针对用Docker构建分布式Redis集群和docker搭建redis集群这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展110redis的哨兵集群redis-clusterdocker安装
针对用 Docker 构建分布式 Redis 集群和docker搭建redis集群这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展110 redis 的哨兵集群 redis-cluster docker 安装、ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis、AWS EC2+Docker+JMeter构建分布式负载测试基础架构、docker --- 高级 ---redis--- 分布式存储系统等相关知识,希望可以帮助到你。
本文目录一览:- 用 Docker 构建分布式 Redis 集群(docker搭建redis集群)
- 110 redis 的哨兵集群 redis-cluster docker 安装
- ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis
- AWS EC2+Docker+JMeter构建分布式负载测试基础架构
- docker --- 高级 ---redis--- 分布式存储系统
")
用 Docker 构建分布式 Redis 集群(docker搭建redis集群)
【编者的话】本文介绍了如何使用 Docker 搭建 Redis 集群,很多读者都在问 Docker 能带来哪些实质性的好处,我想本文就是一个很好的例子。不使用 Docker 你也可以搭建 Redis 集群,那使用 Docker 后会有怎么样的优势了?我想可以用两个词总结:快速和复用。
我们经常会遇到这样一个问题:当我们想进行一个完整的测试的时候,往往缺少硬件或者其它资源。为了满足需求,我可能需要三台服务,或者说三个虚拟机。但是我发现我们没有时间来创建它们,并且如果要物理机的话我们也没有那么多资源。这也是为什么我对 Docker 如此感兴趣,因为它可以解决我的问题。
我想在 Ubuntu 上创建三个运行 Redis 的 Docker 容器,并把它们连接起来,然后我就可以自由的在测试和开发过程中水平的扩展了, 接下来我就给你们展示我是怎么做的,以及这样做的优势。
1. 下载和配置基础镜像
我使用的是非常优秀的 phusion 镜像作为基础镜像,它增加了很多 Docker 忽略的特性, 比如按序启动服务等等, 关于这个镜像的更多信息,可以点击这里了解。
首先,让我们使用 Docker 来 pullphusion 镜像(译者注:建议使用高版本的 Docker 下载,低版本会有问题)。
root@server:/home/sam# docker pull phusion/baseimage
下载完成之后, 你可以通过 docker images 命令看到最新下载的镜像。
root@server:/home/sam# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
phusion/baseimage 0.9.15 cf39b476aeec 3 months ago 289.4 MB
phusion/baseimage latest cf39b476aeec 3 months ago 289.4 MB
这个镜像非常好用,你可以在容器启动的时候指定特定服务的启动顺序, 在这里我想给这个镜像加一个 SSH 密码登录的功能,而不是使用 SSH key。因为是在本地运行,所以不用太担心安全的问题。我们需要创建一个 phusion 的实例, 然后通过 SSH key 登录, 并且修改配置,重启 SSH,之后我们就可以使用 root 登录了。
首先,用 phusion 基础镜像创建一个新的容器。
root@server:/home/sam# docker run -d --name redis phusion/baseimage /sbin/my_init
--enable-insecure-key
/sbin/my_init 是允许 phusion 在容器启动的时候启动你的服务。 enable-insecure-key 允许我们使用‘insecure key‘ssh 进新的容器。
现在我们已经部署了容器, 接下来需要得到它的 IP 地址,可以使用 docker inspect 命令。
root@server:/home/sam# docker inspect redis | grep IPA
"IPAddress": "172.17.0.46",
接下来,下载’insecure key‘并使用它登录这个容器。
root@server:/home/sam# curl -o insecure_key -fSL https://github.com/phusion/baseimage-docker/raw/master/image/insecure_key
root@server:/home/sam# chmod 600 insecure_key
root@server:/home/sam# ssh -i insecure_key root@<IP address>
The authenticity of host ''172.17.0.52 (172.17.0.52)'' can''t be established.
ECDSA key fingerprint is aa:bb:cc:xx:xx:xx:xx:xx:xx:xx:xx:yy:zz:04:bf:04.
Are you sure you want to continue connecting (yes/no)? yes
Warning: Permanently added ''172.17.0.52'' (ECDSA) to the list of known hosts.
root@c36b4bba7dd4:~#
祝贺你, 你现在 SSH 进入容器了!下面你需要修改 SSH,从而我们不再需要’insecure key‘了,为了做到这个,打开’/etc/ssh/sshd_config‘找到下面这一行, 并去掉注释。
PermitRootLogin yes
保存文件, 我们再设置 root 的密码。
root@c36b4bba7dd4:~# passwd
Enter new UNIX password:
Retype new UNIX password:
passwd: password updated successfully
root@c36b4bba7dd4:~#
以上我们做了一些准备工作,接下来我们将在这个容器中安装 Redis。
2 安装 Redis
现在我们已经有了配置好的镜像了,接下来我们需要去下载和安装 Redis,你可以从这里下载到你想要的 Redis,在我们的例子中用到的是 3.0.0 RC1,下载地址是:https://github.com/antirez/red ... ar.gz。
注意:你还需要安装 wget、gcc、make 以及一些其它的工具。可以使用下面的命令:
apt-get update #更新系统
apt-get upgrade #升级系统
apt-get install wget gcc make#安装wget、gcc、make
首先,我们下载 Redis 3.0.0 RC1。
root@e3919192d9e3:/home# wget https://github.com/antirez/redis/archive/3.0.0-rc1.tar.gz
解压这个包并 make。
root@e3919192d9e3:/home# tar -zxvf 3.0.0-rc1.tar.gz
root@e3919192d9e3:/home# cd redis-3.0.0-rc1/
root@e3919192d9e3:/home/redis-3.0.0-rc1# make
最后, 我们把编译好的代码中的几个可执行命令移动到 /usr/bin/ 下面
root@e3919192d9e3:/home/redis-3.0.0-rc1# cd src
root@e3919192d9e3:/home/redis-3.0.0-rc1/src# mv redis-cli redis-server redis-sentinel /usr/bin/
root@e3919192d9e3:/home/redis-3.0.0-rc1/src# cd ..
root@e3919192d9e3:/home/redis-3.0.0-rc1# mkdir -p /etc/redis/
root@e3919192d9e3:/home/redis-3.0.0-rc1# cp redis.conf /etc/redis/redis.conf
现在打开文件 /etc/redis/redis.conf, 找到‘daemonize no’改为‘daemonize yes‘,然后启动它!
