如果您对linux用户空间文件系统filesysteminuserspacefuse简介感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于linux用户空间文件系统filesy
如果您对linux 用户空间文件系统 filesystem in userspace fuse 简介感兴趣,那么本文将是一篇不错的选择,我们将为您详在本文中,您将会了解到关于linux 用户空间文件系统 filesystem in userspace fuse 简介的详细内容,我们还将为您解答linux的用户文件的相关问题,并且为您提供关于Checkpoint/Restore in Userspace(CRIU)安装和使用、fufs 用户空间文件系统、FUSE、FUSE getattr操作是否应该被序列化?的有价值信息。
本文目录一览:- linux 用户空间文件系统 filesystem in userspace fuse 简介(linux的用户文件)
- Checkpoint/Restore in Userspace(CRIU)安装和使用
- fufs 用户空间文件系统
- FUSE
- FUSE getattr操作是否应该被序列化?
")
linux 用户空间文件系统 filesystem in userspace fuse 简介(linux的用户文件)
用户空间文件系统(Filesystem in Userspace,简称FUSE)是操作系统中的概念,指完全在用户态实现的文件系统。目前Linux通过内核模块对此进行支持。一些文件系统如ZFS,glusterfs和luster使用FUSE实现。
Linux用于支持用户空间文件系统的内核模块名叫FUSE,FUSE一词有时特指Linux下的用户空间文件系统。
文件系统是一个通用操作系统重要的组成部分。传统上操作系统在内核层面上对文件系统提供支持。而通常内核态的代码难以调试,生产率较低。
Linux从2.6.14版本开始通过FUSE模块支持在用户空间实现文件系统。
在用户空间实现文件系统能够大幅提高生产率,简化了为操作系统提供新的文件系统的工作量,特别适用于各种虚拟文件系统和网络文件系统。上述ZFS和 glusterfs都属于网络文件系统。但是,在用户态实现文件系统必然会引入额外的内核态/用户态切换带来的开销,对性能会产生一定影响。
目前Linux,FreeBSD,NetBSD,OpenSolaris和Mac OSX支持用户空间态文件系统。

比较知名的用户空间文件系统:
ExpanDrive: 商业文件系统,实现了SFTP/FTP/FTPS协议;
glusterFS: 用于集群的分布式文件系统,可以扩展到PB级;
SSHFS: 通过SSH协议访问远程文件系统;
GmailFS: 通过文件系统方式访问GMail;
EncFS: 加密的虚拟文件系统
NTFS-3G和Captive NTFS,在非Windows中对NTFS文件系统提供支持;
WikipediaFS : 支持通过文件系统接口访问Wikipedia上的文章;
升阳公司的Lustre: 和glusterFS类似但更早的一个集群文件系统
ZFS: Luster的Linux版;
archivemount:
HDFS: Hadoop提供的分布式文件系统。HDFS可以通过一系列命令访问,并不一定经过Linux FUSE;
安装和使用")
Checkpoint/Restore in Userspace(CRIU)安装和使用
下一篇:Checkpoint/Restore In Userspace(CRIU)使用细节
1.安装
- 方法一:从源码安装,个人不推荐,虽然最后成功了,但是浪费时间,有兴趣可参考 Ubuntu CRIU安装
- 方法二:使用Linux命令:
yum install criu
2.检测
- 使用命令:
criu check出现Looks good.字样表示安装成功
3.使用
- 编写简单小程序test.c
vim test.c #使用vim编辑C程序#include<stdio.h> #include<unistd.h> //代码没有跑过,大概就是这个样子 int main(){ int i = 0; for(;i<100;i++){ printf("第%d次\n",i); sleep(1); }
return 0; }:wq #保存并退出文件编辑 - 创建文件夹,命名checkpoint(命名可以随便写)
mkdir checkpoint - 使用命令创建检查点
