此处将为大家介绍关于已解决:Elasticsearch报错:exception[type=search_phase_execution_exception,reason=allshardsfailed
此处将为大家介绍关于已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]的详细内容,此外,我们还将为您介绍关于.search.SearchPhaseExecutionException: all shards failed、Django/ Haystack错误:elasticsearch.exceptions.RequestError:TransportError(400,'parsing_exception',…)、ElasticSearch 429 Too Many Requests circuit_breaking_exception、Elasticsearch document_missing_exception的有用信息。
本文目录一览:- 已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]
- .search.SearchPhaseExecutionException: all shards failed
- Django/ Haystack错误:elasticsearch.exceptions.RequestError:TransportError(400,'parsing_exception',…)
- ElasticSearch 429 Too Many Requests circuit_breaking_exception
- Elasticsearch document_missing_exception
![已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]](http://www.gvkun.com/zb_users/upload/2025/04/b6843ee2-931b-484b-a55b-435d7a126bd31743651571498.jpg "已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]")
已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]
Exception in thread "main" ElasticsearchStatusException[Elasticsearch exception [type=search_phase_execution_exception, reason=all shards failed]]; nested: ElasticsearchException[Elasticsearch exception [type=illegal_argument_exception, reason=Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]]; nested: ElasticsearchException[Elasticsearch exception [type=illegal_argument_exception, reason=Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.]];
at org.elasticsearch.rest.BytesRestResponse.errorFromXContent(BytesRestResponse.java:177)
at org.elasticsearch.client.RestHighLevelClient.parseEntity(RestHighLevelClient.java:1727)
at org.elasticsearch.client.RestHighLevelClient.parseResponseException(RestHighLevelClient.java:1704)
at org.elasticsearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1467)
at org.elasticsearch.client.RestHighLevelClient.performRequest(RestHighLevelClient.java:1424)
at org.elasticsearch.client.RestHighLevelClient.performRequestAndParseEntity(RestHighLevelClient.java:1394)
at org.elasticsearch.client.RestHighLevelClient.search(RestHighLevelClient.java:930)
at com.softsec.util.demoTime.main(demoTime.java:98)
Suppressed: org.elasticsearch.client.ResponseException: method [POST], host [http://192.168.101.92:9200], URI [/news/_search?typed_keys=true&ignore_unavailable=false&expand_wildcards=open&allow_no_indices=true&ignore_throttled=true&search_type=query_then_fetch&batched_reduce_size=512&ccs_minimize_roundtrips=true], status line [HTTP/1.1 400 Bad Request]
{"error":{"root_cause":[{"type":"illegal_argument_exception","reason":"Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}],"type":"search_phase_execution_exception","reason":"all shards failed","phase":"query","grouped":true,"failed_shards":[{"shard":0,"index":"news","node":"8GuMfo5aRz2CCgl49bY0aQ","reason":{"type":"illegal_argument_exception","reason":"Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}}],"caused_by":{"type":"illegal_argument_exception","reason":"Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead.","caused_by":{"type":"illegal_argument_exception","reason":"Fielddata is disabled on text fields by default. Set fielddata=true on [content_type] in order to load fielddata in memory by uninverting the inverted index. Note that this can however use significant memory. Alternatively use a keyword field instead."}}},"status":400}
at org.elasticsearch.client.RestClient.convertResponse(RestClient.java:253)
at org.elasticsearch.client.RestClient.performRequest(RestClient.java:231)
at org.elasticsearch.client.RestClient.performRequest(RestClient.java:205)
at org.elasticsearch.client.RestHighLevelClient.internalPerformRequest(RestHighLevelClient.java:1454)
... 4 more这个原因是因为我的分组聚合查询的字符串(content_type)类型是 text 类型

原因分析:
当使用到 term 查询的时候,由于是精准匹配,所以查询的关键字在 es 上的类型,必须是 keyword 而不能是 text,比如你的搜索条件是 ”name”:” 蔡虚坤”, 那么该 name 字段的 es 类型得是 keyword,而不能是 text
在 es 中,只有 keyword 类型的字符串可以使用 AggregationBuilders.terms ("aggs-class") 来分组聚合,想要分组查询,指定根据分组字段的 keyword 属性就可以了(如下图);
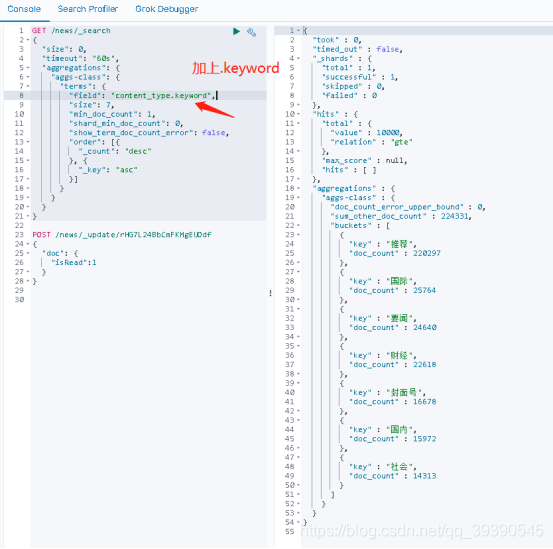
在我们的 Java 代码中怎么修改呢?如下,加上 ".keyword" 就可以了

之前的报错下面追加上:

本文同步分享在 博客 “_陈哈哈”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。

.search.SearchPhaseExecutionException: all shards failed
org.elasticsearch.action.search.SearchPhaseExecutionException: all shards failed
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseFailure(AbstractSearchAsyncAction.java:293) ~[elasticsearch-6.5.4.jar:6.5.4]
at org.elasticsearch.action.search.AbstractSearchAsyncAction.executeNextPhase(AbstractSearchAsyncAction.java:133) ~[elasticsearch-6.5.4.jar:6.5.4]
at org.elasticsearch.action.search.AbstractSearchAsyncAction.onPhaseDone(AbstractSearchAsyncAction.java:254) ~[elasticsearch-6.5.4.jar:6.5.4]
")
Django/ Haystack错误:elasticsearch.exceptions.RequestError:TransportError(400,'parsing_exception',…)
我在我的Django项目中使用Elasticsearch作为干草堆的后端。我创建了一个搜索如前所述所需的一切在这里。但是,当我搜索时,我抛出了带有TransportError(400,’parsing_exception’,’没有为[过滤器]注册的[查询]’)的追溯错误。
我已经用谷歌搜索了这个问题。但是没有任何解决方案。我很乐意帮助我解决这个问题。
我的回溯:
Traceback (most recent call last): File "c:\python34\lib\site- packages\haystack\backends\elasticsearch_backend.py", line 524, in search_source=True) File "c:\python34\lib\site-packages\elasticsearch\client\utils.py", line 71, in _wrapped return func(*args, params=params, **kwargs) File "c:\python34\lib\site-packages\elasticsearch\client\__init__.py", line 569, in search doc_type, ''_search''), params=params, body=body) File "c:\python34\lib\site-packages\elasticsearch\transport.py", line 327, in perform_request status, headers, data = connection.perform_request(method, url, params, body, ignore=ignore, timeout=timeout) File "c:\python34\lib\site-packages\elasticsearch\connection\http_urllib3.py", line 124, in perform_request self._raise_error(response.status, raw_data) File "c:\python34\lib\site-packages\elasticsearch\connection\base.py", line 122, in _raise_error raise HTTP_EXCEPTIONS.get(status_code, TransportError)(status_code, error_message, additional_info)elasticsearch.exceptions.RequestError: TransportError(400, ''parsing_exception'', ''no [query] registered for [filtered]'')[28/Dec/2016 17:06:58]"GET /search/?q=code HTTP/1.1" 200 395Update-1:降级为Elasticsearch == 1.7.0后的TraceBack
GET /haystack/modelresult/_search?_source=true [status:400 request:0.001s]Failed to query Elasticsearch using ''(code)'': TransportError(400, ''parsing_exception'')Traceback (most recent call last): File "c:\python34\lib\site-packages\haystack\backends\elasticsearch_backend.py", line 524, in search_source=True) File "c:\python34\lib\site-packages\elasticsearch\client\utils.py", line 69, in _wrapped return func(*args, params=params, **kwargs) File "c:\python34\lib\site-packages\elasticsearch\client\__init__.py", line 527, in search doc_type, ''_search''), params=params, body=body) File "c:\python34\lib\site-packages\elasticsearch\transport.py", line 307, in perform_request status, headers, data = connection.perform_request(method, url, params, body, ignore=ignore, timeout=timeout) File "c:\python34\lib\site-packages\elasticsearch\connection\http_urllib3.py", line 93, in perform_request self._raise_error(response.status, raw_data) File "c:\python34\lib\site-packages\elasticsearch\connection\base.py", line 105, in _raise_error raise HTTP_EXCEPTIONS.get(status_code, TransportError)(status_code, error_message, additional_info)elasticsearch.exceptions.RequestError: TransportError(400, ''parsing_exception'')[28/Dec/2016 17:58:50]"GET /search/?q=code HTTP/1.1" 200 395答案1
小编典典没有为[过滤]注册的[查询]
据我所知,您正在运行ES 5.0,并且正在发送的filtered查询已在ES 2.x中弃用,在ES
5.x中已删除。
您需要将其替换为bool/filter查询。
因此,如果您有这样的事情:
{ "query": { "filtered": { "filter": {} } }}只需将其替换为
{ "query": { "bool": { "filter": {} } }}
ElasticSearch 429 Too Many Requests circuit_breaking_exception
Error message
{
"statusCode": 429,
"error": "Too Many Requests",
"message": "[circuit_breaking_exception]
[parent] Data too large, data for [<http_request>] would be [2087772160/1.9gb],
which is larger than the limit of [1503238553/1.3gb],
real usage: [2087772160/1.9gb],
new bytes reserved: [0/0b],
usages [request=0/0b, fielddata=1219/1.1kb, in_flight_requests=0/0b, accounting=605971/591.7kb],
with { bytes_wanted=2087772160 & bytes_limit=1503238553 & durability=\"PERMANENT\" }"
}此时 kibana 已经无法访问,所以必须登陆服务器排查问题。下面先给出解决方法,后介绍问题原因。
解决方案
查看服务状态
