对于ApacheRocketMQ+Hudi快速构建Lakehouse感兴趣的读者,本文将会是一篇不错的选择,并为您提供关于ApacheDoris+ApacheHudi快速搭建指南|Lakehouse使
对于Apache RocketMQ + Hudi 快速构建 Lakehouse感兴趣的读者,本文将会是一篇不错的选择,并为您提供关于Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)、Apache Doris + Iceberg 快速搭建指南|Lakehouse 使用手册(三)、Apache Doris + Paimon 快速搭建指南|Lakehouse 使用手册(二)、Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座的有用信息。
本文目录一览:- Apache RocketMQ + Hudi 快速构建 Lakehouse
- Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)
- Apache Doris + Iceberg 快速搭建指南|Lakehouse 使用手册(三)
- Apache Doris + Paimon 快速搭建指南|Lakehouse 使用手册(二)
- Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座

Apache RocketMQ + Hudi 快速构建 Lakehouse
本文目录
- 背景知识
- 大数据时代的构架演进
- RocketMQ Connector&Stream
- Apache Hudi
- 构建Lakehouse实操
本文标题包含三个关键词:Lakehouse、RocketMQ、Hudi。我们先从整体Lakehouse架构入手,随后逐步分析架构产生的原因、架构组件特点以及构建Lakehouse架构的实操部分。
背景知识
1、Lakehouse架构
Lakehouse最初由Databrick提出,并对Lakehouse架构特征有如下要求:
(1)事务支持
企业内部许多数据管道通常会并发读写数据。对ACID事务的支持确保了多方并发读写数据时的一致性问题;
(2)Schema enforcement and governance
Lakehouse应该有一种方式可以支持模式执行和演进、支持DW schema的范式(如星星或雪花模型),能够对数据完整性进行推理,并且具有健壮的治理和审计机制;
(3)开放性
使用的存储格式是开放式和标准化的(如parquet),并且为各类工具和引擎,包括机器学习和Python/R库,提供API,以便它们可以直接有效地访问数据;
(4)BI支持
Lakehouse可以直接在源数据上使用BI工具。这样可以提高数据新鲜度、减少延迟,并且降低了在数据池和数据仓库中操作两个数据副本的成本;
(5)存储与计算分离
在实践中,这意味着存储和计算使用单独的集群,因此这些系统能够扩展到支持更大的用户并发和数据量。一些现代数仓也具有此属性;
(6)支持从非结构化数据到结构化数据的多种数据类型
Lakehouse可用于存储、优化、分析和访问许多数据应用所需的包括image、video、audio、text以及半结构化数据;
(7)支持各种工作负载
包括数据科学、机器学习以及sql和分析。可能需要多种工具来支持这些工作负载,但它们底层都依赖同一数据存储库;
(8)端到端流
实时报表是许多企业中的标准应用。对流的支持消除了需要构建单独系统来专门用于服务实时数据应用的需求。
从上述对Lakehouse架构的特点描述我们可以看出,针对单一功能,我们可以利用某些开源产品组合构建出一套解决方案。但对于全部功能的支持,目前好像没有一个通用的解决方案。接下来,我们先了解大数据时代主流的数据处理架构是怎样的。
大数据时代的架构演进
1、大数据时代的开源产品
大数据时代的开源产品种类繁多,消息领域的RocketMQ、Kafka;计算领域的flink、spark、storm;存储领域的HDFS、Hbase、Redis、ElasticSearch、Hudi、DeltaLake等等。
为什么会产生这么多开源产品呢?首先在大数据时代数据量越来越大,而且每个业务的需求也各不相同,因此就产生出各种类型的产品供架构师选择,用于支持各类场景。然而众多的品类产品也给架构师们带来一些困扰,比如选型困难、试错成本高、学习成本高、架构复杂等等。

2、当前主流的多层架构
大数据领域的处理处理场景包含数据分析、BI、科学计算、机器学习、指标监控等场景,针对不同场景,业务方会根据业务特点选择不同的计算引擎和存储引擎;例如交易指标可以采用binlog + CDC+ RocketMQ + Flink + Hbase + ELK组合,用于BI和Metric可视化。
(1)多层架构的优点:支持广泛的业务场景;
(2)多层架构的缺点:
- 处理链路长,延迟高;
- 数据副本多,成本翻倍;
- 学习成本高;
造成多层架构缺点主要原因是存储链路和计算链路太长。
- 我们真的需要如此多的解决方案来支持广泛的业务场景吗?Lakehouse架构是否可以统一解决方案?
- 多层架构的存储层是否可以合并?Hudi产品是否能够支持多种存储需求?
- 多层架构的计算层是否可以合并?RocketMQ stream是否能够融合消息层和计算层?

当前主流的多层架构
3、Lakehouse架构产生
Lakehouse架构是多层架构的升级版本,将存储层复杂度继续降低到一层。再进一步压缩计算层,将消息层和计算层融合,RocketMQ stream充当计算的角色。我们得到如下图所示的新架构。新架构中,消息出入口通过RocketMQ connector实现,消息计算层由RocketMQ stream实现,在RocketMQ内部完成消息计算中间态的流转;计算结果通过RocketMQ-Hudi-connector收口落库Hudi,Hudi支持多种索引,并提供统一的API输出给不同产品。

Lakehouse架构
下面我们分析下该架构的特点。
(1)Lakehouse架构的优点:
- 链路更短,更适合实时场景,数据新鲜感高;
- 成本可控,降低了存储成本;
- 学习成本低,对程序员友好;
- 运维复杂度大幅降低;
(2)Lakehouse架构的缺点
对消息产品和数据湖产品的稳定性、易用性等要求高,同时消息产品需要支持计算场景,数据湖产品需要提供强大的索引功能。
(3)选择
在Lakehouse架构中我们选择消息产品RocketMQ和数据湖产品Hudi。
同时,可以利用RocketMQ stream在RocketMQ集群上将计算层放在其中集成,这样就将计算层降低到一层,能够满足绝大部分中小型大数据处理场景。
接下来我们逐步分析RocketMQ和Hudi两款产品的特点。
RocketMQ Connector & Stream

RocketMQ 发展历程图
RocketMQ从2017年开始进入Apache孵化,2018年RocketMQ 4.0发布完成云原生化,2021年RocketMQ 5.0发布全面融合消息、事件、流。
1、业务消息领域首选
RocketMQ作为一款“让人睡得着觉的消息产品”成为业务消息领域的首选,这主要源于产品的以下特点:
(1)金融级高可靠
经历了阿里巴巴双十一的洪峰检验;
(2)极简架构
如下图所示, RocketMQ的架构主要包含两部分包括:源数据集群NameServer Cluster和计算存储集群broker Cluster。

RocketMQ 构架图
NameServer节点无状态,可以非常简单的进行横向扩容。broker节点采用主备方式保证数据高可靠性,支持一主多备的场景,配置灵活。
搭建方式:只需要简单的代码就可以搭建RocketMQ集群:
Jar:
nohup sh bin/mqnamesrv &
nohup sh bin/mqbroker -n localhost:9876 &
On K8S:
kubectl apply -f example/rocketmq_cluster.yaml
(3)极低运维成本
RocketMQ的运维成本很低,提供了很好的CLI工具MQAdmin,MQAdmin提供了丰富的命令支持,覆盖集群健康状态检查、集群进出流量管控等多个方面。例如,mqadmin clusterList一条命令可以获取到当前集群全部节点状态(生产消费流量、延迟、排队长度、磁盘水位等);mqadmin updatebrokerConfig命令可以实时设置broker节点或topic的可读可写状态,从而可以动态摘除临时不可用节点,达到生产消费的流量迁移效果。
(4)丰富的消息类型
RocketMQ支持的消息类型包括:普通消息、事务消息、延迟消息、定时消息、顺序消息等。能够轻松支持大数据场景和业务场景。
(5)高吞吐、低延迟
压测场景主备同步复制模式,每台broker节点都可以将磁盘利用率打满,同时可以将p99延迟控制在毫秒级别。
2、RocketMQ 5.0概况

RocketMQ 5.0是生于云、长于云的云原生消息、事件、流超融合平台,它具有以下特点:
(1)轻量级SDK
- 全面支持云原生通信标准 gRPC 协议;
- 无状态 Pop 消费模式,多语言友好,易集成;
(2)极简架构
- 无外部依赖,降低运维负担;
- 节点间松散耦合,任意服务节点可随时迁移;
(3)可分可合的存储计算分离
- broker 升级为真正的无状态服务节点,无 binding;
- broker 和 Store节点分离部署、独立扩缩;
- 多协议标准支持,无厂商锁定;
- 可分可合,适应多种业务场景,降低运维负担;
如下图所示,计算集群(broker)主要包括抽象模型和相对应的协议适配,以及消费能力和治理能力。存储集群(Store)主要分为消息存储CommitLog(多类型消息存储、多模态存储)和索引存储Index(多元索引)两部分,如果可以充分发挥云上存储的能力,将CommitLog和Index配置在云端的文件系统就可以天然的实现存储和计算分离。

(4)多模存储支持
- 满足不同基础场景下的高可用诉求;
- 充分利用云上基础设施,降低成本;
(5)云原生基础设施:
- 可观测性能力云原生化,OpenTelemetry 标准化;
- Kubernetes 一键式部署扩容交付。

RocketMQ 5.02021年度大事件及未来规划
3、 RocketMQConnector
a、传统数据流

(1)传统数据流的弊端
- 生产者消费者代码需要自己实现,成本高;
- 数据同步的任务没有统一管理;
- 重复开发,代码质量参差不齐;
(2)解决方案:RocketMQ Connector
- 合作共建,复用数据同步任务代码;
- 统一的管理调度,提高资源利用率;
b、RocketMQ Connector数据同步流程

相比传统数据流,RocketMQ connector数据流的不同在于将 source 和 sink 进行统一管理,同时它开放源码,社区也很活跃。
4、RocketMQ Connector架构
如上图所示,RocketMQ Connector架构主要包含Runtime和Worker两部分,另外还有生态Source&Sink。
(1)标准:OpenMessaging
(2)生态:支持ActiveMQ、Cassandra、ES、JDBC、JMS、MongoDB、Kafka、RabbitMQ、MysqL、Flume、Hbase、Redis等大数据领域的大部分产品;
(3)组件:Manager统一管理调度,如果有多个任务可以将所有任务统一进行负载均衡,均匀的分配到不同Worker上,同时Worker可以进行横向扩容。
5、RocketMQ Stream
RocketMQ Stream是一款将计算层压缩到一层的产品。它支持一些常见的算子如window、join、维表,兼容Flink sql、UDF/UDAF/UDTF。

Apache Hudi
Hudi 是一个流式数据湖平台,支持对海量数据快速更新。内置表格式,支持事务的存储层、一系列表服务、数据服务(开箱即用的摄取工具)以及完善的运维监控工具。Hudi 可以将存储卸载到阿里云上的 OSS、AWS 的S3这些存储上。
Hudi的特性包括:
- 事务性写入,MVCC/OCC并发控制;
- 对记录级别的更新、删除的原生支持;
- 面向查询优化:小文件自动管理,针对增量拉取优化的设计,自动压缩、聚类以优化文件布局;

Apache Hudi是一套完整的数据湖平台。它的特点有:
- 各模块紧密集成,自我管理;
- 使用 Spark、Flink、Java 写入;
- 使用 Spark、Flink、Hive、Presto、Trino、Impala、
AWS Athena/Redshift等进行查询; - 进行数据操作的开箱即用工具/服务。
Apache Hudi主要针对以下三类场景进行优化:
1、流式处理栈
(1) 增量处理;
(2) 快速、高效;
(3) 面向行;
(4) 未优化扫描;
2、批处理栈
(1) 批量处理;
(2) 低效;
(3) 扫描、列存格式;
3、增量处理栈
(1) 增量处理;
(2) 快速、高效;
(3) 扫描、列存格式。
构建 Lakehouse 实操
该部分只介绍主流程和实操配置项,本机搭建的实操细节可以参考附录部分。
1、准备工作
RocketMQ version:4.9.0
rocketmq-connect-hudi version:0.0.1-SNAPSHOT
Hudi version:0.8.0
2、构建RocketMQ-Hudi-connector
(1) 下载:
git clone https://github.com/apache/rocketmq-externals.git
(2) 配置:
/data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime/target/distribution/conf/connect.conf 中connector-plugin 路径
(3) 编译:
cd rocketmq-externals/rocketmq-connect-hudi
mvn clean install -DskipTest -U
rocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar就是我们需要使用的rocketmq-hudi-connector
3、运行
(1) 启动或使用现有的RocketMQ集群,并初始化元数据Topic:
connector-cluster-topic (集群信息) connector-config-topic (配置信息)
connector-offset-topic (sink消费进度) connector-position-topic (source数据处理进度 并且为了保证消息有序,每个topic可以只建一个queue)
(2) 启动RocketMQ connector运行时
cd /data/lakehouse/rocketmq-externals/rocketmq-connect/rocketmq-connect-runtime
sh ./run_worker.sh ## Worker可以启动多个
(3) 配置并启动RocketMQ-hudi-connector任务
请求RocketMQ connector runtime创建任务
curl http://${runtime-ip}:${runtime-port}/connectors/${rocketmq-hudi-sink-connector-name} ?config=''{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudisinkConnector","topicNames":"topicc","tablePath":"file:///tmp/hudi_connector_test","tableName":"hudi_connector_test_table","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","src-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/data/lakehouse/config/user.avsc"}’
启动成功会打印如下日志:
2021-09-06 16:23:14 INFO pool-2-thread-1 - Open HoodieJavaWriteClient successfully
(4) 此时向source topic生产的数据会自动写入到1Hudi对应的table中,可以通过Hudi的api进行查询。
4、配置解析
(1) RocketMQ connector需要配置RocketMQ集群信息和connector插件位置,包含:connect工作节点id标识workerid、connect服务命令接收端口httpPort、rocketmq集群namesrvAddr、connect本地配置储存目录storePathRootDir、connector插件目录pluginPaths 。

RocketMQ connector配置表
(2) Hudi任务需要配置Hudi表路径tablePath和表名称tableName,以及Hudi使用的Schema文件。

Hudi任务配置表
点击此处即可查看Lakehouse构建实操视频
附录:在本地Mac系统构建Lakehouse demo
涉及到的组件:rocketmq、rocketmq-connector-runtime、rocketmq-connect-hudi、hudi、hdfs、avro、spark-shell0、启动hdfs
下载hadoop包
https://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.10.1/hadoop-2.10.1.tar.gz
cd /Users/osgoo/Documents/hadoop-2.10.1
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<!-- 可以通过命令hostname 查看主机名字 这里的主机名字是hadoop1-->
<value>hdfs://localhost:9000</value>
</property>
<!--覆盖掉core-default.xml中的默认配置-->
</configuration>
vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
./bin/hdfs namenode -format
./sbin/start-dfs.sh
jps 看下namenode,datanode
lsof -i:9000
./bin/hdfs dfs -mkdir -p /Users/osgoo/Downloads
1、启动rocketmq集群,创建rocketmq-connector内置topic
QickStart:https://rocketmq.apache.org/docs/quick-start/
sh mqadmin updatetopic -t connector-cluster-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-config-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-offset-topic -n localhost:9876 -c DefaultCluster
sh mqadmin updatetopic -t connector-position-topic -n localhost:9876 -c DefaultCluster
2、创建数据入湖的源端topic,testhudi1
sh mqadmin updatetopic -t testhudi1 -n localhost:9876 -c DefaultCluster
3、编译rocketmq-connect-hudi-0.0.1-SNAPSHOT-jar-with-dependencies.jar
cd rocketmq-connect-hudi
mvn clean install -DskipTest -U
4、启动rocketmq-connector runtime
配置connect.conf
--------------
workerId=DEFAULT_WORKER_1
storePathRootDir=/Users/osgoo/Downloads/storeRoot
## Http port for user to access REST API
httpPort=8082
# Rocketmq namesrvAddr
namesrvAddr=localhost:9876
# Source or sink connector jar file dir,The default value is rocketmq-connect-sample
pluginPaths=/Users/osgoo/Downloads/connector-plugins
---------------
拷贝 rocketmq-hudi-connector.jar 到 pluginPaths=/Users/osgoo/Downloads/connector-plugins
sh run_worker.sh
5、配置入湖config
curl http://localhost:8082/connectors/rocketmq-connect-hudi?config=''{"connector-class":"org.apache.rocketmq.connect.hudi.connector.HudisinkConnector","topicNames":"testhudi1","tablePath":"hdfs://localhost:9000/Users/osgoo/Documents/base-path7","tableName":"t7","insertShuffleParallelism":"2","upsertShuffleParallelism":"2","deleteParallelism":"2","source-record-converter":"org.apache.rocketmq.connect.runtime.converter.RocketMQConverter","source-rocketmq":"127.0.0.1:9876","source-cluster":"DefaultCluster","refresh-interval":"10000","schemaPath":"/Users/osgoo/Downloads/user.avsc"}''
6、发送消息到testhudi1
7、## 利用spark读取
cd /Users/osgoo/Downloads/spark-3.1.2-bin-hadoop3.2/bin
./spark-shell \
--packages org.apache.hudi:hudi-spark3-bundle_2.12:0.9.0,org.apache.spark:spark-avro_2.12:3.0.1 \
--conf ''spark.serializer=org.apache.spark.serializer.KryoSerializer''
import org.apache.hudi.QuickstartUtils._
import scala.collection.JavaConversions._
import org.apache.spark.sql.SaveMode._
import org.apache.hudi.DataSourceReadOptions._
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
val tableName = "t7"
val basePath = "hdfs://localhost:9000/Users/osgoo/Documents/base-path7"
val tripsSnapshotDF = spark.
read.
format("hudi").
load(basePath + "/*")
tripsSnapshotDF.createOrReplaceTempView("hudi_trips_snapshot")
spark.sql("select * from hudi_trips_snapshot").show()
欢迎加入钉钉群与 Rocketmq 爱好者讨论交流:

钉钉扫码加群
总结
以上是小编为你收集整理的Apache RocketMQ + Hudi 快速构建 Lakehouse全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
原文地址:https://www.cnblogs.com/alisystemsoftware/p/15898815.html
")
Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)
导读:湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,帮助用户更加便捷地满足各种数据处理分析的需求。在过去多个版本中,Apache Doris 持续加深与数据湖的融合,已演进出一套成熟的湖仓一体解决方案。为便于用户快速入门,我们将通过系列文章介绍 Apache Doris 与各类主流数据湖格式及存储系统的湖仓一体架构搭建指南,包括 Hudi、Iceberg、Paimon、OSS、Delta Lake、Kudu、BigQuery 等,欢迎持续关注。
作为一种全新的开放式的数据管理架构,湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,帮助用户更加便捷地满足各种数据处理分析的需求,在企业的大数据体系中已经得到越来越多的应用。
在过去多个版本中,Apache Doris 持续加深与数据湖的融合,当前已演进出一套成熟的湖仓一体解决方案。
- 自 0.15 版本起,Apache Doris 引入 Hive 和 Iceberg 外部表,尝试在 Apache Iceberg 之上探索与数据湖的能力结合。
- 自 1.2 版本起,Apache Doris 正式引入 Multi-Catalog 功能,实现了多种数据源的自动元数据映射和数据访问、并对外部数据读取和查询执行等方面做了诸多性能优化,完全具备了构建极速易用 Lakehouse 架构的能力。
- 在 2.1 版本中,Apache Doris 湖仓一体架构得到全面加强,不仅增强了主流数据湖格式(Hudi、Iceberg、Paimon 等)的读取和写入能力,还引入了多 SQL 方言兼容、可从原有系统无缝切换至 Apache Doris。在数据科学及大规模数据读取场景上, Doris 集成了 Arrow Flight 高速读取接口,使得数据传输效率实现 100 倍的提升。

Apache Doris + Apache Hudi
Apache Hudi 是目前最主流的开放数据湖格式之一,也是事务性的数据湖管理平台,支持包括 Apache Doris 在内的多种主流查询引擎。Apache Doris 同样对 Apache Hudi 数据表的读取能力进行了增强:
- Copy on Write Table: Snapshot Query
- Merge on Read Table:Snapshot Queries, Read Optimized Queries
- 支持 Time Travel
- 支持 Incremental Read
凭借 Apache Doris 的高性能查询执行以及 Apache Hudi 的实时数据管理能力,可以实现高效、灵活、低成本的数据查询和分析,同时也提供了强大的数据回溯、审计和增量处理功能,当前基于 Apache Doris 和 Apache Hudi 的组合已经在多个社区用户的真实业务场景中得到验证和推广:
- 实时数据分析与处理:比如金融行业交易分析、广告行业实时点击流分析、电商行业用户行为分析等常见场景下,都要求实时的数据更新及查询分析。Hudi 能够实现对数据的实时更新和管理,并保证数据的一致性和可靠性,Doris 则能够实时高效处理大规模数据查询请求,二者结合能够充分满足实时数据分析与处理的需求。
- 数据回溯与审计:对于金融、医疗等对数据安全和准确性要求极高的行业来说,数据回溯和审计是非常重要的功能。Hudi 提供了时间旅行(Time Travel)功能,允许用户查看历史数据状态,结合 Apache Doris 高效查询能力,可快速查找分析任何时间点的数据,实现精确的回溯和审计。
- 增量数据读取与分析:在进行大数据分析时往往面临着数据规模庞大、更新频繁的问题,Hudi 支持增量数据读取,这使得用户可以只需处理变化的数据,不必进行全量数据更新;同时 Apache Doris 的 Incremental Read 功能也可使这一过程更加高效,显著提升了数据处理和分析的效率。
- 跨数据源联邦查询:许多企业数据来源复杂,数据可能存储在不同的数据库中。Doris 的 Multi-Catalog 功能支持多种数据源的自动映射与同步,支持跨数据源的联邦查询。这对于需要从多个数据源中获取和整合数据进行分析的企业来说,极大地缩短了数据流转路径,提升了工作效率。
本文将在 Docker 环境下,为读者介绍如何快速搭建 Apache Doris + Apache Hudi 的测试及演示环境,并对各功能操作进行演示,帮助读者快速入门。
使用指南
本文涉及所有脚本和代码可以从该地址获取:https://github.com/apache/doris/tree/master/samples/datalake/hudi
01 环境准备
本文示例采用 Docker Compose 部署,组件及版本号如下:

02 环境部署
- 创建 Docker 网络
sudo docker network create -d bridge hudi-net
- 启动所有组件
sudo ./start-hudi-compose.sh
- 启动后,可以使用如下脚本,登陆 Spark 命令行或 Doris 命令行:
sudo ./login-spark.sh
sudo ./login-doris.sh
03 数据准备
接下来先通过 Spark 生成 Hudi 的数据。如下方代码所示,集群中已经包含一张名为 customer 的 Hive 表,可以通过这张 Hive 表,创建一个 Hudi 表:
-- ./login-spark.sh
spark-sql> use default;
-- create a COW table
spark-sql> CREATE TABLE customer_cow
USING hudi
TBLPROPERTIES (
type = ''cow'',
primaryKey = ''c_custkey'',
preCombineField = ''c_name''
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
-- create a MOR table
spark-sql> CREATE TABLE customer_mor
USING hudi
TBLPROPERTIES (
type = ''mor'',
primaryKey = ''c_custkey'',
preCombineField = ''c_name''
)
PARTITIONED BY (c_nationkey)
AS SELECT * FROM customer;
04 数据查询
如下所示,Doris 集群中已经创建了名为 hudi 的 Catalog(可通过 HOW CATALOGS 查看)。以下为该 Catalog 的创建语句:
-- 已经创建,无需再次执行
CREATE CATALOG `hive` PROPERTIES (
"type"="hms",
''hive.metastore.uris'' = ''thrift://hive-metastore:9083'',
"s3.access_key" = "minio",
"s3.secret_key" = "minio123",
"s3.endpoint" = "http://minio:9000",
"s3.region" = "us-east-1",
"use_path_style" = "true"
);
- 手动刷新该 Catalog,对创建的 Hudi 表进行同步:
-- ./login-doris.sh
doris> REFRESH CATALOG hive;
- 使用 Spark 操作 Hudi 中的数据,都可以在 Doris 中实时可见,不需要再次刷新 Catalog。我们通过 Spark 分别给 COW 和 MOR 表插入一行数据:
spark-sql> insert into customer_cow values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
spark-sql> insert into customer_mor values (100, "Customer#000000100", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 25);
- 通过 Doris 可以直接查询到最新插入的数据:
doris> use hive.default;
doris> select * from customer_cow where c_custkey = 100;
doris> select * from customer_mor where c_custkey = 100;
- 再通过 Spark 插入
c_custkey=32已经存在的数据,即覆盖已有数据:
spark-sql> insert into customer_cow values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
spark-sql> insert into customer_mor values (32, "Customer#000000032_update", "jD2xZzi", "25-430-914-2194", 3471.59, "BUILDING", "cial ideas. final, furious requests", 15);
- 通过 Doris 可以查询更新后的数据:
doris> select * from customer_cow where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
doris> select * from customer_mor where c_custkey = 32;
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
05 Incremental Read
Incremental Read 是 Hudi 提供的功能特性之一,通过 Incremental Read,用户可以获取指定时间范围的增量数据,从而实现对数据的增量处理。对此, Doris 可对插入c_custkey=100后的变更数据进行查询。如下所示,我们插入了一条c_custkey=32的数据:
doris> select * from customer_cow@incr(''beginTime''=''20240603015018572'');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes(''customer_cow'', ''latest_state'', ''20240603015018572'');
doris> select * from customer_mor@incr(''beginTime''=''20240603015058442'');
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
| 32 | Customer#000000032_update | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 15 |
+-----------+---------------------------+-----------+-----------------+-----------+--------------+-------------------------------------+-------------+
spark-sql> select * from hudi_table_changes(''customer_mor'', ''latest_state'', ''20240603015058442'');
06 TimeTravel
Doris 支持查询指定快照版本的 Hudi 数据,从而实现对数据的 Time Travel 功能。首先,可以通过 Spark 查询两张 Hudi 表的提交历史:
spark-sql> call show_commits(table => ''customer_cow'', limit => 10);
20240603033556094 20240603033558249 commit 448833 0 1 1 183 0 0
20240603015444737 20240603015446588 commit 450238 0 1 1 202 1 0
20240603015018572 20240603015020503 commit 436692 1 0 1 1 0 0
20240603013858098 20240603013907467 commit 44902033 100 0 25 18751 0 0
spark-sql> call show_commits(table => ''customer_mor'', limit => 10);
20240603033745977 20240603033748021 deltacommit 1240 0 1 1 0 0 0
20240603015451860 20240603015453539 deltacommit 1434 0 1 1 1 1 0
20240603015058442 20240603015100120 deltacommit 436691 1 0 1 1 0 0
20240603013918515 20240603013922961 deltacommit 44904040 100 0 25 18751 0 0
接着,可通过 Doris 执行 c_custkey=32 ,查询数据插入之前的数据快照。如下可看到 c_custkey=32 的数据还未更新:
注:Time Travel 语法暂时不支持新优化器,需要先执行set enable_nereids_planner=false;关闭新优化器,该问题将会在后续版本中修复。doris> select * from customer_cow for time as of ''20240603015018572'' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
-- compare with spark-sql
spark-sql> select * from customer_mor timestamp as of ''20240603015018572'' where c_custkey = 32 or c_custkey = 100;
doris> select * from customer_mor for time as of ''20240603015058442'' where c_custkey = 32 or c_custkey = 100;
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| c_custkey | c_name | c_address | c_phone | c_acctbal | c_mktsegment | c_comment | c_nationkey |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
| 100 | Customer#000000100 | jD2xZzi | 25-430-914-2194 | 3471.59 | BUILDING | cial ideas. final, furious requests | 25 |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e | 15 |
+-----------+--------------------+---------------------------------------+-----------------+-----------+--------------+--------------------------------------------------+-------------+
spark-sql> select * from customer_mor timestamp as of ''20240603015058442'' where c_custkey = 32 or c_custkey = 100;
查询优化
Apache Hudi 中的数据大致可以分为两类 —— 基线数据和增量数据。基线数据通常是已经经过合并的 Parquet 文件,而增量数据是指由 INSERT、UPDATE 或 DELETE 产生的数据增量。基线数据可以直接读取,增量数据需要通过 Merge on Read 的方式进行读取。
对于 Hudi COW 表的查询或者 MOR 表的 Read Optimized 查询而言,其数据都属于基线数据,可直接通过 Doris 原生的 Parquet Reader 读取数据文件,且可获得极速的查询响应。而对于增量数据,Doris 需要通过 JNI 调用 Hudi 的 Java SDK 进行访问。为了达到最优的查询性能,Apache Doris 在查询时,会将一个查询中的数据分为基线和增量数据两部分,并分别使用上述方式进行读取。
为验证该优化思路,我们通过 EXPLAIN 语句来查看一个下方示例的查询中,分别有多少基线数据和增量数据。对于 COW 表来说,所有 101 个数据分片均为是基线数据(hudiNativeReadSplits=101/101),因此 COW 表全部可直接通过 Doris Parquet Reader 进行读取,因此可获得最佳的查询性能。对于 ROW 表,大部分数据分片是基线数据(hudiNativeReadSplits=100/101),一个分片数为增量数据,基本也能够获得较好的查询性能。
-- COW table is read natively
doris> explain select * from customer_cow where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_cow |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45338886, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=101/101 |
-- MOR table: because only the base file contains `c_custkey = 32` that is updated, 100 splits are read natively, while the split with log file is read by JNI.
doris> explain select * from customer_mor where c_custkey = 32;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 32) |
| inputSplitNum=101, totalFileSize=45340731, scanRanges=101 |
| partition=26/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=100/101 |
可以通过 Spark 进行一些删除操作,进一步观察 Hudi 基线数据和增量数据的变化:
-- Use delete statement to see more differences
spark-sql> delete from customer_cow where c_custkey = 64;
doris> explain select * from customer_cow where c_custkey = 64;
spark-sql> delete from customer_mor where c_custkey = 64;
doris> explain select * from customer_mor where c_custkey = 64;
此外,还可以通过分区条件进行分区裁剪,从而进一步减少数据量,以提升查询速度。如下示例中,通过分区条件c_nationkey = 15 进行分区裁减,使得查询请求只需要访问一个分区(partition=1/26)的数据即可。
-- customer_xxx is partitioned by c_nationkey, we can use the partition column to prune data
doris> explain select * from customer_mor where c_custkey = 64 and c_nationkey = 15;
| 0:VHUDI_SCAN_NODE(68) |
| table: customer_mor |
| predicates: (c_custkey[#5] = 64), (c_nationkey[#12] = 15) |
| inputSplitNum=4, totalFileSize=1798186, scanRanges=4 |
| partition=1/26 |
| cardinality=1, numNodes=1 |
| pushdown agg=NONE |
| hudiNativeReadSplits=3/4 |
结束语
以上是基于 Apache Doris 与 Apache Hudi 快速搭建测试 / 演示环境的详细指南,后续我们还将陆续推出 Apache Doris 与各类主流数据湖格式及存储系统构建湖仓一体架构的系列指南,包括 Iceberg、Paimon、OSS、Delta Lake 等,欢迎持续关注。
")
Apache Doris + Iceberg 快速搭建指南|Lakehouse 使用手册(三)
湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,能够更加便捷地满足各种数据处理分析的需求。Apache Doris 持续加深与数据湖的融合,已演进出一套成熟的湖仓一体解决方案。我们将通过一系列文章介绍 Apache Doris 与各类主流数据湖格式及存储系统的湖仓一体架构搭建指南,包括 Hudi、Paimon、Iceberg、OSS、Delta Lake、Kudu、BigQuery 等。
- Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)
- Apache Doris + Apache Paimon 快速搭建指南|Lakehouse 使用手册(二)
本文将继续为大家介绍 Lakehouse 使用手册(三)之 Apache Doris + Apache Iceberg 快速搭建指南。
Apache Doris + Apache Iceberg
Apache Iceberg 是一种开源、高性能、高可靠的数据湖表格式,可实现超大规模数据的分析与管理。它支持 Apache Doris 在内的多种主流查询引擎,兼容 HDFS 以及各种对象云存储,具备 ACID、Schema 演进、高级过滤、隐藏分区和分区布局演进等特性,可确保高性能查询以及数据的可靠性及一致性,其时间旅行和版本回滚功能也为数据管理带来较高的灵活性。
Apache Doris 对 Iceberg 多项核心特性提供了原生支持:
- 支持 Hive Metastore、Hadoop、REST、Glue、Google Dataproc Metastore、DLF 等多种 Iceberg Catalog 类型。
- 原生支持 Iceberg V1/V2 表格式,以及 Position Delete、Equality Delete 文件的读取。
- 支持通过表函数查询 Iceberg 表快照历史。
- 支持时间旅行(Time Travel)功能。
- 原生支持 Iceberg 表引擎。可以通过 Apache Doris 直接创建、管理以及将数据写入到 Iceberg 表。支持完善的分区 Transform 函数,从而提供隐藏分区和分区布局演进等能力。
用户可以基于 Apache Doris + Apache Iceberg快速构建高效的湖仓一体解决方案,以灵活应对实时数据分析与处理的各种需求:
- 通过 Doris 高性能查询引擎对 Iceberg 表数据和其他数据源进行关联数据分析,构建统一的联邦数据分析平台。
- 通过 Doris 直接管理和构建 Iceberg 表,在 Doris 中完成对数据的清洗、加工并写入到 Iceberg 表,构建统一的湖仓数据处理平台。
- 通过 Iceberg 表引擎,将 Doris 数据共享给其他上下游系统做进一步处理,构建统一的开放数据存储平台。
未来 ,Apache Iceberg 将作为 Apache Doris 的原生表引擎之一,提供更加完善的湖格式数据的分析、管理功能。 Apache Doris 也将逐步支持包括 Update/Delete/Merge、写回时排序、增量数据读取、元数据管理等 Apache Iceberg 更多高级特性,共同构建统一、高性能、实时的湖仓平台。
接下来,为读者讲解如何在 Docker 环境下快速搭建 Apache Doris + Apache Iceberg 测试 & 演示环境,并展示各功能的使用操作。
使用指南
本文涉及脚本&代码从该地址获取:https://github.com/apache/doris/tree/master/samples/datalake/iceberg\_and\_paimon
01 环境准备
本文示例采用 Docker Compose 部署,组件及版本号如下:

02 环境部署
1. 启动所有组件
bash ./start_all.sh
2. 启动后,可以使用如下脚本,登陆 Doris 命令行:
bash ./start_doris_client.sh
03 创建 Iceberg 表
1. 首先登陆 Doris 命令行后,Doris 集群中已经创建了名为 Iceberg 的 Catalog(可通过 SHOW CATALOGS/ SHOW CREATE CATALOG iceberg查看)。以下为该 Catalog 的创建语句:
-- 已创建,无需执行
CREATE CATALOG `iceberg` PROPERTIES (
"type" = "iceberg",
"iceberg.catalog.type" = "rest",
"warehouse" = "s3://warehouse/",
"uri" = "http://rest:8181",
"s3.access_key" = "admin",
"s3.secret_key" = "password",
"s3.endpoint" = "http://minio:9000"
);
2. 在 Iceberg Catalog 创建数据库和 Iceberg 表:
mysql> SWITCH iceberg;
Query OK, 0 rows affected (0.00 sec)
mysql> CREATE DATABASE nyc;
Query OK, 0 rows affected (0.12 sec)
mysql> CREATE TABLE iceberg.nyc.taxis
(
vendor_id BIGINT,
trip_id BIGINT,
trip_distance FLOAT,
fare_amount DOUBLE,
store_and_fwd_flag STRING,
ts DATETIME
)
PARTITION BY LIST (vendor_id, DAY(ts)) ()
PROPERTIES (
"compression-codec" = "zstd",
"write-format" = "parquet"
);
Query OK, 0 rows affected (0.15 sec)
04 数据写入
1. 向 Iceberg 表中插入数据。
mysql> INSERT INTO iceberg.nyc.taxis
VALUES (1, 1000371, 1.8, 15.32, ''N'', ''2024-01-01 9:15:23''), (2, 1000372, 2.5, 22.15, ''N'', ''2024-01-02 12:10:11''), (2, 1000373, 0.9, 9.01, ''N'', ''2024-01-01 3:25:15''), (1, 1000374, 8.4, 42.13, ''Y'', ''2024-01-03 7:12:33'');
Query OK, 4 rows affected (1.61 sec)
{''status'':''COMMITTED'', ''txnId'':''10085''}
2. 通过 CREATE TABLE AS SELECT 来创建一张 Iceberg 表。
mysql> CREATE TABLE iceberg.nyc.taxis2 AS SELECT * FROM iceberg.nyc.taxis;
Query OK, 6 rows affected (0.25 sec)
{''status'':''COMMITTED'', ''txnId'':''10088''}
05 数据查询
- 简单查询
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.37 sec)
mysql> SELECT * FROM iceberg.nyc.taxis2;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.35 sec)
分区剪裁
mysql> SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= ''2024-01-01'' and ts < ''2024-01-02''; +-----------+---------+---------------+-------------+--------------------+----------------------------+ | vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts | +-----------+---------+---------------+-------------+--------------------+----------------------------+ | 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 | +-----------+---------+---------------+-------------+--------------------+----------------------------+ 1 row in set (0.06 sec) mysql> EXPLAIN VERBOSE SELECT * FROM iceberg.nyc.taxis where vendor_id = 2 and ts >= ''2024-01-01'' and ts < ''2024-01-02''; .... | 0:VICEBERG_SCAN_NODE(71) | table: taxis | predicates: (ts[#5] < ''2024-01-02 00:00:00''), (vendor_id[#0] = 2), (ts[#5] >= ''2024-01-01 00:00:00'') | inputSplitNum=1, totalFileSize=3539, scanRanges=1 | partition=1/0 | backends: | 10002 | s3://warehouse/wh/nyc/taxis/data/vendor_id=2/ts_day=2024-01-01/40e6ca404efa4a44-b888f23546d3a69c_5708e229-2f3d-4b68-a66b-44298a9d9815-0.zstd.parquet start: 0 length: 3539 | cardinality=6, numNodes=1 | pushdown agg=NONE | icebergPredicatePushdown= | ref(name="ts") < 1704153600000000 | ref(name="vendor_id") == 2 | ref(name="ts") >= 1704067200000000 ....
通过EXPLAIN VERBOSE语句的结果可知,vendor_id = 2 and ts >= ''2024-01-01'' and ts < ''2024-01-02''谓词条件,最终只命中一个分区(partition=1/0)。
同时也可知,因为在建表时指定了分区 Transform 函数 DAY(ts),原始数据中的的值 2024-01-01 03:25:15.000000会被转换成文件目录中的分区信息ts_day=2024-01-01。
06 Time Travel
1. 再次插入几行数据。
INSERT INTO iceberg.nyc.taxis VALUES (1, 1000375, 8.8, 55.55, ''Y'', ''2024-01-01 8:10:22''), (3, 1000376, 7.4, 32.35, ''N'', ''2024-01-02 1:14:45'');
Query OK, 2 rows affected (0.17 sec)
{''status'':''COMMITTED'', ''txnId'':''10086''}
mysql> SELECT * FROM iceberg.nyc.taxis;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.11 sec)
2. 使用 iceberg_meta表函数查询表的快照信息
mysql> select * from iceberg_meta("table" = "iceberg.nyc.taxis", "query_type" = "snapshots");
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| committed_at | snapshot_id | parent_id | operation | manifest_list | summary |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| 2024-07-29 03:38:22 | 8483933166442433486 | -1 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-8483933166442433486-1-5f7b7736-8022-4ba1-9db2-51ae7553be4d.avro | {"added-data-files":"4","added-records":"4","added-files-size":"14156","changed-partition-count":"4","total-records":"4","total-files-size":"14156","total-data-files":"4","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
| 2024-07-29 03:40:23 | 4726331391239920914 | 8483933166442433486 | append | s3://warehouse/wh/nyc/taxis/metadata/snap-4726331391239920914-1-6aa3d142-6c9c-4553-9c04-08ad4d49a4ea.avro | {"added-data-files":"2","added-records":"2","added-files-size":"7078","changed-partition-count":"2","total-records":"6","total-files-size":"21234","total-data-files":"6","total-delete-files":"0","total-position-deletes":"0","total-equality-deletes":"0"} |
+---------------------+---------------------+---------------------+-----------+-----------------------------------------------------------------------------------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
2 rows in set (0.07 sec)
3. 使用 FOR VERSION AS OF语句查询指定快照
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 8483933166442433486;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR VERSION AS OF 4726331391239920914;
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000375 | 8.8 | 55.55 | Y | 2024-01-01 08:10:22.000000 |
| 3 | 1000376 | 7.4 | 32.35 | N | 2024-01-02 01:14:45.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
6 rows in set (0.04 sec)
4. 使用 FOR TIME AS OF语句查询指定快照
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:38:23";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.04 sec)
mysql> SELECT * FROM iceberg.nyc.taxis FOR TIME AS OF "2024-07-29 03:40:22";
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| vendor_id | trip_id | trip_distance | fare_amount | store_and_fwd_flag | ts |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
| 2 | 1000373 | 0.9 | 9.01 | N | 2024-01-01 03:25:15.000000 |
| 1 | 1000374 | 8.4 | 42.13 | Y | 2024-01-03 07:12:33.000000 |
| 2 | 1000372 | 2.5 | 22.15 | N | 2024-01-02 12:10:11.000000 |
| 1 | 1000371 | 1.8 | 15.32 | N | 2024-01-01 09:15:23.000000 |
+-----------+---------+---------------+-------------+--------------------+----------------------------+
4 rows in set (0.05 sec)
结束语
以上是基于 Apache Doris 与 Apache Iceberg 快速搭建测试 / 演示环境的详细指南,后续我们还将陆续推出 Apache Doris 与各类主流数据湖格式及存储系统构建湖仓一体架构的系列指南,欢迎持续关注。
")
Apache Doris + Paimon 快速搭建指南|Lakehouse 使用手册(二)
湖仓一体(Data Lakehouse)融合了数据仓库的高性能、实时性以及数据湖的低成本、灵活性等优势,帮助用户更加便捷地满足各种数据处理分析的需求。在过去多个版本中,Apache Doris 持续加深与数据湖的融合,已演进出一套成熟的湖仓一体解决方案。
为便于用户快速入门,我们将通过系列文章介绍 Apache Doris 与各类主流数据湖格式及存储系统的湖仓一体架构搭建指南,包括 Hudi、Iceberg、Paimon、OSS、Delta Lake、Kudu、BigQuery 等。目前,我们已经发布了 Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一),通过此文你可了解到在 Docker 环境下,如何快速搭建 Apache Doris + Apache Hudi 的测试及演示环境。
本文我们将再续前言,为大家介绍 Lakehouse 使用手册(二)之 Apache Doris + Apache Paimon 搭建指南。
Apache Doris + Apache Paimon
Apache Paimon 是一种数据湖格式,并创新性地将数据湖格式和 LSM 结构的优势相结合,成功将高效的实时流更新能力引入数据湖架构中,这使得 Paimon 能够实现数据的高效管理和实时分析,为构建实时湖仓架构提供了强大的支撑。
为了充分发挥 Paimon 的能力,提高对 Paimon 数据的查询效率,Apache Doris 对 Paimon 的多项最新特性提供了原生支持:
- 支持 Hive Metastore、FileSystem 等多种类型的 Paimon Catalog。
- 原生支持 Paimon 0.6 版本发布的 Primary Key Table Read Optimized 功能。
- 原生支持 Paimon 0.8 版本发布的 Primary Key Table Deletion Vector 功能。
基于 Apache Doris 的高性能查询引擎和 Apache Paimon 高效的实时流更新能力,用户可以实现:
- 数据实时入湖: 借助 Paimon 的 LSM-Tree 模型,数据入湖的时效性可以降低到分钟级;同时,Paimon 支持包括聚合、去重、部分列更新在内的多种数据更新能力,使得数据流动更加灵活高效。
- 高性能数据处理分析: Paimon 所提供的 Append Only Table、Read Optimized、Deletion Vector 等技术,可与 Doris 强大的查询引擎对接,实现湖上数据的快速查询及分析响应。
未来 Apache Doris 将会逐步支持包括 Time Travel、增量数据读取在内的 Apache Paimon 更多高级特性,共同构建统一、高性能、实时的湖仓平台。
本文将会再 Docker 环境中,为读者讲解如何快速搭建 Apache Doris + Apache Paimon 测试 & 演示环境,并展示各功能的使用操作。
使用指南
本文涉及脚本&代码从该地址获取:https://github.com/apache/doris/tree/master/samples/datalake/iceberg\_and\_paimon
01 环境准备
本文示例采用 Docker Compose 部署,组件及版本号如下:

Apache Doris 2.1.5 为全新发布:| 下载地址 | Release Notes
02 环境部署
1. 启动所有组件
bash ./start_all.sh
2. 启动后,可以使用如下脚本,登陆 Flink 命令行或 Doris 命令行:
bash ./start_flink_client.sh
bash ./start_doris_client.sh
03 数据准备
首先登陆 Flink 命令行后,可以看到一张预构建的表。表中已经包含一些数据,我们可以通过 Flink SQL 进行查看。
Flink SQL> use paimon.db_paimon;
[INFO] Execute statement succeed.
Flink SQL> show tables;
+------------+
| table name |
+------------+
| customer |
+------------+
1 row in set
Flink SQL> show create table customer;
+------------------------------------------------------------------------+
| result |
+------------------------------------------------------------------------+
| CREATE TABLE `paimon`.`db_paimon`.`customer` (
`c_custkey` INT NOT NULL,
`c_name` VARCHAR(25),
`c_address` VARCHAR(40),
`c_nationkey` INT NOT NULL,
`c_phone` CHAR(15),
`c_acctbal` DECIMAL(12, 2),
`c_mktsegment` CHAR(10),
`c_comment` VARCHAR(117),
CONSTRAINT `PK_c_custkey_c_nationkey` PRIMARY KEY (`c_custkey`, `c_nationkey`) NOT ENFORCED
) PARTITIONED BY (`c_nationkey`)
WITH (
''bucket'' = ''1'',
''path'' = ''s3://warehouse/wh/db_paimon.db/customer'',
''deletion-vectors.enabled'' = ''true''
)
|
+-------------------------------------------------------------------------+
1 row in set
Flink SQL> desc customer;
+--------------+----------------+-------+-----------------------------+--------+-----------+
| name | type | null | key | extras | watermark |
+--------------+----------------+-------+-----------------------------+--------+-----------+
| c_custkey | INT | FALSE | PRI(c_custkey, c_nationkey) | | |
| c_name | VARCHAR(25) | TRUE | | | |
| c_address | VARCHAR(40) | TRUE | | | |
| c_nationkey | INT | FALSE | PRI(c_custkey, c_nationkey) | | |
| c_phone | CHAR(15) | TRUE | | | |
| c_acctbal | DECIMAL(12, 2) | TRUE | | | |
| c_mktsegment | CHAR(10) | TRUE | | | |
| c_comment | VARCHAR(117) | TRUE | | | |
+--------------+----------------+-------+-----------------------------+--------+-----------+
8 rows in set
Flink SQL> select * from customer order by c_custkey limit 4;
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
| 1 | Customer#000000001 | IVhzIApeRb ot,c,E | 15 | 25-989-741-2988 | 711.56 | BUILDING | to the even, regular platel... |
| 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic... |
| 3 | Customer#000000003 | MG9kdTD2WBHm | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic,... |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tl... | 15 | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious ... |
+-----------+--------------------+--------------------------------+-------------+-----------------+-----------+--------------+--------------------------------+
4 rows in set
04 数据查询
如下所示,Doris 集群中已经创建了名为paimon 的 Catalog(可通过 SHOW CATALOGS 查看)。以下为该 Catalog 的创建语句:
-- 已创建,无需执行
CREATE CATALOG `paimon` PROPERTIES (
"type" = "paimon",
"warehouse" = "s3://warehouse/wh/",
"s3.endpoint"="http://minio:9000",
"s3.access_key"="admin",
"s3.secret_key"="password",
"s3.region"="us-east-1"
);
你可登录到 Doris 中查询 Paimon 的数据:
mysql> use paimon.db_paimon;
Reading table information for completion of table and column names
You can turn off this feature to get a quicker startup with -A
Database changed
mysql> show tables;
+---------------------+
| Tables_in_db_paimon |
+---------------------+
| customer |
+---------------------+
1 row in set (0.00 sec)
mysql> select * from customer order by c_custkey limit 4;
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| 1 | Customer#000000001 | IVhzIApeRb ot,c,E | 15 | 25-989-741-2988 | 711.56 | BUILDING | to the even, regular platelets. regular, ironic epitaphs nag e |
| 2 | Customer#000000002 | XSTf4,NCwDVaWNe6tEgvwfmRchLXak | 13 | 23-768-687-3665 | 121.65 | AUTOMOBILE | l accounts. blithely ironic theodolites integrate boldly: caref |
| 3 | Customer#000000003 | MG9kdTD2WBHm | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic, even instructions. express foxes detect slyly. blithely even accounts abov |
| 32 | Customer#000000032 | jD2xZzi UmId,DCtNBLXKj9q0Tlp2iQ6ZcO3J | 15 | 25-430-914-2194 | 3471.53 | BUILDING | cial ideas. final, furious requests across the e |
+-----------+--------------------+---------------------------------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
4 rows in set (1.89 sec)
05 读取增量数据
我们可以通过 Flink SQL 更新 Paimon 表中的数据:
Flink SQL> update customer set c_address=''c_address_update'' where c_nationkey = 1;
[INFO] Submitting SQL update statement to the cluster...
[INFO] SQL update statement has been successfully submitted to the cluster:
Job ID: ff838b7b778a94396b332b0d93c8f7ac
等 Flink SQL 执行完毕后,在 Doris 中可直接查看到最新的数据:
mysql> select * from customer where c_nationkey=1 limit 2;
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| c_custkey | c_name | c_address | c_nationkey | c_phone | c_acctbal | c_mktsegment | c_comment |
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
| 3 | Customer#000000003 | c_address_update | 1 | 11-719-748-3364 | 7498.12 | AUTOMOBILE | deposits eat slyly ironic, even instructions. express foxes detect slyly. blithely even accounts abov |
| 513 | Customer#000000513 | c_address_update | 1 | 11-861-303-6887 | 955.37 | HOUSEHOLD | press along the quickly regular instructions. regular requests against the carefully ironic s |
+-----------+--------------------+-----------------+-------------+-----------------+-----------+--------------+--------------------------------------------------------------------------------------------------------+
2 rows in set (0.19 sec)
Benchmark
我们在 Paimon(0.8)版本的 TPCDS 1000 数据集上进行了简单的测试,分别使用了 Apache Doris 2.1.5 版本和 Trino 422 版本,均开启 Primary Key Table Read Optimized 功能。

从测试结果可以看到,Doris 在标准静态测试集上的平均查询性能是 Trino 的 3 -5 倍,后续我们将针对 Deletion Vector 进行优化,进一步提升真实业务场景下的查询效率。
查询优化
对于基线数据来说,Apache Paimon 在 0.6 版本中引入 Primary Key Table Read Optimized 功能后,使得查询引擎可以直接访问底层的 Parquet/ORC 文件,大幅提升了基线数据的读取效率。对于尚未合并的增量数据( INSERT、UPDATE 或 DELETE 所产生的数据增量)来说,可以通过 Merge-on-Read 的方式进行读取。此外,Paimon 在 0.8 版本中还引入的 Deletion Vector 功能,能够进一步提升查询引擎对增量数据的读取效率。
Apache Doris 支持通过原生的 Reader 读取 Deletion Vector 并进行 Merge on Read,我们通过 Doris 的 EXPLAIN 语句,来演示在一个查询中,基线数据和增量数据的查询方式。
mysql> explain verbose select * from customer where c_nationkey < 3;
+------------------------------------------------------------------------------------------------------------------------------------------------+
| Explain String(Nereids Planner) |
+------------------------------------------------------------------------------------------------------------------------------------------------+
| ............... |
| |
| 0:VPAIMON_SCAN_NODE(68) |
| table: customer |
| predicates: (c_nationkey[#3] < 3) |
| inputSplitNum=4, totalFileSize=238324, scanRanges=4 |
| partition=3/0 |
| backends: |
| 10002 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=1/bucket-0/data-15cee5b7-1bd7-42ca-9314-56d92c62c03b-0.orc start: 0 length: 66600 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=1/bucket-0/data-5d50255a-2215-4010-b976-d5dc656f3444-0.orc start: 0 length: 44501 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=2/bucket-0/data-e98fb7ef-ec2b-4ad5-a496-713cb9481d56-0.orc start: 0 length: 64059 |
| s3://warehouse/wh/db_paimon.db/customer/c_nationkey=0/bucket-0/data-431be05d-50fa-401f-9680-d646757d0f95-0.orc start: 0 length: 63164 |
| cardinality=18751, numNodes=1 |
| pushdown agg=NONE |
| paimonNativeReadSplits=4/4 |
| PaimonSplitStats: |
| SplitStat [type=NATIVE, rowCount=1542, rawFileConvertable=true, hasDeletionVector=true] |
| SplitStat [type=NATIVE, rowCount=750, rawFileConvertable=true, hasDeletionVector=false] |
| SplitStat [type=NATIVE, rowCount=750, rawFileConvertable=true, hasDeletionVector=false] |
| tuple ids: 0
| ............... | |
+------------------------------------------------------------------------------------------------------------------------------------------------+
67 rows in set (0.23 sec)
可以看到,对于刚才通过 Flink SQL 更新的表,包含 4 个分片,并且全部分片都可以通过 Native Reader 进行访问(paimonNativeReadSplits=4/4)。并且第一个分片的hasDeletionVector的属性为 true,表示该分片有对应的 Deletion Vector,读取时会根据 Deletion Vector 进行数据过滤。
结束语
以上是基于 Apache Doris 与 Apache Paimon 快速搭建测试 / 演示环境的详细指南,后续我们还将陆续推出 Apache Doris 与各类主流数据湖格式及存储系统构建湖仓一体架构的系列指南,包括 Iceberg、OSS、Delta Lake 等,欢迎持续关注。

Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座
摘要:本文整理自阿里云开源大数据表存储团队负责人,阿里巴巴高级技术专家李劲松(之信),在 Streaming Lakehouse Meetup 的分享。内容主要分为四个部分:
流计算邂逅数据湖
Paimon CDC 实时入湖
Paimon 不止 CDC 入湖
总结与生态
点击查看原文视频 & 演讲 PPT

一、流计算邂逅数据湖
流计算 1.0 实时预处理
流计算 1.0 架构截止到现在也是非常主流的实时数仓中的一个实时预处理的功能,可以通过流计算把消息队列中的数据(比如:日志数据,CDC 数据等等),通过消息队列将数据读过来,通过流计算,进行数据预处理,最终把结果写到 MySQL 中。
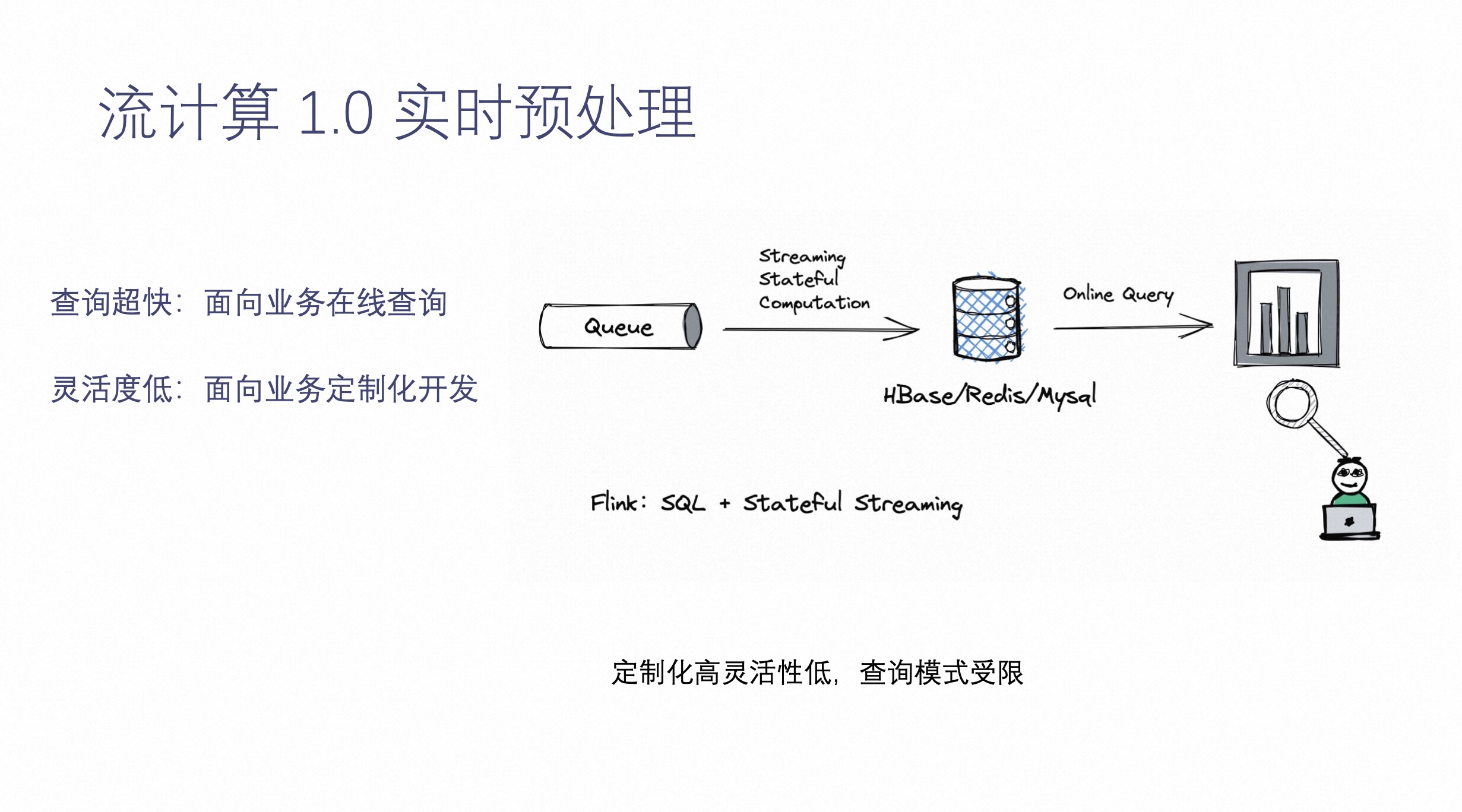
这个系统的典型特点是,它可以面向在线服务的实时查询,这就意味着用户可以把数据通过在线服务查询集成到在线业务中,然后整条链路相当于为每个业务定制的 Pipeline,满足在线业务。这个系统的缺点是,灵活性比较低,面向业务要定制化开发。
流计算 2.0 实时数仓
为了解决灵活性的问题,这就要介绍下流计算 2.0 实时数仓了。
随着计算的发展,越来越多的具有高性能的 OLAP 系统诞生出来,比如 Hologres 等等。它们最大的特点是可以把数据通过结构化的方式落到 OLAP 系统中,可以让业务根据自己灵活的需求来查询这些结构化数据。这样做的好处是,数据落进来之后,数据能够保存比较原始的或经过简单预处理的状态,能够比较灵活的提供给业务方进行实时查询。
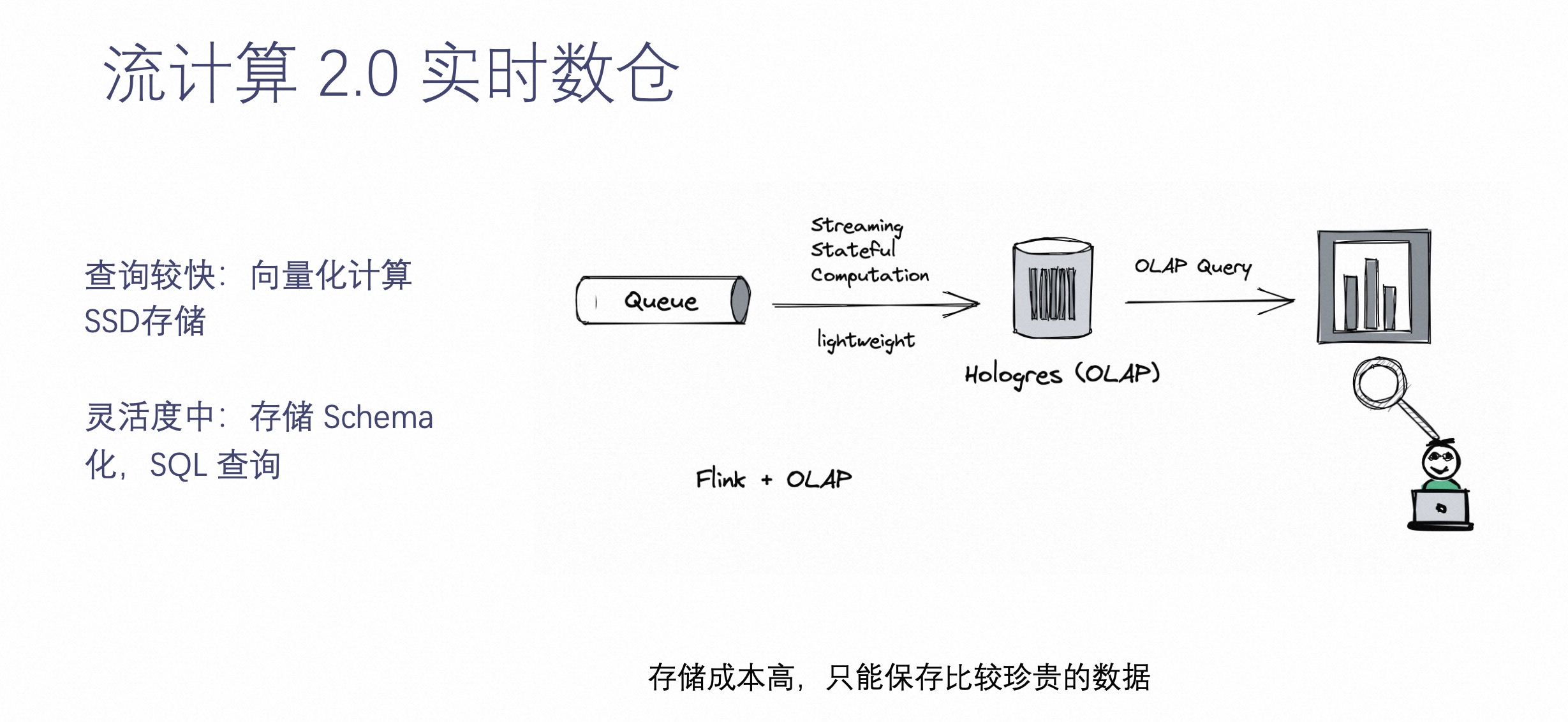
查询性能高,向量化计算 +SSD 存储,实现毫秒响应返回;灵活度适中,比起之前完全的预处理保留了更多的数据和更复杂结构化的模式。但是由于 OLAP 系统成本不低,不能把所有数据都保存到系统中,只将近期的或最重要的数据保存。
流计算 3.0 实时湖仓
基于以上 2.0 的情况,我们引入了流计算的第三个场景 —— 流计算 3.0 实时湖仓。当用户不想再看到实时数据受到限制,灵活性足够大的时候,就可以把离线数仓的数据通过实时化的方式搬到这样一个支持实时化的存储上。把所有实时数据落到存储里面,所有的数据都可以被实时查询。这就是实时湖仓能够解决的问题。
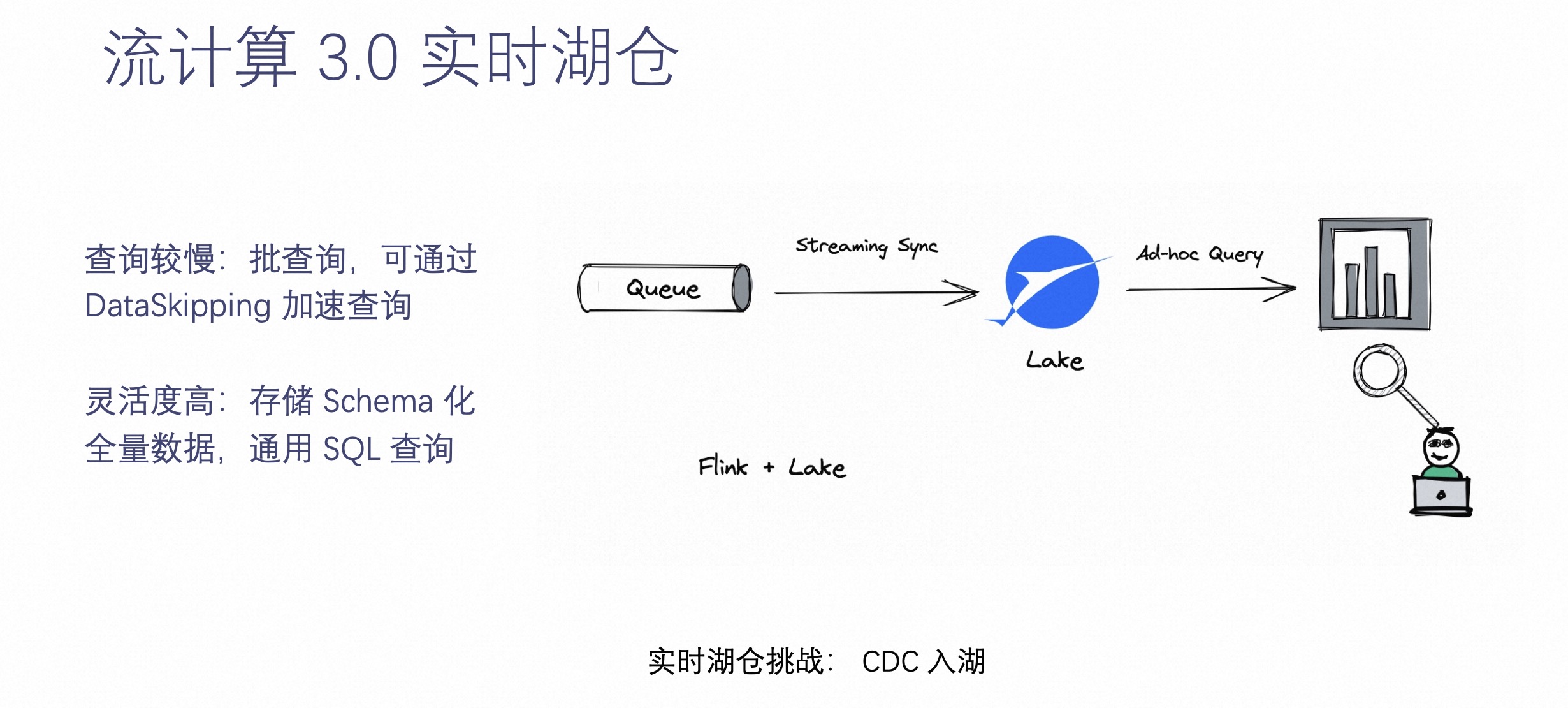
实时湖仓最大限度的解决了灵活度的问题,它可以把所有数据沉淀到湖中,通过实时手段做到业务可查询数据。但是它也带来了一些缺点,它的查询是不如 OLAP 引擎甚至不如在线服务的。所以说,实时湖仓虽然带来了灵活性,但是损失了一些查询的效率。
未来的发展方向是,实时湖仓可以通过更多的 Index 和 DataSkipping 加速查询。这也是 Apache Paimon 诞生的原因。Apache Paimon 就是一个专门为 CDC 处理、流计算而生的数据湖,希望为用户带来舒服、自动湖上流处理体验。
下面将通过一个案例介绍 Apache Paimon 在实时入湖方面做的工作。
二、Paimon CDC 实时入湖
在介绍 Paimon CDC 实时入湖之前,先来看下传统 CDC 入仓是怎么做的。
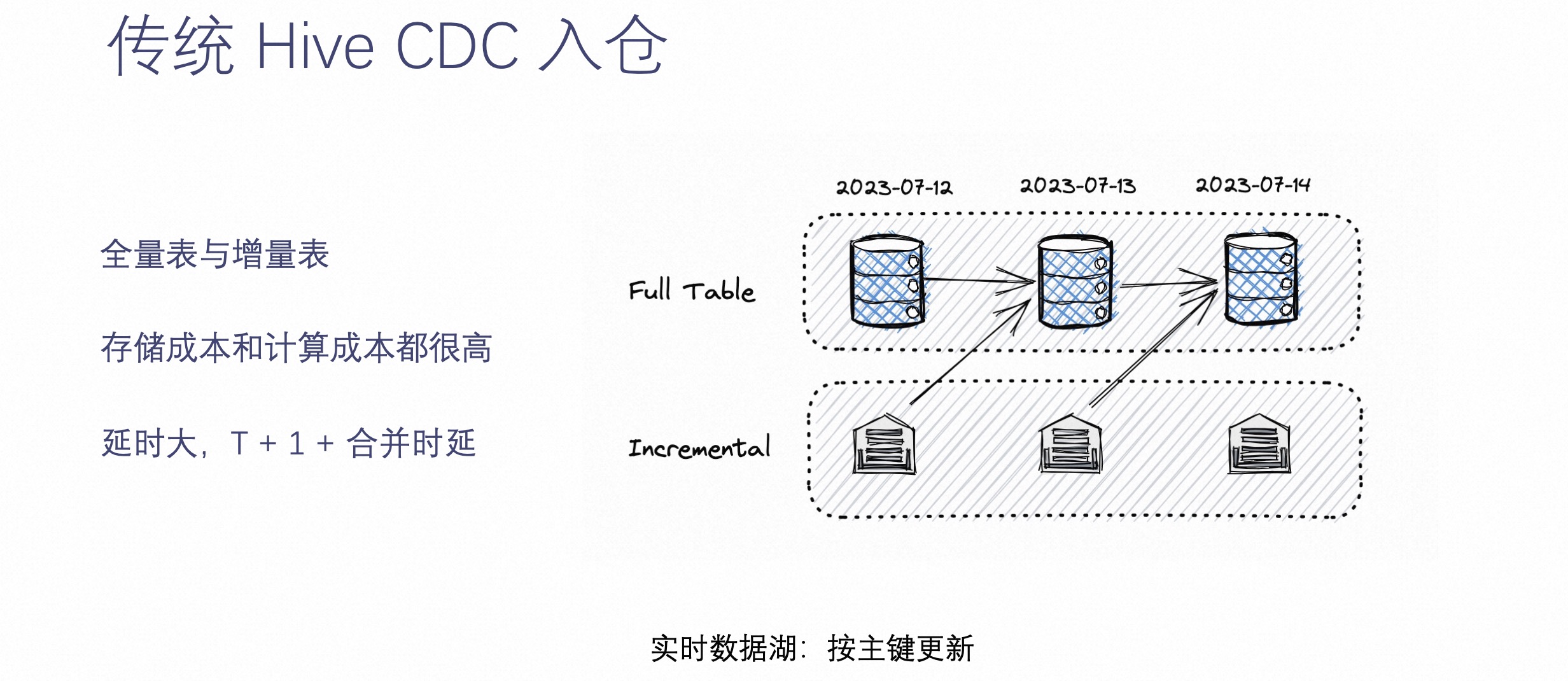
相信运维过数仓的工程师都了解传统数仓的架构。它在解决 CDC 数据的时候,往往是通过上图中全量表加增量表的方式。这种方式是指,每天的增量数据都会落到一个 Hive 增量表中,同时另外维护一个 Hive 的全量表,然后每天增量表的数据就绪后,就把增量表数据和之前的全量表数据进行一次合成,生成一个新的 Hive 全量表。
这种方式的优点是可以实现离线数仓查询每天的全量数据,缺点是全量表每天都会保存一个全量,而增量表每天也会保存当日的增量,所以存储的成本会非常高,同时计算的成本也不低。
另外一个问题是,这种传统的 CDC 入仓方式的延迟性非常大,不但需要 T+1 才能读到昨天的数据,而且还要经过合并延迟,这就对数据湖存储来讲是个很大的挑战。
实时数据湖的基础就是按主键更新,需要有实时更新的能力。Paimon CDC 入湖是怎样的流程呢?如下图所示。
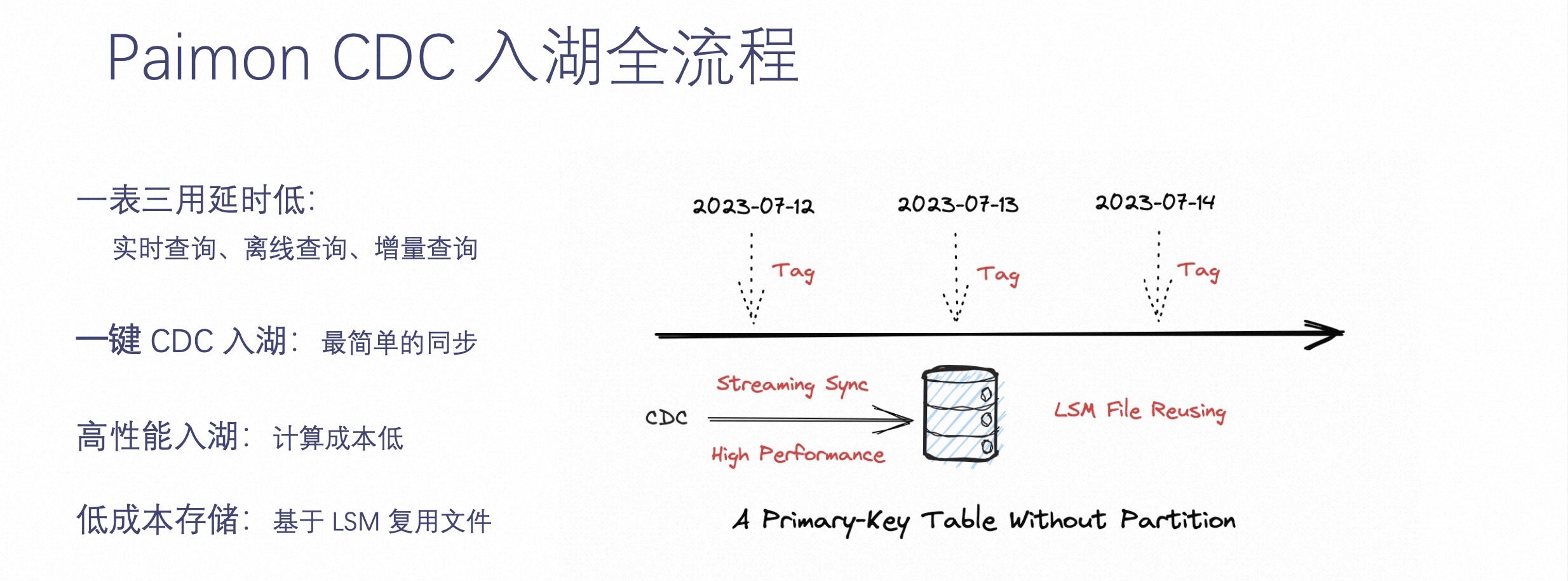
比起上文提到的 Hive 全量表 + 增量表的方式,Paimon 不再需要定义分区表,只需要定义一个主键表即可。这样这个主键表可以通过 Flink CDC 或是 CDC 数据实时 Streaming Sync 到表中,并且在这个基础上,可以每天晚上零点之后打一个 Tag,这个 Tag 可以维护这张表当时的状态,每个 Tag 对应离线的一个分区。
这样一整套架构带来的好处是一张表可以三用而且延迟低,它可以被实时查询、离线查询,也可以通过增量查询的方式,查询两个 Tag 之间的增量数据。
一键 CDC 入湖是 Paimon 专门为实时更新而生的,它可以实现高性能的入湖,并且通过这样的方式,相较于之前的入仓,存储成本大大降低,因为它是基于 LSM 复用文件来实现的。
接下来介绍下 Paimon CDC 简单的数据集成。
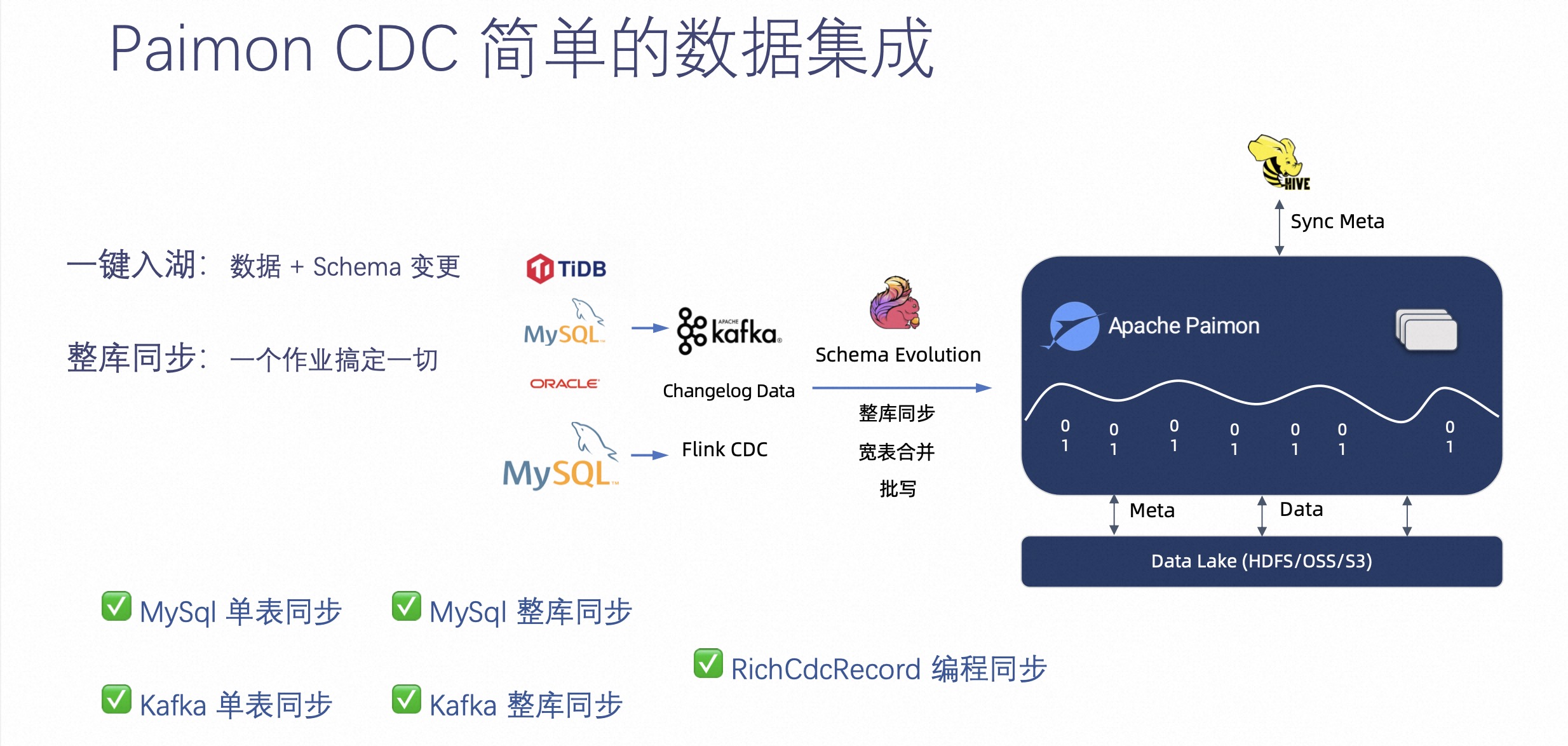
Paimon 集成的 Flink CDC 在开源社区提供了非常方便一键入湖,可以将 Flink CDC 数据同步到 Paimon 中,也可以通过整库同步作业把整个库成百上千的表通过一个作业同步到多个 Paimon 表中。
如上图右侧图表可见,Paimon 在开源社区做的 CDC 入湖不只是有 CDC 入湖单表同步和整库同步,也有 Kafka 单表同步和整个同步。如果这些还不能满足,用户如果有自己的消息队列和自己的格式,也可以通过 RichCdcRecord 这种编程方式达到入湖的效果。
接下来介绍下 Paimon 高性能入湖调优指南。
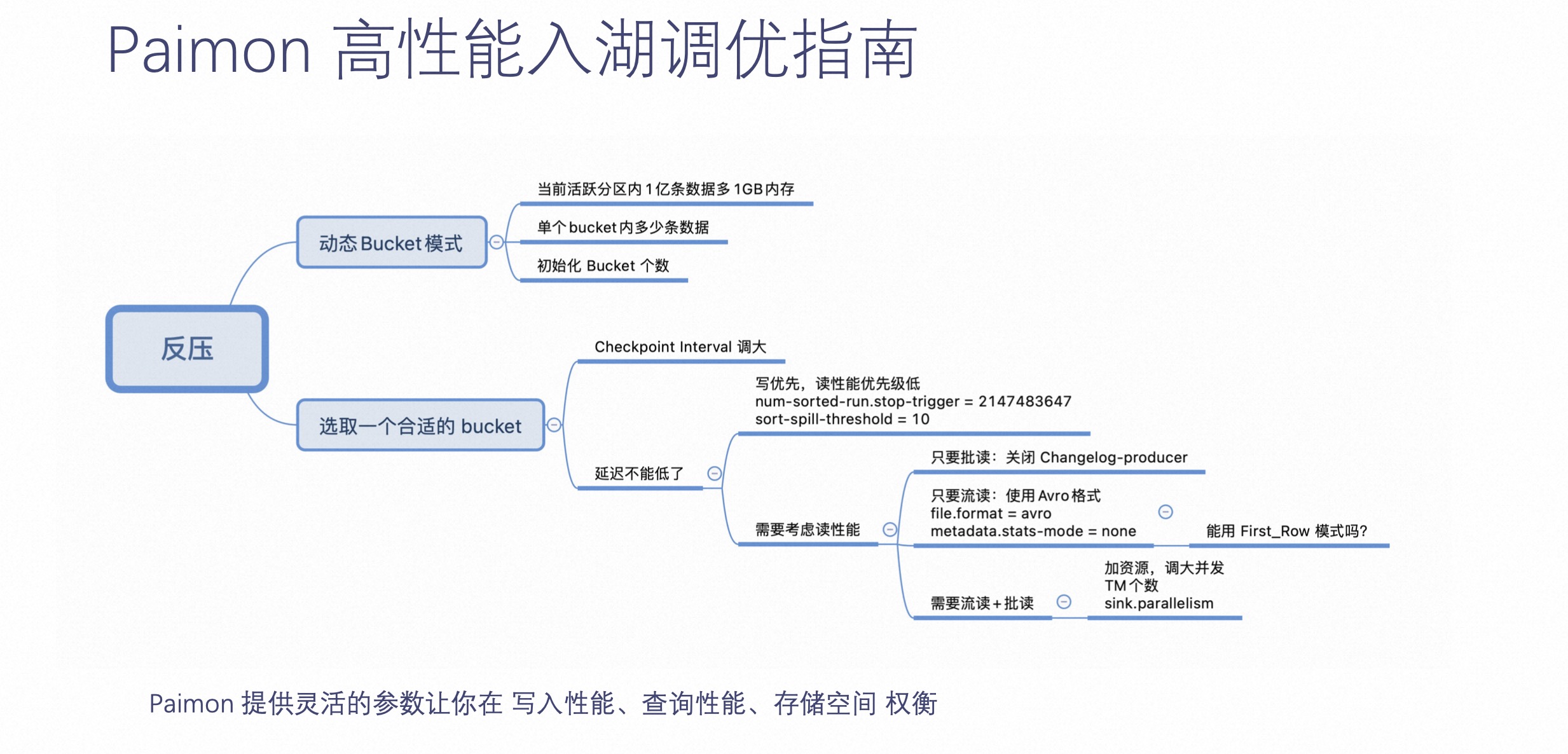
Paimon 在入湖方面,提供了灵活参数,让用户在写入性能、查询性能和存储空间中权衡。举个例子,当用户知晓作业反压了,可以选用 Paimon 的动态 Bucket 模式,也可以通过业务测出一个合适的 Bucket。如果这个时候还反压,可以调整 Checkpoint Interval,或是通过参数指定 Paimon Compaction 实现其永远不阻塞,让写入优先。
总而言之,Paimon 在这里提供了非常灵活的参数,可以让用户在流读、批读和更新场景当中做到相应的权衡。
上文提及 Paimon 是一张没有分区的表,Paimon 如何提供离线视图呢?
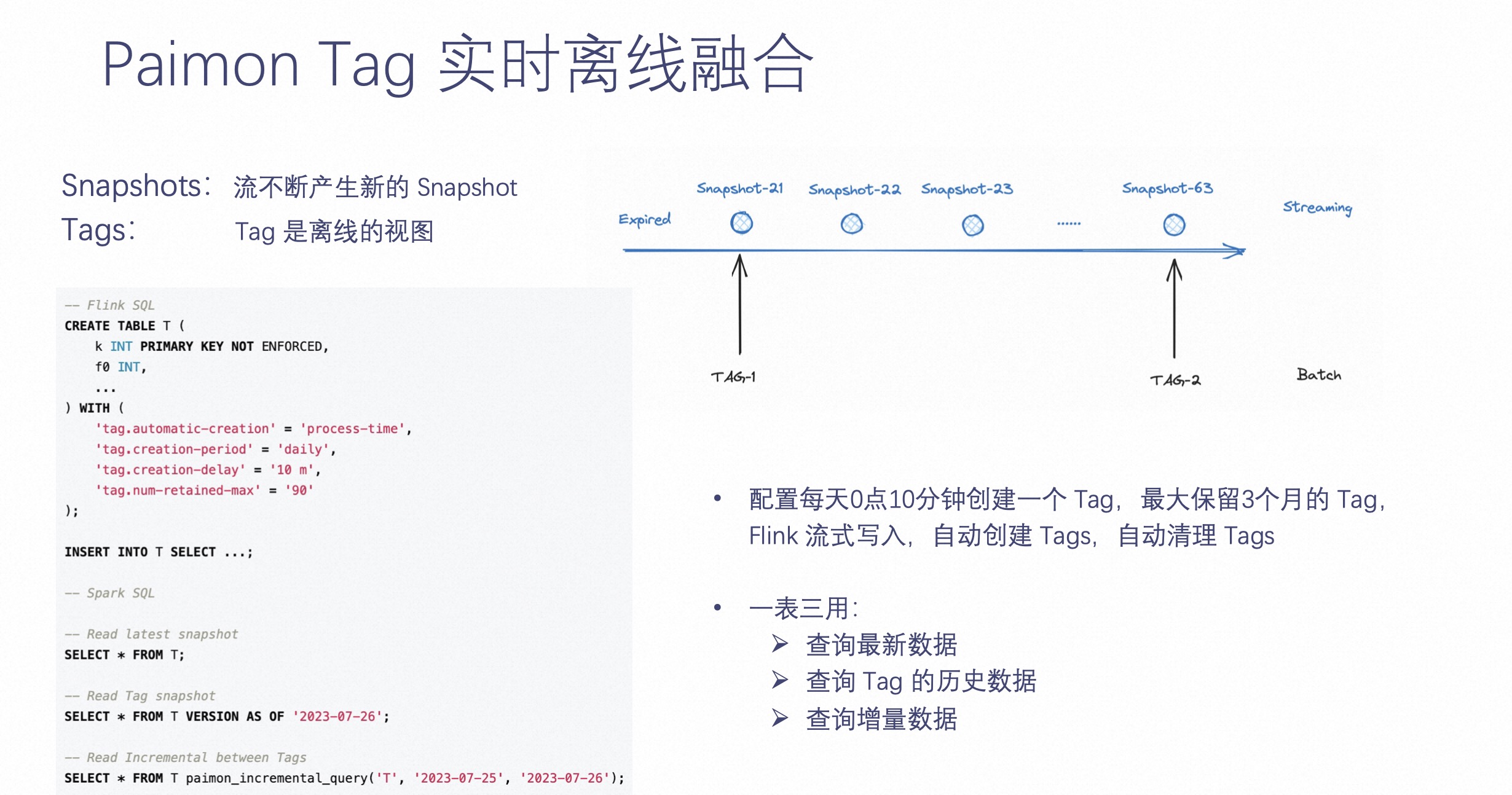
众所周知,离线数仓有个非常重要的东西,就是它需要数据有一个不可变的视图,不然两次计算出的结果就不一样了。所以 Paimon 提供了一个非常重要的功能,即 Create Tag,它可以在 Paimon 中指定一些 Tag,让这些 Tag 永不删除,永远可读。如上图左侧的示意。
第二部分最后一块内容介绍 Paimon LSM 文件存储的复用。
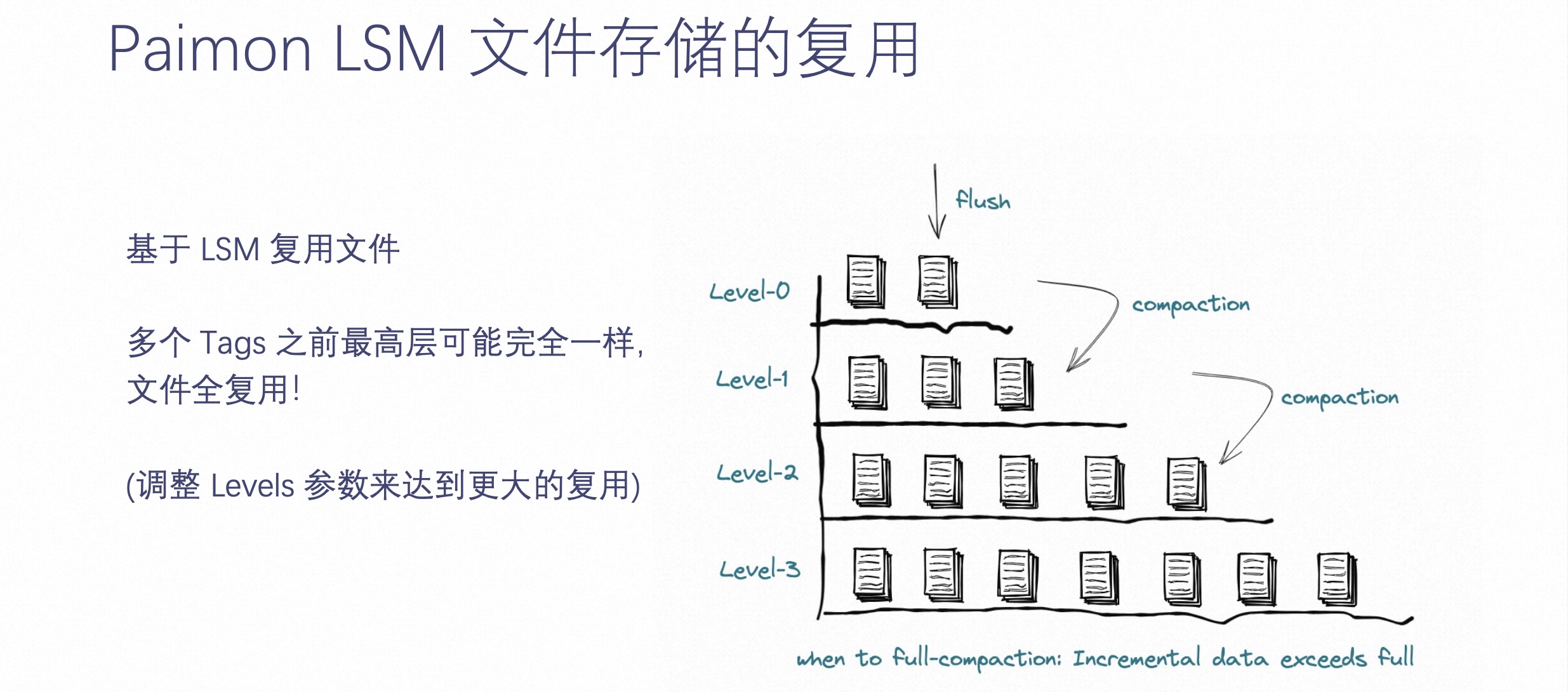
前文提及 Paimon 在这种场景下较之以前的数仓,文件存储会降低数倍甚至降低数十倍或数百倍。为什么它可以达到这样的效果呢?
如上图右侧 LSM 文件示意。LSM 有个特点是,它增量数据来了,不一定需要合并到最底层的数据,也就是说最底层的这些文件,可能两个 Tag 之间完全复用这些文件。因为增量数据不足以让最底层的数据参与合并,这样能达到的效果是两个 Tag 甚至一个月的 Tag,最底层的 LSM 树都没有发生过合并,意味着最底层的文件是全复用的。所以多个 Tag 之间,文件可以完全复用,这样能达到最大的复用效果。
三、Paimon 不止 CDC 入湖
自从 Paimon 进入 Apache 孵化器后,多了非常多的贡献者,这对整个开源社区来讲都是一个飞跃的进展。
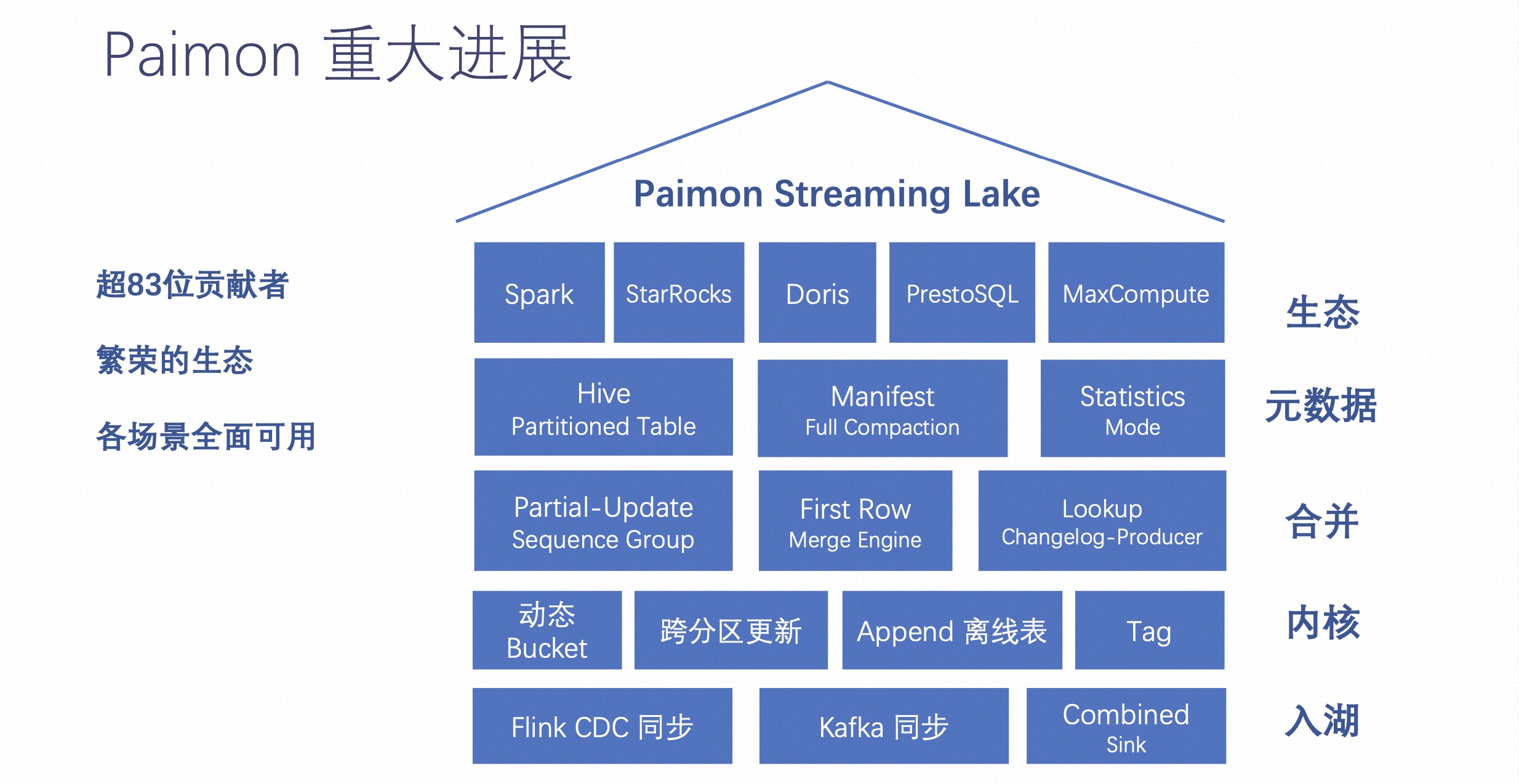
现在 Paimon 有超过 83 位贡献者,形成一个非常繁荣的生态体系,他们不只是来源于阿里巴巴,也有来自其他公司贡献者。通过这些贡献者的贡献,让 Paimon 拥有如上图右侧的全部功能。
Paimon 生态这边取得了比较大的进展。Paimon 之前主要是 Flink、Spark 等,现在还包括 StarsRocks、Doris 和 PrestoSQL 等等。这些都能在它们的计算上查询到 Paimon 的数据。
元数据包含 Hive Partitioned Table,可以通过这个把元数据保存到 HMS 上。用户也可以在 Hive 的 HMS 中查询到 Paimon 有哪些分区。
其他关于合并、内核、入湖等相关内容,可以去官网了解详情: https://paimon.apache.org/
接下来分享三个场景。
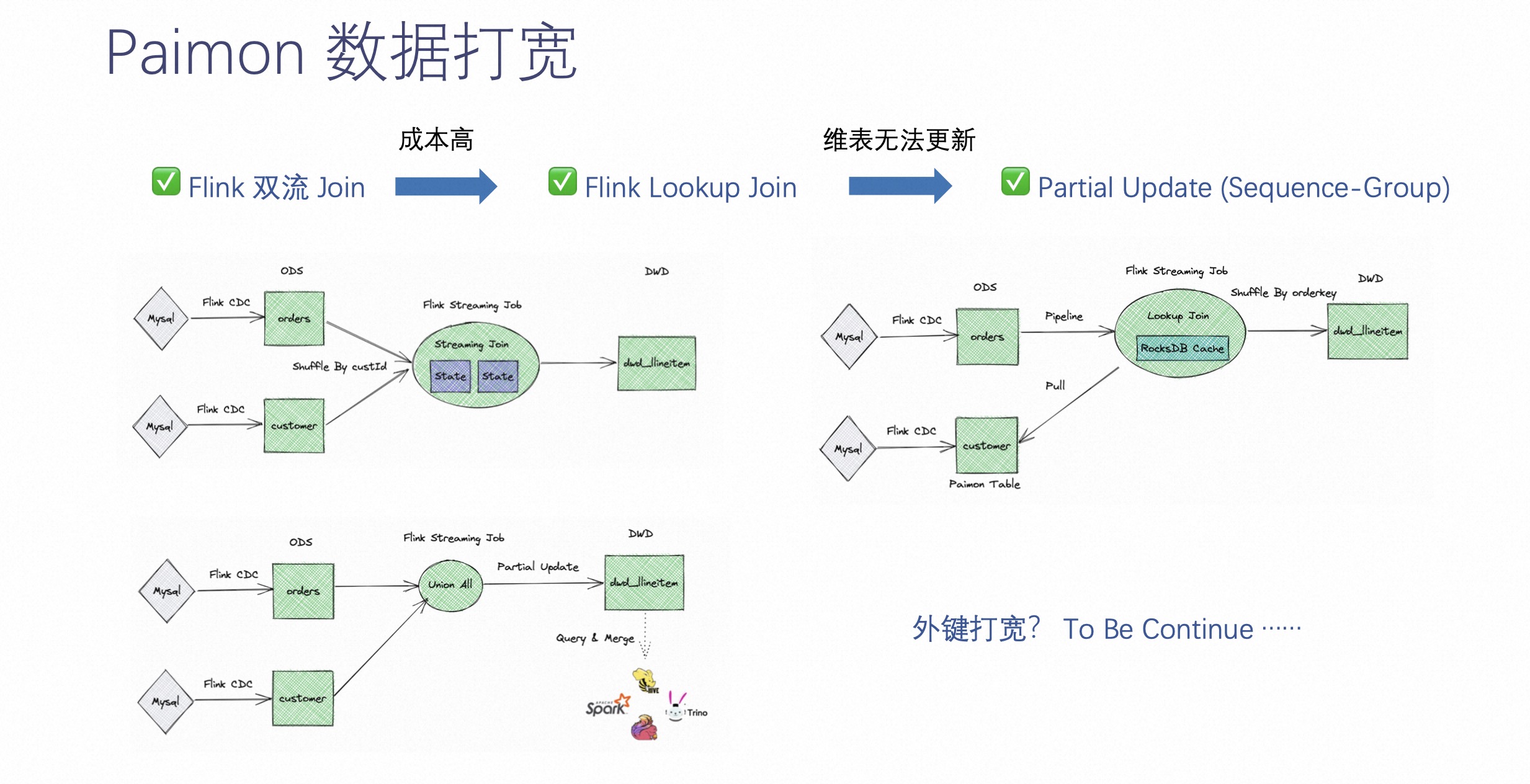
数据打宽在之前的实施中可能用 Flink 双流 join,离线中直接 join。这种方式在实施过程中有个难点就是不适用所有场景,而且成本比较高。
所以 Paimon 这边做了很多工作,包括 Paimon 可以当做 Flink lookup join 的一张表来进行 join,包括 Paimon 的 Partial Update 可以支持同组件的打宽,而且可以定义 sequence-group,让各个字段可以有不同的覆盖方式。
上图中所示意的三种方式简单介绍下。
-
第一种是 Flink 双流 join 的方式,需要维护两边比较大的 state,这也是成本比较高的原因之一。
-
第二种是通过 Flink lookup join 的方式 lookup 到 Paimon 的数据,缺点是维表的更新不能更新到已经 join 的数据上。
-
第三种是通过 Partial Update 的方式,即同组件的打宽的方式。推荐大家使用这种方式,它不仅具有高吞吐,还能带来近实时级别的延迟。
除了以上三种,未来 Paimon 还将争取在外键打宽的能力上投入精力。外键打宽是通过分钟级延时的方式来降低整体实时 join 的打宽成本。
下面介绍两个 Paimon 另外两个能力,即 Paimon 消息队列替代和 Paimon 离线表替代。
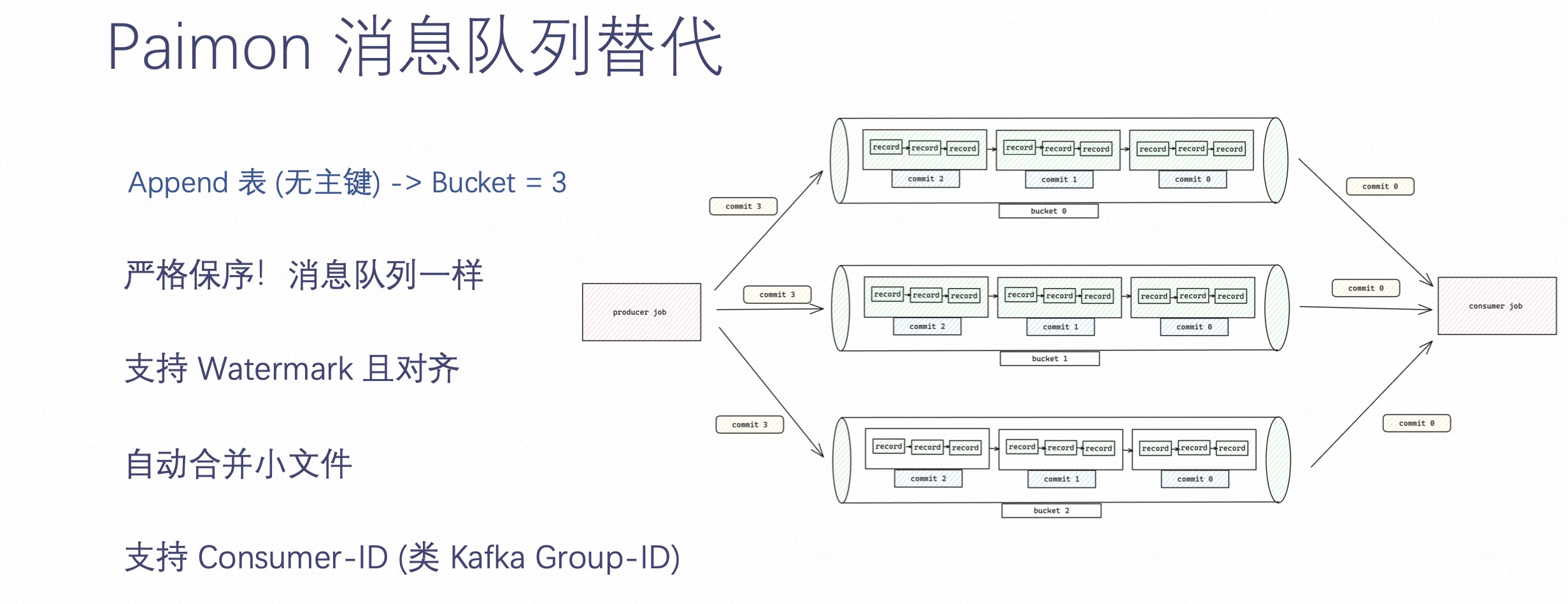
既然 Paimon 面向的是实时,不免有些人就会拿 Paimon 和 Kafka 架构进行对比。Paimon 这边做了很多工作,比如它支持 Append-only 表,即你可以不定义主键,只定义 Bucket number。当定义 Bucket number 的时候,bucket 就类似 Kafka 的 partition 概念,做到了严格保序,跟 Kafka 的消息顺序是一模一样的,而且也支持 Watermark 且对齐。在写入的过程中,能够自动合并小文件,也支持 Consumer ID 消费。
Paimon 在提供消息队列能力的同时,也沉淀了所有的历史数据,而不是像 Kafka 一样只能保存最近几天的数据。
所以通过业务图的方式可以看出,它的整体架构是想通过 Paimon 这种方式让用户在某些实时场景上替换 Kafka。Kafka 真正的能力是提供秒级延时,当业务不需要秒级延时的时候,可以考虑使用 Paimon 来替代消息队列。
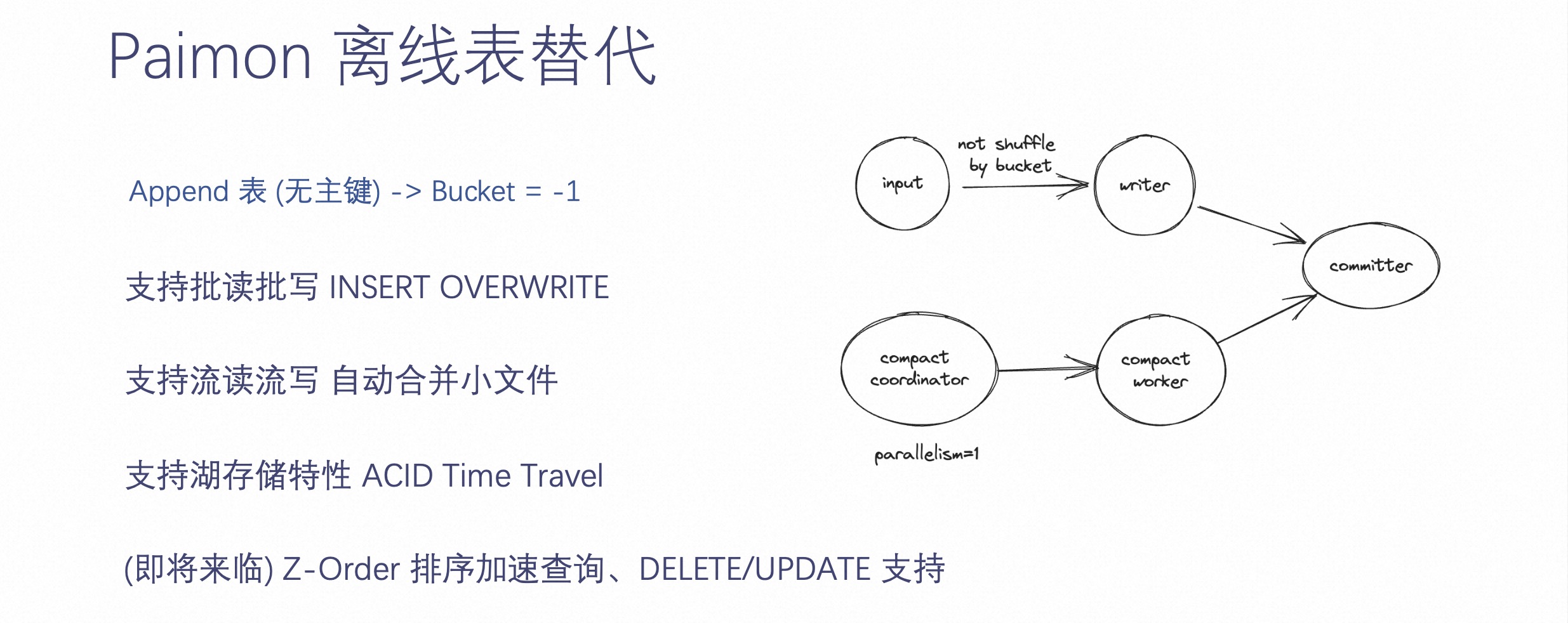
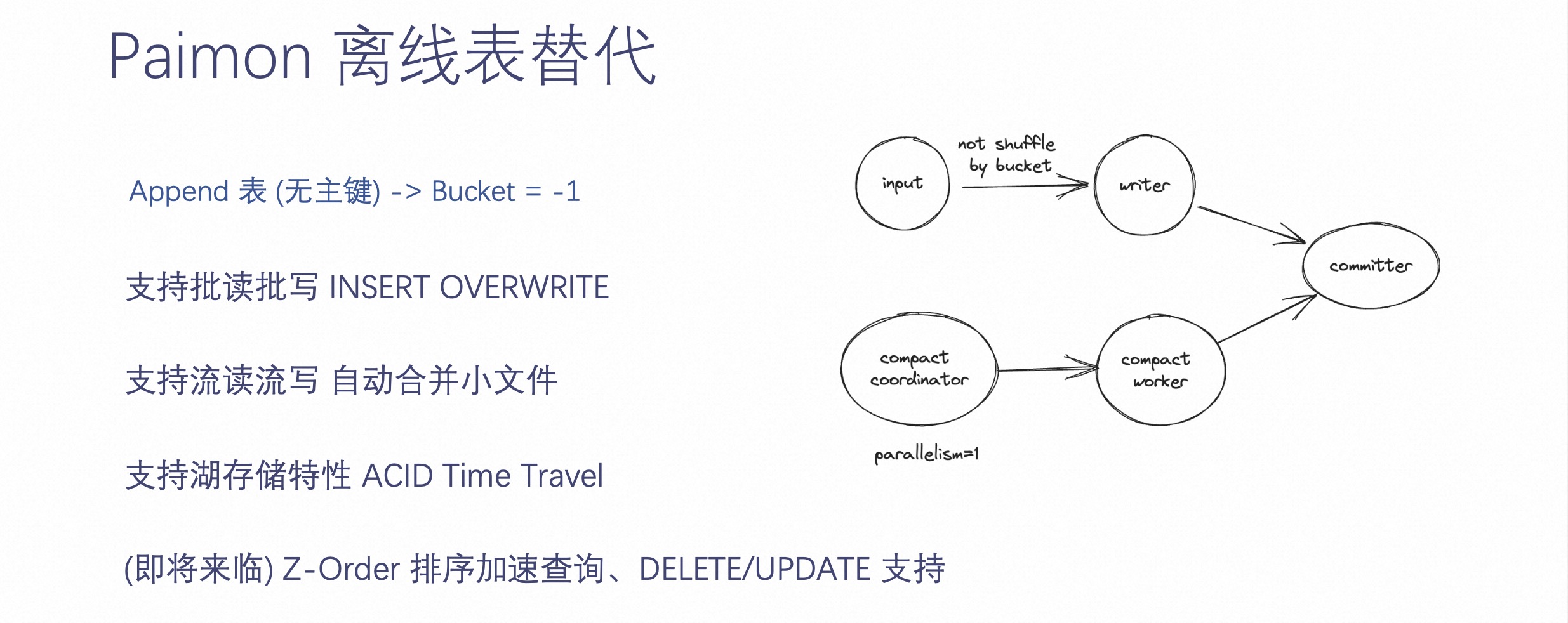
Paimon 是一个数据湖,数据湖最常见的应用是离线表。Paimon 也拥有这样的能力。
在 Append 表定义的时候,把 Bucket 表定义为 - 1,那么 Paimon 就会认为这张表是一张离线表。Paimon 作为一张离线表可以替代原有的 Hive 数仓,比如 Paimon 支持批读批写,支持 INSERT OVERWRITE,也支持流读流写。而且 Paimon 可以自动合并小文件,也支持湖存储特性 ACID、Time Travel、Z-Order 排序加速查询和 Delete、Update 等等。
综上所述,Paimon 基本上能做到大部分离线表的能力。
四、总结与生态

通过前三部分的整体介绍,结论是:Paimon 基本成熟,是 Streaming Lake 的优选。
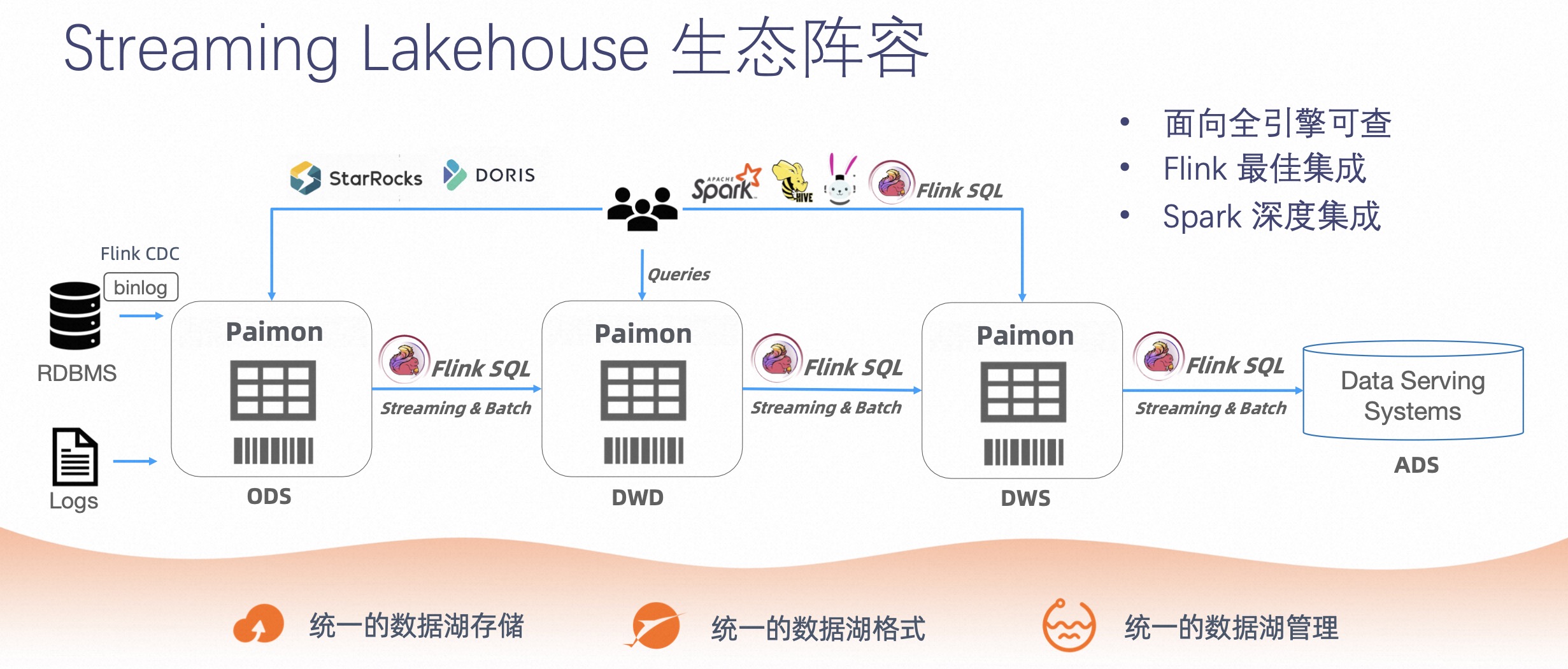
下面介绍下 Streaming Lakehouse 的生态阵容。Streaming Lakehouse 具有以下几个特点:
-
第一,Streaming Lakehouse 具有统一的数据湖存储能力;
-
第二,Streaming Lakehouse 具有统一的数据湖格式;
-
第三,Streaming Lakehouse 具有统一的数据湖管理。
今天 Streaming Lakehouse 拥有非常丰富的生态,它可以通过 Flink CDC,包括数据落到湖中,可以通过 Flink SQL ETL 以 Streaming 的方式,把数据流动起来,也能做到实时数据订正。
在此基础上,Paimon 已经拥有了一个非常好的生态,欢迎大家使用。
最后介绍下阿里云在 Paimon 上的实践。
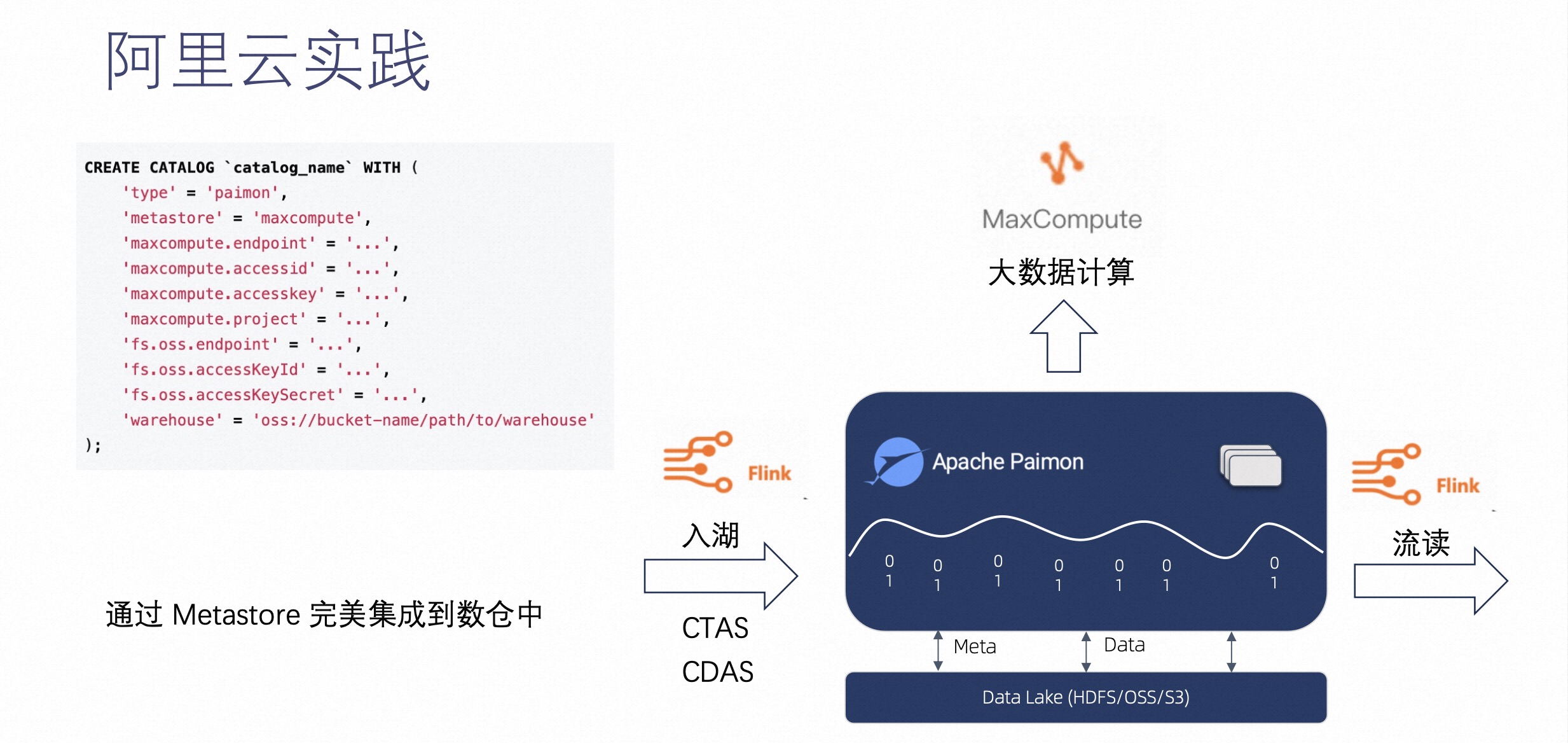
我们将 Paimon 和阿里云的 MaxCompute 产品做了深度集成,如上图右侧可见,这是一个简单的 Flink 的 Create Catalog,用户可以通过 Metastore 完美集成到 MaxCompute 数仓中。
这样指定后,再在 Flink 上创建表,它的元数据就会被同步到 MaxCompute 的元数据中,然后在 MaxCompute 那边就可以直接对这些表进行查询了。这样就可以达到一个 Flink 入湖 MaxCompute 分析这样一个流程。
通过阿里云的实践,我们可以看到 Paimon 的设计是非常灵活且开放的,它可以通过 Metastore 完美集成到阿里云或是其他企业原有的数仓中,集成之后能达到非常好的完整链路的写入和分析的效果。
Q&A
Q:请问 Paimon 是否有 Hudi 的实时旅行一样的功能么?
A:Paimon 本身就支持实时旅行,但是因为 Snapshot 每三分钟就会有一个,一天产生的量很大,也就是说数据的冗余会很大,对于存储成本不友好。所以 Paimon 就提供了 Create Tag 的方式以解决这个问题,Snapshot 可以很快被删掉,你可以创建 Tag 保证 Time Travel 的有效性。
Q:Paimon 一定程度上提供了 Kafka 的能力,提供了很多数据的接入方式,那么如果是文件,有没有特别好的接入方式呢?
A:你的意思是文件不留在 Queue 中,直接流到 Paimon 中。如果是这样的话,目前可以通过 Flink 或是 Spark 的这种批计算调度方式,来把文件同步到 Paimon 中。
Q:Paimon 可以被像 StarRocks 这样的产品查询,那像我们使用阿里云的 ADB,是不是它也可以跟 ADB 有这样的连接,在 ADB 里进行查询?
A:非常好的问题,我认为这是可以的,按时目前还没有和 ADB 集成,后面是可以推进的。
请关注 Paimon
流式数据湖的发展需要你的支持:
- 关注微信公众号:Apache Paimon,了解行业实践与最新动态
- 进入 Paimon 交流钉钉群:搜索 10880001919,讨论技术并得到实时的支持
- Github https://github.com/apache/incubator-paimon 点赞支持
点击查看原文视频 & 演讲 PPT
更多内容


关于Apache RocketMQ + Hudi 快速构建 Lakehouse的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于Apache Doris + Apache Hudi 快速搭建指南|Lakehouse 使用手册(一)、Apache Doris + Iceberg 快速搭建指南|Lakehouse 使用手册(三)、Apache Doris + Paimon 快速搭建指南|Lakehouse 使用手册(二)、Apache Paimon 实时数据湖 Streaming Lakehouse 的存储底座等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