criu dump -D checkpoint -j -t 1446 #程序id一定要使用自己的程序id以下为命令格式
criu dump -D $dir -j -t $pid #设置检查点命令格式
-D 指明检查点文件存储位置,可以使用--images-dir代替
-j 表明被检查的是命令行程序
-t 指明被检查程序的id该命令在程序跑起来之后使用,其中$dir是存储检查点文件的文件夹路径,此处为新建的checkpoint文件夹路径
$pid就是跑起来的程序 ID&pid获取方法,使用命令ps -ef | grep test以下为命令格式
ps -ef | grep $demo_name$demo_name就是你新建程序的名字,此处为test
到此为止,没有出错的话,在 checkpoint文件夹内,将出现很多 img文件,这些文件记录了程序的状态,在恢复时使用 - 程序的重新启动,以上三步,对一个运行的程序创建了快照,若要从快照中恢复程序运行,使用命令
criu restore -D checkpoint -j命令格式
criu restore -D $dir -j #重现程序命令 restore 重现命令 -D 指明检查点文件夹 -j 指明恢复的程序是命令行程序$dir为快照文件存储路径,此处为checkpoint
下一篇: Checkpoint/Restore In Userspace(CRIU)使用细节

fufs 用户空间文件系统
fufs 介绍
FUFS 是一款基于linux c语言版fuse 开发的用户空间文件系统,实现了在linux
中对新浪微盘的基本操作。文件系统实现了对新浪微盘API的封装,当文件系统挂载到用户linux
的某个文件夹下,用户只需像普通文件一样操作自己微盘中的目录和文件。
FUFS的实现,通过fuse 来获取用户文件操作的指令,转而通过fufs自行分装的文件操作函数,来实现对新浪微盘里面的文件的操作。 通过libcurl
库,来实现http报文的发送和接受,通过glib库实现fufs 文件系统inode节点的建立,查询,删除,插入。通过json-
c库,实现对新浪微盘服务器响应报文的解析。
FUFS实现的功能
1 挂载文件系统到linux 中某个文件

2 查询新浪微盘根目录文件

3 查询新浪微盘中某个文件

4 各种类型文件thumbnail的显示

5 文件夹属性的获取

6 新浪微盘里的文件,linux环境读取

7 新浪微盘文件的读写

修改后文件

8 文件系统的卸载

注意:
由于新浪微盘API要求,对用户获取的token,必须在10-15分钟之间进行keep_token操作,因此在实现过程中,FUFS
先将获取的token保存在/tmp/token.log文件中,当fufs文件系统完成挂载后,需要运行src目录里面的token_keep_thread
小程序,它通过读取token.log里的token,在用户指定时间里面进行keep_token操作,保证token的有效性。
目前还没有完成的工作
1 文本文件汉字打开时出现乱码。(主要原因是缺少urlencode函数,对从新浪微盘读取数据的解码获取中文)
2 文件重命名,目录重命名 。即fuse里面的rename函数未完成。
感谢:非常感谢kpfs文件系统的作者Tao Yu ,给我实现新浪微盘文件系统FUFS带来了很多灵感和帮助.
如果有什么问题需要交流,或许你想帮助完善FUFS文件系统,你可以发我邮件。
我的邮箱地址:handsomestone@gmail.com
fufs 官网
https://github.com/handsomestone/FUFS

FUSE
FUSE
什么是 FUSE
Filesystem in Userspace 顾名思义,即在用户空间的文件系统。
为什么要强调用户空间呢?接触过 Linux 内核的同学大概会知道,文件系统一般是实现在内核里面的,比如,Ext4、Fat32、NTFS (Kernel 原生版) 等常见的文件系统,其代码都在内核中,而 FUSE 特殊之处就是,其文件系统的核心逻辑是在用户空间实现的。
为什么 FUSE 会存在
事物的存在的原因之一是其优势大于劣势,下面是它的优劣描述。
优势
- 文件系统的改动不用更新内核
FUSE 的核心逻辑在用户空间,所以修改文件系统的行为绝大部分修改会在用户空间。这在很多场合是一件很方便的事情。 - 很容易实现自己的文件系统
