = new Date(w);
var n2 = new Date(w + 518400000)
console.log(n1);
console.log(n2);
n1包含一周的第一天
n2包含一周的最后一天
至于常数:604800000是一周,以毫秒为单位518400000是六天

javascript – 根据质量和弹跳系数计算球与球碰撞的速度和方向
ballA.vx = (u1x * (m1 - m2) + 2 * m2 * u2x) / (m1 + m2); ballA.vy = (u1y * (m1 - m2) + 2 * m2 * u2y) / (m1 + m2); ballB.vx = (u2x * (m2 - m1) + 2 * m1 * u1x) / (m1 + m2); ballB.vy = (u2y * (m2 - m1) + 2 * m1 * u1y) / (m1 + m2);
但由于该公式是针对一维碰撞而设计的,因此显然效果不佳.
所以我尝试使用this section以下的公式.
但问题是我不知道偏转角是什么以及如何计算它.另外,如何考虑这个公式中的弹跳系数?
编辑:我可能还不清楚.上面的代码确实有效,尽管它可能不是预期的行为,因为原始公式是针对一维碰撞而设计的.因此,我正在尝试的问题是:
>什么是2D等价物?
>如何考虑弹跳系数?
>如何计算碰撞后两个球的方向(用vx和vy表示)?
解决方法
这里承诺的是一个更复杂的物理引擎,但我仍然觉得它很容易跟随(希望!或者我只是浪费了我的时间……大声笑),(网址:http://jsbin.com/otipiv/edit#javascript,live)
function Vector(x,y) {
this.x = x;
this.y = y;
}
Vector.prototype.dot = function (v) {
return this.x * v.x + this.y * v.y;
};
Vector.prototype.length = function() {
return Math.sqrt(this.x * this.x + this.y * this.y);
};
Vector.prototype.normalize = function() {
var s = 1 / this.length();
this.x *= s;
this.y *= s;
return this;
};
Vector.prototype.multiply = function(s) {
return new Vector(this.x * s,this.y * s);
};
Vector.prototype.tx = function(v) {
this.x += v.x;
this.y += v.y;
return this;
};
function BallObject(elasticity,vx,vy) {
this.v = new Vector(vx || 0,vy || 0); // veLocity: m/s^2
this.m = 10; // mass: kg
this.r = 15; // radius of obj
this.p = new Vector(0,0); // position
this.cr = elasticity; // elasticity
}
BallObject.prototype.draw = function(ctx) {
ctx.beginPath();
ctx.arc(this.p.x,this.p.y,this.r,2 * Math.PI);
ctx.closePath();
ctx.fill();
ctx.stroke();
};
BallObject.prototype.update = function(g,dt,ppm) {
this.v.y += g * dt;
this.p.x += this.v.x * dt * ppm;
this.p.y += this.v.y * dt * ppm;
};
BallObject.prototype.collide = function(obj) {
var dt,mT,v1,v2,cr,sm,dn = new Vector(this.p.x - obj.p.x,this.p.y - obj.p.y),sr = this.r + obj.r,// sum of radii
dx = dn.length(); // pre-normalized magnitude
if (dx > sr) {
return; // no collision
}
// sum the masses,normalize the collision vector and get its tangential
sm = this.m + obj.m;
dn.normalize();
dt = new Vector(dn.y,-dn.x);
// avoid double collisions by "un-deforming" balls (larger mass == less tx)
// this is susceptible to rounding errors,"jiggle" behavior and anti-gravity
// suspension of the object get into a strange state
mT = dn.multiply(this.r + obj.r - dx);
this.p.tx(mT.multiply(obj.m / sm));
obj.p.tx(mT.multiply(-this.m / sm));
// this interaction is strange,as the CR describes more than just
// the ball's bounce properties,it describes the level of conservation
// observed in a collision and to be "true" needs to describe,rigidity,// elasticity,level of energy lost to deformation or adhesion,and crazy
// values (such as cr > 1 or cr < 0) for stange edge cases obvIoUsly not
// handled here (see: http://en.wikipedia.org/wiki/Coefficient_of_restitution)
// for Now assume the ball with the least amount of elasticity describes the
// collision as a whole:
cr = Math.min(this.cr,obj.cr);
// cache the magnitude of the applicable component of the relevant veLocity
v1 = dn.multiply(this.v.dot(dn)).length();
v2 = dn.multiply(obj.v.dot(dn)).length();
// maintain the unapplicatble component of the relevant veLocity
// then apply the formula for inelastic collisions
this.v = dt.multiply(this.v.dot(dt));
this.v.tx(dn.multiply((cr * obj.m * (v2 - v1) + this.m * v1 + obj.m * v2) / sm));
// do this once for each object,since we are assuming collide will be called
// only once per "frame" and its also more effiecient for calculation cacheing
// purposes
obj.v = dt.multiply(obj.v.dot(dt));
obj.v.tx(dn.multiply((cr * this.m * (v1 - v2) + obj.m * v2 + this.m * v1) / sm));
};
function FloorObject(floor) {
var py;
this.v = new Vector(0,0);
this.m = 5.9722 * Math.pow(10,24);
