在这里,我们将给大家分享关于SpringBoot2.3.x整合ElasticSearch7.6.2实现PDF,WORD全文检索的知识,让您更了解springbootes全文检索的本质,同时也会涉及到如
在这里,我们将给大家分享关于SpringBoot2.3.x整合ElasticSearch7.6.2 实现PDF,WORD全文检索的知识,让您更了解springboot es 全文检索的本质,同时也会涉及到如何更有效地elasticsearch7.x整合springBoot、elasticsearch入门 springboot2集成elasticsearch 实现全文搜索、elasticsearch安装及与springboot2.x整合、pringboot2.x整合ElasticSearch7.x实战(三)的内容。
本文目录一览:- SpringBoot2.3.x整合ElasticSearch7.6.2 实现PDF,WORD全文检索(springboot es 全文检索)
- elasticsearch7.x整合springBoot
- elasticsearch入门 springboot2集成elasticsearch 实现全文搜索
- elasticsearch安装及与springboot2.x整合
- pringboot2.x整合ElasticSearch7.x实战(三)
")
SpringBoot2.3.x整合ElasticSearch7.6.2 实现PDF,WORD全文检索(springboot es 全文检索)
文章目录
- 1、下载安装,只下载elasticSearch、Kibana即可
- 插件安装
- 定义文本抽取管道
- 2、SpringBoot整合ElasticSearch
- application.yml
- 实体类
- 接口类
- 测试
- 创建索引
- 上传文档
- 搜索
1、下载安装,只下载elasticSearch、Kibana即可
- 下载安装参考Springboot/Springcloud整合ELK平台,(Filebeat方式)日志采集及管理(Elasticsearch+Logstash+Filebeat+Kibana)
- elastic中文社区 下载地址
这里我使用7.6.2的elasticsearch版本, 因为项目使用的springboot2.3.x,避免低版本客户端,高版本索引库·,这里我先退回使用低版本索引库


插件安装
- ik 分词器

- ingest-attachment 这里将链接修改为自己的版本即可
插件下载完成之后,将压缩包解压到 elasticsearch的plugins目录, 之后重启elasticsearch


定义文本抽取管道
PUT /_ingest/pipeline/attachment
{
"description" : "Extract attachment information",
"processors":[
{
"attachment":{
"field":"data",
"indexed_chars" : -1,
"ignore_missing":true
}
},
{
"remove":{"field":"data"}
}]}
2、SpringBoot整合ElasticSearch
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.58</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.20</version>
</dependency>
</dependencies>
application.yml
server:
port: 9090
spring:
application:
name: elasticsearch-service
elasticsearch:
rest:
uris: http://127.0.0.1:9200
实体类
package top.fate.entity;
import lombok.Data;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
/**
* @auther:Wangxl
* @Emile:18335844494@163.com
* @Time:2020/11/2 14:15
*/
@Data
@Document(indexName = "filedata")
public class FileData {
@Field(type = FieldType.Keyword)
private String filePk;
@Field(type = FieldType.Keyword)
private String fileName;
@Field(type = FieldType.Keyword)
private Integer page;
@Field(type = FieldType.Keyword)
private String departmentId;
@Field(type = FieldType.Keyword)
private String ljdm;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String data;
@Field(type = FieldType.Keyword)
private String realName;
@Field(type = FieldType.Keyword)
private String url;
@Field(type = FieldType.Keyword)
private String type;
}
接口类
package top.fate.controller;
import com.alibaba.fastjson.JSON;
import org.elasticsearch.action.index.IndexRequest;
import org.elasticsearch.action.index.IndexResponse;
import org.elasticsearch.action.search.SearchRequest;
import org.elasticsearch.action.search.SearchResponse;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.common.text.Text;
import org.elasticsearch.common.xcontent.XContentType;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.SearchHit;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightBuilder;
import org.elasticsearch.search.fetch.subphase.highlight.HighlightField;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.elasticsearch.core.ElasticsearchRestTemplate;
import org.springframework.data.elasticsearch.core.IndexOperations;
import org.springframework.data.elasticsearch.core.document.Document;
import org.springframework.data.elasticsearch.core.mapping.IndexCoordinates;
import org.springframework.util.Base64Utils;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.RestController;
import top.fate.entity.FileData;
import java.io.File;
import java.io.FileInputStream;
import java.lang.reflect.Method;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.Map;
/**
* @auther:Wangxl
* @Emile:18335844494@163.com
* @Time:2022/6/1 16:33
*/
@RestController
@RequestMapping(value = "fullTextSearch")
public class FullTextSearchController {
@Autowired
private ElasticsearchRestTemplate elasticsearchRestTemplate;
@Autowired
private RestHighLevelClient restHighLevelClient;
@GetMapping("createIndex")
public void add() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(IndexCoordinates.of("testindex"));
indexOperations.create();
Document mapping = indexOperations.createMapping(FileData.class);
indexOperations.putMapping(mapping);
}
@GetMapping("deleteIndex")
public void deleteIndex() {
IndexOperations indexOperations = elasticsearchRestTemplate.indexOps(FileData.class);
indexOperations.delete();
}
@GetMapping("uploadFiletoEs")
public void uploadFiletoEs() {
try {
// File file = new File("D:\\desktop\\Java开发工程师-4年-王晓龙-2022-05.pdf");
File file = new File("D:\\desktop\\Java开发工程师-4年-王晓龙-2022-05.docx");
FileInputStream inputFile = new FileInputStream(file);
byte[] buffer = new byte[(int)file.length()];
inputFile.read(buffer);
inputFile.close();
//将文件转成base64编码
String fileString = Base64Utils.encodetoString(buffer);
FileData fileData = new FileData();
fileData.setFileName(file.getName());
fileData.setFilePk(file.getName());
fileData.setData(fileString);
IndexRequest indexRequest = new IndexRequest("testindex").id(fileData.getFilePk());
indexRequest.source(JSON.toJSONString(fileData),XContentType.JSON);
indexRequest.setPipeline("attachment");
IndexResponse index = restHighLevelClient.index(indexRequest, RequestOptions.DEFAULT);
return;
} catch (Exception e) {
e.printstacktrace();
}
}
@GetMapping("search")
public Object search(@RequestParam("txt") String txt) {
List list = new ArrayList();
try {
SearchRequest searchRequest = new SearchRequest("testindex");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.matchQuery("attachment.content",txt).analyzer("ik_max_word"));
searchRequest.source(builder);
// 返回实际命中数
builder.trackTotalHits(true);
//高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("attachment.content");
highlightBuilder.requireFieldMatch(false);//多个高亮关闭
highlightBuilder.preTags("<span>");
highlightBuilder.postTags("</span>");
builder.Highlighter(highlightBuilder);
SearchResponse search = restHighLevelClient.search(searchRequest, RequestOptions.DEFAULT);
if (search.getHits() != null) {
for (SearchHit documentFields : search.getHits().getHits()) {
Map<String, HighlightField> highlightFields = documentFields.getHighlightFields();
HighlightField title = highlightFields.get("attachment.content");
Map<String, Object> sourceAsMap = documentFields.getSourceAsMap();
if (title != null) {
Text[] fragments = title.fragments();
String n_title = "";
for (Text fragment : fragments) {
n_title += fragment;
}
sourceAsMap.put("data", n_title);
}
list.add(dealObject(sourceAsMap, FileData.class));
}
}
} catch (Exception e) {
e.printstacktrace();
}
return list;
}
/*public static void ignoreSource(Map<String,Object> map) {
for (String key : IGnorE_KEY) {
map.remove(key);
}
}*/
public static <T> T dealObject(Map<String, Object> sourceAsMap, Class<T> clazz) {
try {
// ignoreSource(sourceAsMap);
Iterator<String> keyIterator = sourceAsMap.keySet().iterator();
T t = clazz.newInstance();
while (keyIterator.hasNext()) {
String key = keyIterator.next();
String replaceKey = key.replaceFirst(key.substring(0, 1), key.substring(0, 1).toupperCase());
Method method = null;
try {
method = clazz.getmethod("set" + replaceKey, sourceAsMap.get(key).getClass());
} catch (NoSuchMethodException e) {
continue;
}
method.invoke(t, sourceAsMap.get(key));
}
return t;
} catch (Exception e) {
e.printstacktrace();
}
return null;
}
}
测试
创建索引
localhost:9090/fullTextSearch/createIndex

上传文档
localhost:9090/fullTextSearch/uploadFiletoEs

搜索
localhost:9090/fullTextSearch/search?txt=索引库


elasticsearch7.x整合springBoot
1、导入依赖
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>7.6.2</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
<version>7.6.2</version>
</dependency>2、配置application.xml
elasticsearch:
ip: 你的ip:92003、创建配置类
/**
* 描述: 连接客户端
*
* @author wenye
* @create 2021-03-25 13:22
*/
@Configuration
public class ElasticSearchClientConfig
{
/**
* 超时时间设为5分钟
*/
private static final int TIME_OUT = 5 * 60 * 1000;
private static final int ADDRESS_LENGTH = 2;
private static final String HTTP_SCHEME = "http";
@Value("${elasticsearch.ip}")
String[] ipAddress;
@Bean
public RestClientBuilder restClientBuilder() {
HttpHost[] hosts = Arrays.stream(ipAddress)
.map(this::makeHttpHost)
.filter(Objects::nonNull)
.toArray(HttpHost[]::new);
return RestClient.builder(hosts);
}
@Bean(name = "highLevelClient")
public RestHighLevelClient highLevelClient(@Autowired RestClientBuilder restClientBuilder) {
restClientBuilder.setRequestConfigCallback(
new RestClientBuilder.RequestConfigCallback() {
@Override
public RequestConfig.Builder customizeRequestConfig(
RequestConfig.Builder requestConfigBuilder) {
return requestConfigBuilder.setSocketTimeout(TIME_OUT);
}
});
//TODO 此处可以进行其它操作
return new RestHighLevelClient(restClientBuilder);
}
private HttpHost makeHttpHost(String s) {
assert StringUtils.isNotEmpty(s);
String[] address = s.split(":");
if (address.length == ADDRESS_LENGTH) {
String ip = address[0];
int port = Integer.parseInt(address[1]);
System.err.println(ip+"+"+port);
return new HttpHost(ip, port, HTTP_SCHEME);
} else {
return null;
}
}
}4、实现es中的一些操作、如索引的创建、文档的crud、批量操作、各种查询
/**
* @author : wenye
* @describe 1、jest 以及elasticSearchTemplate(这个不清楚)都被不能调用7.0的版本了年轻人耗子尾汁 7.X使用的是rest来进行通信
* @date : 2021-02-26 19:16
**/
@RestController
@RequestMapping("/elasticsearch")
@Api(tags = "es文档")
public class ElasticSearch {
@Autowired
RestHighLevelClient restHighLevelClient;
/**
* 创建索引
* @throws IOException
*/
@RequestMapping(value = "createindex",method = RequestMethod.POST)
@ApiOperation(value = "创建索引")
public void createIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("test2021030411");
restHighLevelClient.indices().create(request, RequestOptions.DEFAULT);
}
/**
* 测试索引是否存在
*/
@RequestMapping(value = "hashindex",method = RequestMethod.POST)
@ApiOperation(value = "测试索引")
public void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("test2021030411"); //测试test_index1索引是否存在
boolean exists = restHighLevelClient.indices().exists(request, RequestOptions.DEFAULT);
System.out.println("索引是否存在:"+exists);
}
/**
* 删除索引
*/
@RequestMapping(value = "deleteindex",method = RequestMethod.POST)
@ApiOperation(value = "删除索引")
public void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("test2021030411");
AcknowledgedResponse delete = restHighLevelClient.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
/**
* 添加文档
*/
@RequestMapping(value = "adddoc",method = RequestMethod.POST)
@ApiOperation(value = "添加文档")
public void testAddDocument() throws IOException {
//创建对象
ElasticsearchDto elasticSearch = new ElasticsearchDto();
elasticSearch.setAge(11);
elasticSearch.setName("wenye");
//json数据
String value = JSONUtils.toJsonString(elasticSearch);
//创建请求
IndexRequest request = new IndexRequest("test2021030411");
// put /test2021030411/_doc/1
request.id("1");
//设置超时时间 等待主片的响应时间
request.timeout(TimeValue.timeValueSeconds(5));
//刷新策略
request.setRefreshPolicy(WriteRequest.RefreshPolicy.WAIT_UNTIL);
request.setRefreshPolicy("wait_for");
//将数据放入请求
request.source(value, XContentType.JSON);
//执行请求
IndexResponse response = restHighLevelClient.index(request, RequestOptions.DEFAULT);
System.out.println(response.toString());
}
/**
*
* 判断文档是否存在
*/
@RequestMapping(value = "testexistDoc",method = RequestMethod.POST)
@ApiOperation(value = "判断文档")
public void testExistDoc() throws IOException {
GetRequest request = new GetRequest("test2021030411", "1");
//不获取返回的_source的上下文了
//request.fetchSourceContext(new FetchSourceContext(false));
//request.storedFields("_none_");
boolean exists = restHighLevelClient.exists(request, RequestOptions.DEFAULT);
System.out.println("文档是否存在:"+exists);
}
/**
* 获取文档
* @throws IOException
*/
@RequestMapping(value = "getdoc",method = RequestMethod.POST)
@ApiOperation(value = "获取文档")
public RespMessage getDoc() throws IOException {
GetRequest request = new GetRequest("test2021030411", "1");
