以上就是给各位分享Java基础系列:计算机网络基础概念,其中也会对计算机网络技术java是什么进行解释,同时本文还将给你拓展9.1计算机网络基础知识、LINUX教学:计算机基础系列教程三:网络基础之网
以上就是给各位分享Java 基础系列:计算机网络基础概念,其中也会对计算机网络技术java是什么进行解释,同时本文还将给你拓展9.1 计算机网络基础知识、LINUX教学:计算机基础系列教程三:网络基础之网络协议、LINUX教程:计算机基础系列教程一:计算机硬件、程序员内功修炼(一)计算机网络之基础概念等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- Java 基础系列:计算机网络基础概念(计算机网络技术java是什么)
- 9.1 计算机网络基础知识
- LINUX教学:计算机基础系列教程三:网络基础之网络协议
- LINUX教程:计算机基础系列教程一:计算机硬件
- 程序员内功修炼(一)计算机网络之基础概念
")
Java 基础系列:计算机网络基础概念(计算机网络技术java是什么)
来小伙伴们,我们认识一下。
俗世游子:专注技术研究的程序猿
网络
大部分情况下,做开发的程序猿是是不需要和网络打交道的,就比如本人:工作这么多年,去年年初做过一次系统架构,做负载均衡的时候顺带了解了一下这方面的基础知识,其他时候根本用不到。
我们现在就来简单聊一聊,简单到什么程度:
- 开发涉及到网络 IO 方面的问题能知道该怎么解决,
- 面试能说个七七八八就够了
基本知识
首先我们先要明白什么是网络:
不负责任的说,网络是 网络是由若干节点和连接这些节点的链路构成,而这些物理链路将多台计算机连接在一起,组成了我们现在的互联网
促进网络产生的先决条件:
- 芯片技术
要知道,世界上第一台计算机有一个教室那么大,直到集成电路的产生,将电路做到一块完整的半导体硅板上,计算机的体积才下降下来
- 网络理论本身
第二个条件就是网络理论本身,我们现在知道,网络本身分为很多节点,各个节点之间相互关联,我们从起点 A 发送数据到终点 B,发送的数据在网络中会拆分成小包,由于光电传输是非常快的,所以在数据包在网络中传输的时候会通过不同的路线到达终点 B,然后在终点 B 中进行合并
在这个理论中,两个人的贡献非常大:
- Paul Baran 提出的分布式可适应信息块交换集成电路
- Donald Davies 提出的封包交换
两者说的是一个问题,就是封包交换算法,解决数据如何从一个点通过复杂网络到达另一个点的问题
- 材料的发展
在 1858 年的跨大西洋同轴电缆,每分钟传输 120 个字,而我们现在采用的双绞线电缆,通过导线两两缠绕,抵消掉信号的干扰,而不同材料传输速度也不同。目前我们市面上的传输速度已经能到达到 100Mbps,还有比这个更快的,能够快 10 倍
而光纤采用的是光传输,能量在用光传输的时候损耗较低,所以速度最快,能够达到 10Gbps
- 软件应用行业的发展
应用的不断发展也造成了网络的发展,包括现在的 5G,卫星上网
网络模型
随着网络的出现,再加上当时商业力量的介入,网络得到的大力的发展,出现了 OSI 网络模型,即开放式系统互联模型,它是国际标准组织的一次伟大尝试,也是世界上第一个试图在世界范围内规范网络标准的框架
七层模型
模型从上向下分别为:
- 应用层
也就是我们平常使用的客户端,比如微信发送消息,浏览器请求地址等等,这里只负责将请求数据发送出去
- 表示层
负责协商用于传输的数据格式,并转换数据格式。比如现在说的 HTTP 协议,数据量太大的话,数据压缩在这一层,HTTPS 数据加密也在这一层完成
- 会话层
负责管理两个联网实体间的网络,比如客户端和服务器端产生的连接,这条连接维持客户端和服务器端的通信,然后等到连接断开的时候释放链接
- 传输层
从传输层开始,将负责数据的拆成一个个小包,然后将小包进行封包,并将数据从一个实体(服务器或者应用)发送到另一个实体,但是并不负责数据的传输方式
同时在传输层还有以下功能:
- 当数据在传输过程中出现问题后采取方式进行纠正,重发或者其他方式
- 控制传输数据的速率
- 端口寻址,标明参与传输的实体的端口号
- 网络层
负责把封包从一个 IP 地址传输到另一个 IP 地址,这里的核心就是路由算法。需要通过路由算法得到下一个节点的地址
- 数据链路层
在这一层确保两个临近设备间数据的传输,并隐藏底层实现,同时还需要协调传输时速率问题
- 物理层
真正需要发送数据的实际手段,比如:网线,光纤等等的物理方式
看下面的图,用实际例子来理解一下:
需要注意的是,OSI 模型是没有实际可行的方案
TCPIP 协议
实际上,OSI 模型还是存在一些问题比如说:
我们在命令行通过 ping 来测试一个网络,根据我们对 7 层网络模型的认识,这种程序对于会话层和表示层并不是必须的,
而且由于 OSI 模型在当时并没有实际可行的方案,所以罗伯特。卡恩和文顿。顿瑟夫提出了 TCP 协议,对比 OSI 模型只有 5 层,而且在 1975 年做了成功的实验,所以从这一点上 TCP 协议比 OSI 模型更容易让大家接受
它只有 5 层:
- 应用层
这里不变,也是将数据发送出去的过程
- 传输控制层
解决主机到主机之间的传输,在这里常用的也就是我们耳熟能详的 TCP 协议和 UDP 协议
- 网络层
在这一层提供了路由和寻址,通过路由判定和下一跳机制得到下一个要发送出去的节点
- 数据链路层
两个节点之间的物理连接,在这里对数据再次封包发送,常用的就是 ARP 协议
- 物理层
物理层和 OSI 模型不变
深入理解
下面我们来聊一聊在各个层面上我们经常使用的协议
应用层协议:HTTP 协议
基本概念
HTTP 协议,也叫超文本传输协议,是处理客户端和服务器端之间通信的一种协议,在 HTTP 协议中的的请求头和返回体都包含相同的数据格式:
- Request
GET / HTTP/1.1
Host: http://www.baidu.com
...
<消息请求body>
- Response
GET HTTP/1.1 200 ok
...
<返回体>
在 Request 和 Response 中包含很多的属性
只要我们能够按照 HTTP 指定的协议返回,那么我们也可以自己实现一个 Http 服务器,比如:
public class RawHttpSocket {
private ServerSocket serverSocket;
Function<String, String> handler;
public RawHttpSocket(Function<String, String> handler) {
this.handler = handler;
}
public static void main(String[] args) throws IOException {
String body = "<html><head></head><body><pre style=\"word-wrap: break-word; white-space: pre-wrap;\"><h1>Hello world!</h1>\n" +
"</pre></body></html>";
RawHttpSocket rawHttpSocket = new RawHttpSocket((str) -> {
System.out.println(str);
// 第一个 \n 是header结尾 第二个 \n 是header和body的分段
return "HTTP/1.1 200 ok\n\n"+body+"\n";
});
rawHttpSocket.listener(9000);
}
private void listener(int port) throws IOException {
// 建立ServerSocket,绑定端口
serverSocket = new ServerSocket(port);
while (true) {
// 等待Socket建立连接
Socket socket = serverSocket.accept();
new Thread(() -> {
try {
// 处理请求
this.accpet(socket);
} catch (IOException e) {
e.printStackTrace();
}
}).start();
}
}
private void accpet(Socket socket) throws IOException {
System.out.println("a socket created");
// 读取到请求数据
BufferedReader reader = new BufferedReader(new InputStreamReader(socket.getInputStream()));
String line = "";
StringBuffer requestBuffer = new StringBuffer();
// line有可能出现null common-lang3下的工具类:StringUtil
while (StringUtil.isNotBlank((line = reader.readLine()))) {
requestBuffer.append(line).append("\n");
}
String request = requestBuffer.toString();
// 返回数据
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(socket.getOutputStream()));
String response = handler.apply(request);
writer.write(response);
writer.flush();
socket.close();
}
}
URL
我们通常通过 URL 来访问一个网站,URL 也就是我们所说的统一资源定位符,其中由以下部分构成:
像 80 端口,443 端口,URL 中的端口号是可以省略的
DNS 解析
也就是域名解析系统,通常当我们通过 URL 访问某一个网站的的时候,通过 DNS 查询得到当前域名所对应的 IP 地址,然后浏览器再通过返回的 IP 来定位到服务器资源并返回给浏览器,这也就是 DNS 解析的工作原理
但是我们要想一个问题,到目前为止,存在了几十亿的网站,而且有时候一个域名下会解析 N 多个 IP 地址,这种情况下,快速解析到 IP 地址就成为了一个问题,于是出现了分级缓存策略,其实介绍下来就是这样的:
- 当用户访问一个网站的时候,首先会从本地缓存中查找是否存在 DNS 条目,如果有的话就根据该条目直接访问;如果没有的话,回去系统的 hosts 文件下查找,匹配到就访问,否则会请求到 DNS 本地服务商。
这一步的存在会屏蔽掉 80% 的流量请求出去
- 在 DNS 本地服务商中也会存在缓存,如果这里也没有会请求到根服务器中
- 根服务器在分布在全球,而且在其服务器上只存目录,请求过来之后通过网站域名后缀请求到顶级域名服务器中匹配
- 和根服务器一样,顶级域名服务器上也只存目录,最终通过顶级域名服务器的匹配将请求转发到了权威服务器
- 在权威服务器中得到指定的 DNS 条目,最终返回给客户端
和 CDN 技术一样,根据最优规划,DNS 解析会给出最适合当前客户端的 IP
CDN
CDN 技术也是目前架构上使用市场广泛的一种技术,主要可以用来做:
- 流量分发
鸡蛋不放在同一个篮子里,同样的,我们的应用也不会部署在一起,当我们的应用分散在各地机房,应用的请求也需要做相应的调整,可以让用户请求离他们最近的服务器,也可以提升访问的效率
- 数据缓存,包括静态资源和一致性要求低的动态数据
- 不同服务器之间存储的内容都是一样的(镜像文件),这样在访问的时候才能保证一致性
传输控制层常用协议
TCP 协议
TCP 协议是面向连接的,安全可靠的传输协议,并且能够保证数据在传输过程中的完整性
TCP 协议如果需要建立连接,需要进行三次握手操作:
- 客户端发送 SYN(同步消息) 给服务端,通知服务端准备好进行连接,
- 服务端接收到客户端发送的 SYN 后会把 ACK 和服务端的 SYN 消息同时发送给客户端
- 客户端接收到 SYN 消息之后再次给服务端发送一个 ACK 响应消息
三次握手操作,在客户端的角度上来讲:
- 验证了自身的输入流和输出流是没有问题的,
- 最后给服务端的响应消息也是明确告知服务端自己收到了响应消息
等到三次握手全部完成之后,应用层才会开辟线程,开辟对象,开辟文件描述符等等的系统资源
同时,如果客户端想要和服务端断开连接的话,那么要经历四次分手操作:
- 客户端发送断开请求 FIN,服务端接收到 FIN 请求之后会给客户端返回 ACK 响应
- 服务端经过等待,确定可以断开当前连接的时候会给客户端发送 FIN
- 客户端接收到服务端返回的 FIN 请求,当客户端处理完之后,就会给服务端发送 ACK 响应,这时这次的连接全部断开
有商有量,才是和平分手
在 TCP 协议中,三次握手,数据传输,四次分手三者是不可被分割的最小粒度
UDP 协议
相对比 TCP 协议来讲,UDP 比 TCP 简单了很多,UDP 不需要连接,这也就造成了它不是安全可靠的连接,而且会出现数据包丢失的情况,但是 UDP 协议的传输速度比 TCP 快了很多
这种协议适用的场景包括:
- 音视频
- 广播
- ...
最后的话
好了,不聊了,这里欠个债:
网络层的下一跳机制和数据链路层的 ARP 协议,在后面再跟大家聊
骇,感觉有点水啊