this.r = 10000000;
this.p = new Vector(0,py = this.r + floor);
this.update = function() {
this.v.x = 0;
this.v.y = 0;
this.p.x = 0;
this.p.y = py;
};
// custom to minimize unnecessary filling:
this.draw = function(ctx) {
var c = ctx.canvas,s = ctx.scale;
ctx.fillRect(c.width / -2 / s,floor,ctx.canvas.width / s,(ctx.canvas.height / s) - floor);
};
}
FloorObject.prototype = new BallObject(1);
function createCanvasWithControls(objs) {
var addBall = function() { objs.unshift(new BallObject(els.value / 100,(Math.random() * 10) - 5,-20)); },d = document,c = d.createElement('canvas'),b = d.createElement('button'),els = d.createElement('input'),clr = d.createElement('input'),cnt = d.createElement('input'),clrl = d.createElement('label'),cntl = d.createElement('label');
b.innerHTML = 'add ball with elasticity: <span>0.70</span>';
b.onclick = addBall;
els.type = 'range';
els.min = 0;
els.max = 100;
els.step = 1;
els.value = 70;
els.style.display = 'block';
els.onchange = function() {
b.getElementsByTagName('span')[0].innerHTML = (this.value / 100).toFixed(2);
};
clr.type = cnt.type = 'checkBox';
clr.checked = cnt.checked = true;
clrl.style.display = cntl.style.display = 'block';
clrl.appendChild(clr);
clrl.appendChild(d.createTextNode('clear each frame'));
cntl.appendChild(cnt);
cntl.appendChild(d.createTextNode('continuous shower!'));
c.style.border = 'solid 1px #3369ff';
c.style.display = 'block';
c.width = 700;
c.height = 550;
c.shouldClear = function() { return clr.checked; };
d.body.appendChild(c);
d.body.appendChild(els);
d.body.appendChild(b);
d.body.appendChild(clrl);
d.body.appendChild(cntl);
setInterval(function() {
if (cnt.checked) {
addBall();
}
},333);
return c;
}
// start:
var objs = [],c = createCanvasWithControls(objs),ctx = c.getContext('2d'),fps = 30,// target frames per second
ppm = 20,// pixels per meter
g = 9.8,// m/s^2 - acceleration due to gravity
t = new Date().getTime();
// add the floor:
objs.push(new FloorObject(c.height - 10));
// as expando so its accessible in draw [this overides .scale(x,y)]
ctx.scale = 0.5;
ctx.fill;
ctx.stroke;
ctx.transform(ctx.scale,ctx.scale,c.width / 2,c.height / 2);
setInterval(function() {
var i,j,nw = c.width / ctx.scale,nh = c.height / ctx.scale,nt = new Date().getTime(),dt = (nt - t) / 1000;
if (c.shouldClear()) {
ctx.clearRect(nw / -2,nh / -2,nw,nh);
}
for (i = 0; i < objs.length; i++) {
// if a ball > viewport width away from center remove it
while (objs[i].p.x < -nw || objs[i].p.x > nw) {
objs.splice(i,1);
}
objs[i].update(g,ppm,objs,i);
for (j = i + 1; j < objs.length; j++) {
objs[j].collide(objs[i]);
}
objs[i].draw(ctx);
}
t = nt;
},1000 / fps);
真正的“肉”和讨论的起源是obj.collide(obj)方法.
如果我们潜入(我这次评论它,因为它比“最后”复杂得多),你会看到这个等式:,仍然是这一行中唯一使用的:this.v.tx(dn .multiply((cr * obj.m *(v2-v1)this.m * v1 obj.m * v2)/ sm));现在我确定你还在说:“zomg wtf!这是一个相同的单维方程!”但是当你停下来思考它时,“碰撞”只会在一个维度上发生.这就是为什么我们使用矢量方程来提取适用的分量并将碰撞仅应用于那些特定的部分而使其他部分不受影响地继续它们的快乐方式(忽略摩擦并简化碰撞以不考虑动态能量转换力,如评论CR).随着对象复杂性的增加和场景数据点的数量增加,这个概念显然变得更加复杂,以解决诸如畸形,转动惯量,不均匀的质量分布和摩擦点等问题……但是这远远超出了它的范围,它几乎不会值得一提..
基本上,你真正需要“掌握”这个让你觉得直观的概念是Vector方程的基础知识(都位于Vector原型中),它们如何与每个相互作用(它实际上意味着规范化,或者采取一个点) /标量产品,例如,阅读/与知识渊博的人交谈)以及对碰撞如何作用于物体属性的基本理解(质量,速度等……再次,阅读/与知识渊博的人交谈)
我希望这有帮助,祝你好运! -ck
今天的关于javascript根据周数计算日期和js根据日期计算星期的分享已经结束,谢谢您的关注,如果想了解更多关于javascript - 关于计算日期差。、javascript – jQuery计算日期、javascript – 如何从周数和年份获得一周的第一个日期和最后日期?、javascript – 根据质量和弹跳系数计算球与球碰撞的速度和方向的相关知识,请在本站进行查询。
对于想了解为什么在Windows和Solaris上都可以将-Xmx设置为大于计算机上物理和虚拟内存的值?的读者,本文将提供新的信息,并且为您提供关于java – 为什么我能够在Windows和Solaris上将-Xmx设置为大于物理和虚拟内存的值?、Linux 物理内存和虚拟内存设置 (zt)、Linux-物理内存和虚拟内存、win11虚拟内存如何设置 Windows11设置虚拟内存的步骤方法的有价值信息。
本文目录一览:- 为什么在Windows和Solaris上都可以将-Xmx设置为大于计算机上物理和虚拟内存的值?
- java – 为什么我能够在Windows和Solaris上将-Xmx设置为大于物理和虚拟内存的值?
- Linux 物理内存和虚拟内存设置 (zt)
- Linux-物理内存和虚拟内存
- win11虚拟内存如何设置 Windows11设置虚拟内存的步骤方法

