如果您对多个表连接与聚合(mssql/sqlserver)和多表连接sql语句感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解多个表连接与聚合(mssql/sqlserver)的各种细节,并对多
如果您对多个表连接与聚合(mssql / sql server)和多表连接sql语句感兴趣,那么这篇文章一定是您不可错过的。我们将详细讲解多个表连接与聚合(mssql / sql server)的各种细节,并对多表连接sql语句进行深入的分析,此外还有关于django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)、Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题、lnmp 环境里安装 mssql 及 mssql 的 php 扩展、lua 访问 mssql 的驱动(好用的)是哪一个?对 mysql/pgsql 的支持不错,但希望先在 mssql 能用起来的实用技巧。
本文目录一览:- 多个表连接与聚合(mssql / sql server)(多表连接sql语句)
- django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)
- Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
- lnmp 环境里安装 mssql 及 mssql 的 php 扩展
- lua 访问 mssql 的驱动(好用的)是哪一个?对 mysql/pgsql 的支持不错,但希望先在 mssql 能用起来
(多表连接sql语句)")
多个表连接与聚合(mssql / sql server)(多表连接sql语句)
例:
table ta (eid,uid,name,year,etc,etc) table tb (eid,amount,etc)
eid – 两个表之间不匹配
uid,year – 将在两个表中匹配
所以我想从表ta中提取所有列,简单:
select * from ta where eid=''value'';
我想将表tb中的amount列加到我的结果集中,简单:
select a.*,b.amount from ta a inner join tb b on a.year=b.year where a.eid=''value'';
太好了,这很好用.但是如果我在表tb中有多行呢?
执行:
select a.*,sum(b.amount) from ta a inner join tb b on a.uid=b.uid where a.year=''value'';
给我以下错误:
Column ‘ta.eid’ is invalid in the select list because it is not contained in either an aggregate function or the GROUP BY clause.
所以我补充说:
select a.*,sum(b.amount) from ta a inner join tb b on a.uid=b.uid where a.year=''value'' group by ta.uid;
我得到同样的错误!
但是,如果我将查询更改为:
select a.uid,a.year,sum(b.amount) from ta a inner join tb b on a.uid=b.uid where a.year=''value'' group by ta.uid,ta.year;
它有效,但现在我有三列而不是我想要的所有列.
所以,在这一点上,我的问题变成:除了我手动输入我想从两个带有GROUP BY子句的表中拉出的所有列之外,是否有更好,更清晰的结构化查询方式?
解决方法
select a.*,b.sumb
from ta a left join
(select b.uid,sum(b.amount) as sumb
from tb b
group by b.uid
) b
on a.uid=b.uid
where a.year = ''value'';
")
django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)
模块使用的是 pcodbc+django-pyodbc-azure
1 pip install django-pyodbc-azure
2 pip install pyodbc版本分别为
pyodbc==4.0.26
django-pyodbc-azure==2.1.0.0
创建数据库连接
DATABASES = {
''default'': {
''ENGINE'': ''sql_server.pyodbc'',
''HOST'': ''127.0.0.1'',
''PORT'': '''',
''NAME'': ''test'',
''USER'': ''sa'',
''PASSWORD'': ''123'',
''OPTIONS'': {
''driver'': ''ODBC Driver 13 for SQL Server'',
''MARS_Connection'': True,
}
}
}
# set this to False if you want to turn off pyodbc''s connection pooling
# 不想用pyodbc连接就把这句加上?
DATABASE_CONNECTION_POOLING = False在对应的 app/models.py 添加 model
from django.db import models
# Create your models here.
class userinfo(models.Model):
#如果没有models.AutoField,默认会创建一个id的自增列
name = models.CharField(max_length=30)
email = models.EmailField()
memo = models.TextField()项目文件下目录下执行
python manage.py makemigrations
python manage.py migrate报错
django.db.utils.InterfaceError: (''IM002'', ''[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序 (0) (SQLDriverConnect)'')原因是未安装 ODBC 驱动
前往微软官网下载驱动
https://www.microsoft.com/zh-CN/download/details.aspx?id=53339
Microsoft® ODBC Driver 13.1 for SQL Server
如果下载其他版本 ''driver'': 字段要自行修改
再次执行
1 python manage.py makemigrations
2 python manage.py migrate查看数据库

如出现以上表说明连接成功

Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
如何解决Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
我试图弄清楚为什么我在尝试使用 JDBC 接收器连接器将数据从主题接收到 sql Server 数据库时收到“IDENTITY_INSERT”错误,该主题也由连接到的 JDBC 源连接器写入相同的 sql Server 数据库。
总体目标:
目前有一个 sql Server 数据库被后端用于传统意义上的存储,我们正在尝试过渡到使用 Kafka 来实现所有相同的目的,但是 sql Server 数据库暂时必须保留为有些服务仍然依赖它,我们要求将 Kafka 上的所有数据镜像到 sql Server 数据库中。
我正在努力实现的目标:
我正在尝试创建一个设置,其中包含以下内容:
- 一个 sql Server 数据库(所有具有相同主键“id”的表,该主键自动递增并由 sql Server 设置)
- Kafka 集群,包括 Kafka 连接:
- 用于将 sql Server 表中的内容同步到 kafka 主题的 JDBC 源连接器,对于主题和表,我们将其称为 AccountType
- 订阅相同主题的 JD Sink 连接器 AccountType 并将数据接收到 sql Server 数据库中相同的 AccountType 表
预期行为是:
- 如果旧服务在 sql Server 中写入/更新记录
- 源连接器将获取更改并将其写入相应的 Kafka 主题
- 接收器连接器将收到关于同一主题的消息,但是,由于更改源自 sql Server,因此已经从接收器连接器的角度进行了更改,接收器连接器将在主键上找到匹配项,请参阅没有改变,继续前进
- 如果设计用于与 Kafka 一起使用的新服务更新记录并将其写入正确的主题:
- JDBC sink 连接器将接收关于主题的消息作为偏移量
- 由于 sink 连接器配置了 upsert 模式,它会在目标数据库中找到主键的匹配项并更新目标数据库中的相应记录
- 然后源连接器将检测到更改,触发其将更改写入相应的主题
- 此时我的假设是以下两种情况之一会发生:
- 源连接器不会写入主题,因为它只会复制最后一条消息或
- 源连接器会将重复的消息写入主题,但是它会被接收器忽略,因为不会导致数据库记录更改
这种预期行为与我在文档中找到的所有内容一致,并且尽我所能,根据此处找到的 JDBC sink 深度潜水指南:https://rmoff.net/2021/03/12/kafka-connect-jdbc-sink-deep-dive-working-with-primary-keys/[kafka-connect-jdbc-sink-deep-dive-working-with-primary-keys][1]
正在发生的事情:
- Kafka 集群全部启动,数据库为空,两个连接器都创建成功
- 使用外部服务将一行插入到数据库的表中
- 源连接器成功获取更改并将记录写入 Kafka 上的主题(该主题已被转换拆分,因此表示 sql Server 表 PK 的字段已被提取并设置为消息键,并删除从值)
- (问题)接收器连接器然后收到有关该主题的消息,然后...
...这是问题,根据我能找到的几个视频和示例,应该不会发生任何事情,因为该记录在数据库中已经是最新的,但是,它会立即尝试按原样编写整个消息,到目标表,结果如下:
java.sql.BatchUpdateException:当 IDENTITY_INSERT 设置为 OFF 时,无法为表“AccountType”中的标识列插入显式值。
这是有道理的,因为来自主题的消息中有一个主键字段,如果它没有在表中启用,那么它就不应该被允许。只是为了好玩,我尝试在尝试写入之前进行额外的转换以删除 id 字段,而是使用表中的另一个字段,该字段在配置中具有“唯一”约束。当我这次重复这些步骤时,它没有抱怨写入主键,但它仍然立即尝试插入导致另一个错误的记录,因为它会违反唯一约束,这又是完全合理的。
我被困的地方:
如果以上所有内容都有意义,谁能告诉我为什么尽管设置为 upsert,它仍会自动尝试插入?
