如果您想了解【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇和springboot整合elasticsearch7.0的知识,那么本篇文章将是您的不二之选。我们
如果您想了解【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇和springboot整合elasticsearch7.0的知识,那么本篇文章将是您的不二之选。我们将深入剖析【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇的各个方面,并为您解答springboot整合elasticsearch7.0的疑在这篇文章中,我们将为您介绍【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇的相关知识,同时也会详细的解释springboot整合elasticsearch7.0的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- 【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇(springboot整合elasticsearch7.0)
- 2万字长文揭示SpringBoot整合ElasticSearch的高阶妙用!
- ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch
- Elasticsearch7.10.0集群搭建以及SpringBoot整合操作ES
- Elasticsearch学习(3) spring boot整合Elasticsearch的原生方式
")
【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇(springboot整合elasticsearch7.0)
本专栏将从基础开始,循序渐进,以实战为线索,逐步深入SpringBoot相关知识相关知识,打造完整的SpringBoot学习步骤,提升工程化编码能力和思维能力,写出高质量代码。希望大家都能够从中有所收获,也请大家多多支持。
专栏地址:SpringBoot专栏
本文涉及的代码都已放在gitee上:gitee地址
如果文章知识点有错误的地方,请指正!大家一起学习,一起进步。
专栏汇总:专栏汇总
文章目录
- SpringBoot整合ES
- 安装
- 基本操作
- 整合
SpringBoot整合ES
Redis可以使用内存加载数据并实现数据快速访问,MongoDB可以在内存中存储类似对象的数据并实现数据的快速访问,在企业级开发中对于速度的追求是永无止境的。下面要讲的内容也是一款Nosql解决方案,只不过他的作用不是为了直接加速数据的读写,而是加速数据的查询的,叫做ES技术。
ES(Elasticsearch)是一个分布式全文搜索引擎,重点是全文搜索。
那什么是全文搜索呢?比如用户要买一本书,以java为关键字进行搜索,不管是书名中还是书的介绍中,甚至是书的作者名字,只要包含java就作为查询结果返回给用户查看,上述过程就使用了全文搜索技术。搜索的条件不再是仅用于对某一个字段进行比对,而是在一条数据中使用搜索条件去比对更多的字段,只要能匹配上就列入查询结果,这就是全文搜索的目的。而ES技术就是一种可以实现上述效果的技术。
要实现全文搜索的效果,不可能使用数据库中like操作去进行比对,这种效率太低了。ES设计了一种全新的思想,来实现全文搜索。具体操作过程如下:
-
将被查询的字段的数据全部文本信息进行查分,分成若干个词
- 例如“中华人民共和国”就会被拆分成三个词,分别是“中华”、“人民”、“共和国”,此过程有专业术语叫做分词。分词的策略不同,分出的效果不一样,不同的分词策略称为分词器。
-
将分词得到的结果存储起来,对应每条数据的id
-
例如id为1的数据中名称这一项的值是“中华人民共和国”,那么分词结束后,就会出现“中华”对应id为1,“人民”对应id为1,“共和国”对应id为1
-
例如id为2的数据中名称这一项的值是“人民代表大会“,那么分词结束后,就会出现“人民”对应id为2,“代表”对应id为2,“大会”对应id为2
-
此时就会出现如下对应结果,按照上述形式可以对所有文档进行分词。需要注意分词的过程不是仅对一个字段进行,而是对每一个参与查询的字段都执行,最终结果汇总到一个表格中
分词结果关键字 对应id 中华 1 人民 1,2 共和国 1 代表 2 大会 2
-
-
当进行查询时,如果输入“人民”作为查询条件,可以通过上述表格数据进行比对,得到id值1,2,然后根据id值就可以得到查询的结果数据了。
上述过程中分词结果关键字内容每一个都不相同,作用有点类似于数据库中的索引,是用来加速数据查询的。但是数据库中的索引是对某一个字段进行添加索引,而这里的分词结果关键字不是一个完整的字段值,只是一个字段中的其中的一部分内容。并且索引使用时是根据索引内容查找整条数据,全文搜索中的分词结果关键字查询后得到的并不是整条的数据,而是数据的id,要想获得具体数据还要再次查询,因此这里为这种分词结果关键字起了一个全新的名称,叫做倒排索引。
通过上述内容的学习,发现使用ES其实准备工作还是挺多的,必须先建立文档的倒排索引,然后才能继续使用。快速了解一下ES的工作原理,下面直接开始我们的学习,老规矩,先安装,再操作,最后说整合。
安装
windows版安装包下载地址:https://www.elastic.co/cn/downloads/elasticsearch
下载的安装包是解压缩就能使用的zip文件,解压缩完毕后会得到如下文件

- bin目录:包含所有的可执行命令
- config目录:包含ES服务器使用的配置文件
- jdk目录:此目录中包含了一个完整的jdk工具包,版本17,当ES升级时,使用最新版本的jdk确保不会出现版本支持性不足的问题
- lib目录:包含ES运行的依赖jar文件
- logs目录:包含ES运行后产生的所有日志文件
- modules目录:包含ES软件中所有的功能模块,也是一个一个的jar包。和jar目录不同,jar目录是ES运行期间依赖的jar包,modules是ES软件自己的功能jar包
- plugins目录:包含ES软件安装的插件,默认为空
启动服务器
elasticsearch.bat
双击elasticsearch.bat文件即可启动ES服务器,默认服务端口9200。通过浏览器访问http://localhost:9200看到如下信息视为ES服务器正常启动
{
"name" : "CZBK-**********",
"cluster_name" : "elasticsearch",
"cluster_uuid" : "j137DSswTPG8U4Yb-0T1Mg",
"version" : {
"number" : "7.16.2",
"build_flavor" : "default",
"build_type" : "zip",
"build_hash" : "2b937c44140b6559905130a8650c64dbd0879cfb",
"build_date" : "2021-12-18T19:42:46.604893745Z",
"build_snapshot" : false,
"lucene_version" : "8.10.1",
"minimum_wire_compatibility_version" : "6.8.0",
"minimum_index_compatibility_version" : "6.0.0-beta1"
},
"tagline" : "You KNow,for Search"
}
基本操作
ES中保存有我们要查询的数据,只不过格式和数据库存储数据格式不同而已。在ES中我们要先创建倒排索引,这个索引的功能又点类似于数据库的表,然后将数据添加到倒排索引中,添加的数据称为文档。所以要进行ES的操作要先创建索引,再添加文档,这样才能进行后续的查询操作。
要操作ES可以通过Rest风格的请求来进行,也就是说发送一个请求就可以执行一个操作。比如新建索引,删除索引这些操作都可以使用发送请求的形式来进行。
-
创建索引,books是索引名称,下同
PUT请求 http://localhost:9200/books发送请求后,看到如下信息即索引创建成功
{ "ackNowledged": true, "shards_ackNowledged": true, "index": "books" }重复创建已经存在的索引会出现错误信息,reason属性中描述错误原因
{ "error": { "root_cause": [ { "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "books" } ], "type": "resource_already_exists_exception", "reason": "index [books/VgC_XMVAQmedaiBNSgO2-w] already exists", # books索引已经存在 "index_uuid": "VgC_XMVAQmedaiBNSgO2-w", "index": "book" }, "status": 400 } -
查询索引
GET请求 http://localhost:9200/books查询索引得到索引相关信息,如下
{ "book": { "aliases": {}, "mappings": {}, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645768584849", "number_of_replicas": "1", "uuid": "VgC_XMVAQmedaiBNSgO2-w", "version": { "created": "7160299" } } } } }如果查询了不存在的索引,会返回错误信息,例如查询名称为book的索引后信息如下
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [book]", "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "index": "book" } ], "type": "index_not_found_exception", "reason": "no such index [book]", # 没有book索引 "resource.type": "index_or_alias", "resource.id": "book", "index_uuid": "_na_", "status": 404 } -
删除索引
DELETE请求 http://localhost:9200/books删除所有后,给出删除结果
{ "ackNowledged": true }如果重复删除,会给出错误信息,同样在reason属性中描述具体的错误原因
{ "error": { "root_cause": [ { "type": "index_not_found_exception", "reason": "no such index [books]", "reason": "no such index [books]", # 没有books索引 "resource.type": "index_or_alias", "status": 404 } -
创建索引并指定分词器
前面创建的索引是未指定分词器的,可以在创建索引时添加请求参数,设置分词器。目前国内较为流行的分词器是IK分词器,使用前先在下对应的分词器,然后使用。IK分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
分词器下载后解压到ES安装目录的plugins目录中即可,安装分词器后需要重新启动ES服务器。使用IK分词器创建索引格式:
PUT请求 http://localhost:9200/books 请求参数如下(注意是json格式的参数) { "mappings":{ #定义mappings属性,替换创建索引时对应的mappings属性 "properties":{ #定义索引中包含的属性设置 "id":{ #设置索引中包含id属性 "type":"keyword" #当前属性可以被直接搜索 }, "name":{ #设置索引中包含name属性 "type":"text", #当前属性是文本信息,参与分词 "analyzer":"ik_max_word", #使用IK分词器进行分词 "copy_to":"all" #分词结果拷贝到all属性中 }, "type":{ "type":"keyword" }, "description":{ "type":"text", "analyzer":"ik_max_word", "copy_to":"all" }, "all":{ #定义属性,用来描述多个字段的分词结果集合,当前属性可以参与查询 "type":"text", "analyzer":"ik_max_word" } } } } 创建完毕后返回结果和不使用分词器创建索引的结果是一样的,此时可以通过查看索引信息观察到添加的请求参数mappings已经进入到了索引属性中
{ "books": { "aliases": {}, "mappings": { #mappings属性已经被替换 "properties": { "all": { "type": "text", "analyzer": "ik_max_word" }, "description": { "type": "text", "copy_to": [ "all" ], "id": { "type": "keyword" }, "name": { "type": "text", "type": { "type": "keyword" } } }, "settings": { "index": { "routing": { "allocation": { "include": { "_tier_preference": "data_content" } } }, "number_of_shards": "1", "provided_name": "books", "creation_date": "1645769809521", "number_of_replicas": "1", "uuid": "DohYKvr_SZO4KRGmbZYmTQ", "version": { "created": "7160299" } } } } }
目前我们已经有了索引了,但是索引中还没有数据,所以要先添加数据,ES中称数据为文档,下面进行文档操作。
-
添加文档,有三种方式
POST请求 http://localhost:9200/books/_doc #使用系统生成id POST请求 http://localhost:9200/books/_create/1 #使用指定id POST请求 http://localhost:9200/books/_doc/1 #使用指定id,不存在创建,存在更新(版本递增) 文档通过请求参数传递,数据格式json { "name":"springboot", "type":"springboot", "description":"springboot" } -
查询文档
GET请求 http://localhost:9200/books/_doc/1 #查询单个文档 GET请求 http://localhost:9200/books/_search #查询全部文档 -
条件查询
GET请求 http://localhost:9200/books/_search?q=name:springboot # q=查询属性名:查询属性值 -
删除文档
DELETE请求 http://localhost:9200/books/_doc/1 -
修改文档(全量更新)
PUT请求 http://localhost:9200/books/_doc/1 文档通过请求参数传递,数据格式json { "name":"springboot", "description":"springboot" } -
修改文档(部分更新)
POST请求 http://localhost:9200/books/_update/1 文档通过请求参数传递,数据格式json { "doc":{ #部分更新并不是对原始文档进行更新,而是对原始文档对象中的doc属性中的指定属性更新 "name":"springboot" #仅更新提供的属性值,未提供的属性值不参与更新操作 } }
