这篇文章主要围绕mssqlserverEXEC和sp_executesql展开,旨在为您提供一份详细的参考资料。我们将全面介绍mssqlserverEXEC和sp_executesql,同时也会为您带
这篇文章主要围绕mssql server EXEC和sp_executesql展开,旨在为您提供一份详细的参考资料。我们将全面介绍mssql server EXEC和sp_executesql,同时也会为您带来django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)、Docker mssql-server-linux:如何在构建期间启动.sql文件(来自Dockerfile)、Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题、lnmp 环境里安装 mssql 及 mssql 的 php 扩展的实用方法。
本文目录一览:- mssql server EXEC和sp_executesql
- django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)
- Docker mssql-server-linux:如何在构建期间启动.sql文件(来自Dockerfile)
- Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
- lnmp 环境里安装 mssql 及 mssql 的 php 扩展

mssql server EXEC和sp_executesql
mssql server exec和sp_executesql
,EXEC的使用
2,sp_executesql的使用
MSSQL为我们提供了两种动态执行SQL语句的命令,分别是EXEC和
sp_executesql;通常,sp_executesql则更具有优势,它提供了输入输出接口,而EXEC没
有。还有一个最大的好处就是利用sp_executesql,能够重用执行计划,这就大大提供
了执行性能(对于这个我在后面的例子中会详加说明),还可以编写更安全的代码。EXEC
在某些情况下会更灵活。除非您有令人信服的理由使用EXEC,否侧尽量使用
sp_executesql.
1,EXEC的使用
EXEC命令有两种用法,一种是执行一个存储过程,另一种是执行一个动态的批处理。以
下所讲的都是第二种用法。
下面先使用EXEC演示一个例子,代码1
DECLARE @TableName VARCHAR(50),@Sql NVARCHAR(MAX),@OrderID INT;SET
@TableName = ''Orders'';SET @OrderID = 10251;SET @sql = ''SELECT * FROM
''+QUOTENAME(@TableName) +''WHERE OrderID = ''+CAST(@OrderID AS VARCHAR(10))+''
ORDER BY ORDERID DESC''EXEC(@sql);注:这里的EXEC括号中只允许包含一个字符串变
量,但是可以串联多个变量,如果我们这样写EXEC:
EXEC(''SELECT TOP(''+ CAST(@TopCount AS VARCHAR(10)) +'')* FROM ''+QUOTENAME
(@TableName) +'' ORDER BY ORDERID DESC'');
SQL编译器就会报错,编译不通过,而如果我们这样:
EXEC(@sql+@sql2+@sql3);编译器就会通过;
所以最佳的做法是把代码构造到一个变量中,然后再把该变量作为EXEC命令的输入参数
,这样就不会受限制了;
EXEC不提供接口
这里的接口是指,它不能执行一个包含一个带变量符的批处理,这里乍一听好像不明白
,不要紧,我在下面有一个实例,您一看就知道什么意思.
DECLARE @TableName VARCHAR(50),@Sql NVARCHAR(MAX),@OrderID INT;SET
@TableName = ''Orders'';SET @OrderID = 10251;SET @sql = ''SELECT * FROM
''+QUOTENAME(@TableName) +''WHERE OrderID = @OrderID ORDER BY ORDERID
DESC''EXEC(@sql);关键就在SET @sql这一句话中,如果我们运行这个批处理,编译器就
会产生一下错误
Msg 137, Level 15, State 2, Line 1
必须声明标量变量 "@OrderID"。
使用EXEC时,如果您想访问变量,必须把变量内容串联到动态构建的代码字符串中,如
:SET @sql = ''SELECT * FROM ''+QUOTENAME(@TableName) +''WHERE OrderID =
''+CAST(@OrderID AS VARCHAR(10))+'' ORDER BY ORDERID DESC''
串联变量的内容也存在性能方面的弊端。SQL Server为每一个的查询字符串创建新的执
行计划,即使查询模式相同也是这样。为演示这一点,先清空缓存中的执行计划
DBCC FREEPROCCACHE (这个不是本文所涉及的内容,您可以查看MS的MSDN)
http://msdn.microsoft.com/zh-cn/library/ms174283.x
将代码1运行3次,分别对@OrderID 赋予下面3个值,10251,10252,10253。然后使用
下面的代码查询
SELECT cacheobjtype,objtype,usecounts,sql FROM sys.syscacheobjects WHERE sql
")
django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)
