如果您想了解Android原生MediaPlayer和MediaCodec的区别和联系和mediaplayer源码的知识,那么本篇文章将是您的不二之选。我们将深入剖析Android原生MediaPla
如果您想了解Android 原生 MediaPlayer 和 MediaCodec 的区别和联系和mediaplayer源码的知识,那么本篇文章将是您的不二之选。我们将深入剖析Android 原生 MediaPlayer 和 MediaCodec 的区别和联系的各个方面,并为您解答mediaplayer源码的疑在这篇文章中,我们将为您介绍Android 原生 MediaPlayer 和 MediaCodec 的区别和联系的相关知识,同时也会详细的解释mediaplayer源码的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- Android 原生 MediaPlayer 和 MediaCodec 的区别和联系(mediaplayer源码)
- Android MediaPlayer
- Android Mediaplayer MediaController超时
- Android MediaPlayer 和 MediaCodec 的区别和联系(一)
- android mediaplayer 架构
")
Android 原生 MediaPlayer 和 MediaCodec 的区别和联系(mediaplayer源码)
目录:
(3)Android 官方网站 对 MediaPlayer的介绍
正文:
Android 官方网站 对 MediaPlayer的介绍
MediaPlayer
public class MediaPlayer
extends Object implements VolumeAutomation, AudioRouting
MediaPlayer类被用来控制音/视频文件和流的播放。可以在VideoView中找到有关如何使用此类中的方法的示例。
这里涉及的主题是:
1. 状态图
2. 有效和无效状态
3. 权限
4. 注册信息和错误回调
★ 开发者指南
有关如何使用MediaPlayer的更多信息,请阅读Media Playback开发人员指南。
状态图
音/视频文件和流的播放控制是作为一个状态机来进行管理。下图显示了受支持的播放控制操作驱动的MediaPlayer对象的生命周期和状态。 椭圆表示MediaPlayer对象可能驻留的状态。弧表示驱动对象状态转换的播放控制操作。有两种类型的弧。 单箭头的弧表示同步方法调用,而双箭头的弧表示异步方法调用。

从这个状态图中,可以看到MediaPlayer对象具有以下状态:
- 当使用 new 创建MediaPlayer对象或者在调用 reset() 之后,它处于空闲状态; 并且在调用 release() 之后,它处于 End 状态。 在这两个状态之间是MediaPlayer对象的生命周期。
1. 一个新构造的 MediaPlayer 对象 和 调用 reset() 方法后的MediaPlayer对象之间存在微妙但重要的区别。针对这两种情况的空闲状态下调用诸如 getCurrentPosition(), getDuration(), getVideoHeight(),getVideoWidth(),setAudioAttributes(AudioAttributes), setLooping(boolean),setVolume(float, float),pause(), start(), stop(), seekTo(long, int), prepare() or prepareAsync() 方法是程序设计错误。如果在一个 MediaPlayer 对象被构造后任意调用这些方法,则内部播放引擎不会调用用户提供的回调方法OnErrorListener.onError(),并且该对象状态保持不变;但是如果这些方法是在reset()后被调用,则内部播放引擎将调用用户提供的回调方法OnErrorListener.onError(),并且该对象将被转换为 Error 状态。
2. 还建议一旦不再使用MediaPlayer对象,立即调用release(),以便可以立即释放与MediaPlayer对象关联的内部播放器引擎使用的资源。 资源可能包括单一资源(如硬件加速组件)和调用release()失败可能导致MediaPlayer对象的后续实例回退到软件实现或完全失败(?)。 一旦MediaPlayer对象处于End状态,就无法再使用它,也无法将其恢复到任何其他状态。
3. 此外,使用new创建的MediaPlayer对象处于空闲状态,而使用其中一个重载的方便的创建方法创建的对象不处于空闲状态。 实际上,如果使用create方法创建成功,则对象处于Prepared状态。
- 通常,一些播放控制操作可能由于各种原因而失败,例如不支持的音频/视频格式,交错的音频/视频,分辨率太高,流超时等。因此,在这些情况下,关注错误报告和恢复是非常重要的。有时,由于编程错误,也可能在无效状态下调用播放控制操作。在所有这些错误条件下,如果开发者事先通过setOnErrorListener(android.media.MediaPlayer.OnErrorListener)注册了 OnErrorListener ,则内部播放器引擎会调用开发者提供的 OnErrorListener.onError() 方法。
1. 重要的是要注意,一旦发生错误,MediaPlayer对象就会进入错误状态(Error state)(除非如上所述),即使应用程序尚未注册错误监听器也是如此。
2. 为了重用处于错误状态的MediaPlayer对象并从错误中恢复,可以调用reset()将对象恢复到其空闲状态(Idle state)。
3. 让应用程序注册OnErrorListener以查找内部播放器引擎的错误通知是一种很好的编程习惯。
4. 调用譬如 prepare(),prepareAsync()时,或者一个在无效状态(Idle state)重写的 setDataSource 方法时,抛出IllegalStateException 可以防止编程错误。
- 调用 setDataSource(FileDescriptor), 或 setDataSource(String), 或 setDataSource(Context, Uri), 或 setDataSource(FileDescriptor, long, long), 或 setDataSource(MediaDataSource)
将一个 MediaPlayer 对象从空闲状态(Idle state) 转换为 初始状态(Initialized state)。
1. 如果在任何其他状态下调用 setDataSource() ,则抛出 IllegalStateException。
2. 关注从重载的 setDataSource 方法 可能会抛出 IllegalArgumentException 和 IOException 是一种很好的编程习惯。
- 在开始播放之前,MediaPlayer 对象必须先进入准备状态。
1. 有两种方法(同步与异步)可以达到Prepared状态(Prepared state):调用prepare()(同步),一旦方法调用返回就将对象转换为Prepared状态(Prepared state),或者调用prepareAsync()( 异步),它在调用返回后首先将对象转换为Preparation状态(Preparing state)(几乎正确地发生),同时内部播放器引擎继续处理其余的准备工作,直到准备工作完成。 当准备完成或者prepare() 调用返回时,如果事先通过setOnPreparedListener(android.media.MediaPlayer.OnPreparedListener)注册了OnPreparedListener,则内部播放器引擎会调用开发者提供的OnPreparedListener接口的回调方法onPrepared()。
2. 重要的是要注意,准备状态是暂时状态,并且在MediaPlayer对象处于准备状态时调用任何具有副作用的方法的行为是未定义的。
3. 在任何其他状态调用 prepare() 或 prepareAsync() ,则抛出 IllegalStateException。
4. 在Prepared状态(Prepared state)下,可以通过调用相应的set方法来调整音频/音量,screenOnWhilePlaying,循环等属性。
- 要开始播放,必须调用 start() ,start() 返回成功后,MediaPlayer对象则处于 Started状态(Started state)。isPlaying()可用来测试 MediaPlayer对象是否处于 Started状态(Started state)。
1. 处于Started状态(Started state)时,如果事先通过 setOnBufferingUpdateListener(OnBufferingUpdateListener)注册了OnBufferingUpdateListener,则内部播放器引擎会调用用户提供的.OnBufferingUpdateListener.onBufferingUpdate() 回调方法。 此回调允许应用程序在流式传输音频/视频时跟踪缓冲状态。
2. 调用 start() 对已处于Started状态的MediaPlayer对象没有影响。
- 播放可以暂停和停止,并可以调整当前播放位置。 可以通过pause()暂停播放。 当对pause()的调用返回时,MediaPlayer对象进入Paused状态(Pausedstate)。 请注意,从“已启动”状态(Started state)到“暂停”状态(Paused state)的转换(反之亦然)在播放器引擎中异步发生。 在调用isPlaying()时更新状态可能需要一些时间,对于流内容,它可能需要几秒钟。
1. 调用start()以恢复暂停的MediaPlayer对象的播放,并且恢复的播放位置与暂停的位置相同。 当对start()的调用返回时,暂停的MediaPlayer对象将返回到Started状态(Started state)。
2. 调用pause()对已处于Paused状态的MediaPlayer对象没有影响。
- 调用stop()会停止播放并导致处于Started,Paused,Prepared或PlaybackCompleted状态(state)的MediaPlayer进入Stopped状态(Stopped state)。
1. 一旦处于Stopped状态(Stopped state),在调用prepare()或prepareAsync()以将MediaPlayer对象再次设置为Prepared状态(Prepared state)之前,无法启动播放。
2. 调用stop()对已处于Stopped状态(Stopped state)的MediaPlayer对象没有影响。
- 可以通过调用seekTo(long, int)调整播放位置
1. 尽管异步seekTo(long, int)调用立即返回,但实际的寻位操作可能需要一段时间才能完成,特别是对于流式传输的音频/视频。 当实际寻位操作完成时,如果事先通过setOnSeekCompleteListener(OnSeekCompleteListener)注册了OnSeekCompleteListener,则内部播放器引擎会调用开发者提供的OnSeekComplete.onSeekComplete() 。
2. 请注意,seekTo(long, int)也可以在其他状态中调用,例如Prepared,Paused和PlaybackCompleted状态(state)。 当在这些状态中调用seekTo(long, int)时,如果流具有视频且请求的位置有效,则将显示一个视频帧。
3. 此外,可以通过调用getCurrentPosition()来检索实际当前播放位置,这对于需要跟踪播放进度的音乐播放器等应用程序很有帮助。
- 当播放到达流的结尾时,播放完成。
1. 如果使用setLooping(boolean)将循环模式设置为true,则MediaPlayer对象应保持为Started状态(Started state)。
2. 如果循环模式设置为false,则播放器引擎调用开发者提供的回调方法OnCompletion.onCompletion(),如果事先通过 setOnCompletionListener(OnCompletionListener)注册了OnCompletionListener。 调用回调信号表示对象现在处于PlaybackCompleted状态(PlaybackCompleted state)。
3. 在PlaybackCompleted状态(PlaybackCompleted state)下,调用start()可以从音频/视频源的开头重新开始播放。
有效和无效状态
| Method Name | Valid Sates | Invalid States | Comments |
| attachAuxEffect | {Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Idle, Error} | This method must be called after setDataSource. Calling it does not change the object state. |
| getAudioSessionId | any | {} | This method can be called in any state and calling it does not change the object state. |
| getCurrentPosition | {Idle, Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| getDuration | {Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| getVideoHeight | {Idle, Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| getVideoWidth | {Idle, Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| isPlaying | {Idle, Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| pause | {Started, Paused, PlaybackCompleted} | {Idle, Initialized, Prepared, Stopped, Error} | Successful invoke of this method in a valid state transfers the object to the Paused state. Calling this method in an invalid state transfers the object to the Error state. |
| prepare | {Initialized, Stopped} | {Idle, Prepared, Started, Paused, PlaybackCompleted, Error} | Successful invoke of this method in a valid state transfers the object to the Prepared state. Calling this method in an invalid state throws an IllegalStateException. |
| prepareAsync | {Initialized, Stopped} | {Idle, Prepared, Started, Paused, PlaybackCompleted, Error} | Successful invoke of this method in a valid state transfers the object to the Preparing state. Calling this method in an invalid state throws an IllegalStateException. |
| release | any | {} | After release(), the object is no longer available. |
| reset | {Idle, Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted, Error} | {} | After reset(), the object is like being just created. |
| seekTo | {Prepared, Started, Paused, PlaybackCompleted} | {Idle, Initialized, Stopped, Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| setAudioAttributes | {Idle, Initialized, Stopped, Prepared, Started, Paused, PlaybackCompleted} | {Error} | Successful invoke of this method does not change the state. In order for the target audio attributes type to become effective, this method must be called before prepare() or prepareAsync(). |
| setAudioSessionId | {Idle} | {Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted, Error} | This method must be called in idle state as the audio session ID must be known before calling setDataSource. Calling it does not change the object state. |
| setAudioStreamType (deprecated) | {Idle, Initialized, Stopped, Prepared, Started, Paused, PlaybackCompleted} | {Error} | Successful invoke of this method does not change the state. In order for the target audio stream type to become effective, this method must be called before prepare() or prepareAsync(). |
| setAuxEffectSendLevel | any | {} | Calling this method does not change the object state. |
| setDataSource | {Idle} | {Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted, Error} | Successful invoke of this method in a valid state transfers the object to the Initialized state. Calling this method in an invalid state throws an IllegalStateException. |
| setDisplay | any | {} | This method can be called in any state and calling it does not change the object state. |
| setSurface | any | {} | This method can be called in any state and calling it does not change the object state. |
| setVideoScalingMode | {Initialized, Prepared, Started, Paused, Stopped, PlaybackCompleted} | {Idle, Error} | Successful invoke of this method does not change the state. |
| setLooping | {Idle, Initialized, Stopped, Prepared, Started, Paused, PlaybackCompleted} | {Error} | Successful invoke of this method in a valid state does not change the state. Calling this method in an invalid state transfers the object to the Error state. |
| isLooping | any | {} | This method can be called in any state and calling it does not change the object state. |
| setOnBufferingUpdateListener | any | {} | This method can be called in any state and calling it does not change the object state. |
| setOnCompletionListener | any | {} | This method can be called in any state and calling it does not change the object state. |
| setOnErrorListener | any | {} | This method can be called in any state and calling it does not change the object state. |
| setOnPreparedListener | any | {} | This method can be called in any state and calling it does not change the object state. |
| setOnSeekCompleteListener | any | {} | This method can be called in any state and calling it does not change the object state. |
| setPlaybackParams | {Initialized, Prepared, Started, Paused, PlaybackCompleted, Error} | {Idle, Stopped} | This method will change state in some cases, depending on when it''s called. |
| setScreenOnWhilePlaying | any | {} | This method can be called in any state and calling it does not change the object state. |
| setVolume | {Idle, Initialized, Stopped, Prepared, Started, Paused, PlaybackCompleted} | {Error} | Successful invoke of this method does not change the state. |
| setWakeMode | any | {} | This method can be called in any state and calling it does not change the object state. |
| start | {Prepared, Started, Paused, PlaybackCompleted} | {Idle, Initialized, Stopped, Error} | Successful invoke of this method in a valid state transfers the object to the Started state. Calling this method in an invalid state transfers the object to the Error state. |
| stop | {Prepared, Started, Stopped, Paused, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method in a valid state transfers the object to the Stopped state. Calling this method in an invalid state transfers the object to the Error state. |
| getTrackInfo | {Prepared, Started, Stopped, Paused, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method does not change the state. |
| addTimedTextSource | {Prepared, Started, Stopped, Paused, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method does not change the state. |
| selectTrack | {Prepared, Started, Stopped, Paused, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method does not change the state. |
| deselectTrack | {Prepared, Started, Stopped, Paused, PlaybackCompleted} | {Idle, Initialized, Error} | Successful invoke of this method does not change the state. |
权限
可能需要声明相应的WAKE_LOCK权限<uses-permission>元素。
当使用网络内容时该类要求声明 Manifest.permission.INTERNET 权限。
回调
应用程序可能希望注册信息和错误事件,以便在播放或流式传输期间获知某些内部状态更新和可能的运行时错误。注册这些事件是由正确设置相应的监听器(通过调用setOnPreparedListener(OnPreparedListener) setOnPreparedListener,setOnVideoSizeChangedListener(OnVideoSizeChangedListener) setOnVideoSizeChangedListener,setOnSeekCompleteListener(OnSeekCompleteListener)setOnSeekCompleteListener,setOnCompletionListener(OnCompletionListener) setOnCompletionListener,setOnBufferingUpdateListener(OnBufferingUpdateListener) setOnBufferingUpdateListener,setOnInfoListener(OnInfoListener) setOnInfoListener,setOnErrorListener(OnErrorListener) setOnErrorListener等完成)。 为了接收与这些侦听器关联的相应回调,应用程序需要在运行自己的Looper线程上创建MediaPlayer对象(默认情况下,主UI线程正在运行Looper)。

Android MediaPlayer
1.通过静态方法构造
MediaPlayer.create(Context context,int resid);
2.构造方法: MediaPlayer();
设置媒体源: setDataSource(String path);
3.设置是否循环:
setLooping(boolean)
4.播放:
a. prepare() 预处理,调用start()前必须先调用此方法
b. start() 如果没有正在播放,就开始播放
c. pause() 如果palyer不为空,并且正在播放就暂停
d. stop() 如果palyer不为空,并且正在播放就停止
e. isPlaying() 是否正在播放

Android Mediaplayer MediaController超时
香港专业教育学院实现了流媒体的MP3 URL的mediaplayer和mediacontroller.但是,我在TMobile网络上的设备无法获得很好的3G信号,因此可以在EDGE上运行.我假设媒体播放器因流太慢或不完整而崩溃,是否可以设置超时?
解决方法:
MediaPlayer中没有超时方法,但是您可以自己实现-有多种方法可以执行.
我建议其中之一,我用了自己,对我有用-broadcastReceiver
代码如下所示:
public class ConnectivityCheckingReceiver extends WakefulbroadcastReceiver
{
private AlarmManager alarmManager;
private PendingIntent pendingIntent;
@Override
public void onReceive(Context context, Intent intent)
{
if (MusicService.mediaPlayer != null)
{
if (!MusicService.mediaPlayer.isPlaying())
Log.v("Music", "Music is NOT playing");
//stop service and notify user
else
Log.v("Music", "Music is playing");
}
else
{
Log.v("Music", "User stopped player");
}
}
public void setAlarm (Context context, int hour, int minute, int second)
{
alarmManager = (AlarmManager) context.getSystemService(Context.ALARM_SERVICE);
Intent intent = new Intent(context, ConnectivityCheckingReceiver.class);
pendingIntent = PendingIntent.getbroadcast(context, 0, intent, 0);
Calendar calendar = Calendar.getInstance();
calendar.set(Calendar.HOUR_OF_DAY, hour);
calendar.set(Calendar.MINUTE, minute);
calendar.set(Calendar.SECOND, second);
alarmManager.set(AlarmManager.RTC_WAKEUP, calendar.getTimeInMillis(), pendingIntent);
}
}
在活动/服务/片段中添加以下行:
ConnectivityCheckingReceiver conCheck = new ConnectivityCheckingReceiver();
conCheck.setAlarm(context, hour, min, second);
您将需要自己实现小时/分钟/秒检查逻辑,但是使用Joda Time之类的库就可以轻松实现.
并且不要忘记添加到清单中:
<uses-permission android:name="android.permission.WAKE_LOCK" />
<receiver android:name=".receivers.ConnectivityCheckingReceiver" />
附言:我的解决方案不是完美的,但是我没有看到关于此问题的任何好答案,因此,如果找到一个,请分享.
")
Android MediaPlayer 和 MediaCodec 的区别和联系(一)
目录:
(1)概念解释 : 硬解、软解
(2)Intel关于Android MediaCodec的相关说明
正文:
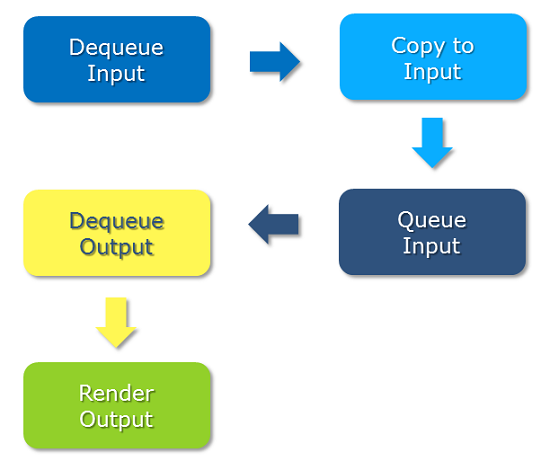

有关详细代码,请参阅 Android 4.3源码中的 EncodeDecodeTest.java。资料来源: http://androidxref.com/4.3_r2.1/xref/cts/tests/tests/media/src/android/media/cts/EncodeDecodeTest.java

android mediaplayer 架构
1引言
Android froyo版本多媒体引擎做了变动,新添加了stagefright框架,并且默认情况android选择stagefright,弃用之前的opencore,仅仅对opencore中的omx-component部分做了引用。
Stagefright自android2.0后才添加,其稳定性有待商榷,是否存在bug也未知,opencore自android诞生起便存在,稳定性有保障。不过,从目前android代码看,opencore有被stagefright取代的趋势,所以在opencore上所作工作也许会无法沿用。Opencore上的开发较stagefright上要复杂耗时些。
2框架变动
以MediaPlayer为例,我们先看一下多媒体的简单框架。

上图可知,stagefright是在MediaPlayerService这一层加入的,和opencore是并列的,在选用opencore还是stagefright的代码切换上也非常容易。
具体stagefright的内部变动,可见下图概述。Stagefright并没有完全抛弃opencore,主要是做了一个OMX层,用来引用opencore的omx-component部分。而stagefright内部而言,与opencore是完全不同的设计。

3具体差异
3.1所支持的文件格式
Opencore所支持的格式。

Stagefright所支持的格式。

3.2 Parser和codec部分开发有差异
Opencore与stagefright两套机制,对于我们的开发而言,主要体现在parser和codec部分。Opencore方面,必须按照其规范完成相应的parser-node,codec则要按照omx规范实现相应的component。Stagefright方面,则要按照其规范实现相应的extractor和decoder。
最基本的实现,二者是相同的,可以共用,差别在封装上,opencore难度和工作量要大。
3.3 数据处理机制不同
Opencore处理流程如下图示。

engine分别创建audio/video datapath,parser/dec/sink作为node节点由各自datapath连接起来,后续node节点由统一调度器调度。
Stagefright处理流程如下图示。

Audioplayer为AwesomePlayer的成员,audioplayer通过callback来驱动数据的获取,awesomeplayer则是通过videoevent来驱动。二者有个共性,就是数据的获取都抽象成mSource->Read()来完成,且read内部把parser和dec绑在一起。
Opencore和stagefright处理机制对比:
(1)Opencore的parser与dec是分离的,各行其职;stagefright则是绑在一起作为一个独立的原子操作。
(2)Stagefright通过callback和videoevent来驱动数据输出;opencore是通过sink-node节点控制输出。
(3)Opencore中parser/dec/sink是并行处理的;stagefright中为串行处理。
3.4 AV同步
Opencore有一个主clock,audio/video分别与该主clock同步,作为输出的判定依据,且audio会不断校准主clock。
Stagefright部分,audio完全是callback驱动数据流,video部分在onVideoEvent里会获取audio的时间戳,是传统的AV时间戳做同步。
3.5 稳定性
客观来讲,opencore存在时间长,相对稳定;stagefright刚推出,肯定会有未预知的bug存在。
4 总结
1.Opencore相对成熟稳定,作为框架采用,风险小;parser/codec集成相对复杂,如果android后续版本弃用opencore转用stagefright,那多媒体引擎的选择是个问题。
2.Stagefright新推出,肯定有未预知的bug,直接采用有潜在风险;parser/codec集成相对容易,架构较opencore做了极大简化,通俗易懂。
3.目前来看opencore支持的文件格式多些。
4.Opencore与stagefright在数据处理机制及AV同步上有很大差异,需要在实际板子上评估性能差异。
5.如果在android froyo版本开发多媒体相关产品,建议采用opencore框架,这样旧版本opencore上的成果可以沿用,且节省项目时间。
6.Opencore支持的文件格式较stagefright丰富。
7.如果项目研发中android出现新版本,或stagefright做了更新,仍然维持opencore不变,多媒体引擎变更问题待ipad后再议。一种选择是一直延续采用opencore,或者在适当时候(认为stagefright足够稳定)切换到stagefright。
Stagefright阅读笔记附录
两套方案对比过程中,基本上把stagefright的代码阅读过一遍,摘录如下,以图为主。
Stagefright整体框图。
Stagefrightplayer里awesomeplayer初始化流程

Awesomeplayer框图,其中涵盖主要节点元素。

Stagefrightrecorder部分

MediaPlayer框图。
MediaRecorder框图。

Libstagefright草图,涵盖了主要节点元素。

今天关于Android 原生 MediaPlayer 和 MediaCodec 的区别和联系和mediaplayer源码的分享就到这里,希望大家有所收获,若想了解更多关于Android MediaPlayer、Android Mediaplayer MediaController超时、Android MediaPlayer 和 MediaCodec 的区别和联系(一)、android mediaplayer 架构等相关知识,可以在本站进行查询。
在这篇文章中,我们将为您详细介绍Flex布局中的align-items属性和align-content属性的区别的内容,并且讨论关于flex align-content的相关问题。此外,我们还会涉及一些关于aligin-items与aligin-content的区别、align-content和align-items的区别、align-conten和align-items之间的区别、align-conten和align-items的区别的知识,以帮助您更全面地了解这个主题。
本文目录一览:- Flex布局中的align-items属性和align-content属性的区别(flex align-content)
- aligin-items与aligin-content的区别
- align-content和align-items的区别
- align-conten和align-items之间的区别
- align-conten和align-items的区别
")
Flex布局中的align-items属性和align-content属性的区别(flex align-content)
在学习flex布局中,发现flex容器的属性,align-items和align-content两个属性都是通过交叉轴对齐的方式,看不出区别,后来通过自己尝试的方法,明白了区别。
1、当容器内的元素只有一行时,使用align-items会使这行元素居中。但是使用align-content没有效果。
使用align-items时效果:
使用align-content时的效果:
2.在多行的效果下,可以看出,多行下,align-content有效果了,是使所有元素都沿着交叉轴居中。而align-items是使每一行的元素在每一行之中各自居中。
使用align-items的效果:
使用align-content的效果: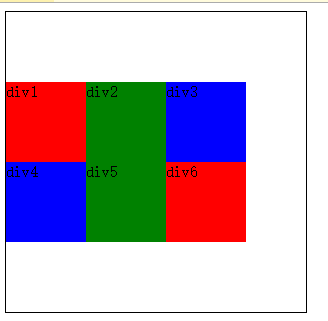
可以发现align-items在单行或者多行元素中都能够生效,而align-content只在多行元素的时候才能生效。

aligin-items与aligin-content的区别
align-items 属性使用于所有的flex容器,它是用来设置每个flex元素在侧轴上的默认对齐方式
aligin-items 与align-content有相同的功能,不过不同点是它是用来让每一个单行元素在容器居中而不是让整个容器居中
demo:align-items:单行元素:
html:
<div class=''flexBox''>
<div class=''box1''></div>
<div class=''box2''></div>
</div>css:
.flexBox {
width: 300px;
height: 500px;
display: flex;
border: 1px solid red;
align-content: center;
}
.box1,
.box2 {
width: 200px;
height: 200px;
background-color: blue;
}
.box2 {
background-color: yellow;
}
修改flexBox的样式,使元素多行:
flex-wrap:wrap;

删除align-items:center; 添加align-content:center;


align-content和align-items的区别
在之前使用弹性布局的时候,align-content与align-items的概念混淆不清,自己特意写了一下来区分.
以下是我的初始代码:
效果是这样子的:
测试一:
那么 在.bigbox中添加align-items:center以后,侧轴居中了,效果如下:
在.bigbox中添加align-content:center以后,没有发生改变:如下:
由此 我们可以看到align-content对单行是没有效果的.
测试二:
我们把这两个盒子变成两行(给.box1加一个margin-right:100px; 给.bigbox加一个 flex-wrap: wrap;属性让这两个小盒子两行显示)
如下图:
在.bigbox中添加align-items:center以后,侧轴居中了,效果如下:
在.bigbox中添加align-content:center以后,效果如下,
那么 通过对比可以发现align-content:center对单行是没有效果的,而align-items:center不管是对单行还是多行都有效果,而在我们日常开发中用的比较多的就是align-items.

align-conten和align-items之间的区别
align-content
作用:
会设置自由盒内部所有行作为一个整体在垂直方向排列方式。针对多行作为一个整体在纵轴上的排列方式,该属性对单行无效。
条件:
必须对父元素设置自由盒属性display:flex;,并且设置排列方式为横向排列flex-direction:row;并且设置换行,flex-wrap:wrap;这样这个属性的设置才会起作用。
设置对象:
这个属性是对她容器内部的项目起作用,对父元素进行设置。
该属性对单行弹性盒子模型无效。该属性定义了当有多根主轴时,即item不止一行时,多行(所有行作为一个整体)在交叉轴(即非主轴)轴上的对齐方式。
align-content可能值含义如下(假设主轴为水平方向):
flex-start:左对齐
flex-end:右对齐
center:居中对齐
space- between:两端对齐
space-around:沿轴线均匀分布
stretch: 默认值。各行将根据其flex-grow值伸展以充分占据剩余空间。会拉伸容器内每行占用的空间,填充方式为给每行下方增加空白
该属性对单行弹性盒子模型无效。拉伸所有行来填满剩余空间。剩余空间平均的再分配给每一行。
取值:
stretch:默认设置,会拉伸容器内每一行的占用的空间,填充方式为给每一行的下方增加空白。第一行默认从容器顶端开始排列。


<!DOCTYPE=html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>
Align-content
</title>
<style>
#father{
width:200px;
display:flex;
flex-direction:row;
flex-wrap:wrap;
align-content:strech;
height:200px;
background-color:grey;
}
.son1{
height:30px;
width:100px;
background-color:orange;
}
.son2{
height:30px;
width:100px;
background-color:red;
}
.son3{
height:30px;
width:100px;
background-color:#08a9b5;
}
</style>
</head>
<body>
<div id="father">
<div>
q
</div>
<div>
w
</div>
<div>
e
</div>
<div>
e
</div>
<div>
e
</div>
</div>
</body>
</html>
Center:这个会取消行与行之间的空白并把所有行作为一个整体在纵轴的方向上垂直居中。

<!DOCTYPE=html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>
关于文档元素测试
</title>
<style>
#father{
width:200px;
display:flex;
flex-direction:row;
flex-wrap:wrap;
align-content:center;
height:200px;
background-color:grey;
}
.son1{
height:30px;
width:100px;
background-color:orange;
}
.son2{
height:30px;
width:100px;
background-color:red;
}
.son3{
height:30px;
width:100px;
background-color:#08a9b5;
}
.son4{
height:30px;
width:100px;
background-color:#9ad1c3;
}
.son5{
height:30px;
width:100px;
background-color:rgb(21,123,126);
}
</style>
</head>
<body>
<div id="father">
<div>
q
</div>
<div>
w
</div>
<div>
e
</div>
<div>
e
</div>
<div>
e
</div>
</div>
</body>
</html>
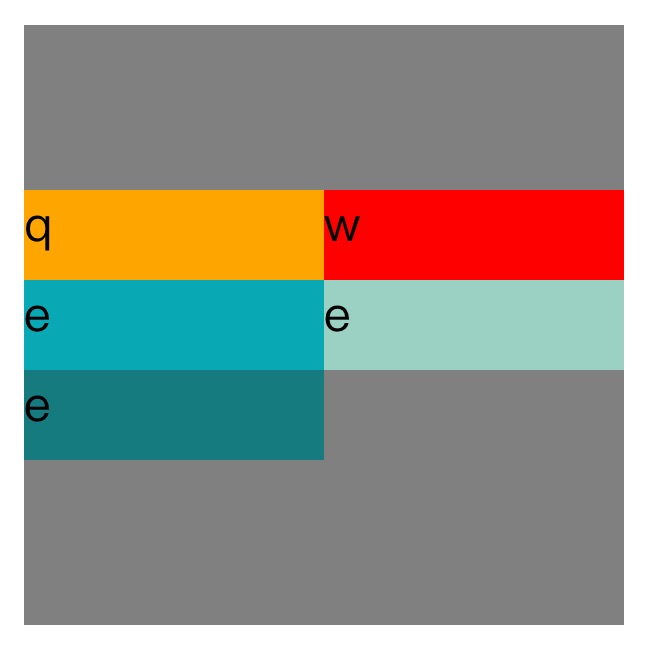
Flex-start:这个会取行之间的空白,并把所有行作为一个整体放在容器顶部。

<!DOCTYPE=html>
<html lang="zh-cn">
<head>
<meta charset="UTF-8">
<title>
关于文档元素测试
</title>
<style>
#father{
width:200px;
display:flex;
flex-direction:row;
flex-wrap:wrap;
align-content:flex-start;
height:200px;
background-color:grey;
}
.son1{
height:30px;
width:100px;
background-color:orange;
}
.son2{
height:30px;
width:100px;
background-color:red;
}
.son3{
height:30px;
width:100px;
background-color:#08a9b5;
}
.son4{
height:30px;
width:100px;
background-color:#9ad1c3;
}
.son5{
height:30px;
width:100px;
background-color:rgb(21,123,126);
}
</style>
</head>
<body>
<div id="father">
<div>
q
</div>
<div>
w
</div>
<div>
e
</div>
<div>
e
</div>
<div>
e
</div>
</div>
</body>
</html>
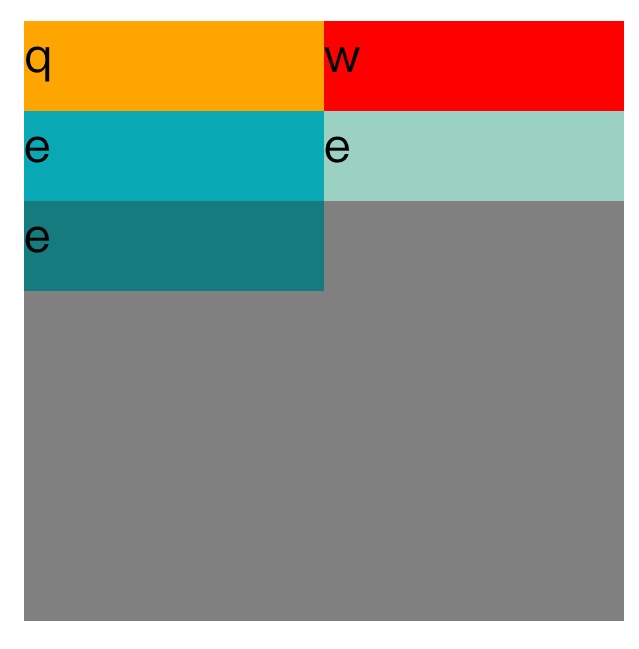
flex-end:这个会取消行之间的空白并把所有行作为一个整体在纵轴方向上,放在容器底部。
align-content:flex-end;
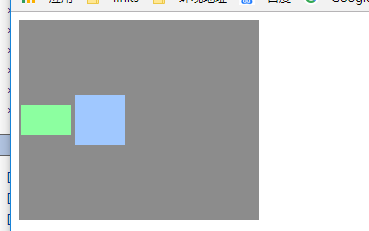
space-between这个会使行在垂直方向两端对齐。即上面的行对齐容器顶部,最下面行对齐容器底部。留相同间隔在每个行之间。
align-content:space-between;
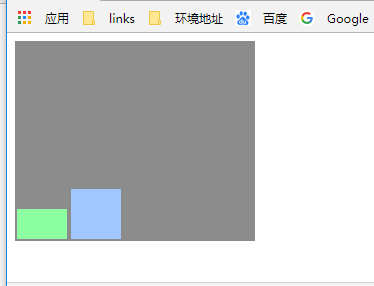
Space-around:这个会使每一行的上下位置保留相同长度空白,使得行之间的空白为两倍的单行空白。
align-content:space-around;

