在这里,我们将给大家分享关于如何计算每行出现的单词中的字母,单词中出现A...Z的知识,让您更了解统计每行几个字母的本质,同时也会涉及到如何更有效地2021-09-05:单词搜索II。给定一个mxn二
在这里,我们将给大家分享关于如何计算每行出现的单词中的字母,单词中出现 A...Z的知识,让您更了解统计每行几个字母的本质,同时也会涉及到如何更有效地2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的、awk脚本统计一组单词中字母出现最多最少频率、bash – 匹配单词列表中的单词并计算出现次数、C程序计算一个单词中的字母数给出错误的内容。
本文目录一览:- 如何计算每行出现的单词中的字母,单词中出现 A...Z(统计每行几个字母)
- 2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的
- awk脚本统计一组单词中字母出现最多最少频率
- bash – 匹配单词列表中的单词并计算出现次数
- C程序计算一个单词中的字母数给出错误
")
如何计算每行出现的单词中的字母,单词中出现 A...Z(统计每行几个字母)
如何解决如何计算每行出现的单词中的字母,单词中出现 A...Z?
我正在通过练习一些基本程序来学习 JAVA。我有一个名为 SampleMain.java 的类文件,我在其中读取每行一个文本文件并将其存储在名为 fileWords 的变量中。
SampleMain.java 中的代码-
public static void readFileData() {
Scanner fileInput = null;
try {
fileInput = new Scanner(new File("data.txt"));
} catch (FileNotFoundException e) {
e.printstacktrace();
}
while(fileInput.hasNextLine()) {
String fileWords = fileInput.nextLine();
System.out.println(fileWords);
}
}
这会打印我的 data.txt 值,如下所示-
Swift
Dotnet
Java
Typescript
Python
我有另一个类文件 Sample1.java,我想在其中执行以下操作。
-
计算字符串 (fileWords) 中单词中的字母总数,并将其存储在另一个名为 total 的变量中,我还想检查该文件是否应该没有任何垃圾值。
-
使用 fileWords 中单词的大写版本,它应该计算单词中 A、B、...、Z 的数量。
我写了如下代码- 示例1.java
public class Sample {
public void countLetters() {
int count = 0;
for (int i = 0; i < SampleMain.wordlist.size(); i++) {
if (Character.isLetter(SampleMain.fileWords.get(i).charat(i)- 25) >= 0 && Character.isLetter(SampleMain.fileWords.get(i) - 25) <= 25) // I''m doing it wrong
SampleMain.total = count++;
}
}
有人可以在这里指导我吗,我在迭代时做错了什么以及我如何纠正它以获得上述计数。
解决方法
tl;dr
使用代码点整数,而不是过时的 char 类型。
"Swift?" // SCORPION character is not a letter.
.codePoints() // Generate a stream of `int` primitive values,one for each character in our input string. Represents the code point number assigned to this character by the Unicode Consortium.
.filter( Character :: isLetter ) //
.count()
详情
char 已过时
char 类型在 Java 中已过时,甚至无法表示 Unicode 中定义的一半字符。学习改用 code point 整数。
代码点流
对于字符串中每个字符的代码点,您可以获得一个 int 原始值流,一个 IntStream。
IntStream codePointsStream = "Swift?".codePoints() ;
显然您希望关注字母与数字、标点符号等。因此,通过根据 Unicode 定义测试 if the character is a letter 进行过滤。
long countLetters = codePointsStream.filter( codePoint -> Character.isLetter( codePoint ) ).count();
我们可以通过使用方法引用来缩短该代码。
long countLetters = codePointsStream.filter( Character :: isLetter ).count();
将代码放在一起。
String input = "Swift?";
IntStream codePointsStream = input.codePoints();
long countLetters = codePointsStream.filter( Character :: isLetter ).count();
System.out.println( "input = " + input + " | countLetters: " + countLetters );
输入 = Swift? |计数字母:5
使用传统的 Java 语法
如果您还不熟悉 lambdas、流和方法引用,我们可以通过将代码点整数的 IntStream 转换为 List 来获得与常规代码相同的效果。
对 boxed() 的调用将 int 原始值转换为 process known as “boxing” 中的 Integer 对象。
List< Integer > codePoints = "Swift?".codePoints().boxed().toList() ; // Before Java 16,replace that `.toList()` with `.collect(Collectors.toList())`.