理论上它可以实现任何天马行空的文件系统,只要一个开发者实现了基本的文件操作。而这个所谓的文件操作也是自己定义的,甚至可以这个操作可能只是一句打印而已,或者是一件超级复杂的事情,只要这个操作符合开发者的要求,他就完成了一个符合开发者需求的文件系统(也许本质上并不是文件系统了,这种情况是有现实例子的)。
劣势
- 效率较低
这是显而易见的,就针对块设备的文件系统而言,用户层肯定不如内核实现的效率高,毕竟用户态 / 内核态切换的开销是少不了的。这也是符合一般软件规律的,越高层次的软件易用性越高,效率越低。
FUSE 实现原理
下面这张图体现了 FUSE 工作的基本套路,是根据 WIki 里的画的,这张图感觉更符合我看到的代码的状况。
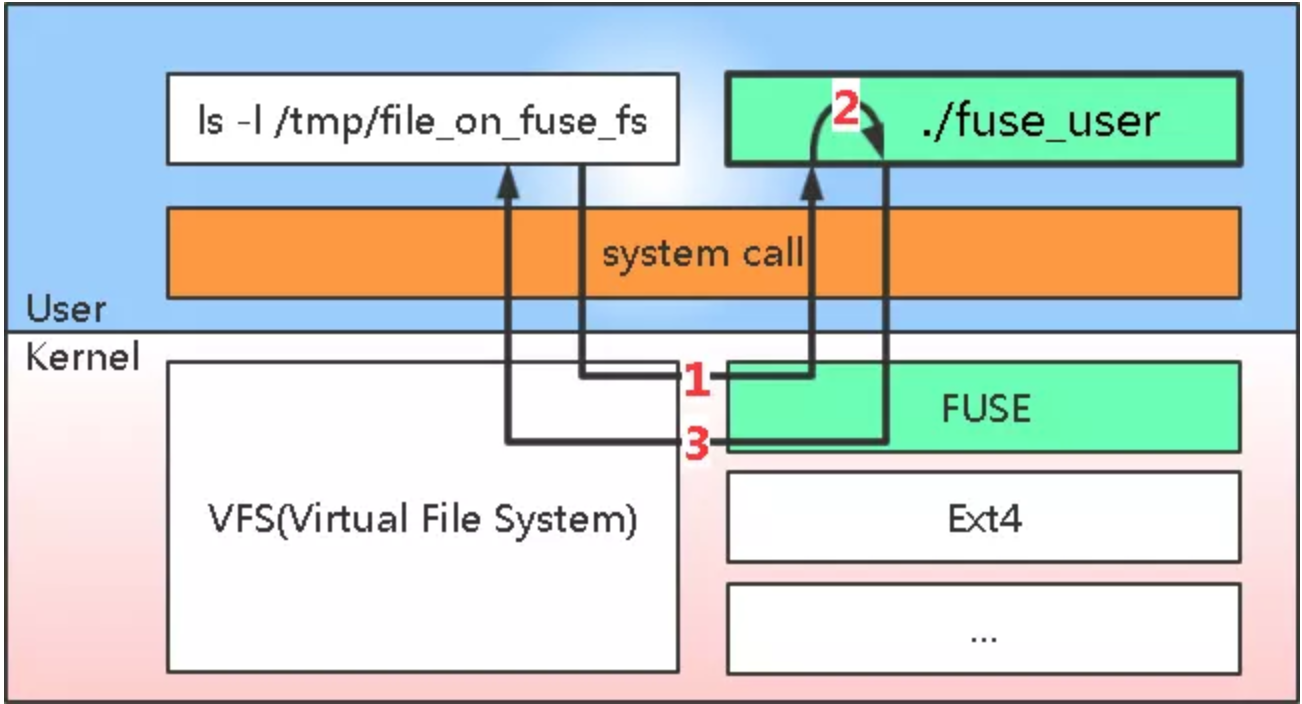
图中体现了 FUSE 的 2 个关键部分(绿色方框),分别是 Kernel 中的那个 FUSE(这里简称 kernel FUSE) 和 user space 中的那个fuse_user程序。其中 kernel FUSE 是负责把从用户层过来的文件系统操作请求传递给fuse_user程序的,而这个fuse_user程序实现了前面所说的文件系统的核心逻辑。
下面分步描述一下在用户对一个 FUSE 分区上的文件执行 ls 命令时发生了什么,当然,这里隐含了个前提,即这个系统的 /tmp 目录已经属于某个 FUSE 分区了,为了达到这种状况,前面还需要有一个 mount 的过程。
图中 1 号折线过程
- 用户敲
ls -l /tmp/file_on_fuse_fs+ 回车
这时ls会调用一些系统调用(例如 stat (2))。 - kernel FUSE 接收用户请求
文件相关的系统调用会进入 VFS 处理,然后 VFS 会根据这个分区的文件系统,找到对应文件系统的实现接口,这里当然是找到 kernel FUSE。 - kernel FUSE 会把收到的操作请求按照 FUSE 定义的通信协议发送给
fuse_user程序
那么问题来了,kernel FUSE 凭什么把消息给 fuse_user,却没给别人呢?
如果看得懂,请体会如下两段代码
// kernel/fs/fuse/dev.c
const struct file_operations fuse_dev_operations = {
.owner = THIS_MODULE,
.open = fuse_dev_open,
.llseek = no_llseek,
.read_iter = fuse_dev_read,
.splice_read = fuse_dev_splice_read,
.write_iter = fuse_dev_write,
.splice_write = fuse_dev_splice_write,
.poll = fuse_dev_poll,
.release = fuse_dev_release,
.fasync = fuse_dev_fasync,
.unlocked_ioctl = fuse_dev_ioctl,
.compat_ioctl = fuse_dev_ioctl,
};
EXPORT_SYMBOL_GPL(fuse_dev_operations);
static struct miscdevice fuse_miscdevice = {
.minor = FUSE_MINOR,
.name = "fuse",
.fops = &fuse_dev_operations,
};
// fuse_user
int fd = open("/dev/fuse", ...);
read(fd, ...);
write(fd, ...);1. 第一段代码说明,FUSE 会创建一个名为 fuse 的混杂设备文件(简称 fuse 设备文件);
2. 第二段代码说明,fuse_user 可以用过读写 fuse 设备文件来与 kernel FUSE 通信,也就是说,fuse_user 可以通过 read 函数主动读取了 kernel FUSE 的请求。
至此 1 号折线走完。
图中 2 号曲线过程
fuse_user收到 kernel FUSE 发来的请求
这个收发请求的机制在文末的参考资料中有提及,感兴趣的同学可以研究一下。fuse_user处理这个请求
这个 “处理” 完全是开发者自己定义的,只要符合开发者的要求就是合适的处理方式,不过本文讨论的是针对块设备的货真价实的文件系统,所以这个 “处理” 必须能够读写块设备上面的内容。
那么一个很简单的问题来了,如果不使用fwrite(3)或write(2)这种方式,怎么写入文件呢?