root@e3919192d9e3:/home/redis-3.0.0-rc1/src# redis-server /etc/redis/redis.conf
root@e3919192d9e3:/home/redis-3.0.0-rc1/src#
好了, Redis 现在已经安装好了,并且在容器里面运行了,使用的配置文件是 /etc/redis/redis.conf。
3. 让 Docker 在启动容器的时候启动 Redis 服务
现在我们的容器正在运行 Redis,并且也可以使用 SSH 登录了,我们还需要让它在容器启动的时候自动启动 Redis 服务,使用 phusion 基础镜像来实现这点相当的容易。首先,因为我们启动容器的时候使用了 /sibn/my_init, 它会去运行任何我们放在 /etc/service/* 下面的程序。所以,对于我们来说,我们只要去创建一个目录以及在这个目录里面再创建一个叫 run 的文件,像下面这样:
root@e3919192d9e3:/etc/service# cd /etc/service
root@e3919192d9e3:/etc/service# mkdir redis
root@e3919192d9e3:/etc/service# cd redis
root@e3919192d9e3:/etc/service/redis# nano run
在这个 run 文件里面,我们加入下面的内容:
#!/bin/sh
set -e
exec /usr/bin/redis-server /etc/redis/redis.conf
最后,记得给 run 文件添加可执行权限。
4. 提交镜像以便于重用
现在我们的 redis 容器运行良好, 我们想要把它保存为伪模板,以便在 Docker 上重复部署。做到这个非常简单,我们只要使用‘docker commit ...’这个镜像到我们本地的库就可以了,像下面这样:
root@server:/home/sam# docker ps -as
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
e3919192d9e3 phusion/baseimage:0.9.15 "/sbin/my_init --ena 3 hours ago Up 3 hours redis 164.9 MB
root@server:/home/sam# docker commit redis redis-cluster-node
root@server:/home/sam# docker images
REPOSITORY TAG IMAGE ID CREATED VIRTUAL SIZE
redis-cluster-node latest babfb02edf4d 5 hours ago 561.2 MB
5. 部署新镜像的 3 个实例
为了解释清楚,我会删除之前创建的容器,以免后面搞晕。首先使用 docker stop redis,之后再 docker rm redis:
root@server:/home/sam# docker stop redis
redis
root@server:/home/sam# docker rm redis
redis
root@server:/home/sam#
很简单,下面让我们部署新镜像的 3 个实例,我们使用了 Docker 的端口映射机制,从而我们就可以使用 Host 服务器的 IP 访问这些实例,我们给这些实例关联的端口如下:
node1 - hostip:7001
node2 - hostip:7002
node3 - hostip:7003
所以我们运行 redis-cli -h 192.168.0.2 -p 7001,它将重定向到 172.17.0.x -p 6379,例如下面我们部署了三个实例:
root@server:/home/sam# docker run -d --name node1 -p 7001:6379 redis-cluster-node /sbin/my_init
cd1c1f96346bdf9c1cec04333c2e849992ecbc4375dcea6b30902dd9842d8c99
root@server:/home/sam# docker run -d --name node2 -p 7002:6379 redis-cluster-node /sbin/my_init
cd1c1f96346bdf9c1cec04333c2e849992ecbc4375dcea6b30902dd9842d8c99
root@server:/home/sam# docker run -d --name node3 -p 7003:6379 redis-cluster-node /sbin/my_init
cd1c1f96346bdf9c1cec04333c2e849992ecbc4375dcea6b30902dd9842d8c99
root@server:/home/sam#
现在我们可以运行 docker ps -as 来查看我们运行的三个 Redis 容器:
root@server:/home/sam# docker ps -as
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES SIZE
a532b4ac60d9 redis-cluster-node:latest "/sbin/my_init" 5 hours ago Up 5 hours 0.0.0.0:7003->6379/tcp node3 2.267 MB
6c8a87a0a76a redis-cluster-node:latest "/sbin/my_init" 5 hours ago Up 5 hours 0.0.0.0:7002->6379/tcp node2 2.318 MB
39e02633ccf8 redis-cluster-node:latest "/sbin/my_init" 5 hours ago Up 5 hours 0.0.0.0:7001->6379/tcp node1 2.334 MB
root@server:/home/sam#
现在我们看到了 3 个容器,分别名字为 node1、node2 和 node3,并且有一个专门的端口与 Redis 服务的端口相映射。为了测试这样的映射是正确的,可以在另外一台机器使用 redis-cli 登录到各个 Redis 服务器上面:
root@server:/home/sam# redis-cli -h 192.168.0.2 -p 7001
redis 192.168.0.16:7001>
root@server:/home/sam# redis-cli -h 192.168.0.2 -p 7002
redis 192.168.0.16:7002>
root@server:/home/sam# redis-cli -h 192.168.0.2 -p 7003
redis 192.168.0.16:7003>
root@server:/home/sam# redis-cli -h 192.168.0.2 -p 7005
Could not connect to Redis at 192.168.0.2:7005: Connection refused
not connected>
正如你看到的, 我们可以使用 hostip+port 登录到对应的 Redis 服务器上, 当我们尝试一个不正确的端口时,却不行。
译者增加: 如果这里验证失败了的可以登录进容器中检查下 Redis 的服务有没有起来:
docker exec -t -i redis bash -l
netstat -anp | grep redis #看看有没有网络监听,如果没有执行下面的命令启动redis服务
redis-server /etc/redis/redis.conf
6. 配置 Redis 的从节点
我们有了三个独立的 Redis 服务器, 现在我们想把它们连接到一起, 从而我们可以测试这个集群的扩展性,对集群的监控,或者是做其它的事情。
我们把 node1 作为主节点,把 node2 和 node3 配置为它的从节点,这可以简单的通过修改 /etc/redis/redis.conf 这个文件来实现。SSH 进入 node2 和 node3 节点,修改配置文件,然后重启容器:
root@server:/home/sam# docker inspect node1 | grep IPA
"IPAddress": "172.17.0.46",
root@server:/home/sam# docker inspect node2 | grep IPA
"IPAddress": "172.17.0.47",
root@server:/home/sam# ssh root@172.17.0.47
root@172.17.0.47''s password:
Last login: Tue Jan 13 11:47:31 2015 from 172.17.42.1
root@6c8a87a0a76a:~# nano /etc/redis/redis.conf
在这个配置文件中我们只要找到‘salveof’这一行,然后去掉注释,修改为 node1 的 ip 地址,像下面这样:
root@6c8a87a0a76a:~# cat /etc/redis/redis.conf | grep slaveof
# Master-Slave replication. Use slaveof to make a Redis instance a copy of
slaveof 172.17.0.46 6379
root@6c8a87a0a76a:~#
最后使用命令 docker restart node2 重启容器, 现在它就是 node1 的一个从节点了。为了验证这个, 使用 redis-cli 分别登录到 node1 和 node2, 在 node1 上运行命令 set hello world, 然后在 node2 上运行 get hello,如果配置正确的话会得到下面的结果:
root@server:/home/sam# redis-cli -h 192.168.0.16 -p 7001
redis 192.168.0.12:7001> set hello world
OK
redis 192.168.0.12:7001> exit
root@server:/home/sam# redis-cli -h 192.168.0.16 -p 7002
redis 192.168.0.12:7002> get hello
"world"
redis 192.168.0.12:7002> exit
root@server:/home/sam#
对于 node3 也做同样的配置即可。
恭喜,基于 Docker 的、拥有三个节点且可水平扩展的 Redis 集群就这样搭好了。
接下来的下一篇博客中,我将给大家展示如何使用 Opsview 去监控 Redis 集群,你可以看到一个像下面这样展示你的集群统计信息的可视化界面:
原文链接:Creating a distributed Redis system using Docker(翻译:左伟 校对:李颖杰)
关注我们的方法:
1. 点击文章标题下的 “dotNET 跨平台” 蓝字,或者在微信搜索 “opendotnet”,加关注
2. 老朋友点击点击右上角 “……” 标志分享到朋友圈
3. 欢迎扫描我们的二维码(长按下面的二维码图片、并选择识别图中的二维码)
本文分享自微信公众号 - dotNET 跨平台(opendotnet)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与 “OSC 源创计划”,欢迎正在阅读的你也加入,一起分享。

110 redis 的哨兵集群 redis-cluster docker 安装
主要内容:
1 哨兵集群:https://blog.csdn.net/yaooch/article/details/80167571
a 哨兵的介绍:Sentinel(哨兵)是 Redis 的高可用性解决方案:由一个或多个 Sentinel 实例组成的 Sentinel 系统可以监视任意多个主服务器,以及这些主服务器属下的所有从服务器,并在被监视的主服务器进入下线状态时,自动将下线主服务器属下的某个从服务器升级为新的主服务器。
b :redis 哨兵配置步骤如下:
1 准备三个 redis 实例,创建三个 redis 配置文件,文件内容如下
port 6379
daemonize yes
logfile "6379.log"
dbfilename "dump-6379.rdb"
dir "/var/redis/data/"
daemonize yes注意:这是主库的配置文件,两个从库的配置文件加上: slaveof 127.0.0.1 6379
2 启动三个 reids 实例: redis-server redis-6379.conf
3 检查三个实例的主从身份: redis-cli -p 6379 info replication
4 配置三个哨兵: redis-sentinel-26379.conf 26380.conf, 26381.conf, 文件内容如下:


// Sentinel节点的端口
port 26379
dir /var/redis/data/
logfile "26379.log"
// 当前Sentinel节点监控 127.0.0.1:6379 这个主节点
// 2代表判断主节点失败至少需要2个Sentinel节点节点同意
// mymaster是主节点的别名
sentinel monitor mymaster 127.0.0.1 6379 2
//每个Sentinel节点都要定期PING命令来判断Redis数据节点和其余Sentinel节点是否可达,如果超过30000毫秒30s且没有回复,则判定不可达
sentinel down-after-milliseconds mymaster 30000
//当Sentinel节点集合对主节点故障判定达成一致时,Sentinel领导者节点会做故障转移操作,选出新的主节点,
原来的从节点会向新的主节点发起复制操作,限制每次向新的主节点发起复制操作的从节点个数为1
sentinel parallel-syncs mymaster 1
//故障转移超时时间为180000毫秒
sentinel failover-timeout mymaster 180000
daemonize yes三个哨兵的配置文件只是端口的不同
5 启动三个哨兵: redis-sentinel redis-sentinel-26379.conf
6 检查哨兵身份信息,检查主从节点健康状态
7 配置完成后,杀死 master 节点,查看主从身份切换是否正常.