以上操作对应的postman:https://www.getpostman.com/collections/97d4d61478f347717dc2
导入方式:

整合
使用springboot整合ES该如何进行呢?老规矩,导入坐标,做配置,使用API接口操作。整合Redis如此,整合MongoDB如此,整合ES依然如此。太没有新意了,其实不是没有新意,这就是springboot的强大之处,所有东西都做成相同规则,对开发者来说非常友好。
下面就开始springboot整合ES,操作步骤如下:
步骤①:导入springboot整合ES的starter坐标
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
步骤②:进行基础配置
spring:
elasticsearch:
rest:
uris: http://localhost:9200
配置ES服务器地址,端口9200
步骤③:使用springboot整合ES的专用客户端接口ElasticsearchRestTemplate来进行操作
@SpringBoottest
class Springboot18EsApplicationTests {
@Autowired
private ElasticsearchRestTemplate template;
}
上述操作形式是ES早期的操作方式,使用的客户端被称为Low Level Client,这种客户端操作方式性能方面略显不足,于是ES开发了全新的客户端操作方式,称为High Level Client。高级别客户端与ES版本同步更新,但是springboot最初整合ES的时候使用的是低级别客户端,所以企业开发需要更换成高级别的客户端模式。
下面使用高级别客户端方式进行springboot整合ES,操作步骤如下:
步骤①:导入springboot整合ES高级别客户端的坐标,此种形式目前没有对应的starter
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>elasticsearch-rest-high-level-client</artifactId>
</dependency>
步骤②:使用编程的形式设置连接的ES服务器,并获取客户端对象
@SpringBoottest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateClient() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
client.close();
}
}
配置ES服务器地址与端口9200,记得客户端使用完毕需要手工关闭。由于当前客户端是手工维护的,因此不能通过自动装配的形式加载对象。
步骤③:使用客户端对象操作ES,例如创建索引
@SpringBoottest
class Springboot18EsApplicationTests {
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
client.close();
}
}
高级别客户端操作是通过发送请求的方式完成所有操作的,ES针对各种不同的操作,设定了各式各样的请求对象,上例中创建索引的对象是CreateIndexRequest,其他操作也会有自己专用的Request对象。
当前操作我们发现,无论进行ES何种操作,第一步永远是获取RestHighLevelClient对象,最后一步永远是关闭该对象的连接。在测试中可以使用测试类的特性去帮助开发者一次性的完成上述操作,但是在业务书写时,还需要自行管理。将上述代码格式转换成使用测试类的初始化方法和销毁方法进行客户端对象的维护。
@SpringBoottest
class Springboot18EsApplicationTests {
@BeforeEach //在测试类中每个操作运行前运行的方法
void setUp() {
HttpHost host = HttpHost.create("http://localhost:9200");
RestClientBuilder builder = RestClient.builder(host);
client = new RestHighLevelClient(builder);
}
@AfterEach //在测试类中每个操作运行后运行的方法
void tearDown() throws IOException {
client.close();
}
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
client.indices().create(request, RequestOptions.DEFAULT);
}
}
现在的书写简化了很多,也更合理。下面使用上述模式将所有的ES操作执行一遍,测试结果
创建索引(IK分词器):
@Test
void testCreateIndexByIK() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("books");
String json = "{\n" +
" \"mappings\":{\n" +
" \"properties\":{\n" +
" \"id\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"name\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\",\n" +
" \"copy_to\":\"all\"\n" +
" },\n" +
" \"type\":{\n" +
" \"type\":\"keyword\"\n" +
" },\n" +
" \"description\":{\n" +
" \"type\":\"text\",\n" +
" \"all\":{\n" +
" \"type\":\"text\",\n" +
" \"analyzer\":\"ik_max_word\"\n" +
" }\n" +
" }\n" +
" }\n" +
"}";
//设置请求中的参数
request.source(json, XContentType.JSON);
client.indices().create(request, RequestOptions.DEFAULT);
}
IK分词器是通过请求参数的形式进行设置的,设置请求参数使用request对象中的source方法进行设置,至于参数是什么,取决于你的操作种类。当请求中需要参数时,均可使用当前形式进行参数设置。
添加文档:
@Test
//添加文档
void testCreateDoc() throws IOException {
Book book = bookDao.selectById(1);
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
client.index(request,RequestOptions.DEFAULT);
}
添加文档使用的请求对象是IndexRequest,与创建索引使用的请求对象不同。
批量添加文档:
@Test
//批量添加文档
void testCreateDocAll() throws IOException {
List<Book> bookList = bookDao.selectList(null);
BulkRequest bulk = new BulkRequest();
for (Book book : bookList) {
IndexRequest request = new IndexRequest("books").id(book.getId().toString());
String json = JSON.toJSONString(book);
request.source(json,XContentType.JSON);
bulk.add(request);
}
client.bulk(bulk,RequestOptions.DEFAULT);
}
批量做时,先创建一个BulkRequest的对象,可以将该对象理解为是一个保存request对象的容器,将所有的请求都初始化好后,添加到BulkRequest对象中,再使用BulkRequest对象的bulk方法,一次性执行完毕。
按id查询文档:
@Test
//按id查询
void testGet() throws IOException {
GetRequest request = new GetRequest("books","1");
GetResponse response = client.get(request, RequestOptions.DEFAULT);
String json = response.getSourceAsstring();
System.out.println(json);
}
根据id查询文档使用的请求对象是GetRequest。
按条件查询文档:
@Test
//按条件查询
void testSearch() throws IOException {
SearchRequest request = new SearchRequest("books");
SearchSourceBuilder builder = new SearchSourceBuilder();
builder.query(QueryBuilders.termQuery("all","spring"));
request.source(builder);
SearchResponse response = client.search(request, RequestOptions.DEFAULT);
SearchHits hits = response.getHits();
for (SearchHit hit : hits) {
String source = hit.getSourceAsstring();
//System.out.println(source);
Book book = JSON.parSEObject(source, Book.class);
System.out.println(book);
}
}
按条件查询文档使用的请求对象是SearchRequest,查询时调用SearchRequest对象的termQuery方法,需要给出查询属性名,此处支持使用合并字段,也就是前面定义索引属性时添加的all属性。
springboot整合ES的操作到这里就说完了,与前期进行springboot整合redis和mongodb的差别还是蛮大的,主要原始就是我们没有使用springboot整合ES的客户端对象。至于操作,由于ES操作种类过多,所以显得操作略微有点复杂。
关于es完整的示例参考:代码链接
总结
- springboot整合ES步骤
- 导入springboot整合ES的High Level Client坐标
- 手工管理客户端对象,包括初始化和关闭操作
- 使用High Level Client根据操作的种类不同,选择不同的Request对象完成对应操作

2万字长文揭示SpringBoot整合ElasticSearch的高阶妙用!
今天我们来来讲解如何在Spring boot的项目中操作Elasticsearch,本章采用的API是官方的Java High Level REST Client v7.9.1。在学习本章以前,你最好已经掌握基本的Java后端开发知识并会使用Spring boot开发框架。由于篇幅的限制,本章只讲解比较常用的代码实现,很多代码可以复用,大家可以在实际项目中举一反三。
8.1 开发前的准备
去码云上下载本章的源代码,地址为https://gitee.com/shenzhanwang/Spring-elastic_search,然后将它导入IDE,它是一个标准的Spring boot工程,该工程的各个package说明如下:
(1)boot.spring.config:包含全局的配置类,例如允许接口跨域的配置。
(2)boot.spring.controller:包含各种后台接口的控制器。
(3)boot.spring,elastic.client:包含连接Elasticsearch的客户端配置类。
(4)boot.spring.elastic.service:包含读写Elasticsearch的通用方法服务,包含建索引、搜索和统计分析的三个服务类。
(5)boot.spring.pagemodel:包含主要用于下发到前端的对象类。
(6)boot.spring.po:包含索引字段结构的对象。
(7)boot.spring.util:包含常用的工具类。
在pom.xml中,需要引入相关的依赖:
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.9.1</version> </dependency> <dependency> <groupId>org.elasticsearch</groupId> <artifactId>elasticsearch</artifactId> <version>7.9.1</version> </dependency>
在包boot.spring.elastic.client中,有一个RestHighLevelClient的客户端,它会读取application.yml中的es.url,向配置的Elasticsearch地址发送请求。使用时,请把es.url的配置改为实际的地址,多个节点之间用逗号隔开。客户端配置类的代码如下:
@Configuration
public class Client {
@Value("${es.url}")
private String esUrl;
@Bean
RestHighLevelClient configRestHighLevelClient() throws Exception {
String[] esUrlArr = esUrl.split(",");
List<HttpHost> httpHosts = new ArrayList<>();
for(String es : esUrlArr){
String[] esUrlPort = es.split(":");
httpHosts.add(new HttpHost(esUrlPort[0], Integer.parseInt(esUrlPort[1]), "http"));
}
return new RestHighLevelClient(RestClient.builder(httpHosts.toArray(new HttpHost[0])));
}
}现在运行该Spring boot项目,访问http://localhost:8080/index就能进入工程的首页,界面如图8.1所示。在后面的章节中,将会陆续介绍导航菜单中的各个功能,完成索引的建立、搜索和统计分析。
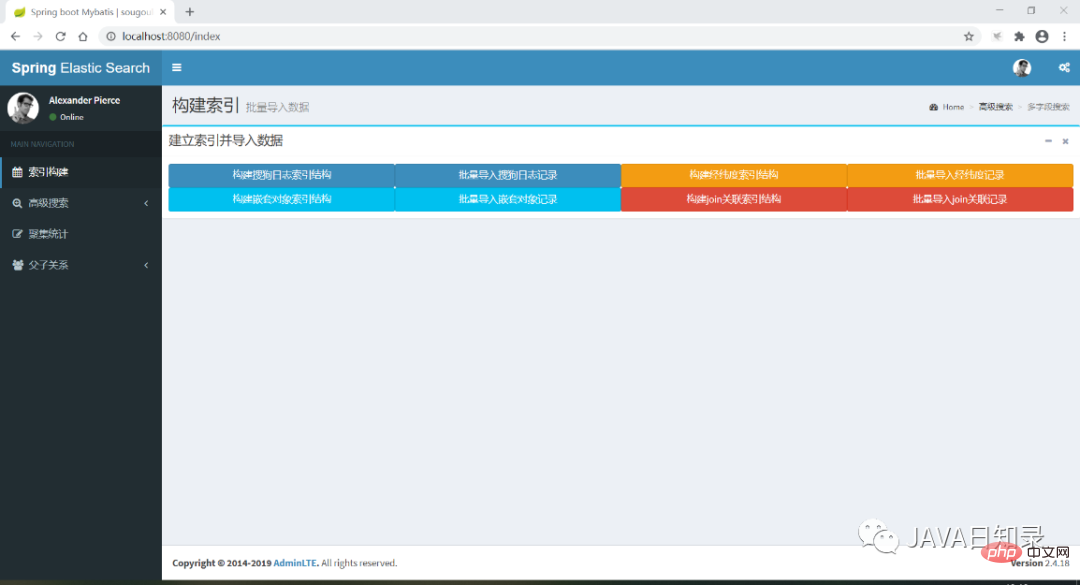
8.2 建立索引并导入数据
本节探讨如何使用Java代码创建索引的映射并写入数据到索引,演示的实例包括四个索引:使用最细粒度分析器进行分词的索引sougoulog、包含经纬度坐标点的索引shop、包含嵌套对象的索引city、包含Join字段的索引cityjoincountry。
8.2.1 创建映射
1.自定义分析器的映射sougoulog
创建sougoulog索引的映射接口在类IndexController中,你可以使用XContentBuilder对象非常优雅地创建json格式的映射,其中关键的代码如下:
@ApiOperation("创建索引sougoulog")
@RequestMapping(value="/createIndexMapping",method = RequestMethod.GET)
@ResponseBody
MSG createMapping() throws Exception{
// 创建sougoulog索引映射
boolean exsit = indexService.existIndex("sougoulog");
if ( exsit == false ) {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
…...
builder.startObject("analyzer");
{
builder.startObject("my_analyzer");
{
builder.field("filter", "my_filter");
builder.field("char_filter", "");
builder.field("type", "custom");
builder.field("tokenizer", "my_tokenizer");
}
builder.endObject();
}
builder.endObject();
…...
builder.startObject("keywords");
{
builder.field("type", "text");
builder.field("analyzer", "my_analyzer");
builder.startObject("fields");
{
builder.startObject("keyword");
{
builder.field("type", "keyword");
builder.field("ignore_above", "256");
}
builder.endObject();
}
builder.endObject();
}
builder.endObject();
......
}
builder.endObject();
System.out.println(builder.prettyPrint());
indexService.createMapping("sougoulog", builder);
}
return new MSG("index success");
}在这个接口中,创建的映射sougoulog包含一个名为my_tokenizer的分析器,并且将这个分析器应用到了keywords、url、userid这三个字段中,它会把这三个字段的文本切割到最细粒度,用于多文本字段搜索的功能。在接口的末尾createMapping方法会根据写好的json结构创建名为sougoulog的映射。indexService的方法createMapping的内容如下:
@Override
public void createMapping(String indexname, XContentBuilder mapping) {
try {
CreateIndexRequest index = new CreateIndexRequest(indexname);
index.source(mapping);
client.indices().create(index, RequestOptions.DEFAULT);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}创建映射时,需要新建一个CreateIndexRequest对象,为该对象设置XContentBuilder载入映射的具体字段信息,最后使用RestHighLevelClient对象发起构建映射的请求。
2.包含经纬度坐标的映射
下面的接口createShopMapping创建了一个名为shop的索引,里面包含一个经纬度坐标字段,其部分代码如下:
@ApiOperation("创建shop索引")
@RequestMapping(value="/createShopMapping",method = RequestMethod.GET)
@ResponseBody
MSG createShopMapping() throws Exception{
// 创建shop索引映射
boolean exsit = indexService.existIndex("shop");
if ( exsit == false ) {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
……
builder.startObject("location");
{
builder.field("type", "geo_point");
}
builder.endObject();
……
}
builder.endObject();
System.out.println(builder.prettyPrint());
indexService.createMapping("shop",builder);
}
return new MSG("index success");
}它的实现过程跟sougoulog索引是一样的,都是先用XContentBuilder构建映射内容,然后由客户端发起CreateIndexRequest请求把索引创建出来。
3.包含嵌套对象的映射
下面的接口createCityMapping创建了一个名为city的索引,它包含一个嵌套对象,用于存放城市所属的国家数据,部分代码如下:
@ApiOperation("创建城市索引")
@RequestMapping(value="/createCityMapping",method = RequestMethod.GET)
@ResponseBody
MSG createCityMapping() throws Exception{
// 创建shop索引映射
boolean exsit=indexService.existIndex("city");
if(exsit==false){
XContentBuilder builder=XContentFactory.jsonBuilder();
builder.startObject();
{
……
builder.startObject("country");
{
builder.field("type","nested");
builder.startObject("properties");
{
……
}
……
indexService.createMapping("city",builder);
}
return new MSG("index success");
}
}
}4.包含join类型的映射
接口createJoinMapping创建一个带有join字段的索引cityjoincountry,该索引包含父关系country、子关系city,其创建方法也是类似的:
@ApiOperation("创建一对多关联索引")
@RequestMapping(value="/createJoinMapping",method = RequestMethod.GET)
@ResponseBody
MSG createJoinMapping() throws Exception {
// 创建shop索引映射
boolean exsit = indexService.existIndex("cityjoincountry");
if ( exsit == false ) {
XContentBuilder builder = XContentFactory.jsonBuilder();
builder.startObject();
{
……
builder.startObject("joinkey");
{
builder.field("type", "join");
builder.startObject("relations");
{
builder.field("country", "city");
}
builder.endObject();
}
builder.endObject();
……
}
builder.endObject();
indexService.createMapping("cityjoincountry",builder);
}
return new MSG("index success");
}8.2.2 写入数据
向索引写入数据的格式通常有两种,一种是使用json字符串格式,另一种是使用Hashmap对象写入各个字段。
1.使用json字符串写入一条数据
向索引写入数据的请求需要使用IndexRequest对象,它可以接收一个索引名称作为参数,通过方法id为索引指定主键,你还需要使用source方法指定传入的数据格式和数据本身的json字符串:
@ApiOperation("索引一个日志文档")
@RequestMapping(value="/indexSougoulog", method = RequestMethod.POST)
@ResponseBody
MSG indexDoc(@RequestBody Sougoulog log){
IndexRequest indexRequest = new IndexRequest("sougoulog").id(String.valueOf(log.getId()));
indexRequest.source(JSON.toJSONString(log), XContentType.JSON);
try {
client.index(indexRequest, RequestOptions.DEFAULT);
} catch(ElasticsearchException e ) {
if (e.status() == RestStatus.CONFLICT) {
System.out.println("写入索引产生冲突"+e.getDetailedMessage());
}
} catch(IOException e) {
e.printStackTrace();
}
return new MSG("index success");
}2.使用Hashmap格式写入数据
使用Hashmap写入数据时,最大的区别是在使用source方法时,要传入Hashmap对象,在IndexServiceImpl中包含了这一方法:
@Override
public void indexDoc(String indexName, String id, Map<String, Object> doc) {
IndexRequest indexRequest = new IndexRequest(indexName).id(id).source(doc);
try {
IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("新增成功" + response.toString());
} catch(ElasticsearchException e ) {
if (e.status() == RestStatus.CONFLICT) {
System.out.println("写入索引产生冲突"+e.getDetailedMessage());
}
} catch(IOException e) {
e.printStackTrace();
}
}3.批量写入数据
批量写入数据在实际应用中更为常见,也支持json格式或Hashmap格式,需要用到批量请求对象BulkRequest。这里列出使用Hashmap批量写入数据的关键代码:
@Override
public void indexDocs(String indexName, List<Map<String, Object>> docs) {
try {
if (null == docs || docs.size() <= 0) {
return;
}
BulkRequest request = new BulkRequest();
for (Map<String, Object> doc : docs) {
request.add(new IndexRequest(indexName).id((String)doc.get("key")).source(doc));
}
BulkResponse bulkResponse = client.bulk(request, RequestOptions.DEFAULT);
……
} catch (IOException e) {
e.printStackTrace();
}
}在这个方法中,传入的参数是包含多个Hashmap的列表,BulkRequest需要循环将每个Hashmap数据载入进来,最后通过客户端的bulk方法一次性提交写入所有的数据。
实际上,四个索引的数据导入都是采用Hashmap格式进行批量导入,数据源在resources文件夹下,有四个txt文件,有四个接口会分别读取这四个文本文件导入到对应的索引中。当你在写入嵌套对象的字段时,你需要将嵌入的文本作为一个单独的Hashmap来写入。
4.写入带有路由的数据
当你想为join字段写入数据时,需要先写入父文档,再写入子文档,并且写入子文档时会带有路由参数,写入数据时,需要给indexRequest对象设置routing参数来指定路由,关键的代码如下:
@Override
public void indexDocWithRouting(String indexName, String route, Map<String, Object> doc) {
IndexRequest indexRequest = new IndexRequest(indexName).id((String)doc
.get("key")).source(doc);
indexRequest.routing(route);
try {
IndexResponse response = client.index(indexRequest, RequestOptions.DEFAULT);
System.out.println("新增成功" + response.toString());
} catch(ElasticsearchException e ) {
if (e.status() == RestStatus.CONFLICT) {
System.out.println("写入索引产生冲突"+e.getDetailedMessage());
}
} catch(IOException e) {
e.printStackTrace();
}
}5.修改数据
修改数据的请求需要使用UpdateRequest对象来实现,该对象需要指定修改数据的主键,如果主键不存在则会报错。为了达到upsert的效果,也就是主键不存在时执行添加操作,需要设置docAsUpsert参数为true。最后调用客户端的update方法即可更新成功:
@Override
public void updateDoc(String indexName, String id, Map<String, Object> doc) {
UpdateRequest request = new UpdateRequest(indexName, id).doc(doc);
request.docAsUpsert(true);
try {
UpdateResponse updateResponse = client.update(request, RequestOptions.DEFAULT);
long version = updateResponse.getVersion();
if (updateResponse.getResult() == DocWriteResponse.Result.CREATED) {
System.out.println("insert success, version is " + version);
} else if (updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {
System.out.println("update success, version is " + version);
}
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}6.删除数据
要删除数据,需要使用DeleteRequest对象,传入索引的名称和主键,调用客户端的删除方法即可,代码如下:
@Override
public int deleteDoc(String indexName, String id) {
DeleteResponse deleteResponse = null;
DeleteRequest request = new DeleteRequest(indexName, id);
try {
deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println("删除成功" + deleteResponse.toString());
if (deleteResponse.getResult() == DocWriteResponse.Result.NOT_FOUND) {
System.out.println("删除失败,文档不存在" + deleteResponse.toString());
return -1;
}
} catch (ElasticsearchException e) {
if (e.status() == RestStatus.CONFLICT) {
System.out.println("删除失败,版本号冲突" + deleteResponse.toString());
return -2;
}
} catch (IOException e) {
e.printStackTrace();
return -3;
}
return 1;
}以上就是几种常规的数据写入方式,请进入工程首页,在“索引构建”菜单下,点击各个按钮,就可以完成每个索引的建立和数据的导入,下一节将演示如何搜索这些索引的数据。
8.3 搜索数据
本节演示前面四个索引数据的几种常规的搜索方法,搜索时,为了实现5.4.1节描述的通用搜索结构模板,需要使用的布尔查询代码如下:
// 创建搜索请求对象
SearchRequest searchRequest = new SearchRequest(request.getQuery().getIndexname());
// 创建搜索请求的构造对象
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
// 设置布尔查询的内容
BoolQueryBuilder builder;
// 添加搜索上下文
builder = QueryBuilders.boolQuery().must(QueryBuilders.matchQuery("name", "zhangsan"));
// 添加过滤上下文
builder.filter(QueryBuilders.rangeQuery("born").from("2010-01-01").to("2011-01-01"));
// 设置布尔查询的结构体到搜索请求
searchSourceBuilder.query(builder);
// 载入搜索请求的参数
searchRequest.source(searchSourceBuilder);
// 由客户端发起布尔查询请求并得到结果
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);SearchSourceBuilder用于构建搜索请求的查询条件,为了创建布尔查询,这里使用了BoolQueryBuilder的must方法创建了一个搜索上下文,然后使用了filter方法创建了一个过滤上下文,你可以把实际用到的查询条件都放入这些上下文中组成需要的业务逻辑。搜索条件的参数设置好以后需要将其载入到SearchSourceBuilder对象中,除了搜索条件,排序、高亮、字段折叠有关的其它搜索参数也可以添加到SearchSourceBuilder中。设置完毕后,将构建好的搜索请求结构写入SearchRequest,最后由客户端发起search请求拿到搜索结果。
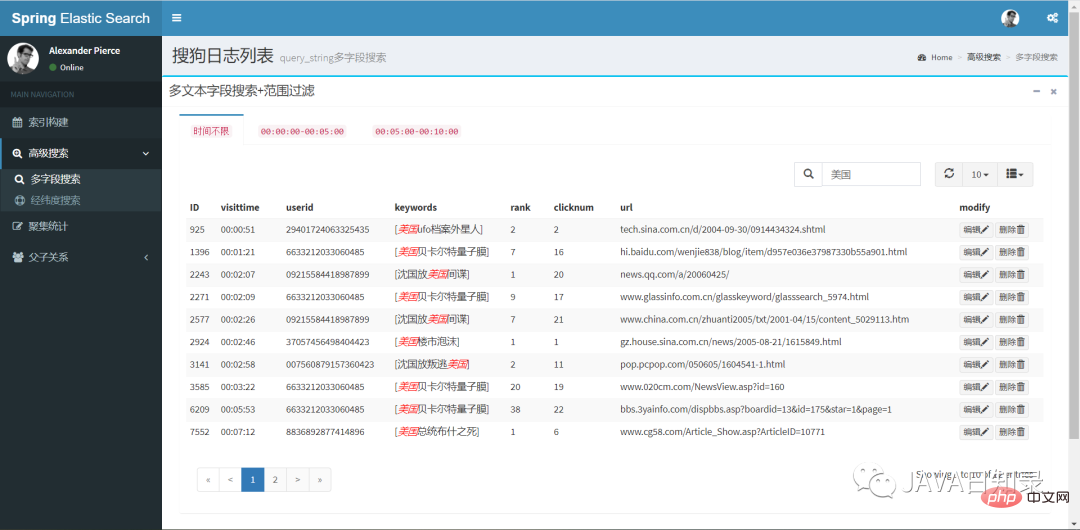
1.多文本字段搜索
在类SearchServiceImpl中,包含了各种不同的搜索方法,为了对sougoulog数据做多文本字段检索,在搜索上下文使用QueryBuilders创建了queryStringQuery,并且在过滤上下文添加了范围查询rangeQuery,核心代码如下:
@Override
public SearchResponse query_string(ElasticSearchRequest request){
SearchRequest searchRequest=new SearchRequest(request.getQuery().getIndexname());
// 如果关键词为空,则返回所有
String content=request.getQuery().getKeyWords();
Integer rows=request.getQuery().getRows();
if(rows==null||rows==0){
rows=10;
}
Integer start=request.getQuery().getStart();
if(content==null||"".equals(content)){
// 查询所有
content="*";
}
SearchSourceBuilder searchSourceBuilder=new SearchSourceBuilder();
// 提取搜索内容
BoolQueryBuilder builder;
if("*".equalsIgnoreCase(content)){
builder=QueryBuilders.boolQuery().must(QueryBuilders.queryStringQuery(content));
}else{
builder=QueryBuilders.boolQuery()
.must(QueryBuilders.queryStringQuery(ToolUtils.handKeyword(content)));
}
// 提取过滤条件
FilterCommand filter=request.getFilter();
if(filter!=null){
if(filter.getStartdate()!=null&&filter.getEnddate()!=null){
builder.filter(QueryBuilders.rangeQuery(filter.getField())
.from(filter.getStartdate()).to(filter.getEnddate()));
}
}
……
searchSourceBuilder.query(builder);
searchRequest.source(searchSourceBuilder);
SearchResponse searchResponse=null;
try{
searchResponse=client.search(searchRequest,RequestOptions.DEFAULT);
}catch(IOException e){
// TODO Auto-generated catch block
e.printStackTrace();
}
return searchResponse;
}这个方法先使用SearchRequest对象创建一个搜索请求,它接收索引名称的参数用于确定搜索范围,然后使用了BoolQueryBuilder创建了一个布尔查询,若要添加搜索的排序,需要给SearchSourceBuilder设置排序的参数:
searchSourceBuilder.sort(request.getQuery().getSort(), SortOrder.ASC);
第一个参数是排序的字段,第二个参数可以控制升序或降序。
为了添加搜索的高亮,需要使用HighlightBuilder,在field方法中指定高亮的字段列表,这里设置了对所有字段高亮,最后也要将高亮参数添加到SearchSourceBuilder中:
// 处理高亮
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("*");
searchSourceBuilder.highlighter(highlightBuilder);为了搜索全部数据并设置分页参数,需要在SearchSourceBuilder中设置以下参数:
// 查询全部 searchSourceBuilder.trackTotalHits(true); searchSourceBuilder.from(start); searchSourceBuilder.size(rows);
Query_string是功能强大的多文本字段搜索方法,具体的使用方式在5.2.6节介绍过,它的搜索效果如图8.2所示。
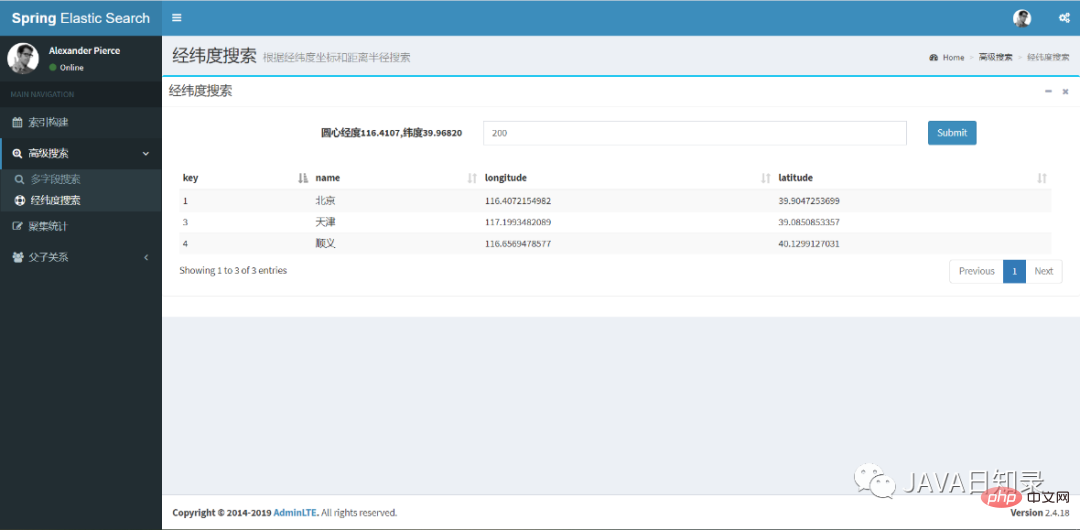
2.经纬度圆形搜索
