针对模块化之seaJs学习和使用和seajs源码这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展Cesium中Scene模块学习和使用、Java8新特性Stream的学习和使用方法、Java
针对模块化之seaJs学习和使用和seajs源码这两个问题,本篇文章进行了详细的解答,同时本文还将给你拓展Cesium中Scene模块学习和使用、Java8 新特性 Stream 的学习和使用方法、JavaScript模块化开发之SeaJS、JavaScript模块化开发之SeaJS_javascript技巧等相关知识,希望可以帮助到你。
本文目录一览:- 模块化之seaJs学习和使用(seajs源码)
- Cesium中Scene模块学习和使用
- Java8 新特性 Stream 的学习和使用方法
- JavaScript模块化开发之SeaJS
- JavaScript模块化开发之SeaJS_javascript技巧
")
模块化之seaJs学习和使用(seajs源码)
使用seaJs也有一阵子了,一直也想抽个时间写个这方面的博客,直到今天才写……也许写的不是很完善,但跟大伙分享也是一种乐趣,不对之处欢迎指出。[抱拳]
时间有限,我这里不过多介绍前端模块化,有兴趣可以去了解。
一、写在前面
seaJs出自前端工程师玉伯之手,一个文件就是一个模块,实现JavaScript的模块化及按模块加载。使用SeaJS可以提高JavaScript代码的可读性和清晰度,确保各个JS文件先后加载的顺序,解决目前JavaScript编程中普遍存在的依赖关系混乱和代码纠缠等问题,方便代码的编写和维护。seaJs遵循的是CMD规范,所以引用一些遵循AMD规范的JS代码,需要进行一些封装处理。譬如常用的JQ就遵循的AMD规范,引用时需要做一些封装:
define(function(){
//jquery源代码
return $.noConflict();
});seaJs浏览器兼容上理论兼容所有的浏览器,包括移动端,所以兼容性很好。同时,API少加上配置简洁清晰,学习成本较低。
二、seaJs的使用
1、模块定义。
define(function(require,exports, module){
require是可以把其他模块导入进来的一个参数,而
exports是可以把模块内的一些属性和方法导出的,
module 是一个对象,上面存储了与当前模块相关联的一些属性和方法。
module.exports = variable;,一个模块要引用其他模块暴露的变量,用
var ref = require(''module_name'');就拿到了引用模块的变量。
来一个最简单的例子。创建学习项目,相关文件及路劲如下:
index.html如下:
<!DOCTYPE html>
<html>
<head>
<title>seaJs学习 --by WZQ</title>
</head>
<body>
<script src="js/sea.js"></script>
<script>
seajs.use(''./js/index.js'');
</script>
</body>
</html>index.js如下:
define(function(require,exports, module){
alert(1);
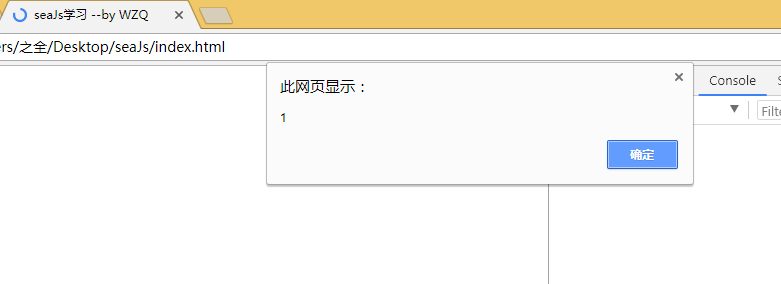
});打开index.html,能执行弹出alert框,就说明引用seajs成功
接着说一下sea.config相关方面的配置。
新建一个seajs.config.js
seajs.config({
// 指定base目录
base: ''./js'',
// 目录长的可以声明别名, 这点十分人性化
alias: {
index: index.js // 左边index是别名,可以直接使用,右边是路径,由于base的存在,只需要雪名称即可,同时.js是可以去掉的
},
// 其他配置自行百度,重点是路径的配置
charset: ''utf-8'',
timeout: 20000,
debug: 0 ,
preload: ["jquery"]
}); 有了配置文件,就方便管理全部的js文件,使用别名,还可以不用担心路劲问题,以后搬运js文件的时候也只需要改配置文件就好了。所以引用的时候使用别名,可以这样写:
seajs.use(''index'');(注意引入配置js)
接着练习一个复杂点的例子:
目录结构:
配置文件seajs.config.js给他们的别名如下:
seajs.config({
// 指定base目录
base: ''./js'',
// 目录长的可以声明别名, 这点十分人性化
alias: {
''index'': ''index.js'', // 左边index是别名,可以直接使用,右边是路径,由于base的存在,只需要雪名称即可,同时.js是可以去掉的
''otherJs'': ''a'',
''bJs'':''b'',
''jquery'': ''jquery.js''
},
// 其他配置自行百度,重点是路径的配置
charset: ''utf-8'',
timeout: 20000,
debug: 0 ,
preload: ["jquery"]
});各个JS文件如下:
index.js
define(function(require,exports, module){
function Example(){
this.people = ''WZQ'';
this.address = ''广州'';
}
Example.prototype.initFn = function(){
console.log(this.people + ''在'' + this.address);
}
module.exports = Example;
});a.js
define(function(require,exports, module){
function Other(){
this.nowTime = ''2018年10月10日''
}
module.exports = Other;
});b.js
define(function(require,exports, module){
var $ = require(''jquery''),
AObj = require(''otherJs'');
var aObj = new AObj();
function TestObj(){
this.time = aObj.nowTime;
}
TestObj.prototype.getTime = function(){
return this.time;
}
var testObj = new TestObj();
var indexFn = {
init: function(){
var time = testObj.getTime();
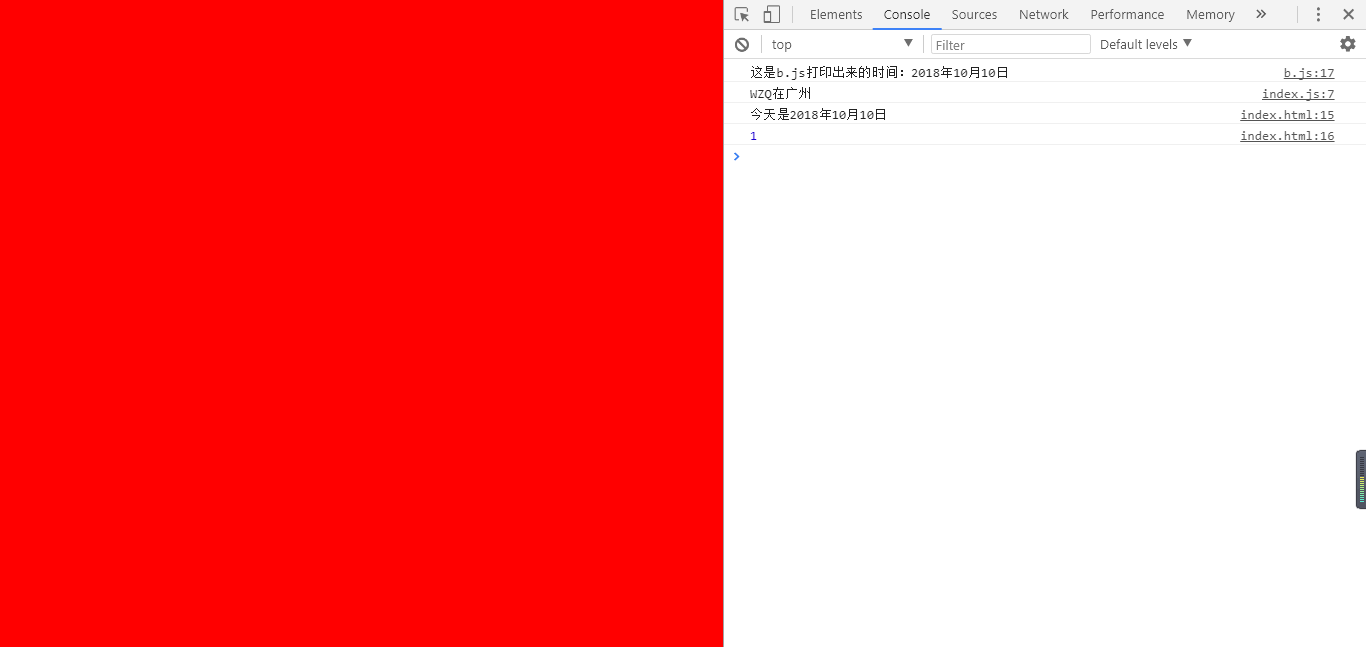
console.log(''这是b.js打印出来的时间:''+ time);
