本文将为您提供关于Linux查看GPU信息和使用情况的详细介绍,我们还将为您解释linux如何查看gpu信息的相关知识,同时,我们还将为您提供关于ChoicheGPUtensorflow-direct
本文将为您提供关于Linux 查看 GPU 信息和使用情况的详细介绍,我们还将为您解释linux如何查看gpu信息的相关知识,同时,我们还将为您提供关于Choiche GPU tensorflow-directml 或 multi-gpu、GCP 中 NVIDIA P100 GPU 和 Committed NVIDIA P100 GPU 限制名称的区别、GPU Mounter - 支持 GPU 热挂载的 Kubernetes 插件、GPU 上的神经网络使用系统 RAM 而不是 GPU 内存的实用信息。
本文目录一览:- Linux 查看 GPU 信息和使用情况(linux如何查看gpu信息)
- Choiche GPU tensorflow-directml 或 multi-gpu
- GCP 中 NVIDIA P100 GPU 和 Committed NVIDIA P100 GPU 限制名称的区别
- GPU Mounter - 支持 GPU 热挂载的 Kubernetes 插件
- GPU 上的神经网络使用系统 RAM 而不是 GPU 内存
")
Linux 查看 GPU 信息和使用情况(linux如何查看gpu信息)
Linux 查看显卡信息:
lspci | grep -i vga
使用 nvidia GPU 可以:
lspci | grep -i nvidia
[root@gpu-server-002 ~]# lspci | grep -i nvidia
02:00.0 VGA compatible controller: NVIDIA Corporation Device 1b06 (rev a1)
02:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
03:00.0 VGA compatible controller: NVIDIA Corporation Device 1b06 (rev a1)
03:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
82:00.0 VGA compatible controller: NVIDIA Corporation Device 1b06 (rev a1)
82:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
83:00.0 VGA compatible controller: NVIDIA Corporation Device 1b06 (rev a1)
83:00.1 Audio device: NVIDIA Corporation Device 10ef (rev a1)
前边的序号 "00:0f.0" 是显卡的代号 (这里是用的虚拟机);
查看指定显卡的详细信息用以下指令:
lspci -v -s 00:0f.0
Linux 查看 Nvidia 显卡信息及使用情况
Nvidia 自带一个命令行工具可以查看显存的使用情况:
nvidia-smi
[root@gpu-server-002 ~]# nvidia-smi
Tue Nov 27 00:20:51 2018
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 384.98 Driver Version: 384.98 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
|===============================+======================+======================|
| 0 GeForce GTX 108... On | 00000000:02:00.0 Off | N/A |
| 66% 85C P2 175W / 250W | 10795MiB / 11172MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 1 GeForce GTX 108... On | 00000000:03:00.0 Off | N/A |
| 56% 83C P2 162W / 250W | 10795MiB / 11172MiB | 100% Default |
+-------------------------------+----------------------+----------------------+
| 2 GeForce GTX 108... On | 00000000:82:00.0 Off | N/A |
| 52% 82C P2 250W / 250W | 10795MiB / 11172MiB | 90% Default |
+-------------------------------+----------------------+----------------------+
| 3 GeForce GTX 108... On | 00000000:83:00.0 Off | N/A |
| 54% 83C P2 126W / 250W | 10795MiB / 11172MiB | 82% Default |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: GPU Memory |
| GPU PID Type Process name Usage |
|=============================================================================|
| 0 11161 C python 10785MiB |
| 1 11161 C python 10785MiB |
| 2 12049 C python 10785MiB |
| 3 12049 C python 10785MiB |
表头释义:
Fan:显示风扇转速,数值在 0 到 100% 之间,是计算机的期望转速,如果计算机不是通过风扇冷却或者风扇坏了,显示出来就是 N/A;
Temp:显卡内部的温度,单位是摄氏度;
Perf:表征性能状态,从 P0 到 P12,P0 表示最大性能,P12 表示状态最小性能;
Pwr:能耗表示;
Bus-Id:涉及 GPU 总线的相关信息;
Disp.A:是 Display Active 的意思,表示 GPU 的显示是否初始化;
Memory Usage:显存的使用率;
Volatile GPU-Util:浮动的 GPU 利用率;
Compute M:计算模式;
下边的 Processes 显示每块 GPU 上每个进程所使用的显存情况。
如果要周期性的输出显卡的使用情况,可以用 watch 指令实现:
watch -n 10 nvidia-smi
命令行参数 - n 后边跟的是执行命令的周期,以 s 为单位。
---------------------
作者:- 牧野 -
来源:CSDN
原文:https://blog.csdn.net/dcrmg/article/details/78146797
版权声明:本文为博主原创文章,转载请附上博文链接!

