对于objective-c–iOSAVFoundation:如何从mp3文件中获取图稿?感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解怎么获取mp3音源,并且为您提供关于DomainAda
对于objective-c – iOS AVFoundation:如何从mp3文件中获取图稿?感兴趣的读者,本文将提供您所需要的所有信息,我们将详细讲解怎么获取mp3音源,并且为您提供关于Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days、Foundation Kit「Learn Objective-C on Mac、iOS AVFoundation:设置视频的方向、ios – 如何从AVFoundation获得光照值?的宝贵知识。
本文目录一览:- objective-c – iOS AVFoundation:如何从mp3文件中获取图稿?(怎么获取mp3音源)
- Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days
- Foundation Kit「Learn Objective-C on Mac
- iOS AVFoundation:设置视频的方向
- ios – 如何从AVFoundation获得光照值?
")
objective-c – iOS AVFoundation:如何从mp3文件中获取图稿?(怎么获取mp3音源)
- (void)Metadata {
AVURLAsset *asset = [AVURLAsset URLAssetWithURL:self.fileURL options:nil];
NSArray *artworks = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyArtwork keySpace:AVMetadataKeySpaceCommon];
NSArray *titles = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyTitle keySpace:AVMetadataKeySpaceCommon];
NSArray *artists = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyArtist keySpace:AVMetadataKeySpaceCommon];
NSArray *albumNames = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyAlbumName keySpace:AVMetadataKeySpaceCommon];
AVMetadataItem *artwork = [artworks objectAtIndex:0];
AVMetadataItem *title = [titles objectAtIndex:0];
AVMetadataItem *artist = [artists objectAtIndex:0];
AVMetadataItem *albumName = [albumNames objectAtIndex:0];
if ([artwork.keySpace isEqualToString:AVMetadataKeySpaceID3]) {
NSDictionary *dictionary = [artwork.value copyWithZone:nil];
self.currentSongArtwork = [UIImage imageWithData:[dictionary objectForKey:@"data"]];
}
else if ([artwork.keySpace isEqualToString:AVMetadataKeySpaceiTunes]) {
self.currentSongArtwork = [UIImage imageWithData:[artwork.value copyWithZone:nil]];
}
self.currentSongTitle = [title.value copyWithZone:nil];
self.currentSongArtist = [artist.value copyWithZone:nil];
self.currentSongalbumName = [albumName.value copyWithZone:nil];
self.currentSongDuration = self.audioPlayer.duration;
}
这适用于从m4a文件中获取图稿,但不适用于mp3文件.如果资产指向mp3文件,则艺术品为空.我做错了什么,我该如何解决?
解决方法
- (void)Metadata {
AVURLAsset *asset = [AVURLAsset URLAssetWithURL:self.fileURL options:nil];
NSArray *titles = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyTitle keySpace:AVMetadataKeySpaceCommon];
NSArray *artists = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyArtist keySpace:AVMetadataKeySpaceCommon];
NSArray *albumNames = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata withKey:AVMetadataCommonKeyAlbumName keySpace:AVMetadataKeySpaceCommon];
AVMetadataItem *title = [titles objectAtIndex:0];
AVMetadataItem *artist = [artists objectAtIndex:0];
AVMetadataItem *albumName = [albumNames objectAtIndex:0];
NSArray *keys = [NSArray arrayWithObjects:@"commonMetadata",nil];
[asset loadValuesAsynchronouslyForKeys:keys completionHandler:^{
NSArray *artworks = [AVMetadataItem MetadataItemsFromArray:asset.commonMetadata
withKey:AVMetadataCommonKeyArtwork
keySpace:AVMetadataKeySpaceCommon];
for (AVMetadataItem *item in artworks) {
if ([item.keySpace isEqualToString:AVMetadataKeySpaceID3]) {
NSDictionary *d = [item.value copyWithZone:nil];
self.currentSongArtwork = [UIImage imageWithData:[d objectForKey:@"data"]];
} else if ([item.keySpace isEqualToString:AVMetadataKeySpaceiTunes]) {
self.currentSongArtwork = [UIImage imageWithData:[item.value copyWithZone:nil]];
}
}
}];
self.currentSongTitle = [title.value copyWithZone:nil];
self.currentSongArtist = [artist.value copyWithZone:nil];
self.currentSongalbumName = [albumName.value copyWithZone:nil];
self.currentSongDuration = self.audioPlayer.duration;
}

Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days
目录
摘要
1、简介
2、相关工作
2.1、图像处理
2.2、目标检测
3、提出的方法
3.1、深度估计和数据清洗
3.3.1、天窗区域识别和移除
3.1.2、基于暗通道先验模型的深度估计
3.1.3、对深度信息的数据清洁
3.2、域适配学习和模型融合
3.2.1、KDE模型
3.2.2、颜色深度的跨域适配
4、实验结果
4.1、评估标准
4.2、定性的评价
4.3、定量评估
5、结论
摘要
多雾天气给户外摄像监控系统带来了很多困难。在雾天,介质的光学衰减和散射效应会使场景辐射产生明显的畸变和退化,使其变得嘈杂和难以分辨。针对这一问题,本文提出了一种基于颜色和深度域的目标检测方法。为了防止错误传播问题,我们在训练过程之前清除深度信息,并从数据库中删除错误样本。采用区域自适应策略自适应地融合颜色域和深度域的决策。在实验中,我们评估了深度信息对雾天目标检测的贡献。通过与其他方法的比较,实验验证了多域自适应策略的优越性。
1、简介
室外摄像监控系统广泛应用于城市区域,在交通管理和安全维护中发挥着重要作用。这些系统在各种天气条件下运行是必要的。然而,雾天给基于视觉的系统带来了许多困难。衰减的场景外观和强噪声是影响退化目标检测结果的两个主要因素。在雾天获取清晰的图像/视频已经做了很多努力,并取得了很好的效果。然而,目前最先进的图像增强方法并不能显著提高目标检测性能。原因有两个。首先,目标检测需要从背景中分割感兴趣的目标。因此,雾天目标检测的关键问题是如何识别目标与背景的偏差。这对于这些增强的图像是困难的,其中包括许多纹理。其次,错误传播阻止使用任何图像预处理程序。图像预处理的初始误差会传播到后续的检测过程中,导致最终目标检测结果的误差。因此,基于预处理的目标检测策略在某些情况下是有问题的。尽管雾霾效应有其缺点,但它为目标检测提供了一种新的线索。根据光学成像模型,霾浓度随深度变化。因此,我们可以通过雾霾浓度的估计来表示未缩放的深度,根据雾霾浓度的点对点差异来表示物体与背景的深度对比。除了颜色域中的RGB信息外,该信息还提供了一种新的目标检测特性。对于雾天霾浓度的估计,最有效的方法是采用暗通道先验模型。暗原色先验模型的优点是可以利用单目图像来估计雾霾浓度。然而,其缺点是对图像噪声十分敏感,因此在霾浓度估计结果中,图像离群点会造成严重的误差。为了解决这一问题,本文采用了一种新的数据清洗方法来过滤深度数据。这可以保证背景模型的正确性,但是会导致深度和颜色域的数据量不相等。采用领域适应学习策略解决了这一问题。利用颜色和深度信息分别训练两个检测器,并结合这两个检测器进行最终的域适应检测。我们方法的新颖之处有三:
(一)雾天基于深度信息的目标检测。为了克服雾天带来的挑战,我们的方法利用深度信息进行目标检测。
(二)基于领域适应学习的雾天背景建模。我们的方法分别使用颜色和深度信息训练背景模型,并通过领域适应学习策略对其进行联合训练。
(三)探索雾天图像的深度和色彩特征。我们的方法探索了颜色和深度域的特征,并将它们融合在雾天的目标检测中。
论文结构如下。在第二部分中,我们介绍了图像处理和雾天目标检测的最新研究进展。第3节介绍了我们提出的方法。实验结果见第4节,我们的结论见第5节。
2、相关工作
在多雾天气中,大多数与目标检测相关的工作都涉及到图像去雾和目标检测方法的结合。前者通常用作增强对象外观的预处理程序,而对象-背景转换由目标检测后处理器标识。
2.1、图像处理
针对雾天图像的雾霾效应,提出了多种图像处理方法。一般来说,雾天的图像处理是通过变换大气散射模型来实现的,可简化为:
![]()
其中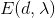 为获得的图像,
为获得的图像,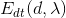 为来自物体辐射的项,
为来自物体辐射的项,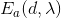 为霾项,d和l分别为光的透射距离和波长。在该模型中,关键问题是传输距离的估计。Narasimhan等人发现霾环境的点对点对比度与点的深度有关。该原理用于去除雾霾,恢复原始场景辐射[11]。用这种方法得到的结果可以提供一个视觉上令人满意的表现。Schechner等人提出了一种基于场景深度随光偏振度变化的深度估计方法。该方法具有良好的物理基础,但需要复杂的偏振成像设备。Liang等人发现光偏振状态随着场景深度的变化而变化,通过改变光偏振的角度可以增强场景的对比度[15,16]。还有许多场景深度和环境光估计使用高级图像功能。Kopf等人引入了一种三维地形模型来估计真实场景深度[17]。该方法将深度、纹理、地理信息等多源信息联合起来进行图像的重放和去雾处理。Nishino等人提出了一种贝叶斯概率方法来估计单幅雾天图像[18]的场景反照率和深度。孟结合上下文正则化
为霾项,d和l分别为光的透射距离和波长。在该模型中,关键问题是传输距离的估计。Narasimhan等人发现霾环境的点对点对比度与点的深度有关。该原理用于去除雾霾,恢复原始场景辐射[11]。用这种方法得到的结果可以提供一个视觉上令人满意的表现。Schechner等人提出了一种基于场景深度随光偏振度变化的深度估计方法。该方法具有良好的物理基础,但需要复杂的偏振成像设备。Liang等人发现光偏振状态随着场景深度的变化而变化,通过改变光偏振的角度可以增强场景的对比度[15,16]。还有许多场景深度和环境光估计使用高级图像功能。Kopf等人引入了一种三维地形模型来估计真实场景深度[17]。该方法将深度、纹理、地理信息等多源信息联合起来进行图像的重放和去雾处理。Nishino等人提出了一种贝叶斯概率方法来估计单幅雾天图像[18]的场景反照率和深度。孟结合上下文正则化 范数和边界约束,提出了一种优化估算光透射参数[19]的方法。与上述方法相比,利用暗通道先验模型实现了一种更有效的策略。根据暗通道先验,在清晰图像中,至少有一个颜色通道上存在某些像素的极低值。因此,雾天图像的暗通道强度指示了依赖深度的雾霾浓度[20]。暗通道模型在平行环境光的情况下工作良好,而当图像中包含天窗时,暗通道模型的性能严重退化。阻塞效应和闪烁伪影造成了问题,因为它们降低了深度估计的准确性。为了解决这些问题,Li在更新暗通道先验模型[21]之前,提出了一个具有强度值的马尔科夫随机场。Wang等人使用恒定强度阈值分割天窗区域,并估计其他区域[22]的环境光。Qing等人提出了一种混合高斯(mix -of- gaussian, MoG)模型来估计天窗分布[23]。最近,Zhu等人将亮度模型与暗通道先验模型相融合来去除图像[24]中的雾霾。
范数和边界约束,提出了一种优化估算光透射参数[19]的方法。与上述方法相比,利用暗通道先验模型实现了一种更有效的策略。根据暗通道先验,在清晰图像中,至少有一个颜色通道上存在某些像素的极低值。因此,雾天图像的暗通道强度指示了依赖深度的雾霾浓度[20]。暗通道模型在平行环境光的情况下工作良好,而当图像中包含天窗时,暗通道模型的性能严重退化。阻塞效应和闪烁伪影造成了问题,因为它们降低了深度估计的准确性。为了解决这些问题,Li在更新暗通道先验模型[21]之前,提出了一个具有强度值的马尔科夫随机场。Wang等人使用恒定强度阈值分割天窗区域,并估计其他区域[22]的环境光。Qing等人提出了一种混合高斯(mix -of- gaussian, MoG)模型来估计天窗分布[23]。最近,Zhu等人将亮度模型与暗通道先验模型相融合来去除图像[24]中的雾霾。
2.2、目标检测
由于雾天的外观退化和雾霾效应,使得目标与背景的偏差严重退化。为了解决这个问题,大多数现有的方法,包括上面提到的方法,都依赖于一个两阶段结构:一个图像预处理程序,然后是一个检测后处理器。该策略的优点和缺点在引言(第一节)中进行了讨论,此外,还有基于最优数学模型的方法。Oreifej提出了一种三项低秩矩阵分解方法,将图像数据分解为场景背景、介质湍流度和感兴趣对象三部分。然后,使用L1规范[25]分割移动目标。Gilles采用几何时空观点来解决大气湍流问题,并建立了一个模型来区分运动物体在湍流情况下的运动。
3、提出的方法
本文提出的新型目标检测方法基于一种域自适应策略。在我们的方法中探索了两个域的信息—颜色和深度。深度信息是使用暗通道先验模型估计的,在暗通道先验模型中,天窗被初始移除。此外,我们还提出了一种数据清理方法来消除错误的深度信息,保证训练数据的正确性。在数据清理过程之后,两个源之间会产生不平等的影响。该问题由领域自适应框架处理,利用颜色和深度信息分别得到的结果自适应地组合生成最终的目标检测结果。我们提出的方法的框架如图1所示。
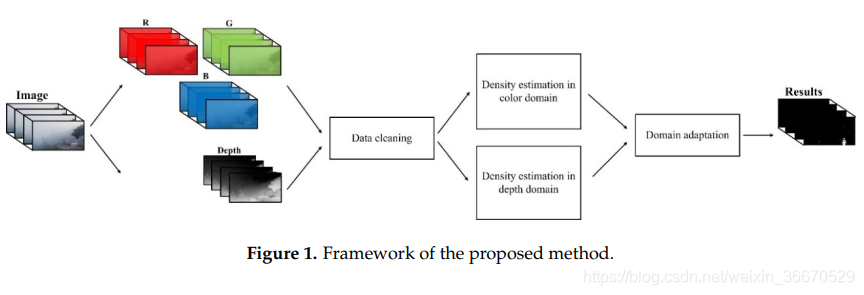
3.1、深度估计和数据清洗
在现有的雾霾环境深度估计方法中,最有效的方法是暗通道先验模型。虽然该模型只允许非尺度测量,但估计结果可以反映出目标与背景的对比。针对天窗区域的去除,提出了一种光学特征相关方法来识别光分量。此外,为了消除训练数据中的错误,根据帧间通信对深度信息进行了清洗。
3.3.1、天窗区域识别和移除
在暗信道先验模型中,天窗区域会引起深度估计的误差。与通过雾霾介质传输的环境光相比,天窗的所有颜色通道的强度都是均匀的,明显高于周围区域[29,30]。在使用暗通道模型时,容易将天窗区域的内容误认为是环境光的表现形式,造成深度估计的严重误差。天窗可以从两个方面进行识别:
(1)低通道变化:与其他光学元件相比,天窗的通道变化相对较小。
(2)距离独立密度:由于雾霾环境中的光散射因子,在天窗区域,任意点的强度与其离光学准直的距离有关。
这两个原则是数学模型,并结合识别天窗区域。对于通道变化,可以建立如下数学模型:
![]()
其中 为RGB颜色空间中x点的方差,
为RGB颜色空间中x点的方差,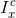 为通道中的强度(红色,
为通道中的强度(红色,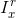 ;绿色,
;绿色,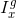 ;而蓝色(
;而蓝色(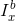 )和
)和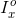 是颜色通道的平均值。对于与距离相关的强度效应,可以利用强度-位置关系对天窗区域进行数学建模,该关系由与整幅图像中最高强度的指数距离进行缩放,如下:
是颜色通道的平均值。对于与距离相关的强度效应,可以利用强度-位置关系对天窗区域进行数学建模,该关系由与整幅图像中最高强度的指数距离进行缩放,如下:
![]()
其中,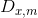 是点x和点m之间的欧氏距离,在整个图像中,点x和点m的强度最大。x = [x1, x2]和m = [m1, m2]是点x和m的空间坐标,将这两个原理与相关计算相结合,可以对天窗的判别函数建模如下:
是点x和点m之间的欧氏距离,在整个图像中,点x和点m的强度最大。x = [x1, x2]和m = [m1, m2]是点x和m的空间坐标,将这两个原理与相关计算相结合,可以对天窗的判别函数建模如下:
![]()
S对应的阈值为T:
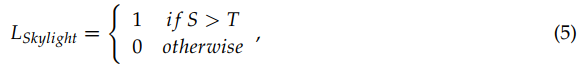
其中corr2()为二维相关计算,T为去除天窗面积的阈值。在没有天窗的区域进行环境光估计和暗通道计算,其中LSkylight = 0。图2显示了三个雾天的天窗识别和深度估计示例。从这些样本中我们可以看出,强度位置与通道变化之间的相关关系可以正确的描述天窗的分布,因为它们的值都在天窗附近的区域内最小。去除天窗后,深度估计结果可以反映出目标与背景之间的视深对比。

3.1.2、基于暗通道先验模型的深度估计
根据暗原色先验模型,在大多数无雾图像中,极低强度值表示至少有一个颜色通道,如下图所示:
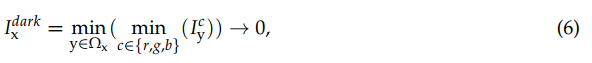
其中, 为邻域中y点的通道,
为邻域中y点的通道,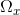 为以x点为中心的局部斑块,暗通道的强度为与深度相关的霾浓度的表示,称为[20]中的传输。因此,深度依赖的霾浓度/传播可以表示为:
为以x点为中心的局部斑块,暗通道的强度为与深度相关的霾浓度的表示,称为[20]中的传输。因此,深度依赖的霾浓度/传播可以表示为:
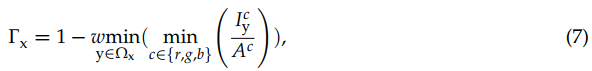
其中w为去雾度系数,表示深度,Ac为环境光,对应整个图像上暗通道的最大值,如下:

如前所述,传输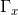 严格依赖于x点处的深度
严格依赖于x点处的深度 ;因此,点对点传输差可以正确地表示点对点深度差。识别目标与背景之间的偏差是目标检测的一个理想属性。因此,在本文中,我们提出了深度
;因此,点对点传输差可以正确地表示点对点深度差。识别目标与背景之间的偏差是目标检测的一个理想属性。因此,在本文中,我们提出了深度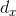 与传输
与传输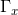 ,即
,即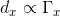 。
。
3.1.3、对深度信息的数据清洁
虽然可以通过3.1.1节所示的方法去除天窗区域,但深度估计中的随机误差(可能由毛刺点引起)是无法避免的。为了解决这一问题,我们提出了一种深度图的数据清洗方法。在视频序列中,帧与帧之间在短时间间隔内的变化很小,变化只出现在有限的补丁中,而大多数像素保持不变,如图3的第一行所示。这说明在较短的时间间隔内,帧与帧之间的相关性很强,对应的深度图也应该如此,否则会出现随机误差,如图3第二行所示。

短时间间隔内帧与深度图之间的一对关联关系可以用数学方法计算如下:

其中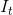 和
和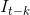 是时间步长t和t−k的帧,
是时间步长t和t−k的帧,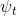 和
和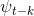 是相应的深度映射。在这里,参数k设计为,对于时间步长t中的深度图
是相应的深度映射。在这里,参数k设计为,对于时间步长t中的深度图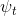 ,
, 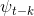 是之前时间步长中最接近的深度图。例如,如果将
是之前时间步长中最接近的深度图。例如,如果将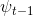 确定为时间步长t - 1的误差,而
确定为时间步长t - 1的误差,而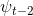 是正确的,则k = 2,
是正确的,则k = 2, ,
, 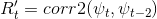 。假设第一帧深度图是正确的,则在以下条件下识别错误:
。假设第一帧深度图是正确的,则在以下条件下识别错误:
![]()
其中l为调节参数。如前所述,这种类型的误差是由随机噪声引起的,如毛刺点。因此,错误不会在很长时间间隔内持续发生。因此,在实际应用中,参数k并不大(一般为1≤k≤3),用于相关计算的时间间隔有限,这使得正确的样本保持了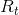 与
与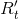 之间的对应关系。这个数据清理过程可以用图3中的示例来说明。理论上,在环境光估计过程中,暗通道先验模型提取暗通道中最亮的点来表示其邻域,提取整幅图像中最亮的斑块来表示环境光。这种方法对图像的毛刺很敏感,因为即使是一个单独的噪声点也会导致环境光估计和深度估计的误差。这是实际应用中由于成像噪声造成的一种常见情况。例如,在第四帧(图3的第一行)中附近的随机噪声由于在暗通道中强度较大而被误认为是环境光的表现。这会导致深度估计错误(第二行的第四帧)。因此,图3中第四帧的深度估计输出与前一帧有明显的不同,尽管它们的输入看起来是相似的。这就是第四帧得到的
之间的对应关系。这个数据清理过程可以用图3中的示例来说明。理论上,在环境光估计过程中,暗通道先验模型提取暗通道中最亮的点来表示其邻域,提取整幅图像中最亮的斑块来表示环境光。这种方法对图像的毛刺很敏感,因为即使是一个单独的噪声点也会导致环境光估计和深度估计的误差。这是实际应用中由于成像噪声造成的一种常见情况。例如,在第四帧(图3的第一行)中附近的随机噪声由于在暗通道中强度较大而被误认为是环境光的表现。这会导致深度估计错误(第二行的第四帧)。因此,图3中第四帧的深度估计输出与前一帧有明显的不同,尽管它们的输入看起来是相似的。这就是第四帧得到的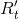 值较低的原因。根据我们提出的数据清洗原理,去掉第四帧的深度估计结果,将第五帧与第三帧进行对比,继续清洗进度。
值较低的原因。根据我们提出的数据清洗原理,去掉第四帧的深度估计结果,将第五帧与第三帧进行对比,继续清洗进度。
3.2、域适配学习和模型融合
利用深度估计方法,对于雾天的任意场景,在颜色和深度域中分别获得两个目标检测源。数据清理之后,这两个域中的数据量是不相等的。该方法采用跨源域自适应的方法,在训练数据较少的背景模型(深度信息)的基础上,利用训练数据较多的背景模型(颜色信息)对背景模型进行改进。这是基于深度比例尺的变化与颜色信息的变化相对应的原理,因为深度偏差可能存在于颜色域中出现对比的边缘。我们使用核密度估计(KDE)来建立颜色和深度域的背景模型。
3.2.1、KDE模型
之所以使用KDE来建立背景模型,是因为它对复杂场景的短期变化具有良好的适应性。从理论上讲,KDE是一个典型的非参数模型,它通过训练样本而不是之前任何关于数据分布的假设来呈现背景。经典的KDE模型可以通过将测试样本与选择的训练样本进行比较,得到如下的数学表达式:

其中N个样本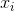 在训练数据中选择用作背景的代表性,
在训练数据中选择用作背景的代表性, 代表了测试样品,
代表了测试样品,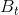 是t时间步的背景模型,和K(x)是内核函数,它满足条件
是t时间步的背景模型,和K(x)是内核函数,它满足条件![]()
3.2.2、颜色深度的跨域适配
彩色图像和深度图的数量用kc和kd表示。数据清洗后,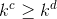 。我们将颜色定义为源域,将深度定义为目标域。在这两个领域,我们计算方向梯度直方图(HOG)来描述局部变化。HOG特征计算图像局部区域内梯度方向出现的次数。这个梯度信息对目标检测很有用,因为它在目标和背景之间的过渡时发生了很大的变化。对于HOG特征,每个像素都有两个特征:星等G和方向q。这些特征可以用离散小波变换(DWT)的LL子带(fLL)数值表示。
。我们将颜色定义为源域,将深度定义为目标域。在这两个领域,我们计算方向梯度直方图(HOG)来描述局部变化。HOG特征计算图像局部区域内梯度方向出现的次数。这个梯度信息对目标检测很有用,因为它在目标和背景之间的过渡时发生了很大的变化。对于HOG特征,每个像素都有两个特征:星等G和方向q。这些特征可以用离散小波变换(DWT)的LL子带(fLL)数值表示。
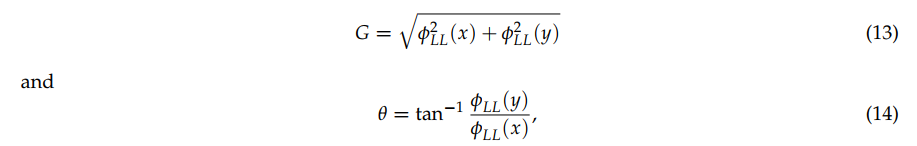
其中,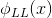 和
和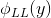 分别是LL子带在x和y方向上的导数。建立目标检测特征的一种直接方法是结合不同领域的HOG特征。然而,由于源域和目标域的特征之间的不平等,这种想法可能不适合本研究。针对这一问题,我们提出了一种基于两个并行流的领域适应学习策略。该方法利用颜色域训练数据的丰富可用性来学习在深度域有效工作的模型,而深度域的例子较少。具体来说,在第t步分别训练了两个独立的背景模型
分别是LL子带在x和y方向上的导数。建立目标检测特征的一种直接方法是结合不同领域的HOG特征。然而,由于源域和目标域的特征之间的不平等,这种想法可能不适合本研究。针对这一问题,我们提出了一种基于两个并行流的领域适应学习策略。该方法利用颜色域训练数据的丰富可用性来学习在深度域有效工作的模型,而深度域的例子较少。具体来说,在第t步分别训练了两个独立的背景模型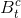 和
和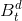 。设
。设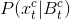 和
和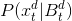 分别为颜色和深度特征的分布。我们可以看到输入特征在两个域的分布是不同的,即
分别为颜色和深度特征的分布。我们可以看到输入特征在两个域的分布是不同的,即 。需要注意的是,如果没有自适应机制,这可能会导致目标域的检测结果较差,因为包含较大的源训练集的彩色域模型在密集的源区域会被训练得很好。我们现在提出了具体的领域适配KDE算法。领域适应的一个最简单的可能的策略是由两个KDE的凸组合组成,这两个KDE是独立于颜色和深度领域学习的。该框架虽然简单,但已被证明具有良好的实证结果。因此,最终的领域适应背景模型Bt可以由两个不同领域的两个背景模型的加权线性组合产生,具体如下:
。需要注意的是,如果没有自适应机制,这可能会导致目标域的检测结果较差,因为包含较大的源训练集的彩色域模型在密集的源区域会被训练得很好。我们现在提出了具体的领域适配KDE算法。领域适应的一个最简单的可能的策略是由两个KDE的凸组合组成,这两个KDE是独立于颜色和深度领域学习的。该框架虽然简单,但已被证明具有良好的实证结果。因此,最终的领域适应背景模型Bt可以由两个不同领域的两个背景模型的加权线性组合产生,具体如下:
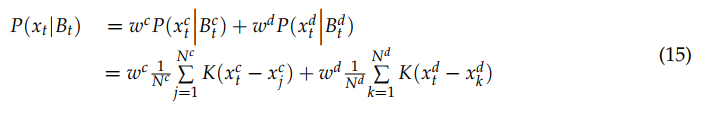
其中,权重参数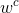 和
和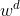 通过最小化目标(深度)域中的检测误差来确定;
通过最小化目标(深度)域中的检测误差来确定;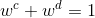 ,
, 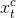 ,
, 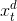 为第t步测试样品;
为第t步测试样品;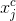 和
和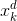 是通过KDE模型学习的背景样本;
是通过KDE模型学习的背景样本;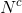 和
和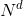 是背景样本的数量。参数
是背景样本的数量。参数![w^c \in [0,1]](https://oscimg.oschina.net/oscnet/up-6c11a5f44a165fba8317b99439c66b24.gif) 、
、![w^d \in [0,1]](https://oscimg.oschina.net/oscnet/up-208e078cc2f5b05c168ead1c0a3c1b2f.gif) 是通过最小化颜色训练集上的多类误差,通过网格搜索确定的。我们通过应用两阶段程序避免了由于学习同一训练集上的假设
是通过最小化颜色训练集上的多类误差,通过网格搜索确定的。我们通过应用两阶段程序避免了由于学习同一训练集上的假设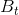 、
、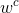 和
和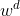 而产生的偏差估计。首先,我们使用交叉验证(使用为KDE找到的超参数值)学习不同的假设,并使用未在该示例上训练的交叉验证假设在每个训练样本上计算预测。其次,我们使用这些预测输出来确定最优的权重。最后,我们使用整个目标训练集来学习背景模型。一般来说,我们的深度-颜色特征学习和融合过程可以用算法1来表示。
而产生的偏差估计。首先,我们使用交叉验证(使用为KDE找到的超参数值)学习不同的假设,并使用未在该示例上训练的交叉验证假设在每个训练样本上计算预测。其次,我们使用这些预测输出来确定最优的权重。最后,我们使用整个目标训练集来学习背景模型。一般来说,我们的深度-颜色特征学习和融合过程可以用算法1来表示。

4、实验结果
为了对我们的方法进行实验评估,我们选择了来自YouTube的公共视频,其中包括雾天的各种场景[33-36]。在雾天获得的50个视频序列包括在这个评估中。对于每个序列,我们只采集了一个视频片段,保持了测试数据的多样性。因此,我们在实验中测试了50个不同的视频片段,共1257帧。对于一个视频切片,连续帧之间的变化非常小。因此,训练数据集的冗余度很高。如果使用所有帧对背景模型进行训练,那么训练过程的时间成本会非常高。为了消除训练样本之间的冗余,我们每隔五帧随机选取一帧。在每一个实验中,我们都将输入帧的分辨率保持为帧的原始分辨率。对于一个视频序列,我们选取了250帧作为训练样本对背景进行建模。首先,我们通过展示有深度信息和没有深度信息的目标检测结果来说明深度信息的贡献。然后,我们的方法与现有的背景建模方法,即spatiotemporal MoG (ST-MoG)、Vibe和DECOLOR进行了实验比较。此外,四元数傅里叶变换(PQFT)方法的相位谱也被选为一种典型的基于预处理/显著性的目标检测方法。对于这些比较的方法,我们使用颜色域提取的特征,而不包括深度特征。因此,域自适应策略的性能可以得到很好的证明。优秀的深度学习方法并没有被纳入我们的实验,因为它们需要大量的训练数据,超出了本研究所收集的数据。目前,没有一个数据库包含在雾天获得的足够的数据来训练深度网络。如果我们使用类似于KDE模型的数据库来实现深度学习方法,那么将很难获得预期的目标检测结果,从而对这些深度学习方法产生不公平的评价。因此,本研究选择的比较方法模型复杂度相对较低,在不同场景中被证明是有效的对象检测方法。参数T和l分别设置为T = 0.8和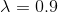 ,实验中暗原色先验的窗口大小为3×3。
,实验中暗原色先验的窗口大小为3×3。
4.1、评估标准
我们的实验评估的ground truth是由10个志愿者提供的标签的平均值得到的。因为我们的方法的目的是检测移动对象的区域,所以我们的ground truth中的移动对象是根据一个假设来识别的:如果移动对象的位移在5个连续的帧中大于10像素,那么我们就可以识别移动对象。这可以防止静态对象和动态噪声的影响。根据PASCAL准则[41],用C来评价检测结果与ground truth的重叠程度:

其中W0为检测结果,W为ground truth。根据以下6项标准对我们的方法进行了评估:准确率(precision, Pr)、相似度(similarity, Sim)、真阳性率(true positive rate, TPR)、F-score,假阳性率(false positive rate, FPR)和误分类率(error classification, PWC)。
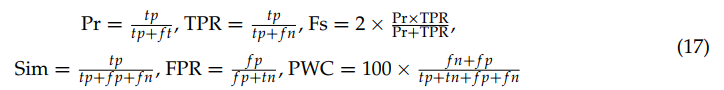
这里,tp、tn、fp和fn分别表示真阳性、真阴性、假阳性和假阴性的数量。
4.2、定性的评价
本文从两个方面进行了论证。首先给出了基于深度信息的目标检测性能,定性地了解了颜色域和深度域结合信息的动机;其次,通过与其他方法的比较,定性地评价了性能。图4显示了雾天三个场景的深度、颜色信息和对应的目标检测结果的地图。我们观察到深度和颜色信息之间的互补关系。一般来说,深度信息对附近的物体更敏感,对背景噪声的去除能力也更好。然而,利用深度信息很难探测到远距离目标。与深度信息相比,颜色信息对远离摄像机的目标检测效果更好。利用颜色信息得到的结果存在点噪声。因此,我们观察到,当使用深度信息时,I和II场景中的一些遥远的物体被遗漏了。然而,深度信息在场景III中表现得更好,因为它识别了使用颜色信息得到的结果中遗漏的行人目标。

定性性能比较如图5所示。这些结果表明不同的方法具有不同的性质。ST-MoG模型具有良好的目标识别能力,但这种方法的缺点可以通过噪声点和结果中的空穴来体现。对于类块目标,Vibe和DECOLOR方法表现出更好的性能。但是,当结构物体靠近相机时,例如第七行和最后一行的样本,脱色的性能相对退化。基于pqft的方法只能提供粗略的结果,描绘的是物体的区域,而不是其精确的轮廓。一般来说,该方法能够正确地检测出目标,特别是邻近目标,从而获得最佳的检测结果。但是,我们的方法在某些情况下会遗漏远处的对象(例如,第三行和第四行的结果)。产生这种误差的原因是我们的方法使用的深度信息是由简单的基于暗渠先验模型的无标度测量给出的,这种方法效率高但分辨率低。因此,那些远离相机的物体很可能被误认为是背景,因为未缩放的深度信息不够敏感,无法区分发生在远离相机的运动。形态学方案,如侵蚀和扩张算子[43]可以进一步介绍,以消除毛刺和噪声的结果。但是,这些方法不能自动运行,我们应该根据具体情况仔细配置控制参数,比如内核的带宽。这可能会导致性能比较的偏差,因为我们很难确定这些参数对于任何特殊结果是否是全局最优的。这就是在ex中维护原始目标检测结果的原因。

4.3、定量评估
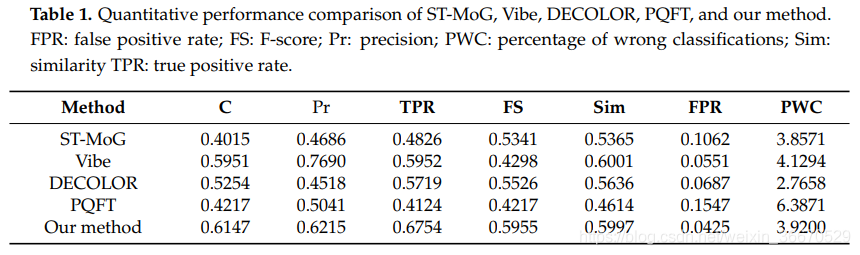
利用上述标准,我们提供了一个定量评价的比较方法和我们的方法。由表1可以看出,我们的方法在四个准则中表现最好,在两个准则中表现次之。最具可比性的表现是通过Vibe方法获得的,因为它在两个标准中是最好的,在三个标准中是次好结果。从表1的得分可以看出,虽然我们的方法在天气好的情况下无法达到我们的性能,但是我们的方法在大多数情况下是可以使用的,因为帕PASCAL准则C > 0.5的平均得分表明检测和跟踪是成功的。
5、结论
为了解决雾天目标检测的问题,本研究对图像数据中的颜色和深度信息进行了探索和融合。为了防止训练数据集中的错误,提出了一系列技巧,如天窗移除和数据清理。我们分别使用颜色和深度域的特征来训练和建立背景模型。这两个背景模型在一个统一的域适应框架下组合,将源域(颜色)模型引入目标域(深度)。在雾天利用公共数据进行的实验中,取得了理想的目标检测结果。实验结果表明,该方法的一个潜在的缺点是难以检测出远距离目标。这个问题可以通过更新深度估计方法来解决。我们的方法是第一个研究基于深度特征的雾天目标检测的方法。该方法可以推广到其他具有深度信息的目标检测任务,如基于RGB-D数据的目标检测。此外,我们在未来的工作中还包括一个雾探测模型,它是在现实条件下的全天候系统的基础。
承接Matlab、Python和C++的编程,机器学习、计算机视觉的理论实现及辅导,本科和硕士的均可,咸鱼交易,专业回答请走知乎,详谈请联系QQ号757160542,非诚勿扰。
本文同步分享在 博客“于小勇”(CSDN)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

Foundation Kit「Learn Objective-C on Mac
Cocoa
Cocoa框架實際上由Foundation Kit和AppKit兩個不同的框架組成.Foundation框架中有很多有用的,面向數據的低級類和數據類型.此框架主要用來處理界面無關的內容,AppKit則包含了所有的用戶接口對象和高級類.
結構體類型
Cocoa中一些類據類型是使用struct實現的,不使用對象實現的原因就在於性能.對象的開銷比較大(對象都是動態分配的).所以對這種數據類型可以使用三種方式賦值.
typedef struct _NSRange{
unsigned int location;
unsigned int length;
}NSRange;
1.
NSRange range;
range.lcation = 17;
range.length = 4;
2.
NSRange range = (17,4);
3.
NSRage range = NSMakeTange(17,4);
其他還有NSPoint,NSSize,NSRect等數據類型也是如此,除了1,2種賦值方法外,也都有對應的函數可以生成數據:NSMakePoint(),NSMakeSize(),NSMakeRect()等.
Nsstring
@""是Nsstring字面量寫法.
Nsstring可以准確地處理Unicode字符串.
+ stringWithFormat: 類級方法,通過格式化字符串和一組參數輸出格式化後的結果.
– isEqualToString: 對象級方法,比較與所給的字符串是否相同.
Cocoa中的字符串是對象,所以不能用 == 號來比較.如果使用 == 號比較兩個字符串對象,那麼事實上是比較了兩個對象的指針.
– compare:與給定的字符串比較(區分大小寫),返回一個枚舉值作為結果.
– compare:options:
– compare:options:range:
– compare:options:range:locale:字符串比較方法,帶選項的版本(如:是否區分大小寫)
– hasPrefix:測試是否以給定的字符串開頭
– hasSuffix:測試是否以給定的字符串結尾
– rangeOfString:查詢給定字符串在字符串對象中的位置.
NSMutableString
Nsstring的子類, NSMutableString是Nsstring的可修改版本.
+ stringWithCapacity:容量建議值.對象會以此方法給出的建議值劃分出一塊內存作為可變字符串對象的初始大小.合理使用可以提高性能.
– appendFormat:向字符串對象追加內容.
– appendString:使用格式化方式向字符串對象追加內容.
– deleteCharactersInRange:從字符串對象的指定范圍中刪除字符串.
集合
NSArray
NSArrary是一個用來存儲對象的有序列表.
限制:只能存儲Objective-C對象.不能存儲C語言中的基本數據類型(如int,float,enum,struct,或者NSArray中的隨機指針),也不能存儲nil或者NULL值.
– count 獲得列表包含的對象數.
– objectAtIndex:獲取特定索引處的對象.索引值超出范圍時,將引發一個異常.
Cocoa框架中對象往往都是以類族的形式實現的.如:NSArray對象可能會在運行時發現其實運作的是NSCFArray(來自Core Foundation框架(C語言的實現版本),很多Cocoa對象都是如此做橋接的).
NSMutableArray
NSArray的可變版本.
+ arrayWithCapacity:以建議值作為初始化大小.
– addobject:追加對象
– removeObjectAtIndex:從指定索引處刪除對象
NSEnumerator
遍歷集合時:
使用for循環向集合對象發送objectAtIndex:消息來獲取對象.
使用枚舉對象來完成遍歷集合的工作.
Mac OS X Tiger 之前的系統,支持的語法:
NSEnumerator *enumerator;
enumerator = [array objectEnumerator];
id thingie;
while(thingie = [enumerator nextObject]){
//something to do.
}
即向集合對象發送objectEnumerator消息,以獲取一個枚舉對象(或者NSEnumerator類或其子類的實例),然後在while循環中向此枚舉對象循環發送nextObject以依次獲取枚舉中的每個對象,直到枚舉的末尾(直到nextObject消息返回一個nil對象).
Mac OS X Leopard之後的系統可使用如下語法:
for (Nsstring *string in array){
//to do something.
}
NSDictionary / NSMutableDictionary
字典對象(及可變型字典對象).
+ dictionaryWithObjectsAndKeys:使用所給的鍵值對建立字典.
– setobject:forKey:添加字典項
– removeObjectForKey:刪除字典項
不要擴展Cocoa框架下的類
Cocoa中許多類都是以類簇的方式實現的.即它們是一群隱藏在通用接口下的與實現相關的類.
比如:使用Nsstring對象的是個,實際上獲得的可能是NSLiteralString,NSCFString,NSSimpleCString,NSBallofString或者其他未寫入文檔的與實現相關的對象.
不要想著為以類簇方式實現的類添加子類,這可能是很痛苦的事情,想要擴展這類類的能力時,可考慮"復合"或者"類別".
數值類
NSNumber
用於包裝基本數據類型,如:int,float等.成為一個對象,以便將基本數據類型放入集合類中.
+ numberWithBool:由布爾型生成對象
+ numberWithChar:字符型
+ numberWithDouble:雙精度浮點型
+ numberWithFloat:單精度浮點型
+ numberWithInt:整型
+ numberWithInteger:ObjC整型
+ numberWithLong:長整型
+ numberWithLongLong:長長整型
+ numberWithShort:短整型
使用以下方法可以從對象中提取回基本數據型值.
– boolValue
– charValue
– decimalValue
– doubleValue
– floatValue
– intValue
– integerValue
– longLongValue
– longValue
– shortValue
都是顧名思義的方法名.
NSValue
NSValue是NSNumber的父類,可以用來包裝任意值.NSNumber不能包裝的struct,也可以用這個類來包裝.
+ valueWithBytes:objCType:第一參數傳入要包裝的數值的地址.第二個參數為數據類型的描述字符串(一般可以直接用@encode命令來生成)
NSRect rect = NSMakeRect(1,2,30,40);
NSValue *value = [NSValue valueWithBytes:&rect objCType:@encode(NSRect)];
[array addobject:value];
使用- getValue:方法可以從NSValue對象中提取出數據的指針(可以看到get前輟的方法約定,總是用來提取指針,而不是值).
NSValue中有一些方法,可以用來快速包裝Cocoa常用結構體數據類型:
+ valueWithPoint:快速包裝NSPoint對象
+ valueWithRange:NSRange
+ valueWithRect:NSRect
+ valueWithSize:NSSize
NSNull
空類型,由於集合類中不能添加nil值(被用來識別為集合的結尾處),所以你可以使用NSNull對象添加到集合中,以表示空(無,沒有)成員.

iOS AVFoundation:设置视频的方向
这可能是,但我不知道如何去做这件事.有关设置方向的文档是关于正确设置以便在设备上显示,我已经实现了建议found here.但是,此建议并未解决为非Apple软件(如VLC或Chrome浏览器)正确设置方向的问题. .
任何人都可以提供有关如何在设备上正确设置方向以便正确显示所有查看软件的信息吗?
解决方法
//转换视频
+(void)convertMOVToMp4:(Nsstring *)movFilePath completion:(void (^)(Nsstring *mp4FilePath))block{
AVURLAsset * videoAsset = [[AVURLAsset alloc]initWithURL:[NSURL fileURLWithPath:movFilePath] options:nil];
AVAssetTrack *sourceAudioTrack = [[videoAsset tracksWithMediaType:AVMediaTypeAudio] objectAtIndex:0];
AVMutableComposition* composition = [AVMutableComposition composition];
AVMutableCompositionTrack *compositionAudioTrack = [composition addMutableTrackWithMediaType:AVMediaTypeAudio
preferredTrackID:kCMPersistentTrackID_Invalid];
[compositionAudioTrack insertTimeRange:CMTimeRangeMake(kCMTimeZero,videoAsset.duration)
ofTrack:sourceAudioTrack
atTime:kCMTimeZero error:nil];
AVAssetExportSession * assetExport = [[AVAssetExportSession alloc] initWithAsset:composition
presetName:AVAssetExportPresetMediumQuality];
Nsstring *exportPath = [movFilePath stringByReplacingOccurrencesOfString:@".MOV" withString:@".mp4"];
NSURL * exportUrl = [NSURL fileURLWithPath:exportPath];
assetExport.outputFileType = AVFileTypeMPEG4;
assetExport.outputURL = exportUrl;
assetExport.shouldOptimizeforNetworkUse = YES;
assetExport.videoComposition = [self getVideoComposition:videoAsset composition:composition];
[assetExport exportAsynchronouslyWithCompletionHandler:
^(void ) {
switch (assetExport.status)
{
case AVAssetExportSessionStatusCompleted:
// export complete
if (block) {
block(exportPath);
}
break;
case AVAssetExportSessionStatusFailed:
block(nil);
break;
case AVAssetExportSessionStatusCancelled:
block(nil);
break;
}
}];
}
//获取当前方向
+(AVMutableVideoComposition *) getVideoComposition:(AVAsset *)asset composition:( AVMutableComposition*)composition{
BOOL isPortrait_ = [self isVideoPortrait:asset];
AVMutableCompositionTrack *compositionVideoTrack = [composition addMutableTrackWithMediaType:AVMediaTypeVideo preferredTrackID:kCMPersistentTrackID_Invalid];
AVAssetTrack *videoTrack = [[asset tracksWithMediaType:AVMediaTypeVideo] objectAtIndex:0];
[compositionVideoTrack insertTimeRange:CMTimeRangeMake(kCMTimeZero,asset.duration) ofTrack:videoTrack atTime:kCMTimeZero error:nil];
AVMutableVideoCompositionLayerInstruction *layerInst = [AVMutableVideoCompositionLayerInstruction videoCompositionLayerInstructionWithAssetTrack:compositionVideoTrack];
CGAffineTransform transform = videoTrack.preferredTransform;
[layerInst setTransform:transform atTime:kCMTimeZero];
AVMutableVideoCompositionInstruction *inst = [AVMutableVideoCompositionInstruction videoCompositionInstruction];
inst.timeRange = CMTimeRangeMake(kCMTimeZero,asset.duration);
inst.layerInstructions = [NSArray arrayWithObject:layerInst];
AVMutableVideoComposition *videoComposition = [AVMutableVideoComposition videoComposition];
videoComposition.instructions = [NSArray arrayWithObject:inst];
CGSize videoSize = videoTrack.naturalSize;
if(isPortrait_) {
NSLog(@"video is portrait ");
videoSize = CGSizeMake(videoSize.height,videoSize.width);
}
videoComposition.renderSize = videoSize;
videoComposition.frameDuration = CMTimeMake(1,30);
videoComposition.renderScale = 1.0;
return videoComposition;
}
//获取视频
+(BOOL) isVideoPortrait:(AVAsset *)asset{
BOOL isPortrait = FALSE;
NSArray *tracks = [asset tracksWithMediaType:AVMediaTypeVideo];
if([tracks count] > 0) {
AVAssetTrack *videoTrack = [tracks objectAtIndex:0];
CGAffineTransform t = videoTrack.preferredTransform;
// Portrait
if(t.a == 0 && t.b == 1.0 && t.c == -1.0 && t.d == 0)
{
isPortrait = YES;
}
// PortraitUpsideDown
if(t.a == 0 && t.b == -1.0 && t.c == 1.0 && t.d == 0) {
isPortrait = YES;
}
// LandscapeRight
if(t.a == 1.0 && t.b == 0 && t.c == 0 && t.d == 1.0)
{
isPortrait = FALSE;
}
// LandscapeLeft
if(t.a == -1.0 && t.b == 0 && t.c == 0 && t.d == -1.0)
{
isPortrait = FALSE;
}
}
return isPortrait;
}

ios – 如何从AVFoundation获得光照值?
谁知道有没有办法知道光的容量?
我知道其中一种方法是使用环境光传感器,但它不鼓励,最终应用程序不允许在市场上
我发现问题非常接近我需要的问题
detecting if iPhone is in a dark room
那个人解释说我可以使用ImageIO框架,读取视频源的每一帧进来的元数据
- (void)captureOutput:(AVCaptureOutput *)captureOutput didOutputSampleBuffer:(CMSampleBufferRef)sampleBuffer fromConnection:(AVCaptureConnection *)connection {
CFDictionaryRef MetadataDict = CMcopyDictionaryOfAttachments(NULL,sampleBuffer,kCMAttachmentMode_ShouldPropagate);
NSDictionary *Metadata = [[NSMutableDictionary alloc] initWithDictionary:(__bridge NSDictionary*)MetadataDict];
CFRelease(MetadataDict);
NSDictionary *exifMetadata = [[Metadata objectForKey:(Nsstring *)kCGImagePropertyExifDictionary] mutablecopy];
float brightnessValue = [[exifMetadata objectForKey:(Nsstring *)kCGImagePropertyExifBrightnessValue] floatValue];
}
但我是iOS的新手,不知道如何在Swift中转换这段代码
提前致谢!
解决方法
可以使用相机的EXIF数据获得近似光度值(以单位勒克斯为单位).请参考以下链接. Using a camera as a lux meter
这里AVFoundation中captureOutput方法的sampleBuffer值用于从相机帧中提取EXIF数据.
func captureOutput(_ captureOutput: AVCaptureOutput!,didOutputSampleBuffer sampleBuffer: CMSampleBuffer!,from connection: AVCaptureConnection!) {
//Retrieving EXIF data of camara frame buffer
let rawMetadata = CMcopyDictionaryOfAttachments(nil,CMAttachmentMode(kCMAttachmentMode_ShouldPropagate))
let Metadata = CFDictionaryCreateMutablecopy(nil,rawMetadata) as NSMutableDictionary
let exifData = Metadata.value(forKey: "{Exif}") as? NSMutableDictionary
let FNumber : Double = exifData?["FNumber"] as! Double
let ExposureTime : Double = exifData?["ExposureTime"] as! Double
let ISOSpeedratingsArray = exifData!["ISOSpeedratings"] as? NSArray
let ISOSpeedratings : Double = ISOSpeedratingsArray![0] as! Double
let CalibrationConstant : Double = 50
//Calculating the luminosity
let luminosity : Double = (CalibrationConstant * FNumber * FNumber ) / ( ExposureTime * ISOSpeedratings )
print(luminosity)}
请注意,CalibrationConstant的值可以根据应用进行校准,如参考文献中所述.
今天关于objective-c – iOS AVFoundation:如何从mp3文件中获取图稿?和怎么获取mp3音源的讲解已经结束,谢谢您的阅读,如果想了解更多关于Domain Adaptation and Adaptive Information Fusion for Object Detection on Foggy Days、Foundation Kit「Learn Objective-C on Mac、iOS AVFoundation:设置视频的方向、ios – 如何从AVFoundation获得光照值?的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

