如果您对AnOverviewofEnd-to-EndExactly-OnceProcessinginApacheFlink(withApacheKafka,too!)感兴趣,那么本文将是一篇不错的选择
如果您对An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)的详细内容,并且为您提供关于10月21日直播预告 | Flink Exactly Once & Kafka-connector 算子、Apache Flink 如何保证 Exactly-Once 语义(其原理分析示例)、Apache Flink 端到端(end-to-end)Exactly-Once 特性概览 (翻译)、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理的有价值信息。
本文目录一览:- An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
- 10月21日直播预告 | Flink Exactly Once & Kafka-connector 算子
- Apache Flink 如何保证 Exactly-Once 语义(其原理分析示例)
- Apache Flink 端到端(end-to-end)Exactly-Once 特性概览 (翻译)
- Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
")
An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)
01 Mar 2018 Piotr Nowojski (@PiotrNowojski) & Mike Winters (@wints)
This post is an adaptation of Piotr Nowojski’s presentation from Flink Forward Berlin 2017. You can find the slides and a recording of the presentation on the Flink Forward Berlin website.
Apache Flink 1.4.0, released in December 2017, introduced a significant milestone for stream processing with Flink: a new feature called TwoPhaseCommitSinkFunction (relevant Jira here) that extracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and a selection of data sources and sinks, including Apache Kafka versions 0.11 and beyond. It provides a layer of abstraction and requires a user to implement only a handful of methods to achieve end-to-end exactly-once semantics.
If that’s all you need to hear, let us point you to the relevant place in the Flink documentation, where you can read about how to put TwoPhaseCommitSinkFunction to use.
But if you’d like to learn more, in this post, we’ll share an in-depth overview of the new feature and what is happening behind the scenes in Flink.
Throughout the rest of this post, we’ll:
- Describe the role of Flink’s checkpoints for guaranteeing exactly-once results within a Flink application.
- Show how Flink interacts with data sources and data sinks via the two-phase commit protocol to deliver end-to-end exactly-once guarantees.
- Walk through a simple example on how to use
TwoPhaseCommitSinkFunctionto implement an exactly-once file sink.
Exactly-once Semantics Within an Apache Flink Application
When we say “exactly-once semantics”, what we mean is that each incoming event affects the final results exactly once. Even in case of a machine or software failure, there’s no duplicate data and no data that goes unprocessed.
Flink has long provided exactly-once semantics within a Flink application. Over the past few years, we’ve written in depth about Flink’s checkpointing, which is at the core of Flink’s ability to provide exactly-once semantics. The Flink documentation also provides a thorough overview of the feature.
Before we continue, here’s a quick summary of the checkpointing algorithm because understanding checkpoints is necessary for understanding this broader topic.
A checkpoint in Flink is a consistent snapshot of:
- The current state of an application
- The position in an input stream
Flink generates checkpoints on a regular, configurable interval and then writes the checkpoint to a persistent storage system, such as S3 or HDFS. Writing the checkpoint data to the persistent storage happens asynchronously, which means that a Flink application continues to process data during the checkpointing process.
In the event of a machine or software failure and upon restart, a Flink application resumes processing from the most recent successfully-completed checkpoint; Flink restores application state and rolls back to the correct position in the input stream from a checkpoint before processing starts again. This means that Flink computes results as though the failure never occurred.
Before Flink 1.4.0, exactly-once semantics were limited to the scope of a Flink application only and did not extend to most of the external systems to which Flink sends data after processing.
But Flink applications operate in conjunction with a wide range of data sinks, and developers should be able to maintain exactly-once semantics beyond the context of one component.
To provide end-to-end exactly-once semantics–that is, semantics that also apply to the external systems that Flink writes to in addition to the state of the Flink application–these external systems must provide a means to commit or roll back writes that coordinate with Flink’s checkpoints.
One common approach for coordinating commits and rollbacks in a distributed system is the two-phase commit protocol. In the next section, we’ll go behind the scenes and discuss how Flink’s TwoPhaseCommitSinkFunction utilizes the two-phase commit protocol to provide end-to-end exactly-once semantics.
End-to-end Exactly Once Applications with Apache Flink
We’ll walk through the two-phase commit protocol and how it enables end-to-end exactly-once semantics in a sample Flink application that reads from and writes to Kafka. Kafka is a popular messaging system to use along with Flink, and Kafka recently added support for transactions with its 0.11 release. This means that Flink now has the necessary mechanism to provide end-to-end exactly-once semantics in applications when receiving data from and writing data to Kafka.
Flink’s support for end-to-end exactly-once semantics is not limited to Kafka and you can use it with any source / sink that provides the necessary coordination mechanism. For example, Pravega, an open-source streaming storage system from Dell/EMC, also supports end-to-end exactly-once semantics with Flink via the TwoPhaseCommitSinkFunction.
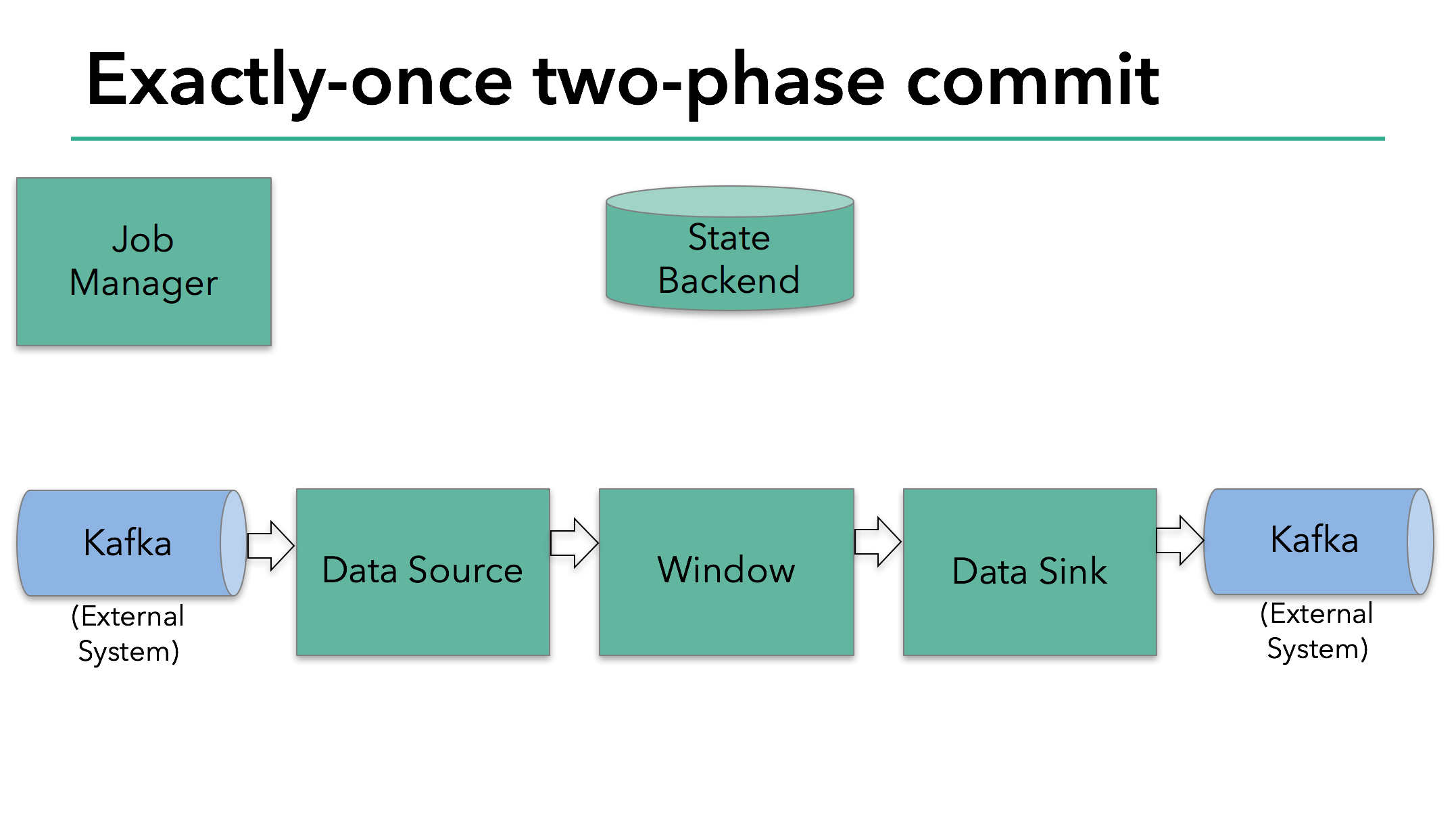
In the sample Flink application that we’ll discuss today, we have:
- A data source that reads from Kafka (in Flink, a KafkaConsumer)
- A windowed aggregation
- A data sink that writes data back to Kafka (in Flink, a KafkaProducer)
For the data sink to provide exactly-once guarantees, it must write all data to Kafka within the scope of a transaction. A commit bundles all writes between two checkpoints.
This ensures that writes are rolled back in case of a failure.
However, in a distributed system with multiple, concurrently-running sink tasks, a simple commit or rollback is not sufficient, because all of the components must “agree” together on committing or rolling back to ensure a consistent result. Flink uses the two-phase commit protocol and its pre-commit phase to address this challenge.
The starting of a checkpoint represents the “pre-commit” phase of our two-phase commit protocol. When a checkpoint starts, the Flink JobManager injects a checkpoint barrier (which separates the records in the data stream into the set that goes into the current checkpoint vs. the set that goes into the next checkpoint) into the data stream.
The barrier is passed from operator to operator. For every operator, it triggers the operator’s state backend to take a snapshot of its state.