2 redis-cluster: https://blog.csdn.net/openbox2008/article/details/80033439
a : 数据分区的介绍: 在介绍 redis cluster 之前,简单介绍分布式数据库的数据分区。所谓的数据分区就是将一个较大的数据集分布在不同的节点上进行缓存。常见的数据分区方式:节点取余,一致性哈希,虚拟槽:在 redis cluster 中使用槽来存储一定范围内的数据集,每个节点上有一定数量的槽。当客户端提交数据时,要根据 crc16 (key)&16383 来计算出数据要落在哪个虚拟槽内。与节点取余和一致性哈希分区不同,虚拟槽分区是服务端分区。客户端可以将数据提交到任意一个 redis cluster 节点上,如果存储该数据的槽不在这个节点上,则返回给客户端目标节点信息,告知客户端向目标节点提交数据。
b : 集群角色有 Master 和 Slave。Master 之间分配 slots,一共 16384 个 slot。Slave 向它指定的 Master 同步数据,实现备份。当其中的一个 Master 无法提供服务时,该 Master 的 Slave 讲提升为 Master,保证集群间 slot 的完整性。一旦其中的某一个 Master 和它的 Slave 都失效,导致了 slot 不完整,集群失效,这时就需要人工去处理了。
c : 为什么要用集群 https://blog.csdn.net/shenjianxz/article/details/59775212
数据量太大,一台服务器的内存是 16-256g, 假如业务需要 500g, 此时应该把数据分到不同的位置,分摊集中式的压力,一堆机器干一件事.
并发问题.redis 官方生成可以达到 10 万 / 每秒,每秒执行 10 万条命令,假如美妙执行 100 万条命令.
d : redis 使用中遇到的瓶颈
我们日常在对于 redis 的使用中,经常会遇到一些问题
1、高可用问题,如何保证 redis 的持续高可用性。
2、容量问题,单实例 redis 内存无法无限扩充,达到 32G 后就进入了 64 位世界,性能下降。
3、并发性能问题,redis 号称单实例 10 万并发,但也是有尽头的。
e : redis-cluster 的优势
1、官方推荐,毋庸置疑。
2、去中心化,集群最大可增加 1000 个节点,性能随节点增加而线性扩展。
3、管理方便,后续可自行增加或摘除节点,移动分槽等等。
4、简单,易上手。
d 集群的配置.https://www.cnblogs.com/pyyu/p/9844093.html
3 docker

ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis
ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IdistributedCache、StackExchangeRedis
前提:一台 Linux 服务器、已安装 Docker。
一,Docker 中运行 Redis
拉取 Redis 镜像
docker pull redis
查询镜像列表
docker imgaes
运行 Redis的几种方法
①运行并且设置 Redis 端口
docker run -p 6379:6379 -d redis:latest redis-server
②
docker run -p 6379:6379 -d {镜像id} redis-server
③持久化
将 Docker 里的 Redis 数据持久化到物理机
docker run -p 6379:6379 -v {物理机路径}:/data -d redis:latest redis-server --appendonly yes
下载 Windows 版的 Redis 管理器
Windows 版本的 Redis Desktop Manager 64位 2019.1(中文版) 下载地址 https://www.7down.com/soft/233274.html
官方正版最新版本下载地址 https://redisdesktop.com/download
另附 Redis 学习教程:
Redis 中文网 https://www.redis.net.cn/
.NET 使用 Redis 学习 地址(貌似这个教程版本过时了) https://www.cnblogs.com/cang12138/p/8884362.html
搭建 Master/Slaver 模式的 Redis 集群 https://blog.csdn.net/lupengfei1009/article/details/88323561#_154
使用 Redis Desktop Manager 连接 Redis

二,ASP.NET Core 使用分布式缓存
ASP.NET Core 中,支持使用多种数据库进行缓存,ASP.NET Core 提供了统一的接口给开发者使用。
IdistributedCache
ASP.NET Core 中,使用 IdistributedCache 为开发者提供统一的缓存使用接口,而不必关注使用的是何种数据库。
IdistributedCache]接口提供了以下方法操作的分布式的缓存实现中的项:
- GetAsync –接受字符串键和检索缓存的项作为
byte[]数组如果在缓存中找到。 - SetAsync –中添加项 (作为
byte[]数组) 到使用字符串键的缓存。 - RefreshAsync –刷新缓存基于其密钥,重置其滑动到期超时值 (如果有) 中的项。
- RemoveAsync –移除缓存项根据其字符串键值。
IdistributedCache 提供的常用方法如下:
| 方法 | 说明 |
|---|---|
| Get(String) | 获取Key(键)的值 |
| GetAsync(String,CancellationToken) | 异步获取键的值 |
| Refresh(String) | 刷新缓存 |
| RefreshAsync(String,CancellationToken) | Refreshes a value in the cache based on its key,resetting its sliding expiration timeout (if any). |
| Remove(String) | 移除某个值 |
| RemoveAsync(String,CancellationToken) | Removes the value with the given key. |
| [Set(String,Byte],DistributedCacheEntryOptions) | Sets a value with the given key. |