为了实现5.3.1节中的经纬度圆形搜索,需要给QueryBuilders使用geoDistanceQuery,其它的部分与之前类似,其关键代码如下:
@Override
public SearchResponse geoDistanceSearch(String index, GeoDistance geo, Integer pagenum, Integer pagesize) {
SearchRequest searchRequest = new SearchRequest("shop");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
BoolQueryBuilder builder;
builder = QueryBuilders.boolQuery().must(QueryBuilders.geoDistanceQuery("location")
.point(geo.getLatitude(), geo.getLongitude())
.distance(geo.getDistance(), DistanceUnit.KILOMETERS));
SearchResponse searchResponse = null;
try {
searchSourceBuilder.query(builder);
searchSourceBuilder.trackTotalHits(true);
searchRequest.source(searchSourceBuilder);
int start = (pagenum - 1) * pagesize;
searchSourceBuilder.from(start);
searchSourceBuilder.size(pagesize);
searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
} catch (IOException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return searchResponse;
}经纬度搜索的前端效果如图8.3所示,你只需要填入检索半径就能找到中心点之内的城市列表。
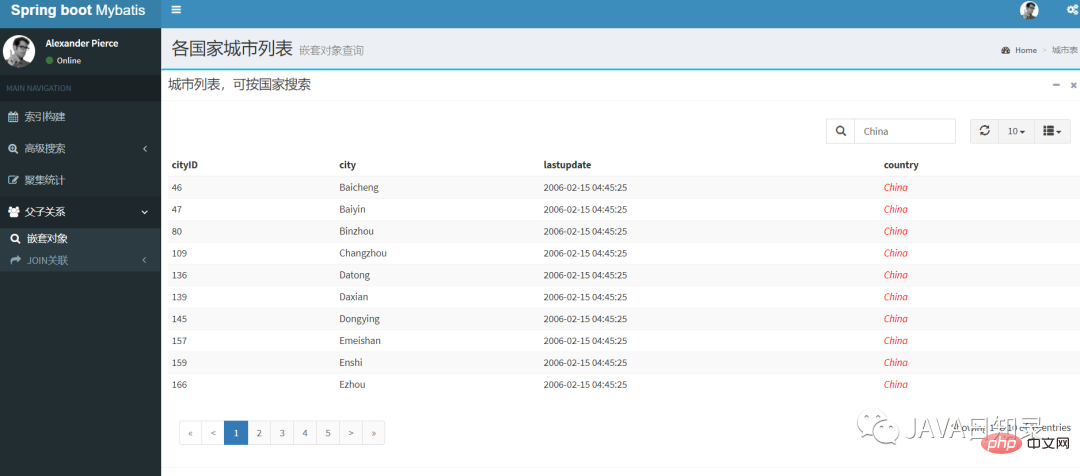
3.嵌套对象搜索
嵌套对象的搜索与其他搜索的重要区别是需要给QueryBuilders使用nestedQuery,该查询需要传入嵌套对象的路径参数,其关键代码如下:
BoolQueryBuilder builder = QueryBuilders.boolQuery() .must(QueryBuilders.nestedQuery(path, QueryBuilders.matchQuery(field, value), ScoreMode.None));
点击工程首页的“嵌套对象”导航菜单,你可以在该页面用国家作为搜索条件搜索嵌套对象,其效果如图8.4所示。
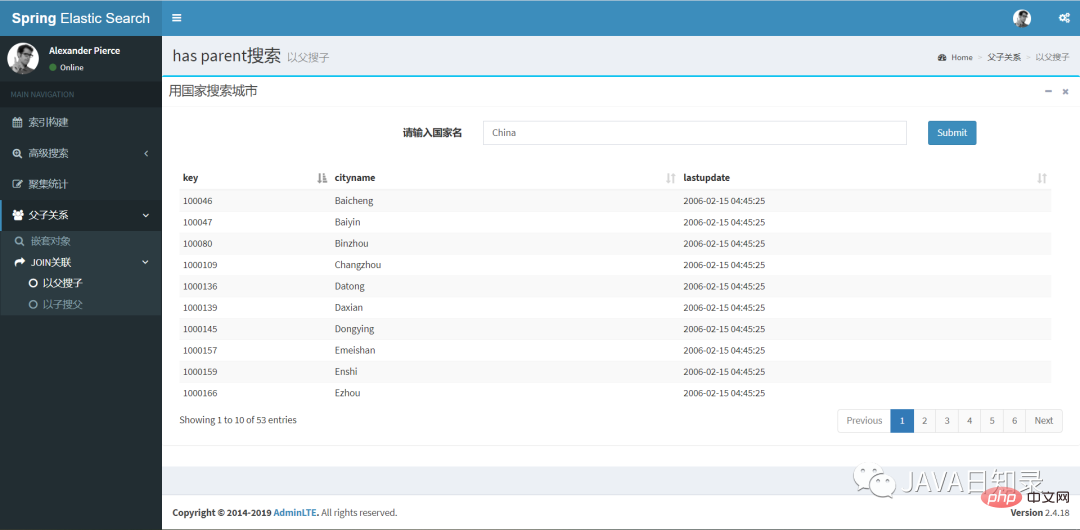
4.以父搜子
索引cityjoincountry已经包含了join类型的父子关联数据,要实现以父搜子,需要使用对象JoinQueryBuilders的hasParentQuery来构建查询条件:
builder = JoinQueryBuilders.hasParentQuery(parenttype, QueryBuilders .termQuery(field, value), false);
这个搜索的hasParentQuery需要传入父关系的名称,然后对父文档做了一个term搜索,参数false表示父文档的相关度不影响子文档的相关度得分。在页面“以父搜子”中,用国家搜索城市的效果如图8.5所示。
5.以子搜父
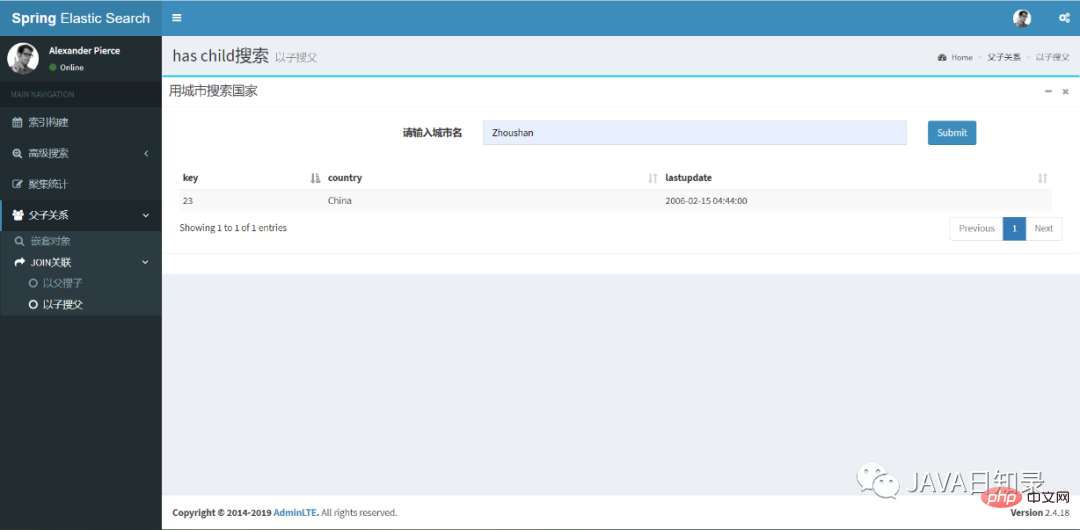
反过来,你可以使用hasChildQuery完成以子搜父的效果,其关键代码如下:
builder = JoinQueryBuilders.hasChildQuery(childtype, QueryBuilders.termQuery(field, value), ScoreMode.None);
对应的前端搜索效果,如图8.6所示。
以上就是几种常规的搜索方法的实现,搜索请求返回的SearchResponse可以用于取出搜索结果下发到前端,常规的方法如下:
SearchHits hits = searchResponse.getHits();
SearchHit[] searchHits = hits.getHits();
for (SearchHit hit : searchHits) {
Map<String, Object> map = hit.getSourceAsMap();
……
}除了这种使用Map的方式拿到搜索结果,还可以直接以json字符串的方式得到搜索结果:
String result = hit.getSourceAsString();
如果要取出高亮结果,可以使用SearchHit对象的getHighlightFields方法,最后得到的fragmentString就是高亮的内容文本:
// 获取高亮结果
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
for (Map.Entry<String, HighlightField> entry : highlightFields.entrySet()) {
String mapKey = entry.getKey();
HighlightField mapValue = entry.getValue();
Text[] fragments = mapValue.fragments();
String fragmentString = fragments[0].string();
……
}8.4 统计分析
这一节来对上面的四个索引做常用的统计分析,你只需要给前面的SearchSourceBuilder传递聚集统计的参数就能达到目的,实现聚集统计的方法在源码的类AggsServiceImpl中。
1.词条聚集
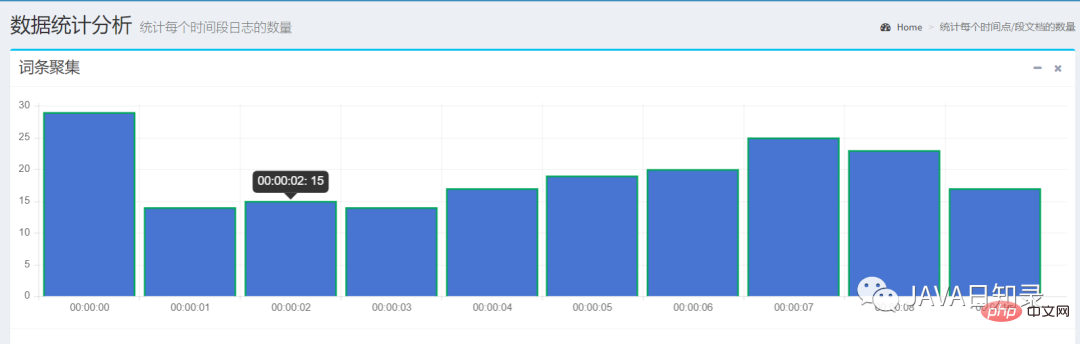
使用TermsAggregationBuilder可以创建一个词条聚集,关键代码如下:
TermsAggregationBuilder aggregation = AggregationBuilders.terms("countnumber")
.field(content.getAggsField()).size(10)
.order(BucketOrder.key(true));
searchSourceBuilder.query(queryBuilder).aggregation(aggregation);这里创建了一个名为countnumber的词条聚集,field参数用于指定聚集的字段,桶的数目为10个,返回的桶按照key的升序排列。
发送请求后,你需要在SearchResponse中使用聚集的名称取出每个桶的聚集结果:
Aggregations result = searchResponse.getAggregations();
Terms byCompanyAggregation = result.get("countnumber");
List<? extends Terms.Bucket> bucketList = byCompanyAggregation.getBuckets();
List<BucketResult> list = new ArrayList<>();
for (Terms.Bucket bucket : bucketList) {
BucketResult br = new BucketResult(bucket.getKeyAsString(), bucket.getDocCount());
list.add(br);
}这个例子选择了日期字段visittime做词条聚集,它会选择前十秒的数据统计出每个时间点的文档数,如图8.7所示。
2.日期直方图聚集
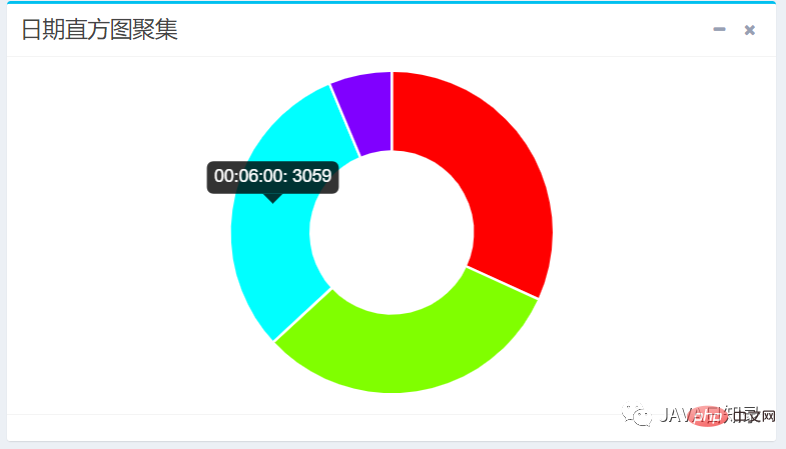
日期直方图聚集需要使用DateHistogramAggregationBuilder进行构建,实现的关键代码如下:
DateHistogramAggregationBuilder dateHistogramAggregationBuilder = AggregationBuilders
.dateHistogram("aggsName")
.field(dateField)
.fixedInterval(DateHistogramInterval.seconds(step))
// .extendedBounds(new ExtendedBounds("2020-09-01 00:00:00", "2020-09-02 05:00:00")
.minDocCount(0L);
searchSourceBuilder.query(queryBuilder).aggregation(dateHistogramAggregationBuilder);上面代码传入的参数分别是聚集的名称,聚集的字段、固定的步长以及最小文档数。如果需要控制返回桶的上下界,则需要添加注释中的参数extendedBounds。
然后,你需要使用聚集的名称取出该请求的结果:
Aggregations jsonAggs = searchResponse.getAggregations();
Histogram dateHistogram = (Histogram) jsonAggs.get("aggsName");
List<? extends Histogram.Bucket> bucketList = dateHistogram.getBuckets();
List<BucketResult> list = new ArrayList<>();
for (Histogram.Bucket bucket : bucketList) {
BucketResult br = new BucketResult(bucket.getKeyAsString(), bucket.getDocCount());
list.add(br);
}以三分钟为时间间隔,在sougoulog索引的visittime字段统计出的日期直方图效果如图8.8所示。
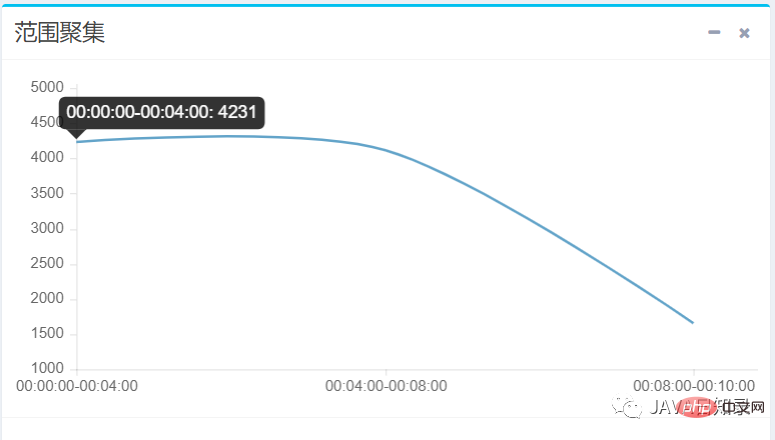
3.范围聚集
使用DateRangeAggregationBuilder可以构建一个范围聚集,你只需传入聚集名称、聚集的字段和一组区间就可以完成:
DateRangeAggregationBuilder dateRangeAggregationBuilder = AggregationBuilders
.dateRange("aggsName")
.field(dateField);
//添加只有下界的区间
dateRangeAggregationBuilder.addUnboundedFrom(from);
//添加只有上界的区间
dateRangeAggregationBuilder.addUnboundedTo(to);
//添加上下界都有的区间
dateRangeAggregationBuilder.addRange(from, to);
searchSourceBuilder.query(queryBuilder).aggregation(dateRangeAggregationBuilder);要取出范围聚集的桶结果,可以使用的下面的代码:
Aggregations jsonAggs = searchResponse.getAggregations();
Range range = (Range) jsonAggs.get("aggsName");
List<? extends Range.Bucket> bucketList = range.getBuckets();
List<BucketResult> list = new ArrayList<>();
for (Range.Bucket bucket : bucketList) {
BucketResult br = new BucketResult(bucket.getKeyAsString(), bucket.getDocCount());
list.add(br);
}在本实例中,前端向聚集请求传递了三个时间范围区间,得到sougoulog在每个时间区间的文档数量,效果如图8.9所示。
4.嵌套聚集
嵌套聚集请求要使用NestedAggregationBuilder进行构造,它的nested方法需要传入聚集的名称和嵌套对象的路径,然后使用subAggregation来添加子聚集完成对嵌套对象的统计,其关键代码如下:
NestedAggregationBuilder aggregation = AggregationBuilders.nested("nestedAggs", "country")
.subAggregation(AggregationBuilders.terms("groupbycountry")
.field("country.countryname.keyword").size(100)
.order(BucketOrder.count(false)));
searchSourceBuilder.query(queryBuilder).aggregation(aggregation);这个请求配置了嵌套对象的路径为country,然后在子聚集中配置了一个词条聚集,它会统计出每个国家出现的次数,从而得到各国家的城市数目的统计。为了取出聚集桶的结果,需要先获取嵌套聚集对象,然后再获取子聚集对象,代码如下:
Nested result = searchResponse.getAggregations().get("nestedAggs");
Terms groupbycountry = result.getAggregations().get("groupbycountry");
List<? extends Terms.Bucket> bucketList = groupbycountry.getBuckets();
List<BucketResult> list = new ArrayList<>();
for (Terms.Bucket bucket : bucketList) {
BucketResult br = new BucketResult(bucket.getKeyAsString(), bucket.getDocCount());
list.add(br);
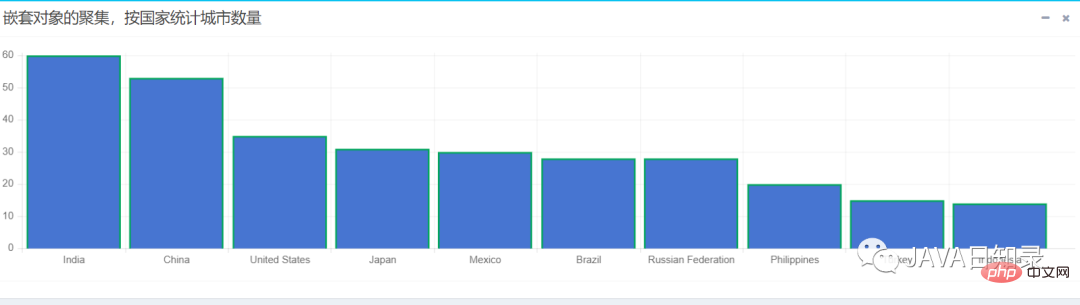
}该嵌套聚集会统计出各国家拥有城市数量的前十名,用柱状图展示的效果如图8.10所示。
以上就是2万字长文揭示SpringBoot整合ElasticSearch的高阶妙用!的详细内容,更多请关注php中文网其它相关文章!

ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch


<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.5.16.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<groupId>com.huarui</groupId>
<artifactId>sb_elasticsearch_jestclient</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>sb_elasticsearch_jestclient</name>
<description>Demo project for Spring Boot</description>
<properties>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.7</version>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</repository>
<repository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-snapshots</id>
<name>Spring Snapshots</name>
<url>https://repo.spring.io/snapshot</url>
<snapshots>
<enabled>true</enabled>
</snapshots>
</pluginRepository>
<pluginRepository>
<id>spring-milestones</id>
<name>Spring Milestones</name>
<url>https://repo.spring.io/milestone</url>
</pluginRepository>
</pluginRepositories>
</project>
<dependency>
<groupId>io.searchbox</groupId>
<artifactId>jest</artifactId>
<version>5.3.3</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.7</version>
</dependency>
spring.elasticsearch.jest.uris = http://192.168.79.129:9200/
spring.elasticsearch.jest.read-timeout = 10000
spring.elasticsearch.jest.username =
spring.elasticsearch.jest.password =
junit
import com.huarui.entity.User;
import io.searchbox.client.JestClient;
import io.searchbox.client.JestResult;
import io.searchbox.core.*;
import io.searchbox.indices.CreateIndex;
import io.searchbox.indices.DeleteIndex;
import io.searchbox.indices.mapping.GetMapping;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.builder.SearchSourceBuilder;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.test.context.junit4.SpringRunner;
import java.io.IOException;
import java.util.ArrayList;
import java.util.List;
@RunWith(SpringRunner.class)
@SpringBootTest
public class ElasticApplicationTests {
private static String indexName = "userindex";
private static String typeName = "user";
@Autowired
JestClient jestClient;
/**
* 新增数据
* @return
* @throws Exception
*/
@Test
public void insert() throws Exception {
User user = new User(1L, "张三", 20, "张三是个Java开发工程师","2018-4-25 11:07:42");
Index index = new Index.Builder(user).index(indexName).type(typeName).build();
try{
JestResult jr = jestClient.execute(index);
System.out.println(jr.isSucceeded());
}catch(IOException e){
e.printStackTrace();
}
}
}

Elasticsearch7.10.0集群搭建以及SpringBoot整合操作ES
Elaticsearch简称为ES,是一个开源的可扩展的分布式的全文检索引擎,它可以近乎实时的存储、检索数 据。本身扩展性很好,可扩展到上百台服务器,处理PB级别的数据。ES使用Java开发并使用Lucene作 为其核心来实现索引和搜索的功能,但是它通过简单的RestfulAPI和javaAPI来隐藏Lucene的复杂性, 从而让全文搜索变得简单。
1.ES集群介绍
Elasticseasrch的架构遵循其基本概念:一个采用Restful API标准的高扩展性和高可用性的实时数据分析的全文搜索引擎。具有以下特性:
- 高扩展性:体现在Elasticsearch添加节点非常简单,新节点无需做复杂的配置,只要配置好集群信 息将会被集群自动发现。
- 高可用性:因为Elasticsearch是分布式的,每个节点都会有备份,所以宕机一两个节点也不会出现 问题,集群会通过备份进行自动复盘。
- 实时性:使用倒排索引来建立存储结构,搜索时常在百毫秒内就可完成。
核心概念
-
集群(Cluster) 一个Elasticsearch集群由多个节点(Node)组成,每个集群都有一个共同的集群名称作为标识
-
节点(Node)
一个Elasticsearch实例即一个Node,一台机器可以有多个实例,正常使用下每个实例都应该 会部署在不同的机器上。Elasticsearch的配置文件中可以通过node.master、node.data来设 置节点类型。
-
节点既有成为主节点的资格,又存储数据
node.master: true node.data: true -
节点没有成为主节点的资格,不参与选举,只会存储数据
node.master: false node.data: true -
不会成为主节点,也不会存储数据,主要是针对海量请求的时候可以进行负载均衡
node.master: false node.data: false
-
-
分片
每个索引有1个或多个分片,每个分片存储不同的数据。分片可分为主分片(primary shard)和复制分片(replica shard),复制分片是主分片的拷贝。默认每个主分片有一个复 制分片,每个索引的复制分片的数量可以动态地调整,复制分片从不与它的主分片在同一个 节点上
-
副本
这里指主分片的副本分片(主分片的拷贝)
- 提高恢复能力:当主分片挂掉时,某个复制分片可以变成主分片
- 提高性能:get 和 search 请求既可以由主分片又可以由复制分片处理
2.ES集群搭建
2.1 集群规划
这里使用四台虚拟机搭建ES集群。
系统版本: Centos7.5
JDK版本: jdk11
**ES版本:**7.10.0
Kibana版本: 7.10.1
| 主机名 | 服务器IP | 是否主节点 | 是否数据节点 |
|---|---|---|---|
| node1 | 192.168.1.161 | 是 | 是 |
| node2 | 192.168.1.162 | 是 | 是 |
| node3 | 192.168.1.163 | 是 | 是 |
| node4 | 192.168.1.164 | 是 | 是 |
2.2 节点搭建
Elasticsearch下载地址:https://www.elastic.co/cn/downloads/elasticsearch
#ES默认不能使用root用户启动,所以要新建elasticsearch用户
useradd elasticsearch
#设置elasticsearch用户密码
passwd elasticsearch
#将安装包上传到,/opt目录下,解压
tar -zxvf elasticsearch-7.10.0-linux-x86_64.tar.gz
#重命名目录
mv elasticsearch-7.10.0 elasticsearch
#分配权限
chown -R elasticsearch:elasticsearch elasticsearch/
修改node1上elasticsearch.yml配置,添加如下配置信息
vi /opt/elasticsearch/config/elasticsearch.yml
cluster.name: my-es-cluster #集群名称 ---
node.name: node-1 # 节点名称,四台分别为node-1到node-4
node.master: true #当前节点是否可以被选举为master节点,是:true、否:false ---
network.host: 0.0.0.0
http.port: 9200
transport.port: 9300 # ---
#初始化一个新的集群时需要此配置来选举master
cluster.initial_master_nodes: ["node-1","node-2","node-3","node-4"]
#写入候选主节点的设备地址 ---
discovery.seed_hosts: ["node1:9300","node2:9300","node3:9300","node4:9300"]
#跨域请求设置
http.cors.enabled: true
http.cors.allow-origin: "*"
node2到node4配置参考node1。注意修改node.name
更多配置项参考
| 配置项 | 说明 |
|---|---|
| cluster.name | 集群名称,相同名称为一个集群 |
| node.name | 节点名称,集群模式下每个节点名称唯一 |
| node.master | 当前节点是否可以被选举为master节点,是:true、否:false |
| node.data | 当前节点是否用于存储数据,是:true、否:false |
| path.data | 索引数据存放的位置 |
| path.logs | 日志文件存放的位置 |
| bootstrap.memory_lock | 需求锁住物理内存,是:true、否:false |
| network.host | 监听地址,用于访问该es |
| http.port | es对外提供的http端口,默认 9200 |
| transport.port | 节点选举的通信端口 默认是9300 |
| discovery.seed_hosts | es7.x 之后新增的配置,写入候选主节点的设备地址,在开启服<br/>务后可以被选为主节点 |
| cluster.initial_master_nodes | es7.x 之后新增的配置,初始化一个新的集群时需要此配置来选<br/>举master |
| http.cors.enabled | 是否支持跨域,是:true,在使用head插件时需要此配置 |
| http.cors.allow-origin "*" | 表示支持所有域名 |
2.3启动
先使用root用户修改系统参数
##1.修改/etc/sysctl.conf
vim /etc/sysctl.conf
##添加
vm.max_map_count=655360
##保存退出。
##执行sysctl -p使配置生效
sysctl -p
##2.改/etc/security/limits.conf
vim /etc/security/limits.conf
###末尾添加
* soft nofile 65536
* hard nofile 65536
* soft nproc 4096
* hard nproc 4096
使用elasticsearch用户启动ES集群
cd /opt/elasticsearch/bin
#后台启动,需要使用elasticsearch用户
./elasticsearch -d
启动完成后可以通过集群监控工具cerebro查看集群状态
3.Kibana安装
Kibana是一个基于Node.js的Elasticsearch索引库数据统计工具,可以利用Elasticsearch的聚合功能,生成各种图表,如柱形图,线状图,饼图等。而且还提供了操作Elasticsearch索引数据的控制台,并且提供了一定的API提示,非常有利于我们学习Elasticsearch的语法。
下载地址:https://www.elastic.co/cn/downloads/kibana
在node1(192.168.1.161)上安装Kibana
##上传安装包kibana-7.10.1-linux-x86_64.tar.gz 到/opt目录
#解压
cd /opt
tar -zxvf kibana-7.10.1-linux-x86_64.tar.gz
mv kibana-7.10.1-linux-x86_64 kibana
#分配权限
chown -R elasticsearch kibana/
chmod -R 777 kibana/
##修改配置文件
vim /opt/kibana/config/kibana.yml
##修改端口,访问ip,elasticsearch服务器ip
server.port: 5601
server.host: "0.0.0.0"
# The URLs of the Elasticsearch instances to use for all your queries.
elasticsearch.hosts: ["http://node1:9200"]
使用elasticsearch用户启动kibana
su - elasticsearch
cd /opt/kibana/bin
##启动
./kibana
访问http://192.168.1.161:5601/
4.安装IK分词器
下载对应版本的分词器,下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 这里我们下载V7.10
下载完成后将elasticsearch-analysis-ik-7.10.0.zip 上传到服务器上/opt/elasticsearch下
##安装分词器插件
cd /opt/elasticsearch/bin
./elasticsearch-plugin install file:///opt/elasticsearch/elasticsearch-analysis-ik-7.10.0.zip
-> Installing file:///opt/elasticsearch/bin/elasticsearch-analysis-ik-7.10.0.zip
-> Downloading file:///opt/elasticsearch/bin/elasticsearch-analysis-ik-7.10.0.zip
[=================================================] 100%
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
@ WARNING: plugin requires additional permissions @
@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@
* java.net.SocketPermission * connect,resolve
See http://docs.oracle.com/javase/8/docs/technotes/guides/security/permissions.html
for descriptions of what these permissions allow and the associated risks.
##按照提示输入y
Continue with installation? [y/N]y
-> Installed analysis-ik
5.索引操作
打开http://192.168.1.161:5601/app/dev_tools#/console
##创建索引,使用ik分词
PUT /books
{
"mappings": {
"properties": {
"name": {
"type": "text",
"analyzer": "ik_smart",
"search_analyzer": "ik_smart"
}
}
}
}
##查看索引
GET books
##查询
POST /books/_search
{
"query":{
"match_all": {}
}
}
POST /books/_search
{
"query": {
"match": {
"name": "十万个为什么"
}
}
}
6.SpringBoot整合操作Elasticsearch
ES提供多种不同的客户端: 1、TransportClient ES提供的传统客户端,官方计划8.0版本删除此客户端。 2、RestClient RestClient是官方推荐使用的,它包括两种:Java Low Level REST Client和 Java High Level REST Client。 ES在6.0之后提供 Java High Level REST Client, 两种客户端官方更推荐使用 Java High Level REST Client, 使用时加入对应版本的依赖即可。
这里我们使用SpringBoot官方spring-boot-starter-data-elasticsearch。对应版本关系如下。
| Spring Data Release Train | Spring Data Elasticsearch | Elasticsearch | Spring Boot |
|---|---|---|---|
| 2020.0.0[1] | 4.1.x[1] | 7.9.3 | 2.4.x[1] |
| Neumann | 4.0.x | 7.6.2 | 2.3.x |
| Moore | 3.2.x | 6.8.12 | 2.2.x |
| Lovelace | 3.1.x | 6.2.2 | 2.1.x |
| Kay[2] | 3.0.x[2] | 5.5.0 | 2.0.x[2] |
| Ingalls[2] | 2.1.x[2] | 2.4.0 | 1.5.x[2] |
因为我们用的ES版本是7.10的,所以这里介绍使用最新的Spring Boot 2.4.1版本进行整合操作。
6.1引入依赖
完整的pom参考如下
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.4.1</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<modelVersion>4.0.0</modelVersion>
<groupId>com.es.demo</groupId>
<artifactId>elasticsearch-demo</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<!--指定ES版本号-->
<elasticsearch.version>7.10.0</elasticsearch.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!-- 引入jdbc支持 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-thymeleaf</artifactId>
</dependency>
</dependencies>
</project>
6.2配置
application.yml配置ES连接信息如下
spring:
elasticsearch:
rest:
uris: node1:9200,node2:9200,node3:9200,node4:9200 ##es集群地址
6.3使用
接下来就可以启动项目,操作ES了。这里可以使用以下三种方式来进行。
先创建模型
@Document(indexName="books")
class Book {
@Id
private String id;
@Field(type = FieldType.text)
private String name;
@Field(type = FieldType.text)
private String summary;
@Field(type = FieldType.Integer)
private Integer price;
// getter/setter ...
}
6.3.1.使用ElasticsearchRestTemplate
ElasticsearchRestTemplate是使用High Level REST Client的ElasticsearchOperations接口的实现。
例如:
@Autowired
private ElasticsearchRestTemplate restTemplate;
@Test
public void testSave() throws IOException {
Book book=new Book();
user.setId("1111");
user.setName("十万个为什么");
user.setSummary("十万个为什么十万个为什么十万个为什么");
user.setPrice(100);
//方法1
IndexQuery indexQuery = new IndexQueryBuilder()
.withId("11")
.withObject(book)
.build();
String documentId = restTemplate.index(indexQuery, IndexCoordinates.of("books"));
//方法2
restTemplate.save(user);
}
6.3.2.使用ElasticsearchRepository
ElasticsearchRepository是 Spring Data ElasticSearch为我们封装好的可进行 crud、分页、排序的接口。使用方式跟我们以前使用的JPA一样。
| Keyword | Sample | Elasticsearch Query String |
|---|---|---|
And |
findByNameAndPrice |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } }} |
Or |
findByNameOrPrice |
{ "query" : { "bool" : { "should" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } }, { "query_string" : { "query" : "?", "fields" : [ "price" ] } } ] } }} |
Is |
findByName |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } }} |
Not |
findByNameNot |
{ "query" : { "bool" : { "must_not" : [ { "query_string" : { "query" : "?", "fields" : [ "name" ] } } ] } }} |
Between |
findByPriceBetween |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
LessThan |
findByPriceLessThan |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : false } } } ] } }} |
LessThanEqual |
findByPriceLessThanEqual |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
GreaterThan |
findByPriceGreaterThan |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : false, "include_upper" : true } } } ] } }} |
GreaterThanEqual |
findByPriceGreaterThan |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } }} |
Before |
findByPriceBefore |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : null, "to" : ?, "include_lower" : true, "include_upper" : true } } } ] } }} |
After |
findByPriceAfter |
{ "query" : { "bool" : { "must" : [ {"range" : {"price" : {"from" : ?, "to" : null, "include_lower" : true, "include_upper" : true } } } ] } }} |
Like |
findByNameLike |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
StartingWith |
findByNameStartingWith |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
EndingWith |
findByNameEndingWith |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
Contains/Containing |
findByNameContaining |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "*?*", "fields" : [ "name" ] }, "analyze_wildcard": true } ] } }} |
In (when annotated as FieldType.Keyword) |
findByNameIn(Collection<String>names) |
{ "query" : { "bool" : { "must" : [ {"bool" : {"must" : [ {"terms" : {"name" : ["?","?"]}} ] } } ] } }} |
In |
findByNameIn(Collection<String>names) |
{ "query": {"bool": {"must": [{"query_string":{"query": "\"?\" \"?\"", "fields": ["name"]}}]}}} |
NotIn (when annotated as FieldType.Keyword) |
findByNameNotIn(Collection<String>names) |
{ "query" : { "bool" : { "must" : [ {"bool" : {"must_not" : [ {"terms" : {"name" : ["?","?"]}} ] } } ] } }} |
NotIn |
findByNameNotIn(Collection<String>names) |
{"query": {"bool": {"must": [{"query_string": {"query": "NOT(\"?\" \"?\")", "fields": ["name"]}}]}}} |
Near |
findByStoreNear |
Not Supported Yet ! |
True |
findByAvailableTrue |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } }} |
False |
findByAvailableFalse |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "false", "fields" : [ "available" ] } } ] } }} |
OrderBy |
findByAvailableTrueOrderByNameDesc |
{ "query" : { "bool" : { "must" : [ { "query_string" : { "query" : "true", "fields" : [ "available" ] } } ] } }, "sort":[{"name":{"order":"desc"}}] } |
例如
interface BookRepository extends Repository<Book, String> {
List<Book> findByNameAndPrice(String name, Integer price);
//分页
List<Book> findByNameAndPrice(String name, Integer price,Pageable page);
}
@Service
public class BookServiceImpl implements BookService {
private static final Logger logger = LogManager.getLogger(BookServiceImpl.class);
@Autowired
private BookRepository bookRepository;
public List<Book> findPage(Book book,int pageNo,int pageSize){
List<Position> list = bookRepository.findByNameAndPrice(book.getName(), book.getPrice(), PageRequest.of(pageNo, pageSize));
return list;
}
}
更多操作参考官方文档。https://docs.spring.io/spring-data/elasticsearch/docs/4.1.2/reference/html/#elasticsearch.repositories
6.3.3 使用原生High Level REST Client
一些复杂的操作也可以直接使用RestHighLevelClient,直接再bean中注入即可使用
@Autowired
private RestHighLevelClient restHighLevelClient;
 spring boot整合Elasticsearch的原生方式")
Elasticsearch学习(3) spring boot整合Elasticsearch的原生方式
前面我们已经介绍了spring boot整合Elasticsearch的jpa方式,这种方式虽然简便,但是依旧无法解决我们较为复杂的业务,所以原生的实现方式学习能够解决这些问题,而原生的学习方式也是Elasticsearch聚合操作的一个基础。
一、修改spring boot 的application.properties配置文件
##端口号
server.port=8880
##es地址
spring.data.elasticsearch.cluster-nodes =127.0.0.1:9300
需要注意的是:如果你的项目中只配置了Elasticsearch的依赖或者是其他nosql的依赖,那么就要在spring boot启动类中添加@SpringBootApplication(exclude = {DataSourceAutoConfiguration.class})注解,这个操作是关闭自动配置数据源文件信息。
二、创建一个Bean层
和spring boot的jpa方式一样,我们需要创建一个bean来作为我们的索引,注意indexName和type的值是你需要查找的索引内容。


import org.springframework.data.elasticsearch.annotations.Document;
@Document(indexName = "article",type = "center")
public class Zoo {
private int id;
private String animal;
private Integer num;
private String breeder;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getAnimal() {
return animal;
}
public void setAnimal(String animal) {
this.animal = animal;
}
public Integer getNum() {
return num;
}
public void setNum(Integer num) {
this.num = num;
}
public String getBreeder() {
return breeder;
}
public void setBreeder(String breeder) {
this.breeder = breeder;
}
public Zoo(int id, String animal, Integer num, String breeder) {
super();
this.id = id;
this.animal = animal;
this.num = num;
this.breeder = breeder;
}
public Zoo() {
super();
}
}三、创建一个dao层
创建的dao层中不需要我们写实现的方法,只需要继承ElasticsearchRepository接口。


import org.springframework.context.annotation.Configuration;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
@Configuration
public interface ZooMapper extends ElasticsearchRepository<Zoo,Integer>{
}四、创建一个Controller层,编写原生代码
一般来说这个操作规范下应该写到service层,由于是测试项目,我就直接写在了controller中,我们直接看一个例子


import java.util.List;
import org.elasticsearch.index.query.BoolQueryBuilder;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.elasticsearch.search.sort.FieldSortBuilder;
import org.elasticsearch.search.sort.SortBuilders;
import org.elasticsearch.search.sort.SortOrder;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.elasticsearch.core.query.SearchQuery;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class UserController {
@Autowired
ZooMapper zooMapper;
// 访问接口地址:localhost:8880/find
//存储数据
@GetMapping("find")
public Object save(){
//1.创建QueryBuilder 可以理解为装查询条件的容器
BoolQueryBuilder builder = QueryBuilders.boolQuery();
//2.设置查询条件,参数1: 字段名 参数2:字段值(为什么中文是一个字而不是词,这个后面在说)
QueryBuilder queryBuilder1=QueryBuilders.termQuery("breeder", "饲");
//设置查询条件多个匹配,参数1: 字段名 参数2:字段值 参数3:字段值
QueryBuilder queryBuilder2=QueryBuilders.termsQuery("animal", "rabbit","lion");
//3.将查询的条件放入容器中
//其中 must相当于SQL中的and should相当于SQL中的or mustNot相当于SQL中的not
builder.must(queryBuilder1);
builder.should(queryBuilder2);
//4.设置排序 参数:需要排序字段 DESC表示降序
FieldSortBuilder sort = SortBuilders.fieldSort("id").order(SortOrder.DESC);
//5.设置分页,参数1:第几页开始(第一页是0),参数2:显示的条数
//在spring 2.0开始后,使用PageRequest.of创建分页参数
PageRequest page =PageRequest.of(0, 2);
//6.在设置好查询条件、排序设置、分页设置后需要将他们放入NativeSearchQueryBuilder 容器中
NativeSearchQueryBuilder nativeSearchQueryBuilder =new NativeSearchQueryBuilder();
//将查询条件放入容器中
nativeSearchQueryBuilder.withQuery(builder);
//将分页放入容器中
nativeSearchQueryBuilder.withPageable(page);
//将排序放入容器中
nativeSearchQueryBuilder.withSort(sort);
//最后将容器组装后,生产NativeSearchQuery
//此时 SearchQuery中的sql为
//select * from zoo where breeder="饲养员1号" or animal in("rabbit","lion") ORDER BY id DESC LIMIT 0,2
SearchQuery query = nativeSearchQueryBuilder.build();
System.out.println("查询的语句:" + query.getQuery().toString());
//7.开始查询
Page<Zoo> listPage = zooMapper.search(query);
//获取总条数
int total = (int) listPage.getTotalElements();
//获取查询的内容
List<Zoo> relist = listPage.getContent();
System.out.println("relist----------------"+relist.toString());
return relist;
}
}在测试之前,我们需要在Elasticsearch中添加一个索引,这个索引和我们刚才创建的bean中配置的indexName和type的值一致。

打开 http://localhost:8888/find,测试我们的代码:

这样做原生的实现方式就已经成功了,接下来就将具体介绍代码中的具体步骤
六、查询条件的具体步骤
这一节主要讲解查询条件的具体功能,在controller中,有这样一段代码:
//2.设置查询条件,参数1: 字段名 参数2:字段值(为什么中文是一个字而不是词,这个后面在说)
QueryBuilder queryBuilder1=QueryBuilders.termQuery("breeder", "饲");
//设置查询条件多个匹配,参数1: 字段名 参数2:字段值 参数3:字段值
QueryBuilder queryBuilder2=QueryBuilders.termsQuery("animal", "rabbit","lion");在这个步骤我们可以看到breeder的值是中文且中文是一个字而不是词,这是因为没有使用分词器的原因,Elasticsearch默认的分片是将中文分解成一个字,英文是单个单词:
1 设置查询条件
//不分词查询 参数1: 字段名,参数2:字段查询值,因为不分词,所以汉字只能查询一个字,英语是一个单词.
QueryBuilder queryBuilder=QueryBuilders.termQuery("breeder", "饲");
//分词查询,采用默认的分词器
QueryBuilder queryBuilder2 = QueryBuilders.matchQuery("breeder", "饲养");
//多个匹配的不分词查询
QueryBuilder queryBuilder=QueryBuilders.termsQuery("animal", "rabbit","lion");
//多个匹配的分词查询
QueryBuilder queryBuilder= QueryBuilders.multiMatchQuery("animal", "r", "l");
//匹配所有文件,相当于就没有设置查询条件
QueryBuilder queryBuilder=QueryBuilders.matchAllQuery();2模糊查询
除了设置普通的查询,elasticsearch还为我们封装了模糊查询
//1.常用的字符串查询
//相当于sql中的 breeder like "饲"
QueryBuilders.queryStringQuery("饲").field("breeder");
//2.推荐与该文档相识的文档
//参数1:字段名 参数2:文档内容
//如果不指定第一个参数,则默认全部,这个是主要用来推荐偏好内容
QueryBuilders.moreLikeThisQuery(new String[] {"animal"}).addLikeText("rabbit");
//3.分词的字段片查询,比如饲养员1号能够被中文分词器分为:饲养员 1 号
//使用下面的方法就能查询‘饲养员’这个片段,如果没有配置分词器,就查询全部
QueryBuilders.prefixQuery("breeder","饲养员 ");
//4.通配符查询,支持* 任意字符串;?任意一个字符与sql中的? *类似
//参数1:字段名 参数2字段值
QueryBuilders.wildcardQuery("animal","r??b*");在第二条偏好文档设置中有一个偏好的权重问题,如果感兴趣可以参考这个博客:https://blog.csdn.net/laigood/article/details/7831713
3 逻辑查询
//闭区间 相当于id>=2 and id<=5
QueryBuilder queryBuilder0 = QueryBuilders.rangeQuery("id").from("2").to("5");
//开区间 相当于id>2 and id<5
//至于后面两个参数的值默认为true也就是闭区间
//如果想半开半闭只需要调整后面两个参数的值即可
QueryBuilder queryBuilder1 = QueryBuilders.rangeQuery("id").from("2").to("5").includeUpper(false).includeLower(false);
//大于 id>2
QueryBuilder queryBuilder2 = QueryBuilders.rangeQuery("id").gt("2");
//大于等于 id>=2
QueryBuilder queryBuilder3 = QueryBuilders.rangeQuery("id").gte("2");
//小于 id <5
QueryBuilder queryBuilder4 = QueryBuilders.rangeQuery("id").lt("5");
//小于等于 id <=5
QueryBuilder queryBuilder5 = QueryBuilders.rangeQuery("id").lte("5");以上就是spring boot整合Elasticsearch的原生方式所有实现方式,这个方式主要是后面的聚合查询的基础。
今天关于【SpringBoot整合NoSql】-----ElasticSearch的安装与操作篇和springboot整合elasticsearch7.0的分享就到这里,希望大家有所收获,若想了解更多关于2万字长文揭示SpringBoot整合ElasticSearch的高阶妙用!、ElasticSearch - 学习笔记 02-springboot 整合 jestclient 操作 elasticSearch、Elasticsearch7.10.0集群搭建以及SpringBoot整合操作ES、Elasticsearch学习(3) spring boot整合Elasticsearch的原生方式等相关知识,可以在本站进行查询。
本文标签:




