在这篇文章中,我们将为您详细介绍ComputerSystemsAProgrammer''sPerspective的内容。此外,我们还会涉及一些关于2016/08/30BusinessLogicadif
在这篇文章中,我们将为您详细介绍Computer Systems A Programmer''s Perspective的内容。此外,我们还会涉及一些关于2016/08/30 Business Logic a different perspective、8 Traits of an Experienced Programmer that every beginner programmer should know、All I Need To Know To Be A Better Programmer I Learned In Kindergarten、Be an female programmer的知识,以帮助您更全面地了解这个主题。
本文目录一览:- Computer Systems A Programmer''s Perspective
- 2016/08/30 Business Logic a different perspective
- 8 Traits of an Experienced Programmer that every beginner programmer should know
- All I Need To Know To Be A Better Programmer I Learned In Kindergarten
- Be an female programmer

Computer Systems A Programmer''s Perspective
阅读笔记 摘自 <i></i> 《深入理解计算机系统》<i></i > 仅记录了感兴趣的内容
- 计算机系统漫游
- 信息就是位 + 上下文
- hello.c 经历的四个阶段
- shell 命令解释器 -- 运行程序
- 系统的硬件组成
- 操作系统管理硬件
- 进程
- 线程
- 虚拟内存
- 文件
- 系统之间利用网络通信
- 并发和并行
- 信息的表示和处理
- 信息存储
- 十六进制表示法
- 字数据大小
- 寻址和字节顺序
- 表示字符串
- 信息存储
- 程序的机器级表示
- C 程序代码示例
- 数据格式
- 访问信息
- 操作数指示符
- 数据传送指令
- 数据传送示例
- 压入和弹出栈数据
- 算术和逻辑操作
- ①加载有效地址
- ②一元和二元操作
- ③移位操作
- 特殊的算术操作
- 控制
- 条件码
- 访问条件码
- 跳转指令
- 跳转指令的编码
- 实现条件分支
- 循环
- 过程
- 运行时栈
- 转移控制
- 数据传送
- 栈上的局部存储
- 寄存器中的局部存储空间
- 递归过程
- 数组分配和访问
- 使用 GDB 调试器
- 内存越界引用和缓冲区溢出
- 对抗缓冲区溢出攻击
- 支持可变长栈帧
- 处理器体系结构
- 程序员可见的状态
- 指令编码
- Y86-64 异常
- Y86-64 的顺序实现
- 存储器层次结构
- 链接
- 编译器驱动程序
- 静态链接
- 目标文件
- 可重定位目标文件
- 符号解析和静态库
- 重定位
- 重定位条目
- 可执行目标文件
- 加载可执行目标文件
- 动态链接共享库
- 从应用程序中加载和链接共享库
- 位置无关代码
- 处理目标文件的工具
- 异常控制流 (ECF)
- 虚拟内存
- 虚拟地址和物理地址
- 操作系统内存管理
- 页表
- 地址翻译
- Linux 虚拟内存机制
- 内存映射机制
- 系统级 I/O
- 网络编程
- 并发编程
计算机系统漫游
计算机系统是由硬件和软件组成的,它们共同工作来运行应用程序
/*hello.c*/
#include<stdio.h>
int main()
{
printf("hello,word\n");
return 0;
}
本次通过追踪 hello 程序的生命周期来开始对系统的初步了解
信息就是位 + 上下文
位 源程序实际上就是一个由值 0 和 1 组成的位(又称比特)序列
大部分的现代计算机系统都使用 ASCII 标准来表示文本字符,这种方式实际上就是用一个唯一的单字节大小的整数值来表示每个字符
对于计算机系统来说,信息就是位,都是由一串比特表示,而区分不同数据对象的唯一方法是我们读到这些数据对象时的上下文,这里先简单理解为通过上下文的信息识别该数据的类型
hello.c 经历的四个阶段
在 Unix 系统上,从源文件到目标文件的转化是由编译器驱动程序完成的:

-
预处理阶段:其实就是预处理 C 程序文件头,并把它直接插入程序文本中,结果就得到另一个 C 程序,通常以.i 作为文件拓展名
-
编译阶段:编译器 (ccl) 将文本文件 hello.i 翻译成文本文件 hello.s,汇编语言程序。该程序包含函数 main 的定义,如下所示:
main:
subq $8, %rsp
movl $.LCO, %edi
call puts
movl $0, %eax
addq $8, %rsp
ret
-
汇编阶段:汇编器(as)将 hello.s 翻译成机器语言指令,把这些指令打包成一种叫做可重定位目标程序的格式,并将结果保存在目标文件 hello.o 中。hello.o 是个二进制文件,都是指令编码
-
链接阶段:hello 程序调用了 printf 函数,它是每个 C 编译器都提供的标准 C 库中的一个函数。printf 函数存在于一个名为 printf.o 的单独的预编译好了的目标文件中,而这个文件必须以某种方式合并到我们的 hello.o 程序中那个。链接器(ld)就负责处理这种合并。结果就得到 hello 文件,他是一个可执行目标文件(简称可执行文件),可以被加载到内存中,由系统执行
shell 命令解释器 -- 运行程序
shell 是一个命令行解释器,它输出一个提示符,等待输入一个命令行,然后执行这个命令,如果该命令行的第一个单词不是一个内置的 shell 命令,那么 shell 就会假设这是一个可执行文件的名字,它将加载并执行这个文件
在 Unix 系统下,我们要运行 hello 程序可以通过在 shell 中输入它的文件名:
linux> ./hello
hello,word
linux>
系统的硬件组成
为了理解运行 hello 程序时发送了什么,我们需要了解一个典型系统的硬件知识
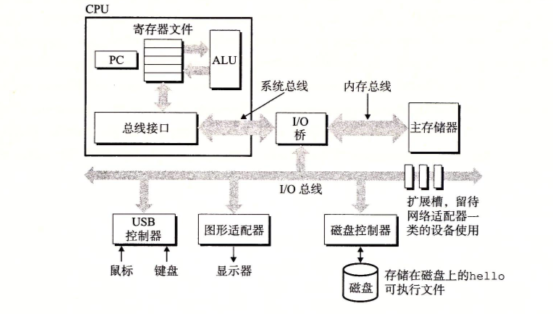
-
总线 贯穿整个系统的一组电子管道,称作总线,它携带信息字节并负责在各个部件间传递。通常总线被设计成传送定长的字节块,也就是字。不同系统设定的字节数不尽相同,主要分为 32 位和 64 位。
-
I/O 设备 I/O 设备是系统与外部世界的联系通道。每个 I/O 设备都通过一个控制器或者适配器与 I/O 总线相连。控制器和适配器之间的区别主要在于他们的封装方式。控制器是 I/O 设备本身或者系统的主印刷电路板(即主板)上的芯片组。而适配器则是一块插在主板插槽上的卡。
-
主存 主存是一个临时存储设备,在处理器执行程序时,用来存放程序和程序处理的数据。而存储器是一个线性的字节数组,每个字节都有其唯一的地址(数组索引),这些地址都是从零开始的,为了便于地址分配,进程资源管理等,后期还会引入虚拟内存的概率。
-
处理器 中央处理单元(CPU),简称处理器,是解释(或执行)存储在主存中指令的引擎。处理器的核心是一个大小为一个字的存储设备(或寄存器),称为程序计数器(PC)。在任何时刻,PC 都指向主存中的某条机器语言指令(即含有该指令的地址)。从系统通电开始,直到系统断电,处理器一直在不断地执行程序计数器指向的指令,再更新程序计数器。 处理器看上去是按照一个非常简单的指令执行模型来操作的,这个模型是由指令集架构决定的。在这个模型中,指令按照严格的顺序执行,而执行一条指令包含执行一系列的步骤。 处理器看上去是它的指令集架构的简单实现,但是实际上现代处理器使用了非常复杂的机制来加速程序的执行。因此,我们将处理器的指令集架构和处理器的微体系结构区分开来:指令集架构描述的是每条机器代码的效果;而微体系结构描述的是处理器实际上是如何实现的。
了解这些基础硬件,应该能够大概描述出运行一个程序所进行的操作。
- 从键盘上读取 hello 命令
- 从磁盘加载可执行文件到主存
- 将输出字符串从存储器写到显示器
- ...
为了加快程序运行的速度,开始出现高速缓存存储器,存储设备形成层次结构
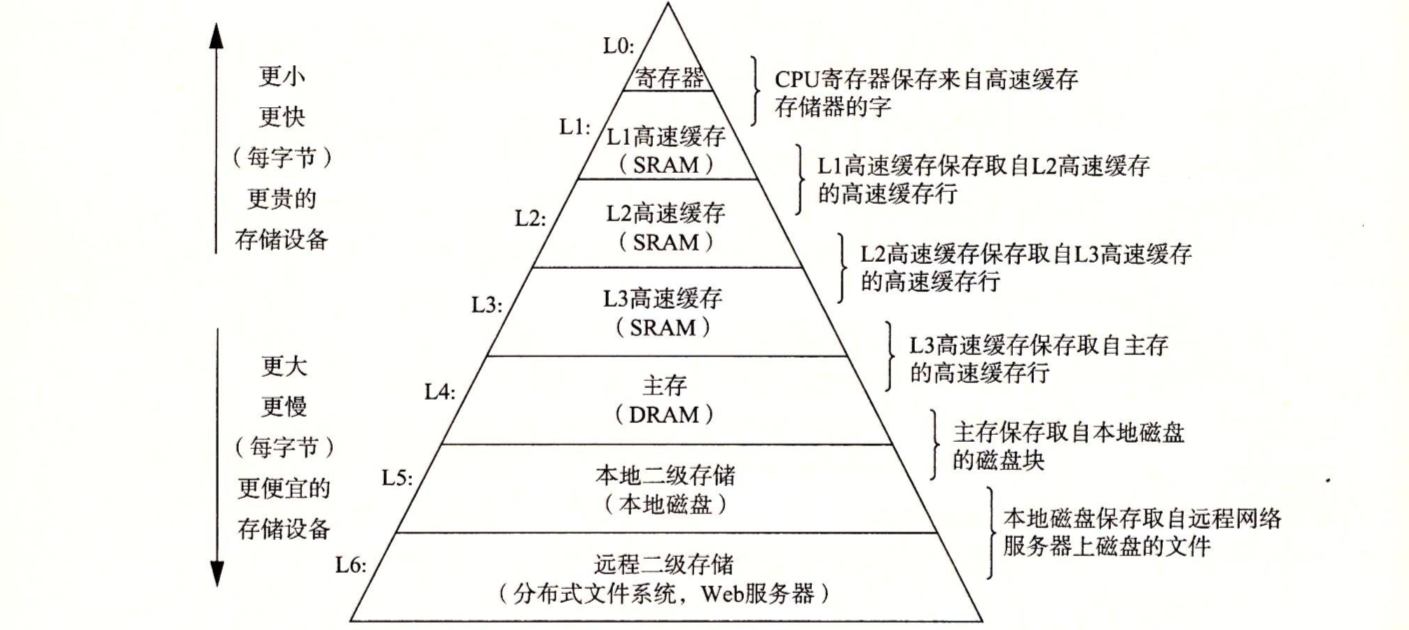
操作系统管理硬件
程序并没有直接访问键盘、显示器、磁盘或者主存,而是依靠操作系统提供的服务,我们可以把操作系统看成是应用程序和硬件之间插入的一层软件,所有应用程序对硬件的操作的尝试都必须通过操作系统
操作系统有两个基本功能: (1)防止硬件被失控的应用程序滥用; (2)向应用程序提供简单一致的机制来控制复杂而又通常大不相同的低级硬件设备;
操作系统通过几个抽象概念来实现这两个功能:进程、虚拟内存、文件
进程
像 hello 这样的程序在现代系统上运行时,操作系统会提供一种假象,就好像系统上只有这个程序在运行。程序看上去是独占地使用处理器、主存和 I/O 设备。
进程实际上是操作系统对一个正在运行的程序的一种抽象。在一个系统上可以同时运行多个程序,而每个进程都好像在独占地使用硬件。而并发运行,则是说一个进程的指令和另一个进程的指令是交错执行的。而操作系统实现这种交错执行的机制称为上下文切换。
操作系统保持跟踪进程运行所需的所有状态信息。这种状态,也就是上下文,包括许多信息,比如 PC 和寄存器文件的当前值,以及主存的内容。
在任何一个时刻,单处理器系统都只能执行一个进程的代码。当操作系统决定要把控制权从当前进程转移到某个新进程时,就会进行上下文切换,即保存当前进程的上下文、恢复新进程的上下文,然后将控制权传递到新进程。新进程就会从它上次停止的地方开始
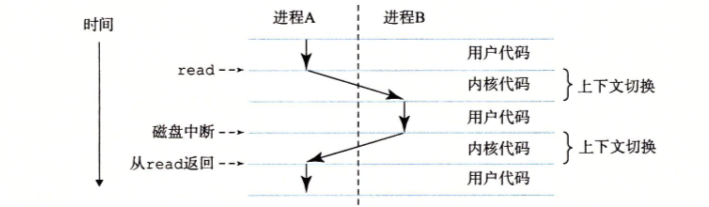
线程
现代系统中,一个进程实际上可以由多个称为线程的执行单元组成,每个线程都运行在进程的上下文中,并共享同样的代码和全局数据。由于网络服务器对并行处理的需求,线程成为越来越多重要的编程模型,因为多线程之间比多进程之间更容易共享数据,比进程更高效
虚拟内存
虚拟内存是一个抽象概念,它为每个进程提供了一个假象,即每个进程都在独占地使用主存。每个进程看到的内存都是一致的,称为虚拟地址空间。
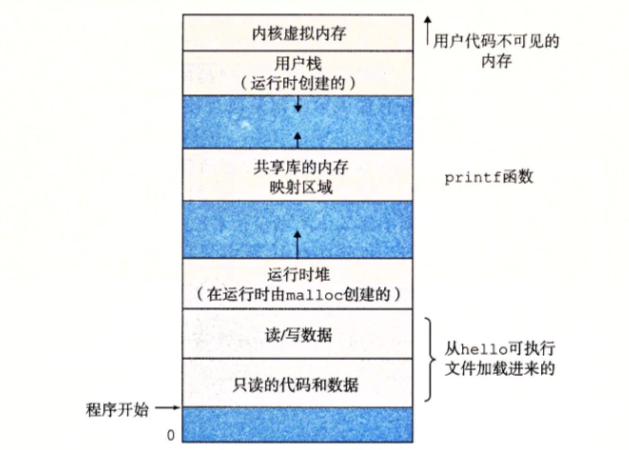
- 程序代码和数据。对所有进程来说,代码是从同一个固定地址开始,紧接着的是和 C 全局变量相对应的数据位置。代码和数据区是直接按照可执行目标文件的内容初始化的
- 堆。代码和数据区后紧随着的是运行时堆。代码和数据区在进程一开始运行时就被指定了大小,与此不同,当调用像 malloc 和 free 这样的 C 标准库函数时,堆可以在运行时动态扩展和收缩。
- 共享库。大约在地址空间的中间部分是一块用来存放 C 标准库和数学库这样的共享库的代码和数据的区域
- 栈。位于用户虚拟地址空间顶部的用户栈,编译器用它来实现函数调用。和堆一样,用户栈在程序执行期间可以动态扩展和收缩。每次调用一个函数时,栈就好增长;从一个函数返回时,栈就会收缩
- 内核虚拟地址。地址空间顶部的区域是为内核保留的。不允许应用程序读写这个区域的内容或者直接调用内核代码定义的函数,必须调用内核来执行这些操作。
虚拟内存的运作需要硬件和操作系统软件之间精密复杂的交互,包括对处理器生成的每个地址的硬件翻译。基本思想是把一个进程虚拟内存的内容存储在磁盘上,然后用主存作为磁盘的高速缓存。
文件
文件就是字节序列。每个外部设备都可以看成是文件,系统中的所有输入输出都是通过使用一小组称为 Unix I/O 的系统函数调用读写文件来实现的
它向应用程序提供了一个统一的试图,来看待系统中可能含有的所有各式各样的 I/O 设备。
系统之间利用网络通信
系统经常通过网络和其他系统连接到一起,从一个单独的系统来看,网络可视为一个 I/O 设备。当系统从主存赋值一串字节到网络适配器时,数据流经过网络到达另一台机器。相似地,系统可以读取其他机器发送来的数据,并把数据复制到自己的内存
譬如:客户端和服务器之间交互的类型在所有网络应用中是最典型的
并发和并行
数字计算机的整个历史中,有两个需求是驱动进步的持续动力:一个是我们想要计算机做得更多,另一个是我们想要计算机运行得更快。
并发:指一个同时具有多个活动的系统; 并行:指的是用并发来是一个系统运行得更快
按照系统层次结构中由高到低的顺序重点强调三个层次
1. 线程级并发 2. 指令级并行 3. 单指令、多数据并行
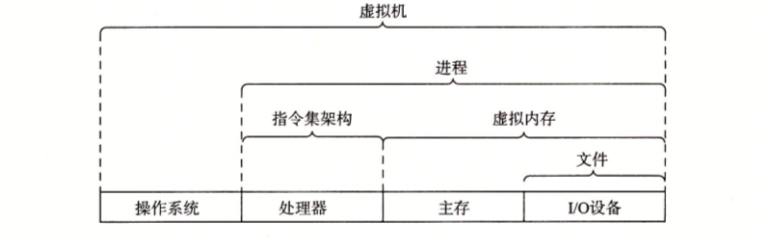
计算机系统提供的一些抽象,计算机系统中的一个重大主题就是提供不同层次的抽象表示,来隐藏实际实现的复杂性
信息的表示和处理
信息存储
计算机通常使用 8 位的块,或者字节(byte), 作为最小的可寻址的内存单位,而不是访问内存中单独的位
机器级程序将内存视为一个非常大的字节数组,称为虚拟内存。内存的每个字节都由一个唯一的数字来标识,称它为地址,所有可能地址的集合称为虚拟地址空间。
每个程序对象可以简单地视为一个字节块,而程序本身就是一个字节序列。
十六进制表示法
在 C 语言中,以 0x 或 0X 开头的数字常量被认为是十六进制 (简写为 “hex”) 的值。例如 0xFA1D37B

记住十六进制数字 A、C 和 F 相应的十进制值 A->10 ; C->12 ; F->15
关于进制间的转换,熟能生巧,忘了就查资料,通常用脚本或工具会比较多
字数据大小
每台计算机都有一个字长,也就是处理器一次处理的最大数据块长度。因为虚拟地址是以这样的一个字来编码的,所以字长决定的最重要的系统参数就是虚拟地址空间的最大大小。也就是说,对于一个字长为 w 位的机器而言,虚拟地址的范围就是 0~2^w-1, 程序最多访问 2^w 个字节
32 位字长限制虚拟地址空间为 4GB,扩展到 64 位字长使得虚拟地址空间为 16EB
"32 位程序" 或 "64 位程序" 区别在于该程序如何编译的,而不是其运行的机器类型
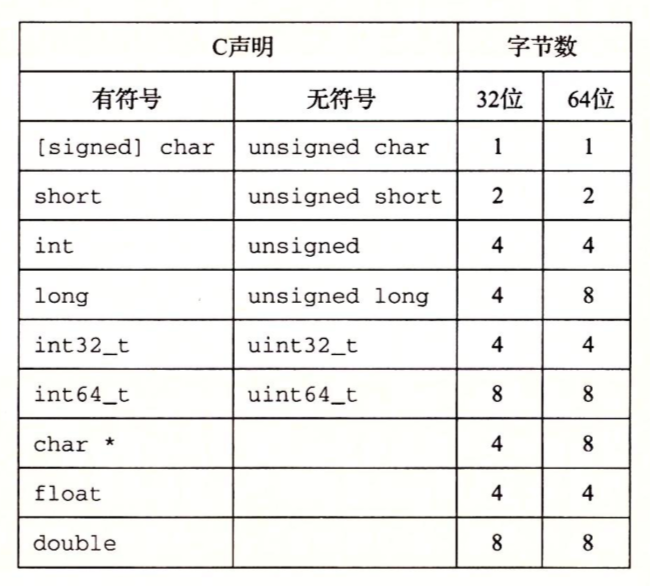 基本 C 数据类型的典型大小(以字节为单位),分配的字节数受程序是如何编译的影响而变化
基本 C 数据类型的典型大小(以字节为单位),分配的字节数受程序是如何编译的影响而变化
寻址和字节顺序
大端法:最高有效字节在最前面 小端法:最低有效字节在最前面
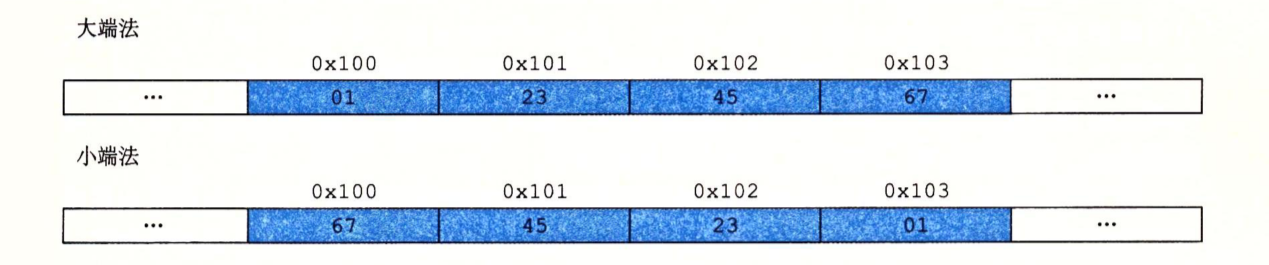
X86 体系都是选用小端模式
这种字节顺序在单一系统上是没有什么区别的,不过有时候,字节顺序会成为问题。
首先是在不同类型的机器之间通过网络传送二进制数据时,一个常见的问题是当小端法机器产生的数据被发送到大端法机器或者反过来时,接收程序会发现,字里的字节成了反序的,这就需要机器在发送时转化为网络标准,而接收方则将网络标准转化为它的内部表示
第二种情况,当阅读表示整数数据的字节序列时字节顺序也很重要。
第三种.......
表示字符串
每个字符都由某个标准编码来表示,最常见的是 ASCII 字符码
使用 ASCII 码作为字符码的任何系统上都将得到相同的结果,与字节顺序和字大小规则无关。因此,文本数据比二进制数据具有更强的平台独立性
ASCII 字符集适合编码英文文档,但是在表达一些特殊字符方面并没有太多办法,因此引入了 unicode 编码,称为 "统一字符集"
关于无符号数、有符号数、小数、浮点数四则运算、规格化、运算溢出等知识,在大学的专业基础课中都有学过,这里不再做补充,理解就好,还是一样,需要用的时候忘了就查资料
需要时,为加深理解再回来重新整理
程序的机器级表示
IA32,x86-64 的 32 位前身,是 Intel 在 1985 年提出的 ISA,指令集体系结构或指令集架构,定义机器级程序的格式和行为,定义处理器状态、指令的格式,以及每条指令对状态的影响
C 程序代码示例
目标是利用编译器 [GCC](https://zh.wikipedia.org/wiki/GCC) 展示如何查看汇编代码,并将它反向映射到高级编程语言中的结构
/*p.c*/
#include <stdio.h>
long mult2(long,long);
void multstore(long x,long y,long *dest){
long t = mult2(x,y);
*dest = t;
}
在命令行上使用 “-S” 选项,就能看到 C 语言编译器产生的汇编代码:
linux> gcc -og -S p.c
这会使 GCC 运行编译器,产生一个汇编文件 p.s,但是不做其他进一步的工作(通常情况下,它还会继续调用汇编器产生目标代码文件)
汇编代码文件包含各种声明:
.file "p.c"
.text
.globl multstore
.type multstore, @function
multstore:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $48, %rsp
movq %rdi, -24(%rbp)
movq %rsi, -32(%rbp)
movq %rdx, -40(%rbp)
movq -32(%rbp), %rdx
movq -24(%rbp), %rax
movq %rdx, %rsi
movq %rax, %rdi
call mult2
movq %rax, -8(%rbp)
movq -40(%rbp), %rax
movq -8(%rbp), %rdx
movq %rdx, (%rax)
nop
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size multstore, .-multstore
.ident "GCC: (Ubuntu 5.4.0-6ubuntu1~16.04.11) 5.4.0 20160609"
.section .note.GNU-stack,"",@progbits
上面代码中,multstore 函数声明下每个缩进去的行都对应一条机器指令。 比如,pushq 指令表示应该将寄存器 % rbp 的内容压入程序栈中。
如果我们使用 "-c" 命令行选项,GCC 会编译并汇编该代码:
linux> gcc -og -c p.c
这就会产生目标代码文件 p.o,它是二进制格式的,所以无法直接查看 下面是文件中一段 16 字节的序列,它的十六进制表示为:
55 48 89 e5 48 83 ec 30 48 89 7d e8 48 89 75 e0
机器执行的程序只是一个字节序列,它是对一系列指令的编码。机器对产生这些指令的源代码几乎一无所知
要查看机器代码文件(可重定位文件)的内容,有一类称为反汇编器(disassembler)的程序非常有用
这些程序根据机器代码产生一种类似于汇编代码的格式。在 Linux 中,带 -d 命令行标志的程序 OBJDUMP(表示 "object dump") 可以充当这个角色:
linux> objdump -d p.o
结果如下:
Disassembly of section .text:
0000000000000000 <multstore>:
0: 55 push %rbp
1: 48 89 e5 mov %rsp,%rbp
4: 48 83 ec 30 sub $0x30,%rsp
8: 48 89 7d e8 mov %rdi,-0x18(%rbp)
c: 48 89 75 e0 mov %rsi,-0x20(%rbp)
10: 48 89 55 d8 mov %rdx,-0x28(%rbp)
14: 48 8b 55 e0 mov -0x20(%rbp),%rdx
18: 48 8b 45 e8 mov -0x18(%rbp),%rax
1c: 48 89 d6 mov %rdx,%rsi
1f: 48 89 c7 mov %rax,%rdi
22: e8 00 00 00 00 callq 27 <multstore+0x27>
27: 48 89 45 f8 mov %rax,-0x8(%rbp)
2b: 48 8b 45 d8 mov -0x28(%rbp),%rax
2f: 48 8b 55 f8 mov -0x8(%rbp),%rdx
33: 48 89 10 mov %rdx,(%rax)
36: 90 nop
37: c9 leaveq
38: c3 retq
在左边,我们看到按照前面给出的字节顺序排列的 16 个十六进制字节值,它们分成了若干组,每组有 1~5 个字节。每组都是一条指令,右边是等价的汇编语言。
其中一些关于机器代码和它的反汇编表示的特性值得注意:
- x86-64 的指令长度从 1 到 15 字节不等,常用的指令以及操作数较少的指令所需的字节数少,而那些不太常用或操作数较多的指令所需字节数较多
- 设计指令格式的方式是,从某个给定位置开始,可以将字节唯一地解码成机器指令。例如,只有质量 pushq % rbp 是以字节值 55 开头的
- 反汇编器只是基于机器代码文件中的字节序列来确定汇编代码。它不需要访问该程序的源代码或汇编代码
- 反汇编器使用的指令命名规则与 GCC 生成的汇编代码使用的有写细微的差别,比如 pushq,‘q'' 完全可以省略
生成实际可执行文件的代码需要对一组目标代码文件运行链接器,而这一组目标代码文件中必须含有一个 main 函数:
/* pp.c */
#include <stdio.h>
void multstore(long,long,long *);
int main(){
long d;
multstore(2,3,&d);
printf("2 * 3--> %ld\n",d );
return 0;
}
long mult2(long a,long b){
long s = a * b;
return s;
}
然后,用如下方法生成可执行文件 prog
linux> gcc -og -o prog pp.c p.c
文件 prog 变成了 8655 个字节,因为它不仅包含了两个过程的代码,还包含了用来启动和终止程序的代码,以及用来与操作系统交互的代码。我们也可以反汇编 prog 文件:
linux> objdump -d prog
反汇编会抽取出各种代码序列:
Disassembly of section .init:
0000000000400428 <_init>:
400428: 48 83 ec 08 sub $0x8,%rsp
40042c: 48 8b 05 c5 0b 20 00 mov 0x200bc5(%rip),%rax # 600ff8 <_DYNAMIC+0x1d0>
400433: 48 85 c0 test %rax,%rax
400436: 74 05 je 40043d <_init+0x15>
400438: e8 53 00 00 00 callq 400490 <__libc_start_main@plt+0x10>
40043d: 48 83 c4 08 add $0x8,%rsp
400441: c3 retq
Disassembly of section .plt:
0000000000400450 <__stack_chk_fail@plt-0x10>:
400450: ff 35 b2 0b 20 00 pushq 0x200bb2(%rip) # 601008 <_GLOBAL_OFFSET_TABLE_+0x8>
400456: ff 25 b4 0b 20 00 jmpq *0x200bb4(%rip) # 601010 <_GLOBAL_OFFSET_TABLE_+0x10>
40045c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000400460 <__stack_chk_fail@plt>:
400460: ff 25 b2 0b 20 00 jmpq *0x200bb2(%rip) # 601018 <_GLOBAL_OFFSET_TABLE_+0x18>
400466: 68 00 00 00 00 pushq $0x0
40046b: e9 e0 ff ff ff jmpq 400450 <_init+0x28>
0000000000400470 <printf@plt>:
400470: ff 25 aa 0b 20 00 jmpq *0x200baa(%rip) # 601020 <_GLOBAL_OFFSET_TABLE_+0x20>
400476: 68 01 00 00 00 pushq $0x1
40047b: e9 d0 ff ff ff jmpq 400450 <_init+0x28>
0000000000400480 <__libc_start_main@plt>:
400480: ff 25 a2 0b 20 00 jmpq *0x200ba2(%rip) # 601028 <_GLOBAL_OFFSET_TABLE_+0x28>
400486: 68 02 00 00 00 pushq $0x2
40048b: e9 c0 ff ff ff jmpq 400450 <_init+0x28>
Disassembly of section .plt.got:
0000000000400490 <.plt.got>:
400490: ff 25 62 0b 20 00 jmpq *0x200b62(%rip) # 600ff8 <_DYNAMIC+0x1d0>
400496: 66 90 xchg %ax,%ax
Disassembly of section .text:
00000000004004a0 <_start>:
4004a0: 31 ed xor %ebp,%ebp
4004a2: 49 89 d1 mov %rdx,%r9
4004a5: 5e pop %rsi
4004a6: 48 89 e2 mov %rsp,%rdx
4004a9: 48 83 e4 f0 and $0xfffffffffffffff0,%rsp
4004ad: 50 push %rax
4004ae: 54 push %rsp
4004af: 49 c7 c0 c0 06 40 00 mov $0x4006c0,%r8
4004b6: 48 c7 c1 50 06 40 00 mov $0x400650,%rcx
4004bd: 48 c7 c7 96 05 40 00 mov $0x400596,%rdi
4004c4: e8 b7 ff ff ff callq 400480 <__libc_start_main@plt>
4004c9: f4 hlt
4004ca: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
00000000004004d0 <deregister_tm_clones>:
4004d0: b8 47 10 60 00 mov $0x601047,%eax
4004d5: 55 push %rbp
4004d6: 48 2d 40 10 60 00 sub $0x601040,%rax
4004dc: 48 83 f8 0e cmp $0xe,%rax
4004e0: 48 89 e5 mov %rsp,%rbp
4004e3: 76 1b jbe 400500 <deregister_tm_clones+0x30>
4004e5: b8 00 00 00 00 mov $0x0,%eax
4004ea: 48 85 c0 test %rax,%rax
4004ed: 74 11 je 400500 <deregister_tm_clones+0x30>
4004ef: 5d pop %rbp
4004f0: bf 40 10 60 00 mov $0x601040,%edi
4004f5: ff e0 jmpq *%rax
4004f7: 66 0f 1f 84 00 00 00 nopw 0x0(%rax,%rax,1)
4004fe: 00 00
400500: 5d pop %rbp
400501: c3 retq
400502: 0f 1f 40 00 nopl 0x0(%rax)
400506: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
40050d: 00 00 00
0000000000400510 <register_tm_clones>:
400510: be 40 10 60 00 mov $0x601040,%esi
400515: 55 push %rbp
400516: 48 81 ee 40 10 60 00 sub $0x601040,%rsi
40051d: 48 c1 fe 03 sar $0x3,%rsi
400521: 48 89 e5 mov %rsp,%rbp
400524: 48 89 f0 mov %rsi,%rax
400527: 48 c1 e8 3f shr $0x3f,%rax
40052b: 48 01 c6 add %rax,%rsi
40052e: 48 d1 fe sar %rsi
400531: 74 15 je 400548 <register_tm_clones+0x38>
400533: b8 00 00 00 00 mov $0x0,%eax
400538: 48 85 c0 test %rax,%rax
40053b: 74 0b je 400548 <register_tm_clones+0x38>
40053d: 5d pop %rbp
40053e: bf 40 10 60 00 mov $0x601040,%edi
400543: ff e0 jmpq *%rax
400545: 0f 1f 00 nopl (%rax)
400548: 5d pop %rbp
400549: c3 retq
40054a: 66 0f 1f 44 00 00 nopw 0x0(%rax,%rax,1)
0000000000400550 <__do_global_dtors_aux>:
400550: 80 3d e9 0a 20 00 00 cmpb $0x0,0x200ae9(%rip) # 601040 <__TMC_END__>
400557: 75 11 jne 40056a <__do_global_dtors_aux+0x1a>
400559: 55 push %rbp
40055a: 48 89 e5 mov %rsp,%rbp
40055d: e8 6e ff ff ff callq 4004d0 <deregister_tm_clones>
400562: 5d pop %rbp
400563: c6 05 d6 0a 20 00 01 movb $0x1,0x200ad6(%rip) # 601040 <__TMC_END__>
40056a: f3 c3 repz retq
40056c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000400570 <frame_dummy>:
400570: bf 20 0e 60 00 mov $0x600e20,%edi
400575: 48 83 3f 00 cmpq $0x0,(%rdi)
400579: 75 05 jne 400580 <frame_dummy+0x10>
40057b: eb 93 jmp 400510 <register_tm_clones>
40057d: 0f 1f 00 nopl (%rax)
400580: b8 00 00 00 00 mov $0x0,%eax
400585: 48 85 c0 test %rax,%rax
400588: 74 f1 je 40057b <frame_dummy+0xb>
40058a: 55 push %rbp
40058b: 48 89 e5 mov %rsp,%rbp
40058e: ff d0 callq *%rax
400590: 5d pop %rbp
400591: e9 7a ff ff ff jmpq 400510 <register_tm_clones>
0000000000400596 <main>:
400596: 55 push %rbp
400597: 48 89 e5 mov %rsp,%rbp
40059a: 48 83 ec 10 sub $0x10,%rsp
40059e: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
4005a5: 00 00
4005a7: 48 89 45 f8 mov %rax,-0x8(%rbp)
4005ab: 31 c0 xor %eax,%eax
4005ad: 48 8d 45 f0 lea -0x10(%rbp),%rax
4005b1: 48 89 c2 mov %rax,%rdx
4005b4: be 03 00 00 00 mov $0x3,%esi
4005b9: bf 02 00 00 00 mov $0x2,%edi
4005be: e8 50 00 00 00 callq 400613 <multstore>
4005c3: 48 8b 45 f0 mov -0x10(%rbp),%rax
4005c7: 48 89 c6 mov %rax,%rsi
4005ca: bf d4 06 40 00 mov $0x4006d4,%edi
4005cf: b8 00 00 00 00 mov $0x0,%eax
4005d4: e8 97 fe ff ff callq 400470 <printf@plt>
4005d9: b8 00 00 00 00 mov $0x0,%eax
4005de: 48 8b 4d f8 mov -0x8(%rbp),%rcx
4005e2: 64 48 33 0c 25 28 00 xor %fs:0x28,%rcx
4005e9: 00 00
4005eb: 74 05 je 4005f2 <main+0x5c>
4005ed: e8 6e fe ff ff callq 400460 <__stack_chk_fail@plt>
4005f2: c9 leaveq
4005f3: c3 retq
00000000004005f4 <mult2>:
4005f4: 55 push %rbp
4005f5: 48 89 e5 mov %rsp,%rbp
4005f8: 48 89 7d e8 mov %rdi,-0x18(%rbp)
4005fc: 48 89 75 e0 mov %rsi,-0x20(%rbp)
400600: 48 8b 45 e8 mov -0x18(%rbp),%rax
400604: 48 0f af 45 e0 imul -0x20(%rbp),%rax
400609: 48 89 45 f8 mov %rax,-0x8(%rbp)
40060d: 48 8b 45 f8 mov -0x8(%rbp),%rax
400611: 5d pop %rbp
400612: c3 retq
0000000000400613 <multstore>:
400613: 55 push %rbp
400614: 48 89 e5 mov %rsp,%rbp
400617: 48 83 ec 30 sub $0x30,%rsp
40061b: 48 89 7d e8 mov %rdi,-0x18(%rbp)
40061f: 48 89 75 e0 mov %rsi,-0x20(%rbp)
400623: 48 89 55 d8 mov %rdx,-0x28(%rbp)
400627: 48 8b 55 e0 mov -0x20(%rbp),%rdx
40062b: 48 8b 45 e8 mov -0x18(%rbp),%rax
40062f: 48 89 d6 mov %rdx,%rsi
400632: 48 89 c7 mov %rax,%rdi
400635: e8 ba ff ff ff callq 4005f4 <mult2>
40063a: 48 89 45 f8 mov %rax,-0x8(%rbp)
40063e: 48 8b 45 d8 mov -0x28(%rbp),%rax
400642: 48 8b 55 f8 mov -0x8(%rbp),%rdx
400646: 48 89 10 mov %rdx,(%rax)
400649: 90 nop
40064a: c9 leaveq
40064b: c3 retq
40064c: 0f 1f 40 00 nopl 0x0(%rax)
0000000000400650 <__libc_csu_init>:
400650: 41 57 push %r15
400652: 41 56 push %r14
400654: 41 89 ff mov %edi,%r15d
400657: 41 55 push %r13
400659: 41 54 push %r12
40065b: 4c 8d 25 ae 07 20 00 lea 0x2007ae(%rip),%r12 # 600e10 <__frame_dummy_init_array_entry>
400662: 55 push %rbp
400663: 48 8d 2d ae 07 20 00 lea 0x2007ae(%rip),%rbp # 600e18 <__init_array_end>
40066a: 53 push %rbx
40066b: 49 89 f6 mov %rsi,%r14
40066e: 49 89 d5 mov %rdx,%r13
400671: 4c 29 e5 sub %r12,%rbp
400674: 48 83 ec 08 sub $0x8,%rsp
400678: 48 c1 fd 03 sar $0x3,%rbp
40067c: e8 a7 fd ff ff callq 400428 <_init>
400681: 48 85 ed test %rbp,%rbp
400684: 74 20 je 4006a6 <__libc_csu_init+0x56>
400686: 31 db xor %ebx,%ebx
400688: 0f 1f 84 00 00 00 00 nopl 0x0(%rax,%rax,1)
40068f: 00
400690: 4c 89 ea mov %r13,%rdx
400693: 4c 89 f6 mov %r14,%rsi
400696: 44 89 ff mov %r15d,%edi
400699: 41 ff 14 dc callq *(%r12,%rbx,8)
40069d: 48 83 c3 01 add $0x1,%rbx
4006a1: 48 39 eb cmp %rbp,%rbx
4006a4: 75 ea jne 400690 <__libc_csu_init+0x40>
4006a6: 48 83 c4 08 add $0x8,%rsp
4006aa: 5b pop %rbx
4006ab: 5d pop %rbp
4006ac: 41 5c pop %r12
4006ae: 41 5d pop %r13
4006b0: 41 5e pop %r14
4006b2: 41 5f pop %r15
4006b4: c3 retq
4006b5: 90 nop
4006b6: 66 2e 0f 1f 84 00 00 nopw %cs:0x0(%rax,%rax,1)
4006bd: 00 00 00
00000000004006c0 <__libc_csu_fini>:
4006c0: f3 c3 repz retq
Disassembly of section .fini:
00000000004006c4 <_fini>:
4006c4: 48 83 ec 08 sub $0x8,%rsp
4006c8: 48 83 c4 08 add $0x8,%rsp
4006cc: c3 retq
抽出一段:
0000000000400613 <multstore>:
400613: 55 push %rbp
400614: 48 89 e5 mov %rsp,%rbp
400617: 48 83 ec 30 sub $0x30,%rsp
40061b: 48 89 7d e8 mov %rdi,-0x18(%rbp)
40061f: 48 89 75 e0 mov %rsi,-0x20(%rbp)
400623: 48 89 55 d8 mov %rdx,-0x28(%rbp)
400627: 48 8b 55 e0 mov -0x20(%rbp),%rdx
40062b: 48 8b 45 e8 mov -0x18(%rbp),%rax
40062f: 48 89 d6 mov %rdx,%rsi
400632: 48 89 c7 mov %rax,%rdi
400635: e8 ba ff ff ff callq 4005f4 <mult2>
40063a: 48 89 45 f8 mov %rax,-0x8(%rbp)
40063e: 48 8b 45 d8 mov -0x28(%rbp),%rax
400642: 48 8b 55 f8 mov -0x8(%rbp),%rdx
400646: 48 89 10 mov %rdx,(%rax)
400649: 90 nop
40064a: c9 leaveq
40064b: c3 retq
40064c: 0f 1f 40 00 nopl 0x0(%rax)
这段代码与之前 p.c 反汇编产生的代码几乎完全一样。其中主要的区别是左边列出的地址不同 ----- 链接器将这段代码的地址移到了一段不同的地址范围中
第二个不同之处在于链接器填上了 callq 指令调用函数 mult2 需要使用的地址;链接器的任务之一就是为函数调用找到匹配的函数的可执行代码的位置。
最后一个区别是多了两行代码,插入这些指令是为了使函数代码变为 16 字节,对程序并没有影响,使得就存储器系统性能而言,能更好地放置下一个代码块
数据格式
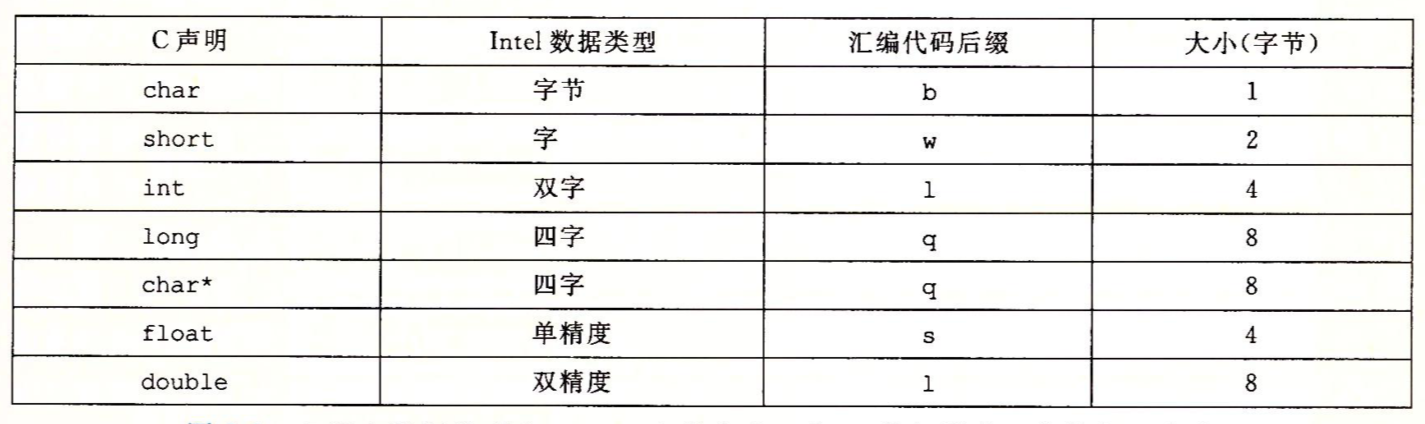
大多数 GCC 生成的汇编代码指令都有一个字符的后缀,表明操作数的大小。例如,数据传送指令由四个变种:movb (传送字节)、movw(传送字)、movl(传送双字)、和 movq(传送四字)
访问信息

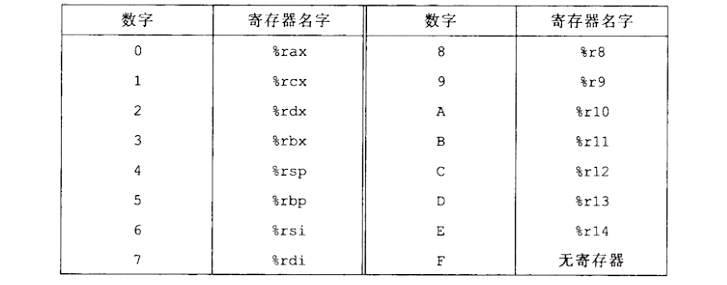
一个 x86-64 的中央处理单元(CPU)包含一组 16 个存储 64 位值得通用目的寄存器,用来存储整数数据和指针
通常有一组标准的编程规范控制着如何使用寄存器来管理栈、传递函数参数、从函数的返回值,以及存储局部和临时数据。
操作数指示符
大多数指令有一个或多个操作数,指示出执行一个操作中要使用的源数据值,以及放置结果的目的位置。
源数据可以以常数形式给出,或是从寄存器或内存中读出。结果可以存放在寄存器或内存中。因此,各种不同的操作数的可能性被分为三种类型:立即数 、寄存器、内存引用
也就是三种基本的寻址方式,可以在学习汇编语言的时候接触到
数据传送指令
最频繁使用的指令是将数据从一个位置复制到另一个位置的指令。
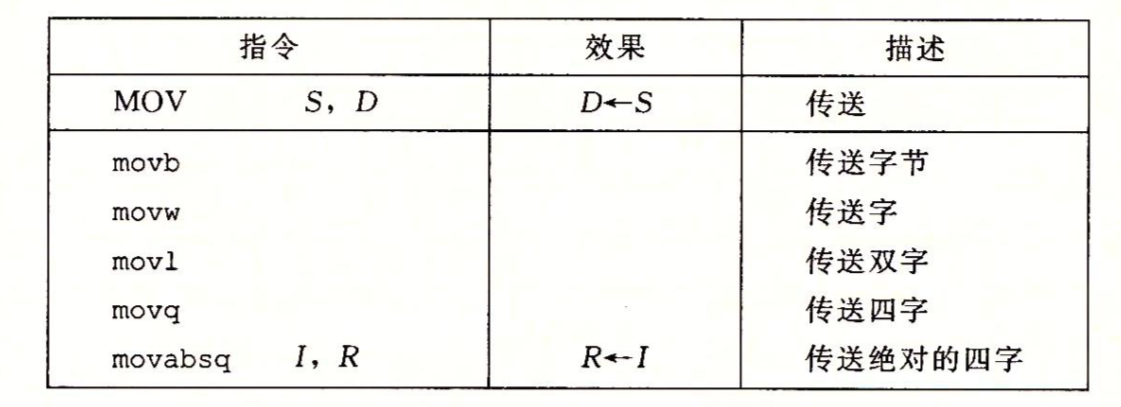
四种不同的指令都执行相同的操作;主要区别在于它们操作的数据大小不同
源操作数指定的值是一个立即数,存储在寄存器中或者内存中。目的操作数指定一个位置,要么是一个寄存器或者,要么是一个内存地址。
x86-64 加了一条限制,传送指令的两个操作数不能都指向内存位置。将一个值从一个内存位置复制到另一个内存位置需要两条指令: 第一条指令将源值加载到寄存器中,第二条将该寄存器值写入目的的位置,也就是必须经过寄存器
mov 指令只会更新目的操作数指定的那些寄存器字节或内存位置,唯一例外的是 movl 指令以寄存器作为目的时,会把该寄存器的高位 4 字节设置为 0
<i></i > 在将较小的源值复制到较大的目的时使用双大小指示符: 第一个字符指定源的大小,第二个指名目的的大小
数据扩展方式
①零扩展:MOVZ 类中的指令把目的中剩余的字节填充为 0
②符号扩展:MOVS 类中的指令通过符号扩展来填充,把源操作的最高位进行复制
数据传送示例
/* C语言代码*/
long exchange(long *xp,long y)
{
long x = *xp;
*xp = y;
return x;
}
/*汇编代码*/
exchange:
movq (%rdi),%rax
movq %rsi,(%rdi)
ret
函数 exchange 由三条指令实现:两条数据传送(movq),加上一条返回函数被调用点的指令(ret)
可知参数通过寄存器传递给函数,函数通过把值存储在寄存器 % rax 或者寄存器的某个低位部分中返回
执行过程描述: 过程参数 xp 和 y 分别存储在寄存器 % rdi 和 % rsi 中。然后,指令 2 从内存中读出 x,把它存放到寄存器 % rax 中,直接实现了 C 程序中的操作 x=xp。稍后,用寄存器 % rax 从这个函数返回一个值,因而返回值就是 x。指令 3 将 y 写入到寄存器 % rdi 中的 xp 指向的内存位置,直接实现了 xp=y。
压入和弹出栈数据
栈是一种数据结构,可以通过添加或者删除值,不过要遵循 “后进先出” 的原则。通过 push 操作把数据压入栈中,通过 pop 操作删除数据;它具有一个属性:弹出的值永远是最近被压入而且仍然在栈中的值。在 x86-64 中,程序栈存放在内存中某个区域,栈向下增长,这样一来,栈顶元素的地址是所有栈中元素地址最低的,栈指针 % rsp 保存着栈顶元素的地址

算术和逻辑操作
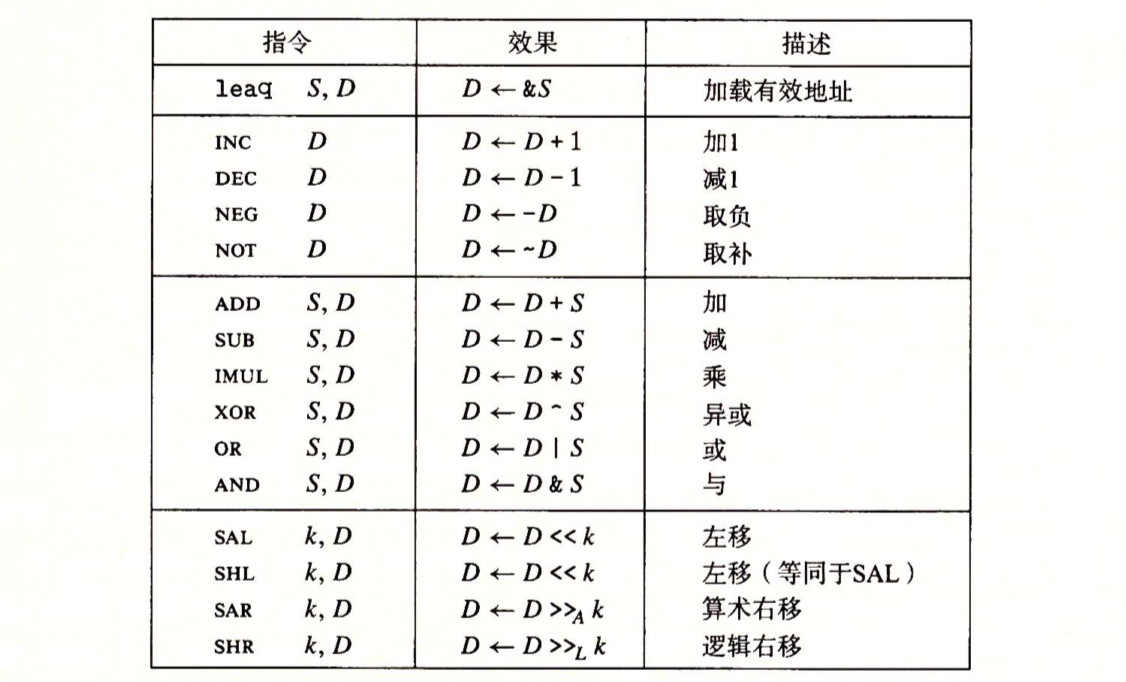
分为四类:加载有效地址、一元操作、二元操作和移位
①加载有效地址
加载有效地址(load effective address)指令 leaq 实际上是 movq 指令的变形。它的指令形式是从内存读数据到寄存器,但实际上它根本就没有引用内存
它的第一个操作数看上去是一个内存引用,但该指令并不是从指定的位置读入数据,而是将有效地址写入到目的操作数。
leaq 指令能执行加法和有限形式的乘法,例如:如果寄存器 % rdx 的值为 x,那么指令 leaq 7 (% rdx,% rdx,4),% rax 将设置寄存器 % rax 的值为 5x+7.
②一元和二元操作
一元操作,只有一个操作数,既是源又是目的。这个操作数可以是一个寄存器,也可以是一个内存位置
二元操作,其中,第二个操作数既是源又是目的。即源操作数是第一个,目的操作数是第二个,最终的结果是放回目的,第二个操作数不能是立即数
③移位操作
先给出移位量,然后第二项给出的是要移位的数。可以进行算术和逻辑移位。移位量可以是一个立即数,或者放在单字节寄存器 % cl 中。原则上 1 字节的移位量是的移位量的编码范围可以达到 2^8-1=255。x86-64 中,移位操作对 w 位长的数据值进行操作,移位量又 % cl 寄存器的低 m 位决定的,这里 2^m=w。高位会被忽略。 例如:寄存器 % cl 的十六进制值为 0xFF 时,指令 salb 会移 7 位,salw 会移 15 位,sall 会移 21 位,而 salq 会移 63 位
左移指令有两个名字:SAL 和 SHL。两者的效果一样的,都是将右边填上 0
右移指令不同,SAR 执行算术移位(填上符号位,其实就是移位后符号不能变),而 SHR 执行逻辑移位(填上 0)
移位操作数的目的操作数可以是一个寄存器或者一个内存位置;只有右移位需要区分符号和无符号数
特殊的算术操作
对两个 64 位有符号或无符号整数相乘得到的乘积需要 128 位来表示。x86-64 指令集对 128 位数的操作提供有限的支持

扩展方式是高 64 位放在 % rdx,低 64 位放在 % rax
控制
到目前为止,我们只考虑了直线代码的行为,也就是指令一条接着一条顺序地执行。但如果要实现条件控制、循环等操作,该怎么办呢
条件码
除了整数寄存器,CPU 还维护着一组单个位的条件码寄存器,它们描述了最近的算术或逻辑操作的属性。还可以检测这些寄存器来执行条件分支指令,常见的条件码有:
CF:进位标志。最近的操作使最高位产生了进位。可用来检查无符号操作的溢出
ZF:零标志。最近的操作得出的结果为 0
SF:符号标志。最近的操作得到的结果为负数
OF:溢出标志。最近的操作导致一个补码溢出 ---- 正溢出或负溢出
leaq 指令不改变任何条件码,因为它是用来进行地址计算的
与条件码相关的指令(只设置条件码而不更新目的寄存器):CMP(比较大小)、TEST(与 AND 指令相同操作)
大多数运算符都会更新目的寄存器,同时设置对应的条件码
访问条件码
条件码通常不会直接读取,常用的使用方法有三种:
①可以根据条件码的某种组合,将一个字节设置为 0 或 1
SET 指令;指令名字的不同后缀指明了他们所考虑的条件码的组合,必须明确指令的后缀表示不同的条件而不是操作数大小

②可以条件跳转到程序的某个其他的部分
③可以有条件地传送数据
跳转指令
正常执行的情况下,指令按照它们出现的顺序一条条地执行。跳转(jump)指令会导致执行切换到程序中一个全新的位置
跳转指令 jmp 可以是无条件跳转;也可以是直接跳转;或者是间接跳转,区别只是跳转目标是否作为指令的一部分编码,是否来源于寄存器或内存位置读出
跳转指令的编码
了解跳转指令的目标如何编码,对研究链接非常有帮助,也能帮助理解反汇编器的输出
实现条件分支
①条件控制
用跳转指令 jmp、jge,结合有条件和无条件跳转
当条件满足时,程序沿一条直线路径执行,当条件不满足时就走另一条
②条件传送(数据)
用 comv 指令
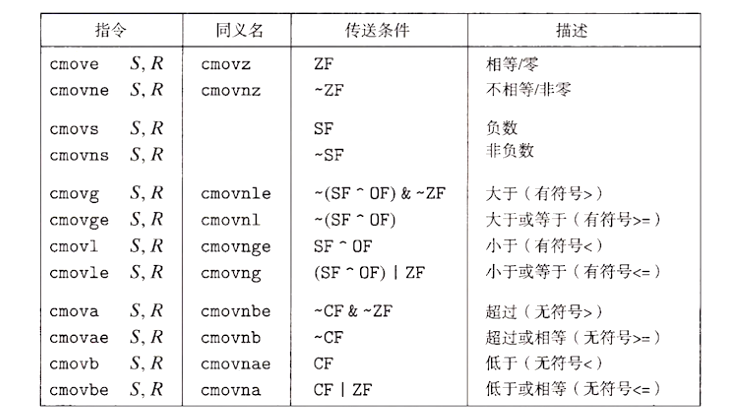
这种方法计算一个条件操作的两种结果,然后再根据条件是否满足从中选取一个
循环
了解常见的几种循环在汇编代码的表示:do、while、for、switch
逆向工程:理解产生的汇编代码与原始代码之间的关系,关键是找到程序值和寄存器之间的映射关系
过程
x86-64 的过程实现包括一组特殊的指令和一些对机器资源(例如寄存器和程序内存)使用的约定规则
要提供对过程的机器级支持,必须要处理许多不同的属性。假设过程 p 调用过程 Q,Q 执行后返回 p。这些动作包括下面一个或多个机制:
传递控制 在进入过程 Q 的时候,程序计数器必须被设置为 Q 的代码的起始地址,然后再返回时,要把程序计数器设置为 p 中调用 Q 后面那条指令的地址
传递数据 p 必须能够向 Q 提供一个或多个参数,Q 必须能够向 p 返回一个值
分配和释放内存 在开始时,Q 可能需要为局部变量分配空间,而在返回前,又必须释放这些存储空间
运行时栈
栈数据结构提供了后进先出的内存管理原则;程序可以用栈来管理它的过程所需要的存储空间,栈和程序寄存器存放着传递控制和数据、分配内存所需的信息。当 p 调用 Q 时,控制和数据信息添加到栈尾,当 p 返回时,这些信息会释放掉
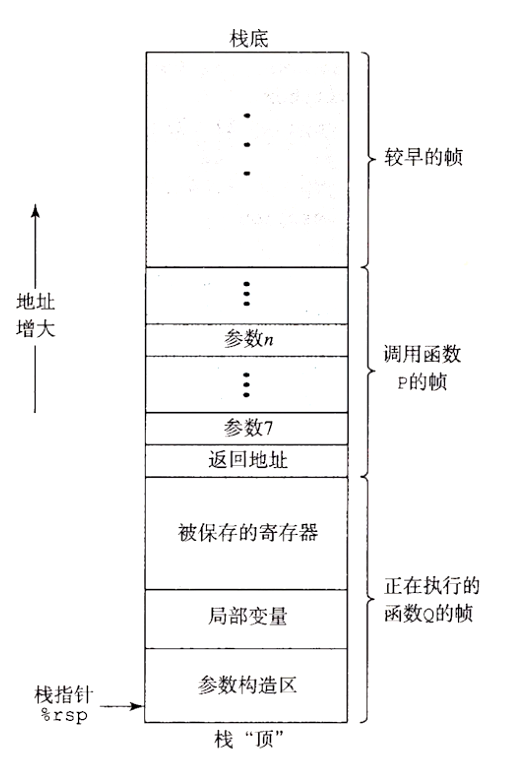
当 x86-64 过程需要的存储空间超出寄存器能够存放的大小时,就会在栈上分配空间。这个部分称为过程的栈帧。当前正在执行的过程的帧总在栈顶,大多数过程的栈帧都是定长的,在过程的开始就分配好了,而实际上,许多函数甚至根本就不需要栈帧。
转移控制
将控制从函数 p 转移到函数 Q 只需要简单地把程序计数器(PC)设置为 Q 的代码起始位置。不过,当稍后从 Q 返回的时候,处理器必须记录好它需要继续 p 的执行的代码位置。在 x86-64 机器中,这个信息是用指令 call Q 调用过程 Q 来记录的。该指令会把地址 A 压入栈中,并将 PC 设置为 Q 的起始地址。压入的地址 A 被称为返回地址,是紧跟着 call 指令后面的那条指令的地址。对应的指令 ret 会从栈中弹出地址 A,并把 PC 设置为 A
数据传送
当调用一个过程时,除了要把控制传递给它并在过程返回时再传递回来之外,过程调用还可能包括把数据作为参数传递,而从过程返回还可能包括一个返回值。x86-64 中,大部分过程间的数据传送是通过寄存器实现。
栈上的局部存储
寄存器不足够存放所有的本地数据;
对一个局部变量使用地址运算符‘&’,因此必须能够为它产生一个地址;
某些局部变量是数组或结构,因此必须能够通过数组或结构引用被访问到
一般来说,过程通过减小栈指针在栈上分配空间。分配的结果作为栈帧的一部分,标号为 “局部变量”
寄存器中的局部存储空间
寄存器组是唯一被所有过程共享的资源
必须确保当一个过程(调用者)调用另一个过程时,被调用者不会覆盖调用者稍后会使用的寄存器值
压入寄存器的值会在栈帧中创建标号 “保存的寄存器”
递归过程
寄存器和栈的惯例使得过程能够递归地调用它们自身。每个过程调用在栈中都有它自己的私有空间,因此多个未完成调用的局部变量不会相互影响。此外,栈的原则很自然地就提供了适当的策略,当过程被调用时分配局部存储,当返回时释放存储
数组分配和访问
C 语言的不同寻常的特点是可以产生指向数组中元素的指针,并对这些指针进行运算。在机器代码中,这些指针会被翻译成地址计算
x86-64 的内存引用指令可以用来简化数组访问。例如,假设 E 是一个 int 型的数组,而我们想计算 E [i],在此,E 的地址存放在寄存器 % rdx 中,而 i 存放在寄存器 % rcx 中,然后,指令 movl (%rdx,%rcx,4),%eax 会执行地址计算 Xe+4i,读这个内存位置的值,并将结果存放到寄存器 % eax 中
使用 GDB 调试器
通过下面的命令行来启动 GDB:
linux> gdb prog

| commands | result |
|---|---|
| quit | 退出 GDB |
| run | 运行程序(在此给出命令行参数) |
| kill | 停止程序 |
| break multstore | 在函数 multstore 入口处设置断点 |
| break * 0x400540 | 在地址 0x400540 |
| delete 1 | 删除断点 1 |
| delete | 删除所有断点 |
| stepi | 执行 1 条指令 |
| stepi 4 | 执行 4 条指令 |
| nexti | 类似 stepi,但以函数调用为单位 |
| continue | 继续执行 |
| finish | 运行到当前函数返回 |
| disas | 反汇编当前函数 |
| disas multstore | 反汇编函数 multstore |
| disas 0x400544 | 反汇编位于地址 0x400544 附件的函数 |
| disas 0x400540,0x40054d | 反汇编指定地址范围内的代码 |
| print /x $rip | 以十六进制输出程序计数器的值 |
| print $rax | 以十进制输出 % rax 的内容 |
| print /x $rax | 以十六进制输出 % rax 的内容 |
| print /t $rax | 以二进制输出 % rax 的内容 |
| print 0x100 | 输出 0x100 的十进制表示 |
| print /x 555 | 输出 555 的十六进制表示 |
| print /x ($rsp+8) | 以十六进制输出 % rsp 的内容加上 8 |
| print *(long *) 0x7fffffffe818 | 输出位于地址 0x7fffffffe818 的长整数 |
| print *(long *)($rsp+8) | 输出位于地址 % rsp+8 处的长整数 |
| x/2g 0x7fffffffe818 | 检查从地址 0x7fffffffe818 开始的双字 |
| x20bmultstore | 检查函数 multstore 的前 20 个字节 |
| info frame | 有关当前栈帧的信息 |
| info registers | 所有寄存器的值 |
| help |
内存越界引用和缓冲区溢出
对越界的数组元素的写操作会破坏存储在栈中的状态信息
一种特别常见的状态破坏称为缓冲区溢出(buffer overflow)。通常,在栈中分配某个字符数组来保存一个字符串,但是字符串的长度超出了为数组分配的空间
缓冲区溢出的一个更加致命的使用就是让程序执行它本来不愿意执行的函数 <br> 通常,输入给程序一个字符串,这个字符串包含一些可执行代码的字节编码,称为攻击编码(exploit code),另外,还有一些字节会用一个指向攻击代码的指针覆盖返回地址。那么,执行 ret 指令的效果就是跳转到攻击代码
在一种攻击形式中,攻击代码会使用系统调用启动一个 shell 程序,给攻击者提供一组操作系统函数。另一种攻击形式中,攻击代码会执行一些未授权的任务,修复栈的破坏,然后第二次执行 ret 指令,(表面上)正常返回到调用者
在 1988 年 11 月,著名的 Internet 蠕虫病毒通过 Internet 以四种不同的方法获取对多计算机的访问。一种是对 finger 守护进程 fingerd 的缓冲区溢出攻击,fingerd 服务 FINGER 命令请求。通过以一个适当的字符串调用 FINGER,蠕虫可以远程的守护进程缓冲区并执行一段代码,让蠕虫访问远程系统。一旦蠕虫获得了对系统的访问,它就能自我复制,几乎完全地消耗掉机器上所有的计算机资源。
对抗缓冲区溢出攻击
1. 栈随机化
为了在系统中插入攻击代码,攻击者既要插入代码,也要插入指向这段代码的指针,这个指针也是攻击字符串的一部分。产生这个指针需要知道这个字符串放置的栈地址。
栈随机化的思想使得栈的位置在程序每次运行时都有变化。因此,即使许多机器都运行同样的代码,他们的栈地址都是不同的
然而一个执著的攻击者总是能够用蛮力克服随机化,他可以反复用不同的地址进行攻击。一种常见的把戏就是在实际的攻击代码前插入很长一段 nop(读作 “no op”,no operatioin 的缩写)指令。执行这种指令除了对程序计数器加一,使之指向下一条指令之外,没有任何效果。只要攻击者能够猜中这段序列中的某个地址,程序就会经过这个序列,到达攻击代码。这个序列常用的术语是 “空操作雪橇(nop sled)”,意思是程序会 “滑过” 这个序列。如果我们建立一个 256 字节的 nop sled,那么枚举 2^15=32768 个起始地址,就能破解 n=2^23 的随机化,这对于一个顽固的攻击者来说,是完全可行的。如果是对于 64 位的系统,就要尝试枚举 2^24=16777216
2. 栈破坏检测
在产生的代码中加入了一种栈保护者机制,来检测缓冲区越界,其思想是在栈帧中任何局部缓冲区与栈状态之间存储一种特殊的金丝雀值,也称哨兵值,是在程序每次运行时随机产生的;在恢复寄存器状态和从函数返回之前,程序检查这个金丝雀值是否杯该函数的某个操作或者该函数调用的某个函数的某个操作改变了,如果是,那么程序异常中止
3. 限制可执行代码区域
消除攻击者想系统中插入可执行代码的能力,限制哪些内存区域能够存放可执行代码。
支持可变长栈帧
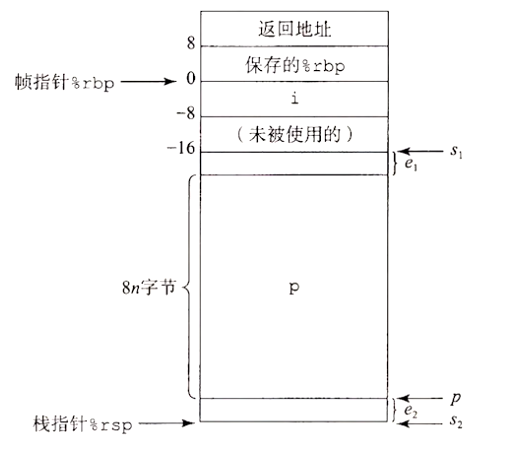
为了管理变长栈帧,x86 代码使用寄存器 % rbp 作为帧指针(frame pointer)(有时称为基指针(base pointer),这也是 % rbp 中 bp 两个字母的由来)。当使用帧指针时,栈帧的组织结构与图中函数 vframe 的情况一样。可以看到代码必须把 % rbp 之前的值保存到栈中,因为它是一个被调用者保存寄存器。然后在函数的整个执行过程中,都使得 % rbp 指向那个时刻栈的位置,然后用固定长度的局部变量相对于 % rbp 的偏移量来引用他们
处理器体系结构
程序员可见的状态
程序中的每条指令都会读取或修改处理器状态的某些部分。这称为程序员可见状态。
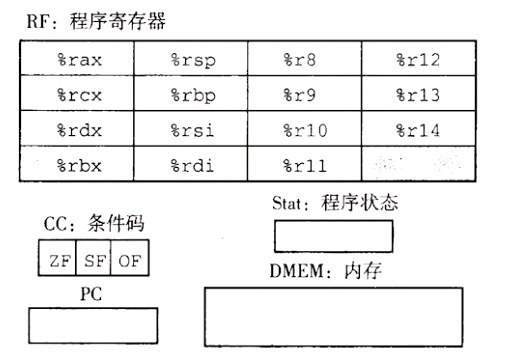
Y86-64 程序员可见状态。同 x86-64 一样,Y86-64 的程序可以访问和修改程序寄存器、状态码、程序计数器(PC)和内存。状态码指明程序是否允许正常,或者发生了某个特殊事件
内存从概念上来说就是一个很大的字节数组,保存着程序和数据。Y86-64 程序用虚拟地址来引用内存位置。硬件和操作系统软件联合起来将虚拟地址翻译成实际物理地址,指明数据实际存在内存中哪个地方。
程序状态的最后一部分是状态码 Stat,它表明程序执行的总体状态
指令编码
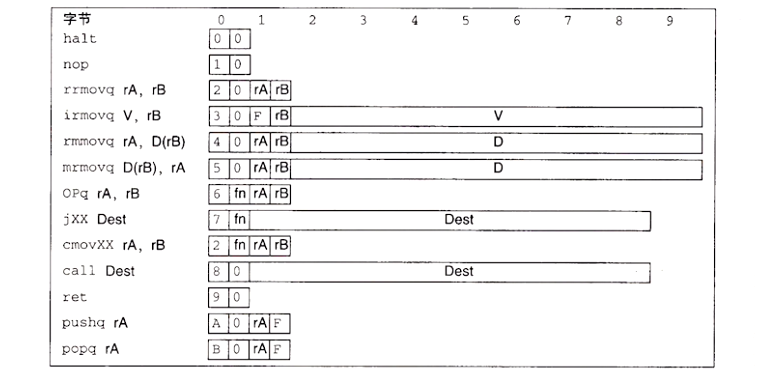
指令的字节级编码。每条指令需要 1~10 个字节不等,这取决于需要哪些字段。每条指令的第一个字节表明指令的类型,这个字节分为两部分,每部分 4 位:高 4 位是代码部分,低 4 位是功能部分
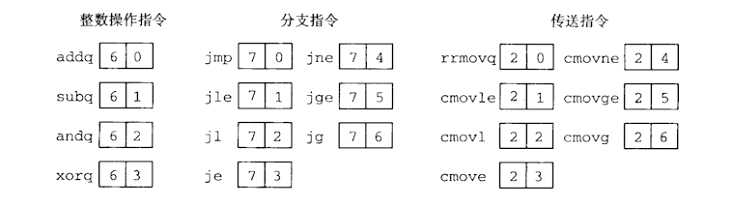
功能值只有在一组相关指令共用一个代码时才有用,区分不同功能。
Y86-64 15 个程序寄存器中每个都有一个相对应的范围在 0 到 0xE 之间的寄存器标识符,程序寄存器存在 CPU 中的一个寄存器文件中,这个寄存器文件就是一个小的、以寄存器 ID 为地址的随机访问存储器。在指令编码中以及在硬件设计中,当需要指明不应访问任何寄存器时,就用 ID 值 0xF 来表示
有的指令只有一个字节长,而有的需要操作数的指令编码就更长一些。指令集的一个重要性质就是字节编码必须唯一的解释。任意一个字节序列要么是一个唯一的指令序列的编码,要么就不是一个合法的字节序列。
例如:用十六进制来表示指令 rmmovq % rsp,0x123456789abcd(% rdx)的字节编码。
rmmovq 的第一个字节为 40. 源寄存器 % rsp 应该编码放在 rA 字段中,而基址寄存器 % rdx 应该编码放在 rB 字段中。两个寄存器的 ID 分别为 4 和 2. 最后,偏移量编码放在 8 字节的常数字中。首先在 0x123456789abcd 的前面填充 0 变成 8 个字节,变成字节序列 00 01 23 45 67 89 ab cd。写成按字节反序就是 4042cdab896745230100
比较 x86-64 和 Y86-64 的指令编码 同 x86-64 中的指令编码相比,Y86-64 的编码简单得多,但是没有那么紧凑。在所有的 Y86-64 指令中,寄存器字段的位置都是固定的,而在不同的 x86-64 指令中,它们的位置是不一样的。x86-64 可以将常数值编码成 1、2、4 或 8 个字节,而 Y86-64 总是将常数值编码成 8 字节
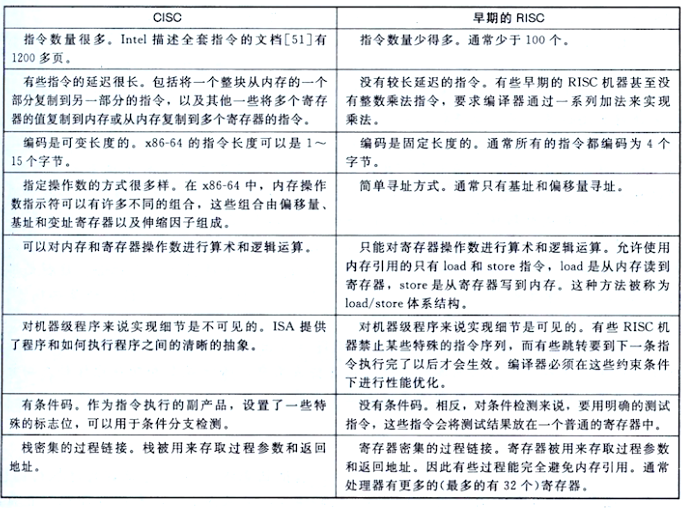
RISC 和 CISC 指令集
Y86-64 异常
对 Y86-64 来说,程序员可见的状态包括状态码 Stat,它描述程序执行的总体状态
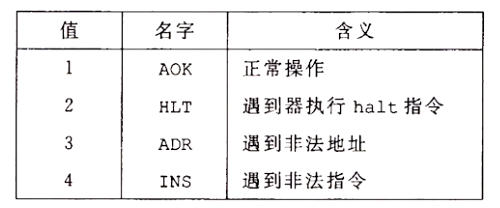
当遇到这些异常的时候,我们简单地让处理器停止执行指令。在更完整的设计中,处理器通常会调用一个异常处理程序,这个过程被指定用来处理遇到的某种类型的异常
Y86-64 的顺序实现
SEQ 处理器,每个时钟周期时间,SEQ 执行处理一条完整指令所需的所有步骤。不过,这需要一个很长的时钟周期时间,因此时钟周期频率会低到不可接受,而最终要实现的是流水线化的处理器
通常,处理一条指令包括很多操作。将它们组织成某个特殊的阶段序列,即使指令的动作差异很大,但所有的指令都遵循统一的序列。每一步的具体处理取决于正在执行的指令。
取指(fetch):取指阶段从内存读取指令字节,地址为程序计数器(PC)的值。从指令中抽取出指令指示符字节的两个四位部分,称为 icode(指令代码)和 ifun(指令功能)。它可能取出一个寄存器指示符字节(寄存器 ID),指明一个或两个寄存器操作数
译码(decode):译码阶段从寄存器文件读入最多两个操作数
执行(execute):在执行阶段,算术 / 逻辑单元(ALU)要么执行指令指明的操作(根据 ifun 的值),计算内存引用的有效地址,要么增加或减少栈指针。在此可能设置条件码,对一条条件指令来说,这个阶段会检验条件码和传送条件,如果条件成立,则更新目标寄存器。同样,对一条跳转指令来说,这个阶段会决定是不是应该选择分支
访存(memory):访存阶段可以将数据写入内存,或者从内存读出数据。
写回(write back):写回阶段最多可以写两个结果到寄存器文件
更新 PC(PC update):将 PC 设置成下一条指令的地址
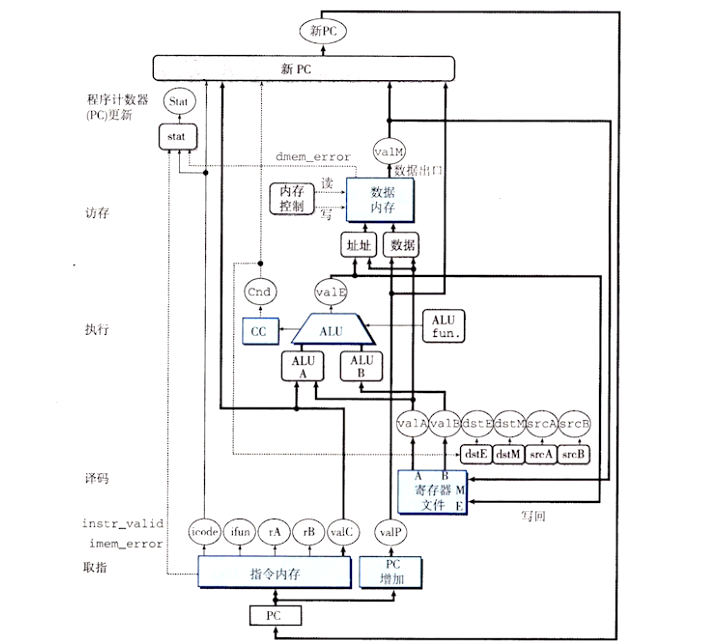
----SEQ 硬件结构
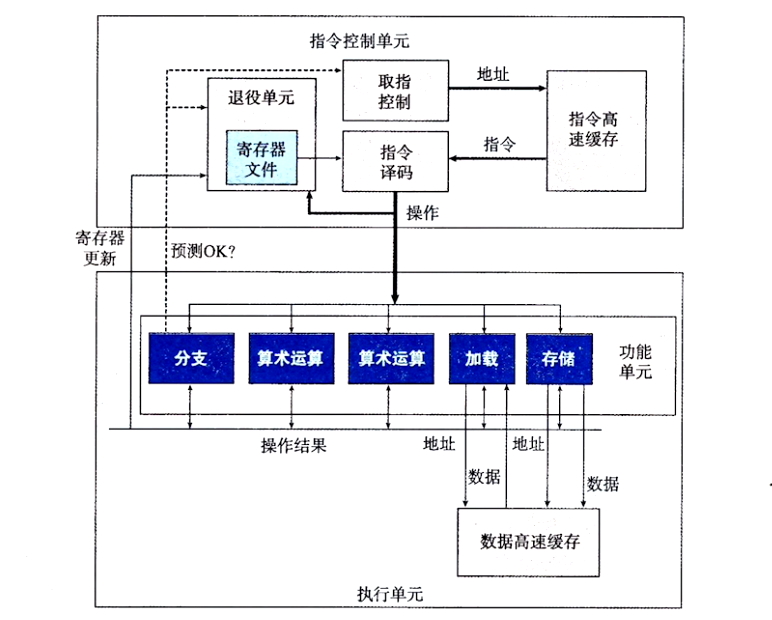
---- 乱序处理器框图
存储器层次结构
本章做了一个大概的浏览,如果已经上过相关计算机基础课程,我想已经对存储器技术及在计算机中的地位有了一定的了解,这本书讲的很详细,这里只做个小结,方便日后需要时再去翻阅 <i></i>
基于存储技术包括随机存储器(RAM)、非易失性存储器(ROM)和磁盘。RAM 有两种基本类型。静态 RAM(SRAM)快一些,但是也贵一些,它即可以用作 CPU 芯片上的高速缓存,也可以也用作芯片下的高速缓存。动态 RAM(DRAM)慢一些,也便宜一些,用作主存和图形帧缓冲区。即使是在关电的时候,ROM 也能保持他们的信息,可以用来存储固件。旋转磁盘是机械的非易失性存储设备,以每个位很低的成本保存大量的数据,但是其访问时间比 DRAM 长很多。固态硬盘(SSD)基于非易失性的闪存,对某些应用来说,越来越成为旋转磁盘的具有吸引力的替代产品.
一般而言,较快的存储技术每个位会更贵,而且容量更小。这些技术的价格和性能属性正在以显著不同的速度变化着。特别的,DRAM 和磁盘访问时间远远大于 CPU 周期时间。系统通过将存储器组织成存储设备的层次结构来弥补这些差异,在这个层次结构中,较小、较快的设备在顶部,较大、较慢的设备在底部。因为编写良好的程序有好的局部性,大多数数据都可以较高层得到服务,如果就是存储系统能以较高层的速度运行,但却有较低层的成本和容量.
链接
链接(linking)是将各种代码和数据片段收集并组合成为一个单一文件的过程,这个文件可被加载(复制)到内存并执行。<br> 在早期的计算机系统中,链接是手动执行的。在现代系统中,链接是由叫链接器(linker)的程序自动执行的。链接器在软件开发中扮演着一个关键的角色,因为它们使得分离编译成为可能,不用担心牵一发动全身。
编译器驱动程序
大多数编译系统提供编译器驱动程序,它代表用户在需要时调用语言预处理器、编译器、汇编器和链接器
举例:
linux> gcc -og -o add main.c sum.c
执行完该指令后,ASCII 码源文件翻译成可执行目标文件过程如下
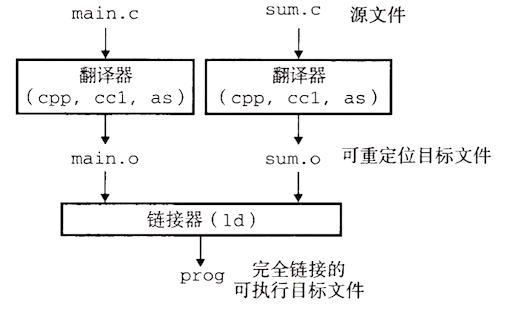

这个过程在前面已经详述过了 --> hello.c 经历的四个阶段
静态链接
可重定位目标文件由各种不同的代码和数据节(section)组成,每一节都是一个连续的字节序列
为了构造可执行文件,链接器必须完成两个主要任务:
- 符号解析 目标文件定义和引用符号,每个符号对应一个函数、一个全局变量或一个静态变量。符号解析的目的是将每个符号引用正好和一个符号定义关联起来
- 重定位 编译器和汇编器生成从地址 0 开始的代码和数据节。链接器通过把每个符号定义与一个内存位置关联起来,从而定位这些节,然后修改所有对这些符号的引用,使得他们指向这个内存位置。
目标文件
目标文件是字节块的集合。这些块包含程序代码,有些包含程序数据,而其他的则包含引导链接器和加载器的数据结构。
目标文件有三种形式:
- 可重定位目标文件 包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。
- 可执行目标文件 包含二进制代码和数据,其形式可以被直接复制到内存并执行。
- 共享目标文件 一种特殊类型的可重定位目标文件,可以在加载或者运行时被动态地加载进内存并链接。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。从技术上来说,一个目标模块就是一个字节序列,而一个目标文件就是一个以文件形式存放在磁盘中的目标模块。
可重定位目标文件
如图是一个典型的 ELF 可重定位目标文件格式。ELF 头以一个 16 字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。夹在 ELF 头和节头部表之间的都是节,节头部表描述中间各个不同节的位置和大小,其中目标文件中每个节都有一个固定的条目。
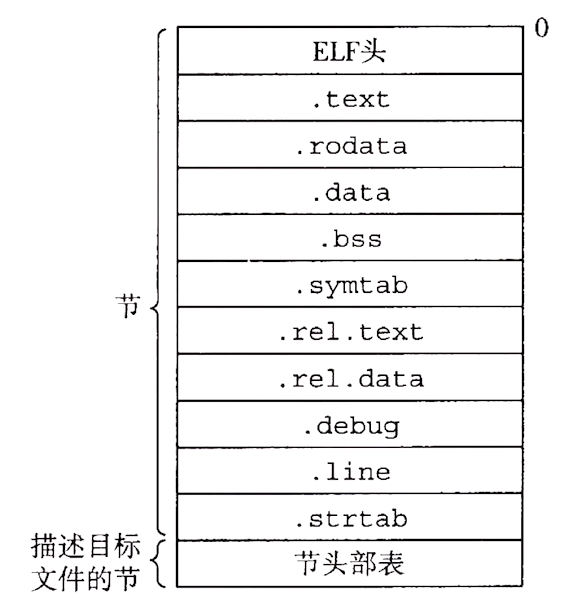
.text:已编译程序的机器代码
.rodata:只读数据
.data:已初始化的全局和静态 C 变量。局部 C 变量在运行时被保存在栈中,即不出现在.data 节中,也不出现在.bss 节(表示未初始化的数据)中
.symtab:一个符号表,它存放在程序中定义和引用的函数和全局变量的信息
.rel.text:一个.text 节中位置的列表,当链接器把这个目标文件和其他文件组合时,需要修改这些位置
.rel.data:被模块引用或定义的所有全局变量的重定位信息
.debug:一个调试符号表,其条目是程序中定义的局部变量和类型定义,程序中定义和引用的全局变量,以及原始的 C 的源文件
.line:原始 C 源程序中行号和.text 节中机器指令之间的映射
.strtab:一个字符串表,其内容包括.symtab 和.debug 节中的符号表,以及节头部表的节名字。字符串表就是以 null 结尾的字符串的序列
符号解析和静态库
在符号解析阶段,链接器从左到右按照它们在编译器驱动程序命令行上出现的顺序来扫描可重定位目标文件和存档文件,将扫描到的符号分为三类,其中一类就是未解析的符号,即需要利用静态库来解析的引用符号 <br> 链接器通常会利用静态库来解析引用:所有的编译系统都有提供一种机制,将所有相关的目标模块打包成为一个单独的文件,它可以用作链接器的输入。当链接器构造一个输出的可执行文件时,它只复制静态库里被应用程序引用的目标模块,例如 libc.a 中的 printf.o 模块
重定位
-
重定位节和符号定义 使程序中的每条指令和全局变量都有唯一的运行时内存地址
-
重定位节中的符号引用 链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时的地址。要执行这一步,链接器依赖于可重定位目标模块中的重定位条目(rel.text、rel.data)
重定位条目
当汇编器生成一个目标模块时,它并不知道数据和代码最终将放在内存中的什么位置。它也不知道这个模块引用的任何外部定义的函数或者全局变量的位置。所以,无论何时汇编器遇到对最终位置未知的目标引用,它就会生成一个重定位条目,告诉链接器在将目标文件合并成可执行文件时如何修改这个引用。代码重定位条目放在.rel.text 中,已初始化数据的重定位条目放在.rel.data 中
ELF 定义了 32 种不同的重定位类型,其中有两种最基本的重定位类型:
-
R_X86_64_PC32 重定位一个使用 32 位 PC 相对地址的引用
-
R_X86_64_32 重定位一个使用 32 位绝对地址的引用,CPU 直接在指令中编码的 32 值作为有效地址
举例:反编译一个可重定位文件,其中一个指令有如下的重定位的形式
指令地址 指令编码 指令 重定位地址 <符号引用>
4004de: e8 05 00 00 00 callq 4004e8 <sum>
可执行目标文件
一个典型的 ELF 可执行文件包含加载程序到内存并运行它所需的所有信息

ELF 头描述文件的总体格式
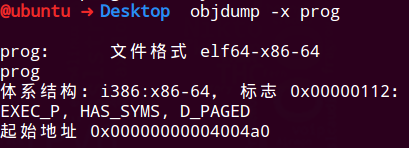
起始地址,也就是程序的入口点(entry point)也就是当程序运行时要执行的第一条指令的地址
.text、.rodata 和.data 节与可重定位目标文件中的节是相识的,除了这些节已经被重定位到它们最终的运行时内存地址外
.init 节定义了一个叫做_init 的函数,程序的初始化代码会调用它。因为可执行文件是完全链接的(已被重定位),所以它不需要 rel 节
ELF 可执行文件被设计得很容易加载到内存,可执行文件的连续的片(chunk)被映射到连续的内存段。程序头部表描述了这种映射关系
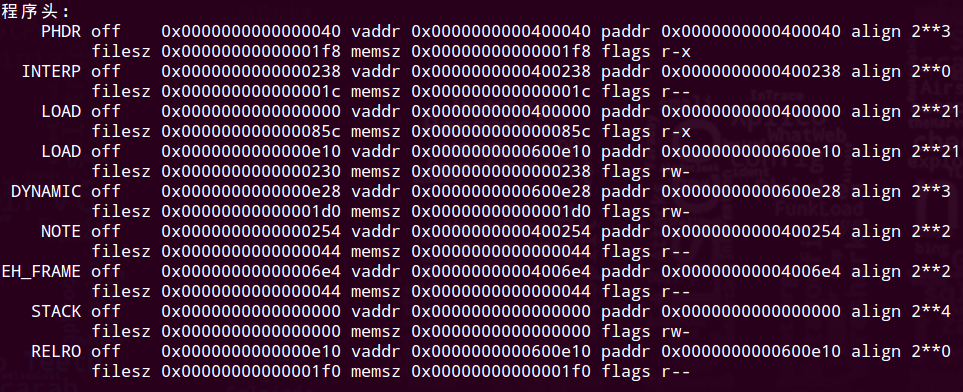
off: 目标文件中的偏移;vaddr/paddr: 内存地址;align: 对齐要求;filesz: 目标文件中的段大小;memsz: 内存中的段大小;flags: 运行时访问权限
这里先只关注可执行目标文件的内容初始化两个内存段。
LOAD off 0x0000000000000000 vaddr 0x0000000000400000 paddr 0x0000000000400000 align 2**21
filesz 0x000000000000085c memsz 0x000000000000085c flags r-x
LOAD off 0x0000000000000e10 vaddr 0x0000000000600e10 paddr 0x0000000000600e10 align 2**21
filesz 0x0000000000000230 memsz 0x0000000000000238 flags rw-
1、2 两行告诉我们第一段(代码段)有读 / 执行 访问权限,开始于内存地址 0x400000 处,总共的内存大小是 0x85c 字节,并且被初始化为可执行目标文件的头 0x85c 字节,其中包括 ELF 头、程序头部表以及.init、.text 和.rodata 节
3、4 行告诉我们第二段(数据段)有读 / 写 访问权限,开始于内存地址 0x600e10 处,总的内存大小为 0x238 字节,并用从目标文件中偏移 0xe10 处开始的.data 节中的 0x230 个字节初始化。该段中剩下的 8 个字节对应于运行时将被初始化为 0 的.bss 数据
对于任何段 s,链接器必须选择一个起始地址 vaddr,使得 vaddr mod align=off mod align
这里,off 是目标文件中段的第一个节的偏移量,align 是程序头部中指定的对齐(2^21=0x200000)
举例:
vaddr mod align = 0x600e10 mod 0x200000 = 0xe10
off mod align = 0xe10 mod 0x200000 = 0xe10
这个对齐要求是一种优化,使得当程序执行时,目标文件中的段能够很有效率地传送到内存中
加载可执行目标文件
首先 shell 会认为 prog 是一个可执行目标文件,通过调用某个驻留在存储器中称为加载器(loader)的操作系统代码来运作它。任何 Linux 程序都可以通过调用 execve 函数来调用加载器。
加载器将可执行目标文件中的代码和数据从磁盘复制到内存中,然后通过跳转到程序的第一条指令或入口点来运行该程序,这个将程序复制到内存并运行的过程叫做加载
每个 Linux 程序都有一个运行时内存映像。在 Linux x86-64 系统中,代码段总是从地址 0x400000 处开始,32 位系统从 0x08048000 处开始,后面是数据段。运行时堆在数据段之后,通过调用 malloc 库往上增长。堆后面的区域是为共享模块保留的。用户栈总是从最大的合法用户地址(2^48-1)开始,向较小内存地址增长。栈上的区域,从地址 2^48 开始,是为内核中的代码和数据保留的,所谓内核就是操作系统驻留在内存的部分
栈顶放在最大的合法用户地址处
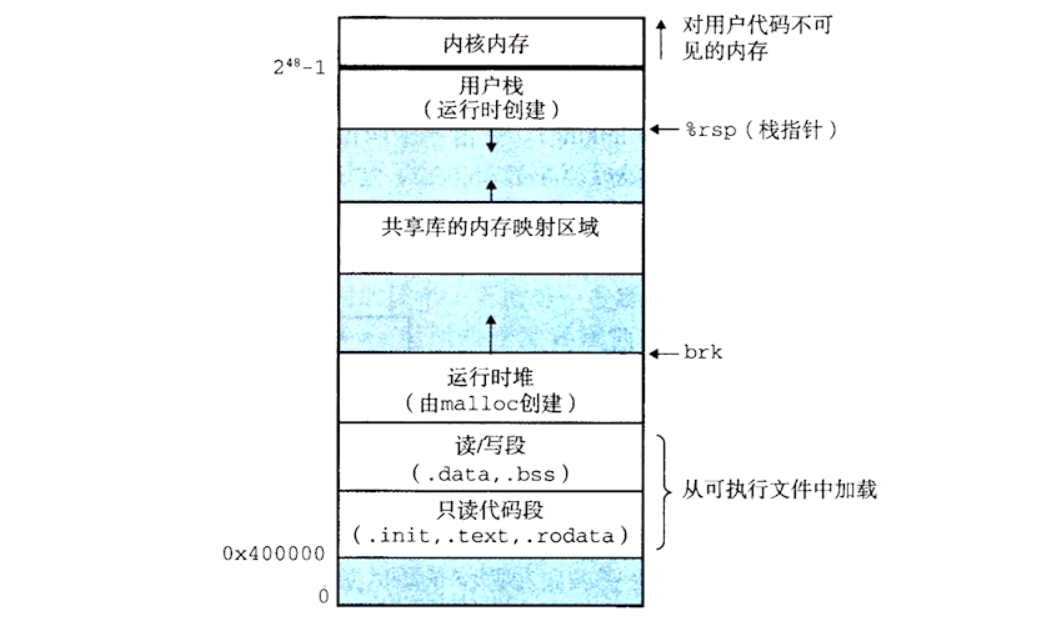
加载器实际是如何工作的?这里做个概述
Linux 系统中每个程序都运行在一个进程上下文中,有自己的虚拟地址空间。当 shell 运行一个程序时,父 shell 进程生成一个子进程,它是父进程的一个复制。子进程通过 execve 系统调用启动加载器。加载器删除子进程现有的虚拟内存段,并创建一组新的代码、数据、堆和栈段。新的栈和堆段被初始化为零。通过将虚拟地址空间中的页映射到可执行文件的页大小的片,新的代码和数据被初始化为可执行文件的内容。最后,加载器跳转到_start 地址,它最终会调用应用程序的 main 函数。除了一些头部信息,在加载过程中没有任何从磁盘到内存的数据复制。直到 CPU 引用一个被映射的虚拟页时才会进行复制,此时,操作系统利用它的页面调度机制自动将页面从磁盘传送到内存
动态链接共享库
共享库(shared library)是致力于解决静态库缺陷的一个现代创新产物。共享库是一个目标模块,在运行或加载时,可以加载到任意的内存地址,并和一个内存中的程序链接起来。这个过程为动态链接(dynamic linking),是由一个叫做动态链接器(dynamic linker)的程序执行的。共享库也成为共享目标(shared object),在 Linux 系统中通常用.so后缀来表示。微软的操作系统大量地使用了共享库,它们称为 DLL(动态链接库)
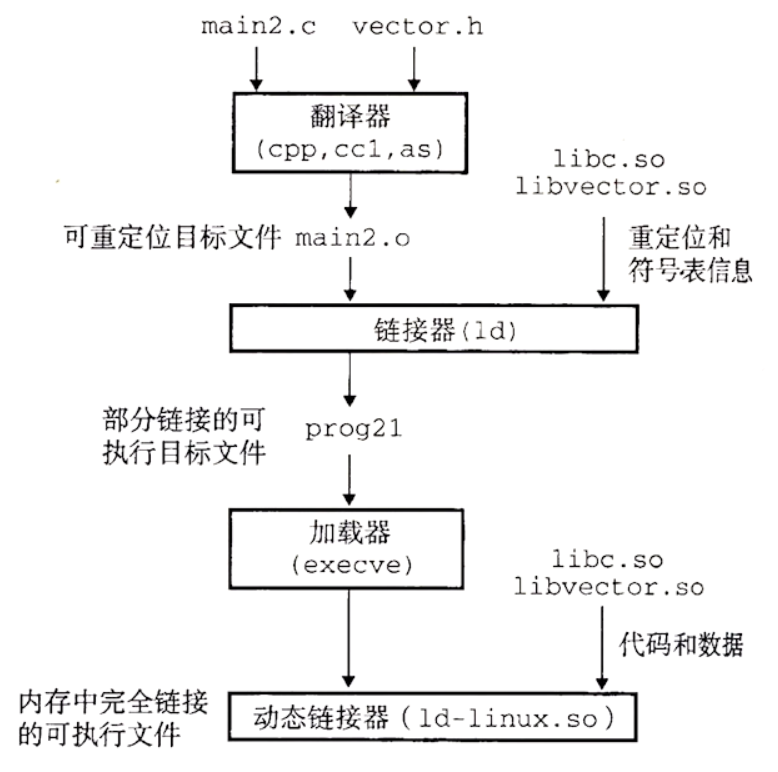
没有任何 libvector.so 的代码和数据节真的被复制到可执行文件 prog21 中。反之,链接器复制了一些重定位和符号表信息,它们使得运行时可以解析对 libvector.so 中代码和数据的引用。
当加载器加载和运行可执行文件 prog21 时,加载部分链接的可执行文件 prog21. 接着,prog21 中包含一个.interp节,这一节包含动态链接器的路径名,动态链接器本身就是一个共享目标,加载器不会像它通常所做的那样将控制传递给应用,而是加载和运行这个动态链接器。然后,动态链接器通过执行重定位完成链接任务:重定位共享库文本和数据到某个内存段,重定位共享库定义的符号的引用
最后,动态链接器将控制传递给应用程序,从这一时刻开始,共享库的位置就固定了,并且在程序执行的过程中都不会改变
从应用程序中加载和链接共享库
这是共享库的一种使用情景,无需在编译时将那些库链接到库中。如:微软 windows 应用开发者分发软件;构建高性能 web 服务器
共享库的主要目的就是运行多个正在运行的进程共享内存中相同的库代码
位置无关代码
为解决多个进程共享程序的一个副本时,造成了库在内存中的分配管理问题
现代系统以这样一种方式编译共享模块的代码段,使得可以把它们加载到内存的任何位置而无需链接器修改。可以加载而无需重定位的代码称为位置无关代码
在 x86-64 系统中,对同一个目标模块中符号的引用是不需要特殊处理使之成为 PIC,可以用 PC 相对寻址来编译这些引用,构造目标文件时由静态链接器重定位。
处理目标文件的工具
ldd:列出一个可执行文件在运行时所需要的共享库
objdunp:所有二进制工具之母。能够显示一个目标文件中所有的信息。它最大的作用是反汇编.text 节中的二进制指令
size:列出目标文件中节的名字和大小
readelf:显示一个目标文件的完整结构,包括 ELF 头中编码的所有信息
异常控制流 (ECF)
异常控制流(ECF)发生在计算机系统的各个层次,是计算机系统中提供并发的基本机制。
在硬件层,异常是由处理器中的事件触发的控制流中的突变。控制流传递给一个软件处理程序,该处理程序进行一些处理,然后返回控制给被中断的控制流
有四种不同类型的异常:中断、故障、终止和陷阱。当一个外部 I/O 设备设置了处理器芯片上的中断管脚时,中断会异步的发生。控制返回到故障指令后面的那条指令,一条指令的执行可能导致故障和终止同步发生。故障处理程序会重新启动故障指令,而终止处理程序从不将控制返回给被中断的流。最后,陷阱就像是用来实现向应用提供操作系统代码的受控的入口点的系统调用的函数调用
在操作系统层,内核用 ECF 提供进程的基本概念。进程提供给应用两个重要的抽象:1)逻辑控制流,它提供给每个程序一个假象,好像它是在独占地使用处理器,2)私有地址空间,它提供给每个程序一个假象,好像它是在独占地使用主存
在操作系统和应用程序之间的接口处,应用程序可以创建子进程,等待它们的子进程停止或者终止,运行新的程序,以及捕获来自其他进程的信号。
最后,在应用层,C 程序可以使用非本地跳转来规避正常的调用 / 返回栈规则,并且直接从一个函数分支到另一个函数
程序和进程
程序时一堆代码和数据;程序可以作为目标文件存在于磁盘上,或者作为段存在于地址空间中。进程是执行中程序的一个具体的实例;程序总是运行在某个进程的上下文中。 fork 函数在新的子进程中运行相同的程序,新的子进程是父进程的复制品。execve 函数在当前进程的上下文中加载并执行一个新的程序。它会覆盖当前进程的地址空间,但并没有创建一个新进程。新的程序仍然有相同的 PID,并且继承了调用 execve 函数时已达开的所有文件描述符
虚拟内存
虚拟内存是对主存的一个抽象。支持虚拟内存的处理器通过使用一种叫做虚拟寻址的间接形式来引用主存。处理器产生一个虚拟地址,在被发送到主存之前,这个地址被翻译成一个物理地址。从虚拟地址空间到物理地址空间的地址翻译要求硬件和软件紧密合作。专门的硬件通过使用页表来翻译虚拟地址,而页表的内容是由操作系统提供的。
虚拟内存提供三个重要的功能。第一,它在主存中自动缓存最近使用的存放磁盘上的虚拟地址空间的内容。虚拟内存缓存中的块叫做页。对磁盘上页的引用会触发缺页,缺页将控制转移到操作系统中的一个缺页处理程序。缺页处理程序将页面从磁盘复制到主存缓存,如果必要,将写回被驱逐的页。第二,虚拟内存简化了内存管理,进而又简化了链接、在进程间共享数据、进程的内存分配以及程序加载。最后,虚拟内存通过在每条页表条目中加入保护位,从而了简化了内存保护。
地址翻译的过程必须和系统中所有的硬件缓存的操作集成在一起。大多数页表条目位于 L1 高速缓存中,但是一个称为 TLB 的页表条目的片上高速缓存,通常会消除访问在 L1 上的页表条目的开销。
现代系统通过将虚拟内存片和磁盘上的文件片关联起来,来初始化虚拟内存片,这个过程称为内存映射。内存映射为共享数据、创建新的进程以及加载程序提供了一种高效的机制。应用可以使用 mmap 函数来手工地创建和删除虚拟地址空间的区域。然而,大多数程序依赖于动态内存分配器,例如 malloc, 它管理虚拟地址空间区域内一个称为堆的区域。动态内存分配器是一个感觉像系统级程序的应用级程序,它直接操作内存,而无需类型系统的很多帮助。分配器有两种类型。显式分配器要求应用显式地释放它们的内存块。隐式分配器 (垃圾收集器) 自动释放任何未使用的和不可达的块。
对于 C 程序员来说,管理和使用虚拟内存是一件困难和容易出错的任务。常见的错误示例包括: 间接引用坏指针,读取未初始化的内存,允许栈缓冲区溢出,假设指针和它们指向的对象大小相同,引用指针而不是它所指向的对象,误解指针运算,引用不存在的变量,以及引起内存泄漏。
后续内容不太想记录,根据感兴趣的点进行补充,便于查询,其他直接阅读书籍理解下了解下即可,网络编程和并发编程貌似不是我读这本书太关注的重点,而且也将在其他书籍研究这块内容,读到这附近我觉得我已经弥补了不熟悉的部分
虚拟内存是单机系统最重要的几个底层原理之一,它由底层硬件和操作系统两者软硬件结合来实现,是硬件异常,硬件地址翻译,主存,磁盘文件和内核的完美交互。它主要提供了 3 个能力:
-
给所有进程提供一致的地址空间,每个进程都认为自己是在独占使用单机系统的存储资源
-
保护每个进程的地址空间不被其他进程破坏,隔离了进程的地址访问
-
根据缓存原理,上层存储是下层存储的缓存,虚拟内存把主存作为磁盘的高速缓存,在主存和磁盘之间根据需要来回传送数据,高效地使用了主存
包括几块内容
-
虚拟地址和物理地址
-
页表
-
地址翻译
-
虚拟内存相关的数据结构
-
内存映射
虚拟地址和物理地址
对于每个进程来说,它使用到的都是虚拟地址,每个进程都看到一样的虚拟地址空间,对于 32 位计算机系统来说,它的虚拟地址空间是 0 - 2^32,也就是 0 - 4G。对于 64 位的计算机系统来说,理论的虚拟地址空间是 0 - 2^64,远高于目前常见的物理内存空间。虚拟地址空间不需要和物理地址空间一样大小。
Linux 内核把虚拟地址空间分为两部分:用户进程空间和内核进程空间,两者的比例一般是 3:1,比如 4G 的虚拟地址空间,3G 用户用户进程,1G 用于内核进程。 在说 CPU 高速缓存的时候说过 CPU 只直接和寄存器和高速缓存打交道,CPU 在执行进程的指令时要取一个实际的物理地址的值的时候主要有几步:
-
把进程指令使用的虚拟地址通过 MMU 转换成物理地址
-
把物理地址映射到高速缓存的缓存行
-
如果高速缓存命中就返回
-
如果不命中,就产生一个缓存缺失中断,从主存相应的物理地址取值,并加载到高速缓存中。CPU 从中断中恢复,继续执行中断前的指令
所以高速缓存是和物理地址相映射的,进程指令中使用到的是虚拟地址。 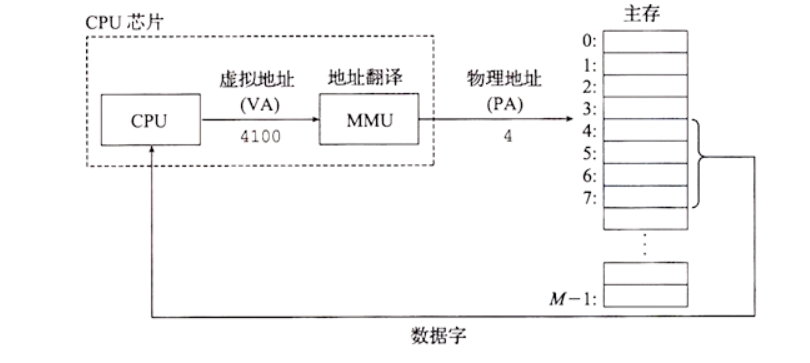
操作系统内存管理
在缓存原理中,数据都是按块来进行逻辑划分的,一次换入 / 换出的数据都是以块为最小单位,这样提高了数据处理的性能。同样的原理应用到具体的内存管理时,使用了页 (page) 来表示块,虚拟地址空间划分为多个固定大小的虚拟页 (Virtual Page, VP),物理地址空间划分为多个固定大小的物理页 (Physical Page, PP), 通常虚拟页大小等于物理页大小,这样简化了虚拟页和物理页的映射。虚拟页的大小通常在 4KB - 2MB 之间。在 JVM 调优的时候有时候会使用 2MB 的大内存页来提高 GC 的性能。
要明白一个重要的概念:
-
对于 CPU 来说,它的目标存储器是物理内存,使用高速缓存做物理内存的缓存
-
同样,对于虚拟内存来说,它的目标存储器是磁盘空间,使用物理内存做磁盘的缓存
所以,从缓存原理的角度来理解,在任何时刻,虚拟页的集合都分为 3 个不相交的子集:
-
未分配的页,即没有任何数据和这些虚拟页关联,不占用任何磁盘空间
-
缓存的页,即已经分配了的虚拟页,并且已经缓存在具体的物理页中
-
未缓存的页,即已经为磁盘文件分配了虚拟页,但是还没有缓存到具体的物理页中

虚拟内存系统和高速缓存系统一样,需要判断一个虚拟页面是否缓存在 DRAM (主存) 中,如果命中,就直接找到对应的物理页。如果不命中,操作系统需要知道这个虚拟页对应磁盘的哪个位置,然后根据相应的替换策略从 DRAM 中选择一个牺牲的物理页,把虚拟页从磁盘中加载到 DRAM 物理主存中
虚拟内存的这种缓存管理机制是通过操作系统内核,MMU (内存管理单元) 中的地址翻译硬件和每个进程存放在主存中的页表 (page table) 数据结构来实现的。
页表
页表 (page table) 是存放在主存中的,每个进程维护一个单独的页表。它是一种管理虚拟内存页和物理内存页映射和缓存状态的数据结构。它逻辑上是由页表条目 (Page Table Entry, PTE) 为基本元素构成的数组。
-
数组的索引号对应着虚拟页号
-
数组的值对应着物理页号
-
数组的值可以留出几位来表示有效位,权限控制位。有效位为 1 的时候表示虚拟页已经缓存。有效位为 0,数组值为 null 时,表示未分配。有效位为 0,数组值不为 null,表示已经分配了虚拟页,但是还未缓存到具体的物理页中。权限控制位有可读,可写,是否需要 root 权限
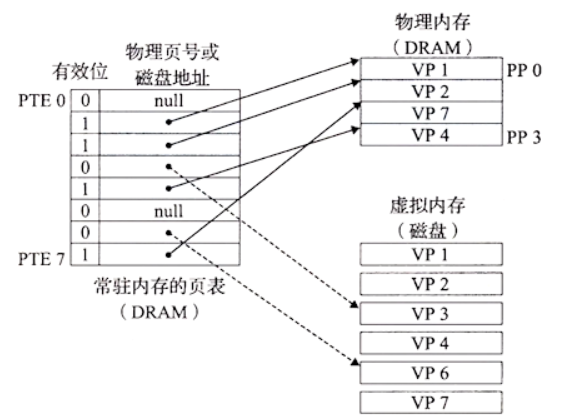
SRAM 缓存表示位于 CPU 和主存之间的 L1、L2 和 L3 高速缓存。
DARM 缓存的命中称为页命中,不命中称为缺页。举个例子来说,
-
CPU 要访问的一个虚拟地址在虚拟页 3 上(VP3),通过地址翻译硬件从页表的 3 号页表条目中取出内容,发现有效位 0,即没有缓存,就产生一个缺页异常
-
缺页异常调用内核的缺页异常处理程序,它会根据替换算法选择一个 DRAM 中的牺牲页,比如 PP3。PP3 中已经缓存了 VP4 对应的磁盘文件的内容,如果 VP4 的内容有改动,就刷新到磁盘中去。然后把 VP3 对应的磁盘文件内容加载到 PP3 中。然后更新页表条目,把 PTE3 指向 PP3, 并修改 PTE4,不再指向 PP3.
-
缺页异常处理程序返回后重新启动缺页异常前的指令,这时候虚拟地址对应的内容已经缓存在主存中了,页命中也可以让地址翻译硬件正常处理了
磁盘和主存之间传送页的活动叫做交换 (swapping) 或者页面调度(页面调入,页面调出)。现代操作系统都采用按需调度的策略,即不命中发生时才调入页面。操作系统都会在主存中分配一块交换区 (swap) 来作缓冲区,加速页面调度。
由于页的交换会引起磁盘流量,所以具有好的局部性的程序可以大大减少磁盘流量,提高性能。而如果局部性不好产生大量缺页,从而导致不断地在磁盘和主存交换页,这种现象叫缓存颠簸。可以用 Unix 的函数 getrusage 来统计缺页的次数
现代操作系统都采用多级页表的方式来压缩页表的大小。举个例子,
-
对于 32 位的机器来说,支持 4G 的虚拟内存大小,如果每个页是 4KB 大小,那么采用一级页表的话,需要 10^6 个页表条目 PTE。32 位机器的页表条目是 4 个字节,那么页表需要 4MB 大小的空间。
-
假设使用 4MB 大小的页,那么只需要 10^3 个页表项。假设每个 4MB 大小的页又分为 4KB 大小的子页,那么每个 4MB 大小的页需要 10^3 个的页表项来指向子页。也就是说可以分为两级页表,第一级页表项只需要 4KB 大小的页表项,每个一级页表项又指向一个 4KB 大小的二级页表,二级页表项则指向实际的物理页。
页表项加载是按需加载的,没有分配的虚拟页不需要建立页表项, 所以可以一开始只建立一级页表项,而二级页表项按需创建,这样大大压缩了页表的空间。
地址翻译
地址翻译就是把 N 个元素的虚拟地址空间 (VAS) 映射到 M 个元素的物理地址空间 (PAS) 的过程。
总结一下地址翻译的过程:
-
CPU 拿到一个虚拟地址,分为两步,先通过页表机制确定该地址所在虚拟页的内容是否从磁盘加载到物理内存页中,然后通过高速缓存机制从该物理地址中取到数据
-
地址翻译硬件要把这个虚拟地址翻译成一个物理地址,从而可以再根据高速缓存的映射关系,把这个物理地址对应的值找到
-
地址翻译硬件利用页表数据结构,TLB 硬件缓存等技术,目的只是把一个虚拟地址映射到一个物理地址。要记住 DRAM 缓存是全相联的,所以一个虚拟地址和一个物理地址是动态关联的,不能直接根据虚拟地址推导出物理地址,必须根据 DRAM 从磁盘把数据缓存到 DRAM 时存到页表时存的实际物理页才能得到实际的物理地址,用物理页 PPN + VPO 就能算出实际的物理地址 (VPO = PPO,所以直接用 VPO 即可)。 PPN 的值是存在页表条目 PTE 中的。地址翻译做了一堆工作,就是为了找到物理页 PPN,然后根据 VPO 页面偏移量,就能定位到实际的物理地址。
-
得到实际物理地址后,根据高速缓存的原理,把一个物理地址映射到高速缓存具体的组,行,块中,找到实际存储的数据。
Linux 虚拟内存机制
Linux 把虚拟内存划分成区域 area 的集合,每个存在的虚拟页面都属于一个 area。一个 area 包含了连续的多个页。Linux 通过 area 相关的数据结构来灵活地管理虚拟内存。
-
内核为每个进程维护了一个单独的任务结构 task_struct
-
task_struct 的 mm 指针指向了 mm_struct,该结构描述了虚拟内存的运行状态
-
mm_struct 的 pgd 指针指向该进程的一级页表的基地址。mmap 指针指向了 vm_area_struct 链表
-
vm_area_struct 是描述 area 结构的一个链表,链表节点的几个重要属性如下:vm_start 表示 area 的开始位置,vm_end 表示 area 的结束位置,vm_prot 描述了 area 内的页的读写权限,vm_flags 描述该 area 内的页面是与其他进程共享还是进程私有,vm_next 指向下一个 area 节点
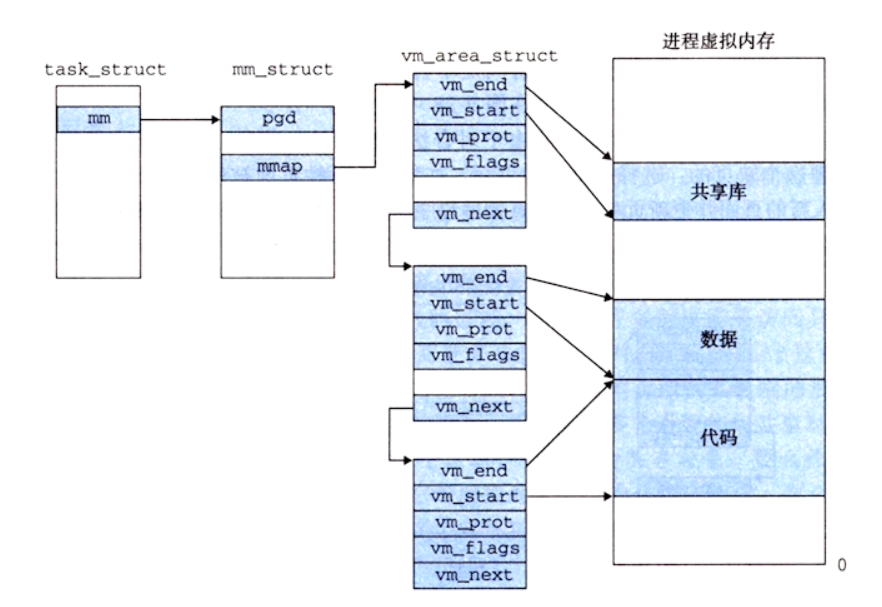
在 Linux 系统中,当 MMU 翻译一个虚拟地址发生缺页异常时,跳转到内核的缺页异常处理程序。
-
Linux 的缺页异常处理程序会先检查一个虚拟地址是哪个 area 内的地址。只需要比较所有 area 结构的 vm_start 和 vm_end 就可以知道。area 都是一个连续的块。如果这个虚拟地址不属于任何一个 area,将发生一个段错误,终止进程
-
要访问的目标地址是否有相应的读写权限,如果没有,将触发一个保护异常,终止进程
-
选择一个牺牲页,如果牺牲页被修改过,那么把它交换出去。从磁盘加载虚拟页内容到物理页,更新页表
内存映射机制
虚拟内存的目标存储器是磁盘,所以虚拟内存区域是和磁盘中的文件对应的。初始化虚拟内存区域的内容时,会把虚拟内存区域和一个磁盘文件对象对应起来,这个过程叫内存映射 (memory mapping)。虚拟内存可以映射的磁盘文件对象包括两种:
-
一个普通的磁盘文件,文件中的内容被分成页大小的块。因为按需进行页面调度,只有真正需要读取这些虚拟页时,才会交换到主存
-
一个匿名文件,匿名文件是内核创建的,内容全是二进制 0,它相当于一个占位符,不会产生实际的磁盘流量。映射到匿名文件中的页叫做请求二进制零的页 (demand zero page)
一旦一个虚拟页面被初始化了,它就在一个由内核维护的专门的交换区 (swap area) 之间换来换去。
由于内存映射机制,所以一个磁盘文件对象可以被多个进程共享访问,也可以被多个进程对象私有访问。如果是共享访问,那么一个进程对这个对象的修改会显示到其他进程。如果是私有访问,内核会采用写时拷贝 copy on write 的方式,如果一个进程要修改一个私有的写时拷贝的对象,会产生一个保护故障,内核会拷贝这个私有对象,写进程会在新的私有对象上修改,其他进程仍指向原来的私有对象。
理解了内存映射机制就可以理解几个重要的函数:
-
fork 函数会创建带有独立虚拟地址空间的新进程,内核会为新进程创建各种数据结构,分配一个唯一的 PID,把当前进程的 mm_struct, area 结构和页表都复制给新进程。两个进程的共享同样的区域,这些区域包括共享的内存映射和私有的内存映射。私有的内存映射区域都被标记为私有的写时拷贝。如果新建的进程对这些虚拟页做修改,那么会触发写时拷贝,为新的进程维护私有的虚拟地址空间。
-
mmap 函数可以创建新的虚拟内存 area, 并把磁盘对象映射到新建的 area。
mmap 可以用作高效的操作文件的方式,直接把一个文件映射到内存,通过修改内存就相当于修改了磁盘文件,减少了普通文件操作的一次拷贝操作。普通文件操作时会先把文件内容从磁盘复制到内核空间管理的一块虚拟内存区域 area,然后内核再把内容复制到用户空间管理的虚拟内存 area。 mmap 相当于创建了一个内核空间和用户空间共享的 area,文件的内容只需要在这个 area 对应的物理内存和磁盘文件之间交换即可。
mmap 也可以通过映射匿名文件的方式来分配内存空间。比如 malloc 当要求分配的内存大小超过了 MMAP_THRESHOLD (默认 128kb) 时,会使用 mmap 私有的,匿名文件的方式来分配大块的内存空间。
动态内存分配
动态内存分配器维护者一个进程的虚拟内存区域,称为堆(heap)。向上生长(向更高地址),对每个进程,内核维护着一个变量 brk,它指向堆的顶部
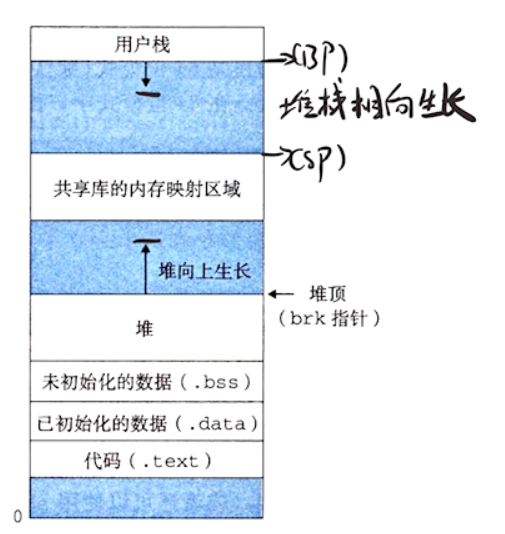
程序使用动态内存分配的最重要的原因是经常直到程序实际运行时才知道某些数据结构的大小
系统级 I/O
Linux 提供了少量的基于 Unix I/O 模型的系统级函数,它们允许应用程序打开、关闭、读和写文件,提取文件的元数据,以及执行 I/O 重定向。Linux 的读和写操作会出现不足值,应用程序必须能正确地预计和处理这种情况。应用程序不应直接调用 UnixI/O 函数,而应该使用 RIO 包,RIO 包通过反复执行读写操作,直到传送完所有的请求数据,自动处理不足值。
Linux 内核使用三个相关的数据结构来表示打开的文件。描述符表中的表项指向打开文件表中的表,项,而打开文件表中的表项又指向 v-node 表中的表项。每个进程都有它自己单独的描述符表,而所有的进程共享同一个打开文件表和 v-node 表。理解这些结构的一般组成就能使我们清楚地理解文件共享和 1/O 重定向。
标准 I/O 库是基于 Unix I/O 实现的,并提供了一组强大的高级 I/O 例程。对于大多数应用程序而言,标准 I/O 更简单,是优于 Unix I/O 的选择。然而,因为对标准 I/O 和网络文件的一些相互不兼容的限制,UnixI/O 比之标准 I/O 更该适用于网络应用程序。
网络编程

每个网络应用都是基于客户端一服务器模型的。根据这个模型,一个应用是由一个服务器和一个或多个客户端组成的。服务器管理资源,以某种方式操作资源,为它的客户端提供服务。客户端 - 服务器模型中的基本操作是客户端 - 服务器事务,它是由客户端请求和跟随其后的服务器响应组成的。
客户端和服务器通过因特网这个全球网络来通信。从程序员的观点来看,我们可以把因特网看成是一个全球范围的主机集合,具有以下几个属性: 1) 每个因特网主机都有一个唯 - 一的 32 位名字,称为它的 IP 地址。2) IP 地址的集合被映射为一个因特网域名的集合。3) 不同因特网主机上的进程能够通过连接互相通信。
客户端和服务器通过使用套接字接口建立连接。一个套接字是连接的一个端点,连接以文件描述符的形式提供给应用程序。套接字接口提供了打开和关闭套接字描述符的函数。客户端和服务器通过读写这些描述符来实现彼此间的通信。
Web 服务器使用 HTTP 协议和它们的客户端 (例如浏览器) 彼此通信。浏览器向服务器请求静态或者动态的内容。对静态内容的请求是通过从服务器磁盘取得文件并把它返回给客户端来服务的。对动态内容的请求是通过在服务器上一个子进程的上下文中运行一个程序并将它的输出返回给客户端来服务的。CGI 标准提供了一。组规则,来管理客户端如何将程序参数传递给服务器,服务器如何将这些参数以及其他信息传递给子进程,以及子进程如何将它的输出发送回客户端。只用几百行 C 代码就能实现一个简单但是有功效的 Web 服务器,它既可以提供静态内容,也可以提供动态内容。
并发编程
一个并发程序是由在时间上重叠的一组逻辑流组成的。三种不同的构建并发程序的机制:进程、I/O 多路复用和线程。我们以一个并发网络服务器作为贯穿全章的应用程序。
进程是由内核自动调度的,而且因为它们有各自独立的虚拟地址空间,所以要实现共享数据,必须要有显式的 IPC 机制。事件驱动程序创建它们自己的并发逻辑流,这些逻辑流被模型化为状态机,用 I/O 多路复用来显式地调度这些流。因为程序运行在一个单一进程中,所以在流之间共享数据速度很快而且很容易。线程是这些方法的混合。同基于进程的流一样,线程也是由内核自动调度的。同基于 I/O 多路复用的流一样,线程是运行在一个单一进程的上下文中的,因此可以快速而方便地共享数据。
无论哪种并发机制,同步对共享数据的并发访问都是一个困难的问题。提出对信号量的 P 和 V 操作就是为了帮助解决这个问题。信号量操作可以用来提供对共享数据的互斥访问,也对诸如生产者 - 消费者程序中有限缓冲区和读者 - 写者系统中的共享对象这样的资源访问进行调度。一个并发预线程化的 echo 服务器提供了信号量使用场景的很好的例子。
并发也引人了其他一些困难的问题。被线程调用的函数必须具有一种称为线程安全的属性。我们定义了四类线程不安全的函数,以及 - - 些将它们变为线程安全的建议。可重人函数是线程安全函数的一个真子集,它不访问任何共享数据。可重人函数通常比不可重人函数更为有效,因为它们不需要任何同步原语。竞争和死锁是并发程序中出现的另一些困难的问题。当程序员错误地假设逻辑流该如何调度时,就会发生竞争。当一个流等待一个永远不会发生的事件时,就会产生死锁。

2016/08/30 Business Logic a different perspective
每天推荐一个英文视频
http://v.qq.com/x/page/z0172y...
https://vimeo.com/131757759
本日看点




8 Traits of an Experienced Programmer that every beginner programmer should know
Referrence: http://whats-online.info/guides-and-info/36/Traits-of-Experienced-Programmer-that-every-beginner-should-know/
Not everybody has the capability to be a good programmer. Most lack the desire,others do not have a high level of practical aptitude and others lack the personality required to make a good programmer. To help you understand just what these ‘personality’ traits are,I will break down some of the traits that an experienced programmer has. Being in the field for 8 years Now,believe me I kNow the ups,downs,tricks and ‘’oh no’s’’ in this field. I will take you through 8 crucial traits of a programmer,which can be emulated by the beginners who wanna make it big in this field.
- Consistency
No programmer wants to be the wonder hit-and-disappear kind of a programmer. A good programmer is reliable. He kNows what it is that he wants,and is willing to keep on programming when need be. Not necessarily a 9-5 person,but one who accomplishes tasks and projects without leaving them hanging.
- Problem solver
As a programmer,I would liken programming to solving a complicated mathematics equations. They are complicated and most seem hard to crack. It is easy to just let go of them and look for a simpler equation to tackle. A programmer is that person who doesn’t give up on a task simply because it seems complicated. They look for solutions to every task. Giving up is a phrase that is never heard of in the world of programming.
- Planning skills
To plan is to see ahead. Instead of hopping into a new project,a good programmer will first study as much as he/ she can concerning the anticipated end product. As soon as that analysis is completed,the programmer ought to first strategize the project structure before inputting the first line of code. Planning goes hand in hand with consistency. So a consistent programmer is also a good planner.
- Excellent communication skills
I do not speak the perfect English,but am I good programmer? The answer is yes. Across the years,I have noticed that most of my peers are not fluent English speaker but they do pass for programmers with excellent communication skills. In programming,good communication skills is the ability to express an idea precisely and efficiently. Good programmers are able to pass their points across well. Programmers who experience a tough time conveying their points across or comprehending what others are telling them,may not be successful in the long run.
- Passion for Programming
This is the most important trait of all times. Passion is everything. Without the willingness to work,it will soon or later go down the drain. Some employed programmers only do the 9 to 5 job,for the salary part of it. These caliber of programmers do not program for long because they only do it for the cash,not for the work. When off from work,nothing close to what they do ever crosses their minds. You do not have to wake up,and go to bed breathing codes. Programmers who lack the passion are never enthused to acquire the best method of doing things and instead,they only engage in a routine,which is not be the best technique of doing things.
- Detail Oriented
This is what separates a patient programmer from an impatient one. Programming involves dealing with codes whose simple mistake Could cost you a whole project. A programmer who pays close consideration to detail will be suggestively more industrIoUs than the one who doesn‘t. This trait involves evaluation of self –conscIoUsness,which is very crucial for a serIoUs consistent programmer.
- Ability to cope with changing trends
Technology is constantly changing and the expertise and capabilities a programmer has currently will probably be out-of-date in the coming years. It is,therefore,key for a programmer to be able and willing to educate him/ herself and follow the up-to-date trends. This way,they find it easy to take part in any ongoing education chances that are presented.
- A good reader
A good programmer reads extensively. Not all the work is about coding. A substantial percentage of a programmer‘s work day is spent in reading. It Could be codes typed by other people,Web sites with examples,papers,or projects. Programmers who do not read extensively,or worse,do not comprehend what they are reading,are mostly incompetent at best,and hazardous at worst.
All in all,a good programmer
? Recognizes that programming is a resourceful art and is nothing interesting
? Takes boundless pride in his job and gets abundant contentment from it
? Attempts to decrease the difficulty of both the problem at hand and the result
? He/she utilizes his time but is never too occupied to help others hit the books
? He/she appreciates positive criticism and offers productive criticism for other programmers as well.
? Has Failed countless times but is always willing to learn from the failures.
? Makes his/her decisions without necessarily relying on other people. Sometimes someone needs to make decisions from his/ her heart without the influence of others.
? is continually learning and gets an excitement from those embarrassing moments. nothing is too serIoUs. Laugh at yourself at times.
Programming is not for the faint-hearted. Do not try programming at your desperation when everything else Could not work out. If you possess the above traits that a good programmer should have,then brace yourself for a life changing experience. Above all,hard work is everything.

All I Need To Know To Be A Better Programmer I Learned In Kindergarten

All I Need To Know To Be A Better Programmer I Learned In Kindergarten
Apr 4, 2007Programming is complicated stuff, but a lot of what makes a good programmer isn't all that different from the earliest learning we did in school.
The inspiration for this list came from the essay "All I Really Need to Know I Learned in Kindergarten" by Robert Fulghum at http://www.robertfulghum.com/.
1. Share everything.
Use open source where possible, and contribute to it when you are able. The collective wisdom of the entire community is better than the limited vision of a few large companies.
2. Play fair.
Give other technologies, frameworks, methodologies and opinions a chance. Don't think your choices are the only ones that work. The other choices may very well be better than yours; it doesn't hurt to check them out with an open mind.
3. Don't hit people.
Like #2, don't attack people just because they happen to use .Net or Java or PHP (I learned my lesson there!). Sometimes they might be more usable and useful than you think. You can learn a lot more from someone when you are not pounding them to a pulp.
4. Clean up your own mess.
Strive to deliver code that works. Never expect QA to find all of your bugs for you. Test your code often, both narrowly and broadly.
5. Don't take things that aren't yours.
Follow the licenses for stuff you use, don't just steal it and claim innocence later.
6. Say you're sorry when you hurt somebody.
Code reviews are a good but rarely used idea. Mentoring programmers with less experience than you helps the entire team. Just don't criticize people openly. Learning is not belittling people. Sometimes people will listen and sometimes they won't. Sometimes you might learn a lot from people you think are inferior to you.
7. Wash your hands before you eat.
Try to understand things before you set out to write code. Do prototyping, check out examples on the web, talk with other folks who do it, or even just play around. Architecting something you've never done before or worked with is tough cold turkey. The end result will work much better if you start with a clue.
8. Flush.
Don't be afraid to replace, rewrite, refactor or give up on something that is crap. Sometimes "when in doubt throw it out" is the best philosophy. Never fall in love with your code.
9. Warm cookies and cold milk are good for you.
Yes, programmers should be well supported in their work environment. A good chair, a quiet place to work, a decent computer and tools that make coding better and easier are essential. Managers should act as umbrellas to keep the crap from flowing down to the programmers. As a programmer, don't accept a life of lowly servitude. If the employer treats you poorly then find one who treats you better.
10. Live a balanced life - learn some and think some and draw and paint and sing and dance and play and work every day some.
I like Google's deal where 20% of your time is devoted to whatever you think it worth working on. Employers should (discretely) offer nap rooms or game rooms or some kind of chillout environment. Programming is hard mental work; sometimes you really need to give your brain a rest. Refuse to routinely work 80 hour weeks as the quality of your work will wipe out any gains in hours.
11. Take a nap every afternoon.
Working 24 hours a day doesn't make you more productive. Take breaks, go home, take a real nap. Often I have solved nasty problems by going home, and the solution came to me as I was driving away, or the next morning.
12. When you go out in the world, watch out for traffic, hold hands and stick together.
Community is good for the soul; read blogs, learn about new languages or frameworks, participate in discussions and see what other people are doing. Just doing your job isn't going to make you a better programmer. Keeping your head down means you will eventually be obsolete.
13. Be aware of wonder. Remember the little seed in the Styrofoam cup: the roots go down and the plant goes up and nobody really knows how or why, but we are all like that.
Every day something new and wonderful appears in the programming (and technology in general) world. Check it out. Be amazed. Learn something new everyday. It keeps your mind fresh, your options open, and your skills up to date. If you think programming is boring or dead then you may need a new career.
14. Goldfish and hamsters and white mice and even the little seed in the Styrofoam cup - they all die. So do we.
Code goes stale and dies. Sometimes you just have to bury it and do it again. Fight against keeping terrible code bases around just to save money.
15. And then remember the Dick-and-Jane books and the first word you learned - the biggest word of all - LOOK.
You won't learn anything at all if you don't try. Everything I learned in programming came from trying new stuff and generally playing around. Every morning I read a lot of sites to see what is happening in the programming world; I have been doing this since my first job in the early 80's (when it meant reading catalogs and magazines).
See, programming is easy when you look at it through 5-year-old eyes.

Be an female programmer
毕业快一年了,如果加上大四那年根本就没怎么在学校待过的话,都快两年了。这说明我做程序员也快两年了。这其中有多少故事也只有我自己知道,从刚开始什么都不会到现在会的也越来越多了,但是掌握得也不够深刻。
一直在想我到底要不要转行呢,有男同事跟我说,一个正常的男人是不会找一个女程序员做老婆的。公司里也有追求者,但都被我一个一个拒绝了,跟前男友分手快半年多了,我现在完全习惯了一个人。一个人去吃饭,一个人下班,一个人散步听音乐。我跟好友说,我现在完全习惯单身了,她说我完了。其实我心底还是很希望能遇见一个自己喜欢的人,谈过恋爱的人都知道,遇见一个自己喜欢并且也喜欢自己的人有多不容易。但是我每天对着电脑,接触的人都是男程序员,有时加班会很晚,到十二点,甚至一两点。记得有一次,我不舒服,但是项目很紧张,快要上线了,负责人没有让我走的意思,但是我实在是写不下去了,也改不了代码了,我拿起包就走了,到外面连车都没的打,我一下子就哭了。感觉好无助,也很孤单。这种感觉很可怕,因为这个时候我就认为我得有个男朋友。
公司加班其实挺严重的,因为有要求平均下班时间,达不到的话会被领导找去讲话的(听说的,不过好像是真的)。每天忙得跟什么一样,有时候周末都没有,哪有时间谈恋爱的,偶尔有个时间,就想自己休息。虽说是这样吧,但是我对爱情还是很期待的,虽然男生不想找女程序员,但是我特别希望找一个男程序做我的男朋友,技术很牛,很聪明,但千万不要绝顶,然后不戴眼镜,身高比我高,肤色跟我一样,偶尔散步可以聊他喜欢聊的,他想聊什么我都可以搭得上话才最好。唔,先把梦做到这吧。该加班了,一会下班。
我们今天的关于Computer Systems A Programmer''s Perspective的分享已经告一段落,感谢您的关注,如果您想了解更多关于2016/08/30 Business Logic a different perspective、8 Traits of an Experienced Programmer that every beginner programmer should know、All I Need To Know To Be A Better Programmer I Learned In Kindergarten、Be an female programmer的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