| [SetAsync(String,Byte],DistributedCacheEntryOptions,CancellationToken) | Sets the value with the given key. |
官方文档很详细https://docs.microsoft.com/zh-cn/dotnet/api/microsoft.extensions.caching.distributed.idistributedcache?view=aspnetcore-2.2
ASP.NET Core 中配置缓存
新建一个 ASP.NET Core WebApi 项目
Nuget 管理器安装
Microsoft.Extensions.Caching.StackExchangeRedis
ConfigureServices 中使用服务
services.AdddistributedMemoryCache();
配置 Redis 服务器
services.AddStackExchangeRedisCache(options =>
{
options.Configuration = "localhost:6379";
options.InstanceName = "mvc";
});
InstanceName 是你自定义的实例名称,创建缓存时会以此名称开头。
这样就配置好了。
使用缓存
修改默认生成的 ValuesController.cs。
注入缓存服务
private readonly IdistributedCache _cache;
public ValuesController(IdistributedCache cache)
{
_cache = cache;
}
设置缓存和使用缓存:
await _cache.GetAsync("{键名}");
_cache.SetAsync("键名",{值},{设置});
删除原来的方法,添加以下代码:
[HttpGet("Set")]
public async Task<JsonResult> SetCache(string setkey,string setvalue)
{
string key = "key1";
if (!string.IsNullOrEmpty(setkey))
key = setkey;
string value = DateTime.Now.ToLongTimeString();
if (!string.IsNullOrEmpty(setvalue))
value = setvalue;
await _cache.SetStringAsync(key,value);
return new JsonResult(new { Code = 200,Message = "设置缓存成功",Data = "key=" + key + " value=" + value });
}
[HttpGet("Get")]
public async Task<JsonResult> GetCache(string setkey)
{
string key = "key1";
if (!string.IsNullOrEmpty(setkey))
key = setkey;
var value = await _cache.GetStringAsync(key);
return new JsonResult(new { Code = 200,Data = "key=" + key + " value=" + value });
}
在 URL 添加 QueryString 可以设置缓存内容,如果没有带参数的话,就使用默认的值。
打开 https://localhost:5001/api/values/set 可以看到设置了默认值。
或者访问 https://localhost:5001/api/values/set?setkey=key11111&setvalue=asafesfdsreg
自定义设置缓存值。

打开 https://localhost:5001/api/values/get?setkey=key11111
可以获取缓存值。
设置缓存过期时间
使用 distributedCacheEntryOptions 可以设置缓存过期时间
distributedCacheEntryOptions 有三个属性,表示相对时间、绝对时间。
使用方法
[HttpGet("Set")]
public async Task<JsonResult> SetCache(string setkey,string setvalue)
{
string key = "key1";
if (!string.IsNullOrEmpty(setkey))
key = setkey;
string value = DateTime.Now.ToLongTimeString();
if (!string.IsNullOrEmpty(setvalue))
value = setvalue;
var options = new distributedCacheEntryOptions()
.SetSlidingExpiration(TimeSpan.FromSeconds(20));
await _cache.SetStringAsync(key,value,options);
return new JsonResult(new { Code = 200,Data = "key=" + key + " value=" + value });
}
缓存 20 秒,20秒过后此缓存将被清除。

AWS EC2+Docker+JMeter构建分布式负载测试基础架构
原文链接
@[Toc]
概述及范围
本文介绍有关如何使用AWS EC2+Docker+JMeter创建分布式负载测试基础架构。 完成所有步骤后,得到的基础结构如下: 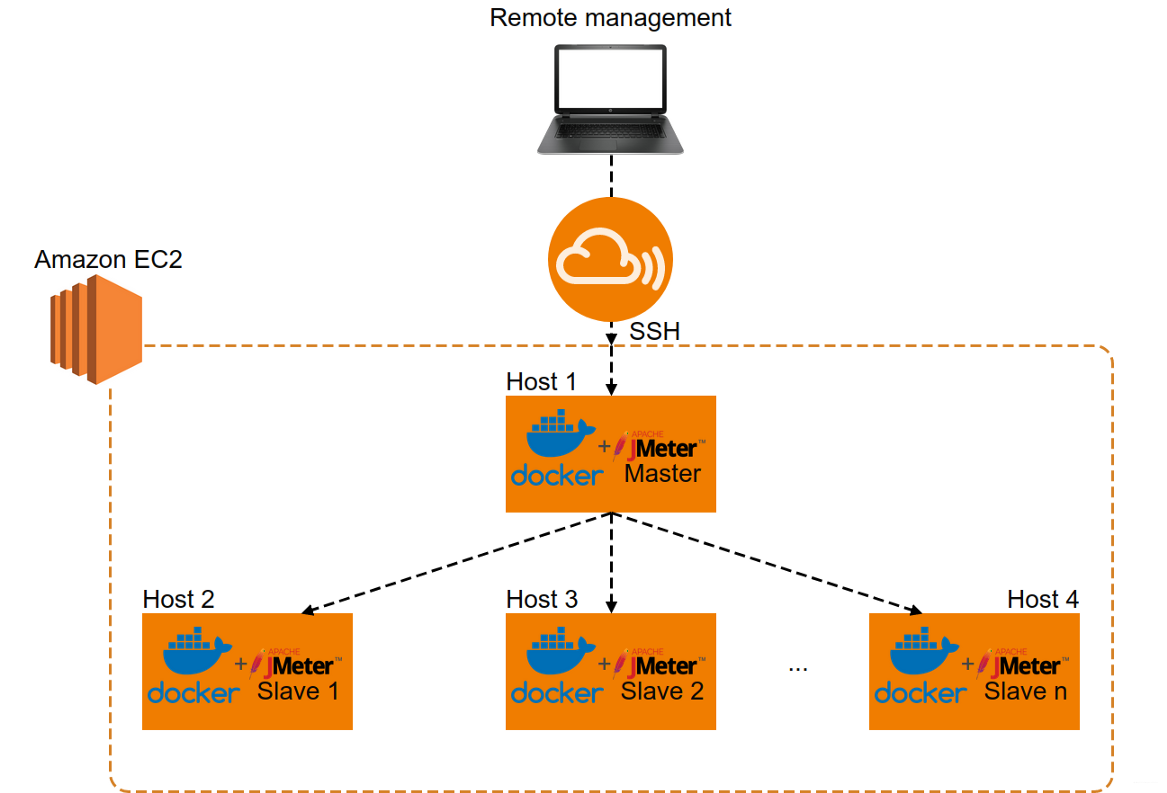
在Part 1中,我们将按照所需的步骤进行操作,以创建适合你需求的自定义JMeter Dockerfiles和映像。 然后,在Part 2中,我们将在AWS EC2设置中使用这些元素。 接下来开始第一步:
前提条件
为了能够顺利的逐步进行配置和操作,你需要上述每个系统(EC2,Docker和JMeter)的一些基本知识。 此外,还需要一个活动的AWS账户才能执行所有步骤。
Part 1: Local setup—本地配置
Step 1: 从Dockerfile创建映像
dockerfile是开始使用docker所需的基本元素或“ cookbook”,因此我们将从此开始。 我们需要建立2层: 1、一是基础层,该层创建运行JMeter实例所需的基本设置; 2、二是逻辑层,它是一个JMeter实例,可以是主节点或从节点;
JMeter base映像的Dockerfile和entrypoint.sh脚本如下所示: Dockerfile:
# Use Java 11 JDK Oracle Linux
FROM openjdk:11-jdk-oracle
MAINTAINER Dragos
# Set the JMeter version you want to use
ARG JMETER_VERSION="5.1.1"
# Set JMeter related environment variables
ENV JMETER_HOME /opt/apache-jmeter-${JMETER_VERSION}
ENV JMETER_BIN ${JMETER_HOME}/bin
ENV JMETER_DOWNLOAD_URL https://archive.apache.org/dist/jmeter/binaries/apache-jmeter-${JMETER_VERSION}.tgz
# Set default values for allocation of system resources (memory) which will be used by JMeter
ENV Xms 256m
ENV Xmx 512m
ENV MaxMetaspaceSize 1024m
# Change timezone to local time
ENV TZ="Europe/Bucharest"
RUN export TZ=$TZ
# Install jmeter
RUN yum -y install curl \
&& mkdir -p /tmp/dependencies \
&& curl -L --silent ${JMETER_DOWNLOAD_URL} > /tmp/dependencies/apache-jmeter-${JMETER_VERSION}.tgz \
&& mkdir -p /opt \
&& tar -xzf /tmp/dependencies/apache-jmeter-${JMETER_VERSION}.tgz -C /opt \
&& rm -rf /tmp/dependencies
# Set JMeter home
ENV PATH $PATH:$JMETER_BIN
# copy our entrypoint
COPY entrypoint.sh /
RUN chmod +x ./entrypoint.sh
# Run command to allocate the default system resources to JMeter at ''docker run''
ENTRYPOINT ["/entrypoint.sh"
Entrypoint.sh:
#!/bin/bash
# Run command to allocate the default or custom system resources (memory) to JMeter at ''docker run''
sed -i ''s/\("${HEAP:="\)\(.*\)\("}"\)/\1-Xms''${Xms}'' -Xmx''${Xmx}'' -XX:MaxMetaspaceSize=''${MaxMetaspaceSize}''\3/'' ${JMETER_BIN}/jmeter
exec "$@"
在基础层之上,可以创建一个Master层和一个Slave层。这些Dockerfile可以根据你的特定要求进行自定义。 现在让我们看一下我们的逻辑层: Master层的Dockerfile:
# Use my custom base image defined above
FROM dragoscampean/testrepo:jmetrubase
MAINTAINER Dragos
# Expose port for JMeter Master
EXPOSE 60000
Slave层的Dockerfile:
# Use my custom base image defined above
FROM dragoscampean/testrepo:jmetrubase
MAINTAINER Dragos
# Expose ports for JMeter Slave
EXPOSE 1099 50000
COPY entrypoint.sh /
RUN chmod +x ./entrypoint.sh
# Run command to allocate the default system resources to JMeter at ''docker run'' and start jmeter-server with all required parameters
ENTRYPOINT ["/entrypoint.sh"]
Slave层的Entrypoint.sh:
#!/bin/bash
# Run command to allocate the default system resources to JMeter at ''docker run''
sed -i ''s/\("${HEAP:="\)\(.*\)\("}"\)/\1-Xms''${Xms}'' -Xmx''${Xmx}'' -XX:MaxMetaspaceSize=''${MaxMetaspaceSize}''\3/'' ${JMETER_BIN}/jmeter &&
$JMETER_HOME/bin/jmeter-server \
-Dserver.rmi.localport=50000 \
-Dserver_port=1099 \
-Dserver.rmi.ssl.disable=true \
-Djava.rmi.server.hostname=$HostIP
exec "$@"
我们不会详细讨论dockerfiles中的所有内容的含义,在网上有很多这样的文档。不过值得一提的是与Dockerfiles绑定在一起的entrypoint shell脚本。
docker entrypoints的作用是在运行时将数据初始化或者配置到容器中。在我们的例子中,我们需要它们来指定JMeter允许使用多少内存,并使用一些自定义配置来启动JMeter服务器,这些配置是基础设施工作所必需的。这将在“Step 2”部分中举例说明。
现在,让我们看一下创建Docker映像所需的命令。顺便说一下,Docker图像表示一组很好地集成在一起的层,是我们需要的环境的稳定快照。 从这样一个映像开始,我们可以生成N个容器,这正是我们在这个特定场景中所需要的,这取决于我们想要模拟的负载。
创建一个简单的docker映像的命令: docker build /path/to/dockerfile
为docker映像创建一个标签: docker tag imageId username/reponame:imageTag
同时创建docker映像和标签: docker build -t username/reponame:imageTag /path/to/dockerfile