模块使用的是 pcodbc+django-pyodbc-azure
1 pip install django-pyodbc-azure
2 pip install pyodbc版本分别为
pyodbc==4.0.26
django-pyodbc-azure==2.1.0.0
创建数据库连接
DATABASES = {
''default'': {
''ENGINE'': ''sql_server.pyodbc'',
''HOST'': ''127.0.0.1'',
''PORT'': '''',
''NAME'': ''test'',
''USER'': ''sa'',
''PASSWORD'': ''123'',
''OPTIONS'': {
''driver'': ''ODBC Driver 13 for SQL Server'',
''MARS_Connection'': True,
}
}
}
# set this to False if you want to turn off pyodbc''s connection pooling
# 不想用pyodbc连接就把这句加上?
DATABASE_CONNECTION_POOLING = False在对应的 app/models.py 添加 model
from django.db import models
# Create your models here.
class userinfo(models.Model):
#如果没有models.AutoField,默认会创建一个id的自增列
name = models.CharField(max_length=30)
email = models.EmailField()
memo = models.TextField()项目文件下目录下执行
python manage.py makemigrations
python manage.py migrate报错
django.db.utils.InterfaceError: (''IM002'', ''[IM002] [Microsoft][ODBC 驱动程序管理器] 未发现数据源名称并且未指定默认驱动程序 (0) (SQLDriverConnect)'')原因是未安装 ODBC 驱动
前往微软官网下载驱动
https://www.microsoft.com/zh-CN/download/details.aspx?id=53339
Microsoft® ODBC Driver 13.1 for SQL Server
如果下载其他版本 ''driver'': 字段要自行修改
再次执行
1 python manage.py makemigrations
2 python manage.py migrate查看数据库

如出现以上表说明连接成功
")
Docker mssql-server-linux:如何在构建期间启动.sql文件(来自Dockerfile)
我正在尝试使用MSsql DB创建自己的Docker镜像以进行开发.它基于microsoft / mssql-server-linux映像.在构建期间,我想将一些.sql文件复制到容器中,然后运行这些脚本(创建数据库模式,表,插入一些数据等).我的Dockerfile看起来像这样:
# use MSsql 2017 image on Ubuntu 16.04
FROM microsoft/mssql-server-linux:2017-latest
# create directory within sql container for database files
RUN mkdir -p /opt/mssql-scripts
# copy the database files from host to container
copY sql/000_create_db.sql /opt/mssql-scripts
# set environment variables
ENV MSsql_SA_PASSWORD=P@ssw0rd
ENV ACCEPT_EULA=Y
# run initial scripts
RUN /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'P@ssw0rd' -i /opt/mssql-scripts/000_create_db.sql
在我看来,000_create_db.sql的内容并不重要.
真正的问题是当我尝试使用命令docker build -t demo构建这个Dockerfile时.我总是得到这些错误:
sqlcmd: Error: Microsoft ODBC Driver 13 for sql Server : Login timeout expired.
sqlcmd: Error: Microsoft ODBC Driver 13 for sql Server : TCP Provider: Error code 0x2749.
sqlcmd: Error: Microsoft ODBC Driver 13 for sql Server : A network-related or instance-specific error has occurred while establishing a connection to sql Server. Server is not found or not accessible. Check if instance name is correct and if sql Server is configured to allow remote connections. For more information see sql Server Books Online..
但是当我删除最后一个命令(运行初始脚本)时,构建并运行图像,并调用相同的命令:
docker build -t demo .
docker run -p 1433:1433 --name mssql -d demo
docker exec -it mssql "bash"
/opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'P@ssw0rd' -i /opt/mssql-scripts/000_create_db.sql
一切都进展顺利.为什么我不能从Dockefile运行脚本?
RUN /opt/mssql/bin/sqlservr --accept-eula & sleep 10 \
&& /opt/mssql-tools/bin/sqlcmd -S localhost -U SA -P 'P@ssw0rd' -i /opt/mssql-scripts/000_create_db.sql \
&& pkill sqlservr

Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
如何解决Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题
我试图弄清楚为什么我在尝试使用 JDBC 接收器连接器将数据从主题接收到 sql Server 数据库时收到“IDENTITY_INSERT”错误,该主题也由连接到的 JDBC 源连接器写入相同的 sql Server 数据库。
总体目标:
目前有一个 sql Server 数据库被后端用于传统意义上的存储,我们正在尝试过渡到使用 Kafka 来实现所有相同的目的,但是 sql Server 数据库暂时必须保留为有些服务仍然依赖它,我们要求将 Kafka 上的所有数据镜像到 sql Server 数据库中。
我正在努力实现的目标:
我正在尝试创建一个设置,其中包含以下内容:
- 一个 sql Server 数据库(所有具有相同主键“id”的表,该主键自动递增并由 sql Server 设置)
- Kafka 集群,包括 Kafka 连接:
- 用于将 sql Server 表中的内容同步到 kafka 主题的 JDBC 源连接器,对于主题和表,我们将其称为 AccountType
- 订阅相同主题的 JD Sink 连接器 AccountType 并将数据接收到 sql Server 数据库中相同的 AccountType 表
预期行为是:
- 如果旧服务在 sql Server 中写入/更新记录
- 源连接器将获取更改并将其写入相应的 Kafka 主题
- 接收器连接器将收到关于同一主题的消息,但是,由于更改源自 sql Server,因此已经从接收器连接器的角度进行了更改,接收器连接器将在主键上找到匹配项,请参阅没有改变,继续前进
- 如果设计用于与 Kafka 一起使用的新服务更新记录并将其写入正确的主题:
- JDBC sink 连接器将接收关于主题的消息作为偏移量
- 由于 sink 连接器配置了 upsert 模式,它会在目标数据库中找到主键的匹配项并更新目标数据库中的相应记录
- 然后源连接器将检测到更改,触发其将更改写入相应的主题
- 此时我的假设是以下两种情况之一会发生:
- 源连接器不会写入主题,因为它只会复制最后一条消息或
- 源连接器会将重复的消息写入主题,但是它会被接收器忽略,因为不会导致数据库记录更改
这种预期行为与我在文档中找到的所有内容一致,并且尽我所能,根据此处找到的 JDBC sink 深度潜水指南:https://rmoff.net/2021/03/12/kafka-connect-jdbc-sink-deep-dive-working-with-primary-keys/[kafka-connect-jdbc-sink-deep-dive-working-with-primary-keys][1]
正在发生的事情:
- Kafka 集群全部启动,数据库为空,两个连接器都创建成功
- 使用外部服务将一行插入到数据库的表中
- 源连接器成功获取更改并将记录写入 Kafka 上的主题(该主题已被转换拆分,因此表示 sql Server 表 PK 的字段已被提取并设置为消息键,并删除从值)
- (问题)接收器连接器然后收到有关该主题的消息,然后...
...这是问题,根据我能找到的几个视频和示例,应该不会发生任何事情,因为该记录在数据库中已经是最新的,但是,它会立即尝试按原样编写整个消息,到目标表,结果如下:
java.sql.BatchUpdateException:当 IDENTITY_INSERT 设置为 OFF 时,无法为表“AccountType”中的标识列插入显式值。
这是有道理的,因为来自主题的消息中有一个主键字段,如果它没有在表中启用,那么它就不应该被允许。只是为了好玩,我尝试在尝试写入之前进行额外的转换以删除 id 字段,而是使用表中的另一个字段,该字段在配置中具有“唯一”约束。当我这次重复这些步骤时,它没有抱怨写入主键,但它仍然立即尝试插入导致另一个错误的记录,因为它会违反唯一约束,这又是完全合理的。
我被困的地方:
如果以上所有内容都有意义,谁能告诉我为什么尽管设置为 upsert,它仍会自动尝试插入?
注意事项:
- 所有这些都是使用 confluent 为 confluent 平台版本 6.2.0 提供的 docker 容器设置的
源连接器配置:
{"connection.url": "jdbc:sqlserver://mssql:1433;databaseName=REDACTED","connection.user":"REDACTED","connection.password":"REDACTED","connection.attempts": "3","connection.backoff.ms": "5000","table.whitelist": "AccountType","db.timezone": "UTC","name": "sql-server-source","connector.class": "io.confluent.connect.jdbc.JdbcSourceConnector","dialect.name": "sqlServerDatabaseDialect","config.action.reload": "restart","topic.creation.enable": "false","tasks.max": "1","mode": "timestamp+incrementing","incrementing.column.name": "id","timestamp.column.name": "created,updated","validate.non.null": true,"key.converter": "org.apache.kafka.connect.converters.LongConverter","value.converter": "io.confluent.connect.json.JsonSchemaConverter","value.converter.schema.registry.url": "http://schema-registry:8081","auto.register.schemas": "true","schema.registry.url": "http://schema-registry:8081","errors.log.include.messages": "true","transforms": "copyFieldToKey,extractKeyFromStruct,removeKeyFromValue","transforms.copyFieldToKey.type": "org.apache.kafka.connect.transforms.ValuetoKey","transforms.copyFieldToKey.fields": "id","transforms.extractKeyFromStruct.type":"org.apache.kafka.connect.transforms.ExtractField$Key","transforms.extractKeyFromStruct.field": "id","transforms.removeKeyFromValue.type":"org.apache.kafka.connect.transforms.ReplaceField$Value","transforms.removeKeyFromValue.blacklist": "id","transforms.extractKeyFromStruct.type":"org.apache.kafka.connect.transforms.ExtractField$Key",}
接收器连接器配置:
{"connection.url": "jdbc:sqlserver://mssql:1433;databaseName=REDACTED","table.name.format": "${topic}","name": "sql-server-sink","connector.class": "io.confluent.connect.jdbc.JdbcSinkConnector","auto.create": "false","auto.evolve": "false","batch.size": "1000","topics": "AccountType","insert.mode": "UPSERT","pk.mode": "record_key","pk.fields": "id",}