注意事项:
- 所有这些都是使用 confluent 为 confluent 平台版本 6.2.0 提供的 docker 容器设置的
源连接器配置:
{"connection.url": "jdbc:sqlserver://mssql:1433;databaseName=REDACTED","connection.user":"REDACTED","connection.password":"REDACTED","connection.attempts": "3","connection.backoff.ms": "5000","table.whitelist": "AccountType","db.timezone": "UTC","name": "sql-server-source","connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector","dialect.name": "sqlServerDatabaseDialect","config.action.reload": "restart","topic.creation.enable": "false","tasks.max": "1","mode": "timestamp+incrementing","incrementing.column.name": "id","timestamp.column.name": "created,updated","validate.non.null": true,"key.converter": "org.apache.kafka.connect.converters.LongConverter","value.converter": "io.confluent.connect.json.JsonSchemaConverter","value.converter.schema.registry.url": "http://schema-registry:8081","auto.register.schemas": "true","schema.registry.url": "http://schema-registry:8081","errors.log.include.messages": "true","transforms": "copyFieldToKey,extractKeyFromStruct,removeKeyFromValue","transforms.copyFieldToKey.type": "org.apache.kafka.connect.transforms.ValuetoKey","transforms.copyFieldToKey.fields": "id","transforms.extractKeyFromStruct.type":"org.apache.kafka.connect.transforms.ExtractField$Key","transforms.extractKeyFromStruct.field": "id","transforms.removeKeyFromValue.type":"org.apache.kafka.connect.transforms.ReplaceField$Value","transforms.removeKeyFromValue.blacklist": "id","transforms.extractKeyFromStruct.type":"org.apache.kafka.connect.transforms.ExtractField$Key",}
接收器连接器配置:
{"connection.url": "jdbc:sqlserver://mssql:1433;databaseName=REDACTED","table.name.format": "${topic}","name": "sql-server-sink","connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","auto.create": "false","auto.evolve": "false","batch.size": "1000","topics": "AccountType","insert.mode": "UPSERT","pk.mode": "record_key","pk.fields": "id",}

lnmp 环境里安装 mssql 及 mssql 的 php 扩展
小活中用到 mssql, 于是在自己 lnmp 环境中安装各 mssql 数据库
步骤如下:
源码编译安装
# tar zxvf freetds-stable.tgz(解压,)
# cd freetds-0.91
# 编译
# ./configure --prefix=/usr/local/freetds --with-tdsver=8.0 --enable-msdblib
# make
# make install
参数解释:
安装 freetds 到目录 /usr/local/freetds:--prefix=/usr/local/freetds
支持 MSSQL2000:--with-tdsver=8.0 --enable-msdblib
配置 FreeTds 的库文件
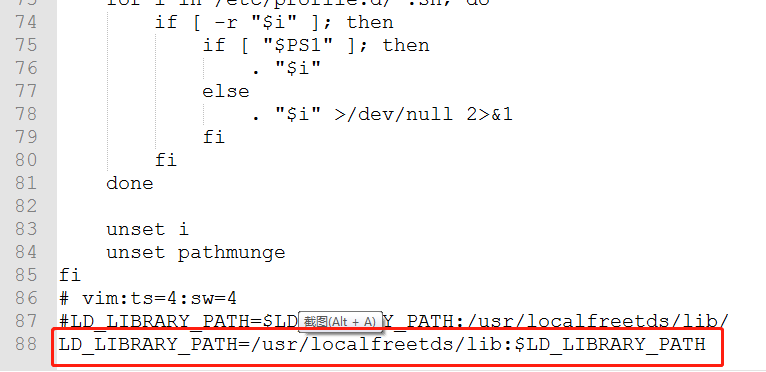
将 freetds 的库文件所在路径配置到 LD_LIBRARY_PATH 参数中:
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/localfreetds/lib/:
或者直接把 etc/bashrc 的文件 bashrc 直接填写上 LD_LIBRARY_PATH=/usr/localfreetds/lib:$LD_LIBRARY_PATH
这么作的目的是为了避免加载 FreeTds 库文件加载不上的情况。
php 里安装 php-mssql 扩展:
cd /download (把php-mssql扩展下载到download目录里)
wget http://cn2.php.net/distributions/php-5.6.30.tar.gz (下载扩展文件,这里要根据你环境中运行的php版本选择对应的扩展版本下载,我这里php是5.6.30的 所以php-mssql扩展下载对应的版本)
tar -zxvf php-5.6.30.tar.gz
cd /php-5.6.30/ext/mssql
/usr/local/php/bin/phpize./configure --with-php-config=/usr/local/php/bin/php-config --with-mssql=/usr/local/freetds/
make && make install 编译安装后的结果 如下图
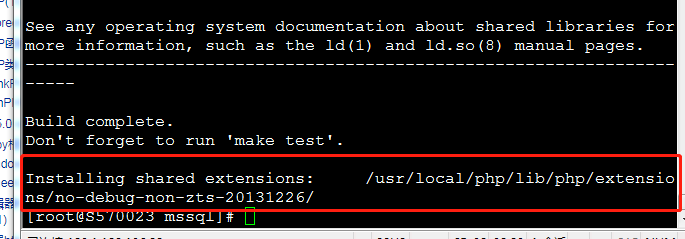
同时 mssql.so 也在 php 扩展文件下生成 (如下图)
把 extension="/usr/local/php/lib/php/extensions/no-debug-non-zts-20131226/mssql.so" 添加到 usr/local/php/lib/php.ini 中

引用扩展后,重启 web 服务,通过 phpinfo 查看扩展 mssql 是否开启成功
重启 php /usr/local/php/sbin/php-fpm reload
重启 nginx 进入 nginx 可执行目录 sbin 下,输入命令./nginx -s reload 即可(或者 /application/nginx/sbin/nginx -s reload)

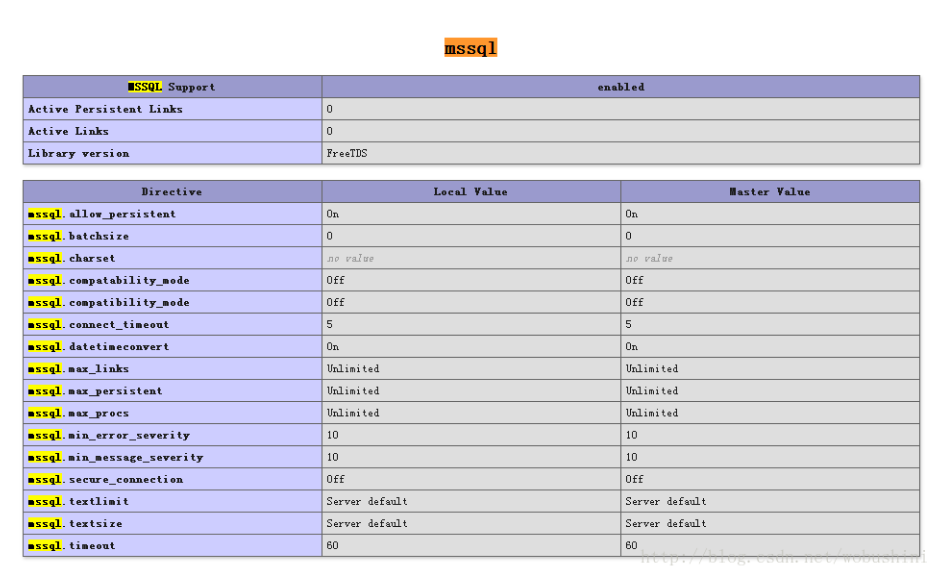
是哪一个?对 mysql/pgsql 的支持不错,但希望先在 mssql 能用起来")
lua 访问 mssql 的驱动(好用的)是哪一个?对 mysql/pgsql 的支持不错,但希望先在 mssql 能用起来
lua 访问 mssql 的驱动(好用的)是哪一个?
lua 对 mysql/pgsql 的支持不错,但对 mssql 的访问,总是不太顺
而目前希望先在 mssql 能用起来
关于多个表连接与聚合(mssql / sql server)和多表连接sql语句的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)、Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题、lnmp 环境里安装 mssql 及 mssql 的 php 扩展、lua 访问 mssql 的驱动(好用的)是哪一个?对 mysql/pgsql 的支持不错,但希望先在 mssql 能用起来等相关内容,可以在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