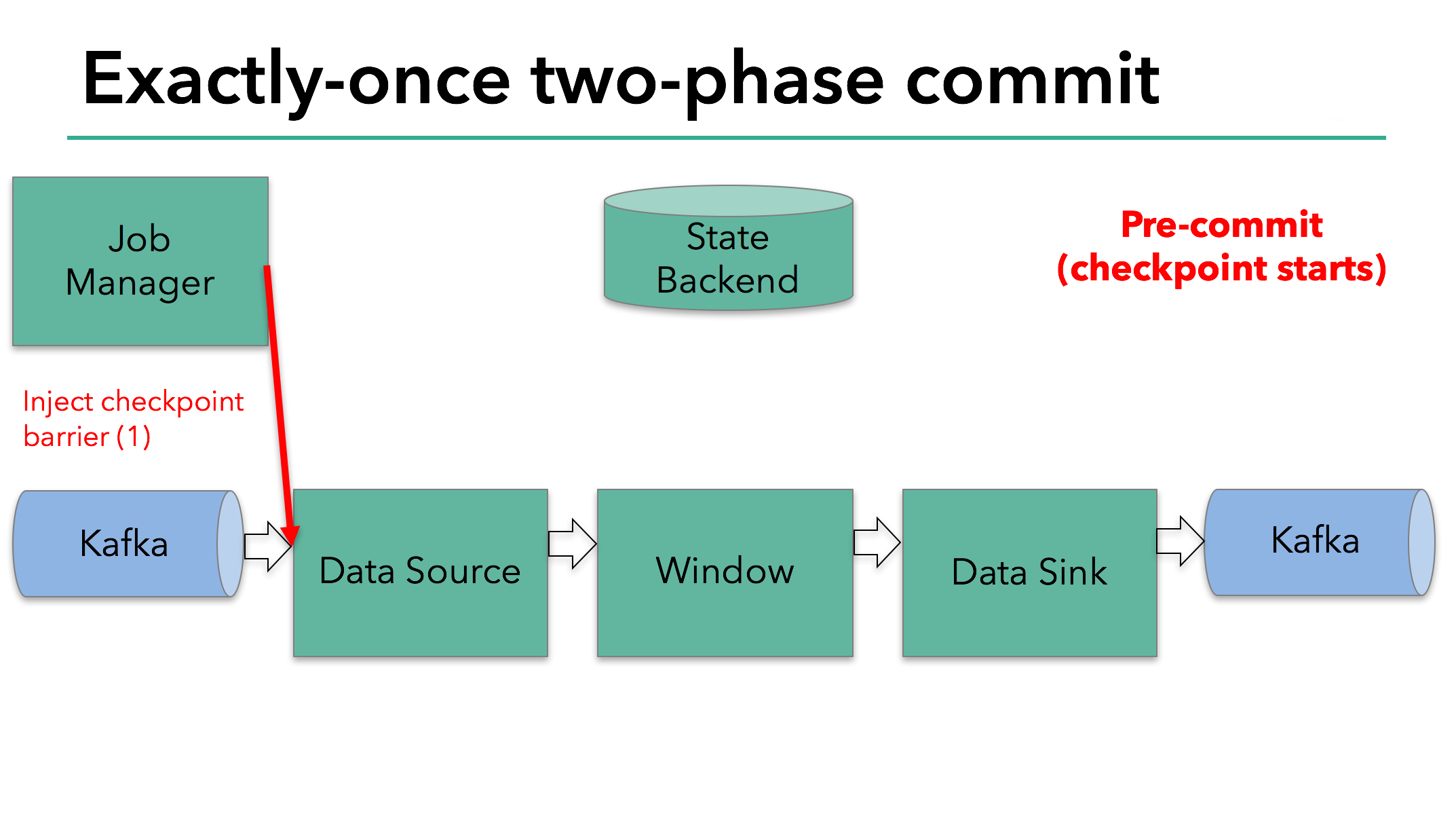
The data source stores its Kafka offsets, and after completing this, it passes the checkpoint barrier to the next operator.
This approach works if an operator has internal state only. Internal state is everything that is stored and managed by Flink’s state backends - for example, the windowed sums in the second operator. When a process has only internal state, there is no need to perform any additional action during pre-commit aside from updating the data in the state backends before it is checkpointed. Flink takes care of correctly committing those writes in case of checkpoint success or aborting them in case of failure.
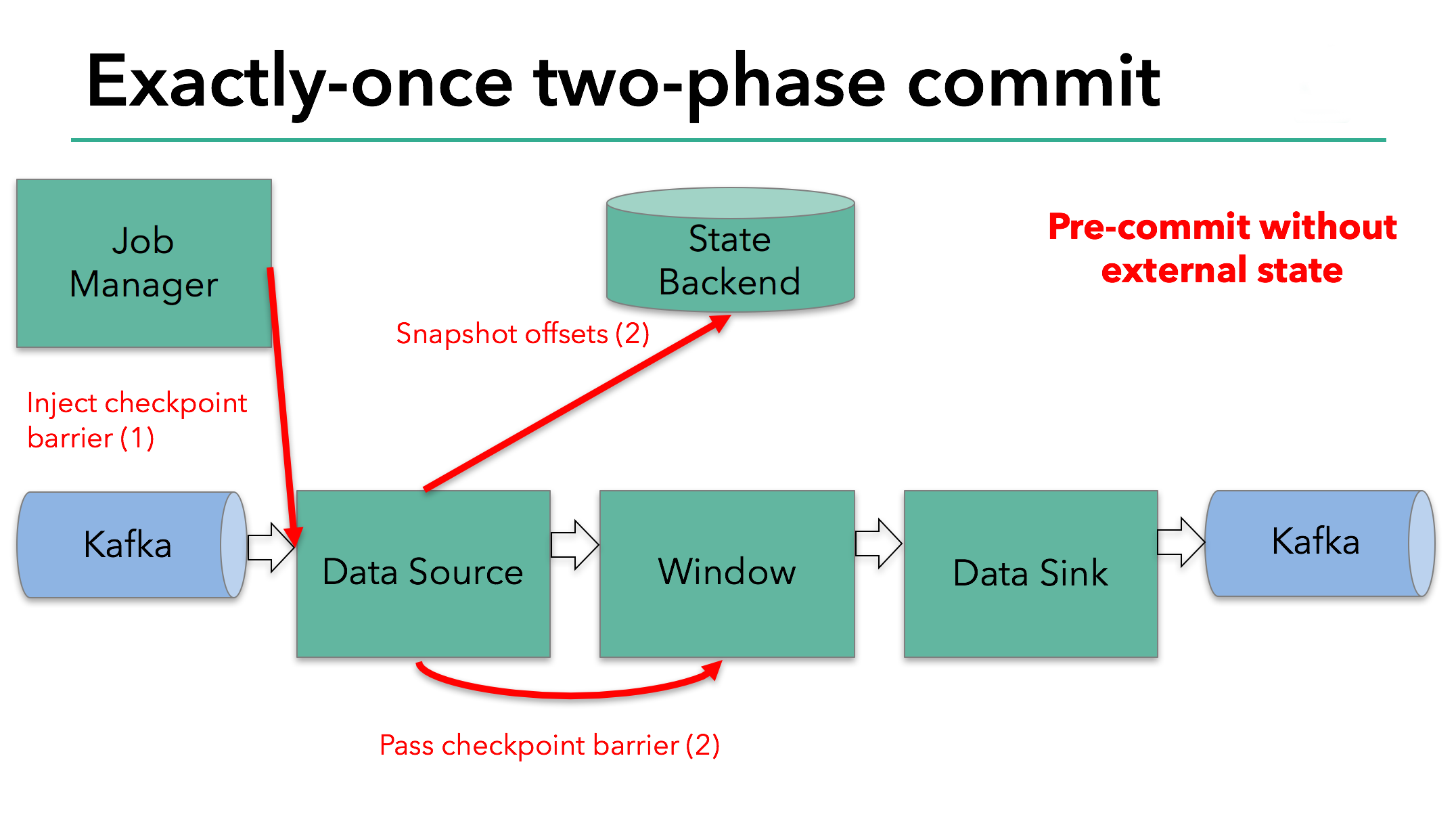
However, when a process has external state, this state must be handled a bit differently. External state usually comes in the form of writes to an external system such as Kafka. In that case, to provide exactly-once guarantees, the external system must provide support for transactions that integrates with a two-phase commit protocol.
We know that the data sink in our example has such external state because it’s writing data to Kafka. In this case, in the pre-commit phase, the data sink must pre-commit its external transaction in addition to writing its state to the state backend.
