如果您想了解numpy.bincount正确理解和numpy.bincount详解的知识,那么本篇文章将是您的不二之选。我们将深入剖析numpy.bincount正确理解的各个方面,并为您解答nump
如果您想了解numpy.bincount正确理解和numpy.bincount详解的知识,那么本篇文章将是您的不二之选。我们将深入剖析numpy.bincount正确理解的各个方面,并为您解答numpy.bincount详解的疑在这篇文章中,我们将为您介绍numpy.bincount正确理解的相关知识,同时也会详细的解释numpy.bincount详解的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:- numpy.bincount正确理解(numpy.bincount详解)
- 2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右
- BI学习笔记之五 - 如何正确理解商业智能(BI)?
- c# – 我应该在IEnumerable的上下文中使用.Count()和.Count
- Column count doesn't match value count at row 1_MySQL
")
numpy.bincount正确理解(numpy.bincount详解)
今天看了个方法,numpy.bincount首先官网文档:
numpy.bincount
-
numpy.bincount(x, weights=None, minlength=0) -
Count number of occurrences of each value in array of non-negative ints.
The number of bins (of size 1) is one larger than the largest value in x. If minlength is specified,there will be at least this number of bins in the output array (though it will be longer if necessary,depending on the contents of x). Each bin gives the number of occurrences of its index value in x. If weights is specified the input array is weighted by it,i.e. if a value
nis found at positioni,out[n] += weight[i]instead ofout[n] += 1.Parameters: - x : array_like,1 dimension,nonnegative ints
-
Input array.
- weights : array_like,optional
-
Weights,array of the same shape as x.
- minlength : int,optional
-
A minimum number of bins for the output array.
New in version 1.6.0.
Returns: - out : ndarray of ints
-
The result of binning the input array. The length of out is equal to
np.amax(x)+1.
Raises: - ValueError
-
If the input is not 1-dimensional,or contains elements with negative values,or if minlength is negative.
- TypeError
-
If the type of the input is float or complex.
大意思是: 一脸懵逼好吧,统计bin在x出现的次数,what is bin?长度是x中最大值的+1,也看了一些博客,有些是这样写的:

仔细看了看这个例子,还是没看懂,难道是我智商有问题?索引值0->7 哪里看出来的?官网文档也没说呀
索引0出现1次?x的索引0上数字是0,缺失出现了1次,1出现3次对的,后面索引2也是1应该也是3呀 什么鬼?怎么结果是1???
最终,我发现了到底是怎么统计的了,这个函数要求x里面的数字是非负正数是有道理的,
函数返回的是固定的array[0,1,2,3,...,N]这个数据对应数字在该数组x中出现的次数。
那么我们来验证一下经典的例子:
x = np.array([0,1,3,2,7])
第一个是看0在x中出现几次,1次;
1出现几次,3次;
2出现几次,1次;
3出现几次,1次;
4出现几次,0次;
5出现几次,0次;
6出现几次,0次;
7出现几次,1次
结果:
np.bincount(x)
array([0,1])
完美,再试一个?
也是对的,为啥要长度的最大值加一呢,显然是这里从0开始计算出现次数的,所以最后一个是最大值,数组长度要加1了。
另外一个验证方式,z的数字求和肯定和np.bincount(z).dot(np.arange(max(z)+1))相等
至于其它参数就不介绍了。




![2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右](http://www.gvkun.com/zb_users/upload/2025/02/9022ae81-ed4a-4de1-8ab8-96ab22b1a2ff1739436716066.jpg "2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右")
2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右
2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右侧小于 nums [i] 的元素的数量。力扣 315。
福大大 答案 2021-11-04:
具体见代码。
代码用 golang 编写。代码如下:
package main
import "fmt"
func main() {
arr := []int{
5, 2, 6, 1}
ret := countSmaller(arr)
fmt.Println(ret)
}
type Node struct {
value int
index int
}
func NewNode(v, i int) *Node {
res := &Node{
}
res.value = v
res.index = i
return res
}
func countSmaller(nums []int) []int {
ans := make([]int, 0)
if len(nums) == 0 {
return ans
}
for i := 0; i < len(nums); i++ {
ans = append(ans, 0)
}
if len(nums) < 2 {
return ans
}
arr := make([]*Node, len(nums))
for i := 0; i < len(arr); i++ {
arr[i] = NewNode(nums[i], i)
}
process(arr, 0, len(arr)-1, ans)
return ans
}
func process(arr []*Node, l int, r int, ans []int) {
if l == r {
return
}
mid := l + ((r - l) >> 1)
process(arr, l, mid, ans)
process(arr, mid+1, r, ans)
merge(arr, l, mid, r, ans)
}
func merge(arr []*Node, l int, m int, r int, ans []int) {
help := make([]*Node, r-l+1)
i := len(help) - 1
p1 := m
p2 := r
for p1 >= l && p2 >= m+1 {
if arr[p1].value > arr[p2].value {
ans[arr[p1].index] = ans[arr[p1].index] + p2 - m
}
if arr[p1].value > arr[p2].value {
help[i] = arr[p1]
i--
p1--
} else {
help[i] = arr[p2]
i--
p2--
}
}
for p1 >= l {
help[i] = arr[p1]
p1--
i--
}
for p2 >= m+1 {
help[i] = arr[p2]
p2--
i--
}
for i := 0; i < len(help); i++ {
arr[l+i] = help[i]
}
}执行结果如下:
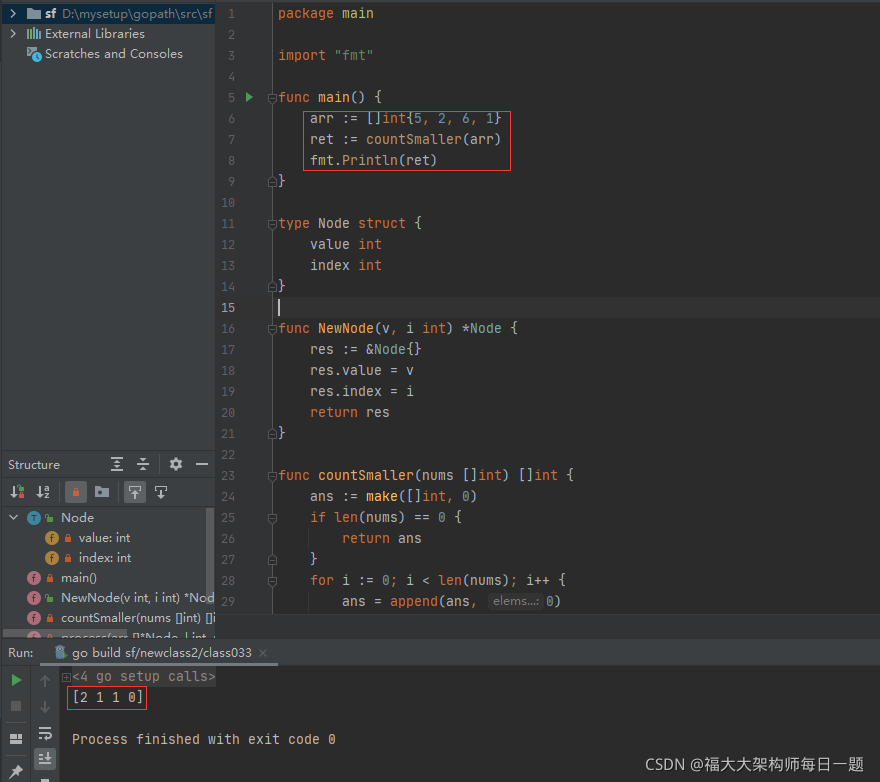
左神 java 代码
?")
BI学习笔记之五 - 如何正确理解商业智能(BI)?
引言
商业智能(BI)是目前在国外企业界和软件开发界受到广泛关注的一个研究方向。可以用两点来总结这种研究热点出现的原因:一、信息技术的高速发展带来了企业利用信息技术提高本身竞争力的巨大空间:信息技术不但使企业获取需要的信息,而且,促进企业对信息的再利用,以此营造企业的竞争优势;二、IT界许多以提供软件平台和工具平台的大公司通过多年与企业的交流,已经认识到企业对商业智能的迫切需求,纷纷加入到从事商业智能的研究与开发上来。IBM建立了专门从事BI方案设计的研究中心,ORACLE、微软等公司纷纷推出了支持BI开发和应用的软件系统,有的直接进入了BI的开发领域。
由于BI尚处于从起步阶段到发展阶段的转变时期,许多人对BI的理解存在一定的偏差。很多人认为BI仅仅是一个进行数据分析的软件包,一些较为悲观的人认为BI是存在于理想家头脑中的、企业永远不可能达到的境界。本文首先系统地诠释了BI的概念,从多个方面总结了BI具有的功能,接着分析了BI的研究内容和发展趋势。为了让读者更加清晰地把BI与MIS系统区别开来,本文讨论了BI与DSS(决策支持系统)、EIS(经理执行系统)的主要区别。最后,本文分析了制约BI健康发展的若干因素。
1.商业智能概述
商业智能不是一个新名词。多年来,企业一直在寻找对商业智能的理解和实现的方式,以增强企业的竞争力。早在80年代,当时“商业智能”的标准是能容易地获得想要的数据和信息。90年代是商业智能真正起步的阶段。到目前为止,关于BI还没有统一的定义,不同的人只是从不同的方面表达了对BI的理解。早在90年代初,Garter Group的Howard Dresner把EUQR(终端查询和报表)、DSS、OLAP称为商业智能。企业使用这些工具使企业获得的优势也被称为商业智能。后来,出现了数据仓库、数据集市技术,以及与之相关的ETL(抽取,转换,上载)、数据清洗、数据挖掘、商业建模等,人们也将这些技术统归为商业智能的领域。目前,存在将商业智能与数据仓库和基于数据仓库的分析方法等同起来的认识趋势。
其实,商业智能代表为提高企业运营性能而采用的一系列方法、技术和软件的总和。商业智能,是帮助企业提高决策能力和运营能力的概念、方法、过程以及软件的集合。对该定义的正确解释,从四个层面展开:
信息系统层面:称为商业智能系统(BI System)的物理基础。表现为具有强大决策分析功能的单独的软件工具和面向特定应用领域的信息系统平台,如SCM、CRM、ERP。与事务型的MIS不同,商业智能系统能提供分析、趋势预测等决策分析功能。
数据分析层面:是一系列算法、工具或模型。首先获取与所关心主题有关的高质量的数据或信息,然后自动或人工参与使用具有分析功能的算法、工具或模型,帮助人们分析信息、得出结论、形成假设、验证假设。
知识发现层面:与数据分析层面一样,是一系列算法、工具或模型。将数据转变成信息,而后通过发现,将信息转变成知识;或者直接将信息转变成知识。
战略层面:将信息或知识应用在提高决策能力和运营能力上;企业建模等。商业智能的战略层面是利用多个数据源的信息以及应用经验和假设来提高企业决策能力的一组概念、方法和过程的集合。它通过对数据的获取、管理和分析,为贯穿企业组织的各种人员提供信息,以提高企业战略决策和战术决策能力。
总之,商业智能的目标是将企业所掌握的信息转换成竞争优势,提高企业决策能力、决策效率、决策准确性。为完成这一目标,商业智能必须具有实现数据分析到知识发现的算法、模型和过程,决策的主题具有广泛的普遍性。这个特点是本文定义商业智能时应特别强调的。
基于以上定义的商业智能应具有以下功能:
数据管理功能:
从多个数据源ETL(抽取、转换、转贮)数据、清洗数据、数据集成能力;大量数据高效存储与维护能力。
数据分析功能
具备OLAP,Legacy等多种数据分析功能;终端信息查询和报表生成能力;数据可视化能力
知识发现功能
从大型数据库中的数据中提取人们感兴趣的知识的能力。这些知识是隐含的、事先未知的、潜在有用的信息,提取的知识表示为概念(concepts),规则(rules),规律(regulations),模式(patterns)等形式。
企业优化功能
辅助企业建模的能力。
2.BI研究内容、发展趋势
商业智能为更好地制订战略和决策提供良好的环境,为特定的应用系统(如客户关系管理CRM、供应链管理SCM、企业资源计划ERP)提供数据环境和决策分析支持。当面向特定应用的特定战略和决策问题,商业智能从数据准备做起,建立或虚拟一个集成的数据环境。在集成的数据环境之上,利用科学的决策分析工具,通过数据分析、知识发现等过程,为战略制订和决策提供支持。最终,是如何解释和执行分析和发现结果的问题。整个过程中,集成的数据环境和决策分析工具是十分重要和不要缺少的。
使用数据仓库和数据集市建造集成的数据环境是逐渐走向成熟、也是目前最理想的做法。数据仓库提供数据存贮环境,而且是面向特定主题的决策支持环境。来自各种数据源中的数据经过清洗、ETL(抽取,转换,上载),按某一主题存贮。数据集市是面向特定主题的小型数据仓库,解决了企业级数据仓库要存储大量数据而带来的建设周期长、造价高、可扩展性差等缺陷。
OLAP是基于数据仓库环境的数据分析工具。用户首先提出自己的假设,然后利用OLAP工具检索查询以验证或否定假设,是用户制动式的分析方式。OLAP解决了基于OLTP分析效率低、不能进行多维分析的缺点。相比较而言,知识发现(大多数人也称数据挖掘)是较难理解的,它利用知识发现工具挖掘事先未知的、潜在有用的知识的过程,是一种主动式自动发现方法。图2是文章总结的商业智能系统框架。
2.1.研究内容
商业智能是利用当今计算机前沿技术作支撑、运用现代管理技术进行指导的应用系统,它的研究热点集中在三个方面:支撑技术的研究、体系结构的研究、应用系统的研究。
2.1.1.支撑技术的研究
商业智能作为一个在90年代末期出现的跨学科新兴领域,必须借鉴两方面的先进成果,一是计算机技术的前沿技术,一是企业管理方面的新理论、新观点。企业管理方面的新理论、新观点为战略制订和决策提供先进的管理模式,帮助企业更好地运营;先进的计算机技术是提高系统性能的有力手段。
商业智能的支撑技术包括以下几项:一是计算机技术,包括:数据仓库、数据集市技术;数据挖掘技术;OLTP、OLAP、Legacy等分析技术;数据可视化技术;计算机网络与WEB技术。二是企业管理,包括:统计、预测等运筹学方法;客户管理、供应链管理、企业资源计划等管理理论和方法;企业建模方法。
支撑技术的研究主要围绕两部分展开:决策支持工具研究和企业建模方法研究。企业建模是为解决如何建立特定企业模式的辅助工具。IDEF 等研究方法是较程式化的企业建模方法,比较新的建模方法包括基于UML的企业建模等方法。数据挖掘算法的研究是目前计算机界研究的热点之一,它逐渐成为一个跨越人工智能、数据统计等多学科的研究领域。决策分析工具的研究还包括各种分析方法的研究。
2.1.2.体系结构的研究
图2描述了一个典型的商业智能体系结构。面向特定应用会有相应改进的体系结构,使商业具有良好的性能,例如:建立如何的数据存贮和数据模型能很好地支持主题和数据分析和知识发现的需要;选择何种决策分析工具,包括选择实现何种任务、选择实现这种任务的何种工具;将分析和发现的信息和知识通过何种接口达到需要的用户等等。
2.1.3.应用系统的研究
对应用系统的研究的重点在于对各个应用领域所面临的决策问题的分析。根据对各类问题的解决方式和解决方案来决定商业智能系统应该提供的功能以及具体实现方法。目前,商业智能被广泛应用于与企业运营过程相关的各个领域,并且在很多领域已经形成其特有体系。目前具有代表性的应用领域包括:企业资源计划(ERP)、客户关系管理(CRM)、企业性能管理(BPM)、人力资源管理(HRM)、供应链管理(SCM)、电子商务(E-business)。
2.2.发展趋势
与DSS、EIS系统相比,商业智能具有更美好的发展前景。近些年来,商业智能市场持续增长。IDC预测,到2005年,BI市场将达到118亿$,平均年增长率为27%("information Access Tools Market Forecast and Analysis: 2001-2005," IDC#24779,June 2001)。随着企业CRM、ERP、SCM等应用系统的引入,企业不停留在事务处理过程而注重有效利用企业的数据为准确和更快的决策提供支持的需求越来越强烈,由此带动的对商业智能的需求将是巨大的。
商业智能的发展趋势可以归纳为以下几点:
功能上具有可配置性、灵活性、可变化性
BI系统的范围从为部门的特定用户服务扩展到为整个企业所有用户服务。同时,由于企业用户在职权、需求上的差异,BI系统提供广泛的、具有针对性的功能。从简单的数据获取,到利用WEB和局域网、广域网进行丰富的交互、决策信息和知识的分析和使用。
解决方案更开放、可扩展、可按用户定制,在保证核心技术的同时,提供客户化的界面
针对不同企业的独特的需求,BI系统在提供核心技术的同时,使系统又具个性化,即在原有方案基础上加入自己的代码和解决方案,增强客户化的接口和扩展特性;可为企业提供基于商业智能平台的定制的工具,使系统具有更大的灵活性和使用范围。
从单独的商业智能向嵌入式商业智能发展
这是目前商业智能应用的一大趋势,即在企业现有的应用系统中,如财务、人力、销售等系统中嵌入商业智能组件,使普遍意义上的事务处理系统具有商业智能的特性。考虑BI系统的某个组件而不是整个BI系统并非一件简单的事,比如将OLAP技术应用到某一个应用系统,一个相对完整的商业智能开发过程,如企业问题分析、方案设计、原型系统开发、系统应用等过程是不可缺少的。
从传统功能向增强型功能转变
增强型的商业智能功能是相对于早期的用sql工具实现查询的商业智能功能。目前应用中的BI系统除实现传统的BI系统功能之外,大多数已实现了图2中数据分析层的功能。而数据挖掘、企业建模是BI系统应该加强的应用,以更好地提高系统性能。
3.BI与DSS、EIS的比较
商业智能作为一种新兴的决策支持体系,与传统的DSS、EIS相比,在以下方面存在明确的优势。
3.1.使用对象范围
商业智能的使用对象不再像DSS、EIS仅仅局限于企业的领导与决策、分析人员,而是扩展到企业组织内外的各类人员,为他们提供决策支持服务,既有企业经理一类的企业领导和高层决策者,又有企业内部各部门的职能人员,还包括客户、供应商、合作伙伴等企业外部用户。
3.2.具有的功能
从以上分析看出,商业智能具有传统DSS、EIS所不具有的强大的数据管理、数据分析与知识发现能力。
3.3.知识库状态
传统的DSS、EIS中的知识库是在建立的系统中设置好的,库中的知识很少发生变化。即使发生变化,采用定期人为更新的方法修改。而BI系统是一个闭合循环的动态系统。图2中的数据源部分来自各应用系统的反馈,并且数据挖掘可以从现有的数据仓库或数据集市中发现新知识,随时对知识库中的内容进行自动修正,所以BI中的知识库是一种动态结构。
但商业智能也存在不足。商业智能的目标与DSS一样,是为了提高企业决策的效率和准确性。但BI是通过数据分析、知识发现工具提供有价值的、辅助决策的信息和知识,用户必须根据这些信息和知识,运用现有的企业知识和经验进行判断,做出决定,极少数具备智能决策的能力。不像专门的决策支持系统那样提供方案生成、方案协调、方案评估等功能,更不具备群体决策的能力。
4.影响BI性能的因素
商业智能利用数据挖掘不断发现新的知识,扩充到现有的企业知识中来。但就目前企业应用现状和算法实现上来看,制约知识发现的因素较多,同时也影响了BI的性能。
4.1.系统智能不能很好地实现
现有数据挖掘算法大多尚不成熟,效率较低。另外,作为BI数据基础的数据仓库或数据集市中数据量一般比较大,新知识形成的速度和准确性比较低,致使现有的BI系统在知识发现方面的能力不能满足用户要求。
4.2.系统工具缺乏
目前大多数BI系统功能集中在数据分析方面,如数据查询、报表、OLAP、数据可视化,很少有开发商在系统中配有知识发现工具。因此,功能比较集中,更深一层次的要求无法满足。
5.结语
目前,我国对BI的研究与开发工作尚未处于起步阶段。突出的问题在于数据分析、知识发现能力、效率低,或者缺乏知识发现,而更像一个操作型应用系统。很难在决策支持方面发挥BI应有的作用。首先应该认识到BI发展、应用的总体趋势,其次多借鉴国外BI成熟的技术和方法,开发或不断完善真正意义上的BI系统。相信本文对国内BI的市场开发和研究会有启发。
原文地址:http://articles.e-works.net.cn/bi/Article35518_2.htm
和.Count")
c# – 我应该在IEnumerable的上下文中使用.Count()和.Count
任何建议或文章,非常感谢.
更新1
在LINQ中反编译.Count()扩展方法之后,如果IEnumerable< T>是ICollection< T>或ICollection,这是大多数答案建议的.现在唯一真正的开销是我可以看到的额外的null和类型检查,这不是很大,我想,但如果性能是最重要的,仍然可以产生小的差异.
这是.NET 4.0中的反编译的LINQ .Count()扩展方法.
public static int Count<TSource>(this IEnumerable<TSource> source)
{
if (source == null)
{
throw Error.ArgumentNull("source");
}
ICollection<TSource> collection = source as ICollection<TSource>;
if (collection != null)
{
return collection.Count;
}
ICollection collection2 = source as ICollection;
if (collection2 != null)
{
return collection2.Count;
}
int num = 0;
checked
{
using (IEnumerator<TSource> enumerator = source.GetEnumerator())
{
while (enumerator.MoveNext())
{
num++;
}
}
return num;
}
}
解决方法
最好的建议是使用Count属性,如果由于性能原因可用.
Is .Count() predominately better saved for queryable collections that are yet to be executed,and therefore don’t have an enumeration yet?
如果您的收藏集是IQueryable< T>而不是IEnumerable< T>那么查询提供者可能能够以某种有效的方式返回计数.在这种情况下,您不会遭受性能损失,但这取决于查询提供者.
一个IQueryable< T>将不会有Count属性,因此在使用扩展方法和属性之间没有选择.但是,如果查询提供程序不提供有效的计算Count()方法,则可以考虑使用.ToList()将集合拉到客户端.这真的取决于你打算如何使用它.

Column count doesn't match value count at row 1_MySQL
在做insert时 遇到这个错误
java.sql.SQLException:Column count doesn''t match value count at row 1
可能是出现在insert数据时字段与表中的字段不匹配。
原来是我在建表时预留了两个空字段的问题……fuuuuuuucccckkkkk
关于numpy.bincount正确理解和numpy.bincount详解的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于2021-11-04:计算右侧小于当前元素的个数。给你 ` 一个整数数组 nums ,按要求返回一个新数组 counts 。数组 counts 有该性质: counts [i] 的值是 nums [i] 右、BI学习笔记之五 - 如何正确理解商业智能(BI)?、c# – 我应该在IEnumerable的上下文中使用.Count()和.Count、Column count doesn't match value count at row 1_MySQL的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