循环您的列表,检查每个元素。如果它通过了字母测试,请增加您的计数器。
int countLetters = 0;
for ( Integer codePoint : codePoints ) {
if ( Character.isLetter( codePoint ) ) { countLetters++; }
}
我使用正则表达式解决你的问题,示例代码如下:
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HelloWorld{
public static void main(String []args){
int total=0;
int upperCaseCount=0;
Pattern letter_pattren = Pattern.compile("[a-zA-Z]");
Pattern upperCase_pattern=Pattern.compile("[A-Z]");
String data="Swift\nDotnet\nJava\nTypescript\nPython";
String[] lines =data.split("\n");
for (String line : lines){
Matcher letterMatcher = letter_pattren.matcher(line);
while (letterMatcher.find()) {
total++;
}
letterMatcher = upperCase_pattern.matcher(line);
while (letterMatcher.find()) {
upperCaseCount++;
}
}
System.out.println("Total letter count:"+total);
System.out.println("Upper Case letter Count:"+upperCaseCount);
}
}
您可以参考此link了解详情。
列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的")
2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的
2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的单元格 内的字母构成,其中 “相邻” 单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。力扣 212。
福大大 答案 2021-09-05:
前缀树。
代码用 golang 编写。代码如下:
package main
import "fmt"
func main() {
board := [][]byte{
{
''o'', ''a'', ''a'', ''n''}, {
''e'', ''t'', ''a'', ''e''}, {
''i'', ''h'', ''k'', ''r''}, {
''i'', ''f'', ''l'', ''v''}}
words := []string{
"oath", "pea", "eat", "rain"}
ret := findWords(board, words)
fmt.Println(ret)
}
type TrieNode struct {
nexts []*TrieNode
pass int
end bool
}
func NewTrieNode() *TrieNode {
ans := &TrieNode{
}
ans.nexts = make([]*TrieNode, 26)
ans.pass = 0
ans.end = false
return ans
}
func fillWord(head *TrieNode, word string) {
head.pass++
chs := []byte(word)
index := 0
node := head
for i := 0; i < len(chs); i++ {
index = int(chs[i] - ''a'')
if node.nexts[index] == nil {
node.nexts[index] = NewTrieNode()
}
node = node.nexts[index]
node.pass++
}
node.end = true
}
