如果您想了解asp.net–使用XMLSchema和OpenXMLSDK进行WordML模板化和.net操作xml的知识,那么本篇文章将是您的不二之选。我们将深入剖析asp.net–使用XMLSche
如果您想了解asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化和.net操作xml的知识,那么本篇文章将是您的不二之选。我们将深入剖析asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化的各个方面,并为您解答.net操作xml的疑在这篇文章中,我们将为您介绍asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化的相关知识,同时也会详细的解释.net操作xml的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化(.net操作xml)
- 28.XSD(XML Schema Definition)用法实例介绍以及C#使用xsd文件验证XML格式
- C# Net 使用openxml提取word中的文本和图片并转为Html
- c# – 如何使用OpenXML SDK 2.5从word文档复制公式?
- c# – 如何使用xmlschemaset和xmlreader.create对xsd模式验证xml
")
asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化(.net操作xml)
我在Google上发现的唯一类似的东西似乎是用带有所需数据的文本元素替换CustomXmlBlock元素.这似乎……凌乱而脆弱.
我还有一个额外的复杂性,一些数据是分层的,包含部分的元素,然后是该部分中的项目.这似乎完全打破了上述方法.
那么,有人可以指出我这样做的正确方向,或建议一个更好的方法来处理模板形式的字母?
解决方法
>您正在做什么,XSD架构映射.这是在Word 2003中引入的.它实际上只是在Word版本中真正活跃,因为当Word 2007问世时,首选的新表单形式变为#2.
>内容控制.更多关于此的信息.
>试图和真实是书签.如果您有兴趣,可以看一篇文章here.
对于内容控件1,概念很简单:将内容控件包装在所需的层次结构中.也就是说,例如,有一个日期选择器内容控件和一个富文本内容控件,然后将它们分组.然后在Rich Text Content Control中放置一个组合框内容控件. Eric White在Processing all Content Parts in an Open XML WordprocessingML Document从Content Controls内部检索内容时撰写了一篇很好的入门文章.本文是对链接Using Open XML WordprocessingML Documents as Data Sources中内容控件的更全面的介绍.
内容控制的更多链接:
> Brian Jones的网站上有很多很棒的文章.我相信这是他的第一次:The Easy Way to Assemble Multiple Word Documents和Create a rich Word document based on your own custom XML (without the need for XSLT).
> Word Content Control Toolkit.可能是使用内容控件的最佳工具.
> Visual How To Content.这里有很多文章涉及内容控制.
1要在Word客户端中手动使用内容控件,请从“选项”中启用“开发人员”功能区,然后插入“内容控件”并从“开发人员功能区”中“控件”组的左侧部分设置其属性.
用法实例介绍以及C#使用xsd文件验证XML格式")
28.XSD(XML Schema Definition)用法实例介绍以及C#使用xsd文件验证XML格式
转自https://www.cnblogs.com/gdjlc/archive/2013/09/08/3308229.html
XML Schema 语言也称作 XML Schema 定义(XML Schema DeFinition,XSD),作用是定义 XML 文档的合法构建模块,类似 DTD,但更加强大。
作用有:
①定义可出现在文档中的元素
②定义可出现在文档中的属性
③定义哪个元素是子元素
④定义子元素的次序
⑤定义子元素的数目
⑥定义元素是否为空,或者是否可包含文本
⑦定义元素和属性的数据类型
⑧定义元素和属性的默认值以及固定值
XSD元素可分为简单元素和复杂元素。
一、简单元素
简易元素指仅包含文本的元素,它不会包含任何其他的元素或属性。
例如XML文档:
<Name>张三</Name>
用XSD可写为
<xs:element name="Name" type="xs:string"/>
此处“Name”是元素的名称,“xs:string”是XML Schema内建的数据类型。
最常用的类型有:xs:string、xs:decimal、xs:integer、xs:boolean、xs:date、xs:time等。
如果要指定元素的默认值或固定值,默认值用default定义,固定值用fixed定义。
<xs:element name="Name" type="xs:string" default="张三"/>
<xs:element name="Name" type="xs:string" fixed="张三"/>
也可限定元素的取值范围,例如限定字符串的长度为2至4,则可写为如下:
<xs:element name="Name">
<xs:simpleType>
<xs:restriction base="xs:string">
<xs:minLength value="2" />
<xs:maxLength value="4" />
</xs:restriction>
</xs:simpleType>
</xs:element>
也可以写成:
<xs:element name="Name" type="tns:T_Name" />
<xs:simpleType name="T_Name">
<xs:restriction base="xs:string">
<xs:minLength value="2" />
<xs:maxLength value="4" />
</xs:restriction>
</xs:simpleType>
二、复合元素
复合元素包含了其他的元素及/或属性。
有四种类型的复合元素:
①空元素
②包含其他元素的元素
③仅包含文本的元素
④包含元素和文本的元素
一个XML代码:
<Person id="1">
<Name>张三</Name>
<Age>120</Age>
</Person>
在 XML Schema 中,可定义为:
<xs:element name="Person" maxOccurs="unbounded">
<xs:complexType>
<xs:sequence>
<xs:element name="Name" type="xs:string" />
<xs:element name="Age" type="xs:string" />
</xs:sequence>
<xs:attribute name="id" type="xs:int" use="required" />
</xs:complexType>
</xs:element>
一些用法说明:
1、maxOccurs="unbounded"
maxOccurs为Occurrence 指示器,Occurrence 指示器用于定义某个元素出现的频率,有2种类型分别是 maxOccurs和minOccurs ,默认值均为 1。
① maxOccurs 指示器:规定某个元素可出现的最大次数
如<xs:element name="Name" type="xs:string" maxOccurs="10"/>
规定元素“Name”最少出现一次(其中 minOccurs 的默认值是 1),最多出现 10 次。
② minOccurs 指示器:规定某个元素能够出现的最小次数
如<xs:element name="Name" type="xs:string" minOccurs="0" maxOccurs="10"/>
规定元素“Name”最少出现0次,最多出现 10 次。
提示:如需使某个元素的出现次数不受限制,使用 maxOccurs="unbounded" 这个声明
上面<xs:element name="Person" maxOccurs="unbounded">表示元素“Person”出现次数最少一次(其中 minOccurs 的默认值是 1),并且任意次数。
2、<xs:sequence>
<xs:sequence>为“Order 指示器”,Order 指示器用于定义元素的顺序,有3种类型分别是All、Choice、Sequence。
① all 指示器:规定子元素可以按照任意顺序出现
② Choice 指示器:规定可出现某个子元素或者可出现另外一个子元素(非此即彼)
③ Sequence 指示器:规定子元素必须按照特定的顺序出现
上面例子代码用<xs:sequence>规定了子元素“Name”和“Age”必须按顺序出现。
3、use="required"
use 指示如何使用属性,有3种:
① optional :属性是可选的并且可以具有任何值。这是默认设置。
<xs:attribute name="id" type="xs:int"/>等价于
<xs:attribute name="id" type="xs:int" use="optional"/>
可验证通过<Person>或<Person id="1">
② required :属性必须出现一次。
<xs:attribute name="id" type="xs:int" use="required"/>
可验证通过<Person id="1">
③ prohibited :不能使用属性。
<xs:attribute name="id" use="prohibited"/>
规定了不能使用id的属性。
实例1(无命名空间):
Persons.xml
<?
xml
version="1.0" encoding="UTF-8"?>
<
Persons
>
<
Person
id="1">
<
Name
>张三</
Name
>
<
Age
>120</
Age
>
</
Person
>
<
Person
id="2">
<
Name
>李四</
Name
>
<
Age
>20</
Age
>
</
Person
>
</
Persons
>
|
Persons.xsd
实例2(有命名空间):
Persons2.xml
<?
xml
version="1.0" encoding="UTF-8"?>
<
Persons
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xmlns="http://www.xxx.com/XxxSystem">
<
Person
id="1">
<
Name
>张三</
Name
>
<
Age
>120</
Age
>
</
Person
>
<
Person
id="2">
<
Name
>李四</
Name
>
<
Age
>20</
Age
>
</
Person
>
</
Persons
>
|
Persons2.xsd
<?
xml
version="1.0" encoding="UTF-8"?>
<
xs:schema
elementFormDefault="qualified"
xmlns:xs="http://www.w3.org/2001/XMLSchema"
xmlns:tns="http://www.xxx.com/XxxSystem" >
<
xs:annotation
>
<
xs:documentation
> 本文档定义Persons.xml的格式 </
xs:documentation
>
</
xs:annotation
>
<
xs:annotation
>
<
xs:documentation
>姓名</
xs:documentation
>
</
xs:annotation
>
<
xs:simpleType
name="T_Name">
<
xs:restriction
base="xs:string">
<
xs:minLength
value="2" />
<
xs:maxLength
value="4" />
</
xs:restriction
>
</
xs:simpleType
>
<
xs:annotation
>
<
xs:documentation
>年龄</
xs:documentation
>
</
xs:annotation
>
<
xs:simpleType
name="T_Age">
<
xs:restriction
base="xs:string">
<
xs:pattern
value="[1-9][0-9]?|1[01][0-9]|120" />
</
xs:restriction
>
</
xs:simpleType
>
<
xs:annotation
>
<
xs:documentation
>属性ID</
xs:documentation
>
</
xs:annotation
>
<
xs:simpleType
name="T_id">
<
xs:restriction
base="xs:int"></
xs:restriction
>
</
xs:simpleType
>
<
xs:element
name="Persons">
<
xs:complexType
>
<
xs:sequence
>
<
xs:element
name="Person" maxOccurs="unbounded" type="tns:T_Person"/>
</
xs:sequence
>
</
xs:complexType
>
</
xs:element
>
<
xs:complexType
name="T_Person">
<
xs:sequence
>
<
xs:element
name="Name" type="tns:T_Name" />
<
xs:element
name="Age" type="tns:T_Age" />
</
xs:sequence
>
<
xs:attribute
name="id" type="tns:T_id" use="required" />
</
xs:complexType
>
</
xs:schema
>
|
C# 使用xsd文件验证XML格式
/// <summary>
/// 通过xsd验证xml格式是否正确,正确返回空字符串,错误返回提示
/// </summary>
/// <param name="xmlFile">xml文件</param>
/// <param name="xsdFile">xsd文件</param>
/// <param name="namespaceUrl">命名空间,无则默认为null</param>
/// <returns></returns>
public
static
string
XmlValidationByXsd(
string
xmlFile,
string
xsdFile,
string
namespaceUrl =
null
)
{
StringBuilder sb =
new
StringBuilder();
XmlReaderSettings settings =
new
XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
settings.Schemas.Add(namespaceUrl,xsdFile);
settings.ValidationEventHandler += (x,y)=>
{
sb.AppendFormat(
"{0}|"
,y.Message);
};
using
(XmlReader reader = XmlReader.Create(xmlFile,settings))
{
try
{
while
(reader.Read());
}
catch
(XmlException ex)
{
sb.AppendFormat(
"{0}|"
,ex.Message);
}
}
return
sb.ToString();
}
|

C# Net 使用openxml提取word中的文本和图片并转为Html
C# Net Core openxml 提取 提出 取 word 文本 图片 Html Text Drawing
C# Net Core openxml 提取 提出 取 word 文本 图片 Html Text Drawing
注:只支持内嵌,不支持公式
------------------------------------------------
---------------文章最后为效果------------
------------------------------------------------
加入包:OpenXml
创建文件:Read.cs
复制下面全部代码到文件 Read.cs
using DocumentFormat.OpenXml;
using DocumentFormat.OpenXml.Packaging;
using DocumentFormat.OpenXml.Wordprocessing;
using System;
using System.Collections.Generic;
using System.IO;
using System.Text;
using System.Xml;
using System.Xml.Xsl;
namespace YCBX.Office.WordXml
{
public class WordRead
{
public static List<string> ReadToHtml(string wordPathStr)
{
return ReadToHtml(new FileStream(wordPathStr, FileMode.Open));
}
public static List<string> ReadToHtml(Stream wordStream)
{
using (WordprocessingDocument doc = WordprocessingDocument.Open(wordStream, false))
{
//XmlWriterSettings settings = new XmlWriterSettings() { OmitXmlDeclaration = true, ConformanceLevel = ConformanceLevel.Auto,DoNotEscapeUriAttributes=true};
List<string> paragraphHtmls = new List<string>();
MainDocumentPart mainPart = doc.MainDocumentPart;
Body body = doc.MainDocumentPart.Document.Body;
//段落
foreach (var paragraph in body.Elements<Paragraph>())
{
StringBuilder paragraphHtml = new StringBuilder();
//块
foreach (var run in paragraph.ChildElements)
{
if (run is Run)
{
foreach (OpenXmlElement openXmlElement in run.Elements())
{
//软回车
if (openXmlElement is Break br)
{
paragraphHtmls.Add(paragraphHtml.ToString());
paragraphHtml = new StringBuilder();
}
//文字块
else if (openXmlElement is Text text)
{
paragraphHtml.Append(text.Text);
}
//图像块
else if (openXmlElement is Drawing drawing)
{
//得到图像的内嵌ID(外嵌没做处理)
var inline = drawing.Inline;
var extent = inline.Extent;
var pic = inline.Graphic.GraphicData.GetFirstChild<DocumentFormat.OpenXml.Drawing.Pictures.Picture>();
var embed = pic.BlipFill.Blip.Embed.Value;
//得到图像流
var part = mainPart.GetPartById(embed);
var stream = part.GetStream();
//流转2进制
byte[] bytes = new byte[stream.Length];
stream.Read(bytes, 0, bytes.Length);
//2进制转base64
string imgHtml = $"<img width=''{ImageExtent.EMU_TO_PX((decimal)extent.Cx.Value).ToString("0.")}'' height=''{ImageExtent.EMU_TO_PX((decimal)extent.Cy.Value).ToString("0.")}'' src=''data:{part.ContentType};base64," + Convert.ToBase64String(bytes) + "'' />";
paragraphHtml.Append(imgHtml);
}
}
}
//else if(run is DocumentFormat.OpenXml.Math.OfficeMath math)
//{
// var x = new XmlDocument();
// x.LoadXml(math.OuterXml);
// using var ms = ConvertToMatchMl(x, settings);
// paragraphHtml.Append(ConvertToLatex(settings, ms));
//}
}
paragraphHtmls.Add(paragraphHtml.ToString());
}
return paragraphHtmls;
}
}
/// <summary>
/// 合并文档
/// </summary>
/// <param name="finalFile"></param>
/// <param name="files"></param>
public static void Combine(string finalFile, List<string> files)
{
if (files.Count < 2)
{
return;
}
File.Copy(files[0], finalFile, true);
using (WordprocessingDocument doc = WordprocessingDocument.Open(finalFile, true))
{
Body b = doc.MainDocumentPart.Document.Body;
for (int i = 1; i < files.Count; i++)
{
using (WordprocessingDocument doc1 = WordprocessingDocument.Open(files[i], true))
{
foreach (var inst in doc1.MainDocumentPart.Document.Body.Elements())
{
b.Append(inst.CloneNode(true));
}
}
}
}
}
private string ConvertToLatex(XmlWriterSettings settings, Stream ms)
{
var latexTransform = new XslCompiledTransform();
latexTransform.Load(Path.Combine(AppContext.BaseDirectory, "xsltml", "mmltex.xsl"), new XsltSettings(true,true),new XmlUrlResolver() );
using var la = new MemoryStream();
latexTransform.Transform(new XmlTextReader(ms), XmlWriter.Create(la, settings));
la.Seek(0, SeekOrigin.Begin);
StreamReader sr = new StreamReader(la, Encoding.UTF8);
return sr.ReadToEnd();
}
private Stream ConvertToMatchMl(XmlDocument xmlDocument, XmlWriterSettings settings)
{
var ms = new MemoryStream();
var xslTransform = new XslCompiledTransform();
xslTransform.Load(Path.Combine(AppContext.BaseDirectory, "xsltml", "OMML2MML.XSL"));
xslTransform.Transform(xmlDocument, XmlWriter.Create(ms, settings));
ms.Seek(0, SeekOrigin.Begin);
return ms;
}
}
}
创建文件:ImageExtent.cs
复制下面全部代码到文件 ImageExtent.cs
using System;
using System.Collections.Generic;
using System.Text;
namespace YCBX.Office.WordXml
{
/// <summary>
/// 图像长度单位转换
/// </summary>
public class ImageExtent
{
private const decimal CM_TO_PX = 96M;
private const decimal INCH_TO_CM = 2.54M;
/// <summary>
/// 厘米到EMU(English Metric Unit)
/// </summary>
private const decimal CM_TO_EMU = 360000M;
/// <summary>
/// EMU(English Metric Unit) 到像素(px)
/// </summary>
/// <param name="EMU"></param>
public static decimal EMU_TO_PX(decimal EMU)
{
return EMU / CM_TO_EMU / INCH_TO_CM * CM_TO_PX;
}
}
}
调用方法:
var sss = new Read().ParagraphHtmlAll("1.docx");
word文件中为:
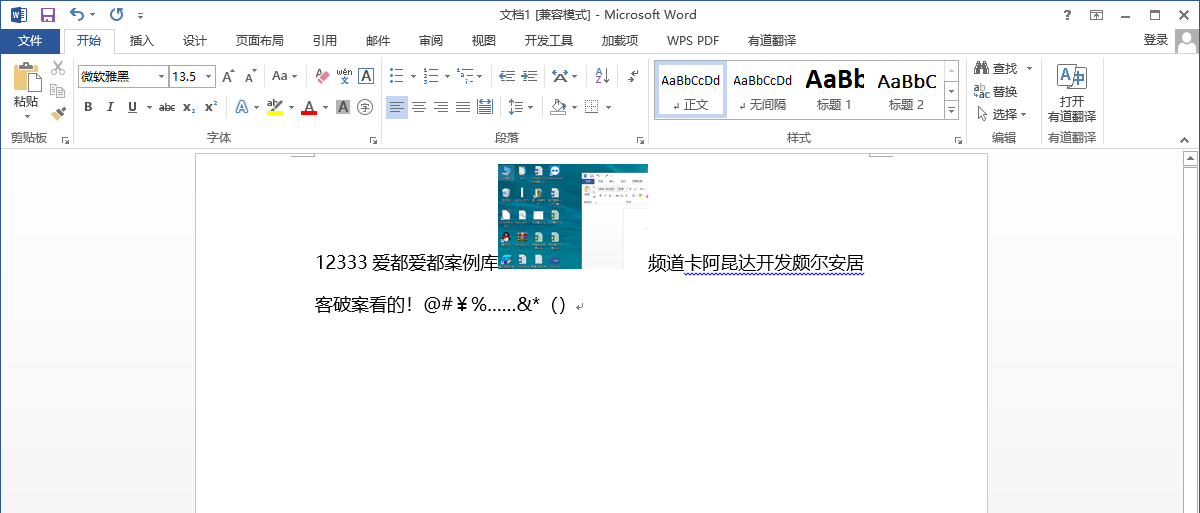
创建一个test.html,将代码放在<body></body>中,查看效果为:
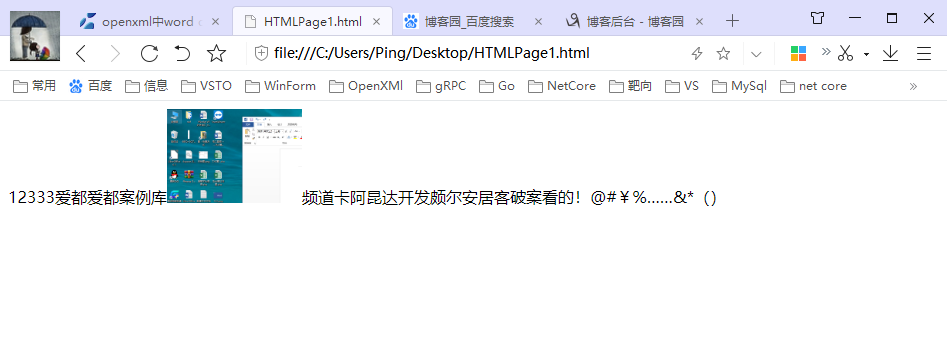
完成
原文出处:https://www.cnblogs.com/ping9719/p/12462478.html

c# – 如何使用OpenXML SDK 2.5从word文档复制公式?
我必须使用带有C#的OpenXML SDK 2.5来复制一个word文档中的公式,然后将它们附加到另一个word文档中.我尝试了下面的代码,它运行成功但是当我试图打开文件时,它说内容有问题.我打开它忽略了警告,但没有显示那些公式.它们只是空白块.
我的代码:
private void CreateNewWordDocument(string document, Exercise[] exercices)
{
using (WordprocessingDocument wordDoc = WordprocessingDocument.Create(document, WordprocessingDocumentType.Document))
{
// Set the content of the document so that Word can open it.
MainDocumentPart mainPart = wordDoc.AddMainDocumentPart();
SetMainDocumentContent(mainPart);
foreach (Exercise ex in exercices)
{
wordDoc.MainDocumentPart.Document.Body.AppendChild(ex.toParagraph().CloneNode(true));
}
wordDoc.MainDocumentPart.Document.Save();
}
}
// Set content of MainDocumentPart.
private void SetMainDocumentContent(MainDocumentPart part)
{
string docXml =
@"<?xml version=""1.0"" encoding=""UTF-8"" standalone=""yes""?>
<w:document xmlns:w=""http://schemas.openxmlformats.org/wordprocessingml/2006/main"">
<w:body><w:p><w:r><w:t>Exercise list!</w:t></w:r></w:p></w:body>
</w:document>";
using (Stream stream = part.GetStream())
{
byte[] buf = (new UTF8Encoding()).GetBytes(docXml);
stream.Write(buf, 0, buf.Length);
}
}
解决方法:
发生这种情况是因为克隆段落时不会复制段落中可引用的所有内容. Word XML格式由多个文件组成,其中一些文件相互引用.如果将段落从一个文档复制到另一个文档,则还需要复制可能存在的任何关系.
OpenXML Productivity Tool对于诊断这些错误非常有用.您可以使用该工具打开文档并要求其验证文档.
我创建了一个测试文档,其中只包含一个超链接并运行您的代码以将内容复制到另一个文档.当我尝试使用Word加载它时,我也遇到了错误,因此我在Productivity Tool中打开它并看到以下输出:
这表明超链接存储为段落中的关系而不是内联,我的新文件引用了不存在的关系.解压缩原始文件和新文件并比较两者显示正在发生的事情:
原始的document.xml:
原始的.rels
生成文件的document.xml
.rels生成的文件
请注意,在生成的文件中,超链接引用了关系rId5,但在生成的文档关系文件中不存在.
值得注意的是,对于简单的源文档,代码可以正常工作,因为没有需要复制的关系.
有两种方法可以解决这个问题.最简单的方法是只复制段落的文本(你将失去所有的样式,图像,超链接等),但它非常简单.你需要做的就是改变
wordDoc.MainDocumentPart.Document.Body.AppendChild(ex.toParagraph().CloneNode(true));
对于
Paragraph para = wordDoc.MainDocumentPart.Document.Body.AppendChild(new Paragraph());
Run run = para.AppendChild(new Run());
run.AppendChild(new Text(ex.toParagraph().InnerText));
实现它的更复杂(也许是正确的)方法是找到关系并将它们复制到新文档中.这样做的代码可能超出了我在这里写的范围,但是在这里有一篇关于这个主题的有趣文章http://blogs.msdn.com/b/ericwhite/archive/2009/02/05/move-insert-delete-paragraphs-in-word-processing-documents-using-the-open-xml-sdk.aspx.
基本上,该博客文章的作者使用Powertools for OpenXML查找关系并将它们从一个文档复制到另一个文档.

c# – 如何使用xmlschemaset和xmlreader.create对xsd模式验证xml
// New Validation Xml.
string xsd_file = filename.Substring(0,filename.Length - 3) + "xsd";
XmlSchema xsd = new XmlSchema();
xsd.sourceUri = xsd_file;
XmlSchemaSet ss = new XmlSchemaSet();
ss.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
ss.Add(xsd);
if (ss.Count > 0)
{
XmlTextReader r = new XmlTextReader(filename2);
XmlReaderSettings settings = new XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
settings.Schemas.Add(ss);
settings.ValidationEventHandler +=new ValidationEventHandler(ValidationCallBack);
XmlReader reader = XmlReader.Create(filename2,settings);
while (reader.Read())
{
}
reader.Close();
}
// Old Validate XML
XmlSchemaCollection sc = new XmlSchemaCollection();
sc.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
sc.Add(null,xsd_file);
if (sc.Count > 0)
{
XmlTextReader r = new XmlTextReader(filename2);
XmlValidatingReader v = new XmlValidatingReader(r);
v.ValidationType = ValidationType.Schema;
v.Schemas.Add(sc);
v.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
while (v.Read())
{
}
v.Close();
}
private void ValidationCallBack(object sender,ValidationEventArgs e)
{
// If Document Validation Fails
isvalid = false;
MessageConsole.Text = "INVALID. Check message and datagridview table.";
richTextBox1.Text = "The document is invalid: " + e.Message;
}
不幸的是,当我运行程序并尝试验证无效的xml文档时,它会给出一个如下错误:“未声明’URNLookup’元素.” URNLookup元素是xml文件的根元素.我总是可以回到旧的验证方法,但那些警告吓到了我.
任何帮助都非常感谢.先感谢您!如果我遗漏任何信息,我会很乐意提供更多信息.
> tf.rz(.NET 3.5 SP1,Visual Studio C#2008)
解决方法
在新验证XML中:
// New Validation Xml.
string xsd_file = filename.Substring(0,filename.Length - 3) + "xsd";
XmlSchema xsd = new XmlSchema();
xsd.sourceUri = xsd_file;
XmlSchemaSet ss = new XmlSchemaSet();
ss.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
ss.Add(null,xsd_file);
if (ss.Count > 0)
{
XmlReaderSettings settings = new XmlReaderSettings();
settings.ValidationType = ValidationType.Schema;
settings.Schemas.Add(ss);
settings.Schemas.Compile();
settings.ValidationEventHandler += new ValidationEventHandler(ValidationCallBack);
XmlTextReader r = new XmlTextReader(filename2);
using (XmlReader reader = XmlReader.Create(r,settings))
{
while (reader.Read())
{
}
}
}
ss.add已更改为具有命名空间和文件字符串.添加了settings.schemas.compile(),并添加了“using(xmlreader reader … …”)的无关紧要的重组.
这页帮助了我很多:http://msdn.microsoft.com/en-us/library/fe6y1sfe(v=vs.80).aspx它现在有效.
我们今天的关于asp.net – 使用XML Schema和OpenXML SDK进行WordML模板化和.net操作xml的分享就到这里,谢谢您的阅读,如果想了解更多关于28.XSD(XML Schema Definition)用法实例介绍以及C#使用xsd文件验证XML格式、C# Net 使用openxml提取word中的文本和图片并转为Html、c# – 如何使用OpenXML SDK 2.5从word文档复制公式?、c# – 如何使用xmlschemaset和xmlreader.create对xsd模式验证xml的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