答案要回到事物的本源,文件是个抽象概念,它本质上只是块设备(例如磁盘、优盘或 SD 卡)上字节的有序排列而已,所以只要能写入块设备,写入文件当然就可以实现。
那么如何读写块设备呢?请想象插入一个优盘,然后体会下面代码。
int fd = open("/dev/block/sda");//或者sda1
pwrite(fd, buf, count, offset);解释一下上面代码。当我们插入一个优盘到 linux 系统时,常见的情况是系统会自动生成 /dev/block/sda 和 /dev/block/sda1 两个块设备文件,所以第一句 open 就是在获取块设备的 fd(file descriptor),然后再用 pwrite 访问这个 fd,将 buf 的内容向 offset 位置写 count 个字节。其中 offset 是写入位置,即从块设备的哪个字节开始写。虽然这里也是用了 write 一类的函数,但是 write 的对象不同哦。
综上所述,再加上 pread 函数,我们对块设备就可以为所欲为了。
至此,2 号曲线走完。
图中 3 号折线过程
fuse_user将处理结果返回给 kernel FUSE- 继续顺着 1 号折线的来路,原路返回处理结果
至此,3 号折线走完。
说完了代码,下面我们用 2 个实际使用的 case(Android 和 NTFS-3G)进行说明。
FUSE 的实现代码
如前面所讲,FUSE 分为 2 部分,分别在 user、kernel spcae 中,在 kernel space 中的部分由 kernel 官方维护,user space 中的部分(仅是个框架,不包括开发者的实现)有一个开源库叫 libfuse,NTFS-3G 就是基于这个 FUSE 框架的实现,另一个我接触到实现是 Android 8.0 的中 SD 卡的文件系统的实现,它没有用 libfuse,完全是谷歌自己写的一个实现。
NTFS-3G 与 FUSE
关于 NTFS-3G
NTFS-3G 是一个叫 Szabolcs Szakacsits 的开发者 2006 年创建的项目,后来他创建了一个公司叫 Tuxera,从事很多 NTFS 文件系统相关的业务,NTFS-3G 这个开源项目,也由这个公司维护至今,它就是一份典型的 FUSE 文件系统实现源码。
代码导读
根据上面所说的原理,这个文件系统中必然存在着块设备和 fuse 设备的 open/close/read/write。下面着重描述 3 个重要动作,分别是打开块设备、打开 fuse 设备和处理 kernel FUSE 请求,啥也不说了,都在代码里了,撸!。
ntfs-3g.c
main——打开块设备
{
...
//打开块设备,opts.device就是块设备的名字,例如"/dev/block/sda1"
//这里就是前面代码中的open来获得fd的动作
err = ntfs_open(opts.device);
==> ctx->vol = ntfs_mount(device, flags);
{
dev = ntfs_device_alloc(name, 0, &ntfs_device_default_io_ops, NULL);
{
//埋下伏笔(1)!!!
//注册了设备文件操作函数
//dev->d_ops->open = ntfs_device_unix_io_open
//dev->d_ops->write = ntfs_device_unix_io_write
dev->d_ops = dops;
dev->d_private = priv_data;
}
...
vol = ntfs_device_mount(dev, flags);
==> vol = ntfs_volume_startup(dev, flags);
{
if ((dev->d_ops->open)(dev, ...))
//为什么会call 到这呢,请看前面的伏笔(1)!!!
==> ntfs_device_unix_io_open(struct ntfs_device *dev, int flags)
//注意了!注意了!open块设备了啊!
//例如,dev->d_name = "/dev/block/sda1"
==> *(int*)dev->d_private = open(dev->d_name, flags);
//埋下伏笔(7)!!!
//注册了设备文件操作函数
vol->dev = dev;
}
}
...
}
从上述代码中可以看到,块设备确实被打开了。
ntfs-3g.c
main——打开fuse设备
{
//前面已经open了块设备
...
fh = mount_fuse(parsed_options);
{
ctx->fc = try_fuse_mount(parsed_options);
==> fc = fuse_mount(opts.mnt_point, &margs);
{
fd = fuse_kern_mount(mountpoint, args);
==> res = fusermount(0, 0, 0, mnt_opts ? mnt_opts : "", mountpoint);
==> res = mount_fuse(mnt, opts);
==> fd = open_fuse_device(&dev);
==> fd = try_open(FUSE_DEV_NEW, devp);
//注意了!注意了!open fuse设备了啊!
//例如,dev = "/dev/fuse"
==> fd = open(dev, O_RDWR);
...
==> ch = fuse_kern_chan_new(fd);
{
struct fuse_chan_ops op = {
//埋下伏笔(2.0)!!!
//注册了设备文件操作函数
//op.receive = fuse_kern_chan_receive
//op.send = fuse_kern_chan_send
.receive = fuse_kern_chan_receive,
.send = fuse_kern_chan_send,
...
};
...
return fuse_chan_new(&op, fd, bufsize, NULL);
==> return fuse_chan_new_common(op, fd, bufsize, data);
{
//埋下伏笔(2.1)!!!
//伏笔(2.0)的op给了ch
//ch->op->receive = fuse_kern_chan_receive
//ch->op->send = fuse_kern_chan_send
ch->op = *op;
//埋下伏笔(3)!!!
