在这篇文章中,我们将带领您了解如何使用elasticsearch配置Jaeger?的全貌,包括elasticsearch配置详解的相关情况。同时,我们还将为您介绍有关Elasticsearch-如何在
在这篇文章中,我们将带领您了解如何使用elasticsearch配置Jaeger?的全貌,包括elasticsearch配置详解的相关情况。同时,我们还将为您介绍有关Elasticsearch - 如何在java中使用elasticsearch查找与地理定位点的匹配项、elasticsearch java api 使用elasticsearch 6.x.x版本,客户端使用5.6.10版本、Elasticsearch 参考指南(重要的Elasticsearch配置)、ElasticSearch 基本操作 ----- 基于 Java 实现 (SpringDataElasticSearch)的知识,以帮助您更好地理解这个主题。
本文目录一览:- 如何使用elasticsearch配置Jaeger?(elasticsearch配置详解)
- Elasticsearch - 如何在java中使用elasticsearch查找与地理定位点的匹配项
- elasticsearch java api 使用elasticsearch 6.x.x版本,客户端使用5.6.10版本
- Elasticsearch 参考指南(重要的Elasticsearch配置)
- ElasticSearch 基本操作 ----- 基于 Java 实现 (SpringDataElasticSearch)
")
如何使用elasticsearch配置Jaeger?(elasticsearch配置详解)
我尝试执行此docker命令以使用Elasticsearch设置Jaeger Agent和Jaeger Collector。
sudo docker run \-p 5775:5775/udp \-p 6831:6831/udp \-p 6832:6832/udp \-p 5778:5778 \-p 16686:16686 \-p 14268:14268 \-e SPAN_STORAGE_TYPE=elasticsearch \--name=jaeger \jaegertracing/all-in-one:latest但是此命令给出以下错误。如何用ElasticSearch配置Jaeger?
"msg":"Failed to init storage factory","error":"health check timeout: no Elasticsearch node available","errorVerbose":"no Elasticsearch node available\答案1
小编典典搜索解决方案一段时间后,我发现了一个docker-compose.yml文件,该文件具有Jaeger
Query,Agent,collector和Elasticsearch配置。
docker-compose.yml
version: "3"services: elasticsearch: image: docker.elastic.co/elasticsearch/elasticsearch:6.3.1 networks: - elastic-jaeger ports: - "127.0.0.1:9200:9200" - "127.0.0.1:9300:9300" restart: on-failure environment: - cluster.name=jaeger-cluster - discovery.type=single-node - http.host=0.0.0.0 - transport.host=127.0.0.1 - ES_JAVA_OPTS=-Xms512m -Xmx512m - xpack.security.enabled=false volumes: - esdata:/usr/share/elasticsearch/data jaeger-collector: image: jaegertracing/jaeger-collector ports: - "14269:14269" - "14268:14268" - "14267:14267" - "9411:9411" networks: - elastic-jaeger restart: on-failure environment: - SPAN_STORAGE_TYPE=elasticsearch command: [ "--es.server-urls=http://elasticsearch:9200", "--es.num-shards=1", "--es.num-replicas=0", "--log-level=error" ] depends_on: - elasticsearch jaeger-agent: image: jaegertracing/jaeger-agent hostname: jaeger-agent command: ["--collector.host-port=jaeger-collector:14267"] ports: - "5775:5775/udp" - "6831:6831/udp" - "6832:6832/udp" - "5778:5778" networks: - elastic-jaeger restart: on-failure environment: - SPAN_STORAGE_TYPE=elasticsearch depends_on: - jaeger-collector jaeger-query: image: jaegertracing/jaeger-query environment: - SPAN_STORAGE_TYPE=elasticsearch - no_proxy=localhost ports: - "16686:16686" - "16687:16687" networks: - elastic-jaeger restart: on-failure command: [ "--es.server-urls=http://elasticsearch:9200", "--span-storage.type=elasticsearch", "--log-level=debug" ] depends_on: - jaeger-agentvolumes: esdata: driver: localnetworks: elastic-jaeger: driver: bridgedocker-compose.yml文件将安装elasticsearch,Jaeger收集器,查询和代理。
安装docker和docker首先组成 https://docs.docker.com/compose/install/#install-
compose
然后,按顺序执行这些命令
1. sudo docker-compose up -d elasticsearch2. sudo docker-compose up -d3. sudo docker ps -a启动所有docker容器-Jaeger代理,收集器,查询和elasticsearch。
sudo docker启动容器ID
访问-> http:// localhost:16686 /

Elasticsearch - 如何在java中使用elasticsearch查找与地理定位点的匹配项
如何解决Elasticsearch - 如何在java中使用elasticsearch查找与地理定位点的匹配项?