9.1 计算机网络基础知识
1 网络体系结构
目前较为主流的网络体系结构是 ISO/OSI 参考模型和 TCP/IP 协议族。这两种体系结构都采用了分层设计和实现的方式,ISO/OSI 参考模型从上而下划分为应用层、表示层、会话层、传输层、网络层、数据链路层和物理层,而 TCP/IP 则将网络划分为应用层、传输层、网络层、链路层。分层设计的好处是,各层可以独立设计和实现,只要保证相邻层之间的调用规范和接口不变,就可以方便、灵活地改变各层的内部实现以进行优化或完成其他需求。
2 网络协议
网络协议是计算机网络中为了进行数据交换而建立的规则、标准或约定的集合,语法、语义和时序是网络协议的三要素。简单地讲,语义表示要做什么,语法表示要怎么做,时序规定了各个时间出现的顺序。语法和语义相对来说比较容易理解,可能有读者在想为啥要严格规定各类时间的时间和顺序。试想,假设早上 8 点 A 和 B 两个同事上班时在公司门口偶遇,A 问 B “吃了吗”,B 没有做任何回答就走了(如何计算 A 的心理阴影面积),中午 12 点下班时两个人在公司门口再次偶遇,B 对 A 说 “吃了”,我们可以想象到 A 看 B 的眼神会是什么样的。
(1)语法:语法规定了用户数据与控制信息的结构与格式。
(2)语义:语义用来解释控制信息每个部分的含义,规定了需要发出何种控制信息,以及需要完成的动作和做出什么样的响应。
(3)时序:时序是对事件发生顺序的详细说明,也可以成为 “同步”。
3 应用层协议
应用层协议直接与最终用户进行交互,用来确定运行在不同终端系统上的应用程序之间如何传递报文。下面简单列出了集中常见的应用层协议。
(1)DNS:域名系统(Domain Name System),用来实现域名与 IP 地址的转换,运行于 UDP 之上,默认使用 53 端口。
(2)FTP:文件传输协议(File Transfer Protocol),可以通过网络在不同平台之间实现文件的传输,是一种基于 TCP 的明文传输协议,默认工作在 21 号端口。
(3)HTTP:超文本传输协议(HyperText Transfer Protocol),运行于 TCP 之上,默认使用 80 端口。
(4)SMTP:简单邮件传输协议(Simple Mail Transfer Protocol),建立在 TCP 的基础上,使用明文传递邮件和发送命令,默认使用 25 号端口。
(5)TELNET:远程登录协议,运行于 TCP 之上,默认使用 23 端口。
4 传输层协议
在传输层主要运行这传输控制协议(Transmission Control Protocol,TCP)和用户数据报协议(User Datagram Protocol,UDP)两个协议,其中 TCP 是面向连接的,具有质量保证的可靠传输协议,但开销较大;UDP 是尽最大能力传输的无连接协议,开销小,常用于视频在线点播之类的应用。TCP 和 UDP 本身并没有优劣之分,仅仅是适用场所不同。在传输层,使用端口号来标识和区分同一台计算机上运行的多个应用层进程,每当创建一个应用层网络进程时系统就会自动分配一个端口号与之关联,是实现网络上端到端通信的重要基础。例如远程桌面连接默认占用 3389 端口,HTTP 默认使用 80 端口,MySQL 使用 3306 端口,MongoDB 使用 27017 端口,大多数情况下 IRC 服务器使用 6667 端口,IMAP 使用 143 端口,Oracle 使用 1521、1158、8080、210 等几个端口,等等。
5 IP 地址
IP 运行于网络层,是网络互连的重要基础。IP 地址(32 位或 128 位二进制数)用来标识网络上的主机,在公开网络上或同一个局域网内部,每台主机都必须使用不同的 IP 地址;而由于网络地址转换(Network Address Translation,NAT)和代理服务器等技术的广泛应用,不同内网之间的主机可以使用相同的 IP 地址。IP 地址于端口号共同标识网络上特定主机上的额特定应用进程,俗称 Socket。
6 MAC 地址
MAC 地址也称为网卡物理地址,是一个 48 位的二进制数,用来标识不同的网卡物理地址。本机的 IP 地址和 MAC 地址可以在命令提示符窗口中使用 ipconfig-all 命令查看。

LINUX教学:计算机基础系列教程三:网络基础之网络协议
《LINUX教学:计算机基础系列教程三:网络基础之网络协议》要点:
本文介绍了LINUX教学:计算机基础系列教程三:网络基础之网络协议,希望对您有用。如果有疑问,可以联系我们。
一. 网络通讯原理
1. 互联网的本色就是一系列的网络协议
有了计算机硬件,操作系统和应用软件,人们就可以使用这台计算机了.然则,此时计算机彼此孤立,无法一同玩耍.


图1
如何让两台彼此孤立的计算机能够产生通信?其实这就类似两个不同国家的人互相交流一样,你只会汉语,对方只会英语,你们是无法沟通的.如果你学会了英语,那你们就可以高效的沟通了.所以,英语作为全球的通用语言,是世界各地人么互相交流的标准工具.那internet其实就是任意两台计算机进行通信的标准.这些标准称之为互联网协议,互联网的本色就是一系列的协议,总称为“互联网协议”(Internet Protocol Suite).
互联网协议的功能:定义计算机如何接入internet,以及接入internet的计算机通信的尺度.
二. 互联网通信模子
1. OSI(Open System Interconnection)七层协定

图2
2. TCP/IP五层模子(Transmission Control Protocol/Internet Protocol)
我们把OSI七层协议中的应用层,表示层,会话层合并为应用层,就得到TCP/IP五层模型.这五层模型就涵盖了整个互联网通信的基来源根基理.

图3

图4
如上图所示,用户感知到的只是最上面一层应用层,自上而下每层都依赖于下一层,越往上越接近用户,越往下越接近硬件.
2.1 物理层
物理层由来:上面提到,孤立的计算机之间要想一起玩,就必需接入internet,言外之意就是计算机之间必需完成组网.