lnmp 环境里安装 mssql 及 mssql 的 php 扩展
小活中用到 mssql, 于是在自己 lnmp 环境中安装各 mssql 数据库
步骤如下:
源码编译安装
# tar zxvf freetds-stable.tgz(解压,)
# cd freetds-0.91
# 编译
# ./configure --prefix=/usr/local/freetds --with-tdsver=8.0 --enable-msdblib
# make
# make install
参数解释:
安装 freetds 到目录 /usr/local/freetds:--prefix=/usr/local/freetds
支持 MSSQL2000:--with-tdsver=8.0 --enable-msdblib
配置 FreeTds 的库文件
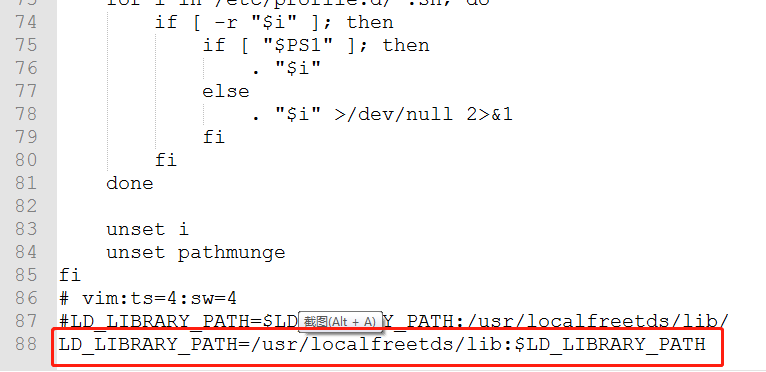
将 freetds 的库文件所在路径配置到 LD_LIBRARY_PATH 参数中:
$ export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/localfreetds/lib/:
或者直接把 etc/bashrc 的文件 bashrc 直接填写上 LD_LIBRARY_PATH=/usr/localfreetds/lib:$LD_LIBRARY_PATH
这么作的目的是为了避免加载 FreeTds 库文件加载不上的情况。
php 里安装 php-mssql 扩展:
cd /download (把php-mssql扩展下载到download目录里)
wget http://cn2.php.net/distributions/php-5.6.30.tar.gz (下载扩展文件,这里要根据你环境中运行的php版本选择对应的扩展版本下载,我这里php是5.6.30的 所以php-mssql扩展下载对应的版本)
tar -zxvf php-5.6.30.tar.gz
cd /php-5.6.30/ext/mssql
/usr/local/php/bin/phpize./configure --with-php-config=/usr/local/php/bin/php-config --with-mssql=/usr/local/freetds/
make && make install 编译安装后的结果 如下图
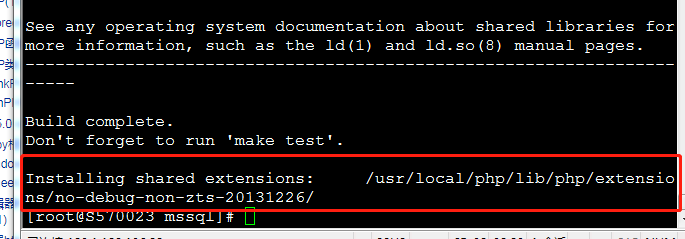
同时 mssql.so 也在 php 扩展文件下生成 (如下图)
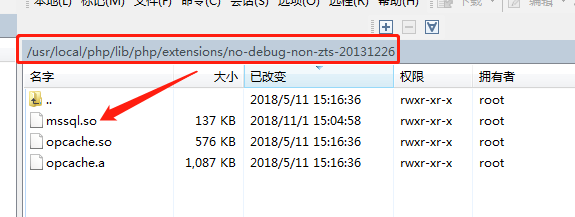
把 extension="/usr/local/php/lib/php/extensions/no-debug-non-zts-20131226/mssql.so" 添加到 usr/local/php/lib/php.ini 中

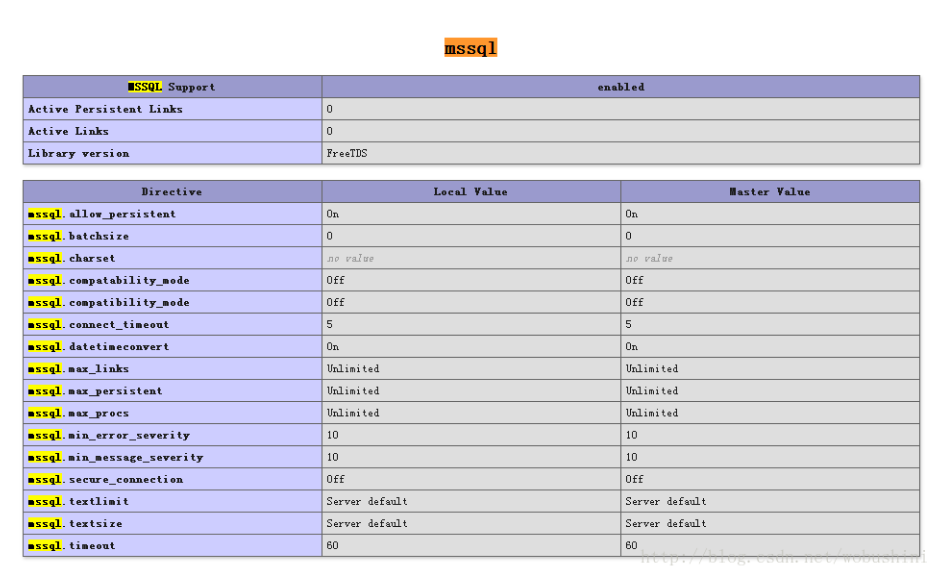
引用扩展后,重启 web 服务,通过 phpinfo 查看扩展 mssql 是否开启成功
重启 php /usr/local/php/sbin/php-fpm reload
重启 nginx 进入 nginx 可执行目录 sbin 下,输入命令./nginx -s reload 即可(或者 /application/nginx/sbin/nginx -s reload)

今天关于mssql server EXEC和sp_executesql的分享就到这里,希望大家有所收获,若想了解更多关于django 连接 mssql 数据库 (django 1.11.11 sql server 2008 R2)、Docker mssql-server-linux:如何在构建期间启动.sql文件(来自Dockerfile)、Kafka Connect + JDBC Source 连接器 + JDBC Sink 连接器 + MSSQL SQL Server = IDENTITY_INSERT 问题、lnmp 环境里安装 mssql 及 mssql 的 php 扩展等相关知识,可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

