对于Elasticsearch与MySQL数据同步感兴趣的读者,本文将会是一篇不错的选择,并为您提供关于canal-1.1.5实时同步MySQL数据到Elasticsearch、canal同步mysq
对于Elasticsearch与MySQL数据同步感兴趣的读者,本文将会是一篇不错的选择,并为您提供关于canal-1.1.5实时同步MySQL数据到Elasticsearch、canal同步mysql数据至elasticSearch、Docker环境下Mysql数据同步到Elasticsearch、Elasticsearch - Logstash实现mysql同步数据到elasticsearch的有用信息。
本文目录一览:- Elasticsearch与MySQL数据同步
- canal-1.1.5实时同步MySQL数据到Elasticsearch
- canal同步mysql数据至elasticSearch
- Docker环境下Mysql数据同步到Elasticsearch
- Elasticsearch - Logstash实现mysql同步数据到elasticsearch

Elasticsearch与MySQL数据同步
Elasticsearch数据同步
elasticsearch中的酒店数据来自于MysqL数据库,因此MysqL数据发生改变时,elasticsearch也必须跟着改变,这个就是elasticsearch与MysqL之间的数据同步。
1、数据同步思路分析
方案一:同步调用
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KS7oCzzf-1654427458461)(images/image-20220605115303237.png)]](https://pic.jb51.cc/2022/06-23/00/125133fc8e99a5ec41c5c6d6f8aefc6a.png)
基本步骤如下:
- hotel-demo对外提供接口,用来修改elasticsearch中的数据
- 酒店管理服务在完成数据库操作后,直接调用hotel-demo提供的接口
方案二:异步通知
![[外链图片转存失败,建议将图片保存下来直接上传(img-xx2DGfGP-1654427458462)(images/image-20220605115321649.png)]](https://pic.jb51.cc/2022/06-23/00/9d1f0be187f74f96bd9129ac50c56127.png)
流程如下:
- hotel-admin对MysqL数据库数据完成增、删、改后,发送MQ消息
- hotel-demo监听MQ,接收到消息后完成elasticsearch数据修改
方案三:监听binlog
![[外链图片转存失败,建议将图片保存下来直接上传(img-YIuDgH9S-1654427458463)(images/image-20220605115337048.png)]](https://pic.jb51.cc/2022/06-23/00/379f5c7317595410e5cbfd805027a262.png)
流程如下:
- 给MysqL开启binlog功能
- MysqL完成增、删、改操作都会记录在binlog中
- hotel-demo基于canal监听binlog变化,实时更新elasticsearch中的内容
小结
方式一:同步调用
- 优点:实现简单,粗暴
- 缺点:业务耦合度高
方式二:异步通知
- 优点:低耦合,实现难度一般
- 缺点:依赖mq的可靠性
方式三:监听binlog
- 优点:完全解除服务间耦合
- 缺点:开启binlog增加数据库负担、实现复杂度高
2、实现Elasticsearch与数据库数据同步
导入项目完成对酒店数据的【增删改查】实现数据同步操作
![[外链图片转存失败,建议将图片保存下来直接上传(img-5a94nQxU-1654427458464)(images/image-20220605131653811.png)]](https://pic.jb51.cc/2022/06-23/00/c726698f92b68132135ea7ca111a9f41.png)
hotel-admin项目作为酒店管理的微服务。当酒店数据发生增、删、改时,要求对elasticsearch中数据也要完成相同操作。
步骤:
-
创建hotel-admin项目,启动并测试酒店数据的CRUD
-
声明exchange、queue、RoutingKey
-
在hotel-admin中的增、删、改业务中完成消息发送
-
在hotel-demo中完成消息监听,并更新elasticsearch中数据
-
启动并测试数据同步功能
2.1、hotel_demo声明交换机、队列
![[外链图片转存失败,建议将图片保存下来直接上传(img-Riui9FAv-1654427458464)(images/image-20220605135101049.png)]](https://pic.jb51.cc/2022/06-23/00/9e4cc61ea1261ffc465ce25b6e8c0bad.png)
在hotel-admin、hotel-demo中引入rabbitmq的依赖:
<!--amqp-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
配置springboot核心配置文件yml
spring:
rabbitmq:
host: 192.168.26.131
port: 5672
username: itcast
password: 123321
virtual-host: /
在hotel-demo项目中定义一个类记录交换机和队列的名称
package cn.itcast.hotel.constants;
/**
* 项目名称:hotel-demo
* 描述:定义全局的交换机和队列以及RoutingKey
*
* @author zhong
* @date 2022-06-05 14:00
*/
public class MqConstants {
/**
* 交换机名称
*/
public final static String HOTEL_EXCHANGE = "hotel.topic";
/**
* 监听新增和修改队列
*/
public final static String HOTEL_INSERT_QUEUE = "hotel.insert.queue";
/**
* 监听删除的队列
*/
public final static String HOTEL_DELETE_QUEUE = "hotel.delete.queue";
/**
* 新增或修改的RoutingKey
*/
public final static String HOTEL_INSERT_KEY = "hotel.insert";
/**
* 删除的RoutingKey
*/
public final static String HOTEL_DELETE_KEY = "hotel.delete";
}
在hotel-demo中,定义配置类,声明队列、交换机之间的绑定关系:
package cn.itcast.hotel.config;
import cn.itcast.hotel.constants.MqConstants;
import org.springframework.amqp.core.Binding;
import org.springframework.amqp.core.BindingBuilder;
import org.springframework.amqp.core.Queue;
import org.springframework.amqp.core.TopicExchange;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