物理层功能:主要是基于电器特性发送高下电压(电信号),高电压对应数字1,低电压对应数字0.
2.2 数据链路层
数据链路层由来:单纯的电信号0和1没有任何意义,必需规定电信号多少位一组,每组什么意思.
数据链路层的功能:界说了电信号的分组方式.
以太网协定(ethernet):
早期的时候各个公司都有本身的分组方式,后来形成了统一的标准,即以太网协议.
ethernet划定
一组电信号组成一个数据包,叫做“帧”
每一数据帧分成:报头header和数据data两部门
| header | data |
header包括:(固定18个字节)
发送者/源地址,6个字节
接管者/目标地址,6个字节
数据类型,6个字节
data包括:(最短46字节,最长1500字节)
数据包的详细内容
header长度+data长度=最短64字节,最长1518字节,跨越最大限制就分片发送.
Mac地址:
header中包括的源和目标地址由来:ethernet规定接入internet的设备都必须具备网卡,发送端和接收端的地址便是指网卡的地址,即mac地址.
mac地址:每块网卡出厂时都被烧制上一个世界唯一的mac地址,长度为48位2进制,通常由12位16进制数表现(前六位是厂商编号,后六位是流水线号).

图6
广播:
有了mac地址,同一网络内的两台主机就可以通信了(一台主机通过arp协议获取另外一台主机的mac地址).ethernet采纳最原始的方式,广播的方式进行通信,即计算机通信基本靠吼.

图7
2.3 收集层
网络层由来:有了ethernet、mac地址、广播的发送方式,世界上的计算机就可以彼此通信了,问题是世界范围的互联网是由一个个彼此隔离的小的局域网组成的,那么如果所有的通信都采纳以太网的广播方式,那么一台机器发送的包全世界都会收到,这就不仅仅是效率低的问题了,这会是一种灾难.

图8
所以,必须找出一种办法来区分哪些计算机属于同一广播域,哪些不是,如果是就采用广播的方式发送,如果不是,就采用路由的方式(向不同广播域/子网分发数据包),mac地址是无法区分的,它只跟厂商有关.
网络层功能:引入一套新的地址用来区分分歧的广播域/子网,这套地址即网络地址.
IP协定:
规定网络地址的协议叫IP协议,它定义的地址称之为IP地址,广泛采用的v4版本即IPV4,它规定网络地址由32位2进制表现,范围0.0.0.0~255.255.255.255一个IP地址通常写成四段十进制数,例:172.16.10.1.
IP地址分成两部分,网络部分(标识子网)和主机部分(标识主机).单纯的IP地址段只是标识了IP地址的种类,从网络部分或主机部分都无法辨识一个IP所处的子网.例:172.16.10.1与172.16.10.2并不克不及确定二者处于同一子网.
子网掩码:
所谓”子网掩码”,就是表示子网络特征的一个参数.它在形式上等同于IP地址,也是一个32位二进制数字,它的网络部分全部为1,主机部分全部为0.好比,IP地址172.16.10.1,如果已知网络部分是前24位,主机部分是后8位,那么子网络掩码就是11111111.11111111.11111111.00000000,写成十进制就是255.255.255.0.
通过”子网掩码”,我们就能判断,任意两个IP地址是否处在同一个子网络.办法是将两个IP地址与子网掩码分别进行AND运算(两个数位都为1,运算结果为1,否则为0),然后比较结果是否相同,如果是的话,就表明它们在同一个子网络中,否则就不是.比如,已知IP地址172.16.10.1和172.16.10.2的子网掩码都是255.255.255.0,请问它们是否在同一个子网络?两者与子网掩码分别进行AND运算:
172.16.10.1: 10101100.00010000.00001010.000000001
255255.255.255.0: 11111111.11111111.11111111.00000000
AND运算得网络地址成果:10101100.00010000.00001010.000000001->172.16.10.0
172.16.10.2: 10101100.00010000.00001010.000000010
255255.255.255.0: 11111111.11111111.11111111.00000000
AND运算得网络地址成果:10101100.00010000.00001010.000000001->172.16.10.0
成果都是172.16.10.0,因此它们在同一个子网络.
总结一下,IP协议的作用主要有两个,一个是为每一台计算机分派IP地址,另一个是确定哪些地址在同一个子网络.
_baidu_page_break_tag_IP数据包:
IP数据包也分为header和data部门,无须为IP包定义单独的栏位,直接放入以太网包的data部门
head:长度为20到60字节
data:最长为65,515字节
而以太网数据包的”数据”部分,最长只有1500字节.因此,如果IP数据包超过了1500字节,它就必要分割成几个以太网数据包,分开发送了.
| 以太网头 | IP头 | IP数据 |
ARP协定(Address Resolution Protocol):
ARP协议由来:计算机通信基本靠吼,即广播的方式,所有上层的包到最后都要封装上以太网头,然后通过以太网协议发送,在谈及以太网协议时候,我门了解到通信是基于mac的广播方式实现,计算机在发包时,获取自身的mac是容易的,如何获取目标主机的mac,就必要通过ARP协议.
ARP协议功效:广播的方式发送数据包,获取目标主机的mac地址.
协议事情方式:每台主机ip都是已知的.
例如:主机172.16.10.10/24拜访172.16.10.11/24
首先通过IP地址和子网掩码区分出本身所处的子网
阐发172.16.10.10/24与172.16.10.11/24处于同一网络(如果不是同一网络,那么下表中目标IP为172.16.10.1,通过ARP获取的是网关的mac)
| 源mac | 目标mac | 源IP | 目标IP | 数据部门 | |
| 发送端主机 | 发送端mac | FF:FF:FF:FF:FF:FF | 172.16.10.10/24 | 172.16.10.11/24 | 数据 |
这个包会以广播的方式在发送端所处的子网内传输,所有主机接收后拆开包,发现目标IP为本身的,就响应,返回本身的mac.
2.4 传输层
传输层的由来:网络层的IP帮我们区分子网,以太网层的mac帮我们找到主机,然后大家使用的都是应用程序,你的电脑上可能同时开启qq,暴风影音,等多个应用程序,那么我们通过IP和mac找到了一台特定的主机,如何标识这台主机上的应用程序,答案便是端口,端口即应用程序与网卡关联的编号.
传输层功能:建立端口到端口的通信.弥补:端口范围0~65535,0~1023为系统占用端口.
TCP协定:
可靠传输,TCP数据包没有长度限制,理论上可以无限长,但是为了保证网络的效率,通常TCP数据包的长度不会跨越IP数据包的长度,以确保单个TCP数据包不必再分割.
| 以太网头 | IP头 | TCP头 | 数据 |
UDP协定(User Datagram Protocol):
弗成靠传输,”报头”部分一共只有8个字节,总长度不超过65,535字节,正好放进一个IP数据包.
| 以太网头 | IP头 | UDP头 |
数据 |

图9. TCP报文

图10. TCP三次握手和四次挥手
2.5 利用层
应用层由来:用户使用的都是应用程序,均工作于应用层,互联网是开放的,大家都可以开发本身的应用程序,数据多种多样,必须规定好数据的组织形式 .
应用层功能:规定应用程序的数据格式.例:TCP协议可以为各种各样的程序传递数据,好比Email、WWW、FTP等等.那么,必须有不同协议规定电子邮件、网页、FTP数据的格式,这些应用程序协议就构成了”应用层”.

图11
2.6 Socket
我们知道两个进程如果需要进行通讯最基本的一个前提是能够唯一的标示一个进程,在当地进程通讯中我们可以使用PID来唯一标示一个进程,但PID只在当地唯一,网络中的两个进程PID冲突几率很大,这时候我们需要另辟它径了,我们知道IP层的IP地址可以唯一标示主机,而TCP层协议和端口号可以唯一标示主机的一个进程,这样我们可以利用IP地址+协议+端口号唯一标示网络中的一个进程.
能够唯一标示网络中的进程后,它们就可以利用socket进行通信了,什么是socket呢?我们常常把socket翻译为套接字,socket是在应用层和传输层之间的一个抽象层,它把TCP/IP层复杂的操作抽象为几个简单的接口供应用层调用已实现进程在网络中通信.