为什么在Windows和Solaris上都可以将-Xmx设置为大于计算机上物理和虚拟内存的值?
在具有12GB RAM和33GB虚拟内存的64位Windows计算机上(每个任务管理器),我能够以不可能的-
Xmx设置3.5TB运行Java(1.6.0_03-b05),但在35TB时失败。它工作时和失败时的逻辑是什么?35TB的错误似乎暗示它正在尝试在启动时保留空间。为什么对-
Xmx(而不是-Xms)这样做?
C:\ temp> java -Xmx3500g ostest os.arch = amd64 13781729280字节RAMC:\ temp> java -Xmx35000g ostest VM初始化期间发生错误 无法为对象堆保留足够的空间 无法创建Java虚拟机。在Solaris(4GB RAM,Java 1.5.0_16)上,我几乎放弃了1 PB的设置-Xmx设置的上限。我不了解何时在-Xmx设置上出错的逻辑。
devsun1.mgo:/ export / home / mgo> java -d64 -Xmx1000000g ostestos.arch = sparcv94294967296字节RAM答案1
小编典典至少对于Windows的Sun 64位VM 1.6.0_17,ObjectStartArray ::
initialize将在VM启动时为每512字节堆分配1字节。启动具有35TB堆的VM将导致VM立即分配70GB,因此在您的系统上将失败。
Sun的32位VM(因此我假设是64位VM)在计算最大堆时未考虑可用的物理内存,而仅受Windows和Linux上2GB可寻址内存或Solaris上4GB或在启动时可能无法为管理区域分配足够的内存。
如果考虑一下,对照可用的物理内存检查最大堆值的合理性就没有多大意义。X GB的物理内存并不意味着在需要时VM可以使用X
GB,它也可以被其他进程使用,因此VM需要一种方法来应对这样的情况:需要更多的堆而不是从操作系统。如果VM没有损坏,则无法从OS分配内存时,将引发OutOfMemoryErrors,就像已达到最大堆大小一样。