GetResponse response = restHighLevelClient.get(request, RequestOptions.DEFAULT);
System.out.println(response.getSourceAsString());
System.out.println(response);
return RespHandler.success(response.getSourceAsString());
}
/**
* 更新文档
*/
@RequestMapping(value = "updatedoc",method = RequestMethod.POST)
@ApiOperation(value = "更新文档")
void testUpdateDoc() throws IOException {
ElasticsearchDto elasticSearch = new ElasticsearchDto();
elasticSearch.setAge(11);
elasticSearch.setName("wenye");
UpdateRequest request = new UpdateRequest("test2021030411", "1");
//超时时间
//request.timeout("5s");
String value = JSONUtils.toJsonString(elasticSearch);
request.doc(value,XContentType.JSON);
UpdateResponse response = restHighLevelClient.update(request, RequestOptions.DEFAULT);
}
/**
* 删除文档
*/
@RequestMapping(value = "deletedoc",method = RequestMethod.POST)
@ApiOperation(value = "删除文档")
void deleteDoc() throws IOException {
DeleteRequest request = new DeleteRequest("test2021030411","1");
restHighLevelClient.delete(request,RequestOptions.DEFAULT);
}
/**
* 批量操作
* @return
*/
@RequestMapping(value = "bullkdoc",method = RequestMethod.POST)
@ApiOperation(value = "文档批量操作")
public RespMessage bullkdoc() {
BulkRequest request = new BulkRequest();
request.add(new DeleteRequest("test2021030411", "3"));
request.add(new UpdateRequest("test2021030411", "2")
.doc(XContentType.JSON,"other", "test"));
request.add(new IndexRequest("test2021030411").id("4")
.source(XContentType.JSON,"field", "baz"));
try {
restHighLevelClient.bulk(request,RequestOptions.DEFAULT);
} catch (IOException e) {
e.printStackTrace();
}
return RespHandler.success();
}
void simpleSearch() throws IOException {
}
/**
* matchAll搜索
*/
@RequestMapping(value = "matchallquery",method = RequestMethod.POST)
@ApiOperation(value = "匹配所有")
public RespMessage matchAllquery() throws IOException {
SearchRequest request = new SearchRequest("test2021030411");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件 可以使用QueryBuilders工具来实现
//QueryBuilders.termQuery精确匹配
MatchAllQueryBuilder matchAllQueryBuilder = QueryBuilders.matchAllQuery();
sourceBuilder.query(matchAllQueryBuilder);
sourceBuilder.timeout(new TimeValue(20, TimeUnit.SECONDS));
sourceBuilder.from(0); //查询结果从第几条数据开始返回
sourceBuilder.size(5);//一次返回几条数据
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//遍历输出
for (SearchHit fields : response.getHits().getHits()) {
System.out.println(fields.getSourceAsString());
}
return RespHandler.success(response.getHits());
}
/**
* match搜索
*/
@RequestMapping(value = "scrollquery",method = RequestMethod.POST)
@ApiOperation(value = "匹配搜索")
public RespMessage scrollquery() throws IOException {
SearchRequest request = new SearchRequest("test2021030411");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件 可以使用QueryBuilders工具来实现
//QueryBuilders.termQuery精确匹配
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "文烨");
sourceBuilder.query(matchQueryBuilder);
sourceBuilder.timeout(new TimeValue(20, TimeUnit.SECONDS));
sourceBuilder.from(0); //查询结果从第几条数据开始返回
sourceBuilder.size(5);//一次返回几条数据
//高亮搜索
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title");
highlightBuilder.requireFieldMatch(false);
highlightBuilder.preTags("<spancolor:red''");
highlightBuilder.postTags("</span>");
sourceBuilder.highlighter(highlightBuilder);
//执行查询
request.source(sourceBuilder);
//滚动设置
request.scroll(TimeValue.timeValueMinutes(1L));
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
String scrollId = response.getScrollId();
SearchHits hits = response.getHits();
//解析结果
for (SearchHit hit : response.getHits().getHits()) {
//执行搜索后,取出高亮字段
Map<String, HighlightField> highlightFieldMap = hit.getHighlightFields();
HighlightField title = highlightFieldMap.get("title");
Map<String, Object> stringObjectMap = hit.getSourceAsMap();//原来的结果
//解析高亮字段
if (title != null) {
//取出高亮查询中具体的高亮字段
Text[] fra = title.fragments();
String new_title = "";
for (Text text:fra) {
new_title += text;
}
stringObjectMap.put("title",new_title);
}
}
return RespHandler.success(hits);
// return RespHandler.success(scrollId);
}
/**
* match搜索, scroll配置
*/
@RequestMapping(value = "msearch",method = RequestMethod.POST)
@ApiOperation(value = "滚动搜索")
public RespMessage msearch() throws IOException {
MultiSearchRequest multiSearchRequest = new MultiSearchRequest();
SearchRequest request = new SearchRequest("test2021030411");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//QueryBuilders.termQuery精确匹配
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("name", "文烨");
///设置高亮
sourceBuilder.highlighter();
sourceBuilder.query(matchQueryBuilder);
sourceBuilder.timeout(new TimeValue(20, TimeUnit.SECONDS));
request.source(sourceBuilder);
multiSearchRequest.add(request);
SearchRequest request2 = new SearchRequest("test2021030411");
//构建搜索条件
SearchSourceBuilder sourceBuilder2 = new SearchSourceBuilder();
//QueryBuilders.termQuery精确匹配
MatchQueryBuilder matchQueryBuilder2 = QueryBuilders.matchQuery("name", "文烨");
sourceBuilder.query(matchQueryBuilder);
sourceBuilder.timeout(new TimeValue(20, TimeUnit.SECONDS));
request2.source(sourceBuilder2);
multiSearchRequest.add(request2);
//滚动设置
MultiSearchResponse msearch = restHighLevelClient.msearch(multiSearchRequest, RequestOptions.DEFAULT);
MultiSearchResponse.Item[] responses = msearch.getResponses();
return RespHandler.success(responses);
// return RespHandler.success(scrollId);
}
/**
* term搜索
*/
@RequestMapping(value = "termquery",method = RequestMethod.POST)
@ApiOperation(value = "精准查询")
void termSearch() throws IOException {
SearchRequest request = new SearchRequest("test2021030411");
//构建搜索条件
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
//查询条件 可以使用QueryBuilders工具来实现
//QueryBuilders.termQuery精确匹配
TermQueryBuilder queryBuilder = QueryBuilders.termQuery("name", "user1");
sourceBuilder.query(queryBuilder);
sourceBuilder.timeout(new TimeValue(20, TimeUnit.SECONDS));
sourceBuilder.from(0); //查询结果从第几条数据开始返回
sourceBuilder.size(5);//一次返回几条数据
request.source(sourceBuilder);
SearchResponse response = restHighLevelClient.search(request, RequestOptions.DEFAULT);
//遍历输出
for (SearchHit fields : response.getHits().getHits()) {
System.out.println(fields.getSourceAsString());
}
}
}

elasticsearch入门 springboot2集成elasticsearch 实现全文搜索
springboot整合elasticsearch常用的方式有以下三种
1,Java API@H_301_7@这种方式基于TCP和ES通信,官方已经明确表示在ES 7.0版本中将弃用TransportClient客户端,且在8.0版本中完全移除它,所以不提倡。2,REST Client@H_301_7@
上面的方式1是基于TCP和ES通信的(而且TransPort将来会被抛弃……),官方也给出了基于HTTP的客户端REST Client(推荐使用),官方给出来的REST Client有Java Low Level REST Client和Java Hight Level REST Client两个,前者兼容所有版本的ES,后者是基于前者开发出来的,只暴露了部分API,待完善3,spring-data-elasticsearch@H_301_7@
除了上述方式,Spring也提供了本身基于SpringData实现的一套方案spring-data-elasticsearch我们今天就来为大家讲解spring-data-elasticsearch这种方式来集成es。为什们推荐这种呢,因为这种方式spring为我们封装了常见的es操作。和使用jpa操作数据库一样方便。用过jpa的同学一定知道。@H_301_7@
jpa只需要简单继承JpaRepository就可以实现对数据库表的crud操作@H_301_7@
public interface UserRepository extends JpaRepository<UserBean, Long> {}@H_301_7@
spring-data-elasticsearch同样,只要继承ElasticsearchRepository就可以实现常见的es操作了。@H_301_7@
public interface UserESRepository extends ElasticsearchRepository<UserBean, Long> {}@H_301_7@
下面我们就来讲解下springboot2继承 spring-data-elasticsearch的具体步骤。@H_301_7@
springboot版本Elasticsearch版本2.1.3.RELEASE6.4.3@H_301_7@
一,首先是创建springboot项目
@H_301_7@ @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
如上图箭头所指,springboot版本选2.1.3,然后添加web和elasticsearch仓库@H_301_7@
创建项目完成后,我们完整的pom.xml文件如下<?xml version="1.0" encoding="UTF-8"?>@H_301_7@
<project xmlns="http://maven.apache.org/POM/4.0.0"@H_301_7@
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"@H_301_7@
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">@H_301_7@
<modelVersion>4.0.0</modelVersion>@H_301_7@
<parent>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-starter-parent</artifactId>@H_301_7@
<version>2.1.3.RELEASE</version>@H_301_7@
<relativePath/> <!-- lookup parent from repository -->@H_301_7@
</parent>@H_301_7@
<groupId>com.qcl</groupId>@H_301_7@
<artifactId>es</artifactId>@H_301_7@
<version>0.0.1</version>@H_301_7@
<name>es</name>@H_301_7@
<description>Demo project for Spring Boot</description>@H_301_7@
<properties>@H_301_7@
<java.version>1.8</java.version>@H_301_7@
</properties>@H_301_7@
<dependencies>@H_301_7@
<dependency>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>@H_301_7@
</dependency>@H_301_7@
<dependency>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-starter-web</artifactId>@H_301_7@
</dependency>@H_301_7@
<dependency>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-starter-test</artifactId>@H_301_7@
<scope>test</scope>@H_301_7@
</dependency>@H_301_7@
</dependencies>@H_301_7@
<build>@H_301_7@
<plugins>@H_301_7@
<plugin>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-maven-plugin</artifactId>@H_301_7@
</plugin>@H_301_7@
</plugins>@H_301_7@
</build>@H_301_7@
</project>@H_301_7@
spring-boot-starter-data-elasticsearch:就是我们所需要集成的es。@H_301_7@
<dependency>@H_301_7@
<groupId>org.springframework.boot</groupId>@H_301_7@
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>@H_301_7@
</dependency>@H_301_7@
二,下载elasticsearch本地版本
这里下载本地elasticsearch,其实和我们下载本地MysqL是一样的,你要用elasticsearch肯定要下载一个本地版本用来存储查询数据啊。@H_301_7@下面来简单的讲解下elasticsearch版本的下载步骤@H_301_7@
1,到官网@H_301_7@
https://www.elastic.co/downloads/@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
选择箭头所指,点击download@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
选择你所对应的系统,这里要注意,虽然官方最新版本是6.6.2,我们springboot项目里使用的是6.4.3版本。这个没有关系的,官方版本是向下兼容的。2,下载成功后解压,并进入到config文件夹下@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
进入config文件夹后,找到elasticsearch.yml@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
然后用下面这个文件替换elasticsearch.yml里面的内容@H_301_7@
# ======================== Elasticsearch Configuration =========================@H_301_7@
#@H_301_7@
# NOTE: Elasticsearch comes with reasonable defaults for most settings.@H_301_7@
# Before you set out to tweak and tune the configuration, make sure you@H_301_7@
# understand what are you trying to accomplish and the consequences.@H_301_7@
#@H_301_7@
# The primary way of configuring a node is via this file. This template lists@H_301_7@
# the most important settings you may want to configure for a production cluster.@H_301_7@
#@H_301_7@
# Please consult the documentation for further information on configuration options:@H_301_7@
# https://www.elastic.co/guide/en/elasticsearch/reference/index.html@H_301_7@
#@H_301_7@
# ---------------------------------- Cluster -----------------------------------@H_301_7@
#@H_301_7@
# Use a descriptive name for your cluster:@H_301_7@
#@H_301_7@
cluster.name: my-application@H_301_7@
#@H_301_7@
# ------------------------------------ Node ------------------------------------@H_301_7@
#@H_301_7@
# Use a descriptive name for the node:@H_301_7@
#@H_301_7@
node.name: node-1@H_301_7@
#@H_301_7@
# Add custom attributes to the node:@H_301_7@
#@H_301_7@
#node.attr.rack: r1@H_301_7@
#@H_301_7@
# ----------------------------------- Paths ------------------------------------@H_301_7@
#@H_301_7@
# Path to directory where to store the data (separate multiple locations by comma):@H_301_7@
#@H_301_7@
#path.data: /path/to/data@H_301_7@
#@H_301_7@
# Path to log files:@H_301_7@
#@H_301_7@
#path.logs: /path/to/logs@H_301_7@
#@H_301_7@
# ----------------------------------- Memory -----------------------------------@H_301_7@
#@H_301_7@
# Lock the memory on startup:@H_301_7@
#@H_301_7@
#bootstrap.memory_lock: true@H_301_7@
#@H_301_7@
# Make sure that the heap size is set to about half the memory available@H_301_7@
# on the system and that the owner of the process is allowed to use this@H_301_7@
# limit.@H_301_7@
#@H_301_7@
# Elasticsearch performs poorly when the system is swapping the memory.@H_301_7@
#@H_301_7@
# ---------------------------------- Network -----------------------------------@H_301_7@
#@H_301_7@
# Set the bind address to a specific IP (IPv4 or IPv6):@H_301_7@
#@H_301_7@