//打开fuse设备的fd给了ch
ch->fd = fd;
}
}
}
//埋下伏笔(4.0)!!!
//ntfs_3g_ops.write = ntfs_fuse_write
fh = fuse_new(ctx->fc, &args , &ntfs_3g_ops, sizeof(ntfs_3g_ops), NULL);
//埋下伏笔(5.0)!!!
//llop = fuse_path_ops
//fuse_path_ops.write = fuse_lib_write
==> f->se = fuse_lowlevel_new(args, &llop, sizeof(llop), f);
{
struct fuse_session_ops sop = {
//埋下伏笔(6.0)!!!
//sop.process = fuse_ll_process
.process = fuse_ll_process,
...
};
...
//埋下伏笔(4.1)!!!
//f->fs->op = ntfs_3g_ops
//f->fs->op.write = ntfs_fuse_write
fs = fuse_fs_new(op, op_size, user_data);
==> memcpy(&fs->op, op, op_size);
f->fs = fs;
...
//埋下伏笔(5.1)!!!
//op = llop = fuse_path_ops
//f->op->write = fuse_lib_write
memcpy(&f->op, op, op_size);
...
se = fuse_session_new(&sop, f);
{
//埋下伏笔(6.1)!!!
//sop给了se
se->op = *op;
se->data = data;
}
}
}
...
}
从上述代码中可以看到,fuse 混杂设备确实被打开了。
ntfs-3g.c
main——处理kernel FUSE请求
{
//前面已经open了块设备和fuse设备
...
fuse_loop(fh);
==> return fuse_session_loop(f->se);
{
//这个循环中不停地响应着kernel FUSE的请求
while (!fuse_session_exited(se)) {
struct fuse_chan *tmpch = ch;
res = fuse_chan_recv(&tmpch, buf, bufsize);
==> return ch->op.receive(chp, buf, size);
//为啥call到这?请看伏笔(2.x)
==> fuse_kern_chan_receive
{
//fuse_chan_fd(ch)是什么?请看伏笔(3)
res = read(fuse_chan_fd(ch), buf, size);
}
...
fuse_session_process(se, buf, res, tmpch);
==> se->op.process(se->data, buf, len, ch);
//为啥call到这?请看伏笔(6.x)
==> fuse_ll_process
/**********
static struct {
void (*func)(fuse_req_t, fuse_ino_t, const void *);
const char *name;
} fuse_ll_ops[] = {
...
[FUSE_WRITE] = { do_write, "WRITE" },
...
};
***********/
//假设我们在进行写(FUSE_WRITE)操作
==> fuse_ll_ops[in->opcode].func(req, in->nodeid, inarg);
==> do_write
==> req->f->op.write(req, nodeid, PARAM(arg), arg->size, arg->offset, &fi);
//为啥call到这?请看伏笔(5.x)
==> fuse_lib_write
{
...
res = fuse_fs_write(f->fs, path, buf, size, off, fi);
==> return fs->op.write(path, buf, size, off, fi);
//为啥call到这?请看伏笔(4.x)
==> ntfs_fuse_write
==> s64 ret = ntfs_attr_pwrite(na, offset, size, buf + total);
//vol->dev是什么?请看伏笔(7)
==> written = ntfs_pwrite(vol->dev, ...);
==> written = dops->pwrite(dev, ...);
//为啥call到这?请看伏笔(1)
==> ntfs_device_unix_io_pwrite
//注意了!注意了!对块设备文件pwrite了啊!
//DEV_FD(dev)是什么?请看前面打开块设备的地方
==> return pwrite(DEV_FD(dev), buf, count, offset);
...
fuse_reply_write(req, res);
==> return send_reply_ok(req, &arg, sizeof(arg));
==> return send_reply(req, 0, arg, argsize);
==> return send_reply_iov(req, error, iov, count);
==> res = fuse_chan_send(req->ch, iov, count);
==> return ch->op.send(ch, iov, count);
==> fuse_kern_chan_send
//注意了!注意了!对fuse设备文件writev了啊!
//虽然和write不同,但也是向fuse设备文件的fd写东西
//fuse_chan_fd(ch)是什么?请看伏笔(3)
==> ssize_t res = writev(fuse_chan_fd(ch), iov, count);
...
}
}
}
//收尾工作
...
}
光练不说傻把式,还得说一下。
从上述代码中可以看到,“写” 的用户请求是用 ntfs_fuse_write 函数处理的,struct fuse_operations ntfs_3g_ops 就是开发者要实现的文件系统核心逻辑,这些文件操作在打开 fuse 设备过程 (mount_fuse 函数) 中被绑定到那些核心数据结构中。在最后处理文件系统请求时调用,最终以直接访问块设备的方式实现了 “处理”。然后,以写入 fuse 设备文件的方式将 “处理” 结果发给 kernel FUSE。
Android 与 FUSE
Android 代码到哪看
谈到 Android,由于众所周知的原因,首先要说怎么在中国大陆访问它的代码,这事靠百度可以解决,如果只是看看,用这些网站在线看就好了。
Android 代码浏览网站 1
Android 代码浏览网站 2
Android 8.0 的 FUSE
Android 里面用的并不是 NTFS-3G 所使用的 libfuse,因为我接触到的是 AN8 (Android 8.0) 的代码,所以就基于它来再次领略一下 FUSE 文件系统的实现。代码在 AN8/system/core/sdcard,下面有 3 个代码文件
AN8/system/core/sdcard
├── Android.mk
├── fuse.cpp
├── fuse.h
└── sdcard.cpp // main函数在这里!!!sdcard.cpp 是对 SD 卡文件系统处理的代码。谷歌搞了个 sdcardfs 文件系统,当系统支持 sdcardfs,并且用户要求使用时,就会优先用这个文件系统挂载 SD 卡,否则就用 FUSE 挂载。也就是说,对于 AN8 来说,FUSE 是 sdcardfs 的备胎,下面代码反映了这绿油油的事实。
int main(int argc, char **argv) {
//各种准备工作
...
if (should_use_sdcardfs()) {
//如果应该用sdcardfs,就运行sdcardfs
run_sdcardfs(...);
} else {
//否则,就运行FUSE
run(...);
}
return 1;
}
下面创建了 3 个 start_handler 的线程,看得出来它们之间有些区别。为什么是这 3 个?我也不知道,那就是 AN8 的实现问题了,不是本文重点。
static void run(...) {
//准备工作
...
//埋下伏笔(1)
//这些dest_path后面会用到
snprintf(fuse_default.dest_path, PATH_MAX, "/mnt/runtime/default/%s", label);
snprintf(fuse_read.dest_path, PATH_MAX, "/mnt/runtime/read/%s", label);
snprintf(fuse_write.dest_path, PATH_MAX, "/mnt/runtime/write/%s", label);
handler_default.fuse = &fuse_default;
handler_read.fuse = &fuse_read;
handler_write.fuse = &fuse_write;
...
if (fuse_setup(&fuse_default, AID_SDCARD_RW, 0006)
|| fuse_setup(&fuse_read, AID_EVERYBODY, ...)
|| fuse_setup(&fuse_write, AID_EVERYBODY, full_write ? 0007 : 0027))
==> fuse_setup
{
//注意了!注意了!打开fuse设备文件了啊!
//埋下伏笔(2)
//注意这个fd,后面会用到
fuse->fd = TEMP_FAILURE_RETRY(open("/dev/fuse", O_RDWR | O_CLOEXEC));
//欲知fuse->dest_path是什么,请看伏笔(1)
mount("/dev/fuse", fuse->dest_path,...)
}
...
if (pthread_create(&thread_default, NULL, start_handler, &handler_default)
|| pthread_create(&thread_read, NULL, start_handler, &handler_read)
|| pthread_create(&thread_write, NULL, start_handler, &handler_write)) {
LOG(FATAL) << "failed to pthread_create";
}
// 一些不会退出的loop
...
}
在上面代码中,打开了 fuse 设备文件,同时创建了 3 个 FUSE 用户线程来处理 kernel FUSE 的请求。
start_handler ==> handle_fuse_requests
{
for (;;) {
//欲知fuse->fd是什么,请看伏笔(2)
read(fuse->fd,...);
...
//埋下伏笔(3)
//data是kernel FUSE发来的请求
int res = handle_fuse_request(fuse, handler, hdr, data, data_len);
//以一个顺利的写请求为例
==> return handle_write(fuse, handler, hdr, req, buffer);
{
struct handle *h = static_cast<struct handle*>(id_to_ptr(req->fh));
...
//注意了!注意了!写块设备文件了啊!
//欲知h->fd是什么,它源自伏笔(3)提到的data,所以它来自kernel FUSE
//它是怎么来的呢?此处设下一个悬念(1)
res = TEMP_FAILURE_RETRY(pwrite64(h->fd, buffer, req->size, req->offset));
...
fuse_reply(fuse, hdr->unique, &out, sizeof(out));
//注意了!注意了!写fuse设备文件了啊!
//欲知fuse->fd是什么,请看伏笔(2)
==> ssize_t ret = TEMP_FAILURE_RETRY(writev(fuse->fd, vec, 2));
...
}
...
}
}
在上面代码中,读取了 kernel FUSE 的请求,然后处理,即写入了块设备文件,最后发回结果给 kernel FUSE。
这段代码中有一个悬念,后文会揭露。
Kernel FUSE
代码在哪
- Kernel 代码
Kernel 官网、Github 镜像 - FUSE 路径
Kernel fuse 代码在 linux/fs/fuse 目录
代码导读
我对这里没有多少研究,怕误人子弟,所以不展开了,仅仅围绕前面代码中的悬念 (1) 进行说明。前面的悬念 (1) 在于那个来自 kernel FUSE 的 fd 是在哪里赋值的。下面先从读 fuse 设备文件说起,因为这里就是获取 kernel FUSE 请求的现场。
读写 fuse 设备文件
前面的 FUSE 文件系统实现中,它们与 kernel FUSE 沟通都是通过读写 fuse 设备文件实现的,而这个设备文件的读写操作就定义在 struct file_operations fuse_dev_operations 中。
//dev.c
const struct file_operations fuse_dev_operations = {
...
.read_iter = fuse_dev_read,
.splice_read = fuse_dev_splice_read,
.write_iter = fuse_dev_write,
.splice_write = fuse_dev_splice_write,
...
};
我看了半天才想到,上面这部分代码对我们揭开悬念没有帮助,因为这里只是把请求从某处读出来给用户层而已,所以它并不生产请求,只是请求的搬运工。回顾一下原理,直接给 kernel FUSE 创建请求的是 VFS,所以应该从对接 VFS 的那部分 kernel FUSE 的代码寻找线索。另外一个重要线索就是在 AN8 的代码中,处理写请求时用到了 struct fuse_write_in 这个结构体,悬念处的 fd 值就是源于 fuse_write_in.fh,关键是它定义在 kernel 的头文件里哟,你懂的。
神秘的 fh
在 kernel 里搜 struct fuse_write_in 就很容易发现,fuse_write_in.fh 的赋值在 fuse_write_fill 里面。下面的代码描述的是每个 FUSE 文件系统中的文件的 “写” 过程,从这个过程中可以观察到,这个 fh 就在 file->private_data 中,file->private_data 的实际类型是 struct fuse_file*。
static const struct file_operations fuse_file_operations = {
...
.write_iter = fuse_file_write_iter,
==> written_buffered = fuse_perform_write(file, mapping, from, pos);
==> num_written = fuse_send_write_pages(...);
==> res = fuse_send_write(req, &io, pos, count, NULL);
{
struct fuse_file *ff = file->private_data;
...
fuse_write_fill(req, ff, pos, count);
{
struct fuse_write_in *inarg = &req->misc.write.in;
...
//inarg->fh = file->private_data->fh
inarg->fh = ff->fh;
}
}
...
};
void fuse_init_file_inode(struct inode *inode)
{
inode->i_fop = &fuse_file_operations;
inode->i_data.a_ops = &fuse_file_aops;
}
神秘的 private_data—— 一切还在用户层
暮然回首,那 fd 还在用户层,请看代码 (AN8 中)。
static int handle_open(struct fuse* fuse, struct fuse_handler* handler,
const struct fuse_in_header* hdr, const struct fuse_open_in* req)
{
...
node = lookup_node_and_path_by_id_locked(fuse, hdr->nodeid, path, sizeof(path));
...
//注意了!注意了!打开块设备文件了啊!
//悬念(1)被揭露了
h->fd = TEMP_FAILURE_RETRY(open(path, req->flags));
out.fh = ptr_to_id(h);
fuse_reply(fuse, hdr->unique, &out, sizeof(out));
...
}
上面这段代码是 AN8 的 FUSE 实现打开文件的函数,这就是 AN8 FUSE 打开块设备文件的现场了。为什么是 open 呢?此处与 kernel 中的 file->private_data 有什么关系呢?请看下面代码。
int fuse_do_open(struct fuse_conn *fc, u64 nodeid, struct file *file,
bool isdir)
{
...
//这里就通向了用户层的open,用户层那个fh就通过outarg传了回来
err = fuse_send_open(fc, nodeid, file, opcode, &outarg);
ff->fh = outarg.fh;
ff->open_flags = outarg.open_flags;
...
//file->private_data->fh = outarg.fh
//outarg就是悬念(1)被揭露现场的那个out
file->private_data = fuse_file_get(ff);
==> return ff;
...
}
与 NTFS-3G 相比,AN8 利用每个文件的 struct file.private_data 来传递块设备文件的 fd,并在 open 文件的时候打开块设备。

FUSE getattr操作是否应该被序列化?
