针对right_join和mutate不会保留R中的索引这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展(转载)Mysql----Join用法(Innerjoin,Leftjoin,Right
针对right_join和mutate不会保留R中的索引这个问题,本篇文章进行了详细的解答,同时本文还将给你拓展(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化、Binary XML file line #2: You must supply a layout_height attribute inflate、Hive的join操作,left join,right join,inner join、inner join 与 left join 和 right join 之间的区别等相关知识,希望可以帮助到你。
本文目录一览:- right_join和mutate不会保留R中的索引
- (转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化
- Binary XML file line #2: You must supply a layout_height attribute inflate
- Hive的join操作,left join,right join,inner join
- inner join 与 left join 和 right join 之间的区别

right_join和mutate不会保留R中的索引
对于dplyr,如果您执行right_join(x,y),则结果将包括x的匹配行的子集,然后是y的不匹配行的子集。
从R文档中有关变异联接的文档中,返回的值为:
与x具有相同类型的对象。的行和列的顺序 x尽可能保留。输出具有以下内容 属性:
对于inner_join(),是x行的子集。对于left_join(),所有x行。对于 right_join(),x行的子集,后跟不匹配的y行。对于 full_join(),全部x行,后跟不匹配的y行。
这就是为什么在结果data.frame的开头有3个匹配的行。
要获得期望的结果并保留df的行顺序,请尝试使用left_join,如下所示:
df2 <- stack(master) %>%
type.convert(as.is = TRUE)
df %>%
left_join(df2,by = c('column' = 'values')) %>%
mutate(output = coalesce(ind,column))
输出
column ind output
1 <NA>
2 <NA>
3 <NA>
4 <NA>
5 <NA>
6 <NA>
7 <NA>
8 <NA>
9 <NA>
10 <NA>
11 <NA>
12 <NA>
13 <NA>
14 <NA>
15 <NA>
16 <NA>
17 P Parent Parent
18 C Child Child
19 C Child Child
 Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化")
(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化
http://blog.csdn.net/ochangwen/article/details/52346610
前期数据准备
CREATE TABLE atable(
aID int( 1 ) AUTO_INCREMENT PRIMARY KEY ,
aNum char( 20 ));
CREATE TABLE btable(
bID int( 1 ) NOT NULL AUTO_INCREMENT PRIMARY KEY ,
bName char( 20 ) );
INSERT INTO atable
VALUES ( 1, ''a20050111'' ) , ( 2, ''a20050112'' ) , ( 3, ''a20050113'' ) , ( 4, ''a20050114'' ) , ( 5, ''a20050115'' ) ;
INSERT INTO btable
VALUES ( 1, '' 2006032401'' ) , ( 2, ''2006032402'' ) , ( 3, ''2006032403'' ) , ( 4, ''2006032404'' ) , ( 8, ''2006032408'' ) ;
-------------------------------------------------------------------------------------------
atable:左表;btable:右表。
JOIN 按照功能大致分为如下三类:
1).inner join(内连接,或等值连接):取得两个表中存在连接匹配关系的记录。
2).left join(左连接):取得左表(atable)完全记录,即是右表(btable)并无对应匹配记录。
3).right join(右连接):与 LEFT JOIN 相反,取得右表(btable)完全记录,即是左表(atable)并无匹配对应记录。
注意:mysql不支持Full join,不过可以通过 union 关键字来合并 left join 与 right join来模拟full join.
一、Inner join
内连接,也叫等值连接,inner join产生同时符合A和B的一组数据。
接下来给出一个列子用于解释下面几种分类。如下两个表(A,B)
- mysql> select * from atable inner join btable on atable.aid=btable.bid;
- +-----+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- +-----+-----------+-----+-------------+

二、Left join
left join,(或left outer join:在Mysql中两者等价,推荐使用left join.)左连接从左表(A)产生一套完整的记录,与匹配的记录(右表(B)) .如果没有匹配,右侧将包含null。
- mysql> select * from atable left join btable on atable.aid=btable.bid;
- +-----+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | NULL | NULL |
- +-----+-----------+------+-------------+

------------------------------------------------------------------------------------------------------------
2).如果想只从左表(A)中产生一套记录,但不包含右表(B)的记录,可以通过设置where语句来执行,如下
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> where atable.aid is null or btable.bid is null;
- +-----+-----------+------+-------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------+
- | 5 | a20050115 | NULL | NULL |
- +-----+-----------+------+-------+

-----------------------------------------------------------------------------------------
同理,还可以模拟inner join. 如下:
- mysql> select * from atable left join btable on atable.aid=btable.bid where atable.aid is not null and btable.bid is not null;
- +-----+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- +-----+-----------+------+-------------+
------------------------------------------------------------------------------------------
三、Right join
同Left join
- mysql> select * from atable right join btable on atable.aid=btable.bid;
- +------+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +------+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+-----+-------------+
四、差集
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> where btable.bid is null
- -> union
- -> select * from atable right join btable on atable.aid=btable.bid
- -> where atable.aid is null;
- +------+-----------+------+------------+
- | aID | aNum | bID | bName |
- +------+-----------+------+------------+
- | 5 | a20050115 | NULL | NULL |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+------+------------+

-----------------------------------------------------------------------------------
五.Cross join
交叉连接,得到的结果是两个表的乘积,即笛卡尔积
笛卡尔(Descartes)乘积又叫直积。假设集合A={a,b},集合B={0,1,2},则两个集合的笛卡尔积为{(a,0),(a,1),(a,2),(b,0),(b,1), (b,2)}。可以扩展到多个集合的情况。类似的例子有,如果A表示某学校学生的集合,B表示该学校所有课程的集合,则A与B的笛卡尔积表示所有可能的选课情况。
- mysql> select * from atable cross join btable;
- +-----+-----------+-----+-------------+
- | aID | aNum | bID | bName |
- +-----+-----------+-----+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 1 | 2006032401 |
- | 3 | a20050113 | 1 | 2006032401 |
- | 4 | a20050114 | 1 | 2006032401 |
- | 5 | a20050115 | 1 | 2006032401 |
- | 1 | a20050111 | 2 | 2006032402 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 2 | 2006032402 |
- | 4 | a20050114 | 2 | 2006032402 |
- | 5 | a20050115 | 2 | 2006032402 |
- | 1 | a20050111 | 3 | 2006032403 |
- | 2 | a20050112 | 3 | 2006032403 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 3 | 2006032403 |
- | 5 | a20050115 | 3 | 2006032403 |
- | 1 | a20050111 | 4 | 2006032404 |
- | 2 | a20050112 | 4 | 2006032404 |
- | 3 | a20050113 | 4 | 2006032404 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | 4 | 2006032404 |
- | 1 | a20050111 | 8 | 2006032408 |
- | 2 | a20050112 | 8 | 2006032408 |
- | 3 | a20050113 | 8 | 2006032408 |
- | 4 | a20050114 | 8 | 2006032408 |
- | 5 | a20050115 | 8 | 2006032408 |
- +-----+-----------+-----+-------------+
- 25 rows in set (0.00 sec)
- <pre><code class="hljs cs"><span class="hljs-function">#再执行:mysql> <span class="hljs-keyword">select</span> * <span class="hljs-keyword">from</span> A inner <span class="hljs-keyword">join</span> B</span>; 试一试 (与上面的结果一样)
- <span class="hljs-meta">#在执行mysql> select * from A cross join B on A.name = B.name; 试一试</span></code>
实际上,在 MySQL 中(仅限于 MySQL) CROSS JOIN 与 INNER JOIN 的表现是一样的,在不指定 ON 条件得到的结果都是笛卡尔积,反之取得两个表完全匹配的结果。 inner join 与 cross join 可以省略 inner 或 cross关键字,因此下面的 SQL 效果是一样的:
- ... FROM table1 INNER JOIN table2
- ... FROM table1 CROSS JOIN table2
- ... FROM table1 JOIN table2
六.union实现Full join
全连接产生的所有记录(双方匹配记录)在表A和表B。如果没有匹配,则对面将包含null。与差集类似。
- mysql> select * from atable left join btable on atable.aid=btable.bid
- -> union
- -> select * from atable right join btable on atable.aid=btable.bid;
- +------+-----------+------+-------------+
- | aID | aNum | bID | bName |
- +------+-----------+------+-------------+
- | 1 | a20050111 | 1 | 2006032401 |
- | 2 | a20050112 | 2 | 2006032402 |
- | 3 | a20050113 | 3 | 2006032403 |
- | 4 | a20050114 | 4 | 2006032404 |
- | 5 | a20050115 | NULL | NULL |
- | NULL | NULL | 8 | 2006032408 |
- +------+-----------+------+-------------+

--------------------------------------------------------------------------------------------------------
七.性能优化
1.显示(explicit) inner join VS 隐式(implicit) inner join
- select * from
- table a inner join table b
- on a.id = b.id;
VS
- select a.*, b.*
- from table a, table b
- where a.id = b.id;
数据库中比较(10w数据)得之,它们用时几乎相同,第一个是显示的inner join,后一个是隐式的inner join。
2.left join/right join VS inner join
尽量用inner join.避免 left join 和 null.
在使用left join(或right join)时,应该清楚的知道以下几点:
(1). on与 where的执行顺序
ON 条件(“A LEFT JOIN B ON 条件表达式”中的ON)用来决定如何从 B 表中检索数据行。如果 B 表中没有任何一行数据匹配 ON 的条件,将会额外生成一行所有列为 NULL 的数据,在匹配阶段 WHERE 子句的条件都不会被使用。仅在匹配阶段完成以后,WHERE 子句条件才会被使用。它将从匹配阶段产生的数据中检索过滤。
所以我们要注意:在使用Left (right) join的时候,一定要在先给出尽可能多的匹配满足条件,减少Where的执行。如:
- select * from A
- inner join B on B.name = A.name
- left join C on C.name = B.name
- left join D on D.id = C.id
- where C.status>1 and D.status=1;
下面这种写法更省时
- select * from A
- inner join B on B.name = A.name
- left join C on C.name = B.name and C.status>1
- left join D on D.id = C.id and D.status=1
(2).注意ON 子句和 WHERE 子句的不同
- mysql> SELECT * FROM product LEFT JOIN product_details
- ON (product.id = product_details.id)
- AND product_details.id=2;
- +----+--------+------+--------+-------+
- | id | amount | id | weight | exist |
- +----+--------+------+--------+-------+
- | 1 | 100 | NULL | NULL | NULL |
- | 2 | 200 | 2 | 22 | 0 |
- | 3 | 300 | NULL | NULL | NULL |
- | 4 | 400 | NULL | NULL | NULL |
- +----+--------+------+--------+-------+
- 4 rows in set (0.00 sec)
- mysql> SELECT * FROM product LEFT JOIN product_details
- ON (product.id = product_details.id)
- WHERE product_details.id=2;
- +----+--------+----+--------+-------+
- | id | amount | id | weight | exist |
- +----+--------+----+--------+-------+
- | 2 | 200 | 2 | 22 | 0 |
- +----+--------+----+--------+-------+
- 1 row in set (0.01 sec)
从上可知,第一条查询使用 ON 条件决定了从 LEFT JOIN的 product_details表中检索符合的所有数据行。第二条查询做了简单的LEFT JOIN,然后使用 WHERE 子句从 LEFT JOIN的数据中过滤掉不符合条件的数据行。
(3).尽量避免子查询,而用join
往往性能这玩意儿,更多时候体现在数据量比较大的时候,此时,我们应该避免复杂的子查询。如下:
- insert into t1(a1) select b1 from t2
- where not exists(select 1 from t1 where t1.id = t2.r_id);
下面这个更好
- insert into t1(a1)
- select b1 from t2
- left join (select distinct t1.id from t1 ) t1 on t1.id = t2.r_id
- where t1.id is null;

Binary XML file line #2: You must supply a layout_height attribute inflate
Android开发中遇到的奇葩问题之一:
java.lang.NullPointerException,java.lang.RuntimeException:Binary XML file line #2: You must supply a layout_height attribute inflate,
遇到这个问题说明你在非主流上测试,或者说是在部分模拟器上测试,或者是在写布局文件的时候少了什么东西,比如是写成这样的:
<Button xmlns:android="http//schemas.android.com/apk/res/android"
android:layout_width="30dp"
android:layout_height="10dp"
android:text="test" />
那你只是需要改成这样的 (区别是http后面少了冒号哈哈哈哈哈哈)
<Button xmlns:android="http://schemas.android.com/apk/res/android"
android:layout_width="30dp"
android:layout_height="10dp"
android:text="test" />
或者这样的错误
<LinearLayoutxmlns:android="http://schemas.android.com/apk/res/android">
android:layout_width="20dp"
android:layout_height="5dp"
android:id="@+id/tablerow01">
其他的遇到的情况是如果不是在include的时候出现的那么请关闭浏览器标签,重新找解决方案,否则请听我重现我的bug。
情景重现:我在添加布局的时候是这么写的
<include
android:id="@+id/test"
layout="@layout/activity_base"></include>
然后,在大部分的测试机上跑起来都是正常的,当用到OPPO A31 手机的时候报错,错误就是以上显示的。
这个时候只需要这只include的width和height属性就好就像这样
<include
android:id="@+id/test"
layout="@layout/activity_base"
android:layout_width="match_parent"
android:layout_height="30dp"></include>
(PS :如果写成如下情况也还是原来的错误)
<include
android:id="@+id/test"
layout="@layout/activity_base"
android:layout_width="match_parent"
android:layout_height="@dimen/fab_margin"></include>
这个错误具体的原理我百思不得其解,如有解决希望多交流(PoarryScript@gmail.com)

Hive的join操作,left join,right join,inner join
hive执行引擎会将hql转化成mapreduce作业
map side join除外,map负责分发数据,具体的join在reduce端进行
1.如果多表基于不同的列做join,则无法在一轮mapreduce将相关数据shuffle到统一一个reducer,对于多表的join,hive会将前面的表缓存在reducer的内存中,然后后面的表会流式的进入reducer做join.为了防止oom,通常将大表放在最后。
hive中分为map join和common join
common join
map阶段:
读取源表数据,
map输出以join on条件中的列为key,如果join有多个关联键,则以这些关联键的组合作为key.
value为 join之后所关心的列,也会包含tag信息,用于标注value对应哪个表
按key进行排序
shuffle阶段:
根据key进行hash,根据hash推送到不同的reduce中,保证两个表中相同的key在同一个reduce中
reduce阶段:
通过key完成join,通过tag来识别不同表的数据
map join
通常用于一个小表join大表,小表标准由hive.mapjoin.smalltable.filesize决定,设置hive.auto.convert.join为true,小表达到标准会自动转为mapjoin
mapjoin可以看做broadcast join,将小表数据加载到内存,没有shuffle过程,加快处理速度,但是数据量大容易出现oom,
普通join会有shuffle,影响效率,同时会出现数据倾斜

inner join 与 left join 和 right join 之间的区别

要对这个理解之前,我们先对相关连接来做一个回忆。
首先做试验的两张表数据如下:student 表和对应的 grade 成绩表
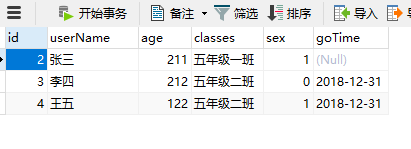

1:inner join ,inner join 可以理解为 “有效的连接”,就是根据 on 后面的关联条件,两张表中都有的数据才会显示,下面举个例子
SELECT
*
FROM
student stu
INNER JOIN grade gra on stu.id = gra.c_stuId查询结果如下:
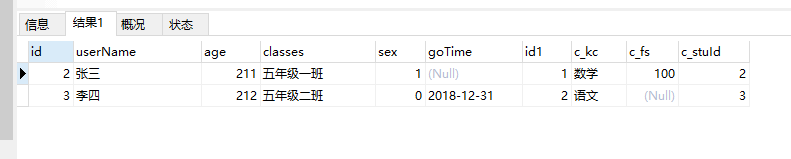
可以看到,id=3 的这条数据并没有查出来,这是因为在 grade 里面,c_stuId 并没有等于 3 的这条数据。根据上面也可以看出,其实 INNER JOIN 可以直接用 where 来替代。
2:left join:理解为 “主全显,后看 on”(主表数据不受影响),即主表全显示,连接后的表看 on 后面的选择条件,left join 后面的条件,并不会影响左表的数据显示,左表数据会全部显示出来,连接的表如果没有数据,则全部显示为 null,看下面例子:
SELECT
*
FROM
student stu
LEFT JOIN grade gra on stu.id = gra.c_stuId结果如下:

可以看出,左表 student 数据全部都显示出来,而连接的表,注意看红色部分,因为没有数据,则全部显示为 null。这也和刚刚说的想符合,连接的主表 student 数据不受影响,全显示,连接后的表数据看 on 后面的条件。
3:right join right join 理解为 “主看 on, 后全显”(右表数据不受影响),即右表数据全部显示,主表数据看 on 后面的选择条件,看下面例子:
1 SELECT
2 *
3 FROM
4 student stu
5 RIGHT JOIN grade gra on stu.id = gra.c_stuId 
可以看出。right join 对右边连接的 grade 表数据没有影响,全部显示出来,而对左表的数据则是根据筛选后的条件来显示,其余的显示为 null;
综上,可以对他们之间的使用有较基础的理解。
今天关于right_join和mutate不会保留R中的索引的分享就到这里,希望大家有所收获,若想了解更多关于(转载) Mysql----Join用法(Inner join,Left join,Right join, Cross join, Union模拟Full join)及---性能优化、Binary XML file line #2: You must supply a layout_height attribute inflate、Hive的join操作,left join,right join,inner join、inner join 与 left join 和 right join 之间的区别等相关知识,可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

