本文的目的是介绍Keras:重塑连接LSTM和转换的详细情况,特别关注keras搭建lstm网络的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Keras:重塑连接L
本文的目的是介绍Keras:重塑连接LSTM和转换的详细情况,特别关注keras搭建lstm网络的相关信息。我们将通过专业的研究、有关数据的分析等多种方式,为您呈现一个全面的了解Keras:重塑连接LSTM和转换的机会,同时也不会遗漏关于BI-LSTM and CRF using Keras、Keras + LSTM 做回归demo、keras bilstm 序列标注、Keras LSTM带屏蔽层的可变长度输入的知识。
本文目录一览:- Keras:重塑连接LSTM和转换(keras搭建lstm网络)
- BI-LSTM and CRF using Keras
- Keras + LSTM 做回归demo
- keras bilstm 序列标注
- Keras LSTM带屏蔽层的可变长度输入
")
Keras:重塑连接LSTM和转换(keras搭建lstm网络)
这个问题也作为github问题存在。我想在Keras中建立一个包含2D卷积和LSTM层的神经网络。
网络应将MNIST分类。MNIST中的训练数据是60000个手写数字从0到9的灰度图像。每个图像为28x28像素。
我将图像分为四个部分(左/右,上/下),并以四个顺序重新排列它们,以获取LSTM的序列。
| | |1 | 2|
|image| -> ------- -> 4 sequences: |1|2|3|4|,|4|3|2|1|,|1|3|2|4|,|4|2|3|1|
| | |3 | 4|
其中一个小子图像的尺寸为14 x14。这四个序列沿宽度堆叠在一起(宽度或高度无关)。
这将创建形状为[60000,4,1,56,14]的向量,其中:
- 60000是样本数
- 4是序列中的元素数(时间步数)
- 1是颜色的深度(灰度)
- 56和14是宽度和高度
现在,应该将其提供给Keras模型。问题是要更改CNN和LSTM之间的输入尺寸。我在网上搜索并发现了以下问题:Python
keras如何在将卷积层转换为lstm层后更改输入的大小
解决方案似乎是一个Reshape层,该层使图像变平但保留了时间步长(与Flatten层相反,该层会使除batch_size之外的所有内容都塌陷)。
到目前为止,这是我的代码:
nb_filters=32
kernel_size=(3,3)
pool_size=(2,2)
nb_classes=10
batch_size=64
model=Sequential()
model.add(Convolution2D(nb_filters,kernel_size[0],kernel_size[1],border_mode="valid",input_shape=[1,56,14]))
model.add(Activation("relu"))
model.add(Convolution2D(nb_filters,kernel_size[1]))
model.add(Activation("relu"))
model.add(MaxPooling2D(pool_size=pool_size))
model.add(Reshape((56*14,)))
model.add(Dropout(0.25))
model.add(LSTM(5))
model.add(Dense(50))
model.add(Dense(nb_classes))
model.add(Activation("softmax"))
此代码创建一条错误消息:
ValueError:新数组的总大小必须保持不变
显然,“重塑”层的输入不正确。另外,我也尝试将时间步长传递给Reshape层:
model.add(Reshape((4,56*14)))
这感觉不对,在任何情况下,错误都保持不变。
我这样做正确吗?重塑层是连接CNN和LSTM的合适工具吗?
解决这个问题的方法相当复杂。例如:https :
//github.com/fchollet/keras/pull/1456
一个TimeDistributed层,它似乎在随后的层中隐藏了时间步维度。
或这样:https :
//github.com/anayebi/keras-extra
一组用于组合CNN和LSTM的特殊层。
如果有一个简单的Reshape可以解决问题,为什么会有这么复杂的解决方案(至少对我来说它们看起来很复杂)?
更新 :
令人尴尬的是,我忘记了合并和(由于缺乏填充)卷积也会改变尺寸。
kgrm建议我使用它model.summary()来检查尺寸。
重塑层之前的层的输出是(None,32,26,5),我将重塑更改为:model.add(Reshape((32*26*5,)))。
现在ValueError消失了,相反LSTM抱怨了:
例外:输入0与lstm_5层不兼容:预期ndim = 3,找到的ndim = 2
似乎我需要将时间步维度传递给整个网络。我怎样才能做到这一点
?如果我将其添加到卷积的input_shape中,它也会抱怨:Convolution2D(nb_filters,input_shape=[4,1,14])
例外:输入0与层卷积不兼容2d_44:预期ndim = 4,找到的ndim = 5

BI-LSTM and CRF using Keras
问题 1:CUDA_ERROR_OUT_OF_MEMORY: How to activate multiple GPUs from Keras in Tensorflow
import keras.backend as K
config = K.tf.ConfigProto()
config.gpu_options.allow_growth = True
session = K.tf.Session(config=config)
讀作者的 code 就能了解數據的格式了。
在 process_data.py 檔案裡。
稍微解釋一下。
### 原始數據 ###
老 B-PER
王 I-PER
很 O
喜 O
歡 O
中 B-LOC
國 I-LOC
妹 O
子 O
### 要丟進 LSTM 的數據 ###
X_train 應該是長這樣 [0, 1, 15, 24, 65, 102, 103, 54, 63] 之類的,這裡代表每個字的 index。
y_train 應該是長這樣 [1, 2, 0, 0, 0, 3, 4, 0, 0] 之類的,代表對應到的字的 NE。
最後再把每個句子做個 padding 就能丟進 LSTM 了。
至於怎麼轉換成數據序列的,就請您自行研究研究 process_data.py 唄!
配置显存
https://www.jianshu.com/p/99fca5b7fd8a
==================================
使用预训练词向量
=================================
Keras 模型中使用预训练的词向量
Word2vec,为一群用来产生词嵌入的相关模型。这些模型为浅而双层的神经网络,用来训练以重新建构语言学之词文本。网络以词表现,并且需猜测相邻位置的输入词,在 word2vec 中词袋模型假设下,词的顺序是不重要的。训练完成之后,word2vec 模型可用来映射每个词到一个向量,可用来表示词对词之间的关系。该向量为神经网络之隐藏层。
https://zh.wikipedia.org/wiki/Word2vec
在这篇 在 Keras 模型中使用预训练的词向量 讲述了如何利用预先训练好的 GloVe 模型,本文基本大同小异。只写一些不同的地方,更想的可以看这篇文章。
总体思路就是给 Embedding 层提供一个 [ word_token : word_vector] 的词典来初始化向量,并且标记为不可训练。
解析 word2vec 模型,其中:
word2idx保存词语和 token 的对应关系,语料库 tokenize 时候需要。embeddings_matrix存储所有 word2vec 中所有向量的数组,用于初始化模型Embedding层
|
|
使用方法:
|
|

Keras + LSTM 做回归demo
学习神经网络
想拿lstm 做回归, 网上找demo 基本三种: sin拟合cos 那个, 比特币价格预测(我用相同的代码和数据没有跑成功, 我太菜了)和keras 的一个例子
我基于keras 那个实现了一个, 这里贴一下我的代码.
import numpy as np
np.random.seed(1337)
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
import keras
from keras.models import Sequential
from keras.layers import Activation
from keras.layers import LSTM
from keras.layers import Dropout
from keras.layers import Dense
# 数据的数量
datan = 400
X = np.linspace(-1, 2, datan)
np.random.shuffle(X)
# 构造y y=3*x + 2 并加上一个0-0.5 的随机数
Y = 3.3 * X + 2 + np.random.normal(0, 0.5, (datan, ))
# 展示一下数据
plt.scatter(X, Y)
plt.show() 
# 训练集测试集划分 2:1
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.33, random_state=42)
# 一些参数
neurons = 128
activation_function = ''tanh'' # 激活函数
loss = ''mse'' # 损失函数
optimizer="adam" # 优化函数
dropout = 0.01
model = Sequential()
model.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_function))
model.add(Dropout(dropout))
model.add(LSTM(neurons, return_sequences=True, activation=activation_function))
model.add(Dropout(dropout))
model.add(LSTM(neurons, activation=activation_function))
model.add(Dropout(dropout))
model.add(Dense(output_dim=1, input_dim=1))
#
model.compile(loss=loss, optimizer=optimizer)
# training 训练
print(''Training -----------'')
epochs = 2001
for step in range(epochs):
cost = model.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f''{step} train cost: '', cost)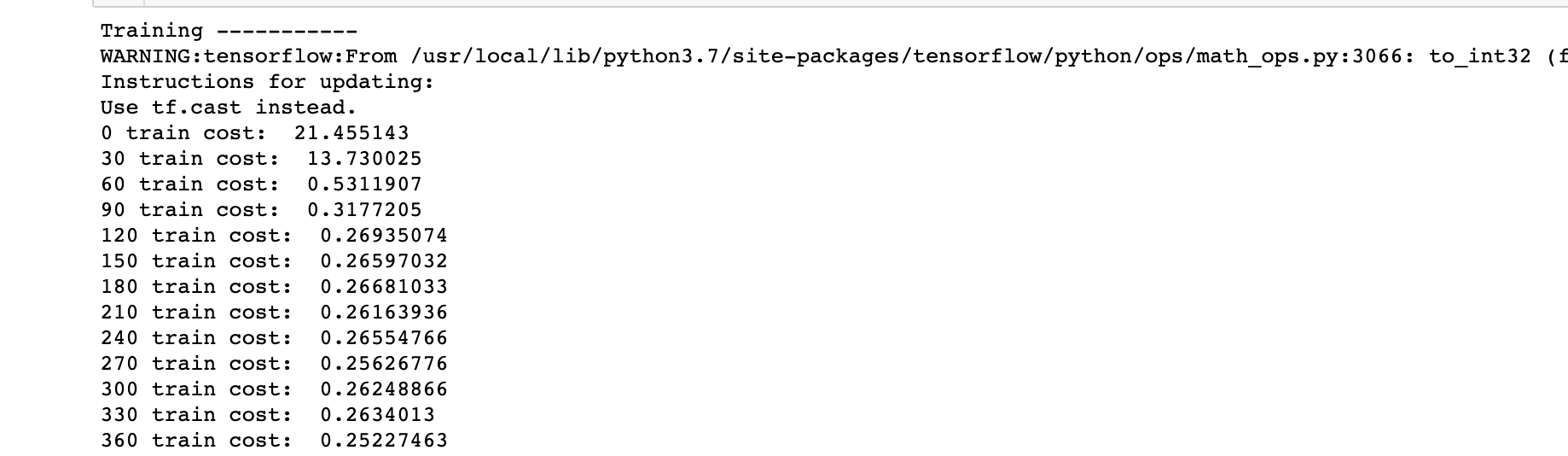
# 测试
print(''Testing ------------'')
cost = model.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print(''test cost:'', cost) 
# 打印预测结果
Y_pred = model.predict(X_test[:, np.newaxis, np.newaxis])
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred, ''ro'')
plt.show() 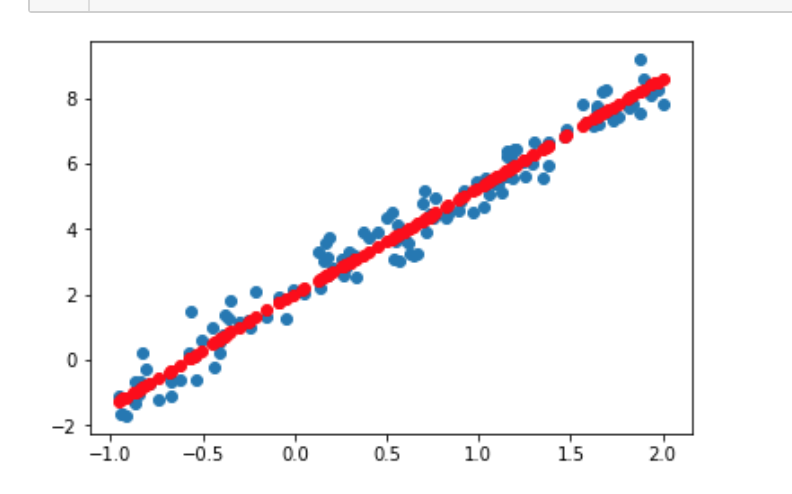
loss_history = {}
def run(X_train, Y_train, X_test, Y_test, epochs, activation_func=''tanh'', loss_func=''mse'', opt_func=''sgd''):
"""
这里是对上面代码的封装, 我测试了一下各种优化函数的效率
可用的目标函数
mean_squared_error或mse
mean_absolute_error或mae
mean_absolute_percentage_error或mape
mean_squared_logarithmic_error或msle
squared_hinge
hinge
categorical_hinge
binary_crossentropy(亦称作对数损失,logloss)
logcosh
categorical_crossentropy:亦称作多类的对数损失,注意使用该目标函数时,需要将标签转化为形如(nb_samples, nb_classes)的二值序列
sparse_categorical_crossentrop:如上,但接受稀疏标签。注意,使用该函数时仍然需要你的标签与输出值的维度相同,你可能需要在标签数据上增加一个维度:np.expand_dims(y,-1)
kullback_leibler_divergence:从预测值概率分布Q到真值概率分布P的信息增益,用以度量两个分布的差异.
poisson:即(predictions - targets * log(predictions))的均值
cosine_proximity:即预测值与真实标签的余弦距离平均值的相反数
优化函数
sgd
RMSprop
Adagrad
Adadelta
Adam
Adamax
Nadam
"""
mdl = Sequential()
mdl.add(LSTM(neurons, return_sequences=True, input_shape=(1, 1), activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, return_sequences=True, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(LSTM(neurons, activation=activation_func))
mdl.add(Dropout(dropout))
mdl.add(Dense(output_dim=1, input_dim=1))
#
mdl.compile(optimizer=opt_func, loss=loss_func)
#
print(''Training -----------'')
loss_history[opt_func] = []
for step in range(epochs):
cost = mdl.train_on_batch(X_train[:, np.newaxis, np.newaxis], Y_train)
if step % 30 == 0:
print(f''{step} train cost: '', cost)
loss_history[opt_func].append(cost)
# test
print(''Testing ------------'')
cost = mdl.evaluate(X_test[:, np.newaxis, np.newaxis], Y_test, batch_size=40)
print(''test cost:'', cost)
#
Y_pred = mdl.predict(X_test[:, np.newaxis, np.newaxis])
plt.scatter(X_test, Y_test)
plt.plot(X_test, Y_pred, ''ro'')
return plt
run(X_train, Y_train, X_test, Y_test, 2000)
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''Adagrad'')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''Nadam'')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''Adadelta'')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''RMSprop'')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''Adam'')
run(X_train, Y_train, X_test, Y_test, 2000, opt_func=''Adamax'')
#
arr = [i*30 for i in range(len(loss_history[''sgd'']))]
plt.plot(arr, loss_history[''sgd''], ''b--'')
plt.plot(arr, loss_history[''RMSprop''], ''r--'')
plt.plot(arr, loss_history[''Adagrad''], color=''orange'', line--'')
plt.plot(arr, loss_history[''Adadelta''], ''g--'')
plt.plot(arr, loss_history[''Adam''], color=''coral'', line--'')
plt.plot(arr, loss_history[''Adamax''], color=''tomato'', line--'')
plt.plot(arr, loss_history[''Nadam''], color=''darkkhaki'', line--'')
plt最快的是 adadelta, 最慢的sgd. 其他差不多.

keras bilstm 序列标注
from random import random
from numpy import array
from numpy import cumsum
from keras.models import Sequential
from keras.layers import LSTM
from keras.layers import Dense
from keras.layers import TimeDistributed
# create a sequence classification instance
def get_sequence(n_timesteps):
# create a sequence of random numbers in [0,1]
X = array([random() for _ in range(n_timesteps)])
# calculate cut-off value to change class values
limit = n_timesteps/4.0
# determine the class outcome for each item in cumulative sequence
y = array([0 if x < limit else 1 for x in cumsum(X)])
# reshape input and output data to be suitable for LSTMs
X = X.reshape(1, n_timesteps, 1)
y = y.reshape(1, n_timesteps, 1)
return X, y
# define problem properties
n_timesteps = 10
# define LSTM
model = Sequential()
model.add(LSTM(20, input_shape=(n_timesteps, 1), return_sequences=True))
model.add(TimeDistributed(Dense(1, activation=''sigmoid'')))
model.compile(loss=''binary_crossentropy'', optimizer=''adam'', metrics=[''acc''])
# train LSTM
for epoch in range(1000):
# generate new random sequence
X,y = get_sequence(n_timesteps)
# fit model for one epoch on this sequence
model.fit(X, y, epochs=1, batch_size=1, verbose=2)
# evaluate LSTM
X,y = get_sequence(n_timesteps)
yhat = model.predict_classes(X, verbose=0)
for i in range(n_timesteps):
print(''Expected:'', y[0, i], ''Predicted'', yhat[0, i])

Keras LSTM带屏蔽层的可变长度输入
我知道这是一个有很多问题的主题,但是我找不到解决问题的办法。
我正在使用遮罩层在可变长度输入上训练LSTM网络,但似乎没有任何效果。
输入形状(100、362、24),其中362为最大序列长度,特征为24,特征数为100,样本数为100(划分为75列/有效值为25)。
输出形状(100,362,1)随后转换为(100,362-N,1)。
这是我的网络的代码:
from keras import Sequential
from keras.layers import Embedding,Masking,LSTM,Lambda
import keras.backend as K
# O O O
# example for N:3 | | |
# O O O O O O
# | | | | | |
# O O O O O O
N = 5
y= y[:,N:,:]
x_train = x[:75]
x_test = x[75:]
y_train = y[:75]
y_test = y[75:]
model = Sequential()
model.add(Masking(mask_value=0.,input_shape=(timesteps,features)))
model.add(LSTM(128,return_sequences=True))
model.add(LSTM(64,return_sequences=True))
model.add(LSTM(1,return_sequences=True))
model.add(Lambda(lambda x: x[:,:]))
model.compile('adam','mae')
print(model.summary())
history = model.fit(x_train,y_train,epochs=3,batch_size=15,validation_data=[x_test,y_test])
我的数据最后被填充。例:
>> x_test[10,350]
array([0.,0.,0.],dtype=float32)
问题在于掩模层似乎没有作用。我可以看到训练过程中打印出的损耗值,它等于我计算出的没有遮罩的损耗值:
Layer (type) Output Shape Param #
=================================================================
masking_1 (Masking) (None,362,24) 0
_________________________________________________________________
lstm_1 (LSTM) (None,128) 78336
_________________________________________________________________
lstm_2 (LSTM) (None,64) 49408
_________________________________________________________________
lstm_3 (LSTM) (None,1) 264
_________________________________________________________________
lambda_1 (Lambda) (None,357,1) 0
=================================================================
Total params: 128,008
Trainable params: 128,008
Non-trainable params: 0
_________________________________________________________________
None
Train on 75 samples,validate on 25 samples
Epoch 1/3
75/75 [==============================] - 8s 113ms/step - loss: 0.1711 - val_loss: 0.1814
Epoch 2/3
75/75 [==============================] - 5s 64ms/step - loss: 0.1591 - val_loss: 0.1307
Epoch 3/3
75/75 [==============================] - 5s 63ms/step - loss: 0.1057 - val_loss: 0.1034
>> from sklearn.metrics import mean_absolute_error
>> out = model.predict(x_test,batch_size=1)
>> print('wo mask',mean_absolute_error(y_test.ravel(),out.ravel()))
>> print('w mask',mean_absolute_error(y_test[~(x_test[:,N:] == 0).all(axis=2)].ravel(),out[~(x_test[:,N:] == 0).all(axis=2)].ravel()))
wo mask 0.10343371
w mask 0.16236152
此外,如果我将nan值用作屏蔽的输出值,则可以看到nan在训练过程中传播(损耗等于nan)。
使遮罩层按预期工作时我缺少什么?
我们今天的关于Keras:重塑连接LSTM和转换和keras搭建lstm网络的分享已经告一段落,感谢您的关注,如果您想了解更多关于BI-LSTM and CRF using Keras、Keras + LSTM 做回归demo、keras bilstm 序列标注、Keras LSTM带屏蔽层的可变长度输入的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

