在本文中,我们将给您介绍关于使用计算图搭建灵活的推荐系统的详细内容,并且为您解答计算图模型的相关问题,此外,我们还将为您提供关于C++函数指针与Qt框架:搭建灵活的GUI应用、C++中的推荐系统技术、
在本文中,我们将给您介绍关于使用计算图搭建灵活的推荐系统的详细内容,并且为您解答计算图模型的相关问题,此外,我们还将为您提供关于C++ 函数指针与 Qt 框架:搭建灵活的 GUI 应用、C++中的推荐系统技术、Mahout的推荐系统、RecSim 可配置的推荐系统仿真平台 使用指南的知识。
本文目录一览:")
使用计算图搭建灵活的推荐系统(计算图模型)
在上一篇《认识推荐系统》中,粗略地讲了讲推荐系统地架构,从召回到排序再到重排序,这三个东西是非常灵活多变的。比如,召回来源的个数可以变,每个找回来源召回的 Item 数量可以变,排序算法可以变,重排序规则也可以变,反正比齐天大圣厉害,不止七十二变。
那我们程序员怎么办,每天都改代码然后上线吗?在此介绍一个解决方案,用计算图来描述你的召回、排序、重排序,做到每次仅需要改一改配置,新的流程就可以上线。
什么是计算图
计算图,它是一个图,并且是一个 DAG (有向无环图)。先说说这个有向无环图,这在离散数学里教过。这种图的边有方向,这就是有向。并且从图中任意一点开始走,都走不会原来的点,这就是无环。下面是一张从 Wiki 上借用的图。

那么在计算图中,每个节点和边都代表着什么呢?比较抽象的来说,每个节点就是一个处理流程,节点与节点之间流动的是信息。
具体来说,召回可以是其中的一个节点,比如召回热门数据,因为热门数据一般已经建好了索引存储在了类似于 Redis 的内存数据库中,所以它并不需要输入,输出则是一堆热门的 Item。不过有一些召回节点是需要输入的,比如基于 Item 的协同过滤方法,你需要将这个 User 的历史交互过的 Item 作为输入,才能获得召回的 Item。而拿取 User 的历史交互 Item 信息,这又可以是一个节点,它没有输入,输出则是 User 的历史交互 Item 信息。
排序也可以是其中的一个节点。将所有召回的 Item,经过去重和过滤后(去重和过滤也是图中的节点),输入排序的节点。根据你排序的方法不同,你可能还需要其它的输入,比如说这些召回的 Item 的信息(包括 Item 的点击数、展现数、类别等等),当前请求的 User 信息(User 喜欢点什么样 Item 的统计信息),一些历史信息等等。这些东西可以通过预计算存入内存数据库中,然后直接在定义一些节点来获取即可。而排序节点的输出就是输入的 Item,不过这些 Item 都被打上了一个分数,用以表示 User 对它们的喜好程度。
重排序和排序基本相同,不过它是一组节点。比如有的节点负责把置顶信息插入结果,有的节点给 Item 的排序分数进行加权降权再 Sort。下面就是一张实际推荐系统的计算图。

为什么要用计算图
灵活,可以随意添加删除处理过程,你只需要定义好节点即可。
方便快捷,可以通过配置来描述推荐的整体流程,降低了使用难度。
只要你的节点定义地足够 DRY,你可以适应任何变化,或者说面对变化时能更加从容。因为你只需要在代码中添加一些新的节点就可以了。
怎么实现计算图
首先,你要明确一些实体,计算图中的实体就是节点和图。
计算图要完成的工作有,读取配置,执行节点,执行图并返回结果,大概就是这三个接口;而节点则是需要指明其输入输出,也就是得有两个成员变量来表示这个,同时应该提供一个接口来执行。
下面展示一个 YAML 表示的计算图配置,就是上面流程图所展现的流程,作为实现的参考。
graph:
hot:
user_history:
item_CF:
- user_history
deep_learning:
- user_history
dedupe:
- hot
- item_CF
- deep_learning
recomended_history:
filter:
- dedupe
- recomended_history
gbdt_rank:
- filter
rerank_top:
- gbdt_rank
rerank_weight:
- rerank_top
end:
- rerank_weight
nodes:
hot:
func: hot
limit: 100
# ...
# ...可以看出,配置里在 graph 中指定了图的依赖关系,然后在 nodes 里指定图中每个节点的函数以及特定的参数。这样,一张完整的计算图基本定义完成了。
结语
感谢您的阅读~
如有问题讨论,欢迎留言或者加公众号



C++ 函数指针与 Qt 框架:搭建灵活的 GUI 应用
函数指针在

C++ 函数指针与 Qt 框架:构建灵活的 GUI 应用
概述
函数指针是 C++ 中强大的工具,它允许您将函数作为变量传递。这在 GUI 编程中非常有用,因为您可以灵活地将不同的函数分配给事件处理程序。Qt 框架广泛使用函数指针,为构建动态且可定制的 GUI 提供了极大的灵活性。
函数指针的基础知识
函数指针是指向函数的指针。语法如下:
returnType (*function_pointer_name)(param_list);
其中:
立即学习“C++免费学习笔记(深入)”;
点击下载“修复打印机驱动工具”;
- returnType 是函数返回的值的类型。
- function_pointer_name 是函数指针的名称。
- param_list 是函数参数的类型列表。
要获取某个函数的指针,可以使用类型转换运算符 &:
returnType (*function_pointer_name)(param_list) = &function_name;
在 Qt 中使用函数指针
Qt 框架提供了一个方便的方法来使用函数指针:信号和槽。信号是在对象中触发的事件,而槽是响应信号的函数。您可以将函数指针分配给槽,以指定当信号触发时执行的函数。
例如,以下是将在单击按钮时打印文本的槽函数:
void printText()
{
qDebug() << "Button clicked!";
}要将槽函数分配给按钮的 clicked 信号,请使用 connect() 函数:
QObject::connect(button, SIGNAL(clicked()), &printText, SLOT());
实战案例
下面是使用函数指针和 Qt 框架构建 GUI 应用的实战案例:
#include <QtWidgets>
int main(int argc, char **argv)
{
QApplication a(argc, argv);
// 创建一个按钮
QPushButton button("Print Text");
// 将函数指针分配给 clicked 信号
QObject::connect(&button, SIGNAL(clicked()), &printText, SLOT());
// 显示按钮
button.show();
// 运行事件循环
return a.exec();
}说明:
- 此程序创建了一个按钮,并将在单击按钮时打印文本。
- QObject::connect() 函数将 printText 函数指针分配给按钮的 clicked 信号。
- 应用程序事件循环将处理
结论
通过结合函数指针和 Qt 框架,您可以构建灵活且可定制的 GUI 应用。使用函数指针,您可以根据需要动态分配不同的函数给事件处理程序。这对于创建交互式且响应迅速的界面至关重要。
以上就是C++ 函数指针与 Qt 框架:搭建灵活的 GUI 应用的详细内容,更多请关注php中文网其它相关文章!

C++中的推荐系统技术

推荐系统技术在今天的社会中已经成为了一个不可或缺的部分,它通过分析用户行为和需求,为用户推荐更加符合他们兴趣和需求的内容。在这些技术中,C++是最流行和广泛使用的一种编程语言,因为它可以提供更好的性能和灵活性。在本文中,我们将探讨C++中的推荐系统技术及其实现方法。
首先,推荐系统的基础是数据处理和分析技术,这些技术在C++中的应用非常广泛。例如,可以使用C++的STL(标准模板库)来处理大量的数据,并使用STL容器来处理简单和复杂的数据结构。此外,可以使用C++的算法库来在大量数据中查找和比较数据,以便更好地了解用户的兴趣和需求。此外,特别是在大规模数据集的情况下,使用一些常见的算法如K均值聚类、奇异值分解(SVD)等,来对用户数据和物品数据进行建模和挖掘,以便更好地了解用户的兴趣和需求。
其次,C++中可以使用模板来实现推荐算法的算法设计和细节实现。例如,可以使用模板类和模板函数来实现一些基本的推荐算法,如协同过滤(Collaborative Filtering)和基于内容(Content-Based)的推荐算法。通过此方法,可以使用模板类型来存储用户和物品的相关数据,并使用模板函数来计算用户对物品的兴趣度得分。此外,在模板设计中,还可以使用CUDA来实现GPU加速,以处理大规模数据集并提高性能。
最后,对于C++开发人员来说,了解一些开源的C++推荐系统库,如LibRec、MyMediaLite、Grouplens等,是必不可少的。这些库可以提供基于C++的推荐算法的实现和调用代码,其中包括使用协同过滤、矩阵分解等算法来实现推荐系统。开发人员可以根据自己的需求和数据集选择最适合自己的库,并将其集成到自己的应用程序中。
立即学习“C++免费学习笔记(深入)”;
总之,在C++中实现推荐系统需要掌握先进的数据分析和处理技术、了解模板设计以及熟悉开源库的使用。本文讨论的是一些常见的技术和方法,当然,还有更多的解决方案可以考虑,需要根据自己的需求和应用场景进行选择。无论如何,C++作为一种高性能、灵活和可扩展的编程语言,可以为推荐系统实现提供强大的支持。
以上就是C++中的推荐系统技术的详细内容,更多请关注php中文网其它相关文章!