我是 elasticSearch 的新手,我正在尝试查询与地图上特定点匹配的文档,我正在使用 GeoPoint 对象,我需要进行一个返回所有“地理区域”的查询包含此句点,但我对 elasticsearch 查询有些困惑。
我仍然没有正确理解为了执行这些操作我的文档必须具有的结构,在这里我离开我正在调用的文档的类
@Data
@Document(indexName = "geozona")
public class GeozonaElasticDTO {
@Id
@Field(type = FieldType.Long)
private long id;
@Field(type = FieldType.Text)
private UUID uuid;
@Field(type = FieldType.Text)
private String nombre;
@Field(type = FieldType.Text)
private String descripcion;
private List<UUID> etiquetas;
private List<UUID> lugares;
private List<UUID> geozonaLimiteVeLocidad;
@Field(type = FieldType.Text)
private EnumTipoGeozona tipoGeozona;
@Field(type = FieldType.Double)
private Double radio;
@Field(type = FieldType.Text)
private String pathEncode;
@Field(type = FieldType.Object)
@GeoPointField
private List<GeoPoint> points;
@Field(type = FieldType.Double)
private double puntoDeReferenciaLatitud;
@Field(type = FieldType.Double)
private double puntoDeReferenciaLongitud;
@Field(type = FieldType.Integer)
private int limiteDeOrientacionGradoInicio;
@Field(type = FieldType.Integer)
private int limiteDeOrientacionGradoTermino;
@Field(type = FieldType.Integer)
private Integer ancho;
@Field(type = FieldType.Boolean)
private boolean eliminado;
@Field(type = FieldType.Date,format = DateFormat.custom,pattern = "uuuu-MM-dd''T''HH:mm:ssZ")
private zoneddatetime fechaCreacion;
@Field(type = FieldType.Date,pattern = "uuuu-MM-dd''T''HH:mm:ssZ")
private zoneddatetime fechaActualizacion;
@Field(type = FieldType.Integer)
private int version;
}
这是我在弹性服务器中的类的结构
"geozona": {
"aliases": {},"mappings": {
"properties": {
"_class": {
"type": "text","fields": {
"keyword": {
"type": "keyword","ignore_above": 256
}
}
},"ancho": {
"type": "integer"
},"descripcion": {
"type": "text"
},"eliminado": {
"type": "boolean"
},"etiquetas": {
"type": "text","fechaActualizacion": {
"type": "date","format": "uuuu-MM-dd''T''HH:mm:ssZ"
},"fechaCreacion": {
"type": "date","geozonaLimiteVeLocidad": {
"type": "text","id": {
"type": "keyword"
},"limiteDeOrientacionGradoInicio": {
"type": "integer"
},"limiteDeOrientacionGradoTermino": {
"type": "integer"
},"lugares": {
"type": "text","nombre": {
"type": "text"
},"pathEncode": {
"type": "text"
},"points": {
"type": "geo_point"
},"puntoDeReferenciaLatitud": {
"type": "double"
},"puntoDeReferenciaLongitud": {
"type": "double"
},"radio": {
"type": "double"
