想了解javainfluxDB工具类的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于javainfluxdb示例的相关问题,此外,我们还将为您介绍关于GaussDB(forInflux)与开
想了解java influx DB工具类的新动态吗?本文将为您提供详细的信息,我们还将为您解答关于java influxdb示例的相关问题,此外,我们还将为您介绍关于GaussDB(for Influx)与开源企业版性能对比、grafana+prometheus 使用 influx DB、Grafana/Influx Db 对数据源的身份验证失败、influx - java client的新知识。
本文目录一览:- java influx DB工具类(java influxdb示例)
- GaussDB(for Influx)与开源企业版性能对比
- grafana+prometheus 使用 influx DB
- Grafana/Influx Db 对数据源的身份验证失败
- influx - java client
")
java influx DB工具类(java influxdb示例)
配置
application-properties:
spring.influxdb.url=${influxdb_host:127.0.0.1}
spring.influxdb.port=${influxdb_port:8086}
spring.influxdb.username=${influxdb_username:root}
spring.influxdb.password=${influxdb_password:root}
spring.influxdb.database=${influxdb_database:test}
InfluxDBConfig
import com....utils.InfluxDBConnect; import org.springframework.beans.factory.annotation.Value; import org.springframework.boot.context.properties.ConfigurationProperties; import org.springframework.context.annotation.Bean; import org.springframework.context.annotation.Configuration; @ConfigurationProperties("application.properties") @Configuration public class InfluxDBConfig { @Value("${spring.influxdb.username}") private String username; @Value("${spring.influxdb.password}") private String password; @Value("${spring.influxdb.url}") private String url; @Value("${spring.influxdb.port}") private String port; @Value("${spring.influxdb.database}") private String database; @Bean public InfluxDBConnect getInfluxDBConnect(){ InfluxDBConnect influxDB = new InfluxDBConnect(username,password,"http://"+url+":"+port,database); influxDB.influxDbBuild(); influxDB.createRetentionPolicy(); return influxDB; } }
工具类
influxDBConnect类:
import lombok.Data; import org.influxdb.InfluxDB; import org.influxdb.InfluxDBFactory; import org.influxdb.dto.BatchPoints; import org.influxdb.dto.Point; import org.influxdb.dto.Query; import org.influxdb.dto.QueryResult; import java.util.Map; import java.util.concurrent.TimeUnit; @Data public class InfluxDBConnect { private String username;// 用户名 private String password;// 密码 private String openurl;// 连接地址 private String database;// 数据库 private InfluxDB influxDB; public InfluxDBConnect(String username,String password,String openurl,String database) { this.username = username; this.password = password; this.openurl = openurl; this.database = database; } /** 连接时序数据库;获得InfluxDB **/ public InfluxDB influxDbBuild() { if (influxDB == null) { influxDB = InfluxDBFactory.connect(openurl,username,password); influxDB.createDatabase(database); } return influxDB; } /** * 设置数据保存策略 defalut 策略名 /database 数据库名/ 30d 数据保存时限30天/ 1 副本个数为1/ 结尾DEFAULT * 表示 设为默认的策略 */ public void createRetentionPolicy() { String command = String.format("CREATE RETENTION POLICY \"%s\" ON \"%s\" DURATION %s REPLICATION %s DEFAULT","defalut",database,"7200d",1); this.query(command); } /** * 查询 * * @param command 查询语句 * @return */ public QueryResult query(String command) { return influxDB.query(new Query(command,database)); } public QueryResult query(String command,TimeUnit unit) { return influxDB.query(new Query(command,database),unit); } /** * 插入 * @param measurement 表 * @param tags 标签 * @param fields 字段 */ public void insert(String measurement,Map<String,String> tags,Object> fields,long time) { Point.Builder builder = Point.measurement(measurement); builder.time(time,TimeUnit.MILLISECONDS); builder.tag(tags); builder.fields(fields); influxDB.write(database,"",builder.build()); } /** * 插入 * @param measurement 表 * @param tags 标签 * @param fields 字段 */ public void insert(String measurement,Object> fields){ Point.Builder builder = Point.measurement(measurement); builder.tag(tags); builder.fields(fields); influxDB.write(database,builder.build()); } /** * 插入 * @param batchPoints 批量插入 */ public void batchInsert(BatchPoints batchPoints){ influxDB.write(batchPoints); } /** * 删除 * @param command 删除语句 * @return 返回错误信息 */ public String deleteMeasurementData(String command) { QueryResult result = influxDB.query(new Query(command,database)); return result.getError(); } /** * 创建数据库 * @param dbname */ public void createDB(String dbname) { influxDB.createDatabase(dbname); } /** * 删除数据库 * * @param dbname */ public void deleteDB(String dbname) { influxDB.deleteDatabase(dbname); } }
查询返回值包的层数很多,可以预处理
import lombok.extern.slf4j.Slf4j; import org.influxdb.dto.QueryResult; import java.math.BigDecimal; import java.util.ArrayList; import java.util.LinkedHashMap; import java.util.List; import java.util.Map; import java.util.concurrent.TimeUnit; @Slf4j public class InfluxdbUtil { public static List<Object> queryInfluxdb(String query_sql,String table_type,InfluxDBConnect influxDB) { long starttime = System.currentTimeMillis(); QueryResult result = influxDB.query(query_sql.toString(),TimeUnit.MILLISECONDS); long endtime = System.currentTimeMillis(); List<Object> influx_data_list = getInfluxData(result.getResults().get(0),table_type); return influx_data_list; } public static List<Object> getInfluxData(QueryResult.Result result,String table_type) { List<Object> influx_data_list = null; if (null != result) { influx_data_list = new ArrayList<>(); List<QueryResult.Series> series = result.getSeries(); if (null != series && series.size() > 0) { for (QueryResult.Series serie : series) { List<List<Object>> values = serie.getValues(); List<Object> result_list = getInfluxDataAndBuild(values,serie,table_type); influx_data_list.addAll(result_list); } } } return influx_data_list; } public static List<Object> getInfluxDataAndBuild(List<List<Object>> values,QueryResult.Series serie,String table_type) { List<Object> influx_data_list = new ArrayList<>(); List<String> influx_cloumns = serie.getColumns(); Map<String,String> influx_tags = serie.getTags(); Map<String,Object> build_maps; if (values.size() > 0) { for (int i = 0; i < values.size(); i++) { build_maps = new LinkedHashMap<>(); if (null != influx_tags) { for (Map.Entry<String,String> entry : influx_tags.entrySet()) { String entry_key = entry.getKey(); if (entry_key.contains("tag_")) { entry_key = entry_key.substring(4); } build_maps.put(entry_key,entry.getValue()); } } Object[] influx_Obj = values.get(i).toArray(); for (int j = 0; j < influx_Obj.length; j++) { String build_maps_key = influx_cloumns.get(j); if (build_maps_key.equals("time")) { if (table_type.equals("normal")) { BigDecimal bd = new BigDecimal(String.valueOf(influx_Obj[j])); build_maps.put("timestamp",bd.toPlainString()); } else if (table_type.equals("polymerize")) { // build_maps.put("timestamp",DateUtil.datetoStampAndAddMinute(String.valueOf(influx_Obj[j]))); } } else { if (build_maps_key.contains("tag_")) { build_maps_key = build_maps_key.substring(4); } build_maps.put(build_maps_key,influx_Obj[j]); } } influx_data_list.add(build_maps); } } return influx_data_list; } }
与开源企业版性能对比")
GaussDB(for Influx)与开源企业版性能对比
摘要:相比于企业版InfluxDB,GaussDB(for Influx)能为客户提供更高的写入能力、更稳定的查询能力、更高的数据压缩率,高效满足各大时序应用场景需求。
本文分享自华为云社区《华为云GaussDB(for Influx)揭秘第八期:GaussDB(for Influx)与开源企业版性能对比》,作者:高斯Influx官方博客 。
“你们的数据库性能怎么样?”
“能不能满足我们的业务?”
“和其他数据库对比性能有优势么?”
…
客户在使用数据库时常有这样的担心和疑问。
本文从测试方案、测试工具、测试场景、测试结果等方面详细介绍了GaussDB(for Influx)和开源InfluxDB集群在X86架构下的性能测试情况。测试结果显示,GaussDB(for Influx)较企业版InfluxDB集群能提供更高的写入性能、更低的访问延迟以及更高的数据压缩率。
1. 测试方案
1.1 资源配置
服务端配置
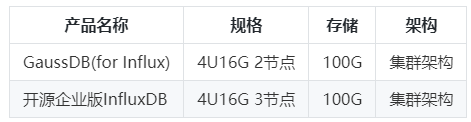
1.2 测试工具
测试工具为开源性能工具TS-benchMark。
2. 测试设计
2.1 测试模型
本次测试采用风力发电数据模型,每个风场50个设备,每个设备50个传感器,1个风场1个线程,通过load数据的线程数来控制时间线的大小,通过收集时间的长短来控制数据量。
模型每条数据大小约为24字节,具体的类型如下:
Timestamp | farm | device |sensor | value
2.2 测试数据量
测试数据分为两个场景,大数据量和小数据量,具体数据量如下:

注:企业版InfluxDB在插入到47亿数据时OOM,以下性能对比都基于此数据量。
2.3 测试场景
2.3.1 数据写入场景
- batch_size(每个批次写入的数据量) 固定为50,线程数分别从1、2、4、8、16、32、64、128、256、512 递增;
- 线程数(客户端并发请求的连接数)固定为8, batch_size分别从50、100、150、200、250、300 递增。
2.3.2 数据查询场景
单线程进行不同语句的查询,并统计其时延信息。
第一类查询: 所有TAG查询
select *
from sensor
where f=''f1'' and d=''d2'' and s=''s1'' and time>=1514768400000000000 and time<=1514772000000000000第二类查询: TAG + VALUE查询
select *
from sensor
where f=''f1'' and s=''d2'' and value>=3.0 and time>=1514768400000000000 and time<1514854800000000000第三类查询: 聚合查询
select mean(value)
from sensor
where f=''f1'' and s=''s1'' and time>=1514768400000000000 and time<=1514854800000000000 group by f,d,s,time(1h)第四类查询: 或条件查询
select *
from sensor
where f=''f1'' and (s=''s1'' or s=''s2'' or s=''s3'' or s=''s4'' or s=''s5'') and time>=1514768400000000000 and time<=1514769150000000000第五类查询: 单个TAG查询
select *
from sensor
where f=''f1'' and time>=1514768400000000000 and time<=15147691500000000003. 测试结果分析
3.1 写入吞性能比对
在小数据量场景下,GaussDB(for Influx)的写入性能是企业版InfluxDB的13倍左右,在大数据量的场景下可以达到1.8倍左右。
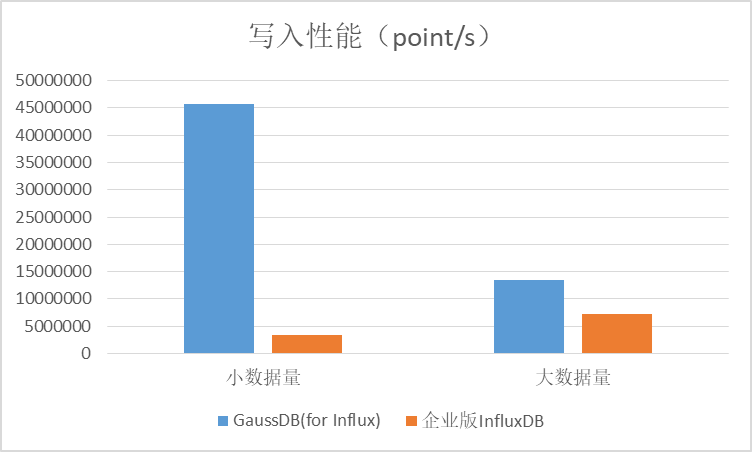
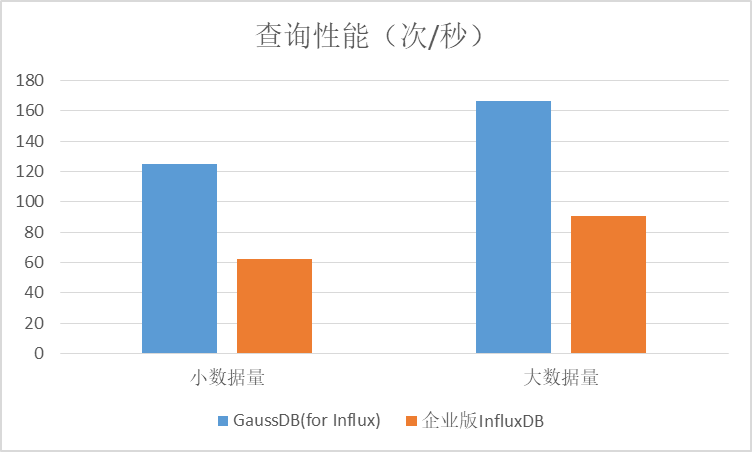
3.2 查询性能对比
1)第一类查询(所有TAG查询):无论是大数据量还是小数据量场景下,GaussDB(for Influx)的吞吐量是开源InfluxDB企业版的2倍左右。
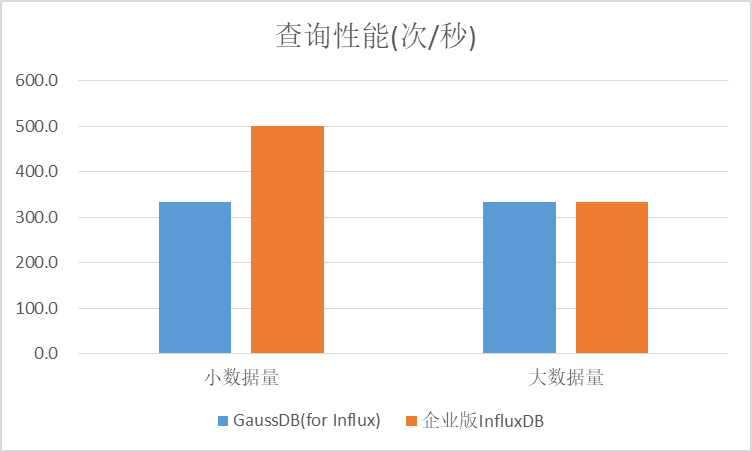
2)第二类查询(TAG + VALUE查询):在小数据量场景下,开源InfluxDB企业版性能高于GaussDB(for Influx),GaussDB(for Influx)在大数据量和小数据量场景下性能基本持平。
3)第三类查询(聚合查询):GaussDB(for Influx)查询性能明显优于开源InfluxDB企业版,在小数据量场景下是开源版本的14倍,大数据量下也是开源版本的8倍左右。
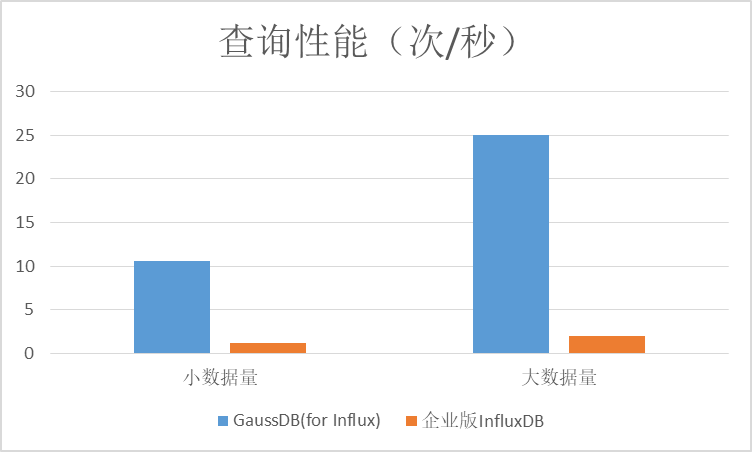
4)第四类查询(或条件查询):GaussDB(for Influx)查询性能在两种场景下比较稳定,开源企业版InfluxDB在两种场景下差异较大;GaussDB(for Influx)在小数据量场景下表现优于开源版,在大数据量场景下低于开源版。

5)第五类查询(单个TAG查询):GaussDB(for Influx)查询性能在两种场景下比较稳定,在大数据量场景下低于开源版。
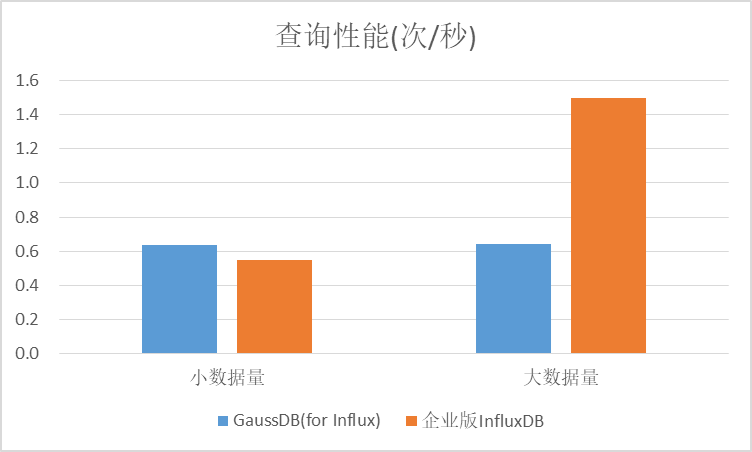
3.3 数据压缩率对比
在250万时间线场景下,GaussDB(for Influx)导入了151亿条数据,导入前数据大小为337.5G,导入后为49.8G,压缩率为6.8;开源企业版导入了47亿条数据,导入前105G,导入后21.3G,压缩率为4.9。GaussDB(for Influx)压缩率是开源企业版的1.4倍左右。
Influx引擎采用LSM tree架构,随着后台compaction的进行,压缩率会进一步提升,当前数据对比是数据刚导入时的结果。
4. 总结
在GaussDB(for Influx)2节点对比开源版3节点场景下,GaussDB(for Influx)给客户带来了更高的写入能力、更稳定的查询能力、更高的压缩率。GaussDB(for Influx)写入能力在小数据量场景下是开源企业版的13倍,在大数据量场景下是开源企业版的1.8倍;查询能力在两种场景下表现稳定,在大部分查询场景下优于开源企业版;在压缩率方面,同样数据模型下,高出开源版本40%。
除了以上优势外,GaussDB(for Influx)还在集群化、冷热分级存储、高可用方面也做了深度优化,能更好地满足时序应用的各种场景。
5. 结束
本文作者:华为 云数据库创新Lab & 华为云时空数据库团队
更多技术文章,关注GaussDB(for Influx)官方博客:
https://bbs.huaweicloud.com/community/usersnew/id_1586596796288328
Lab官网:https://www.huaweicloud.com/lab/clouddb/home.html
产品首页:https://www.huaweicloud.com/product/gaussdbforinflux.html
欢迎加入我们!
云数据库创新Lab(成都、北京)简历投递邮箱:xiangyu9@huawei.com
华为云时空数据库团队(西安、深圳)简历投递邮箱:yujiandong@huawei.com
点击关注,第一时间了解华为云新鲜技术~

grafana+prometheus 使用 influx DB
如何解决grafana+prometheus 使用 influx DB
我们现有的 Grafana 仪表板使用 Prometheus 作为源并使用 PromQL 查询数据。 由于我们希望将数据保留更长的时间(例如:2个月)并且数据量非常大,我们将 Prometheus 切换到 Influx DB,使用 remote_write 和 remote_read: https://devopstales.github.io/monitoring/prometheus-influxdb/
是否可以切换 Grafana 仪表板以使用存储在我们的配置和现有仪表板中的 influx 中的数据,并使用现有的 PromQL 查询从 InfluxDB 检索数据?
预先感谢您的帮助

Grafana/Influx Db 对数据源的身份验证失败
如何解决Grafana/Influx Db 对数据源的身份验证失败
我正在尝试集成 grafana 和 influxdb 以获得一些指标。但不确定当我尝试测试它时,对数据源的身份验证失败。请帮我解决这个问题。
这是下面的 yaml 和 conf 文件。
Docker-compose 文件
version: "3"services:grafana:image: grafana/grafanacontainer_name: grafanarestart: alwaysports:- 3000:3000networks:- monitoringvolumes:- grafana-volume:/vol01/Docker/monitoringenvironment:- GF_LOG_LEVEL=debug- GF_DATAPROXY_LOGGING=true- GF_DATAPROXY_TIMEOUT=60influxdb:image: influxdbcontainer_name: influxdbrestart: alwaysports:- 8086:8086networks:- monitoringvolumes:- influxdb-volume:/vol01/Docker/monitoringenvironment:- INFLUXDB_DB=telegraf- INFLUXDB_USER=telegraf- INFLUXDB_ADMIN_ENABLED=true- INFLUXDB_HTTP_AUTH_ENABLED=false- INFLUXDB_ADMIN_USER=admin- INFLUXDB_ADMIN_PASSWORD=Welcome1- GF_LOG_LEVEL=debug- GF_DATAPROXY_LOGGING=truetelegraf:image: telegrafcontainer_name: telegrafrestart: alwaysextra_hosts:- "influxdb:18.216.224.127"environment:ST_PROC: /rootfs/procHOST_SYS: /rootfs/sysHOST_ETC: /rootfs/etcvolumes:- ./telegraf.conf:/etc/telegraf/telegraf.conf:ro- /var/run/docker.sock:/var/run/docker.sock:ro- /sys:/rootfs/sys:ro- /proc:/rootfs/proc:ro- /etc:/rootfs/etc:ronetworks:monitoring:volumes:grafana-volume:
配置文件
[global_tags][agent]interval = "60s"round_interval = truemetric_batch_size = 1000metric_buffer_limit = 10000collection_jitter = "0s"flush_interval = "10s"flush_jitter = "0s"precision = ""hostname = "18.216.224.127"omit_hostname = false[[outputs.influxdb]]urls = ["http://18.216.224.127:8086"]database = "telegraf"timeout = "5s"username = "telegraf"password = "Welcome1"[[inputs.ping]]interval = "5s"urls = ["192.168.0.44","192.168.0.131","192.168.0.130","google.com","amazon.com","github.com"]count = 4ping_interval = 1.0timeout = 2.0[[inputs.cpu]]percpu = truetotalcpu = truecollect_cpu_time = falsereport_active = false[[inputs.disk]]ignore_fs = ["tmpfs","devtmpfs","devfs","iso9660","overlay","aufs","squashfs"][[inputs.diskio]][[inputs.kernel]][[inputs.mem]][[inputs.processes]][[inputs.swap]][[inputs.system]]
错误
t=2021-05-08T11:02:29+0000 lvl=info msg="数据源认证失败" logger=data-proxy-log userId=1 orgId=1 uname=admin path=/api/datasources /proxy/1/query remote_addr=108.237.178.97 referer=http://18.216.224.127:3000/datasources/edit/1/ body="{"code":"unauthorized","message":"Unauthorized"}"状态码=401 t=2

influx - java client
maven
<dependency>
<groupId>org.influxdb</groupId>
<artifactId>influxdb-java</artifactId>
<version>${influxdb.version}</version>
</dependency>
spring application.yml
spring:
influx:
url: http://localhost:8086
user: canaan
password: 123456
database: test
java junit test
import lombok.Data;
import lombok.experimental.Accessors;
import okhttp3.OkHttpClient;
import org.influxdb.InfluxDB;
import org.influxdb.annotation.Column;
import org.influxdb.annotation.Measurement;
import org.influxdb.dto.Point;
import org.influxdb.dto.Query;
import org.influxdb.dto.QueryResult;
import org.influxdb.impl.InfluxDBImpl;
import org.junit.jupiter.api.BeforeAll;
import org.junit.jupiter.api.Test;
import java.util.concurrent.TimeUnit;
class InfluxDBTest {
static InfluxDB influxDB = null;
@BeforeAll
static void before() {
influxDB = influxDB();
influxDB.setDatabase("test");
influxDB.setRetentionPolicy("autogen");
// influxDB.setLogLevel()
// influxDB.ping()
// influxDB.version()
// influxDB.flush();
// influxDB.close();
// influxDB.disableBatch();
// influxDB.disableGzip()
// influxDB.enableBatch()
// influxDB.enableGzip()
// influxDB.isGzipEnabled()
// influxDB.isBatchEnabled()
}
public static InfluxDB influxDB() {
return new InfluxDBImpl("http://localhost:8086", "username", "password",
new OkHttpClient.Builder());
}
@Test
void query() {
// Query query = new Query("select * from test.autogen.device_status");
// Query query = new Query("select * from autogen.device_status");
Query query = new Query("select * from device_status");
QueryResult queryResult = influxDB.query(query);
for (QueryResult.Result result : queryResult.getResults()) {
for (QueryResult.Series series : result.getSeries()) {
System.out.println(series);
}
}
}
@Test
void write() {
DeviceStatus deviceStatus = new DeviceStatus()
.setStatus("2")
.setDeviceCode("YB002")
.setDuration(56L);
Point point = Point.measurementByPOJO(DeviceStatus.class)
.addFieldsFromPOJO(deviceStatus)
.time(System.currentTimeMillis(), TimeUnit.MILLISECONDS)
.build();
influxDB.write("test", "autogen", point);
}
@Data
@Accessors(chain = true)
@Measurement(name = "device_status")
public static class DeviceStatus {
/*field*/
@Column(name = "duration")
private Long duration;
/*tag*/
@Column(name = "device_code", tag = true)
private String deviceCode;
@Column(name = "status", tag = true)
private String status;
}
}
今天关于java influx DB工具类和java influxdb示例的讲解已经结束,谢谢您的阅读,如果想了解更多关于GaussDB(for Influx)与开源企业版性能对比、grafana+prometheus 使用 influx DB、Grafana/Influx Db 对数据源的身份验证失败、influx - java client的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