Mahout的推荐系统
Mahout的推荐系统
- 什么是推荐系统
- 为什使用推荐系统
- 推荐系统中的算法
什么是推荐系统
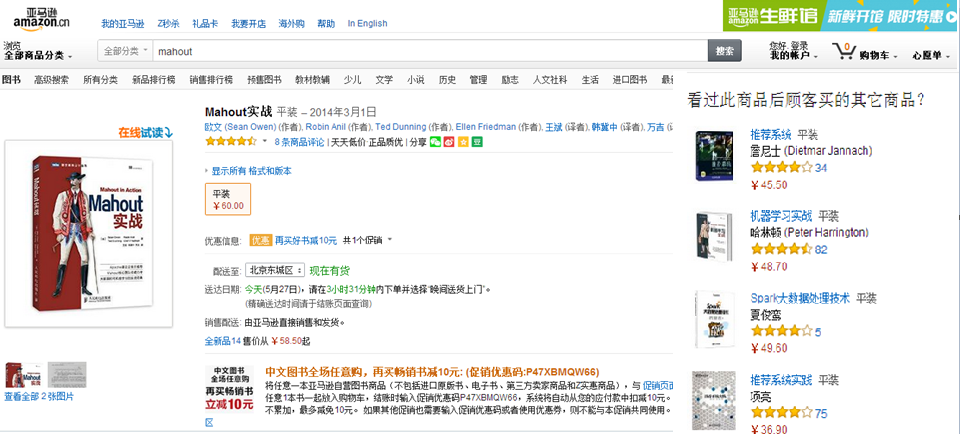
为什么使用推荐系统?
促进厂商商品销售,帮助用户找到想要的商品
推荐系统无处不在,体现在生活的各个方面
图书推荐;QQ好友推荐;优酷,爱奇艺的视频推荐;豆瓣的音乐推荐;大从点评的餐饮推荐;世纪佳缘的相亲推荐;智联招聘的职业推荐。
亚马逊的推荐系统深入到网站的各类商品,为亚马逊带来了至少30%的销售额。
推荐引擎工作原理
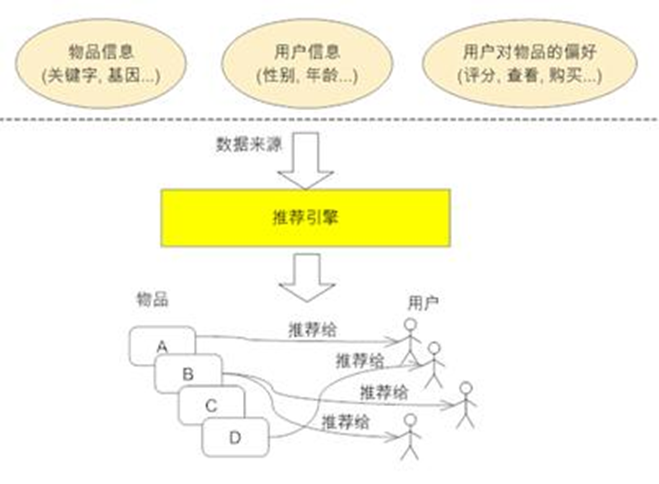
推荐系统主要向用户推荐可能感兴趣商品的系统。系统会给用户以TopN推荐给用户商品。
系统主要使用的数据是用户的历史商品购买记录,这部分数据存放在公司的数据库中。
Mahout的推荐系统整体架构
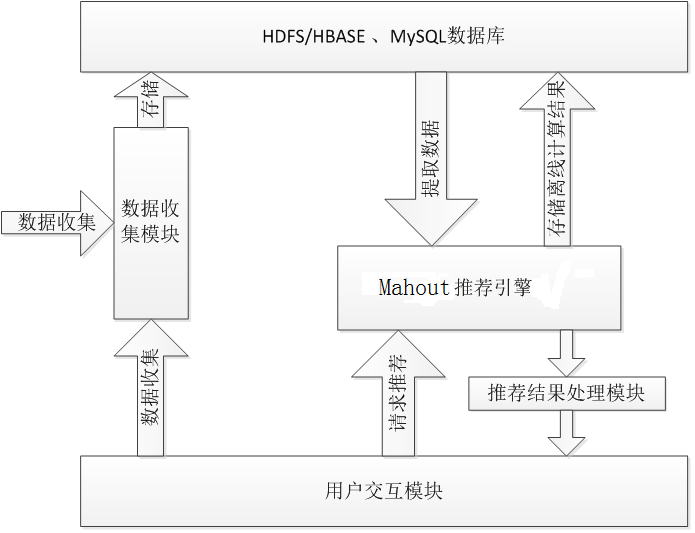
推荐系统的实现
推荐系统中的算法
- Apriori算法
- 基于用户
- 基于内容
- 基于协同过滤(用的最多)
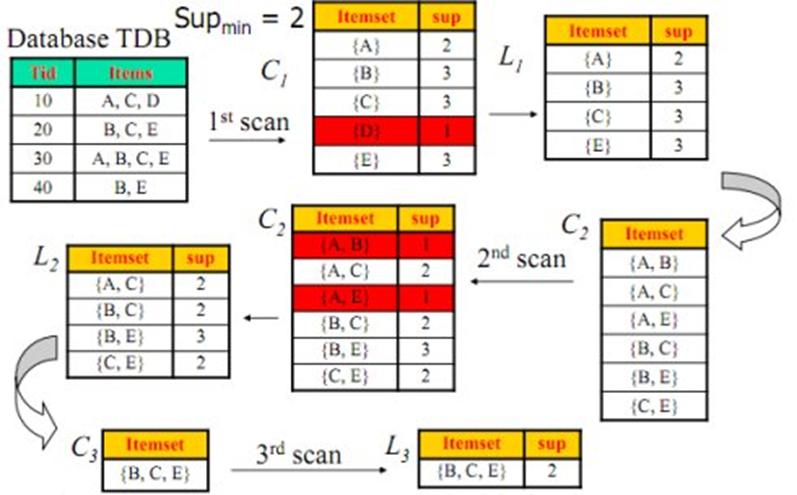
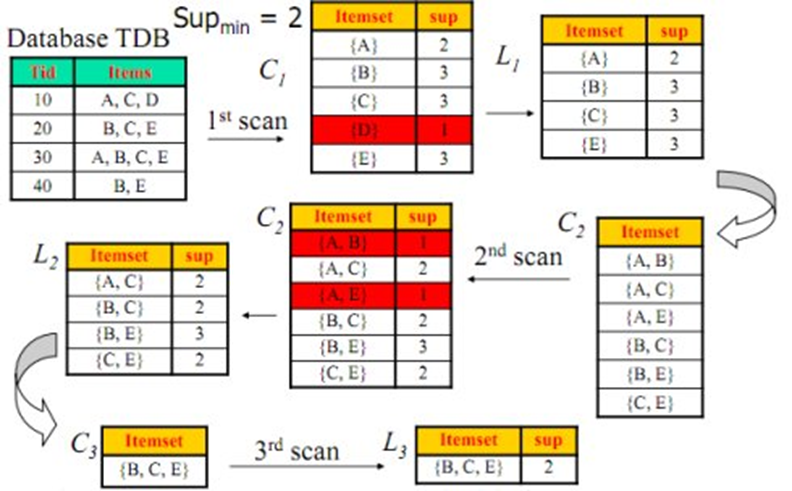
Apriori算法-购物篮分析(关联分析)
“啤酒与尿布”的故事产生于20世纪90年代的美国沃尔玛超市。沃尔玛的超市管理人员分析销售数据时发现了一个令人难于理解的现象:在某些特定的情况下,“啤酒”与“尿布”两件看上去毫无关系的商品会经常出现在同一个购物篮中,这种独特的销售现象引起了管理人员的注意,经过后续调查发现。
原来,美国的妇女通常在家照顾孩子,所以她们经常会嘱咐丈夫在下班回家的路上为孩子买尿布,而丈夫在买尿布的同时又会顺手购买自己爱喝的啤酒。这样就会出现啤酒与尿布这两件看上去不相干的商品经常会出现在同一个购物篮的现象。
这个发现为商家带来了大量的利润,但是如何从浩如烟海却又杂乱无章的数据中,发现啤酒和尿布销售之间的联系呢?
Apriori算法的产生
1993年美国学者Agrawal提出通过分析购物篮中的商品集合,从而找出商品之间关联关系的关联算法,并根据商品之间的关系,找出客户的购买行为。Agrawal从数学及计算机算法角度提出了商品关联关系的计算方法——Apriori算法。
沃尔玛从上个世纪90年代尝试将Aprior算 法引入到POS机数据分析中,并获得了成功,于是产生了“啤酒与尿布”的故事。
Apriori算法
如何寻找?
在历史购物记录中,一些商品总是在一起购买。但人看上去不是那么的直观的,而是隐蔽的。让计算机做这事,设法计算法让计算机自动去找,找到这样的模式(规律)。
目标:寻找那些总是一起出现商品。
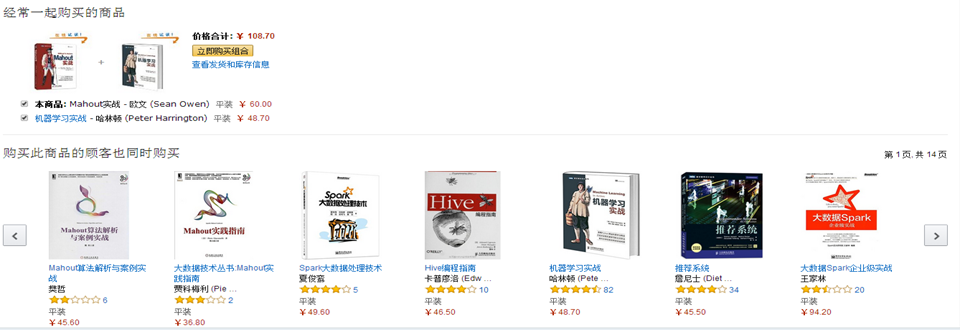
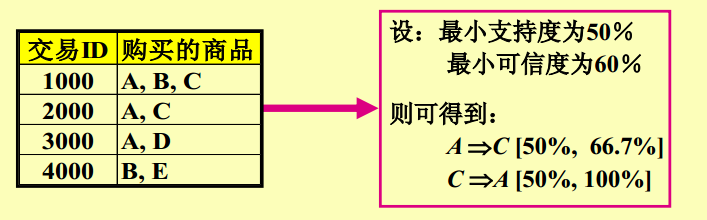
mahout实战—>机器学习实战
《mahout实战》与《机器学习实战》一起购买的记录数占所有商品记录总数的比例——支持度(整体)
买了《mahout实战》与《机器学习实战》一起购买的记录数占所有购买《mahout实战》记录数的比例——置信度(局部)
需要达到一定的阈值
支持度、置信度越大,商品出现一起购买的次数就越多,可信度就越大。
支持度:在所有的商品记录中有2%量是购买《mahout实战》与《机器学习实战》
置信度:买《mahout实战》的顾客中有60%的顾客购买了《机器学习实战》
作用:找到商品购买记录中反复一起出现的商品,帮能助营销人员做更好的策略,帮助顾客方便购买。
策略:
1、同时购买的商品放一起
2、同时购买的商品放两端
支持度、置信度转化为数学语言进行计算:
A表示《mahout实战》 B表示《机器学习实战》
support(A->B) = P(AB) (《mahout实战》和《机器学习实战》一起买占总的购买记录的比例)
confidence(A->B) = P(B|A) (购买了《mahout实战》后,买《机器学习实战》占的比例)
项集:项的集合称为项集,即商品的组合。
k项集:k种商品的组合,不关心商品件数,仅商品的种类。
项集频率:商品的购买记录数,简称为项集频率,支持度计数。
注意,定义项集的支持度有时称为相对支持度,而出现的频率(比例)称为绝对支持度。
频繁项集:如果项集的相对支持度满足给定的最小支持度阈值,则该项集是频繁项集。
强关联规则:满足给定支持度和置信度阈值的关联规则
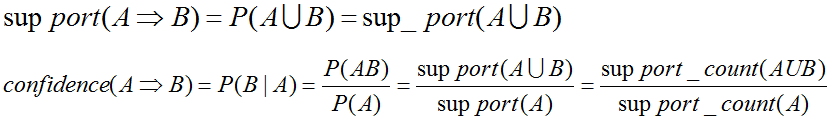
A=>B的置信度可以由A于A U B的支持度计数计算推出。满足最小支持度计数的项集为频繁项集。
找关联规则问题,归结为找频繁项集。
注意:A=>B,B=>A的不同
明确问题
1、找出总是在一起出现的商品组合
2、提出衡量标准支持度、置信度(达到一定的阈值)
3、给出支持度、置信度直观计算方法
4、得出在计算方法中起决定因素的是频繁项集
5、由频繁项集轻松找到强关联规则
找关联规则--------->找频繁项集
步骤:
1. 找出所有的频繁项集;这个项集出现的次数至少与要求的最小计数一样。如在100次购买记录中,至少一起出现30次。
2. 由频繁项集产生强关联规则;这些关联规则满足最小支持度与最小置信度。
Apriori算法
先验性质:频繁项集的所有非空子集也一定是频繁的。
逆否命题:若一个项集是非频繁的,则它的任何超集也是非频繁的
Apriori挑战
挑战
多次数据库扫描
巨大数量的候补项集
繁琐的支持度计算
改善Apriori: 基本想法
减少扫描数据库的次数
减少候选项集的数量
简化候选项集的支持度计算
FPGROWTH算法(有名)
基于用户的推荐技术
基于内容(物品)的推荐技术
协同过滤推荐技术
协同
指协调两个或者两个以上的不同资源或者个体,协同一致地完成某一目标的过程或能力。
原理
协同过滤技术是基于用户对项目的历史偏好,发掘项目之间的相关性,或者是发掘用户间的相关性,根据这些相关性进行推荐。
类别
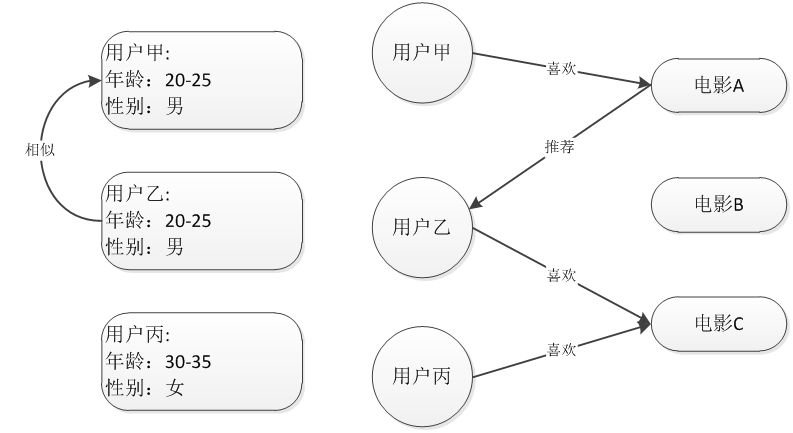
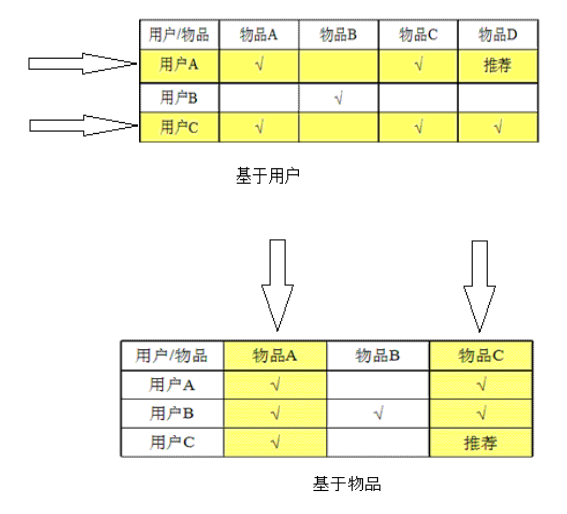
基于用户的协同过滤推荐 Uesr_CF
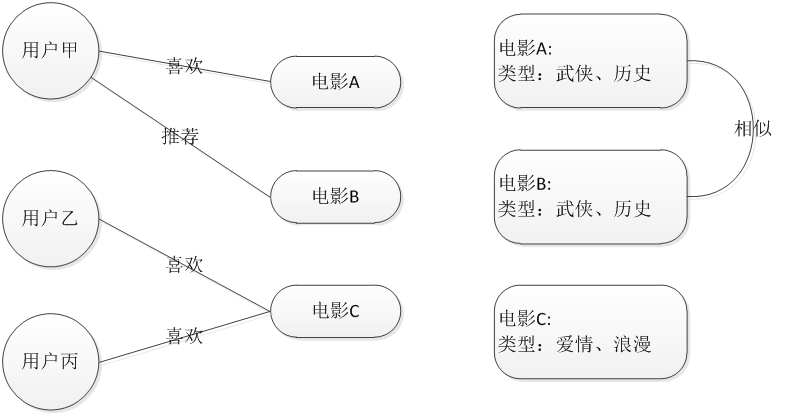
基于物品的协同过滤推荐 Item_CF
基于用户的协同过滤推荐技术
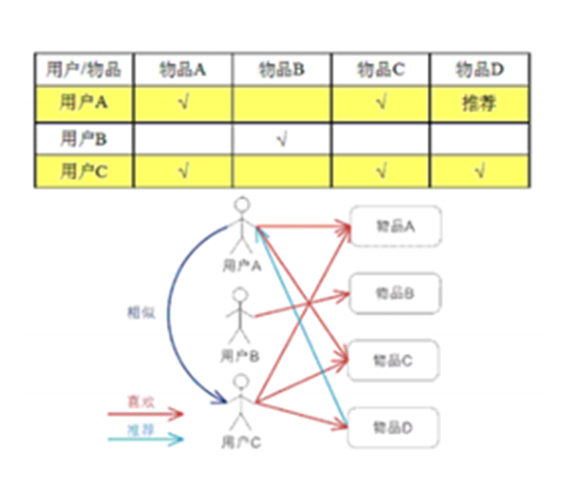
基于物品的协同过滤推荐技术(评分)
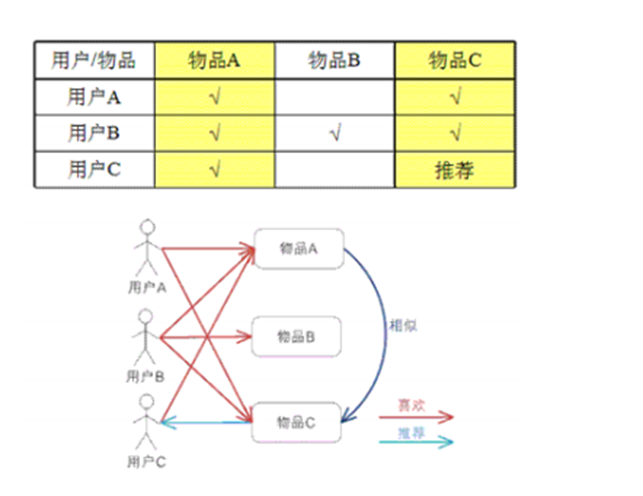
实现协同过滤的步骤
1、收集用户偏好
2、找到相似的用户或物品
3、计算推荐
收集用户偏好的方法(评分)
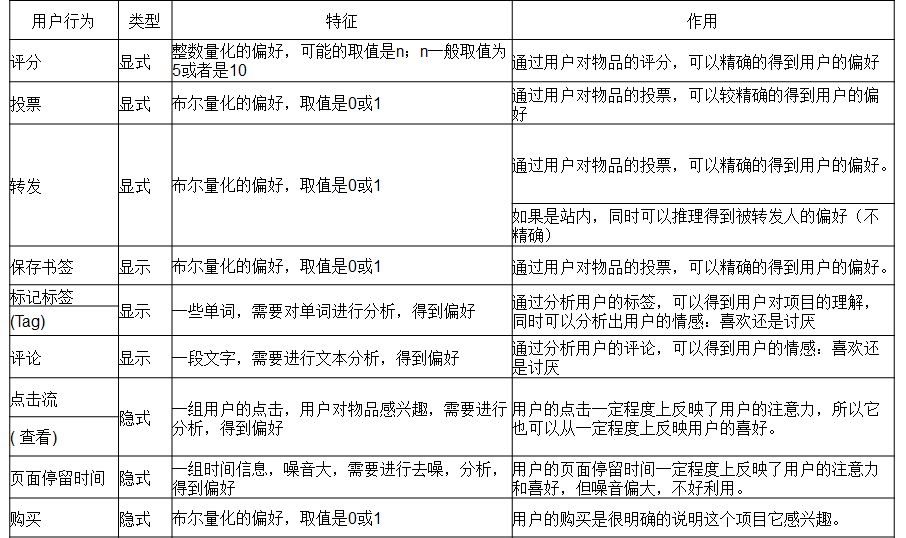
每行3个字段,依次是用户ID,物品ID,用户对物品的评分(0-5分,每0.5分为一个评分点!)

计算相似性
用户,物品,评分
什么人喜欢什么,以及程度
相似性的度量
欧氏距离相似度
皮尔森相似度
余弦相似度
秩相关系数相似度
曼哈顿距离相似度
对数似然相似度
欧氏距离相似度计算

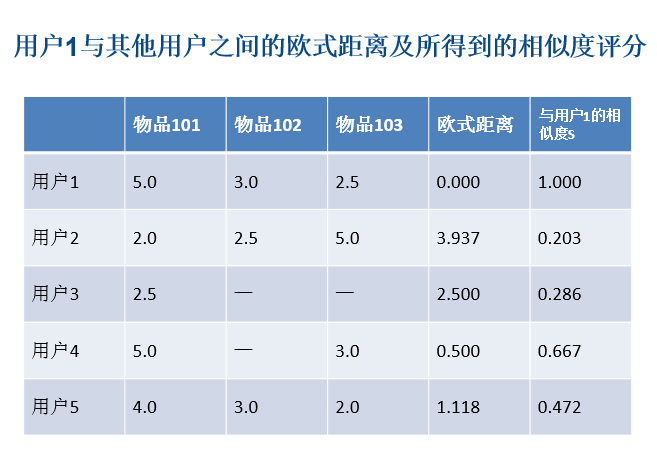
协同过滤推荐,一般要做好以下几个步骤:
1)收集用户偏好
通过用户的行为诸如评分,投票,转发,保存,书签,标记,评论,点击流,页面停留时间,是否购买等获得。所有这些信息都数字化,用一个二维矩阵表示出来。
2)数据减噪与归一化操作
用户偏好的二维矩阵,一维是用户列表,另一维是物品列表,值是用户对物品的偏好,一般是 [0,1] 或者 [-1, 1] 的浮点数值。
3)找相似的用户和物品,计算相似用户或相似物品的相似度。
4)根据相似度作为用户、物品的协同过滤推荐。
总结
Apriori
协同过滤

RecSim 可配置的推荐系统仿真平台 使用指南
文章目录
-
- 1. RecSim介绍
- 2. RecSim安装
-
- 2.1. 环境配置
- 2.2. 安装步骤
- 3. 运行RecSim示例
- 4. 自定义RecSim环境
-
- 4.1. 概览
- 4.2. 模拟场景:专业 vs 喜闻乐见
-
- 4.2.1. 记录模型 document
- 4.2.2. 用户模型 user
-
- 4.2.2.1. 用户状态和用户采样器
- 4.2.2.2. 响应模型
- 4.2.2.3. 用户模型
- 4.2.2.4. 与Agent的交互
- 4.2.3. 模拟场景的试运行
- 5. 自定义Agent
-
- 5.1. 观测 Observation
- 5.2. 候选列表 Slate
- 5.3. 搭建Agent
-
- 5.3.1. 简单Agent
- 5.3.2. 层次化Agent结构
-
- 5.3.2.1. ClusterClickStats
- 5.3.2.2. AbstractClickBandit
- 6. RecSim参考文档
1. RecSim介绍
RecSim是一个可配置的推荐系统仿真平台,它通过真实推荐系统的用户数据来构建模拟可控的仿真环境,为推荐系统模型算法的开发、测评以及对比提供了便利的环境。同时,它作为开源系统为研究人员提供了强化学习与推荐系统的交叉研究环境、并支持模型与算法的重用与分享,也为学术界和工业界提供了协作的平台,在无需暴露用户数据和敏感的行业策略的情况下就能进行有效的研究。
2. RecSim安装
2.1. 环境配置
RecSim开发者给出的示例中使用的TensorFlow版本是Tensorflow 1.15.0,然而默认安装的TensorFlow是Tensorflow 2.x,由于这两个版本的TensorFlow差异巨大,因此必须先解决TensorFlow的版本问题才能正常运行示例代码。
这里建议选择先修改TensorFlow版本到Tensorflow 1.15.0,再体验完RecSim的示例代码后再自行升级或换用其他工具。
根据 TensorFlow Windows设置 中的提示,无论是CPU版本还是GPU版本的Tensorflow 1.15.0,都仅适用于Python 3.5-3.7。如果是按照GPU版本,还需要额外注意一下 cuDNN 和 CUDA 的版本:
| 版本 | Python 版本 | 编译器 | 构建工具 | cuDNN | CUDA |
|---|---|---|---|---|---|
| tensorflow-1.15.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 | × | × |
| tensorflow_gpu-1.15.0 | 3.5-3.7 | MSVC 2017 | Bazel 0.26.1 | 7.4 | 10 |
如果自己设备上的Python版本不在Python 3.5-3.7这个范围内,建议使用模拟环境(如Pycharm的venv)或者 重新安装
在确定自己的Python版本之后,并且安装好RecSim后,使用如下代码更改TensorFlow版本(选其中一个安装即可):
pip install tensorflow==1.15.0 # CPU版本
pip install tensorflow_gpu==1.15.0 # GPU版本
博主最终选择的配置如下:
| 工具 | 版本 |
|---|---|
| Python | 3.7 (Pycharm模拟环境) |
| cuDNN | cuDNN v7.4.2, for CUDA 10.0 |
| CUDA | CUDA Toolkit 10.0 |
| tensorflow | tensorflow_gpu 1.15.0 |
2.2. 安装步骤
打开终端,使用如下命令下载安装RecSim:
python -m pip install --upgrade pip
pip install recsim
如果上述命令一直连接不成功,那么可以到 recsim· PyPI 下载recsim-0.2.4.tar.gz,在命令提示符下转到解压后的目录,再输入:
python setup.py install
等待一段时间之后如果显示了如下信息,则说明安装成功:
Successfully built recsim gym
Installing collected packages: gym, google-pasta, gin-config, gast, flatbuffers, astunparse, tensorflow, dopamine-rl, recsim
Successfully installed astunparse-1.6.3 dopamine-rl-3.0.1 flatbuffers-1.12 gast-0.3.3 gin-config-0.4.0 google-pasta-0.2.0 gym-0.18.0 recsim-0.2.4 tensorflow-2.4.0
接着在GitHub上把 google-research/recsim 中的代码下载下来,解压后是一个名为recsim-master 的目录,用常用的编辑器或IDE打开该目录下的 ./recsim-master/recsim-master/recsim目录,这里面是整个RecSim的Python代码。
例如用Pycharm打开./recsim-master/recsim-master/recsim目录后显示如下:

3. 运行RecSim示例
在github下载的RecSim架构自带有以下论文的复现代码:
SlateQ: A Tractable Decomposition for Reinforcement Learning with Recommendation Sets. IJCAI 2019: 2592-2599
找到 main.py ,其内容如下:
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
from absl import app
from absl import flags
import numpy as np
from recsim.agents import full_slate_q_agent
from recsim.environments import interest_evolution
from recsim.simulator import runner_lib
FLAGS = flags.FLAGS
def create_agent(sess, environment, eval_mode, summary_writer=None):
kwargs = {
''observation_space'': environment.observation_space,
''action_space'': environment.action_space,
''summary_writer'': summary_writer,
''eval_mode'': eval_mode,
}
return full_slate_q_agent.FullSlateQAgent(sess, **kwargs)
def main(argv):
if len(argv) > 1:
raise app.UsageError(''Too many command-line arguments.'')
runner_lib.load_gin_configs(FLAGS.gin_files, FLAGS.gin_bindings)
seed = 0
slate_size = 2
np.random.seed(seed)
env_config = {
''num_candidates'': 5,
''slate_size'': slate_size,
''resample_documents'': True,
''seed'': seed,
}
runner = runner_lib.TrainRunner(
base_dir=FLAGS.base_dir,
create_agent_fn=create_agent,
env=interest_evolution.create_environment(env_config),
episode_log_file=FLAGS.episode_log_file,
max_training_steps=50,
num_iterations=10)
runner.run_experiment()
runner = runner_lib.EvalRunner(
base_dir=FLAGS.base_dir,
create_agent_fn=create_agent,
env=interest_evolution.create_environment(env_config),
max_eval_episodes=5,
test_mode=True)
runner.run_experiment()
if __name__ == ''__main__'':
flags.mark_flag_as_required(''base_dir'')
app.run(main)
在终端输入:
# Linux (Windows要把"/"改成"\\")
# base_dir 指定了输出目录
# gin_bindings 指定了数据绑定参数
python main.py --base_dir=./tmp/interest_evolution --gin_bindings=simulator.runner_lib.Runner.max_steps_per_episode=50
等待其训练结束,在终端下找到最后输出的eval_file地址:
I0105 14:22:51.851023 7280 runner_lib.py:483] eval_file: .\\tmp\\interest_evolution\eval_5\returns_500
然后复制eval_file文件的目录,带入到以下终端命令中,例如:
# 注意logdir填写 ./tmp/interest_evolution/eval_5/
# 而不是 ./tmp/interest_evolution/eval_5/returns_500
tensorboard --logdir=./tmp/interest_evolution/eval_5/ --host=127.0.0.1
执行之后会得到一个本地链接,用浏览器打开它
2021-01-05 14:52:00.686903: I tensorflow/stream_executor/platform/default/dso_loader.cc:44] Successfully opened dynamic library cudart64_100.dll
TensorBoard 1.15.0 at http://127.0.0.1:6006/ (Press CTRL+C to quit)
在浏览器地址栏输入http://127.0.0.1:6006/后可以得到如下界面,这就是TensorFlow训练过程的图形化的显示了:

4. 自定义RecSim环境
首先我们来看一下RecSim的架构图,下图中的绿色和蓝色块表示了RecSim中实现的类。本节将解释这些类,以及描述它们通过何种方式聚合在一起。并且通过一些小例子来说明它们的具体组织实现方式。

4.1. 概览
一个RecSim模拟步骤大致可以概括如下:
- 记录(document)数据库为推荐器提供 D D D 个记录的语料库。每个步骤都可以有不同的记录数据集(由采样或某个“候选生成”过程产生),或在整个模拟过程中采用固定的记录数据集。每个记录都由一个特征列表表示。在完全可观察到的情况下,推荐器会观察每个记录拥有的可以影响用户状态和记录选择(以及用户响应的其他方面)的特征,除此之外,大多数场景都包含了一些无法直接观察到的特征。
- 推荐器会观察 D D D 个记录(及其特征)以及用户对最后一个推荐的响应。然后选择(可能是有序的) 其中 k k k 个记录,并将它们呈现给用户。排序可能会影响用户选择或用户状态,因此是否排序以及如何排序取决于我们的模拟目的。
- 用户查看记录候选列表并选择其中一个记录,或不选择任何一个记录。之后用户状态会变化,并且输出一个观察结果,推荐器在下一次迭代时检查该观察结果。观察通常包括关于用户对所选择记录内容的反馈,以及关于用户隐藏状态的潜在线索。通常,用户的状态是不完全可见的。
如果我们仔细看上面的图表,我们会注意到沿着弧线的信息流是无循环的,这意味着RecSim环境是一个动态贝叶斯网络(DBN),其中的各种盒子代表条件概率分布。现在我们将简单模拟一个问题场景并实现它。
4.2. 模拟场景:专业 vs 喜闻乐见
考虑以下场景:我们的语料库元素的特征有两种,分别是专业的记录和喜闻乐见的记录(document)。
喜闻乐见的记录在用户中有很高的参与度,但长期过度参与这些记录会导致用户满意度下降。另一方面,专业的记录在用户中的参与度相对较低,但参与专业的记录会带来长期的满足感。我们将这种记录的属性建模为一个连续特征,称为专业度(Prof),其值设定在 [ 0 , 1 ] [0,1] [0,1]区间内。得分为1的记录是非常专业的,而得分为0的记录是非常让用户喜闻乐见的。
用户的隐藏状态由一个一维的满意度变量组成。每次参与更多的专业的记录时,满意度会增加,反之,参与喜闻乐见的记录时会降低满意度。在参与一个记录时,用户的参与度可以通过某些特征来度量(例如观看时长等)。预期参与度的大小与用户的满意度成正比,与记录内容的专业度成反比。
我们的目标是找到专业和喜闻乐见的最佳比例组合,以便长期保持用户粘性。在接下来的讨论中,我们将讨论不同组件的在本模拟场景中的实现方法。
RecSim中的user(用户)和document(记录)提供了实例化上述场景的所有组件所需的抽象类。
首先导入需要的RecSim包
from gym import spaces
import numpy as np
from recsim import document
from recsim import user
from recsim.simulator import environment
from recsim.simulator import recsim_gym
4.2.1. 记录模型 document
RecSim 记录(document)是继承自RecSim.document.AbstractDocument的类。它是document模型、Agent和用户(user)之间的主要交换单元。document类实现本质上是底层document特征(所有可见的和隐藏的特征)的容器。基类需要实现一个observation_space()静态方法,将document可见特征的格式声明为OpenAI gym空间,以及一个create_observe()函数,该函数返回所述空间的实现。另外,每个document必须有一个唯一的整数ID。
在我们的模拟场景中,document只有一个特征,即它们的专业度(Prof),用一维空间Box来表示。
# 记录(document)模型
class SIMDocument(document.AbstractDocument):
def __init__(self, doc_id, prof):
self.prof = prof
super(SIMDocument, self).__init__(doc_id)
# 构建环境,返回OpenAI gym动作空间的实现
def create_observation(self):
return np.array([self.prof])
# 将document的可见特征的格式声明为OpenAI gym动作空间
@staticmethod
def observation_space():
return spaces.Box(shape=(1,), dtype=np.float32, low=0.0, high=1.0)
# 返回document对象的描述信息,自动调用
def __str__(self):
return "Document {} with Prof {}.".format(self._doc_id, self.prof)
实现了document模型之后,我们现在需要设计一个document采样器。document采样器用于按一定规则生成或抽取document,可以在每个步骤或每个会话结束之后调用采样器来重新生成语料库(这取决于runner_lib的设置)。document在sample_document()函数中生成,它按我们设定的分布规则采样document。
在我们的模拟场景中,采样器按均匀分布生成document(包含document的id、专业度Prof)。
# document采样器模型
class SIMDocumentSampler(document.AbstractDocumentSampler):
# 采样器初始化,自动调用
def __init__(self, doc_ctor=SIMDocument, **kwargs):
super(SIMDocumentSampler, self).__init__(doc_ctor, **kwargs)
self._doc_count = 0
# 对document采样
def sample_document(self):
doc_features = {
}
doc_features[''doc_id''] = self._doc_count # 赋予ID
doc_features[''prof''] = self._rng.random_sample() # 均匀分布采样
self._doc_count += 1 # ID自增1
return self._doc_ctor(**doc_features)
有了document模型以及document采样器之后,就可以模拟document了。如下代码,我们用采样器生成了5个document模型,它们分别都有各自的专业度(Prof)
# 临时调试用
if __name__ == ''__main__'':
sampler = SIMDocumentSampler() # 实例化一个采样器
# 采样5个document
for i in range(5):
print(sampler.sample_document())
d = sampler.sample_document()
print("Documents have observation space:", d.observation_space(), "\nAn example realization is: ", d.create_observation())
输出:
Document 0 with Prof 0.5488135039273248.
Document 1 with Prof 0.7151893663724195.
Document 2 with Prof 0.6027633760716439.
Document 3 with Prof 0.5448831829968969.
Document 4 with Prof 0.4236547993389047.
Documents have observation space: Box(0.0, 1.0, (1,), float32)
An example realization is: [0.64589411]
Process finished with exit code 0
4.2.2. 用户模型 user
上一节中我们构造了一个可用的document模型以及它的采样器,现在我们来构造用户模型。
用户模型由以下组件组成:
- 用户状态
- 用户采样器(用户启动状态的分布)
- 用户状态转换模型
- 用户响应。
本模拟场景的用户模型如下:
- 每个用户都有一个被称为专业记录曝光度( npe t \text{npe}_t npet)和满意度( sat t \text{sat}_t satt)的特性。它们通过线性关系联系起来,反映了满意度不可能是无限的这一事实。表达为: sat t = σ ( τ ⋅ enga t ) \text{sat}_t=\sigma(\tau\cdot\text{enga}_t) satt=σ(τ⋅engat)其中 τ \tau τ是用户敏感性参数。由公式可知满意度 sat t \text{sat}_t satt与专业记录曝光度( npe t \text{npe}_t npet)是双向相关的,所以只需要知道其中一个就可以跟踪用户状态了。
- 给定一个记录候选列表(slate) S S S,用户根据一个以记录的喜闻乐见程度作为特征的多项逻辑选择模型(multinomial logit choice model)选择一个记录 d i d_i di: p ( user choose d i from slate S ) ∼ e 1 − p r o f ( d i ) p(\text{user choose }d_i \text{ from slate }S)\sim e^{1-prof(d_i)} p(user choose di from slate S)∼e1−prof(di)之所以使用 1 − p r o f ( d i ) 1-prof(d_i) 1−prof(di),是因为喜闻乐见的记录更容易被用户选择。
- 一旦用户从记录候选列表(slate) S S S选择了一个记录,专业记录曝光度( npe t \text{npe}_t npet)就会变化为: enga t + 1 = β ⋅ enga t + 2 ( p d − 1 2 ) + N ( 0 , η ) \text{enga}_{t+1}=\beta\cdot\text{enga}_t+2(p_d-\frac{1}{2})+\mathscr{N}(0,\eta) engat+1=β⋅engat+2(pd−21)+N(0,η)其中 β \beta β是某个用户的折扣因子, p d p_d pd是所选记录的专业度, N ( 0 , η ) \mathscr{N}(0,\eta) N(0,η)是呈正态分布的噪声数据。
- 最后,用户查看所选记录的时间为 s d s_d sd秒,其中 s d s_d sd是根据以下公式生成的: s d ∼ log ( N ( p d μ p + ( 1 − p d ) μ l , p d σ p + ( 1 − p d ) σ l ) ) s_d\sim\log\biggl(\mathscr{N}(p_d\mu_p+(1-p_d)\mu_l,p_d\sigma_p+(1-p_d)\sigma_l)\biggr) sd∼log(N(pdμp+(1−pd)μl,pdσp+(1−pd)σl))即一个对数正态分布,其值是在纯专业分布 ( μ p , σ p ) (\mu_p, \sigma_p) (μp,σp)和纯喜闻乐见分布 ( μ l , σ l ) (\mu_l,\sigma_l) (μl,σl)之间的线性插值。
因此,用户状态是由元组 ( sat , τ , β , η , μ p , σ p , μ l , σ l ) (\text{sat},\tau,\beta,\eta,\mu_p, \sigma_p,\mu_l,\sigma_l) (sat,τ,β,η,μp,σp,μl,σl)定义的。满意度变量 sat \text{sat} sat是状态中唯一的动态部分,而其他参数是由用户定义的,并且是静态不变的。从技术上讲,我们不需要将它们作为状态的一部分,而是应该硬编码它们,但是,将它们作为状态的一部分可以使得我们能够采样出具有不同属性的用户。
4.2.2.1. 用户状态和用户采样器
与document类似,我们首先实现一个用户状态类,作为所有用户状态参数的容器。与AbstractDocument类似,AbstractUserState基类要求我们实现observation_space()和create_observations(),它们用于在每次迭代时向Agent提供关于用户状态的部分(或全部)信息。
我们也有对Session时间的限制,在本模拟场景中,会话长度将固定为某个常量,所以不在时间预算模型中明确说明,但我们也可以将其视为用户状态的一部分,并利用它做点其他的事情。
最后,我们将实现一个score_document()方法,该方法将document映射到一个非负实数。
class SIMUserState(user.AbstractUserState):
def __init__(self, memory_discount, sensitivity, innovation_stddev,
like_mean, like_stddev, prof_mean, prof_stddev,
net_professional_exposure, time_budget, observation_noise_stddev=0.1):
# 用户状态转化模型参数
self.memory_discount = memory_discount
self.sensitivity = sensitivity
self.innovation_stddev = innovation_stddev
# 对数正态分布参数
self.like_mean = like_mean
self.like_stddev = like_stddev
self.prof_mean = prof_mean
self.prof_stddev = prof_stddev
# 状态变量
self.net_professional_exposure = net_professional_exposure
self.satisfaction = 1 / (1 + np.exp(-sensitivity * net_professional_exposure))
self.time_budget = time_budget
# 噪声数据
self._observation_noise = observation_noise_stddev
def create_observation(self):
# 用户的状态是隐藏的
clip_low, clip_high = (-1.0 / (1.0 * self._observation_noise),
1.0 / (1.0 * self._observation_noise))
noise = stats.truncnorm(clip_low, clip_high, loc=0.0, scale=self._observation_noise).rvs()
noisy_sat = self.satisfaction + noise
return np.array([noisy_sat, ])
@staticmethod
def observation_space():
return spaces.Box(shape=(1,), dtype=np.float32, low=-2.0, high=2.0)
# 对document评分——用户更有可能选择更喜闻乐见的内容。
def score_document(self, doc_obs):
return 1 - doc_obs
同样与我们的document模型类似,我们需要一个启动状态采样器,它为每个会话设置初始化的用户状态。
对于本模拟场景,我们将只对开头的专业记录曝光度( npe t \text{npe}_t npet)进行采样,并保持所有静态参数相同,这意味着我们是以不同的满意度处理同一个用户。当然,我们也可以随机生成具有不同参数的用户。
注意,如果 η = 0 \eta = 0 η=0, 则 npe t \text{npe}_t npet的值始终在 [ − 1 1 − β , … , 1 1 − β ] \left[-\frac{1}{1-\beta},\ldots,\frac{1}{1-\beta} \right] [−1−β1,…,1−β1]区间内,所以作为初始分布,我们只在这个范围内均匀抽样。根据基类的要求,采样代码必须在sample_user()中实现。
class SIMStaticUserSampler(user.AbstractUserSampler):
_state_parameters = None
def __init__(self,
user_ctor=SIMUserState,
memory_discount=0.9,
sensitivity=0.01,
innovation_stddev=0.05,
like_mean=5.0,
like_stddev=1.0,
prof_mean=4.0,
prof_stddev=1.0,
time_budget=60,
**kwargs):
self._state_parameters = {
''memory_discount'': memory_discount,
''sensitivity'': sensitivity,
''innovation_stddev'': innovation_stddev,
''like_mean'': like_mean,
''like_stddev'': like_stddev,
''prof_mean'': prof_mean,
''prof_stddev'': prof_stddev,
''time_budget'': time_budget}
super(SIMStaticUserSampler, self).__init__(user_ctor, **kwargs)
def sample_user(self):
starting_npe = ((self._rng.random_sample() - .5)*(1 / (1.0 - self._state_parameters[''memory_discount''])))
self._state_parameters[''net_professional_exposure''] = starting_npe
return self._user_ctor(**self._state_parameters)
至此,我们可以开始采样一些用户,例如下面的代码就采样了1000个用户,并且用直方图表示了不同专业记录曝光度区间范围内的用户数量各为多少
if __name__ == ''__main__'':
sampler = SIMStaticUserSampler()
starting_npe = []
for i in range(1000):
sampled_user = sampler.sample_user()
starting_npe.append(sampled_user.net_professional_exposure)
plt.hist(starting_npe,edgecolor=''white'',linewidth=1) # import matplotlib.pyplot as plt
plt.show()

4.2.2.2. 响应模型
接下来要构造user response类。RecSim将为候选列表中的每个推荐项目生成一个响应。Agent看到的响应内容是用户对推荐的特定document的反馈(在SIMUserState.create_observation中生成非特定document的反馈)。
class SIMResponse(user.AbstractResponse):
# 参与度最大值
MAX_ENGAGEMENT_MAGNITUDE = 100.0
def __init__(self, clicked=False, engagement=0.0):
self.clicked = clicked
self.engagement = engagement
def create_observation(self):
return {
''click'': int(self.clicked), ''engagement'': np.array(self.engagement)}
@classmethod
def response_space(cls):
# engagement的范围是[0,MAX_ENGAGEMENT_MAGNITUDE]
return spaces.Dict({
''click'': spaces.Discrete(2),
''engagement'': spaces.Box(
low=0.0,
high=cls.MAX_ENGAGEMENT_MAGNITUDE,
shape=tuple(),
dtype=np.float32)})
4.2.2.3. 用户模型
现在我们已经有了为会话生成用户的方法,接下来需要指定实际的用户行为。RecSim用户模型(源自recsim.user.AbstractUserModel)负责以下三个动作:
- 维护用户的状态;
- 根据推荐的结果,更新用户状态;
- 生成对一系列建议的响应。
为此,用户模型需要实现基类的update_state()和simulate_response()方法,以及控制会话于何时结束的is_terminal,这是通过self.time_budget的自减来实现的。
我们的初始化很简单,只将需要response_model构造函数、用户采样器和候选列表大小传递给AbstractUserModel基类就可以了。
def __init__(self, slate_size, seed=0):
super(SIMUserModel, self).__init__(SIMResponse, SIMStaticUserSampler(SIMUserState, seed=seed), slate_size)
self.choice_model = MultinomialLogitChoiceModel({
}) # from choice_model import MultinomialLogitChoiceModel
simulate_response()方法用于接受由Agent生成的SIMDocuments的候选列表,并输出用户响应列表。响应列表中的第 k k k个响应对应推荐列表中的第 k k k个document。在这种情况下,我们根据我们的选择模型选择一个document进行点击,并产生一个参与度。我们让未点击的document的响应为空,或者用其他更好的方式来操作(例如记录用户是否检查了该文档等等)。
def simulate_response(self, slate_documents):
# 空响应列表
responses = [self._response_model_ctor() for _ in slate_documents]
# 从选择模型获取点击
self.choice_model.score_documents(self._user_state, [doc.create_observation() for doc in slate_documents])
scores = self.choice_model.scores
selected_index = self.choice_model.choose_item()
# 填充点击项
self._generate_response(slate_documents[selected_index], responses[selected_index])
return responses
def _generate_response(self, doc, response):
response.clicked = True
# 专业记录和喜闻乐见记录之间的线性插值
engagement_loc = (doc.prof * self._user_state.like_mean + (1 - doc.prof) * self._user_state.prof_mean)
engagement_loc *= self._user_state.satisfaction
engagement_scale = (doc.prof * self._user_state.like_stddev + ((1 - doc.prof) * self._user_state.prof_stddev))
log_engagement = np.random.normal(loc=engagement_loc, scale=engagement_scale)
response.engagement = np.exp(log_engagement)
update_state()方法是用户状态转换的关键。它使用推荐的候选列表以及用户实际的选择(响应)来诱导状态转换。状态被直接修改,所以函数没有任何返回值。
def update_state(self, slate_documents, responses):
for doc, response in zip(slate_documents, responses):
if response.clicked:
innovation = np.random.normal(scale=self._user_state.innovation_stddev)
net_professional_exposure = (self._user_state.memory_discount * self._user_state.net_professional_exposure - 2.0 * (doc.prof - 0.5) + innovation)
self._user_state.net_professional_exposure = net_professional_exposure
satisfaction = 1 / (1.0 + np.exp(-self._user_state.sensitivity * net_professional_exposure))
self._user_state.satisfaction = satisfaction
self._user_state.time_budget -= 1
return
最后,当时间预算time_budge小于等于0时,会话过期。
def is_terminal(self):
# 返回一个布尔值,指示会话是否结束
return self._user_state.time_budget <= 0
我们把上面所讲的所有函数组件封装在一个类中,命名为SIMUserModel,继承user.AbstractUserModel基类。
class SIMUserModel(user.AbstractUserModel):
def __init__(self, slate_size, seed=0):
...
def simulate_response(self, slate_documents):
...
def _generate_response(self, doc, response):
...
def update_state(self, slate_documents, responses):
...
def is_terminal(self):
...
最后,我们将所有组件(包括document组件和user组件)配置到一个环境中。
if __name__ == ''__main__'':
slate_size = 3
num_candidates = 10
simenv = environment.Environment(
SIMUserModel(slate_size),
SIMDocumentSampler(),
num_candidates,
slate_size,
resample_documents=True)
4.2.2.4. 与Agent的交互
我们现在已经实现了一个模拟环境。为了在这种环境中训练和评估Agent,我们还需要设定一个奖励函数,用于将一组反应映射到实数域。假设我们想要最大化点击文档的参与度,那么就可以这样设定奖励函数:
def clicked_engagement_reward(responses):
reward = 0.0
for response in responses:
if response.clicked:
reward += response.engagement
return reward
现在,我们只需使用OpenAI gym包装器载入我们的模拟环境即可,从4.2.3. 模拟场景的试运行的随机执行结果可以看到,observation_1的用户满意度比observation_0的用户满意度高了不少。
if __name__ == ''__main__'':
''''''
其他语句
''''''
sim_gym_env = recsim_gym.RecSimGymEnv(simenv, clicked_engagement_reward)
observation_0 = sim_gym_env.reset()
print(''Observation 0'') # 用户观测到的环境 0
print(''Available documents'') # 输出候选列表中的所有document
doc_strings = [''doc_id '' + key + " prof " + str(value) for key, value
in observation_0[''doc''].items()]
print(''\n''.join(doc_strings))
print(''Noisy user state observation'')
print(observation_0[''user'']) # 用户满意度
recommendation_slate_0 = [0, 1, 2] # Agent 推荐出候选列表(slate)的前三个document
observation_1, reward, done, _ = sim_gym_env.step(recommendation_slate_0) # 环境状态转移
print(''Observation 1'') # 用户观测到的环境 1
print(''Available documents'') # 输出候选列表中的所有document
doc_strings = [''doc_id '' + key + " prof " + str(value) for key, value
in observation_1[''doc''].items()]
print(''\n''.join(doc_strings))
rsp_strings = [str(response) for response in observation_1[''response'']]
print(''User responses to documents in the slate'')
print(''\n''.join(rsp_strings)) # 输出用户参与(响应)情况
print(''Noisy user state observation'')
print(observation_1[''user'']) # 用户满意度
4.2.3. 模拟场景的试运行
完整代码请关注公众号:推荐系统新视野(RecView)。回复“recsim模拟场景”获取

输出:
Observation 0
Available documents
doc_id 10 prof [0.79172504]
doc_id 11 prof [0.52889492]
doc_id 12 prof [0.56804456]
doc_id 13 prof [0.92559664]
doc_id 14 prof [0.07103606]
doc_id 15 prof [0.0871293]
doc_id 16 prof [0.0202184]
doc_id 17 prof [0.83261985]
doc_id 18 prof [0.77815675]
doc_id 19 prof [0.87001215]
Noisy user state observation
[0.51296355]
Observation 1
Available documents
doc_id 20 prof [0.97861834]
doc_id 21 prof [0.79915856]
doc_id 22 prof [0.46147936]
doc_id 23 prof [0.78052918]
doc_id 24 prof [0.11827443]
doc_id 25 prof [0.63992102]
doc_id 26 prof [0.14335329]
doc_id 27 prof [0.94466892]
doc_id 28 prof [0.52184832]
doc_id 29 prof [0.41466194]
User responses to documents in the slate
{
''click'': 0, ''engagement'': array(0.)}
{
''click'': 1, ''engagement'': array(55.75022179)}
{
''click'': 0, ''engagement'': array(0.)}
Noisy user state observation
[0.5730411]
Process finished with exit code 0
5. 自定义Agent
在熟悉了RecSim的整体架构以及各个组件之间是如何组合在一起成为一个完整的模拟环境之后,我们现在只剩Agent需要开发了。要弄清楚Agent与RecSim之间的交互方式,可以从下面两个角度入手:
- RecSim向Agent提供什么数据?以及如何提供数据?数据处理的结果是什么?
- RecSim为开发Agent提供哪些功能?
在了解RecSim给Agent提供的功能之前,我们再看一看RecSim的架构图。
把关注点放在图中Agent所在的区域,我们可以得出以下Agent的四种作用:
- 接收用户状态(用户可见特征);
- 接收用户对推荐的响应(用户响应);
- 接收一组记录 D D D(记录可见特征)。
- 输出大小为 K K K的记录候选列表,以提供给用户选择模型和用户转换模型使用。
为了更好地理解RecSim为开发Agent提供的API,我们将在RecSim的兴趣探索(interest exploration)环境中实现一个简单的bandit Agent。
假设整个环境由巨量的记录组成,这些记录聚集成不同主题。在RecSim中,我们也假设用户聚集成不同类型,于是有了:
记录对用户的吸引力 = 记录的质量 + 主题对用户(用户类型)的吸引力 \text{记录对用户的吸引力}=\text{记录的质量}+\text{主题对用户(用户类型)的吸引力} 记录对用户的吸引力=记录的质量+主题对用户(用户类型)的吸引力
这自然会造成这样一种情况:一个目光短浅的Agent会根据预测的点击率对记录进行排名,它会青睐高质量的记录,因为这样的记录在所有用户类型中都有很高的先验概率被点击。这导致Agent忽视探索可能带来的利益,从而选择了没这么好的策略。为了克服这种情况,就需要人为控制Agent采取积极的探索策略。
我们先定义Agent的各种方法,然后将其封装到一个类中。在这之前,我们先实例化一个模拟环境,以便进行后续处理。
首先导入需要的包
import functools
from gym import spaces
import numpy as np
import matplotlib.pyplot as plt
from scipy import stats
from recsim import agent
from recsim import document
from recsim import user
from recsim.choice_model import MultinomialLogitChoiceModel
from recsim.simulator import environment
from recsim.simulator import recsim_gym
from recsim.simulator import runner_lib
from recsim.environments import interest_exploration
这里我们只使用RecSim提供的create_environment()函数对环境进行初始化,也就是仅构造一个基础环境,而不添加任何其他的属性。在构建了环境之后,调用reset()方法对环境进行初始化,从而使用户可以得到最初的观测结果:
env_config = {
''slate_size'': 2,
''seed'': 0,
''num_candidates'': 15,
''resample_documents'': True}
ie_environment = interest_exploration.create_environment(env_config)
initial_observation = ie_environment.reset()
5.1. 观测 Observation
用户的观测即用户看到的部分环境,RecSim中,用户的观测可以表示成有3个键的字典:
- “user” : 表示架构图中的"用户可见特征";
- “doc” : 包含当前值得推荐的记录及其可见特征,
- “response” : 表示用户对最后一组推荐的响应(“用户响应”)。在这个阶段,“响应”键是空白的,将被设置为None,因为还没有提出任何建议。
print(''User Observable Features'')
print(initial_observation[''user''])
print(''User Response'')
print(initial_observation[''response''])
print(''Document Observable Features'')
for doc_id, doc_features in initial_observation[''doc''].items():
print(''ID:'', doc_id, ''features:'', doc_features)
输出:
User Observable Features
[]
User Response
None
Document Observable Features
ID: 15 features: {
''quality'': array(1.22720163), ''cluster_id'': 1}
ID: 16 features: {
''quality'': array(1.29258489), ''cluster_id'': 1}
ID: 17 features: {
''quality'': array(1.23977078), ''cluster_id'': 1}
ID: 18 features: {
''quality'': array(1.46045555), ''cluster_id'': 1}
ID: 19 features: {
''quality'': array(2.10233425), ''cluster_id'': 0}
ID: 20 features: {
''quality'': array(1.09572905), ''cluster_id'': 1}
ID: 21 features: {
''quality'': array(2.37256963), ''cluster_id'': 0}
ID: 22 features: {
''quality'': array(1.34928002), ''cluster_id'': 1}
ID: 23 features: {
''quality'': array(1.00670188), ''cluster_id'': 1}
ID: 24 features: {
''quality'': array(1.20448562), ''cluster_id'': 1}
ID: 25 features: {
''quality'': array(2.18351159), ''cluster_id'': 0}
ID: 26 features: {
''quality'': array(1.19411585), ''cluster_id'': 1}
ID: 27 features: {
''quality'': array(1.03514646), ''cluster_id'': 1}
ID: 28 features: {
''quality'': array(2.29592623), ''cluster_id'': 0}
ID: 29 features: {
''quality'': array(2.05936556), ''cluster_id'': 0}
Process finished with exit code 0
此时,我们得到了一个由15个记录(num_candidates)组成的语料库,每个记录都由它们的主题(cluster_id)和质量分数(quality)表示。
用户观测的格式规范可以作为OpenAI gym空间的环境特征,它也在初始化时提供给Agent
print(''Document observation space'')
for key, space in ie_environment.observation_space[''doc''].spaces.items():
print(key, '':'', space)
print(''Response observation space'')
print(ie_environment.observation_space[''response''])
print(''User observation space'')
try:
print(ie_environment.observation_space[''user''])
except ValueError:
# ValueError: zero-size array to reduction operation minimum which has no identity
# 从上一段代码的输出结果可以看出,此时没有用户可见特征,则用户可见特征空间为空
print("Box(0,)")
输出:
Document observation space
15 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
16 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
17 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
18 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
19 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
20 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
21 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
22 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
23 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
24 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
25 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
26 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
27 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
28 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
29 : Dict(cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32))
Response observation space
Tuple(Dict(click:Discrete(2), cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32)), Dict(click:Discrete(2), cluster_id:Discrete(2), quality:Box(0.0, inf, (), float32)))
User observation space
Box(0,)
5.2. 候选列表 Slate
RecSim的候选列表是前 K K K个索引[''doc'']的列表。例如, K K K为2的候选列表可以将上述15个记录表示为:
slate = [0, 1]
for slate_doc in slate:
print(list(initial_observation[''doc''].items())[slate_doc])
输出:
(''15'', {
''quality'': array(1.22720163), ''cluster_id'': 1})
(''16'', {
''quality'': array(1.29258489), ''cluster_id'': 1})
环境的动作空间是一个 N ∗ N N*N N∗N记录大小的多维离散空间
print(ie_environment.action_space)
输出:
MultiDiscrete([15 15])
当候选列表被用户选用时,环境就会生成一个新的观察结果以及对Agent的奖励,这个过程称为状态转移,Agent的主要工作就是为模拟的每个状态转移步骤,并生成有效的候选推荐列表。
observation, reward, done, _ = ie_environment.step(slate)
5.3. 搭建Agent
5.3.1. 简单Agent
现在我们来实现一个功能简单的Agent。首先导入包。
from recsim.agent import AbstractEpisodicRecommenderAgent
RecSim的Agent类继承自AbstractEpisodicRecommenderAgent。Agent初始化所需的参数是observation_space和action_space,我们可以用这两个参数来验证环境是否满足Agent进行操作的先决条件。
class StaticAgent(AbstractEpisodicRecommenderAgent):
def __init__(self, observation_space, action_space):
# 检查document语料库是否足够大
if len(observation_space[''doc''].spaces) < len(action_space.nvec):
raise RuntimeError(''Slate size larger than size of the corpus.'')
super(StaticAgent, self).__init__(action_space)
def step(self, reward, observation):
print(observation)
return list(range(self._slate_size))
这个Agent命名为StaticAgent,含义是它会静态地推荐语料库的前 K K K个记录。我们现在可以使用runner_lib在RecSim中运行它。
def create_agent(sess, environment, eval_mode, summary_writer=None):
return StaticAgent(environment.observation_space, environment.action_space)
# Windows改成''.\\tmp\\recsim\\''
tmp_base_dir = ''./tmp/recsim/''
runner = runner_lib.EvalRunner(
base_dir=tmp_base_dir,
create_agent_fn=create_agent,
env=ie_environment,
max_eval_episodes=1,
max_steps_per_episode=5,
test_mode=True)
# 运行Agent
# runner.run_experiment()
构建好runner后,就可以打开tensorboard来观察runner的运行过程
tensorboard --logdir=./tmp/recsim/eval_1/ --host=127.0.0.1
实际上,由于我们没有进行任何操作,所以此时tensorboard中是没有任何数据的。
5.3.2. 层次化Agent结构
在5.3.1. 简单Agent中我们构造了一个基本的Agent,接下来,我们试着把多个Agent组合起来组成一个Agent层,其中每个单独的Agent称为“基Agent”。
我们使用bandit算法来揭示用户对每个主题的平均参与度。也就是说,每个主题都视作一条arm。一旦算法选择了一个主题,我们就可以从这个主题中获取质量最高的记录。
当推荐多个产品时,通常会发生这样的情况:在一个会话期内,用户将与某些产品产生一些交互,这些交互中会蕴含一些用户的意图信息。有时,用户会进行显式的查询(例如输入搜索词),此时的用户意图十分明显。然而大多数情况下,用户的意图是隐藏的,即用户通过从一组物品中选择来间接地展示自己的意图。假设我们已经通过某种方法得知了用户意图,那么就可以用一个特定于产品的策略来实现Agent。
Agent层的构造方法是模块化的,RecSim提供了一组易于扩展的Agent构建块,可以将单个Agent组合到层次化结构中以构建复杂的Agent结构,如下图所示:

从图中可以清晰看到,Agent层依赖于一个或多个基Agent来实现:
- Agent层接收用户观测和来自环境的反馈;
- 原始用户观测需进行预处理后再传递给Agent层中的基Agent。
- 每个基Agent都输出候选列表(或抽象操作),然后进行后处理,以创建/输出最终候选列表(或具体操作)。
通过修改Agent层的前处理和后处理功能定义,可以发挥很多有意思的作用。例如,一个层可以被用作纯特征提取器,即它可以从用户观测中提取一些特征,并将其传递给基Agent,同时不需要再进行后处理。
前处理层-基Agent层-后处理层的分层结构设计有利于特征工程和Agent工程的解耦。通过修改奖励函数,可以实现各种不同的规范化器。Agent层也可以是动态的,以便于预处理或后处理函数可以实现参数更新或加入学习机制。
5.3.2.1. ClusterClickStats
ClusterClickStats负责为Agent探索提供必要的、足够的统计信息。在本节的最开始,我们介绍了兴趣探索(Interest Exploration)环境,它提供了用户点击的反馈,但没有跟踪累积点击次数。由于在实际项目中维护这样的统计数据通常是有意义的,所以RecSim实现了这样一个功能性Agent层来完成这一工作,下面我们来介绍一下ClusterClickStats。
ClusterClickStats监控了响应流,响应空间中有键"click"和"cluster_id",分别代表点击量和聚集簇的编号。
首先导入包
from recsim.agents.layers.cluster_click_statistics import ClusterClickStatsLayer
ClusterClickStats的构造函数与其基Agent(这里就用上面的StaticAgent)一致,且不会对候选列表进行任何后处理,也就是说基Agent输出的候选列表会直接发送给用户。
一旦基Agent实例化,ClusterClickStats将向其基Agent的观测空间中注入足够的统计信息。
static_agent = StaticAgent(ie_environment.observation_space, ie_environment.action_space)
static_agent.step(reward, observation)
输出:
{
''user'': array([], dtype=float64), ''doc'': OrderedDict([
(''30'', {
''quality'': array(2.48922445), ''cluster_id'': 0}),
(''31'', {
''quality'': array(2.12592661), ''cluster_id'': 0}),
(''32'', {
''quality'': array(1.27448139), ''cluster_id'': 1}),
(''33'', {
''quality'': array(1.21799112), ''cluster_id'': 1}),
(''34'', {
''quality'': array(1.17770375), ''cluster_id'': 1}),
(''35'', {
''quality'': array(2.07948915), ''cluster_id'': 0}),
(''36'', {
''quality'': array(1.14167652), ''cluster_id'': 1}),
(''37'', {
''quality'': array(1.20529165), ''cluster_id'': 1}),
(''38'', {
''quality'': array(1.2424684), ''cluster_id'': 1}),
(''39'', {
''quality'': array(1.87279668), ''cluster_id'': 0}),
(''40'', {
''quality'': array(1.19644888), ''cluster_id'': 1}),
(''41'', {
''quality'': array(1.28254021), ''cluster_id'': 1}),
(''42'', {
''quality'': array(2.01558539), ''cluster_id'': 0}),
(''43'', {
''quality'': array(2.46400483), ''cluster_id'': 0}),
(''44'', {
''quality'': array(1.33980633), ''cluster_id'': 1})]),
''response'': (
{
''click'': 0, ''quality'': array(1.22720163), ''cluster_id'': 1},
{
''click'': 0, ''quality'': array(1.29258489), ''cluster_id'': 1})}
cluster_static_agent = ClusterClickStatsLayer(StaticAgent, ie_environment.observation_space, ie_environment.action_space)
cluster_static_agent.step(reward, observation)
输出:
{
''user'': {
''raw_observation'': array([], dtype=float64), ''sufficient_statistics'': {
''impression_count'': array([0, 2]),
''click_count'': array([0, 0])}},
''doc'': OrderedDict([
(''30'', {
''quality'': array(2.48922445), ''cluster_id'': 0}),
(''31'', {
''quality'': array(2.12592661), ''cluster_id'': 0}),
(''32'', {
''quality'': array(1.27448139), ''cluster_id'': 1}),
(''33'', {
''quality'': array(1.21799112), ''cluster_id'': 1}),
(''34'', {
''quality'': array(1.17770375), ''cluster_id'': 1}),
(''35'', {
''quality'': array(2.07948915), ''cluster_id'': 0}),
(''36'', {
''quality'': array(1.14167652), ''cluster_id'': 1}),
(''37'', {
''quality'': array(1.20529165), ''cluster_id'': 1}),
(''38'', {
''quality'': array(1.2424684), ''cluster_id'': 1}),
(''39'', {
''quality'': array(1.87279668), ''cluster_id'': 0}),
(''40'', {
''quality'': array(1.19644888), ''cluster_id'': 1}),
(''41'', {
''quality'': array(1.28254021), ''cluster_id'': 1}),
(''42'', {
''quality'': array(2.01558539), ''cluster_id'': 0}),
(''43'', {
''quality'': array(2.46400483), ''cluster_id'': 0}),
(''44'', {
''quality'': array(1.33980633), ''cluster_id'': 1})]), ''response'': (
{
''click'': 0, ''quality'': array(1.22720163), ''cluster_id'': 1},
{
''click'': 0, ''quality'': array(1.29258489), ''cluster_id'': 1})}
如上输出结果中,“user"字段有了一个新键"sufficient_statistics”,而之前的用户观测(空的)在"raw_observe"键下,之所以这样做是为了避免命名冲突。
5.3.2.2. AbstractClickBandit
AbstractClickBandit负责实现实际的bandit策略,RecSim提供了一个功能性抽象bandit——AbstractClickBandit,它将基Agent的候选列表作为输入,并其视为arm进行强化学习。
它利用几个已经实现的bandit策略(UCB1、KL-UCB、ThompsonSampling)中的一个来构建策略,以实现相对于最佳策略(这是先验未知的)的次线性遗憾(sub-linear regret),具体选择哪个bandit策略取决于对环境的要求。
首先导入包:
from recsim.agents.layers.abstract_click_bandit import AbstractClickBanditLayer
要实例化一个抽象bandit,必须提供一个基Agent的候选列表。在我们的示例中,每个主题都有一个基Agent。该Agent只从语料库中检索属于该主题的document,并根据质量对它们进行排序。
class GreedyClusterAgent(agent.AbstractEpisodicRecommenderAgent):
"""Agent根据质量对主题的所有document进行排序"""
def __init__(self, observation_space, action_space, cluster_id, **kwargs):
del observation_space
super(GreedyClusterAgent, self).__init__(action_space)
self._cluster_id = cluster_id
def step(self, reward, observation):
del reward
my_docs = []
my_doc_quality = []
for i, doc in enumerate(observation[''doc''].values()):
if doc[''cluster_id''] == self._cluster_id:
my_docs.append(i)
my_doc_quality.append(doc[''quality''])
if not bool(my_docs):
return []
sorted_indices = np.argsort(my_doc_quality)[::-1]
return list(np.array(my_docs)[sorted_indices])
然后为每个集群实例化一个GreedyClusterAgent。
num_topics = list(ie_environment.observation_space.spaces[''doc''].spaces.values())[0].spaces[''cluster_id''].n
base_agent_ctors = [
functools.partial(GreedyClusterAgent, cluster_id=i)
for i in range(num_topics)
]
接下来实例化ClusterClickStatsLayer,并命名为Cluster_Bandit
bandit_ctor = functools.partial(AbstractClickBanditLayer, arm_base_agent_ctors=base_agent_ctors)
cluster_bandit = ClusterClickStatsLayer(bandit_ctor, ie_environment.observation_space, ie_environment.action_space)
现在ClusterClickStatsLayer可以正常工作了,运行之后会输出一个最终候选列表,也就是推荐给用户的记录
observation0 = ie_environment.reset()
slate = cluster_bandit.begin_episode(observation0)
print("Cluster bandit slate 0:")
doc_list = list(observation0[''doc''].values())
for doc_position in slate:
print(doc_list[doc_position])
输出:
Cluster bandit slate 0:
{
''quality'': array(1.46868751), ''cluster_id'': 1}
{
''quality'': array(1.42269182), ''cluster_id'': 1}
6. RecSim参考文档
仅仅了解上面几节所讲的内容还不能让我们随心所欲的开发RecSim,更多的内容请参考./recsim-master/recsim-master/docs/api_docs/python中的参考文档
今天关于使用计算图搭建灵活的推荐系统和计算图模型的讲解已经结束,谢谢您的阅读,如果想了解更多关于C++ 函数指针与 Qt 框架:搭建灵活的 GUI 应用、C++中的推荐系统技术、Mahout的推荐系统、RecSim 可配置的推荐系统仿真平台 使用指南的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