/**
* 项目名称:hotel-demo
* 描述:创建交换机和队列,绑定关系
*
* @author zhong
* @date 2022-06-05 14:06
*/
@Configuration
public class MqConfig {
/**
* 1、定义持久化交换机
* @return
*/
@Bean
public TopicExchange topicExchange() {
return new TopicExchange(MqConstants.HOTEL_EXCHANGE,true,false);
}
/**
* 2、创建新增的队列,持久化
*/
@Bean
public Queue insertQueue(){
return new Queue(MqConstants.HOTEL_INSERT_QUEUE, true);
}
/**
* 3、创建新增的队列,持久化
*/
@Bean
public Queue deleteQueue(){
return new Queue(MqConstants.HOTEL_DELETE_QUEUE, true);
}
/**
* 4、定义交换机和队列的绑定关系以及通信的值
*/
@Bean
public Binding insertQueueBinding(){
return BindingBuilder.bind(insertQueue()).to(topicExchange()).with(MqConstants.HOTEL_INSERT_KEY);
}
/**
* 5、定义删除的交换机和队列关系以及通讯的值
* @return
*/
@Bean
public Binding deleteQueueBinding(){
return BindingBuilder.bind(deleteQueue()).to(topicExchange()).with(MqConstants.HOTEL_DELETE_KEY);
}
}
2.2、hotel_admin声明交换机、队列发送更新信息
- 引入依赖
- 添加yml配置文件,连接队列
- 复制
MqConstants类到constants包中 - 因为交换机和队列已经在消费者
hotel_demo中创建了,接下来就在提供者中发送消息
在控制器中注入发送消息的RabbitTemplate和对应的消息发送内容
因为队列是占内存的,所以我们直接传递一个id过去就可以了
/**
* 注入发送消息类
*/
@Autowired
private RabbitTemplate rabbitTemplate;
// 添加、修改数据中加入
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_INSERT_KEY,hotel.getId());
// 删除类中加入
rabbitTemplate.convertAndSend(MqConstants.HOTEL_EXCHANGE,MqConstants.HOTEL_DELETE_KEY,id);
2.3、在hotel_demo消费者中监听队列消息
当我们监听到队列的信息后就需要对文档库等做一个操作,所以这里注入了
IHotelService业务层的接口,下面就要创建这些接口的实现类
package cn.itcast.hotel.mq;
import cn.itcast.hotel.constants.MqConstants;
import cn.itcast.hotel.service.IHotelService;
import org.springframework.amqp.rabbit.annotation.RabbitListener;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
/**
* 项目名称:hotel-demo
* 描述:监听发送的队列消息
*
* @author zhong
* @date 2022-06-05 14:29
*/
@Component
public class HotelListener {
@Autowired
IHotelService hotelService;
/**
* 监听酒店添加或修改的队列
* @param id
*/
@RabbitListener(priority = MqConstants.HOTEL_INSERT_QUEUE)
public void listenerHotelInsertOrUpdate(Long id){
// 调用修改
hotelService.insertById(id);
}
/**
* 监听酒店删除队列消息
* @param id
*/
@RabbitListener(priority = MqConstants.HOTEL_DELETE_QUEUE)
public void listenerHotelInsertOrDelete(Long id){
// 调用删除
hotelService.deleteById(id);
}
}
2.4、创建监听调用的实现类
但提供者有消息发送过来的时候就会执行下面的两段代码
/**
* 删除数据监听
* @param id
*/
@Override
public void deleteById(Long id) {
try {
// 1、获取request
DeleteRequest request = new DeleteRequest("hotel").id(id.toString());
// 2、发送请求
client.delete(request,RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
/**
* 修改数据(添加)监听
* @param id
*/
@Override
public void insertById(Long id) {
try {
// 0、根据id查询数据库数据【实现了MP接口可以直接调用】
Hotel hotel = getById(id);
// 转换类型
HotelDoc hotelDoc = new HotelDoc(hotel);
// 1、获取request
IndexRequest request = new IndexRequest("hotel").id(hotel.getId().toString());
// 2、准备JSON文档
request.source(JSON.toJSONString(hotelDoc), XContentType.JSON);
// 3、发送请求
client.index(request, RequestOptions.DEFAULT);
} catch (IOException e) {
throw new RuntimeException(e);
}
}
2.6、测试
-
重启服务消费者
hotel_demo查看管理页面队列和交换机绑定关系
![[外链图片转存失败,建议将图片保存下来直接上传(img-bE60WwjS-1654427458465)(images/image-20220605145550547.png)]](https://pic.jb51.cc/2022/06-23/00/42e090bd0a3a29732715472a948489ed.png)
交换机绑定
![[外链图片转存失败,建议将图片保存下来直接上传(img-2Dxmw32H-1654427458466)(images/image-20220605145607061.png)]](https://pic.jb51.cc/2022/06-23/00/7e4d99226dd231259488a0b267d3d73a.png)
-
重启服务提供者
hotel_admin -
修改酒店消息然后返回刷新页面的消息,查看酒店信息是否修改了

canal-1.1.5实时同步MySQL数据到Elasticsearch
一、环境准备
1、jkd 8+
2、MysqL 5.7+
3、Elasticsearch 7+
4、kibana 7+
5、canal.adapter 1.1.5
二、部署
一、创建数据库CanalDb和表UserInfo
SET NAMES utf8mb4; SET FOREIGN_KEY_CHECKS = 0; -- ---------------------------- -- Table structure for UserInfo -- ---------------------------- DROP TABLE IF EXISTS `UserInfo`; CREATE TABLE `UserInfo` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_name` varchar(255) CHaraCTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL, `phone` varchar(255) CHaraCTER SET utf8mb4 COLLATE utf8mb4_general_ci DEFAULT NULL, `age` int(11) DEFAULT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 5 CHaraCTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; SET FOREIGN_KEY_CHECKS = 1;

二、kibana创建索引
PUT canal_product
{
"mappings": {
"properties": {
"user_name": {
"type": "text"
},
"phone": {
"type": "text"
},
"age": {
"type": "integer"
}
}
}
}

三、下载安装canal.adapter
github:https://github.com/alibaba/canal/releases/tag/canal-1.1.5
额外需要下载v1.1.5-alpha-2快照版本的canal.adapter-1.1.5.tar.gz(release1.1.5版本的jar包有bug)
分别解压缩后,将v1.1.5-alpha-2解压缩文件夹下plugin文件夹中的 client-adapter.es7x-1.1.5-SNAPSHOT-jar-with-dependencies.jar 替换掉release版本的plugin文件的 client-adapter.es7x-1.1.5-jar-with-dependencies.jar,并重命名,再将该jar赋予权限 chmod 777 client-adapter.es7x-1.1.5-jar-with-dependencies.jar

1、解压并修改配置文件 conf/application.yml
只需要修改特定的几处即可,关于各节点说明可参考官方说明:https://help.aliyun.com/document_detail/135297.html
srcDataSources:
defaultDS:
url: jdbc:MysqL://127.0.0.1:3306/CanalDb?useUnicode=true&characterEncoding=utf-8&useSSL=false
username: canal
password: canal
- name: es7
hosts: 127.0.0.1:9200 # 127.0.0.1:9200 for rest mode ,127.0.0.1:9003 for transport mode
properties:
mode: rest #transport or rest
security.auth: es:22222 # only used for rest mode
cluster.name: elasticsearch # es集群节点名称

2、启动服务
# 启动服务 ./bin/startup.sh
3、查看日志是否启动成功
cat logs/adapter/adapter.log
如图所示

4、实时同步
向数据库中插入一条数据
INSERT INTO `CanalDb`.`UserInfo`( `user_name`, `phone`, `age`) VALUES ('张三', '10086', 99);
查看日志

kibana查看索引数据
GET canal_product/_search

5、全量同步,修改conf/es7/mytest_user.yml配置文件,或者新建一个yml文件也可
dataSourceKey: defaultDS # 源数据源的key, 对应上面配置的srcDataSources中的值
destination: example # canal的instance或者MQ的topic
groupId: g1 # 对应MQ模式下的groupId, 只会同步对应groupId的数据
esMapping:
_index: canal_product # es 的索引名称
_id: _id # es 的_id, 如果不配置该项必须配置下面的pk项_id则会由es自动分配
sql: "SELECT
p.id as _id,
p.user_name,
p.phone,
p.age
FROM
UserInfo p " # sql映射
etlCondition: "where p.id>={}" #etl的条件参数
commitBatch: 3000 # 提交批大小

curl -X POST http://127.0.0.1:8081/etl/es7/mytest_user.yml


学习链接:https://help.aliyun.com/document_detail/135297.html
https://blog.csdn.net/zh1998wx/article/details/123101442?spm=1001.2101.3001.6650.1&utm_medium=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-123101442-blog-125808233.pc_relevant_aa&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2%7Edefault%7ECTRLIST%7Edefault-1-123101442-blog-125808233.pc_relevant_aa&utm_relevant_index=1

canal同步mysql数据至elasticSearch
数据库账号授权
因为canal是模拟mysql的slave去偷取msql的binlog操作日志达到同步的效果,所以需要给账号授权;
GRANT ALL PRIVILEGES ON *.* TO ''root''@''%'' IDENTIFIED BY ''123456'' WITH GRANT OPTION;FLUSH PRIVILEGES;
用户名:root 密码: 123456 指向ip(允许访问的ip): %代表所有Ip,此处也可以输入Ip来指定Ip
开启mysql binlog模式
找到mysql配置文件,windows一般在C:\ProgramData\MySQL\MySQL Server 5.7
Linux一般在/etc/my.cnf;添加如下内容:
log-bin=mysql-bin binlog-format=ROW server-id=1
然后重启mysql,查看binlog是否开启:show variables like ''%log_bin%''; log_bin为on即开启成功。
配置canaldePloyer
进入conf/example/instance.properties配置文件并更改如下配置
canal.instance.master.address=127.0.0.1:3306 canal.instance.dbUsername=root (第一步所授权的账号) canal.instance.dbPassword=123456 canal.instance.defaultDatabaseName=test canal.instance.filter.regex=test.tzg_course_t,test.tzg_school_t (表过滤:设置要同步的表)
配置完成即可启动;
配置canalAdapter
配置application.yml
进入conf/application.yml;
将defaultDS改为自己的数据库配置
srcDataSources:
defaultDS:
url: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true
username: root
password: 123456
配置自己的es
- name: es
hosts: 127.0.0.1:9300 #transport端口
properties:
cluster.name: tzg #集群名
配置数据抽取文件
上述步骤配置完成保存后回到上级目录,再进入es目录,创建一个yml配置文件类似如下:
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: tzg_business.tzg_course #待同步es index,要提前建好
_type: _doc #文档类型
_id: _id #文档_id和相同
upsert: true
# pk: id
sql: "select c.id as _id,c.id as id,s.area_id as areaId,s.area as area,s.district_id as districtId,s.district as district,s.city_id as cityId,s.city as city,c.category as category,c.category_id as categoryId,c.title as title ,c.school_id as schoolId,c.description as description,
c.score as score,c.tags as tags,c.cover_img_id as coverImgId,c.recommended as recommended,c.promote as promote,
c.last_modify_time as lastModifyTime,c.create_time as createTime from tzg_course_t c left join tzg_school_t s on c.school_id= s.id"
# objFields:
# _labels: array:;
# etlCondition: "where a.c_time>=''{0}''"
commitBatch: 3000
配置完成启动canalAdapter即可;增加修改数据库数据看是否同步es;
deployer: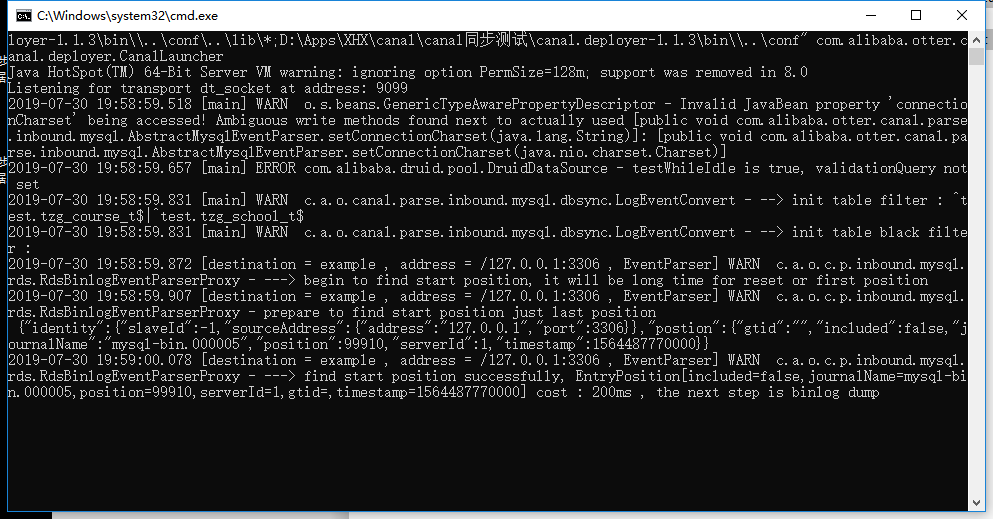
adapter: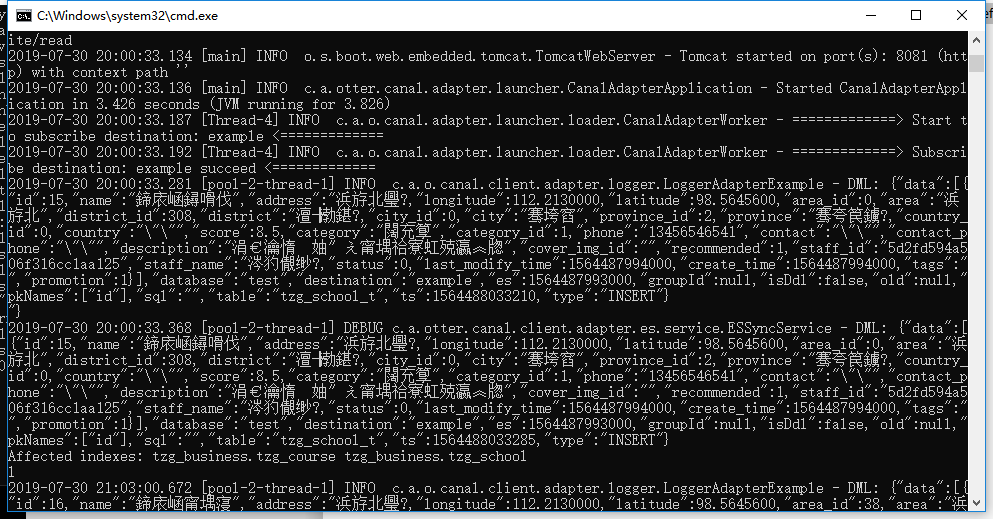

Docker环境下Mysql数据同步到Elasticsearch
写在前面
mysql数据同步es的实现原理一般有两种:
-
通过sql语句定时查询进行同步。
- elasticsearch-jdbc
- [logstash-jdbc]logstash官方(https://www.elastic.co/blog/l...
-
使用binlog进行同步
- 大神的开源项目go-mysql-elasticsearch
这里主要介绍logstash-jdbc这种方法主要是因为这种方法的是官方项目,更新维护的比较频繁,使用起来也比较放心,当然它也有一定的弊端。废话不多开始正题。
编排docker环境
本文是在docker环境下构建的环境,首先自然需要安装docker,笔者的版本为18.09.2。因为一直开发使用的是laradock的环境,这里依旧是使用这个环境为基础添加的es和logstash。因为mysql没有作任何变动,关于mysql的安装编排自行参考laradock文档。其实包括es和logstash的编排都很简单。
编排Elasticsearch
es的docker文件Dockerfile
FROM elasticsearch:7.3.0
EXPOSE 9200 9300docker-compose.yml文件
elasticsearch:
build: ./elasticsearch
volumes:
- elasticsearch:/usr/share/elasticsearch/data
environment:
- cluster.name=laradock-cluster
- node.name=laradock-node
- bootstrap.memory_lock=true
- "ES_JAVA_OPTS=-Xms512m -Xmx512m"
- cluster.initial_master_nodes=laradock-node
ulimits:
memlock:
soft: -1
hard: -1
ports:
- "${ELASTICSEARCH_HOST_HTTP_PORT}:9200"
- "${ELASTICSEARCH_HOST_TRANSPORT_PORT}:9300"
depends_on:
- php-fpm
networks:
- frontend
- backenddocker-compose up -d elasticsearch mysql启动镜像,可以测试一下发现es和mysql应该已经启动了。
编排logstash
既然是使用logstash-jdbc插件来实现同步,那我们的重点就是在编排logstash上了。
logstash-jdbc是通过java连接mysql的,所以我们首先需要一个jdbc的jar文件,可以从官网下载,得到一个jar文件,将它copy进docker的编排目录里,当然也可以编排时使用docker下载。
笔者的logstash的编排目录

dockerfile文件
FROM logstash:7.3.0
USER root
RUN rm -f /usr/share/logstash/pipeline/logstash.conf
RUN curl -L -o /usr/share/logstash/lib/mysql-connector-java-5.1.47.jar https://repo1.maven.org/maven2/mysql/mysql-connector-java/5.1.47/mysql-connector-java-5.1.47.jar
ADD ./pipeline/ /usr/share/logstash/pipeline/
ADD ./config /usr/share/logstash/config/
ADD mysql-connector-java-8.0.18.jar /usr/share/logstash/logstash-core/lib/jars/mysql/mysql-connector-java-8.0.18.jar
RUN logstash-plugin install logstash-input-jdbc同步任务配置文件mysql/mysql.conf
input {
jdbc {
# 这里是jdbc连接mysql的语句,第二个mysql是因为这个docker项目内部访问需要网络桥接原因,你可以自行修改
jdbc_connection_string => "jdbc:mysql://mysql:3306/koudai"
jdbc_user => "root"
jdbc_password => "root"
# 驱动; /usr/share/logstash/config/mysql/ 为logstash插件启动是查找jar文件的默认目录
jdbc_driver_library => "/usr/share/logstash/config/mysql/mysql-connector-java-8.0.18.jar"
# 驱动类名
jdbc_driver_class => "com.mysql.jdbc.Driver"
jdbc_paging_enabled => "true"
jdbc_page_size => "50000"
jdbc_default_timezone => "Asia/Shanghai"
# sql文件名
statement_filepath => "/usr/share/logstash/config/mysql/task.sql"
# 监听间隔[分、时、天、月、年]
schedule => "* * * * *"
type => "user"
# 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中
record_last_run => true
# 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值.
use_column_value => true
# 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键
tracking_column => "lastmodifiedTime"
tracking_column_type => "timestamp"
last_run_metadata_path => "./last_record/logstash_article_last_time"
# 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录
clean_run => false
# 是否将 字段(column) 名称转小写
lowercase_column_names => false
}
}
output {
elasticsearch {
# 同理是因为这个docker项目内部访问需要网络桥接原因
hosts => ["http://elasticsearch:9200"]
index => "user"
document_id => "%{uid}"
}
}同步mysql
select * from kdgx_partner_charge_user更多使用可以参考这里
自此mysql中的新增数据就可以同步到es了。

Elasticsearch - Logstash实现mysql同步数据到elasticsearch
有的时候,我们在做查询时,由于查询条件的多样、变化多端(比如根据时间查、根据名称模糊查、根据id查等等),或者查询的数据来自很多不同的库表或者系统,这时就很难以一个较快的速度(几百毫秒)去从关系型数据库中直接获取我们想要的数据。
针对上面的情况,可以考虑使用elasticsearch来进行数据的汇总,然后提供给后台进行搜索,可以大大提高检索的效率。
数据在存储在关系型数据库(如mysql)中,我们怎样将这部分数据转移到elasticsearch中。这篇文章将介绍一个同步神器:logstash-input-jdbc
安装
- 在官网下载最新的安装包:
wget https://artifacts.elastic.co/downloads/logstash/logstash-6.2.4.tar.gz解压并转移目录:
tar zxvf logstash-6.2.4.tar.gz mv ./logstash-6.2.4 /usr/local/logstash
配置
- 安装插件
由于这里是从mysql同步数据到elasticsearch,所以需要安装jdbc的入插件和elasticsearch的出插件:logstash-input-jdbc、logstash-output-elasticsearch
安装效果图如下所示:
- 下载mysql连接库
由于logstash是ruby开发的,所以这里要下载mysql的连接库jar包,从官网下载,我这里下载的是:mysql-connector-java-5.1.46.jar
将下载好的mysql-connector-java-5.1.46.jar,放至/usr/local/logstash/config/目录下。- 修改配置文件
在config目录下,创建配置文件(logstash-mysql-es.conf):这里有几个注意点:input { jdbc { # mysql相关jdbc配置 jdbc_connection_string => "jdbc:mysql://10.112.76.30:3306/jack_test?useUnicode=true&characterEncoding=utf-8&useSSL=false" jdbc_user => "root" jdbc_password => "123456" # jdbc连接mysql驱动的文件目录,可去官网下载:https://dev.mysql.com/downloads/connector/j/ jdbc_driver_library => "./config/mysql-connector-java-5.1.46.jar" # the name of the driver class for mysql jdbc_driver_class => "com.mysql.jdbc.Driver" jdbc_paging_enabled => true jdbc_page_size => "50000" jdbc_default_timezone =>"Asia/Shanghai" # mysql文件, 也可以直接写SQL语句在此处,如下: # statement => "select * from t_order where update_time >= :sql_last_value;" statement_filepath => "./config/jdbc.sql" # 这里类似crontab,可以定制定时操作,比如每分钟执行一次同步(分 时 天 月 年) schedule => "* * * * *" #type => "jdbc" # 是否记录上次执行结果, 如果为真,将会把上次执行到的 tracking_column 字段的值记录下来,保存到 last_run_metadata_path 指定的文件中 #record_last_run => true # 是否需要记录某个column 的值,如果record_last_run为真,可以自定义我们需要 track 的 column 名称,此时该参数就要为 true. 否则默认 track 的是 timestamp 的值. use_column_value => true # 如果 use_column_value 为真,需配置此参数. track 的数据库 column 名,该 column 必须是递增的. 一般是mysql主键 tracking_column => "update_time" tracking_column_type => "timestamp" last_run_metadata_path => "./logstash_capital_bill_last_id" # 是否清除 last_run_metadata_path 的记录,如果为真那么每次都相当于从头开始查询所有的数据库记录 clean_run => false #是否将 字段(column) 名称转小写 lowercase_column_names => false } } output { elasticsearch { hosts => "10.112.76.31:9200" index => "mysql_order" document_id => "%{id}" template_overwrite => true } # 这里输出调试,正式运行时可以注释掉 stdout { codec => json_lines } }
(1)jdbc_driver_library
mysql-connector-java-5.1.46.jar的存放目录,这个一定要配置正确,支持全路径和相对路径。如果配置不对,将会报“can ”错误。
(2)sql_last_value
标志目前logstash同步的位置信息(类似offset)。比如id、updatetime。logstash通过这个标志,可以判断目前同步到哪一条数据。
(3)statement、statement_filepath
statement:执行同步的sql语句,可以同步部分数据。
statement_filepath:存储执行同步的sql语句。不和statement同时使用。
(4)schedule
定时器,表示每隔多长时间同步一次数据。格式类似crontab。
(5)tracking_column、tracking_column_type
tracking_column:表示表中哪一列用于判断logstash同步的位置信息。与sql_last_value比较判断是否需要同步这条数据。
tracking_column_type:racking_column指定列的类型。支持两种类型:numeric(默认)、timestamp。注意:如果列是时间字段(比如updateTime),一定要指定这个类型为timestamp。我就踩了这个大坑。。。一直同步不成功!!!
(6)last_run_metadata_path
存储sql_last_value值的文件名称及位置。
(7)document_id
生成elasticsearch的文档值,尽量使用同步的数据中已有的唯一标识。比如同步订单数据,可以使用订单号。


启动
在根目录下,执行命令:
nohup bin/logstash -f config/logstash-mysql-es.conf > logs/logstash.out &效果图如下:
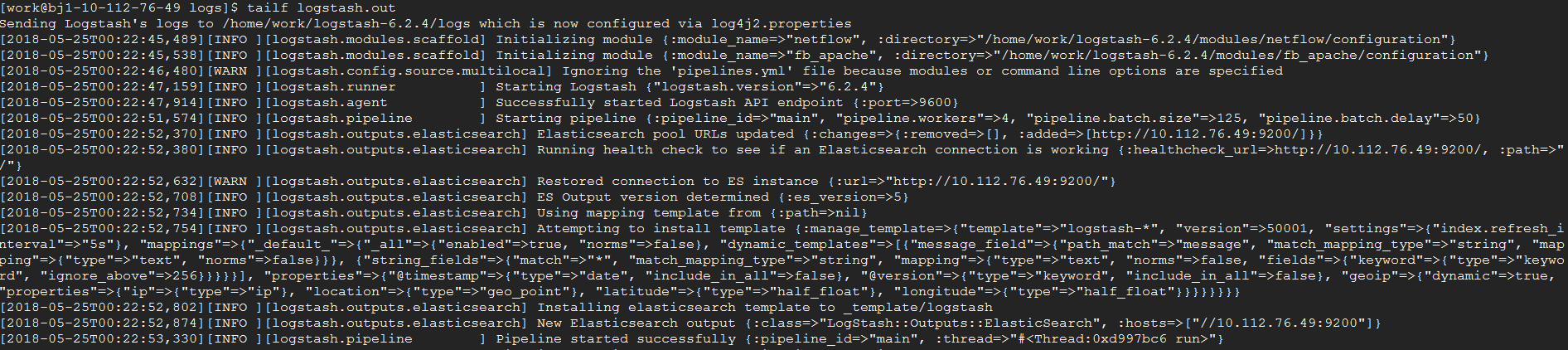
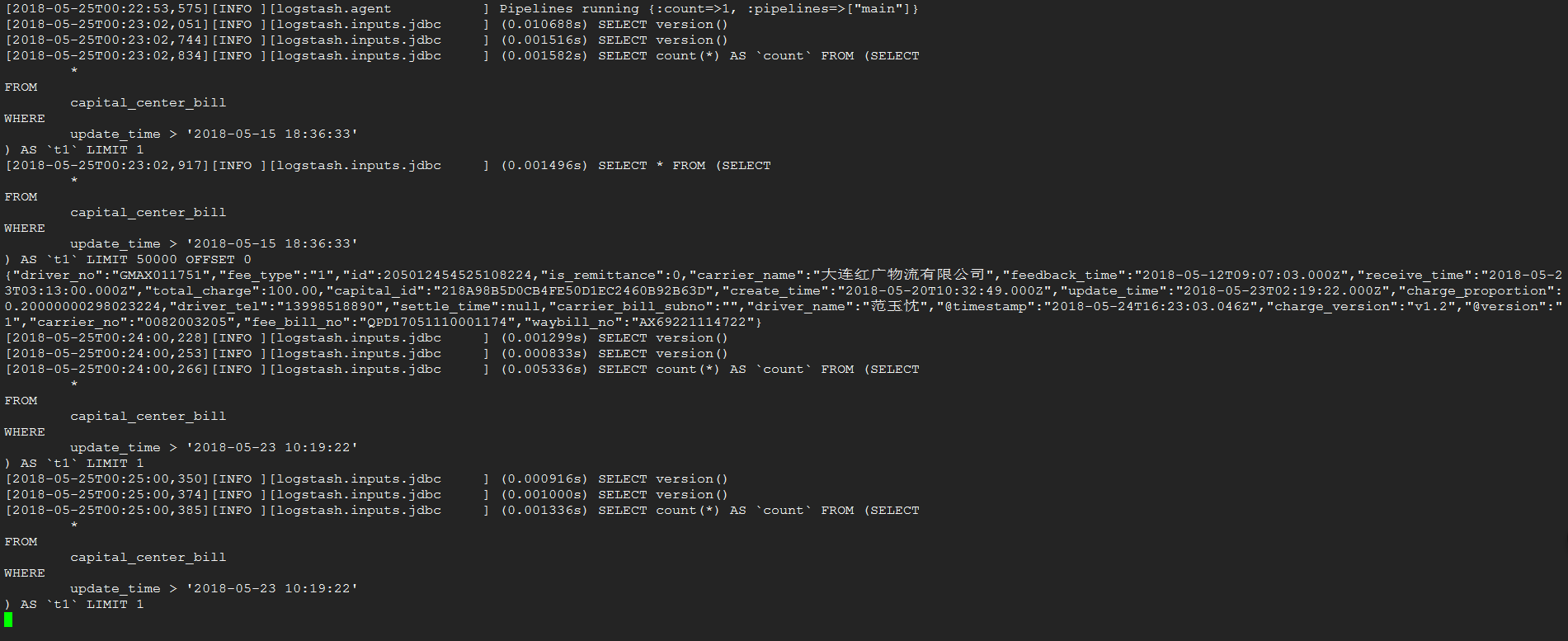
同步
完成了一条数据的同步
关于Elasticsearch与MySQL数据同步的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于canal-1.1.5实时同步MySQL数据到Elasticsearch、canal同步mysql数据至elasticSearch、Docker环境下Mysql数据同步到Elasticsearch、Elasticsearch - Logstash实现mysql同步数据到elasticsearch的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