Choiche GPU tensorflow-directml 或 multi-gpu
如何解决Choiche GPU tensorflow-directml 或 multi-gpu
我正在 Windows PC 上使用 tensorflow 训练模型,但训练量很低,所以我正在尝试将 tensorflow 配置为使用 GPU。 我安装了 tensorflow-directml(在 python 3.6 的 conda 环境中),因为我的 GPU 是 AMD Radeon GPU。 用这个简单的代码
import tensorflow as tf
tf.test.is_gpu_available()
我收到此输出
2021-05-14 11:02:30.113880:我 tensorflow/core/platform/cpu_feature_guard.cc:142] 你的 cpu 支持 此 TensorFlow 二进制文件未编译为使用的说明:AVX2 2021-05-14 11:02:30.121580:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库 C:\\Users\\v.rocca\\anaconda3\\envs\\tfradeon\\lib\\site-packages\\tensorflow_core\\python/directml.adbd007a01a52364381a1c71ebb6fa1b2389c88d.dll 2021-05-14 11:02:30.765470:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:249] DirectML 设备枚举:找到 2 个兼容的适配器。 2021-05-14 11:02:30.984834:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 0 上创建设备(Radeon (TM) 530)2021-05-14 11:02:31.150992:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库Kernel32.dll 2021-05-14 11:02:31.174716:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 1 上创建设备(Intel(R) UHD Graphics 620)True
因此,tensorflow 使用 Intel 的集成 GPU 而不是 Radeon GPU。 如果我从管理硬件中禁用英特尔 GPU,我会在输出中收到正确的 GPU
2021-05-14 10:47:09.171568:我 tensorflow/core/platform/cpu_feature_guard.cc:142] 你的 cpu 支持 此 TensorFlow 二进制文件未编译为使用的说明:AVX2 2021-05-14 10:47:09.176828:我 张量流/stream_executor/platform/default/dso_loader.cc:99] 成功打开动态库 C:\\Users\\v.rocca\\anaconda3\\envs\\tfradeon\\lib\\site-packages\\tensorflow_core\\python/directml.adbd007a01a52364381a1c71ebb6fa1b2389c88d.dll 2021-05-14 10:47:09.421265:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:249] DirectML 设备枚举:找到 1 个兼容的适配器。 2021-05-14 10:47:09.626567:我 张量流/核心/common_runtime/dml/dml_device_cache.cc:185] DirectML: 在适配器 0 上创建设备(Radeon (TM) 530)
我不想每次都禁用英特尔 GPU,所以这是我的问题。 是否可以选择我想使用的 GPU?或者是否可以同时使用两个 GPU? 谢谢
解决方法
来自Microsoft:
gpu_config = tf.GPUOptions()
gpu_config.visible_device_list = "1"
session = tf.Session(config=tf.ConfigProto(gpu_options=gpu_config))

GCP 中 NVIDIA P100 GPU 和 Committed NVIDIA P100 GPU 限制名称的区别
如何解决GCP 中 NVIDIA P100 GPU 和 Committed NVIDIA P100 GPU 限制名称的区别
目前,我正在尝试提高 GKE 中 NVIDIA P100 GPU 的配额限制。当我使用限制名称在配额中进行过滤时,我会得到两种类型的选项 - NVIDIA P100 GPU 和承诺的 NVIDIA P100 GPU。这两者有什么区别?
解决方法
顾名思义:
- NVIDIA P100 GPU:您可以在项目中使用的 GPU 配额(并附加到 GCE)。仅当 GPU 连接到活动的 GCE 时,您才需要付费。
- 已提交的 NVIDIA P100 GPU:您可以在项目中提交(预留)的 GPU 配额。即使不使用或连接到虚拟机,您也要为此 GPU 付费,但您将获得折扣

GPU Mounter - 支持 GPU 热挂载的 Kubernetes 插件

前言
GPU Mounter 是一个支持动态调整运行中 Pod 可用 GPU 资源的 Kubernetes 插件,已经开源在 GitHub[1]:
-
支持 Pod 可用 GPU 资源的动态调整 -
兼容 Kubernetes 调度器 -
无侵入式修改 -
REST API 接口 -
一键部署
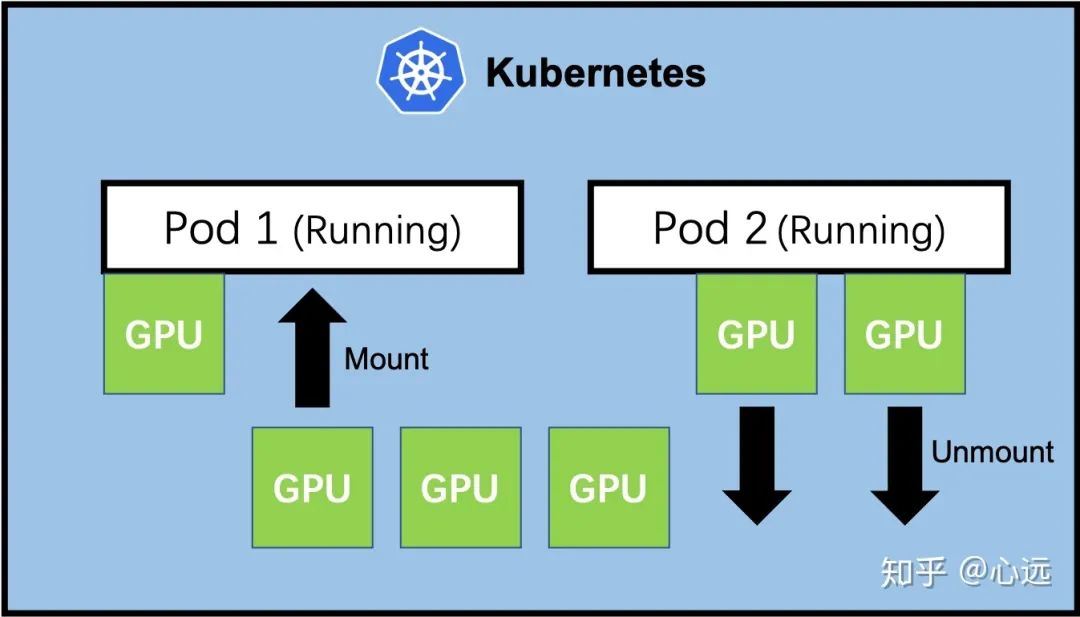
下面聊一聊我对 GPU 容器化和 GPU 挂载的认识,以及为什么需要 GPU 热挂载。
1. GPU 容器化与 GPU 挂载
GPU 挂载很好理解,即为容器或 Pod 挂载 GPU 资源,允许容器中的应用程序使用。在容器化的趋势席卷各个领域的今天,深度学习也同样无法 “幸免”。各大云服务提供商,推出了自己的深度学习云平台(如国内阿里 PAI、腾讯 TI-ONE、百度 BML,国外 AWS Sagemaker 等),深度学习领域的研究者,也开始倾向于在本地采用 Docker 容器的方式构建深度学习训练环境。截止到目前 DockerHub 上 tensorflow 镜像被超过 10M 次,pytorch 镜像被拉取超过 1M 次,可见容器化的影响。
谈到深度学习的容器化,GPU 挂载是一个绕不开的话题,为此 Docker、Kubernetes、Nvidia 都做出了很多贡献:
-
Nvidia 贡献了 nvidia-docker、nvidia-container-runtime、k8s-deivice-plugin 等,支持在 Docker 和 Kubernetes 环境下使用 Nvidia GPU 资源