java – 为什么我能够在Windows和Solaris上将-Xmx设置为大于物理和虚拟内存的值?
C:\temp>java -Xmx3500g ostest os.arch=amd64 13781729280 Bytes RAM C:\temp>java -Xmx35000g ostest Error occurred during initialization of VM Could not reserve enough space for object heap Could not create the Java virtual machine.
在Solaris(4GB RAM,Java 1.5.0_16)上,我几乎放弃了1 PB,我可以设置-Xmx的高度.我不明白它何时会在-Xmx设置上出错的逻辑.
devsun1.mgo:/export/home/mgo> java -d64 -Xmx1000000g ostest os.arch=sparcv9 4294967296 Bytes RAM
解决方法
在计算最大堆时,Sun的32位VM(以及我认为64位VM)没有考虑可用的物理内存,但仅限于Windows和Linux上的2GB可寻址内存或Solaris上的4GB或可能无法在启动时为管理区域分配足够的内存.
如果你考虑一下,检查最大堆值对可用物理内存的完整性没有多大意义. X GB的物理内存并不意味着X GB在需要时可用于VM,它也可以被其他进程使用,因此VM需要一种方法来应对需要比从无论如何操作系统.如果VM未中断,则如果无法从OS分配内存,则抛出OutOfMemoryErrors,就像已达到最大堆大小一样.
")
Linux 物理内存和虚拟内存设置 (zt)

- 使用内核源代码中的定义
PHYS_OFFSET:系统内存的物理起始地址,板级相关,在 include/asm-arm/arch-xxx/memory.h 中
PAGE_OFFSET:系统内存的虚拟起始地址,体系结构相关,为 0xC0000000,在 include/asm-arm/memory.h 中
MEM_SIZE:系统内存大小,如果板级(include/asm-arm/arch-xxx/xxx.h)没有指定,则使用体系结构的缺省值 16M(arch/arm/kernel/setup.c)
在没有内存命令从内核命令行(cmdline)传入的情况下 ,setup_arch () 函数 (arch/arm/kernel/setup.c 文件中) 会使用 PHYS_OFFSET 和 MEM_SIZE 指定为系统内存并且映射到 PAGE_OFFSET。 - 通过 fixup 函数设置
通过 fixup_xxx () 函数(arch/arm/mach-xxx/arch.c)设置内存的起始地址和大小,映射到 PAGE_OFFSET,此项设置会覆盖 (1) 的设置 - 通过内核命令行传入
如果内核命令行中有系统内存相关的命令(mem=XXXM [@YYY])则会覆盖掉 (1),(2) 中所介绍的映射而将 XXX 作为内存大小,YYY 作为内存物理起始地址(如果有)映射到 PAGE_OFFSET

Linux-物理内存和虚拟内存
概述
想必在linux上写过程序的同学都有分析进程占用多少内存的经历,或者被问到这样的问题——你的程序在运行时占用了多少内存(物理内存)?通常我们可以通过top命令查看进程占用了多少内存。这里我们可以看到VIRT、RES和SHR三个重要的指标,他们分别代表什么意思呢?这是本文需要跟大家一起探讨的问题。当然如果更加深入一点,你可能会问进程所占用的那些物理内存都用在了哪些地方?这时候top命令可能不能给到你你所想要的答案了,不过我们可以分析proc文件系统提供的smaps文件,这个文件详尽地列出了当前进程所占用物理内存的使用情况。
关于内存的两个概念
要理解top命令关于内存使用情况的输出,我们必须首先搞清楚虚拟内存(Virtual Memory)和驻留内存(Resident Memory)两个概念。
虚拟内存
首先需要强调的是虚拟内存不同于物理内存,虽然两者都包含内存字眼但是它们属于两个不同层面的概念。进程占用虚拟内存空间大并非意味着程序的物理内存也一定占用很大。虚拟内存是操作系统内核为了对进程地址空间进行管理(process address space management)而精心设计的一个逻辑意义上的内存空间概念。我们程序中的指针其实都是这个虚拟内存空间中的地址。比如我们在写完一段C++程序之后都需要采用g++进行编译,这时候编译器采用的地址其实就是虚拟内存空间的地址。因为这时候程序还没有运行,何谈物理内存空间地址?凡是程序运行过程中可能需要用到的指令或者数据都必须在虚拟内存空间中。既然说虚拟内存是一个逻辑意义上(假象的)的内存空间,为了能够让程序在物理机器上运行,那么必须有一套机制可以让这些假象的虚拟内存空间映射到物理内存空间(实实在在的RAM内存条上的空间)。这其实就是操作系统中页映射表(page table)所做的事情了。内核会为系统中每一个进程维护一份相互独立的页映射表。。页映射表的基本原理是将程序运行过程中需要访问的一段虚拟内存空间通过页映射表映射到一段物理内存空间上,这样CPU访问对应虚拟内存地址的时候就可以通过这种查找页映射表的机制访问物理内存上的某个对应的地址。“页(page)”是虚拟内存空间向物理内存空间映射的基本单元。
下图1演示了虚拟内存空间和物理内存空间的相互关系,它们通过Page Table关联起来。其中虚拟内存空间中着色的部分分别被映射到物理内存空间对应相同着色的部分。而虚拟内存空间中灰色的部分表示在物理内存空间中没有与之对应的部分,也就是说灰色部分没有被映射到物理内存空间中。这么做也是本着“按需映射”的指导思想,因为虚拟内存空间很大,可能其中很多部分在一次程序运行过程中根本不需要访问,所以也就没有必要将虚拟内存空间中的这些部分映射到物理内存空间上。
到这里为止已经基本阐述了什么是虚拟内存了。总结一下就是,虚拟内存是一个假象的内存空间,在程序运行过程中虚拟内存空间中需要被访问的部分会被映射到物理内存空间中。虚拟内存空间大只能表示程序运行过程中可访问的空间比较大,不代表物理内存空间占用也大。

(详细:https://blog.csdn.net/zl1zl2zl3/article/details/85536305)
-
驻留内存
驻留内存,顾名思义是指那些被映射到进程虚拟内存空间的物理内存。上图1中,在系统物理内存空间中被着色的部分都是驻留内存。比如,A1、A2、A3和A4是进程A的驻留内存;B1、B2和B3是进程B的驻留内存。进程的驻留内存就是进程实实在在占用的物理内存。一般我们所讲的进程占用了多少内存,其实就是说的占用了多少驻留内存而不是多少虚拟内存。因为虚拟内存大并不意味着占用的物理内存大。
关于虚拟内存和驻留内存这两个概念我们说到这里。下面一部分我们来看看top命令中VIRT、RES和SHR分别代表什么意思。
top命令中VIRT、RES和SHR的含义
搞清楚了虚拟内存的概念之后解释VIRT的含义就很简单了。VIRT表示的是进程虚拟内存空间大小。对应到图1中的进程A来说就是A1、A2、A3、A4以及灰色部分所有空间的总和。也就是说VIRT包含了在已经映射到物理内存空间的部分和尚未映射到物理内存空间的部分总和。
RES的含义是指进程虚拟内存空间中已经映射到物理内存空间的那部分的大小。对应到图1中的进程A来说就是A1、A2、A3以及A4几个部分空间的总和。所以说,看进程在运行过程中占用了多少内存应该看RES的值而不是VIRT的值。
最后来看看SHR所表示的含义。SHR是share(共享)的缩写,它表示的是进程占用的共享内存大小。在上图1中我们看到进程A虚拟内存空间中的A4和进程B虚拟内存空间中的B3都映射到了物理内存空间的A4/B3部分。咋一看很奇怪。为什么会出现这样的情况呢?其实我们写的程序会依赖于很多外部的动态库(.so),比如libc.so、libld.so等等。这些动态库在内存中仅仅会保存/映射一份,如果某个进程运行时需要这个动态库,那么动态加载器会将这块内存映射到对应进程的虚拟内存空间中。多个进展之间通过共享内存的方式相互通信也会出现这样的情况。这么一来,就会出现不同进程的虚拟内存空间会映射到相同的物理内存空间。这部分物理内存空间其实是被多个进程所共享的,所以我们将他们称为共享内存,用SHR来表示。某个进程占用的内存除了和别的进程共享的内存之外就是自己的独占内存了。所以要计算进程独占内存的大小只要用RES的值减去SHR值即可。
进程的smaps文件
通过top命令我们已经能看出进程的虚拟空间大小(VIRT)、占用的物理内存(RES)以及和其他进程共享的内存(SHR)。但是仅此而已,如果我想知道如下问题:
- 进程的虚拟内存空间的分布情况,比如heap占用了多少空间、文件映射(mmap)占用了多少空间、stack占用了多少空间?
- 进程是否有被交换到swap空间的内存,如果有,被交换出去的大小?
- mmap方式打开的数据文件有多少页在内存中是脏页(dirty page)没有被写回到磁盘的?
- mmap方式打开的数据文件当前有多少页面已经在内存中,有多少页面还在磁盘中没有加载到page cahe中?
- 等等
以上这些问题都无法通过top命令给出答案,但是有时候这些问题正是我们在对程序进行性能瓶颈分析和优化时所需要回答的问题。所幸的是,世界上解决问题的方法总比问题本身要多得多。linux通过proc文件系统为每个进程都提供了一个smaps文件,通过分析该文件我们就可以一一回答以上提出的问题。
在smaps文件中,每一条记录(如下图2所示)表示进程虚拟内存空间中一块连续的区域。其中第一行从左到右依次表示地址范围、权限标识、映射文件偏移、设备号、inode、文件路径。详细解释可以参见understanding-linux-proc-id-maps。
接下来8个字段的含义分别如下:
- Size:表示该映射区域在虚拟内存空间中的大小。
- Rss:表示该映射区域当前在物理内存中占用了多少空间
- Shared_Clean:和其他进程共享的未被改写的page的大小
- Shared_Dirty: 和其他进程共享的被改写的page的大小
- Private_Clean:未被改写的私有页面的大小。
- Private_Dirty: 已被改写的私有页面的大小。
- Swap:表示非mmap内存(也叫anonymous memory,比如malloc动态分配出来的内存)由于物理内存不足被swap到交换空间的大小。
- Pss:该虚拟内存区域平摊计算后使用的物理内存大小(有些内存会和其他进程共享,例如mmap进来的)。比如该区域所映射的物理内存部分同时也被另一个进程映射了,且该部分物理内存的大小为1000KB,那么该进程分摊其中一半的内存,即Pss=500KB


win11虚拟内存如何设置 Windows11设置虚拟内存的步骤方法
一般在玩游戏的时候,如果提示内存不足的话我们可以考虑给电脑设置虚拟内存.有网友刚接触win11系统,不知道win11如何设置虚拟内存.下面小编就教下大家win11设置虚拟内存的方法.更多
1.按下Win,或者点击任务栏上的开始图标,然后点击显示的设置.

2.系统设置窗口,右方系统设置下,点击关于(设备规格,改为电脑规格);

3.系统-关于,找到相关链接中的高级系统设置;

4.在系统属性窗口、高级选项卡、点击性能(视觉效果、处理器计划、内存使用、虚拟内存);

5.性能选项窗口,高级选项卡下,找到虚拟内存,点击下面的更改,即可设置虚拟内存(虚拟内存通常设为物理内存的1.5倍);

没有收到微软推送通知?看这里,在线安装win11,无需顾虑微软升级的推送限制,步骤如下

我们今天的关于为什么在Windows和Solaris上都可以将-Xmx设置为大于计算机上物理和虚拟内存的值?的分享已经告一段落,感谢您的关注,如果您想了解更多关于java – 为什么我能够在Windows和Solaris上将-Xmx设置为大于物理和虚拟内存的值?、Linux 物理内存和虚拟内存设置 (zt)、Linux-物理内存和虚拟内存、win11虚拟内存如何设置 Windows11设置虚拟内存的步骤方法的相关信息,请在本站查询。
本文将介绍Apache Spark需要5到6分钟的时间,即可简单地计算出Cassandra的1条Billon行的详细情况,特别是关于apache spark使用场景的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于Apache Cassandra 0.6 正式版发布、Apache Cassandra 0.6.0 RC1 发布、Apache Cassandra 0.6.6 发布、Apache Cassandra 0.6.8发布的知识。
本文目录一览:- Apache Spark需要5到6分钟的时间,即可简单地计算出Cassandra的1条Billon行(apache spark使用场景)
- Apache Cassandra 0.6 正式版发布
- Apache Cassandra 0.6.0 RC1 发布
- Apache Cassandra 0.6.6 发布
- Apache Cassandra 0.6.8发布
")
Apache Spark需要5到6分钟的时间,即可简单地计算出Cassandra的1条Billon行(apache spark使用场景)
我正在使用Spark
Cassandra连接器。从Cassandra表中获取数据需要5到6分钟。在Spark中,我在日志中看到了许多任务和Executor。原因可能是Spark将流程分为许多任务!
下面是我的代码示例:
public static void main(String[] args) { SparkConf conf = new SparkConf(true).setMaster("local[4]") .setAppName("App_Name") .set("spark.cassandra.connection.host", "127.0.0.1"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<Demo_Bean> empRDD = javaFunctions(sc).cassandraTable("dev", "demo"); System.out.println("Row Count"+empRDD.count());}答案1
小编典典在Google上搜索后,我在最新的spark-cassandra-
connector中喜欢了这个问题。参数spark.cassandra.input.split.size_in_mb Default value是64
MB,在代码中被解释为64个字节。所以尝试 spark.cassandra.input.split.size_in_mb = 64 * 1024 *1024 = 67108864
听到就是一个例子:
public static void main(String[] args) { SparkConf conf = new SparkConf(true).setMaster("local[4]") .setAppName("App_Name") .set("spark.cassandra.connection.host", "127.0.0.1") .set("spark.cassandra.input.split.size_in_mb","67108864"); JavaSparkContext sc = new JavaSparkContext(conf); JavaRDD<Demo_Bean> empRDD = javaFunctions(sc).cassandraTable("dev", "demo"); System.out.println("Row Count"+empRDD.count());}
Apache Cassandra 0.6 正式版发布
Apache Cassandra是一套开源分布式Key-Value存储系统。
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能 是比较简单的事情,只管在群集里面添加节点就可以了。
Apache Cassandra 0.6 版本新特性包括:
1. 支持 Apache Hadoop 分布式文件系统;
2. 集成行数据缓存;
3. 性能进一步得以提升,差不多有30%的改进;
下载 Apache Cassandra 0.6 正式版

Apache Cassandra 0.6.0 RC1 发布
Apache Cassandra是一套开源分布式数据库管理系统。它最初 由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。
主要特性:
- 分布式
- 基于column的结构化
- 高伸展性
Cassandra的主要特点就是它不是一个数据库,而是由一堆数据库节点共同构成的一个分布式网络服务,对Cassandra 的一个写操作,会被复制到其他节点上去,对Cassandra的读操作,也会被路由到某个节点上面去读取。对于一个Cassandra群集来说,扩展性能 是比较简单的事情,只管在群集里面添加节点就可以了。
该版本与 0.6.0 Beta3 相比较,改进如下:
* JMX drain to flush memtables and run through commit log (CASSANDRA-880)
* Bootstrapping can skip ranges under the right conditions (CASSANDRA-902)
* fix merging row versions in range_slice for CL > ONE (CASSANDRA-884)
* default write ConsistencyLeven chaned from ZERO to ONE
* fix for index entries spanning mmap buffer boundaries (CASSANDRA-857)
* use lexical comparison if time part of TimeUUIDs are the same (CASSANDRA-907)
* bound read, mutation, and response stages to fix possible OOM during log replay (CASSANDRA-885)
* Use microseconds-since-epoch (UTC) in cli, instead of milliseconds
* Treat batch_mutate Deletion with null supercolumn as "apply this predicate to top level supercolumns" (CASSANDRA-834)
* Streaming destination nodes do not update their JMX status (CASSANDRA-916)
* Fix internal RPC timeout calculation (CASSANDRA-911)
* Added Pig loadfunc to contrib/pig (CASSANDRA-910)
下载地址:

Apache Cassandra 0.6.6 发布
Apache Cassandra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。
主要特性:
- 分布式
- 基于column的结构化
- 高伸展性
Apache Cassandra 0.6.6 版本的改进内容请看 CHANGES。
另外 Apache Cassandra 0.7.0 Beta2 也已发布。
下载 Apache Cassandra 0.6.6

Apache Cassandra 0.6.8发布
0.6.8 更新内容:
* Update windows .bat files to work outside of main Cassandra directory (CASSANDRA-1713)
* fix read repair regression from 0.6.7 (CASSANDRA-1727)
* more-efficient read repair (CASSANDRA-1719)
Apache Cassandra是一套开源分布式Key-Value存储系统。它最初由Facebook开发,用于储存特别大的数据。Facebook目前在使用此系统。
主要特性:
- 分布式
- 基于column的结构化
- 高伸展性
关于Apache Spark需要5到6分钟的时间,即可简单地计算出Cassandra的1条Billon行和apache spark使用场景的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Apache Cassandra 0.6 正式版发布、Apache Cassandra 0.6.0 RC1 发布、Apache Cassandra 0.6.6 发布、Apache Cassandra 0.6.8发布的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

