在本文中,我们将详细介绍【Meetup预告】OpenMLDBxDolphinScheduler链接特征工程与调度环节,打造端到端MLOps工作流的各个方面,同时,我们也将为您带来关于ApacheDol
在本文中,我们将详细介绍【Meetup 预告】OpenMLDB x DolphinScheduler 链接特征工程与调度环节,打造端到端 MLOps 工作流的各个方面,同时,我们也将为您带来关于Apache DolphinScheduler & Doris 联合Meetup、Apache DolphinScheduler & Doris 联合线上 Meetup、Apache DolphinScheduler 1.2.1 发布,分布式工作流任务调度系统、Apache DolphinScheduler&TiDB联合Meetup的有用知识。
本文目录一览:- 【Meetup 预告】OpenMLDB x DolphinScheduler 链接特征工程与调度环节,打造端到端 MLOps 工作流
- Apache DolphinScheduler & Doris 联合Meetup
- Apache DolphinScheduler & Doris 联合线上 Meetup
- Apache DolphinScheduler 1.2.1 发布,分布式工作流任务调度系统
- Apache DolphinScheduler&TiDB联合Meetup

【Meetup 预告】OpenMLDB x DolphinScheduler 链接特征工程与调度环节,打造端到端 MLOps 工作流
2022年5月28日(周六)上午10:00-12:00,开源机器学习数据库 openmlDB 第三期 Meetup 将以线上直播的形式展开。

活动背景
openmlDB v0.5.0 在近期正式发布,性能、成本、灵活 再攀高峰!此次 Meetup 将为大家介绍 openmlDB v0.5.0版本的新功能,并邀请来自 DolphinScheduler 的技术大咖一起分享 DolphinScheduler 的技术实现及落地应用。本次活动,我们将发布与 DolphinScheduler 合作开发的 Dolphinscheduler openmldb Task ,将特征平台能力融入 DolphinScheduler 的工作流,为数据科学家实现 AI 模型构建及应用上线提供便利。
简要介绍
openmlDB PMC core member 卢冕,将从低成本、高性能的线上线下一致性特征平台开源解决方案切入,为大家介绍 openmlDB v0.5.0 新版本以及其性能改进、成本降低、灵活性增加的新特性。
白鲸开源联合创始人 代立冬,将深度解析 Apache DolphinScheduler 技术原理和最佳实践,带领你洞见大数据调度系统的最新进展和发展趋势。
白鲸开源高级算法工程师 周捷光,将以 DolphinScheduler 遇上 MLOps 为议题,基于两者的碰撞创新展示 DolphinScheduler 在机器学习领域的目前成就以及未来路径。
openmlDB 研发架构师 黄威带来 DolphinScheduler openmlDB Task 实操演示,引导你链接特征工程与调度环节,打通端到端的 MLOps 工作流。
具体日程参见海报,直播信息会在 openmlDB 技术交流群中同步,欢迎未进群的朋友扫描海报入群收看~
分享抢先看
openmlDB v0.5.0 介绍:线上线下一致的生产级特征平台
【演讲提纲】
- 人工智能工程化落地的数据和特征挑战
- openmlDB:线上线下一致的生产级特征计算平台
- v0.5.0 新特性介绍:性能改进、成本降低、灵活性增加
【听众收益】 - 深刻了解到目前企业进行人工智能工程化落地过程中碰到的数据和特征的痛点
- 了解低成本高性能的线上线下一致性的特征平台开源解决方案 – openmlDB
- 了解 openmlDB 整体的线上线下一致性的设计架构理念,以及面向企业级应用的产品特性
- 了解新发布的 openmlDB v0.5.0 的新特性,性能改进、成本降低、灵活性增加
Apache DolphinScheduler 技术原理和最佳实践
【演讲提纲】
- Apache DolphinScheduler 简介
- Apache DolphinScheduler 的架构运行原理
- Apache DolphinScheduler 的最新进展
- Apache DolphinScheduler 应用案例实践
- Apache DolphinScheduler Roadmap
【听众收益】 - 了解调度系统的架构设计
- 了解中国十分流行的大数据调度系统的最新进展
- 了解 DolphinScheduler 的用户实践
- 了解调度系统的发展趋势
当 DolphinScheduler 遇上 MLOps
【演讲提纲】
- DolphinScheduler 与MLOps 的碰撞
- DolphinScheduler 目前支持的机器学习任务类型
- Jupyter Notebook 与 MLflow 使用演示
- DolphinScheduler 在机器学习领域的后续任务类型支持
【听众收益】 - 了解到 DolphinScheduler 在机器学习领域任务调度的进展
- 了解到 Jupter Notebook 与 MLflow 在 DolphinScheduler 上的使用方法
DolphinScheduler openmlDB Task 实操演示
【演讲提纲】
- DolphinScheduler Task 简介
- DolphinScheduler openmlDB Task介绍
- DolphinScheduler openmlDB Task实战演示
【听众收益】 - 了解DolphinScheduler Task的框架与实现
- 了解DolphinScheduler openmlDB Task的实现方式
- 了解DolphinScheduler openmlDB Task的使用方法
总结
以上是小编为你收集整理的【Meetup 预告】OpenMLDB x DolphinScheduler 链接特征工程与调度环节,打造端到端 MLOps 工作流全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
原文地址:https://www.cnblogs.com/4paradigm-opensource/p/16294710.html

Apache DolphinScheduler & Doris 联合Meetup
主题 Apache DolphinScheduler & Doris 联合Meetup
活动介绍
2020年,大数据成为国家基建的一个重要组成,大数据在越来越多的领域展现威力,越来越多的公司选择拥抱大数据。在这种背景下,必然绕不开的一个话题就是apache基金会,apache旗下拥有广泛被使用的开源软件,中国本土开源也展露头角,本次联合2个Apache大数据项目的用户以及爱好者一起分享开源技术,一起为中国本土开源献力
Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
Apache DolphinScheduler是一个分布式去中心化,易扩展的可视化DAG工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
活动时间
沙龙时间:2020-07-25 14:00
面向人群:对开源技术感兴趣的小伙伴均可参与
议程安排
14:00 - 14:40 Introduction of Doris core features - pre-aggregation engine and materialized view
《Doris核心功能介绍--预聚合引擎和物化视图》 缪翎,百度研发工程师,Doris PPMC
14:40 - 15:10 Distributed task management platform, making job submit easier
《分布式作业管理平台,让作业提交变得更简单》 李杰,奇安信大数据研发工程师,主要参与DolphinScheduler和Flink的开发与维护
15:10 - 15:50 Doris global dictionary design and implementation based on hive table
《Doris基于hive表的全局字典设计与实现 》 王博,美团点评数据开发工程师,主要参与Doris和Kylin的开发与维护
15:50 - 16:30 DolphinScheduler architecture evolution journey
《DolphinScheduler架构演进之旅》 乔占卫,易观大数据平台技术专家,DolphinScheduler PPMC
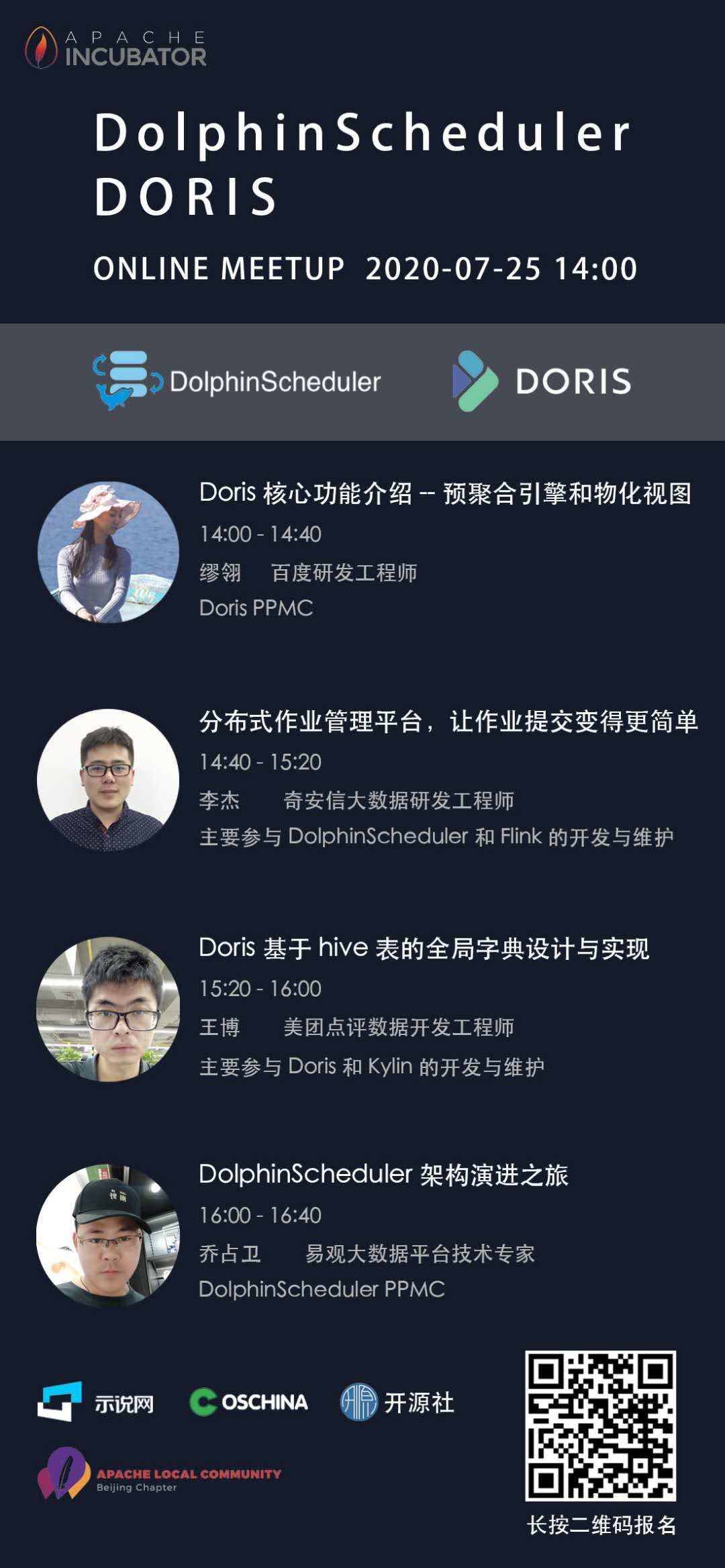

Apache DolphinScheduler & Doris 联合线上 Meetup
01
—
活动介绍
2020年,大数据成为国家基建的一个重要组成,大数据在越来越多的领域展现威力。随着大数据的应用场景越来越多,大家对数据的响应速度和数据加工工作流的方便程度也提出了更高的要求。在这种背景下,相信做过大数据的技术小伙伴应该对 Apache 一词不会陌生,Apache 基金会旗下拥有被广泛使用的众多开源软件,本次特地邀请到 2 个本土的 Apache 大数据应用项目的开发者来一起分享解决数据响应速度和数据工作流任务调度方面的开源技术,一起为中国开源献力。
Apache Doris(Incubating)是一个现代化的 MPP 分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris 的分布式架构非常简洁,易于运维,并且可以支持 10PB 以上的超大数据集。
Apache DolphinScheduler(Incubating) 是一个分布式去中心化,易扩展的可视化工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在大数据处理流程中开箱即用。
02
—
活动时间
时间:2020-07-25 14:00
面向人群:对开源技术感兴趣的小伙伴均可参与
03
—
议程安排
14:00 - 14:40 Introduction of Doris core features - pre-aggregation engine and materialized view
《Doris核心功能介绍--预聚合引擎和物化视图》 缪翎,百度研发工程师,Doris PPMC
14:40 - 15:10 Distributed task management platform, making job submit easier
《分布式作业管理平台,让作业提交变得更简单》 李杰,奇安信大数据研发工程师,主要参与DolphinScheduler和Flink的开发与维护
15:10 - 15:50 Doris global dictionary design and implementation based on hive table
《Doris基于hive表的全局字典设计与实现 》 王博,美团点评数据开发工程师,主要参与Doris和Kylin的开发与维护
15:50 - 16:30 DolphinScheduler architecture evolution journey
《DolphinScheduler架构演进之旅》 乔占卫,易观大数据平台技术专家,DolphinScheduler PPMC
Free disscussion
非常欢迎对本次活动感兴趣的伙伴扫描图中二维码进行报名,非常期待大家的参与!
04
—
关于 ALC Beijing
作为全球最大开源消费国, Apache 软件基金会(ASF)在国内有广泛的群众基础,如何将这些开源项目用户发展转换成为社区的贡献者、开发者, 甚至成为开源项目的发起者、维护者是一个值得深思的问题。
基于对这个问题的思考,我们创建了ALC-Beijing(Apache Local Community-Beijing),并且致力于通过(但不限于)下述行动帮助开源爱好者更好的在 Apache 社区生根发芽:
举办线上和线下沙龙,将本地的开发与用户聚焦在一起。
通过分享开源开发经验,鼓励更多的人参与到 ASF 的项目开发中来。
为 ASF 的项目寻找相互合作的机会,让这些项目能够更加茁壮的成长。
介绍 ASF 管理和运作开源项目的成功之道,帮助大家更好地运作开源项目。

开源社简介
开源社是由国内外支持开源的企业,社区及个人,依“贡献,共识,共治”原则,所组织的厂商中立、纯志愿者、非营利的开源联盟,旨在共创健康可持续发展的开源生态体系,并推动中国开源社区成为全球开源软件的积极参与及贡献者。我们专注于开源治理、国际接轨、社区发展和开源项目。
相关阅读 | Related Reading
项目开源一年多就从 ASF 毕业,开发者可以从中学到什么
开源社媒体组招募 | 找暑期实习的小伙伴看过来
暑期2020“大咖说开源”之吴雪 | 开源的商业创新
关于在开源社区中的“工作倦怠”,你所需要知道的事
本文分享自微信公众号 - 开源社(kaiyuanshe)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

Apache DolphinScheduler 1.2.1 发布,分布式工作流任务调度系统
Apache DolphinScheduler 于 2020 年 2 月 24 日正式发布 1.2.1 版,发布内容如下:
新特性:
-
[#1497] 通过 API 创建的工作流在前端展示时自动调整布局。
-
[#747] Worker server 运行日志脱敏。
-
[#1635] 配置文件适当合并。
-
[#1547] 节点内容编辑支持全屏缩放。
增强:
-
[#184] 被工作流引用的 worker 不能被删除。
-
[#1441] 可创建包含 "." 的用户名。
-
[#839] 可切换 Spark 版本。
-
[#1511] 前后端编译文件合并。
-
[#1509] 去除 Master 和 Worker 监听端口(5566,7788)。
-
[#1575] 去除 kazoo ,简化部署。
-
[#1300] 邮件内容可右对齐。
-
[#1599] 增加前端部署的 nginx 配置文件。
-
支持 Mac 进行开发和 debug。
Bug 修复:
-
特定情况下弹出框不能关闭。
-
[#1399] 日志信息中字段顺序错误。
-
[#1379] sql 任务节点日期转换错误。
-
[#1477] 特定情况下,数据库延迟的时候,任务会一直执行。
-
[#1514] 队列关联用户后修改队列信息,新修改的队列信息未保存到数据库。
-
[#1768] 用户管理分页错误。
-
[#1770] 用户取消租户关联后,仍能使用原租户 hdfs 的资源。
-
[#1779] 子进程失败后仍显示成功。
-
[#1789] 通过任务实例页面查看任务执行历史显示错误。
-
[#1810] 特定情况下,依赖节点不显示具体依赖。
-
[#1816] 添加多个依赖后,再添加新的依赖时,依赖列表读取错误。
-
[#1828] UDF 授权后,UDF 文件路径授权错误。
更多发布信息可移步:
https://github.com/apache/incubator-dolphinscheduler/releases/tag/1.2.1
近期社区也收到了来自社区贡献者的诸多新特性贡献,比如 DataX , Sqoop 数据同步、条件判断任务类型;DolphinScheduler 的 Ambari 插件化部署等等新功能,预计不久后就会发布。
DolphinScheduler 设计特点:
Apache DolphinScheduler 是一个分布式去中心化,易扩展的可视化 DAG 工作流任务调度系统。致力于解决数据处理流程中错综复杂的依赖关系,使调度系统在数据处理流程中开箱即用。
-
以 DAG 图的方式将 Task 按照任务的依赖关系关联起来,可实时可视化监控任务的运行状态
-
支持丰富的任务类型:Shell、MR、Spark、Flink、SQL (mysql、postgresql、hive、sparksql)、Python、Http、Sub_Process、Procedure 等
-
支持工作流定时调度、依赖调度、手动调度、手动暂停 / 停止 / 恢复,同时支持失败重试 / 告警、从指定节点恢复失败、Kill 任务等操作
-
支持工作流优先级、任务优先级及任务的故障转移及任务超时告警 / 失败
-
支持工作流全局参数及节点自定义参数设置
-
支持资源文件的在线上传 / 下载,管理等,支持在线文件创建、编辑
-
支持任务日志在线查看及滚动、在线下载日志等
-
实现集群 HA,通过 Zookeeper 实现 Master 集群和 Worker 集群去中心化
-
支持对 Master/Worker cpu load,memory,cpu 在线查看
-
支持工作流运行历史树形 / 甘特图展示、支持任务状态统计、流程状态统计
-
支持补数
-
支持多租户
-
支持国际化
在线 DEMO 试用: http://106.75.43.194:8888/
系统部分截图







在用公司 (部分统计,Wanted: who''s using DolphinScheduler)
已经有大量知名企业和科研机构在使用 Apache DolphinScheduler,来处理各类调度和定时任务:

加入 Apache DolphinScheduler
在使用 DolphinScheduler 的过程中,如果您有任何问题或者想法、建议,都可以通过 Apache 邮件列表参与到 DolphinScheduler 的社区建设中来。
发送订阅邮件也非常简单,步骤如下:
1. 用自己的邮箱向 dev-subscribe@dolphinscheduler.apache.org 发送一封邮件,主题和内容任意。
2. 接收确认邮件并回复。 完成步骤 1 后,您将收到一封来自 dev-help@dolphinscheduler.apache.org 的确认邮件(如未收到,请确认邮件是否被自动归入垃圾邮件、推广邮件、订阅邮件等文件夹)。然后直接回复该邮件,或点击邮件里的链接快捷回复即可,主题和内容任意。
接收欢迎邮件。 完成以上步骤后,您会收到一封主题为 WELCOME to dev@dolphinscheduler.apache.org 的欢迎邮件,至此您已成功订阅 Apache DolphinScheduler(Incubating)的邮件列表。
强烈推荐订阅开发邮件列表,与社区保持最新信息同步,这一点非常重要。

Apache DolphinScheduler&TiDB联合Meetup
在软件开发领域有一个流行的原则:Don’t Repeat Yourself(DRY),翻译过来就是:**不要重复造轮子**。而开源项目最基本的目的,其实就是为了不让大家重复造轮子。
尤其是在大数据这样一个高速发展的领域,现在各类企业都有使用大量的开源软件,当发现开源项目不能满足场景业务需求的时候,越来越多的开发者也开始关注技术生态的“外延”,结合各类场景打磨企业适用的技术架构,在此背景下,技术软件如何让更多用户能“轻松上手”、“简单应用”就显得更加重要。
2022年6月18日,Apache DolphinScheduler社区联合TiDB社区共同举办的Meetup即将重磅开启!我们也有幸邀请到了阿里云、国内跨境电商巨头SHEIN、TiDB社区等企业的资深大数据工程师与开发者,从数据库、数据调度、应用开发、技术外延等话题探讨在两个开源项目的开发实践。
无论你是热衷于钻研开源技术的开发者,还是“大数据调度+数据库”的开源资深爱好者,都能这些前沿的案例从中获得全新的灵感。无论你是Apache DolphineScheduler&TiDB的开发工程师还是个人爱好者,来到本次Meetup,你一定能听到一手的分享,得到一手的收获!

我们今天的关于【Meetup 预告】OpenMLDB x DolphinScheduler 链接特征工程与调度环节,打造端到端 MLOps 工作流的分享已经告一段落,感谢您的关注,如果您想了解更多关于Apache DolphinScheduler & Doris 联合Meetup、Apache DolphinScheduler & Doris 联合线上 Meetup、Apache DolphinScheduler 1.2.1 发布,分布式工作流任务调度系统、Apache DolphinScheduler&TiDB联合Meetup的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

