本篇文章给大家谈谈shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,以及shell特殊符号的知识点,同时本文还将给你拓展11.17shell特殊符号cut命令,
本篇文章给大家谈谈shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,以及shell 特殊符号的知识点,同时本文还将给你拓展11.17 shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,shell特殊符号、25.shell特殊符号cut命令 sort wc uniq tee tr split命令、5-5 8 特殊符号 cut sort wc uniq tee tr split、8.10 shell特殊符号cut, sort,wc,uniq, tee,tr,split命令等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令(shell 特殊符号)
- 11.17 shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,shell特殊符号
- 25.shell特殊符号cut命令 sort wc uniq tee tr split命令
- 5-5 8 特殊符号 cut sort wc uniq tee tr split
- 8.10 shell特殊符号cut, sort,wc,uniq, tee,tr,split命令
")
shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令(shell 特殊符号)
笔记内容:
l8.10 shell特殊符号cut命令
l8.11 sort_wc_uniq命令
l8.12 tee_tr_split命令
l8.13 shell特殊符号下
笔记日期:2017.8.16
8.10 shell特殊符号cut命令
特殊符号:
1.* 任意个任意字符通配符

2.? 任意一个字符
3.# 注释字符
一条命令前面加注释字符的话,命令就不会执
4.\ 脱义字符,有些字符是命令,所以需要脱义符来让这个字符变成普通字符,而非命令字符:
5.| 管道符,把前面命令的输出结果交给后面的命令执行
cut命令可以分割字符串,可以指定某个字符进行分割,例如我要分割passwd文件里的字符串,并以冒号为分割符,然后指定查看第一段字符串:
如果要查看两段需要加个逗号:
想要查看一个范围可以这么写:
使用-c选项可以查看第几个字符,例如我也要查看第四个字符:
8.11 sort_wc_uniq命令
sort命令可以对字符串或数字排序,排序的方法是安照ASCII码排序的,例如我排序passwd文件的内容:
例如排序一个含有特殊字符的文件:
加-n选项会照数字去排序,这时相对于数字来说字母和特殊符号相当于是零:
-r则是倒序排序:
wc -l命令是统计行数的:
加-m选项则是统计字符数,包括换行符:
加- w选项是安照单词统计,这个单词是以逗号或者空格分开的一个个词:
uniq命令是去掉重复的字符:
uniq命令可以和sort命令搭配使用,先排序去重:
8.12 tee_tr_split命令
tee命令和输出重定向有点像,它们的区别是tee是可以看到输出重定向的结果,>则不能看到:
tee -a 追加重定向:
tr命令是用来替换字符的,针对字符来操作的:
split切割命令,可以用来切割文件,因为有些文件太大了,不方便查看,所以需要使用split来切割成多个文件来方便查看,split可以针对大小切割也可以针对行数切割:
8.13 shell特殊符号下
想要把多条命令写在一行里,就需要使用分号分割:
||是或者的意思,写在两条命令中间的话只要左边的命令执行成功,那么右边的命令就不会执行。如果左边的命令执行失败,那么右边的命令就会执行:
&&是并且的意思,只有左边的命令执行成功的时候,右边才会执行,只要左边的命令没有执行成功,那么右边的命令一定不会被执行:

11.17 shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,shell特殊符号
8.10 shell特殊符号 & cut命令
特殊符号:
1. * 任意个任意字符通配符
![]()
2. ? 任意一个字符
![]()
3. # 注释字符
一条命令前面加注释字符的话,命令就不会执行

4. \ 脱义字符,有些字符是命令,所以需要脱义符来让这个字符变成普通字符,而非命令字符:
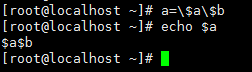
5. | 管道符,把前面命令的输出结果交给后面的命令执行
![]()

cut命令可以分割字符串,可以指定某个字符进行分割,例如我要分割passwd文件里的字符串,并以冒号为分割符,然后指定查看第一段字符串:

如果要查看两段需要加个逗号:

想要查看一个范围可以这么写:

使用 -c 选项可以查看第几个字符:

8.11 sort_wc_uniq命令
sort命令可以对字符串或数字排序,排序的方法是安照ASCII码排序的,例如排序passwd文件的内容:
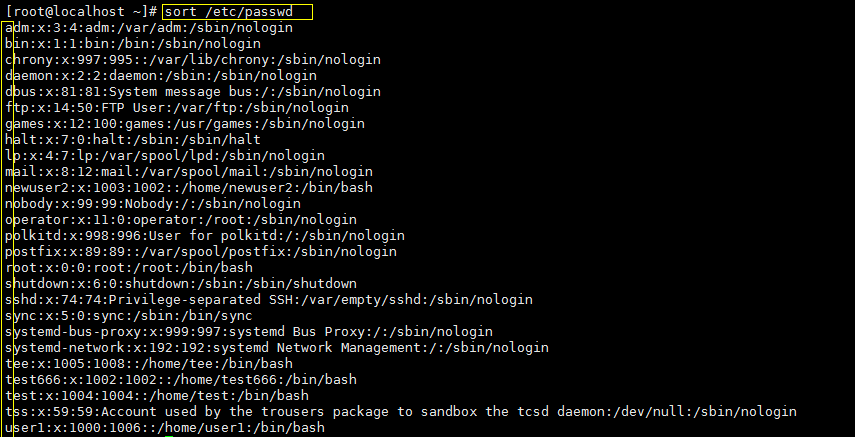
(按照字母排序的)
例如排序一个含有特殊字符的文件:vi aaa.txt
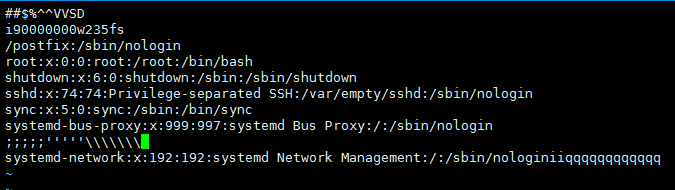
加 -n 选项会照数字去排序,这时相对于数字来说字母和特殊符号相当于是零:
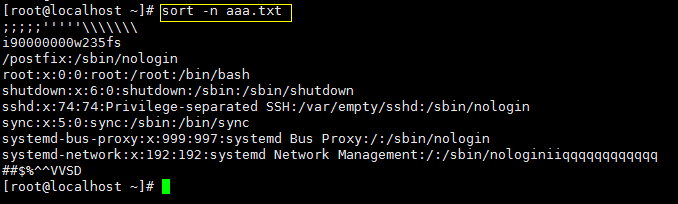
-r 则是倒序排序:
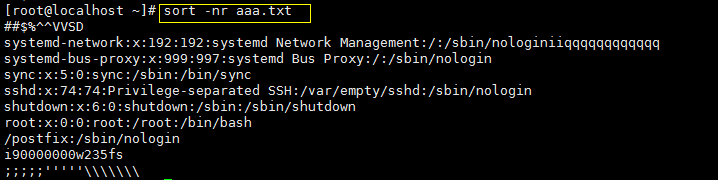
wc -l 命令是统计行数的:
![]()
加 -m 选项则是统计字符数,包括换行符:
![]()
加 -w 选项是安照单词统计,这个单词是以逗号或者空格分开的一个个词:
![]()
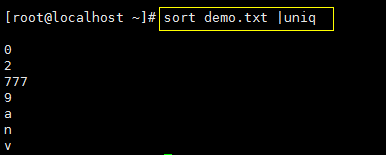
uniq 命令是去掉重复的字符:

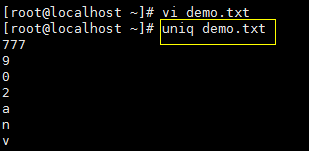
uniq命令可以和sort命令搭配使用,先排序去重:
8.12 tee_tr_split命令
tee命令,后跟文件名,类似于重定向“>”,但是比重定向多了一个功能,在把文件写入后面所跟的文件中的同时,还显示在屏幕上。

tee -a 追加重定向。
tr命令是用来替换字符的,针对字符来操作的:

split切割命令,可以用来切割文件,因为有些文件太大了,不方便查看,所以需要使用split来切割成多个文件来方便查看,split可以针对大小切割也可以针对行数切割:
常用选项 : -b 依据大小来分割文档,单位为byte
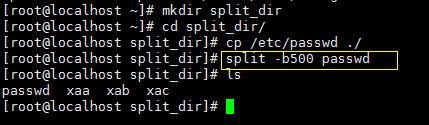
也可以指定目标文件名。 如:split -b500 passwd 123
-l :依据行数来分割文档
8.13 shell特殊符号下

想要把多条命令写在一行里,就需要使用分号分割:
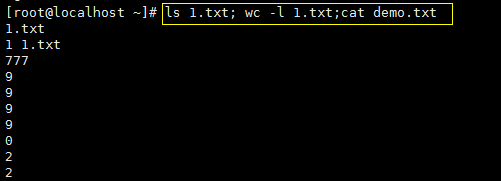
|| 是 或者 的意思,写在两条命令中间的话只要左边的命令执行成功,那么右边的命令就不会执行。如果左边的命令执行失败,那么右边的命令就会执行:


&& 是 并且 的意思,只有左边的命令执行成功的时候,右边才会执行,只要左边的命令没有执行成功,那么右边的命令一定不会被执行:

25.shell特殊符号cut命令 sort wc uniq tee tr split命令
8.10 shell特殊符号cut命令
8.11 sort wc uniq命令
8.12 tee tr split命令
8.13 shell特殊符号下
8.10 shell特殊符号cut命令:
~1. *任意个任意字符
通配符
~2. ?任意一个字符
代表任意的一个字符
~3. #注释字符
前面加#,代表不生效。可用在解释说明
~4. \脱义字符 (详细看实例)
取消掉原意,只代表他本身,可用\
~5. |管道符 下面有讲和管道符有关的命令
实例
4.
[root@afeilinux-01 ~]# a=1
[root@afeilinux-01 ~]# b=2
[root@afeilinux-01 ~]# c=$a$b 我们想让c=$a$b这串字符本身是不生效的,因为我们用$会调用a的变量
[root@afeilinux-01 ~]# echo $c 所以他会显示,a和b的变量
12
[root@afeilinux-01 ~]# c=''$a$b'' 我们可以加单引号来代表c=$a$b的本身
[root@afeilinux-01 ~]# echo $c
$a$b
[root@afeilinux-01 ~]# c=\$a\$b 也可以用脱义字符\反推一下,来代表$a或$b这些字符本身
[root@afeilinux-01 ~]# echo $c
$a$b
----------------------------------------------------------------------------------------------------------------------------------------------------
8.11 sort wc uniq命令:
几个和管道有关的命令
~1. cut分割,-d分隔符 -f指定段号 -c指定第几个字符
~2. sort排序,-n以数字排序 -r反序 -t分隔符 -kn1/-kn1,n2
遵循阿斯玛ASCII排序
-n会以数字排序,字母和特殊字符会默认为0.需注意
-nr会以数字反序来排列。跟-n是相反的
-t指定几段去排序,几乎用不到,作为了解
~3. wc -l统计行数 -m统计字符数 -w统计词
-l统计行数,之前用过
-m统计字符数时,也会统计隐藏字符,比如换行符$
-w以空白字符作为分隔符,来统计有多少词 用的不多,作为了解
~4. uniq去重,-c统计行数
一般跟sort同时使用,先排序,后去重。sort 2.txt |uniq
实例:
1.
[root@afeilinux-01 ~]# cat /etc/passwd | head -2 我们列出passwd的前两行
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@afeilinux-01 ~]# cat /etc/passwd | head -2 |cut -d ":" -f 1 用cut分割,-d表示用什么分割,用双引号引起来。-f表示分隔符:的第一段
root
bin[root@afeilinux-01 ~]# cat /etc/passwd | head -2 |cut -d ":" -f 1,2 cut一二段的时候用,分割
root:x
bin:x
[root@afeilinux-01 ~]# cat /etc/passwd | head -2 | cut -d ":" -f 1-3 cut一二三段的时候,直接写1-3即可
root:x:0
bin:x:1
[root@afeilinux-01 ~]# cat /etc/passwd |head -2 |cut -c 4 用-c的时候就不要用-d -f了,指定第几个字符。前两行的第四个字符就是 t和:
t
:[root@afeilinux-01 ~]# sort /etc/passwd 会发现sort后的排序是按照abcdefg来排序的
adm:x:3:4:adm:/var/adm:/sbin/nologin
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
chrony:x:998:996::/var/lib/chrony:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
dbus:x:81:81:System message bus:/:/sbin/nologin
ftp:x:14:50:FTP User:/var/ftp:/sbin/nologin
games:x:12:100:games:/usr/games:/sbin/nologin
halt:x:7:0:halt:/sbin:/sbin/halt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
[root@afeilinux-01 ~]# head /etc/passwd >> 1.txt 我们再来追加一些到1.txt
[root@afeilinux-01 ~]# vim !$ 并在里面加点特殊字符
vim 1.txt
[root@afeilinux-01 ~]# sort 1.txt 在sort,他会这样排序
222eqweqw
%231243214214214
[244234
adm:x:3:4:adm:/var/adm:/sbin/nologin
!asrar
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
halt:x:7:0:halt:/sbin:/sbin/halt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
operator:x:11:0:operator:/root:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
]saffsdfds
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
sync:x:5:0:sync:/sbin:/bin/sync
3.
[root@afeilinux-01 ~]# wc -l 22.txt 行数 3行
5 22.txt[root@afeilinux-01 ~]# wc -m 22.txt 统计字符数,隐藏字符也会统计,比如换行符$
71 22.txt
[root@afeilinux-01 ~]# cat -A 22.txt 用cat -A就可以看到换行符
111111111111111$
22222222222222222$
3333333333333333333333$
444444444444$
$
[root@afeilinux-01 ~]# wc -w 22.txt
4 22.txt
[root@afeilinux-01 ~]# cat !$
cat 22.txt
111111111111111
22222222222222222
3333333333333333333333
444444444444
4.
[root@afeilinux-01 ~]# cat 2.txt 先cat一下
33
555
666
555
666111
333
444
333
555
666
[root@afeilinux-01 ~]# uniq 2.txt uniq并没有什么效果,因为没有sort
111111111111111
111111111111111
33333333333333
66666666666666
22222222222222
33333333333333
4444444444444
5555555555555
6666666666666
7777777777777777
8888888888888
99999999999999
[root@afeilinux-01 ~]# sort 2.txt | uniq 我们先sort再uniq,就去重了
111111111111111
22222222222222
33333333333333
4444444444444
5555555555555
6666666666666
66666666666666
7777777777777777
8888888888888
99999999999999
----------------------------------------------------------------------------------------------------------------------------------------------------
8.12 tee tr split命令:
~5. tee和>类似,重定向的同时还在屏幕显示
需要加|,|tee这样来用
tee -a追加的效果,并在屏幕上显示。类似于>>
~6. tr替换字符,tr ''a'' ''b'',大小写替换tr ''[a-z]'' ''[A-Z]''
~7. split 切割,-b大小(默认单位字节),-l行数
将一个大文件切割成多个小文件
实例:
5.
[root@afeilinux-01 ~]# sort 2.txt |uniq -c >a.txt 用>并不会显示在屏幕上
[root@afeilinux-01 ~]# sort 2.txt |uniq -c |tee a.txt 将>换成|tee,重定向的同时还能打印在屏幕上
2 111111111111111
1 22222222222222
2 33333333333333
1 4444444444444
1 5555555555555
1 6666666666666
1 66666666666666
1 7777777777777777
1 8888888888888
1 99999999999999
6.
[root@afeilinux-01 ~]# echo ''aminglinux'' |tr ''a'' ''b''
bminglinux[root@afeilinux-01 ~]# echo ''aminglinux'' |tr ''a-z'' ''A-Z''
AMINGLINUX
[root@afeilinux-01 ~]# echo ''aminglinux'' |tr ''[al]'' ''[AL]'' 支持多个,但要加[]
AmingLinux
7.
[root@afeilinux-01 ~]# find /etc/ -type f -name ''*conf'' -exec cat {} >> a.txt \;
[root@afeilinux-01 ~]# du -sh a.txt
224K a.txt
[root@afeilinux-01 test]# split -b 100k a.txt 指定100k一个分割
[root@afeilinux-01 test]# ls
22.txt 2.txt a.txt xaa xab xaca.txt xaa xab xac 不指定名字以x开头
[root@afeilinux-01 test]# split -b 100k a.txt abc. 指定名字为abc.开头
[root@afeilinux-01 test]# ls
22.txt 2.txt abc.aa abc.ab abc.ac a.txt xaa xab xac[root@afeilinux-01 test]# split -l 1000 a.txt abc. 指定1000行一个分割
[root@afeilinux-01 test]# ls
abc.aa abc.ab abc.ac abc.ad abc.ae abc.af abc.ag a.txt xaa xab xac
----------------------------------------------------------------------------------------------------------------------------------------------------
8.13 shell特殊符号下:
~1. $变量前缀。!$组合,正则里面表示行尾
~2. ;多条命令写到一行。用分号分割
~3. ~用户家目录,后面正则表达式表示匹配符
~4. &放到命令后面,会把命令丢到后台
~5. > >> 2> 2>> &>
&>表示正确的和错误的都输入到一个文件里去
~6. []指定字符中的一个,[0-9],[a-zA-Z],[abc]
~7. ||和&&,用于命令之间
||运行在shell当中表示或者的意思
||放在两条命令之间,前面的命令执行不成功会执行后面的命令。前面的执行成功不在执行后面的
&&与||相反
&&放在两条命令之间,前面的命令执行成功才会执行后面的命令。前面的命令不成功不会执行后面的命令
实例:
2.
[root@afeilinux-01 ~]# du -sh 22.txt ; wc -l 2.txt 多条命令之间用;分割
4.0K 22.txt
12 2.txt 显示两条不同的命令
7.
[root@afeilinux-01 ~]# ls
1.txt 22.txt 2.txt anaconda-ks.cfg
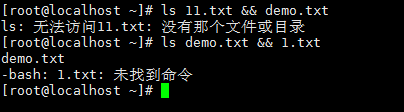
[root@afeilinux-01 ~]# ls 11.txt || wc -l 2.txt ||前面执行不成功,才执行后面的
ls: 无法访问11.txt: 没有那个文件或目录
12 2.txt
[root@afeilinux-01 ~]# ls 1.txt || wc -l 2.txt ||前面执行成功,不执行后面的
1.txt[root@afeilinux-01 ~]# ls 1.txt && wc -l 2.txt &&前面的执行成功,才执行后面的
1.txt
12 2.txt[root@afeilinux-01 ~]# ls 11.txt && wc -l 2.txt &&前面的执行不成功,不执行后面的
ls: 无法访问11.txt: 没有那个文件或目录
扩展实例:
如果一个目录不存在,我才创建
[ -d axin ]
[root@afeilinux-01 ~]# ls
1.txt 22.txt 2.txt abc.aa abc.ab abc.ac abc.ad abc.ae abc.af abc.ag a.txt xaa xab xac[root@afeilinux-01 ~]# [ -d axin ] || mkdir axin 使用||,前面的不存在,才创建
[root@afeilinux-01 ~]# ls
1.txt 22.txt 2.txt abc.aa abc.ab abc.ac abc.ad abc.ae abc.af abc.ag a.txt axin xaa xab xac如果使用&&呢?
[root@afeilinux-01 ~]# [ -d axin ] && mkdir axin 使用&&,前面的虽然成功了,但执行后面已经存在的目录就会报错
mkdir: 无法创建目录"axin": 文件已存在

5-5 8 特殊符号 cut sort wc uniq tee tr split
8.10 shell特殊符号cut命令
特殊符号
- “*” 代表零个或多个字符
- “?” 代表一个字符
- “#” 注释符号
- “\” 脱意符号
- “|” 管道符
cut用法
[root@lixiang01 ~]# cat /etc/passwd |head -2
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
[root@lixiang01 ~]# cat /etc/passwd |head -2 |cut -d ":" -f 1,5
root:root
bin:bin
- cut分割,用来显示行中的指定部分
- -d 判定分隔符
- -f 要那段
- -c指定第几个字符
8.11 sort_wc_uniq命令
sort 用法
按字符编码表排序
[root@lixiang01 ~]# head /etc/passwd > 1.txt
[root@lixiang01 ~]# vi 1.txt
[root@lixiang01 ~]# sort 1.txt
<
>
@#
2112
222
3421
432
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
{e33
]f
*%$#fs
halt:x:7:0:halt:/sbin:/sbin/halt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
perator:x:11:0:operator:/root:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
sfae
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
sjfoen
sync:x:5:0:sync:/sbin:/bin/sync
按字符的数值排序
[root@lixiang01 ~]# sort -n 1.txt
<
>
@#
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
{e33
]f
*%$#fs
halt:x:7:0:halt:/sbin:/sbin/halt
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
perator:x:11:0:operator:/root:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
sfae
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
sjfoen
sync:x:5:0:sync:/sbin:/bin/sync
222
432
2112
3421
倒置参数:-r
[root@lixiang01 ~]# sort -n -r 1.txt
3421
2112
432
222
sync:x:5:0:sync:/sbin:/bin/sync
sjfoen
shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
sfae
root:x:0:0:root:/root:/bin/bash
perator:x:11:0:operator:/root:/sbin/nologin
mail:x:8:12:mail:/var/spool/mail:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
halt:x:7:0:halt:/sbin:/sbin/halt
*%$#fs
]f
{e33
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
@#
>
<
- sort 排序,将文件进行排序,并将排序结果标准输出(按ASCⅡ排序需要调整/etc/)
- -n 以数字排序
- -r 反序
- -t分隔符
- -kn1/-kn1,n2 指定段排序
wc 用法
[root@lixiang01 ~]#
[root@lixiang01 ~]# wc -m 1.txt 字符数
436 1.txt
[root@lixiang01 ~]# wc -w 1.txt 词汇数(只要不空格就算一个词)
22 1.txt
[root@lixiang01 ~]# wc -l 1.txt 行数
22 1.txt
- wc 统计,统计并打印换行符,词数,字符数
- -l 统计行数
- -m 统计字符数
- -w 统计词
uniq用法
[root@lixiang01 ~]# vi 2.txt
[root@lixiang01 ~]# sort 2.txt |uniq -c
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
- uniq 去重,
- -c显示重复数
- 单独使用只能去重相邻行,常常与sort结合使用
8.12 tee_tr_split命令
tee用法
[root@lixiang01 ~]# >a.txt
[root@lixiang01 ~]# cat a.txt
[root@lixiang01 ~]# sort 2.txt |uniq -c |tee a.txt
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
[root@lixiang01 ~]# cat a.txt
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
[root@lixiang01 ~]# sort 2.txt |uniq -c |tee -a a.txt
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
[root@lixiang01 ~]# cat a.txt
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
3 1
2 112
2 123
1 2
2 33
3 4
2 5
2 6
- tee, 和>类似,重定向的同时还在屏幕显示
- -a 类似追加重定向
tr 用法
[root@lixiang01 ~]# echo "axianglinux" |tr ''[al]'' ''[AL]''
AxiAngLinux
- tr替换字符,tr''a''''b'',大小写替换tr‘[a-z]''''[A-Z]''
split用法
[root@lixiang01 test]# find /etc/ -type f -name "*conf" -exec cat {} >> a.txt \;
[root@lixiang01 test]# split -b 10000 a.txt
[root@lixiang01 test]# ls
a.txt xab xad xaf xah xaj xal xan xap
xaa xac xae xag xai xak xam xao xaq
[root@lixiang01 test]# cat a.txt >> b.txt
[root@lixiang01 test]# cat a.txt >> b.txt
[root@lixiang01 test]# rm -f x*
[root@lixiang01 test]# rm -f a*
[root@lixiang01 test]# wc -l b.txt
8662 b.txt
[root@lixiang01 test]# split -l 1000 b.txt
[root@lixiang01 test]# ls
b.txt xaa xab xac xad xae xaf xag xah xai
[root@lixiang01 test]# wc -l *
8662 b.txt
1000 xaa
1000 xab
1000 xac
1000 xad
1000 xae
1000 xaf
1000 xag
1000 xah
662 xai
17324 总用量
[root@lixiang01 test]#
- split切割,可以将一个大文件分割成很多个小文件
- -b大小(默认单位字节),
- -l行数
8.13 shell特殊符号下
- $ 变量前缀,!$组合,正则里面表示行尾
- ; 多条命令写到一行,用分号分割,可以逐个执行并按顺序输出
- ~ 用户家目录,会把命令丢到后台
- & 放到命令后面,会把命令丢到后台
- > >> 2> 2>> &> //正确重定向 正确追加 错误重定向 错误追加 不区分重定向
- []指定字符中的一个,[0-9],[a-zA-Z],[abc]
- ||和&&,用于命令之间,
||和&&用法
||表示你不行我来就来,&&表示你先来,可以我就上
[root@lixiang01 ~]# ls 1a.txt ; wc -l 2.txt
ls: 无法访问1a.txt: 没有那个文件或目录
17 2.txt
[root@lixiang01 ~]# ls 1a.txt || wc -l 2.txt //前面命令不成功,继续
ls: 无法访问1a.txt: 没有那个文件或目录
17 2.txt
[root@lixiang01 ~]# ls 1.txt || wc -l 2.txt //前面命令成功则停止
1.txt
[root@lixiang01 ~]# ls 1a.txt && wc -l 2.txt //前面命令不成功,停止
ls: 无法访问1a.txt: 没有那个文件或目录
[root@lixiang01 ~]# ls 1.txt && wc -l 2.txt //前面命令成功,继续
1.txt
17 2.txt
相关测验题目:http://ask.apelearn.com/question/5437
扩展
- source exec 区别 http://alsww.blog.51cto.com/2001924/1113112
- Linux特殊符号大全http://ask.apelearn.com/question/7720
- sort并未按ASCII排序 http://blog.csdn.net/zenghui08/article/details/7938975

8.10 shell特殊符号cut, sort,wc,uniq, tee,tr,split命令
shell特殊符号cut命令
- cut 分割,-d 分隔符 -f 指定段号 -c 指定第几个字符
- sort 排序, -n 以数字排序 -r 反序 -t 分隔符 -kn1/-kn1,n2
- wc -l 统计行数 -m 统计字符数 -w 统计词
- uniq 去重, -c统计行数
- tee 和>类似,重定向的同时还在屏幕显示
- tr 替换字符,tr ''a'' ''b'',大小写替换tr ''[a-z]'' ''[A-Z]''
- split 切割,-b大小(默认单位字节),-l行数
cut命令
- cut命令用来截取某个字符串
- 格式:cut –d “分割符” 文件名
- -d:后面跟分割字符,分割字符用双引号括起来;
- -f:后面跟接第几段字符串
- -c:后面接第几个字符
- 截取第1到第3段
[root@linux-128 ~]# head -5 1.txt |cut -d ":" -f 1-3
root:x:0
bin:x:1
daemon:x:2
adm:x:3
lp:x:4
- 截取第1段和第3段
[root@linux-128 ~]# head -5 1.txt |cut -d ":" -f 1,3
root:0
bin:1
daemon:2
adm:3
lp:4
- 截取第2个字符
[root@linux-128 ~]# head -5 1.txt |cut -c 2
o
i
a
d
p
- 截取第2个字符到第5个字符
[root@linux-128 ~]# head -5 1.txt |cut -c 2-5
oot:
in:x
aemo
dm:x
p:x:
sort命令
- sort命令用做排序,格式sort [-t 分割符] [-kn1,n2] [-nur],n1,n2指的是数字
- -t 分割符
- -k 按第几列排序;区间范围用逗号-k3,5
- -n 按数字排序
- -r 反序排序,按从打到小排序
- -u 去重复
- -un 字母开头的会识别成重复内容,如skj1 a weotj 都会认为是重复内容,只显示数字内容
- sort 不加任何选项,从首行字符向后,依次按ASCII码值进行比较,按升序排序
[root@linux-128 ~]# vim 2.txt
111
111
111
111aaa
121
!@#$@123
1asd
abab
abab
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
- 以数字排序
[root@linux-128 ~]# sort -n 2.txt
!@#$@123
abab
abab
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
1asd
111
111
111
111aaa
121
- 注意:如果有字母或者特殊符号,在数字排序中,都默认看成0.
- 反向排序
[root@linux-128 ~]# sort -nr 2.txt
121
111aaa
111
111
111
1asd
root:x:0:0:root:/root:/bin/bash
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
abab
abab
!@#$@123
- 去重复,这里把字母都看成了0,然后去重复。
[root@linux-128 ~]# sort -nu 2.txt
abab
1asd
111
121
wc命令
- wc命令用于统计文档的行数,字符数,单词数。
- -l 统计行数
- -m统计字符数
- -w统计单词数
- 查看文件3.txt 行数
[root@linux-128 ~]# cat 3.txt
abab
1asd
111
121
[root@linux-128 ~]# wc -l 3.txt
4 3.txt
- 查看文件3.txt字符有多少个,$为行尾字符
[root@linux-128 ~]# cat -A 3.txt
abab$
1asd$
111$
121$
[root@linux-128 ~]# wc -m 3.txt
18 3.txt
- -w统计单词,它是以空格或者空白字符来分割。
[root@linux-128 ~]# cat 3.txt
abab
1asd
111
121
[root@linux-128 ~]# wc -w 3.txt
4 3.txt
- 如果wc后面不加任何选项,直接跟文档,则会把行数,单词数,字符数依次输出。
[root@linux-128 ~]# wc 3.txt
4 4 18 3.txt
uniq命令
- uniq命令用来删除重复的行,通常和sort连在一起使用
- -c选项比较常用,它表示统计重复的行数,并把行数写在前面
[root@linux-128 ~]# sort 2.txt
111
111
111
111aaa
121
!@#$@123
1asd
abab
abab
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
- 先排序然后删除重复行
[root@linux-128 ~]# sort 2.txt |uniq -c
3 111
1 111aaa
1 121
1 !@#$@123
1 1asd
2 abab
1 adm:x:3:4:adm:/var/adm:/sbin/nologin
1 bin:x:1:1:bin:/bin:/sbin/nologin
1 daemon:x:2:2:daemon:/sbin:/sbin/nologin
1 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
1 root:x:0:0:root:/root:/bin/bash
[root@linux-128 ~]# sort 2.txt |uniq
111
111aaa
121
!@#$@123
1asd
abab
adm:x:3:4:adm:/var/adm:/sbin/nologin
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
root:x:0:0:root:/root:/bin/bash
tee命令
- tee命令后面文件名,其作用类似于重定向>;但是它比重定向多一个显示在屏幕上的功能;
[root@linux-128 ~]# cat 3.txt >4.txt
[root@linux-128 ~]# cat 3.txt |tee 4.txt
abab
1asd
111
121
- tee –a 相当于追加重定向>>;它多了一个显示在屏幕上的功能
[root@linux-128 ~]# cat 3.txt |tee -a 4.txt
abab
1asd
111
121
[root@linux-128 ~]# cat 3.txt |tee -a 4.txt
abab
1asd
111
121
[root@linux-128 ~]# cat 4.txt
abab
1asd
111
121
abab
1asd
111
121
abab
1asd
111
121
命令tr
- tr命令用于替换字符
[root@linux-128 ~]# cat 3.txt |tr ''a'' ''A''
AbAb
1Asd
111
121
[root@linux-128 ~]# cat 3.txt |tr ''[a-z]'' ''[A-Z]''
ABAB
1ASD
111
121
split命令
- split 用于分割文档
- split -l 按行来分割
- split -b 按大小来分割
- split -b
[root@linux-128 ~]# mkdir test
[root@linux-128 ~]# cd test
[root@linux-128 test]# find /etc/ -type f -name "*.conf" -exec cat {} >1.txt \;
[root@linux-128 test]# du -sh 1.txt
252K 1.txt
[root@linux-128 test]# split -b 50k 1.txt
[root@linux-128 test]# ls
1.txt xaa xab xac xad xae xaf
- split –l
[root@linux-128 test]# wc -l 1.txt
6479 1.txt
[root@linux-128 test]# split -l 1000 1.txt
[root@linux-128 test]# ls
1.txt xaa xab xac xad xae xaf xag
- split 后面如果不指定文件名,则会以xaa,xab。。。这样的文件名来存取切割后的文件
- 指定目标分割文件名 为abc.
[root@linux-128 test]# split -l 1000 1.txt abc.
[root@linux-128 test]# ls
1.txt abc.aa abc.ab abc.ac abc.ad abc.ae abc.af abc.ag
特殊符号
- $ 变量前缀,!$组合,正则里面表示行尾
- ;多条命令写到一行,用分号分割
- ~ 用户家目录,后面正则表达式表示匹配符
- & 放到命令后面,会把命令丢到后台
- 重定向 > 追加重定向>> 错误重定向2> 错误追加重定向2>> 正确和错误重定向&>
- [ ] 指定字符中的一个,[0-9],[a-zA-Z],[abc]
- || 和 && ,用于命令之间
- $:可以作为变量前面的标示符,可以和!结合起来使用,在正则里面表示行尾
[root@linux-128 test]# ls /root
11.txt 123 1.txt 2.txt 3.txt anaconda-ks.cfg d6z
11.txt.bak 1a.txt +2 321.txt 4.txt a.txt test
12 1.log 23.txt 321.txt.bak ab.txt b.txt 工号.txt
[root@linux-128 test]# ls !$
ls /root
11.txt 123 1.txt 2.txt 3.txt anaconda-ks.cfg d6z
11.txt.bak 1a.txt +2 321.txt 4.txt a.txt test
12 1.log 23.txt 321.txt.bak ab.txt b.txt 工号.txt
- ; 多条命令写在一行,用;分割
[root@linux-128 ~]# cat 2.txt;cat 3.txt
111
111aaa
121
111
abab
1asd
abab
!@#$@123
111
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
abab
1asd
111
121
-
~ 家目录,后面正则表示匹配符
-
重定向(正确) > ,会覆盖以前的内容
[root@linux-128 ~]# echo "121212">3.txt
[root@linux-128 ~]# cat 3.txt
121212
- 追加重定向(正确)>>
[root@linux-128 ~]# echo "ababab">>3.txt
[root@linux-128 ~]# cat 3.txt
121212
Ababab
- 错误重定向 2>
[root@linux-128 ~]# cat 5.txt 2>6.txt
[root@linux-128 ~]# cat 6.txt
cat: 5.txt: 没有那个文件或目录
- 错误追加重定向 2>>
[root@linux-128 ~]# cat 6.txt
cat: 5.txt: 没有那个文件或目录
cat: 5.txt: 没有那个文件或目录
- &> 错误和正确都重定向到某个文件里面。
[root@linux-128 ~]# cat 3.txt 5.txt &> 6.txt
[root@linux-128 ~]# cat 6.txt
121212
ababab
cat: 5.txt: 没有那个文件或目录
- shell中的链接符号 && || ;
- && 前面命令执行成功后,才会执行后面的命令;如果前面执行不成功,后面命令不执行
- || 前面的命令执行不成功,才会执行后面的命令;如果前面命令执行成功,后面命令不执行
- ; 左边的命令成功与否,后边的命令都会执行
今天关于shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令和shell 特殊符号的分享就到这里,希望大家有所收获,若想了解更多关于11.17 shell特殊符号cut命令,sort_wc_uniq命令,tee_tr_split命令,shell特殊符号、25.shell特殊符号cut命令 sort wc uniq tee tr split命令、5-5 8 特殊符号 cut sort wc uniq tee tr split、8.10 shell特殊符号cut, sort,wc,uniq, tee,tr,split命令等相关知识,可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

