对于想了解Elasticsearch:路径下的嵌套对象不是嵌套类型的读者,本文将是一篇不可错过的文章,我们将详细介绍elasticsearch嵌套对象,并且为您提供关于&Elasticsearch探索
对于想了解Elasticsearch:路径下的嵌套对象不是嵌套类型的读者,本文将是一篇不可错过的文章,我们将详细介绍elasticsearch 嵌套对象,并且为您提供关于&Elasticsearch探索:嵌套对象、Elastic Search嵌套对象查询、Elasticsearch 2.4,对嵌套对象不起作用存在过滤器、Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货的有价值信息。
本文目录一览:- Elasticsearch:路径下的嵌套对象不是嵌套类型(elasticsearch 嵌套对象)
- &Elasticsearch探索:嵌套对象
- Elastic Search嵌套对象查询
- Elasticsearch 2.4,对嵌套对象不起作用存在过滤器
- Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货
")
Elasticsearch:路径下的嵌套对象不是嵌套类型(elasticsearch 嵌套对象)
我一直在尝试搜索包含嵌套字段的文档。我创建了这样的嵌套映射:
{ "message": { "properties": { "messages": { "type": "nested", "properties": { "message_id": { "type": "string" }, "message_text": { "type": "string" }, "message_nick": { "type": "string" } } } } }}我的搜索如下所示:
curl -XGET ''localhost:9200/thread_and_messages/thread/_search'' \ -d ''{"query": {"bool": {"must": [{"match": {"thread_name": "Banana"}}, {"nested": {"path": "messages", "query": {"bool": {"must": [{"match": {"messages.message_text": "Banana"}}]}}}]}}}}''但是我收到此错误消息:
QueryParsingException[[thread_and_messages] [nested] nested object under path [messages] is not of nested type]编辑
我仍然收到此错误。我正在通过Java执行此操作,因此这是我要创建的文档:
{ "_id": { "path": "3", "thread_id": "3", "thread_name": "Banana", "created": "Wed Mar 25 2015", "first_nick": "AdminTech", "messages": [ { "message_id": "9", "message_text": "Banana", "message_nick": "AdminTech" } ] }}像这样创建索引:
CreateIndexRequestBuilder indexRequest = client.admin().indices().prepareCreate(INDEX).addMapping("message", mapping);我认为我可能对文档编制了错误的索引。
答案1
小编典典TLDR:"type": "nested",输入您的嵌套类型。
假设我们有一个普通类型,并且嵌套了另一个类型:
{ "some_index": { "mappings": { "normal_type": { "properties": { "nested_type": { "type": "nested", "properties": { "address": { "type": "string" }, "country": { "type": "string" } } }, "first_name": { "type": "string" }, "last_name": { "type": "string" } } } } }}该"type": "nested",行是"path":分配给的嵌套查询所必需的nested_type,如下所示:
GET /some_index/normal_type/_search{ "query": { "nested": { "query": { "bool": {} }, "path": "nested_type" } }}该"type": "nested",行似乎仅在较新的Elasticsearch版本中需要(自1.1.1开始)。

&Elasticsearch探索:嵌套对象

官网地址:https://www.elastic.co/guide/cn/elasticsearch/guide/current/nested-objects.html
简介
由于在 Elasticsearch 中单个文档的增删改都是原子性操作,那么将相关实体数据都存储在同一文档中也就理所当然。 比如说,我们可以将订单及其明细数据存储在一个文档中。又比如,我们可以将一篇博客文章的评论以一个 comments 数组的形式和博客文章放在一起:
PUT /my_index/blogpost/1
{
"title": "Nest eggs",
"body": "Making your money work...",
"tags": [ "cash", "shares" ],
"comments": [ # 如果我们依赖字段自动映射,那么 comments 字段会自动映射为 object 类型。
{
"name": "John Smith",
"comment": "Great article",
"age": 28,
"stars": 4,
"date": "2014-09-01"
},
{
"name": "Alice White",
"comment": "More like this please",
"age": 31,
"stars": 5,
"date": "2014-10-22"
}
]
}由于所有的信息都在一个文档中,当我们查询时就没有必要去联合文章和评论文档,查询效率就很高。
但是当我们使用如下查询时,上面的文档也会被当做是符合条件的结果:
GET /_search
{
"query": {
"bool": {
"must": [
{ "match": { "name": "Alice" }},
{ "match": { "age": 28 }} # Alice实际是31岁,不是28!
]
}
}
}正如我们在 对象数组 中讨论的一样,出现上面这种问题的原因是 JSON 格式的文档被处理成如下的扁平式键值对的结构。
{
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ],
"comments.name": [ alice, john, smith, white ],
"comments.comment": [ article, great, like, more, please, this ],
"comments.age": [ 28, 31 ],
"comments.stars": [ 4, 5 ],
"comments.date": [ 2014-09-01, 2014-10-22 ]
}Alice 和 31 、 John 和 2014-09-01 之间的相关性信息不再存在。虽然 object 类型 (参见 内部对象) 在存储 单一对象 时非常有用,但对于对象数组的搜索而言,毫无用处。
嵌套对象 就是来解决这个问题的。将 comments 字段类型设置为 nested 而不是 object 后,每一个嵌套对象都会被索引为一个 隐藏的独立文档 ,举例如下:
{ # 第一个 嵌套文档
"comments.name": [ john, smith ],
"comments.comment": [ article, great ],
"comments.age": [ 28 ],
"comments.stars": [ 4 ],
"comments.date": [ 2014-09-01 ]
}
{ # 第二个 嵌套文档
"comments.name": [ alice, white ],
"comments.comment": [ like, more, please, this ],
"comments.age": [ 31 ],
"comments.stars": [ 5 ],
"comments.date": [ 2014-10-22 ]
}
{ # 根文档 或者也可称为父文档
"title": [ eggs, nest ],
"body": [ making, money, work, your ],
"tags": [ cash, shares ]
}在独立索引每一个嵌套对象后,对象中每个字段的相关性得以保留。我们查询时,也仅仅返回那些真正符合条件的文档。
不仅如此,由于嵌套文档直接存储在文档内部,查询时嵌套文档和根文档联合成本很低,速度和单独存储几乎一样。
嵌套文档是隐藏存储的,我们不能直接获取。如果要增删改一个嵌套对象,我们必须把整个文档重新索引才可以。值得注意的是,查询的时候返回的是整个文档,而不是嵌套文档本身。
嵌套对象映射
设置一个字段为 nested 很简单 — 你只需要将字段类型 object 替换为 nested 即可:
PUT /my_index
{
"mappings": {
"blogpost": {
"properties": {
"comments": {
"type": "nested", # nested 字段类型的设置参数与 object 相同。
"properties": {
"name": { "type": "string" },
"comment": { "type": "string" },
"age": { "type": "short" },
"stars": { "type": "short" },
"date": { "type": "date" }
}
}
}
}
}
}这就是需要设置的一切。至此,所有 comments 对象会被索引在独立的嵌套文档中。可以查看 nested 类型参考文档 获取更多详细信息。
嵌套对象查询
由于嵌套对象 被索引在独立隐藏的文档中,我们无法直接查询它们。 相应地,我们必须使用 nested 查询 去获取它们:
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "eggs" # title 子句是查询根文档的。
}
},
{
"nested": {
"path": "comments", # nested 子句作用于嵌套字段 comments 。在此查询中,既不能查询根文档字段,也不能查询其他嵌套文档。
"query": {
"bool": {
"must": [ # comments.name 和 comments.age 子句操作在同一个嵌套文档中。
{
"match": {
"comments.name": "john"
}
},
{
"match": {
"comments.age": 28
}
}
]
}
}
}
}
]
}}}
nested字段可以包含其他的nested字段。同样地,nested查询也可以包含其他的nested查询。而嵌套的层次会按照你所期待的被应用。
nested 查询肯定可以匹配到多个嵌套的文档。每一个匹配的嵌套文档都有自己的相关度得分,但是这众多的分数最终需要汇聚为可供根文档使用的一个分数。
默认情况下,根文档的分数是这些嵌套文档分数的平均值。可以通过设置 score_mode 参数来控制这个得分策略,相关策略有 avg (平均值), max (最大值), sum (加和) 和 none (直接返回 1.0 常数值分数)。
GET /my_index/blogpost/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "eggs"
}
},
{
"nested": {
"path": "comments",
"score_mode": "max", # 返回最优匹配嵌套文档的 _score 给根文档使用。
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "john"
}
},
{
"match": {
"comments.age": 28
}
}
]
}
}
}
}
]
}
}
}
如果
nested查询放在一个布尔查询的filter子句中,其表现就像一个nested查询,只是score_mode参数不再生效。因为它被用于不打分的查询中 — 只是符合或不符合条件,不必打分 — 那么score_mode就没有任何意义,因为根本就没有要打分的地方。
使用嵌套字段排序
尽管嵌套字段的值存储于独立的嵌套文档中,但依然有方法按照嵌套字段的值排序。 让我们添加另一个记录,以使得结果更有意思:
PUT /my_index/blogpost/2
{
"title": "Investment secrets",
"body": "What they don''t tell you ...",
"tags": [ "shares", "equities" ],
"comments": [
{
"name": "Mary Brown",
"comment": "Lies, lies, lies",
"age": 42,
"stars": 1,
"date": "2014-10-18"
},
{
"name": "John Smith",
"comment": "You''re making it up!",
"age": 28,
"stars": 2,
"date": "2014-10-16"
}
]
}假如我们想要查询在10月份收到评论的博客文章,并且按照 stars 数的最小值来由小到大排序,那么查询语句如下:
GET /_search
{
"query": {
"nested": { # 此处的 nested 查询将结果限定为在10月份收到过评论的博客文章。
"path": "comments",
"filter": {
"range": {
"comments.date": {
"gte": "2014-10-01",
"lt": "2014-11-01"
}
}
}
}
},
"sort": {
"comments.stars": { # 结果按照匹配的评论中 comment.stars 字段的最小值 (min) 来由小到大 (asc) 排序。
"order": "asc", # 结果按照匹配的评论中 comment.stars 字段的最小值 (min) 来由小到大 (asc) 排序。
"mode": "min", # 结果按照匹配的评论中 comment.stars 字段的最小值 (min) 来由小到大 (asc) 排序。
"nested_path": "comments", # 排序子句中的 nested_path 和 nested_filter 和 query 子句中的 nested 查询相同,原因在下面有解释。
"nested_filter": {
"range": {
"comments.date": {
"gte": "2014-10-01",
"lt": "2014-11-01"
}
}
}
}
}
}我们为什么要用 nested_path 和 nested_filter 重复查询条件呢?原因在于,排序发生在查询执行之后。 查询条件限定了在10月份收到评论的博客文档,但返回的是博客文档。如果我们不在排序子句中加入 nested_filter , 那么我们对博客文档的排序将基于博客文档的所有评论,而不是仅仅在10月份接收到的评论。
嵌套聚合
在查询的时候,我们使用 nested 查询 就可以获取嵌套对象的信息。同理, nested 聚合允许我们对嵌套对象里的字段进行聚合操作。
GET /my_index/blogpost/_search
{
"size" : 0,
"aggs": {
"comments": { # nested 聚合 “进入” 嵌套的 comments 对象。
"nested": {
"path": "comments"
},
"aggs": {
"by_month": {
"date_histogram": { # comment对象根据 comments.date 字段的月份值被分到不同的桶。
"field": "comments.date",
"interval": "month",
"format": "yyyy-MM"
},
"aggs": {
"avg_stars": { # 计算每个桶内star的平均数量。
"avg": {
"field": "comments.stars"
}
}
}
}
}
}
}
}从下面的结果可以看出聚合是在嵌套文档层面进行的:
...
"aggregations": {
"comments": {
"doc_count": 4,
"by_month": {
"buckets": [
{
"key_as_string": "2014-09",
"key": 1409529600000,
"doc_count": 1, # 总共有4个 comments 对象 :1个对象在9月的桶里,3个对象在10月的桶里。
"avg_stars": {
"value": 4
}
},
{
"key_as_string": "2014-10",
"key": 1412121600000,
"doc_count": 3, # 总共有4个 comments 对象 :1个对象在9月的桶里,3个对象在10月的桶里。
"avg_stars": {
"value": 2.6666666666666665
}
}
]
}
}
}
...1. 逆向嵌套聚合
nested 聚合 只能对嵌套文档的字段进行操作。 根文档或者其他嵌套文档的字段对它是不可见的。 然而,通过 reverse_nested 聚合,我们可以 走出 嵌套层级,回到父级文档进行操作。
例如,我们要基于评论者的年龄找出评论者感兴趣 tags 的分布。 comment.age 是一个嵌套字段,但 tags 在根文档中:
GET /my_index/blogpost/_search
{
"size" : 0,
"aggs": {
"comments": {
"nested": { # nested 聚合进入 comments 对象。
"path": "comments"
},
"aggs": {
"age_group": {
"histogram": { # histogram 聚合基于 comments.age 做分组,每10年一个分组。
"field": "comments.age",
"interval": 10
},
"aggs": {
"blogposts": {
"reverse_nested": {}, # reverse_nested 聚合退回根文档。
"aggs": {
"tags": {
"terms": { # terms 聚合计算每个分组年龄段的评论者最常用的标签词。
"field": "tags"
}
}
}
}
}
}
}
}
}
}简略结果如下所示:
..
"aggregations": {
"comments": {
"doc_count": 4, # 一共有4条评论。
"age_group": {
"buckets": [
{
"key": 20, # 在20岁到30岁之间总共有两条评论。
"doc_count": 2, # 在20岁到30岁之间总共有两条评论。
"blogposts": {
"doc_count": 2, # 这些评论包含在两篇博客文章中。
"tags": {
"doc_count_error_upper_bound": 0,
"buckets": [ # 在这些博客文章中最热门的标签是 shares、 cash、equities。
{ "key": "shares", "doc_count": 2 },
{ "key": "cash", "doc_count": 1 },
{ "key": "equities", "doc_count": 1 }
]
}
}
},
...2. 嵌套对象的使用时机
嵌套对象 在只有一个主要实体时非常有用,这个主要实体包含有限个紧密关联但又不是很重要的实体,例如我们的 blogpost 对象包含评论对象。 在基于评论的内容查找博客文章时, nested 查询有很大的用处,并且可以提供更快的查询效率。
嵌套模型的缺点如下:
- 当对嵌套文档做增加、修改或者删除时,整个文档都要重新被索引。嵌套文档越多,这带来的成本就越大。
- 查询结果返回的是整个文档,而不仅仅是匹配的嵌套文档。尽管目前有计划支持只返回根文档中最佳匹配的嵌套文档,但目前还不支持。
有时你需要在主文档和其关联实体之间做一个完整的隔离设计。这个隔离是由 父子关联 提供的。
实例分享

嵌套文档看似与文档内有一个集合字段类似,但是实则有很大区别,以上面图中嵌套文档为例,留言1,留言2,留言3虽然都在当前文章所在的文档内,但是在内部其实存储为4个独立文档,如下图所示。

同时,嵌套文档的字段类型需要设置为nested,设置成nested后的不能被直接查询,需要使用nested查询。
1. NEW索引
{
"title": "这是一篇文章",
"body": "这是一篇文章,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-04"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-04"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
创建索引名和type均为blog的索引,其中comments字段为嵌套文档类型,需要将type设置为nested,其余都是一些正常的字段设置Setting:
PUT /test_book
{
"settings": {
"number_of_shards": 1,
"analysis": {
"analyzer": {
"index_ansj_analyzer": {
"type": "custom",
"tokenizer": "index_ansj",
"filter": [
"my_synonym",
"asciifolding"
]
},
"comma": {
"type": "pattern",
"pattern": ","
},
"shingle_analyzer": {
"type": "custom",
"tokenizer": "standard",
"filter": [
"lowercase",
"shingle_filter"
]
}
},
"filter": {
"my_synonym": {
"type": "synonym",
"synonyms_path": "analysis/synonym.txt"
},
"shingle_filter": {
"type": "shingle",
"min_shingle_size": 2,
"max_shingle_size": 2,
"output_unigrams": false
}
}
}
}
}
设置Mapping:
PUT /test_book/_mapping/_doc
{
"_doc": {
"properties": {
"comments": {
"type": "nested",
"properties": {
"date": {
"type": "date"
},
"name": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"comment": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"age": {
"type": "long"
}
}
},
"body": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
},
"title": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword"
}
}
}
}
}
}2. PUT数据
PUT test_book/_doc/1
{
"title":"这是一篇文章",
"body":"这是一篇文章,从哪里说起呢? ... ...",
"comments":[
{
"name":"张三",
"comment":"写的不错",
"age":28,
"date":"2020-05-04"
},
{
"name":"李四",
"comment":"写的很好",
"age":20,
"date":"2020-05-04"
},
{
"name":"王五",
"comment":"这是一篇非常棒的文章",
"age":31,
"date":"2020-05-01"
}
]
}
PUT test_book/_doc/2
{
"title": "这是一篇文章2",
"body": "这是一篇文章2,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-11"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-16"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
PUT test_book/_doc/3
{
"title": "这是一篇文章3",
"body": "这是一篇文章3,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-05-03"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-05-20"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-05-01"
}
]
}
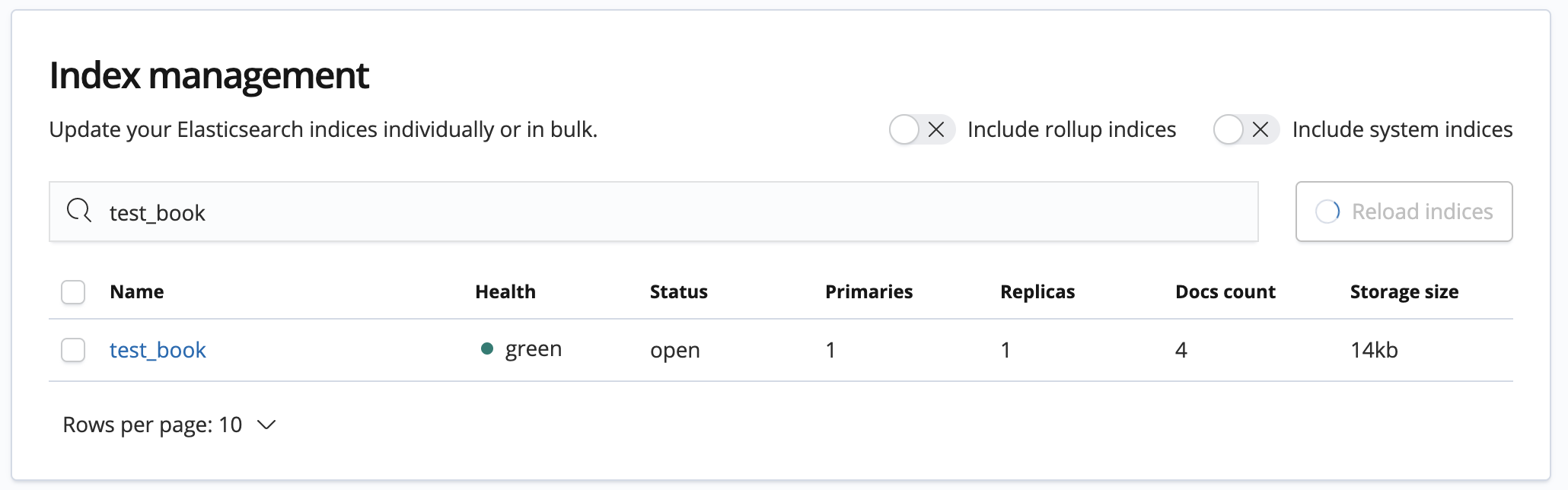
POST test_book/_search
{
"query": {
"match_all": {}
}
}
结果:
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 1.0,
"hits" : [
{
"_index" : "test_book",
"_type" : "_doc",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"title" : "这是一篇文章",
"body" : "这是一篇文章,从哪里说起呢? ... ...",
"comments" : [
{
"name" : "张三",
"comment" : "写的不错",
"age" : 28,
"date" : "2020-05-04"
},
{
"name" : "李四",
"comment" : "写的很好",
"age" : 20,
"date" : "2020-05-04"
},
{
"name" : "王五",
"comment" : "这是一篇非常棒的文章",
"age" : 31,
"date" : "2020-05-01"
}
]
}
}
]
}
}
3. 查询数据
直接查询根文档:
POST test_book/_search
{
"query": {
"match": {
"title.keyword": "这是一篇文章"
}
}
}
查询结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 0.2876821,
"hits" : [
{
"_index" : "test_book",
"_type" : "_doc",
"_id" : "1",
"_score" : 0.2876821,
"_source" : {
"title" : "这是一篇文章",
"body" : "这是一篇文章,从哪里说起呢? ... ...",
"comments" : [
{
"name" : "张三",
"comment" : "写的不错",
"age" : 28,
"date" : "2020-05-04"
},
{
"name" : "李四",
"comment" : "写的很好",
"age" : 20,
"date" : "2020-05-04"
},
{
"name" : "王五",
"comment" : "这是一篇非常棒的文章",
"age" : 31,
"date" : "2020-05-01"
}
]
}
}
]
}
}
备注:要是想直接查询内部文档是查询不到的,需要加上nested即可
POST test_book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "文章"
}
},
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
]
}
}
}
查询结果:
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 1,
"max_score" : 2.5370226,
"hits" : [
{
"_index" : "test_book",
"_type" : "_doc",
"_id" : "1",
"_score" : 2.5370226,
"_source" : {
"title" : "这是一篇文章",
"body" : "这是一篇文章,从哪里说起呢? ... ...",
"comments" : [
{
"name" : "张三",
"comment" : "写的不错",
"age" : 28,
"date" : "2020-05-04"
},
{
"name" : "李四",
"comment" : "写的很好",
"age" : 20,
"date" : "2020-05-04"
},
{
"name" : "王五",
"comment" : "这是一篇非常棒的文章",
"age" : 31,
"date" : "2020-05-01"
}
]
}
}
]
}
}
备注:nested中查询的是嵌套文档的内容,语法与正常查询时一致。
nested 查询肯定可以匹配到多个嵌套的文档。每一个匹配的嵌套文档都有自己的相关度得分,但是这众多的分数最终需要汇聚为可供根文档使用的一个分数。
默认情况下,根文档的分数是这些嵌套文档分数的平均值。可以通过设置 score_mode 参数来控制这个得分策略,相关策略有 avg (平均值), max (最大值), sum (加和) 和 none (直接返回 1.0 常数值分数)。
4. 排序
POST test_book/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"title": "文章"
}
},
{
"nested": {
"path": "comments",
"query": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
]
}
},
"sort": {
"comments.date": {
"order": "desc",
"mode": "max",
"nested_path": "comments",
"nested_filter": {
"bool": {
"must": [
{
"match": {
"comments.name": "张三"
}
}
]
}
}
}
}
}
备注:需要注意的是,在sort内,又添加了nested_filter来过滤一遍上面嵌套文档的查询条件,原因是这样的,在嵌套文档查询排序时是先按照条件进行查询,查询后再进行排序,那么可能由于数据的原因,导致排序的字段不是按照匹配上的数据进行排序5. 聚合
聚合的场景可能也比较常见,其实熟悉上面嵌套文档的使用的话,对聚合文档使用难度应该也不大。
PUT test_book/_doc/4
{
"title": "这是一篇文章4",
"body": "这是一篇文章4,从哪里说起呢? ... ...",
"comments": [
{
"name": "张三",
"comment": "写的不错",
"age": 28,
"date": "2020-03-03"
},
{
"name": "李四",
"comment": "写的很好",
"age": 20,
"date": "2020-04-20"
},
{
"name": "王五",
"comment": "这是一篇非常棒的文章",
"age": 31,
"date": "2020-06-01"
}
]
}举例:需要查询每个月评论人数的平均数,查询语句如下:
POST test_book/_search
{
"size": 0,
"aggs": {
"comments": {
"nested": {
"path": "comments"
},
"aggs": {
"by_month": {
"date_histogram": {
"field": "comments.date",
"interval": "month",
"format": "yyyy-MM"
},
"aggs": {
"avg_stars": {
"avg": {
"field": "comments.age"
}
}
}
}
}
}
}
}
查询结果:
{
"took" : 16,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : 4,
"max_score" : 0.0,
"hits" : [ ]
},
"aggregations" : {
"comments" : {
"doc_count" : 12,
"by_month" : {
"buckets" : [
{
"key_as_string" : "2020-03",
"key" : 1583020800000,
"doc_count" : 1,
"avg_stars" : {
"value" : 28.0
}
},
{
"key_as_string" : "2020-04",
"key" : 1585699200000,
"doc_count" : 1,
"avg_stars" : {
"value" : 20.0
}
},
{
"key_as_string" : "2020-05",
"key" : 1588291200000,
"doc_count" : 9,
"avg_stars" : {
"value" : 26.333333333333332
}
},
{
"key_as_string" : "2020-06",
"key" : 1590969600000,
"doc_count" : 1,
"avg_stars" : {
"value" : 31.0
}
}
]
}
}
}
}
备注:正如本文所说,嵌套文档中,所有内容都在同一个文档内,这就导致嵌套文档进行增加、修改或者删除时,整个文档都要重新被索引。嵌套文档越多,这带来的成本就越大。

Elastic Search嵌套对象查询
我有一个如下所示的elasticsearch索引集合,
"_index":"test","_type":"abc","_source":{ "file_name":"xyz.ex" "metadata":{ "format":".ex" "profile":[ {"date_value" : "2018-05-30T00:00:00", "key_id" : "1", "type" : "date", "value" : [ "30-05-2018" ] }, { "key_id" : "2", "type" : "freetext", "value" : [ "New york" ] }}现在,我需要通过匹配key_id其值来搜索文档。(key_id是一些字段,其值存储在其中"value")对于key_id=''1''字段,如果value= "30-05-2018"与上面的文档匹配。
我尝试将其映射为嵌套对象,但是无法编写查询来搜索2个或更多key_id匹配其各自值的查询。
答案1
小编典典这就是我要做的。您需要通过bool/filter(或bool/must)两个嵌套查询对每个条件对进行AND
运算,因为您要匹配同一父文档中的两个不同的嵌套元素。
{ "query": { "bool": { "filter": [ { "nested": { "path": "metadata.profile", "query": { "bool": { "filter": [ { "term": { "metadata.profile.f1": "a" } }, { "term": { "metadata.profile.f2": true } } ] } } } }, { "nested": { "path": "metadata.profile", "query": { "bool": { "filter": [ { "term": { "metadata.profile.f1": "b" } }, { "term": { "metadata.profile.f2": false } } ] } } } } ] } }}
Elasticsearch 2.4,对嵌套对象不起作用存在过滤器
我的映射是:
"properties": {
"user": {
"type": "nested","properties": {
"id": {
"type": "integer"
},"is_active": {
"type": "boolean","null_value": false
},"username": {
"type": "string"
}
}
},我想获取所有没有user字段的文档。
我试过了:
GET /index/type/_search
{
"query": {
"bool": {
"must_not": [
{
"exists": {
"field": "user"
}
}
]
}
}
}
返回所有文档。基于ElasticSearch2.x,存在用于嵌套字段的过滤器不起作用的问题,我也尝试过:
GET /index/type/_search
{
"query": {
"nested": {
"path": "user","query": {
"bool": {
"must_not": [
{
"exists": {
"field": "user"
}
}
]
}
}
}
}
}
返回0个文档。
使所有缺少该user字段的文档的正确查询是什么?

Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货
一、什么是 ES Nested 嵌套
Elasticsearch 有很多数据类型,大致如下:
- 基本数据类型:
- string 类型。ES 7.x 中,string 类型会升级为:text 和 keyword。keyword 可以排序;text 默认分词,不可以排序。
- 数据类型:integer、long 等
- 时间类型、布尔类型、二进制类型、区间类型等
- 复杂数据类型:
- 数组类型:Array
- 对象类型:Object
- Nested 类型
- 特定数据类型:地理位置、IP 等
注意:tring/nested/array 类型字段不能用作排序字段。因此 string 类型会升级为:text 和 keyword。keyword 可以排序,text 默认分词,不可以排序。
2.1 那什么是 Nested 类型?
Elasticsearch 7.x 文档中,这样写到:
The nested type is a specialised version of the object datatype that allows arrays of objects to be indexed in a way that they can be queried independently of each other.
Nested (嵌套)类型,是特殊的对象类型,特殊的地方是索引对象数组方式不同,允许数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
2.2 如何使用 Nested 类型?
在 ES 的 my_index 索引中存储 users 字段。比如说:
{
"group" : "fans",
"users" : [
{
"name" : "John",
"age" : "23"
},
{
"name" : "Alice",
"age" : "18"
}
]
}
其实存储看上去跟 Object 类型一样,只不过底层原理对数组 users 字段索引方式不同。设置 users 字段的索引方式 Nested 嵌套类型:
curl -X PUT "localhost:9200/my_index" -H ''Content-Type: application/json'' -d''
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
''
二、Nested Query 应用场景或案例
比如小老弟我有一波小粉丝,users 字段类型是 object。存储如下:
{
"group" : "bysocket_fans",
"users" : [
{
"name" : "John",
"age" : "23"
},
{
"name" : "Alice",
"age" : "18"
}
]
}
{
"group" : "路人甲_fans",
"users" : [
{
"name" : "Alice",
"age" : "22"
},
{
"name" : "Jeff",
"age" : "18"
}
]
}
比如 18 岁大姑娘 Alice 是小老弟我的粉丝,她也可能是周杰伦的粉丝。那这边就有一个需求,即应用场景:
如何找到 18 岁大姑娘 Alice {"name" : "Alice","age" : "18"} 关注的所有明星呢?
如果用老的查询语句是这样搜索的:
GET /my_index/_search?pretty
{
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "Alice"
}
},
{
"match": {
"users.age": 18
}
}
]
}
}
}
结果发现结果是不对的,路人甲 这条记录也出现了。 因为匹配到了第一个 Alice + 第二个 Jeff 的 18。所以这种查询不满足这个场景
那么需要使用 Nested 类型并用 Nested 查询,即让数组中的对象各自地进行索引。目的是对象之间彼此独立被查询出来。
三、Nested Query 实战
3.1 设置 Nested 类型
根据 2.2 如何使用 Nested 类型,将 users 字段类型从 object 修改为 nested:
curl -X PUT "localhost:9200/my_index" -H ''Content-Type: application/json'' -d''
{
"mappings": {
"properties": {
"users": {
"type": "nested"
}
}
}
}
''
3.2 Nested Query
修改后,对应的 Nested Query ,如下:
GET /my_index/_search?pretty
{
"query": {
"bool": {
"must": [
{
"nested": {
"path": "users",
"query": {
"bool": {
"must": [
{
"match": {
"users.name": "Alice"
}
},
{
"match": {
"users.age": 18
}
}
]
}
}
}
}
]
}
}
}
语法很简单就是:
- key 以 "nested" 开头
- path 就是嵌套对象数组的字段名
- 其他
- score_mode (可选的)匹配子对象的分数相关性分数。avg (默认,使用所有匹配子对象的平均相关性分数)
- ignore_unmapped (可选的)是否忽略 path 未映射,不返回任何文档而不是错误。默认为 false,如果 path 不对就报错
这样查询得结果就是对的。
四、Nested Query 性能
这边测试过,给大家一个测试报告和建议。
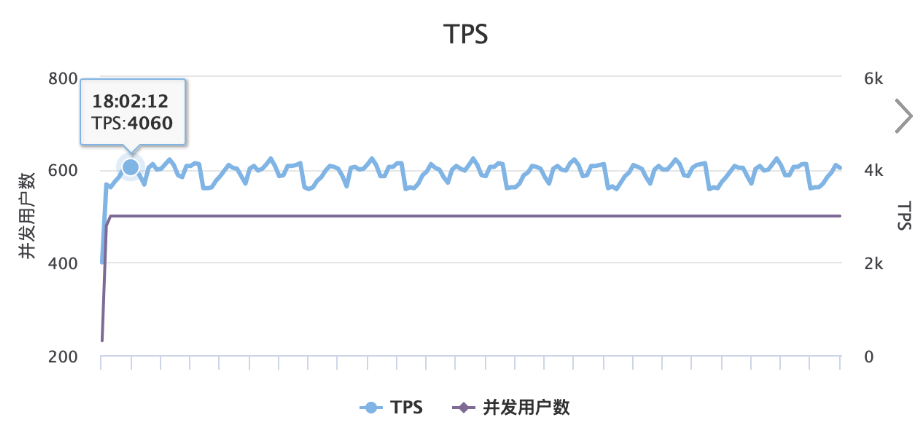
压测环境:3 个 server ,6 个 ES 节点
压测结论: 使用上小节查询语句,50 并发情况下,导致千兆网卡被打满了。TPS 4000 左右,如果提高并发,就会增加 RT。所以如果高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
建议:泥瓦匠建议,你听听看
- 性能:Common Query 远远大于 Nested Query 远远大于 Parent/Child Query
- 性能优化:首先考虑减少后面两种 Query
- 性能优化:Nested Query 业务可以优化下。比如上一小节完全可以多存一个 fanIds 数组。搜索两次,第一次查确定 18 岁大姑娘 Alice 的 fanId,第二次根据 fanId 搜索即可
- 性能优化:实在没办法,高性能大流量情况下,必须用 Nested 应该从网络流量方向进行优化。二者,尽量减少大数据对象的返回
(完)
参考资料:
- https://blog.csdn.net/laoyang360/article/details/82950393
- https://www.elastic.co/guide/en/elasticsearch/reference/7.2/search-aggregations-bucket-reverse-nested-aggregation.html
我们今天的关于Elasticsearch:路径下的嵌套对象不是嵌套类型和elasticsearch 嵌套对象的分享就到这里,谢谢您的阅读,如果想了解更多关于&Elasticsearch探索:嵌套对象、Elastic Search嵌套对象查询、Elasticsearch 2.4,对嵌套对象不起作用存在过滤器、Elasticsearch 7.x Nested 嵌套类型查询 | ES 干货的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

