本篇文章给大家谈谈实战CentOS系统部署Hadoop集群服务,以及centoshadoop集群搭建的知识点,同时本文还将给你拓展008-Centos7.x安装Ambari2.2.2+HDP2.4.2
本篇文章给大家谈谈实战CentOS系统部署Hadoop集群服务,以及centos hadoop集群搭建的知识点,同时本文还将给你拓展008-Centos 7.x安装 Ambari 2.2.2 + HDP 2.4.2 搭建Hadoop集群、02.centos7上搭建hadoop集群、Ambari2.6.0+HDP2.6.3部署Hadoop集群、AMBARI部署HADOOP集群(3)等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- 实战CentOS系统部署Hadoop集群服务(centos hadoop集群搭建)
- 008-Centos 7.x安装 Ambari 2.2.2 + HDP 2.4.2 搭建Hadoop集群
- 02.centos7上搭建hadoop集群
- Ambari2.6.0+HDP2.6.3部署Hadoop集群
- AMBARI部署HADOOP集群(3)
")
实战CentOS系统部署Hadoop集群服务(centos hadoop集群搭建)
| Hadoop是一个由Apache基金会所开发的分布式系统基础架构,Hadoop实现了一个分布式文件系统(Hadoop distributed File System),简称HDFS。HDFS有高容错性特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序;HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。 |
HDFS架构图
Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
HDFS(Hadoop distribution File System),称为Hadoop分布式文件系统,主要特点:
- HDFS最小以64MB的数据块存储文件,相比其他文件系统中的4KB~32KB分块大得多。
- HDFS在时延的基础上对吞吐量进行了优化,它能够高效处理了对大文件的读请求流,但不擅长对众多小文件的定位请求
- HDFS对普通的“一次写入,多次读取”的工作负载进行了优化。
- 每个存储节点运行着一个称为Datanode的进程,它管理着相应主机上的所有数据块。这些存储节点都由一个称为NameNode的主进程来协调,该进程运行于一台独立进程上。
- 与磁盘阵列中设置物理冗余来处理磁盘故障或类似策略不同,HDFS使用副本来处理故障,每个由文件组成的数据块存储在集群众的多个节点,HDFS的NameNode不断监视各个Datanode发来的报告。
客户端,提交MapReduce作业;jobtracker,协调作业的运行,jobtracker是一个java应用程序,它的主类是JobTracker;tasktracker。运行作业划分后的任务,tasktracker是一个java应用程序,TaskTracker是主类。
Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。它主要有以下几个优点:
高可靠性:Hadoop按位存储和处理数据的能力值得人们信赖。
高扩展性:Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
高效性:Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
高容错性:Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
低成本:与一体机、商用数据仓库以及QlikView、Yonghong Z-Suite等数据集市相比,hadoop是开源的,项目的软件成本因此会大大降低。
Hadoop带有用Java语言编写的框架,因此运行在 Linux 生产平台上是非常理想的。Hadoop 上的应用程序也可以使用其他语言编写,比如 C++。
Hadoop官网:http://hadoop.apache.org/
保持Hadoop集群每个节点配置环境一致,安装java,配置ssh。
实验环境:
Platform:xen vm
OS: CentOS 6.8
Software: hadoop-2.7.3-src.tar.gz,jdk-8u101-linux-x64.rpm
| Hostname | IP Address | OS version | Hadoop role | Node role |
| linux-node1 | 192.168.0.89 | CentOS 6.8 | Master | namenode |
| linux-node2 | 192.168.0.90 | CentOS 6.8 | Slave | datenode |
| linux-node3 | 192.168.0.91 | CentOS 6.8 | Slave | datenode |
| linux-node4 | 192.168.0.92 | CentOS 6.8 | Slave | datenode |
#把需要的软件包下载下来上传到集群的各个节点上
#Hadoop集群中的每个节点的hosts文件都需要修改
[root@linux-node1 ~]# cat /etc/hosts 127.0.0.1 localhost localhost.localdomain linux-node1 192.168.0.89 linux-node1 192.168.0.90 linux-node2 192.168.0.91 linux-node3 192.168.0.92 linux-node4
#提前把下载好的JDK(rpm包)上传到服务器上,然后安装
rpm -ivh jdk-8u101-linux-x64.rpm export JAVA_HOME=/usr/java/jdk1.8.0_101/ export PATH=$JAVA_HOME/bin:$PATH # java -version java version "1.8.0_101" Java(TM) SE Runtime Environment (build 1.8.0_101-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.101-b13,mixed mode)
#创建hadoop用户,设置使用sudo
[root@linux-node1 ~]# useradd hadoop && echo hadoop | passwd --stdin hadoop [root@linux-node1 ~]# echo "hadoopALL=(ALL) nopASSWD:ALL" >> /etc/sudoers [root@linux-node1 ~]# su - hadoop [hadoop@linux-node1 ~]$ cd /usr/local/src/ [hadoop@linux-node1src]$wget http://apache.fayea.com/hadoop/common/hadoop-2.7.3/hadoop-2.7.3.tar.gz [hadoop@linux-node1 src]$ sudo tar zxvf hadoop-2.7.3.tar.gz -C /home/hadoop/ && cd /home/hadoop [hadoop@linux-node1 home/hadoop]$ sudo mv hadoop-2.7.3/ hadoop [hadoop@linux-node1 home/hadoop]$ sudo chown -R hadoop:hadoop hadoop/
#将hadoop的二进制目录添加到PATH变量,并设置HADOOP_HOME环境变量
[hadoop@linux-node1 home/hadoop]$ export HADOOP_HOME=/home/hadoop/hadoop/ [hadoop@linux-node1 home/hadoop]$ export PATH=$HADOOP_HOME/bin:$PATH
[hadoop@linux-node1 ~]$ mkdir -p /home/hadoop/dfs/{name,data}
[hadoop@linux-node1 ~]$ mkdir -p /home/hadoop/tmp
#节点存储数据备份目录
sudo mkdir -p /data/hdfs/{name,data}
sudo chown -R hadoop:hadoop /data/
#上述操作需在hadoop集群的每个节点都操作
#设置集群主节点免密码登陆其他节点
[hadoop@linux-node1 ~]$ ssh-keygen -t rsa [hadoop@linux-node1 ~]$ ssh-copy-id linux-node1@192.168.0.90 [hadoop@linux-node1 ~]$ ssh-copy-id linux-node2@192.168.0.91 [hadoop@linux-node1 ~]$ ssh-copy-id linux-node3@192.168.0.92
#测试ssh登录
文件位置:/home/hadoop/hadoop/etc/hadoop,文件名称:hadoop-env.sh、yarn-evn.sh、slaves、core-site.xml、hdfs-site.xml、mapred-site.xml、 yarn-site.xml
(1)配置hadoop-env.sh文件
#在hadoop安装路径下,进入hadoop/etc/hadoop/目录并编辑hadoop-env.sh,修改JAVA_HOME为JAVA的安装路径
[hadoop@linux-node1 home/hadoop]$ cd hadoop/etc/hadoop/
[hadoop@linux-node1 hadoop]$ egrep JAVA_HOME hadoop-env.sh
# The only required environment variable is JAVA_HOME. All others are
# set JAVA_HOME in this file,so that it is correctly defined on
#export JAVA_HOME=${JAVA_HOME}
export JAVA_HOME=/usr/java/jdk1.8.0_101/
(2)配置yarn.sh文件
指定yran框架的java运行环境,该文件是yarn框架运行环境的配置文件,需要修改JAVA_HOME的位置。
[hadoop@linux-node1 hadoop]$ grep JAVA_HOME yarn-env.sh # export JAVA_HOME=/home/y/libexec/jdk1.6.0/ export JAVA_HOME=/usr/java/jdk1.8.0_101/
(3)配置slaves文件
指定Datanode数据存储服务器,将所有的Datanode的机器的主机名写入到此文件中,如下:
[hadoop@linux-node1 hadoop]$ cat slaves linux-node2 linux-node3 linux-node4
Hadoop 3种运行模式
本地独立模式:Hadoop的所有组件,如NameNode,Datanode,Jobtracker,Tasktracker都运行在一个java进程中。
伪分布式模式:Hadoop的各个组件都拥有一个单独的Java虚拟机,它们之间通过网络套接字通信。
完全分布式模式:Hadoop分布在多台主机上,不同的组件根据工作性质的不同安装在不通的Guest上。
#配置完全分布式模式
(4)修改core-site.xml文件,添加红色区域的代码,注意蓝色标注的内容
<configuration> <property> <name>fs.default.name</name> <value>hdfs://linux-node1:9000</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>file:/home/hadoop/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
(5)修改hdfs-site.xml文件
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux-node1:9001</value> <description># 通过web界面来查看HDFS状态 </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>2</value> <description># 每个Block有2个备份</description> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
(6)修改mapred-site.xml
这个是mapreduce任务的配置,由于hadoop2.x使用了yarn框架,所以要实现分布式部署,必须在mapreduce.framework.name属性下配置为yarn。mapred.map.tasks和mapred.reduce.tasks分别为map和reduce的任务数。
[hadoop@linux-node1 hadoop]$ cp mapred-site.xml.template mapred-site.xml <configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>linux-node1:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux-node1:19888</value> </property> </configuration>
(7)配置节点yarn-site.xml
#该文件为yarn架构的相关配置
<?xml version="1.0"?> <!-- mapred-site.xml --> <configuration> <property> <name>mapred.child.java.opts</name> <value>-Xmx400m</value> <!--Not marked as final so jobs can include JVM debuggung options --> </property> </configuration> <?xml version="1.0"?> <!-- yarn-site.xml --> <configuration> <!-- Site specific YARN configuration properties --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>linux-node1:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>linux-node1:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>linux-node1:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>linux-node1:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>linux-node1:8088</value> </property> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>8192</value> </property> </configuration>
scp -r /home/hadoop/hadoop/ 192.168.0.90:/home/hadoop/ scp -r /home/hadoop/hadoop/ 192.168.0.91:/home/hadoop/ scp -r /home/hadoop/hadoop/ 192.168.0.92:/home/hadoop/
/home/hadoop/hadoop/bin/hdfs namenode –format
#echo $? #sudo yum –y install tree # tree /home/hadoop/dfs
/home/hadoop/hadoop/sbin/start-dfs.sh /home/hadoop/hadoop/sbin/stop-dfs.sh
#namenode节点上面查看进程
ps aux | grep --color namenode
#Datanode上面查看进程
ps aux | grep --color datanode
[hadoop@linux-node1 .ssh]$ /home/hadoop/hadoop/sbin/start-yarn.sh starting yarn daemons
#NameNode节点上查看进程
ps aux | grep --color resourcemanager
#Datanode节点上查看进程
ps aux | grep --color nodemanager
注:start-dfs.sh和start-yarn.sh这两个脚本可用start-all.sh代替
/home/hadoop/hadoop/sbin/stop-all.sh /home/hadoop/hadoop/sbin/start-all.sh
#在NameNode节点上
[hadoop@linux-node1 ~]$ /home/hadoop/hadoop/sbin/mr-jobhistory-daemon.sh start historyserver starting historyserver,logging to /home/hadoop/hadoop/logs/mapred-hadoop-historyserver-linux-node1.out
/home/hadoop/hadoop/bin/hdfs dfsadmin –report
#查看文件块组成,一个文件由那些块组成
/home/hadoop/hadoop/bin/hdfs fsck / -files -blocks
查看HDFS状态:http://192.168.0.89:50070/
查看Hadoop集群状态:http://192.168.0.89:8088/

008-Centos 7.x安装 Ambari 2.2.2 + HDP 2.4.2 搭建Hadoop集群
1.安装环境说明
安装前先安装好 Centos 7.2, jdk-8u91, mysql5.7.13
一共有3台机器,一个是主节点192.168.111.10,两个是从:192.168.111.11,192.168.111.12
2.操作系统环境准备
2.1 配置SSH免密码登录
主节点里root用户登录执行如下步骤
ssh-keygen
cd ~/.ssh/
cat id_rsa.pub >>authorized_keys
chmod 700 ~/.ssh
chmod 600 ~/.ssh/authorized_keys先在从节点登录root执行命令
mkdir ~/.ssh/分发主节点里配置好的authorized_keys到各从节点
scp /root/.ssh/authorized_keys root@192.168.111.11:/root/.ssh/authorized_keys
scp /root/.ssh/authorized_keys root@192.168.111.12:/root/.ssh/authorized_keys2.2 创建ambari系统用户和用户组
只在主节点操作
添加ambari安装、运行用户和用户组,也可以不创建新用户,直接使用root或者系统其他账号
adduser ambari
passwd ambari2.3 开启NTP服务
所有集群上节点都需要操作
Centos 7 命令
yum install ntp
systemctl is-enabled ntpd
systemctl enable ntpd
systemctl start ntpdCentos 6 命令
yum install ntpd
chkconfig --list ntpd
chkconfig ntpd
service ntpd start2.4 检查DNS和NSCD
所有节点都要设置
ambari在安装时需要配置全域名,所以需要检查DNS。为了减轻DNS的负担, 建议在节点里用 Name Service Caching Daemon (NSCD)
vi /etc/hosts
192.168.111.10 bjlhx1510 bjlhx1510.hadoop
192.168.111.11 bjlhx1511 bjlhx1511.hadoop
192.168.111.12 bjlhx1512 bjlhx1512.hadoop每台节点里配置FQDN,如下以主节点为例
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=bjlhx1510.hadoop2.5 关闭防火墙
所有节点都要设置
Centos 7 命令
systemctl disable firewalld
systemctl stop firewalld Centos 6 命令
chkconfig iptables off
/etc/init.d/iptables stop2.6 关闭SELinux
所有节点都要设置
查看SELinux状态:
sestatus如果SELinux status参数为enabled即为开启状态
SELinux status: enabled
临时关闭,不用重启机器:
setenforce 0修改配置文件需要重启机器:
vi /etc/sysconfig/selinux
SELINUX=disabled3.制作本地源
制作本地源只需在主节点上进行即可
3.1 相关准备工作
3.1.1安装 Apache HTTP 服务器
安装HTTP 服务器,允许 http 服务通过防火墙(永久)
yum install httpd
firewall-cmd --add-service=http
firewall-cmd --permanent --add-service=http添加 Apache 服务到系统层使其随系统自动启动
systemctl start httpd.service
systemctl enable httpd.service3.1.2 安装本地源制作相关工具
yum install yum-utils createrepo3.2 下载安装资源
下载 Ambari 2.2.2 , HDP 2.4.2 的安装资源,本次安装是在Centos 7 上,只列出centos7的资源,其他系统的请现在对用系统的资源
Ambari 2.2.2 下载资源
| OS | Format | URL |
|---|---|---|
| CentOS 7 | Base URL | http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0 |
| CentOS 7 | Repo File | http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.2.0/ambari.repo |
| CentOS 7 | Tarball md5 asc | http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0/ambari-2.2.2.0-centos7.tar.gz |
HDP 2.4.2 下载资源
| OS | Repository Name | Format | URL |
|---|---|---|---|
| CentOS 7 | HDP | Base URL | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0 |
| CentOS 7 | HDP | Repo File | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/hdp.repo |
| CentOS 7 | HDP | Tarball md5 asc | http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/HDP-2.4.2.0-centos7-rpm.tar.gz |
| CentOS 7 | HDP-UTILS | Base URL | http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7 |
| CentOS 7 | HDP-UTILS | Repo File | http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7/HDP-UTILS-1.1.0.20-centos7.tar.gz |
下载上面列表的中的压缩包,
需要下载的压缩包如下:
#Ambari 2.2.2
axel http://public-repo-1.hortonworks.com/ambari/centos7/2.x/updates/2.2.2.0/ambari-2.2.2.0-centos7.tar.gz
#HDP 2.4.2
axel http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.0.0/HDP-2.4.0.0-centos7-rpm.tar.gz
#HDP-UTILS 1.1.0
axel http://public-repo-1.hortonworks.com/HDP-UTILS-1.1.0.20/repos/centos7/HDP-UTILS-1.1.0.20-centos7.tar.gz在httpd网站根目录,默认是即/var/www/html/,创建目录ambari,
并且将下载的压缩包解压到/var/www/html/ambari目录
cd /var/www/html/
mkdir ambari
cd /var/www/html/ambari/
tar -zxvf ambari-2.2.2.0-centos7.tar.gz
tar -zxvf HDP-2.4.2.0-centos7-rpm.tar.gz
tar -zxvf HDP-UTILS-1.1.0.20-centos7.tar.gz验证httd网站是否可用,可以使用links 命令或者浏览器直接访问下面的地址:
links http://172.31.83.171/ambari/结果如下

3.3 配置ambari、HDP、HDP-UTILS的本地源
首先下载上面资源列表中的相应repo文件,
axel http://public-repo-1.hortonworks.com/ambari/centos6/2.x/updates/2.2.2.0/ambari.repo
axel http://public-repo-1.hortonworks.com/HDP/centos7/2.x/updates/2.4.2.0/hdp.repo
修改其中的URL为本地的地址,相关配置如下:

02.centos7上搭建hadoop集群
接上一篇 https://www.cnblogs.com/yjm0330/p/10069224.html
一、准备工作:无密登陆
1、编辑/etc/hosts文件,分别增加
192.168.2.245 spark01
192.168.2.246 spark02
2、互拼,看通否
spark01上执行: ping -c 3 spark02
spark02上执行: ping -c 3 spark01
备注:ping -c 3 spark02中,-c 3表示ping 3次
3、生成密钥
ssh-keygen -t rsa -P ''''
查看生成密钥的文件目录
# ls /root/.ssh
id_rsa id_rsa.pub
同理,在spark02/03上执行相同的命令。
4、在spark01上创建authorized_keys文件
接下来要做的事情是在3台机器的/root/.ssh/目录下都存入一个内容相同的文件,文件名称叫authorized_keys,文件内容是我们刚才为3台机器生成的公钥。为了方便,我下面的步骤是现在spark01上生成authorized_keys文件,然后把3台机器刚才生成的公钥加入到这个spark01的authorized_keys文件里,然后在将这个authorized_keys文件复制到spark0r2和spark033上面。
首先使用命令,在spark01的/root/.ssh/目录中生成一个名为authorized_keys的文件,命令是:
touch /root/.ssh/authorized_keys
使用命令看,是否生成成功,命令是:
ls /root/.ssh/
其次将spark01上的/root/.ssh/id_rsa.pub文件内容,spark02上的/root/.ssh/id_rsa.pub文件内容,spark03上的/root/.ssh/id_rsa.pub文件内容复制到这个authorized_keys文件中,复制的方法很多了,可以用cat命令和vim命令结合来弄,也可以直接把这3台机器上的/root/.ssh/id_rsa.pub文件下载到本地,在本地将authorized_keys文件编辑好在上载到这3台机器上。
最终每台机器上我的/root/.ssh/id_rsa.pub内容是:
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC2/aeN0k+OyTxRc7nylSpMNsUYFDyvDoYIXLNdZmfa/FP4eCbwjIVhDtpo2l02JrB7EI+ywlDlK9AJHzJ07Qrvwh1MddJm+gZhEdiZWFgOCAXDdSqjhVfxaJSYu8x1tnisLBJFp5pBgqz11DmAjMA4irRxLBXjVvevNRmKYnbLLtObcxpS2E3q5cG3SK/+M9tnTiXqwM8aDFkPUpEVWyJCBvFnIe79gw93UjT/zrCrrk6x6sWBbAOZO5NR7+o5ZSXBfJcL7589KCkBKUMSdi2JKi35RXnEwB0OU8hJKmXbR04s5U06h/s+xhzPi7FgGtFiN4CCML3JIAW/qoC9By2t root@spark01
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQC6Sys9e5XsuifyDLE1qlcF5gfnUyLk99yrQfIOOe4yv0eBAAvk0df93Sg1DpJwEFoBhDaL/zE0P5tomwtaznuU243tCSmny9f62lZB2LWOYy/zOqfu/UYfUo7w6dOo8i8rpOczPuexMhwo1mL1r3u9o6Q+eATKjd6Wo+MsR+0y/QRO03/XrqefqpB169DTOHANmQ4Dxan61gz7hEjdJD3jtQvnCIZHcs2Vw10zjTeUyb1W77Sy90TSvjRnKMAeccHMXl20LsAGLKYeBTMQ5o8rt0ucgbGtlSD21gIo5fxyLAch4F2b5HtgYAs0qBem3w9rbPJt9iD76BChCjdIA7lJ root@spark02
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCsDuHuz3SIxSf+f2vR5myootWPz78eEy7dRzNEOEnjTLErgcPur1NOGP79dI4sxbU4tPBAwPpzC3rsY7kaXlgLn8dHJzg6EZW+SRRGBXn78yEyHlUvraT3X/xJKEOMW962O3IBfEExhzBtxSXPjkN2f/yiZ00PJKw3hoUhtoLAE19DsTzikUHYAEm11OENObCMkmJ/4WpK3tdOt8YkWOMBJzseVaNsQLa5/E3GYRfrR1itclBSKbq29JrTgI0tj9l29Rr9HwImEIif2ZBW83PrXPnVvyYkBkt8K+bAe5tEbNHb1qo6aOiSJfXdrfVnkMLpaXgDhJENoz3HyD1waECP root@spark03
5、将authorized_keys文件复制到其他机器
spark01机器的/root/.ssh/目录下已经有authorized_keys这个文件了,该文件的内容也已经OK了,接下来要将该文件复制到spakr02的/root/.ssh/和spark03的/root/.ssh/。
6、测试使用ssh进行无密登录
spark01上面:ssh sparl02
成功,退出用exit,同理spark02上面:ssh spark01
二、安装JDK
1、下载对应centos内核的jdk版本
查看安装的centos的内核是32还是64:getconf LONG_BIT
下载Linux版的JDK,例如我下载的是Linux版的JKD1.8,文件是jdk-8u191-linux-x64.tar.gz
地址是:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
2、x-shell 实现windows和linux文件互传
在opt目录下新建一个名为java的目录,目的是将jdk-8u191-linux-x64.tar.gz拷贝到该目录下
mkdir java
x-shell实现文件互传是基于zmedom协议,需要查看centos是否已经安装lrzsz:
输入rz命令,看是否已经安装了lrzsz,如果没有安装则执行 yum -y install lrzsz命令进行安装。
安装成功后,输入rpm命令确认是否正确安装。
使用 rz -y命令进行文件上传,此时会弹出上传的窗口:
选择要上传的文件,点击确定即可将本地文件上传到Linux上,如图表示成功上传文件。
使用ls命令可以看到文件已经上传到了当前目录下:
[root@spark01 java]# ls
jdk-8u191-linux-x64.tar.gz
3、解压安装jdk
tar -zxvf jdk-8u121-linux-x64.tar.gz 回车
可以看到在java目录下新生成一个文件夹:jdk1.8.0_191
4、修改配置文件
进入/etc/profile文件,vi修改,在最后加上下面:
export JAVA_HOME=/opt/java/jdk1.8.0_191
export CLASSPATH=$:CLASSPATH:${JAVA_HOME}/lib/
export PATH=$PATH:${JAVA_HOME}/bin
备注:centos6不用{},centos7需要{JAVA_HOME}
然后source /etc/profile,验证:
java -version
三、安装Hadoop
注意: 3台机器上都需要重复下面所讲的步骤。
1、上载文件并解压缩
在opt目录下新建一个名为hadoop的目录,并将下载得到的hadoop-2.8.0.tar上载到该目录下, 进入到该目录,执行命令:
cd /opt/hadoop
执行解压命令:
tar -zxvf hadoop-2.8.0.tar.gz
说明:3台机器都要进行上述操作,解压缩后得到一个名为hadoop-2.8.0的目录。
2、新建几个目录
在/root目录下新建几个目录,复制粘贴执行下面的命令:
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data
3、 修改etc/hadoop中的一系列配置文件
修改/opt/hadoop/hadoop-2.8.0/etc/hadoop目录内的一系列文件。基本上都是在<configuration>节点内加入配置。
3.1 vi core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/root/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://spark01:9000</value>
</property>
3.2 vi hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_191
3.3 vi hdfs-site.xml
<property>
<name>dfs.name.dir</name>
<value>/root/hadoop/dfs/name</value>
<description>Path on the local filesystem where theNameNode stores the namespace and transactions logs persistently.</description>
</property>
<property>
<name>dfs.data.dir</name>
<value>/root/hadoop/dfs/data</value>
<description>Comma separated list of paths on the localfilesystem of a DataNode where it should store its blocks.</description>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
3.4 cp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml.template /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml
3.5 vi mapred-site.xml
<property>
<name>mapred.job.tracker</name>
<value>spark01:49001</value>
</property>
<property>
<name>mapred.local.dir</name>
<value>/root/hadoop/var</value>
</property>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
3.6 vi slaves
spark02
3.7 vi yarn-site.xml
<property>
<name>yarn.resourcemanager.hostname</name>
<value>spark01</value>
</property>
<property>
<description>The address of the applications manager interface in the RM.</description>
<name>yarn.resourcemanager.address</name>
<value>${yarn.resourcemanager.hostname}:8032</value>
</property>
<property>
<description>The address of the scheduler interface.</description>
<name>yarn.resourcemanager.scheduler.address</name>
<value>${yarn.resourcemanager.hostname}:8030</value>
</property>
<property>
<description>The http address of the RM web application.</description>
<name>yarn.resourcemanager.webapp.address</name>
<value>${yarn.resourcemanager.hostname}:8088</value>
</property>
<property>
<description>The https adddress of the RM web application.</description>
<name>yarn.resourcemanager.webapp.https.address</name>
<value>${yarn.resourcemanager.hostname}:8090</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>${yarn.resourcemanager.hostname}:8031</value>
</property>
<property>
<description>The address of the RM admin interface.</description>
<name>yarn.resourcemanager.admin.address</name>
<value>${yarn.resourcemanager.hostname}:8033</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>3048</value>
<discription>每个节点可用内存,单位MB,默认8182MB</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>3048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
3.8 把hadoop配置文件从spark01复制到spark02、03
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/core-site.xml spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/hadoop-env.sh spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/hdfs-site.xml spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/mapred-site.xml spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/slaves spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
scp /opt/hadoop/hadoop-2.8.0/etc/hadoop/yarn-site.xml spark02:/opt/hadoop/hadoop-2.8.0/etc/hadoop/
3.9 测试hadoop
1、在namenode上执行初始化
因为spark01是namenode,spark02和spark03都是datanode,所以只需要对spark01进行初始化操作,也就是对hdfs进行格式化。
进入到spark01这台机器的/opt/hadoop/hadoop-2.8.0/bin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.0/bin
执行初始化脚本,也就是执行命令:
./hadoop namenode -format
格式化成功后,可以在看到在/root/hadoop/dfs/name/目录多了一个current目录,而且该目录内有一系列文件.
2、在namenode上执行启动命令
因为hserver1是namenode,hserver2和hserver3都是datanode,所以只需要再hserver1上执行启动命令即可。
进入到hserver1这台机器的/opt/hadoop/hadoop-2.8.0/sbin目录,也就是执行命令:
cd /opt/hadoop/hadoop-2.8.0/sbin
执行初始化脚本,也就是执行命令:
./start-all.sh
第一次执行上面的启动命令,会需要我们进行交互操作,在问答界面上输入yes回车
3、测试hadoop
haddoop启动了,需要测试一下hadoop是否正常。
执行命令,关闭防火墙,CentOS7下,命令是:
systemctl stop firewalld.service
spark01是我们的namanode,该机器的IP是192.168.2.245,在本地电脑访问如下地址:
http://192.168.2.245:50070/ 自动跳转到了overview页面
在本地浏览器里访问如下地址:
http://192.168.2.245:8088/ 自动跳转到了cluster页面

Ambari2.6.0+HDP2.6.3部署Hadoop集群
一.环境准备
1.修改hostname(所有节点)
-
临时生效
[root@localhost ~] hostname localhost -
永久生效
[root@localhost ~] vi /etc/hosts 127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4 ::1 localhost localhost.localdomain localhost6 localhost6.localdomain6 192.168.31.11 hdm01.xx.cn hdm01 192.168.31.12 hdm02.xx.cn hdm02 192.168.31.13 hddata01.xx.cn hddata01
2.配置SSH免密(所有节点)
-
生成秘钥(所有节点都生成一份)
[root@localhost ~] cd ~ [root@localhost ~] mkdir .ssh [root@localhost ~] cd .ssh [root@localhost .ssh] ssh-keygen -t rsa #生成秘钥 -
配置免密互通(主节点下操作)
[root@localhost .ssh] cat id_rsa.pub >> authorized_keys #分别把上一步各个节点生成的公共秘钥追加到主节点的/root/.ssh/authorized_keys中 [root@localhost .ssh] ssh hostname cat /root/.ssh/id_rsa.pub >> authorized_keys #把主节点上已汇总到所有节点公共秘钥的/root/.ssh/authorized_keys分发到各个节点/root/.ssh/下 [root@localhost .ssh] scp ./authorized_keys hostname:/root/.ssh/ [root@localhost .ssh] chmod 600 ~/.ssh [root@localhost .ssh] chmod 600 ~/.ssh/authorized_keys
3.开启NTP服务(所有节点)
-
关闭chronyd服务
#临时关闭 [root@localhost ~] systemctl stop chronyd #永久关闭 [root@localhost ~] systemctl disable chronyd -
开启NTP服务
#查看是否已安装NTP [root@localhost ~] rpm -qa |grep ntp #如未安装,则安装NTP [root@localhost ~] yum install ntp #启动NTP服务 [root@localhost ~] systemctl start ntpd #开启开机自动启动NTP服务 [root@localhost ~] systemctl enable ntpd #查看NTP服务状态 [root@localhost ~] systemctl status ntpd
4.配置FQDN(所有节点)
[root@localhost ~] vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=localhost5.允许HTTP通过防火墙(所有节点)
[root@localhost ~] rpm -qa |grep http #查看是否安装http
[root@localhost ~] yum -y install httpd #如未安装,则安装
[root@localhost ~] firewall-cmd --add-service=http #临时开放http
[root@localhost ~] firewall-cmd --permanent --add-service=http #永久开放http
[root@localhost ~] systemctl start httpd.service #临时添加服务随系统自动启动
[root@localhost ~] systemctl enable httpd.service #永久添加服务随系统自动启动")
AMBARI部署HADOOP集群(3)
1. 安装ambari-server
yum -y install ambari-server2. ambari server 需要一个数据库存储元数据,默认使用的 Postgres 数据库。默认的用户名和密码是: ambari/bigdata 。但是一般情况下,后面还要安装 hive 和 Ranger,也需要一个存元数据的数据库,所以使用一个mysql 做为数据库。需要为 ambari 创建相应的数据库和用户。安装MySQL及配置
(1) 下载并安装MySQL官方的 Yum Repository
[root@localhost ~]# wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm使用上面的命令就直接下载了安装用的Yum Repository,大概25KB的样子,然后就可以直接yum安装了。
[root@localhost ~]# yum -y install mysql57-community-release-el7-10.noarch.rpm之后就开始安装MySQL服务器。
[root@localhost ~]# yum -y install mysql-community-server这步可能会花些时间,安装完成后就会覆盖掉之前的mariadb。
至此MySQL就安装完成了,然后是对MySQL的一些设置。
(2)MySQL数据库设置
首先启动MySQL
[root@localhost ~]# systemctl start mysqld.service查看MySQL运行状态,运行状态如图:
[root@localhost ~]# systemctl status mysqld.service此时MySQL已经开始正常运行,不过要想进入MySQL还得先找出此时root用户的密码,通过如下命令可以在日志文件中找出密码:
[root@localhost ~]# grep "password" /var/log/mysqld.log
如下命令进入数据库:
[root@localhost ~]# mysql -uroot -p输入初始密码,此时不能做任何事情,因为MySQL默认必须修改密码之后才能操作数据库:
mysql> ALTER USER ''root''@''localhost'' IDENTIFIED BY ''new password'';这里有个问题,新密码设置的时候如果设置的过于简单会报错,我们就设计复杂的密码吧。安全起见大小写下划线数字都用上。
但此时还有一个问题,就是因为安装了Yum Repository,以后每次yum操作都会自动更新,需要把这个卸载掉:
[root@localhost ~]# yum -y remove mysql57-community-release-el7-10.noarch此时才算真的完成了mysql的安装,开始配置ambari。
create database ambari default character set=''utf8'';CREATE USER ''ambaridba''@''localhost'' IDENTIFIED BY ''你的密码'';
CREATE USER ''ambaridba''@''%'' IDENTIFIED BY ''你的密码'';
GRANT ALL PRIVILEGES ON ambari.* TO ''ambaridba''@''localhost'';
GRANT ALL PRIVILEGES ON ambari.* TO ''ambaridba''@''%'';
FLUSH PRIVILEGES;
3. 配置 ambari-server
ambari-server setup3.1 如果没有设置 SELinux=disable,会有一个警告信息,按回车,接受默认值(y)。按照前面2篇中的步骤的话,已经设置过这个值的,这一步会自动跳过。
注意: 这个值的生效是需要重启电脑的。如果没有重启,则会有警告信息。设置完成后,启动 ambari server,控制台显示成功启动,但是无法通过浏览器访问。后来重启电脑后才可以。不知道是不是必须要这样才能访问 ambari server。
3.2 设置运行 ambari server 的用户,默认会使用 root。可以键入 y,回车后输入一个其它的用户

3.3 选择 JDK。为了使用统一的 JDK,这里选择自定义的 JDK。然后会要求输入 JAVA_HOME 的路径,一定不能在用户的目录下,安装在/usr 和/opt为好。
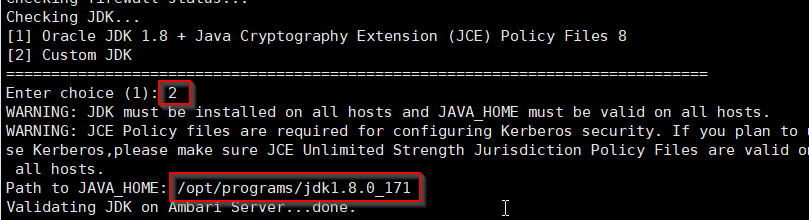
3.4 GPL License , 这一步必须选择 y.

3.5 配置元数据库的连接信息
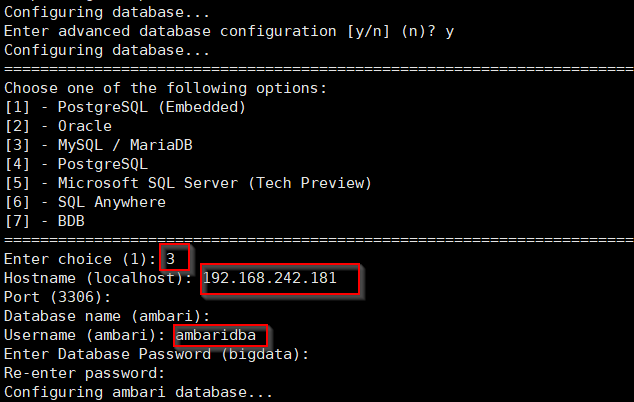
3.6 输入数据库驱动的 jar 包的路径,这个jar包是自己下载的,可以下载最高版本的,然后放到某一目录,如下图。

3.7 进行远程数据库连接信息配置。选择 y

3.8 运行下面的命令。
ambari-server setup --jdbc-db=mysql --jdbc-driver=/opt/soft/mysql-connector-java-5.1.43.jar虽然在上面的步骤中已经设置过了,但是不知道为什么,在后续安装 hive 时,测试连接存储 hive 元数据的数据库时,始终连不上。停掉 ambari-server 后,运行上面的命令后,才能连接成功。
3.9 创建表
在MySQL中执行:使用root登陆。
mysql> source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql4. 启动 ambari-server 。启动成功后,可以访问: http://<ip>:8080 用户和密码是: admin/admin
ambari-server start(1)如果报如下的错误,
Starting ambari-server
ERROR: Exiting with exit code 1.
REASON: Unable to detect a system user for Ambari Server.
- If this is a new setup, then run the "ambari-server setup" command to create the user
- If this is an upgrade of an existing setup, run the "ambari-server upgrade" command.
Refer to the Ambari documentation for more information on setup and upgrade.运行下面的命令,设置 ambari-server.user 的值为 root,或者另外一个系统用户
vi /etc/ambari-server/conf/ambari.properties(2)如果出现下面的错误,需要运行: yum install -y mysql-connector-java*
Starting ambari-server
Ambari Server running with administrator privileges.
ERROR: Exiting with exit code -1.
REASON: Before starting Ambari Server, you must copy the MySQL JDBC driver JAR file to /usr/share/java and set property "server.jdbc.driver.path=[path/to/custom_jdbc_driver]" in ambari.properties.把上面 3.6 步骤中的 jar 包复制到 /usr/shar/java 目录下,不需要修改 ambari.properties 里的 server.jdbc.driver.path 的值(这个值在上面的步骤中已经设置了)。
cp /opt/soft/mysql-connector-java-5.1.43.jar /usr/share/java/
注意:/usr/share/java为JAVA_HOME目录。
(3) 其它错误的话,可以查看启动日志
more /var/log/ambari-server/ambari-server.log我事先没有创建库,会报数据库不存在的错误。如果报什么什么表不存在的话,需要把 /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql 中的初始化语句跑到数据库中。
mysql> source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
4. 停止和查看 ambari-server 的状态
ambari-server stop
ambari-server status
今天关于实战CentOS系统部署Hadoop集群服务和centos hadoop集群搭建的分享就到这里,希望大家有所收获,若想了解更多关于008-Centos 7.x安装 Ambari 2.2.2 + HDP 2.4.2 搭建Hadoop集群、02.centos7上搭建hadoop集群、Ambari2.6.0+HDP2.6.3部署Hadoop集群、AMBARI部署HADOOP集群(3)等相关知识,可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