Step 2: 从一个映像创建一个容器
现在我们已经准备好映像,可以开始从中创建容器,在其中可以实际运行性能测试脚本。 创建一个新的容器: sudo docker run -dit --name containername repository:tag or imageId /bin/bash
启动/停止容器: docker start containerId docker stop containerId
访问正在运行的容器: docker exec -it containerId or containerName /bin/bash
到目前为止,如果你一直使用类似于Step 1中提供的Dockerfile,那么您应该拥有一个完全可用的Java + JMeter容器。 你可以通过检查工具版本来测试它,看看是否有任何错误,甚至可以尝试运行你计划在AWS中扩展的脚本(所有这些都应该在运行的容器中完成): Jmeter -v Java -version Jmeter -n -t -J numberOfThreads=1 /path/to/script.jmx -l /path/to/logfile.jtl
Step 3: 将映像Push/Pull到Dockerhub或任何私有的Docker仓库(docker登录CLI后)
测试创建的图像是否符合要求的标准(容器内的所有内容),通常,最好将此图像保存到存储库中。然后,你可以在后续随时从那里提取它,而不必每次都从Dockerfile构建它。
Push映像到dockerhub: docker push username/reponame:imageTag
从dockerhub中Pull已存在的映像(例如jdk映像): docker pull openjdk:version
到此为止,这意味着您已经为cloud setup准备好了一组功能强大的JMeter从属映像和主映像。
Part 2: Cloud端基础架构——Infrastructure
可以使用EC2免费层实例,最多750小时/月,持续1年,因此有很多时间进行试验。 注意:对于下面提供的示例,我使用了Ubuntu Server 18.04 LTS实例,因此提供的命令可能无法在其他Linux发行版上使用。
Step 4: 创建安全组——Security Group
使容器内的JMeter实例(master实例或slave实例)能够通信,自定义安全组已定义并将其附加到每个主机:
入站规则(Inbound rules):  出站规则(Outbound rules):
出站规则(Outbound rules): 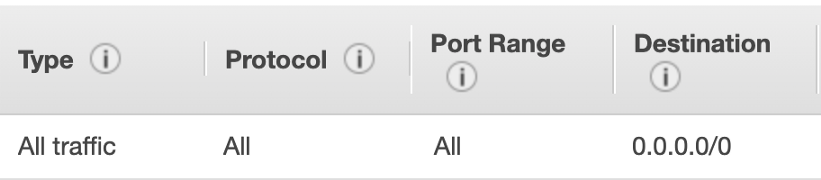 注意:确保将要成为负载测试基础结构部分的所有实例分配给此安全组,否则它们可能无法相互通信。
注意:确保将要成为负载测试基础结构部分的所有实例分配给此安全组,否则它们可能无法相互通信。
Step 5: 创建一个IAM策略(可选)
假设您只需要一个由1个JMeter主节点和2个从节点组成的基础架构。在这种情况下,访问每个实例并对其进行配置(安装docker +启动容器)相对容易。
但是,如果需要处理的实例超过3个,会发生什么情况呢?
手动逐个配置变得极其乏味,手动并不是一个好主意。 这时,你将需要一个系统,能够管理你正在使用的大量容器。一些著名的工具,如谷歌的Kubernetes,或者Rancher等工具。
由于当前使用的是AWS,因此这两种解决方案似乎过于庞大了,因为亚马逊针对这一点提供了一个开箱即用的解决方案: “Run Command”功能使我们可以同时在多个EC2实例上执行Shell脚本。因此,我们不必访问每个实例,安装docker并一次一个实例地启动容器。
能够通过“Run Command”功能在EC2实例上执行命令的唯一要求是,适当的IAM角色已与该实例相关联。我将IAM策略命名为“ EC2Command”,并为每个新创建的实例选择了该策略(但是稍后可以通过“attach/replace role”功能将该角色分配给该实例): 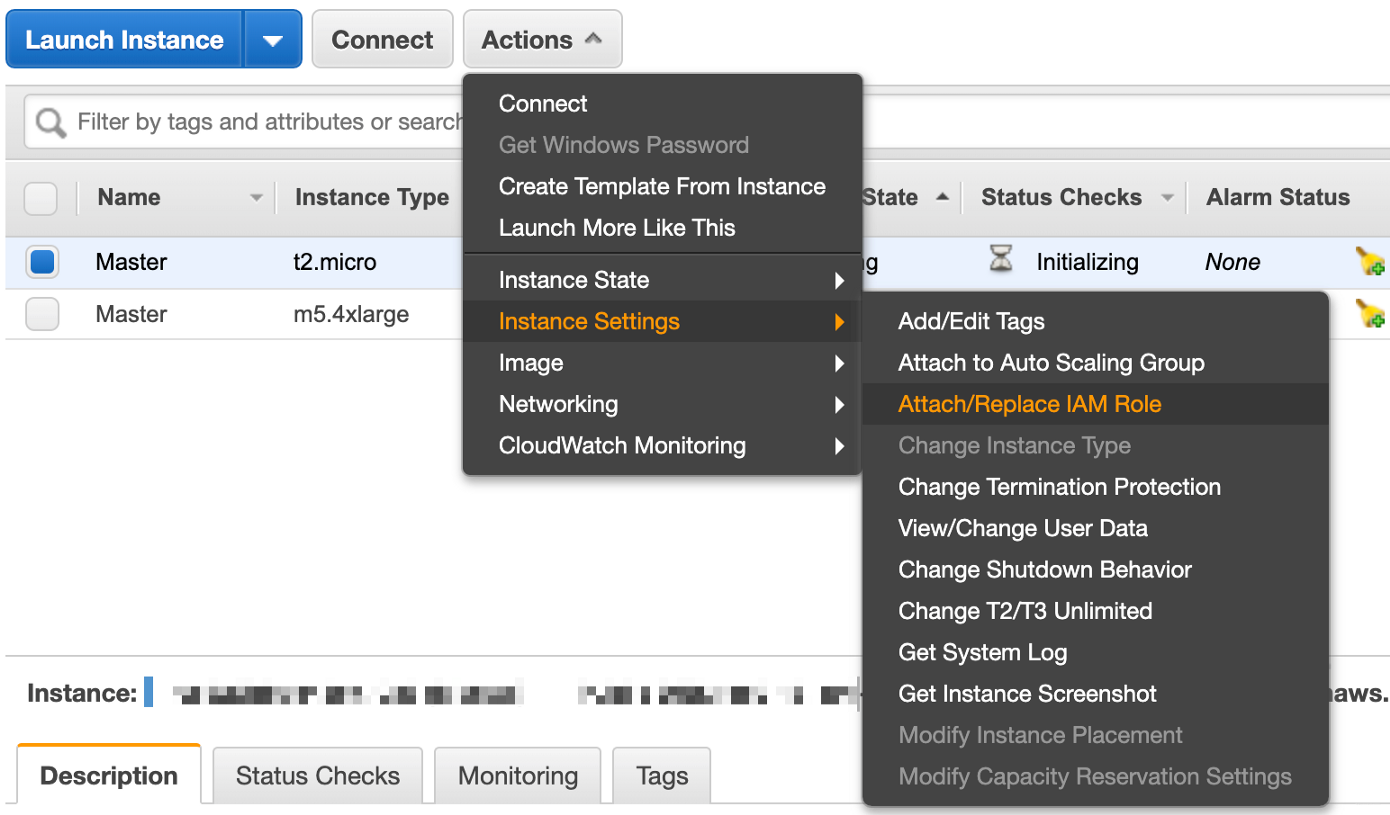
 当您创建角色时,请确保将“AmazonEC2RoleforSSM”策略附加到您的角色上,这样就可以了。
当您创建角色时,请确保将“AmazonEC2RoleforSSM”策略附加到您的角色上,这样就可以了。 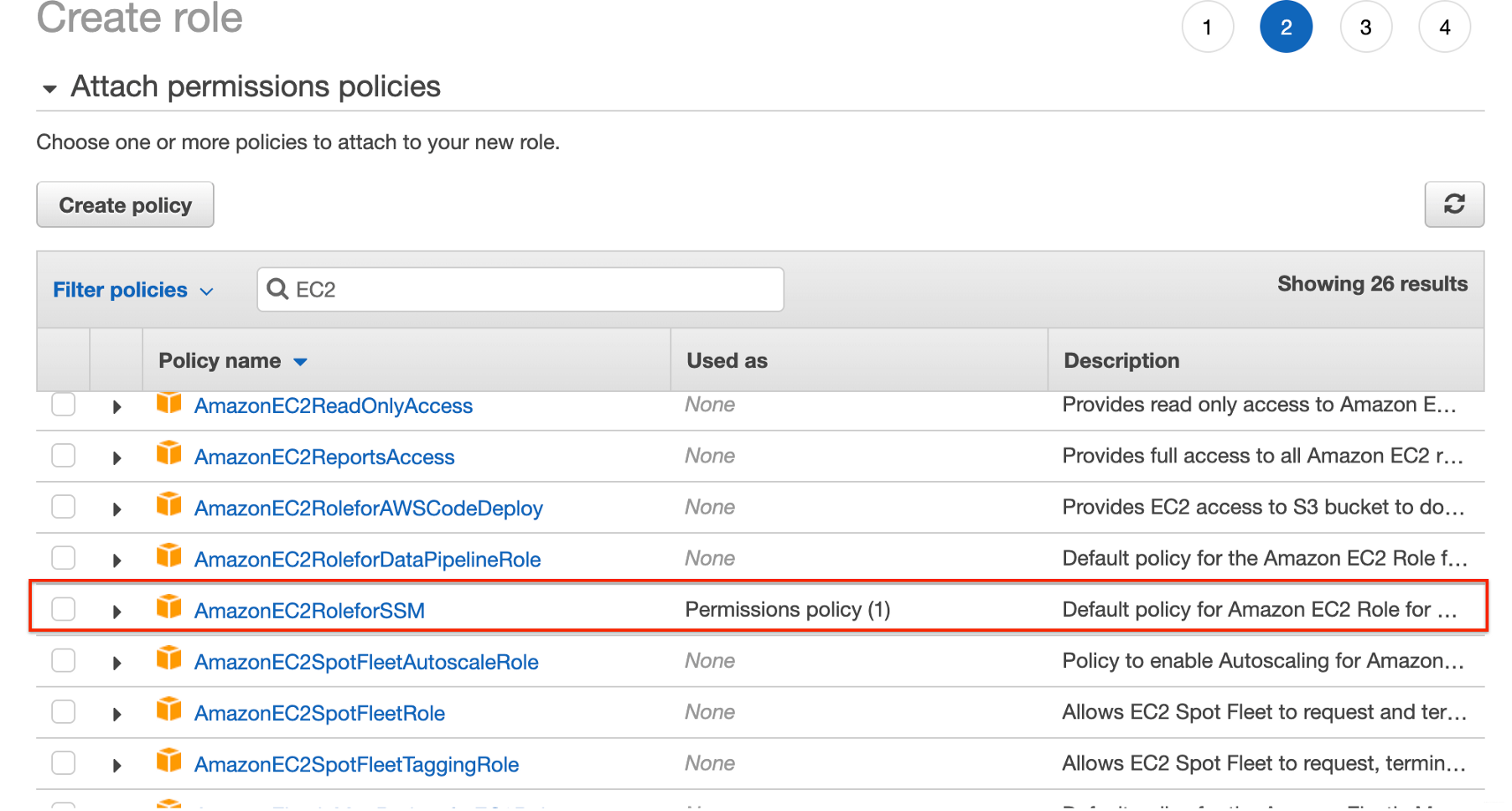 现在您可以使用“Run command”功能对多个实例批量执行脚本。 这将我们带入流程的下一步。
现在您可以使用“Run command”功能对多个实例批量执行脚本。 这将我们带入流程的下一步。
Step 6: 在测试机器上安装Docker
现在,你需要在EC2主机上安装docker,以便可以启动容器并将它们连接在一起以进行分布式负载测试。 直接使用命令(直接在Ubuntu上的实例终端中执行):
sudo apt-get install curl apt-transport-https ca-certificates software-properties-common \
&& curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add \
&& sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" \
&& sudo apt-get update \
&& sudo apt-get install -y docker-ce \
&& sudo usermod -aG docker $USER \
&& sudo curl -L "https://github.com/docker/compose/releases/download/1.23.2/docker-compose-$(uname -s)-$(uname -m)" -o /usr/local/bin/docker-compose \
&& sudo chmod +x /usr/local/bin/docker-compose \
&& sudo ln -s /usr/local/bin/docker-compose /usr/bin/docker-compose
通过“Run command”执行的Shell脚本:
#!/bin/bash
sudo apt-get install curl apt-transport-https ca-certificates software-properties-common
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable"
sudo apt-get update
sudo apt-get install -y docker-ce
USER_DOCKER=$(getent passwd {1000..60000} | grep "/bin/bash" | awk -F: ''{ print $1}'')
sudo usermod -aG docker $USER_DOCKER
理想情况下,您将在多个EC2实例上运行第二个脚本,之后它们都将具有可用的Docker版本。 下一步是配置主节点和从属节点:
Step 7: 配置主节点——Master Node
在某些情况下,你甚至不需要多个从属节点来分布式运行测试,比如,当你有一台功能强大的主机并且该计算机能够生成目标的负载量时,对于这种特定情况,不需要Step 8和Step 9。对于这种情况,你甚至不想使用容器并直接在主机上安装JMeter。
但是,假设你确实需要一个Master + Slaves系统,然后继续启动Master容器: 直接使用命令(直接在Ubuntu上的实例终端中执行):
HostIP=$(ip route show | awk ''/default/ {print $9}'') \
&& docker pull dragoscampean/testrepo:jmetrumaster \
&& docker run -dit --name master --network host -e HostIP=$HostIP -e Xms=256m -e Xmx=512m -e MaxMetaspaceSize=512m -v /opt/Sharedvolume:/opt/Sharedvolume dragoscampean/testrepo:jmetrumaster /bin/bash
通过“Run command”执行的Shell脚本:
#!/bin/bash
HostIP=$(ip route show | awk ''/default/ {print $9}'')
docker pull dragoscampean/testrepo:jmetrumaster
docker run -dit --name master --network host -e HostIP=$HostIP -e Xms=256m -e Xmx=512m -e MaxMetaspaceSize=512m -v /opt/Sharedvolume:/opt/Sharedvolume dragoscampean/testrepo:jmetrumaster /bin/bash
脚本的第一行将机器的私有IP存储在变量“HostIP”中。主的HostIP不用于任何目的,仅使用从属节点的HostIP。我们将在Step 9看到具体要做什么。现在,请记住,你可以快速访问每个容器中主机的专用IP地址。
第二行很简单,只是从适当的仓库中获取图像。
最后一行创建我们将要使用的容器。此命令中有一些要点: 1、''--network host ''命令启用主机连网,这意味着容器内的应用程序(JMeter),将在‘entrypoint.sh’脚本公开的端口上可用。如果没有它,我就无法进行设置。问题是,即使脚本是在从节点上执行的,由于错误(java.rmi.ConnectException: Connection refused to host:masterPrivateIP),主节点上也没有聚集任何结果。注意,我在较老版本的JMeter(如3.x.x)中没有遇到这个问题
2、‘- e Xms=256m -e Xmx=512m -e MaxMetaspaceSize=512m’ 是Xms和Xmx的参数化,MaxMetaspaceSize决定了允许使用JMeter的内存量。这是通过首先在容器内设置一些环境变量来完成的。然后,在“ entrypoint.sh”脚本中运行命令,将更改JMeter的“ / bin”文件夹中的“JMeter”文件。如果未指定这些值,则使用默认值。
要进一步了解这些变量代表什么以及如何设置它们,请阅读以下内容: Xmx计算如下:系统总内存-(OS使用的内存+ JVM使用的内存+在计算机上运行所需的任何其他脚本) 如果您有一台专用的测试机器,为避免在测试运行时重新分配Xms,请从一开始就设置Xms = Xmx。
MaxMetaspaceSize跟踪所有加载的类元数据和静态内容(静态方法,原始变量和对象引用)
例如: 一台专用机器上64 GB RAM Xmx = 56G Xms = 56G MaxMetaspaceSize = 4096 MB 这为操作系统和其他进程留下了将近4GB的空间,这绰绰有余。
3、-v /opt/Sharedvolume:/opt/Sharedvolume userName/repoName:imageTag 该命令只是将主机上的文件夹映射到容器内的文件夹,你将在其中保存脚本文件和生成的日志。我们将不做进一步详细介绍,但是如果您想了解有关卷映射的更多信息,请参阅本文和迷你教程。
Step 8: 配置从节点——Slave Nodes
“ HostIP”变量仅在“entrypoint.sh”脚本中用于此处,以启用从master服务器到slave服务器的远程访问(“-Djava.rmi。server.hostname = $ HostIP”)。 直接使用命令(直接在Ubuntu上的实例终端中执行):
HostIP=$(ip route show | awk ''/default/ {print $9}'') \
&& docker pull dragoscampean/testrepo:jmetruslave \
&& docker run -dit --name slave --network host -e HostIP=$HostIP -e HostIP=$HostIP -e Xms=256m -e Xmx=512m -e MaxMetaspaceSize=512m dragoscampean/testrepo:jmetruslave /bin/bash
通过“Run command”执行的Shell脚本:
#!/bin/bash
HostIP=$(ip route show | awk ''/default/ {print $9}'')
docker pull dragoscampean/testrepo:jmetruslave
docker run -dit --name slave --network host -e HostIP=$HostIP -e Xms=256m -e Xmx=512m -e MaxMetaspaceSize=512m dragoscampean/testrepo:jmetruslave /bin/bash
Step 9: 分布式模式下运行脚本
到此,准备就绪,可以开始运行测试了。这是我们需要在master主节点上运行以开始运行分布式测试的命令:
jmeter -n -t /path/to/scriptFile.jmx -Dserver.rmi.ssl.disable=true -R host1PrivateIP, host2PrivateIP,..., hostNPrivateIP -l /path/to/logfile.jtl
总结:
按照上面的操作步骤,可以实现AWS EC2+Jmeter+Docker的分布式性能测试,可能会遇到一些问题,完全没问题那是不可能的。 比如: 该文提到了一个EC2实例中有太多Websocket连接时可能遇到的问题。 另一个例子是我的一位同事在对Apache服务器进行负载测试时遇到的情况,他会在JMeter中遇到各种连接错误,我们最初认为这是来自被测试的服务器。解决这个问题的方法来自这篇简短的文章。
我在一个项目中偶然发现的一个问题是,在尝试从一台计算机执行大约20000个线程时,进行了一些数据驱动的测试。如果在Linux / MacOS终端中键入“ ulimit -a”,则会看到名为“ open files”的行。问题在于该属性在测试计算机上设置为1024。使用JMeter运行数据驱动的测试时,此工具将为每个启动的线程打开.csv文件或描述符,一旦并行线程数超过1024,我将收到错误消息。 解决方案: 是从''/etc/security/limits''文件中编辑''open files''的最大值,并设置为''unlimited''。
原文出处:https://www.cnblogs.com/PeterZhang1520389703/p/12423950.html

docker --- 高级 ---redis--- 分布式存储系统
场景:cluster (集群) 模式 - docker 版哈希槽分区进行亿级数据存储 1-2 亿数据需要缓存,请问如何设计存储?
分布式存储 ---- 多台 redis
1、有 3 个 rdis 主机,哈希算法 --- 取余 Hash (key)/3
2、一致性 Hash 算法
(1) 一致性哈希环【0,2^32-1】
一致性 Hash 算法将整个哈希值空间组织成一个虚拟的圆环
(2)服务器 ip 节点映射
(3)key 落到服务器的落键规则
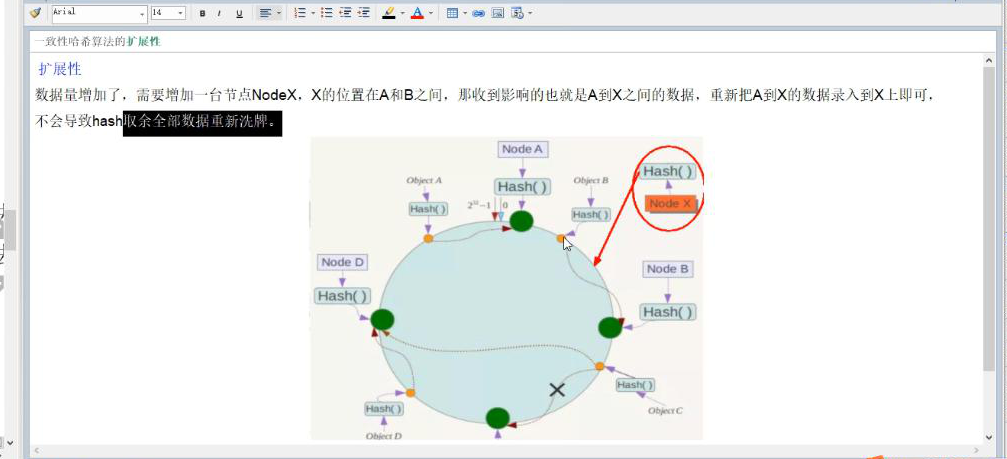
优点:容错性、扩展性 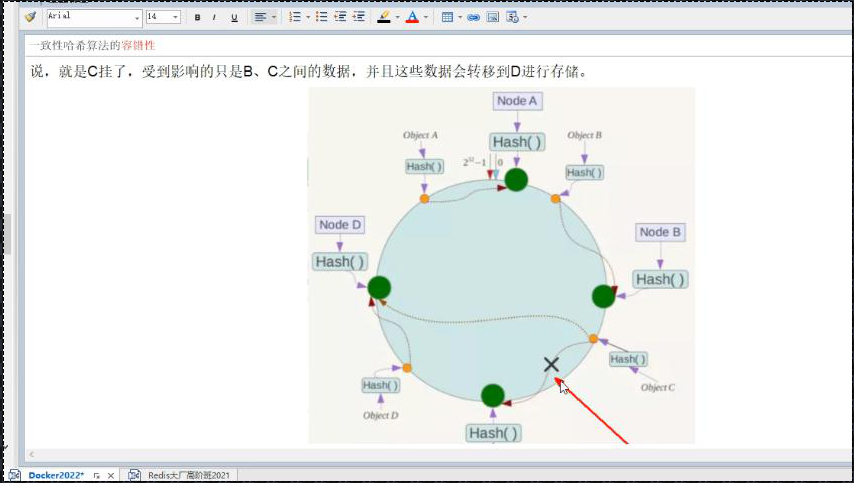
缺点:数据倾斜问题 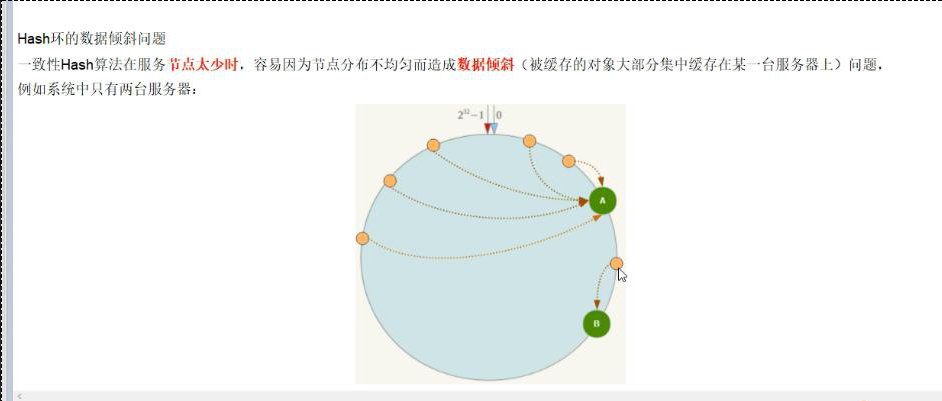
3、哈希槽分区 数据 ---- 槽 ----redis---- 一个集群最大槽为 16384 个。 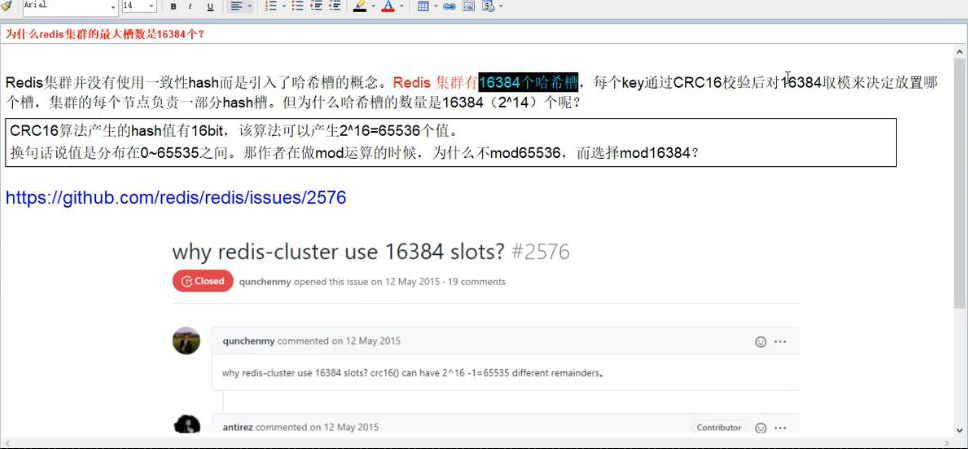
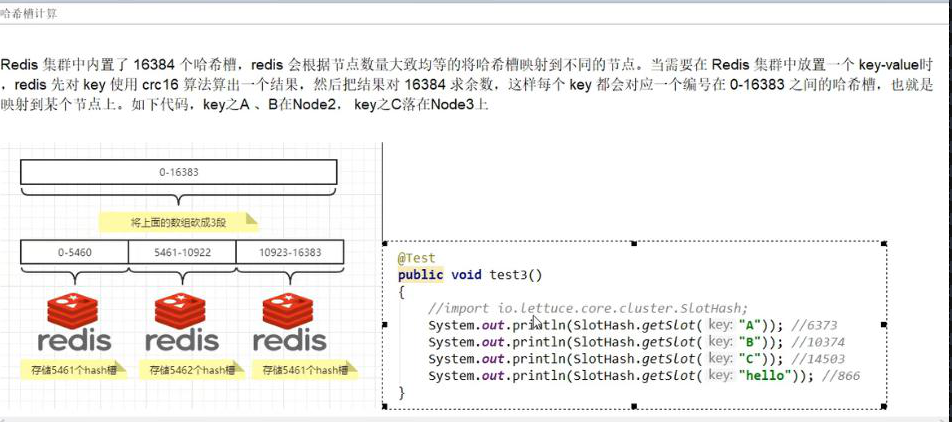
拉取 redis:6.0.8 镜像
docker pull redis:6.0.8 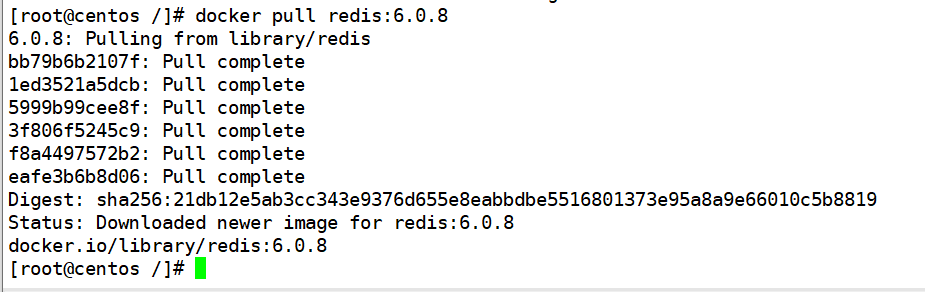
创建 redis 集群 ---3 主 3 从
docker run -d --name redis-node-1 --net host --privileged=true -v /data/redis/share/redis-node-1:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6381
docker run -d --name redis-node-2 --net host --privileged=true -v /data/redis/share/redis-node-2:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6382
docker run -d --name redis-node-3 --net host --privileged=true -v /data/redis/share/redis-node-3:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6383
docker run -d --name redis-node-4 --net host --privileged=true -v /data/redis/share/redis-node-4:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6384
docker run -d --name redis-node-5 --net host --privileged=true -v /data/redis/share/redis-node-5:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6385
docker run -d --name redis-node-6 --net host --privileged=true -v /data/redis/share/redis-node-6:/date redis:6.0.8 --cluster-enabled yes --appendonly yes --port 6386


构建主从关系 -- 进入容器内执行,进入 redis-node-1
docker exec -it redis-node-1 /bin/bash
redis-cli --cluster create 192.168.1.133:6381 192.168.1.133:6382 192.168.1.133:6383 192.168.1.133:6384 192.168.1.133:6385 192.168.1.133:6386 --cluster-replicas 1
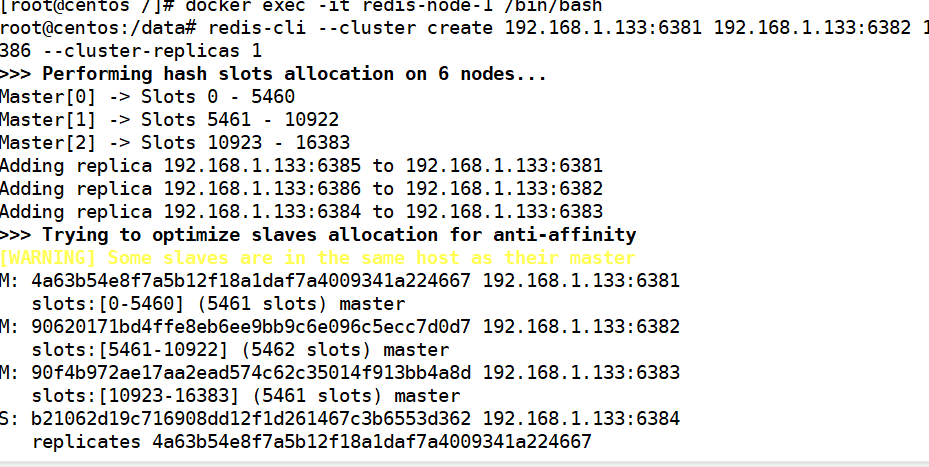
输入 yes, 确定分配
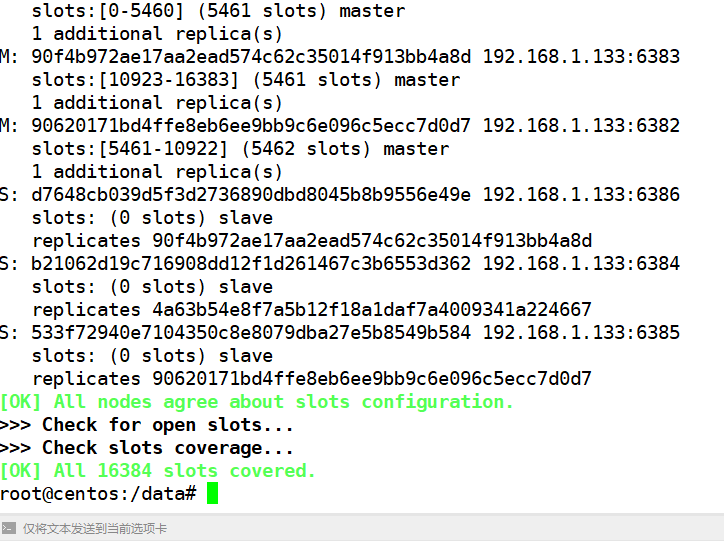
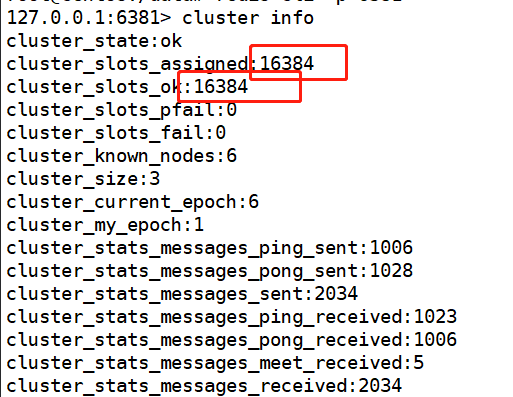
以 6381 为切入点,查看集群状态
redis-cli -p 6381
cluster info
cluster nodes

这个图可以看出谁是谁的从
6383 主 --6386 从
6381 主 --6384 从
6382 主 --6385 从
今天的关于用 Docker 构建分布式 Redis 集群和docker搭建redis集群的分享已经结束,谢谢您的关注,如果想了解更多关于110 redis 的哨兵集群 redis-cluster docker 安装、ASP.NET Core 使用 Redis 实现分布式缓存:Docker、IDistributedCache、StackExchangeRedis、AWS EC2+Docker+JMeter构建分布式负载测试基础架构、docker --- 高级 ---redis--- 分布式存储系统的相关知识,请在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