func generatePath(path []byte) string {
//LinkedList<Character>
str := make([]byte, len(path))
index := 0
for _, cha := range path {
str[index] = cha
index++
}
return string(str)
}
func findWords(board [][]byte, words []string) []string {
head := NewTrieNode() // 前缀树最顶端的头
set := make(map[string]struct{
})
for _, word := range words {
if _, ok := set[word]; !ok {
fillWord(head, word)
set[word] = struct{
}{
}
}
}
// 答案
ans := make([]string, 0)
// 沿途走过的字符,收集起来,存在path里
path := make([]byte, 0)
for row := 0; row < len(board); row++ {
for col := 0; col < len(board[0]); col++ {
// 枚举在board中的所有位置
// 每一个位置出发的情况下,答案都收集
process(board, row, col, &path, head, &ans)
}
}
return ans
}
// 从board[row][col]位置的字符出发,
// 之前的路径上,走过的字符,记录在path里
// cur还没有登上,有待检查能不能登上去的前缀树的节点
// 如果找到words中的某个str,就记录在 res里
// 返回值,从row,col 出发,一共找到了多少个str
func process(board [][]byte, row int, col int, path *[]byte, cur *TrieNode, res *[]string) int {
cha := board[row][col]
if cha == 0 {
// 这个row col位置是之前走过的位置
return 0
}
// (row,col) 不是回头路 cha 有效
index := cha - ''a''
// 如果没路,或者这条路上最终的字符串之前加入过结果里
if cur.nexts[index] == nil || cur.nexts[index].pass == 0 {
return 0
}
// 没有走回头路且能登上去
cur = cur.nexts[index]
*path = append(*path, cha) // 当前位置的字符加到路径里去
fix := 0 // 从row和col位置出发,后续一共搞定了多少答案
// 当我来到row col位置,如果决定不往后走了。是不是已经搞定了某个字符串了
if cur.end {
*res = append(*res, generatePath(*path))
cur.end = false
fix++
}
// 往上、下、左、右,四个方向尝试
board[row][col] = 0
if row > 0 {
fix += process(board, row-1, col, path, cur, res)
}
if row < len(board)-1 {
fix += process(board, row+1, col, path, cur, res)
}
if col > 0 {
fix += process(board, row, col-1, path, cur, res)
}
if col < len(board[0])-1 {
fix += process(board, row, col+1, path, cur, res)
}
board[row][col] = cha
//path.pollLast()
*path = (*path)[0 : len(*path)-1]
cur.pass -= fix
return fix
}执行结果如下:
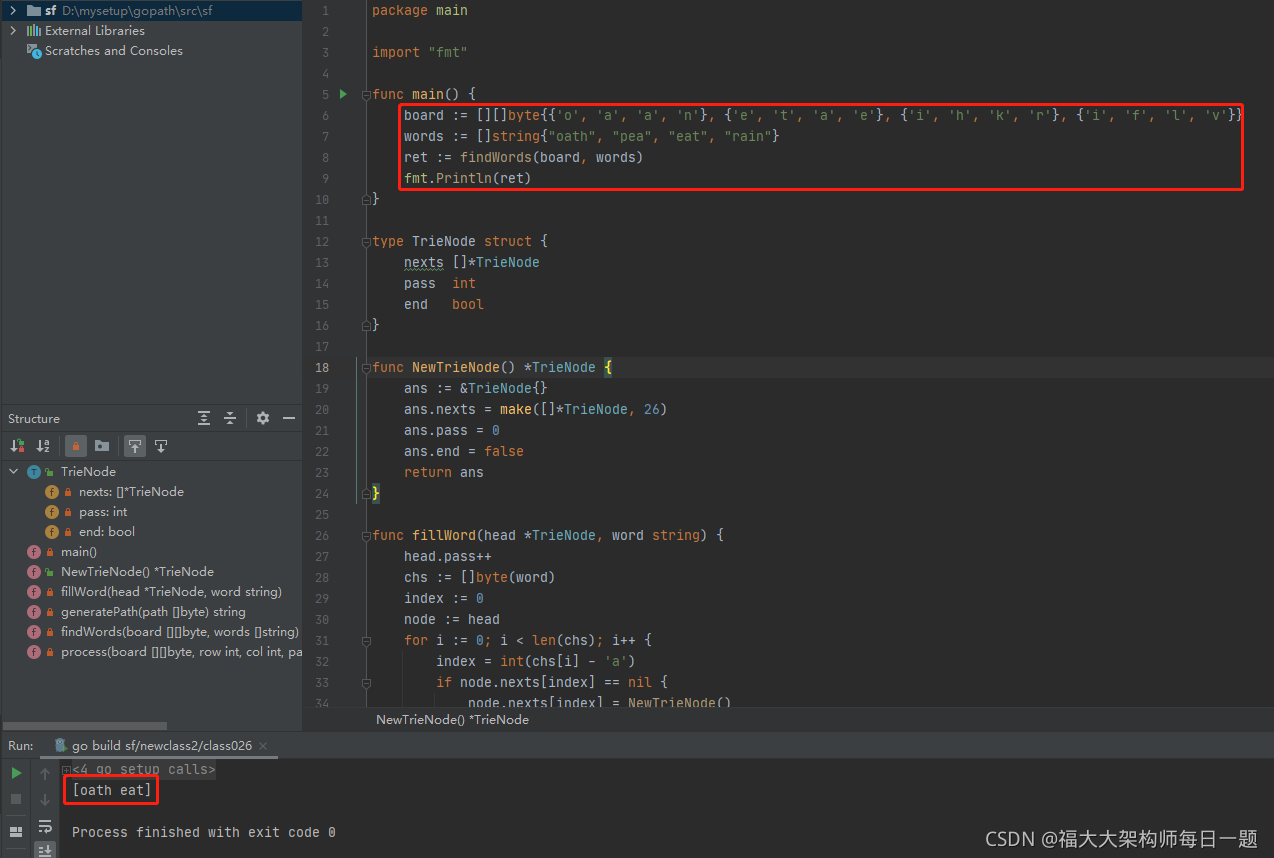
左神 java 代码

awk脚本统计一组单词中字母出现最多最少频率
编写一个 awk 脚本来找到一组单词中出现次数最多(和最少)的单词。
近一段时间,我开始编写一个小游戏,在这个小游戏里,玩家使用一个个字母块来组成单词。编写这个游戏之前,我需要先知道常见英文单词中每个字母的使用频率,这样一来,我就可以找到一组更有用的字母块。字母频次统计在很多地方都有相关讨论,包括在 维基百科 上,但我还是想要自己来实现。
Linux 系统在 /usr/share/dict/words 文件中提供了一个单词列表,所以我已经有了一个现成的单词列表。然而,尽管这个 words 文件包含了很多我想要的单词,却也包含了一些我不想要的。我想要的单词首先不能是复合词(即不包含连接符和空格的单词),也不能是专有名词(即不包含大写字母单词)。为了得到这个结果,我可以运行 grep 命令来取出只由小写字母组成的行:
$ grep ''^[a-z]*$'' /usr/share/dict/words
这个正则表达式的作用是让 grep 去匹配仅包含小写字母的行。表达式中的字符 ^ 和 $ 分别代表了这一行的开始和结束。[a-z] 分组仅匹配从 “a” 到 “z” 的小写字母。
下面是一个输出示例:
$ grep ''^[a-z]*$'' /usr/share/dict/words | head
a
aa
aaa
aah
aahed
aahing
aahs
aal
aalii
aaliis
没错,这些都是合法的单词。比如,“aahed” 是 “aah” 的过去式,表示在放松时的感叹,而 “aalii” 是一种浓密的热带灌木。
现在我只需要编写一个 gawk 脚本来统计出单词中各个字母出现的次数,然后打印出每个字母的相对频率。
字母计数
一种使用 gawk 来统计字母个数的方式是,遍历每行输入中的每一个字符,然后对 “a” 到 “z” 之间的每个字母进行计数。substr 函数会返回一个给定长度的子串,它可以只包含一个字符,也可以是更长的字符串。比如,下面的示例代码能够取到输入中的每一个字符 c:
{
len = length($0); for (i = 1; i <= len; i++) {
c = substr($0, i, 1);
}
}
如果使用一个全局字符串变量 LETTERS 来存储字母表,我就可以借助 index 函数来找到某个字符在字母表中的位置。我将扩展 gawk 代码示例,让它在输入数据中只取范围在 “a” 到 “z” 的字母:
BEGIN { LETTERS = "abcdefghijklmnopqrstuvwxyz" }
{
len = length($0); for (i = 1; i <= len; i++) {
c = substr($0, i, 1);
ltr = index(LETTERS, c);
}
}
需要注意的是,index 函数将返回字母在 LETTERS 字符串中首次出现的位置,第一个位置返回 1,如果没有找到则返回 0。如果我有一个大小为 26 的数组,我就可以利用这个数组来统计每个字母出现的次数。我将在下面的示例代码中添加这个功能,每当一个字母出现在输入中,我就让它对应的数组元素值增加 1(使用 ++):
BEGIN { LETTERS = "abcdefghijklmnopqrstuvwxyz" }
{
len = length($0); for (i = 1; i <= len; i++) {
c = substr($0, i, 1);
ltr = index(LETTERS, c);
if (ltr > 0) {
++count[ltr];
}
}
}
打印相对频率
当 gawk 脚本统计完所有的字母后,我希望它能输出每个字母的频率。毕竟,我对输入中各个字母的个数没有兴趣,我更关心它们的 相对频率。
我将先统计字母 “a” 的个数,然后把它和剩余 “b” 到 “z” 字母的个数比较:
END {
min = count[1]; for (ltr = 2; ltr <= 26; ltr++) {
if (count[ltr] < min) {
min = count[ltr];
}
}
}
在循环的最后,变量 min 会等于最少的出现次数,我可以把它为基准,为字母的个数设定一个参照值,然后计算打印出每个字母的相对频率。比如,如果出现次数最少的字母是 “q”,那么 min 就会等于 “q” 的出现次数。
接下来,我会遍历每个字母,打印出它和它的相对频率。我通过把每个字母的个数都除以 min 的方式来计算出它的相对频率,这意味着出现次数最少的字母的相对频率是 1。如果另一个字母出现的次数恰好是最少次数的两倍,那么这个字母的相对频率就是 2。我只关心整数,所以 2.1 和 2.9 对我来说是一样的(都是 2)。
END {
min = count[1]; for (ltr = 2; ltr <= 26; ltr++) {
if (count[ltr] < min) {
min = count[ltr];
}
}
for (ltr = 1; ltr <= 26; ltr++) {
print substr(LETTERS, ltr, 1), int(count[ltr] / min);
}
}
最后的完整程序
现在,我已经有了一个能够统计输入中各个字母的相对频率的 gawk 脚本:
#!/usr/bin/gawk -f
# 只统计 a-z 的字符,忽略 A-Z 和其他的字符
BEGIN { LETTERS = "abcdefghijklmnopqrstuvwxyz" }
{
len = length($0); for (i = 1; i <= len; i++) {
c = substr($0, i, 1);
ltr = index(LETTERS, c);
if (ltr < 0) {
++count[ltr];
}
}
}
# 打印每个字符的相对频率
END {
min = count[1]; for (ltr = 2; ltr <= 26; ltr++) {
if (count[ltr] < min) {
min = count[ltr];
}
}
for (ltr = 1; ltr <= 26; ltr++) {
print substr(LETTERS, ltr, 1), int(count[ltr] / min);
}
}
我将把这段程序保存到名为 letter-freq.awk 的文件中,这样一来,我就可以在命令行中更方便地使用它。
如果你愿意的话,你也可以使用 chmod +x 命令把这个文件设为可独立执行。第一行中的 #!/usr/bin/gawk -f 表示 Linux 会使用 /usr/bin/gawk 把这个文件当作一个脚本来运行。由于 gawk 命令行使用 -f 来指定它要运行的脚本文件名,你需要在末尾加上 -f。如此一来,当你在 shell 中执行 letter-freq.awk,它会被解释为 /usr/bin/gawk -f letter-freq.awk。
接下来我将用几个简单的输入来测试这个脚本。比如,如果我给我的 gawk 脚本输入整个字母表,每个字母的相对频率都应该是 1:
$ echo abcdefghijklmnopqrstuvwxyz | gawk -f letter-freq.awk a 1 b 1 c 1 d 1 e 1 f 1 g 1 h 1 i 1 j 1 k 1 l 1 m 1 n 1 o 1 p 1 q 1 r 1 s 1 t 1 u 1 v 1 w 1 x 1 y 1 z 1
还是使用上述例子,只不过这次我在输入中添加了一个字母 “e”,此时的输出结果中,“e” 的相对频率会是 2,而其他字母的相对频率仍然会是 1:
$ echo abcdeefghijklmnopqrstuvwxyz | gawk -f letter-freq.awk a 1 b 1 c 1 d 1 e 2 f 1 g 1 h 1 i 1 j 1 k 1 l 1 m 1 n 1 o 1 p 1 q 1 r 1 s 1 t 1 u 1 v 1 w 1 x 1 y 1 z 1
现在我可以跨出最大的一步了!我将使用 grep 命令和 /usr/share/dict/words 文件,统计所有仅由小写字母组成的单词中,各个字母的相对使用频率:
$ grep ''^[a-z]*$'' /usr/share/dict/words | gawk -f letter-freq.awk a 53 b 12 c 28 d 21 e 72 f 7 g 15 h 17 i 58 j 1 k 5 l 36 m 19 n 47 o 47 p 21 q 1 r 46 s 48 t 44 u 25 v 6 w 4 x 1 y 13 z 2
在 /usr/share/dict/words 文件的所有小写单词中,字母 “j”、“q” 和 “x” 出现的相对频率最低,字母 “z” 也使用得很少。不出意料,字母 “e” 是使用频率最高的。
via: https://opensource.com/article/21/4/gawk-letter-game
以上就是awk脚本统计一组单词中字母出现最多最少频率的详细内容,更多关于awk脚本统计字母频率的资料请关注其它相关文章!
- awk统计文件中某关键词出现次数的命令
- shell 里 awk print 的用法详解
- awk中查看包含某两列字符的用法
- Linux 中awk 提取包含某个关键字的段落

bash – 匹配单词列表中的单词并计算出现次数
例如,我的单词列表可以由以下内容组成:
good bad cupid banana apple
然后我想将这些单词中的每一个与我的文本文件进行比较,这可能是这样的:
有时我会前往好的地方,而不是坏的地方.例如,我想去天堂,遇到一个吃苹果的丘比特.也许我会看到神话中的生物吃其他水果,如苹果,香蕉和其他好水果.
我希望我的输出能够生成列出的单词每次出现的次数.我有办法做到这一点是awk和for循环但我真的希望避免for循环因为它将需要永远,因为我的真实单词列表大约10000字长.
所以在这种情况下,我的输出应该是(我认为)9,因为它计算该列表上一个单词的总出现次数.
顺便说一句,该段是完全随机的.
解决方法
perl -nE'BEGIN{open my$fh,"<",shift;my@a=map lc,map/(\w+)/g,<$fh>;@h{@a}=(0)x@a;close$fh}exists$h{$_}and$h{$_}++for map lc,/(\w+)/g}{for(keys%h){say"$_: $h{$_}";$s+=$h{$_}}say"Total: $s"' word.list input.txt

C程序计算一个单词中的字母数给出错误
如何解决C程序计算一个单词中的字母数给出错误?
代码如下:
#include<stdio.h>
int main()
{
int alpha = 0,input;
while((input = getchar() != EOF))
{
if(isalpha(input))
alpha++;
}
printf("Num of alpha is %d",alpha);
return(0);
}
我收到错误
isalpha 未在此范围内声明
在 DevC++ 编译器上编译时。
解决方法
isalpha() 在 ctype.h
知道即使 isalpha(以及所有 isxxx 系列函数)的参数是 int,the behavior is undefined if the argument is negative. 所以如果你是在 char 签名为默认值的机器上,除非您先进行转换,否则您可能会遇到麻烦。像这样:
char c;
// Some code
if(isalpha((unsigned char) c)) {
总是为这些函数强制转换是一个好习惯。但是,不要使用强制转换作为消除警告的 goto。它可以轻松隐藏错误。在大多数需要强制转换的情况下,您的代码在其他方面是错误的。 Rant about casting
这些函数(以及许多其他返回 int 作为布尔值的 C 函数)的另一个缺陷是它们需要在 false 时返回零,但在 true 时允许返回任何非零值。所以像这样的检查完全是胡说八道:
if( isalpha(c) == 1 )
改为执行以下任一操作:
if( isalpha(c) != 0 ) // If not zero
if( isalpha(c) ) // Use directly as Boolean (recommended)
if( !! isalpha(c) == 1) // Double negation turns non zero to 1
关于如何计算每行出现的单词中的字母,单词中出现 A...Z和统计每行几个字母的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于2021-09-05:单词搜索 II。给定一个 m x n 二维字符网格 board 和一个单词(字符串)列表 words,找出所有同时在二维网格和字典中出现的单词。单词必须按照字母顺序,通过 相邻的、awk脚本统计一组单词中字母出现最多最少频率、bash – 匹配单词列表中的单词并计算出现次数、C程序计算一个单词中的字母数给出错误等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