图12
socket起源于UNIX,在UNIX一切皆文件哲学的思想下,socket是一种"打开—读/写—关闭"模式的实现,服务器和客户端各自维护一个"文件",在建立连接打开后,可以向本身文件写入内容供对方读取或者读取对方内容,通讯结束时关闭文件.
三. 网络通讯实现
想实现网络通讯,每台主机需具备四要素:本机的IP地址;子网掩码;网关的IP地址;DNS的IP地址.
获取这四要素分两种方式:1.静态获取,即手动设置装备摆设;2.动态获取,通过DHCP获取.
| 以太网头 | IP头 | UDP头 | DHCP数据包 |
(1)最前面的”以太网标头”,设置发出方(本机)的MAC地址和接收方(DHCP服务器)的MAC地址.前者便是本机网卡的MAC地址,后者这时不知道,就填入一个广播地址:FF-FF-FF-FF-FF-FF.
(2)后面的”IP标头”,设置发出方的IP地址和接收方的IP地址.这时,对付这两者,本机都不知道.于是,发出方的IP地址就设为0.0.0.0,接收方的IP地址设为255.255.255.255.
(3)最后的”UDP标头”,设置发出方的端口和接收方的端口.这一部门是DHCP协议规定好的,发出方是68端口,接收方是67端口.
这个数据包构造完成后,就可以发出了.以太网是广播发送,同一个子网络的每台计算机都收到了这个包.因为接收方的MAC地址是FF-FF-FF-FF-FF-FF,看不出是发给谁的,所以每台收到这个包的计算机,还必须分析这个包的IP地址,才能确定是不是发给本身的.当看到发出方IP地址是0.0.0.0,接收方是255.255.255.255,于是DHCP服务器知道”这个包是发给我的”,而其他计算机就可以丢弃这个包.
接下来,DHCP服务器读出这个包的数据内容,分配好IP地址,发送回去一个”DHCP响应”数据包.这个响应包的结构也是类似的,以太网标头的MAC地址是双方的网卡地址,IP标头的IP地址是DHCP服务器的IP地址(发出方)和255.255.255.255(接收方),UDP标头的端口是67(发出方)和68(接收方),分配给哀求端的IP地址和本网络的具体参数则包含在Data部分.
新加入的计算机收到这个响应包,于是就知道了本身的IP地址、子网掩码、网关地址、DNS服务器等等参数.
四. 网络通讯流程
1. 本机获取
- 本机的IP地址:192.168.1.100
- 子网掩码:255.255.255.0
- 网关的IP地址:192.168.1.1
- DNS的IP地址:8.8.8.8
2. 打开浏览器,想要拜访Google,在地址栏输入了网址:www.google.com
3. DNS协定(基于UDP协定)

图13
13台根DNS:
A.root-servers.net198.41.0.4美国
B.root-servers.net192.228.79.201美国(另支持IPv6)
C.root-servers.net192.33.4.12法国
D.root-servers.net128.8.10.90美国
E.root-servers.net192.203.230.10美国
F.root-servers.net192.5.5.241美国(另支持IPv6)
G.root-servers.net192.112.36.4美国
H.root-servers.net128.63.2.53美国(另支持IPv6)
I.root-servers.net192.36.148.17瑞典
J.root-servers.net192.58.128.30美国
K.root-servers.net193.0.14.129英国(另支持IPv6)
L.root-servers.net198.32.64.12美国
M.root-servers.net202.12.27.33日本(另支持IPv6)
域名界说:http://jingyan.baidu.com/article/1974b289a649daf4b1f774cb.html
顶级域名:以.com,.net,.org,.cn等等属于国际顶级域名,根据目前的国际互联网域名体系,国际顶级域名分为两类:类别顶级域名(gTLD)和地舆顶级域名(ccTLD)两种.类别顶级域名是以"COM"、"NET"、"ORG"、"BIZ"、"INFO"等结尾的域名,均由国外公司负责管理.地舆顶级域名是以国家或地区代码为结尾的域名,如"CN"代表中国,"UK"代表英国.地舆顶级域名一般由各个国家或地区负责管理.
二级域名:二级域名是以顶级域名为基础的地理域名,比方中国的二级域有,.com.cn,.net.cn,.org.cn,.gd.cn等.子域名是其父域名的子域名,比方父域名是abc.com,子域名就是www.abc.com或者*.abc.com.
一般来说,二级域名是域名的一条记录,比如alidiedie.com是一个域名,www.alidiedie.com是其中比较常用的记录,一般默认是用这个,但是类似*.alidiedie.com的域名全部称作是alidiedie.com的二级.
4. HTTP部门的内容,类似于下面这样:
GET / HTTP/1.1
Host: www.google.com
Connection: keep-alive
User-Agent: Mozilla/5.0 (Windows NT 6.1) ……
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8
Accept-Encoding: gzip,deflate,sdch
Accept-Language: zh-CN,zh;q=0.8
Accept-Charset: GBK,utf-8;q=0.7,*;q=0.3
Cookie: … …
我们假定这个部门的长度为4960字节,它会被嵌在TCP数据包之中.
5. TCP协定
TCP数据包必要设置端口,接收方(Google)的HTTP端口默认是80,发送方(本机)的端口是一个随机生成的1024-65535之间的整数,假定为51775.
TCP数据包的标头长度为20字节,加上嵌入HTTP的数据包,总长度变为4980字节.
6. IP协定
然后,TCP数据包再嵌入IP数据包.IP数据包必要设置双方的IP地址,这是已知的,发送方是192.168.1.100(本机),接收方是172.194.72.105(Google).
IP数据包的标头长度为20字节,加上嵌入的TCP数据包,总长度变为5000字节.
7 以太网协定
最后,IP数据包嵌入以太网数据包.以太网数据包必要设置双方的MAC地址,发送方为本机的网卡MAC地址,接收方为网关192.168.1.1的MAC地址(通过ARP协议得到).
以太网数据包的数据部分,最大长度为1500字节,而现在的IP数据包长度为5000字节.因此,IP数据包必须分割成四个包.因为每个包都有本身的IP标头(20字节),所以四个包的IP数据包的长度分别为1500、1500、1500、560.

图14
8. 服务器端相应
经过多个网关的转发,Google的服务器172.194.72.105,收到了这四个以太网数据包.根据IP标头的序号,Google将四个包拼起来,取出完整的TCP数据包,然后读出里面的”HTTP哀求”,接着做出”HTTP响应”,再用TCP协议发回来.
本机收到HTTP响应以后,就可以将网页显示出来,完成一次网络通讯.
本文永远更新链接地址:
《LINUX教学:计算机基础系列教程三:网络基础之网络协议》是否对您有启发,欢迎查看更多与《LINUX教学:计算机基础系列教程三:网络基础之网络协议》相关教程,学精学透。小编PHP学院为您提供精彩教程。

LINUX教程:计算机基础系列教程一:计算机硬件
《LINUX教程:计算机基础系列教程一:计算机硬件》要点:
本文介绍了LINUX教程:计算机基础系列教程一:计算机硬件,希望对您有用。如果有疑问,可以联系我们。
计算机(Computer),俗称电脑,是一种能够依照事先存储的程序,自动、高速地进行大量数值运算和各种信息处理的现代化智能电子设备.计算机硬件发展史(From Egon)
计算机体系
一台完整的计算机硬件系统由以下5部门构成:运算器、存储器、控制器、输入设备、输出设备.


cpu(Center Processing Unit,集运算及控制)
整个计算机硬件系统中,最重要的当属cpu了,它在整个计算机系统中的作用就相当于我们的大脑.它从内存中取指令->解码->执行,然后再取指令->解码->执行下一条指令,周而复始,直至整个程序被执行完成.因为拜访内存以得到指令或数据的时间比cpu执行指令花费的时间要长得多,所以,cpu内部都有一些用来保存关键变量和临时数据的寄存器,这样通常在cpu的指令集中专门提供一些指令,用来将一个字(可以理解为数据)从内存调入寄存器,以及将一个字从寄存器存入内存.cpu其他的指令集可以把来自寄存器、内存的操作数据组合,或者用两者产生一个结果,比如将两个字相加并把结果存在寄存器或内存中.这样再次调用寄存器中的指令就会使等待时间大大缩短.
存放器的分类:
1.保留变量和临时结果的通用寄存器.
2.多数计算机还有一些对程序员设计的专门寄存器,其中之一便是程序计数器(或称为指令指针),它保留了将要取出的下一条指令的内存地址.在指令取出后,程序计算器就被更新以便执行后期的指令.
3.另外一个寄存器便是堆栈指针,它指向内存中当前栈的顶端.该栈包括已经进入但是还没有退出的每个过程中的一个框架.在一个过程的堆栈框架中保存了有关的输入参数、局部变量以及那些没有保存在寄存器中的临时变量.
4.最后一个非常重要的寄存器就是程序状态字寄存器(Program Status Word,PSW),这个寄存器包括了条码位(由比较指令设置)、cpu优先级、模式(用户态或内核态),以及各种其他控制位.用户通常读入整个PSW,但是只对其中少量的字段写入.在系统调用和I/O中,PSW非常非常非常非常非常非常重要.
除了在嵌入式系统中的非常简单的cpu之外,多半cpu都有两种模式,即内核态与用户态.通常,PSW中有一个二进制位控制这两种模式.
内核态:当cpu在内核态运行时,cpu可以执行指令集中所有的指令,很明显,所有的指令中包含了使用硬件的所有功能.(操作系统在内核态下运行,从而可以拜访整个硬件)
用户态:用户程序在用户态下运行,仅仅只能执行cpu整个指令集的一个子集,该子集中不包括操作硬件功能的部分,因此,一般情况下,在用户态中有关I/O和内存保护(操作系统占用的内存是受保护的,不能被别的程序占用),当然,在用户态下,将PSW中的模式设置成内核态也是禁止的.
那为什么需要设计出两种工作模式呢?由于需要限制不同的程序之间的拜访能力,防止他们获取别的程序的内存数据,或者获取外围设备的数据,并发送到网络,cpu从而划分出两个权限等级.
所有用户程序都是运行在用户态的,但是有时候程序确实需要做一些内核态的事情,例如从硬盘读取数据,或者从键盘获取输入等.而唯一可以做这些事情的就是操作系统,所以此时程序就需要向操作系统哀求以程序的名义来执行这些操作.
这时必要一个这样的机制: 用户态程序切换到内核态,但是不能控制在内核态中执行的指令,这种机制叫系统调用(system call),在cpu中的实现称之为陷阱指令(Trap Instruction).
它们的事情流程如下:
- 用户态程序将一些数据值放在寄存器中,或者使用参数创建一个堆栈(stack frame),以此表明需要操作系统提供的服务.
- 用户态程序执行陷阱指令.
- cpu切换到内核态,并跳到位于内存指定位置的指令,这些指令是操作系统的一部分,他们具有内存保护,不可被用户态程序访问.
- 这些指令称之为陷阱(trap)或者系统调用处理器(system call handler).他们会读取程序放入内存的数据参数,并执行程序哀求的服务.
- 系统调用完成后,操作系统会重置cpu为用户态并返回系统调用的结果.
多线程和多核芯片
Moore定律指出,芯片中的晶体管数量每18个月翻一倍,随着晶体管数量的增多,更强大的功能成为了可能,如
I.第一步增强:在cpu芯片中加入更大的缓存,一级缓存L1,用和cpu相同的材质制成,cpu访问它没有延时.
II.第二步增强:一个cpu中的处理逻辑增多,intel公司首次提出,称为多线程(multithreading)或超线程(hyperthreading),对用户来说一个有两个线程的cpu就相当于两个cpu.多线程运行cpu保持两个不同的线程状态,可以在纳秒级的时间内来回切换,速度快到你看到的结果是并发的,伪并行的,然而多线程不提供真正的并行处理,一个cpu同一时刻只能处理一个进程(一个进程中至少一个线程,进程是资源单位而线程才是cpu的执行单位).
III.第三步增强:除了多线程,还出现了包含2个或者4个完整处理器的cpu芯片,如下图.要使用这类多核芯片肯定需要有多处理操作系统.