Inherit:使得元素的这个属性继承自它的父元素。
innitial:使元素这个属性为默认初始值。
指定了当前Flex容器的每一行中的items项目在此行上在交叉轴上的对齐方式
指定了每一行内items相对彼此自身的在交叉轴上的对齐方式。可能的值有flex-start|flex-end|center|baseline|stretch,当主轴水平时,其具体含义为
flex-start:当items设置了高度时的默认值。顶端对齐 。(针对设置了高度的items)
flex-end:底部对齐。(针对items设置了高度)
center:竖直方向上居中对齐 (同上)
baseline:item第一行文字的底部对齐 (同上)
stretch:默认值。(针对没有设置高度的items)当item都未设置高度,而且是单行时,item将和容器等高对齐。当item都设置了高度时,设置strentch与flex-start的效果
一样。当items有的设置了高度
有的没有设置高度,并且是单行。如下图:
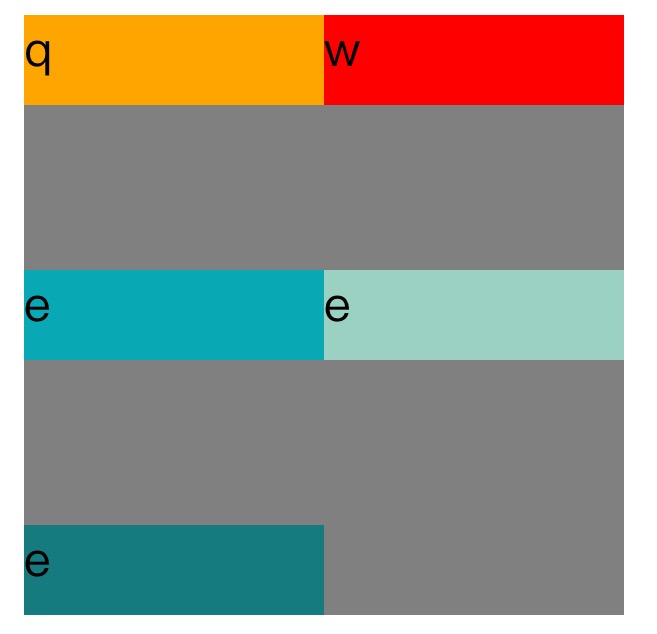
因为单行设置align-content无效,所以如果items有设置高度,并且align-items设置为align-items:center的效果如下图
因为单行设置align-content无效,所以如果items有设置高度,并且align-items设置为align-items:flex-start的效果如下图.
在items设置了高度时,flex-start和stech的样式一样。

因为单行设置align-content无效,所以如果items有设置高度,并且align-items设置为align-items:flex-end的效果如下图
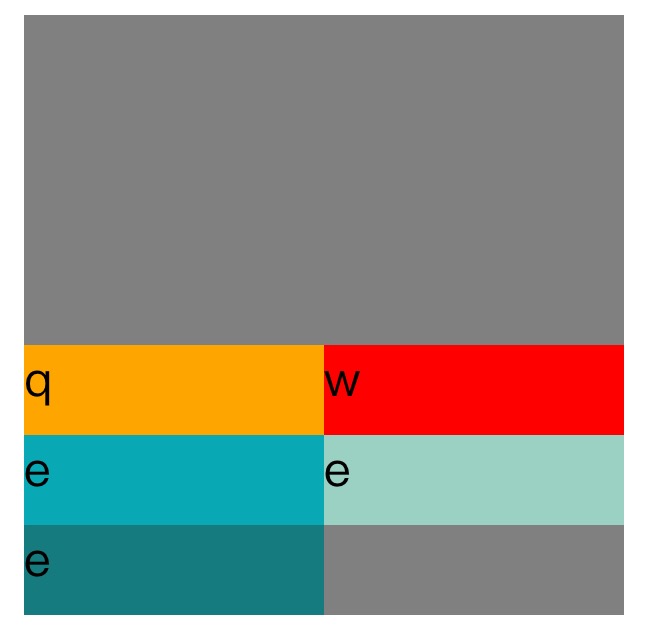
总结两者的区别:
首先:
#container {
display: flex;
height: 200px;
width: 240px;
flex-wrap: wrap;
align-content: center;
align-items: center;
background-color: #8c8c8c;
justify-content: center;
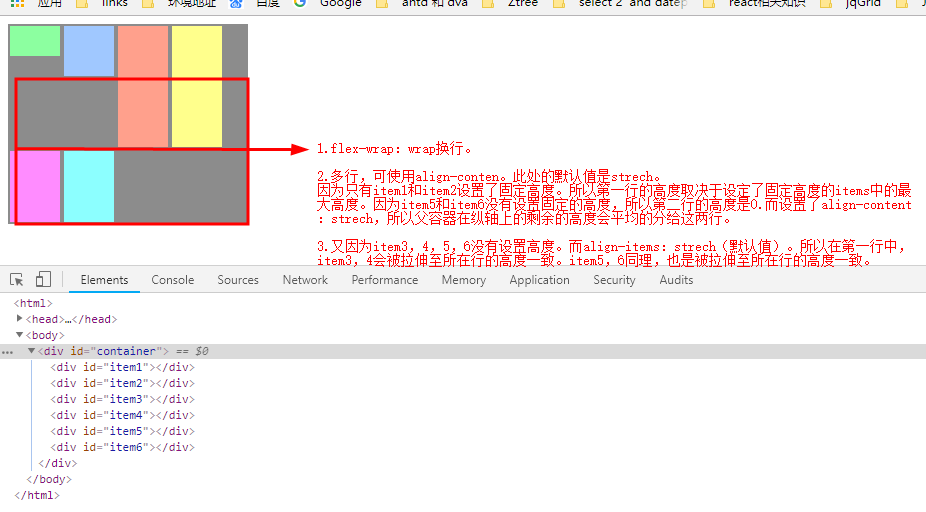
}效果图如下:
#container {
display: flex;
height: 200px;
width: 240px;
flex-wrap: wrap;
align-content: flex-start;
align-items: flex-start;
background-color: #8c8c8c;
justify-content: flex-start;
}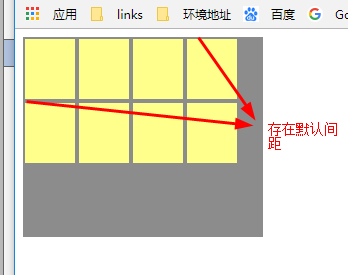
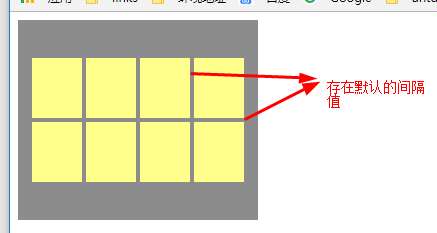
以上可知,在没有设置align-content为strech时,既没有把父容器的多余的空间分配每行时,在每个item之间和行与行之间存在默认的距离值。
设置父容器

#container {
display: flex;
height:200px;
width: 240px;
flex-wrap: wrap;
align-content:center;
align-items: center;
background-color: #8c8c8c;
justify-content: center
}
效果如下

设置父容器:

#container {
display: flex;
height:200px;
width: 240px;
flex-wrap: wrap;
align-content: flex-start;
align-items: center;
background-color: #8c8c8c;
justify-content: center
}
效果如下:

设置父容器

#container {
display: flex;
height:200px;
width: 240px;
flex-wrap: wrap;
align-content:center;
align-items: flex-start;
background-color: #8c8c8c;
justify-content: flex-end
}


align-conten和align-items的区别
align-conten和align-items之间的区别
align-items:
align-items属性适用于所有的flex容器,它是用来设置每个flex元素在侧轴上的默认对齐方式。
align-items和align-content有相同的功能,不过不同点是它是用来让每一个单行的容器居中而不是让整个容器居中。
aligin-conten:
align-content属性只适用于多行的flex容器,并且当侧轴上有多余空间使flex容器内的flex线对齐。
作用:
会设置自由盒内部所有行作为一个整体在垂直方向排列方式。针对多行作为一个整体在纵轴上的排列方式,该属性对单行无效。
条件:
必须对父元素设置自由盒属性display:flex;,并且设置排列方式为横向排列flex-direction:row;并且设置换行,flex-wrap:wrap;这样这个属性的设置才会起作用。
align-content可能值含义如下: flex-start:左对齐 flex-end:右对齐 center:居中对齐 space- between:两端对齐 space-around:沿轴线均匀分布 stretch: 默认值。各行将根据其flex-grow值伸展以充分占据剩余空间。会拉伸容器内每行占用的空间,填充方式为给每行下方增加空白
比如:


如果child-1的width设置为100px,child-2的width设置为30px,这样child-2会排列在一行上

总结
以上是小编为你收集整理的align-conten和align-items的区别全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
原文地址:https://www.cnblogs.com/-ting/p/11783960.html
今天关于Flex布局中的align-items属性和align-content属性的区别和flex align-content的讲解已经结束,谢谢您的阅读,如果想了解更多关于aligin-items与aligin-content的区别、align-content和align-items的区别、align-conten和align-items之间的区别、align-conten和align-items的区别的相关知识,请在本站搜索。
在本文中,您将会了解到关于Eclipse 导入netty 示例程序的新资讯,同时我们还将为您解释eclipse导入netbeans项目的相关在本文中,我们将带你探索Eclipse 导入netty 示例程序的奥秘,分析eclipse导入netbeans项目的特点,并给出一些关于1-3 eclipse myeclipse .1-4 程序的移植(导入导出)、ClassNotFoundException:运行在jetty内部的org.eclipse.jetty.util.component.AbstractLifeCycle、eclipse installer 安装的新版本 eclipse 导入旧版本 eclipse 插件、Eclipse Jetty 12.0.0 发布的实用技巧。
本文目录一览:- Eclipse 导入netty 示例程序(eclipse导入netbeans项目)
- 1-3 eclipse myeclipse .1-4 程序的移植(导入导出)
- ClassNotFoundException:运行在jetty内部的org.eclipse.jetty.util.component.AbstractLifeCycle
- eclipse installer 安装的新版本 eclipse 导入旧版本 eclipse 插件
- Eclipse Jetty 12.0.0 发布
")
Eclipse 导入netty 示例程序(eclipse导入netbeans项目)
1. import - General - Projects from folder
选择源码程序,导入即可。
2. 此时的项目 Build path ->No action available
进入Navigator 视图, 修改 .project
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures> 最好是复制一份新的项目的.project 文件 然后需要修改 name 标签内容即可
<?xml version="1.0" encoding="UTF-8"?>
<projectDescription>
<name>netty-example-4.1.1.Final-sources</name>
<comment></comment>
<projects>
</projects>
<buildSpec>
<buildCommand>
<name>org.eclipse.jdt.core.javabuilder</name>
<arguments>
</arguments>
</buildCommand>
</buildSpec>
<natures>
<nature>org.eclipse.jdt.core.javanature</nature>
</natures>
res>
</projectDescription>
3. 添加 jre 环境 及 netty jar包
netty 包 就不多说了
jre : build - configure build path - libraries - add library - jre system library
4. 运行 项目中的main 方法 提示:无法加载主类
io 包上 右键 build to path --> use as source folder
以下步骤看情况是否需要:
查看 .classpath 文件中的内容是否正确
源文件位置:src
核心包:con
jar 位置:lib
输出class位置:output
5. 添加项目后 Problems 里面 报错
The project was not built since its build path is incomplete. Cannot find the class file for java.lang.Object. Fix the build path then try building this project
The type java.lang.Object cannot be resolved. It is indirectly referenced from required .class files
这个是 缺少 jre 环境 报的错, 在第四步 已经添加 这个错误会变成其他的错误
例如 netty example 会缺少 一下几种 jar 包
barchat-udt-core --> The type com.barchart.udt.TypeUDT cannot be resolved
protobuf-java
slf4j-api
")
1-3 eclipse myeclipse .1-4 程序的移植(导入导出)
src--放置源代码文件
myeclipse是对eclipse 的扩展
可创建源程序的时候一并创建包

“包” 属性--location
import(导入)

ClassNotFoundException:运行在jetty内部的org.eclipse.jetty.util.component.AbstractLifeCycle
我在Ubuntu 13.04上在jetty中运行servlet时遇到了问题。 服务器使用apt-get安装,并开始使用sudo service jetty start 。 该应用程序需要类org.eclipse.jetty.util.component.AbstractLifeCycle但我得到一个类未find错误。 这是堆栈跟踪:
java.lang.NoClassDefFoundError: org/eclipse/jetty/util/component/AbstractLifeCycle at java.lang.classLoader.defineClass1(Native Method) at java.lang.classLoader.defineClass(ClassLoader.java:788) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.urlclassloader.defineClass(urlclassloader.java:447) at java.net.urlclassloader.access$100(urlclassloader.java:71) at java.net.urlclassloader$1.run(urlclassloader.java:361) at java.net.urlclassloader$1.run(urlclassloader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.urlclassloader.findClass(urlclassloader.java:354) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:420) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:382) at org.cometd.server.CometdServlet.newbayeuxServer(CometdServlet.java:130) at org.cometd.server.CometdServlet.init(CometdServlet.java:64) at org.cometd.annotation.AnnotationCometdServlet.init(AnnotationCometdServlet.java:54) at javax.servlet.GenericServlet.init(GenericServlet.java:244) at org.eclipse.jetty.servlet.ServletHolder.initServlet(ServletHolder.java:542) at org.eclipse.jetty.servlet.ServletHolder.getServlet(ServletHolder.java:424) at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:671) at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:505) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:138) at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:564) at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:213) at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1094) at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:432) at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:175) at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1028) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:136) at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:258) at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:109) at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:97) at org.eclipse.jetty.server.Server.handle(Server.java:445) at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:267) at org.eclipse.jetty.server.httpconnection.onFillable(httpconnection.java:224) at org.eclipse.jetty.io.AbstractConnection$ReadCallback.run(AbstractConnection.java:358) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:601) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:532) at java.lang.Thread.run(Thread.java:724) Caused by: java.lang.classNotFoundException: org.eclipse.jetty.util.component.AbstractLifeCycle at java.net.urlclassloader$1.run(urlclassloader.java:366) at java.net.urlclassloader$1.run(urlclassloader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.urlclassloader.findClass(urlclassloader.java:354) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:420) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:382) ... 37 more Caused by: java.lang.classNotFoundException: org.eclipse.jetty.util.component.AbstractLifeCycle at java.net.urlclassloader$1.run(urlclassloader.java:366) at java.net.urlclassloader$1.run(urlclassloader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.urlclassloader.findClass(urlclassloader.java:354) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:420) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:382) at java.lang.classLoader.defineClass1(Native Method) at java.lang.classLoader.defineClass(ClassLoader.java:788) at java.security.SecureClassLoader.defineClass(SecureClassLoader.java:142) at java.net.urlclassloader.defineClass(urlclassloader.java:447) at java.net.urlclassloader.access$100(urlclassloader.java:71) at java.net.urlclassloader$1.run(urlclassloader.java:361) at java.net.urlclassloader$1.run(urlclassloader.java:355) at java.security.AccessController.doPrivileged(Native Method) at java.net.urlclassloader.findClass(urlclassloader.java:354) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:420) at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:382) at org.cometd.server.CometdServlet.newbayeuxServer(CometdServlet.java:130) at org.cometd.server.CometdServlet.init(CometdServlet.java:64) at org.cometd.annotation.AnnotationCometdServlet.init(AnnotationCometdServlet.java:54) at javax.servlet.GenericServlet.init(GenericServlet.java:244) at org.eclipse.jetty.servlet.ServletHolder.initServlet(ServletHolder.java:542) at org.eclipse.jetty.servlet.ServletHolder.getServlet(ServletHolder.java:424) at org.eclipse.jetty.servlet.ServletHolder.handle(ServletHolder.java:671) at org.eclipse.jetty.servlet.ServletHandler.doHandle(ServletHandler.java:505) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:138) at org.eclipse.jetty.security.SecurityHandler.handle(SecurityHandler.java:564) at org.eclipse.jetty.server.session.SessionHandler.doHandle(SessionHandler.java:213) at org.eclipse.jetty.server.handler.ContextHandler.doHandle(ContextHandler.java:1094) at org.eclipse.jetty.servlet.ServletHandler.doScope(ServletHandler.java:432) at org.eclipse.jetty.server.session.SessionHandler.doScope(SessionHandler.java:175) at org.eclipse.jetty.server.handler.ContextHandler.doScope(ContextHandler.java:1028) at org.eclipse.jetty.server.handler.ScopedHandler.handle(ScopedHandler.java:136) at org.eclipse.jetty.server.handler.ContextHandlerCollection.handle(ContextHandlerCollection.java:258) at org.eclipse.jetty.server.handler.HandlerCollection.handle(HandlerCollection.java:109) at org.eclipse.jetty.server.handler.HandlerWrapper.handle(HandlerWrapper.java:97) at org.eclipse.jetty.server.Server.handle(Server.java:445) at org.eclipse.jetty.server.HttpChannel.handle(HttpChannel.java:267) at org.eclipse.jetty.server.httpconnection.onFillable(httpconnection.java:224) at org.eclipse.jetty.io.AbstractConnection$ReadCallback.run(AbstractConnection.java:358) at org.eclipse.jetty.util.thread.QueuedThreadPool.runJob(QueuedThreadPool.java:601) at org.eclipse.jetty.util.thread.QueuedThreadPool$3.run(QueuedThreadPool.java:532) at java.lang.Thread.run(Thread.java:724)
到目前为止我有:
1)检查用于启动jetty的命令以使用ps查找类path:
/usr/lib/jvm/java-7-openjdk-amd64/jre/bin/java -Djetty.home=/opt/jetty -Dovc.db_config=/home/ubuntu/ovc/data/ovc-repo/config/sql.properties -Dovc.repo_loc=/home/ubuntu/ovc/data/ovc-repo -cp /opt/jetty/lib/jetty-xml-9.0.4.v20130625.jar:/opt/jetty/lib/servlet-api-3.0.jar:/opt/jetty/lib/jetty-http-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-continuation-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-server-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-security-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-servlet-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-webapp-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-deploy-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-jmx-9.0.4.v20130625.jar:/opt/jetty/lib/jsp/com.sun.el-2.2.0.v201303151357.jar:/opt/jetty/lib/jsp/javax.el-2.2.0.v201303151357.jar:/opt/jetty/lib/jsp/javax.servlet.jsp.jstl-1.2.0.v201105211821.jar:/opt/jetty/lib/jsp/javax.servlet.jsp-2.2.0.v201112011158.jar:/opt/jetty/lib/jsp/org.apache.jasper.glassfish-2.2.2.v201112011158.jar:/opt/jetty/lib/jsp/org.apache.taglibs.standard.glassfish-1.2.0.v201112081803.jar:/opt/jetty/lib/jsp/org.eclipse.jdt.core-3.8.2.v20130121.jar:/opt/jetty/resources:/opt/jetty/lib/websocket/websocket-api-9.0.4.v20130625.jar:/opt/jetty/lib/websocket/websocket-client-9.0.4.v20130625.jar:/opt/jetty/lib/websocket/websocket-common-9.0.4.v20130625.jar:/opt/jetty/lib/websocket/websocket-server-9.0.4.v20130625.jar:/opt/jetty/lib/websocket/websocket-servlet-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-util-9.0.4.v20130625.jar:/opt/jetty/lib/jetty-io-9.0.4.v20130625.jar org.eclipse.jetty.xml.XmlConfiguration /tmp/start2620351902332669076.properties /opt/jetty/etc/jetty.xml /opt/jetty/etc/jetty-jmx.xml /opt/jetty/etc/jetty-http.xml /opt/jetty/etc/jetty-deploy.xml /opt/jetty/etc/jetty-logging.xml /opt/jetty/etc/jetty-started.xml
2)检查应该包含缺less的类的jar:
docker工人:合并多个图像
Pyqtdocker在窗口最小化和恢复时隐藏
运行“docker-compose up”会在Windows上引发“没有模块名为fnctl”的错误
如何在Docker中分配一个名称来运行容器?
Docker容器中的简单REST Web服务器
~$ jar -tf /opt/jetty/lib/jetty-util-9.0.4.v20130625.jar | grep AbstractLife org/eclipse/jetty/util/component/AbstractLifeCycle$AbstractLifeCycleListener.class org/eclipse/jetty/util/component/AbstractLifeCycle.class
任何人都可以提出一个关于接下来要检查什么的build议,我没有想法? 谢谢。
当我从Docker容器中运行它时,gdb没有命中任何断点
在Windows Server 2016 TP4上安装Docker
从Windows文件浏览器访问Docker容器文件
如何访问docker定制桥networking中的端口
ImportError:窗口上的泊坞窗工具栏上没有名为…的模块
把jetty-util-9.0.4.v20130625.jar放到你的webapp的WEB-INF/lib/
从stacktrace中可以看到,您正尝试使用webapp中的jetty-util中找到的类。
at org.eclipse.jetty.webapp.WebAppClassLoader.loadClass(WebAppClassLoader.java:420)
这告诉你, Web应用程序需要jetty-util的类。
由于web应用程序类加载器的隔离以及Jetty中的各种规则 , org.eclipse.jetty.util.*的类不是由服务器提供的,必须由webapp自己的WEB-INF/lib目录提供。
在你的webapps/YOURWAR.xml ,在<Configure> (在org.eclipse.jetty.util.前面-很重要):
<Call name="prependserverClass"> <Arg>-org.eclipse.jetty.util.</Arg> </Call>
您需要预先安排它,因为顺序很重要,默认添加的最后一个是org.eclipse.jetty. 如eclipse.org上记录的那样 。 所以调用addserverClass将是一个no-op,作为org.eclipse.jetty.util. 已经被org.eclipse.jetty.排除了org.eclipse.jetty. 。
Joakim Erdfelt指出,如果有人需要一段pom代码,就把它放在pom文件中:
<dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>9.3.6.v20151106</version> </dependency>
在部署环境中,只要确保你的服务器classpath包含了Spring jar库(例如spring-2.5.6.jar)。
对于Spring3,ContextLoaderlistner被移动到spring-web.jar,你可以从Maven中央仓库获取库。
<dependency> <groupId>org.springframework</groupId> <artifactId>spring-web</artifactId> <version>3.0.5.RELEASE</version> </dependency>
http://www.mkyong.com/spring/spring-error-classnotfoundexception-org-springframework-web-context-contextloaderlistener/

eclipse installer 安装的新版本 eclipse 导入旧版本 eclipse 插件
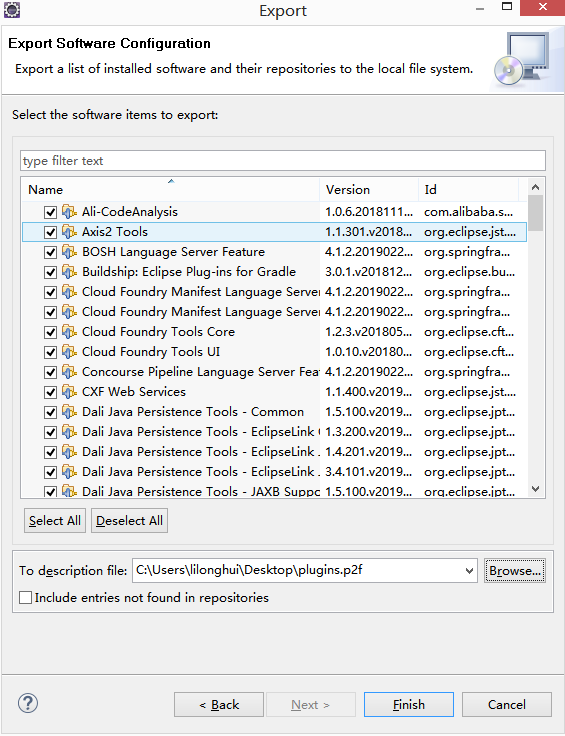
打开旧版本eclipse,选择File -> Export... -> Install -> Installed Software Items to File,点击Next
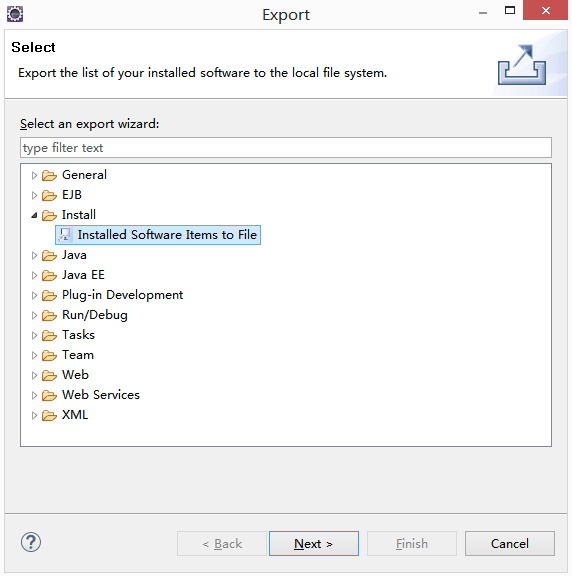
点击Select All选中所有插件,点击Browse...选择一个路径,点击Finish导出.p2f文件
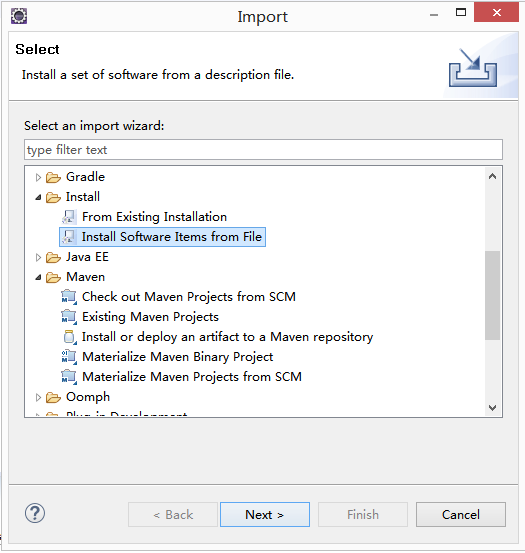
打开新下载的eclipse,选择File -> import... -> Install -> Install Software Items from File,点击Next
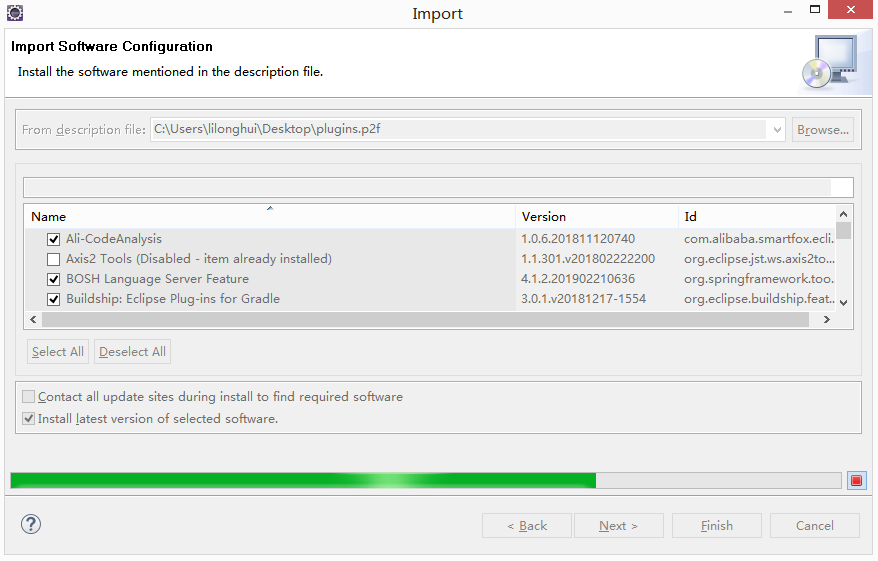
点击Browse...选择刚才导出的.p2f文件,点击Next
导入完成后,点击Next
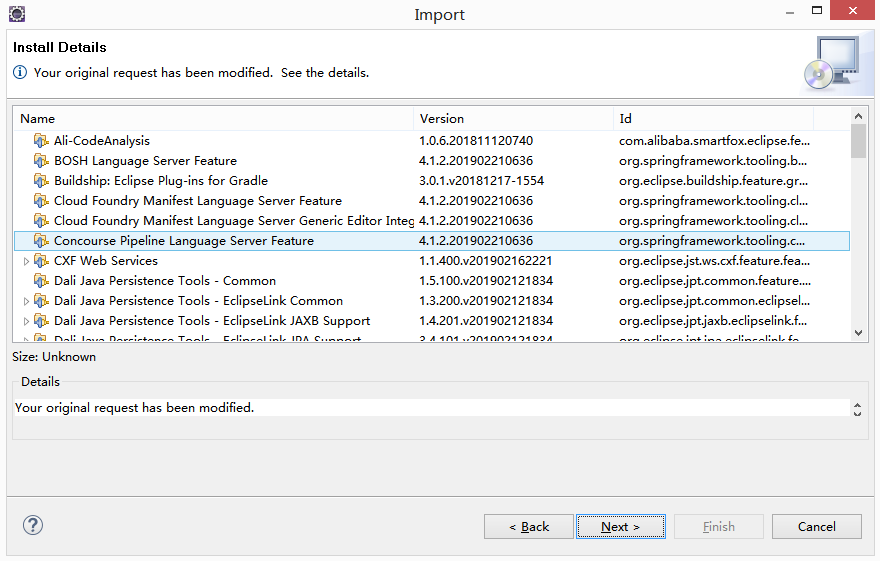
选择I accept the terms of the license agreements,点击Finish安装插件
安装完成后弹出如下对话框,选择Install anyway

接着弹出如下对话框,选择Select All,然后点击Accept selected
安装完成后重启eclipse
eclipse除了插件之外的其余配置都是跟着workspace走,启动新eclipse后选择旧版本的workspace路径即可

Eclipse Jetty 12.0.0 发布

Eclipse Jetty 12.0.0 现已可用,此版本包括对 Jetty 结构的重大更改。
Jetty Core
- Jetty Server / Jetty Client core 现在已 100% 脱离任何特定的 Jakarta EE 技术(如 Jakarta Servlet)。用户可以独立于任何特定的 EE 环境使用该层。
Jetty EE 环境
- 最初支持 3 个环境:
- EE10 - Jakarta EE 10 (jakarta.*) - Servlet 6 - JSP 3.1 - JSTL 3.0 - WebSocket 2.1
- EE9 - Jakarta EE 9 (jakarta.*) - Servlet 5 - JSP 3.0 - JSTL 2.0 - WebSocket 2.0
- EE8 - Jakarta EE 8 (javax.*) - Servlet 4 - JSP 2.3 - JSTL 1.1 - WebSocket 1.1
- Jetty 集成 - 与外部项目集成的地方
- NoSql
- Memcached
- Infinispan
- Hazelcast
Changelog
- #10231 - DefaultServlet 不再支持 POST 和 OPTIONS 并返回 405
- #10229 - HttpConfiguration.setIdleTimeout () 中断长时间运行的请求
- #10227 - EE10 无法通过
HttpServletResponse.addCookie(jakarta.servlet.http.Cookie)使用 Cookie 属性 - #10205 - 修复了 jetty 12 ee8 websocket 演示
- #10178 - 修复演示规范 Web 应用程序失败
- #10165 - 在 ee9 和 ee10 Source 中将 JAVAX_API 重命名为 JAKARTA_API
- #10155 - 在
HttpServletResponse.getWriter().println()之后的 EE10 Servlet include 会从响应中省略Content-Length - #10135 - Websocket:在 batchMode 下使用 PerMessageDeflateExtension 和 flush 会向客户端发送 FLUSH_FRAME。
详情可查看更新说明。
关于Eclipse 导入netty 示例程序和eclipse导入netbeans项目的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于1-3 eclipse myeclipse .1-4 程序的移植(导入导出)、ClassNotFoundException:运行在jetty内部的org.eclipse.jetty.util.component.AbstractLifeCycle、eclipse installer 安装的新版本 eclipse 导入旧版本 eclipse 插件、Eclipse Jetty 12.0.0 发布的相关知识,请在本站寻找。
如果您对AppImage Auto-Upgrade Failure Because of APPIMAGE NO Found感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解AppImage Auto-Upgrade Failure Because of APPIMAGE NO Found的各种细节,此外还有关于'ppm upgrade failed: DBD::SQLite::db selectrow_array failed: database disk image is malformed' 问题的解决、Add support for Android 9-patch images in BorderImage、AppIcon 和 LaunchImage、AppImage应用启动报错:Cannot mount AppImage, please check your FUSE setup.的实用技巧。
本文目录一览:- AppImage Auto-Upgrade Failure Because of APPIMAGE NO Found
- 'ppm upgrade failed: DBD::SQLite::db selectrow_array failed: database disk image is malformed' 问题的解决
- Add support for Android 9-patch images in BorderImage
- AppIcon 和 LaunchImage
- AppImage应用启动报错:Cannot mount AppImage, please check your FUSE setup.

AppImage Auto-Upgrade Failure Because of APPIMAGE NO Found
1. What hanppened?
We build a cross-platform application with electron. But its auto upgrade feature does not works. In order to explain, we image we have build a desktop application: app.AppImage. When we start the application in terminal and check the latest the version, there are some output information look like below:
Error: Error: APPIMAGE env is not defined
at t.newError (/tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:1:12502)
at Object.task (/tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:142:178326)
at h.executeDownload (/tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:1:254868)
at async /tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:315:180714
at async EventEmitter.Hr (/tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:315:180675)
09:30:53.222 › Cannot dispatch error event: TypeError: Error processing argument at index 1, conversion failure from Error: APPIMAGE env is not defined
at Object.showErrorBox (/tmp/.mount_no-app2Kmp8v/resources/electron.asar/browser/api/dialog.js:163:24)
at h.<anonymous> (/tmp/.mount_no-app2Kmp8v/resources/app.asar/dist/main.js:315:179401)
You will more detail inforamtion from output if you start with a debug flag like below
chmod +x app.AppImage
DEBUG=true ./app.AppImage
You will find the APPIMAGE environment parameter is existing. Yes, it is here, but you program can not find it.
2. Code checking & Research
2.1 from research
- APPIMAGE env is not defined
- Best way to pass variables through Webpack?
According some github issue, we know some pulugin for example: DefinePlugin will reset the environment parameters. Maybe this is the reason.
2.2 from code
...
const stringified = {
''process.env'': Object.keys(raw).reduce(
(env, key) => {
env[key] = JSON.stringify(raw[key]);
return env;
}, {}
),
};
new webpack.DefinePlugin(stringified)
...
From the code, we find the we use the DefinePlugin to pass some environment parameter for building. And the important thing is that the whole process.env is rewrited.
3. How to fix?
We have find the reason and there two way to fix the bug:
- append
APPIMAGEto the existing code - only rewrite some process.env parameters, look like below:
const envParames = {};
Object.keys(raw).forEach(k => {
envParames[`process.env.${k}`] = JSON.stringify(raw[k])
});
new webpack.DefinePlugin(envParames)
Because the APPIMAGE is a runtime environment, we can not set the value in building time. So the second it is right way to fix. Build a new application with new code, we test the app.AppImage auto upgrade function, it works now.
4. What have learned?
4.1 there are two kind of environment parameter
- build time
- runtime
4.2 never to rewrite whole process.env, only set the what you need
4.3 Summary
if your code running some website, you maybe never to care about runtime environment parameter. But if you code will build to some package application eg: command line tools / desktop application, you should care about the runtime environment.
5. Other useful article
- Type 2 AppImage runtime: the APPIMAGE is a absolute path with symlinks resolved

'ppm upgrade failed: DBD::SQLite::db selectrow_array failed: database disk image is malformed' 问题的解决
问题:
用ppm升级Perl软件包,出现错误:
ppm upgrade Failed: DBD::sqlite::db selectrow_array Failed: database disk image is malformed
解决办法:
打开目录C:\Users\zzz\AppData\Local/ActiveState/ActivePerl/。例如,在我的电脑(Win7 64位)上文件夹里的文件如图所示:
删除此目录下的所有文件和文件夹即可修复。

Add support for Android 9-patch images in BorderImage
The 9-patch image implementation in Qt Quick Controls 1 is an internal implementation detail of the Android style. It cannot handle .9.png image files out of the box, but takes a normal image without borders and the border information separately (as it was provided by the Ministro style assets).
- http://code.qt.io/cgit/qt/qtquickcontrols.git/tree/src/controls/Styles/Android/qquickandroid9patch_p.h
- http://code.qt.io/cgit/qt/qtquickcontrols.git/tree/src/controls/Styles/Android/qquickandroid9patch.cpp
The existing implementation could serve as a fine starting point for implementing a proper generic QQuickNinePatchImage. It just needs to read/strip the border information from the image file instead of providing such QVariantLists for the borders in the API. ![]()

AppIcon 和 LaunchImage
AppIcon 和 LaunchImage 命名必须正确
因为Apple 存储图片和资源文件的路径是在 XXX.app 中,我们在将图片放入我们的工程目录中时,build 后图片会拷贝到 XXX.app 中,在 XXX.app 中显示的命名如下,如果要动态修改图片的话,在我们将图片拖到.xcassets中时,命名就必须按照这样的标准,否则在取的时候会取不到,从而无法修改 成功

想要不提交新的版本就修改 AppIcon 或者 LaunchImage
原博中的图片是提前存储在工程目录中的,也就是说这个目录是你一早可以拿到的,但是如果我们想要动态去修改图片的话,一般是通过服务器,拿到的图片 我们只能存在沙盒路径,而通过脚本是拿不到真机沙盒路径的,因为脚本运行在 XCode 中,Build 时就已经运行,而沙盒路径是 Build 之后才能知道,况且沙盒路径还是在真机上,我们的脚本无法预知你的沙盒路径,更作用不到真机上,所以最终这条思路是行不通的
去做这样的尝试是因为我们的产品经理非说 人家是可以做到的,必须让我们做,然而我并没有做到,最终的结果是我气势汹汹地去告诉他这个没法做到,然后他同意在原来的 LaunchIamge 上盖一层视图。

AppImage应用启动报错:Cannot mount AppImage, please check your FUSE setup.
AppImage应用启动报错:Cannot mount AppImage, please check your FUSE setup.
Cannot mount AppImage, please check your FUSE setup.
You might still be able to extract the contents of this AppImage
if you run it with the --appimage-extract option.
See https://github.com/AppImage/AppImageKit/wiki/FUSE
for more information
open dir error: No such file or directory参考错误提示信息,执行命令, 解压文件:
# /path/xxxxxxxxxx.AppImage --appimage-extract
在解压目录找到文件:AppRun,双击打开应用即可!
我们今天的关于AppImage Auto-Upgrade Failure Because of APPIMAGE NO Found的分享就到这里,谢谢您的阅读,如果想了解更多关于'ppm upgrade failed: DBD::SQLite::db selectrow_array failed: database disk image is malformed' 问题的解决、Add support for Android 9-patch images in BorderImage、AppIcon 和 LaunchImage、AppImage应用启动报错:Cannot mount AppImage, please check your FUSE setup.的相关信息,可以在本站进行搜索。
此处将为大家介绍关于树莓派 4B 使用 docker 安装 redis6.0.8 的优化方案的详细内容,并且为您解答有关树莓派安装docker-compose的相关问题,此外,我们还将为您介绍关于1337_树莓派上安装docker、centos6 使用 docker 部署 redis 主从、docker 一小时快速入门之利用docker安装Redis、Docker 安装 Redis 以配置文件启动 redis的有用信息。
本文目录一览:- 树莓派 4B 使用 docker 安装 redis6.0.8 的优化方案(树莓派安装docker-compose)
- 1337_树莓派上安装docker
- centos6 使用 docker 部署 redis 主从
- docker 一小时快速入门之利用docker安装Redis
- Docker 安装 Redis 以配置文件启动 redis
")
树莓派 4B 使用 docker 安装 redis6.0.8 的优化方案(树莓派安装docker-compose)
硬件:Raspberry Pi 4B(4g 或 8g 版本)
系统:Ubuntu 20.04.1 LTS
Docker:20.10.5
mysql 镜像:redis:6.0.8
- 注意:因为我们树莓派 4B 本身并非 x86,而是 arm 架构,且我们的系统装的是 64 位 ubuntu,因此镜像只能选择 arm64v8 架构的镜像。这里的 redis:6.0.8 镜像是支持多架构的,arm 和 x86 服务器都可以用。
启动 redis
$ docker run --rm --name redis -p 6379:6379 --privileged=true redis:6.0.8 redis-server
1:C 07 Apr 2021 13:31:45.311 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 07 Apr 2021 13:31:45.311 # Redis version=6.0.8, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 07 Apr 2021 13:31:45.311 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
1:M 07 Apr 2021 13:31:45.317 # Not listening to IPv6: unsupported
1:M 07 Apr 2021 13:31:45.318 * Running mode=standalone, port=6379.
1:M 07 Apr 2021 13:31:45.318 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
1:M 07 Apr 2021 13:31:45.318 # Server initialized
1:M 07 Apr 2021 13:31:45.318 # WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add ''vm.overcommit_memory = 1'' to /etc/sysctl.conf and then reboot or run the command ''sysctl vm.overcommit_memory=1'' for this to take effect.
1:M 07 Apr 2021 13:31:45.319 * Ready to accept connections
显然 docker 下默认启动 redis-server 会有两个警告,下面分别就这两个警告分别给出解决方案。
修改系统参数解决第二个警告
- 修改 sysctl.conf
# (
cat <<EOF
vm.overcommit_memory=1
EOF
) >> /etc/sysctl.conf
以上操作是解决 redis-server 默认启动提示的第二个警告的持久方案,本方案需要服务器重启
修改 docker 启动命令增加 --sysctl net.core.somaxconn=1024 参数解决第一个警告
重新启动 redis
$ docker run --rm --sysctl net.core.somaxconn=1024 --name redis -p 6379:6379 --privileged=true redis:6.0.8 redis-server
1:C 07 Apr 2021 13:45:44.811 # oO0OoO0OoO0Oo Redis is starting oO0OoO0OoO0Oo
1:C 07 Apr 2021 13:45:44.811 # Redis version=6.0.8, bits=64, commit=00000000, modified=0, pid=1, just started
1:C 07 Apr 2021 13:45:44.811 # Warning: no config file specified, using the default config. In order to specify a config file use redis-server /path/to/redis.conf
1:M 07 Apr 2021 13:45:44.817 # Not listening to IPv6: unsupported
1:M 07 Apr 2021 13:45:44.818 * Running mode=standalone, port=6379.
1:M 07 Apr 2021 13:45:44.818 # Server initialized
1:M 07 Apr 2021 13:45:44.819 * Ready to accept connections
如上所示,这次重启 redis 后,之前的两个警告信息没有了。
参考
- 树莓派 4B 安装 Ubuntu 20.04 LTS
- 树莓派 4B 安装 docker18.09.9

1337_树莓派上安装docker
全部学习汇总: GitHub - GreyZhang/little_bits_of_raspberry_pi: my hacking trip about raspberry pi.
我入手过好几个树莓派,但是一直都是蒙尘的状态,直到最近两年才成了我日常中一直用的工具。我的树莓派主要是一个samba服务,再加一点点挂机的下载功能。但是,树莓派是一个被大家玩出花的设备,能够做一个其他的探索也是很有意思的。今天,决定尝试一下docker,而docker一直以来也是我不熟悉的一块技术领域。
安装docker之前,首先得确保已经安装了环境处理所需要的工具。如果没有安装,可以执行以下的命令进行安装:
sudo apt-get install apt-transport-https ca-certificates curl gnupg2 software-properties-common
接下来,配置GPG公钥。在处理的时候,首先得确认创建目标文件所在的目录,否则执行后面的处理的时候会提示无法创建相应的文件。因此,需要先创建好keyrings的目录,具体参考下面的位置。

之后执行: curl -fsSL https://download.docker.com/linux/debian/gpg | sudo gpg --dearmor -o /etc/apt/keyrings/docker.gpg
接下来,添加清华源的软件仓库:
echo \
"deb [arch=$(dpkg --print-architecture) signed-by=/etc/apt/keyrings/docker.gpg] https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/debian \
$(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list > /dev/null
接下来,就可以安装docker了。
sudo apt-get update
sudo apt-get install docker-ce
值得一说的是,我现在用的树莓派的系统是32bit的。而之前看docker的网络上的百科类的介绍的时候说这个是只支持64bit系统的,看起来还是有一些不同。或许,现在32bit后来又跟上了?
这个docker的安装包还是很大的,我这个8GB的SD看起来后面会有吃紧的时候了。以后,SD还得再升级一下,换一个空间够折腾的用用。

centos6 使用 docker 部署 redis 主从
目录结构:
/redis
/Dockerfile
/Readme
/redis-3.2.8.tar.gz
/start.sh
Dockerfile:
FROM centos
MAINTAINER qiongtao.li hnatao@126.com
ADD ./redis-3.2.8.tar.gz /opt
ADD ./start.sh /opt/start_redis.sh
RUN echo "Asia/shanghai" > /etc/timezone \
&& cp /usr/share/zoneinfo/Asia/Shanghai /etc/localtime \
&& yum -y install gcc make \
&& ln -s /opt/redis-3.2.8 /opt/redis \
&& cd /opt/redis && make && make install
EXPOSE 6379
ENTRYPOINT ["sh", "/opt/start_redis.sh"]start.sh
role=$1
port=6379
password=Abc123
redis_conf=/opt/redis/redis.conf
dir=/data/redis
logfile=/data/redis/redis.log
mkdir -p $dir
sed -i "s|bind 127.0.0.1|bind 0.0.0.0|g" $redis_conf
sed -i "s|# requirepass foobared|requirepass ${password}|g" $redis_conf
sed -i "s|dir ./|dir ${dir}|g" $redis_conf
sed -i "s|logfile \"\"|logfile ${logfile}|g" $redis_conf
if [ "$role" == "slave" ]; then
echo "slave"
sed -i "s|# slaveof <masterip> <masterport>|slaveof redis-master ${port}|g" $redis_conf
sed -i "s|# masterauth <master-password>|masterauth ${password}|g" $redis_conf
else
echo "master"
fi
redis-server $redis_confReadme
docker rm -f redis-master redis-slave-1 redis-slave-2
docker rmi -f redis
docker build -t redis .
docker run -d --name redis-master redis
docker run -d --name redis-slave-1 --link redis-master:redis-master redis slave
docker run -d --name redis-slave-2 --link redis-master:redis-master redis slave
docker ps -a
docker exec redis-master redis-cli -a Abc123 set name hnatao
docker exec redis-master redis-cli -a Abc123 get name
docker exec redis-slave-1 redis-cli -a Abc123 get name
docker exec redis-slave-2 redis-cli -a Abc123 get name
docker exec redis-master grep -E "bind|dir|require|logfile|slaveof|masterauth" /opt/redis/redis.conf
docker exec redis-slave-1 grep -E "bind|dir|require|logfile|slaveof|masterauth" /opt/redis/redis.conf
docker exec redis-slave-2 grep -E "bind|dir|require|logfile|slaveof|masterauth" /opt/redis/redis.conf
docker exec redis-master redis-cli -a Abc123 info
docker exec redis-slave-1 redis-cli -a Abc123 info
docker exec redis-slave-2 redis-cli -a Abc123 info测试安装部署
cat Readme|while read line; do $line; done

docker 一小时快速入门之利用docker安装Redis
利用docker方式快捷安装redis
#该方式默认下载的最新版本镜像,如需要下载指定版本在redis后面跟:版本号 docker pull redis #查看当前下载redis的镜像 docker images redis #启动 映射到外部的6677 ---> redis客户端直接用服务器ip:6677端口即可请求到redis docker run -it -p 6677:6379 redis
#查看当前运行的容器 docker ps -a
在宿主机创建映射文件 #创建配置目录 mkdir -p /u01/docker/redis/conf #创建数据目录 mkdir -p /u01/docker/redis/data #创建redis配置文件 touch /u01/docker/redis/conf/redis.conf vi /u01/docker/redis/conf/redis.conf redis.conf文件中填写如下内容 #守护进程 daemonize no #注释绑定本地IP #bind 127.0.0.1 #关闭保护模式 protected-mode no #设置口令 requirepass 123456
重新创建目录映射到宿主机的redis容器 #创建启动容器 docker run -it -d --privileged=true -p 6677:6379 -v /u01/docker/redis/conf/redis.conf:/etc/redis/redis.conf -v /u01/docker/redis/data:/data --name redis-5.0 redis /etc/redis/redis.conf --appendonly yes
#参数说明 -d: 后台运行容器,并返回容器ID -i: 以交互模式运行容器,通常与 -t 同时使用 -t: 为容器重新分配一个伪输入终端,通常与 -i 同时使用 --privileged=true:容器内的root拥有真正root权限,否则容器内root只是外部普通用户权限 -v /home/docker/redis/conf/redis.conf:/etc/redis/redis.conf:映射配置文件 -v /home/docker/redis/data:/data:映射数据目录 redis-server /etc/redis/redis.conf:指定配置文件启动redis-server进程 --name : 指定容器名称,这个最好加上,不然看docker进程的时候会很尴尬 --appendonly yes:开启数据持久化
#docker命令批量删除状态为Exited的容器 docker rm $(docker ps -q -f status=exited) 删除容器 根据容器CONTAINER ID #docker rm <CONTAINER ID>
可以用"docker ps -n 5 "看一下最新前5个的container
要查看启动的centos容器中的输出,可以使用如下方式: $ docker logs $CONTAINER_ID ##在container外面查看它的输出 $ docker attach $CONTAINER_ID ##连接上容器实时查看:
docker 容器 启动/ 关闭/重启
docker start 容器id docker stop 容器id docker restart 容器id
docker 服务随系统启动而启动
#systemctl enable docker.service
docker中的不同镜像创建的容器 随系统启动而启动 未启动的容器 #docker run --restart=always 启动中的容器: #docker update --restart=always <CONTAINER ID>

Docker 安装 Redis 以配置文件启动 redis
一。拉取镜像
//拉取redis镜像
docker pull redis
//查看所有镜像
docker images二. redis 配置文件修改 (重要)
/root/redis/redis01/conf/redis.conf 中daemonize=NO。非后台模式,如果为YES 会的导致 redis 无法启动,因为后台会导致docker无任务可做而退出。三 执行 docker
docker run -p 6378:6379 --name redis01 -v /root/redis/redis01/conf/redis.conf:/etc/redis/redis.conf -v /root/redis/redis01/data:/data -d redis redis-server /etc/redis/redis.conf --appendonly yes1. -p 6378:6379 容器 redis 端口 6379 映射 宿主机未 6378
2. --name redis01 容器 名字 为 redis01
3. -v /root/redis/redis01/conf/redis.conf:/etc/redis/redis.conf 容器 /etc/redis/redis.conf 配置文件 映射宿主机 /root/redis/redis01/conf/redis.conf。 会将宿主机的配置文件复制到 docker 中。
重要: 配置文件映射,docker 镜像 redis 默认无配置文件。
4 -v /root/redis/redis01/data:/data 容器 /data 映射到宿主机 /root/redis/redis01/data
5.-d redis 后台模式启动 redis
6. redis-server /etc/redis/redis.conf redis 将以 /etc/redis/redis.conf 为配置文件启动
7. --appendonly yes 开启 redis 持久化
重要: docker 镜像 reids 默认 无配置文件启动
今天的关于树莓派 4B 使用 docker 安装 redis6.0.8 的优化方案和树莓派安装docker-compose的分享已经结束,谢谢您的关注,如果想了解更多关于1337_树莓派上安装docker、centos6 使用 docker 部署 redis 主从、docker 一小时快速入门之利用docker安装Redis、Docker 安装 Redis 以配置文件启动 redis的相关知识,请在本站进行查询。
如果您对jquery load加载页面导致被加载页面中的UEditor失效感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于jquery load加载页面导致被加载页面中的UEditor失效的详细内容,并且为您提供关于ajax load 加载页面 样式失效、dijit.layout.ContentPane href加载页面后,被加载页脚本不执行的解决办法、javascript – 使用jQuery加载页面后加载外部脚本、javascript – 通过jQuery的load()加载页面的一部分时显示加载动画的有价值信息。
本文目录一览:- jquery load加载页面导致被加载页面中的UEditor失效
- ajax load 加载页面 样式失效
- dijit.layout.ContentPane href加载页面后,被加载页脚本不执行的解决办法
- javascript – 使用jQuery加载页面后加载外部脚本
- javascript – 通过jQuery的load()加载页面的一部分时显示加载动画

jquery load加载页面导致被加载页面中的UEditor失效
今天在使用百度富文本编辑器时候,发现菜单栏点击第一次的时候富文本编辑器加载没问题,但是第二次点的时候就不能加载编辑器。一度怀疑是不是百度富编辑器使用上出了错误,但是如果是使用上出现了错误那么应该在第一次加载的时候就应该不能加载。因为使用的是jquery的load来模拟框架加载页面,那会不会是load导致被加载页面中的富编辑器加载失败呢?突然在UEditor的官方文档看到这个方法UE.delEditor(),在页面每次初始化的时候,先删除掉以前的编辑器,再次进行初始化。
解决方法:
在每个UE.getEditor之前删除UE
UE.delEditor(''XXX'');

ajax load 加载页面 样式失效
ajax load 加载页面 样式失效
在 a.jsp页面 采用jquery 的load放法加载进来的b.jsp页面样式失效,怎么解决?
高手指教

dijit.layout.ContentPane href加载页面后,被加载页脚本不执行的解决办法
使用dijit/layout/ContentPane的href属性加载页面时,被加载页的dojo代码、javascript代码都不被执行
<div data-dojo-type="dijit/layout/ContentPane" title="基本信息" data-dojo-props='href:"test.html"'></div>test.html:
<html>
<head>
<script >
var s= new dijit.Dialog({ title:"测试页" }).show();
</script>
</head>
<body></body>
</html>
解决办法,使用dojox/layout/ContentPane:
<div data-dojo-type="dojox/layout/ContentPane" title="基本信息" data-dojo-props='href:"test.html"'></div>

javascript – 使用jQuery加载页面后加载外部脚本
我有点困惑如何做到这一点,基本上我有一个页面,通过JavaScript插入Facebook Share按钮:
<script src="http://static.ak.fbcdn.net/connect.PHP/js/FB.Share" type="text/javascript"></script>
问题是它阻止了该部分的页面加载,如何在页面加载后插入此标记并仍然执行脚本?我想以一种不引人注目的方式做到这一点,想法?
解决方法:
使用$(document).ready中的jQuery getScript命令.这将在页面加载后下载脚本.例:
$(document).ready(function() {
$.getScript("http://static.ak.fbcdn.net/connect.PHP/js/FB.Share", function() {
alert("Script loaded and executed.");
});
});
加载页面的一部分时显示加载动画")
javascript – 通过jQuery的load()加载页面的一部分时显示加载动画
在我的网站上,我想通过jQuery的load()函数动态加载“页面”,我想添加一个加载动画.
function loadPage(){
$("#content").load("example.html");
}
我将把代码放在哪里显示< div id =“loading”>< / div>而jQuery加载该内容??
提前致谢.
解决方法:
使用.load()的回调函数在完成时隐藏加载div.
function loadPage(){
$('#loading').show();
$("#content").load("example.html", function () { //calback function
$('#loading').hide();
});
}
今天关于jquery load加载页面导致被加载页面中的UEditor失效的讲解已经结束,谢谢您的阅读,如果想了解更多关于ajax load 加载页面 样式失效、dijit.layout.ContentPane href加载页面后,被加载页脚本不执行的解决办法、javascript – 使用jQuery加载页面后加载外部脚本、javascript – 通过jQuery的load()加载页面的一部分时显示加载动画的相关知识,请在本站搜索。
以上就是给各位分享list(destructive),同时本文还将给你拓展C ++中''struct''和''typedef struct''之间的区别?、C ++中''struct''和''typedef struct''之间的区别? - Difference between ''struct'' and ''typedef struct'' in C++?、c – is_constructible和is_destructible不受朋友声明的影响、c – std:map析构函数是否调用了Key Destructors以及Value Destructors?等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- list(destructive)
- C ++中''struct''和''typedef struct''之间的区别?
- C ++中''struct''和''typedef struct''之间的区别? - Difference between ''struct'' and ''typedef struct'' in C++?
- c – is_constructible和is_destructible不受朋友声明的影响
- c – std:map析构函数是否调用了Key Destructors以及Value Destructors?
")
list(destructive)
(append head .... tail)
copy-from-orign ... ->tail
orign ... -> tail
append will copy head to tail-1 ,and point it''s copy list cdr to the tail.
So if the tail changes,and the new list will change to.

C ++中''struct''和''typedef struct''之间的区别?
在C ++中,之间有什么区别:
struct Foo { ... };
和
typedef struct { ... } Foo;
#1楼
您不能对typedef结构使用forward声明。
struct本身是一个匿名类型,因此您没有实际名称来转发声明。
typedef struct{
int one;
int two;
}myStruct;
像这样的前瞻声明不会起作用:
struct myStruct; //forward declaration fails
void blah(myStruct* pStruct);
//error C2371: ''myStruct'' : redefinition; different basic types
#2楼
C ++中''typedef struct''和''struct''之间的一个重要区别是''typedef structs''中的内联成员初始化将不起作用。
// the ''x'' in this struct will NOT be initialised to zero
typedef struct { int x = 0; } Foo;
// the ''x'' in this struct WILL be initialised to zero
struct Foo { int x = 0; };
#3楼
Struct是创建数据类型。 typedef用于设置数据类型的昵称。
#4楼
C ++没有区别,但是我相信它会允许你在不明确地执行的情况下声明struct Foo的实例:
struct Foo bar;
#5楼
在C ++中,只有一个微妙的区别。 这是C的延续,它有所作为。
C语言标准( C89§3.1.2.3 , C99§6.2.3和C11§6.2.3 )要求为不同类别的标识符分别命名空间,包括标记标识符 (用于struct / union / enum )和普通标识符 (用于typedef和其他标识符)。
如果你刚才说:
struct Foo { ... };
Foo x;
您会收到编译器错误,因为Foo仅在标记名称空间中定义。
您必须将其声明为:
struct Foo x;
每当你想要引用Foo ,你总是要把它称为struct Foo 。 这会很快烦人,所以你可以添加一个typedef :
struct Foo { ... };
typedef struct Foo Foo;
现在struct Foo (在标记命名空间中)和普通Foo (在普通标识符命名空间中)都引用相同的东西,并且您可以在没有struct关键字的情况下自由声明Foo类型的对象。
构造:
typedef struct Foo { ... } Foo;
只是声明和typedef的缩写。
最后,
typedef struct { ... } Foo;
声明一个匿名结构并为其创建一个typedef 。 因此,使用此构造,它在标记名称空间中没有名称,只有typedef名称空间中的名称。 这意味着它也无法向前宣布。 如果要进行前向声明,则必须在标记名称空间中为其指定名称 。
在C ++中,所有struct / union / enum / class声明都像隐式typedef一样,只要该名称不被另一个具有相同名称的声明隐藏。 有关详细信息,请参阅Michael Burr的答案 。

C ++中''struct''和''typedef struct''之间的区别? - Difference between ''struct'' and ''typedef struct'' in C++?
问题:
In C++, is there any difference between: 在C ++中,之间有什么区别:
struct Foo { ... };
and 和
typedef struct { ... } Foo;
解决方案:
参考一: https://stackoom.com/question/2ZIG/C-中-struct-和-typedef-struct-之间的区别参考二: https://oldbug.net/q/2ZIG/Difference-between-struct-and-typedef-struct-in-C

c – is_constructible和is_destructible不受朋友声明的影响
关于`is_constructible,cppreference.com says:
Access checks are performed as if from a context unrelated to T and any of the types in Args. Only the validity of the immediate context of the variable deFinition is considered.
(该网站没有解释is_destructible如何处理访问检查,但访问修饰符确实会影响is_destructible的行为,因此我希望它的工作方式与is_constructible相同.)
因此,在我看来,这段代码不应该编译,因为在检查的直接上下文中,构造函数和析构函数是可用的,如局部变量实例化所证明的:
class Private
{
Private() {}
~Private() {}
friend class Friend;
};
class Friend
{
public:
Friend()
{
// Both of these should fire,but they do not.
static_assert(
!std::is_constructible<Private>::value,"the constructor is public");
static_assert(
!std::is_destructible<Private>::value,"the destructor is public");
// There is no error here.
Private p;
}
};
……但是Coliru compiles it without error(使用GCC或Clang).
这是两个编译器中的错误(或至少是不合格),或者cppreference.com是否歪曲了标准,还是我误解了cppreference.com的声明?
解决方法
Access checks are performed as if from a context unrelated to
Tand
any of the types inArgs.
说.根据定义,“T的朋友”不“与T无关”.
“immediate context”是一个艺术术语,但无论如何,句子是在谈论假设变量定义的直接上下文,而不是使用is_constructible.
使is_constructible检查依赖于上下文是疯狂的;这意味着相同的类型is_constructible< T,Args ...>在不同的上下文中具有不同的基类.

c – std:map析构函数是否调用了Key Destructors以及Value Destructors?
Foo ( )
{
std:map<std:string,int> myMap;
myMap[std::string("Bar")] = 2983;
}
我相信它没有泄漏,但在这一点上找不到具体的文件.
解决方法
§23.2.1
表96 – 集装箱要求(续)
(&a)->X() void the destructor is applied to every element of a; all the memory is deallocated.
关于list(destructive)的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于C ++中''struct''和''typedef struct''之间的区别?、C ++中''struct''和''typedef struct''之间的区别? - Difference between ''struct'' and ''typedef struct'' in C++?、c – is_constructible和is_destructible不受朋友声明的影响、c – std:map析构函数是否调用了Key Destructors以及Value Destructors?的相关信息,请在本站寻找。
对于想了解个人总结之Eclipse关联SVN的读者,本文将提供新的信息,我们将详细介绍eclipse 关联svn,并且为您提供关于eclipse myeclipse 安装离线svn svn使用简单步骤、eclipse svn 不能提交代码 关键字: eclipse svn team、Eclipse 下的 Subclipse 插件如何更换 SVN 账号、eclipse 中配置 SVN 报:unable to load default svn clien的有价值信息。
本文目录一览:- 个人总结之Eclipse关联SVN(eclipse 关联svn)
- eclipse myeclipse 安装离线svn svn使用简单步骤
- eclipse svn 不能提交代码 关键字: eclipse svn team
- Eclipse 下的 Subclipse 插件如何更换 SVN 账号
- eclipse 中配置 SVN 报:unable to load default svn clien
")
个人总结之Eclipse关联SVN(eclipse 关联svn)
好久没写博客了, 这几天重新使用了下Eclipse,关联下SVN等,所以做下记录,以便以后再次使用
我以前使用的是3.7.2版的,但是因为要嵌入个三方控件,人家最低要求是3.8,所以只好重新下载了个4.4的Eclipse,记得要设置ADT,help----install new software----add----archive处输入下载的ADT压缩包即可,然后select all,一直next就好了,这时候adt就可安装成功
Eclipse然后要关联SVN的话,其实和安装ADT差不多,也是 help----install new software----add----archive处输入svn的压缩包即可,selectall然后next就可以,这时候就在安装了,一路next,然后重启Eclipse,重启后右键,import后,这时候就会出现 ,
,
然后从svn中chectout项目,然后点击next出现
第一次关联这时候选中创建新的点next,
然后输入svn地址,从上面chectout项目就可以了

eclipse myeclipse 安装离线svn svn使用简单步骤
1,eclipse目录下建个目录links 里面新建文件svn.link 存放svn的目录path=//Users//maikaochen//soft//adt-bundle-mac-x86_64-20140702//eclipse//svn1.8(MAC版) path=D:\\myeclipse\\MyEclipse 10\\svn1.8(windows版)
2,svn1.8目录拷贝到 eclipse目录下面 svn1.8下载
3,eclipse目录下configuration目录下config.ini
org.eclipse.update.reconcile=false 改为 true,然后重启eclipse发现安装上svn
然后将上面的改回false.
为了避免冲突,每次上传时都要与资源同步一下看看那些冲突,没有上传
第一次获得svn checkout.
每次update后修改代码,然后就可以commit
如果添加新的文件,commit前 加add
如果多人同时修改一个文件,导致冲突,如一个变量名重了,就需要diff,然后改掉冲突上传

eclipse svn 不能提交代码 关键字: eclipse svn team
问题现象:
1.6.0 版本 subversion 导入项目到版本库 在 TortoiseSVN 中能正常获取数据,也能正常更新 / 提交
将 check out 出来的项目导入到 eclipse,eclipse 下的 svn 插件不能正常识别此项目(team 里面没有相关功能)
解决过程:
1 试着 check out 其他服务器下的 svn 版本库中的项目并导入,插件能正常识别
2 最开始以为是因为使用了 Apache 的 http svn 服务导致的,改成了 svn 自带的 svnserver 服务,重新导入,eclipse 下的 svn 插件依然不认识此项目
3 认为可能是因为 svn 服务器版本过高 1.6.0(相对于 eclipse 插件的版本 1.1.8),下载最新版本的插件(1.6.2),依然失败
4 右键此项目,team 中选择 share project 选项,选择 svn,提示已经存在,可以使用已经存在的路径进行管理,finish 之,问题成功解决
最终解决方案:
右键项目 - team--share project-- 选择 svn--finish 问题解决

Eclipse 下的 Subclipse 插件如何更换 SVN 账号
之前电脑上用的 Eclipse 已经使用 Subclipse 插件从服务器上 checkout 项目的代码并保存了用户名口令。现在这台机器要给其他同事使用,需要更换 SVN 的账号密码,废弃了 SVN Location 重建后还是一样用的原来老的用户名和口令。
如何清除已经记下的用户名口令呢?

eclipse 中配置 SVN 报:unable to load default svn clien
unable to load default svn client
在 Win7 下的 Eclipse,安装了 subclipse 1.10.x,已经选中了 subclipse 和 subversion Client Adapter。但是,在新建 SVN 资源库时,出现 unable to load default svn client 错误,在
Help --> Install new Software --> Work with: (svn_1.10.x -http://subclipse.tigris.org/update_1.10.x) 选中 subclipse 下的 Subversion JavaHL Native Library Adpter 即可。
关于个人总结之Eclipse关联SVN和eclipse 关联svn的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于eclipse myeclipse 安装离线svn svn使用简单步骤、eclipse svn 不能提交代码 关键字: eclipse svn team、Eclipse 下的 Subclipse 插件如何更换 SVN 账号、eclipse 中配置 SVN 报:unable to load default svn clien的相关知识,请在本站寻找。
对于DES明文加密感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解加密所有明文密码,并且为您提供关于AES加密/解密 IOS 端,JAVA端 通用,不限明文字符长度、CTF&爬虫:掌握这些特征,一秒识别密文加密方式、go加密算法:CBC对称加密(一)--3DES/AES、HTTP使用RSA公钥加密算法加密明文的宝贵知识。
本文目录一览:- DES明文加密(加密所有明文密码)
- AES加密/解密 IOS 端,JAVA端 通用,不限明文字符长度
- CTF&爬虫:掌握这些特征,一秒识别密文加密方式
- go加密算法:CBC对称加密(一)--3DES/AES
- HTTP使用RSA公钥加密算法加密明文
")
DES明文加密(加密所有明文密码)
public class DES {
private static final String DES_ALGORITHM = "DES";
public static String encryption(String plainData, String secretKey) throws Exception {
Cipher cipher = null;
try {
cipher = Cipher.getInstance(DES_ALGORITHM);
cipher.init(Cipher.ENCRYPT_MODE, generateKey(secretKey));
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
} catch (NoSuchPaddingException e) {
e.printStackTrace();
} catch (InvalidKeyException e) {
}
try {
// 为了防止解密时报javax.crypto.IllegalBlockSizeException: Input length must
// be multiple of 8 when decrypting with padded cipher异常,
// 不能把加密后的字节数组直接转换成字符串
byte[] buf = cipher.doFinal(plainData.getBytes());
return Base64Utils.encode(buf);
} catch (IllegalBlockSizeException e) {
e.printStackTrace();
throw new Exception("IllegalBlockSizeException", e);
} catch (BadPaddingException e) {
e.printStackTrace();
throw new Exception("BadPaddingException", e);
}
}
/**
* DES解密
* @param secretData 密码字符串
* @param secretKey 解密密钥
* @return 原始字符串
* @throws Exception
*/
public static String decryption(String secretData, String secretKey) throws Exception {
Cipher cipher = null;
try {
cipher = Cipher.getInstance(DES_ALGORITHM);
cipher.init(Cipher.DECRYPT_MODE, generateKey(secretKey));
} catch (NoSuchAlgorithmException e) {
e.printStackTrace();
throw new Exception("NoSuchAlgorithmException", e);
} catch (NoSuchPaddingException e) {
e.printStackTrace();
throw new Exception("NoSuchPaddingException", e);
} catch (InvalidKeyException e) {
e.printStackTrace();
throw new Exception("InvalidKeyException", e);
}
try {
byte[] buf = cipher.doFinal(Base64Utils.decode(secretData.toCharArray()));
return new String(buf);
} catch (IllegalBlockSizeException e) {
e.printStackTrace();
throw new Exception("IllegalBlockSizeException", e);
} catch (BadPaddingException e) {
e.printStackTrace();
throw new Exception("BadPaddingException", e);
}
}
/**
* 获得秘密密钥
*
* @param secretKey
* @return
* @throws NoSuchAlgorithmException
* @throws InvalidKeySpecException
* @throws InvalidKeyException
*/
private static SecretKey generateKey(String secretKey)
throws NoSuchAlgorithmException, InvalidKeySpecException, InvalidKeyException {
SecretKeyFactory keyFactory = SecretKeyFactory.getInstance(DES_ALGORITHM);
DESKeySpec keySpec = new DESKeySpec(secretKey.getBytes());
keyFactory.generateSecret(keySpec);
return keyFactory.generateSecret(keySpec);
}
static private class Base64Utils {
static private char[] alphabet = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
.toCharArray();
static private byte[] codes = new byte[256];
static {
for (int i = 0; i < 256; i++)
codes[i] = -1;
for (int i = ''A''; i <= ''Z''; i++)
codes[i] = (byte) (i - ''A'');
for (int i = ''a''; i <= ''z''; i++)
codes[i] = (byte) (26 + i - ''a'');
for (int i = ''0''; i <= ''9''; i++)
codes[i] = (byte) (52 + i - ''0'');
codes[''+''] = 62;
codes[''/''] = 63;
}
/**
* 将原始数据编码为base64编码
*/
static private String encode(byte[] data) {
char[] out = new char[((data.length + 2) / 3) * 4];
for (int i = 0, index = 0; i < data.length; i += 3, index += 4) {
boolean quad = false;
boolean trip = false;
int val = (0xFF & (int) data[i]);
val <<= 8;
if ((i + 1) < data.length) {
val |= (0xFF & (int) data[i + 1]);
trip = true;
}
val <<= 8;
if ((i + 2) < data.length) {
val |= (0xFF & (int) data[i + 2]);
quad = true;
}
out[index + 3] = alphabet[(quad ? (val & 0x3F) : 64)];
val >>= 6;
out[index + 2] = alphabet[(trip ? (val & 0x3F) : 64)];
val >>= 6;
out[index + 1] = alphabet[val & 0x3F];
val >>= 6;
out[index + 0] = alphabet[val & 0x3F];
}
return new String(out);
}
/**
* 将base64编码的数据解码成原始数据
*/
static private byte[] decode(char[] data) {
int len = ((data.length + 3) / 4) * 3;
if (data.length > 0 && data[data.length - 1] == ''='')
--len;
if (data.length > 1 && data[data.length - 2] == ''='')
--len;
byte[] out = new byte[len];
int shift = 0;
int accum = 0;
int index = 0;
for (int ix = 0; ix < data.length; ix++) {
int value = codes[data[ix] & 0xFF];
if (value >= 0) {
accum <<= 6;
shift += 6;
accum |= value;
if (shift >= 8) {
shift -= 8;
out[index++] = (byte) ((accum >> shift) & 0xff);
}
}
}
if (index != out.length)
throw new Error("miscalculated data length!");
return out;
}
}
}
用的时候这里的第二个参数必须是大于等于8位以上的串,否则会报错
DES.encryption("410105198703080212","key12345");

AES加密/解密 IOS 端,JAVA端 通用,不限明文字符长度
测试发现,当前问题是:
明文字符长度<=15时, IOS 端的 AES 加密结果和 JAVA 端是一样的
明文字符长度>15时, IOS 的加密和 JAVA 的加密是不同的, 但都可以在各自语言中成功解密
解决办法就不说了,直接上代码
- (NSData *)AESOperation:(CCOperation)operation key:(NSString *)key iv:(NSString *)iv aesType:(AesType)aesType
{
NSUInteger aesKeySizeType;
NSUInteger aesBlockSizeType = kCCBlockSizeAES128;
CCAlgorithm aesAlgorithmType = kCCAlgorithmAES128;
switch (aesType) {
case kAesType128:
aesKeySizeType = kCCKeySizeAES256;
break;
case kAesType192:
aesKeySizeType = kCCKeySizeAES192;
break;
case kAesType256:
aesKeySizeType = kCCKeySizeAES256;
break;
default:
aesKeySizeType = kCCKeySizeAES256;
break;
}
char keyPtr[aesKeySizeType + 1];
memset(keyPtr, 0, sizeof(keyPtr));
[key getCString:keyPtr maxLength:sizeof(keyPtr) encoding:NSUTF8StringEncoding];
char ivPtr[aesBlockSizeType + 1];
memset(ivPtr, 0, sizeof(ivPtr));
[iv getCString:ivPtr maxLength:sizeof(ivPtr) encoding:NSUTF8StringEncoding];
NSUInteger dataLength = [self length];
size_t bufferSize = dataLength + aesBlockSizeType;
void *buffer = malloc(bufferSize);
size_t numBytesCrypted = 0;
CCCryptorStatus cryptStatus = CCCrypt(operation,
aesAlgorithmType,
kCCOptionPKCS7Padding | kCCOptionECBMode,
keyPtr,
aesBlockSizeType,
ivPtr,
[self bytes],
dataLength,
buffer,
bufferSize,
&numBytesCrypted);
NSData *data = nil;
if (cryptStatus == kCCSuccess) {
data = [NSData dataWithBytesNoCopy:buffer length:numBytesCrypted];
}
return data;
}最重要的部分是这一句的 kCCOptionPKCS7Padding | kCCOptionECBMode ,
CCCryptorStatus cryptStatus = CCCrypt(operation,
aesAlgorithmType,
kCCOptionPKCS7Padding | kCCOptionECBMode,
keyPtr,
aesBlockSizeType,
ivPtr,
[self bytes],
dataLength,
buffer,
bufferSize,
&numBytesCrypted);一般网上的只会有其中一个,导致加密明文>15个字符时,结果和 JAVA 的加密结果不同.
具体原因~希望有大牛可以解惑!