# supervisorctl status
elasticSearch RUNNING pid 1838, uptime 6:03:37
jaeger-collector RUNNING pid 2572, uptime 6:03:10
jaeger-query RUNNING pid 2571, uptime 6:03:10
kibana RUNNING pid 5048, uptime 5:42:22发现ES及其它服务运行状态都正常。
查看节点状态 (略)
curl -XGET ''[http://localhost:9200/\_nodes/stats?pretty](http://localhost:9200/_nodes/stats?pretty)'' |less清理fileddata cache
curl -XPOST ''[http://localhost:9200/\_all/\_cache/clear?fielddata=true](http://localhost:9200/_all/_cache/clear?fielddata=true)''尝试清理fileddata cache后,发现服务仍然无法正常访问。
查看所有indexs
curl -X GET ''[http://127.0.0.1:9200/\_cat/indices?v](http://127.0.0.1:9200/_cat/indices?v)''删除所有 jaeger开头 的index
如果你的数据是日志或非重要的数据,可以把相关的index先删除。
curl -X DELETE "localhost:9200/jaeger\*?pretty"
修改fielddata配置
curl -H "Content-Type: application/json" -XPUT ''[http://localhost:9200/\_cluster/settings](http://localhost:9200/_cluster/settings)'' -d ''{
"persistent" : {
"indices.breaker.fielddata.limit":"40%"
}
}''这个限制是按对内存的百分比设置的。fielddata断路器默认设置堆的 60% 作为 fielddata 大小的上限。
解决问题的关键点在这,修改 indices.breaker.fielddata.limit 的默认配置。修改后重启服务器就OK了。
重启服务
supervisorctl restart elasticSearch && supervisorctl restart jaeger-collector && supervisorctl restart jaeger-query && supervisorctl restart kibana问题分析
经排查,原来是ES默认的缓存设置让缓存区只进不出引起的,具体分析一下。
- ES缓存区概述
- ES在查询时,会将索引数据缓存在内存(JVM)中:

上图是ES的JVM Heap中的状况,可以看到有两条界限:驱逐线 和 断路器。当缓存数据到达驱逐线时,会自动驱逐掉部分数据,把缓存保持在安全的范围内。
当用户准备执行某个查询操作时,断路器就起作用了,缓存数据+当前查询需要缓存的数据量到达断路器限制时,会返回Data too large错误,阻止用户进行这个查询操作。
ES把缓存数据分成两类,FieldData和其他数据,我们接下来详细看FieldData,它是造成我们这次异常的“元凶”。
FieldData
ES配置中提到的FieldData指的是字段数据。当排序(sort),统计(aggs)时,ES把涉及到的字段数据全部读取到内存(JVM Heap)中进行操作。相当于进行了数据缓存,提升查询效率。
监控FieldData
仔细监控fielddata使用了多少内存以及是否有数据被驱逐是非常重要的。 ielddata缓存使用可以通过下面的方式来监控
# 对于单个索引使用 {ref}indices-stats.html[indices-stats API]
GET /_stats/fielddata?fields=*
# 对于单个节点使用 {ref}cluster-nodes-stats.html[nodes-stats API]
GET /_nodes/stats/indices/fielddata?fields=*
#或者甚至单个节点单个索引
GET /_nodes/stats/indices/fielddata?level=indices&fields=*
# 通过设置 ?fields=* 内存使用按照每个字段分解了fielddata中的memory_size_in_bytes表示已使用的内存总数,而evictions(驱逐)为0。且经过一段时间观察,字段所占内存大小都没有变化。由此推断,当下的缓存处于无法有效驱逐的状态。
Cache配置
indices.fielddata.cache.size 配置fieldData的Cache大小,可以配百分比也可以配一个准确的数值。cache到达约定的内存大小时会自动清理,驱逐一部分FieldData数据以便容纳新数据。默认值为unbounded无限。
indices.fielddata.cache.expire用于约定多久没有访问到的数据会被驱逐,默认值为-1,即无限。expire配置不推荐使用,按时间驱逐数据会大量消耗性能。而且这个设置在不久之后的版本中将会废弃。
看来,Data too large异常就是由于fielddata.cache的默认值为unbounded导致的了。
FieldData格式
除了缓存取大小之外,我们还可以控制字段数据缓存到内存中的格式。
在mapping中,我们可以这样设置:
{
"tag": {
"type": "string",
"fielddata": {
"format": "fst"
}
}
}对于String类型,format 有以下几种:paged_bytes (默认):使用大量的内存来存储这个字段的terms和索引。fst:用 FST 的形式来存储 terms。这在 terms 有较多共同前缀的情况下可以节约使用的内存,但访问速度上比 paged_bytes 要慢。doc_values:fieldData 始终存放在 disk 中,不加载进内存。访问速度最慢且只有在 index:no/not_analyzed 的情况适用。
对于数字和地理数据也有可选的 format,但相对 String 更为简单,具体可在api中查看。
从上面我们可以得知一个信息:我们除了配置缓存区大小以外,还可以对不是特别重要却量很大的 String 类型字段选择使用 fst 缓存类型来压缩大小。
断路器
fieldData 的缓存配置中,有一个点会引起我们的疑问:fielddata 的大小是在数据被加载之后才校验的。假如下一个查询准备加载进来的 fieldData 让缓存区超过可用堆大小会发生什么?很遗憾的是,它将产生一个 OOM 异常。
断路器就是用来控制 cache 加载的,它预估当前查询申请使用内存的量,并加以限制。断路器的配置如下:
indices.breaker.fielddata.limit:这个 fielddata 断路器限制fielddata的大小,默认情况下为堆大小的60%。
indices.breaker.request.limit:这个 request 断路器估算完成查询的其他部分要求的结构的大小, 默认情况下限制它们到堆大小的40%。
indices.breaker.total.limit:这个 total 断路器封装了 request 和 fielddata 断路器去确保默认情况下这2个部分使用的总内存不超过堆大小的70%。查询
/_cluster/settings设置
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.fielddata.limit": "60%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.request.limit": "40%"
}
}
PUT /_cluster/settings
{
"persistent": {
"indices.breaker.total.limit": "70%"
}
}
断路器限制可以通过文件 config/elasticsearch.yml 指定,也可以在集群上动态更新:
PUT /_cluster/settings
{
"persistent" : {
"indices.breaker.fielddata.limit" : 40%
}
}当缓存区大小到达断路器所配置的大小时会发生什么事呢?答案是:会返回开头我们说的 Data too large 异常。这个设定是希望引起用户对 ES 服务的反思,我们的配置有问题吗?是不是查询语句的形式不对,一条查询语句需要使用这么多缓存吗?
在文件 config/elasticsearch.yml 文件中设置缓存使用回收
indices.fielddata.cache.size: 40%总结
- 这次Data too large异常是ES默认配置的一个坑,我们没有配置indices.fielddata.cache.size,它就不回收缓存了。缓存到达限制大小,无法往里插入数据。个人感觉这个默认配置不友好,不知ES是否在未来版本有所改进。
- 当前fieldData缓存区大小 < indices.fielddata.cache.size
- 当前fieldData缓存区大小+下一个查询加载进来的fieldData < indices.breaker.fielddata.limit
- fielddata.limit的配置需要比fielddata.cache.size稍大。而fieldData缓存到达fielddata.cache.size的时候就会启动自动清理机制。expire配置不建议使用。
- indices.breaker.request.limit限制查询的其他部分需要用的内存大小。indices.breaker.total.limit限制总(fieldData+其他部分)大小。
- 创建mapping时,可以设置fieldData format控制缓存数据格式。
参考
https://www.codetd.com/en/article/8070413
https://elasticsearch.cn/question/6642
Doc Values and Fielddata限制内存使用
https://discuss.elastic.co/t/unable-to-start-kibana-and-circuit-breaking-exception/191860
https://www.cnblogs.com/sanduzxcvbnm/p/11982476.html
https://www.elastic.co/guide/en/elasticsearch/reference/6.5/indices-clearcache.html

Elasticsearch document_missing_exception
是的,您是正确的,document_missing_exception仅是由于ES中不存在所请求的文档,您可以轻松查看ES源代码以发现该问题,并且仅在被调用的地方来自UpdateRequest和this方法注释对此进行了更好的解释:
通过ES代码
/**
* Sets the index request to be used if the document does not exists. Otherwise,a
* {@link org.elasticsearch.index.engine.DocumentMissingException} is thrown.
*/
public UpdateRequest upsert(IndexRequest upsertRequest) {
this.upsertRequest = upsertRequest;
return this;
}
今天关于已解决:Elasticsearch 报错:exception [type=search_phase_execution_exception, reason=all shards failed]的讲解已经结束,谢谢您的阅读,如果想了解更多关于.search.SearchPhaseExecutionException: all shards failed、Django/ Haystack错误:elasticsearch.exceptions.RequestError:TransportError(400,'parsing_exception',…)、ElasticSearch 429 Too Many Requests circuit_breaking_exception、Elasticsearch document_missing_exception的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