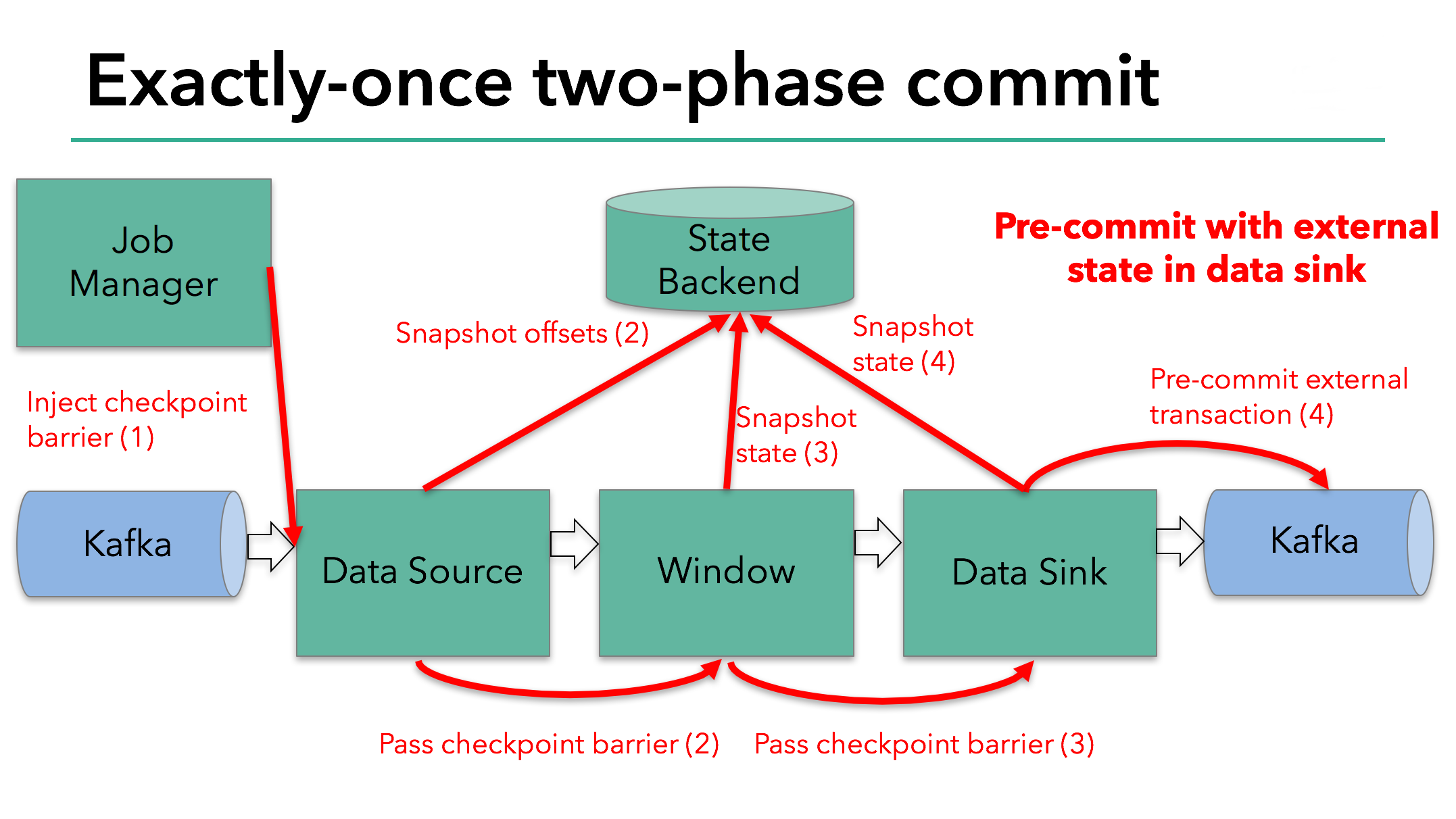
The pre-commit phase finishes when the checkpoint barrier passes through all of the operators and the triggered snapshot callbacks complete. At this point the checkpoint completed successfully and consists of the state of the entire application, including pre-committed external state. In case of a failure, we would re-initialize the application from this checkpoint.
The next step is to notify all operators that the checkpoint has succeeded. This is the commit phase of the two-phase commit protocol and the JobManager issues checkpoint-completed callbacks for every operator in the application. The data source and window operator have no external state, and so in the commit phase, these operators don’t have to take any action. The data sink does have external state, though, and commits the transaction with the external writes.
So let’s put all of these different pieces together:
- Once all of the operators complete their pre-commit, they issue a commit.
- If at least one pre-commit fails, all others are aborted, and we roll back to the previous successfully-completed checkpoint.
- After a successful pre-commit, the commit must be guaranteed to eventually succeed – both our operators and our external system need to make this guarantee. If a commit fails (for example, due to an intermittent network issue), the entire Flink application fails, restarts according to the user’s restart strategy, and there is another commit attempt. This process is critical because if the commit does not eventually succeed, data loss occurs.
Therefore, we can be sure that all operators agree on the final outcome of the checkpoint: all operators agree that the data is either committed or that the commit is aborted and rolled back.
Implementing the Two-Phase Commit Operator in Flink
All the logic required to put a two-phase commit protocol together can be a little bit complicated and that’s why Flink extracts the common logic of the two-phase commit protocol into the abstract TwoPhaseCommitSinkFunction class.
Let’s discuss how to extend a TwoPhaseCommitSinkFunction on a simple file-based example. We need to implement only four methods and present their implementations for an exactly-once file sink:
beginTransaction -to begin the transaction, we create a temporary file in a temporary directory on our destination file system. Subsequently, we can write data to this file as we process it.preCommit -on pre-commit, we flush the file, close it, and never write to it again. We’ll also start a new transaction for any subsequent writes that belong to the next checkpoint.commit -on commit, we atomically move the pre-committed file to the actual destination directory. Please note that this increases the latency in the visibility of the output data.abort -on abort, we delete the temporary file.
As we know, if there’s any failure, Flink restores the state of the application to the latest successful checkpoint. One potential catch is in a rare case when the failure occurs after a successful pre-commit but before notification of that fact (a commit) reaches our operator. In that case, Flink restores our operator to the state that has already been pre-committed but not yet committed.
We must save enough information about pre-committed transactions in checkpointed state to be able to either abort or commit transactions after a restart. In our example, this would be the path to the temporary file and target directory.
The TwoPhaseCommitSinkFunction takes this scenario into account, and it always issues a preemptive commit when restoring state from a checkpoint. It is our responsibility to implement a commit in an idempotent way. Generally, this shouldn’t be an issue. In our example, we can recognize such a situation: the temporary file is not in the temporary directory, but has already been moved to the target directory.
There are a handful of other edge cases that TwoPhaseCommitSinkFunction takes into account, too. Learn more in the Flink documentation.
Wrapping Up
If you’ve made it this far, thanks for staying with us through a detailed post. Here are some key points that we covered:
- Flink’s checkpointing system serves as Flink’s basis for supporting a two-phase commit protocol and providing end-to-end exactly-once semantics.
- An advantage of this approach is that Flink does not materialize data in transit the way that some other systems do–there’s no need to write every stage of the computation to disk as is the case is most batch processing.
- Flink’s new
TwoPhaseCommitSinkFunctionextracts the common logic of the two-phase commit protocol and makes it possible to build end-to-end exactly-once applications with Flink and external systems that support transactions - Starting with Flink 1.4.0, both the Pravega and Kafka 0.11 producers provide exactly-once semantics; Kafka introduced transactions for the first time in Kafka 0.11, which is what made the Kafka exactly-once producer possible in Flink.
- The Kafka 0.11 producer is implemented on top of the
TwoPhaseCommitSinkFunction, and it offers very low overhead compared to the at-least-once Kafka producer.
We’re very excited about what this new feature enables, and we look forward to being able to support additional producers with the TwoPhaseCommitSinkFunction in the future.
This post first appeared on the data Artisans blog and was contributed to Apache Flink and the Flink blog by the original authors Piotr Nowojski and Mike Winters.

10月21日直播预告 | Flink Exactly Once & Kafka-connector 算子
10月21日晚19点,袋鼠云数栈技术研发团队开发工程师——小刀,将会为大家直播分享《Flink Exactly Once & Kafka-connector 算子》。
课程内容主要包括以下四点:
1.Kafka-connector 在Flinkx 中的使用
2.Kafka-connector 如何进行分片
3.Kafka-connector 如何实现Exactly Once
4.数据序列化和指标监控
通过本次课程能了解Flink Kafka-connector 的分片逻辑,并知道如何去自定义监控Flink消费Kafka过程中的指标信息,比如Partition 消费延迟等等。
本次活动将会在钉钉群、微信视频号和B站同步直播,欢迎大家准时参加!
