本文将分享Python爬虫基础讲解:数据持久化——json及CSV模块简介的详细内容,并且还将对python爬虫json数据解析进行详尽解释,此外,我们还将为大家带来关于pythoncsv、json、
本文将分享Python爬虫基础讲解:数据持久化——json 及 CSV模块简介的详细内容,并且还将对python爬虫json数据解析进行详尽解释,此外,我们还将为大家带来关于python csv、json、pickle数据持久化、Python CSV模块简介、Python Scrapy 爬虫框架爬取推特信息及数据持久化、python 基础之数据持久化存储的相关知识,希望对你有所帮助。
本文目录一览:- Python爬虫基础讲解:数据持久化——json 及 CSV模块简介(python爬虫json数据解析)
- python csv、json、pickle数据持久化
- Python CSV模块简介
- Python Scrapy 爬虫框架爬取推特信息及数据持久化
- python 基础之数据持久化存储
")
Python爬虫基础讲解:数据持久化——json 及 CSV模块简介(python爬虫json数据解析)
json
目的:
将Python对象编码为JSON字符串,并将JSON字符串解码为Python对象。
json模块提供了API,将内存中的Python对象转换为」JSON序列。JSON具有以多种语言(尤其是JavaScript)实现的优点。它在RESTAPI中 Web服务端和客户端之间的通信被广泛应用,同时对于应用程序间通信需求也很有用。下面演示如何将一个Python数据结构转换为JSON:
1. 编码和解码
Python 的默认原生类型(str,int,float,list,tuple和dict)。
import json
data = {
'name ' : 'Acme',
' shares ' : 100,
'price ' : 542.23
}
json_str = json.dumps(data)
print(json_str)
表面上看,类似于Python repr()的输出。虽然内容看似是一样,但是类型却已经发生改变
print(type(json_str))
从无序的字典到有序的字符串,这个过程被称之为序列化。
最终我们将json保存到文件
with open('data.json ',mode='w',encoding='utf-8') as f:
f.write(json_str)
1.1 中文字符串问题
import json
data = {
'name ' : '青灯',
'shares': 100,
'price' : 542.23
}
#将字典序列化为json
json_str = json.dumps(data)
# 写入json数据
with open( ' data.json',mode='w', encoding='utf-8 ' ) as f:
f.write(json_str)
# filename:data.json
{ "name": "\u9752\u706f","shares" : 100,"price": 542.23}
解决办法: json_str = json. dumps(data,ensure_ascii=False)
2. 读取数字
将json数据变为字典类型的这个过程被称之为反序列化
#读取json数据
with open( ' data.json ', 'r', encoding='utf-8') as f:
#反序列化
data = json.1oad(f)
#打印数据
print(data)
print(data[ 'name '])
- 格式化输出
JSON的结果是更易于阅读的。dumps()函数接受几个参数以使输出更易读结果。
import json
data = {'a ' : 'A','b' : (2,4),'c' : 3.0}
print( 'DATA: ', repr(data)) # DATA: { 'a' : 'A', 'b ': (2,4),'c': 3.0}
unsorted = json.dumps(data)
print( '7SON: ', json.dumps(data)) #JSON: {"a": "A","b":[2,4],"c": 3.03}
编码,然后重新解码可能不会给出完全相同类型的对象。
特别是,元组成为了列表。
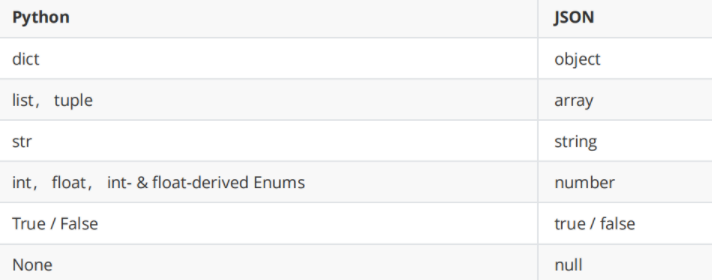
JSON跟Python中的字典其实是一样一样的,事实上JSON的数据类型和Python的数据类型是很容易找到对应关系的,如下面两张表所示。
学习更多知识或解答疑问、源码、教程请点击
CSV模块简介
csv文件格式是一种通用的电子表格和数据库导入导出格式。最近我调用RPC处理服务器数据时,经常需要将数据做个存档便使用了这一方便的格式。
python中有一个读写csv文件的包,直接import csv即可。利用这个python包可以很方便对csv文件进行操作,一些简单的用法如下。
1. 写入文件
我们把需要写入的数据放到列表中,写文件时会把列表中的元素写入到csv文件中。
import csv
ll = [[1,2,3,4],
[1,2,3,4],
[5,6,7,8],
[5,6,7,8]]
with open( ' example1.csv', 'w' , newline=' ') as csvfile:
"""
delimiter:分割符
"""
spamwriter = csv.writer(csvfile,delimiter=',')
for 1 in 11:
spamwriter.writerow([1,2,3,4])
可能遇到的问题:直接使用这种写法会导致文件每一行后面会多一个空行。使用newline=’'解决
使用open直接写入
with open( 'examp1e2.csv', 'w') as csvfile:
"""
delimiter:分割符
"""
for 1 in 17:
csvfile.write(",".join(map(str,1)))
csvfile.write( ' \n ')
2. 读取文件
import csv
with open( ' example.csv ' , encoding='utf-8' ) as f:
csv_reader = csv.reader(f)
for row in csv_reader:
print(row)
fi7e: example.csv csv数据

默认的情况下,读和写使用逗号做分隔符(delimiter),当遇到特殊情况是,可以根据需要手动指定字符,例如:
with open( ' example.csv', encoding='utf-8' ) as f:
reader = csv.reader(f,delimiter=',')
for row in reader:
print(row)
上述示例指定冒号作为分隔符
有点需要注意的是,当用writer写数据时,None 会被写成空字符串,浮点类型会被调用repr()方法转化成字符串。所以非字符串类型的数据会被str()成字符串存储。所以当涉及到unicode 字符串时,可以自己手动编码后存储或者使用csv提供的unicodewriter 。
3. 写入与读取字典
csv还提供了一种类似于字典方式的读写,方式如下:

其中fieldnames指定字典的 key值,如果reader里没有指定那么默认第一行的元素,在writer里一定要指定这个。
#%%写
import csv
with open( ' names.csv', 'w ') as csvfile:
fieldnames = ['first_name ', 'last_name ']
writer = csv.Dictwriter(csvfi1e,fieldnames=fieldnames)
writer.writeheader()
writer.writerow(i'first_name ' : 'Baked', 'last_name ' : 'Beans' })
writer.writerow(i'first_name ' : 'love1y'})
writer.writerow(i 'first_name ' : 'wonderfu7 ', '7ast_name': 'spam ' })
#%%读
import csv
with open( ' names.csv ', newline=' ') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row[ 'first_name'],row[ ' 1ast_name ' ])

python csv、json、pickle数据持久化
1. csv/json/pickle基本概念
csv:CSV(Comma Separated Values)格式是电子表格和数据库最常见的导入和导出格式。用文本文件形式储存的表格数据,可以使用excel打开,易于阅读,
json:数据交换格式。用于提升网络传输效率,可以字符串和python之间的转换,可用于网页上这种数据传输,支持跨语言
pickle:pickle模块实现了用于对Python对象结构进行序列化和反序列化的二进制协议,人类无法识别
在pickle协议和JSON(JavaScript对象表示法)之间存在根本区别:
JSON是一种文本序列化格式(它输出unicode文本,虽然大多数时候它被编码为utf-8),而pickle是一个二进制序列化格式;
JSON是人类可读的,而pickle不是;
JSON是可互操作的,并且在Python生态系统之外广泛使用,而pickle是特定于Python的;
默认情况下,JSON只能表示Python内建类型的一个子集,并且没有自定义类; pickle可以代表极大数量的Python类型
(其中许多是通过巧妙地使用Python内省功能自动实现的;复杂的情况可以通过实现specific object APIs来解决)。
2 csv/json/pickle基本使用方法
1. csv
1. csv模块API说明
csv模块的reader和writer对象读取和写入序列。程序员还可以使用DictReader和DictWriter类以字典形式读取和写入数据。
csv模块定义以下函数:
1.csv.reader(csvfile, dialect=''excel'', **fmtparams)
1.返回一个读取器对象,它将在给定的csvfile中迭代。csvfile可以是任何支持iterator协议的对象,并且每次调用__next__()方法时返回一个字符串 - file objects和列表对象都是合适的。
2.如果csvfile是文件对象,则应使用newline=''''打开它。如果没有使用newline="",写到文件中会在每行结束加个\t换行符
2.csv.writer(csvfile, dialect=''excel'', **fmtparams)
返回一个writer对象,可以使用writerow(data),writerows(datas)
csv模块定义以下类:
1.class csv.DictReader(csvfile, fieldnames=None, restkey=None, restval=None, dialect=''excel'', *args, **kwds)
创建一个对象,其操作类似于普通读取器,但将读取的信息映射到一个dict中,其中的键由可选的fieldnames参数给出。
fieldnames参数是一个sequence,其元素按顺序与输入数据的字段相关联。这些元素成为结果字典的键。
2.class csv.DictWriter(csvfile, fieldnames, restval='''', extrasaction=''raise'', dialect=''excel'', *args, **kwds)
创建一个操作类似于常规writer的对象,但将字典映射到输出行。
fieldnames参数是一个sequence,用于标识传递给writerow()方法的字典中的值被写入csvfile。
如果传递给writerow()方法的字典包含fieldnames中未找到的键,则可选的extrasaction参数指示要执行的操作。
2.csv具体代码示例
import csv
# 例一
with open(''test.csv'', ''w'', encoding=''utf-8'',newline="") as f:
lst = [''活下去的诀窍是'', ''保持愚蠢'', ''又不能知道自己有多蠢'']
writer = csv.writer(f)
writer.writerows(lst)
or #使用writerow
for x in lst:
writer.writerow(x)
#注意open文件应设置encoding和newline参数
#writer() 通过 writerrow() 或 writerrows() 写入一行或多行数据。
# 例二
with open(''test.csv'', ''w'', encoding=''utf-8'', newline="") as csvfile:
fieldnames = [''name'', ''age'', ''sex'']
d = [{''name'': ''小明'',''age'': 32,''sex'': ''男''},
{''name'': ''小强'',''age'': 12,''sex'': ''男''},
{''name'': ''小蓝'',''age'': 22,''sex'': ''男''}]
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerows(d)
#DictWriter() 必须指定参数 fieldnames 说明键名,通过 writeheader() 将键名写入,通过 writerrow() 或 writerrows() 写入一行或多行字典数据。
# 读操作
with open(''test.csv'', newline='''',encoding=''utf-8'') as csvfile:
t = csv.reader(csvfile, delimiter='' '')
for row in t:
print(t)
with open(''test.csv'') as csvfile:
reader = csv.DictReader(csvfile)
for row in reader:
print(row[''name''], row[''age''])
#DictReader() 返回有序字典,使得数据可通过字典的形式访问,键名由参数 fieldnames 指定,默认为读取的第一行。
2. json简单使用介绍
1. json模块API说明
python转换json
json.dump(obj, fp, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
1.将obj序列化为fp,json模块总是产生str对象,而不是bytes对象。因此,fp.write()必须支持str输入。
2.如果 skipkeys 的值为 true (默认为: False), 那么不是基本类型 (str, int, float, bool, None)的字典键将会被跳过, 而不是引发一个 TypeError 异常.
3.如果indent是非负整数或字符串,缩进
4.separator = (item_separator, key_separator),默认('','','':'')
5.sort_keys为真(默认值:False),则字典的输出将按键排序。
6.遇见复杂的python无法转换时使用default参数,覆盖default()方法以序列化其他类型
json.dumps(obj, skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, cls=None, indent=None, separators=None, default=None, sort_keys=False, **kw)
同上用法
json转换python
json.load(fp, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
1.object_hook是一个可选的函数,它将被任何对象字面值解码(dict)的结果调用。
2.parse_float(如果指定)将使用要解码的每个JSON浮点的字符串进行调用。
json.loads(s, encoding=None, cls=None, object_hook=None, parse_float=None, parse_int=None, parse_constant=None, object_pairs_hook=None, **kw)
同上用法
对于复杂的结构我们可以自定义解码和编码
class json.JSONDecoder(object_hook=None, parse_float=None, parse_int=None, parse_constant=None, strict=True, object_pairs_hook=None)
class json.JSONEncoder(skipkeys=False, ensure_ascii=True, check_circular=True, allow_nan=True, sort_keys=False, indent=None, separators=None, default=None)
2. json具体使用示例
import json
# 简单编码===========================================
print json.dumps([''foo'', {''bar'': (''baz'', None, 1.0, 2)}])
# ["foo", {"bar": ["baz", null, 1.0, 2]}]
obj = [''foo'', {''bar'': (''baz'', None, 1.0, 2)}]
a= json.dumps(obj)
# 反序列化
print json.loads(a)
# [u''foo'', {u''bar'': [u''baz'', None, 1.0, 2]}]
#字典排序
print json.dumps({"c": 0, "b": 0, "a": 0}, sort_keys=True)
# {"a": 0, "b": 0, "c": 0}
#自定义分隔符
print json.dumps([1,2,3,{''4'': 5, ''6'': 7}], sort_keys=True, separators=('','','':''))
# [1,2,3,{"4":5,"6":7}]
print json.dumps([1,2,3,{''4'': 5, ''6'': 7}], sort_keys=True, separators=(''/'',''-''))
# [1/2/3/{"4"-5/"6"-7}]
#增加缩进,增强可读性,但缩进空格会使数据变大
print json.dumps({''4'': 5, ''6'': 7}, sort_keys=True,indent=2, separators=('','', '': ''))
# {
# "4": 5,
# "6": 7
# }
# 另一个比较有用的dumps参数是skipkeys,默认为False。
# dumps方法存储dict对象时,key必须是str类型,如果出现了其他类型的话,那么会产生TypeError异常,如果开启该参数,设为True的话,会忽略这个key。
data = {''a'':1,(1,2):123}
print json.dumps(data,skipkeys=True)
#{"a": 1}
#将对象序列化并保存到文件
obj1 = [''foo1'', {''bar'': (''baz'', None, 1.0, 2)}]
obj2 = [''foo2'', {''bar'': (''baz'', None, 1.0, 2)}]
with open(r"json.txt","w+") as f:
json.dump(obj1,f)
json.dump(obj2,f)
with open(r"json.txt","r") as f:
print json.load(f)
print(json.load(f))
3.pickle使用
1.pickle模块API说明
pickle模块实现了用于对Python对象结构进行序列化和反序列化的二进制协议
1.pickle.dump(obj, file, protocol=None, *, fix_imports=True)
将obj的腌制表示写入打开的file object 文件。这相当于Pickler(文件, 协议).dump(obj)。
2.pickle.dumps(obj, protocol=None, *, fix_imports=True)
将对象的腌制表示作为bytes对象返回,而不是将其写入文件。
3.pickle.load(file, *, fix_imports=True, encoding="ASCII", errors="strict")
从打开的文件对象file读取pickled对象表示形式,并返回其中重新构建的对象层次结构。它等同于Unpickler(file).load()。
4.pickle.loads(bytes_object, *, fix_imports=True, encoding="ASCII", errors="strict")
从bytes对象读取腌制对象层次结构,并返回其中指定的重构对象层次结构。
2.pickle具体示例
import pickle
#序列化操作
d = [ ''person1'':{''name'':''jack'',''age'':33}, ''person2'':{''name'':''tom'',''age'':133}]
pk = pickle.dumps(d)
#反序列化操作
src_dic = {"date":date.today(),"oth":([1,"a"],None,True,False),}
det_str = pickle.dumps(src_dic)
#写到文件中,注意使用"wb"
with open(''pickle.txt'', ''wb'') as f:
d = [{''安其拉'': 1, ''是否'': 2}, {''李白'': 12, ''分'': 22}, {''后羿'': 13, ''b'': 24}]
pickle.dump(d, f)
dd = [{''a'': 1, ''拉克丝'': 2}, {''老子'': 12, ''b'': 22}, {''a'': 13, ''b'': 24}]
pickle.dump(dd, f)
#读取文件"rb"
with open(''pickle.txt'', ''rb'') as f:
while True:
try:
row = pickle.load(f)
print(row)
except Exception as e:
print(e)
break
3.使用场景
1.pickle主要用于存储计算过数据,保存下来下次使用直接获取,特点是他的读写效率高于一般文件,存储大小也更小 2.json主要用于网络直接传递数据,存储一些结构化数据 3.CSV 通常用于在电子表格软件和纯文本之间交互数据。实际上,CSV 都不算是一个真正的结构化数据,CSV 文件内容仅仅是一些用逗号分隔的原始字符串值。

Python CSV模块简介
CSV
csv文件格式是一种通用的电子表格和数据库导入导出格式。最近我调用RPC处理服务器数据时,经常需要将数据做个存档便使用了这一方便的格式。
简介
Python csv模块封装了常用的功能,使用的简单例子如下:
# 读取csv文件
import csv
with open(''some.csv'', ''rb'') as f: # 采用b的方式处理可以省去很多问题
reader = csv.reader(f)
for row in reader:
# do something with row, such as row[0],row[1]
import csv
with open(''some.csv'', ''wb'') as f: # 采用b的方式处理可以省去很多问题
writer = csv.writer(f)
writer.writerows(someiterable)
默认的情况下, 读和写使用逗号做分隔符(delimiter),用双引号作为引用符(quotechar),当遇到特殊情况是,可以根据需要手动指定字符, 例如:
import csv
with open(''passwd'', ''rb'') as f:
reader = csv.reader(f, delimiter='':'', quoting=csv.QUOTE_NONE)
for row in reader:
print row
上述示例指定冒号作为分隔符,并且指定quote方式为不引用。这意味着读的时候都认为内容是不被默认引用符(")包围的。quoting的可选项为: QUOTE_ALL, QUOTE_MINIMAL, QUOTE_NONNUMERIC, QUOTE_NONE.
有点需要注意的是,当用writer写数据时, None 会被写成空字符串,浮点类型会被调用 repr() 方法转化成字符串。所以非字符串类型的数据会被 str() 成字符串存储。所以当涉及到unicode字符串时,可以自己手动编码后存储或者使用csv提供的 UnicodeWriter, 具体可参见这里。
字典方式地读写
csv还提供了一种类似于字典方式的读写,方式如下:
格式如下:
class csv.DictReader(csvfile, fieldnames=None, restkey=None, restval=None, dialect=''excel'', *args, **kwds)
class csv.DictWriter(csvfile, fieldnames, restval='''', extrasaction=''raise'', dialect=''excel'', *args, **kwds)
其中fieldnames指定字典的key值,如果reader里没有指定那么默认第一行的元素,在writer里一定要指定这个。
使用示例
# 读
>>> import csv
>>> with open(''names.csv'') as csvfile:
... reader = csv.DictReader(csvfile)
... for row in reader:
... print(row[''first_name''], row[''last_name''])
...
Baked Beans
Lovely Spam
Wonderful Spam
# 写
import csv
with open(''names.csv'', ''w'') as csvfile:
fieldnames = [''first_name'', ''last_name'']
writer = csv.DictWriter(csvfile, fieldnames=fieldnames)
writer.writeheader()
writer.writerow({''first_name'': ''Baked'', ''last_name'': ''Beans''})
writer.writerow({''first_name'': ''Lovely'', ''last_name'': ''Spam''})
writer.writerow({''first_name'': ''Wonderful'', ''last_name'': ''Spam''})
其它
csv模块还涉及了其它的概念,比如 Dialects, 还提供了供错误处理的 exception csv.Error 等,因为实际使用较少及就不累赘在此。更多参考官方文档。
参考资料
https://docs.python.org/2/lib...