-
Docker 从 19.03 版本开始原生支持
--gpus参数对接 nvidia-container-runtime -
Kubernetes 从 1.8 版本开始提供 Device Plugin 接口,解耦源代码中对 Nvidia GPU 的原生支持
因为有了上述工作,我们在 Docker 或 Kubernetes 环境中想要使用 GPU,只需一个--gpus参数或者一个nvidia.com/gpu资源字段即可完成 GPU 资源的挂载。
2. 当前 GPU 挂载方案的不足
当前的 GPU 容器化的方案仍然存在一点不足,无法动态调整一个已经正在运行的容器或 Pod 可用的 GPU 资源。即我们必须在启动容器时就一次设定好容器可用的 GPU 资源,如果容器已经启动而我们又想要调整其 GPU 资源,只能先关掉这个容器,重新设定后再启动。
也许正处于这一限制,当前各大深度学习云平台均无法支持调整一个运行中实例的 GPU 资源的特性。
关于 Docker 和 Kubernetes 为什么没有解决这一问题,我的理解是容器或 Pod 通常被认为应该是无状态的(Stateless),应该维持其不变性(Immutability),即容器启动后就不应该更改其配置,如果有需要,应该基于一个满足要求的镜像重新开启新的容器。从容器的通用应用场景来看,这种观点是没有问题的,但是在深度学习平台场景下,这一点我认为值得商榷,深度学习应用的依赖通常比较复杂,难以构建标准统一的 “万能” 镜像即插即用。而出于安全的原因,平台一般只允许用户使用平台提供的通用镜像,因此用户不得不破坏不变性,在运行中的容器里安装各种复杂依赖,因此深度学习平台的容器应该被认为是有状态的。
3. 什么是 / 为什么需要 GPU 热挂载?
GPU 热挂载即调整一个运行中容器的 GPU 资源,能够增加或删除一个运行中的容器可用的 GPU 资源而无需暂停或重启容器。
GPU 热挂载这个场景在深度学习云平台上其实很常见,我们来考虑下用户使用深度学习云平台的基本流程。
-
用户启动一个实例后实际上还需要基于平台提供的基础镜像环境再去下载导入数据集和安装其他复杂的依赖库,这一过程数据集规模较大或代码依赖在较为复杂时可能需要耗费较长时间,然而由于无法在环境准备完成后再挂载 GPU 资源,用户不得不在一开始启动实例时就申请所需 GPU 资源。在上述准备环境的过程中 GPU 实际上处于闲置状态,对用户来说需要承受昂贵的 GPU 费用,对平台而言降低了整个平台的资源利用率。
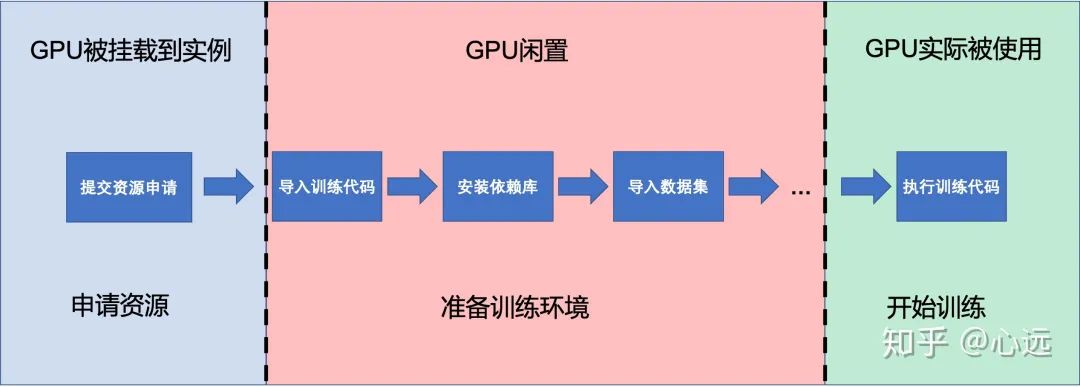
而如果有了 GPU 热挂载的特性,我们就可以将上述流程优化成下图:
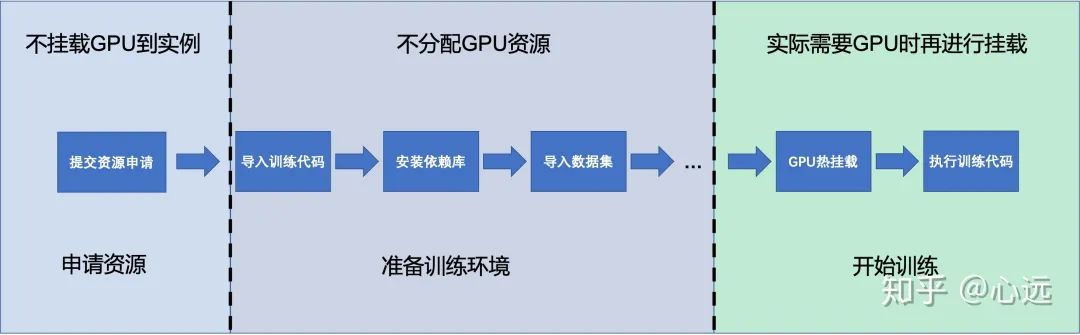
显而易见 GPU 的闲置时间可以大大减少。
4. GPU Mounter - 支持 GPU 热挂载的 Kubernetes 插件
出于上面的原因,我开源了一个 Kubernetes 插件支持 GPU 资源的热挂载。
利用 GPU 热挂载这一特性我们就可以将上述的流程优化成如下:
具体部署与使用详见 GitHub 仓库[2]的 README。
如果觉得有价值希望能点一个 star 让更多人看到,也欢迎提 Issue 和 PR 帮助我更好的改进这个项目。
参考资料
GitHub: https://link.zhihu.com/?target=https%3A//github.com/pokerfaceSad/GPUMounter
[2]GitHub 仓库: https://link.zhihu.com/?target=https%3A//github.com/pokerfaceSad/GPUMounter
原文链接:https://zhuanlan.zhihu.com/p/338251170


你可能还喜欢
点击下方图片即可阅读


云原生是一种信仰
关注公众号
后台回复◉k8s◉获取史上最方便快捷的 Kubernetes 高可用部署工具,只需一条命令,连 ssh 都不需要!


点击 "阅读原文" 获取更好的阅读体验!
发现朋友圈变“安静”了吗?
本文分享自微信公众号 - 云原生实验室(cloud_native_yang)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。

GPU 上的神经网络使用系统 RAM 而不是 GPU 内存
如何解决GPU 上的神经网络使用系统 RAM 而不是 GPU 内存
我使用 PyTorch 构建了一个基本的聊天机器人,在训练代码中,我将神经网络和训练数据都移到了 GPU。但是,当我运行该程序时,它最多使用 2GB 的内存。使用了一点 gpu 内存,但没有那么多。当我运行相同的程序时,但这次在 cpu 上,它只需要大约 900mb 的内存。 谁能告诉我为什么会这样?我附上了我的代码,以及几个屏幕截图。 对不起,如果答案很明显,我是深度学习的新手。
我的代码:
import torch
import torch.nn as nn
from torch.utils.data import Dataset,DataLoader
import numpy as np
from nltk_utils import tokenizer,stem,bag_of_words
import pandas as pd
device = torch.device("cuda")
#Neural Network
class NeuralNetwork(nn.Module):
def __init__(self,input_size,hidden_size,num_classes):
super().__init__()
self.l1 = nn.Linear(input_size,hidden_size)
self.l2 = nn.Linear(hidden_size,hidden_size)
self.l3 = nn.Linear(hidden_size,hidden_size)
self.l4 = nn.Linear(hidden_size,num_classes)
self.relu = nn.ReLU()
def forward(self,x):
out = self.relu(self.l1(x))
out = self.relu(self.l2(out))
out = self.relu(self.l3(out))
out = self.l4(out)
return out
#data initialization
data = pd.read_csv("path_to_train_data")
data = data.dropna(axis=0)
allwords = []
taglist = []
xy = []
ignorewords = ["?","!","''",","]
taglist.extend(x for x in data["tag"] if x not in taglist)
#developing vocabulary
for x in data["pattern"]:
w = tokenizer(x)
allwords.extend(stem(y) for y in w if y not in ignorewords)
#making training data
for indx,x in enumerate(data["pattern"]):
w = tokenizer(x)
bag = bag_of_words(w,allwords)
tag = taglist.index(data["tag"].iloc[indx])
xy.append((bag,tag))
xtrain = np.array([x[0] for x in xy])
ytrain = np.array([x[1] for x in xy])
class TestDataset(Dataset):
def __init__(self):
self.num_classes = len(xtrain)
self.xdata = torch.from_numpy(xtrain.astype(np.float32))
self.ydata = torch.from_numpy(ytrain.astype(np.float32))
def __getitem__(self,index):
return self.xdata[index],self.ydata[index]
def __len__(self):
return self.num_classes
dataset = TestDataset()
train_data = DataLoader(dataset=dataset,batch_size=8,shuffle=True,num_workers=0,pin_memory=True)
inputSize = len(xtrain[0])
hiddenSize = 32
outputSize = len(taglist)
model = NeuralNetwork(inputSize,hiddenSize,outputSize).to(device)
criterion = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters())
epochs = 5000
for epoch in range(epochs):
for (words,labels) in train_data:
words = words.to(device)
labels = labels.type(torch.LongTensor)
labels = labels.to(device)
y_pred = model(words)
loss = criterion(y_pred,labels)
optimizer.zero_grad(set_to_none=True)
loss.backward()
optimizer.step()
with torch.no_grad():
if (epoch + 1) % 10 == 0:
print(f"epoch: {epoch + 1},loss: {loss:.30f}")
在 GPU 上运行时: GPU utilization, RAM utilization
在 cpu 上运行时: RAM utilization
解决方法
RAM 是您的数据堆叠以进行处理的地方,然后将堆栈传输到 SRAM 或以其他方式称为缓存,它是最接近 CPU 的内存(称为主机)。为系统选择 RAM 内存的一般规则被认为等于或大于 GPU 内存。
例如:如果 GPU 内存为 8GB,您需要具有 8GB 或更大的 RAM 以确保最佳性能。
因此,当在 GPU(称为设备)上运行时,您的数据会直接传输到 GPU 以执行张量运算。但是在 CPU 上它不能执行并行计算,因此使用较少的 RAM 内存。
您可以尝试使用不同的batch_sizes 并观察RAM 使用情况。请注意,如果您的一批数据不适合 GPU 内存,您将看到 CUDA 内存不足错误。
我们今天的关于Linux 查看 GPU 信息和使用情况和linux如何查看gpu信息的分享已经告一段落,感谢您的关注,如果您想了解更多关于Choiche GPU tensorflow-directml 或 multi-gpu、GCP 中 NVIDIA P100 GPU 和 Committed NVIDIA P100 GPU 限制名称的区别、GPU Mounter - 支持 GPU 热挂载的 Kubernetes 插件、GPU 上的神经网络使用系统 RAM 而不是 GPU 内存的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