CTF&爬虫:掌握这些特征,一秒识别密文加密方式

关注微信公众号:K哥爬虫,持续分享爬虫进阶、JS/安卓逆向等技术干货!
前言
爬虫工程师在做加密参数逆向的时候,经常会遇到各种各样的加密算法、编码、混淆,每个算法都有其对应的特征,对于一些较小的网站,往往直接引用这些官方算法,没有进行魔改等其他操作,这种情况下,如果我们能熟悉常见算法的特征,通过密文就能猜测出使用的哪种算法、编码、混淆,将会大大提高工作效率!在 CTF 中通常也会有密码类的题目,掌握一些常见密文特征也是 CTFer 们必备的技能!
本文将介绍以下编码和加密算法的特征:
- 编码:Base 系列、Unicode、Escape、URL、Hex;
- 算法:MD5、SHA 系列、HMAC 系列、RSA、AES、DES、3DES、RC4、Rabbit、SM 系列;
- 混淆:Obfuscator、JJEncode、AAEncode、JSFuck、Jother、Brainfuck、Ook!、Trivial brainfuck substitution;
- 其他:恺撒密码、栅栏密码、猪圈密码、摩斯密码、培根密码、维吉尼亚密码、与佛论禅、当铺密码。
PS:常见加密算法原理以及在 Python 和 JavaScript 中的实现方法可参见K哥以前的文章:【爬虫知识】爬虫常见加密解密算法
编码系列
Base 系列编码
Base64 是我们最常见的编码,除此之外,其实还有 Base16、Base32、Base58、Base85、Base100 等,他们之间最明显的区别就是使用了不同数量的可打印字符对任意字节数据进行编码,比如 Base64 使用了64个可打印字符(A-Z、a-z、0-9、+、/),Base16 使用了16个可打印字符(A-F、0-9),这里主要讲怎么快速识别,其具体原理可自行百度,Base 系列主要特征如下:
- Base16:结尾没有等号,数字要多于字母;
- Base32:字母要多于数字,明文数量超过10个,结尾可能会有很多等号;
- Base58:结尾没有等号,字母要多于数字;
- Base64:一般情况下结尾都会有1个或者2个等号,明文很少的时候可能没有;
- Base85:等号一般出现在字符串中间,含有一些奇怪的字符;
- Base100:密文由 Emoji 表情组成。
示例:
| 编码类型 | 示例一 | 示例二 |
|---|---|---|
| 明文 | 01234567890 | administrators |
| Base16 | 3031323334353637383930 | 61646D696E6973747261746F7273 |
| Base32 | GAYTEMZUGU3DOOBZGA====== | MFSG22LONFZXI4TBORXXE4Y= |
| Base58 | cX8j8pvGzppMKVb | BNF5dFLUTN5XwM1yLoF |
| Base64 | MDEyMzQ1Njc4OTA= | YWRtaW5pc3RyYXRvcnM= |
| Base85 | 0JP==1c70M3&rY | @:X4hDJ=06Eaa''.EcV |
| Base100 | | |
Unicode 编码
Unicode 又称为统一码、万国码、单一码,是一种在计算机上使用的字符编码。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。其主要特征如下:
- 以
\u、&#或&#x开头,后面是数字加字母组合
PS:\u 开头和 &#x 开头是一样的,都是16进制 Unicode 字符的不同写法,&# 则是 Unicode 字符10进制的写法,此外,&# 和 &#x 开头的,也称为 HTML 字符实体转换,字符实体是用一个编号写入 HTML 代码中来代替一个字符,在 HTML 中,某些字符是预留的,如果希望正确地显示预留字符,就必须在 HTML 源代码中使用字符实体。
| 编码类型 | 示例一 | 示例二 |
|---|---|---|
| 明文 | 12345 | admin |
| Unicode | \u0031\u0032\u0033\u0034\u0035 | \u0061\u0064\u006d\u0069\u006e |
Escape 编码
Escape 编码又叫 %u 编码,Escape 编码就是字符对应 UTF-16BE 表示方式前面加 %u,Escape 不会对 ASCII 字母和数字进行编码,也不会对下面这些 ASCII 标点符号进行编码: * @ - _ + . / ,其他所有的字符都会被转义序列替换。其主要特征如下:
- 以
%u开头,后面是数字加字母组合
| 编码类型 | 示例一 | 示例二 |
|---|---|---|
| 明文 | K哥爬虫 | 我爱Python |
| Escape | K%u54E5%u722C%u866B | %u6211%u7231Python |
URL / Hex 编码
URL 和 Hex 编码的结果是一样的,不同的是当你用 URL 编码网址时是不会把 http、https 关键字和 /、?、&、= 等连接符进行编码的,而 Hex 编码则全部转化了,其主要特征如下:
- 以
%开头,后面是数字加字母组合
| 编码类型 | 示例 |
|---|---|
| 明文 | https://www.kuaidaili.com/ |
| Unicode | https://%77%77%77%2E%6B%75%61%69%64%61%69%6C%69%2E%63%6F%6D/ |
| Hex | %68%74%74%70%73%3a%2f%2f%77%77%77%2e%6b%75%61%69%64%61%69%6c%69%2e%63%6f%6d%2f |
加密算法
MD5
MD5 实质是一种消息摘要算法,一个数据的 MD5 值是唯一的,同一个数据不可能计算出多个不同的 MD5 值,但是,不同数据计算出来的 MD5 值是有可能一样的,知道一个 MD5 值,理论上是无法还原出它的原始数据的,MD5 是最容易辨别的,主要特征如下:
- 密文一般为 16 位或者 32 位,其中 16 位是取的 32 位第 9~25 位的值;
- 组成方式为字母(a-f)和数字(0-9)混合,字母可以全部是大写或者小写。
除了通过密文特征来判断以外,我们还可以搜索源代码,标准 MD5 的源码里是包含了一些特定的值的,没有这些特定值,就无法实现 MD5:
0123456789ABCDEF、0123456789abcdef1732584193、-271733879、-1732584194、271733878
PS:某些特殊情况下,密文的长度也有可能不止 16 位或者 32 位,有可能是在官方算法上有一些魔改,通常也是在 16 位的基础上,左右填充了一些随机字符串。
示例:
| 编码类型 | 示例一 | 示例二 |
|---|---|---|
| 明文 | 123456 | admin |
| MD5(16位小写) | 49ba59abbe56e057 | 7a57a5a743894a0e |
| MD5(16位大写) | 49BA59ABBE56E057 | 7A57A5A743894A0E |
| MD5(32位小写) | e10adc3949ba59abbe56e057f20f883e | 21232f297a57a5a743894a0e4a801fc3 |
| MD5(32位大写) | E10ADC3949BA59ABBE56E057F20F883E | 21232F297A57A5A743894A0E4A801FC3 |
SHA 系列
SHA 是比 MD5 更安全一点的摘要算法,SHA 通常指 SHA 家族算法,分别是 SHA-1、SHA-2、SHA-3,其中 SHA-2 是 SHA-224、SHA-256、SHA-384、SHA-512 的并称,SHA-3 是 SHA3-224、SHA3-256、SHA3-384、SHA3-512、SHAKE128、SHAKE256 的并称,其名字的后缀的数字就代表了结果的大小(bit),注意,SHAKE 算法结果的大小并不是固定的,其他算法特征如下:
- SHA-1:字母(a-f)和数字(0-9)混合,固定位数 40 位;
- SHA-224/SHA3-224:字母(a-f)和数字(0-9)混合,固定位数 56 位;
- SHA-256/SHA3-256:字母(a-f)和数字(0-9)混合,固定位数 64 位;
- SHA-384/SHA3-384:字母(a-f)和数字(0-9)混合,固定位数 96 位;
- SHA-512/SHA3-512:字母(a-f)和数字(0-9)混合,固定位数 128 位。
示例:
| 编码类型 | 示例 |
|---|---|
| 明文 | 123456 |
| SHA-1 | 7c4a8d09ca3762af61e59520943dc26494f8941b |
| SHA-256 | 8d969eef6ecad3c29a3a629280e686cf0c3f5d5a86aff3ca12020c923adc6c92 |
| SHA3-256 | c888c9ce9e098d5864d3ded6ebcc140a12142263bace3a23a36f9905f12bd64a |
HMAC 系列
HMAC 这种算法就是在 MD5、SHA 两种加密的基础上引入了秘钥,其密文也和 MD5、SHA 类似,密文的长度和使用的 MD5、SHA 算法对应密文的长度是一样的。特征如下:
- HMAC-MD5:字母(a-f)和数字(0-9)混合,位数一般为 32 位;
- HMAC-SHA-1:字母(a-f)和数字(0-9)混合,固定位数 40 位;
- HMAC-SHA-224 / HMAC-SHA3-224:字母(a-f)和数字(0-9)混合,固定位数 56 位;
- HMAC-SHA-256 / HMAC-SHA3-256:字母(a-f)和数字(0-9)混合,固定位数 64 位;
- HMAC-SHA-384 / HMAC-SHA3-384:字母(a-f)和数字(0-9)混合,固定位数 96 位;
- HMAC-SHA-512 / HMAC-SHA3-512:字母(a-f)和数字(0-9)混合,固定位数 128 位。
HMAC 和 SHA、MD5 的密文都很像,当无法确定是否为 HMAC 时,可以通过其名称搜索到加密方法,如果传入了密钥 key,说明就是 HMAC,当然你也可以直接当做是 SHA 或 MD5 来解,解密失败时就得考虑是否有密钥,是否为 HMAC 了,在 JS 中,通常一个 HMAC 加密方法是这样写的:
function HmacSHA1Encrypt(word, key) {
return CryptoJS.HmacSHA1(word, key).toString();
}示例(密钥 123456abcde):
| 编码类型 | 示例 |
|---|---|
| 明文 | 123456 |
| HMAC-MD5 | 432bb95bb00005ddce4a1c757488ed95 |
| HMAC-SHA-1 | 37a04076b7736c44460d330ee0d00014428b175e |
| HMAC-SHA-256 | 50cb1345366df11140fb91b43caaf69627e3f5529705ddf6b0d0cae67986e585 |
| HMAC-SHA3-256 | b808ed9f66436e89fba527a01d1d6044318fea8599d9f39bfb6bec4843964bf3 |
RSA
RSA 加密算法是一种非对称加密算法,通过公钥加密结果,必须私钥解密。 同样私钥加密结果,公钥可以解密,应用非常广泛,在网站中通常使用 JSEncrypt 库来实现,其最大的特征就是有一个设置公钥的过程,我们可以通过以下方法来快速初步判断是否为 RSA 算法:
- 搜索关键词
new JSEncrypt(),JSEncrypt等,一般会使用 JSEncrypt 库,会有 new 一个实例对象的操作; - 搜索关键词
setPublicKey、setKey、setPrivateKey、getPublicKey等,一般实现的代码里都含有设置密钥的过程; RSA 的私钥、公钥、明文、密文长度也有一定对应关系,也可以从这方面初步判断:
私钥长度(Base64) 公钥长度(Base64) 明文长度 密文长度 428 128 1~53 88 812 216 1~117 172 1588 392 1~245 344
AES、DES、3DES、RC4、Rabbit 等
AES、DES、3DES、RC4、Rabbit 等加密算法的密文通常没有固定的长度,他们通常使用 crypto-js 来实现,比如 AES 加解密示例如下:
CryptoJS = require("crypto-js")
var key = CryptoJS.enc.Utf8.parse("0123456789abcdef");
var iv = CryptoJS.enc.Utf8.parse("0123456789abcdef");
function AESEncrypt(word) {
var srcs = CryptoJS.enc.Utf8.parse(word);
var encrypted = CryptoJS.AES.encrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return encrypted.toString();
}
function AESDecrypt(word) {
var srcs = word;
var decrypt = CryptoJS.AES.decrypt(srcs, key, {
iv: iv,
mode: CryptoJS.mode.CBC,
padding: CryptoJS.pad.Pkcs7
});
return decrypt.toString(CryptoJS.enc.Utf8);
}
console.log(AESEncrypt("K哥爬虫"))
console.log(AESDecrypt("nSk3wCd92s08sQ9N+VHNvA=="))在 crypto-js 中,也有一些特定的关键字,我们可以通过搜索这些关键字来快速定位到 crypto-js:
CryptoJS、crypto-js、iv、mode、padding、createEncryptor、createDecryptorABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/=、0xffffffff、0xffff
定位到 CryptoJS 后,观察加密方法,比如 AES 就是 CryptoJS.AES.encrypt,DES 就是 CryptoJS.DES.encrypt,3DES 就是 CryptoJS.TripleDES.encrypt,注意他的 iv、mode、padding,拿下来就可以本地复现了。
SM 系列
SM 代表商密,即商业密码,是我国发布的一系列国产加密算法,SM 系列包括:SM1、SM2、SM3 、SM4、SM7、SM9,其中 SM1 和 SM7 的算法不公开,SM 系列算法在我国一些 gov 网站上有应用,有关国产加密算法 K 哥前期文章有介绍:《爬虫逆向基础,认识 SM1-SM9、ZUC 国密算法》,本文不再赘述。
在 SM 的 JavaScript 代码中一般会存在以下关键字,可以通过搜索关键字定位:
SM2、SM3、SM4FFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00000000FFFFFFFFFFFFFFFFFFFFFFFEFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFFF00000000FFFFFFFFFFFFFFFC28E9FA9E9D9F5E344D5A9E4BCF6509A7F39789F515AB8F92DDBCBD414D940E93abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789getPublicKeyFromPrivateKey、doEncrypt、doDecrypt、doSignature
混淆系列
Obfuscator
Obfuscator 就是混淆的意思,简称 OB 混淆,实战可参考K哥以前的文章:【JS 逆向百例】W店UA,OB反混淆,抓包替换CORS跨域错误分析,OB 混淆具有以下特征:
- 一般由一个大数组或者含有大数组的函数、一个自执行函数、解密函数和加密后的函数四部分组成;
- 函数名和变量名通常以
_0x或者0x开头,后接 1~6 位数字或字母组合; - 自执行函数,进行移位操作,有明显的 push、shift 关键字;
一段正常的代码如下:
function hi() {
console.log("Hello World!");
}
hi();经过 OB 混淆后的结果:
function _0x3f26() {
var _0x2dad75 = [''5881925kTCKCP'', ''Hello\x20World!'', ''600mDvfGa'', ''699564jYNxbu'', ''1083271cEvuvT'', ''log'', ''18sKjcFY'', ''214857eMgFSU'', ''77856FUKcuE'', ''736425OzpdFI'', ''737172JqcGMg''];
_0x3f26 = function () {
return _0x2dad75;
};
return _0x3f26();
}
(function (_0x307c88, _0x4f8223) {
var _0x32807d = _0x1fe9, _0x330c58 = _0x307c88();
while (!![]) {
try {
var _0x5d6354 = parseInt(_0x32807d(0x6f)) / 0x1 + parseInt(_0x32807d(0x6e)) / 0x2 + parseInt(_0x32807d(0x70)) / 0x3 + -parseInt(_0x32807d(0x69)) / 0x4 + parseInt(_0x32807d(0x71)) / 0x5 + parseInt(_0x32807d(0x6c)) / 0x6 * (parseInt(_0x32807d(0x6a)) / 0x7) + -parseInt(_0x32807d(0x73)) / 0x8 * (parseInt(_0x32807d(0x6d)) / 0x9);
if (_0x5d6354 === _0x4f8223) break; else _0x330c58[''push''](_0x330c58[''shift'']());
} catch (_0x3f18e4) {
_0x330c58[''push''](_0x330c58[''shift'']());
}
}
}(_0x3f26, 0xaa023));
function _0x1fe9(_0xa907e7, _0x410a46) {
var _0x3f261f = _0x3f26();
return _0x1fe9 = function (_0x1fe950, _0x5a08da) {
_0x1fe950 = _0x1fe950 - 0x69;
var _0x82a06 = _0x3f261f[_0x1fe950];
return _0x82a06;
}, _0x1fe9(_0xa907e7, _0x410a46);
}
function hi() {
var _0x12a222 = _0x1fe9;
console[_0x12a222(0x6b)](_0x12a222(0x72));
}
hi();JJEncode
JJEncode、AAEncode、JSFuck 都是同一个作者,实战可参考K哥以前的文章:【JS 逆向百例】网洛者反爬练习平台第二题:JJEncode 加密,JJEncode 具有以下特征:
- 大量
$、_符号,大量重复的自定义变量; - 仅由 18 个符号组成:
[]()!+,\"$.:;_{}~=
正常的一段 JS 代码:
alert("Hello, JavaScript" )经过 JJEncode 混淆(自定义变量名为 $)之后的代码:
$=~[];$={___:++$,$$$$:(![]+"")[$],__$:++$,$_$_:(![]+"")[$],_$_:++$,$_$$:({}+"")[$],$$_$:($[$]+"")[$],_$$:++$,$$$_:(!""+"")[$],$__:++$,$_$:++$,$$__:({}+"")[$],$$_:++$,$$$:++$,$___:++$,$__$:++$};$.$_=($.$_=$+"")[$.$_$]+($._$=$.$_[$.__$])+($.$$=($.$+"")[$.__$])+((!$)+"")[$._$$]+($.__=$.$_[$.$$_])+($.$=(!""+"")[$.__$])+($._=(!""+"")[$._$_])+$.$_[$.$_$]+$.__+$._$+$.$;$.$$=$.$+(!""+"")[$._$$]+$.__+$._+$.$+$.$$;$.$=($.___)[$.$_][$.$_];$.$($.$($.$$+"\""+$.$_$_+(![]+"")[$._$_]+$.$$$_+"\\"+$.__$+$.$$_+$._$_+$.__+"(\\\"\\"+$.__$+$.__$+$.___+$.$$$_+(![]+"")[$._$_]+(![]+"")[$._$_]+$._$+",\\"+$.$__+$.___+"\\"+$.__$+$.__$+$._$_+$.$_$_+"\\"+$.__$+$.$$_+$.$$_+$.$_$_+"\\"+$.__$+$._$_+$._$$+$.$$__+"\\"+$.__$+$.$$_+$._$_+"\\"+$.__$+$.$_$+$.__$+"\\"+$.__$+$.$$_+$.___+$.__+"\\\"\\"+$.$__+$.___+")"+"\"")())();AAEncode
JJEncode、AAEncode、JSFuck 都是同一个作者,实战可参考K哥以前的文章:【JS 逆向百例】网洛者反爬练习平台第三题:AAEncode 加密,AAEncode 具有以下特征:
- 仅由日式表情符号组成
正常的一段 JS 代码:
alert("Hello, JavaScript")经过 AAEncode 混淆之后的代码:
゚ω゚ノ= /`m´)ノ ~┻━┻ //*´∇`*/ [''_'']; o=(゚ー゚) =_=3; c=(゚Θ゚) =(゚ー゚)-(゚ー゚); (゚Д゚) =(゚Θ゚)= (o^_^o)/ (o^_^o);(゚Д゚)={゚Θ゚: ''_'' ,゚ω゚ノ : ((゚ω゚ノ==3) +''_'') [゚Θ゚] ,゚ー゚ノ :(゚ω゚ノ+ ''_'')[o^_^o -(゚Θ゚)] ,゚Д゚ノ:((゚ー゚==3) +''_'')[゚ー゚] }; (゚Д゚) [゚Θ゚] =((゚ω゚ノ==3) +''_'') [c^_^o];(゚Д゚) [''c''] = ((゚Д゚)+''_'') [ (゚ー゚)+(゚ー゚)-(゚Θ゚) ];(゚Д゚) [''o''] = ((゚Д゚)+''_'') [゚Θ゚];(゚o゚)=(゚Д゚) [''c'']+(゚Д゚) [''o'']+(゚ω゚ノ +''_'')[゚Θ゚]+ ((゚ω゚ノ==3) +''_'') [゚ー゚] + ((゚Д゚) +''_'') [(゚ー゚)+(゚ー゚)]+ ((゚ー゚==3) +''_'') [゚Θ゚]+((゚ー゚==3) +''_'') [(゚ー゚) - (゚Θ゚)]+(゚Д゚) [''c'']+((゚Д゚)+''_'') [(゚ー゚)+(゚ー゚)]+ (゚Д゚) [''o'']+((゚ー゚==3) +''_'') [゚Θ゚];(゚Д゚) [''_''] =(o^_^o) [゚o゚] [゚o゚];(゚ε゚)=((゚ー゚==3) +''_'') [゚Θ゚]+ (゚Д゚) .゚Д゚ノ+((゚Д゚)+''_'') [(゚ー゚) + (゚ー゚)]+((゚ー゚==3) +''_'') [o^_^o -゚Θ゚]+((゚ー゚==3) +''_'') [゚Θ゚]+ (゚ω゚ノ +''_'') [゚Θ゚]; (゚ー゚)+=(゚Θ゚); (゚Д゚)[゚ε゚]=''\\''; (゚Д゚).゚Θ゚ノ=(゚Д゚+ ゚ー゚)[o^_^o -(゚Θ゚)];(o゚ー゚o)=(゚ω゚ノ +''_'')[c^_^o];(゚Д゚) [゚o゚]=''\"'';(゚Д゚) [''_''] ( (゚Д゚) [''_''] (゚ε゚+(゚Д゚)[゚o゚]+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ ((゚ー゚) + (o^_^o))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) +(o^_^o))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) - (゚Θ゚))+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ (゚ー゚)+ (o^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (c^_^o)+ (゚Д゚)[゚ε゚]+(゚Θ゚)+ ((o^_^o) +(o^_^o))+ (゚ー゚)+ (゚Д゚)[゚ε゚]+(゚ー゚)+ ((o^_^o) - (゚Θ゚))+ (゚Д゚)[゚ε゚]+((゚ー゚) + (゚Θ゚))+ (゚Θ゚)+ (゚Д゚)[゚o゚]) (゚Θ゚)) (''_'');JSFuck
JJEncode、AAEncode、JSFuck 都是同一个作者,实战可参考K哥以前的文章:【JS 逆向百例】网洛者反爬练习平台第四题:JSFuck 加密,JSFuck 具有以下特征:
- 仅由 6 个符号组成:
[]()!+
正常的一段 JS 代码:
alert(1)经过 JSFuck 混淆之后的代码类似于:
[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]][([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]((!![]+[])[+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+([][[]]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+!+[]]+(+[![]]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]+(+(!+[]+!+[]+!+[]+[+!+[]]))[(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([]+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]][([][[]]+[])[+!+[]]+(![]+[])[+!+[]]+((+[])[([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+([][[]]+[])[+!+[]]+(![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[])[+!+[]]+([][[]]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+[]]+(!![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[+!+[]+[+[]]]+(!![]+[])[+!+[]]]+[])[+!+[]+[+!+[]]]+(!![]+[])[!+[]+!+[]+!+[]]]](!+[]+!+[]+!+[]+[!+[]+!+[]])+(![]+[])[+!+[]]+(![]+[])[!+[]+!+[]])()((![]+[])[+!+[]]+(![]+[])[!+[]+!+[]]+(!![]+[])[!+[]+!+[]+!+[]]+(!![]+[])[+!+[]]+(!![]+[])[+[]]+([][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]]+[])[+!+[]+[!+[]+!+[]+!+[]]]+[+!+[]]+([+[]]+![]+[][(![]+[])[+[]]+(![]+[])[!+[]+!+[]]+(![]+[])[+!+[]]+(!![]+[])[+[]]])[!+[]+!+[]+[+[]]])Jother
Jother 混淆和 JSFuck 有点儿类似,唯一的区别就是密文比 JSFuck 多了 {},其解密方式和 JSFuck 是一样的,Jother 混淆现在不太常见了,也很难找到在线混淆之类的工具了,原作者有个在线页面也关闭了,不过仍然可以了解一下,Jother 混淆具有以下特征:
- 仅由 8 个符号组成:
[]()!+{}
正常的一段代码:
function anonymous(
) {
return location
}经过 Jother 混淆之后的代码类似于:
[][(![]+[])[!![]+!![]+!![]]+({}+[])[+!![]]+(!![]+[])[+!![]]+(!![]+[])[+[]]][({}+[])[!![]+!![]+!![]+!![]+!![]]+({}+[])[+!![]]+({}[[]]+[])[+!![]]+(![]+[])[!![]+!![]+!![]]+(!![]+[])[+[]]+(!![]+[])[+!![]]+({}[[]]+[])[+[]]+({}+[])[!![]+!![]+!![]+!![]+!![]]+(!![]+[])[+[]]+({}+[])[+!![]]+(!![]+[])[+!![]]]((!![]+[])[+!![]]+(!![]+[])[!![]+!![]+!![]]+(!![]+[])[+[]]+({}[[]]+[])[+[]]+(!![]+[])[+!![]]+({}[[]]+[])[+!![]]+({}+[])[!![]+!![]+!![]+!![]+!![]+!![]+!![]]+(![]+[])[!![]+!![]]+({}+[])[+!![]]+({}+[])[!![]+!![]+!![]+!![]+!![]]+(![]+[])[+!![]]+(!![]+[])[+[]]+({}[[]]+[])[!![]+!![]+!![]+!![]+!![]]+({}+[])[+!![]]+({}[[]]+[])[+!![]])()Brainfuck
Brainfuck 实际上是一种极小化的计算机语言,又称为 BF 语言,该语言以其极简主义着称,仅包含八个简单的命令、一个数据指针和一个指令指针,这种语言在爬虫领域也可以是一种反爬手段,可以视为一种混淆方式,虽然不常见,这里给一个在线体验的网址:https://copy.sh/brainfuck/tex... ,感兴趣的同志可以深入研究一下,Brainfuck 具有以下特征:
- 仅由
<>+-.[]组成; - 大量的
+-符号。
正常的一段代码:
alert("Hello, Brainfuck")经过 Brainfuck 混淆之后的代码类似于:
--[----->+<]>-----.+++++++++++.-------.+++++++++++++.++.+[--->+<]>+.------.++[->++<]>.-[->+++++<]>++.+++++++..+++.[->+++++<]>+.------------.+[->++<]>.---[----->+<]>-.+++[->+++<]>++.++++++++.+++++.--------.-[--->+<]>--.+[->+++<]>+.++++++++.+[++>---<]>.+++++++.Ook!
Ook! 和 Brainfuck 的原理都是类似的,只不过符号有差异,同样的,这种语言在爬虫领域也可以是一种反爬手段,可以视为一种混淆方式,虽然不常见,在线体验的网址:https://www.splitbrain.org/se... ,Ook! 具有以下特征:
- 完整 Ook!:仅由 3 种符号组成
Ook.、Ook?、Ook! - Short Ook!:仅由 3 种符号组成
.!?
正常的一段代码:
alert("Hello, Ook!")经过 Ook! 混淆之后的代码类似于:
Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook? Ook. Ook? Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook? Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook? Ook! Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook? Ook. Ook? Ook! Ook. Ook? Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook! Ook. Ook. Ook. Ook! Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook. Ook! Ook. Ook? Ook. Trivial brainfuck substitution
Trivial brainfuck substitution 不是一种单一的编程语言,而是一大类编程语言,成员超过 20 个,前面提到的 Brainfuck、Ook! 都是其中的一员,在爬虫领域中,说实话这种稀奇古怪的混淆其实并不常见,但是在一些 CTF 中有可能会出现,作为爬虫工程师也可以了解了解,具体可以参考:https://esolangs.org/wiki/Tri...
其他
恺撒密码
恺撒密码(Caesar cipher)又称为恺撒加密、恺撒变换、变换加密,它是一种替换加密的技术,明文中的所有字母都在字母表上向后(或向前)按照一个固定数目进行偏移后被替换成密文。例如,当偏移量是 3 的时候,所有的字母 A 将被替换成 D,B 变成 E,以此类推。这个加密方法是以罗马共和时期恺撒的名字命名的,当年恺撒曾用此方法与其将军们进行联系。
根据偏移量的不同,还存在若干特定的恺撒密码名称:偏移量为10:Avocat(A→K);偏移量为13:ROT13;偏移量为-5:Cassis (K 6);偏移量为-6:Cassette (K 7)
示例(偏移量 3):
- 明文字母表:ABCDEFGHIJKLMNOPQRSTUVWXYZ
- 密文字母表:DEFGHIJKLMNOPQRSTUVWXYZABC
栅栏密码
栅栏密码就是把要加密的明文分成 N 个一组,然后把每组的第 1 个字连起来,形成一段无规律的话。栅栏密码本身有一个潜规则,就是组成栅栏的字母一般不会太多,一般不超过 30 个。
示例:明文为 THE LONGEST DAY MUST HAVE AN END。加密时,把将要传递的信息中的字母交替排成上下两行:
T E O G S D Y U T A E N N
H L N E T A M S H V A E D
将下面一行字母排在上面一行的后边组合成密文:
TEOGSDYUTAENN HLNETAMSHVAED
栅栏密码还有一种变种,称为栅栏密码 W 型,它会先把明文类似 W 形状进行排列,然后再按栏目顺序 1-N,取每一栏的所有字符值,组成加密后密文,比如字符串 123456789,采用栏目数为 3 时,明文将采用如下排列:
1—5—9
-2-4-6-8-
–3—7–
取每一栏所有字符串,组成加密后密文:159246837
猪圈密码
猪圈密码也称为朱高密码、共济会暗号、共济会密码或共济会员密码,是一种以格子为基础的简单替代式密码。只能对字母加解密并且符号无法复制,粘贴后会直接显示明文,即使使用符号,也不会影响密码分析,亦可用在其它替代式的方法。曾经是美国内战时盟军使用的密码,目前仅在密码教学、各种竞赛中使用。

摩斯密码
摩斯密码(Morse code),又称为摩尔斯电码、摩斯电码,是一种时通时断的信号代码,这种信号代码通过不同的排列顺序来表达不同的英文字母、数字和标点符号等。
26个字母的摩斯密码表
| 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 |
|---|---|---|---|---|---|---|---|
| A | .━ | B | ━ ... | C | ━ .━ . | D | ━ .. |
| E | . | F | ..━ . | G | ━ ━ . | H | .... |
| I | .. | J | .━ ━ ━ | K | ━ .━ | L | .━ .. |
| M | ━ ━ | N | ━ . | O | ━ ━ ━ | P | .━ ━ . |
| Q | ━ ━ .━ | R | .━ . | S | ... | T | ━ |
| U | ..━ | V | ...━ | W | .━ ━ | X | ━ ..━ |
| Y | ━ .━ ━ | Z | ━ ━ .. |
10个数字的摩斯密码表
| 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 |
|---|---|---|---|---|---|---|---|
| 0 | ━ ━ ━ ━ ━ | 1 | .━ ━ ━ ━ | 2 | ..━ ━ ━ | 3 | ...━ ━ |
| 4 | ....━ | 5 | ..... | 6 | ━ .... | 7 | ━ ━ ... |
| 8 | ━ ━ ━ .. | 9 | ━ ━ ━ ━ . |
标点符号的摩斯密码表
| 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 | 字符 | 摩斯码 |
|---|---|---|---|---|---|---|---|
| . | .━ .━ .━ | : | ━ ━ ━ ... | , | ━ ━ ..━ ━ | ; | ━ .━ .━ . |
| ? | ..━ ━ .. | = | ━ ...━ | '' | .━ ━ ━ ━ . | / | ━ ..━ . |
| ! | ━ .━ .━ ━ | ━ | ━ ....━ | _ | ..━ ━ .━ | " | .━ ..━ . |
| ( | ━ .━ ━ . | ) | ━ .━ ━ .━ | $ | ...━ ..━ | & | . ... |
| @ | .━ ━ .━ . |
培根密码
培根密码,又名倍康尼密码(Bacon''s cipher)是由法兰西斯·培根发明的一种隐写术,它是一种本质上用二进制数设计的,没有用通常的0和1来表示,而是采用a和b,看到一串的a和b,并且五个一组,那么就是培根加密了。
第一种方式:
| 字符 | 培根密码 | 字符 | 培根密码 | 字符 | 培根密码 | 字符 | 培根密码 |
|---|---|---|---|---|---|---|---|
| A | aaaaa | H | aabbb | O | abbba | V | babab |
| B | aaaab | I | abaaa | P | abbbb | W | babba |
| C | aaaba | J | abaab | Q | baaaa | X | babbb |
| D | aaabb | K | ababa | R | baaab | Y | bbaaa |
| E | aabaa | L | ababb | S | baaba | Z | bbaab |
| F | aabab | M | abbaa | T | baabb | ||
| G | aabba | N | abbab | U | babaa |
第二种方式:
| 字符 | 培根密码 | 字符 | 培根密码 | 字符 | 培根密码 | 字符 | 培根密码 |
|---|---|---|---|---|---|---|---|
| a | AAAAA | h | AABBB | p | ABBBA | x | BABAB |
| b | AAAAB | i-j | ABAAA | q | ABBBB | y | BABBA |
| c | AAABA | k | ABAAB | r | BAAAA | z | BABBB |
| d | AAABB | l | ABABA | s | BAAAB | ||
| e | AABAA | m | ABABB | t | BAABA | ||
| f | AABAB | n | ABBAA | u-v | BAABB | ||
| g | AABBA | o | ABBAB | w | BABAA |
示例:
- 明文:kuaidaili
- 密文:ABABABABAAAAAAAABAAAAAABBAAAAAABAAAABABBABAAA
维吉尼亚密码
维吉尼亚密码是在凯撒密码基础上产生的一种加密方法,它将凯撒密码的全部25种位移排序为一张表,与原字母序列共同组成26行及26列的字母表。另外,维吉尼亚密码必须有一个密钥,这个密钥由字母组成,最少一个,最多可与明文字母数量相等。维吉尼亚密码表如下:

示例:
- 明文:I''ve got it.
- 密钥:ok
- 密文:W''fs qcd wd.
首先,密钥长度需要与明文长度相同,如果少于明文长度,则重复拼接直到相同。示例的明文长度为8个字母(非字母均被忽略),密钥会被程序补全为 okokokok,然后根据维吉尼亚密码表进行加密:明文第一个字母是 I,密钥第一个字母是 o,在表格中找到 I 列与 o 行相交点,字母 W 就是密文第一个字母,同理,v 列与 k 行交点字母是 F,e 列与 o 行交点字母是 S,以此类推。注意:维吉尼亚密码只对字母进行加密,不区分大小写,若文本中出现非字母字符会原样保留,如果输入多行文本,每行是单独加密的。
与佛论禅
字符串转换后,是一些佛语,在线体验:https://keyfc.net/bbs/tools/t...
示例:
- 明文:K哥爬虫
- 密文:佛曰:哆室梵阿俱顛哆礙孕奢大皤帝罰藝哆伽密謹爍舍呐栗皤夷密
当铺密码
当铺密码在 CTF 比赛题目中出现过。该加密算法是根据当前汉字有多少笔画出头,对应的明文就是数字几。
示例:
- 明文:王夫 井工 夫口 由中人 井中 夫夫 由中大
- 密文:67 84 70 123 82 77 125

--3DES/AES")
go加密算法:CBC对称加密(一)--3DES/AES
其实对称加密中的:DES\3DES\AES 采取的加解密步骤一致,只是小的细节不太一样.大家多看看就能写出来了// rsao1.go
package main
import (
"bytes"
"crypto/aes"
"crypto/cipher"
"crypto/des"
"fmt"
)
/*
明文加密的分组操作
.分组的长度 = 密钥的长度 //key = 64bit/8
.将每组数据和密钥进行位运算
.每组的密文长度 = 每组的明文长度
*/
func main() {
fmt.Println("=== des 加解密 ===")
scr := []byte("少壮不努力,活该你单身")
key := []byte("12345678")
src := encryptDES(scr, key)
//fmt.Println("enpadding", src):每次运行加密后的数据一样
des := decryptDES(src, key)
fmt.Println("depadding", des)
fmt.Println("=== 3des 加解密 ===")
scr1 := []byte("少壮不努力,活该你单身,223333")
key1 := []byte("aaabbbaa12345678ccddeeff")
src1 := encryptTripleDES(scr1, key1)
//fmt.Println("enpadding", src1):每次运行加密后的数据一样
des1 := decryptTripleDES(src1, key1)
fmt.Println("depadding", des1)
fmt.Println("=== aes 加解密 ===")
scra := []byte("少壮不努力,活该你单身,223333")
keya := []byte("aaabbbaa12345678")
srca := encryptAES(scra, keya)
//fmt.Println("enpadding", srca):每次运行加密后的数据一样
desa := decryptAES(srca, keya)
fmt.Println("depadding", desa)
}
func padding(src []byte, blockSize int) []byte {
//func padding(src []byte, blockSize int) {
//1.截取加密代码 段数
fmt.Println("enpadding", src)
padding := blockSize - len(src)%blockSize
//2.有余数
padText := bytes.Repeat([]byte{byte(padding)}, padding)
//3.添加余数
src = append(src, padText...)
return src
}
func Depadding(src []byte) []byte {
//1.取出最后一个元素
lasteum := int(src[len(src)-1])
//2.删除和最后一个元素相等长的字节
//fmt.Println("src", src)
newText := src[:len(src)-lasteum]
return newText
}
//des加解密
//加密
func encryptDES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := des.NewCipher(key)
if err != nil {
panic(err)
}
//2.对src进行填充
src = padding(src, block.BlockSize())
//3.返回blockModel
//vi := []byte("aaaabbbb")
//blockModel := cipher.NewCBCEncrypter(block, vi)
//fmt.Println("src[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCEncrypter(block, key[:block.BlockSize()])
//4.crypto加密连续块
blockModel.CryptBlocks(src, src)
return src
}
//解密
func decryptDES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := des.NewCipher(key)
if err != nil {
panic(err)
}
//2.crypto解密
//vi := []byte("aaaabbbb")
//fmt.Println("src[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCDecrypter(block, key[:block.BlockSize()])
//3.解密连续块
blockModel.CryptBlocks(src, src)
//.删除填充数组
src = Depadding(src)
return src
}
//3des加解密
//3des加密
func encryptTripleDES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := des.NewTripleDESCipher(key)
if err != nil {
panic(err)
}
//2.对src进行填充
src = padding(src, block.BlockSize())
//3.返回blockModel
//vi := []byte("aaaabbbb")
//blockModel := cipher.NewCBCEncrypter(block, vi)
//fmt.Println("src[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCEncrypter(block, key[:block.BlockSize()])
//4.crypto加密连续块
blockModel.CryptBlocks(src, src)
return src
}
/*
要求密钥长度:
.16 ,24 ,32 byte
.在go接口中指定的密钥长度为16字节
分组长度
.16 ,24 ,32 byte
.分组长度和密钥长度相等
*/
//3des解密
func decryptTripleDES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := des.NewTripleDESCipher(key)
if err != nil {
panic(err)
}
//2.crypto解密
//vi := []byte("aaaabbbb")
//fmt.Println("src[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCDecrypter(block, key[:block.BlockSize()])
//3.解密连续块
blockModel.CryptBlocks(src, src)
//.删除填充数组
src = Depadding(src)
return src
}
//aes加解密
//aes加密
func encryptAES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := aes.NewCipher(key)
if err != nil {
panic(err)
}
//2.对src进行填充
src = padding(src, block.BlockSize())
//3.返回blockModel
//vi := []byte("aaaabbbb")
//blockModel := cipher.NewCBCEncrypter(block, vi)
//fmt.Println("key[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCEncrypter(block, key[:block.BlockSize()]) //block.BlockSize() ==len(key)
//4.crypto加密连续块
blockModel.CryptBlocks(src, src)
return src
}
//aes解密
func decryptAES(src, key []byte) []byte {
//1.创建并返回一个使用DES算法的cipher.Block接口。
block, err := aes.NewCipher(key)
if err != nil {
panic(err)
}
//2.crypto解密
//vi := []byte("aaaabbbb")
//fmt.Println("src[:block.BlockSize()]", key[:block.BlockSize()])
blockModel := cipher.NewCBCDecrypter(block, key[:block.BlockSize()]) //block.BlockSize() ==len(key)
//3.解密连续块
blockModel.CryptBlocks(src, src)
//.删除填充数组
src = Depadding(src)
return src
}

HTTP使用RSA公钥加密算法加密明文
网站想要加密传输数据以防被窃取,最可靠的方式莫过于使用公钥加密算法加密,使用HTTPS协议的网站在整个传输过程中都使用了这个技术,对于未能使用HTTPS的HTTP网站我们也可以自行实现。
功能说明
由于HTTP是直接传输明文数据的,在网络安全越发严峻的今天,未经加密的HTTP方式已经变得岌岌可危,谷歌公司更是直接表明在搜索结果中会优先考虑使用HTTPS加密的网站。
尽管整体趋势是向HTTPS倾斜的,但是由于诸多服务器以及CDN等服务商还没全面兼容HTTPS协议,目前要实现整站切换至HTTPS协议可行性还不高。
同时安全形势又刻不容缓,对此,我们可以自行实现RSA加密私密信息。
算法说明
由于多梦数学不是很好,RSA公钥加密算法的具体实现多梦就不多说了,对算法的实现有兴趣的童鞋可以去看看阮一峰的“RSA算法原理”,下面多梦就说说RSA算法的效果。
RSA算法是非对称加密算法的一种,也叫公钥加密。
和对称加密算法不同的是,对称加密算法是加密和解密都使用同一把钥匙同一种规则,也就是如果你知道怎么加密的,你就知道怎么解密了。所以算法和密钥不能泄露,否则加密就无意义了。
而公钥加密算法则是同时拥有两把钥匙,一个叫公钥,一个叫私钥。这两个钥匙是对应的,使用公钥加密的内容只有使用私钥才能解密,使用私钥加密的内容只有使用公钥才能解密。所以算法和公钥都是可以公开的,只要私钥还是私密的,就是安全的。
实现思路
由于我们是加密HTTP要发送的数据,所以加密过程是要在客户端浏览器完成的,算法和密钥都需要在发送HTTP数据之前就已经存在浏览器中,此时使用对称加密算法已经无意义,因为别人根据你这个加密可以直接解密。
所以我们需要选择非对称性加密,在网页中引入算法和公钥加密,然后发送HTTP数据到服务器,服务器再根据私钥解密。因为私钥是私密的,所以算法和公钥公开也是无法解密,也是安全的。
具体到HTTP请求的加密实现,就是在网页提交表单数据之前使用JavaScript实现公钥加密数据,然后服务器接受到加密数据后,使用PHP或其他服务器语言进行私钥解密。
扩展阅读
使用JavaScript实现OpenSSL RSA加密和解密:https://github.com/travist/jsencrypt
使用PHP实现OpenSSL RSA加密和解密:http://php.net/manual/zh/ref.openssl.php
今天关于DES明文加密和加密所有明文密码的介绍到此结束,谢谢您的阅读,有关AES加密/解密 IOS 端,JAVA端 通用,不限明文字符长度、CTF&爬虫:掌握这些特征,一秒识别密文加密方式、go加密算法:CBC对称加密(一)--3DES/AES、HTTP使用RSA公钥加密算法加密明文等更多相关知识的信息可以在本站进行查询。
对于想了解TabPageIndicator+UnderlinePageIndicator+ViewPager+Fragment+懒加载的读者,本文将是一篇不可错过的文章,我们将详细介绍懒加载怎么实现,并且为您提供关于038 Android Magicindicator开源框架实现viewpager底部圆形指示器、Adapter数据更新之后, TabPageIndicator不显示问题、Andorid ViewPager+PageAdapter+Fragment实现多个tab页、Android Fragment + ViewPager 的懒加载实现的有价值信息。
本文目录一览:- TabPageIndicator+UnderlinePageIndicator+ViewPager+Fragment+懒加载(懒加载怎么实现)
- 038 Android Magicindicator开源框架实现viewpager底部圆形指示器
- Adapter数据更新之后, TabPageIndicator不显示问题
- Andorid ViewPager+PageAdapter+Fragment实现多个tab页
- Android Fragment + ViewPager 的懒加载实现
")
TabPageIndicator+UnderlinePageIndicator+ViewPager+Fragment+懒加载(懒加载怎么实现)
//导航栏
tab_indicator = (TabPageIndicator) findViewById(R.id.tab_indicator);
//下划线
line_indicator = (UnderlinePageIndicator)findViewById(R.id.line_indicator);
line_indicator.setFades(false);//一直显示
mViewPager = (ViewPager)findViewById(R.id.mViewPager);
MyAdapter adapter = new MyAdapter(getSupportFragmentManager(),fragmentList,TITLE);
mViewPager.setAdapter(adapter);
//将导航栏和pager绑定
tab_indicator.setViewPager(mViewPager);
//将导航栏和下划线绑定
tab_indicator.setOnPageChangeListener(line_indicator);
//将Indicator和ViewPager绑定到一起,并且要先给ViewPager设置adapter以后,才可将他俩绑定到一起,重要步骤
line_indicator.setViewPager(mViewPager);
//如果要设置监听ViewPager中包含的Fragment的改变(滑动切换页面),
//使用OnPageChangeListener为它指定一个监听器,那么不能像之前那样直接设置在ViewPager上了,而要设置在Indicator上
line_indicator.setOnPageChangeListener(new OnPageChangeListener() {
@Override
public void onPageSelected(int position) {
int item = mViewPager.getCurrentItem();
MyToastUtils.show(MainActivity.this, TITLE[item]);
}
@Override
public void onPageScrolled(int arg0, float arg1, int arg2) {
}
@Override
public void onPageScrollStateChanged(int arg0) {
}
});
}<com.viewpagerindicator.TabPageIndicator
android:id="@+id/tab_indicator"
android:layout_width="match_parent"
android:layout_height="wrap_content"
/>
<com.viewpagerindicator.UnderlinePageIndicator
android:id="@+id/line_indicator"
android:layout_width="match_parent"
android:layout_height="2dp"
/>
<android.support.v4.view.ViewPager
android:id="@+id/mViewPager"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_weight="1" >
</android.support.v4.view.ViewPager>至于懒加载,在之前我转载了一篇,可以用下

038 Android Magicindicator开源框架实现viewpager底部圆形指示器
1.Magicindicator介绍
Magicindicator是一个强大、可定制、易扩展的 ViewPager 指示器框架。是ViewPagerIndicator、TabLayout、PagerSlidingTabStrip的最佳替代品。支持角标,更支持在非ViewPager场景下使用(使用hide()、show()切换Fragment或使用setVisibility切换FrameLayout里的View等)。
2.Magicindicator使用环境配置
repositories {
...
maven {
url "https://jitpack.io"
}
}
dependencies {
...
compile ''com.github.hackware1993:MagicIndicator:1.5.0''
}3.利用Magicindicator实现viewpager底部的圆形指示器
(1)xml布局
<?xml version="1.0" encoding="utf-8"?>
<LinearLayout
xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="match_parent"
android:layout_height="match_parent"
android:orientation="vertical">
<!--利用帧布局实现在viewpager上添加标题-->
<FrameLayout
android:layout_width="match_parent"
android:layout_height="180dp">
<!--利用ViewPager实现轮播图效果-->
<android.support.v4.view.ViewPager
android:id="@+id/vp_news_center"
android:layout_width="match_parent"
android:layout_height="match_parent">
</android.support.v4.view.ViewPager>
<RelativeLayout
android:layout_width="match_parent"
android:layout_height="wrap_content"
android:layout_gravity="bottom"
android:background="#a000"
android:padding="10dp">
<TextView
android:id="@+id/tv_news_vp_title"
android:text="标题"
android:textColor="#fff"
android:textSize="16dp"
android:layout_width="wrap_content"
android:layout_height="wrap_content" />
<!--MagicIndicator的使用-->
<net.lucode.hackware.magicindicator.MagicIndicator
android:id="@+id/magic_indicator1"
android:layout_width="wrap_content"
android:layout_alignParentRight="true"
android:layout_centerVertical="true"
android:layout_height="wrap_content" />
</RelativeLayout>
</FrameLayout>
</LinearLayout>(2)java后台
package com.example.administrator.test66smartbeijing.fragment;
import android.annotation.SuppressLint;
import android.graphics.Color;
import android.os.Bundle;
import android.support.annotation.NonNull;
import android.support.annotation.Nullable;
import android.support.v4.app.Fragment;
import android.support.v4.view.PagerAdapter;
import android.support.v4.view.ViewPager;
import android.view.LayoutInflater;
import android.view.View;
import android.view.ViewGroup;
import android.widget.ImageView;
import android.widget.TextView;
import com.alibaba.fastjson.JSONObject;
import com.bumptech.glide.Glide;
import com.example.administrator.test66smartbeijing.R;
import com.example.administrator.test66smartbeijing.javabean.NewsMenu;
import com.example.administrator.test66smartbeijing.javabean.NewsTabBean;
import com.example.administrator.test66smartbeijing.utils.CacheUtils;
import com.example.administrator.test66smartbeijing.utils.ConstantValue;
import com.example.administrator.test66smartbeijing.utils.RecyclerAdapter;
import net.lucode.hackware.magicindicator.MagicIndicator;
import net.lucode.hackware.magicindicator.ViewPagerHelper;
import net.lucode.hackware.magicindicator.buildins.circlenavigator.CircleNavigator;
import org.xutils.common.Callback;
import org.xutils.http.RequestParams;
import org.xutils.image.ImageOptions;
import org.xutils.x;
import java.util.ArrayList;
import static android.media.AudioRecord.MetricsConstants.CHANNELS;
/**
*
*/
public class TabDataFragment extends Fragment {
String queryResultStr="";
NewsMenu newsMenu;
ArrayList<NewsTabBean.TopNews> topnews;
private ViewPager viewPager;
TextView tv_news_vp_title;
public TabDataFragment() {
}
@SuppressLint("ValidFragment")
public TabDataFragment(NewsMenu newsMenu) {
this.newsMenu=newsMenu;
}
//新建一个Fragment实例
public static Fragment newInstance() {
TabDataFragment fragment = new TabDataFragment();
return fragment;
}
@Nullable
@Override
public View onCreateView(LayoutInflater inflater, ViewGroup container, Bundle savedInstanceState) {
// LayoutInflater.inflate()的功能是将一段 XML 资源文件加载成为 View。所以通常用于将 XML 文件实例化为 View。然后获取 View 上的组件最后操作之。
View rootView = inflater.inflate(R.layout.fragment_tab_data, container, false);
viewPager = rootView.findViewById(R.id.vp_news_center);
tv_news_vp_title=rootView.findViewById(R.id.tv_news_vp_title);
getDataFromServer();
return rootView;
}
/**
* viewPager的数据适配器
*/
class NewsCenterAdapter extends PagerAdapter{
@Override
public int getCount() {
return topnews.size();
}
@Override
public boolean isViewFromObject(@NonNull View view, @NonNull Object object) {
return view==object;
}
@NonNull
@Override
public Object instantiateItem(@NonNull ViewGroup container, int position) {
ImageView imageView=new ImageView(getActivity());
//imageView.setImageResource(R.mipmap.news_pic_default);
String imageUrlTemp=topnews.get(position).topimage;
//String imageUrl="http://118.25.152.62:8080/zhbj/10007/1452327318UU91.jpg";
String imageUrl=ConstantValue.SERVER_URL+imageUrlTemp.substring(25);
System.out.println(imageUrl);
//利用Glide开源框架,加载网络图片
Glide.with(getActivity()).load(imageUrl).into(imageView);
container.addView(imageView);
return imageView;
}
//销毁item
@Override
public void destroyItem(@NonNull ViewGroup container, int position, @NonNull Object object) {
container.removeView((View) object);
}
}
/**
* 从服务器获取数据
*/
private void getDataFromServer() {
//请求地址
String url=ConstantValue.SERVER_URL+newsMenu.data.get(0).children.get(0).url;
RequestParams params = new RequestParams(url);
x.http().get(params, new Callback.CommonCallback<String>() {
@Override
public void onSuccess(String result) {
//解析result
queryResultStr=result;
System.out.println(result);
processData(queryResultStr);
//写缓存
CacheUtils.setCache(ConstantValue.NEWSCENTER_URL,queryResultStr,getActivity());
}
//请求异常后的回调方法
@Override
public void onError(Throwable ex, boolean isOnCallback) {
}
//主动调用取消请求的回调方法
@Override
public void onCancelled(CancelledException cex) {
}
@Override
public void onFinished() {
}
});
}
/**
* @param queryResultStr 服务器返回结果
*/
private void processData(String queryResultStr) {
NewsTabBean newsTabBean = JSONObject.parseObject(queryResultStr,NewsTabBean.class);
//利用viewPager实现图片轮播效果
topnews = newsTabBean.data.topnews;
if(topnews!=null){
viewPager.setAdapter(new NewsCenterAdapter());
viewPager.setOnPageChangeListener(new ViewPager.OnPageChangeListener() {
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
}
@Override
public void onPageSelected(int position) {
//设置viewpager上图片的标题
tv_news_vp_title.setText(topnews.get(position).title);
}
@Override
public void onPageScrollStateChanged(int state) {
}
});
//更新第一个头条新闻标题
tv_news_vp_title.setText(topnews.get(0).title);
initMagicIndicator1();
}
}
/**
* 初始化MagicIndicator
*/
private void initMagicIndicator1() {
MagicIndicator magicIndicator = getActivity().findViewById(R.id.magic_indicator1);
CircleNavigator circleNavigator = new CircleNavigator(getActivity());
circleNavigator.setCircleCount(topnews.size());
circleNavigator.setCircleColor(Color.RED);
circleNavigator.setCircleClickListener(new CircleNavigator.OnCircleClickListener() {
@Override
public void onClick(int index) {
viewPager.setCurrentItem(index);
}
});
magicIndicator.setNavigator(circleNavigator);
ViewPagerHelper.bind(magicIndicator, viewPager);
}
}4.效果图


Adapter数据更新之后, TabPageIndicator不显示问题
在Adapter set 了数据之后, 发现Tab数据并没有更新, 后来发现Adapter的notifyDataSetChange只会通知Viewpager更新数据, 而不会影响到TabPageIndicator
解决方案
TabPageIndicator.notifyDataSetChanged()

Andorid ViewPager+PageAdapter+Fragment实现多个tab页
一、文章内容
现在常见的Android或者iOS应用中都可以看到一个页面的下面有多个tab,点击不同的tab页面重新加载。现使用Android提供的ViewPager、PageAdapter和Fragment简单实现这一功能。
二、ViewPager简介
首先为了让页面能够左右滑动,我们需要采用ViewPager这一Android官方提供的组件。在Android Reference中有提到,ViewPager让用户可以左右滑动来切换页面,当然也可以通过点击底部的tab来切换页面。使用ViewPager方式简单,需要以下两步:
添加相应的布局文件
<android.support.v4.view.ViewPager
android:id="@+id/t_ViewPager"
android:layout_width="match_parent"
android:layout_height="0dp"
android:layout_weight="1" />
在代码中加载布局文件并显示
ViewPager t_ViewPager = (ViewPager) findViewById(R.id.t_ViewPager);
但viewpager具体的职责应该负责加载、缓存view页面和切换显示不同的fragment。加载和缓存view暂且不深入讨论,对于滑动页面显示新的fragment,这里简单的说一下。
三、OnPageChangeListener简介
OnPageChangeListener是ViewPager类内部的一个接口,它就是负责对界面滑动的监听。它总共有三个方法,源码如下:
public interface OnPageChangeListener {
/**
* This method will be invoked when the current page is scrolled, either as part
* of a programmatically initiated smooth scroll or a user initiated touch scroll.
*
* @param position Position index of the first page currently being displayed.
* Page position+1 will be visible if positionOffset is nonzero.
* @param positionOffset Value from [0, 1) indicating the offset from the page at position.
* @param positionOffsetPixels Value in pixels indicating the offset from position.
*/
void onPageScrolled(int position, float positionOffset, int positionOffsetPixels);
/**
* This method will be invoked when a new page becomes selected. Animation is not
* necessarily complete.
*
* @param position Position index of the new selected page.
*/
void onPageSelected(int position);
/**
* Called when the scroll state changes. Useful for discovering when the user
* begins dragging, when the pager is automatically settling to the current page,
* or when it is fully stopped/idle.
*
* @param state The new scroll state.
* @see ViewPager#SCROLL_STATE_IDLE
* @see ViewPager#SCROLL_STATE_DRAGGING
* @see ViewPager#SCROLL_STATE_SETTLING
*/
void onPageScrollStateChanged(int state);
}
三个方法共同处理页面滑动相关的监听,第一个方法onPageScrolled(int position, float positionOffset, int positionOffsetPixels)是在页面滑动过程中不断的调用;第二个方法onPageSelected(int position)会在一个新的页面被选中时被调用(页面被选中也有相应的判定法则);第三个方法onPageSelected(int position),会在用户的滑动状态改变时调用。OnPageChangeListener解决的是动作相关的问题,但数据我们还没有解决,也就是存放所以我们还需要一个存放所有的view的组件,我们使用FragmentPagerAdapter,用来存放所有的fragment。
四、FragmentPagerApapter简介
FragmentPagerApapter继承自PagerAdapter,所以我们可以新建一个类,继承FragmentPagerApapter并实现它的一些方法来存放所有的fragment。FragmentPagerApapter主要的管理fragment的方法如下:
@Override
public Fragment getItem(int position) {
return fragments.get(position);
}
@Override
public int getItemPosition(Object object) {
return super.getItemPosition(object);
}
@Override
public int getCount() {
return fragments.size();
}
通过方法名就能知道每个方法时有什么作用,就不再赘述。
四、应用demo
创建ViewPager
ViewPager t_ViewPager = (ViewPager) findViewById(R.id.t_ViewPager);
自定义一个adapter,继承FragmentPagerAdapter并实现OnPageChangeListener
//这种实现参考了GitHub上一个开源项目(https://github.com/yingLanNull/AlphaTabsIndicator),但对刷新自己重新实现了一下
private class AdapterAndListener extends FragmentPagerAdapter implements ViewPager.OnPageChangeListener {
private List<Fragment> fragments = new ArrayList<>();
private String[] titles = {"班级", "发布", "我"};
public MainAdapter(FragmentManager fm) {
super(fm);
fragments.add(TextFragment3.newInstance(titles[(int)(Math.random()*3)]));
fragments.add(TextFragment2.newInstance(titles[(int)(Math.random()*3)]));
fragments.add(TPersonalInfoFragment.getInstance(loginResult));
}
@Override
public Fragment getItem(int position) {
return fragments.get(position);
}
@Override
public int getItemPosition(Object object) {
return super.getItemPosition(object);
}
@Override
public int getCount() {
return fragments.size();
}
@Override
public void onPageScrolled(int position, float positionOffset, int positionOffsetPixels) {
}
@Override
public void onPageSelected(int position) {
if (position==2){
((TPersonalInfoFragment)fragments.get(position)).update();
}
}
@Override
public void onPageScrollStateChanged(int state) {
}
}
这里的AdapterAndListener在继承FragmentPagerAdapter的同时并实现了ViewPager.OnPageChangeListener接口,所以它在管理所有页面的同时可以对页面的动作进行监听,根据用户的动作(如切换页面)而更新相应的方法。如:
@Override
public void onPageSelected(int position) {
if (position==2){
((TPersonalInfoFragment)fragments.get(position)).update();
}
}
当用户滑动到第三个界面时,则调用对应的fragment的更新方法
自定义fragment的设计
public class TPersonalInfoFragment extends Fragment {
private JSONObject shownData;
private TextView usernameView;
private TextView nameView;
private TextView typeView;
private TextView genderView;
private TextView emailView;
private TextView schoolIdView;
@Nullable
@Override
public View onCreateView(LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
View personalInfoView = inflater.inflate(R.layout.fragment_teacher_personal, container, false);
Log.d("teacher","done2");
usernameView = (TextView) personalInfoView.findViewById(R.id.t_username);
nameView = (TextView) personalInfoView.findViewById(R.id.t_name);
typeView = (TextView) personalInfoView.findViewById(R.id.t_type);
genderView = (TextView) personalInfoView.findViewById(R.id.t_gender);
emailView = (TextView) personalInfoView.findViewById(R.id.t_email);
schoolIdView = (TextView) personalInfoView.findViewById(R.id.t_schoolId);
if (shownData!=null){
try {
usernameView.setText(shownData.getString("username"));
nameView.setText(shownData.getString("name"));
typeView.setText(DataTransform.transformType(shownData.getString("type")));
genderView.setText(DataTransform.transformGender(shownData.getString("gender")));
emailView.setText(shownData.getString("email"));
schoolIdView.setText(shownData.getString("schoolId"));
} catch (JSONException e) {
e.printStackTrace();
}
}
return personalInfoView;
}
public static TPersonalInfoFragment getInstance(JSONObject data){
TPersonalInfoFragment fragment = new TPersonalInfoFragment();
Log.d("teacher","done1");
fragment.shownData = data;
return fragment;
}
public void update(){
UserInfo userInfo = (UserInfo) getActivity().getApplication();
final JSONObject param = new JSONObject();
try {
param.put("username",userInfo.getUserName());
param.put("password",userInfo.getPassword());
} catch (JSONException e) {
e.printStackTrace();
}
final Handler handler = new Handler();
new Thread(new Runnable() {
@Override
public void run() {
final JSONObject newData = NetUtil.myPost("/user/auth",param);
handler.post(new Runnable() {
@Override
public void run() {
if (!shownData.equals(newData)){
shownData = newData;
try {
usernameView.setText(newData.getString("username"));
nameView.setText(newData.getString("name"));
typeView.setText(DataTransform.transformType(newData.getString("type")));
genderView.setText(DataTransform.transformGender(newData.getString("gender")));
emailView.setText(newData.getString("email"));
schoolIdView.setText(newData.getString("schoolId"));
} catch (JSONException e) {
e.printStackTrace();
}
}
}
});
}
}).start();
}
}
在TPersonalInfoFragment中,提供一个获取TPersonalInfoFragment 实例getInstance方法,需要传入用户登录之后服务器返回的一个JsonObject,然后根据onCreateView()方法在创建fragment界面的时候调用,设置相应的数据并展示。此外,TPersonalInfoFragment中还有一个update()方法,在实现onPageSelected(int position)方法时,调用这个update()方法,从服务器获取新的数据并更新不同组件上的数据,从而实现刷功能。(注意:这边请求服务端数据必须重新开启一个线程执。)

Android Fragment + ViewPager 的懒加载实现
概述
Android 日常开发中除了四个组件之外,还有一种使用频率很高的组件 ——Fragment。在使用时我们通常需要在 Fragment 的各种生命周期方法中处理数据加载、页面刷新和资源释放等逻辑操作。
但是当 Fragment 遇上了 ViewPager,事情就变得有点不一样了。Fragment 的生命周期变得不再那么可控,当显示 Fragment A 时,相邻的 Fragment B 的一些生命周期方法也会触发。这是因为 ViewPager 为了优化切换效果,使切换更流畅、顺滑,引入了预加载和缓存机制。通常会预加载前一个和后一个 Fragment,让前一个和后一个 Fragment 提前初始化。
当页面布局过于复杂或者数据量比较大,甚至当 Fragment 中有播放器时,预加载会耗费资源,造成页面卡顿甚至页面播放器出现异常报错。
懒加载
使用懒加载的意义就在于只有当 Fragment 被显示时,才会去加载耗费资源的素材和数据,可以节省资源、提升页面流畅度,而且让流程变得更可控。
实现思路
Fragment 中提供了一对可见性相关的方法 setUserVisibleHint(boolean isVisibleToUser) 和 getUserVisibleHint() 可以通过重写 setUserVisibleHint() 来监听页面可见性变化,当页面从不可见变为可见时触发加载数据方法,反之也可以实现页面从可见到不可见时部分资源的释放操作。
懒加载实现
先实现一个 Fragment + ViewPager 的结构(实现很简单省略了),依次有三个 Fragment 为:AFragment、BFragment 和 CFragemtn,三个 Fragment 分别继承基类 BaseLazyLoadFragment。
生命周期变化
在基类中添加生命周期方法的打印,如下图:
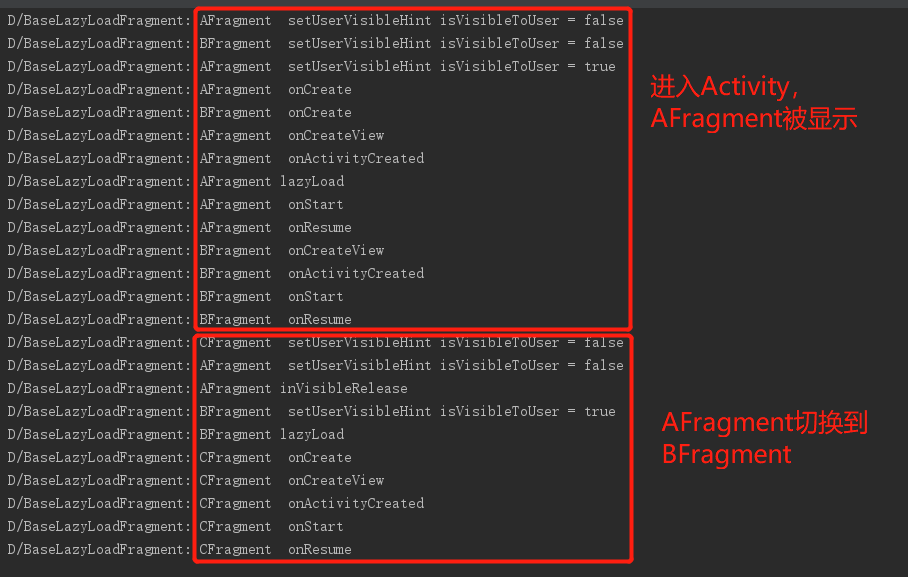
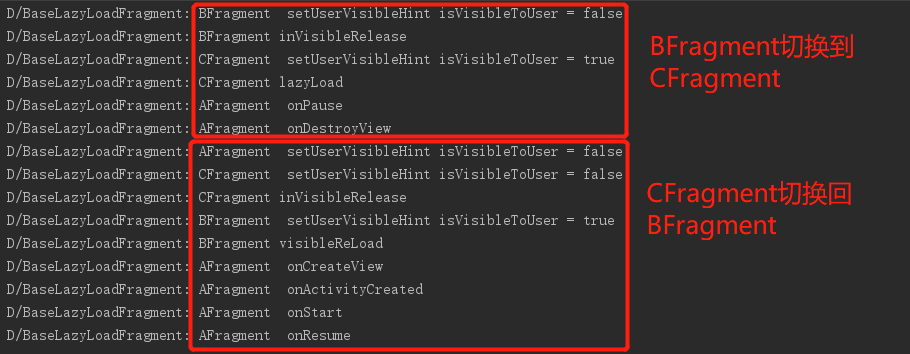
从 Fragment 的生命周期变化可以看出,需要注意的有几点:
setUserVisibleHint()方法的调用在onCreateView()方法之前。- 进入 Activity 时第一个被显示的 Fragment,会调用两次
setUserVisibleHint()第一次值为 false,第二次值为 true。 - ViewPager 的预加载会让还没显示的 Fragment 提前初始化。
- 当 AFragment 切换到 BFragment 时,会先调用 AFragment 的
setUserVisibleHint(false)方法,后调用 BFragment 的setUserVisibleHint(true), 我们可以在 AFragment 中做部分资源的释放操作。 - 当 BFragment 切换到 AFragment 时,AFragment 会执行
onDestroyView()方法释放持有的布局资源,但是 AFragment 中的数据资源并没有释放。 - 当从 CFragment 切换回 BFragment 时,AFragment 会重新初始化。
代码实现
基于以上几点问题,我们通过来通过代码实现 BaseLazyLoadFragment。
public abstract class BaseLazyLoadFragment extends BaseFragment {
protected String TAG = BaseLazyLoadFragment.class.getSimpleName() + this.toString();
//布局是否初始化完成
private boolean isLayoutInitialized = false;
//懒加载完成
private boolean isLazyLoadFinished = false;
//记录页面可见性
private boolean isVisibleToUser = false;
//不可见时释放部分资源
private boolean isInVisibleRelease = false;
@Override
public void onCreate(@Nullable Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
Log.d(TAG, getClass().getSimpleName() + " onCreate");
}
@Nullable
@Override
public View onCreateView(@NonNull LayoutInflater inflater, @Nullable ViewGroup container, @Nullable Bundle savedInstanceState) {
super.onCreateView(inflater, container,savedInstanceState);
Log.d(TAG, getClass().getSimpleName() + " onCreateView");
initView();
return rootView;
}
@Override
public void onDestroyView() {
super.onDestroyView();
Log.d(TAG, getClass().getSimpleName() + " onDestroyView");
//页面释放后,重置布局初始化状态变量
isLayoutInitialized = false;
this.rootView = null;
}
@Override
public void onActivityCreated(@Nullable Bundle savedInstanceState) {
super.onActivityCreated(savedInstanceState);
Log.d(TAG, getClass().getSimpleName() + " onActivityCreated");
//此方法是在第一次初始化时onCreateView之后触发的
//onCreateView和onActivityCreated中分别应该初始化哪些数据可以参考:
//https://stackoverflow.com/questions/8041206/android-fragment-oncreateview-vs-onactivitycreated
isLayoutInitialized = true;
//第一次初始化后需要处理一次可见性事件
//因为第一次初始化时setUserVisibleHint方法的触发要先于onCreateView
dispatchVisibleEvent();
}
@Override
public void onStart() {
super.onStart();
Log.d(TAG, getClass().getSimpleName() + " onStart");
}
@Override
public void onResume() {
super.onResume();
Log.d(TAG, getClass().getSimpleName() + " onResume");
//页面从其他Activity返回时,重新加载被释放的资源
if(isLazyLoadFinished && isLayoutInitialized && isInVisibleRelease && isVisibleToUser){
// visibleReLoad();
resume();
isInVisibleRelease = false;
}
}
@Override
public void onPause() {
super.onPause();
Log.d(TAG, getClass().getSimpleName() + " onPause");
//当从Fragment切换到其他Activity释放部分资源
if(isLazyLoadFinished && isVisibleToUser){
//页面从可见切换到不可见时触发,可以释放部分资源,配合reload方法再次进入页面时加载
// inVisibleRelease();
pause();
isInVisibleRelease = true;
}
}
@Override
public void onDestroy() {
super.onDestroy();
Log.d(TAG, getClass().getSimpleName() + " onDestroy");
//重置所有数据
this.rootView = null;
isLayoutInitialized = false;
isLazyLoadFinished = false;
isVisibleToUser = false;
isInVisibleRelease = false;
}
@Override
public void setUserVisibleHint(boolean isVisibleToUser) {
super.setUserVisibleHint(isVisibleToUser);
Log.d(TAG, getClass().getSimpleName() + " setUserVisibleHint isVisibleToUser = " + isVisibleToUser);
dispatchVisibleEvent();
}
/**
* 处理可见性事件
*/
private void dispatchVisibleEvent(){
Log.d(TAG, getClass().getSimpleName() + " dispatchVisibleEvent isVisibleToUser = " + getUserVisibleHint()
+ " --- isLayoutInitialized = " + isLayoutInitialized + " --- isLazyLoadFinished = " + isLazyLoadFinished);
if(getUserVisibleHint() && isLayoutInitialized){
//可见
if(!isLazyLoadFinished){
//第一次可见,懒加载
lazyLoad();
isLazyLoadFinished = true;
} else{
//非第一次可见,刷新数据
visibleReLoad();
}
} else{
if(isLazyLoadFinished && isVisibleToUser){
//页面从可见切换到不可见时触发,可以释放部分资源,配合reload方法再次进入页面时加载
inVisibleRelease();
}
}
//处理完可见性事件之后修改isVisibleToUser状态
this.isVisibleToUser = getUserVisibleHint();
}
/**
* 初始化View
*/
protected abstract void initView();
/**
* 绑定布局
* @return 布局ID
*/
protected abstract int initLayout();
/**
* 懒加载<br/>
* 只会在初始化后第一次可见时调用一次。
*/
protected abstract void lazyLoad();
/**
* 刷新数据加载<br/>
* 配合{@link #lazyLoad()},在页面非第一次可见时刷新数据
* 左右切换Fragment时触发
*/
protected abstract void visibleReLoad();
/**
* 当页面从可见变为不可见时,释放部分数据和资源。<br/>
* 比如页面播放器的释放或者一些特别占资源的数据的释放
* 左右切换Fragment时触发
*/
protected abstract void inVisibleRelease();
/**
* 当从其他页面返回,重新可见
*/
protected abstract void resume();
/**
* 进入其他页面触发
*/
protected abstract void pause();
}
代码注释比较详细了,简单说一下。BaseLazyLoadFragment 中提供了
lazyLoad()方法当页面被显示时做懒加载;visibleReLoad()方法当页面没有被释放且从不可见状态切换到可见时刷新数据用;inVisibleRelease()方法当页面从可见状态切换到不可见时,做部分资源释放(如播放器等)。- 同样支持当切换到其他 Activity 时,触发
inVisibleRelease()方法做资源释放,从 Activity 返回页面时触发visibleReLoad()刷新加载数据。
androidx 的实现方式
以下部分涉及 Fragment 的生命周期相关内容,不熟悉的建议自行补习,借用一张官方说明图。官方说明

我们将项目迁移到 androidx 之后会发现 setUserVisibleHint 和 getUserVisibleHint 方法被标记为 @Deprecated 废弃了。方法注释中写明了通过 FragmentTransaction 中的 setMaxLifecycle() 方法来替换。
setMaxLifecycle
setMaxLifecycle 是在 androidx 之后,FragmentTransaction 中添加的方法,用于控制 Fragment 的最大生命周期。
fragmentTransaction = fragmentManager.beginTransaction();
//replace或add
fragmentTransaction.replace(R.id.fragment_frm, movieFragmentX);
//设置最大生命周期:Resume
fragmentTransaction.setMaxLifecycle(movieFragmentX, Lifecycle.State.RESUMED);
fragmentTransaction.commit();
注意:setMaxLifecycle 方法必须在 replace 或 add 之后使用,要不然会抛出异常。
设置之后 Fragment 的生命周期只会执行到 onResume()。
State 的取值类型有以下几种,对应的生命周期执行到哪步方法注释中有具体说明。
/**
* Lifecycle states. You can consider the states as the nodes in a graph and
* {@link Event}s as the edges between these nodes.
*/
@SuppressWarnings("WeakerAccess")
public enum State {
/**
* Destroyed state for a LifecycleOwner. After this event, this Lifecycle will not dispatch
* any more events. For instance, for an {@link android.app.Activity}, this state is reached
* <b>right before</b> Activity''s {@link android.app.Activity#onDestroy() onDestroy} call.
*/
DESTROYED,
/**
* Initialized state for a LifecycleOwner. For an {@link android.app.Activity}, this is
* the state when it is constructed but has not received
* {@link android.app.Activity#onCreate(android.os.Bundle) onCreate} yet.
*/
INITIALIZED,
/**
* Created state for a LifecycleOwner. For an {@link android.app.Activity}, this state
* is reached in two cases:
* <ul>
* <li>after {@link android.app.Activity#onCreate(android.os.Bundle) onCreate} call;
* <li><b>right before</b> {@link android.app.Activity#onStop() onStop} call.
* </ul>
*/
CREATED,
/**
* Started state for a LifecycleOwner. For an {@link android.app.Activity}, this state
* is reached in two cases:
* <ul>
* <li>after {@link android.app.Activity#onStart() onStart} call;
* <li><b>right before</b> {@link android.app.Activity#onPause() onPause} call.
* </ul>
*/
STARTED,
/**
* Resumed state for a LifecycleOwner. For an {@link android.app.Activity}, this state
* is reached after {@link android.app.Activity#onResume() onResume} is called.
*/
RESUMED;
/**
* Compares if this State is greater or equal to the given {@code state}.
*
* @param state State to compare with
* @return true if this State is greater or equal to the given {@code state}
*/
public boolean isAtLeast(@NonNull State state) {
return compareTo(state) >= 0;
}
}
阅读上面源码中的注释会发现 CREATED 和 STARTED 这两个类型相比其他类型注释中多了一句 right before{@link android.app.Activity#onPause() onPause} call. 怎么理解这句话呢?
如果 Fragment 已经正常显示,生命周期执行到 onResume(),再设置 setMaxLifecycle 到 CREATED 或 STARTED,那么 Fragment 的生命周期会相应的回退到 onStop() 或 onPause(),也就是对应方法注释中的解释。
单独使用 setMaxLifecycle():
fragmentTransaction = fragmentManager.beginTransaction();
fragmentTransaction.setMaxLifecycle(movieFragmentX, Lifecycle.State.CREATED);
fragmentTransaction.commit();
log 如下图:
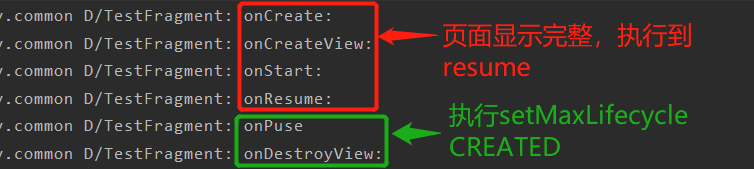
懒加载实现
既然 androidx 已经提供了 setMaxLifecycle() 来精确控制 Fragment 的生命周期,我们只需要通过 setMaxLifecycle() 来控制显示的 Fragment 的生命周期就可以实现懒加载功能,实际上 android 已经为我们提供了现成的实现方式。
当我们把项目迁移到 androidx 之后,会发现 FragmentAdapter 和 FragmentStatePagerAdapter 都添加了一个构造方法。
//FragmentStatePagerAdapter构造方法
public FragmentStatePagerAdapter(@NonNull FragmentManager fm,
@Behavior int behavior) {
mFragmentManager = fm;
mBehavior = behavior;
}
//FragmentPagerAdapter构造方法
public FragmentPagerAdapter(@NonNull FragmentManager fm,
@Behavior int behavior) {
mFragmentManager = fm;
mBehavior = behavior;
}
添加了一个 behavior 参数,behavior 的取值如下:
@IntDef({BEHAVIOR_SET_USER_VISIBLE_HINT, BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT})
private @interface Behavior { }
//.....
/**
* Indicates that {@link Fragment#setUserVisibleHint(boolean)} will be called when the current
* fragment changes.
*
* @deprecated This behavior relies on the deprecated
* {@link Fragment#setUserVisibleHint(boolean)} API. Use
* {@link #BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT} to switch to its replacement,
* {@link FragmentTransaction#setMaxLifecycle}.
* @see #FragmentPagerAdapter(FragmentManager, int)
*/
@Deprecated
public static final int BEHAVIOR_SET_USER_VISIBLE_HINT = 0;
/**
* Indicates that only the current fragment will be in the {@link Lifecycle.State#RESUMED}
* state. All other Fragments are capped at {@link Lifecycle.State#STARTED}.
*
* @see #FragmentPagerAdapter(FragmentManager, int)
*/
public static final int BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT = 1;
以 FragmentPagerAdapter 为例,通过查看源码的 setPrimaryItem() 方法。
@SuppressWarnings({"ReferenceEquality", "deprecation"})
@Override
public void setPrimaryItem(@NonNull ViewGroup container, int position, @NonNull Object object) {
Fragment fragment = (Fragment)object;
if (fragment != mCurrentPrimaryItem) {
if (mCurrentPrimaryItem != null) {
//当前显示Fragment
mCurrentPrimaryItem.setMenuVisibility(false);
if (mBehavior == BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT) {
if (mCurTransaction == null) {
mCurTransaction = mFragmentManager.beginTransaction();
}
//最大生命周期设置为STARTED,生命周期回退到onPause
mCurTransaction.setMaxLifecycle(mCurrentPrimaryItem, Lifecycle.State.STARTED);
} else {
//可见性设置为false
mCurrentPrimaryItem.setUserVisibleHint(false);
}
}
//将要显示的Fragment
fragment.setMenuVisibility(true);
if (mBehavior == BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT) {
if (mCurTransaction == null) {
mCurTransaction = mFragmentManager.beginTransaction();
}
//最大生命周期设置为RESUMED
mCurTransaction.setMaxLifecycle(fragment, Lifecycle.State.RESUMED);
} else {
//可见性设置为true
fragment.setUserVisibleHint(true);
}
//赋值
mCurrentPrimaryItem = fragment;
}
}
代码比较简单很好理解
- 当
mBehavior设置为BEHAVIOR_RESUME_ONLY_CURRENT_FRAGMENT会通过setMaxLifecycle来修改当前 Fragment 和将要显示的 Fragment 的状态,使得只有正在显示的 Fragment 执行到onResume()方法,其他 Fragment 只会执行到onStart()方法,并且当 Fragment 切换到不显示状态时触发onpause()方法。 - 当
mBehavior设置为BEHAVIOR_SET_USER_VISIBLE_HINT时,会当 frament 可见性发生变化时调用setUserVisibleHint(),也就是跟我们上面提到的第一种懒加载实现方式一样。
到这里懒加载的实现基本就清晰了,我们只需要在 onResume() 中处理需要延时加载的逻辑,并在 onPause() 中做相应的释放就可以了。
关于TabPageIndicator+UnderlinePageIndicator+ViewPager+Fragment+懒加载和懒加载怎么实现的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于038 Android Magicindicator开源框架实现viewpager底部圆形指示器、Adapter数据更新之后, TabPageIndicator不显示问题、Andorid ViewPager+PageAdapter+Fragment实现多个tab页、Android Fragment + ViewPager 的懒加载实现的相关信息,请在本站寻找。
在本文中,我们将为您详细介绍IDEA 远程调试 docker 环境的 SpringBoot 项目的相关知识,并且为您解答关于idea远程docker部署启动的疑问,此外,我们还会提供一些关于Docker之IntelliJ IDEA部署SpringBoot应用到Docker、docker环境安装及springboot+docker在idea上实现一键部署远程服务器、idea + springBoot 项目配置远程调试、idea docker docker-compose 发布 springboot 站点到 tomcat的有用信息。
本文目录一览:- IDEA 远程调试 docker 环境的 SpringBoot 项目(idea远程docker部署启动)
- Docker之IntelliJ IDEA部署SpringBoot应用到Docker
- docker环境安装及springboot+docker在idea上实现一键部署远程服务器
- idea + springBoot 项目配置远程调试
- idea docker docker-compose 发布 springboot 站点到 tomcat
")
IDEA 远程调试 docker 环境的 SpringBoot 项目(idea远程docker部署启动)
前言:首先要知道的是,JVM 是支持远程调试的,这是重点!IDEA 的远程调试 remote,也只是在此基础上,进行的支持。
背景:内网部署服务,即使在内网环境,也不能本地直接访问数据库,还需要特殊认证(比如需要登录 4A),所以也不方便本地调试(其实也是有解决方式的,跳转 Xshell 隧道)。
工具:IntelliJ IDEA 2020.2
端口准备(关键点):
docker 容器服务真实端口:8812,容器服务暴露端口:8824
docker 服务远程调试真实端口:5005,远程调试暴露的端口:8925
注意:不论是暴露的远程调试端口,还是真实的远程调试端口,都要跟 docker 容器服务的端口区分开
步骤:
一、打开 idea,点击 “Edit Configurations”:

二、在打开的 “Run/Debug Configurations” 窗口中,点击 “+” 打开 “Add New Configuration” 窗口,选择 “Remote”:
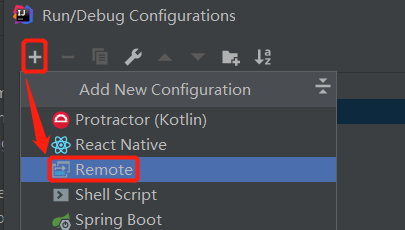
三、远程调试配置,如下:
1.Host:远程服务 ip
2.Port:远程服务端口号,注意,本次配置的 8925 为 docker 服务暴露的远程调试端口,而真实的远程调试端口为 5005,故在配置 Dockerfile 文件时配置的端口为 5005,启动 docker 服务时,需要做好端口映射,-p 8925:5005。
3.Command line arguments for remote JVM:需要复制并配置到远程服务的 JVM 启动环境中
4.Use module classpath:本地源码
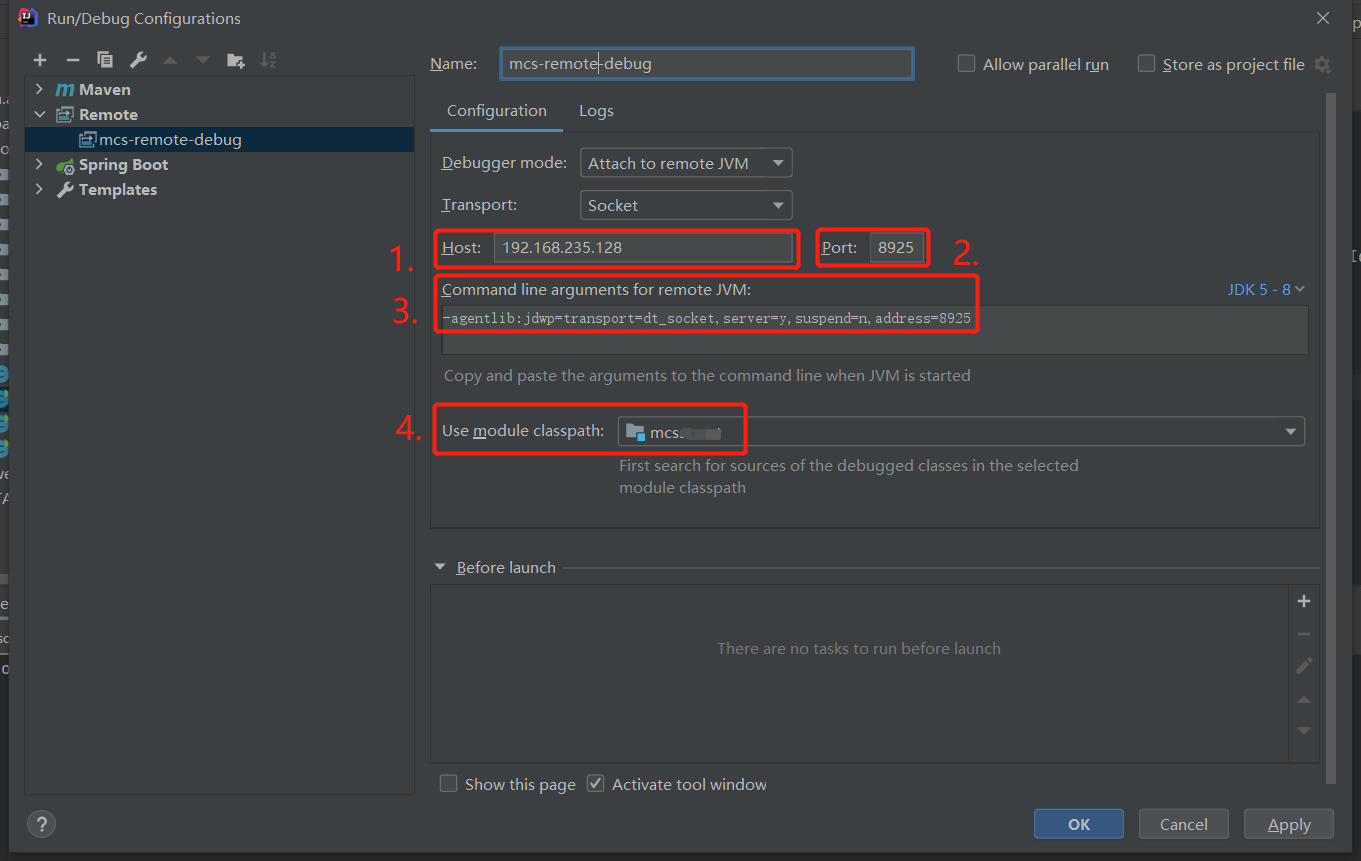
四、配置 docker 的 Dockerfile 文件
其中,address 即为远程调试真实端口,这里配置为 5005。
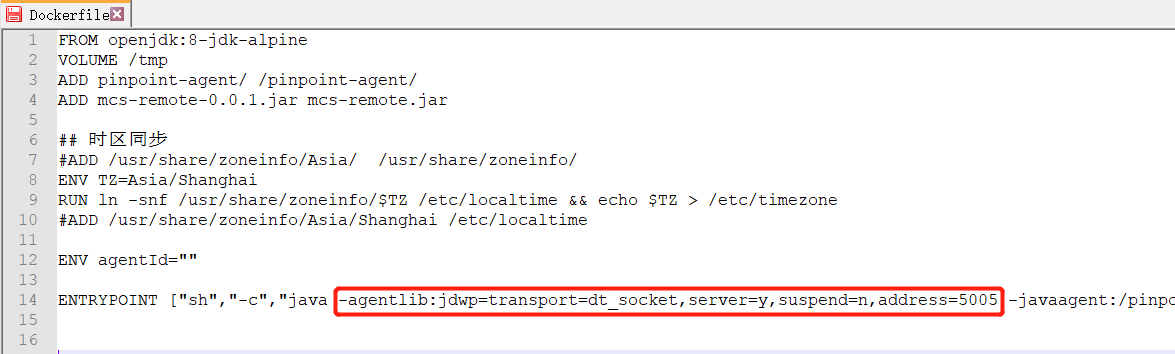
五、启动 docker 服务
docker run -d --name mcs-remote --restart=always -p 8824:8812 -p 8925:5005 -e agentId="MCS-REMOTE-27.61" mcs-remote:20210113
六、idea 中启动配置的 remote 调试服务,启动成功:
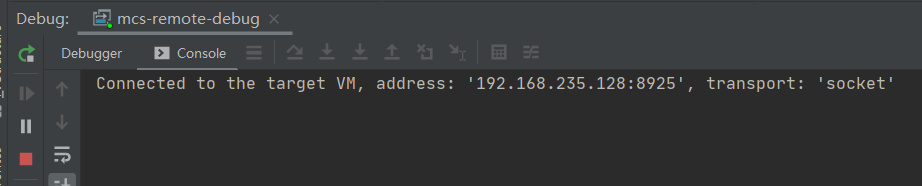
七、访问,调试
在 idea 中,需要调试的代码块中,打上断点,然后正常访问 http://192.168.235.128:8824/mcs-remote/cust/getRecommandCount,即可跳入断点。
提示:上面有关 docker 的配置文件和命令,只需要关注标记出来的,其余不必非要和博主的一样。

Docker之IntelliJ IDEA部署SpringBoot应用到Docker
Docker开启远程访问
vim /usr/lib/systemd/system/docker.service
在 ExecStart=/usr/bin/dockerd-current 后 增加 -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
最终为 ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock
systemctl daemon-reload
systemctl restart docker
查看端口是否开启
netstat -nlpt
测试2375是否通
curl http://127.0.0.1:2375/info
打开2375防火墙
firewall-cmd --zone=public --add-port=2375/tcp --permanent
firewall-cmd --reload
IntelliJ IDEA安装Docker插件
搜索docker安装并重启
重启后继续打开File->settings->Build...->Docker->点击+号->选中TCP socket->输入你服务器的ip和docker远程连接的端口号2375,name可以随便取名,比如docker-connect-test
输入后会自动建立连接,如果这时候你看到显示连接成功后->apply->ok.
如果显示连接失败,请关闭windows防火墙,并确认服务器端防火墙的2375端口是否已开放且处于监听状态(netstat -tnl 去找一下是否有2375且显示Listen状态)
成功后可以在IDEA左下角找到Docker,或者通过依次打开view -> toolwindows -> Docker打开
点击左上角的运行按钮,即可连接到服务器的docker
Spring Boot服务docker部署
新建一个Spring Boot工程,设置端口为8080,在工程里写一个REST接口,如下,简单返回一个字符串
@Controller
public class HelloController {
@RequestMapping("/hello")
@ResponseBody
public String hello() {
return "hello world";
}
}
在项目应用根目录下增加一个Dockerfile文件,内容如下
FROM java:8
VOLUME /tmp
ADD target/SpringBootTest-1.0.0.jar SpringBootTest-1.0.0.jar
RUN bash -c ''touch /SpringBootTest-1.0.0.jar''
EXPOSE 8080
ENTRYPOINT ["java","-Djava.security.egd=file:/dev/./urandom","-jar","/SpringBootTest-1.0.0.jar"]
修改pom文件,添加properties,添加plugin
<properties>
<!-- 镜像前缀 -->
<docker.image.prefix>zns</docker.image.prefix>
</properties>
<plugin>
<groupId>com.spotify</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>1.0.0</version>
<configuration>
<imageName>${docker.image.prefix}/${project.artifactId}</imageName>
<!--<dockerHost>http://docker服务器ip:2375</dockerHost> -->
<dockerDirectory></dockerDirectory>
<resources>
<resource>
<targetPath>/</targetPath>
<directory>${project.build.directory}</directory>
<include>${project.build.finalName}.jar</include>
</resource>
</resources>
</configuration>
</plugin>
点击run->edit configuration,增加一个Docker配置,选择dockerfile类型,在弹出的界面填写信息
name可以随便取名
Server选择刚刚创建的docker-connect-test
Dockerfile选择dockerfile文件的位置
Image tag填写镜像名称 比如zns/springboottest:1.0.0
Container name填写容器名称 比如zns-springboottest
Bind ports填写服务器主机端口和docker容器端口映射 比如 18080:8080,注意这里的8080需跟EXPOSE 8080设置的端口一致
点击确定
然后启动SpringBoot应用和刚刚配置的docker应用
服务器打开18080防火墙
firewall-cmd --zone=public --add-port=18080/tcp --permanent
firewall-cmd --reload
访问服务器ip加上18080端口测试

docker环境安装及springboot+docker在idea上实现一键部署远程服务器
以下均是在虚拟机上操作的环境
一、docker安装
1、检查内核版本,必须是3.10及以上(docker要求centos系统的内核版本高于3.10)
uname ‐r
#如果系统版本较低,则使用yum update更新内核
2、安装docker
yum install docker
3、输入y确认安装
4、启动docker
[root@localhost ~]# systemctl start docker
[root@localhost ~]# docker ‐v
Docker version 1.12.6, build 3e8e77d/1.12.6
5、开机启动docker
[root@localhost ~]# systemctl enable docker
Created symlink from /etc/systemd/system/multi‐user.target.wants/docker.service to
/usr/lib/systemd/system/docker.service.
6、停止docker
systemctl stop docker
二、Docker 配置
1、修改镜像文件拉取地址为ustc
vi /etc/docker/daemon.json
{
"storage-driver":"devicemapper",
"registry-mirrors": ["http://hub-mirror.c.163.com"],
"registry-mirrors": ["https://njrds9qc.mirror.aliyuncs.com"]
}
2、编辑/lib/systemd/system/docker.service文件
Vim /lib/systemd/system/docker.service文件
原文件部分内容:
ExecStart=/usr/bin/dockerd-current \
--add-runtime docker-runc=/usr/libexec/docker/docker-runc-current \
--default-runtime=docker-runc \
--exec-opt native.cgroupdriver=systemd \
--userland-proxy-path=/usr/libexec/docker/docker-proxy-current \
--init-path=/usr/libexec/docker/docker-init-current \
--seccomp-profile=/etc/docker/seccomp.json \
$OPTIONS \
$DOCKER_STORAGE_OPTIONS \
$DOCKER_NETWORK_OPTIONS \
$ADD_REGISTRY \
$BLOCK_REGISTRY \
$INSECURE_REGISTRY \
$REGISTRIES
这上述部分全部删掉:
并重新写成如下部分内容:
ExecStart=/usr/bin/dockerd -H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock -H tcp://0.0.0.0:7654
其他参数不变,重启docker
systemctl daemon-reload
systemctl restart docker.service
完成后,查看是否启动正常,并且可以看到版本信息
[root@docker system]# docker version
三、springboot+docker实现一键部署
1、idea中安装dockerfile插件
打开Idea,从File->Settings->Plugins->Install JetBrains plugin进入插件安装界面,在搜索框中输入docker,可以看到Docker integration,点击右边的Install按钮进行安装。安装后重启Idea。
当提示successful时表示成功
2、在springboot项目中的pom中添加打包docker的插件
<plugin>
<groupId>com.spotify</groupId>
<artifactId>docker-maven-plugin</artifactId>
<version>1.0.0</version>
<!--将插件绑定在某个phase执行-->
<executions>
<execution>
<id>build-image</id>
<!--将插件绑定在package这个phase上。也就是说,用户只需执行mvn package ,就会自动执行mvn docker:build-->
<phase>package</phase>
<goals>
<goal>build</goal>
</goals>
</execution>
</executions>
<configuration>
<!--指定生成的镜像名-->
<imageName>${docker.image.prefix}/${project.artifactId}</imageName>
<!--指定标签-->
<imageTags>
<imageTag>latest</imageTag>
</imageTags>
<!-- 指定 Dockerfile 路径 ${project.basedir}:项目根路径下-->
<dockerDirectory>${project.basedir}</dockerDirectory>
<!--<dockerDirectory>src/main</dockerDirectory>-->
<imageName>${project.artifactId}</imageName>
<!--指定远程 docker api地址-->
<dockerHost>http://172.20.10.7:2375</dockerHost>
<!-- 这里是复制 jar 包到 docker 容器指定目录配置 -->
<resources>
<resource>
<targetPath>/</targetPath>
<!--jar 包所在的路径 此处配置的 即对应 target 目录-->
<directory>${project.build.directory}</directory>
<!-- 需要包含的 jar包 ,这里对应的是 Dockerfile中添加的文件名 -->
<include>${project.build.finalName}.jar</include>
</resource>
</resources>
<!-- 以下两行是为了docker push到DockerHub使用的。 -->
<serverId>docker-hub</serverId>
<registryUrl>https://index.docker.io/v1</registryUrl>
</configuration>
</plugin>
3、配置Dockerfile文件
#指定基础镜像,在其上进行定制
FROM java:8
#这里的 /tmp 目录就会在运行时自动挂载为匿名卷,任何向 /tmp 中写入的信息都不会记录进容器存储层
VOLUME /tmp
#复制上下文目录下的target/demo-1.0.0.jar 到容器里
COPY demo-0.0.1.jar demo-1.0.0.jar
#bash方式执行,使demo-1.0.0.jar可访问
#RUN新建立一层,在其上执行这些命令,执行结束后, commit 这一层的修改,构成新的镜像。
RUN bash -c "touch /demo-1.0.0.jar"
#声明运行时容器提供服务端口,这只是一个声明,在运行时并不会因为这个声明应用就会开启这个端口的服务
EXPOSE 8080
#指定容器启动程序及参数 <ENTRYPOINT> "<CMD>"
ENTRYPOINT ["java","-jar","demo-1.0.0.jar"]
4、创建docker镜像
在idea中执行package进行打包
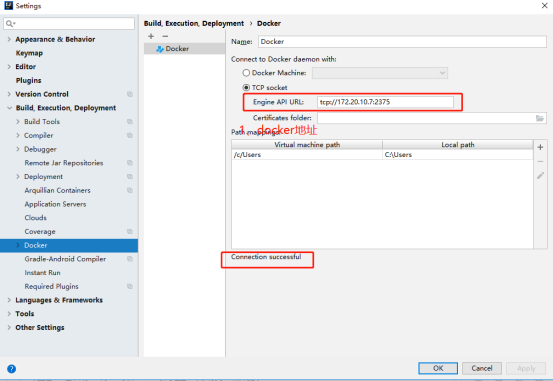
切换到docker控制台,即可看到对应的demo镜像
选中镜像,点击右键,创建镜像容器
配置好镜像id和端口映射,点击run操作即可一键部署到linux服务器,且自动启动
然后在浏览器上就可以直接访问应用了

idea + springBoot 项目配置远程调试
1. 打包 springBoot 项目包放在 linux 服务器上
2. 贴上启动项目的批处理代码
#!/bin/bash
export BUILD_ID=dontKillMe
pid=`ps -ef | grep /home/rivamed/fw-fhvc/flvcat-hvc-exec-v2.0.0.11.war | grep -v grep | awk ''{print $2}''`
if [ -n "$pid" ]
then
kill -9 $pid
fi
#指定最后编译好的jar存放的位置
www_path=/home/rivamed/fw-fhvc
#Jenkins中编译好的jar名称
jar_name=flvcat-hvc-exec-v2.0.0.11.war
source /etc/profile
#进入最后指定存放jar的位置
cd ${www_path}
war_path=${www_path}/${jar_name}
config_path=${www_path}/config
echo "开始启动"
nohup java -jar -Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=8401 -Dfile.encoding=UTF-8 -Dcas.standalone.config="$config_path" "$war_path" > nohup.out 2>&1 &
> nohup.out
tail -f nohup.out因为在启动命令上加上了一下指令 才能使用远程调试
-Xdebug -Xrunjdwp:transport=dt_socket,server=y,suspend=n,address=84013.idea 中配置远程调试
选择 Edit Configurations
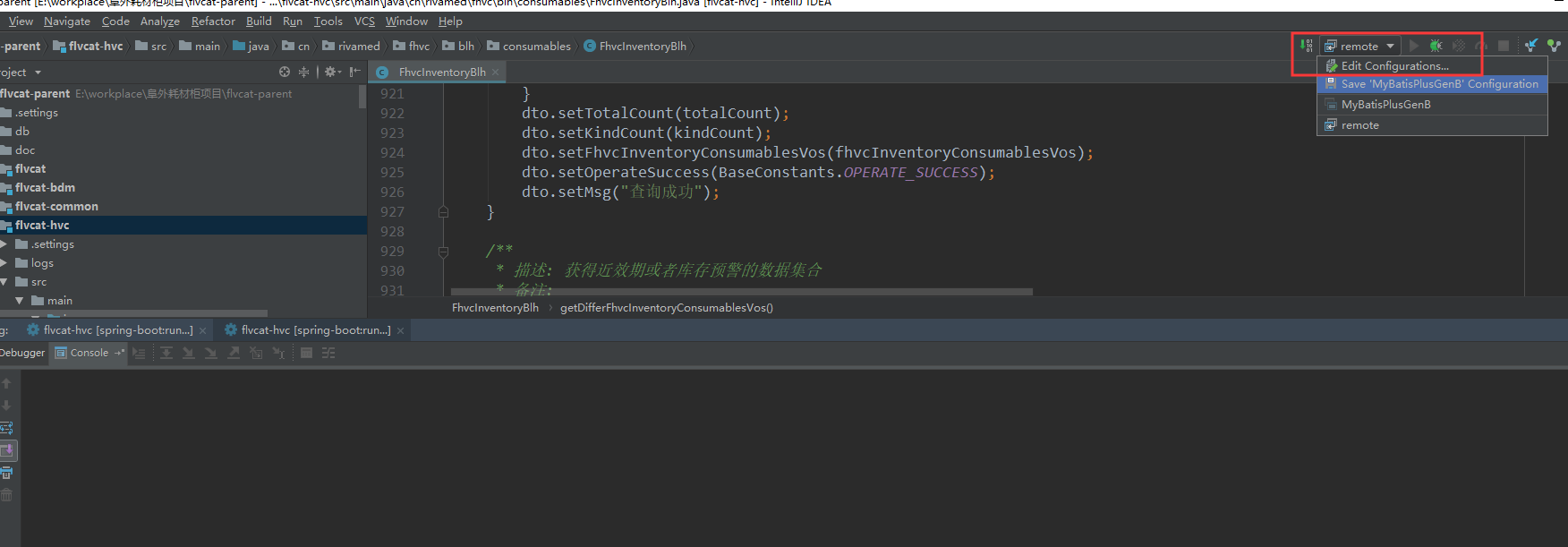
添加启动配置
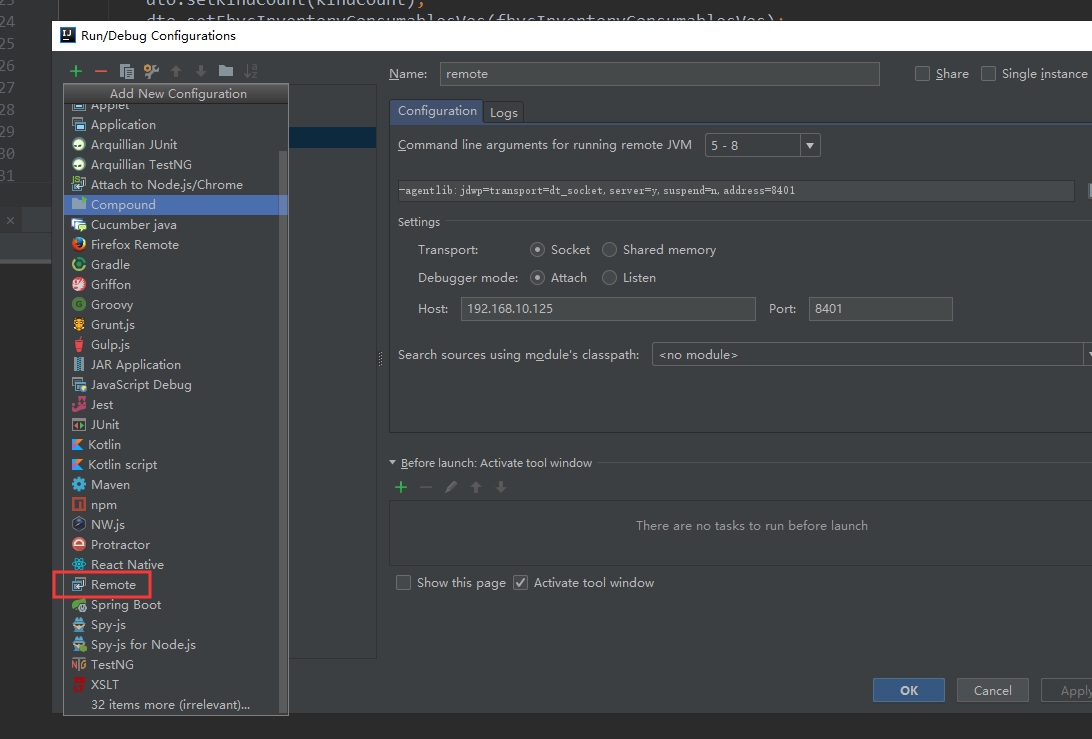
编辑配置

效果预览
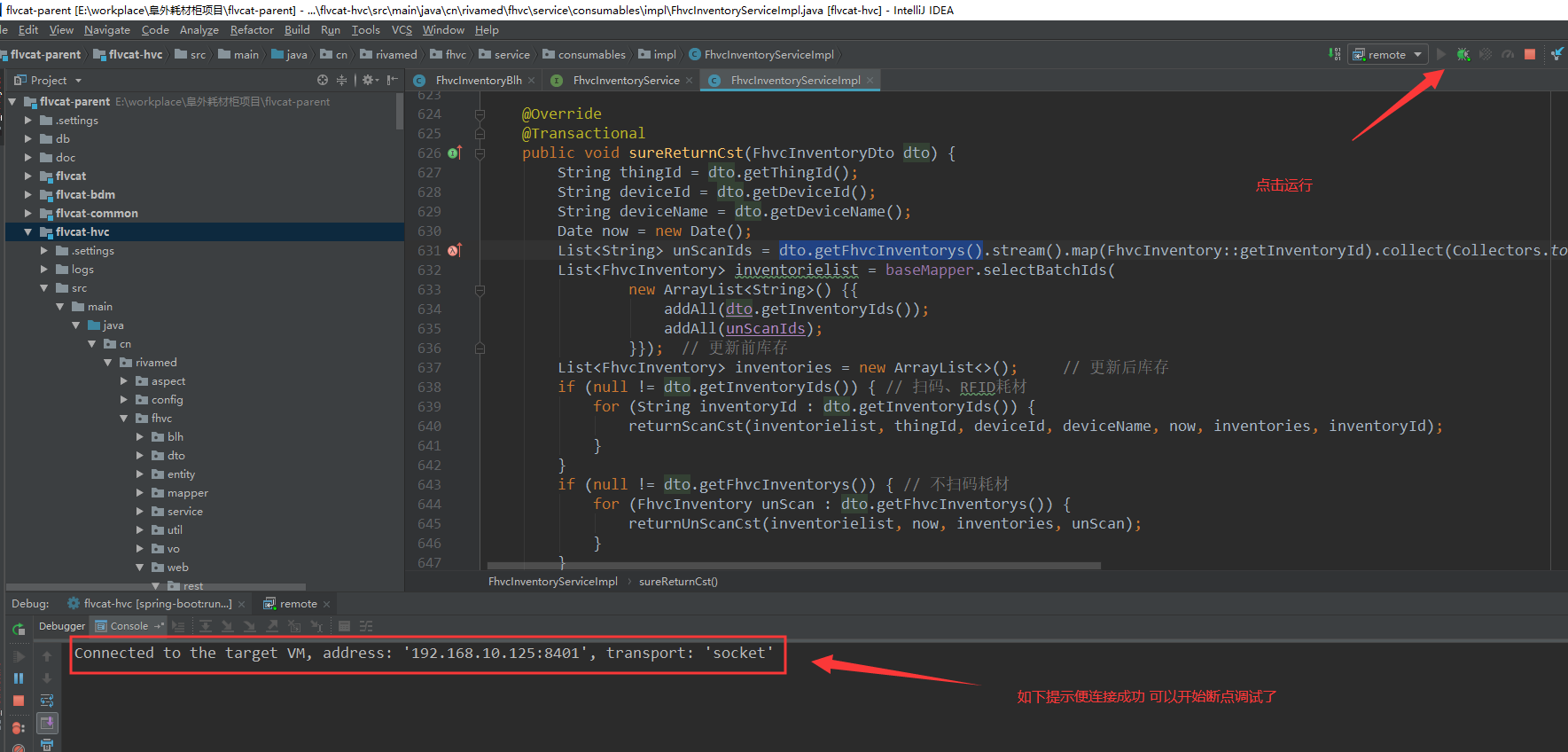


idea docker docker-compose 发布 springboot 站点到 tomcat
允许 docker 被远程访问
见:https://www.cnblogs.com/wintersoft/p/10921396.html
教程:https://spring.io/guides/gs/spring-boot-docker/#initial
在 idea 新建项目
spring boot 启动类加上
@RestController和
@RequestMapping("/")
public String home() {
return "Hello Docker!";
}
在启动类同级,新建 Servletinitializer 类
import org.springframework.boot.builder.SpringApplicationBuilder;
import org.springframework.boot.web.servlet.support.SpringBootServletInitializer;
public class Servletinitializer extends SpringBootServletInitializer {
@Override
protected SpringApplicationBuilder
configure(SpringApplicationBuilder builder) {
return builder.sources(DockerDemo2Application.class);
}
}
pom.xml 加入
<packaging>war</packaging>和
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-tomcat</artifactId>
<scope>provided</scope>
</dependency>
<dependency>
<groupId>org.apache.tomcat.embed</groupId>
<artifactId>tomcat-embed-jasper</artifactId>
<scope>provided</scope>
</dependency>
点击 idea 右上的 Edit Confgurations -> + -> Docker -> Dockerfile,配置如图

生成 war 包,终端输入:mvn clean package
项目根目录新建 /tomcat/conf
复制 tomcat 的 server.xml 到 /tomcat/conf
若没有 tomcat 配置文件可以下载一个,如:
wget -P /opt/downloads http://mirrors.tuna.tsinghua.edu.cn/apache/tomcat/tomcat-9/v9.0.20/bin/apache-tomcat-9.0.20.tar.gz
tar zxvf /opt/downloads/apache-tomcat-9.0.20.tar.gz -C /optserver.xml 的 host 节点内添加 <Context path=""docBase="app"reloadable="true"debug="0" />
项目根目录创建 Dockerfile
FROM tomcat
MAINTAINER sundong
ARG WAR=docker-demo2-1.0.0.war
COPY /tomcat/conf/server.xml /publish/tomcat/conf/server.xml
COPY target/$WAR /publish/app/$WAR
RUN mkdir $CATALINA_HOME/webapps/app \
&& cp /publish/app/$WAR $CATALINA_HOME/webapps/app \
&& cp /publish/tomcat/conf/server.xml $CATALINA_HOME/conf \
&& unzip $CATALINA_HOME/webapps/app/$WAR -d $CATALINA_HOME/webapps/app/ \
&& rm $CATALINA_HOME/webapps/app/$WAR \
&& cd $CATALINA_HOME/webapps/app && echo "succ" > a.txt
EXPOSE 8080项目根目录创建 docker-compose.yml
version: ''3.4''
services:
dockerweb:
image: dockerdemox2:latest
container_name: dockerdemox2
restart: always
build:
context: .
dockerfile: Dockerfile
volumes:
- ./tomcat:/publish/tomcat
- ./target:/publish/app
ports:
- "28080:8080"
解决 tomcat 启动慢
https://www.cnblogs.com/wintersoft/p/10942845.html
把项目中的 target 文件夹的 war 包、tomcat 文件夹、Dockerfile 和 docker-compose.yml 复制到 centos
进入 centos 网站目录
docker-compose up --build
或
docker-compose build
docker-compose up
浏览器输入 192.168.1.102:38080,测试站点是否启动成功
若没问题,退出后,以守护进程启动站点
docker-compose up -d
今天的关于IDEA 远程调试 docker 环境的 SpringBoot 项目和idea远程docker部署启动的分享已经结束,谢谢您的关注,如果想了解更多关于Docker之IntelliJ IDEA部署SpringBoot应用到Docker、docker环境安装及springboot+docker在idea上实现一键部署远程服务器、idea + springBoot 项目配置远程调试、idea docker docker-compose 发布 springboot 站点到 tomcat的相关知识,请在本站进行查询。
在本文中,我们将详细介绍java中stringBuilder的用法的各个方面,并为您提供关于java stringbuilder用法的相关解答,同时,我们也将为您带来关于Java StringBuilder的用法示例、Java 中String StringBuilder 与 StringBuffer详解及用法实例、java中String StringBuffer 、 StringBuilder 、String的示例分析、Java中String,StringBuffer,StringBuilder的区别的有用知识。
本文目录一览:- java中stringBuilder的用法(java stringbuilder用法)
- Java StringBuilder的用法示例
- Java 中String StringBuilder 与 StringBuffer详解及用法实例
- java中String StringBuffer 、 StringBuilder 、String的示例分析
- Java中String,StringBuffer,StringBuilder的区别
")
java中stringBuilder的用法(java stringbuilder用法)
String对象是不可改变的。每次使用 System.String类中的方法之一时,都要在内存中创建一个新的字符串对象,这就需要为该新对象分配新的空间。在需要对字符串执行重复修改的情况下,与创建新的 String对象相关的系统开销可能会非常昂贵。如果要修改字符串而不创建新的对象,则可以使用System.Text.StringBuilder类。例如,当在一个循环中将许多字符串连接在一起时,使用 StringBuilder类可以提升性能。
通过用一个重载的构造函数方法初始化变量,可以创建 StringBuilder类的新实例,正如以下示例中所阐释的那样。
StringBuilder MyStringBuilder = new StringBuilder("Hello World!");
(一)设置容量和长度
虽然 StringBuilder对象是动态对象,允许扩充它所封装的字符串中字符的数量,但是您可以为它可容纳的最大字符数指定一个值。此值称为该对象的容量,不应将它与当前 StringBuilder对象容纳的字符串长度混淆在一起。例如,可以创建 StringBuilder类的带有字符串“Hello”(长度为 5)的一个新实例,同时可以指定该对象的最大容量为 25。当修改 StringBuilder时,在达到容量之前,它不会为其自己重新分配空间。当达到容量时,将自动分配新的空间且容量翻倍。可以使用重载的构造函数之一来指定 StringBuilder类的容量。以下代码示例指定可以将 MyStringBuilder对象扩充到最大 25个空白。
StringBuilderMyStringBuilder = new StringBuilder("Hello World!", 25);
另外,可以使用读/写 Capacity属性来设置对象的最大长度。以下代码示例使用 Capacity属性来定义对象的最大长度。
MyStringBuilder.Capacity= 25;
(二)下面列出了此类的几个常用方法:
(1)Append 方法可用来将文本或对象的字符串表示形式添加到由当前 StringBuilder对象表示的字符串的结尾处。以下示例将一个 StringBuilder对象初始化为“Hello World”,然后将一些文本追加到该对象的结尾处。将根据需要自动分配空间。
StringBuilderMyStringBuilder = new StringBuilder("Hello World!");
MyStringBuilder.Append(" What a beautiful day.");
Console.WriteLine(MyStringBuilder);
此示例将 Hello World! What abeautiful day.显示到控制台。
(2)AppendFormat 方法将文本添加到 StringBuilder的结尾处,而且实现了 IFormattable接口,因此可接受格式化部分中描述的标准格式字符串。可以使用此方法来自定义变量的格式并将这些值追加到 StringBuilder的后面。以下示例使用 AppendFormat方法将一个设置为货币值格式的整数值放置到 StringBuilder的结尾。
int MyInt= 25;
StringBuilder MyStringBuilder = new StringBuilder("Your total is ");
MyStringBuilder.AppendFormat("{0:C} ", MyInt);
Console.WriteLine(MyStringBuilder);
此示例将 Your total is $25.00显示到控制台。
(3)Insert 方法将字符串或对象添加到当前 StringBuilder中的指定位置。以下示例使用此方法将一个单词插入到 StringBuilder的第六个位置。
StringBuilderMyStringBuilder = new StringBuilder("Hello World!");
MyStringBuilder.Insert(6,"Beautiful ");
Console.WriteLine(MyStringBuilder);
此示例将 Hello BeautifulWorld!显示到控制台。
(4)可以使用 Remove方法从当前 StringBuilder中移除指定数量的字符,移除过程从指定的从零开始的索引处开始。以下示例使用 Remove方法缩短 StringBuilder。
StringBuilderMyStringBuilder = new StringBuilder("Hello World!");
MyStringBuilder.Remove(5,7);
Console.WriteLine(MyStringBuilder);
此示例将 Hello显示到控制台。
(5)使用 Replace方法,可以用另一个指定的字符来替换 StringBuilder对象内的字符。以下示例使用 Replace方法来搜索 StringBuilder对象,查找所有的感叹号字符 (!),并用问号字符 (?)来替换它们。
StringBuilderMyStringBuilder = new StringBuilder("Hello World!");
MyStringBuilder.Replace(''!'', ''?'');
Console.WriteLine(MyStringBuilder);
此示例将 Hello World?显示到控制台
getSqlMapClientTemplate().queryForList((new StringBuilder()).append(entityClass.getName()).append(".select").toString(), null);
Java的StringBuilder类
如果程序对附加字符串的需求很频繁,不建议使用+来进行字符串的串联。可以考虑使用java.lang.StringBuilder 类,使用这个类所产生的对象默认会有16个字符的长度,您也可以自行指定初始长度。如果附加的字符超出可容纳的长度,则StringBuilder 对象会自动增加长度以容纳被附加的字符。如果有频繁作字符串附加的需求,使用StringBuilder 类能使效率大大提高。如下代码:
Java代码
public class AppendStringTest
{
public static void main(String[] args)
{
String text = "" ;
long beginTime = System.currentTimeMillis();
for ( int i= 0 ;i< 10000 ;i++)
text = text + i;
long endTime = System.currentTimeMillis();
System.out.println("执行时间:" +(endTime-beginTime));
StringBuilder sb = new StringBuilder ( "" );
beginTime = System.currentTimeMillis();
for ( int i= 0 ;i< 10000 ;i++)
sb.append(String.valueOf(i));
endTime = System.currentTimeMillis();
System.out.println("执行时间:" +(endTime-beginTime));
}
}
public class AppendStringTest
{
public static void main(String[] args)
{
String text = "";
long beginTime = System.currentTimeMillis();
for(int i=0;i<10000;i++)
text = text + i;
long endTime = System.currentTimeMillis();
System.out.println("执行时间:"+(endTime-beginTime));
StringBuilder sb = new StringBuilder ("");
beginTime = System.currentTimeMillis();
for(int i=0;i<10000;i++)
sb.append(String.valueOf(i));
endTime = System.currentTimeMillis();
System.out.println("执行时间:"+(endTime-beginTime));
}
} 此段代码输出:
执行时间:3188
执行时间:15
StringBuilder 是j2se1.5.0才新增的类,在此之前的版本若有相同的需求,则使用java.util.StringBuffer。事实上 StringBuilder 被设计为与StringBuffer具有相同的操作接口。在单机非线程(MultiThread)的情况下使用StringBuilder 会有较好的效率,因为StringBuilder 没有处理同步的问题。StringBuffer则会处理同步问题,如果StringBuilder 会有多线程下被操作,则要改用StringBuffer,让对象自行管理同步问题。

Java StringBuilder的用法示例
这篇文章主要给大家介绍了关于Java StringBuilder用法的相关资料,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友们下面随着小编来一起学习学习吧
StringBuilder简介
StringBuilder 最早出现在JDK1.5,是一个字符拼接的工具类,它和StringBuffer一样都继承自父类AbstractStringBuilder,在AbstractStringBuilder中使用char[] value字符数组保存字符串,但是没有用final关键字修饰,所以StringBuilder是可变的。性能
StringBuilder 对字符串的操作是直接改变字符串对象本身,而不是生成新的对象,所以新能开销小。
与StringBuffer相比StringBuilder的性能略高(15%~30%),StringBuffer为保证多线程情况下的安全性(synchronize加锁)而牺牲了性能,以时间来换取安全。而StringBuilder则没有保证线程的安全,从而性能略高于StringBuffer。
使用场景
频繁使用字符串拼接的时候可以用StringBuilder(推荐)或者StringBuffer。
用法
一、StringBuilder对象的创建(下文builder是StringBuilder创建出来的对象)
1.常规创建
StringBuilder builder = new StringBuilder();
2.在创建的时候添加初始字符串
StringBuilder builder = new StringBuilder("abc");
3.在创建的时候添加初始长度
StringBuilder builder = new StringBuilder(初始长度);
这里需要注意的是如果在StringBuilder的对象创建时没有指定长度,StringBuilder对象会自动生成一个16位的字符数组
二、StringBuilder对象的方法
数据的种类可以有:
类型
Object
String
StringBuffer
CharSequence
char[]
boolean
char
int
long
float
double
1.builder.append()
作用:追加数据
builder.append("just");
在加入新字符串时,不会在内存中新开辟字符串空间,只是给原有的字符串尾部加入新字符串
2.builder.insert()
作用:向指定位置插入数据
builder.insert(0, "you");
每次加入新字符串之后都会改变字符串中每个字符的地址
插入后原始指定位置的数据向后移
3.builder.deleteCharat()
作用:删除指定位置的数据
builder.deleteCharat(index);
4.builder.delete( )
作用:删除指定范围的数据左闭右开
builder.delete(beginIndex, endindex);
范围:从开始位置到结束位置的前一个
5.builder.toString()
作用:将对象中的数据以字符串的形式返回
builder.toString();
6.builder.reverse()
作用:将对象中的数据反转
builder.reverse();
注意
原始数组长度不够时,在传入新字符串时会增加数组长度,并将原来的数据传到新数组中,反复添加遇到这种情况时会对内存造成损耗,为了避免这种情况,可以在创建时提前给StringBuilder对象设置长度:StringBuilder builder = new StringBuilder(初始长度)。
总结
到此这篇关于Java StringBuilder用法的文章就介绍到这了,更多相关Java StringBuilder用法内容请搜索小编以前的文章或继续浏览下面的相关文章希望大家以后多多支持小编!

Java 中String StringBuilder 与 StringBuffer详解及用法实例
在Android/Java开发中,用来处理字符串常用的类有3种: String、StringBuilder、StringBuffer。
它们的异同点:
1) 都是 final 类,都不允许被继承;
2) String 长度是不可变的,StringBuffer、StringBuilder 长度是可变的;
3) StringBuffer 是线程安全的,StringBuilder 不是线程安全的。
String VS StringBuffer
String 类型和StringBuffer的主要性能区别:String是不可变的对象,因此在每次对String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象,所以经常改变内容的字符串最好不要用 String ,因为每次生成对象都会对系统性能产生影响,特别当内存中无引用对象多了以后, JVM 的 GC 就会开始工作,性能就会降低。
使用 StringBuffer 类时,每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。所以多数情况下推荐使用 StringBuffer ,特别是字符串对象经常改变的情况下。
在某些特别情况下, String 对象的字符串拼接其实是被 Java Compiler 编译成了 StringBuffer 对象的拼接,所以这些时候 String 对象的速度并不会比 StringBuffer 对象慢,例如:
String s1 = “This is only a” + “ simple” + “ test”; StringBuffer Sb = new StringBuilder(“This is only a”).append(“ simple”).append(“ test”);
生成 String s1对象的速度并不比 StringBuffer慢。其实在Java Compiler里,自动做了如下转换:
Java Compiler直接把上述第一条语句编译为:
String s2 = “This is only a”; String s3 = “ simple”; String s4 = “ test”; String s1 = s2 + s3 + s4;
这时候,Java Compiler会规规矩矩的按照原来的方式去做,String的concatenation(即+)操作利用了StringBuilder(或StringBuffer)的append方法实现,此时,对于上述情况,若s2,s3,s4采用String定义,拼接时需要额外创建一个StringBuffer(或StringBuilder),之后将StringBuffer转换为String;若采用StringBuffer(或StringBuilder),则不需额外创建StringBuffer。
StringBuilder
StringBuilder是5.0新增的。此类提供一个与 StringBuffer 兼容的 API,但不保证同步。该类被设计用作 StringBuffer 的一个简易替换,用在字符串缓冲区被单个线程使用的时候(这种情况很普遍)。如果可能,建议优先采用该类,因为在大多数实现中,它比 StringBuffer 要快。两者的方法基本相同。
使用策略
1) 基本原则:如果要操作少量的数据,用String ;单线程操作大量数据,用StringBuilder ;多线程操作大量数据,用StringBuffer。
2) 不要使用String类的”+”来进行频繁的拼接,因为那样的性能极差的,应该使用StringBuffer或StringBuilder类,这在Java的优化上是一条比较重要的原则。例如:
String result = "";
for (String s : hugeArray) {
result = result + s;
}
// 使用StringBuilder
StringBuilder sb = new StringBuilder();
for (String s : hugeArray) {
sb.append(s);
}
String result = sb.toString();
当出现上面的情况时,显然我们要采用第二种方法,因为第一种方法,每次循环都会创建一个String result用于保存结果,除此之外二者基本相同.
3) StringBuilder一般使用在方法内部来完成类似”+”功能,因为是线程不安全的,所以用完以后可以丢弃。StringBuffer主要用在全局变量中。
4) 相同情况下使用 StirngBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。而在现实的模块化编程中,负责某一模块的程序员不一定能清晰地判断该模块是否会放入多线程的环境中运行,因此:除非确定系统的瓶颈是在 StringBuffer 上,并且确定你的模块不会运行在多线程模式下,才可以采用StringBuilder;否则还是用StringBuffer。
感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
您可能感兴趣的文章:
- 全面解释java中StringBuilder、StringBuffer、String类之间的关系
- 深入解析StringBuffer和StringBuilder的区别
- Java之String、StringBuffer、StringBuilder的区别分析
- Java那点事――StringBuffer与StringBuilder原理与区别
- java 中String和StringBuffer与StringBuilder的区别及使用方法
- Java StringBuilder和StringBuffer源码分析
- Java 中 String,StringBuffer 和 StringBuilder 的区别及用法
- 详细分析Java中String、StringBuffer、StringBuilder类的性能
- Java中StringBuffer和StringBuilder区别
- JDK源码分析之String、StringBuilder和StringBuffer

java中String StringBuffer 、 StringBuilder 、String的示例分析
这篇文章主要为大家展示了“java中String StringBuffer 、 StringBuilder 、String的示例分析”,内容简而易懂,条理清晰,希望能够帮助大家解决疑惑,下面让小编带领大家一起研究并学习一下“java中String StringBuffer 、 StringBuilder 、String的示例分析”这篇文章吧。
可变性
简单的来说:String 类中使用 final 关键字修饰字符数组来保存字符串,private final char value[],所以 String 对象是不可变的。而StringBuilder 与 StringBuffer 都继承自 AbstractStringBuilder 类,在 AbstractStringBuilder 中也是使用字符数组保存字符串char[]value 但是没有用 final 关键字修饰,所以这两种对象都是可变的。
StringBuilder 与 StringBuffer 的构造方法都是调用父类构造方法也就是 AbstractStringBuilder 实现的,大家可以自行查阅源码。
线程安全性
String 中的对象是不可变的,也就可以理解为常量,线程安全。AbstractStringBuilder 是 StringBuilder 与 StringBuffer 的公共父类,定义了一些字符串的基本操作,如 expandCapacity、append、insert、indexOf 等公共方法。StringBuffer 对方法加了同步锁或者对调用的方法加了同步锁,所以是线程安全的。StringBuilder 并没有对方法进行加同步锁,所以是非线程安全的。
性能
每次对 String 类型进行改变的时候,都会生成一个新的 String 对象,然后将指针指向新的 String 对象。StringBuffer 每次都会对 StringBuffer 对象本身进行操作,而不是生成新的对象并改变对象引用。相同情况下使用 StringBuilder 相比使用 StringBuffer 仅能获得 10%~15% 左右的性能提升,但却要冒多线程不安全的风险。
对于三者使用的总结:
操作少量的数据: 适用String
单线程操作字符串缓冲区下操作大量数据: 适用StringBuilder
多线程操作字符串缓冲区下操作大量数据: 适用StringBuffer
以上是“java中String StringBuffer 、 StringBuilder 、String的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注小编行业资讯频道!

Java中String,StringBuffer,StringBuilder的区别
- String 字符串常量
- StringBuffer 字符串变量(线程安全)
- StringBuilder 字符串变量(非线程安全)
运行速度 StringBuilder > StringBuffer > String
String 字符串常量(JVM优化的结果)
错误认识:String可以修改
String z = "入门";
z = z + "小站";
原因
final修饰,不可变
private final char value[];JVM 处理这段代码的过程是这样的:首先创建 z 对象,赋值“入门” ,然后处理第二行代码时,再创建一个 z 对象,赋值 “小站”,然后将第一个 z 对象垃圾回收。
StringBuffer 字符串变量(线程安全)
对象在构造的过程中,首先按照默认大小申请一个字符数组(char[]), 默认容量为 16 个字符,但如果超出,会使用 Arrays.copyOf() 成倍扩容 16,32,64, 128...,当然这样会影响性能,因此可以在创建对象时按照需要自定义其容量没有final修饰,可变,本质是一个字符数组
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
// .....
}synchronized修饰,线程安全
public synchronized StringBuffer append(Object obj) {
toStringCache = null;
super.append(String.valueOf(obj));
return this;
}StringBuilder 字符串变量(非线程安全)
对象在构造的过程中,首先按照默认大小申请一个字符数组(char[]), 默认容量为 16 个字符,但如果超出,会使用 Arrays.copyOf() 成倍扩容 16,32,64, 128...,当然这样会影响性能,因此可以在创建对象时按照需要自定义其容量.
字符串变量,本质是一个字符数组
abstract class AbstractStringBuilder implements Appendable, CharSequence {
/**
* The value is used for character storage.
*/
char[] value;
//......
}线程不安全,没有加锁
@Override
public StringBuilder append(CharSequence s) {
super.append(s);
return this;
}String字符串不能被修改带来的好处
- 只有当字符串是不可变的,字符串池才有可能实现。字符串池的实现可以在运行时节约很多heap空间,因为不同的字符串变量都指向池中的同一个字符串。但如果字符串是可变的,那么String interning将不能实现(译者注:String interning是指对不同的字符串仅仅只保存一个,即不会保存多个相同的字符串。),因为这样的话,如果变量改变了它的值,那么其它指向这个值的变量的值也会一起改变。
- 如果字符串是可变的,那么会引起很严重的安全问题。譬如,数据库的用户名、密码都是以字符串的形式传入来获得数据库的连接,或者在socket编程中,主机名和端口都是以字符串的形式传入。因为字符串是不可变的,所以它的值是不可改变的,否则黑客们可以钻到空子,改变字符串指向的对象的值,造成安全漏洞。
- 因为字符串是不可变的,所以是多线程安全的,同一个字符串实例可以被多个线程共享。这样便不用因为线程安全问题而使用同步。字符串自己便是线程安全的。
- 类加载器要用到字符串,不可变性提供了安全性,以便正确的类被加载。譬如你想加载java.sql.Connection类,而这个值被改成了myhacked.Connection,那么会对你的数据库造成不可知的破坏。
- 因为字符串是不可变的,所以在它创建的时候hashcode就被缓存了,不需要重新计算。这就使得字符串很适合作为Map中的键,字符串的处理速度要快过其它的键对象。这就是HashMap中的键往往都使用字符串。
总结
- 单线程环境中使用StringBuilder,多线程使用StringBuffer
- 大量循环拼接字符串使用StringBuilder或StringBuffer,避免使用"+"拼接(在循环中,每执行一次 “+”,都会创建一个 String 对象,因此会有大量对象创建和回收的消耗)
原文: https://rumenz.com/rumenbiji/Java-String-StringBuffer-StringBuilder.html

今天关于java中stringBuilder的用法和java stringbuilder用法的分享就到这里,希望大家有所收获,若想了解更多关于Java StringBuilder的用法示例、Java 中String StringBuilder 与 StringBuffer详解及用法实例、java中String StringBuffer 、 StringBuilder 、String的示例分析、Java中String,StringBuffer,StringBuilder的区别等相关知识,可以在本站进行查询。
在本文中,您将会了解到关于>/dev/null 2>&1的新资讯,同时我们还将为您解释/dev/null 2>&1 &有什么用的相关在本文中,我们将带你探索>/dev/null 2>&1的奥秘,分析/dev/null 2>&1 &有什么用的特点,并给出一些关于/dev/null 2>&1 解释、/dev/null 2>1 2>&1 >与>> 的意思、/dev/null 位桶、/dev/null与/dev/zero区别的实用技巧。
本文目录一览:- >/dev/null 2>&1(/dev/null 2>&1 &有什么用)
- /dev/null 2>&1 解释
- /dev/null 2>1 2>&1 >与>> 的意思
- /dev/null 位桶
- /dev/null与/dev/zero区别
")
>/dev/null 2>&1(/dev/null 2>&1 &有什么用)

/dev/null 2>&1 解释
经常可以在一些脚本,尤其是在crontab调用时发现如下形式的命令调用
/tmp/test.sh > /tmp/test.log 2>&1
前半部分/tmp/test.sh > /tmp/test.log很容易理解,那么后面的2>&1是怎么回事呢?
要解释这个问题,还是得提到文件重定向。我们知道>和 <是文件重定向符。那么1和2是什么?在shell中,每个进程都和三个系统文件相关联:标准输入stdin,标准输出stdout和标准错误stderr,三个系统文件的文件描述符分别为0,1和2。所以这里2> &1 的意思就是将标准错误也输出到标准输出当中。
下面通过一个例子来展示2>&1有什么作用:
$ cat test.sh
t
date
test.sh中包含两个命令,其中t是一个不存在的命令,执行会报错,默认情况下,错误会输出到stderr。date则能正确执行,并且输出时间信息,默认输出到stdout
./test.sh > test1.log
./test.sh: line 1: t: command not found
$ cat test1.log
Tue Oct 9 20:51:50 CST 2007
可以看到,date的执行结果被重定向到log文件中了,而t无法执行的错误则只打印在屏幕上。
阅读全文>>

/dev/null 2>1 2>&1 >与>> 的意思
在linux中,0,1,2,/dev/null,>,>>的意思:
标准输入stdin的文件描述符为0
标准输出stdout的文件描述符为1
标准错误stderr的文件描述符为2
/dev/null为空设备,相当于垃圾桶
输出重定向符号为>
>为覆盖
>>为追加
2>1与2>&1的区别
2>1把标准错误stderr重定向到文件1中
2>&1把标准错误stderr重定向到标准输出stdout
示例:
test.sh
#! /bin/sh
t
date标准输出重定向到log,标准错误输出到终端上
$ ls
test.sh
$ ./test.sh > log
./test.sh: 3: ./test.sh: t: not found
$ ls
log test.sh
$ cat log
2017年 06月 28日 星期三 09:30:39 CST(删除log文件)标准输出重定向到log,标准错误重定向到文件1
$ ls
log test.sh
$ rm log
$ ls
test.sh
$ ./test.sh > log 2>1
$ ls
1 log test.sh
$ cat log
2017年 06月 28日 星期三 09:34:32 CST
$ cat 1
./test.sh: 3: ./test.sh: t: not found(删除log文件及1文件)标准输出重定向到log,标准错误重定向到标准输出
$ ls
1 log test.sh
$ rm 1 log
$ ls
test.sh
$ ./test.sh > log 2>&1
$ ls
log test.sh
$ cat log
./test.sh: 3: ./test.sh: t: not found
2017年 06月 28日 星期三 09:36:49 CST(删除log文件)标准输出重定向到空设备
$ ls
log test.sh
$ rm log
$ ls
test.sh
$ ./test.sh >/dev/null
./test.sh: 3: ./test.sh: t: not found
$ ls
test.sh标准错误重定向到空设备
$ ls
test.sh
$ ./test.sh 2>/dev/null
2017年 06月 29日 星期四 14:23:41 CST
$ ls
test.sh标准输出和标准错误全定向到空设备
$ ls
test.sh
$ ./test.sh >/dev/null 2>&1
$ ls
test.sh

/dev/null 位桶
把/dev/null看作"黑洞". 它非常等价于一个只写文件. 所有写入它的内容都会永远丢失. 而尝试从它那儿读取内容则什么也读不到. 然而, /dev/null对命令行和脚本都非常的有用.
禁止标准输出.
1 cat $filename >/dev/null
2 # 文件内容丢失,而不会输出到标准输出.禁止标准错误
1 rm $badname 2>/dev/null
2 # 这样错误信息[标准错误]就被丢到太平洋去了.禁止标准输出和标准错误的输出.
1 cat $filename 2>/dev/null >/dev/null
2 # 如果"$filename"不存在,将不会有任何错误信息提示.
3 # 如果"$filename"存在, 文件的内容不会打印到标准输出.
4 # 因此Therefore, 上面的代码根本不会输出任何信息.
5 # 当只想测试命令的退出码而不想有任何输出时非常有用。
6 #-----------测试命令的退出 begin ----------------------#
7 # ls dddd 2>/dev/null 8
8 # echo $? //输出命令退出代码:0为命令正常执行,1-255为有出错。
9 #-----------测试命令的退出 end-----------#
10# cat $filename &>/dev/null
11 # 也可以, 由 Baris Cicek 指出.清除日志文件内容
1 cat /dev/null > /var/log/messages
2 # : > /var/log/messages 有同样的效果, 但不会产生新的进程.(因为:是内建的)
3
4 cat /dev/null > /var/log/wtmp例子 28-1. 隐藏cookie而不再使用
1 if [ -f ~/.netscape/cookies ] # 如果存在则删除.
2 then
3 rm -f ~/.netscape/cookies
4 fi
5
6 ln -s /dev/null ~/.netscape/cookies
7 # 现在所有的cookies都会丢入黑洞而不会保存在磁盘上了.
/dev/null与/dev/zero区别
/dev/null和/dev/zero的区别
/dev/null,外号叫无底洞,你可以向它输出任何数据,它通吃,并且不会撑着!
/dev/zero,是一个输入设备,你可你用它来初始化文件。该设备无穷尽地提供0,可以使用任何你需要的数目——设备提供的要多的多。他可以用于向设备或文件写入字符串0。
/dev/null——它是空设备,也称为位桶(bit bucket)。任何写入它的输出都会被抛弃。如果不想让消息以标准输出显示或写入文件,那么可以将消息重定向到位桶。
if=/dev/zero of=./test.txt bs=1k count=1
ls –l
total 4
-rw-r--r-- 1 oracle dba 1024 Jul 15 16:56 test.txt
find / -name access_log 2>/dev/null
使用/dev/null
把/dev/null看作”黑洞”, 它等价于一个只写文件,所有写入它的内容都会永远丢失.,而尝试从它那儿读取内容则什么也读不到。然而, /dev/null对命令行和脚本都非常的有用
禁止标准输出
cat $filename >/dev/null #文件内容丢失,而不会输出到标准输出.
禁止标准错误
rm $badname 2>/dev/null #这样错误信息[标准错误]就被丢到太平洋去了
禁止标准输出和标准错误的输出
cat $filename 2>/dev/null >/dev/null
如果”$filename”不存在,将不会有任何错误信息提示;如果”$filename”存在, 文件的内容不会打印到标准输出。因此,上面的代码根本不会输出任何信息。当只想测试命令的退出码而不想有任何输出时非常有用。
使用/dev/zero
像/dev/null一样, /dev/zero也是一个伪文件, 但它实际上产生连续不断的null的流(二进制的零流,而不是ASCII型的)。 写入它的输出会丢失不见, 而从/dev/zero读出一连串的null也比较困难, 虽然这也能通过od或一个十六进制编辑器来做到。
/dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,就像临时交换文件。
用/dev/zero创建一个交换临时文件
#!/bin/bash
# 创建一个交换文件.
ROOT_UID=0 # Root 用户的 $UID 是 0.
E_WRONG_USER=65 # 不是 root?
FILE=/swap
BLOCKSIZE=1024
MINBLOCKS=40
SUCCESS=0
# 这个脚本必须用root来运行.
if [ "$UID" -ne "$ROOT_UID" ]
then
echo; echo "You must be root to run this script."; echo
exit $E_WRONG_USER
fi
blocks=${1:-$MINBLOCKS} # 如果命令行没有指定,
if [ "$blocks" -lt $MINBLOCKS ]
then
blocks=$MINBLOCKS # 最少要有 40 个块长.
fi
echo "Creating swap file of size $blocks blocks (KB)."
dd if=/dev/zero of=$FILE bs=$BLOCKSIZE count=$blocks # 把零写入文件.
mkswap $FILE $blocks # 将此文件建为交换文件(或称交换分区).
swapon $FILE # 激活交换文件.
echo "Swap file created and activated."
exit $SUCCESS
我们今天的关于>/dev/null 2>&1和/dev/null 2>&1 &有什么用的分享已经告一段落,感谢您的关注,如果您想了解更多关于/dev/null 2>&1 解释、/dev/null 2>1 2>&1 >与>> 的意思、/dev/null 位桶、/dev/null与/dev/zero区别的相关信息,请在本站查询。
在本文中,您将会了解到关于RPM 包 rpmbuild SPEC 文件深度说明的新资讯,同时我们还将为您解释rpm package的相关在本文中,我们将带你探索RPM 包 rpmbuild SPEC 文件深度说明的奥秘,分析rpm package的特点,并给出一些关于centos – rpmbuild库注册’需要’、centos – 禁用rpmbuild自动要求查找、centos7 rpmbuild 打包 openssh8.0p1 并升级、centos7 升级 openssl1.1.1i(rpmbuild 打包后 rpm 方式升级)的实用技巧。
本文目录一览:- RPM 包 rpmbuild SPEC 文件深度说明(rpm package)
- centos – rpmbuild库注册’需要’
- centos – 禁用rpmbuild自动要求查找
- centos7 rpmbuild 打包 openssh8.0p1 并升级
- centos7 升级 openssl1.1.1i(rpmbuild 打包后 rpm 方式升级)
")
RPM 包 rpmbuild SPEC 文件深度说明(rpm package)
http://hlee.iteye.com/blog/343499
上一篇日志写到,为什么要制作 rpm 包,以及如何使用.src.rpm 文件生成 rpm 包。最后部分还看到.src.rpm 的内容,实际上 就是由.tar.gz 源码、补丁软件和.spec 脚本组成的。由此知道,使用.spec 生成 rpm 包是比较简单的,因为.src.rpm 通常都是由软件开 发者或者第三方的专业制作人根据源码调试好的,所以,只要处理好平台兼容性和相关的版本,不会遇到太大的问题。
但我觉得单纯明白用.spec 生成 rpm 是不够的。常见有两个原因值得我们去了解用如何用源码制作 rpm:这是最常见的原因。负责任的开发者应提供 rpm 方式的二进制软件包,以便用户选择使用。但也很常见就是软件作者只是发布了源码,最后一部分的编译和安装需要用户自行解决。我不想深究对错问题,反正知道有这样的情况就可以了;
2、自行打包一些文件或自己开发了一套软件
当 然,使用 tar 包或 cpio 等也可以打包文件,甚至比制作 rpm 要简单很多。但如果您想在安装的过程中就把一套额外的软件部署完毕,那使用 rpm 方式通常 是是唯一的方法。而且 rpm 还有数据库协助软件升级、文件校验等,结合 yum 升级方式,没有理由不选择 rpm,特别是对于最终用户,我认为提供 rpm 包是 最佳的方法。
一、编写 spec 脚本
由前面的日志了解到,生成 rpm 除了源码外,最重要的就是懂得编写.spec 脚本。rpm 建包的原理其实并不复杂,可以理解为按照标准的格式整理一些信息,包括:软件基础信息,以及安装、卸载前后执行的脚本,对源码包解压、打补丁、编译,安装路径和文件等。
实际过程中,最关键的地方,是要清楚虚拟路径的位置,以及宏的定义。
二、关键字
spec 脚本包括很多关键字,主要有:
Summary: 软件包的内容概要
Version: 软件的实际版本号,例如:1.0.1 等,后面可使用 %{version} 引用
Release: 发布序列号,例如:1linuxing 等,标明第几次打包,后面可使用 %{release} 引用
Group: 软件分组,建议使用标准分组
License: 软件授权方式,通常就是 GPL
Source: 源代码包,可以带多个用 Source1、Source2 等源,后面也可以用 %{source1}、%{source2} 引用
BuildRoot: 这个是安装或编译时使用的 “虚拟目录”,考虑到多用户的环境,一般定义为:
%{_tmppath}/%{name}-%{version}-%{release}-root
或
%{_tmppath}/%{name}-%{version}-%{release}-buildroot-%(%{__id_u} -n}
该参数非常重要,因为在生成 rpm 的过程中,执行 make install 时就会把软件安装到上述的路径中,在打包的时候,同样依赖 “虚拟目录” 为 “根目录” 进行操作。
后面可使用 $RPM_BUILD_ROOT 方式引用。
URL: 软件的主页
Vendor: 发行商或打包组织的信息,例如 RedFlag Co,Ltd
Disstribution: 发行版标识
Patch: 补丁源码,可使用 Patch1、Patch2 等标识多个补丁,使用 % patch0 或 %{patch0} 引用
Prefix: %{_prefix} 这个主要是为了解决今后安装 rpm 包时,并不一定把软件安装到 rpm 中打包的目录的情况。这样,必须在这里定义该标识,并在编写 % install 脚本的时候引用,才能实现 rpm 安装时重新指定位置的功能
Prefix: %{_sysconfdir} 这个原因和上面的一样,但由于 %{_prefix} 指 /usr,而对于其他的文件,例如 /etc 下的配置文件,则需要用 %{_sysconfdir} 标识
Build Arch: 指编译的目标处理器架构,noarch 标识不指定,但通常都是以 /usr/lib/rpm/marcros 中的内容为默认值
Requires: 该 rpm 包所依赖的软件包名称,可以用 >= 或 <= 表示大于或小于某一特定版本,例如:
libpng-devel >= 1.0.20 zlib
※“>=” 号两边需用空格隔开,而不同软件名称也用空格分开
还有例如 PreReq、Requires (pre)、Requires (post)、Requires (preun)、Requires (postun)、BuildRequires 等都是针对不同阶段的依赖指定
Provides: 指明本软件一些特定的功能,以便其他 rpm 识别
Packager: 打包者的信息
%description 软件的详细说明
三、spec 脚本主体
spec 脚本的主体中也包括了很多关键字和描述,下面会一一列举。我会把一些特别需要留意的地方标注出来。
%prep 预处理脚本
%setup -n %{name}-%{version} 把源码包解压并放好
通常是从 /usr/src/asianux/SOURCES 里的包解压到 /usr/src/asianux/BUILD/%{name}-%{version} 中。
一般用 % setup -c 就可以了,但有两种情况:一就是同时编译多个源码包,二就是源码的 tar 包的名称与解压出来的目录不一致,此时,就需要使用 - n 参数指定一下了。
%patch 打补丁
通常补丁都会一起在源码 tar.gz 包中,或放到 SOURCES 目录下。一般参数为:
% patch -p1 使用前面定义的 Patch 补丁进行,-p1 是忽略 patch 的第一层目录
% Patch2 -p1 -b xxx.patch 打上指定的补丁,-b 是指生成备份文件
◎补充一下
% setup -n newdir 将软件包解压在 newdir 目录。
% setup -c 解压缩之前先产生目录。
% setup -b num 将第 num 个 source 文件解压缩。
% setup -T 不使用 default 的解压缩操作。
% setup -T -b 0 将第 0 个源代码文件解压缩。
% setup -c -n newdir 指定目录名称 newdir,并在此目录产生 rpm 套件。
% patch 最简单的补丁方式,自动指定 patch level。
% patch 0 使用第 0 个补丁文件,相当于 % patch ?p 0。
% patch -s 不显示打补丁时的信息。
% patch -T 将所有打补丁时产生的输出文件删除。
%configure 这个不是关键字,而是 rpm 定义的标准宏命令。意思是执行源代码的 configure 配置
在 /usr/src/asianux/BUILD/%{name}-%{version} 目录中进行 ,使用标准写法,会引用 /usr/lib/rpm/marcros 中定义的参数。
另一种不标准的写法是,可参考源码中的参数自定义,例如:
%build 开始构建包
在 /usr/src/asianux/BUILD/%{name}-%{version} 目录中进行 make 的工作 ,常见写法:
都是一些优化参数,定义在 /usr/lib/rpm/marcros 中
%install 开始把软件安装到虚拟的根目录中
在 /usr/src/asianux/BUILD/%{name}-%{version} 目录中进行 make install 的操作。 这个很重要,因为如果这里的路径不对的话,则下面 % file 中寻找文件的时候就会失败。 常见内容有:
%makeinstall 这不是关键字,而是 rpm 定义的标准宏命令。也可以使用非标准写法:
或
需要说明的是,这里的 % install 主要就是为了后面的 % file 服务的。所以,还可以使用常规的系统命令:
cp -a * $RPM_BUILD_ROOT/
%clean 清理临时文件
通常内容为:
rm -rf $RPM_BUILD_DIR/%{name}-%{version}
※注意区分 $RPM_BUILD_ROOT 和 $RPM_BUILD_DIR:
$RPM_BUILD_ROOT 是指开头定义的 BuildRoot,而 $RPM_BUILD_DIR 通常就是指 /usr/src/asianux/BUILD,其中,前面的才是 % file 需要的。
%pre rpm 安装前执行的脚本
%post rpm 安装后执行的脚本
%preun rpm 卸载前执行的脚本
%postun rpm 卸载后执行的脚本
% files 定义那些文件或目录会放入 rpm 中
这里会在虚拟根目录下进行,千万不要写绝对路径,而应用宏或变量表示相对路径。 如果描述为目录,表示目录中除 % exclude 外的所有文件。
%defattr (-,root,root) 指定包装文件的属性,分别是 (mode,owner,group),- 表示默认值,对文本文件是 0644,可执行文件是 0755
%exclude 列出不想打包到 rpm 中的文件
※小心,如果 % exclude 指定的文件不存在,也会出错的。
%changelog 变更日志
下面的.spec 脚本是一个比较简单的范例,其作用是把一个目录中的所有文件都打包为一个 rpm 包。
1、前期工作
我们假设需要打包的目录就是我们的源码文件。 这样,可以暂时忽略比较麻烦的打补丁、编译等问题,而且也是一种常见的方式。 在编写.spec 脚本前,需要准备好 “源码”,也就是目录,内容比较简单:
total 4
drwxr-xr-x 3 root root 4096 Jun 4 14:45 demo
[root @mail html]# ll demo/
total 4
drwxr-xr-x 3 root root 4096 Jun 4 14:45 images
-rw-r--r-- 1 root root 0 Jun 4 14:45 index.html
因为 rpm 只认 tar.gz 格式,所以,必须打包好并移动到 SOURCES 目录中:
demo/
demo/images/
demo/images/logo.gif/
demo/index.html
[root @mail html]# mv demo.tar.gz /usr/src/asianux/SOURCES/
2、demo.spec 的内容
准备工作完成,下面就是范例用的脚本内容:
[root @mail SPECS]# cat demo.spec
Name: suite
Version: 1.0.0
Release: 1
License: GPL
Group: System
Source: demo.tar.gz
BuildRoot: %{_tmppath}/%{name}-%{version}-%{release}-root
Url: http://www.linuxfly.org
Packager: Linuxing
Prefix: %{_prefix}
Prefix: %{_sysconfdir}
%define userpath /var/www/html/demo
%description
Just a test rpm suite.
%prep
%setup -c
%install
install -d $RPM_BUILD_ROOT%{userpath}
cp -a %{name}* $RPM_BUILD_ROOT%{userpath}
%clean
rm -rf $RPM_BUILD_ROOT
rm -rf $RPM_BUILD_DIR/%{name}-%{version}
%files
%defattr(-,root,root)
%{userpath}
下载:
 下载文件
下载文件
※特别需要注意的是:% install 部分使用的是绝对路径,而 % file 部分使用则是相对路径,虽然其描述的是同一个地方。千万不要写错。
1、扩展
虽然上面的范例很简陋,而且缺少 % build 部分,但实际上只要记住两点:
a)就是 % build 和 % install 的过程中,都必须把编译和安装的文件定义到 “虚拟根目录” 中。
make -f admin/Makefile.common cvs
./configure --prefix=%{_prefix} --enable-final --disable-debug \
--with-extra-includes=%{_includedir}/freetype2 --includedir=%{_includedir}
make
%install
rm -fr $RPM_BUILD_ROOT
make DESTDIR=$RPM_BUILD_ROOT install
cp -r $RPM_BUILD_ROOT%{_datadir}/apps/kolourpaint/icons/hicolor/* $RPM_BUILD_ROOT%{_datadir}/icons/crystalsvg/
b)就是 % file 中必须明白,用的是相对目录
%defattr(-,root,root)
%{_bindir}
%{_libdir}
%{_datadir}
%exclude %{_libdir}/debug
如果把
%defattr(-,root,root)
%{_bindir}
写成
%defattr(-,root,root)
/usr/bin
则打包的会是根目录下的 /usr/bin 中所有的文件。
2、一些 rpm 相关信息
rpm 软件包系统的标准分组:/usr/share/doc/rpm-4.3.3/GROUPS
各种宏定义: /usr/lib/rpm/macros
已经安装的 rpm 包数据库: /var/lib/rpm
如果要避免生成 debuginfo 包:这个是默认会生成的 rpm 包。则可以使用下面的命令:
如果 rpm 包已经做好,但在安装的时候想修改默认路径,则可以:
又或者同时修改多个路径:
3、制作补丁
详细看参考: [原] 使用 diff 同 patch 工具
4、如何编写 % file 段
由于必须在 % file 中包括所有套件中的文件,所以,我们需要清楚编译完的套件到底包括那些文件?
常见的做法是,人工模拟一次编译的过程:
make
make DESTDIR=/usr/local/xxx install
或
make prefix=/usr/local/xxx install
这样,整个套件的内容就会被放到 /usr/local/xxx 中,可根据情况编写 % file 和 % exclude 段。
※当然,这个只能对源码按 GNU 方式编写,并使用 GNU autotool 创建的包有效,若自定义 Makefile 则不能一概而论。
5、关于 rpm 中的执行脚本
如果正在制作的 rpm 包是准备作为放到系统安装光盘中的话,则需要考虑 rpm 中定义的脚本是否有问题。由于系统在安装的时候只是依赖于一个小环境进行,而该环境与实际安装完的环境有很大的区别,所以,大部分的脚本在该安装环境中都是无法生效,甚至会带来麻烦的。
所以,对于这样的,需要放到安装光盘中的套件,不加入执行脚本是较佳的方法。
另外,为提供操作中可参考的信息,rpm 还提供了一种信号机制:不同的操作会返回不同的信息,并放到默认变量 $1 中。
可这样使用:
if [ "$1" = "0" ]; then
/sbin/ldconfig
fi
六、参考文献:
1. http://www-900.ibm.com/developerWorks/cn/linux/management/package/rpm/part1/index.shtml[/url]
2. http://www-900.ibm.com/developerWorks/cn/linux/management/package/rpm/part2/index.shtml
3. http://www-900.ibm.com/developerWorks/cn/linux/management/package/rpm/part3/index.shtml
4. /usr/share/doc/rpm-4.3.2/
5. http://www.rpm.org/RPM-HOWTO/build.html#SCRIPTS
6. http://www.linuxfans.org/nuke/modules.php?name=Forums&file=printview&t=86980&start=0
最近在些 SPEC,发现其中的宏路径太难记了,GOOGLE 一下,发现 FERDORA 已经有介绍了。
可以通过命令rpm --showrc查看实现代码。另外直接通过 rpm --eval "%{macro}"来查看具体对应路径。
比如我们要查看 %{_bindir} 的路径,就可以使用命令 rpm --eval "%{ _bindir}"来查看。
另外,所有的宏都可以在 /usr/lib/rpm/macros里找到。
下面是宏对应路径一览表:
Macros mimicking autoconf variables
%{_sysconfdir} /etc
%{_prefix} /usr
%{_exec_prefix} %{_prefix}
%{_bindir} %{_exec_prefix}/bin
%{_lib} lib (lib64 on 64bit systems)
%{_libdir} %{_exec_prefix}/%{_lib}
%{_libexecdir} %{_exec_prefix}/libexec
%{_sbindir} %{_exec_prefix}/sbin
%{_sharedstatedir} /var/lib
%{_datadir} %{_prefix}/share
%{_includedir} %{_prefix}/include
%{_oldincludedir} /usr/include
%{_infodir} /usr/share/info
%{_mandir} /usr/share/man
%{_localstatedir} /var
%{_initddir} %{_sysconfdir}/rc.d/init.dNote: On releases older than Fedora 10 (and EPEL), %{_initddir} does not exist. Instead, you should use the deprecated%{_initrddir} macro.
RPM directory macros
%{_topdir} %{getenv:HOME}/rpmbuild
%{_builddir} %{_topdir}/BUILD
%{_rpmdir} %{_topdir}/RPMS
%{_sourcedir} %{_topdir}/SOURCES
%{_specdir} %{_topdir}/SPECS
%{_srcrpmdir} %{_topdir}/SRPMS
%{_buildrootdir} %{_topdir}/BUILDROOTNote: On releases older than Fedora 10 (and EPEL), %{_buildrootdir} does not exist.
Build flags macros
%{_global_cflags} -O2 -g -pipe
%{_optflags} %{__global_cflags} -m32 -march=i386 -mtune=pentium4 # if redhat-rpm-config is installedOther macros
%{_var} /var
%{_tmppath} %{_var}/tmp
%{_usr} /usr
%{_usrsrc} %{_usr}/src
%{_docdir} %{_datadir}/docReference:
http://fedoraproject.org/wiki/Packaging/RPMMacros#RPM_directory_macros

centos – rpmbuild库注册’需要’
大图:
我正在为自定义的PHP构建一个内部rpm.我构建了一个可以工作的rpm,但是生成了我不能使用’nodeps’似乎无法满足的库要求,我希望避免这些要求以确保在将来的使用中满足其他要求.
造成这个问题的原因:
(像往常一样在linux中归结为专有软件)…是Oracle客户端库.我为它构建的RPM没有正确地注册它的’provide’,因此RPM知道它提供了这个库功能.
%prep
%setup -q -n %{shortname}-%{version}
%build
%install
mkdir -p %{buildroot}/%{prefix}
mkdir -p %{buildroot}/%{_sysconfdir}/profile.d
mkdir -p %{buildroot}%{_sysconfdir}/ld.so.conf.d
cp -a %{_builddir}/%{shortname}-%{version} %{buildroot}/%{prefix}/
%{__install} -m 644 -p %{SOURCE1} \
$RPM_BUILD_ROOT%{_sysconfdir}/profile.d/oracle-instantclient.sh
echo %{prefix}/%{shortname}-%{version}>%{buildroot}%{_sysconfdir}/ld.so.conf.d/%{name}.conf
rm -fv /opt/%{shortname}-%{version} /opt/%{shortname} /thisDir/%{shortname}-%{version} /thisDir/%{shortname}
ln -sv %{prefix}/%{shortname}-%{version} /opt/
ln -sv /opt/%{shortname}-%{version} /opt/%{shortname}
ln -sv %{prefix}/%{shortname}-%{version} /thisDir/
ln -sv /thisDir/%{shortname}-%{version} /thisDir/%{shortname}
chown -h user:user /opt/%{shortname}-%{version} /opt/%{shortname} /thisDir/%{shortname}-%{version} /thisDir/%{shortname}
%clean
rm -rf %{buildroot}
%files
###%defattr(-,root,root,0755)
%{prefix}/%{shortname}-%{version}
/%{_sysconfdir}/profile.d/%{name}.sh
/%{_sysconfdir}/ld.so.conf.d/%{name}.conf
%post -p /sbin/ldconfig
%postun
rm -f /%{_sysconfdir}/profile.d/%{name}.sh /%{_sysconfdir}/ld.so.conf.d/%{name}.conf
rm -rfv /opt/%{shortname}-%{version} /opt/%{shortname} /thisDir/%{shortname}-%{version} /thisDir/%{shortname} %{_sysconfdir}/profile.d/%{source1}
ldconfig
rm -rf %{prefix}/%{shortname}-%{version}
rm -fv /opt/%{shortname}-%{version}
rm -fv /opt/%{shortname}
rm -fv /thisDir/%{shortname}-%{version}
rm -fv /thisDir/%{shortname}
rm -fv %{_sysconfdir}/profile.d/%{name}.sh
/sbin/ldconfig
其中大部分只是提供我们在整个环境中用于标准位置的符号链接的脚本;功能部分是ldconfig.为确保rpmbuild获得“提供”,我做错了什么?我很难找到有关如何在Cent6中的当代rpmbuild中工作的文档.
解决方法:
您正在尝试自动添加Oracle库的soname
作为提供:这个包?
最简单的方法就是输入提供:
直接在* .spec文件中.
如果您希望自动提取,可以使用rpmdeps
像这样提取soname依赖项:
$echo /lib64/libpopt.so.0.0.0 | /usr/lib/rpm/rpmdeps -P
libpopt.so.0()(64bit)
libpopt.so.0(LIBPOPT_0)(64bit)
在* .spec文件中执行上面的%(…)管道中的上述内容:
Provides: %(echo /lib64/libpopt.so.0.0.0 | /usr/lib/rpm/rpmdeps -P)
根据需要更改Oracle库的路径.

centos – 禁用rpmbuild自动要求查找
我无法找到抑制此行为的命令行或spec文件选项.希望我只是看起来不够努力.
解决方法

centos7 rpmbuild 打包 openssh8.0p1 并升级
此文档提供方法为官方源码 build 成 rpm 后,用 rpm 进行升级,在 Centos7.5.1804 下实现,其他环境未经测试。
1.Rpmbuild 打包
Rpmbuild 环境要与目标环境一样(即在 centos7.5.1804 上编译)
#安装依赖
yum install rpm-build pam-devel zlib zlib-devel perl krb5-devel pam-devel gcc make wget libX11-devel xmkmf libXt-devel initscripts -y
yum install openssl openssl-devel -y
#创建编译目录
mkdir -p ~/rpmbuild/{SOURCES,SPECS} && cd ~/rpmbuild/SOURCES/
#下载源码包和依赖包
wget http://ftp.riken.jp/Linux/momonga/6/Everything/SOURCES/x11-ssh-askpass-1.2.4.1.tar.gz
wget https://cloudflare.cdn.openbsd.org/pub/OpenBSD/OpenSSH/portable/openssh-8.0p1.tar.gz
tar xf openssh-8.0p1.tar.gz
#拷贝配置文件
cp openssh-8.3p1/contrib/redhat/openssh.spec ~/rpmbuild/SPECS/
cd ~/rpmbuild/SPECS/
#修改配置文件
sed -i -e "s/%define no_gnome_askpass 0/%define no_gnome_askpass 1/g" openssh.spec
sed -i -e "s/%define no_x11_askpass 0/%define no_x11_askpass 1/g" openssh.spec
#编译
rpmbuild -ba openssh.spec
#如果编译过程中报 openssl-devel 的问题,可以下面注释掉依赖
sed -i ''s/BuildRequires: openssl-devel < 1.1/#BuildRequires: openssl-devel < 1.1/g'' openssh.spec
2. 安装包说明
[root@testserver3 tmp]# ll
total 8300
-rw-r--r--. 1 root root 4034560 Jan 8 11:13 openssh-8.0p1-1.el7.offline.tar #U 盘携带包
-rw-r--r--. 1 root root 4464640 Jan 7 16:44 openssh-8.3p1-1.el7.offline.tar
[root@testserver3 tmp]# tar xf openssh-8.0p1-1.el7.offline.tar
[root@testserver3 tmp]# ll openssh-8.0p1-1.el7.offline
total 3936
-rw-r--r--. 1 root root 514232 Jan 8 11:12 openssh-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 505616 Jan 8 11:12 openssh-clients-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 2603832 Jan 8 11:12 openssh-debuginfo-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 400260 Jan 8 11:12 openssh-server-8.0p1-1.el7.centos.x86_64.rpm
[root@testserver3 openssl-1.1.1i.el7.offline]#
注:以上 rpm 包为根据官方源码包 openssh-8.0p1.tar.gz rpmbuild 生成
3.安装
2.1.安装前查看状态
[root@testserver3 openssh-8.0p1-1.el7.offline]# rpm -qa |grep openssh
openssh-server-7.4p1-16.el7.x86_64
openssh-clients-7.4p1-16.el7.x86_64
openssh-7.4p1-16.el7.x86_64
2.2.执行升级
[root@testserver3 openssh-8.0p1-1.el7.offline]# ll
total 3936
-rw-r--r--. 1 root root 514232 Jan 8 11:12 openssh-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 505616 Jan 8 11:12 openssh-clients-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 2603832 Jan 8 11:12 openssh-debuginfo-8.0p1-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 400260 Jan 8 11:12 openssh-server-8.0p1-1.el7.centos.x86_64.rpm
[root@testserver3 openssh-8.0p1-1.el7.offline]# rpm -Uvh *.rpm
Preparing... ################################# [100%]
Updating / installing...
1:openssh-8.0p1-1.el7.centos ################################# [ 14%]
2:openssh-clients-8.0p1-1.el7.cento################################# [ 29%]
3:openssh-server-8.0p1-1.el7.centos################################# [ 43%]
4:openssh-debuginfo-8.0p1-1.el7.cen################################# [ 57%]
Cleaning up / removing...
5:openssh-server-7.4p1-16.el7 ################################# [ 71%]
6:openssh-clients-7.4p1-16.el7 ################################# [ 86%]
7:openssh-7.4p1-16.el7 ################################# [100%]
2.3.安装新版本及验证
[root@testserver3 openssh-8.0p1-1.el7.offline]# rpm -qa |grep openssh
openssh-clients-8.0p1-1.el7.centos.x86_64
openssh-debuginfo-8.0p1-1.el7.centos.x86_64
openssh-8.0p1-1.el7.centos.x86_64
openssh-server-8.0p1-1.el7.centos.x86_64
[root@testserver3 openssh-8.0p1-1.el7.offline]# ssh -V
OpenSSH_8.0p1, OpenSSL 1.0.2k-fips 26 Jan 2017
以上 openssh 的版本更新成功,但 ssh 无法启动,下面操作去解决。
2.4.更新下面 3 个 sshd_config 配置参数如下:
# grep -E ''PermitRootLogin|UsePAM|PasswordAuthentication'' /etc/ssh/sshd_config |grep -Ev ''^#''
PermitRootLogin yes
PasswordAuthentication yes
UsePAM no
2.5.重启 sshd 服务,验证 SSH 可正常登陆
[root@testserver3 openssh-8.0p1-1.el7.offline]# systemctl restart sshd
")
centos7 升级 openssl1.1.1i(rpmbuild 打包后 rpm 方式升级)
此文档提供方法为官方源码 build 成 rpm 后,用 rpm 进行升级,在 Centos7.5.1804 下实现,其他环境未经测试(南网数据库环境为 7.5.1804)。
1,
#下面内容可拷贝成脚本执行
#!/bin/bash
set -e
set -v
mkdir ~/openssl && cd ~/openssl
yum -y install \
curl \
which \
make \
gcc \
perl \
perl-WWW-Curl \
rpm-build
# Get openssl tarball
cp /root/openssl-1.1.1i.tar.gz ./
# SPEC file
cat << ''EOF'' > ~/openssl/openssl.spec
Summary: OpenSSL 1.1.1i for Centos
Name: openssl
Version: %{?version}%{!?version:1.1.1i}
Release: 1%{?dist}
Obsoletes: %{name} <= %{version}
Provides: %{name} = %{version}
URL: https://www.openssl.org/
License: GPLv2+
Source: https://www.openssl.org/source/%{name}-%{version}.tar.gz
BuildRequires: make gcc perl perl-WWW-Curl
BuildRoot: %{_tmppath}/%{name}-%{version}-%{release}-root
%global openssldir /usr/openssl
%description
OpenSSL RPM for version 1.1.1i on Centos
%package devel
Summary: Development files for programs which will use the openssl library
Group: Development/Libraries
Requires: %{name} = %{version}-%{release}
%description devel
OpenSSL RPM for version 1.1.1i on Centos (development package)
%prep
%setup -q
%build
./config --prefix=%{openssldir} --openssldir=%{openssldir}
make
%install
[ "%{buildroot}" != "/" ] && %{__rm} -rf %{buildroot}
%make_install
mkdir -p %{buildroot}%{_bindir}
mkdir -p %{buildroot}%{_libdir}
ln -sf %{openssldir}/lib/libssl.so.1.1 %{buildroot}%{_libdir}
ln -sf %{openssldir}/lib/libcrypto.so.1.1 %{buildroot}%{_libdir}
ln -sf %{openssldir}/bin/openssl %{buildroot}%{_bindir}
%clean
[ "%{buildroot}" != "/" ] && %{__rm} -rf %{buildroot}
%files
%{openssldir}
%defattr(-,root,root)
/usr/bin/openssl
/usr/lib64/libcrypto.so.1.1
/usr/lib64/libssl.so.1.1
%files devel
%{openssldir}/include/*
%defattr(-,root,root)
%post -p /sbin/ldconfig
%postun -p /sbin/ldconfig
EOF
mkdir -p /root/rpmbuild/{BUILD,RPMS,SOURCES,SPECS,SRPMS}
cp ~/openssl/openssl.spec /root/rpmbuild/SPECS/openssl.spec
mv openssl-1.1.1i.tar.gz /root/rpmbuild/SOURCES
cd /root/rpmbuild/SPECS && \
rpmbuild \
-D "version 1.1.1i" \
-ba openssl.spec
# Before Uninstall Openssl : rpm -qa openssl
# Uninstall Current Openssl Vesion : yum -y remove openssl
# For install: rpm -ivvh /root/rpmbuild/RPMS/x86_64/openssl-1.1.1i-1.el7.x86_64.rpm --nodeps
# Verify install: rpm -qa openssl
# openssl version1. 安装包说明
[root@testserver3 tmp]# ls
openssl-1.1.1i.el7.offline.tar #U盘带此包
[root@testserver3 tmp]# tar xf openssl-1.1.1i.el7.offline.tar
[root@testserver3 tmp]# ls
openssl-1.1.1i.el7.offline openssl-1.1.1i.el7.offline.tar
[root@testserver3 tmp]# cd openssl-1.1.1i.el7.offline
[root@testserver3 openssl-1.1.1i.el7.offline]# ll
total 5636
-rw-r--r--. 1 root root 5395212 Jan 7 15:14 openssl-1.1.1i-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 133324 Jan 7 15:14 openssl-debuginfo-1.1.1i-1.el7.centos.x86_64.rpm
-rw-r--r--. 1 root root 234584 Jan 7 15:14 openssl-devel-1.1.1i-1.el7.centos.x86_64.rpm
[root@testserver3 openssl-1.1.1i.el7.offline]#
注:以上 rpm 包为根据官方源码包 openssl-1.1.1i.tar.gz rpmbuild 生成,本升级只用到 openssl-1.1.1i-1.el7.centos.x86_64.rpm 这个包。(rpmbuild 打包脚本后面提供)
2.安装
2.1.安装前查看状态
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -aq openssl
openssl-1.0.2k-12.el7.x86_64
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -qa |grep openssl
openssl-libs-1.0.2k-12.el7.x86_64
openssl-1.0.2k-12.el7.x86_64
xmlsec1-openssl-1.2.20-7.el7_4.x86_642.2.卸载当前版本 openssl
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -e openssl –nodeps
[root@testserver3 openssl-1.1.1i.el7.offline]# openssl
-bash: /usr/bin/openssl: No such file or directory
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -aq openssl
[root@testserver3 openssl-1.1.1i.el7.offline]#
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -qa |grep openssl
openssl-libs-1.0.2k-12.el7.x86_64
xmlsec1-openssl-1.2.20-7.el7_4.x86_642.3.安装新版本及验证
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -ivh openssl-1.1.1i-1.el7.centos.x86_64.rpm --nodeps
Preparing... ################################# [100%]
Updating / installing...
1:openssl-1.1.1i-1.el7.centos ################################# [100%]
[root@testserver3 openssl-1.1.1i.el7.offline]#
[root@testserver3 openssl-1.1.1i.el7.offline]#
[root@testserver3 openssl-1.1.1i.el7.offline]# rpm -aq openssl
openssl-1.1.1i-1.el7.centos.x86_64
[root@testserver3 openssl-1.1.1i.el7.offline]#
[root@testserver3 openssl-1.1.1i.el7.offline]# openssl version
OpenSSL 1.1.1i 8 Dec 2020注:更新后要验证服务器可以正常登陆
我们今天的关于RPM 包 rpmbuild SPEC 文件深度说明和rpm package的分享已经告一段落,感谢您的关注,如果您想了解更多关于centos – rpmbuild库注册’需要’、centos – 禁用rpmbuild自动要求查找、centos7 rpmbuild 打包 openssh8.0p1 并升级、centos7 升级 openssl1.1.1i(rpmbuild 打包后 rpm 方式升级)的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