直播观看方式:
钉钉群直播参与方式:扫描图中二维码或钉钉搜索群号(30537511)
微信视频号:数栈研习社
B站直播间地址:
https://live.bilibili.com/22920407?visit_id=12ss4w90sqv4
B站直播间ID:袋鼠云 (22920407)

更多技术交流方式
想面对面技术交流?想看技术大佬直播?加入钉钉群“袋鼠云开源框架技术交流群”(群号:30537511)
想体验更多数栈开源项目?在Github社区或Gitee社区搜索“FlinkX”开源项目
Github开源项目地址:
https://github.com/DTStack/flinkx
Gitee开源项目地址:
https://gitee.com/dtstack_dev_0/flinkx
")
Apache Flink 如何保证 Exactly-Once 语义(其原理分析示例)
一、引言
在大数据处理中,数据的一致性和准确性是至关重要的。Apache Flink 是一个流处理和批处理的开源平台,它提供了丰富的语义保证,其中之一就是 Exactly-Once 语义。Exactly-Once 语义确保每个事件或记录只被处理一次,即使在发生故障的情况下也能保持这一保证。本文将深入探讨 Flink 是如何保证 Exactly-Once 语义的,包括其原理分析和相关示例。
二、Exactly-Once 语义的重要性
在分布式系统中,由于网络分区、节点故障等原因,数据可能会丢失或重复处理。这可能导致数据的不一致性和准确性问题。Exactly-Once 语义通过确保每个事件只被处理一次,有效解决了这些问题,从而提高了数据处理的可靠性和准确性。
三、Flink 保证 Exactly-Once 语义的原理
Flink 通过以下两种机制来实现 Exactly-Once 语义:
- 状态一致性检查点(Checkpointing)
Flink 使用状态一致性检查点来定期保存和恢复作业的状态。当作业发生故障时,Flink 可以从最近的检查点恢复,并重新处理从该检查点开始的所有数据。为了确保 Exactly-Once 语义,Flink 在每个检查点都会记录已经处理过的数据位置(如 Kafka 的偏移量)。当从检查点恢复时,Flink 会跳过已经处理过的数据,只处理新的数据。 - Two-Phase Commit(2PC)协议
对于外部存储系统(如数据库、文件系统等),Flink 使用 Two-Phase Commit 协议来确保数据的一致性。在预提交阶段,Flink 将数据写入外部存储系统的临时位置,并记录相应的日志。在提交阶段,如果所有任务都成功完成,Flink 会将临时数据移动到最终位置,并删除相应的日志。如果某个任务失败,Flink 会根据日志回滚到预提交阶段的状态,并重新处理数据。
四、原理分析
- 状态一致性检查点
Flink 在每个检查点都会生成一个全局唯一的 ID,并将该 ID 与作业的状态一起保存。
当作业发生故障时,Flink 会从最近的检查点恢复,并重新处理从该检查点开始的所有数据。
Flink 使用异步的方式生成检查点,以减少对正常处理流程的影响。
Flink 还提供了自定义检查点策略的功能,以便用户根据实际需求进行配置。 - Two-Phase Commit 协议
Flink 在预提交阶段将数据写入外部存储系统的临时位置,并记录相应的日志。
在提交阶段,Flink 会等待所有任务都成功完成后再进行提交操作。
如果某个任务失败,Flink 会根据日志回滚到预提交阶段的状态,并重新处理数据。
Two-Phase Commit 协议确保了外部存储系统中数据的一致性和准确性。
五、示例
假设我们有一个 Flink 作业,它从 Kafka 中读取数据并将其写入到 HDFS 中。为了确保 Exactly-Once 语义,我们可以按照以下步骤进行配置:
启用状态一致性检查点
在 Flink 作业的配置中启用状态一致性检查点,并设置合适的检查点间隔和超时时间。env.enableCheckpointing(checkpointInterval); // 设置检查点间隔 env.setCheckpointTimeout(checkpointTimeout); // 设置检查点超时时间配置外部存储系统的写入策略
对于 HDFS 的写入操作,我们可以使用 Flink 提供的 BucketingSink 或 FileSystemSink,并配置为使用 Two-Phase Commit 协议。// 示例:使用 BucketingSink 写入 HDFS BucketingSink<String> hdfsSink = new BucketingSink<>("hdfs://path/to/output") .setBucketer(new DateTimeBucketer<String>("yyyy-MM-dd--HH")) .setBatchSize(1024) // 设置每个批次的记录数 .setBatchRolloverInterval(60000); // 设置批次滚动的时间间隔(毫秒) // 将数据流连接到 HDFS Sink dataStream.addSink(hdfsSink);六、总结
Apache Flink 通过状态一致性检查点和 Two-Phase Commit 协议来确保 Exactly-Once 语义。这些机制确保了数据在分布式系统中的一致性和准确性,从而提高了大数据处理的可靠性和准确性。在实际应用中,我们可以根据具体需求配置 Flink 的检查点策略和外部存储系统的写入策略,以实现更好的性能和可靠性。
Exactly-Once 特性概览 (翻译)")
Apache Flink 端到端(end-to-end)Exactly-Once 特性概览 (翻译)
Apache Flink 端到端(end-to-end)Exactly-Once 特性概览
本文是 flink 博文的翻译,原文链接 https://flink.apache.org/features/2018/03/01/end-to-end-exactly-once-apache-flink.html
2017 年 12 月份发布的 Apache Flink 1.4 版本,引进了一个重要的特性:TwoPhaseCommitSinkFunction (关联 Jirahttps://issues.apache.org/jira/browse/FLINK-7210) ,它抽取了两阶段提交协议的公共部分,使得构建端到端 Excatly-Once 的 Flink 程序变为了可能。这些外部系统包括 Kafka0.11 及以上的版本,以及一些其他的数据输入(data sources)和数据接收 (data sink)。它提供了一个抽象层,需要用户自己手动去实现 Exactly-Once 语义。
如果仅仅是使用,可以查看这个文档 https://ci.apache.org/projects/flink/flink-docs-release-1.4/api/java/org/apache/flink/streaming/api/functions/sink/TwoPhaseCommitSinkFunction.html。
如果想要了解更多,这篇文章我们会深入了解这个特性,以及 Flink 背后做的工作。
纵览全篇,有以下几点:
- 描述 Flink checkpoints 的作用,以及它是如何保障 Flink 程序 Exactly-Once 的语义的。
- 展现 Flink 如何与两阶段提交协议与输入输出(data sources and data sinks)交互,借此传递端到端的 Exactly-Once 语义保证。
- 通过一个简单的例子来展现如何使用 TwoPhaseCommitSinkFunction,来实现 Exactly-Once 的文件输出(file sink)。
Apache Flink 程序的 Exactly-Once 语义
当我们在讨论 Exactly-Once 语义的时候,我们指的是每一个到来的事件仅会影响最终结果一次。就算机器宕机或者软件崩溃,即没有数据重复,也没有数据丢失。
Flink 很久之前就提供了 Exactly-Once 语义。在过去的几年时间里,我们对 Flink 的 checkpoint 做了深入的描述 ,这个是 Flink 能够提供 Exactly-Once 语义的核心。Flink 文档也对这个特性做了深入的介绍 。
在我们继续之前,有一个关于 checkpoint 算法的简要介绍,这对于了解更广的主题来说是十分必要的。
一个 checkpoint 是 Flink 的一致性快照,它包括:
- 程序当前的状态
- 输入流的位置
Flink 通过一个可配置的时间,周期性的生成 checkpoint,将它写入到存储中,例如 S3 或者 HDFS。写入到存储的过程是异步的,意味着 Flink 程序在 checkpoint 运行的同时还可以处理数据。
在机器或者程序遇到错误重启的时候,Flink 程序会使用最新的 checkpoint 进行恢复。Flink 会恢复程序的状态,将输入流回滚到 checkpoint 保存的位置,然后重新开始运行。这意味着 Flink 可以像没有发生错误一样计算结果。
在 Flink 1.4.0 版本之前,Flink 仅保证 Flink 程序内部的 Exactly-Once 语义,没有扩展到在 Flink 数据处理完成后存储的外部系统。
Flink 程序可以和不同的接收器(sink)交互,开发者需要有能力在一个组件的上下文中维持 Exactly-Once 语义。
为了提供端到端 Exactly-Once 语义,除了 Flink 应用程序本身的状态,Flink 写入的外部存储也需要满足这个语义。也就是说,这些外部系统必须提供提交或者回滚的方法,然后通过 Flink 的 checkpoint 来协调。
在分布式系统中,协调提交和回滚的通用做法是两阶段提交。接下来,我们讨论 Flink 的 TwoPhaseCommitSinkFunction 如何使用两阶段提交协议来保证端到端的 Exactly-Once 语义。
Flink 程序端到端的 Exactly-Once 语义
我们简略的看一下两阶段提交协议,以及它如何在一个读写 Kafka 的 Flink 实例程序中提供端到端的 Exactly-Once 语义。Kafka 是一个流行的消息中间件,经常被拿来和 Flink 一起使用,Kafka 在最近的 0.11 版本中添加了对事务的支持。这意味着现在 Flink 读写 Kafka 有了必要的支持,使之能提供端到端的 Exactly-Once 语义。
Flink 对端到端的 Exactly-Once 语义不仅仅局限在 Kafka,你可以使用任一输入输出源(source、sink),只要他们提供了必要的协调机制。例如 Pravega ,来自 DELL/EMC 的流数据存储系统,通过 Flink 的 TwoPhaseCommitSinkFunction 也能支持端到端的 Exactly-Once 语义。
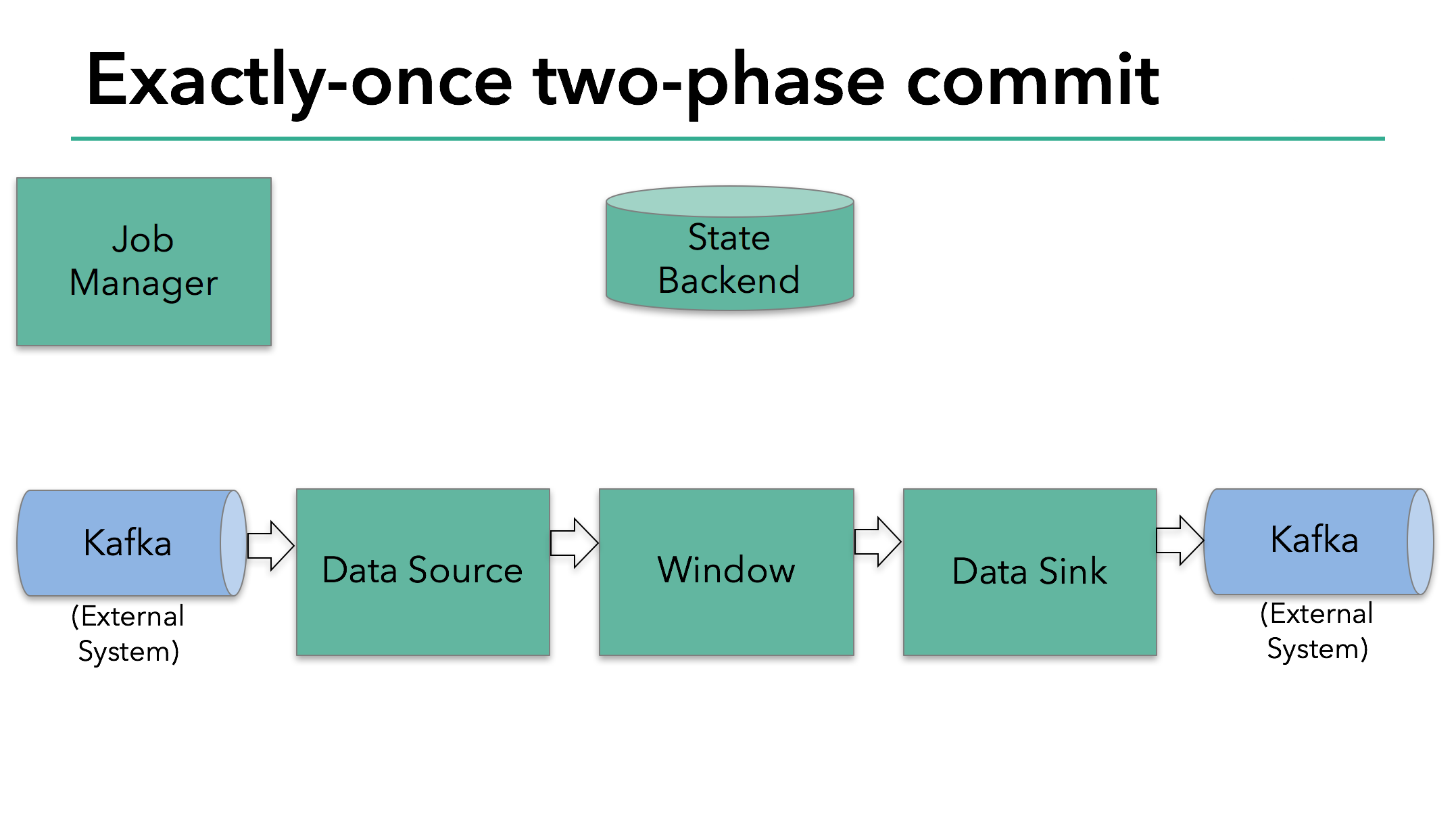
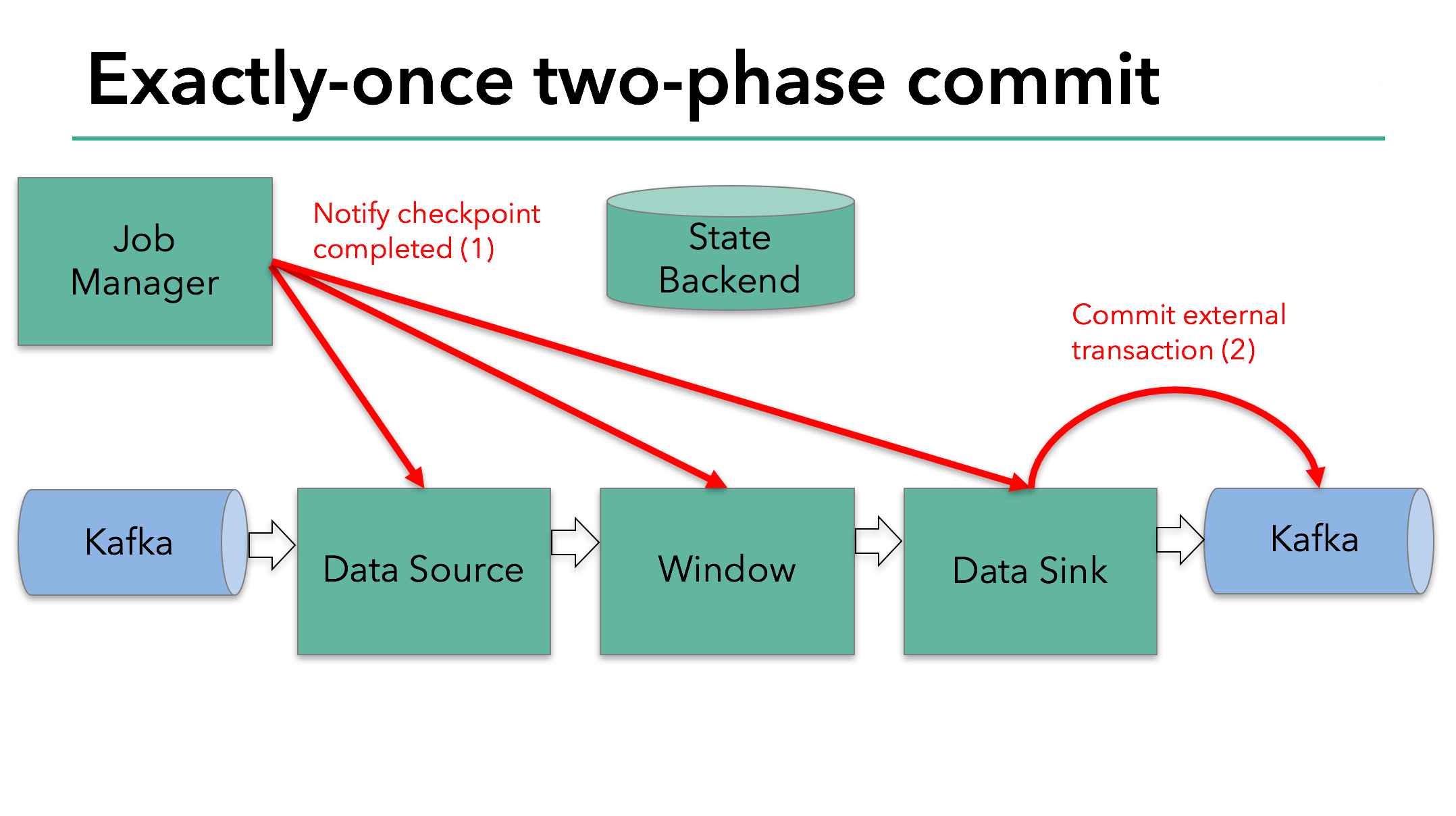
在这个示例程序中,我们有:
- 从 Kafka 读取数据的 data source(KafkaConsumer,在 Flink 中)
- 窗口聚合
- 将数据写回到 Kafka 的 data sink(KafkaProducer,在 Flink 中)
在 data sink 中要保证 Exactly-Once 语义,它必须将所有的写入数据通过一个事务提交到 Kafka。在两个 checkpoint 之间,一个提交绑定了所有要写入的数据。
这保证了当出错的时候,写入的数据可以被回滚。
然而在分布式系统中,通常拥有多个并行执行的写入任务,简单的提交和回滚是效率低下的。为了保证一致性,所有的组件必须先达成一致,才能进行提交或者回滚。Flink 使用了两阶段提交协议以及预提交阶段来解决这个问题。
在 checkpoint 开始的时候,即两阶段提交中的预提交阶段。首先,Flink 的 JobManager 在数据流中注入一个 checkpoint 屏障(它将数据流中的记录分割开,一些进入到当前的 checkpoint,另一些进入下一个 checkpoint)。
屏障通过 operator 传递。对于每一个 operator,它将触发 operator 的状态快照写入到 state backend。
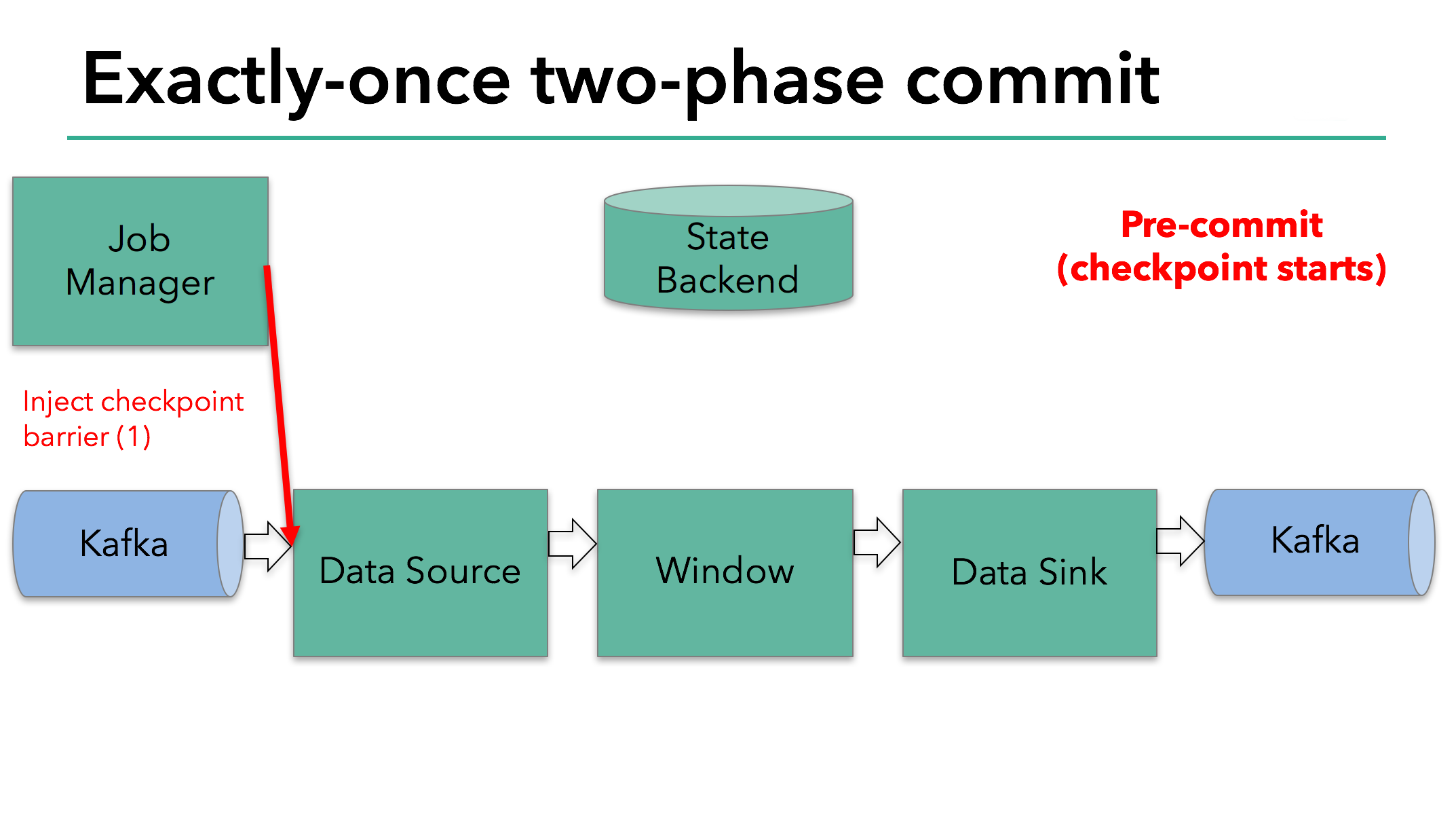
data source 保存了 Kafka 的 offset,之后把 checkpoint 屏障传递到后续的 operator。
这种方式仅适用于 operator 有他的内部状态。内部状态是指,Flink state backends 保存和管理的内容 - 举例来说,第二个 operator 中 window 聚合算出来的 sum。当一个进程有它的内部状态的时候,除了在 checkpoint 之前将需要将数据更改写入到 state backend,不需要在预提交阶段做其他的动作。在 checkpoint 成功的时候,Flink 会正确的提交这些写入,在 checkpoint 失败的时候会终止提交。 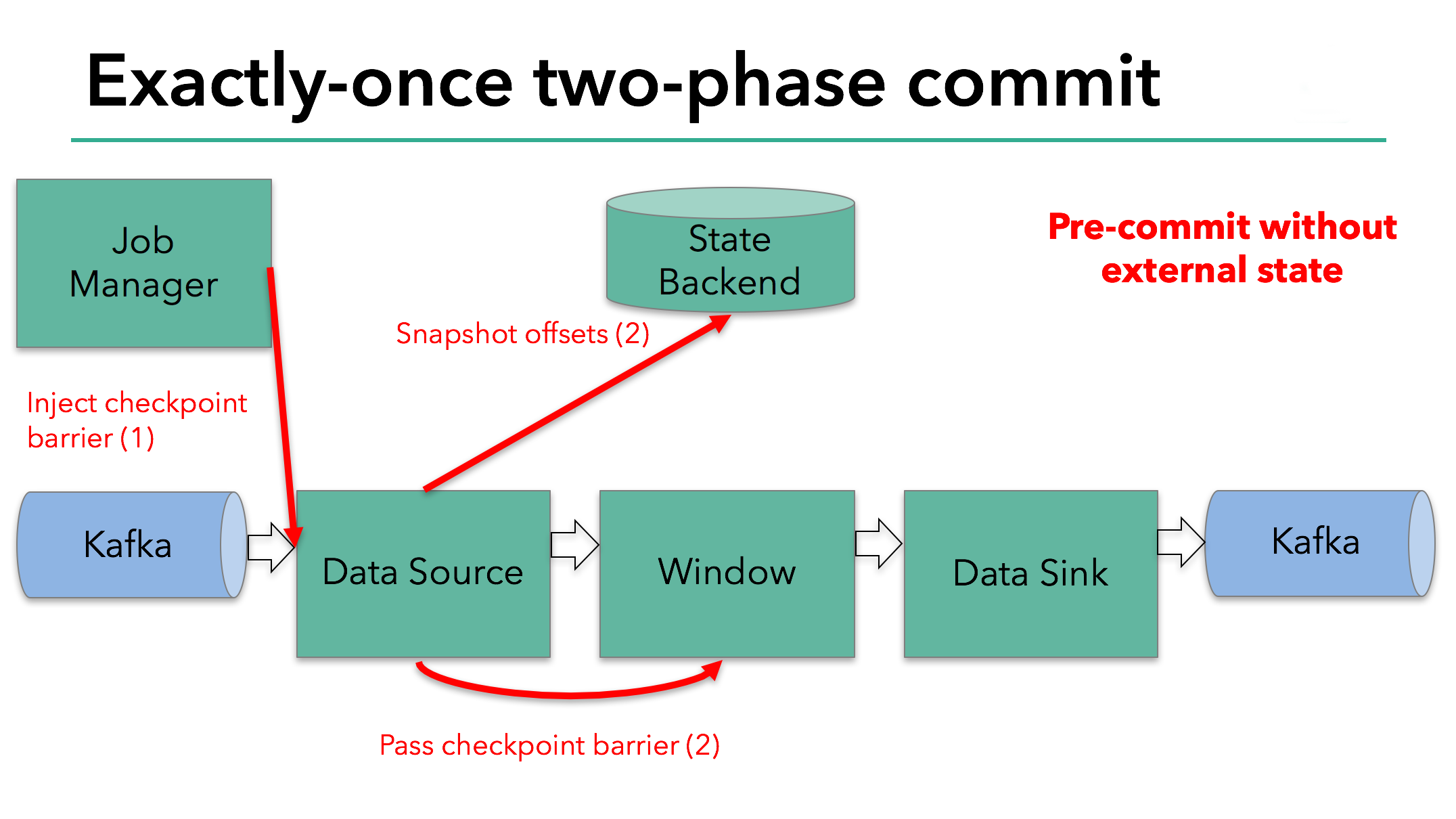
然而,当一个进程有外部状态的时候,需要用一种不同的方式来处理。外部状态通常由需要写入的外部系统引入,例如 Kafka。因此,为了提供 Exactly-Once 保证,外部系统必须提供事务支持,借此和两阶段提交协议交互。
我们知道在我们的例子中,由于需要将数据写到 Kafka,data sink 有外部的状态。因此,在预提交阶段,除了将状态写入到 state backend 之外,data sink 必须预提交自己的外部事务。
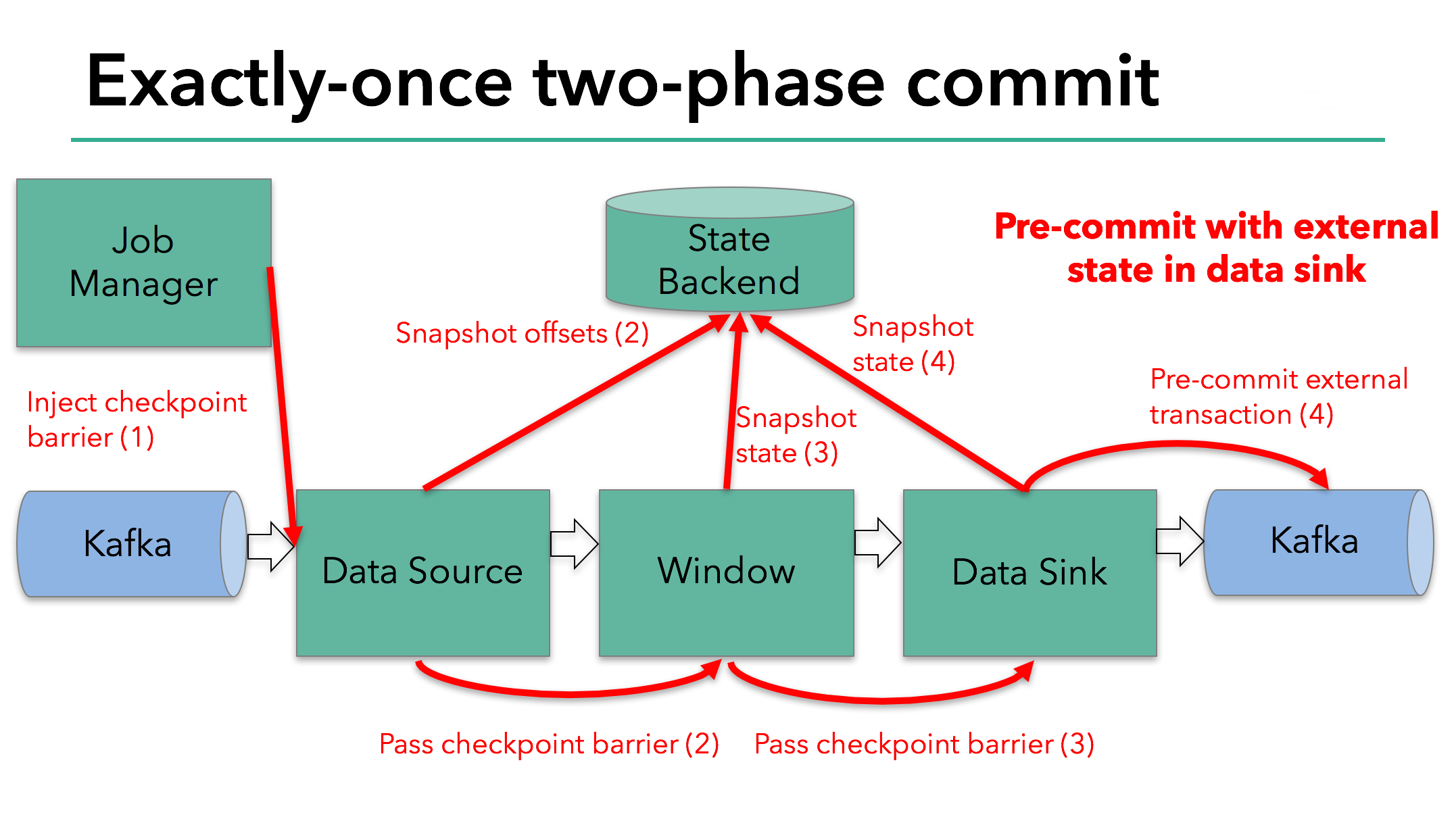
当 checkpoint 屏障在所有 operator 中都传递了一遍,以及它触发的快照写入完成,预提交阶段结束。这个时候,快照成功结束,整个程序的状态,包括预提交的外部状态是一致的。万一出错的时候,我们可以通过 checkpoint 重新初始化。
下一步是通知所有 operator,checkpoint 已经成功了。这时两阶段提交中的提交阶段,Jobmanager 为程序中的每一个 operator 发起 checkpoint 已经完成的回调。data source 和 window operator 没有外部的状态,在提交阶段中,这些 operator 不会执行任何动作。data sink 拥有外部状态,所以通过事务提交外部写入。
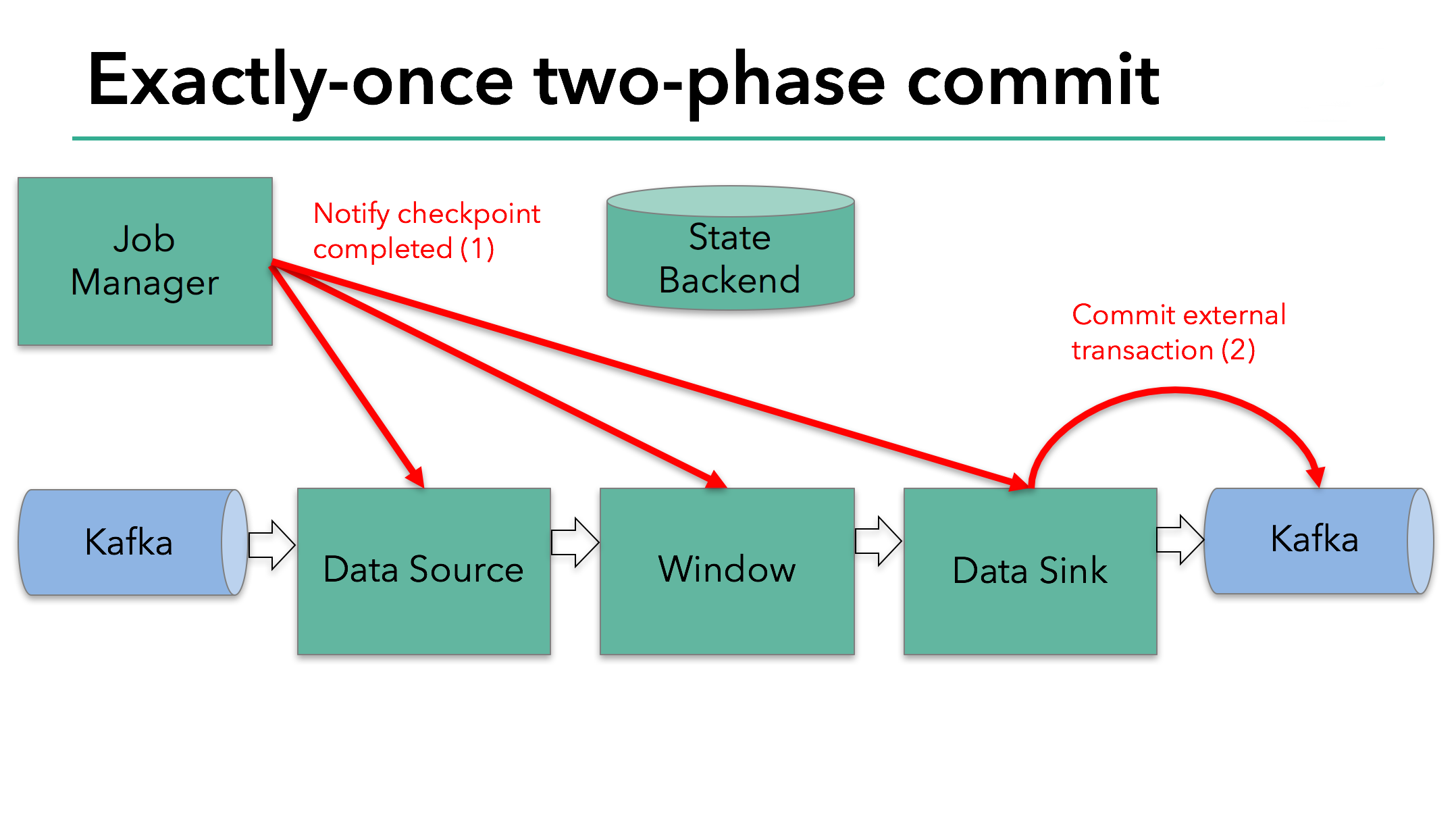
让我们对上述的知识点汇总一下:
- 一旦所有的 operator 完成预提交,就提交一个 commit。
- 如果至少有一个预提交失败,其他的都会失败,这时回滚到上一个 checkpoint 保存的位置。
- 预提交成功后,提交的 commit 也需要保障最终成功 - operator 和外部系统需要提供这个保障。如果 commit 失败了(比如网络中断引起的故障),整个 flink 程序也因此失败,它会根据用户的重启策略重启,可能还会有一个尝试性的提交。这个过程非常严苛,因为如果提交没有最终生效,会导致数据丢失。
因此,我们可以确定所有的 operator 同意 checkpoint 的最终结果:要么都同意提交数据,要么提交被终止然后回滚。
在 Flink 程序中实现两阶段提交
完整的实现两阶段提交协议可能会有一点复杂,因此 Flink 将通用逻辑提取到一个 abstract 的类 TwoPhaseCommitSinkFunction。
让我们通过一个简单的文件操作例子来说明如何使用 TwoPhaseCommitSinkFunction。我们只需要实现四个 method,并使 sink 呈现 Exactly-Once 语义。
- beginTransaction - 在事务开始前,我们在目标文件系统上面的临时目录上创建一个临时文件。随后,我们在程序处理的时候可以将数据写入到这个文件。
- preCommit - 在预提交阶段,我们刷新文件到磁盘,关闭文件,不要重新打开写入。我们也会为下一个 checkpoint 的文件写入开启一个新的事务。
- commit - 在提交阶段,我们原子性的将预提交阶段的文件移动到真正的目标目录。需要注意的是,这增加了输出数据的可见性的延迟。
- abort - 在终止阶段,我们删除临时文件。
我们知道,如果步骤中有任何错误,Flink 会通过最新的 checkpoint 来恢复程序状态。在一个罕见的场景中,预提交成功了,在通知到达 operator 之前失败了。这时候,Flink 将 operator 的状态恢复到预提交阶段,即还未真正提交的时候。
为了能在重启的时候能够正确的终止或者提交事务,我们需要在预提交阶段将足够的信息保存到 checkpoint 中。在这个例子中,这些信息是临时文件以及目标目录的地址。
TwoPhaseCommitSinkFunction 已经把这个场景考虑进去了,在从 checkpoint 恢复的时候,它会优先提交一个 commit。我们的任务是将 commit 实现成一个幂等的操作。一般的,这不是难题。在这个例子中,我们可以发现这种情况:临时文件不在临时目录中,但是已经移动到目标目录了。
在 TwoPhaseCommitSinkFunction 中,有一些其他的边界条件也考虑在内了。通过 Flink 文档查看更多。
总结
如果你看到了这么后面,很感谢你通读这个详细的帖子。以下是我们主要覆盖的关键点:
- Flink 的 checkpoint 系统是它支撑两阶段协议和保障 Exactly-Once 语义的基础设施,
- 这种实现方案的优点是,Flink 不像其他系统那样,通过网络传输存储数据 - 它不需要像大部分批处理程序那样,将每一个计算结果保存到磁盘。
- Flink 的 TwoPhaseCommitSinkFunction 提取了两阶段提交协议的通用部分,通过这个方法结合 Flink 以及支持事务的外部系统,可以构建端到端的 Exactly-Once 程序。
- 从 Flink 1.4.0 开始,Pravega 和 Kafka 0.11 producer 提供了 Exactly-Once 语义;通过 Kafka 在 0.11 版本第一次引入的事务,为在 Flink 中使用 Kafka producer 提供 Exactly-Once 语义提供了可能性。
- Kafka 0.11 版本的 producer 是在 TwoPhaseCommitSinkFunction 基础上实现的,它 at-least-once 的 producer 的基础上增加了很小的开销。
我们为这个特性能提供的功能感到很兴奋,今后希望能找到更多支持 TwoPhaseCommitSinkFunction 的 producer。

Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理
文章目录:
- Apache Flink 应用程序中的 Exactly-Once 语义
- Flink 应用程序端到端的 Exactly-Once 语义
- 示例 Flink 应用程序启动预提交阶段
- 在 Flink 中实现两阶段提交 Operator
- 总结
Apache Flink 自2017年12月发布的1.4.0版本开始,为流计算引入了一个重要的里程碑特性:TwoPhaseCommitSinkFunction(相关的Jira)。它提取了两阶段提交协议的通用逻辑,使得通过Flink来构建端到端的Exactly-Once程序成为可能。同时支持一些数据源(source)和输出端(sink),包括Apache Kafka 0.11及更高版本。它提供了一个抽象层,用户只需要实现少数方法就能实现端到端的Exactly-Once语义。
有关TwoPhaseCommitSinkFunction的使用详见文档: TwoPhaseCommitSinkFunction。或者可以直接阅读Kafka 0.11 sink的文档: kafka。
接下来会详细分析这个新功能以及Flink的实现逻辑,分为如下几点。
- 描述Flink checkpoint机制是如何保证Flink程序结果的Exactly-Once的
- 显示Flink如何通过两阶段提交协议与数据源和数据输出端交互,以提供端到端的Exactly-Once保证
- 通过一个简单的示例,了解如何使用TwoPhaseCommitSinkFunction实现Exactly-Once的文件输出
一、Apache Flink应用程序中的Exactly-Once语义
当我们说『Exactly-Once』时,指的是每个输入的事件只影响最终结果一次。即使机器或软件出现故障,既没有重复数据,也不会丢数据。
Flink很久之前就提供了Exactly-Once语义。在过去几年中,我们对Flink的checkpoint机制有过深入的描述,这是Flink有能力提供Exactly-Once语义的核心。Flink文档还提供了该功能的全面概述。
在继续之前,先看下对checkpoint机制的简要介绍,这对理解后面的主题至关重要。
- 次checkpoint是以下内容的一致性快照:
- 应用程序的当前状态
- 输入流的位置
Flink可以配置一个固定的时间点,定期产生checkpoint,将checkpoint的数据写入持久存储系统,例如S3或HDFS。将checkpoint数据写入持久存储是异步发生的,这意味着Flink应用程序在checkpoint过程中可以继续处理数据。
如果发生机器或软件故障,重新启动后,Flink应用程序将从最新的checkpoint点恢复处理; Flink会恢复应用程序状态,将输入流回滚到上次checkpoint保存的位置,然后重新开始运行。这意味着Flink可以像从未发生过故障一样计算结果。
在Flink 1.4.0之前,Exactly-Once语义仅限于Flink应用程序内部,并没有扩展到Flink数据处理完后发送的大多数外部系统。Flink应用程序与各种数据输出端进行交互,开发人员需要有能力自己维护组件的上下文来保证Exactly-Once语义。
为了提供端到端的Exactly-Once语义 – 也就是说,除了Flink应用程序内部,Flink写入的外部系统也需要能满足Exactly-Once语义 – 这些外部系统必须提供提交或回滚的方法,然后通过Flink的checkpoint机制来协调。
分布式系统中,协调提交和回滚的常用方法是两阶段提交协议。在下一节中,我们将讨论Flink的TwoPhaseCommitSinkFunction是如何利用两阶段提交协议来提供端到端的Exactly-Once语义。
二、Flink应用程序端到端的Exactly-Once语义
我们将介绍两阶段提交协议,以及它如何在一个读写Kafka的Flink程序中实现端到端的Exactly-Once语义。Kafka是一个流行的消息中间件,经常与Flink一起使用。Kafka在最近的0.11版本中添加了对事务的支持。这意味着现在通过Flink读写Kafaka,并提供端到端的Exactly-Once语义有了必要的支持。
Flink对端到端的Exactly-Once语义的支持不仅局限于Kafka,您可以将它与任何一个提供了必要的协调机制的源/输出端一起使用。例如Pravega,来自DELL/EMC的开源流媒体存储系统,通过Flink的TwoPhaseCommitSinkFunction也能支持端到端的Exactly-Once语义。

在今天讨论的这个示例程序中,我们有:
- 从Kafka读取的数据源(Flink内置的KafkaConsumer)
- 窗口聚合
- 将数据写回Kafka的数据输出端(Flink内置的KafkaProducer)
要使数据输出端提供Exactly-Once保证,它必须将所有数据通过一个事务提交给Kafka。提交捆绑了两个checkpoint之间的所有要写入的数据。这可确保在发生故障时能回滚写入的数据。但是在分布式系统中,通常会有多个并发运行的写入任务的,简单的提交或回滚是不够的,因为所有组件必须在提交或回滚时“一致”才能确保一致的结果。Flink使用两阶段提交协议及预提交阶段来解决这个问题。
在checkpoint开始的时候,即两阶段提交协议的“预提交”阶段。当checkpoint开始时,Flink的JobManager会将checkpoint barrier(将数据流中的记录分为进入当前checkpoint与进入下一个checkpoint)注入数据流。
brarrier在operator之间传递。对于每一个operator,它触发operator的状态快照写入到state backend。

数据源保存了消费Kafka的偏移量(offset),之后将checkpoint barrier传递给下一个operator。
这种方式仅适用于operator具有『内部』状态。所谓内部状态,是指Flink state backend保存和管理的 -例如,第二个operator中window聚合算出来的sum值。当一个进程有它的内部状态的时候,除了在checkpoint之前需要将数据变更写入到state backend,不需要在预提交阶段执行任何其他操作。Flink负责在checkpoint成功的情况下正确提交这些写入,或者在出现故障时中止这些写入。

三、示例Flink应用程序启动预提交阶段
但是,当进程具有『外部』状态时,需要作些额外的处理。外部状态通常以写入外部系统(如Kafka)的形式出现。在这种情况下,为了提供Exactly-Once保证,外部系统必须支持事务,这样才能和两阶段提交协议集成。
