在这里,我们将给大家分享关于SQLServer-尝试对表进行非规范化的知识,同时也会涉及到如何更有效地.net–我们应该对数据库进行非规范化以提高性能吗?、nosql–RavenDB–修补非规范化引用
在这里,我们将给大家分享关于SQL Server-尝试对表进行非规范化的知识,同时也会涉及到如何更有效地.net – 我们应该对数据库进行非规范化以提高性能吗?、nosql – RavenDB – 修补非规范化引用的集合、PHP-在CQRS中进行非规范化的最佳实践是什么?、SQL Server - SQL Server 2019 启用SQL Server验证Super Administrator(sa)用户登录的内容。
本文目录一览:- SQL Server-尝试对表进行非规范化
- .net – 我们应该对数据库进行非规范化以提高性能吗?
- nosql – RavenDB – 修补非规范化引用的集合
- PHP-在CQRS中进行非规范化的最佳实践是什么?
- SQL Server - SQL Server 2019 启用SQL Server验证Super Administrator(sa)用户登录

SQL Server-尝试对表进行非规范化
对标题表示歉意,但我试图做的事情甚至超出我的水平,甚至让我解释一下。
假设我有一个表,其中包含变量人员,食品和数量:
Person food Amount Mike Butter 3 Mike Milk 4 Mike Chicken 2 Tim Milk 4 John Chicken 2通过在查询中将表与其自身连接起来,我成功地列出了一个列表,其中食物是新变量的基础,而值是数量。上表将变为:
Person Butter Milk ChickenMike 3 4 2该代码大约是:
Select a.person, b.amount as Butter, c.amount as Milk, d.amount as Chickenfrom PersonFoodAmount ainner join PersonFoodAmount b on a.person = b.personinner join PersonFoodAmount c on a.person=c.personwhere b.food=''Butter'' and c.food=''Milk''and d.food=''Chicken''现在,这给了我迈克,因为他已选中所有复选框。但是我还需要部分匹配:
Person Butter Milk ChickenMike 3 4 2Tim NULL 4 NULLJohn NULL Null 2我尝试了所有类型的连接,包括完全外部连接,但我仍然只能得到配备完整冰箱的人员。
有什么建议?
答案1
小编典典您可以使用Pivot进行此操作。
DECLARE @PersonStuff TABLE (Person varchar(10), Food varchar(10), Amount INT)INSERT INTO @PersonStuff VALUES(''Mike'',''Butter'', 3),(''Mike'',''Milk'', 4),(''Mike'',''Chicken'', 2),(''Tim'',''Milk'', 4),(''John'',''Chicken'', 2)SELECT * FROM ( SELECT * FROM @PersonStuff ) AS SourceTablePIVOT ( AVG(Amount) FOR Food IN ( [Butter],[Milk],[Chicken] ) ) AS PivotTable结果:
Person Butter Milk ChickenJohn NULL NULL 2Mike 3 4 2Tim NULL 4 NULL
.net – 我们应该对数据库进行非规范化以提高性能吗?
我们的Measurement实体类是持有单一度量的类,如下所示:
public class Measurement
{
public virtual Guid Id { get; private set; }
public virtual Device Device { get; private set; }
public virtual Timestamp Timestamp { get; private set; }
public virtual IList<VectorValue> Vectors { get; private set; }
}
向量值存储在单独的表中,以便它们中的每一个通过外键引用其父测量.
我们已经做了几件事情来确保生成的sql(合理)的效率:我们使用Guid.Comb来生成ID,我们在单个事务中刷新大约500个项目,ADO.Net批量大小设置为100(I认为sqlIte不支持批量更新,但稍后可能会有用.
问题
现在我们可以每秒插入150-200个测量(这不够快,尽管这是我们正在讨论的sqlite).看看生成的sql,我们可以看到,在单个事务中,我们插入(如预期的):
> 1个时间戳
> 1测量
> 8个矢量值
这意味着我们实际上在做多10倍的单表插入:1500-2000每秒.
如果我们将所有(所有8个向量值和时间戳)都放入测量表(添加9个专用列)中,似乎可以将插入速度提高10倍.
切换到sql服务器将提高性能,但是我们想知道是否有可能避免与数据库组织方式相关的不必要的性能成本.
[编辑]
使用内存中的sqlite我可以获得约350个项目/秒(3500个单表插入),我相信与NHibernate一样好(参考这篇文章:http://ayende.com/Blog/archive/2009/08/22/nhibernate-perf-tricks.aspx).
但是我也可以切换到sql服务器并停止假设事情,对吧?一旦我测试,我会更新我的帖子.
[更新]
我已经转移到sql服务器并平整了我的层次结构,我通过存储3000个测量/秒来测试它几个小时,似乎工作正常.
解决方法
基本上,您的理想情况可能是拥有一个单独的数据库(或者甚至只需在同一个数据库中分离表,如果需要),将数据采集作为一个完全独立的事项,将其以需要处理的格式它.
这并不意味着您需要丢弃您在当前数据库结构周围创建的实体:只要您也应该创建这些非规范化表并使其成为一个ETL.您可以使用SSIS(尽管它仍然是相当错误和易怒)将数据定期进入您的标准化表,甚至是C#应用程序或其他批量加载过程.
编辑:这是假设,当然,您的分析不需要实时完成:只是数据的收集.人们通常不需要(有时甚至不愿意)实时更新分析数据.这是在纸上听起来不错的东西之一,但实际上是没有必要的.
如果有些分析这些数据的人需要实时访问,那么您可以根据需要构建一个针对“裸机”非规范化事务数据的工具集,但是当您真正了解需求时,您可以非常频繁地执行分析,不需要真正的实时(在某些情况下,他们更喜欢使用更静态的数据集!):在这种情况下,定期的ETL可以运行得很好.你只需要与目标用户聚在一起,找出真正需要的内容.

nosql – RavenDB – 修补非规范化引用的集合
public class Movie
{
public string Id { get; set; }
public string Name { get; set; }
public List<ActorReference> Actors { get; set; }
}
public class Actor
{
public string Id { get; set; }
public string Name { get; set; }
public string Biography { get; set; }
public string AnotherDetailProperty { get; set; }
}
public class ActorReference
{
public string Id { get; set; }
public string Name { get; set; }
}
现在,如果演员名称发生变化我想确保,所有引用电影也会更新.因此,我首先创建一个索引,让我查询涉及特定actor的所有电影:
public class Movies_ByActorId : AbstractIndexCreationTask<Movie>
{
public Movies_ByActorId()
{
Map = movies => from movie in movies
from actor in movie.Actors
select new { ActorId = actor.Id };
}
}
好的,现在我想解雇补丁命令……
Session.Advanced.DatabaseCommands.UpdateByIndex(
"Movies/ByActorId",new IndexQuery
{
Query = "ActorId:" + actorWhoseNameHasChanged.Id
},new[]
{
new PatchRequest
{
Type = PatchCommandType.Modify,Name = "Actors",nested = new[]
{
// WHAT TO DO HERE?
}
}
},allowStale: false);
有人可以帮我完成上面的代码块,因为我完全不知道,我怎么只能更新代表改变的actor的非规范化引用的名称.
我担心RavendB不支持这种补丁请求,我需要手动加载和存储所有电影,这是我出于性能原因肯定要避免的.
解决方法

PHP-在CQRS中进行非规范化的最佳实践是什么?
我正在尝试创建一个守护进程来对我的数据库进行非规范化.
我使用ActiveMQ作为队列管理器
我有2个数据库:关系数据库(写复制)和非规范化数据库(用于读取)
我的问题是对我的真实数据库进行非规范化的最佳实践是什么,我有一些想法:
> MySQL代理(带有lua)读取队列(这是可能的)
>在MysqL中触发
> Java守护程序作为读取队列的服务
> Cron标签? (但我会有很多延迟时间
通过研究Eventide如何实现(在Ruby中)https://eventide-project.org/,您可以学到更多有关事件源的知识.
我也对使用域事件的CQRS进行了简短介绍:http://lucisferre.net/2010/11/04/a-brief-introduction-to-cqrs/
但是,这并不能真正回答您的紧迫问题,最终,采购可能不适合您.由于您已将“写入”模型的状态存储在关系数据库中,因此触发器是一种可行的解决方法,但是您将使系统变得非常以数据为中心.如果您可以使用代码中的触发器来完成相同的事情,那将更加干净和可测试.
为此,我仍将使用域事件模式,并使用事件总线将事件发布到负责更新读取模型的事件处理程序.
可以将这些事件和处理程序想像成sql触发器,但要基于您的域设计及其行为. Udi Dahan围绕这种方法有很多很好的资料,其中使用域事件来更新读取模型,但不使用事件源. http://www.udidahan.com/?blog=true
用户登录")
SQL Server - SQL Server 2019 启用SQL Server验证Super Administrator(sa)用户登录
SQL Server 2019 启用SQL Server验证Super Administrator(sa)用户登录
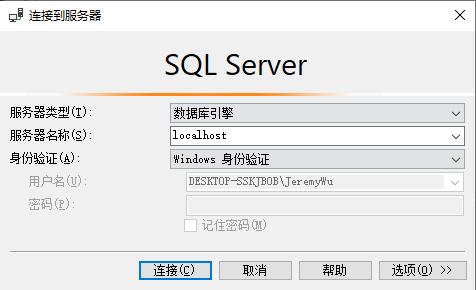
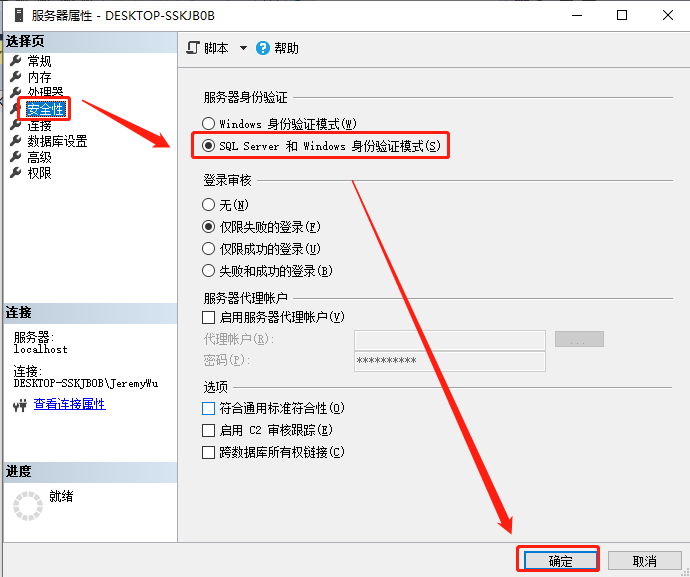
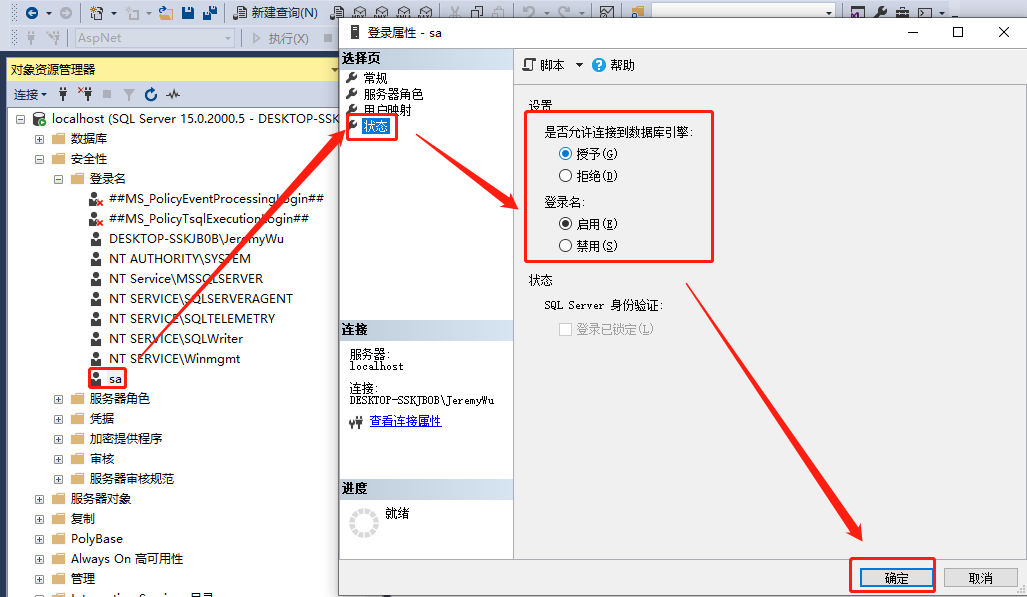
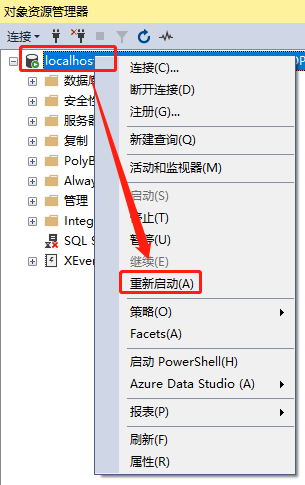
在项目开发过程中通常连接SQL Server时需要用SQL Server方式,所以我们需要先开启这种验证方式,然后再根据需要添加项目用户,设定相关权限。
先用Windows身份验证方式连接数据库,然后按照如下几步设置,完成后重启服务,切换验证方式即可使用sa登录。

作者:Jeremy.Wu
出处:https://www.cnblogs.com/jeremywucnblog/
本文版权归作者和博客园共有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文连接,否则保留追究法律责任的权利。
关于SQL Server-尝试对表进行非规范化的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于.net – 我们应该对数据库进行非规范化以提高性能吗?、nosql – RavenDB – 修补非规范化引用的集合、PHP-在CQRS中进行非规范化的最佳实践是什么?、SQL Server - SQL Server 2019 启用SQL Server验证Super Administrator(sa)用户登录的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