$(''body'').css(''background'', ''red'');
}
}
indexFn.init();
});index.html<!DOCTYPE html>
<html>
<head>
<title>seaJs学习 --by WZQ</title>
</head>
<body>
<script src="js/sea.js"></script>
<script src="js/seajs.config.js"></script>
<script>
seajs.use([''index'', ''otherJs'', ''jquery'', ''bJs''], function(Example, Other, $){
var example = new Example();
example.initFn();
var other = new Other();
console.log(''今天是'' + other.nowTime);
console.log($(''body'').length); //引入jquery之后能直接用$是因为对JQ做了CMD封装,最后一行代码return $.noConflict();的缘故
});
</script>
</body>
</html>然后最后运行结果如下即可:

Cesium中Scene模块学习和使用
Scene是Cesium中比较重要的模块之一,因为学习Cesium初期,部分api还没使用到,我就从实用性的角度,将我实战中所用到的相关api进行分析,并逐步进行补充。
设置地球模型底图颜色和场景的背景颜色
通过scene可以找到globe球体的属性,并通过globe的baseColor属性修改地球模型底图的颜色。
const viewer = new Viewer(''cesiumContainer'')
const scene = viewer.scene
scene.globe.baseColor = Cesium.Color.BLACK
设置场景背景颜色,可以先通过scene.skybox隐藏星空盒子背景,然后通过scene.backgroundColor修改背景颜色。
scene.skybox = false
scene.backgroundColor = Cesium.Color.CORNFLOWERBLUE
通过鼠标事件获取场景中某个坐标或者某个实例数据
我在实现鼠标事件交互时,会获取地图中的坐标或者想通过点击某个实例点来获取它的id,这个时候就需要通过scene.pick(position)方法来获取相关数据。
这里handler是Cesium的一个事件监听实例,callback是一个回调函数,这是一个单击事件,具体我们看一下,通过鼠标点击地图中的某一实例点,可以获取到对应的坐标position,通过scene.pick()接收一个坐标数据,则会返回实例点的具体数据(pickedObject)。
const normalEvent = {
click: function(handler, callback) {
handler.setInputAction( movement => {
const position = movement.position
const pickedObject = viewer.scene.pick(position)
callback(pickedObject, position)
}, Cesium.ScreenSpaceEventType.LEFT_CLICK)
},
dbclick:...
}

性能提高
在初期学习时,我构建的地图实例的帧数感人,特别是在大量数据加载时,Cesium给出了一个提高性能的方案,提供了scene.requestRenderMode接口,该属性接收一个布尔值,如果设置为true,则只会在指定情况下进行渲染。这些环境包括:
- 通过Cesium的摄像模块api修改视图位置或方向。
- 仿真时间超过了指定的阈值。
- 加载在地形,图像,3D瓷砖,或数据源,包括每个单独的瓷砖加载。在较低的级别,当通过URI或blob解析web请求或从web工作者返回异步流程时,将触发此操作。
- 添加、删除或更改全球图像层。
- 地理高程模型改变。
- 场景模式变化。
- 框架是用Cesium API显式呈现的。
除开上述情况,其它通过Cesium API执行的操作不会主动进行渲染,也可以理解为只监听上述情况对应的API进行渲染。这样在空闲状态下,CPU的利用率会大大降低,提高性能。

配置scene.requestRenderMode属性方法:
// new Viwer实例时进行配置
const viewer = new Cesium.Viewer(''cesiumContainer'', {
requestRenderMode : true
});
// 或者new了Viewer实例之后配置
const viewer = new Cesium.Viewer(''cesiumContainer'')
viewer.scene.requestRenderMode = true
那如果我们希望使用上述场景以外的某个API时也进行渲染,应该怎么办呢,Cesium提供了scene.requestRender()方法手动渲染,如在隐藏星空背景后,执行一次scene.requestRender()方法进行渲染。
// Hides the stars
scene.skyBox.show = false
// Explicitly render a new frame
scene.requestRender()
还有一种情况,如果场景中有随时间变化的元素,比如动画、灯光变化、水面罩或视频,就要考虑到设置多少秒渲染一次,以提高性能。因为如果有动态元素,在默认情况下,会0.0秒进行一次渲染。Cesium提供了scene.maximumRenderTimeChange API,接收Number类型数据,设置多少秒后请求一个新帧。
const viewer = new Cesium.Viewer(''cesiumContainer'', {
requestRenderMode : true,
maximumRenderTimeChange : 0.5
})
如果没有随时间变化的元素,则可将maximumRenderTimeChange设置为无穷大
var viewer = new Cesium.Viewer(''cesiumContainer'', {
requestRenderMode : true,
maximumRenderTimeChange : Infinity
})
性能优化参考网站:Improving Performance with Explicit Rendering
如发现我有理解错误的请指教。

Java8 新特性 Stream 的学习和使用方法
流(Stream)
流是 java 8 中新引入的特性,用来处理集合中的数据,Stream 是一个来自数据源的元素队列并支持聚合操作。
- Java 中 Stream 不会存储元素。
- 数据源 流的来源。 可以是集合,数组,I/O channel, 产生器 generator 等。
- 聚合操作 类似 SQL 语句一样的操作, 比如 filter, map, reduce, find, match, sorted 等。
Stream 操作还有几个特征:
- 只遍历一次。我们可以把流想象成一条流水线,流水线的源头是我们的数据源 (一个集合),数据源中的元素依次被输送到流水线上,我们可以在流水线上对元素进行各种操作。一旦元素走到了流水线的另一头,那么这些元素就被 “消费掉了”,我们无法再对这个流进行操作。当然,我们可以从数据源那里再获得一个新的流重新遍历一遍。
- Pipelining: 中间操作都会返回流对象本身。 这样多个操作可以串联成一个管道, 如同流式风格(fluent style)。 这样做可以对操作进行优化, 比如延迟执行 (laziness) 和短路 ( short-circuiting)。
- 内部迭代: 以前对集合遍历都是通过 Iterator 或者 For-Each 的方式,显式的在集合外部进行迭代, 这叫做外部迭代。 Stream 提供了内部迭代的方式, 通过访问者模式 (Visitor) 实现。
流的使用
流的使用过程有三步:
- 获取流;
- 中间操作,得到一个新的流;
- 最终操作,获取结果。
获取流
流有两种:
- stream () : 创建串行流。
- parallelStream () : 创建并行流。
并行流的特点就是将一个大任务切分成多个小任务,无序一起执行,当然如果我们需要顺序输出的话可以使用 forEachOrdered,速度会比串行流快一些。它通过默认的 ForkJoinPool, 可能提高你的多线程任务的速度。
从集合获取流
List<FarmEntity> list = service.getBySql(sql1);
Stream<FarmEntity> stream = list.stream();
从数组获取流
String[] arrays = {"你", "我", "她"};
Stream<String> stream = Arrays.stream(arrays);
从值获取流
Stream<String> stream = Stream.of("你", "我", "她");
从文件获取流
try {
Stream<String> file =Files.lines(Paths.get("D:\\zhangkai\\WorkSpace\\Git\\hexo\\_config.yml"));
file.forEach(System.out::println);
} catch (Exception e) {
}
使用 NIO 获取流,可以打印出文本文件的内容。
流的操作
filter 过滤
filter 函数接收一个 Lambda 表达式作为参数,该表达式返回 boolean,在执行过程中,流将元素逐一输送给 filter,并筛选出执行结果为 true 的元素。
String[] strings = {"珊瑚", "阳光", "细腻", "冷暖", "阳光"};
Arrays.stream(strings).filter(n -> n.startsWith("冷")).forEach(System.out::print);
distinct 去重
Arrays.stream(strings).distinct().forEach(System.out::print);
limit 截取
截取前面两个单位:
Arrays.stream(strings).limit(2).forEach(System.out::print);
skip 跳过
和上面的 limit 相反,跳过前面两个
map 映射
map 方法用于映射每个元素到对应的结果。 给每个词语后面加个 “兮”
Arrays.stream(strings).map(s -> s + "兮").forEach(System.out::println);
输出:
珊瑚兮
阳光兮
细腻兮
冷暖兮
阳光兮
sorted 排序
//Arrays.stream(strings).sorted((x, y) -> x.compareTo(y)).forEach(System.out::println);
Arrays.stream(strings).sorted(String::compareTo).forEach(System.out::println);
输出:
冷暖
珊瑚
细腻
阳光
阳光
java8 以前排序:
// Before Java 8 sorted
System.out.println("java8以前排序:");
List<String> list1 = Arrays.asList(strings);
list1.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
System.out.printf("java8 以前的排序:%s%n", list1);
输出:
java8以前排序:
java8 以前的排序:[冷暖, 珊瑚, 细腻, 阳光, 阳光]
HashMap 根据 value 值排序 key:
Map<String, Integer> map = new HashMap<>();
map.put("spring", 1);
map.put("summer", 2);
map.put("autumn", 3);
map.put("winter", 4);
map.entrySet().stream()
.sorted((a, b) -> b.getValue().compareTo(a.getValue()))
.forEach(a -> System.out.println(a.getKey()));
输出结果:
winter
autumn
summer
spring
统计
//统计
List<Integer> list4 = Arrays.asList(1, 2, 3, 4, 1);
IntSummaryStatistics stats = list4.stream().mapToInt((x) -> x).summaryStatistics();
System.out.println("Highest number in List : " + stats.getMax());
System.out.println("Lowest number in List : " + stats.getMin());
System.out.println("Sum of all numbers : " + stats.getSum());
System.out.println("Average of all numbers : " + stats.getAverage());
运行结果:
Highest number in List : 4
Lowest number in List : 1
Sum of all numbers : 11
Average of all numbers : 2.2
match 匹配
anyMatch用于判断流中是否存在至少一个元素满足指定的条件,这个判断条件通过 Lambda 表达式传递给 anyMatch,执行结果为boolean类型。noneMatch与 allMatch 恰恰相反,它用于判断流中的所有元素是否都不满足指定条件findAny能够从流中随便选一个元素出来,它返回一个 Optional 类型的元素。
Boolean result1 = Arrays.stream(strings).allMatch(s -> s.equals("java"));
System.out.println(result1);
Boolean reslut2 = Arrays.stream(strings).noneMatch(s -> s.equals("java"));
System.out.println(reslut2);
//随机读取一个
Optional<String> getResult = Arrays.stream(strings).findAny();
System.out.println(getResult);
System.out.printf("获取Optional中的值:%s%n", getResult.get());
运行结果:
false
true
Optional[冷暖]
获取Optional中的值:冷暖
Optional 是 Java8 新加入的一个容器,这个容器只存 1 个或 0 个元素,它用于防止出现 NullpointException,它提供如下方法:
isPresent()判断容器中是否有值。ifPresent(Consume lambda)容器若不为空则执行括号中的 Lambda 表达式。T get()获取容器中的元素,若容器为空则抛出 NoSuchElement 异常。T orElse(T other)获取容器中的元素,若容器为空则返回括号中的默认值。
reduce 归约
求和:
//归约
//第一种方法求和
String connectStrings = Arrays.stream(strings).reduce("", (x, y) -> x + y);
System.out.println(connectStrings);
// 第二种方法求和
String connectStrings1 = Arrays.stream(strings).reduce("", TestStream::getConnectStrings);
System.out.println(connectStrings1);
getConnectStrings 方法:
/**
* Connect Strings
* @param s1 参数1
* @param s2 参数2
* @return java.lang.String
*/
private static String getConnectStrings(String s1, String s2) {
return s1 + s2;
}
reduce 中第一个参数是初始值,第二个参数是方法引用。
数据流
StreamAPI 提供了三种数值流:IntStream、DoubleStream、LongStream,也提供了将普通流转换成数值流的三种方法:mapToInt、mapToDouble、mapToLong。
每种数值流都提供了数值计算函数,如 max、min、sum 等。
下面使用 mapToInt 为例:
String[] numberStrings = {"1", "2", "3"};
// mapToInt参数: 需要转换成相应的类型方法
IntStream intStream = Arrays.stream(numberStrings).mapToInt(Integer::valueOf);
//使用对应的 Optional 接收
OptionalInt optionalNumber = intStream.max();
// 取值,给默认值 0,为空结果为0
System.out.printf("numberStrings''s max number is: %s%n", optionalNumber.orElse(0));
打印结果:
numberStrings''s max number is: 3
由于数值流可能为空,并且给空的数值流计算最大值是没有意义的,因此 max 函数返回 OptionalInt,它是 Optional 的一个子类,能够判断流是否为空,并对流为空的情况作相应的处理。 所以可以直接使用 OptionalInt.getAsInt() 获取容器的值。
为空的话捕捉异常:
java.util.NoSuchElementException: No value present
at java.util.OptionalInt.getAsInt(OptionalInt.java:118)
at com.wuwii.test.TestStream.main(TestStream.java:105)
此外,mapToInt、mapToDouble、mapToLong 进行数值操作后的返回结果分别为:OptionalInt、OptionalDouble、OptionalLong。
Collectors 集合归约
将流转换成集合和聚合元素。
//Collectors 集合归约
// toList
List<String> list2 = Arrays.stream(strings).collect(Collectors.toList());
// Get String by connected
String connectStrings2 = Arrays.stream(strings).collect(Collectors.joining(","));
System.out.printf("Collectors toList: %s , Conlletors Join Strings: %s%n", list2, connectStrings2);
打印结果:
Collectors toList: [冷暖, 珊瑚, 细腻, 阳光, 阳光] , Conlletors Join Strings: 冷暖,珊瑚,细腻,阳光,阳光
后面补充: Collectors 中还有一个 groupingBy () 方法,比较实用,例子来源网上 < a rel="external nofollow" target="_blank" href="https://nkcoder.github.io/2016/01/24/java-8-stream-api/"> 使用 Java 8 中的 Stream</a>
groupingBy()表示根据某一个字段或条件进行分组,返回一个Map,其中 key 为分组的字段或条件,value 默认为 list,groupingByConcurrent()是其并发版本:
Map<String, List<Locale>> countryToLocaleList = Stream.of(Locale.getAvailableLocales())
.collect(Collectors.groupingBy(l -> l.getDisplayCountry()));
- 如果
groupingBy()分组的依据是一个 bool 条件,则 key 的值为 true/false,此时与 partitioningBy () 等价,且partitioningBy()的效率更高:
// predicate
Map<Boolean, List<Locale>> englishAndOtherLocales = Stream.of(Locale.getAvailableLocales())
.collect(Collectors.groupingBy(l -> l.getDisplayLanguage().equalsIgnoreCase("English")));
// partitioningBy
Map<Boolean, List<Locale>> englishAndOtherLocales2 = Stream.of(Locale.getAvailableLocales())
.collect(Collectors.partitioningBy(l -> l.getDisplayLanguage().equalsIgnoreCase("English")));
groupingBy()提供第二个参数,表示 downstream,即对分组后的 value 作进一步的处理:
// 返回set,而不是list:
Map<String, Set<Locale>> countryToLocaleSet = Stream.of(Locale.getAvailableLocales())
.collect(Collectors.groupingBy(l -> l.getDisplayCountry(), Collectors.toSet()));
// 返回value集合中元素的数量:
Map<String, Long> countryToLocaleCounts = Stream.of(Locale.getAvailableLocales())
.collect(Collectors.groupingBy(l -> l.getDisplayCountry(), Collectors.counting()));
// 对value集合中的元素求和:
Map<String, Integer> cityToPopulationSum = Stream.of(cities)
.collect(Collectors.groupingBy(City::getName, Collectors.summingInt(City::getPopulation)));
// 对value的某一个字段求最大值,注意value是Optional的:
Map<String, Optional<City>> cityToPopulationMax = Stream.of(cities)
.collect(Collectors.groupingBy(City::getName,
Collectors.maxBy(Comparator.comparing(City::getPopulation))));
// 使用mapping对value的字段进行map处理:
Map<String, Optional<String>> stateToNameMax = Stream.of(cities)
.collect(Collectors.groupingBy(City::getState, Collectors.mapping(City::getName,
Collectors.maxBy(Comparator.comparing(String::length)))));
Map<String, Set<String>> stateToNameSet = Stream.of(cities)
.collect(Collectors.groupingBy(City::getState,
Collectors.mapping(City::getName, Collectors.toSet())));
// 通过summarizingXXX获取统计结果:
Map<String, IntSummaryStatistics> stateToPopulationSummary = Stream.of(cities)
.collect(Collectors.groupingBy(City::getState, Collectors.summarizingInt(City::getPopulation)));
reducing()
// 可以对结果作更复杂的处理,但是reducing()却并不常用:
Map<String, String> stateToNameJoining = Stream.of(cities)
.collect(Collectors.groupingBy(City::getState, Collectors.reducing("", City::getName,
(s, t) -> s.length() == 0 ? t : s + ", " + t)));
// 比如上例可以通过mapping达到同样的效果:
Map<String, String> stateToNameJoining2 = Stream.of(cities)
.collect(Collectors.groupingBy(City::getState,
Collectors.mapping(City::getName, Collectors.joining(", ")
)));
完整代码
package com.wuwii.test;
import java.nio.file.Files;
import java.nio.file.Paths;
import java.util.*;
import java.util.stream.Collectors;
import java.util.stream.IntStream;
import java.util.stream.Stream;
public class TestStream {
public static void main(String[] args) {
// Get Stream from file
System.out.println("读取文件:");
try {
Stream<String> file = Files.lines(Paths.get("D:\\zhangkai\\WorkSpace\\Git\\hexo\\_config.yml"));
file.forEach(System.out::println);
} catch (Exception e) {
}
// Get Stream by Filter
String[] strings = {"珊瑚", "阳光", "细腻", "冷暖", "阳光"};
Arrays.stream(strings).filter(n -> n.startsWith("冷")).forEach(System.out::print);
// Get Stream by Distinct
System.out.println("去重:");
Arrays.stream(strings).distinct().forEach(System.out::print);
// Get Stream by Limit
System.out.println("截取:");
Arrays.stream(strings).limit(2).forEach(System.out::print);
// Get Stream by Skip
System.out.println("跳过:");
Arrays.stream(strings).skip(2).forEach(System.out::print);
// Java 8 sorted
System.out.println("排序:");
//Arrays.stream(strings).sorted((x, y) -> x.compareTo(y)).forEach(System.out::println);
Arrays.stream(strings).sorted(String::compareTo).forEach(System.out::println);
// Before Java 8 sorted
System.out.println("java8以前排序:");
List<String> list1 = Arrays.asList(strings);