network.host: 0.0.0.0@H_301_7@
#@H_301_7@
# Set a custom port for HTTP:@H_301_7@
#@H_301_7@
http.port: 9200@H_301_7@
#@H_301_7@
# For more information, consult the network module documentation.@H_301_7@
#@H_301_7@
# --------------------------------- discovery ----------------------------------@H_301_7@
#@H_301_7@
# Pass an initial list of hosts to perform discovery when new node is started:@H_301_7@
# The default list of hosts is ["127.0.0.1", "[::1]"]@H_301_7@
#@H_301_7@
#discovery.zen.ping.unicast.hosts: ["host1", "host2"]@H_301_7@
#@H_301_7@
# Prevent the "split brain" by configuring the majority of nodes (total number of master-eligible nodes / 2 + 1):@H_301_7@
#@H_301_7@
#discovery.zen.minimum_master_nodes:@H_301_7@
#@H_301_7@
# For more information, consult the zen discovery module documentation.@H_301_7@
#@H_301_7@
# ---------------------------------- Gateway -----------------------------------@H_301_7@
#@H_301_7@
# Block initial recovery after a full cluster restart until N nodes are started:@H_301_7@
#@H_301_7@
#gateway.recover_after_nodes: 3@H_301_7@
#@H_301_7@
# For more information, consult the gateway module documentation.@H_301_7@
#@H_301_7@
# ---------------------------------- VarIoUs -----------------------------------@H_301_7@
#@H_301_7@
# Require explicit names when deleting indices:@H_301_7@
#@H_301_7@
#action.destructive_requires_name: true@H_301_7@
#qcl自己加的@H_301_7@
http.cors.enabled: true@H_301_7@
http.cors.allow-origin: "*"@H_301_7@
node.master: true@H_301_7@
node.data: true@H_301_7@
这里的cluster.name: my-application就代表我们的es的名称叫my-application@H_301_7@
3,启动es@H_301_7@
进入到bin文件@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
点击elasticsearch脚本,即可启动es,脚本运行完,在浏览器中输入http://localhost:9200/如果出现下面信息,就代表es启动成功。@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
三,配置es
在创建的springboot项目下的application.yml做如下配置@H_301_7@ @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
#url相关配置,这里配置url的基本url@H_301_7@
server:@H_301_7@
port: 8080@H_301_7@
spring:@H_301_7@
## Elasticsearch配置文件(必须)@H_301_7@
## 该配置和Elasticsearch本地文件config下的elasticsearch.yml中的配置信息有关@H_301_7@
data:@H_301_7@
elasticsearch:@H_301_7@
cluster-name: my-application@H_301_7@
cluster-nodes: 127.0.0.1:9300@H_301_7@
四,添加数据到es,并实现搜索
1,创建bean@H_301_7@我们像jpa那样,创建es自己的bean,如下package com.qcl.es;@H_301_7@
import org.springframework.data.annotation.Id;@H_301_7@
import org.springframework.data.elasticsearch.annotations.Document;@H_301_7@
import org.springframework.data.elasticsearch.annotations.Field;@H_301_7@
import org.springframework.data.elasticsearch.annotations.FieldType;@H_301_7@
/**@H_301_7@
* Created by qcl on 2018/7/10.@H_301_7@
* ES相关@H_301_7@
*/@H_301_7@
@Document(indexName = "user", type = "docs", shards = 1, replicas = 0)@H_301_7@
public class UserES {@H_301_7@
//主键自增长@H_301_7@
@Id@H_301_7@
private Long id;//主键@H_301_7@
@Field(type = FieldType.Text, analyzer = "ik_max_word")@H_301_7@
private String userName;@H_301_7@
private String userPhone;@H_301_7@
public Long getId() {@H_301_7@
return id;@H_301_7@
}@H_301_7@
public void setId(Long id) {@H_301_7@
this.id = id;@H_301_7@
}@H_301_7@
public String getUserName() {@H_301_7@
return userName;@H_301_7@
}@H_301_7@
public void setUserName(String userName) {@H_301_7@
this.userName = userName;@H_301_7@
}@H_301_7@
public String getUserPhone() {@H_301_7@
return userPhone;@H_301_7@
}@H_301_7@
public void setUserPhone(String userPhone) {@H_301_7@
this.userPhone = userPhone;@H_301_7@
}@H_301_7@
@Override@H_301_7@
public String toString() {@H_301_7@
return "UserES{" +@H_301_7@
"userId=" + id +@H_301_7@
", userName='" + userName + ''' +@H_301_7@
", userPhone='" + userPhone + ''' +@H_301_7@
'}';@H_301_7@
}@H_301_7@
}@H_301_7@
2,创建操作数据的Repository@H_301_7@
package com.qcl.es;@H_301_7@
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;@H_301_7@
/**@H_301_7@
* Created by qcl on 2019-03-23@H_301_7@
* 微信:2501902696@H_301_7@
* desc:@H_301_7@
*/@H_301_7@
public interface UserESRepository extends ElasticsearchRepository<UserES, Long> {}@H_301_7@
3,创建controller@H_301_7@
package com.qcl.es;@H_301_7@
import org.elasticsearch.index.query.QueryBuilders;@H_301_7@
import org.springframework.beans.factory.annotation.Autowired;@H_301_7@
import org.springframework.data.domain.Page;@H_301_7@
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;@H_301_7@
import org.springframework.web.bind.annotation.GetMapping;@H_301_7@
import org.springframework.web.bind.annotation.RequestParam;@H_301_7@
import org.springframework.web.bind.annotation.RestController;@H_301_7@
/**@H_301_7@
* Created by qcl on 2019-03-23@H_301_7@
* 微信:2501902696@H_301_7@
* desc:@H_301_7@
*/@H_301_7@
@RestController@H_301_7@
public class UserController {@H_301_7@
@Autowired@H_301_7@
private UserESRepository repositoryES;@H_301_7@
@GetMapping("/create")@H_301_7@
public String create(@H_301_7@
@RequestParam("id") Long id,@H_301_7@
@RequestParam("userName") String userName,@H_301_7@
@RequestParam("userPhone") String userPhone) {@H_301_7@
UserES userES = new UserES();@H_301_7@
userES.setId(id);@H_301_7@
userES.setUserName(userName);@H_301_7@
userES.setUserPhone(userPhone);@H_301_7@
return repositoryES.save(userES).toString();@H_301_7@
}@H_301_7@
private String names;@H_301_7@
@GetMapping("/get")@H_301_7@
public String get() {@H_301_7@
names = "";@H_301_7@
Iterable<UserES> userES = repositoryES.findAll();@H_301_7@
userES.forEach(userES1 -> {@H_301_7@
names += userES1.toString() + "n";@H_301_7@
});@H_301_7@
return names;@H_301_7@
}@H_301_7@
private String searchs = "";@H_301_7@
@GetMapping("/search")@H_301_7@
public String search(@RequestParam("searchKey") String searchKey) {@H_301_7@
searchs = "";@H_301_7@
// 构建查询条件@H_301_7@
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();@H_301_7@
// 添加基本分词查询@H_301_7@
queryBuilder.withQuery(QueryBuilders.matchQuery("userName", searchKey));@H_301_7@
// 搜索,获取结果@H_301_7@
Page<UserES> items = repositoryES.search(queryBuilder.build());@H_301_7@
// 总条数@H_301_7@
long total = items.getTotalElements();@H_301_7@
searchs += "总共数据数:" + total + "n";@H_301_7@
items.forEach(userES -> {@H_301_7@
searchs += userES.toString() + "n";@H_301_7@
});@H_301_7@
return searchs;@H_301_7@
}@H_301_7@
}@H_301_7@
启动springboot项目@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
我们简单的实现了@H_301_7@
往es里插入数据查询所有数据根据搜索key,搜索信息验证@H_301_7@
插入一个userName='李四'&userPhone='272501902696'的数据http://localhost:8080/create?id=5&userName='李四'&userPhone='272501902696'@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
查询上面的数据是否插入成功,可以看到李四这条数据已经成功插入。@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
搜索 userName包含'四'的信息,可以看到,成功感搜索到一条@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
搜索 userName包含'石'的信息,可以看到,成功感搜索到4条@H_301_7@
 @H_301_7@@H_301_7@
@H_301_7@@H_301_7@
到此我们就实现了springboot集成es的功能。后面我们再做复杂搜索就基于这个基础上做对应的操作即可。@H_301_7@
有任何关于编程的问题都可以留言或者私信我,我看到后会及时解答。@H_301_7@
编程小石头,码农一枚,非著名全栈开发人员。分享自己的一些经验,学习心得,希望后来人少走弯路,少填坑。@H_301_7@

elasticsearch安装及与springboot2.x整合
关于elasticsearch是什么、elasticsearch的原理及elasticsearch能干什么,就不多说了,主要记录下自己的一个使用过程。
1、安装
elasticsearch是用java编写的,所以它的运行离不开jdk,jdk的安装这里不再啰嗦,我使用的是虚拟机是centos7,已经装好了jdk1.8,下面说下自己安装elasticsearch的过程。
(1)到官网 https://www.elastic.co/guide/en/elasticsearch/reference/current/install-elasticsearch.html,查看各个操作系统的安装方式,找到对应的,我的是centos7,以root身份登录,执行 wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-6.5.1.tar.gz。
(2)解压 tar -zvxf elasticsearch-6.5.1.tar.gz -C /usr/local
(3)默认ES 6.X 是不允许root用户运行的,否则ES运行的时候会报错,所以我们需要创建新的用户,groupadd es ——>useradd es -g es——>passwd es 按照提示设置密码即可。修改权限 chown -R es:es elasticsearch-6.5.1
(4)修改配置,支持外网访问(记得关防火墙),在合适的位置创建两个文件夹,分别用来存储elasticsearch的数据和日志,执行vim config/elasticsearch.yml,取消下列对应的项的注释并修改
cluster.name: li-application #集群名称,可以自行修改
node.name: linux-2 #节点名称,自行修改
network.host: 0.0.0.0 #主机地址,这里写本机IP
http.port: 9200 #端口
path.data: /var/lib/es 数据存储位置
path.logs: /var/logs/es 日志存储位置
(5)执行vim /etc/security/limits.conf,在结尾加上如下配置,其中es是用户名
es soft nofile 65536
es hard nofile 131072
es soft nproc 4096
es hard nproc 4096
(6)执行 vi /etc/sysctl.conf,在文件末尾添加 vm.max_map_count=655360,保存,并执行命令 sysctl -p
(7)切换到es用户,进入/usr/local/elasticsearch-6.5.1,执行./bin/elasticsearch -d (后台启动)。
(8)执行 curl -i localhost:9200,会有一个测试信息的响应,表示安装成功。
2、整合springboot2.0
(1)引入依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--集合工具包-->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>19.0</version>
</dependency>(2)添加配置,注意端口号是9300
spring.data.elasticsearch.cluster-name=my-application
spring.data.elasticsearch.cluster-nodes=192.168.1.126:9300
spring.data.elasticsearch.repositories.enabled=true
server.port=11111(3)编写对应的代码
package com.example.demo;
import org.springframework.data.elasticsearch.annotations.Document;
import com.fasterxml.jackson.annotation.JsonProperty;
//indexName代表所以名称,type代表表名称
@Document(indexName = "wantu_notice_info", type = "doc")
public class Notice {
//id
@JsonProperty("auto_id")
private Long id;
//标题
@JsonProperty("title")
private String title;
//公告标签
@JsonProperty("exchange_mc")
private String exchangeMc;
//公告发布时间
@JsonProperty("create_time")
private String originCreateTime;
//公告阅读数量
@JsonProperty("read_count")
private Integer readCount;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getExchangeMc() {
return exchangeMc;
}
public void setExchangeMc(String exchangeMc) {
this.exchangeMc = exchangeMc;
}
public String getOriginCreateTime() {
return originCreateTime;
}
public void setOriginCreateTime(String originCreateTime) {
this.originCreateTime = originCreateTime;
}
public Integer getReadCount() {
return readCount;
}
public void setReadCount(Integer readCount) {
this.readCount = readCount;
}
public Notice(Long id, String title, String exchangeMc, String originCreateTime, Integer readCount) {
super();
this.id = id;
this.title = title;
this.exchangeMc = exchangeMc;
this.originCreateTime = originCreateTime;
this.readCount = readCount;
}
public Notice() {
super();
}
}package com.example.demo;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Component;
@Component
public interface NoticeRepository extends ElasticsearchRepository<Notice, Long> {
}package com.example.demo;
import java.util.ArrayList;
import java.util.List;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Pageable;
import org.springframework.data.web.PageableDefault;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RestController;
import com.google.common.collect.Lists;
@RestController
@RequestMapping("/api/v1/article")
public class NoticeController {
@Autowired
private NoticeRepository nticeRepository;
@GetMapping("/save")
public Object save(long id, String title){
Notice article = new Notice();
article.setId(id);
article.setReadCount(123);
article.setTitle(title);
return nticeRepository.save(article);
}
/**
* @param title 搜索标题
* @param pageable page = 第几页参数, value = 每页显示条数
*/
@GetMapping("/search")
public Object search(String title ,@PageableDefault() Pageable pag){
//按标题进行搜索
QueryBuilder builder = QueryBuilders.matchQuery("title", title);
//如果实体和数据的名称对应就会自动封装,pageable分页参数
Iterable<Notice> listIt = nticeRepository.search(builder, pag);
//Iterable转list
List<Notice> list= Lists.newArrayList(listIt);
return list;
}
@RequestMapping("/all")
public List<Notice> all() throws Exception {
Iterable<Notice> data = nticeRepository.findAll();
List<Notice> ds = new ArrayList<>();
for (Notice d : data) {
ds.add(d);
}
return ds;
}
@RequestMapping("/id")
public Object findid(long id) throws Exception {
return nticeRepository.findById(id).get();
}
}启动项目,先添加几条数据,然后依次访问全部记录、带"三"的记录、带"吃饭"的记录,效果如下:


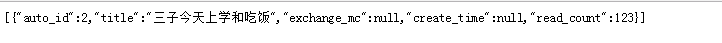
")
pringboot2.x整合ElasticSearch7.x实战(三)
大概阅读10分钟
本教程是系列教程,对于初学者可以对 ES 有一个整体认识和实践实战。
还没开始的同学,建议先读一下系列攻略目录:Springboot2.x整合ElasticSearch7.x实战目录
本篇幅是继上一篇 Springboot2.x整合ElasticSearch7.x实战(二) ,适合初学 Elasticsearch 的小白,可以跟着整个教程做一个练习。
[toc]
第五章 Mapping详解
Mapping 是整个 ES 搜索引擎中最重要的一部分之一,学会构建一个好的索引,可以让我们的搜索引擎更高效,更节省资源。
什么是 Mapping?
Mapping 是Elasticsearch 中一种术语, Mapping 类似于数据库中的表结构定义 schema,它有以下几个作用:
1. 定义索引中的字段的名称
2. 定义字段的数据类型,比如字符串、数字、布尔
3. 字段,倒排索引的相关配置,比如设置某个字段为不被索引、记录 position(位置) 等
在 ES 早期版本,一个索引下是可以有多个 Type ,从 7.0 开始,一个索引只有一个 Type,也可以说一个 Type 有一个 Mapping 定义。
了解了什么是 Mapping 后,接下来对 Mapping 的设置坐下介绍:
Maping设置
dynamic (动态Mapping)
官网参考:https://www.elastic.co/guide/en/elasticsearch/reference/7.1/mapping.html
PUT users
{
"mappings": {
"_doc": {
"dynamic": false
}
}
}在创建一个索引的时候,可以对 dynamic 进行设置,可以设成 false、true 或者 strict。
比如一个新的文档,这个文档包含一个字段,当 Dynamic 设置为 true 时,这个文档可以被索引进 ES,这个字段也可以被索引,也就是这个字段可以被搜索,Mapping 也同时被更新;当 dynamic 被设置为 false 时候,存在新增字段的数据写入,该数据可以被索引,但是新增字段被丢弃;当设置成 strict 模式时候,数据写入直接出错。
index
另外还有 index 参数,用来控制当前字段是否被索引,默认为 true,如果设为 false(有些业务场景,某些字段不希望被搜索到),则该字段不可被搜索。
# index属性控制 字段是否可以被索引
PUT user_test
{
"mappings": {
"properties": {
"firstName":{
"type": "text"
},
"lastName":{
"type": "text"
},
"mobile" :{
"type": "text",
"index": false
}
}
}
}index_options
参数 index_options 用于控制倒排索引记录的内容,有如下 4 种配置:
- doc:只记录 doc id
- freqs:记录 doc id 和 term frequencies
- positions:记录 doc id、term frequencies 和 term position
- offsets:记录 doc id、term frequencies、term position 和 character offects
另外,text 类型默认配置为 positions,其他类型默认为 doc,记录内容越多,占用存储空间越大。
null_value
null_value 主要是当字段遇到 null 值时的处理策略,默认为 NULL,即空值,此时 ES 会默认忽略该值,可以通过设定该值设定字段的默认值,另外只有 KeyWord 类型支持设定 null_value。
- 示例
# 设定Null_value
DELETE users
PUT users
{
"mappings" : {
"properties" : {
"firstName" : {
"type" : "text"
},
"lastName" : {
"type" : "text"
},
"mobile" : {
"type" : "keyword",
"null_value": "NULL"
}
}
}
}
PUT users/_doc/1
{
"firstName":"Zhang",
"lastName": "Fubing",
"mobile": null
}
PUT users/_doc/2
{
"firstName":"Zhang",
"lastName": "Fubing2"
}
# 查看结果,有且仅有_id为2的记录
GET users/_search
{
"query": {
"match": {
"mobile":"NULL"
}
}
}_all
这个属性现在使用很少,不做深入讲解
参考官网:https://www.elastic.co/guide/cn/elasticsearch/guide/current/root-object.html
copy_to
这个属性用于将当前字段拷贝到指定字段。
- _all在7.x版本已经被copy_to所代替
- 可用于满足特定场景
- copy_to将字段数值拷贝到目标字段,实现类似_all的作用
- copy_to的目标字段不出现在_source中
DELETE users
PUT users
{
"mappings": {
"properties": {
"firstName":{
"type": "text",
"copy_to": "fullName"
},
"lastName":{
"type": "text",
"copy_to": "fullName"
}
}
}
}
PUT users/_doc/1
{
"firstName":"Li",
"lastName": "Sunke"
}
//没有新建字段
GET users/_doc/1
{
"_index" : "users",
"_type" : "_doc",
"_id" : "1",
"_version" : 1,
"_seq_no" : 0,
"_primary_term" : 1,
"found" : true,
"_source" : {
"firstName" : "Li",
"lastName" : "Sunke"
}
}
GET users/_search?q=fullName:(Li sunke)
以前的用法是:
curl -XPUT ''localhost:9200/my_index?pretty'' -H ''Content-Type: application/json'' -d''
{
"mappings": {
"my_type": {
"properties": {
"first_name": {
"type": "text",
"copy_to": "full_name" # 1
},
"last_name": {
"type": "text",
"copy_to": "full_name" # 2
},
"full_name": {
"type": "text"
}
}
}
}
}
''
curl -XPUT ''localhost:9200/my_index/my_type/1?pretty'' -H ''Content-Type: application/json'' -d''
{
"first_name": "John",
"last_name": "Smith"
}
''
curl -XGET ''localhost:9200/my_index/_search?pretty'' -H ''Content-Type: application/json'' -d''
{
"query": {
"match": {
"full_name": { # 3
"query": "John Smith",
"operator": "and"
}
}
}
}
''- first_name(名字)和 last_name(姓氏)字段复制到full_name 字段;
- first_name(名字)和 last_name(姓氏)字段仍然可以分别查询;
- full_name 可以通过 first_name(名字)和 last_name(姓氏)来查询;
一些要点:
- 复制的是字段值,而不是 term(词条)(由分析过程产生).
- _source 字段不会被修改来显示复制的值.
- 相同的值可以复制到多个字段,通过 "copy_to": [ "field_1", "field_2" ] 来操作.
分词器analyzer和arch_analyzer
PUT /my_index
{
"mappings": {
"properties": {
"text": {
"type": "text",
"fields": {
"english": {
"type": "text",
"analyzer": "english",
"search_analyzer": "english"
}
}
}
}
}
}
#使用_analyze 测试分词器
GET my_index/_analyze
{
"field": "text",
"text": "The quick Brown Foxes."
}
GET my_index/_analyze
{
"field": "text.english",
"text": "The quick Brown Foxes."
}构建Mapping方式
我们知道 Mapping 是可以通过我们插入的文档自动生成索引,但是可能还是有一些问题。例如:生成的字段类型不正确,字段的附加属性不满足我们的需求。这是我们可以通过显式Mapping的方式来解决。俩种方法:
- 参考官网api,纯手写
- 构建临时索引;写入一些样本数据;通过Maping API 查询临时文件的动态Mapping 定义;修改后、再使用此配置创建索引;删除临时索引;
推荐第二种,不容易出错,效率高。
类型自动识别
ES 类型的自动识别是基于 JSON 的格式,如果输入的是 JSON 是字符串且格式为日期格式,ES 会自动设置成 Date 类型;当输入的字符串是数字的时候,ES 默认会当成字符串来处理,可以通过设置来转换成合适的类型;如果输入的是 Text 字段的时候,ES 会自动增加 keyword 子字段,还有一些自动识别如下图所示:
- Demo:
# 写入文档,查看 Mapping
PUT mapping_test/_doc/1
{
"firstName": "Chan", -- Text
"lastName": "Jackie", -- Text
"loginDate": "2018-07-24T10:29:48.103Z" -- Date
}
# Dynamic Mapping,推断字段的类型
PUT mapping_test/_doc/1
{
"uid": "123", -- Text
"isVip": false, -- Boolean
"isAdmin": "true", -- Text
"age": 19, -- Long
"heigh": 180 -- Long
}
# 查看 Dynamic Mapping
GET mapping_test/_mapping映射参数
mappings 中field定义选择:
"field": {
"type": "text", //文本类型
"index": "false"// ,设置成false,字段将不会被索引
"analyzer":"ik"//指定分词器
"boost":1.23//字段级别的分数加权
"doc_values":false//对not_analyzed字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
"fielddata":{"loading" : "eager" }//Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
"fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"index_options":"docs"//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"store":false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
}总结一下:
- 与域数据格式及约束相关的参数:normalizer,format,ignore_above,ignore_malformed,coerce
- 与索引相关的参数:index,dynamic,enabled
- 与存储策略相关的参数:store, fielddata,doc_values
- 分析器相关参数:analyzer,search_analyzer
- 其它参数:boost,copy_to,null_value
对于这些参数的描述主要基于笔者的理解,可能有不准确之处。实际上这些参数与ES的实现机制(如存储结构,索引结构密切有关),只能在实际应用中去慢慢体会。
字段数据类型
ES 字段类型类似于 MySQL 中的字段类型,ES 字段类型主要有:核心类型、复杂类型、地理类型以及特殊类型,具体的数据类型如下图所示:
核心类型
从图中可以看出核心类型可以划分为字符串类型、数字类型、日期类型、布尔类型、基于 BASE64 的二进制类型、范围类型。
字符串类型
其中,在 ES 7.x 有两种字符串类型:text 和 keyword,在 ES 5.x 之后 string 类型已经不再支持了。
text 类型适用于需要被全文检索的字段,例如新闻正文、邮件内容等比较长的文字,text 类型会被 Lucene 分词器(Analyzer)处理为一个个词项,并使用 Lucene 倒排索引存储,text 字段不能被用于排序,如果需要使用该类型的字段只需要在定义映射时指定 JSON 中对应字段的 type 为 text。
keyword 适合简短、结构化字符串,例如主机名、姓名、商品名称等,可以用于过滤、排序、聚合检索,也可以用于精确查询。
数字类型
数字类型分为 long、integer、short、byte、double、float、half_float、scaled_float。
数字类型的字段在满足需求的前提下应当尽量选择范围较小的数据类型,字段长度越短,搜索效率越高,对于浮点数,可以优先考虑使用 scaled_float 类型,该类型可以通过缩放因子来精确浮点数,例如 12.34 可以转换为 1234 来存储。
日期类型
在 ES 中日期可以为以下形式:
格式化的日期字符串,例如 2020-03-17 00:00、2020/03/17
时间戳(和 1970-01-01 00:00:00 UTC 的差值),单位毫秒或者秒
即使是格式化的日期字符串,ES 底层依然采用的是时间戳的形式存储。
布尔类型
JSON 文档中同样存在布尔类型,不过 JSON 字符串类型也可以被 ES 转换为布尔类型存储,前提是字符串的取值为 true 或者 false,布尔类型常用于检索中的过滤条件。
二进制类型
二进制类型 binary 接受 BASE64 编码的字符串,默认 store 属性为 false,并且不可以被搜索。
范围类型
范围类型可以用来表达一个数据的区间,可以分为5种:integer_range、float_range、long_range、double_range 以及 date_range。
复杂类型
复合类型主要有对象类型(object)和嵌套类型(nested):
对象类型
JSON 字符串允许嵌套对象,一个文档可以嵌套多个、多层对象。可以通过对象类型来存储二级文档,不过由于 Lucene 并没有内部对象的概念,ES 会将原 JSON 文档扁平化,例如文档:
{
"name": {
"first": "wu",
"last": "px"
}
}
实际上 ES 会将其转换为以下格式,并通过 Lucene 存储,即使 name 是 object 类型:
{
"name.first": "wu",
"name.last": "px"
}
嵌套类型
嵌套类型可以看成是一个特殊的对象类型,可以让对象数组独立检索,例如文档:
{
"group": "users",
"username": [
{ "first": "wu", "last": "px"},
{ "first": "hu", "last": "xy"},
{ "first": "wu", "last": "mx"}
]
}
username 字段是一个 JSON 数组,并且每个数组对象都是一个 JSON 对象。如果将 username 设置为对象类型,那么 ES 会将其转换为:
{
"group": "users",
"username.first": ["wu", "hu", "wu"],
"username.last": ["px", "xy", "mx"]
}
可以看出转换后的 JSON 文档中 first 和 last 的关联丢失了,如果尝试搜索 first 为 wu,last 为 xy 的文档,那么成功会检索出上述文档,但是 wu 和 xy 在原 JSON 文档中并不属于同一个 JSON 对象,应当是不匹配的,即检索不出任何结果。
嵌套类型就是为了解决这种问题的,嵌套类型将数组中的每个 JSON 对象作为独立的隐藏文档来存储,每个嵌套的对象都能够独立地被搜索,所以上述案例中虽然表面上只有 1 个文档,但实际上是存储了 4 个文档。
地理类型
地理类型字段分为两种:经纬度类型和地理区域类型:
经纬度类型
经纬度类型字段(geo_point)可以存储经纬度相关信息,通过地理类型的字段,可以用来实现诸如查找在指定地理区域内相关的文档、根据距离排序、根据地理位置修改评分规则等需求。
地理区域类型
经纬度类型可以表达一个点,而 geo_shape 类型可以表达一块地理区域,区域的形状可以是任意多边形,也可以是点、线、面、多点、多线、多面等几何类型。
特殊类型
特殊类型包括 IP 类型、过滤器类型、Join 类型、别名类型等,在这里简单介绍下 IP 类型和 Join 类型,其他特殊类型可以查看官方文档。
IP 类型
IP 类型的字段可以用来存储 IPv4 或者 IPv6 地址,如果需要存储 IP 类型的字段,需要手动定义映射:
{
"mappings": {
"properties": {
"my_ip": {
"type": "ip"
}
}
}
}
Join类型
Join 类型是 ES 6.x 引入的类型,以取代淘汰的 _parent 元字段,用来实现文档的一对一、一对多的关系,主要用来做父子查询。
Join 类型的 Mapping 如下:
PUT my_index
{
"mappings": {
"properties": {
"my_join_field": {
"type": "join",
"relations": {
"question": "answer"
}
}
}
}
}
其中,my_join_field 为 Join 类型字段的名称;relations 指定关系:question 是 answer 的父类。
例如定义一个 ID 为 1 的父文档:
PUT my_join_index/1?refresh
{
"text": "This is a question",
"my_join_field": "question"
}
接下来定义一个子文档,该文档指定了父文档 ID 为 1:
PUT my_join_index/_doc/2?routing=1&refresh
{
"text": "This is an answer",
"my_join_field": {
"name": "answer",
"parent": "1"
}
}
join参考:https://www.elastic.co/guide/en/elasticsearch/reference/current/parent-join.html
关于SpringBoot2.3.x整合ElasticSearch7.6.2 实现PDF,WORD全文检索和springboot es 全文检索的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于elasticsearch7.x整合springBoot、elasticsearch入门 springboot2集成elasticsearch 实现全文搜索、elasticsearch安装及与springboot2.x整合、pringboot2.x整合ElasticSearch7.x实战(三)的相关知识,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