在本文示例中的数据需要写入Kafka,因此数据输出端(Data Sink)有外部状态。在这种情况下,在预提交阶段,除了将其状态写入state backend之外,数据输出端还必须预先提交其外部事务。

当checkpoint barrier在所有operator都传递了一遍,并且触发的checkpoint回调成功完成时,预提交阶段就结束了。所有触发的状态快照都被视为该checkpoint的一部分。checkpoint是整个应用程序状态的快照,包括预先提交的外部状态。如果发生故障,我们可以回滚到上次成功完成快照的时间点。
下一步是通知所有operator,checkpoint已经成功了。这是两阶段提交协议的提交阶段,JobManager为应用程序中的每个operator发出checkpoint已完成的回调。
数据源和 widnow operator没有外部状态,因此在提交阶段,这些operator不必执行任何操作。但是,数据输出端(Data Sink)拥有外部状态,此时应该提交外部事务。

我们对上述知识点总结下:
- 旦所有operator完成预提交,就提交一个commit。
- 如果至少有一个预提交失败,则所有其他提交都将中止,我们将回滚到上一个成功完成的checkpoint。
- 在预提交成功之后,提交的commit需要保证最终成功 – operator和外部系统都需要保障这点。如果commit失败(例如,由于间歇性网络问题),整个Flink应用程序将失败,应用程序将根据用户的重启策略重新启动,还会尝试再提交。这个过程至关重要,因为如果commit最终没有成功,将会导致数据丢失。
因此,我们可以确定所有operator都同意checkpoint的最终结果:所有operator都同意数据已提交,或提交被中止并回滚。
四、在Flink中实现两阶段提交Operator
完整的实现两阶段提交协议可能有点复杂,这就是为什么Flink将它的通用逻辑提取到抽象类TwoPhaseCommitSinkFunction中的原因。
接下来基于输出到文件的简单示例,说明如何使用TwoPhaseCommitSinkFunction。用户只需要实现四个函数,就能为数据输出端实现Exactly-Once语义:
- beginTransaction – 在事务开始前,我们在目标文件系统的临时目录中创建一个临时文件。随后,我们可以在处理数据时将数据写入此文件。
- preCommit – 在预提交阶段,我们刷新文件到存储,关闭文件,不再重新写入。我们还将为属于下一个checkpoint的任何后续文件写入启动一个新的事务。
- commit – 在提交阶段,我们将预提交阶段的文件原子地移动到真正的目标目录。需要注意的是,这会增加输出数据可见性的延迟。
- abort – 在中止阶段,我们删除临时文件。
我们知道,如果发生任何故障,Flink会将应用程序的状态恢复到最新的一次checkpoint点。一种极端的情况是,预提交成功了,但在这次commit的通知到达operator之前发生了故障。在这种情况下,Flink会将operator的状态恢复到已经预提交,但尚未真正提交的状态。
我们需要在预提交阶段保存足够多的信息到checkpoint状态中,以便在重启后能正确的中止或提交事务。在这个例子中,这些信息是临时文件和目标目录的路径。
TwoPhaseCommitSinkFunction已经把这种情况考虑在内了,并且在从checkpoint点恢复状态时,会优先发出一个commit。我们需要以幂等方式实现提交,一般来说,这并不难。在这个示例中,我们可以识别出这样的情况:临时文件不在临时目录中,但已经移动到目标目录了。
在TwoPhaseCommitSinkFunction中,还有一些其他边界情况也会考虑在内,请参考Flink文档了解更多信息。
总结
总结下本文涉及的一些要点:
- Flink的checkpoint机制是支持两阶段提交协议并提供端到端的Exactly-Once语义的基础。
- 这个方案的优点是: Flink不像其他一些系统那样,通过网络传输存储数据 – 不需要像大多数批处理程序那样将计算的每个阶段写入磁盘。
- Flink的TwoPhaseCommitSinkFunction提取了两阶段提交协议的通用逻辑,基于此将Flink和支持事务的外部系统结合,构建端到端的Exactly-Once成为可能。
- 从Flink 1.4.0开始,Pravega和Kafka 0.11 producer都提供了Exactly-Once语义;Kafka在0.11版本首次引入了事务,为在Flink程序中使用Kafka producer提供Exactly-Once语义提供了可能性。
- Kafaka 0.11 producer的事务是在TwoPhaseCommitSinkFunction基础上实现的,和at-least-once producer相比只增加了非常低的开销。
这是个令人兴奋的功能,期待Flink TwoPhaseCommitSinkFunction在未来支持更多的数据接收端。
via:https://www.ververica.com/blog/end-to-end-exactly-once-processing-apache-flink-apache-kafka翻译| 周凯波
周凯波,阿里巴巴技术专家,四川大学硕士,2010年毕业后加入阿里搜索事业部,从事搜索离线平台的研发工作,参与将搜索后台数据处理架构从MapReduce到Flink的重构。目前在阿里计算平台事业部,专注于基于Flink的一站式计算平台的建设。
本文作者:apache_flink
阅读原文
本文为云栖社区原创内容,未经允许不得转载。
今天关于An Overview of End-to-End Exactly-Once Processing in Apache Flink (with Apache Kafka, too!)的介绍到此结束,谢谢您的阅读,有关10月21日直播预告 | Flink Exactly Once & Kafka-connector 算子、Apache Flink 如何保证 Exactly-Once 语义(其原理分析示例)、Apache Flink 端到端(end-to-end)Exactly-Once 特性概览 (翻译)、Apache Flink 结合 Kafka 构建端到端的 Exactly-Once 处理等更多相关知识的信息可以在本站进行查询。
本文标签:




