对于在既有系统中打通ApacheIgnite、MySQL和Node.js感兴趣的读者,本文将提供您所需要的所有信息,并且为您提供关于ApacheCassandra和ApacheIgnite:关系并置和
对于在既有系统中打通Apache Ignite、MySQL和Node.js感兴趣的读者,本文将提供您所需要的所有信息,并且为您提供关于Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL、Apache Cassandra和Apache Ignite:通过Ignite增强Apache Cassandra、Apache Ignite 1.8.0 发布,全新的 SQL 网格、Apache Ignite 2.13.0 版本发布,全新的基于 Calcite 的 SQL 引擎的宝贵知识。
本文目录一览:- 在既有系统中打通Apache Ignite、MySQL和Node.js
- Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL
- Apache Cassandra和Apache Ignite:通过Ignite增强Apache Cassandra
- Apache Ignite 1.8.0 发布,全新的 SQL 网格
- Apache Ignite 2.13.0 版本发布,全新的基于 Calcite 的 SQL 引擎

在既有系统中打通Apache Ignite、MySQL和Node.js
介绍
在本系列的第一篇文章中,安装了Node.js、Ignite的Node.js瘦客户端包,并且测试了一个示例应用。在本文中,可以看一下Ignite在处理其它数据源(比如关系数据库)的已有数据时,一个很有用的场景。
通常在行业领域,很多系统还有着巨大的商业价值,它们必须得到维护甚至加强,未被开发的领域已经很少见了。而Ignite可以用于组织中的遗留系统或传统系统,以增加它们的价值并提供新的可能性,例如具有水平可扩展性的集群计算、显著的内存级性能优势以及使用机器和深度学习的新应用等等。
具体可以看一个示例,其中在关系数据库中已经有了一些数据,然后了解Ignite如何将该数据缓存到内存中,对该内存数据执行SQL操作并将更改回写关系数据库,这里将使用一些Node.js代码来访问Ignite并执行一些SQL查询。
已有的数据库系统
本文中使用了MySQL,并且其中已经准备好了一个名为world的数据库,里面已经加载了部分数据。
这个world数据库的结构为有三张关系表,具体如下:
- country:代表世界上的国家(239行数据);
- city:代表国家的部分城市信息(4079行数据);
- countrylanguage:各个国家说的语言(984行数据)。
接下来,确认MySQL是否已经成功启动,并接受外部连接。
Web控制台和Web代理
为了访问MySQL数据库的模式信息,需要使用Ignite的Web控制台,在本文中为了方便,使用的是GridGain托管的服务,不过Web控制台的源代码是可以下载的,可以在本地构建然后在公司的防火墙后面运行,具体细节可以参见相关的文档。
还需要一个Web代理,它可以从Web控制台中下载,如下图所示:
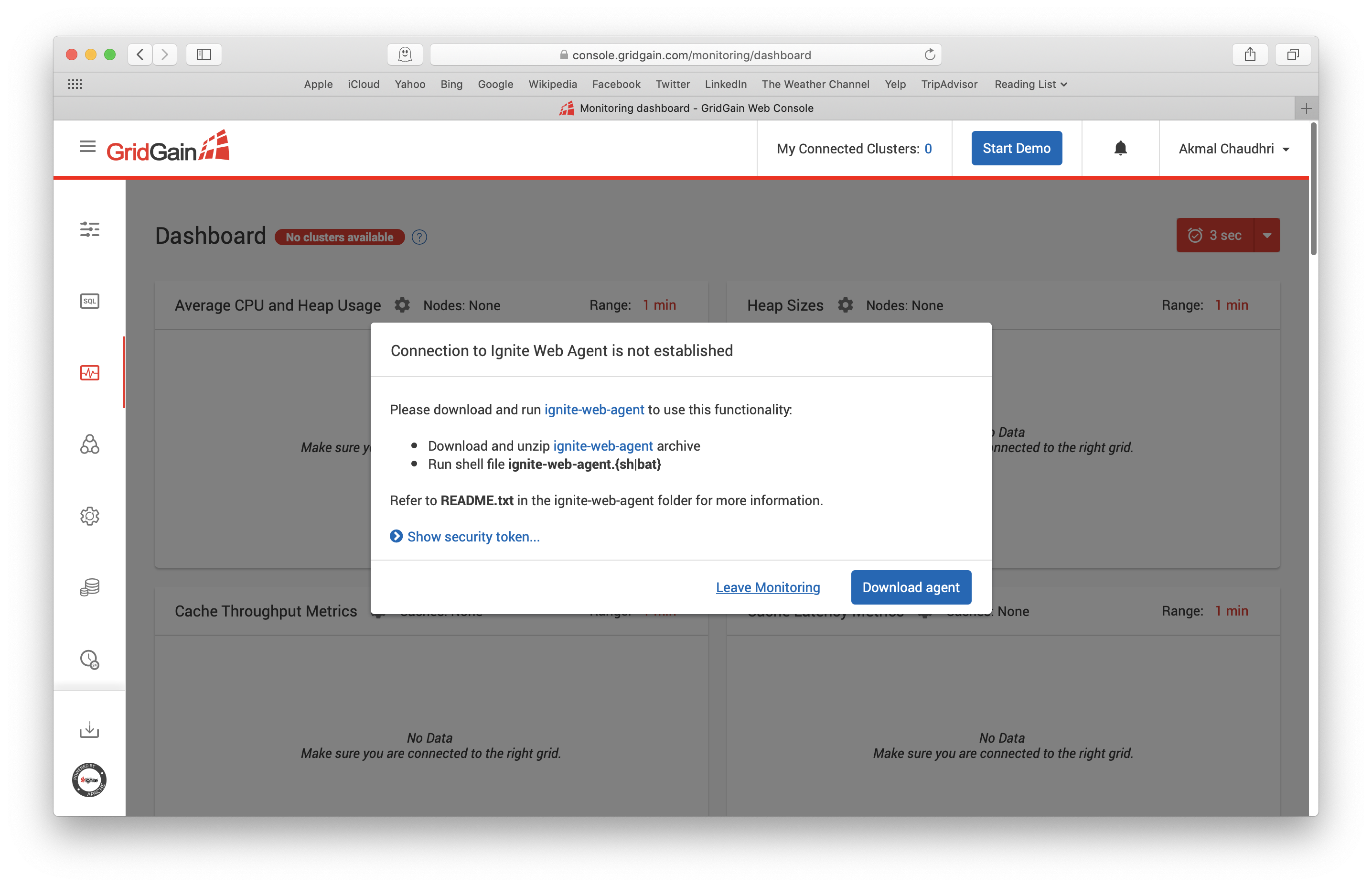
Web代理的zip包下载完成之后,可以解压该文件,目录结构大致如下图所示:
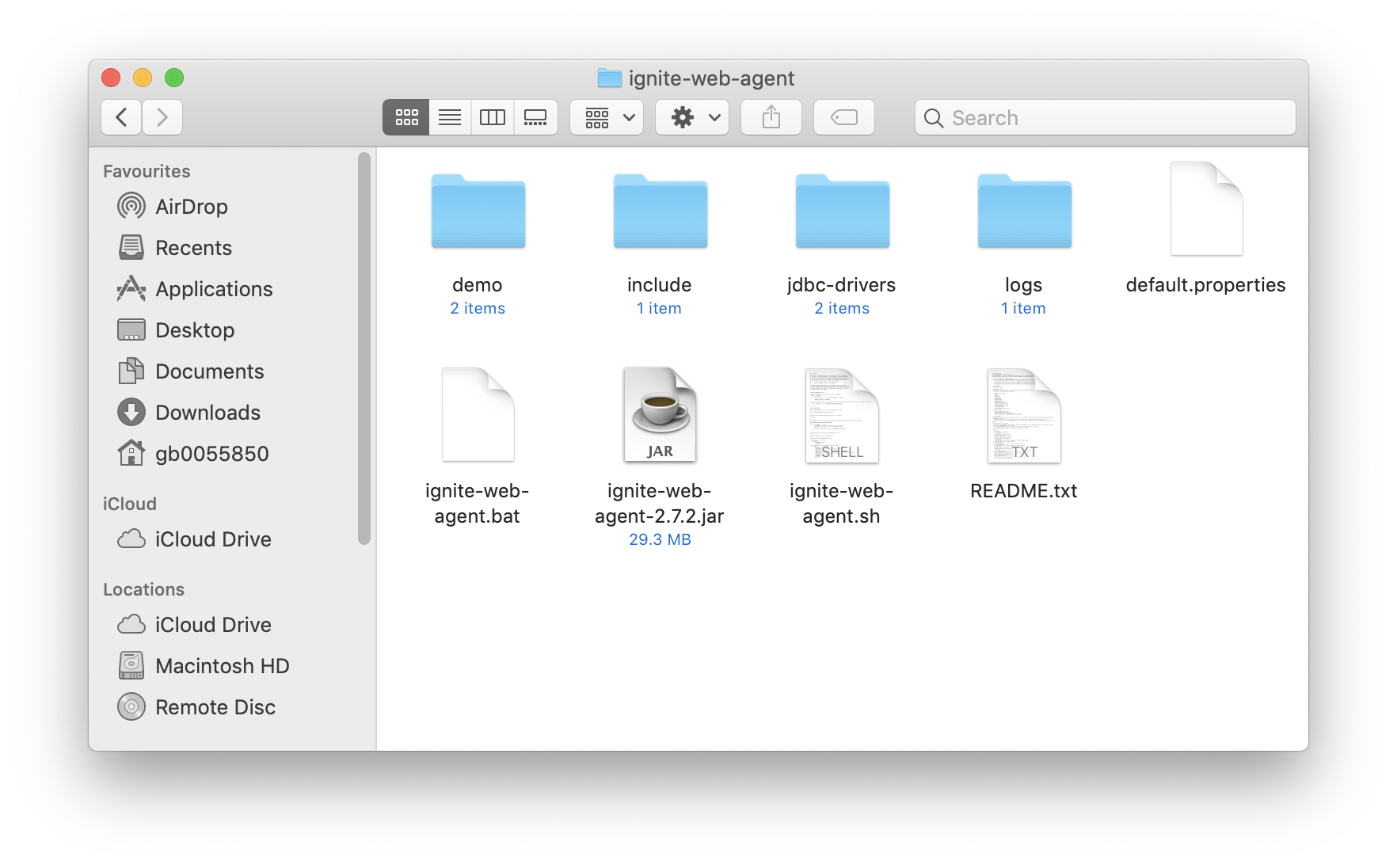
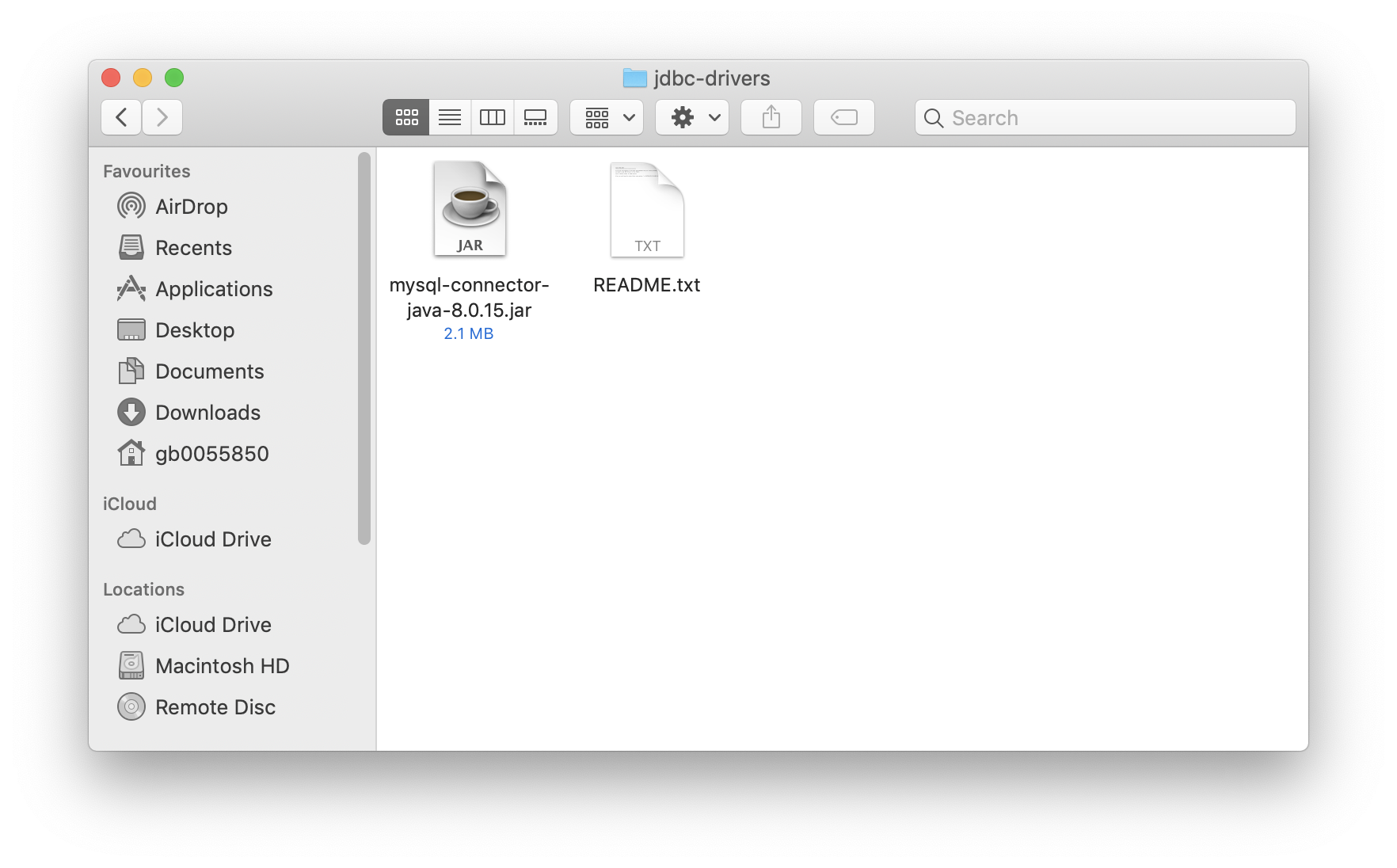
注意这里有个名为jdbc-drivers的目录,因为本例需要访问MySQL,所以需要下载MySQL的驱动,然后将jar文件放在该文件夹中,如下图所示:
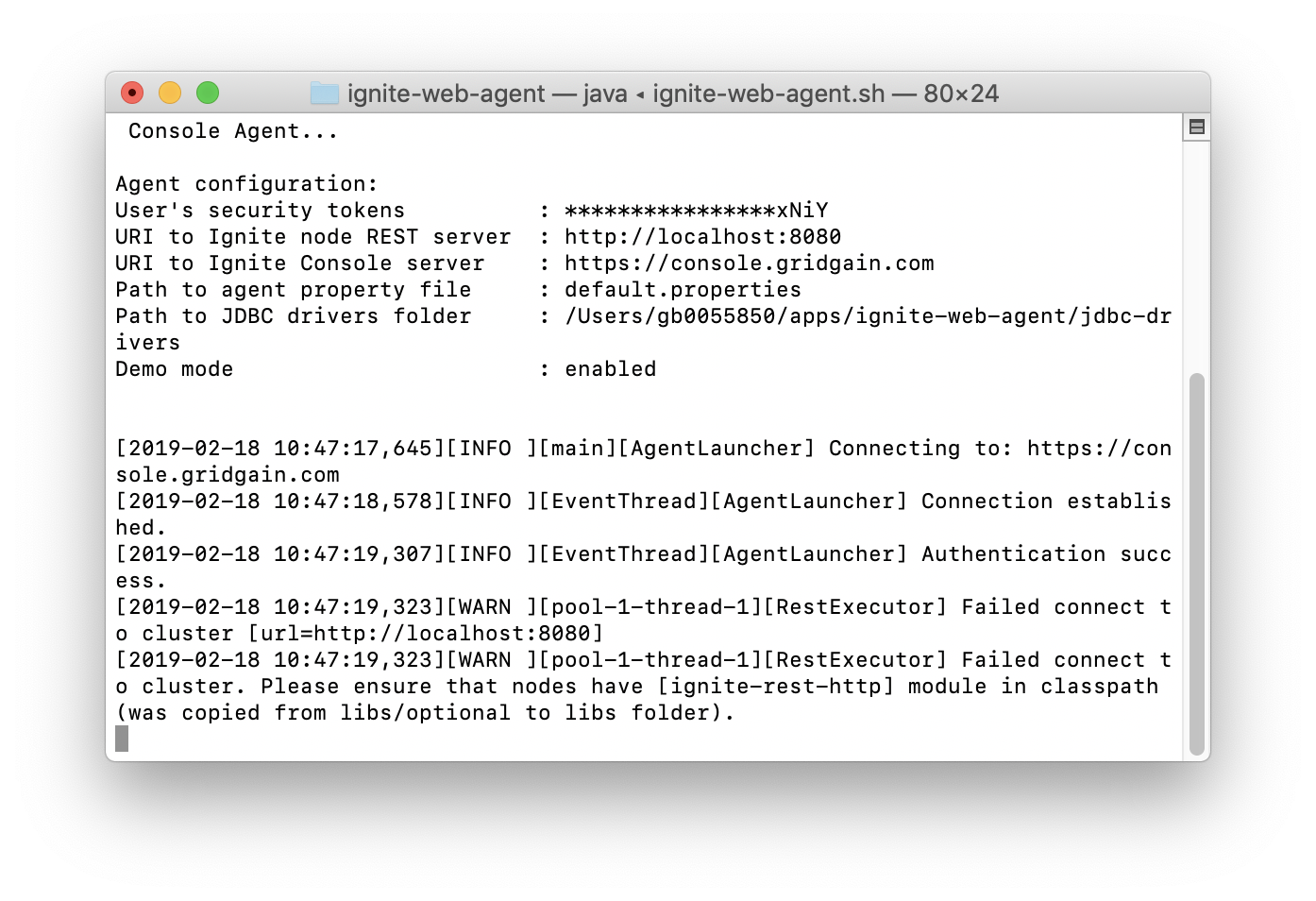
下面从终端窗口中启动Web代理,如下:
./ignite-web-agent.sh
输出大致如下图所示:
从MySQL中导入模式
下面就可以导入模式信息了,在Web控制台的Configuration页面中,右上角有一个Import from Database按钮,如下图所示:
点击该按钮之后,输出大致如下图所示:
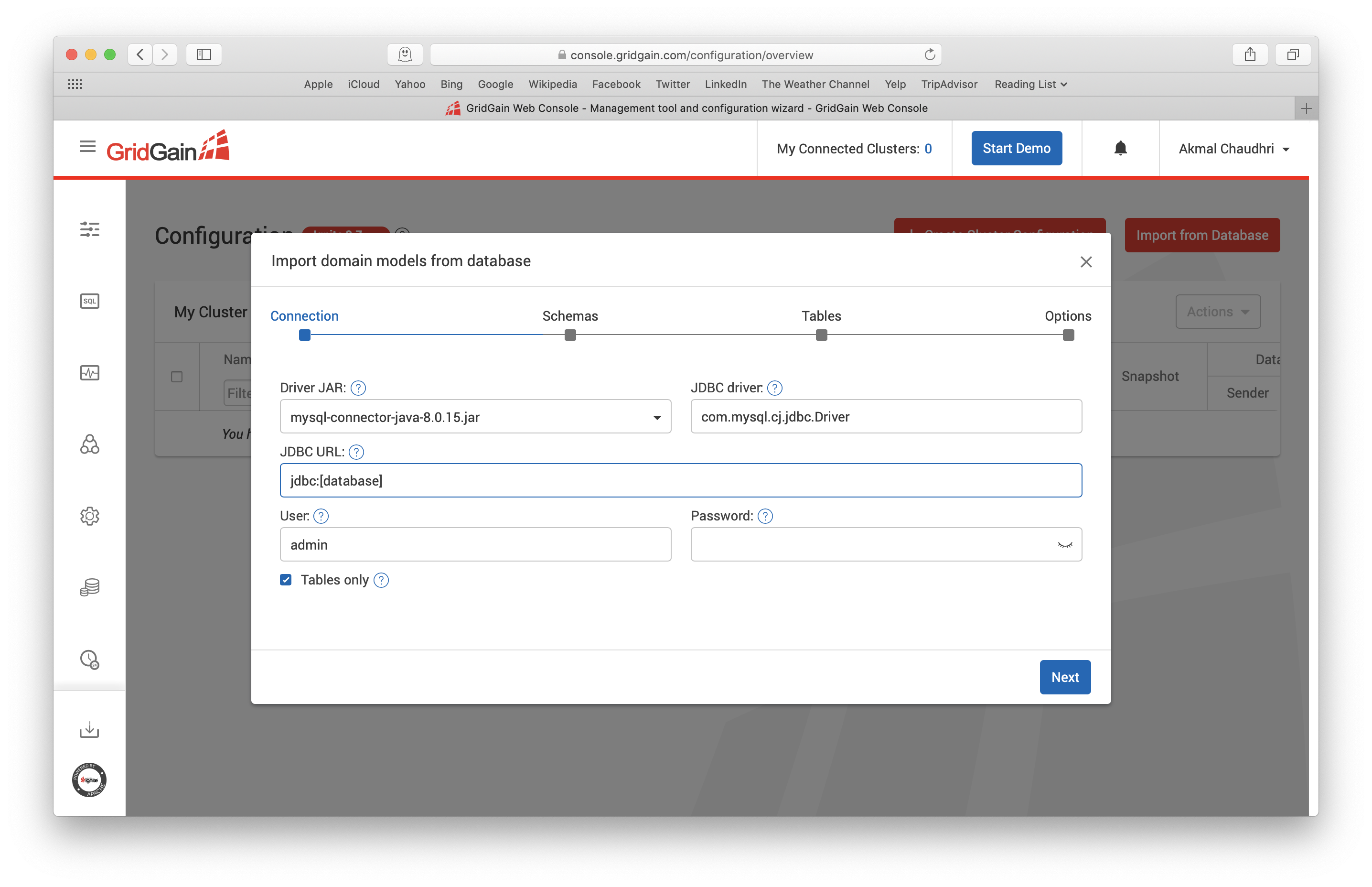
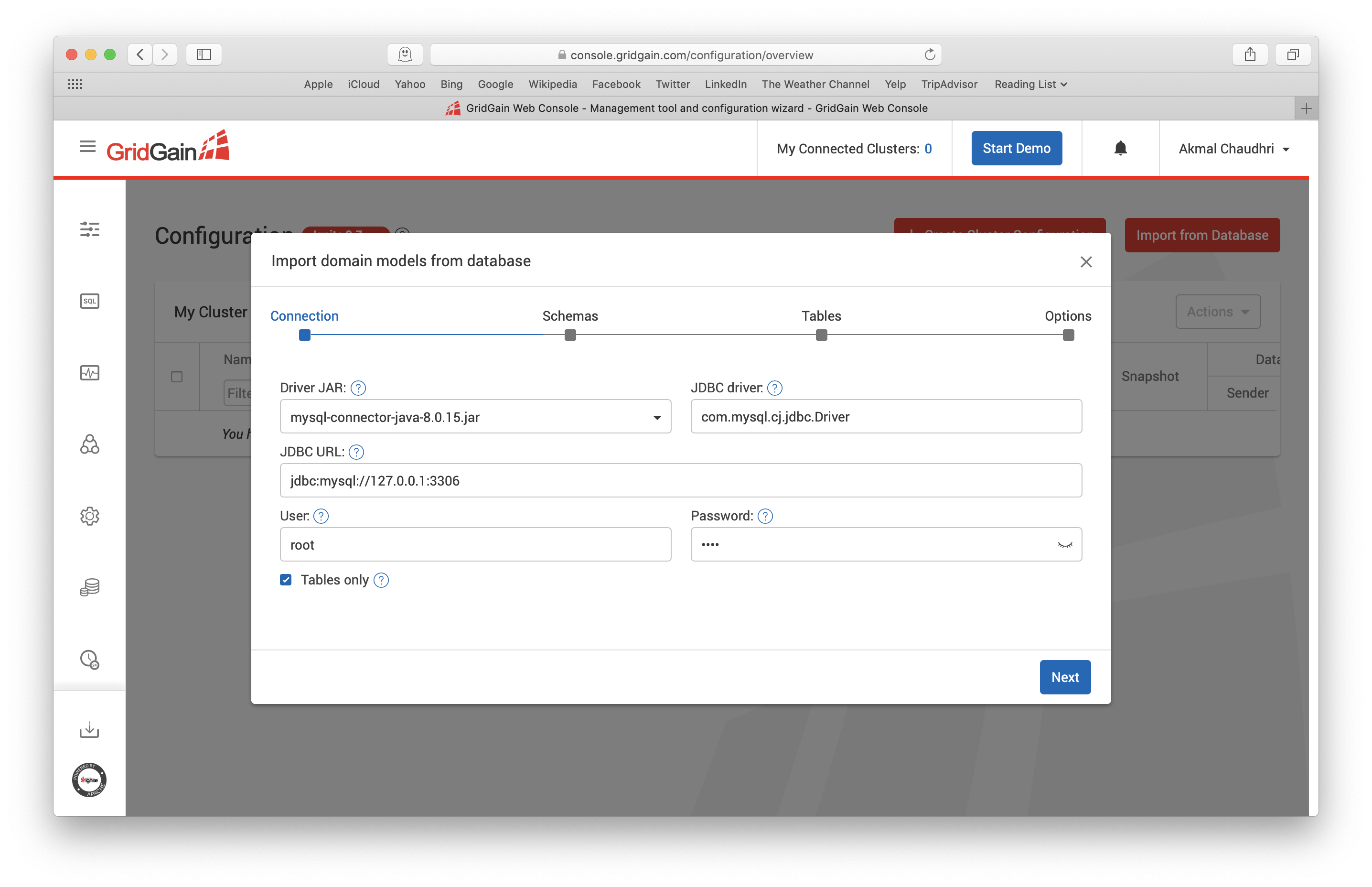
在这个界面中,需要输入MySQL服务器的JDBC URL、User和Password,大致如下图所示:
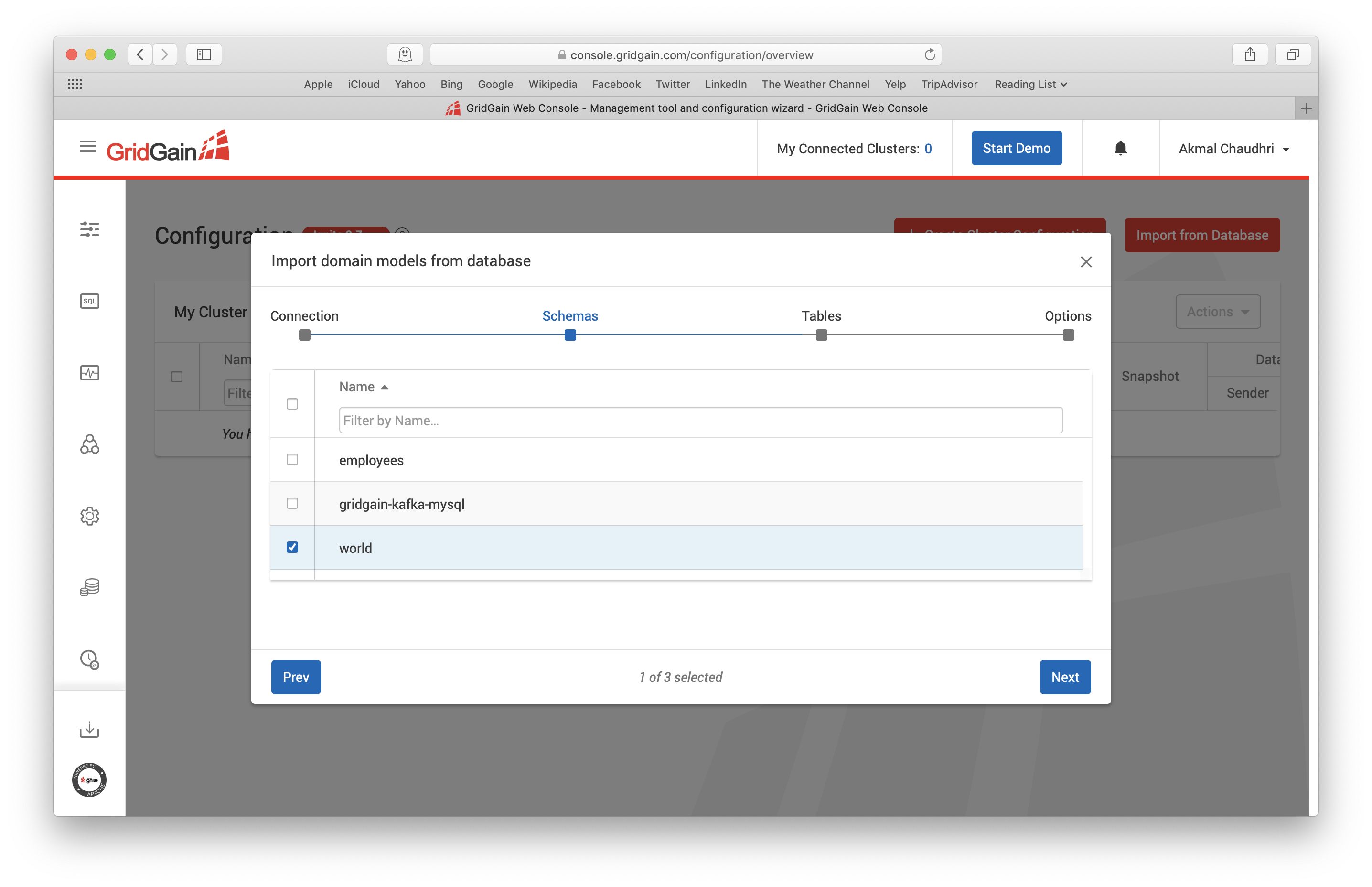
填完之后点击Next,这时就会看到各个数据库模式,然后把除了world模式之外的都取消掉,如下图所示:
选好之后,点击Next,就会看到3张表,如下图所示:
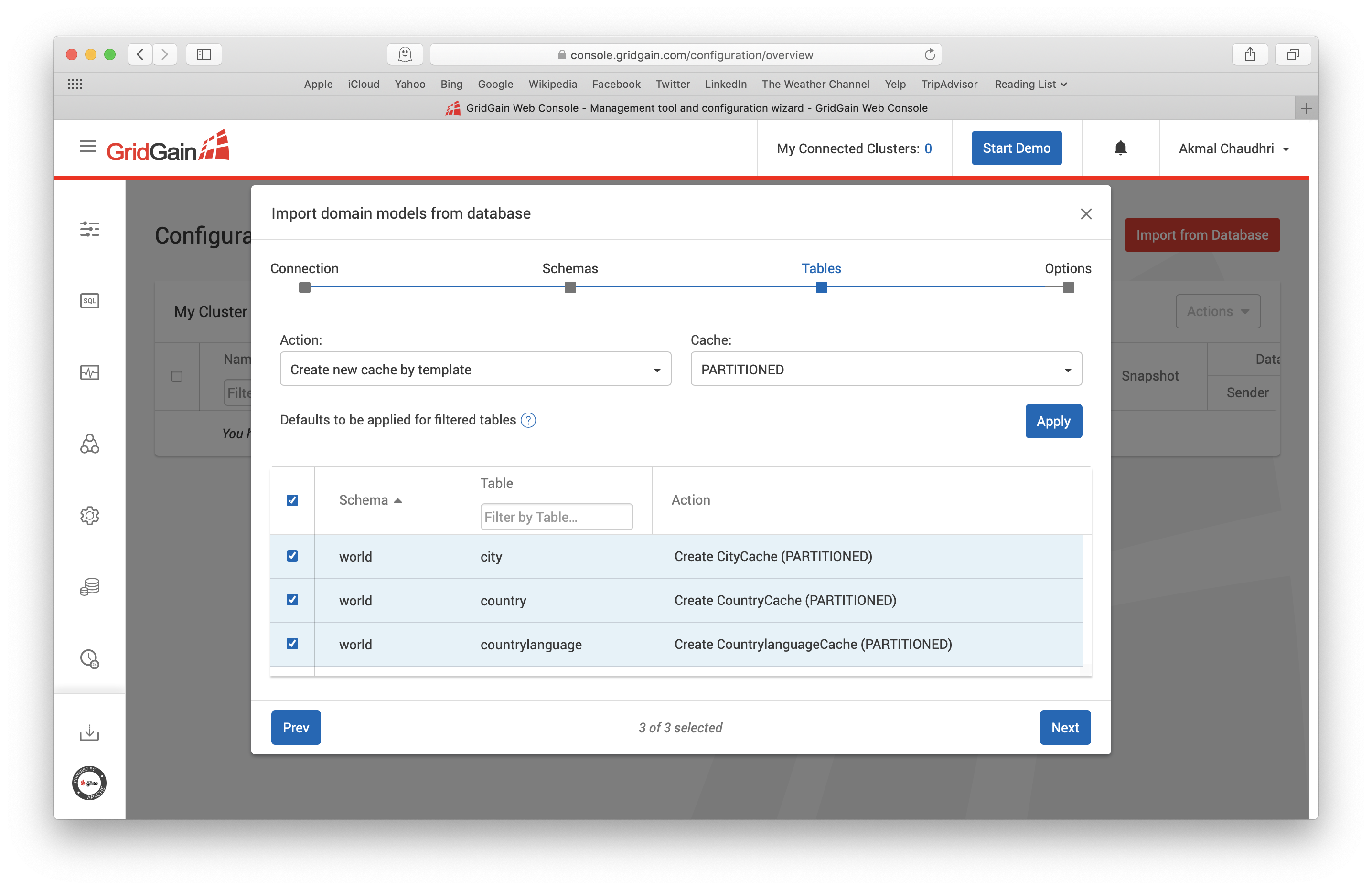
对于本文来说,这页面中的默认值就可以了,然后点击Next,这会跳到如下图所示的页面:
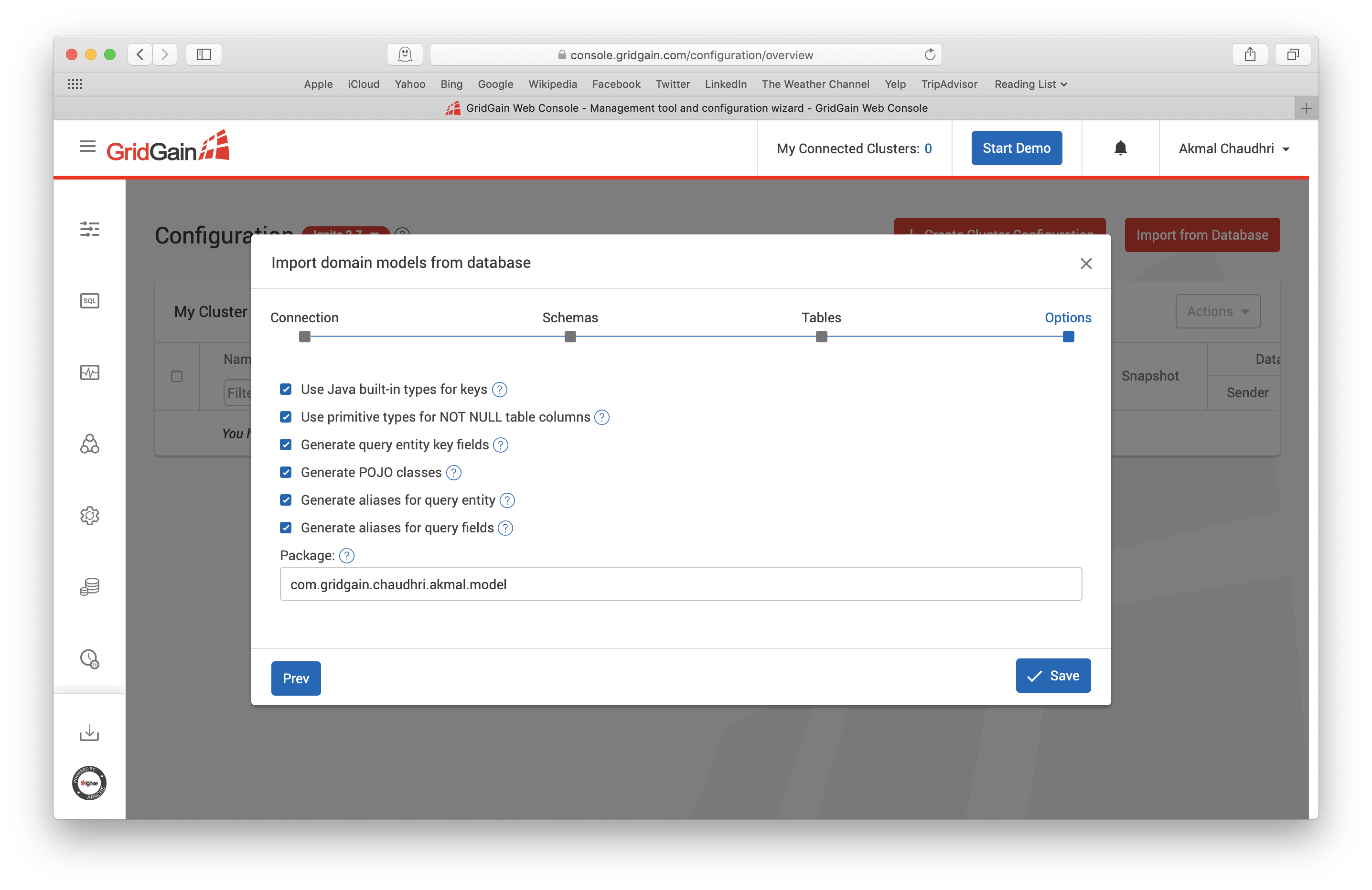
对于本文来说,这个页面的默认值就可以,然后点击Save:
接下来在Configuration页面,可以看到列出了一个新的名为ImportedCluster配置项,如下图所示:
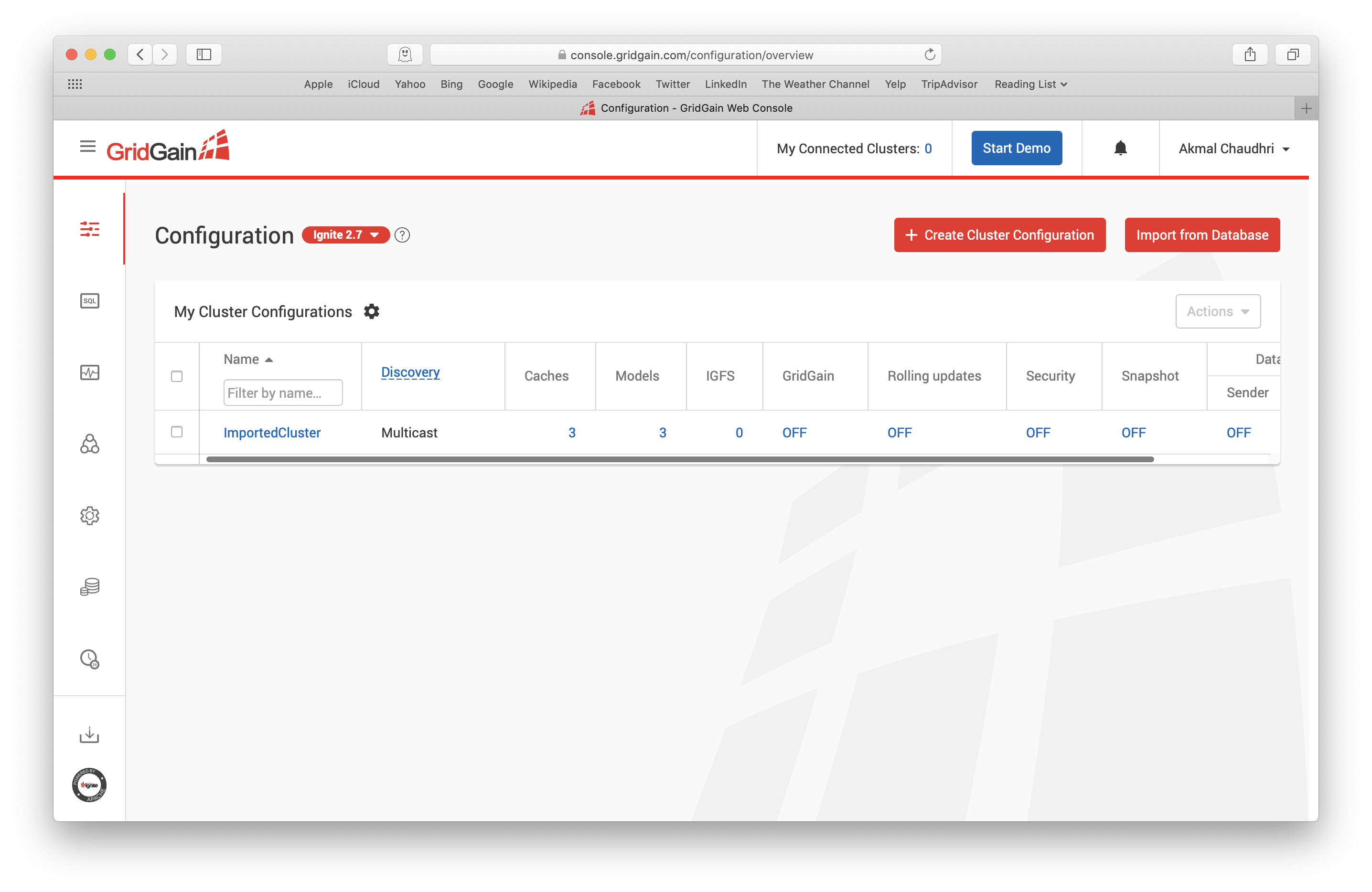
为了满足业务需求,这个配置是可以修改的。
修改配置
如果点击上图中的ImportedCluster,就会跳转到下面的页面:
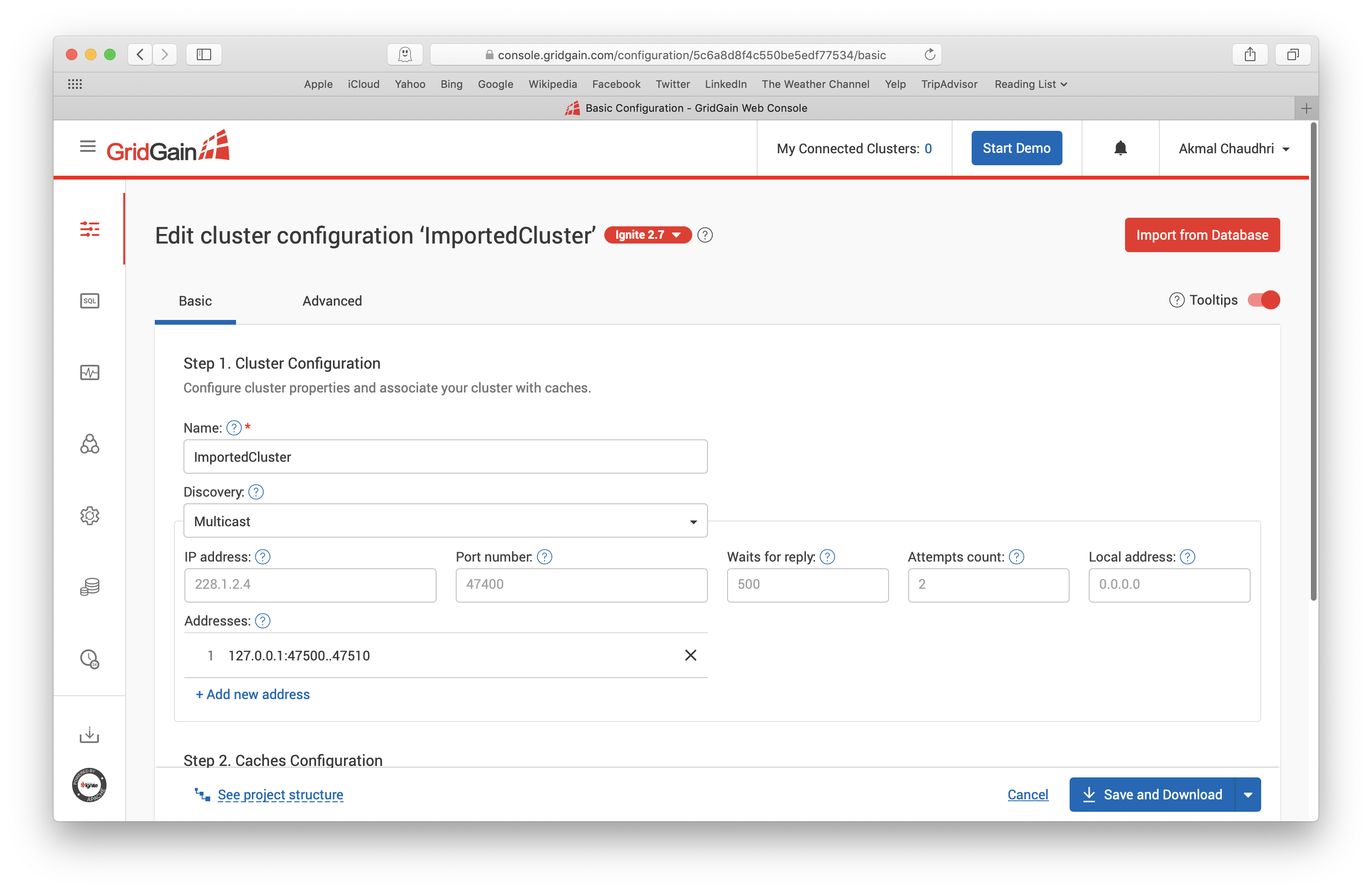
这个界面中有两个选项卡:Basic和Advanced。
在Basic选项卡中,集群的配置名(第一步),如果往下滚动,Ignite存储的名字(第二步),还有其它的若干个参数,都可以修改,在本例中,会维持这个页面中的默认值。
在Advanced选项卡中,还有其它的子项,包括Cluster、SQL Scheme、Caches、IGFS和GridGain,如下图所示,如果需要,这里面的很多参数都可以微调:
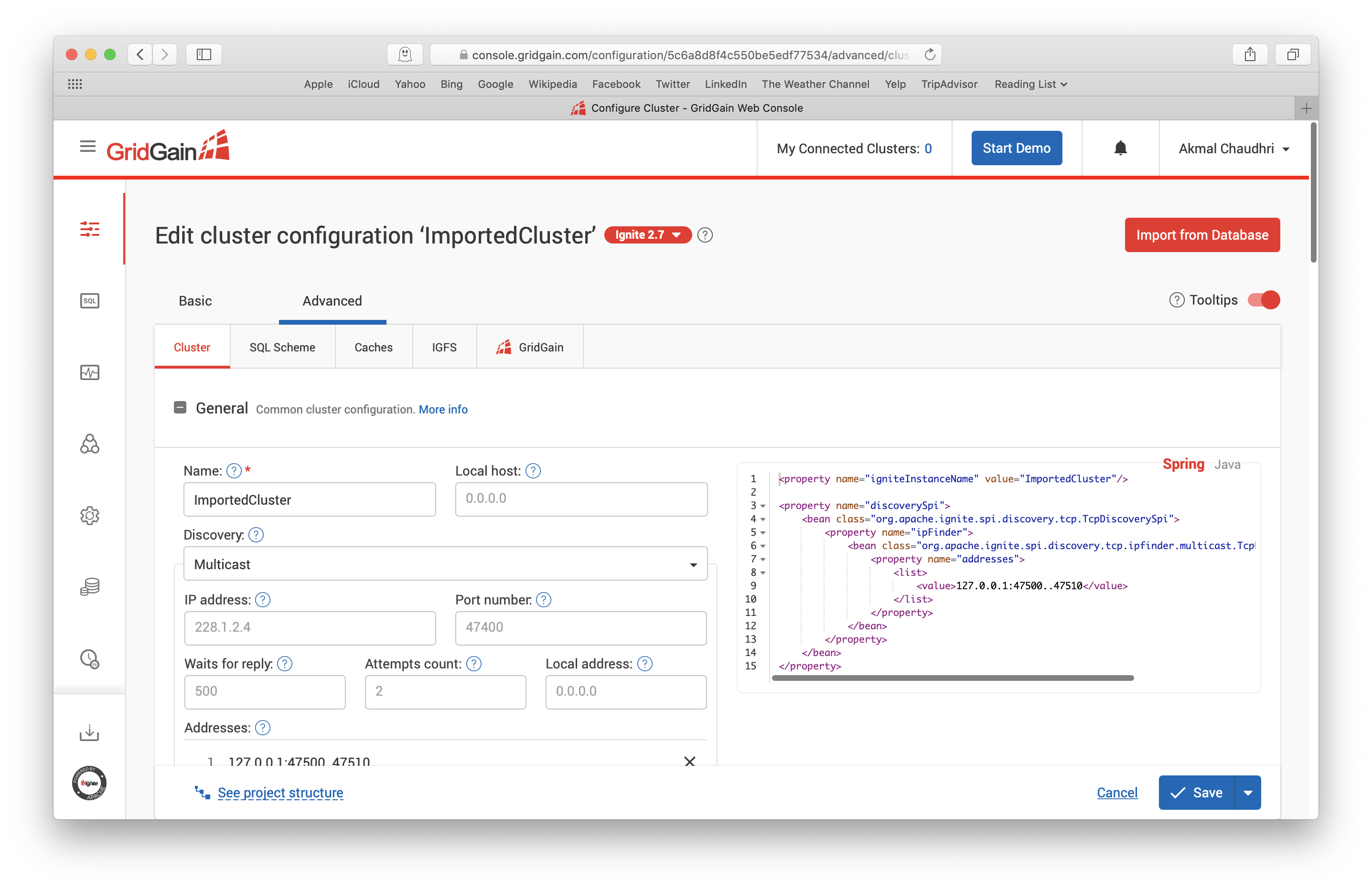
这里选择SQL Scheme选项卡,选中City这一行,如下图所示,然后向下滚动并展开Domain model for SQL query部分:
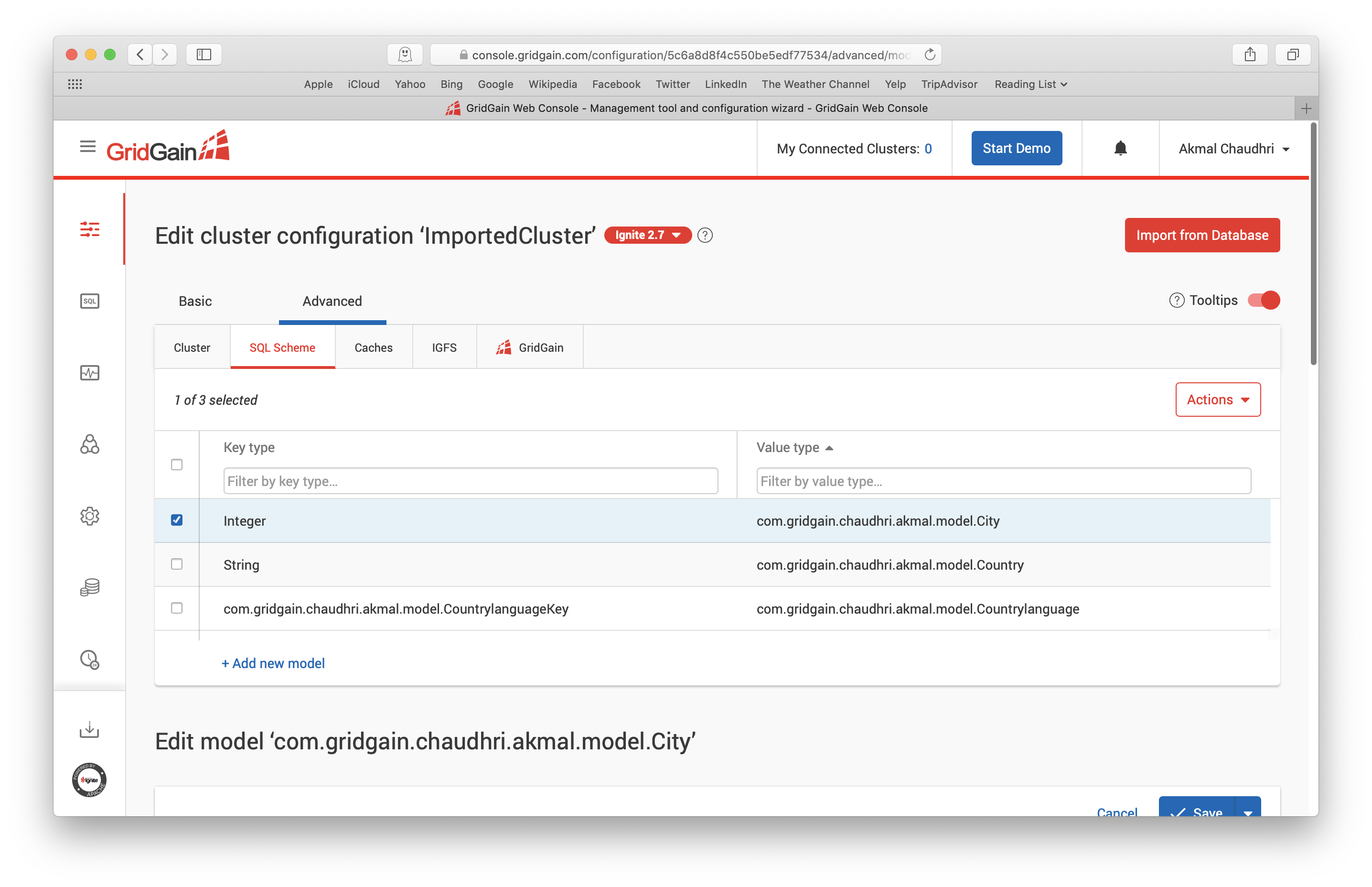
这里有一个indexes子项,值为CountryCode,如果点击它,可以进行修改,如下图所示:
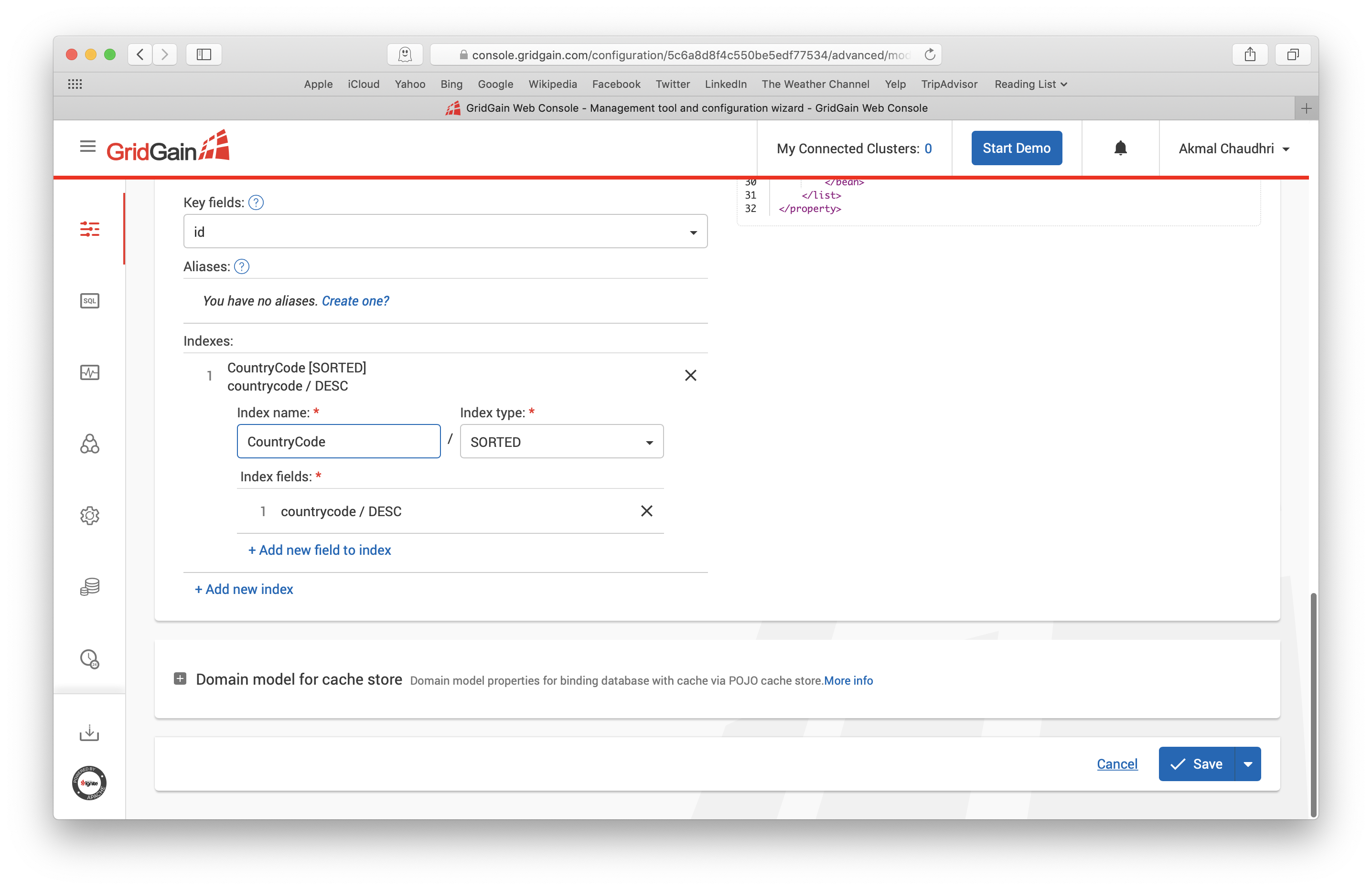
这里将索引名改为idx_country_code,然后点击Save按钮。接下来为Countrylanguage重复前图和上图的过程,将索引名改为idx_lang_country_code 之后保存更改,做这些修改,可以确保索引名在整个Ignite模式中是唯一的。
下面选择Caches选项卡,首先选择CityCache,如下图所示,然后往下滚动并展开Queries & Indexing部分:
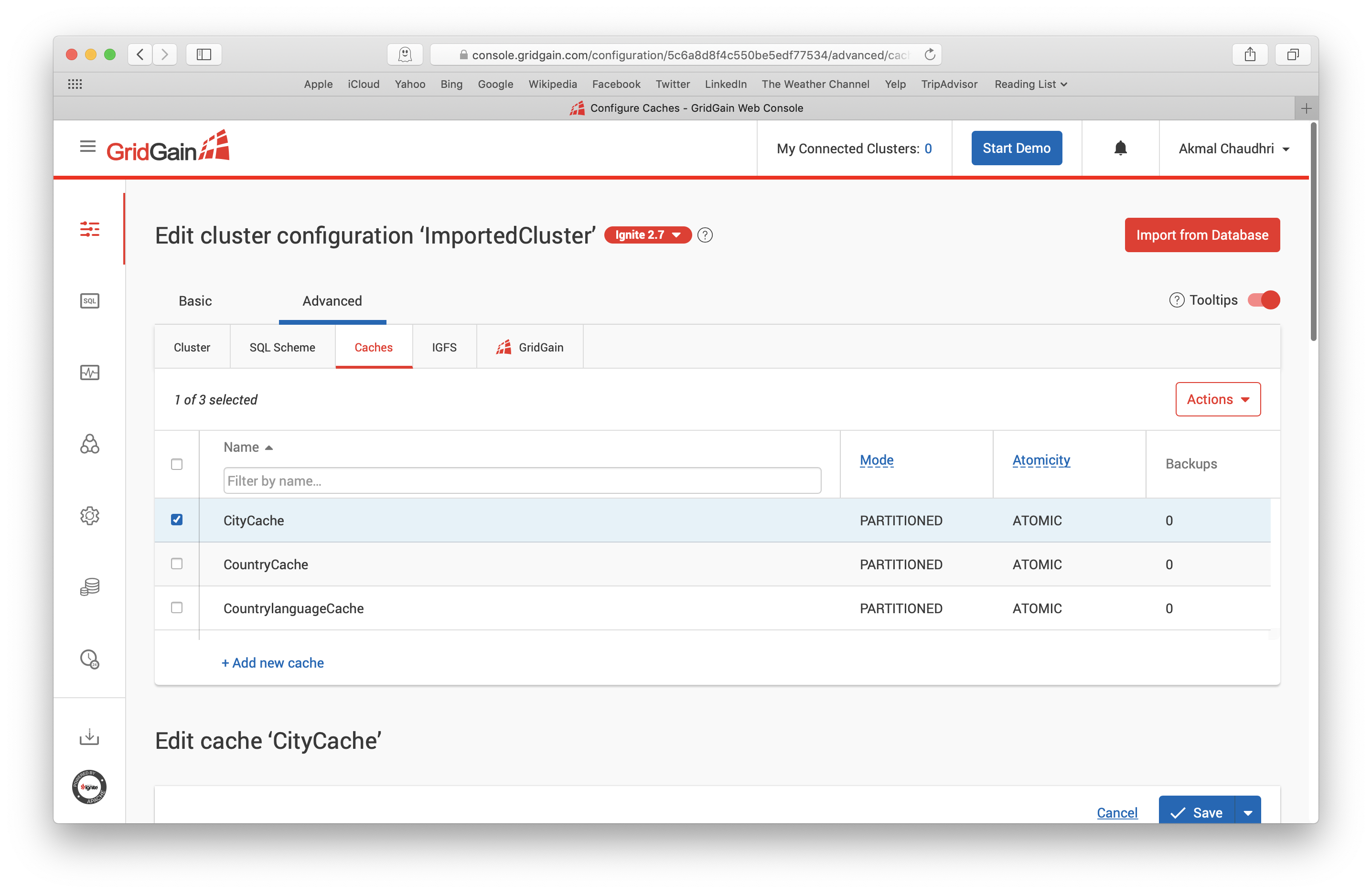
在Queries & Indexing中,有一个值为空名为SQL schema name的字段,在这里输入PUBLIC后保存变更,然后为CountryCache和CountrylanguageCache重复这个过程。
最后,返回到Configuration页面,选中ImportedCluster然后在Actions下拉框中下载这个工程,如下图所示:
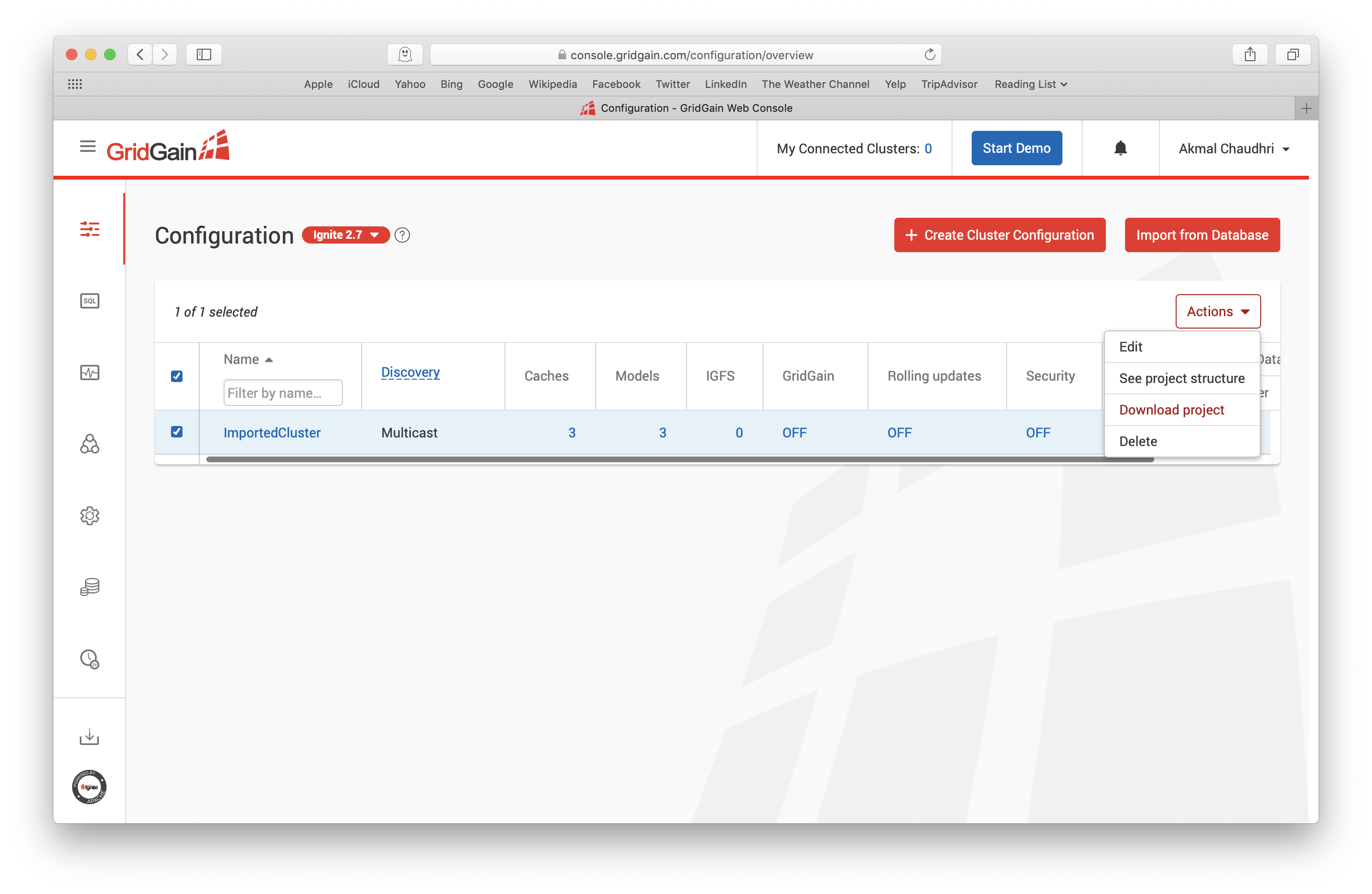
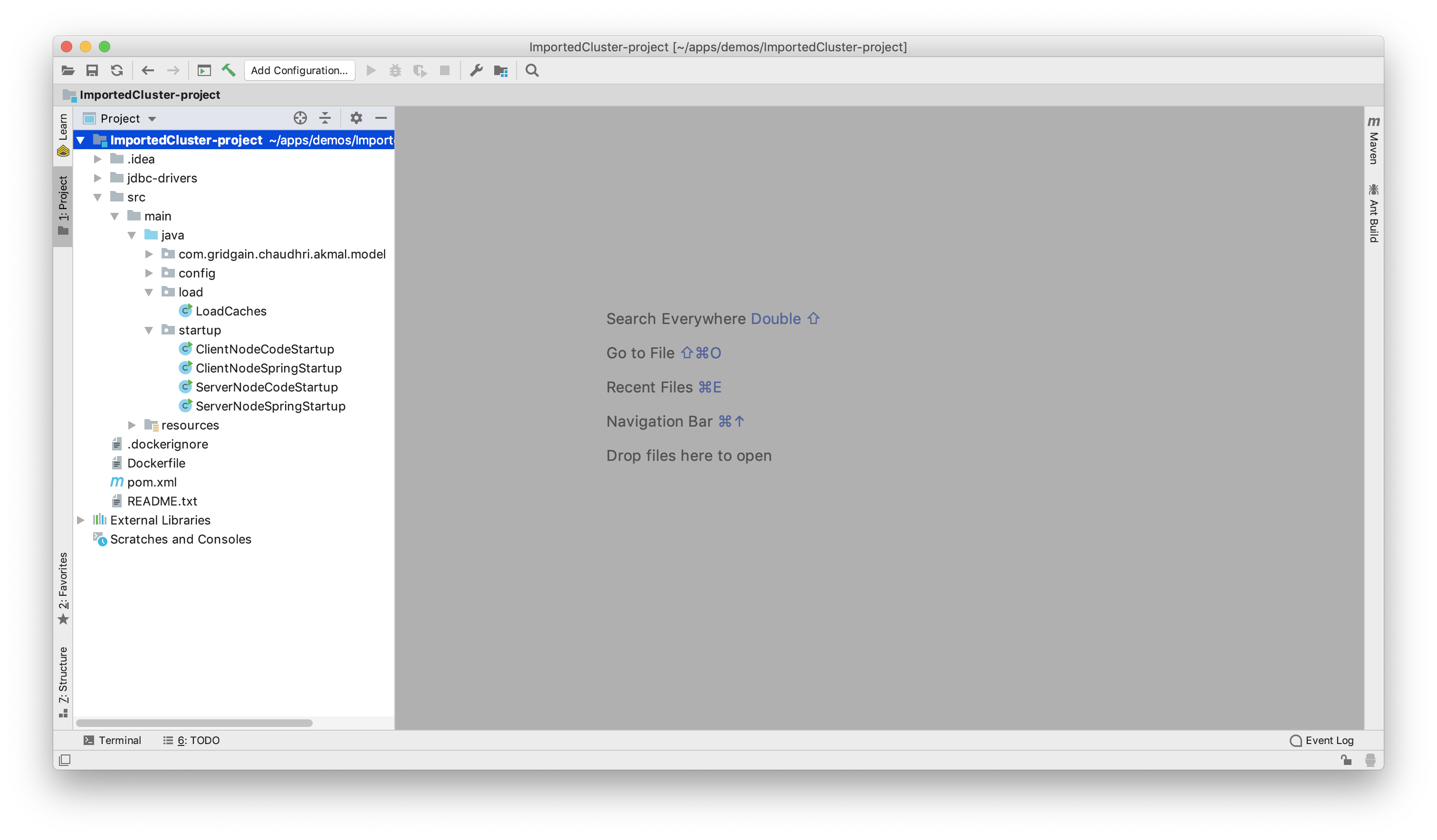
这时会保存一个名为ImportedCluster-project.zip的文件,解压这个文件之后就可以在IDE中通过读取其中的pom.xml文件创建一个新的工程,如下图所示:
在pom.xml文件中,在dependencies下面,需要检查一下mysql-connector-java依赖,如果缺失,需要加一下,如下所示:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.15</version>
</dependency>
这里的版本号匹配了之前使用的JDBC驱动的版本号。
在这个工程中,在resources文件夹下面,有一个名为secret.properties的文件,如下图所示:
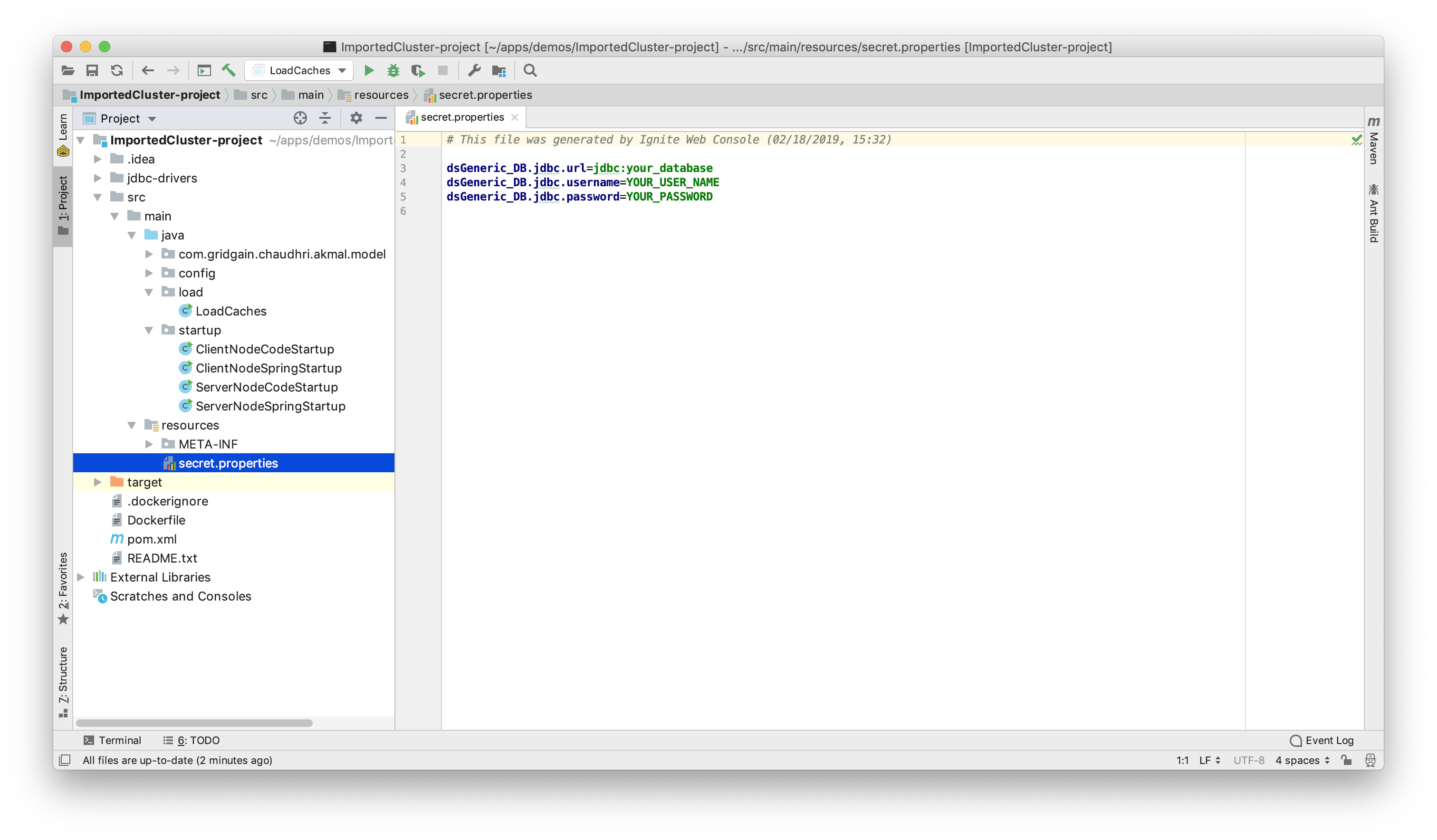
这里需要填入之前使用的JDBC URL、Username和Password,然后保存修改。
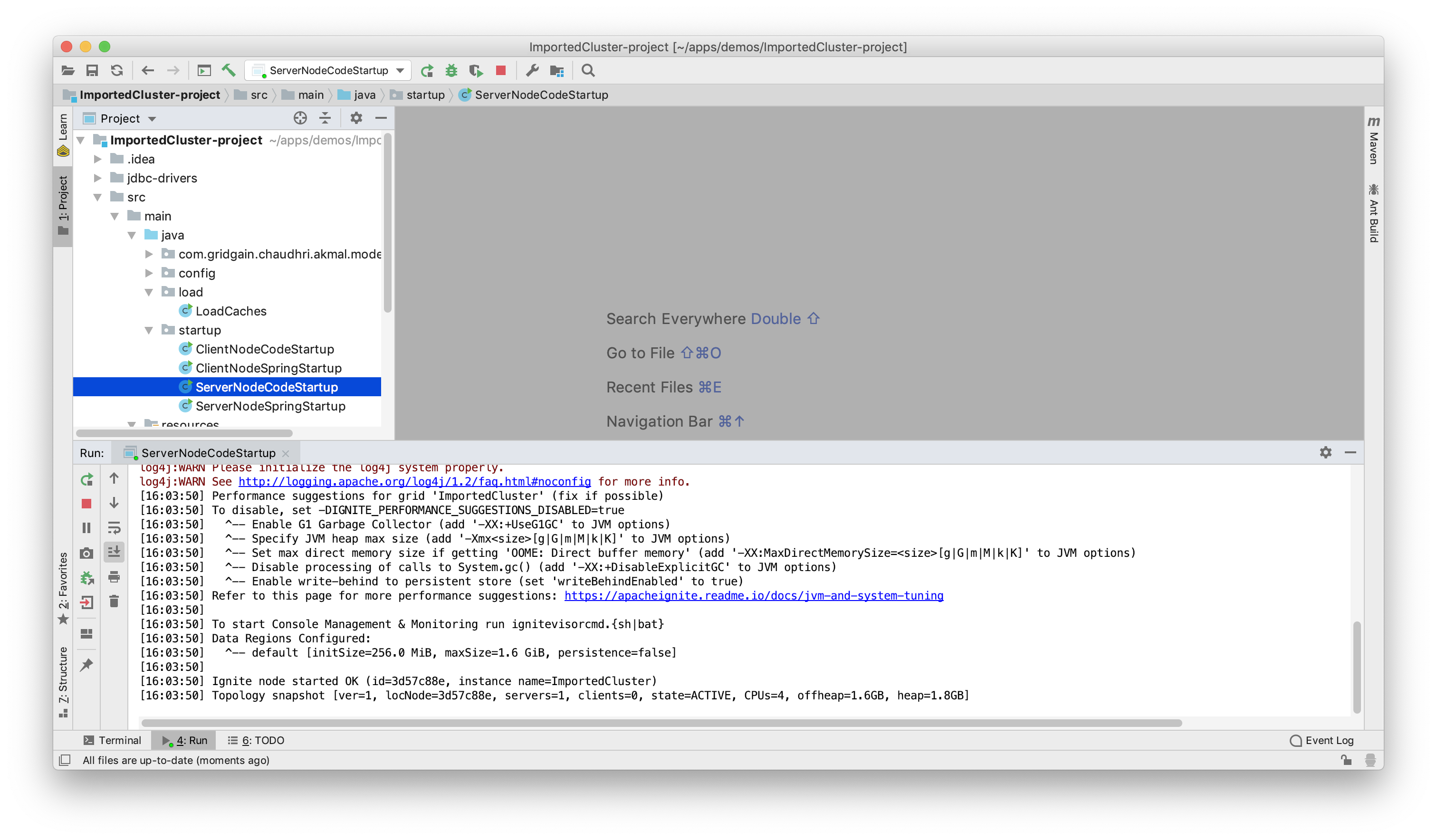
工程重新构建之后,就可以启动一个Ignite服务端节点,如下图所示:
接下来,通过运行LoadCaches,可以把MySQL中的数据加载进Ignite存储,如下图所示:
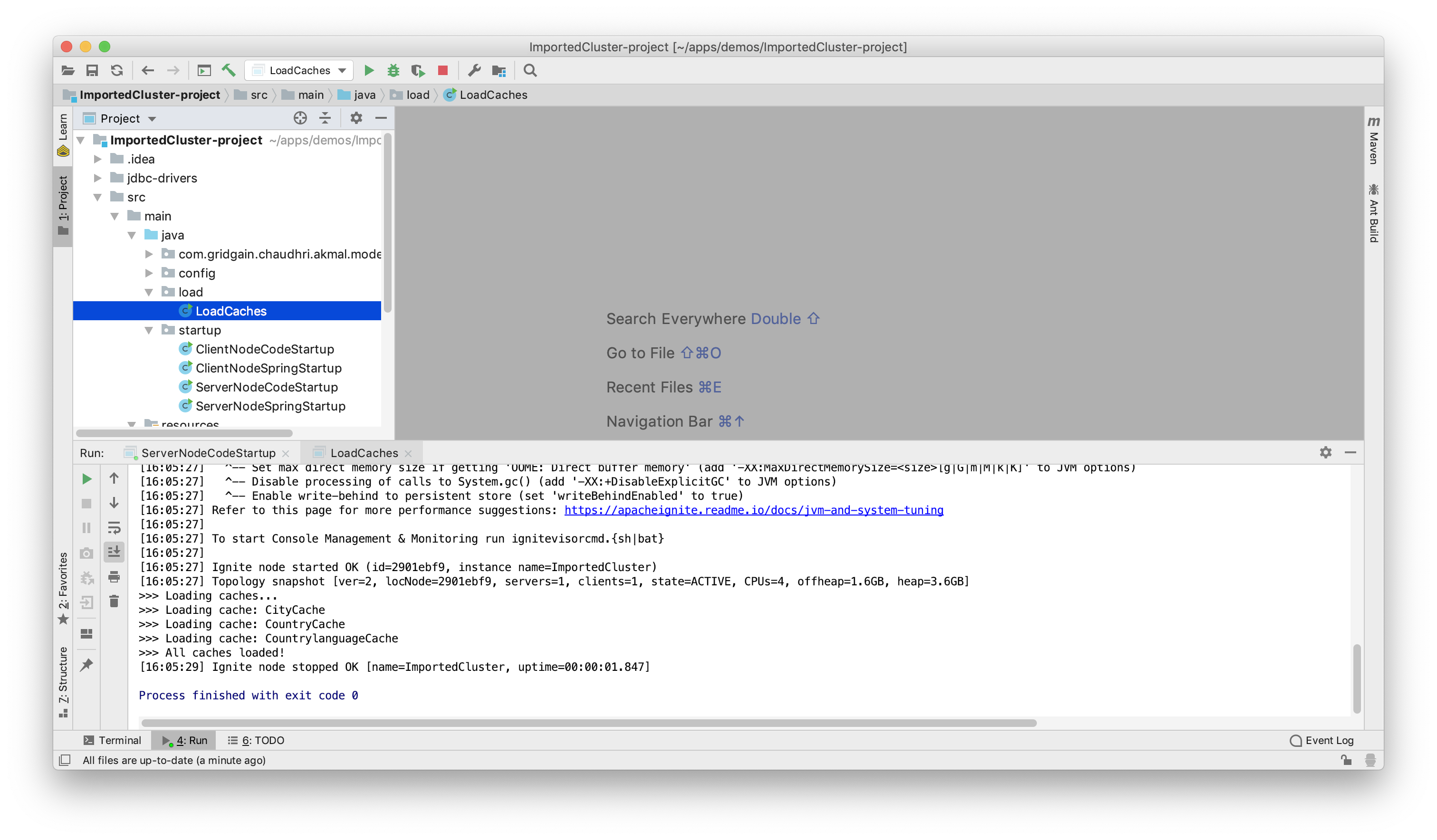
在Web控制台中,转到Monitoring > Dashboard > Caches,可以看到Ignite存储已经创建并且数据也已经成功加载,如下图所示:
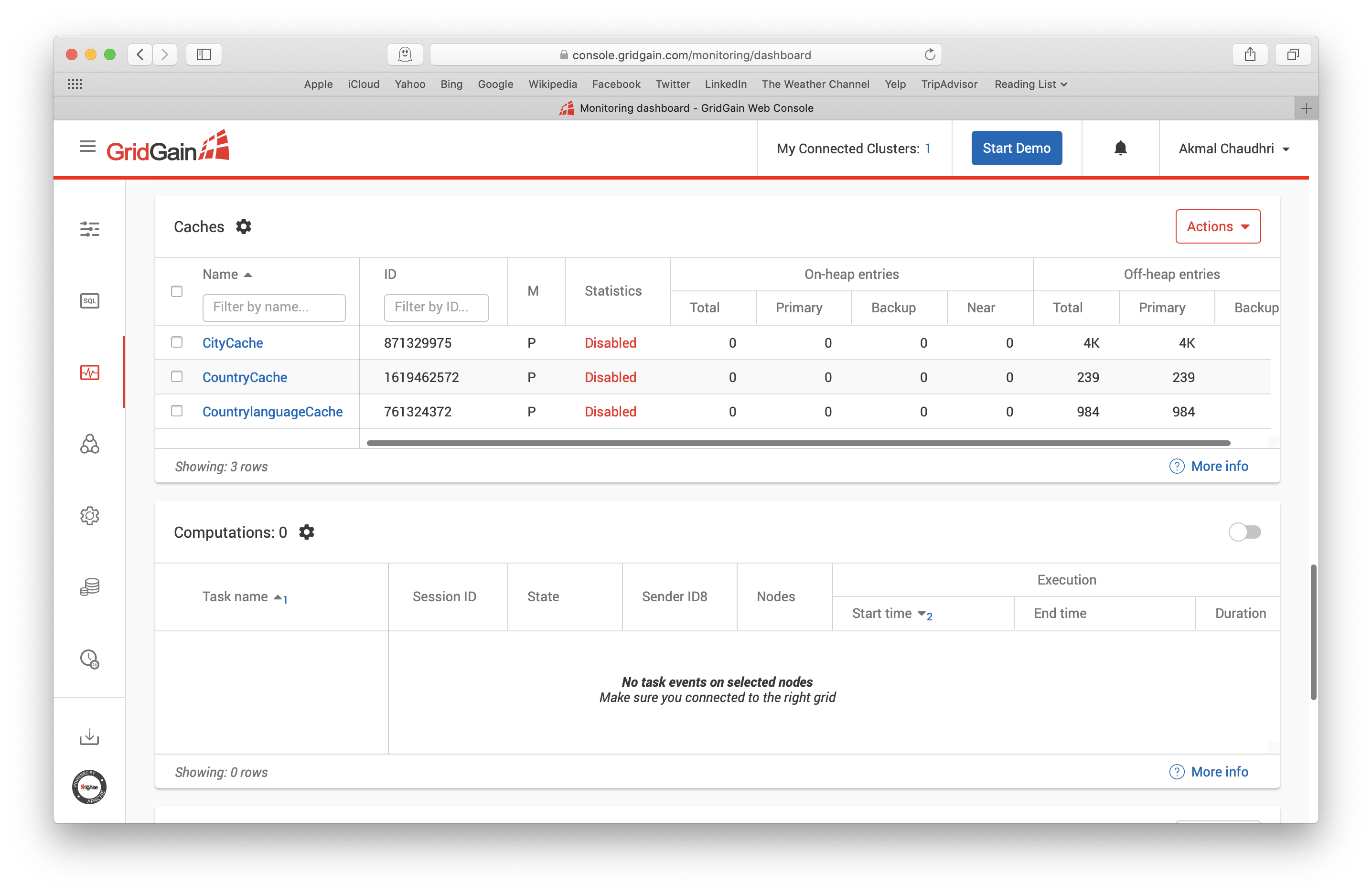
Ignite现在已经运行起来,创建了存储并且从MySQL中加载了数据,这时就可以通过任意数量不同的接口接入Ignite,不过本文会使用Node.js瘦客户端。
Node.js瘦客户端
使用Ignite提供的Node.js版本SQL示例作为模板,可以创建若干个Node.js应用,然后执行下表中列出的SQL查询,完整的Node.js应用代码可以参见GitHub,在下面的例子中,该Node.js应用在Ignite的Node.js示例文件夹中运行:
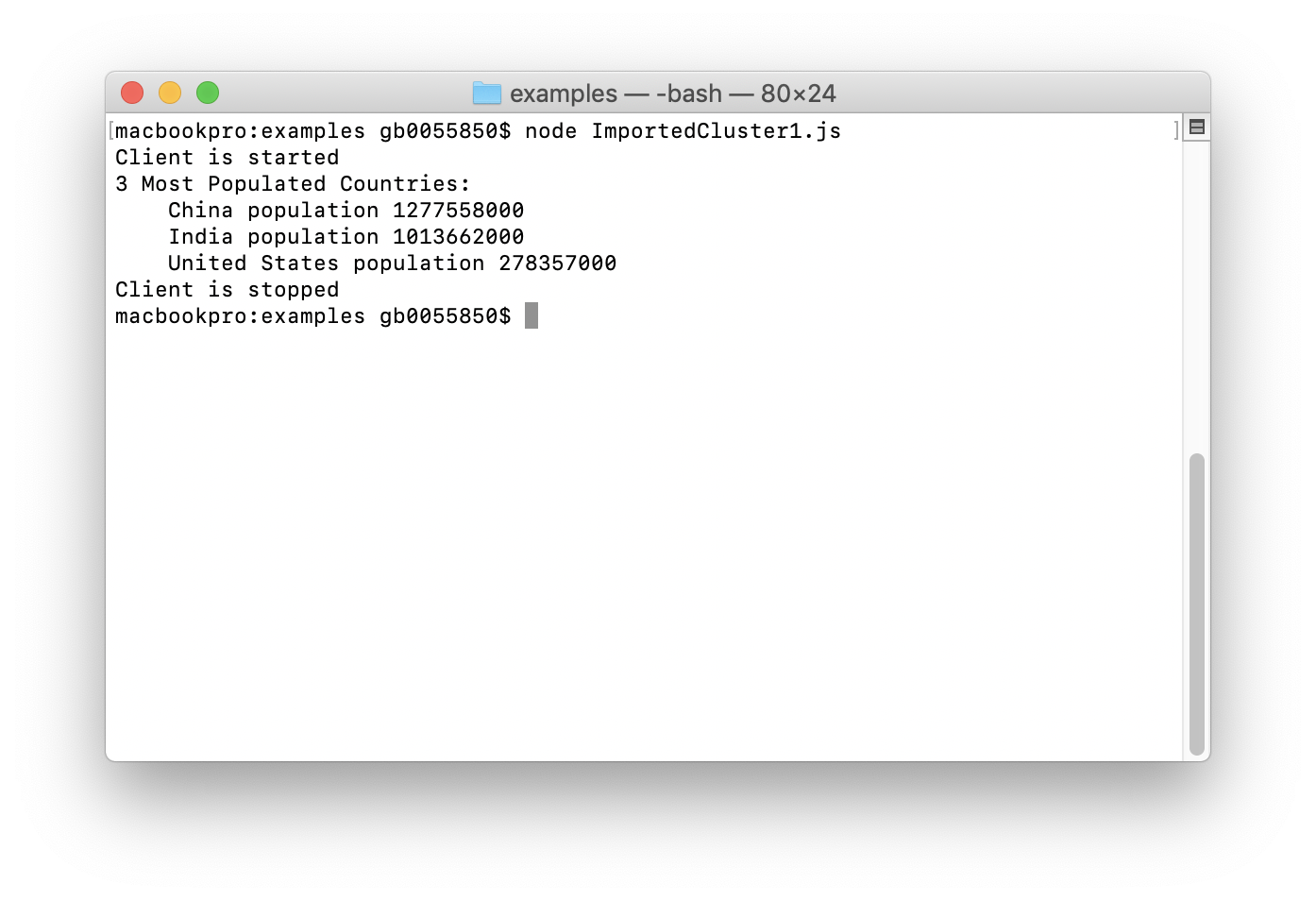
Q1:3个人口最多的国家
SELECT name, MAX(population)
AS max_pop FROM country
GROUP BY name, population
ORDER BY max_pop
DESC LIMIT 3
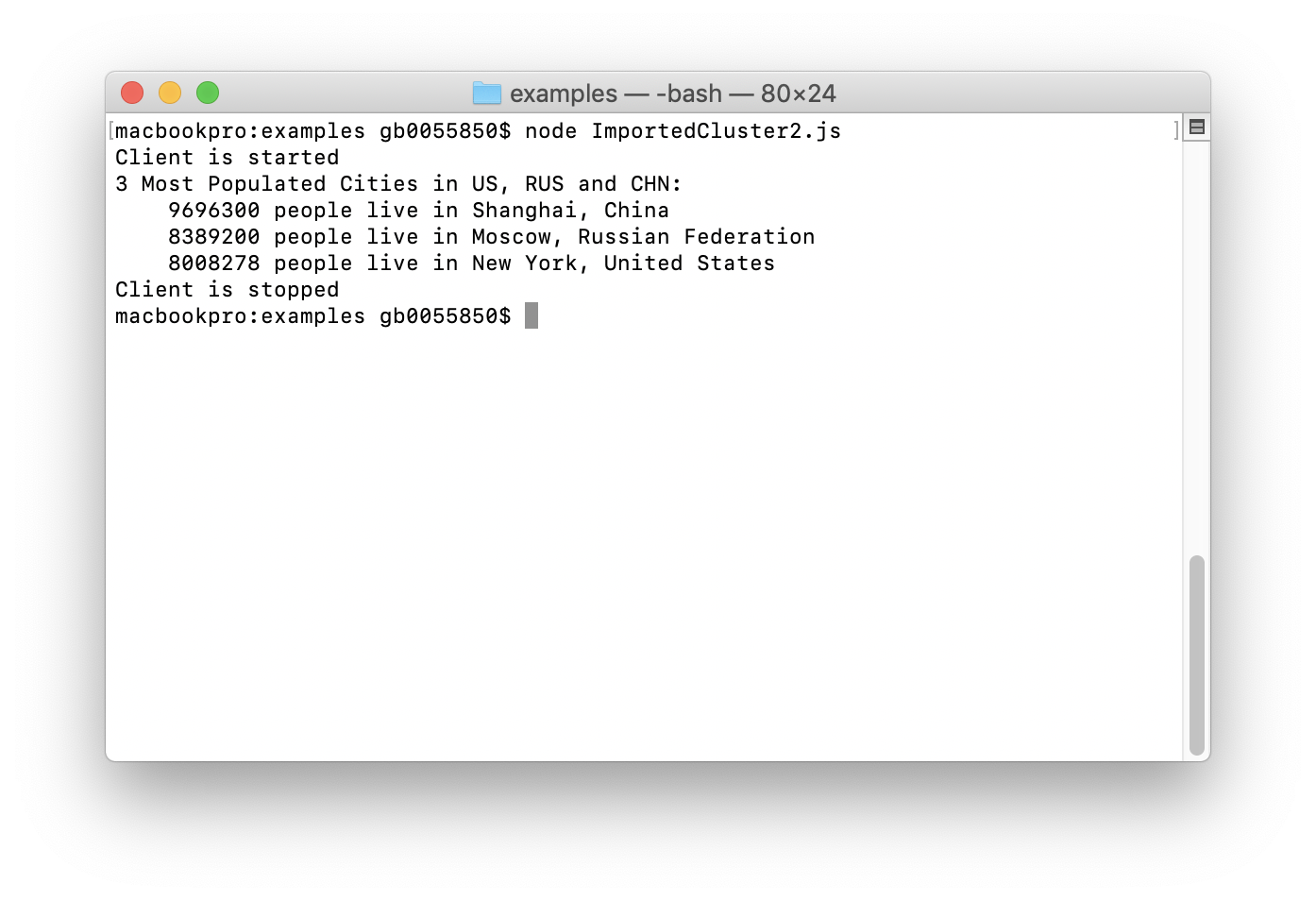
Q2:US、RUS和CHN中3个人口最多的城市
SELECT country.name, city.name, MAX(city.population)
AS max_pop FROM country
JOIN city ON city.countrycode = country.code
WHERE country.code IN (''USA'',''RUS'',''CHN'')
GROUP BY country.name, city.name
ORDER BY max_pop
DESC LIMIT 3
Q3:更新国家名称
UPDATE country
SET name = ''USA''
WHERE name = ''United States''
Q4:恢复国家名称
UPDATE country
SET name = ''United States''
WHERE name = ''USA''
Q1的输出如下图所示:
Q2比Q1复杂些,包含了两个表的关联,Q2的输出大致如下图所示:
Q3执行了一个更新操作,Q3执行完之后,Ignite的缓存会被更新,并且更新会被回写到MySQL中,保持两者之间的同步。可以使用DBeaver确认一下,首先在Country表中找到值为United States的行,如下图所示:
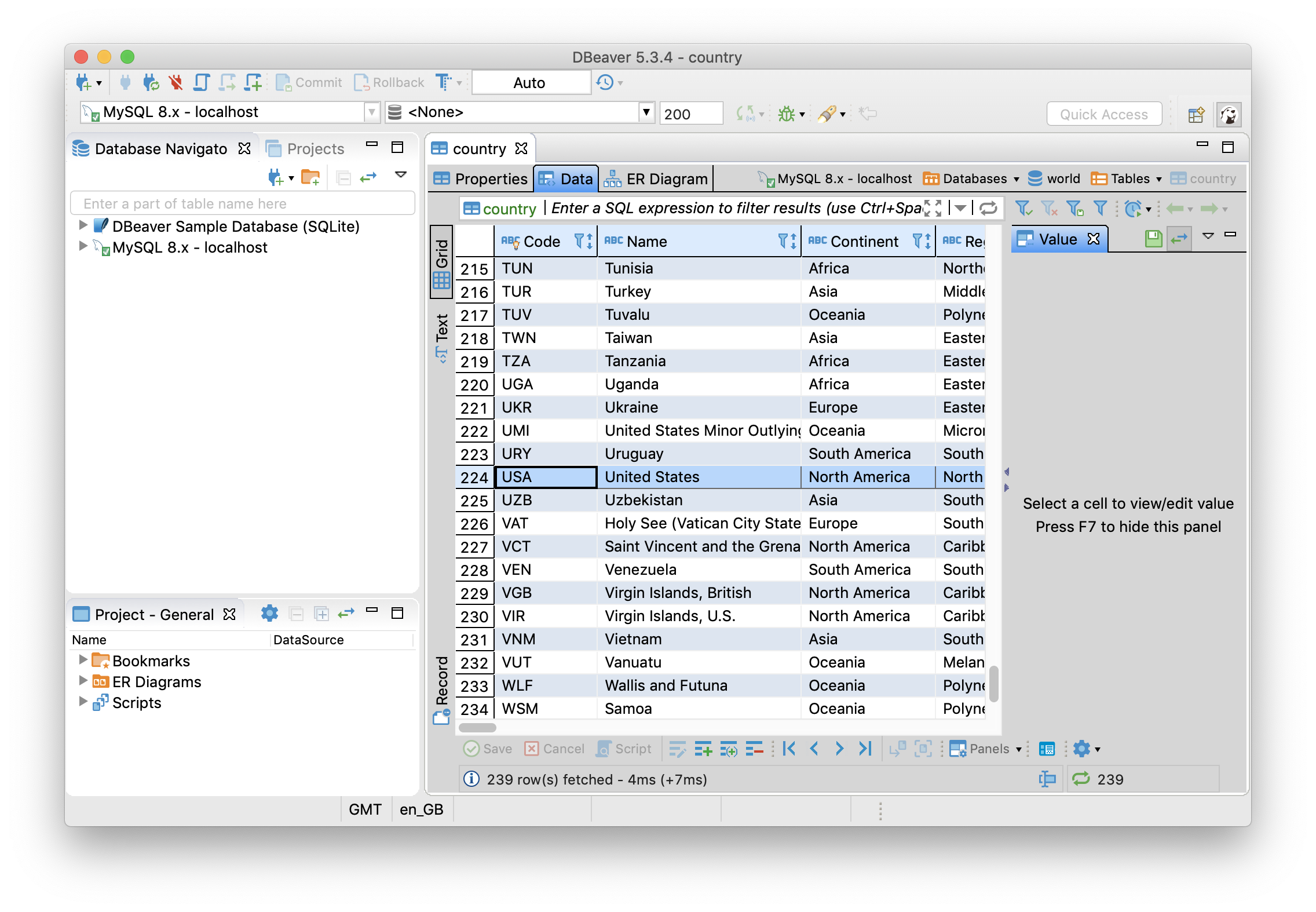
Q3执行完之后刷新一下DBeaver,可以看到Name字段的值已经变为USA,如下图所示:
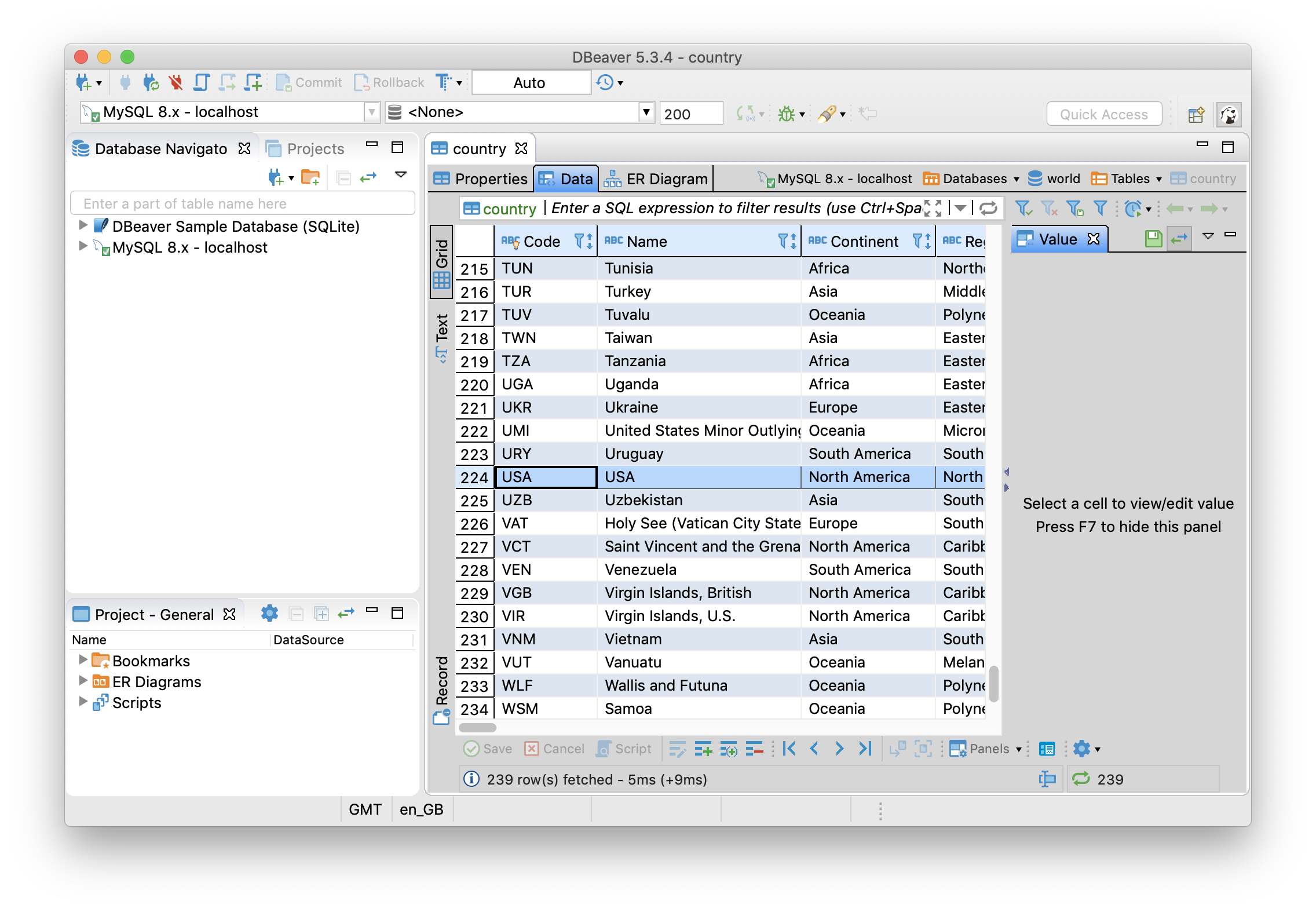
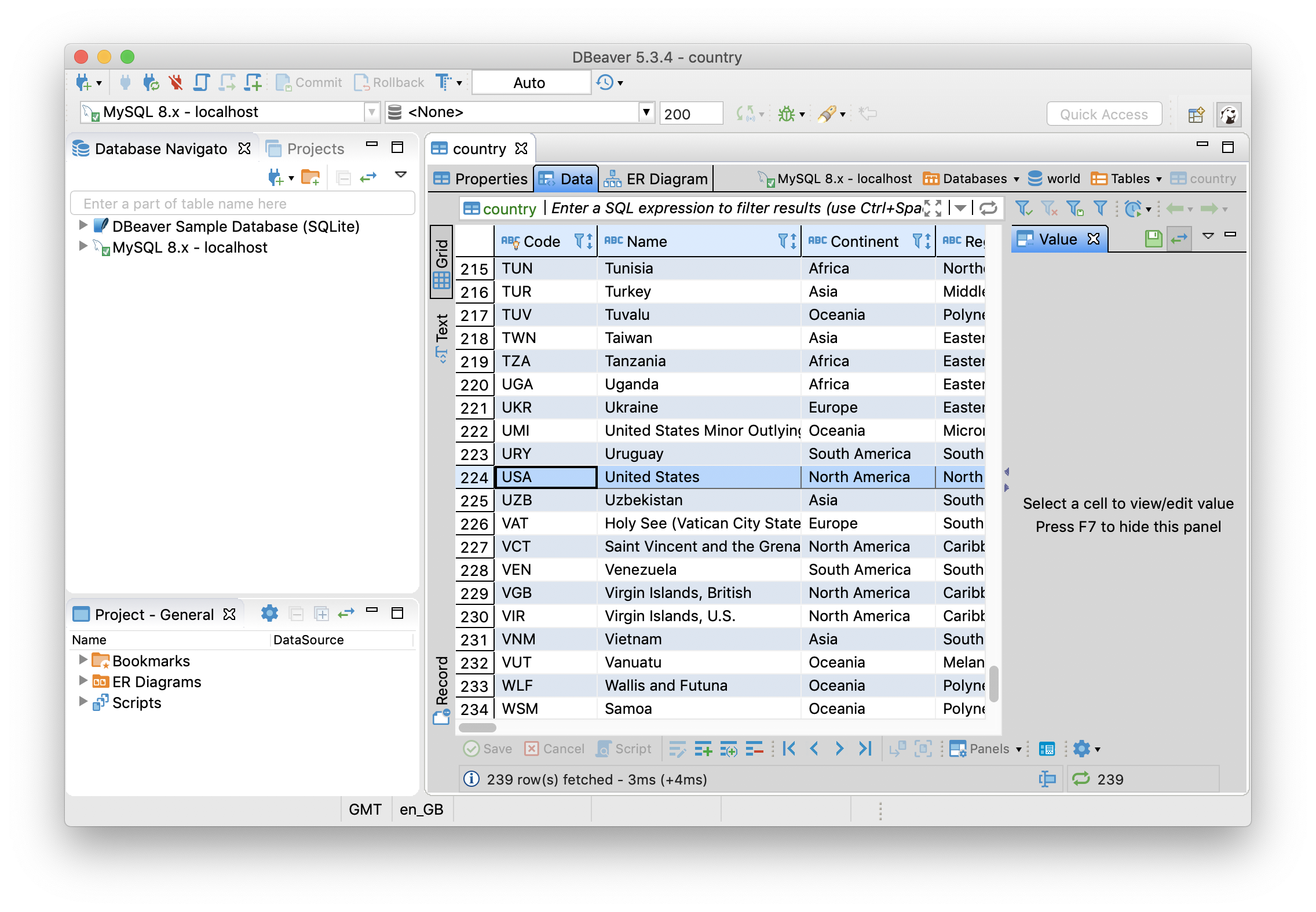
Q4恢复了原来的值,通过执行这个SQL然后刷新一下DBeaver可以进行验证,如下图所示:
下一步
通过修改和调整Ignite附带的示例,可以进一步测试Node.js瘦客户端。此外,Web控制台提供了许多选项,可用于从现有数据库系统微调和调整模式信息,具体可以参见Web控制台的相关文档。
总结
在本文中,了解了如何从现有的MySQL数据库系统中获取模式信息并创建一个Ignite工程。这个Ignite工程能够将数据从MySQL服务器复制到Ignite存储,然后在该数据中执行查询。从规模上看,Ignite可以利用集群计算的强大功能使操作并行化,在内存中快速执行查询并进行分析,甚至机器和深度学习,同时还保留现有系统的商业价值。虽然在本示例中使用了Node.js瘦客户端,不过Ignite还支持其它编程语言的瘦客户端。

Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL
在上一篇文章中,回顾和总结了 Cassandra 中使用的查询驱动数据模型(或者说非常规数据模型)方法论的缺陷。事实证明,如果不对查询有深入的了解,通过该方法论将无法开发高效的应用。实际上,这种场景的应用架构上会变得更加的复杂,难于维护,并且会造成很大的数据冗余。
此外,这个问题通常会被这样的观点掩盖:“如果想要扩展性、速度以及高可用性,那么就得准备存储多份数据,并且牺牲 SQL 和强一致性。”,这个论调十年前可能是正确的,但是现在完全错误!
没那么夸张,我们选择了另一个 ASF 成员,Apache Ignite。在本文中,会讲解基于 Ignite 的应用架构,然后衡量它的维护成本。
我们选择的应用仍然是跟踪所有厂商生产的车辆,然后了解每个单一厂商的产能,如果看过第一篇文章,那么应该知道关系模型如下:
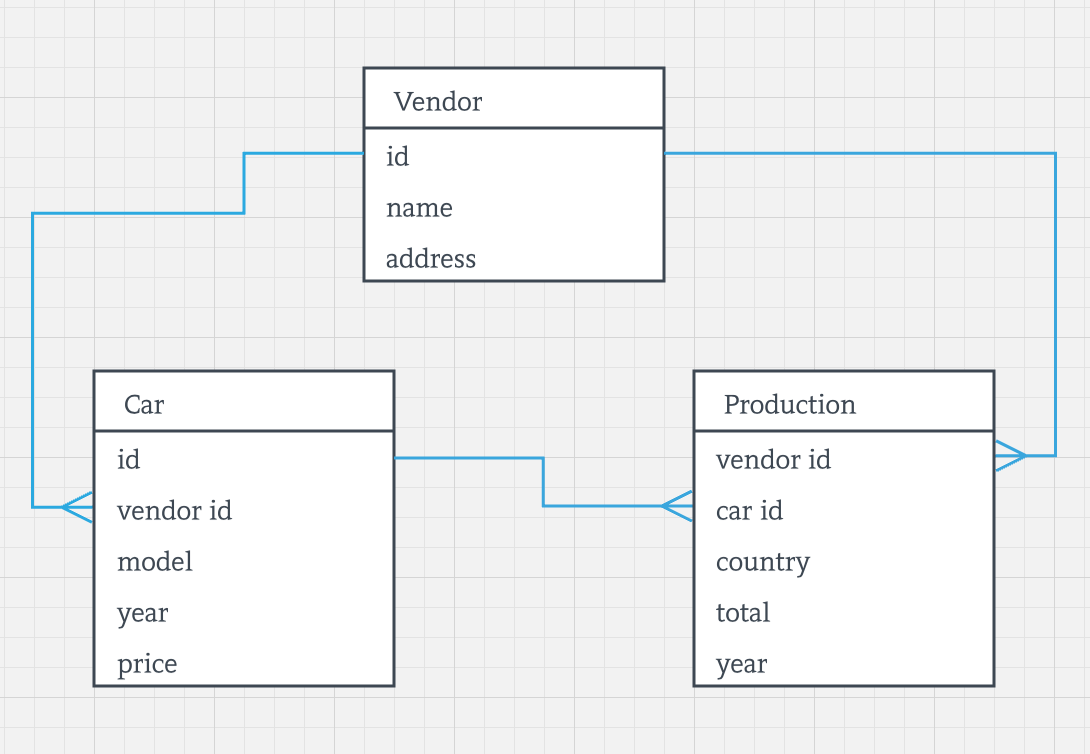
下一步,可以使用 Ignite 的 CREATE TABLE 命令创建这三个表,然后运行由 SQL 驱动的应用了么?不一定,如果不需要对存储于不同表中的数据进行关联操作,那么是可以的。但是根据前文,前提是应用需要支持两种关联的查询:
- Q1:获取一个厂商在特定的时间段内生产的车型。
- Q2:获取一个厂商特定车型的产量。
在 Cassandra 的案例中,我们为每个查询创建了一张表规避了关联的问题,那么用 Ignite,是不是还要经历同样的过程?完全不用。事实上,Ignite 的非并置的关联已经完全可用,如果三个表已经建好了,那么不需要什么额外的工作。但是,这没有比并置的高效和快速。因此,首先要多学习一下关系并置,然后了解这个概念在 Ignite 中是如何使用的。
基于并置关联的数据模型
关系并置在 Ignite(还有其他的分布式数据库,比如 Google Spanner 以及 MemSQL)中是一个强大的概念,它可以在以一个集群节点上存储相关的数据。那么哪些数据是相关的呢?尤其是在关系数据库的背景下,这非常简单,只需要在业务对象之间标示一个父子关系,在 CREATE TABLE 语句中指定一个关系键就可以了,剩下的就交给 Ignite 了!
还是拿车辆和厂商的应用举例,使用厂商作为父实体,车辆作为子实体是合理的。比如,按照这样配置好之后,某个厂商生产的所有车辆数据都会存储于同一个节点上,如下图所示:
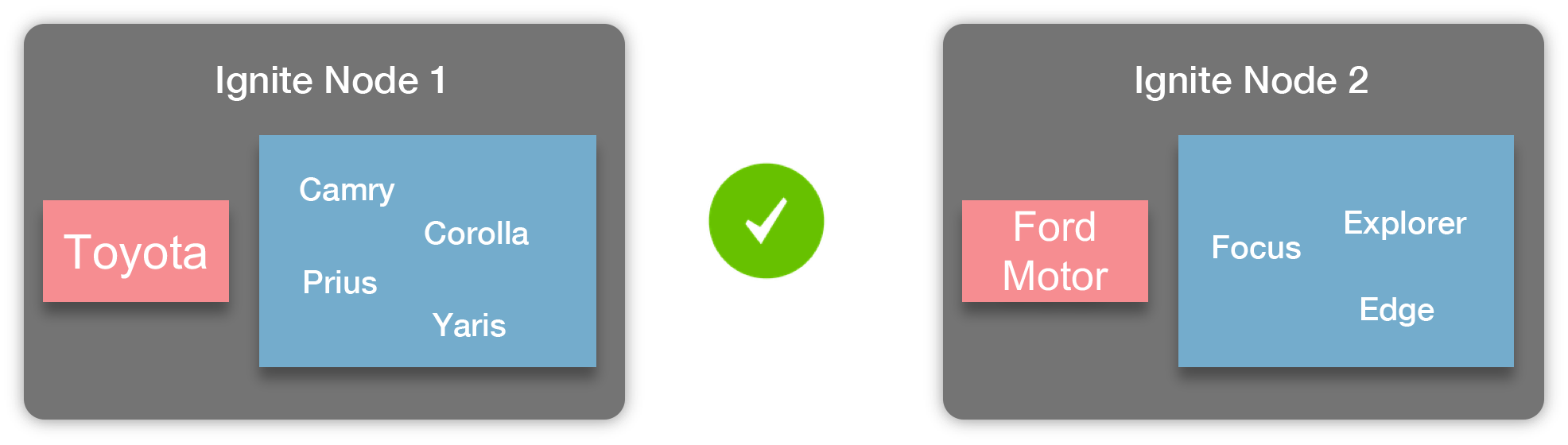
如图所示,丰田生产的车辆都存储于节点 1,而福特生产的车辆都存储于节点 2,这就是关系并置,车辆都会存储于对应的厂商所在的节点上。
要做到这样的数据分布,Vendor 表的 SQL 定义如下:
CREATE TABLE Vendor (
id INT PRIMARY KEY,
name VARCHAR,
address VARCHAR
);
厂商数据会在整个集群中随机地分布,Ignite 会使用主键列计算厂商数据所在的节点。 下一个是 Car 表:
CREATE TABLE Car (
id INT,
vendor_id INT,
model VARCHAR,
year INT,
price float,
PRIMARY KEY(id, vendor_id)
) WITH "affinityKey=vendor_id";
车辆表有一个 affinityKey 参数,配置为 vendor_id 列,它告诉 Ignite,车辆存储于 vendor_id 对应的集群节点。
在 Production 表上重复同样的过程,它的数据也是存储于 vendor_id 对应的集群节点上,如下:
CREATE TABLE Production (
id INT,
car_id INT,
vendor_id INT,
country VARCHAR,
total INT,
year INT,
PRIMARY KEY(id, car_id, vendor_id)
) WITH "affinityKey=vendor_id";
这样数据模型就建完了,下一步就进入应用的代码,然后开发必要的查询。
带关联的 SQL 查询
Ignite 集群可以使用我们熟悉的 SQL 进行查询,它支持分布式的 SQL 关联以及二级索引。 Ignite 支持两种类型的关联:并置和非并置。假定要关联的表已经并置,并且本地数据全部可用,那么并置的关联会避免数据 (关联所需的)的移动,这是在分布式数据库中效率最高、性能最好的。如果部分表无法实现关系并置,但是还需要进行关联,那么非并置的关联就是一个备份计划。这种类型的关联速度较慢,因为在关联时它需要在集群节点间进行数据的移动。
之前,已经配置好了 Vendor、Car 和 Production 表,下一步就是利用并置关联的优势,为 Q1 写一个 SQL:
SELECT c.model, p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = ''Ford Motor'' and p.year >= 2017
ORDER BY p.year;
还能更快么?当然能。下面为 Vendor.name 和 Production.year 列定义二级索引:
CREATE INDEX vendor_name_id ON Vendor (name);
CREATE INDEX prod_year_id ON Production (year);
针对 Q2 的查询也不需要额外的工作:
SELECT p.country, p.total, p.year FROM Vendor as v
JOIN Production as p ON v.id = p.vendor_id
JOIN Car as c ON c.id = p.car_id
WHERE v.name = ''Ford Motor'' and c.model = ''Explorer'';
现在,如果老板要求增加一个新特性时,很快就能构造出一套新的 SQL 满足他。 完成!作为比较,如果要支持 Q2,可以看看基于 Cassandra 的架构是怎么搞的。
架构简化:任务完成!
Ignite 的基于关系并置的数据模型,针对 Cassandra 的基于查询驱动的模型有如下的优点:
- 应用的数据层基于熟悉的关系模型进行建模,易于维护;
- 数据使用标准的 SQL 语法进行访问;
- 关系并置提供了现代分布式数据库的更多好处:
- 高效和高性能的分布式关联;
- 并置计算 ;
使用 Ignite 替代 Cassandra,简化的软件架构并不是唯一的好处,过段时间,还会有关于强一致性和内存极性能方面的想法。
本文译自 Denis Magda 的博客。

Apache Cassandra和Apache Ignite:通过Ignite增强Apache Cassandra
Apache Cassandra是开源分布式NoSQL磁盘数据库的领导者之一,作为关键的基础设施,已经部署在诸如Netflix、eBay、Expedia等很多公司中,它因为速度、可线性扩展至上千个节点、一流的数据中心复制而广受欢迎。
Apache Ignite是一个以内存为中心的分布式数据库、缓存和处理平台,可以针对PB级的数据,以内存级的速度处理事务、分析和流式负载,支持JCache、SQL99、ACID事务以及机器学习。
Apache Cassandra在它的领域,是一个经典的解决方案,和任何特定领域解决方案一样,它的优势是建立在一些妥协之上的,一个典型的因素就是受到磁盘存储的限制,Cassandra已经做了尽可能多的优化来解决这些问题。
举个权衡的例子:缺乏ACID和SQL支持之后,就无法随意进行事务和分析,如果数据事先没有进行很好的适配,这些妥协因素,就会对用户造成逻辑上的困扰,导致产品的不正确使用,甚至负体验,或者导致数据在不同类型的存储之间共享,基础设施碎片化以及应用的数据逻辑复杂化。
但是,作为Cassandra的用户,是否可以将其与Apache Ignite一起使用呢?作为前提,目的是维护既有的Cassandra系统然后解决它的局限性,答案是:是,我们可以将Ignite作为一个内存层,部署在Cassandra之上,本文之后就会介绍如何实现。
1.Cassandra的限制
首先,先简要地过一下主要的限制,这些是我们要解决的问题:
- 受到磁盘或者SSD特性的限制,带宽和响应时间受到限制;
- 数据结构为顺序地读和写进行了优化,没有为传统关系型数据操作的性能优化进行适配,他无法进行数据的标准化以及高效地进行关联操作,并对诸如GROUP BY以及ORDER等进行了严格的限制;
- 因为第二条的原因,缺乏对SQL的支持也导致CQL的功能很有限;
- 缺少ACID事务;
虽然可以将Cassandra用于其他的用途,那也没问题,但是如果能解决这些问题,会显著增强Cassandra的能力。通过组合人和马,可以得到一个骑手,这相对于单独的人和马,已经是一个完全不同的事物。
那么如何规避这些限制呢?
传统的方法是分割数据,一部分存储于Cassandra中,其他的Cassandra无法保证的部分,存储于不同的系统中。
这个方法的缺点是增加了复杂性(潜在地也可能导致速度以及质量的下降)和增加了维护成本,和使用一个系统做数据存储相比,应用需要组合处理来自不同数据源的数据,甚至,任何其他系统的弱化都可能产生严重的负面影响,迫使基础设施团队疲于奔命。
2.Apache Ignite作为一个内存层
另一个方法是将另一个系统放到Cassandra之上,责任划分之后,Ignite可以提供如下的能力:
- 解决了由于磁盘带来的性能限制:Ignite完全在内存中运行,这是目前最快和最廉价的存储之一!
- 完全支持标准的SQL99:包括关联、GROUP BY、ORDER BY以及DML,可以标准化数据,便于分析,关注内存性能,打开HTAP的潜力,对生产数据进行实时分析;
- 支持JDBC和ODBC标准:便于和已有工具集成,比如Tableau,以及像Hibernate或者Spring Data这样的框架;
- 支持ACID事务:如果必须要求一致性,那么这个就是必要的;
- 分布式计算、流式数据处理、机器学习:可以使用Ignite提供的技术红利快速实现很多新的业务场景。
Ignite集群使用Cassandra的数据进行查询,开启通写之后会将所有的数据变更回写到Cassandra,下一步,Ignite中持有了数据,就可以自由地使用SQL、运行事务以及享受内存级的速度。
此外,数据也可以使用比如Tableau这样的可视化工具进行实时的分析。
3.配置
下一步,通过一个Ignite和Cassandra集成的简单示例,来说明它们如何一起工作以及可以获得那些特性。
首先,在Cassandra中创建必要的表,注入一些数据,然后初始化一个Java工程,写一些DTO类,然后就会展示核心部分:配置Ignite与Cassandra一起工作。
示例采用了macOS,Cassandra3.10以及Ignite2.3,在Linux中,命令类似。
3.1.Cassandra的表和数据
首先,将Cassandra的发行包放在~ / Downloads文件夹,然后进入该文件夹解压:
$ cd ~/Downloads
$ tar xzvf apache-cassandra-3.10-bin.tar.gz
$ cd apache-cassandra-3.10
使用默认配置启动Cassandra,用于测试这样够了:
$ bin/cassandra
下一步,使用Cassandra的交互式终端创建测试用的数据结构。这里使用常见的id作为主键,对于Cassandra中的表,主键的选择很重要,它关系到后续的数据提取,但是本示例中做了简化:
$ cd ~/Downloads/apache-cassandra-3.10
$ bin/cqlsh
CREATE KEYSPACE IgniteTest WITH replication = {''class'': ''SimpleStrategy'', ''replication_factor'' : 1};
USE IgniteTest;
CREATE TABLE catalog_category (id bigint primary key, parent_id bigint, name text, description text);
CREATE TABLE catalog_good (id bigint primary key, categoryId bigint, name text, description text, price bigint, oldPrice bigint);
INSERT INTO catalog_category (id, parentId, name, description) VALUES (1, NULL, ''Appliances'', ''Appliances for households!'');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (2, 1, ''Refrigirators'', ''The best fridges we have!'');
INSERT INTO catalog_category (id, parentId, name, description) VALUES (3, 1, ''Washing machines'', ''Engineered for exceptional usage!'');
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (1, 2, ''Fridge Buzzword'', ''Best fridge of 2027!'', 1000, NULL);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (2, 2, ''Fridge Foobar'', ''The cheapest offer!'', 300, 900);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (3, 2, ''Fridge Barbaz'', ''Premium fridge in your kitchen!'', 500000, 300000);
INSERT INTO catalog_good (id, categoryId, name, description, price, oldPrice) VALUES (4, 3, ''Appliance Habr#'', ''Washes, squeezes, dries!'', 10000, NULL);
检查一下保存的数据是否正确:
cqlsh:ignitetest> SELECT * FROM catalog_category;
id | description | name | parentId
----+--------------------------------------------+--------------------+-----------
1 | Appliances for households! | Appliances | null
2 | The best fridges we have! | Refrigirators | 1
3 | Engineered for exceptional usage! | Washing machines | 1
(3 rows)
cqlsh:ignitetest> SELECT * FROM catalog_good;
id | categoryId | description | name | oldPrice | price
----+-------------+---------------------------+----------------------+-----------+--------
1 | 2 | Best fridge of 2027! | Fridge Buzzword | null | 1000
2 | 2 | The cheapest offer! | Fridge Foobar | 900 | 300
4 | 3 | Washes, squeezes, dries! | Appliance Habr# | null | 10000
3 | 2 | Premium fridge in your kitchen! | Fridge Barbaz | 300000 | 500000
(4 rows)
3.2.初始化Java工程
Ignite的使用有两种方式:一个是从官网下载发行包,然后将jar文件加入类路径并且使用XML进行配置,或者将Ignite作为Java工程的Maven依赖,本文会使用第二种方式。
使用Maven创建一个新的工程然后加入如下的库:
ignite-cassandra-store:用于Cassandra集成;ignite-spring:使用Spring XML文件配置Ignite。
这两个库都依赖ignite-core,它包含了Ignite的核心功能:
<dependencies>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-spring</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.apache.ignite</groupId>
<artifactId>ignite-cassandra-store</artifactId>
<version>2.3.0</version>
</dependency>
</dependencies>
下一步,创建DTO类,用于映射Cassandra的表:
import org.apache.ignite.cache.query.annotations.QuerySqlField;
public class CatalogCategory {
@QuerySqlField private long id;
@QuerySqlField private Long parentId;
@QuerySqlField private String name;
@QuerySqlField private String description;
// public getters and setters
}
public class CatalogGood {
@QuerySqlField private long id;
@QuerySqlField private long categoryId;
@QuerySqlField private String name;
@QuerySqlField private String description;
@QuerySqlField private long price;
@QuerySqlField private long oldPrice;
// public getters and setters
}
在这些属性上添加了@QuerySqlField注解是为了可以通过Ignite SQL查询到,如果一个属性未加注该注解,它是无法通过SQL进行提取或者通过它进行过滤的。
当然还可以进行微调,比如定义索引以及全文检索,但是这超出了本文的范围,配置Ignite SQL的更多信息,可以查看对应的文档。
3.3.配置Ignite
在src/main/resources目录中创建一个名为apacheignite-cassandra.xml的配置文件,下面是完整的配置,关键部分后续还会说明:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd">
<beanname="cassandra">
<property name="contactPoints" value="127.0.0.1"/>
</bean>
<bean>
<property name="cacheConfiguration">
<list>
<bean>
<property name="name" value="CatalogCategory"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_category"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogCategory</value>
</list>
</property>
<property name="cacheStoreFactory">
<bean>
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean>
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistencestrategy="PRIMITIVE" column="id"/>
<valuePersistencestrategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>
</bean>
<bean>
<property name="name" value="CatalogGood"/>
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_good"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogGood</value>
</list>
</property>
<property name="cacheStoreFactory">
<bean>
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean>
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_good">
<keyPersistencestrategy="PRIMITIVE" column="id"/>
<valuePersistencestrategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>
</bean>
</list>
</property>
</bean>
</beans>
上述配置可以分为两个部分,首先,定义一个连接Cassandra的数据源,第二是Ignite本身的配置。 第一部分的配置比较简单:
<beanname="cassandra">
<property name="contactPoints" value="127.0.0.1"/>
</bean>
使用IP地址来定义要连接的Cassandra数据源。
下一步要配置Ignite,在本例中,和默认的配置相比只有很小的区别,只是覆写了cacheConfiguration属性,它包含了一组映射到Cassandra表的Ignite缓存:
<bean>
<property name="cacheConfiguration">
<list>
...
</list>
</property>
</bean>
第一个缓存映射到Cassandra的catalog_category表:
<bean>
<property name="name" value="CatalogCategory"/>
...
</bean>
每个缓存都开启了通读和通写模式,比如,如果对Ignite执行了写入操作,那么Ignite会自动发送一个更新操作给Cassandra,接下来,指定了在Ignite中使用catalog_category模式:
<property name="readThrough" value="true"/>
<property name="writeThrough" value="true"/>
<property name="sqlSchema" value="catalog_category"/>
<property name="indexedTypes">
<list>
<value type="java.lang.Class">java.lang.Long</value>
<value type="java.lang.Class">com.gridgain.test.model.CatalogCategory</value>
</list>
</property>
最后,建立到Cassandra的连接,这里面有两个主要的子片段,首先,要指向之前创建的数据源,然后,要将Ignite缓存和Cassandra的表建立关联。
本来,通过persistenceSettings属性指向一个外部的配置映射的XML配置文件是比较好的,但是为了简化,将这段XML作为CDATA片段直接嵌入了Spring的配置文件:
<property name="cacheStoreFactory">
<bean>
<property name="dataSource" ref="cassandra"/>
<property name="persistenceSettings">
<bean>
<constructor-arg type="java.lang.String"><value><![CDATA[
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistencestrategy="PRIMITIVE" column="id"/>
<valuePersistencestrategy="POJO"/>
</persistence>]]></value></constructor-arg>
</bean>
</property>
</bean>
</property>
映射的配置看上去非常简单明了:
<persistence keyspace="IgniteTest" table="catalog_category">
<keyPersistencestrategy="PRIMITIVE" column="id"/>
<valuePersistencestrategy="POJO"/>
</persistence>
在最上层(persistence标签),声明了键空间(本例中为IgniteTest)和要关联的表(catalog_category),然后声明了Ignite缓存的主键为Long类型,这是个基本类型,它对应了Cassandra表中的id列。在本例中,值为CatalogCategory类,借助于反射(策略为POJO),建立了和Cassandra表中的列的关联。
关于映射的更多细节,超出了本文的细节,具体可以看相关的文档。
第二部分与产品数据有关的缓存配置,大体相同。
3.4.启动
使用下面的类可以启动:
package com.gridgain.test;
import org.apache.ignite.Ignite;
import org.apache.ignite.Ignition;
public class Starter {
public static void main(String... args) throws Exception {
final Ignite ignite = Ignition.start("apacheignite-cassandra.xml");
ignite.cache("CatalogCategory").loadCache(null);
ignite.cache("CatalogGood").loadCache(null);
}
}
这里使用了Ignition.start(...)方法来启动一个Ignite节点,ignite.cache(...).loadCache(null)方法用于将Cassandra中的数据预加载到Ignite中。
3.5.SQL
Ignite集群启动,接入Cassandra之后,就可以执行Ignite SQL查询了。比如,可以使用任何支持JDBC或者ODBC的客户端,在本例中使用了SquirrelSQL,首先需要为工具添加Ignite的JDBC驱动:  使用
使用jdbc:ignite://localhost/CatalogGood这样的URL形式建立一个连接,这里localhost是Ignite集群中一个节点的地址,然后CatalogGood是默认请求的缓存名。  最后,可以执行几个SQL查询:
最后,可以执行几个SQL查询:
SELECT cg.name goodName, cg.price goodPrice, cc.name category, pcc.name parentCategory
FROM catalog_category.CatalogCategory cc
JOIN catalog_category.CatalogCategory pcc
ON cc.parentId = pcc.id
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id;
| goodName | goodPrice | category | parentCategory |
|---|---|---|---|
| Fridge Buzzword | 1000 | Refrigerators | Appliances |
| Fridge Foobar | 300 | Refrigerators | Appliances |
| Fridge Barbaz | 500,000 | Refrigerators | Appliances |
| Appliance Habr # | 10000 | Washing machines | Appliances |
SELECT cc.name, AVG(cg.price) avgPrice
FROM catalog_category.CatalogCategory cc
JOIN catalog_good.CatalogGood cg
ON cg.categoryId = cc.id
WHERE cg.price <= 100000
GROUP BY cc.id;
| name | avgPrice |
|---|---|
| Refrigerators | 650 |
| Washing machines | 10000 |
4.结论
在这个简单的示例中,展示了如何通过引入Ignite,为已有的Cassandra系统带来了内存级性能的SQL功能。因此,如果正受到本文提到的Cassandra限制的困扰,那么就需要考虑一下Ignite这个备选的技术方案。
本文译自GridGain的业务架构师Artem Schitow的博客。

Apache Ignite 1.8.0 发布,全新的 SQL 网格
Apache Ignite 发布说明
Apache Ignite In-Memory Data Fabric 1.8
Ignite:
SQL: 新增对DML操作的支持 (INSERT, UPDATE, DELETE, MERGE)
SQL: 聚合时改进了DISTINCT 关键字的处理
Hadoop: 新增了对MapR 发行版的支持
Visor: 改进了SQL 统计
新增了Redis 协议的支持
新增了事务死锁
非常多的稳定性和容错性改进。
Ignite.NET:
新增了ASP.NET 的Session状态存储Provider。
新增了对Entity Framework 二级缓存的支持。
定制化日志记录器支持: NLog, Apache log4Net
ODBC driver:
新增了DML 操作支持
新增了对分布式关联的支持
新增了对DSN 的支持
性能提升。

Apache Ignite 2.13.0 版本发布,全新的基于 Calcite 的 SQL 引擎
Apache Ignite 版本发布说明
Apache Ignite 分布式内存数据库 2.13.0
(!) 警告:
- 之前已被废弃的服务网络功能被删除。
Ignite:
- 新增''snapshotTransferRate''分布式属性来限制创建快照文件的速率;
- 启动时新增CDC硬链接检查;
- 在Calcite查询引擎中新增JDBC和ODBC的批处理支持;
- 在快照恢复操作过程中新增JMX的管理接口和指标输出;
- 新增重建损坏索引的维护任务;
- 新增SNAPSHOT系统视图来显示本地的快照;
- 新增ServiceCallContext,在服务调用时可以隐式传递额外的参数;
- 新增一个选项,使用control.sh可以执行同步的快照命令;
- 插件新增以扩展的方式执行拓扑验证的能力;
- 新增加密快照的动态恢复;
- 在Ignite的发布周期中新增ignite-parent构件;
- 新增试验性的基于Calcite的SQL引擎;
- CDC中新增支持非默认的页面大小;
- 事务监控的配置支持保存到磁盘;
- ignite-cdc.sh 和 ignite.sh支持不同的JVM选项参数;
- 系统数据区新增支持不同的配置;
- 将分区映射序列化到磁盘,来避免节点启动时间长的问题;
- 新增服务方法调用持续时间直方图指标;
- 新增支持JDK17;
- 在控制脚本的一致性检查命令中新增支持IGNITE_TO_STRING_INCLUDE_SENSITIVE选项;
- 在控制脚本的一致性检查命令中新增status选项;
- 线程池新增任务执行时间指标;
- 在本地事件监听器中新增支持LifecycleAware接口;
- 如果配置了PriorityQueueCollisionSpi新增支持修改计算任务的优先级;
- 废弃了IgniteServices#service(String)和IgniteServices#services(String);
- 废弃了IGNITE_WAIT_FOR_BACKUPS_ON_SHUTDOWN系统属性;
- 废弃ignite-log4j模块;
- 修复了当记录中包含多个DataEntry时CDC状态恢复方面的问题;
- 修复了在客户端节点创建GeoSpatial索引的问题;
- 修复了IndexQuery无法正确处理_val字段索引的问题;
- 修复了JmxSystemViewExporterSpi中列类型为空时导致的空指针问题;
- 修复了PersistenceTask中的空指针问题;
- 修复了并发执行缓存销毁和激活事务时的空指针问题;
- 修复了消息解组的分布式处理过程中的空指针问题;
- 修复了使用BinaryObjects执行invokeAsync时的NoClassDefFound错误问题;
- 修复了在com.sun.management.OperatingSystemMXBean不存在时的NoClassDefFoundError错误问题;
- 修复了ODBC连接超时问题;
- 修复了客户端中执行隐式事务提交时导致PME故障的问题;
- 修复了握手过程中TLS 1.3冻结的问题;
- 修复了一个如果请求是从另一个副本发起的,则在近缓存/副本中更新TTL的罕见问题;
- 修复了部分JMX命令失败时报告反序列化错误的问题;
- 修复了一个会导致集群冻结失败的问题;
- 修复了一个导致基于速度的写入限制无法保护检查点缓冲区不被耗尽的问题;
- 修复了一个客户端重连后导致IgniteLock处理不正确的问题;
- 修复了一个在缓存启动时导致"Failed to get page store for the given cache ID"错误的问题;
- 修复了在Karaf容器内导致新节点加入集群失败的一个问题;
- 修复了由于关联赋值历史短导致的服务端节点故障的问题;
- 修复了带有“IN”条件的查询和子查询返回乘法数据时的问题;
- 修复了使用IgniteAtomicSequence中导致AssertionError错误的问题;
- 修复了原始对象中包含多个集合或引用字段的情况下生成二进制对象的问题;
- 修复了持久化原子缓存时的一致性问题;
- 修复了重新激活时过期处理故障的问题;
- 修复了表并发删除时的查询故障问题;
- 修复了DECIMAL和VARCHAR列类型索引碎片整理失败的问题;
- 修复了配置了本地标志和使用POJO参数时,SqlFieldsQuery无法使用索引扫描数据的问题;
- 修复了日志记录过程中出现ClosedChannelException异常的问题;
- 修复了IgniteStripedThreadPoolExecutor中指标处理不正确的问题;
- 修复了读修复中值检查缺失的问题;
- 修复了WAL Reader解析groupId/cacheId不正确的问题;
- 修复了ClosedChannelException异常导致的节点故障问题;
- 修复了ClassNotFoundException: wrong validation for Object type导致的节点故障问题;
- 修复了在错误的CRC上执行页面恢复时无法将页面标记为脏页面的问题;
- 修复了对等类加载错误处理方面的问题;
- 修复了基于速度的限流中可能出现的资源耗尽问题;
- 修复了由恶意或垃圾数据导致的瘦客户端协议处理过程中的潜在OOM问题;
- 修复了快速删除和更新操作中潜在的数据损坏问题;
- 修复了查询引擎允许插入逻辑上相等的联合主键数据行的问题;
- 修复了客户端节点加入集群时水平再平衡重新赋值导致的数据平衡问题;
- 修复了CdcLoader导致的SpringContext实例化问题;
- 修复了使用wrap_key和value_type引起的表操作失败问题;
- 修复了启用分区裁剪和查询并行化之后执行查询时副本数计算不正确的问题;
- 实现了内存缓存的CDC;
- 实现了Ignite固化内存的NUMA感知分配;
- 实现了读修复策略;
- 实现了服务中基于注解的ServiceContext注入;
- 实现了二进制对象内的数组类型支持;
- 实现了按原始列类型生成创建表sql键类型;
- 实现了控制脚本读修复命令的命名参数支持;
- 实现了CDC的监控和日志输出;
- 改进了IndexQuery的索引行过滤;
- 改进了内存数据区的持久化数据结构消息的日志相关处理;
- 改进了节点启动时从WAL日志恢复数据分区状态的处理;
- 改进了快照分区移动;
- 删除了共享内存通信客户端;
- 删除了旧的服务网格实现;
- 更新JNR POSIX依赖至3.1.15;
- 更新Mesos依赖至1.11.0;
- 更新hadoop-yarn-client依赖至3.3.1;
- 更新sfl4j依赖至1.7.33;
- 更新Spring依赖至5.2.21.RELEASE;
- 更新zookeeper依赖至3.8.0。
Java瘦客户端:
- 新增了在错误消息中附加服务端异常堆栈的选项;
- 新增了周期性心跳消息来提高连接可靠性。
JDBC/ODBC:
- 修复了空结果集时的不正确查询处理;
- 修复了调用SQLConnect时的链接失败问题;
- 修复了执行set streaming on/off方面的问题;
- 修复了SSL密钥存储不是强制参数的问题;
- 修复了SQLGetStmtAttr(SQL_ATTR_ROW_ARRAY_SIZE)处理不正确的问题;
.Net:
- 瘦客户端服务新增了GetServiceDescriptors;
- 新增了ThinClientConfiguration.SendServerExceptionStackTraceToClient;
- 新增了服务相关的指标;
- 修复了Alpine Linux环境中抛出EntryPointNotFoundException异常的问题;
- 修复了当类型中删除字段时二进制模式缺失的问题;
- 修复了节点重启后平台缓存没有从持久化存储中恢复数据的问题;
- 修复了''System.Enum''字段的序列化问题。
.Net瘦客户端:
- 新增了IClientRetryPolicy接口,用于控制由于连接问题导致操作失败时的重试行为;
- 新增了周期性心跳消息来提高连接可靠性。
C++:
- CacheEntryEvent中新增了EventType字段;
- 修复了OpenSSL共享库顺序,新增了OpenSSL 3.0.x支持;
- 新增了IClientRetryPolicy接口,用于控制由于连接问题导致操作失败时的重试行为;
- 新增了ClientServices#serviceDescriptors;
- 改进了内存使用来避免额外的缓冲区复制。
C++瘦客户端:
- 修复了SSL密钥存储不是强制参数的问题;
- 实现了异步网络事件处理;
- 实现了持续查询。
SQL:
- CREATE TABLE语句中新增了指定主键和关联键索引内联值的功能;
- 修复了子查询常量优化方面的问题。
今天关于在既有系统中打通Apache Ignite、MySQL和Node.js的介绍到此结束,谢谢您的阅读,有关Apache Cassandra 和 Apache Ignite:关系并置和分布式 SQL、Apache Cassandra和Apache Ignite:通过Ignite增强Apache Cassandra、Apache Ignite 1.8.0 发布,全新的 SQL 网格、Apache Ignite 2.13.0 版本发布,全新的基于 Calcite 的 SQL 引擎等更多相关知识的信息可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