Python Scrapy 爬虫框架爬取推特信息及数据持久化
最近要做一个国内外新冠疫情的热点信息的收集系统,所以,需要爬取推特上的一些数据,然后做数据分类及情绪分析。作为一名合格的程序员,我们要有「拿来主义精神」,借助别人的轮子来实现自己的项目,而不是从头搭建。
一、爬虫框架Scrapy
Scrapy 是用Python实现一个为爬取网站数据、提取结构性数据而编写的应用框架。专业的事情交给专业的框架来做,所以,本项目我们确定使用 Scrapy 框架来进行数据爬取。如果对 Scrapy 还不熟悉,可以看我之前写的这篇博文帮你快速上手,Python Scrapy爬虫框架学习 。
二、寻找开源项目
在开始一个项目之前,避免重复造轮子,所以通过关键词 「Scrapy」,「Twitter」在 GitHub上搜索是否有现成的开源项目。

通过搜索,我们发现有很多符合条件的开源项目,那么如何选择这些项目呢?有三个条件,第一是Star数,Star数多说明项目质量应该不错得到了大家的认可,第二是,更新时间,说明这个项目一直在维护,第三是,文档是否完整,通过文档我们可以快速使用这个开源项目。所以,通过以上三个条件,我们看了下排在第一个的开源项目很不错,star数颇高,最近更新时间在几个月前,而且文档很详细,因此我们就用这个项目做二次开发,项目GitHub地址:jonbakerfish/TweetScraper。
三、本地安装及调试
1、拉取项目
It requires Scrapy and PyMongo (Also install MongoDB if you want to save the data to database). Setting up:
$ git clone https://github.com/jonbakerfish/TweetScraper.git
$ cd TweetScraper/
$ pip install -r requirements.txt #add ''--user'' if you are not root
$ scrapy list
$ #If the output is ''TweetScraper'', then you are ready to go.2、数据持久化
通过阅读文档,我们发现该项目有三种持久化数据的方式,第一种是保存在文件中,第二种是保存在Mongo中,第三种是保存在MySQL数据库中。因为我们抓取的数据需要做后期的分析,所以,需要将数据保存在MySQL中。
抓取到的数据默认是以Json格式保存在磁盘 ./Data/tweet/ 中的,所以,需要修改配置文件 TweetScraper/settings.py。
ITEM_PIPELINES = {
# ''TweetScraper.pipelines.SaveToFilePipeline'':100,
#''TweetScraper.pipelines.SaveToMongoPipeline'':100, # replace `SaveToFilePipeline` with this to use MongoDB
''TweetScraper.pipelines.SavetoMySQLPipeline'':100, # replace `SaveToFilePipeline` with this to use MySQL
}
#settings for mysql
MYSQL_SERVER = "18.126.219.16"
MYSQL_DB = "scraper"
MYSQL_TABLE = "tweets" # the table will be created automatically
MYSQL_USER = "root" # MySQL user to use (should have INSERT access granted to the Database/Table
MYSQL_PWD = "admin123456" # MySQL user''s password3、测试
进入到项目的根目录下,运行以下命令:
# 进入到项目目录
# cd /work/Code/scraper/TweetScraper
scrapy crawl TweetScraper -a query="Novel coronavirus,#COVID-19"注意,抓取Twitter的数据需要科学上网或者服务器部署在国外,我使用的是国外的服务器。
[root@cs TweetScraper]# scrapy crawl TweetScraper -a query="Novel coronavirus,#COVID-19"
2020-04-16 19:22:40 [scrapy.utils.log] INFO: Scrapy 2.0.1 started (bot: TweetScraper)
2020-04-16 19:22:40 [scrapy.utils.log] INFO: Versions: lxml 4.2.1.0, libxml2 2.9.8, cssselect 1.1.0, parsel 1.5.2, w3lib 1.21.0, Twisted 20.3.0, Python 3.6.5 |Anaconda, Inc.| (default, Apr 29 2018, 16:14:56) - [GCC 7.2.0], pyOpenSSL 18.0.0 (OpenSSL 1.0.2o 27 Mar 2018), cryptography 2.2.2, Platform Linux-3.10.0-862.el7.x86_64-x86_64-with-centos-7.5.1804-Core
2020-04-16 19:22:40 [scrapy.crawler] INFO: Overridden settings:
{''BOT_NAME'': ''TweetScraper'',
''LOG_LEVEL'': ''INFO'',
''NEWSPIDER_MODULE'': ''TweetScraper.spiders'',
''SPIDER_MODULES'': [''TweetScraper.spiders''],
''USER_AGENT'': ''TweetScraper''}
2020-04-16 19:22:40 [scrapy.extensions.telnet] INFO: Telnet Password: 1fb55da389e595db
2020-04-16 19:22:40 [scrapy.middleware] INFO: Enabled extensions:
[''scrapy.extensions.corestats.CoreStats'',
''scrapy.extensions.telnet.TelnetConsole'',
''scrapy.extensions.memusage.MemoryUsage'',
''scrapy.extensions.logstats.LogStats'']
2020-04-16 19:22:41 [scrapy.middleware] INFO: Enabled downloader middlewares:
[''scrapy.downloadermiddlewares.httpauth.HttpAuthMiddleware'',
''scrapy.downloadermiddlewares.downloadtimeout.DownloadTimeoutMiddleware'',
''scrapy.downloadermiddlewares.defaultheaders.DefaultHeadersMiddleware'',
''scrapy.downloadermiddlewares.useragent.UserAgentMiddleware'',
''scrapy.downloadermiddlewares.retry.RetryMiddleware'',
''scrapy.downloadermiddlewares.redirect.MetaRefreshMiddleware'',
''scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware'',
''scrapy.downloadermiddlewares.redirect.RedirectMiddleware'',
''scrapy.downloadermiddlewares.cookies.CookiesMiddleware'',
''scrapy.downloadermiddlewares.httpproxy.HttpProxyMiddleware'',
''scrapy.downloadermiddlewares.stats.DownloaderStats'']
2020-04-16 19:22:41 [scrapy.middleware] INFO: Enabled spider middlewares:
[''scrapy.spidermiddlewares.httperror.HttpErrorMiddleware'',
''scrapy.spidermiddlewares.offsite.OffsiteMiddleware'',
''scrapy.spidermiddlewares.referer.RefererMiddleware'',
''scrapy.spidermiddlewares.urllength.UrlLengthMiddleware'',
''scrapy.spidermiddlewares.depth.DepthMiddleware'']
Mysql连接成功###################################### MySQLCursorBuffered: (Nothing executed yet)
2020-04-16 19:22:41 [TweetScraper.pipelines] INFO: Table ''tweets'' already exists
2020-04-16 19:22:41 [scrapy.middleware] INFO: Enabled item pipelines:
[''TweetScraper.pipelines.SavetoMySQLPipeline'']
2020-04-16 19:22:41 [scrapy.core.engine] INFO: Spider opened
2020-04-16 19:22:41 [scrapy.extensions.logstats] INFO: Crawled 0 pages (at 0 pages/min), scraped 0 items (at 0 items/min)
2020-04-16 19:22:41 [scrapy.extensions.telnet] INFO: Telnet console listening on 127.0.0.1:6023
2020-04-16 19:23:45 [scrapy.extensions.logstats] INFO: Crawled 1 pages (at 1 pages/min), scraped 11 items (at 11 items/min)
2020-04-16 19:24:44 [scrapy.extensions.logstats] INFO: Crawled 2 pages (at 1 pages/min), scraped 22 items (at 11 items/min)
^C2020-04-16 19:26:27 [scrapy.crawler] INFO: Received SIGINT, shutting down gracefully. Send again to force
2020-04-16 19:26:27 [scrapy.core.engine] INFO: Closing spider (shutdown)
2020-04-16 19:26:43 [scrapy.extensions.logstats] INFO: Crawled 3 pages (at 1 pages/min), scraped 44 items (at 11 items/min)

我们可以看到,该项目运行OK,抓取到的数据也已经被保存在数据库了。
四、清洗数据
因为抓取到的Twitter上有表情等特殊符号,在插入数据库时会报错,所以,这里需要对抓取的内容信息进行清洗。
TweetScraper/utils.py 文件新增filter_emoji过滤方法
import re
def filter_emoji(desstr, restr=''''):
"""
filter emoji
desstr: origin str
restr: replace str
"""
# filter emoji
try:
res = re.compile(u''[\U00010000-\U0010ffff]'')
except re.error:
res = re.compile(u''[\uD800-\uDBFF][\uDC00-\uDFFF]'')
return res.sub(restr, desstr)
在 TweetCrawler.py 文件中调用该方法:
from TweetScraper.utils import filter_emoji
def parse_tweet_item(self, items):
for item in items:
try:
tweet = Tweet()
tweet[''usernameTweet''] = item.xpath(''.//span[@]/b/text()'').extract()[0]
ID = item.xpath(''.//@data-tweet-id'').extract()
if not ID:
continue
tweet[''ID''] = ID[0]
### get text content
tweet[''text''] = '' ''.join(
item.xpath(''.//div[@]/p//text()'').extract()).replace('' # '',
''#'').replace(
'' @ '', ''@'')
### clear data[20200416]
# tweet[''text''] = re.sub(r"[\s+\.\!\/_,$%^*(+\"\'')]+|[+——?【】?~@#¥%……&*]+|\\n+|\\r+|(\\xa0)+|(\\u3000)+|\\t", "", tweet[''text'']);
# 过滤掉表情符号【20200417】
tweet[''text''] = filter_emoji(tweet[''text''], '''')
if tweet[''text''] == '''':
# If there is not text, we ignore the tweet
continue
### get meta data
tweet[''url''] = item.xpath(''.//@data-permalink-path'').extract()[0]
nbr_retweet = item.css(''span.ProfileTweet-action--retweet > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_retweet:
tweet[''nbr_retweet''] = int(nbr_retweet[0])
else:
tweet[''nbr_retweet''] = 0
nbr_favorite = item.css(''span.ProfileTweet-action--favorite > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_favorite:
tweet[''nbr_favorite''] = int(nbr_favorite[0])
else:
tweet[''nbr_favorite''] = 0
nbr_reply = item.css(''span.ProfileTweet-action--reply > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_reply:
tweet[''nbr_reply''] = int(nbr_reply[0])
else:
tweet[''nbr_reply''] = 0
tweet[''datetime''] = datetime.fromtimestamp(int(
item.xpath(''.//div[@]/small[@]/a/span/@data-time'').extract()[
0])).strftime(''%Y-%m-%d %H:%M:%S'')
### get photo
has_cards = item.xpath(''.//@data-card-type'').extract()
if has_cards and has_cards[0] == ''photo'':
tweet[''has_image''] = True
tweet[''images''] = item.xpath(''.//*/div/@data-image-url'').extract()
elif has_cards:
logger.debug(''Not handle "data-card-type":\n%s'' % item.xpath(''.'').extract()[0])
### get animated_gif
has_cards = item.xpath(''.//@data-card2-type'').extract()
if has_cards:
if has_cards[0] == ''animated_gif'':
tweet[''has_video''] = True
tweet[''videos''] = item.xpath(''.//*/source/@video-src'').extract()
elif has_cards[0] == ''player'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''summary_large_image'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''amplify'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''summary'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''__entity_video'':
pass # TODO
# tweet[''has_media''] = True
# tweet[''medias''] = item.xpath(''.//*/div/@data-src'').extract()
else: # there are many other types of card2 !!!!
logger.debug(''Not handle "data-card2-type":\n%s'' % item.xpath(''.'').extract()[0])
is_reply = item.xpath(''.//div[@]'').extract()
tweet[''is_reply''] = is_reply != []
is_retweet = item.xpath(''.//span[@]'').extract()
tweet[''is_retweet''] = is_retweet != []
tweet[''user_id''] = item.xpath(''.//@data-user-id'').extract()[0]
yield tweet
if self.crawl_user:
### get user info
user = User()
user[''ID''] = tweet[''user_id'']
user[''name''] = item.xpath(''.//@data-name'').extract()[0]
user[''screen_name''] = item.xpath(''.//@data-screen-name'').extract()[0]
user[''avatar''] = \
item.xpath(''.//div[@]/div[@]/a/img/@src'').extract()[0]
yield user
except:
logger.error("Error tweet:\n%s" % item.xpath(''.'').extract()[0])
# raise通过数据清洗,现在可以正常插入到表里了。
五、翻译成中文
我们可以看到,爬取的数据内容有多个国家的语言,如英文、日语、阿拉伯语、法语等,为了能够知道是什么意思,需要将这些文字翻译成中文,怎么翻译呢?其实很简单,GitHub上有一个开源的Python 谷歌翻译包ssut/py-googletrans ,该项目非常强大,可以自动识别语言并且翻译成我们指定的语言,我们只需安装即可使用。
1、安装
$ pip install googletrans2、使用
>>> from googletrans import Translator
>>> translator = Translator()
>>> translator.translate(''안녕하세요.'')
# <Translated src=ko dest=en text=Good evening. pronunciation=Good evening.>
>>> translator.translate(''안녕하세요.'', dest=''ja'')
# <Translated src=ko dest=ja text=こんにちは。 pronunciation=Kon''nichiwa.>
>>> translator.translate(''veritas lux mea'', src=''la'')
# <Translated src=la dest=en text=The truth is my light pronunciation=The truth is my light>from googletrans import Translator
destination = ''zh-CN'' # 翻译为中文
t = ''안녕하세요.''
res = Translator().translate(t, dest=destination).text
print(res)
你好3、引用到项目
在 TweetCrawler.py 文件中调用该方法,并且需要在数据库中新增加一个字段 text_cn。
# google translate[20200416]
# @see https://github.com/ssut/py-googletrans
from googletrans import Translator
def parse_tweet_item(self, items):
for item in items:
try:
tweet = Tweet()
tweet[''usernameTweet''] = item.xpath(''.//span[@]/b/text()'').extract()[0]
ID = item.xpath(''.//@data-tweet-id'').extract()
if not ID:
continue
tweet[''ID''] = ID[0]
### get text content
tweet[''text''] = '' ''.join(
item.xpath(''.//div[@]/p//text()'').extract()).replace('' # '',
''#'').replace(
'' @ '', ''@'')
### clear data[20200416]
# tweet[''text''] = re.sub(r"[\s+\.\!\/_,$%^*(+\"\'')]+|[+——?【】?~@#¥%……&*]+|\\n+|\\r+|(\\xa0)+|(\\u3000)+|\\t", "", tweet[''text'']);
# 过滤掉表情符号【20200417】
tweet[''text''] = filter_emoji(tweet[''text''], '''')
# 翻译成中文 Translate Chinese【20200417】
tweet[''text_cn''] = Translator().translate(tweet[''text''],''zh-CN'').text;
if tweet[''text''] == '''':
# If there is not text, we ignore the tweet
continue
### get meta data
tweet[''url''] = item.xpath(''.//@data-permalink-path'').extract()[0]
nbr_retweet = item.css(''span.ProfileTweet-action--retweet > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_retweet:
tweet[''nbr_retweet''] = int(nbr_retweet[0])
else:
tweet[''nbr_retweet''] = 0
nbr_favorite = item.css(''span.ProfileTweet-action--favorite > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_favorite:
tweet[''nbr_favorite''] = int(nbr_favorite[0])
else:
tweet[''nbr_favorite''] = 0
nbr_reply = item.css(''span.ProfileTweet-action--reply > span.ProfileTweet-actionCount'').xpath(
''@data-tweet-stat-count'').extract()
if nbr_reply:
tweet[''nbr_reply''] = int(nbr_reply[0])
else:
tweet[''nbr_reply''] = 0
tweet[''datetime''] = datetime.fromtimestamp(int(
item.xpath(''.//div[@]/small[@]/a/span/@data-time'').extract()[
0])).strftime(''%Y-%m-%d %H:%M:%S'')
### get photo
has_cards = item.xpath(''.//@data-card-type'').extract()
if has_cards and has_cards[0] == ''photo'':
tweet[''has_image''] = True
tweet[''images''] = item.xpath(''.//*/div/@data-image-url'').extract()
elif has_cards:
logger.debug(''Not handle "data-card-type":\n%s'' % item.xpath(''.'').extract()[0])
### get animated_gif
has_cards = item.xpath(''.//@data-card2-type'').extract()
if has_cards:
if has_cards[0] == ''animated_gif'':
tweet[''has_video''] = True
tweet[''videos''] = item.xpath(''.//*/source/@video-src'').extract()
elif has_cards[0] == ''player'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''summary_large_image'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''amplify'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''summary'':
tweet[''has_media''] = True
tweet[''medias''] = item.xpath(''.//*/div/@data-card-url'').extract()
elif has_cards[0] == ''__entity_video'':
pass # TODO
# tweet[''has_media''] = True
# tweet[''medias''] = item.xpath(''.//*/div/@data-src'').extract()
else: # there are many other types of card2 !!!!
logger.debug(''Not handle "data-card2-type":\n%s'' % item.xpath(''.'').extract()[0])
is_reply = item.xpath(''.//div[@]'').extract()
tweet[''is_reply''] = is_reply != []
is_retweet = item.xpath(''.//span[@]'').extract()
tweet[''is_retweet''] = is_retweet != []
tweet[''user_id''] = item.xpath(''.//@data-user-id'').extract()[0]
yield tweet
if self.crawl_user:
### get user info
user = User()
user[''ID''] = tweet[''user_id'']
user[''name''] = item.xpath(''.//@data-name'').extract()[0]
user[''screen_name''] = item.xpath(''.//@data-screen-name'').extract()[0]
user[''avatar''] = \
item.xpath(''.//div[@]/div[@]/a/img/@src'').extract()[0]
yield user
except:
logger.error("Error tweet:\n%s" % item.xpath(''.'').extract()[0])
# raiseitems.py 中新增加字段
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
from scrapy import Item, Field
class Tweet(Item):
ID = Field() # tweet id
url = Field() # tweet url
datetime = Field() # post time
text = Field() # text content
text_cn = Field() # text Chinese content (新增字段)
user_id = Field() # user id管道 piplines.py 文件中修改数据库持久化的方法,新增加text_cn字段
class SavetoMySQLPipeline(object):
'''''' pipeline that save data to mysql ''''''
def __init__(self):
# connect to mysql server
self.cnx = mysql.connector.connect(
user=SETTINGS["MYSQL_USER"],
password=SETTINGS["MYSQL_PWD"],
host=SETTINGS["MYSQL_SERVER"],
database=SETTINGS["MYSQL_DB"],
buffered=True)
self.cursor = self.cnx.cursor()
print(''Mysql连接成功######################################'', self.cursor)
self.table_name = SETTINGS["MYSQL_TABLE"]
create_table_query = "CREATE TABLE `" + self.table_name + "` (\
`ID` CHAR(20) NOT NULL,\
`url` VARCHAR(140) NOT NULL,\
`datetime` VARCHAR(22),\
`text` VARCHAR(280),\
`text_cn` VARCHAR(280),\
`user_id` CHAR(20) NOT NULL,\
`usernameTweet` VARCHAR(20) NOT NULL\
)"
try:
self.cursor.execute(create_table_query)
except mysql.connector.Error as err:
logger.info(err.msg)
else:
self.cnx.commit()
def find_one(self, trait, value):
select_query = "SELECT " + trait + " FROM " + self.table_name + " WHERE " + trait + " = " + value + ";"
try:
val = self.cursor.execute(select_query)
except mysql.connector.Error as err:
return False
if (val == None):
return False
else:
return True
def check_vals(self, item):
ID = item[''ID'']
url = item[''url'']
datetime = item[''datetime'']
text = item[''text'']
user_id = item[''user_id'']
username = item[''usernameTweet'']
if (ID is None):
return False
elif (user_id is None):
return False
elif (url is None):
return False
elif (text is None):
return False
elif (username is None):
return False
elif (datetime is None):
return False
else:
return True
def insert_one(self, item):
ret = self.check_vals(item)
if not ret:
return None
ID = item[''ID'']
user_id = item[''user_id'']
url = item[''url'']
text = item[''text'']
text_cn = item[''text_cn'']
username = item[''usernameTweet'']
datetime = item[''datetime'']
insert_query = ''INSERT INTO '' + self.table_name + '' (ID, url, datetime, text, text_cn, user_id, usernameTweet )''
insert_query += '' VALUES ( %s, %s, %s, %s, %s, %s, %s)''
insert_query += '' ON DUPLICATE KEY UPDATE''
insert_query += '' url = %s, datetime = %s, text= %s, text_cn= %s, user_id = %s, usernameTweet = %s''
try:
self.cursor.execute(insert_query, (
ID,
url,
datetime,
text,
text_cn,
user_id,
username,
url,
datetime,
text,
text_cn,
user_id,
username
))
# insert and updadte parameter,so repeat
except mysql.connector.Error as err:
logger.info(err.msg)
else:
self.cnx.commit()
def process_item(self, item, spider):
if isinstance(item, Tweet):
self.insert_one(dict(item)) # Item is inserted or updated.
logger.debug("Add tweet:%s" %item[''url''])
4、再次运行
然后再次运行该命令:
scrapy crawl TweetScraper -a query="Novel coronavirus,#COVID-19"
可以看到数据库中已经将外文翻译成中文了^_^。
相关文章:
Python Scrapy爬虫框架学习
ssut/py-googletrans 谷歌翻译

python 基础之数据持久化存储
###数据持久化存储
- 说明:持久化存储方案,普通文件、数据库、序列化
- 示例:
```python
import pickle
class Person:
def __init__(self, name, age):
self.name = name
self.age = age
def __str__(self):
return ''name:{} age:{}''.format(self.name, self.age)
xiaoming = Person(''xiaoming'', 20)
# print(xiaoming)
# 序列化:会将对象转换为bytes
# s = pickle.dumps(xiaoming)
# print(s)
# 反序列化:从bytes中解析出对象
# xm = pickle.loads(s)
# print(xm, type(xm))
# 直接保存到文件
# fp = open(''data.txt'', ''wb'')
# pickle.dump(xiaoming, fp)
# fp.close()
# 从文件中读取对象
fp = open(''data.txt'', ''rb'')
xm = pickle.load(fp)
print(xm, type(xm))
今天关于Python爬虫基础讲解:数据持久化——json 及 CSV模块简介和python爬虫json数据解析的介绍到此结束,谢谢您的阅读,有关python csv、json、pickle数据持久化、Python CSV模块简介、Python Scrapy 爬虫框架爬取推特信息及数据持久化、python 基础之数据持久化存储等更多相关知识的信息可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