图3
存储器
由于硬件技术的限制,我们可以制造出容量很小但很快的存储器,也可以制造出容量很大但很慢的存储器,鱼与熊掌不可兼得,不可能制造出访问速度又快容量又大的存储器.因此,现代计算机都把存储器分成若干级,称为Memory Hierarchy,依照离cpu由近到远的顺序依次是cpu寄存器、Cache、内存、硬盘,越靠近cpu的存储器容量越小但访问速度越快,下图给出了各种存储器的容量和访问速度的典型值.

寄存器、Cache和内存中的数据都是掉电丢失的,这称为易失性存储器(Volatile Memory),与之相对的,硬盘是一种非易失性存储器(Non-volatile Memory).
除了拜访寄存器由程序指令直接控制之外,拜访其它存储器都不是由指令直接控制的,有些是硬件自动完成的,有些是操作系统配合硬件完成的.
Cache从内存取数据时一次取一个Cache Line缓存起来,操作系统从硬盘取数据时一次取 几KB缓存起来,都是希望这些数据以后会被拜访到.大多数程序的行为都具有局部性 (Locality)的特点:它们会花费大量的时间反复执行一小段代码(例如循环),或者反 复拜访一个很小的地址范围中的数据(例如拜访一个数组).所以预读缓存的办法是很有 效的:cpu取一条指令,我把它相邻的指令也都缓存起来,cpu很可能马上就会取 到;cpu拜访一个数据,我把它相邻的数据也都缓存起来,cpu很可能马上就会拜访到. 设想有两台计算机,一台有32KB的Cache,另一台没有Cache,而内存都是512MB的,硬盘都是100GB的,虽然多出来32KB的Cache和内存、硬盘的容量相比微不足道,但由 于局部性原理,有Cache的计算机明显会快很多.高速存储器即使容量只能做得很小也能 显著提升计算机的性能,这就是Memory Hierarchy的意义所在.
寄存器即L1缓存:
用与cpu相同材质制造,与cpu一样快,因而cpu拜访它无延时,典型容量是:在32位cpu中为32*32,在64位cpu中为64*64,在两种情况下容量均<1KB.
高速缓存即L2缓存:
主要由硬件控制高速缓存的存取,内存中有高速缓存行按照0~64字节为行0,64~127为行1......最常用的高速缓存行放置在cpu内部或者非常接近cpu的高速缓存中.当某个程序需要读一个存储字时,高速缓存硬件检查所需要的高速缓存行是否在高速缓存中.如果是,则称为高速缓存命中,缓存满足了哀求,就不需要通过总线把访问哀求送往主存(内存),这毕竟是慢的.高速缓存的命中通常需要两个时钟周期.高速缓存未命中,就必须访问内存,这需要付出大量的时间代价.由于高速缓存价格昂贵,所以其大小有限,有些机器具有两级甚至三级高速缓存,每一级高速缓存比前一级慢但是容量大.
缓存在计算机科学的许多领域中起着重要的作用,并不仅仅只是RAM(随机存取存储器)的缓存行.只要存在大量的资源可以划分为小的部分,那么这些资源中的某些部分肯定会比其他部分更频繁地得到使用.此时用缓存可以带来性能上的提升.一个典型的例子就是操作系统一直在使用缓存,比如,多数操作系统在内存中保存频繁使用的文件(的一部分),以避免从磁盘中重复地调用这些文件,类似的/root/a/b/c/d/e/f/a.txt的长路径名转换成该文件所在的磁盘地址的结果然后放入缓存,可以避免重复寻找地址,还有一个web页面的URL地址转换为网络地址(IP)地址后,这个转换结果也可以缓存起来供将来使用.
缓存是一个好方法,在现代cpu中设计了两个缓存,再看图3中的两种cpu设计.第一级缓存称为L1总是在cpu中,通常用来将已经解码的指令调入cpu的执行引擎,对那些频繁使用的数据自,多少芯片还会依照第二L1缓存 ...另外往往设计有二级缓存L2,用来存放近来经常使用的内存字.L1与L2的差别在于对cpu对L1的访问无时间延迟,而对L2的访问则有1-2个时钟周期(即1-2ns)的延迟.
内存:
再往下一层是主存,此乃存储器系统的主力,主存通常称为随机拜访存储RAM,就是我们通常所说的内存,容量一直在不断攀升,所有不能再高速缓存中找到的,都会到主存中找,主存是易失性存储,断电后数据全部消失.
除了主存RAM之外,许多计算机已经在使用少量的非易失性随机拜访存储如ROM(Read Only Memory,ROM),在电源切断之后,非易失性存储的内容并不会丢失,ROM只读存储器在工厂中就被编程完毕,然后再也不能修改.ROM速度快且便宜,在有些计算机中,用于启动计算机的引导加载模块就存放在ROM中,另外一些I/O卡也采用ROM处理底层设备的控制.
EEPROM(Electrically Erasable PROM,电可擦除可编程ROM)和闪存(flash memory)也是非易失性的,但是与ROM相反,他们可以擦除和重写.不过重写时花费的时间比写入RAM要多.在便携式电子设备中,闪存通常作为存储媒介.闪存是数码相机中的胶卷,是便携式音译播放器的磁盘,还应用于固态硬盘.闪存在速度上介于RAM和磁盘之间,但与磁盘不同的是,闪存擦除的次数过多,就被磨损了.
还有一类存储器就是CMOS,它是易失性的,许多计算机利用CMOS存储器来保持当前时间和日期.CMOS存储器和递增时间的电路由一小块电池驱动,即使计算机没有加电,时间也仍然可以正确地更新,除此之外CMOS还可以保存配置的参数,哪一个是启动磁盘等,之所以采用CMOS是因为它耗电非常少,一块工厂原装电池往往能使用若干年,但是当电池失效时,相关的配置和时间等都将丢失.
磁盘:
磁盘低速的原因是因为它是一种机械装置,在磁盘中有一个或多个金属盘片,它们以5400,7200或10800rpm(RPM =revolutions per minute 每分钟多少转 )的速度旋转.从边缘开始有一个机械臂悬在盘面上,这类似于老式黑胶唱片机上的拾音臂.信息写在磁盘上的一些列的同心圆上,是一连串的2进制位(称为bit位),为了统计方便,8个bit称为一个字节bytes,1024bytes=1k,1024k=1M,1024M=1G,所以我们平时所说的磁盘容量最终指的就是磁盘能写多少个2进制位.
每个磁头可以读取一段环形区域,称为磁道.把一个机械手臂位置上所有的磁道合起来,组成一个柱面.每个磁道划成若干扇区,扇区典型的值是512字节.
数据都存放于一段一段的扇区,即磁道这个圆圈的一小段圆圈,从磁盘读取一段数据需要经历寻道时间和延迟时间.
平均寻道时间:
机械手臂从一个柱面随机移动到相邻的柱面的时间成为寻到时间,找到了磁道就以为着招到了数据所在的那个圈圈,但是还不知道数据具体这个圆圈的具体位置.
平均延迟时间:
机械臂到达正确的磁道之后还必须等待旋转到数据所在的扇区下,这段时间称为延迟时间.
虚拟内存:
许多计算机支持虚拟内存机制,该机制使计算机可以运行大于物理内存的程序,办法是将正在使用的程序放入内存取执行,而暂时不需要执行的程序放到磁盘的某块地方,这块地方称为虚拟内存,在linux中称为swap.这种机制的核心在于快速地映射内存地址,由cpu中的一个部件负责,称为存储器管理单元(Memory Management Unit,MMU).
PS:从一个程序切换到另外一个程序,称为上下文切换(context switch),缓存和MMU的出现提升了系统的性能,尤其是上下文切换.