},"tipoGeozona": {
"type": "text"
},"uuid": {
"type": "text"
},"version": {
"type": "integer"
}
}
},"settings": {
"index": {
"refresh_interval": "1s","number_of_shards": "1","provided_name": "geozona","creation_date": "1609949683125","store": {
"type": "fs"
},"number_of_replicas": "1","uuid": "m-y7Qa5wSwGmDA3TVm4HkA","version": {
"created": "7090299"
}
}
}
}
}
如果有人能指导我如何开始正确处理地理定位点与弹性的重合,那将对我有很大帮助。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

elasticsearch java api 使用elasticsearch 6.x.x版本,客户端使用5.6.10版本
es的添加数据方法中 索引index字段不允许为大写字符串,必须全部为小写字符串
public void bulkCreatIndex(){
TransportClient client = es.getClient();
int i = 1;
// bulk单次批操作量
final int BatchSize = 10000;
BulkRequestBuilder bulkRequest = client.prepareBulk();
// 遍历JSONArray,数据量庞大时,for循环比foreach循环效率更高一些
for (i = 1; i <= jsonArray.size(); i++) {
// setSource为上传的文本文档
bulkRequest.add(client.prepareIndex(index.toLowerCase(), type).setSource(jsonArray.getJSONObject(i-1).toString()));
// 每10000条数据执行一次bulk批量操作
if (0 == i % BatchSize) {
bulkRequest.execute().actionGet();
bulkRequest = client.prepareBulk();//此处是bulkRequest执行完成之后会重新创建一个bulkRequest避免下次提交出现重复的数据,如果是一次性全部提交可以不用使用此处
}
}
bulkRequest.execute().actionGet();
bulkRequest = client.prepareBulk();
}
查询方法
public void search(){
Client client = esmanager.getClient();
RangeQueryBuilder rangequerybuilder = QueryBuilders.rangeQuery("startdate").from(startdate).to(enddate);//建立查询是所使用条件startdate 从from startdate开始至enddate结束,
SearchRequestBuilder responsebuilder = client.prepareSearch(index).setTypes(type);//创建查询使用方法
SearchResponse myresponse = responsebuilder
.setQuery(QueryBuilders.boolQuery().must(rangequerybuilder))//添加查询条件
.setFrom(from).setSize(size).addSort("startdate", SortOrder.ASC) // 分页 并且根据startdate进行排序
.setExplain(true).execute().actionGet();
SearchHits hits = myresponse.getHits();//searchhits 为查询结果相当于jdbc中的ResultSet
for (int i = 0; i < hits.getHits().length; i++) {
hits.getHits()[i].getSourceAsMap().get(key)
}
根据业务进行方法的修改,本方法制作一个demo参考为主。
")
Elasticsearch 参考指南(重要的Elasticsearch配置)
重要的Elasticsearch配置
虽然Elasticsearch只需要很少的配置,但是在投入生产之前需要考虑许多设置。
path.data和path.logs
如果你使用.zip或.tar.gz归档,数据和日志目录都是$ES_HOME的子文件夹,如果这些重要的文件夹被保留在它们的默认位置,那么在升级到新版本时,它们很有可能被删除。
在生产使用中,你几乎肯定希望更改数据和日志文件夹的位置:
path:
logs: /var/log/elasticsearch
data: /var/data/elasticsearchRPM和Debian发行版已经为数据和日志使用了自定义路径。
path.data设置可以设置为多个路径,在这种情况下,所有路径都将用于存储数据(尽管属于单个碎片的文件都将存储在相同的数据路径上):
path:
data:
- /mnt/elasticsearch_1
- /mnt/elasticsearch_2
- /mnt/elasticsearch_3cluster.name
节点只有在与集群中的所有其他节点共享其cluster.name时才能加入集群,默认的名称是elasticsearch,但是应该将其更改为描述集群用途的适当名称。
cluster.name: logging-prod确保不要在不同的环境中重用相同的集群名称,否则可能会导致节点加入错误的集群。
node.name
默认情况下,Elasticsearch将使用随机生成的UUID的前7个字符作为节点id。注意,节点id是持久的并且在节点重新启动时不会更改,因此默认节点名也不会更改。
值得配置一个更有意义的名称,这个名称在重新启动节点之后也具有持久化的优势:
node.name: prod-data-2节点名也可以设置为服务器的主机名如下:
node.name: ${HOSTNAME}network.host
在默认情况下,Elasticsearch只绑定回环地址 — 例如,127.0.0.1和[::1],这足以在服务器上运行单个开发节点。
实际上,可以从单个节点上相同的$ES_HOME位置启动多个节点,这对于测试Elasticsearch形成集群的能力是很有用的,但是这并不是推荐用于生产的配置。
为了与其他服务器上的节点进行通信并形成集群,你的节点将需要绑定到非回环地址,虽然有许多网络设置,但通常你需要配置的只是network.host:
network.host: 192.168.1.10network.host设置还可以理解一些特殊值,如_local_、_site_、_global_和像:ip4和:ip6的修饰符,详细信息可以在network.host的特殊值中找到。
很快你就可以为network.host提供一个自定义设置,Elasticsearch假定你正在从开发模式转换到生产模式,并将许多系统启动检查从警告升级到异常,有关更多信息,请参见开发模式与生产模式。
发现设置
Elasticsearch使用一种名为“Zen discovery”的自定义发现实现,用于节点到节点的集群和主选择,在开始生产之前应该配置两个重要的发现设置。
discovery.zen.ping.unicast.hosts
在没有任何网络配置的情况下,Elasticsearch将绑定到可用的回环地址,并扫描端口9300到9305,以尝试连接到同一服务器上运行的其他节点,这提供了自动集群体验,而无需进行任何配置。
当节点在其他服务器上形成集群时,你必须提供集群中可能存在的其他节点的种子列表,可以指定如下:
discovery.zen.ping.unicast.hosts:
- 192.168.1.10:9300
- 192.168.1.11
- seeds.mydomain.com- 如果没有指定端口号,端口将默认为
transport.profiles.default.port,并且回退到transport.tcp.port - 解析到多个IP地址的主机名将尝试所有已解析的地址
discovery.zen.minimum_master_nodes
为了防止数据丢失,配置discovery.zen.minimum_master_nodes非常重要,使每个适合的主节点都知道要形成集群必须可见的适合的主节点的最小数目。
如果没有这种设置,遭受网络故障的集群有可能被分割成两个独立的集群 - 脑分裂 - 这将导致数据丢失,使用minimum_master_nodes避免脑分裂提供了一个更详细的解释。
为了避免脑分裂,这个设置应该设置为适合的主节点的法定数量:
(master_eligible_nodes / 2) + 1换句话说,如果有三个适合的主节点,那么最小主节点应该设置为(3 / 2) + 1或2:
discovery.zen.minimum_master_nodes: 2堆大小设置
在默认情况下,Elasticsearch告诉JVM使用最小和最大大小为1GB的堆,在迁移到生产时,重要的是配置堆大小以确保Elasticsearch有足够的可用堆。
Elasticsearch将在jvm.options中通过Xms(最小堆大小)和Xmx(最大堆大小)的设置分配指定的整个堆。
这些设置的值取决于服务器上可用RAM的总数,好的经验法则是:
- 设置最小堆大小(
Xms)和最大堆大小(Xmx)彼此相等。 - 对Elasticsearch可用的堆越多,它用于缓存的内存就越多。但是请注意,过多的堆可能会使你陷入长时间的垃圾收集停顿。
- 将
Xmx设置为不超过物理RAM的50%,以确保有足够的物理RAM留给内核文件系统缓存。 -
不要将
Xmx设置在JVM用于压缩对象指针的截点之上(被压缩的oops)。确切的截点不同,但接近32GB,你可以通过在日志中查找如下所示的行来验证你是否处于限制之下:heap size [1.9gb], compressed ordinary object pointers [true] -
更好的方法是,尽量低于零基础被压缩的oops阈值。确切的截点不同,但在大多数系统中26GB是安全的,但在某些系统中可能高达30GB。你可以通过使用JVM选项
-XX:+UnlockDiagnosticVMOptions -XX:+PrintCompressedOopsMode启动Elasticsearch,并查找如下所示的行来验证你是否处于限制之下:heap address: 0x000000011be00000, size: 27648 MB, zero based Compressed Oops显示零基础被压缩的oops被启用,而不是:
heap address: 0x0000000118400000, size: 28672 MB, Compressed Oops with base: 0x00000001183ff000
下面是如何通过jvm.options设置堆大小的示例:
-Xms2g
-Xmx2g - 设置最小堆大小为2g
- 设置最大堆大小为2g
还可以通过环境变量设置堆大小,这可以通过注释jvm.options文件中的Xms和Xmx设置来实现,并通过ES_JAVA_OPTS设置这些值:
ES_JAVA_OPTS="-Xms2g -Xmx2g" ./bin/elasticsearch
ES_JAVA_OPTS="-Xms4000m -Xmx4000m" ./bin/elasticsearch- 设置最小和最大堆大小为2GB
- 设置最小和最大堆大小为4000MB
为Windows服务配置堆与上面的不同,最初为Windows服务填充的值可以如上所述进行配置,但在被安装为服务之后会有所不同,有关更多细节,请参阅Windows服务文档。
JVM堆转储文件路径
默认情况,Elasticsearch配置JVM将内存溢出异常堆转储到默认数据目录(RPM和Debian包发行版的/var/lib/elasticsearch目录,和Elasticsearch的tar和zip存档发行版的安装根目录下的的data目录)。如果此路径不适合接收堆转储,你应该在jvm.options中修改条目-XX:HeapDumpPath=...。如果你指定了一个目录,JVM将根据运行实例的PID为堆转储生成一个文件名。如果你指定了一个固定的文件名而不是目录,那么当JVM需要在内存溢出的异常上执行堆转储时,该文件必须不存在,否则堆转储将失败。
GC日志记录
默认情况下,Elasticsearch支持GC日志,它们在jvm.options中配置,并默认为与Elasticsearch日志相同的默认位置。默认配置每64MB滚动日志一次,最多可以占用2g的磁盘空间。
临时目录
默认情况下,Elasticsearch使用一个私有的临时目录,启动脚本直接在系统临时目录下创建它。
在一些Linux发行版中,如果文件和目录最近没有被访问过,系统实用程序将从/tmp中清除它们。如果需要临时目录的特性长时间没有使用,这可能导致在Elasticsearch运行时删除私有临时目录,如果随后使用了需要临时目录的特性,则会导致问题。
如果你使用.deb或.rpm包安装Elasticsearch,并在systemd下运行,那么Elasticsearch使用的私有临时目录将被排除在定期清理之外。
但是,如果你打算在Linux上运行.tar.gz发行版一段较长的时间,那么你应该考虑为Elasticsearch创建一个专用的临时目录,它不在清除旧文件和目录的路径下。这个目录应该有权限设置,以便只有Elasticsearch运行的用户才能访问它,然后在启动Elasticsearch之前设置$ES_TMPDIR环境变量指向它。
JVM致命错误日志
默认情况下,Elasticsearch配置JVM将致命错误日志写入默认日志目录(这里是RPM和Debian软件包发行版的/var/log/elasticsearch,以及tar和zip归档发行版的Elasticsearch安装根目录下的logs目录)。这些是JVM在遇到致命错误(例如,分段故障)时生成的日志。如果此路径不适合接收日志,你应该修改在jvm.options中-XX:ErrorFile=…条目到另一个路径。
上一篇:配置Elasticsearch
下一篇:重要的系统配置
")
ElasticSearch 基本操作 ----- 基于 Java 实现 (SpringDataElasticSearch)
一。创建工程、导入坐标
1. 选择 Next

2. 填写名称、选择位置、填写公司或组织、选择 Finish
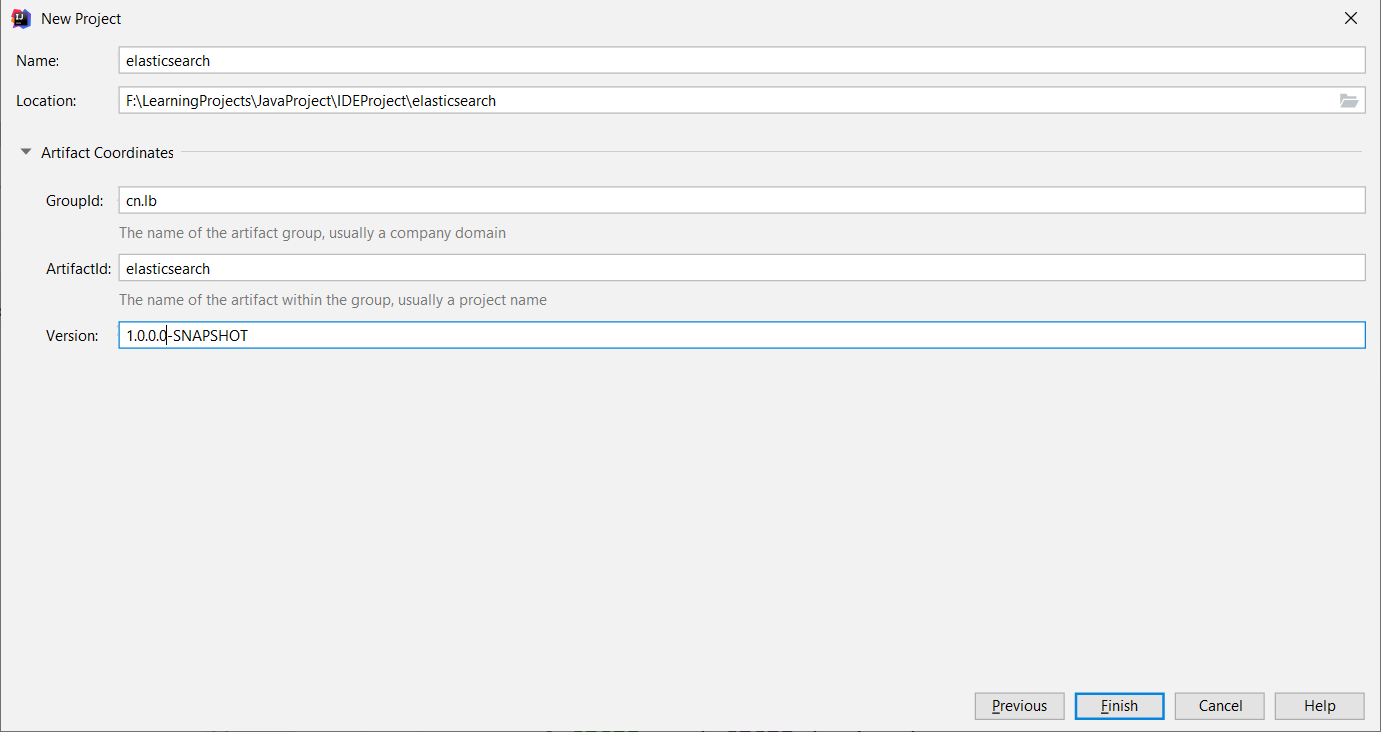
3. 导入坐标
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>cn.lb</groupId>
<artifactId>elasticsearch</artifactId>
<version>1.0.0.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>6.3.1</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>6.3.1</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-to-slf4j</artifactId>
<version>2.9.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
<version>1.7.24</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-simple</artifactId>
<version>1.7.21</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-core</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-annotations</artifactId>
<version>2.8.1</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-elasticsearch</artifactId>
<version>3.0.5.RELEASE</version>
<exclusions>
<exclusion>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-test</artifactId>
<version>5.0.4.RELEASE</version>
</dependency>
</dependencies>
</project>4. 创建实体类:Article
package cn.lb.es.entity;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
@Document(indexName = "index_blog",type="article")
public class Article {
@Id
@Field(type= FieldType.Long,store = true)
private long id;
@Field(type =FieldType.text,store = true,analyzer = "ik_smart")
private String title;
@Field(type = FieldType.text,store = true,analyzer = "ik_smart")
private String content;
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title=''" + title + ''\'''' +
", content=''" + content + ''\'''' +
''}'';
}
public long getId() {
return id;
}
public void setId(long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
}5. 创建接口
package cn.lb.es.repositories;
import cn.lb.es.entity.Article;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.data.repository.NoRepositoryBean;
import java.util.List;
public interface ArticleRepository extends ElasticsearchRepository<Article, Long> {
List<Article> findByTitle(String title);
List<Article> findByTitleOrContent(String title, String content);
List<Article> findByTitleOrContent(String title, String content, Pageable pageable);
}6. 添加配置
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:elasticsearch="http://www.springframework.org/schema/data/elasticsearch"
xsi:schemaLocation="
http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/data/elasticsearch
http://www.springframework.org/schema/data/elasticsearch/spring-elasticsearch-1.0.xsd
">
<!--elastic客户对象的配置-->
<elasticsearch:transport-client id="esClient" cluster-name="my-elasticsearch"
cluster-nodes="127.0.0.1:9300,127.0.0.1:9301,127.0.0.1:9302"/>
<!--配置包扫描器,扫描dao的接口-->
<elasticsearch:repositories base-package="cn.lb.es.repositories"/>
<!---->
<bean id="elasticsearchTemplate" class="org.springframework.data.elasticsearch.core.ElasticsearchTemplate">
<constructor-arg name="client" ref="esClient"/>
</bean>
</beans>7. 测试
import cn.lb.es.entity.Article;
import cn.lb.es.repositories.ArticleRepository;
import org.elasticsearch.index.query.QueryBuilder;
import org.elasticsearch.index.query.QueryBuilders;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.core.ElasticsearchTemplate;
import org.springframework.data.elasticsearch.core.query.NativeSearchQuery;
import org.springframework.data.elasticsearch.core.query.NativeSearchQueryBuilder;
import org.springframework.data.web.PageableDefault;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import java.util.List;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration("classpath:applicationContext.xml")
public class SpringDataElasticSearchTest {
@Autowired
private ArticleRepository articleRepositrory;
@Autowired
private ElasticsearchTemplate template;
@Test
public void createIndex() throws Exception{
template.createIndex(Article.class);
}
@Test
public void addDocument() throws Exception
{
Article article =new Article();
article.setId(i);
article.setTitle("IntelliJ IDEA 编译Java程序出现 ''Error:java: 无效的源发行版: 9'' 的解决方案");
article.setContent("最新安装的IntelliJ IDEA 2018.1编译器,创建Java Project,并选择之前安装好的Eclipse配置的JDK,如图所示:");
articleRepositrory.save(article);
}
@Test
public void deleteDocumentId() throws Exception
{
articleRepositrory.deleteById(2l);
//articleRepositrory.deleteAll();
}
@Test
public void findByTitle() throws Exception
{
List<Article> list=articleRepositrory.findByTitle("9");
list.stream().forEach(a-> System.out.println(a));
}
@Test
public void findByTitleOrContent() throws Exception
{
Pageable pageable=PageRequest.of(0,15);
List<Article> list = articleRepositrory.findByTitleOrContent("9", "n", pageable);
list.forEach(a-> System.out.println(a));
}
@Test
public void nativeSearchQuery() throws Exception
{
NativeSearchQuery query=new NativeSearchQueryBuilder()
.withQuery(QueryBuilders.queryStringQuery("Java是最好的语言").defaultField(
"title"
)).withPageable(PageRequest.of(0,15)).build();
List<Article> list = template.queryForList(query, Article.class);
list.forEach(a-> System.out.println(a));
}
}
今天关于如何使用elasticsearch配置Jaeger?和elasticsearch配置详解的讲解已经结束,谢谢您的阅读,如果想了解更多关于Elasticsearch - 如何在java中使用elasticsearch查找与地理定位点的匹配项、elasticsearch java api 使用elasticsearch 6.x.x版本,客户端使用5.6.10版本、Elasticsearch 参考指南(重要的Elasticsearch配置)、ElasticSearch 基本操作 ----- 基于 Java 实现 (SpringDataElasticSearch)的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