list1.sort(new Comparator<String>() {
@Override
public int compare(String o1, String o2) {
return o1.compareTo(o2);
}
});
System.out.printf("java8 以前的排序:%s%n", list1);
//Handle map
System.out.println("map 映射:");
Arrays.stream(strings).map(s -> s + "兮").forEach(System.out::println);
//Match
Boolean result1 = Arrays.stream(strings).allMatch(s -> s.equals("java"));
System.out.println(result1);
Boolean reslut2 = Arrays.stream(strings).noneMatch(s -> s.equals("java"));
System.out.println(reslut2);
//findAny to find anyone
Optional<String> getResult = Arrays.stream(strings).findAny();
System.out.println(getResult);
System.out.printf("获取Optional中的值:%s%n", getResult.get());
//统计
List<Integer> list4 = Arrays.asList(1, 2, 3, 4, 1);
IntSummaryStatistics stats = list4.stream().mapToInt((x) -> x).summaryStatistics();
System.out.println("Highest number in List : " + stats.getMax());
System.out.println("Lowest number in List : " + stats.getMin());
System.out.println("Sum of all numbers : " + stats.getSum());
System.out.println("Average of all numbers : " + stats.getAverage());
//归约
//第一种方法求和
String connectStrings = Arrays.stream(strings).reduce("", (x, y) -> x + y);
System.out.println(connectStrings);
// 第二种方法求和
String connectStrings1 = Arrays.stream(strings).reduce("", TestStream::getConnectStrings);
System.out.println(connectStrings1);
//Collectors 集合归约
// toList
List<String> list2 = Arrays.stream(strings).collect(Collectors.toList());
// Get String by connected
String connectStrings2 = Arrays.stream(strings).collect(Collectors.joining(","));
System.out.printf("Collectors toList: %s , Conlletors Join Strings: %s%n", list2, connectStrings2);
String[] numberStrings = {"1", "2", "3"};
// mapToInt参数: 需要转换成相应的类型方法
IntStream intStream = Arrays.stream(numberStrings).mapToInt(Integer::valueOf);
//使用对应的 Optional 接收
OptionalInt optionalNumber = intStream.max();
// 取值,给默认值 0,为空结果为0
System.out.printf("numberStrings''s max number is: %s%n", optionalNumber.orElse(0));
}
/**
* 拼接字符串
*
* @param s1 参数1
* @param s2 参数2
* @return java.lang.String
*/
private static String getConnectStrings(String s1, String s2) {
return s1 + s2;
}
}

JavaScript模块化开发之SeaJS
前言
SeaJS是一个遵循Commonjs规范的JavaScript模块加载框架,可以实现JavaScript的模块化开发及加载机制。使用SeaJS可以提高JavaScript代码的可读性和清晰度,解决目前JavaScript编程中普遍存在的依赖关系混乱和代码纠缠等问题,方便代码的编写和维护。
SeaJS本身遵循KISS(Keep it Simple,Stupid)理念进行开发,后续的几个版本更新也都是吵着这个方向迈进。
如何使用SeaJS
下载及安装在这里不赘述了,不了解的请查询官网。
基本开发原则 •一切皆为模块:SeaJS中的模块概念有点类似于面向对象中的类--模块可以拥有数据和方法,数据和方法可以定义为公共或私有,公共数据和方法可以供别的模块调用。
•每个模块应该都定义在一个单独的js文件中,即一个对应一个模块。
模块的定义和编写
模块定义函数define
SeaJS中使用define函数定义一个模块。define可以接收三个参数:
define可以接收的参数分别是模块ID,依赖模块数组及工厂函数。
•如果只有一个参数,则赋值给factory
•如果有两个参数,第二个赋值给factory,第一个如果是数组则赋值给deps,否则赋值给id
•如果有三个参数,则分别赋值
但是,包括SeaJS官网示例在内几乎所有用到define的地方都只传递一个工厂函数进去,类似于如下代码:



![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