图5

图6
更多详情见请继续阅读下一页的出色内容:
I/O设备
cpu和存储器并不是操作系统唯一需要管理的资源,I/O设备也是非常重要的一环.I/O设备一般包括两个部分:设备控制器和设备本身.
控制器:是查找主板上的一块芯片或一组芯片(硬盘,网卡,声卡等都需要插到一个口上,这个口连的便是控制器),控制器负责控制连接的设备,它从操作系统接收命令,比如读硬盘数据,然后就对硬盘设备发起读哀求来读出内容.
控制器的功能:通常情况下对设备的控制是非常复杂和具体的,控制器的任务就是为操作系统屏蔽这些复杂而具体的工作,提供给操作系统一个简单而清晰的接口
设备本身:有相对简单的接口且标准的,这样大家都可以为其编写驱动程序了.要想调用设备,必须根据该接口编写复杂而具体的程序,于是有了控制器提供设备驱动接口给操作系统.必须把设备驱动程序安装到操作系统中.
总线
从概念上讲,一台简单的个人计算机可以抽象为类似图7的模型,cpu、内存以及I/O设备都由一条系统总线(bus)连接起来并通过总线与其他设备通信.但是随着处理器和存储器速度越来越快,单总线很难处理总线的交通流量了,于是呈现了图8的多总线模式,他们处理I/O设备及cpu到存储器的速度都更快.
北桥即PCI桥:衔接高速设备
南桥即ISA桥:衔接慢速设备

图7

图8
启动计算机
在计算机的主板上有一个基本的输入输出法式(Basic Input Output System,BIOS)
BIOS就相当于一个小的操作系统,它有底层的I/O软件,包含读键盘,写屏幕,进行磁盘I/O,该程序存放于一非易失性闪存RAM中.
启动流程:
1.计算机加电.
2.BIOS开端运行,检测硬件:cpu、内存、硬盘等.
3.BIOS读取CMOS存储器中的参数,选择启动装备.
4.从启动设备上读取第一个扇区的内容.(MBR主引导记录512字节,前446为引导信息,后64为分区信息,最后两个为标记位)
5.依据分区信息读入bootloader启动装载模块,启动操作系统.
6.然后操作系统询问BIOS,以获得配置信息.对于每种设备,系统会检查其设备驱动程序是否存在,如果没有,系统则会要求用户安装设备驱动程序.一旦有了全部的设备驱动程序,操作系统就将它们调入内核.然后初始有关的表格(如进程表),创建必要的进程,并在每个终端上启动登录程序或GUI.
本文永远更新链接地址:
小编PHP培训学院每天发布《LINUX教程:计算机基础系列教程一:计算机硬件》等实战技能,PHP、MysqL、LINUX、APP、JS,CSS全面培养人才。
计算机网络之基础概念")
程序员内功修炼(一)计算机网络之基础概念
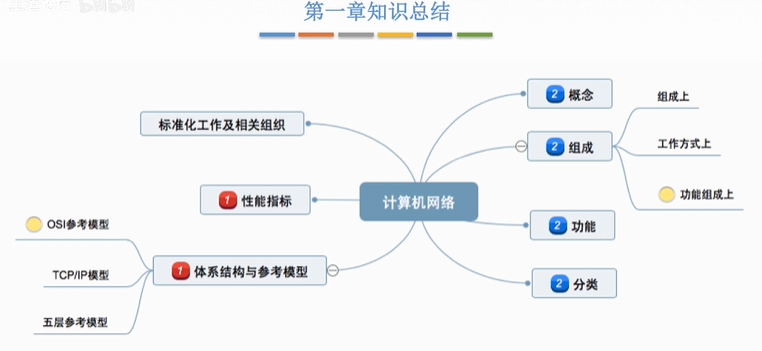
1、计算机网络 概念、组成、功能、分类
一、计算机网络的概念
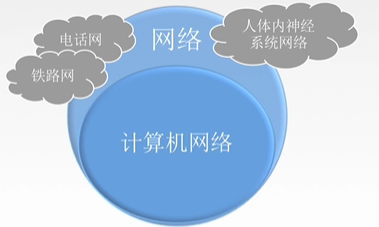
计算机网络:是一个将分散的、具有独立功能的计算机系统,通过通信设备与线路连接起来,由功能完善的软件实现资源共享和信息传递的系统。

计算机网络是互连的、自治的计算机集合。
互连-互联互通 通信链路
自治-无主从关系
二、计算机网络的功能

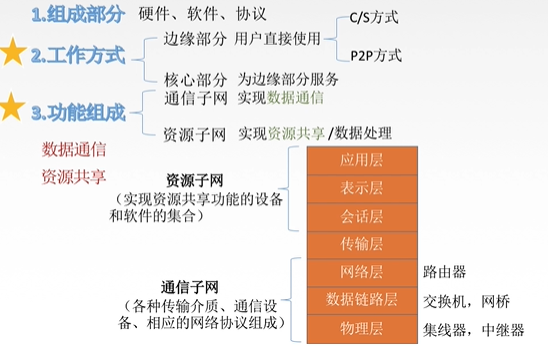
三、计算机网络的组成
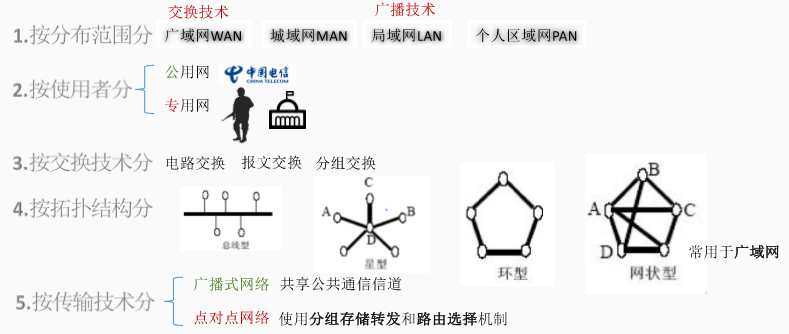
四、计算机网络的分类
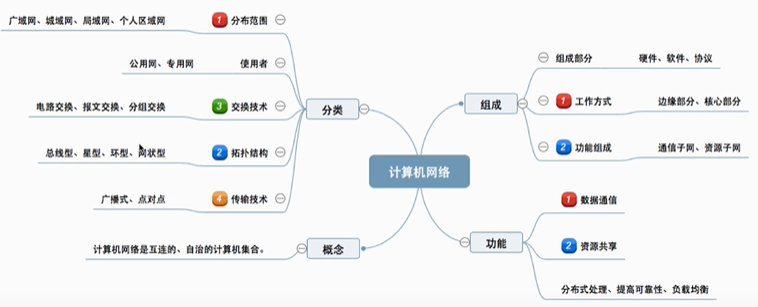
五、脑图梳理
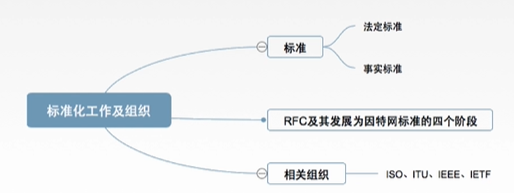
2、计算机网络标准化工作及相关组织
一、标准化工作
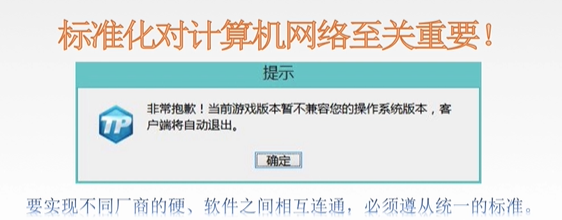


二、相关组织

三、脑图梳理
3、计算机网络速率相关性能指标
一、速率

二、带宽
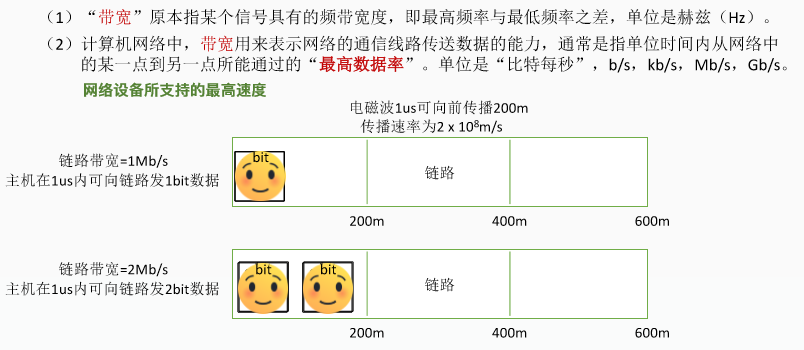
三、吞吐量

4、时延、时延带宽积、RTT和利用率
一、时延
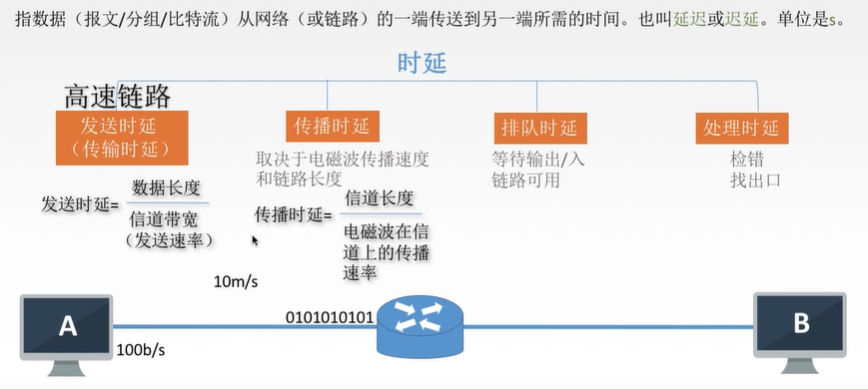
二、时延带宽积
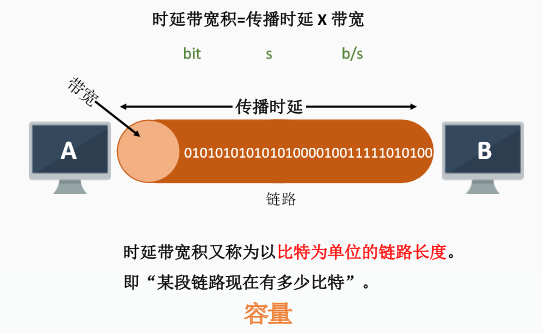
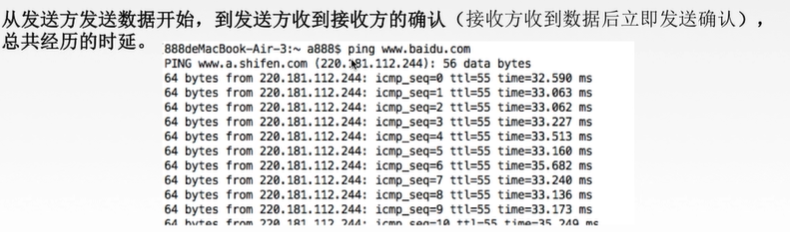
三、往返时延RTT

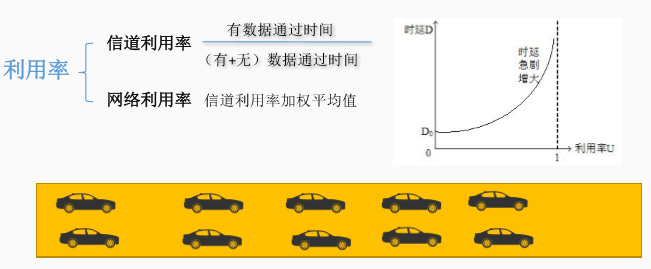
四、利用率
五、脑图梳理

5、分层结构、协议、接口、服务
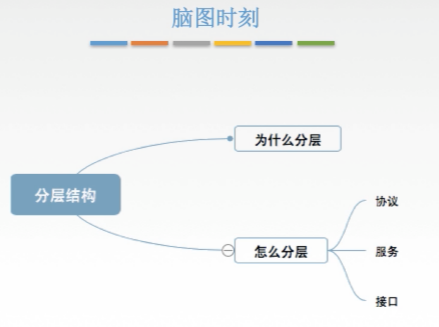
一、为什么要分层
二、怎么分层
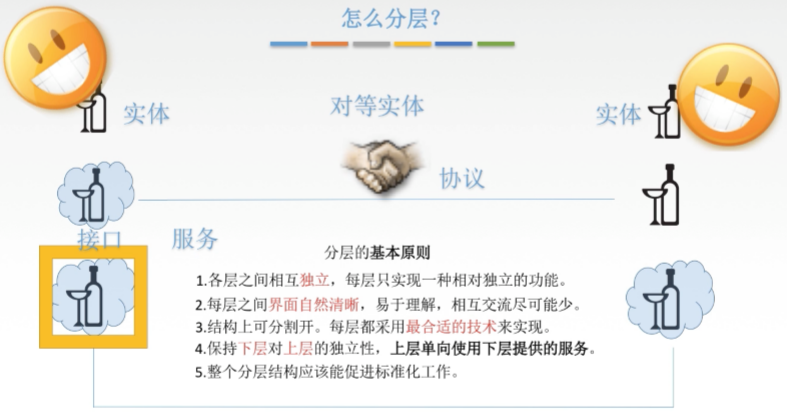
三、正式认识分层结构
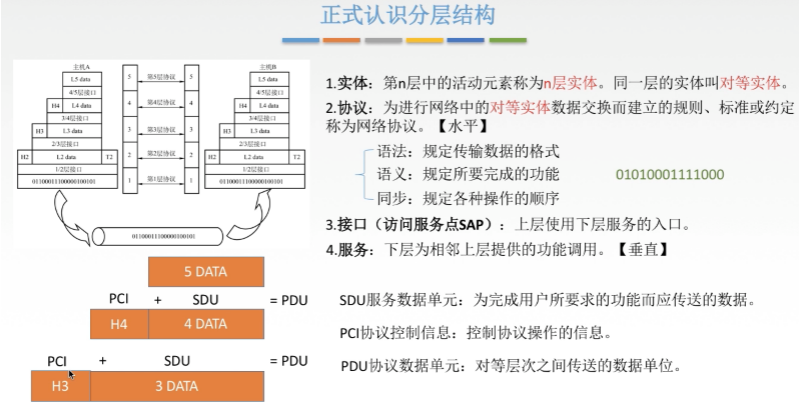
四、概念总结

五、脑图梳理
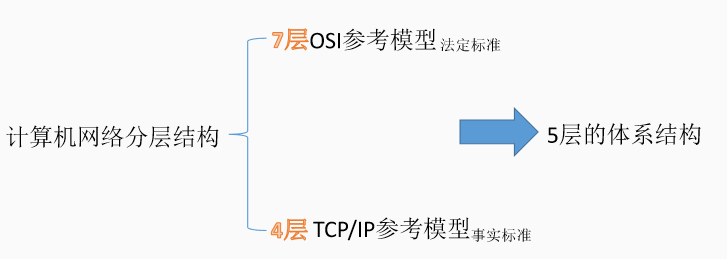
6、OSI参考模型
一、OSI参考模型由来
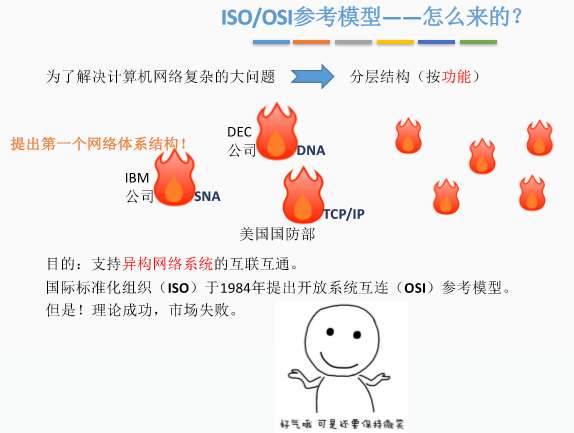
二、ISO参考模型

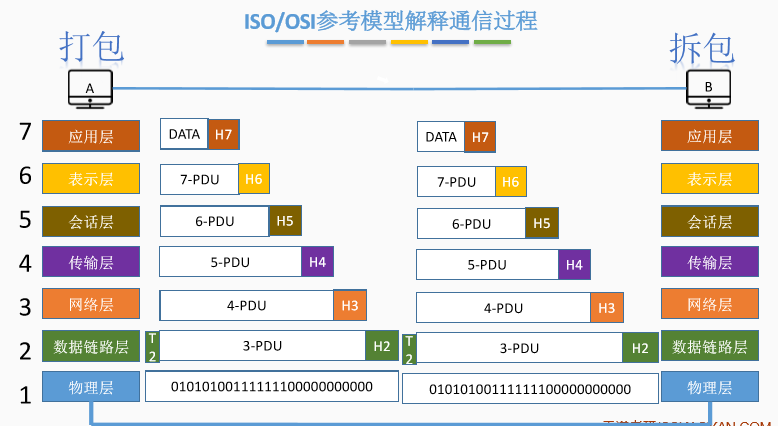
三、ISO参考模型解释通信过程

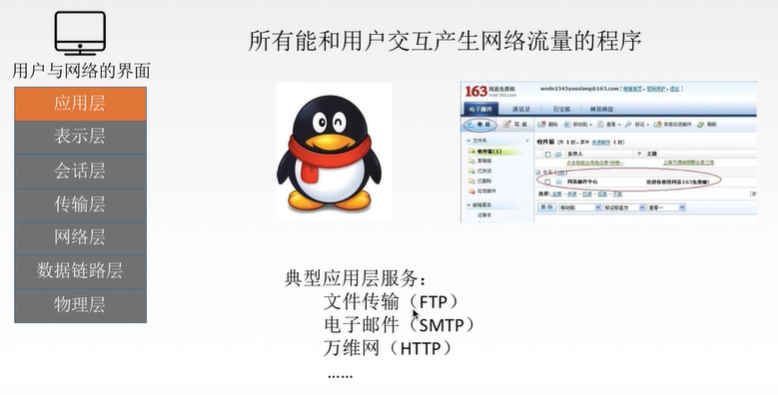
四、应用层
五、表示层
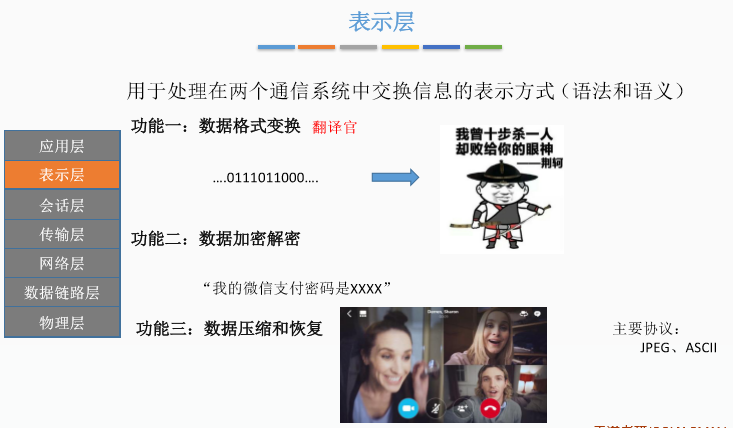
六、会话层
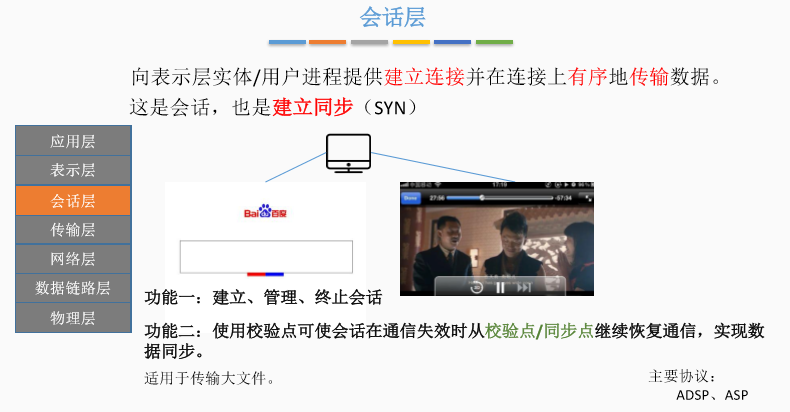
七、传输层
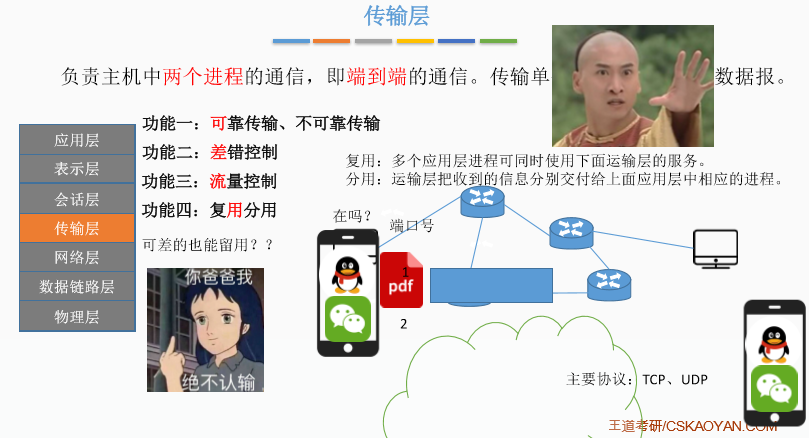
八、网络层
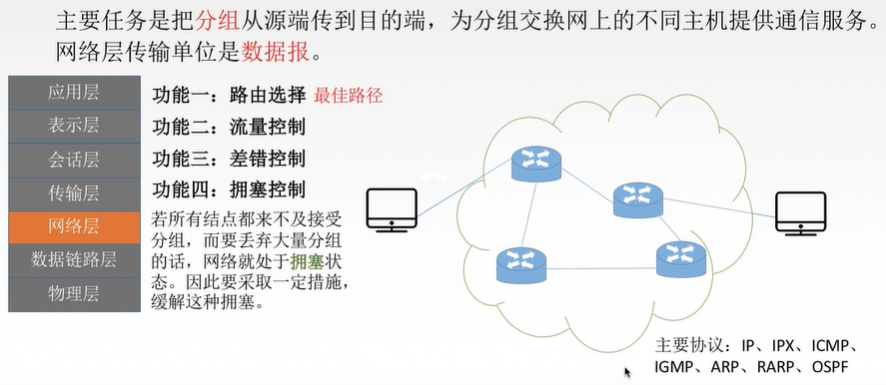
九、数据链路层
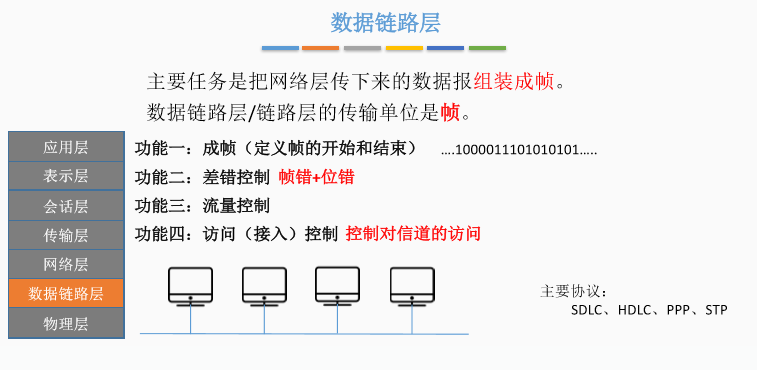
十、物理层
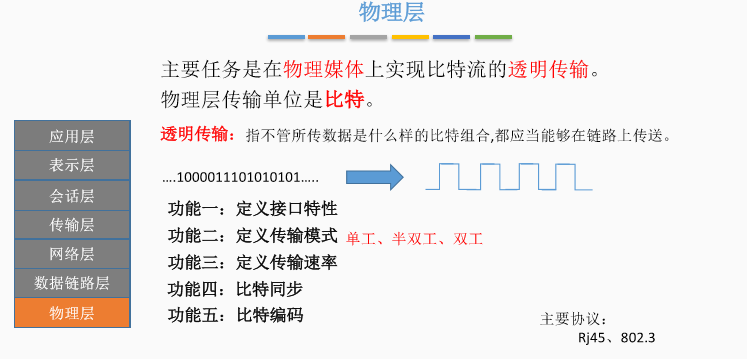
十一、脑图梳理
七、TCP、IP参考模型和五层参考模型
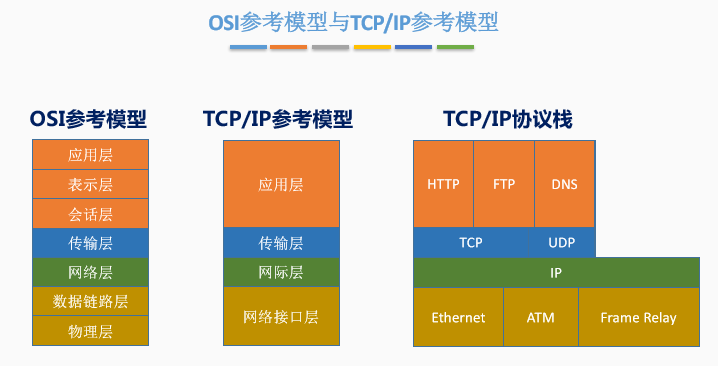
一、OSI参考模型与TCP、IP参考模型相同点

二、OSI参考模型与TCP、IP参考模型不同点

三、五层参考模型

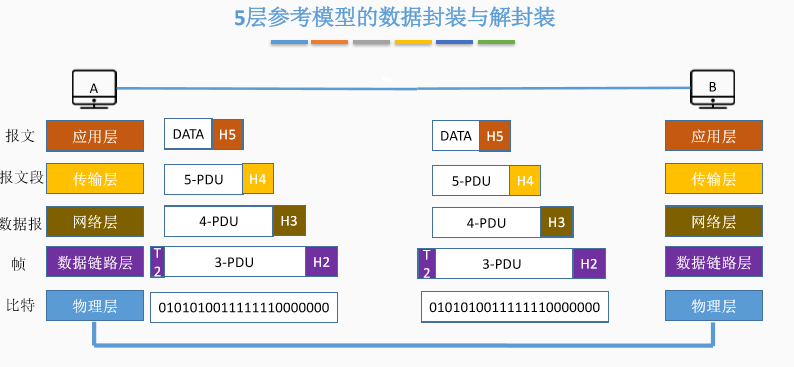
四、五层参考模型的数据封装与解封装
五、第一章知识总结
参考链接
https://www.bilibili.com/video/av70228743
关于Java 基础系列:计算机网络基础概念和计算机网络技术java是什么的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于9.1 计算机网络基础知识、LINUX教学:计算机基础系列教程三:网络基础之网络协议、LINUX教程:计算机基础系列教程一:计算机硬件、程序员内功修炼(一)计算机网络之基础概念等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