我正在实现一个FUSE文件系统,旨在通过熟悉的POSIX调用来访问实际存储在RESTful API后面的文件。 文件系统第一次检索到文件系统时会caching文件,以便在随后的访问中更容易使用文件。
我以multithreading模式运行文件系统(这是FUSE的默认模式),但发现getattr调用似乎被序列化,即使其他调用可以并行进行。
打开文件时,FUSE总是先调用getattr,而我支持的客户端需要这个初始调用返回的文件大小是准确的(我没有任何控制权)。 这意味着,如果我没有caching文件,我需要通过RESTful API调用实际获取信息。 有时这些呼叫会在高延迟的networking上发生,往返时间大约为600ms。
由于getattr调用明显的顺序特性,对当前未caching的文件的任何访问都将导致整个文件系统在getattr服务期间阻止任何新操作。
/ usr / bin / ld:编译jni项目时找不到-ljvm:
Windows 2008:虚拟文件系统(如FUSE)
无法将基于熔丝的卷暴露给Docker容器
文件系统加速 – “查找”命令
fork()后出现libCurl SSL错误
我已经提出了很多方法来解决这个问题,但都看起来很丑或冗长,真的我只想getattr调用像所有其他调用似的并行运行。
看看源代码,我不明白为什么getattr应该是这样的行为,FUSE确实locking了tree_lock互斥体,但仅用于读取,并且没有写入同时发生。
为了在这个问题上发布一些简单的东西,我敲了一个令人难以置信的基本实现,它只是支持getattr,并且可以轻松演示这个问题。
#ifndef FUSE_USE_VERSION #define FUSE_USE_VERSION 22 #endif #include <fuse.h> #include <iostream> static int GetAttr(const char *path,struct stat *stbuf) { std::cout << "Before: " << path << std::endl; sleep(5); std::cout << "After: " << path << std::endl; return -1; } static struct fuse_operations ops; int main(int argc,char *argv[]) { ops.getattr = GetAttr; return fuse_main(argc,argv,&ops); }
使用几个terminal在(大致)同时在path上调用ls表明第二个getattr调用仅在第一个完成时开始,这导致第二个ls取代5而花费大约10秒。
1号航站楼
$ date; sudo ls /mnt/cachefs/file1.ext; date Tue Aug 27 16:56:34 BST 2013 ls: /mnt/cachefs/file1.ext: Operation not permitted Tue Aug 27 16:56:39 BST 2013
2号航站楼
$ date; sudo ls /mnt/cachefs/file2.ext; date Tue Aug 27 16:56:35 BST 2013 ls: /mnt/cachefs/file2.ext: Operation not permitted Tue Aug 27 16:56:44 BST 2013
如您所见,与ls之前的两个date输出的时间差仅相差1秒,但ls之后的两个时间差相差5秒,这对应于GetAttr函数中的延迟。 这表明第二个电话在FUSE深处被阻塞。
产量
$ sudo ./cachefs /mnt/cachefs -f -d unique: 1,opcode: INIT (26),nodeid: 0,insize: 56 INIT: 7.10 flags=0x0000000b max_readahead=0x00020000 INIT: 7.8 flags=0x00000000 max_readahead=0x00020000 max_write=0x00020000 unique: 1,error: 0 (Success),outsize: 40 unique: 2,opcode: LOOKUP (1),nodeid: 1,insize: 50 LOOKUP /file1.ext Before: /file1.ext After: /file1.ext unique: 2,error: -1 (Operation not permitted),outsize: 16 unique: 3,insize: 50 LOOKUP /file2.ext Before: /file2.ext After: /file2.ext unique: 3,outsize: 16
上面的代码和示例与实际应用程序或应用程序的使用方式没有任何关系,但performance出相同的行为。 我没有在上面的例子中显示过,但是我发现一旦getattr调用完成,后续打开的调用就可以并行运行了,就像我期望的那样。
我search了文档,试图解释这种行为,并试图find其他人报告类似的经验,但似乎无法find任何东西。 可能是因为getattr的大多数实现会很快,所以你不会注意到它是否被序列化,或者是因为我在configuration中做了一些愚蠢的事情。 我正在使用FUSE 2.7.4版本,所以可能这是一个已经修复的旧bug。
如果有人对此有任何的见解,将不胜感激!
保险丝2.9中的fuse.ko作为内核模块的替代品
如何使用保险丝在远程机器上安装目录?
为什么鹦鹉螺提前读取目录?
“同步”和“同步”系统调用是否映射到FUSE的“fsync”调用?
Linux块设备模拟和保险丝
我注册了FUSE邮件列表,张贴了我的问题,最近得到了Miklos Szeredi的回复:
查找(即首先查找与名称关联的文件)是按目录序列化的。 这是在VFS(内核中的通用文件系统部分),所以基本上任何文件系统都容易受到这个问题的影响,而不仅仅是保险丝。
非常感谢Miklos的帮助。 有关完整的线程,请参阅http://fuse.996288.n3.nabble.com/GetAttr-calls-being-serialised-td11741.html 。
我也注意到序列化是按目录的,即如果两个文件都在同一个目录下,就可以看到上面的效果,但是如果它们在不同的目录下,则看不到上面的效果。 对于我的应用程序来说,这种缓解对我来说已经足够了,我的文件系统的客户端使用目录,所以当我可能期望很多getattr调用紧密连续时,它们都发生在同一个目录中的可能性足够低,担心。
对于那些缓解不够的人来说,如果你的文件系统支持目录列表,你可能会利用David Strauss的建议,即使用readdir调用来触发缓存:
在我们的文件系统中,我们尝试在readdir期间预取和缓存属性信息(这将不可避免地被请求),所以我们不必为每个后端打开后端。
由于到我的文件系统的后端没有目录的概念,我无法利用他的建议,但希望这将有助于其他人。
今天关于linux 用户空间文件系统 filesystem in userspace fuse 简介和linux的用户文件的分享就到这里,希望大家有所收获,若想了解更多关于Checkpoint/Restore in Userspace(CRIU)安装和使用、fufs 用户空间文件系统、FUSE、FUSE getattr操作是否应该被序列化?等相关知识,可以在本站进行查询。
本文标签:




