本文将为您提供关于JSP,MySQL和UTF-8的详细介绍,同时,我们还将为您提供关于appserv的mysql和独立的php,apache,mysql的查询响应速度不一样、JDBC连接MySQL5,
本文将为您提供关于JSP,MySQL和UTF-8的详细介绍,同时,我们还将为您提供关于appserv的mysql和独立的php,apache,mysql的查询响应速度不一样、JDBC连接MySQL5,MySQL6,MySQL8 以及MySQL连接慢的解决办法、MySQL Charset--UTF8和UTF8MB4对比测试、MySQL 字符集utf8和utf-8的关系的实用信息。
本文目录一览:- JSP,MySQL和UTF-8
- appserv的mysql和独立的php,apache,mysql的查询响应速度不一样
- JDBC连接MySQL5,MySQL6,MySQL8 以及MySQL连接慢的解决办法
- MySQL Charset--UTF8和UTF8MB4对比测试
- MySQL 字符集utf8和utf-8的关系

JSP,MySQL和UTF-8
我正在思考,通过表单输入的国际字符不会完全按照输入的方式存储,并且存储的数据也不会像存储在数据库中那样返回。
如果我输入“çanakçömlekpatladı”并单击保存,则我使用的页面将显示“çanakçömlekpatladı”,但数据库已存储“çanakçömlekpatlad”?如果再次访问该页面,则会显示“anakmlmlek
patlad?”,如果我单击“保存”而不更改任何内容,数据库将存储“ anak’mlek patlad?”。然后浏览器显示“?anak ?? mlek
patlad?”
我的MySQL服务器具有以下配置:
default-collation=utf8collation_server=utf8_unicode_cicharacter_set_server=utf8default-character-set=utf8数据库字符集为utf8,数据库排序规则为utf8_unicode_ci,我使用的表设置为相同。
我的JSP文件的第一行是:
<%@ page language="java" contentType="text/html; charset=UTF-8" pageEncoding="UTF-8" %>html标头是这样的:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><title>Test</title></head>我编译了一个EncodingFilter类,它是:
import java.io.IOException;import javax.servlet.*;public class EncodingFilter implements Filter{ public EncodingFilter() { } public void init(FilterConfig filterconfig) throws ServletException { filterConfig = filterconfig; encoding = filterConfig.getInitParameter("encoding"); } public void doFilter(ServletRequest servletrequest, ServletResponse servletresponse, FilterChain filterchain) throws IOException, ServletException { servletrequest.setCharacterEncoding(encoding); filterchain.doFilter(servletrequest, servletresponse); } public void destroy() { } private String encoding; private FilterConfig filterConfig;}我的web.xml文件中引用了此类,如下所示:
<filter><filter-name>EncodingFilter</filter-name><filter-class>EncodingFilter</filter-class><init-param><param-name>encoding</param-name><param-value>UTF-8</param-value></init-param></filter><filter-mapping><filter-name>EncodingFilter</filter-name><url-pattern>/*</url-pattern></filter-mapping>我已经重新启动系统,因此重新启动了Tomcat和MySQL服务器,检查了日志,以上任何配置都没有错误。
谁能帮忙,不然我没头发了吗?
答案1
小编典典解决了这个问题,我放弃了以前的db java类,并编写了一个新的db函数,因为以前的开发类似乎引起了双重编码问题。
我得到的错误是,直接将手工输入“çanakçömlekpatladı”直接输入数据库,该错误与MySQL有关的问题没有真正在varchar字段上传递UTF-8有关。我将字段更新为varbinary后,一切正常。
希望这对某人有帮助,我敢肯定我的头发会长出来,谢谢所有提供建议的人。

appserv的mysql和独立的php,apache,mysql的查询响应速度不一样
apachemysqlphp数据
之前用appserv的mysql里面十万条数据用php查询时的响应速度是ms极的,现在用独立的php,apache,mysql的查询响应速度好慢基本是要一两秒,为什么会这样子呢?

JDBC连接MySQL5,MySQL6,MySQL8 以及MySQL连接慢的解决办法
6对比5的主要区别是驱动和地区
1.JDBC连接Mysql5:
driverClassName=com.mysql.jdbc.Driver
url=jdbc:mysql://localhost:3306/xingyu4j?&useUnicode=true&characterEncoding=UTF-8&useSSL=false
username=root
password=
2.JDBC连接Mysql6:
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC&zeroDateTimeBehavior=convertToNull&useUnicode=true&characterEncoding=UTF-8&useSSL=false
username=root
password=
3.JDBC连接Mysql8:
driverClassName=com.mysql.cj.jdbc.Driver
url=jdbc:mysql://localhost:3306/test?serverTimezone=UTC&zeroDateTimeBehavior=CONVERT_TO_NULL&useUnicode=true&characterEncoding=UTF-8&useSSL=false
username=root
password=
4.MySQL连接慢
编辑/etc/mysql/my.cnf (不同安装方式版本位置不同,具体位置 find / -name my.cnf 查询)
在[mysqld]下面加入
skip-name-resolve
保存后重启mysql

MySQL Charset--UTF8和UTF8MB4对比测试
UTF8和UTF8MB4
在早期MySQL版本中,使用只支持最长三字节的UTF8字符集便可以存放所有Unicode字符。随着Unicode的完善,Unicode字符集收录的字符数量越来越多,最新版本的UTF8需要使用1到4个字节来存放Unicode字符,而MySQL为保持版本兼容,依旧使用最多3字节的UTF8字符集,并在MySQL 5.5.3版本引入UTF8MB4字符集来支持4字节的Unicode字符。
汉字 '''' 和 '' '' 是异体字,读音均为xi,但两个字的unicode不同:
对应的UNICODE是 \ud850\udeee;
对应的UTF8是 ��
对应的HEX编码是 %f0%a4%8b%ae熙 对应的UNICODE是 \u7199
熙 对应的UTF8是 熙
熙 对应的HEX编码是 %e7%86%99
在UTF8字符集模式下测试
创建测试表:
CREATE TABLE `tb5001` (
`ID` INT(11) NOT NULL AUTO_INCREMENT,
`C1` VARBINARY(100) DEFAULT NULL,
`C2` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`ID`)
) ENGINE=INNODB AUTO_INCREMENT=33 DEFAULT CHARSET=utf8mb4在UTF8字符集下测试
SET NAMES utf8;
INSERT INTO TB5001(C1,C2)
SELECT '''','''';INSERT INTO TB5001(C1,C2)
SELECT ''熙'',''熙'';
SELECT * FROM TB5001;执行第一条INSERT有警告,警告信息为:
Warning Code : 1300
Invalid utf8 character string: ''F0A48B''
Warning Code : 1366
Incorrect string value: ''\xF0\xA4\x8B\xAE'' for column ''C2'' at row 1查询结果为:
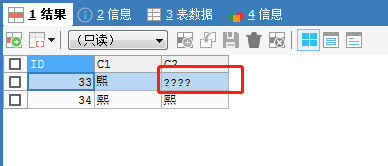
在UTF8字符集下,VARCHAR类型"无法支持“四字节的"",但VARBINARY不受字符集影响。
在UTF8MB4字符集模式下测试
测试脚本
SET NAMES utf8mb4;
INSERT INTO TB5001(C1,C2)
SELECT '''','''';
INSERT INTO TB5001(C1,C2)
SELECT ''熙'',''熙'';
SELECT * FROM TB5001;测试中无任何警告,查询结果:
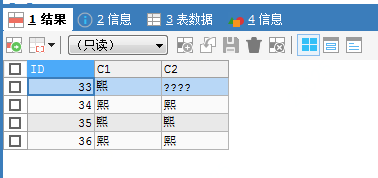
在UTF8MB4字符集下,VARCHAR类型"完美支持“四字节的"",但VARBINARY不受字符集影响。
乱码问题
表TB5001字符集已定义为UTF8MB4,表上C1列的字符集也是UTF8MB4,为啥还出现乱码呢?
测试脚本:
SET NAMES utf8;
SELECT * FROM TB5001;
SET NAMES utf8mb4;
SELECT * FROM TB5001;测试对比图:
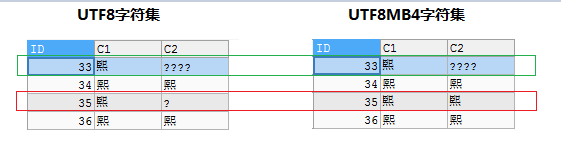
虽然表上C1列的字符集是UTF8MB4,能存放4字节的字符,但:
1、对于ID=33的记录,由于在插入时使用UTF8字符集,在插入到C1列前''''字已经发生乱码,存储到C1列中数据也是乱码,因此无论读取时使用UTF8还是UTF8MB4都是乱码。
2、对于ID-35的记录,由于在插入时使用UTF8MB4字符集,插入C1列前和存储到C1中都正常,在读取时使用UTF8MB4能正常读取,但在读取使用UTF8是乱码。
SET NAMES x相当于执行下面三条语句:
SET character_set_client = x;
SET character_set_results = x;
SET character_set_connection = x;要保证数据库正常存储4字节的表情符合生僻字,除将数据库相关表和列设置为UTF8MB4外,还需要确保操作数据库时使用UTF8MB4,需重点关注以下几个方面:
1、数据库启动配置参数
2、应用与数据库连接配置
3、DBA日常运维操作
如DBA操作过程中,使用mysql客户端连接到数据库执行操作,而mysql客户端可能使用默认UTF8字符集(default-character-set),导出乱码问题。
在xshell工具下粘贴下面代码:
SELECT '''','''';
SELECT ''熙'',''熙'';将代码粘贴到vim工具中自动变为:
SELECT ''<d850><deee>'',''<d850><deee>'';
SELECT ''熙'',''熙'';将代码粘贴到mysql命令总变为:
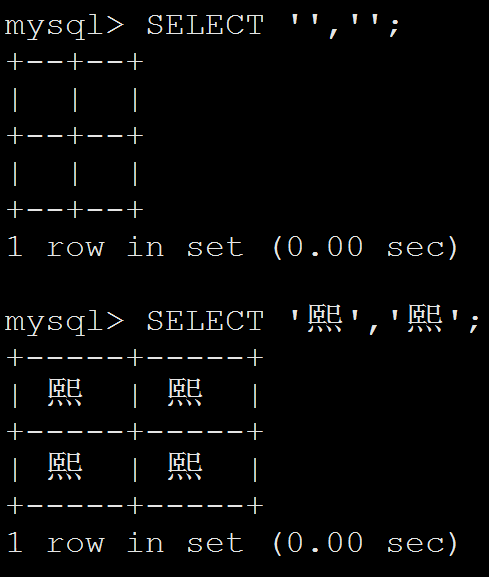
因此建议DBA在日常运维中关注生僻字和表情符,避免异常。
参考:http://seanlook.com/2016/10/23/mysql-utf8mb4/

MySQL 字符集utf8和utf-8的关系
[toc]
什么是字符集(character set)
- 字符的二进制编码方式
- 二进制编码到一套字符的映射
- 二进制->编码->字符
校对规则(collation)
- 在字符集内用于比较字符的一套规则
ASCII码
- 1个字节由8个二进制位组成
- 1个字节可表示256种不同的状态(256个不同符号)
- ASCII码规定了128个字符(数字、英文字符和一些标点符号)的编码
Unicode国际化支持
- 世界上存在多种编码方式,同一个二进制数字被解释成了不同的符号
- 现存 编码 不能在多语言环境中使用,诞生了Unicode(统一码)
- 一个字符的Unicode编码是确定的
- Unicode编码实现方式各不相同
- Unicode的实现方式称为Unicode转化格式(UTF)
UTF-8
- UTF-8是Unicode的实现方式之一
- 其它实现方式还有UTF-16, UTF-32
- 变长编码,一个符号使用1~4个字节表示
- utf8是MySQL存储Unicode数据的一种可选方法
utf8
- MySQL中实现了UTF-8编码的unicode 字符集
- MySQL中utf8是utf8mb3的别名
- utf8中,一个符号使用1~3个节点表示
- 对UTF-8支持不彻底,可采用utf8mb4字符集
utf8与utf8mb4的关系
- 都是实现了UTF-8编码的unicode 字符集
- utf8仅支持基本多语言平面Basic Multilingual Plane (BMP)
- utf8mb4支持BMP之外的补充字符(如emoji,emoji 是一种特殊的 Unicode 编码)
- utf8 一个字符最多使用3个字节存储,utf8mb4 一个字符最多使用4个字节存储
- 对于BMP字符,utf8和utf8mb4具有相同的编码,相同的长度
- 对于非BMP字符,utf8mb4使用4个字节来存储,utf8不能存储非BMP字符
- innodb中默认最大可对767个字节建立索引
- 使用utf8 的列最多可对255个字符建立索引
- 使用utf8mb4 的列最多可对191个字符建立索引
超集
- 字符集A,B ,B支持的所有字符A都支持,A 是B超集
- 比如 GBK字符集是GB2312字符集的超集,它们又都是ASCII字符集的超集
- utf8mb4是utf8的超集
字符集设置
set names x 等价于
- set character_set_client=x;
- set character_set_connection=x;
- set character_set_results=x;
--default-character-set 用户连接时设置字符集 等价于
- set character_set_client=x;
- set character_set_connection=x;
- set character_set_result=x; init-connect=set names binary
- 让client和server交互的时候以 什么模式(不做任何转化)来传送
default-character-set
- 设置[mysql]和[client] 中的字符集
character-set-server
- 设置[mysqld] 进程的默认字符集
collation-server
- 设置[mysqld] 进程的默认校对规则
- utf8_general_ci 查找、排序不区分大小写
- utf8_bin 查找、排序区分大小写
参考 Unicode Support 字符集与编码杂谈 ASCII,Unicode 和 UTF-8
清官谈mysql中utf8和utf8mb4区别
原文出处:https://www.cnblogs.com/YangJiaXin/p/10772229.html
今天关于JSP,MySQL和UTF-8的介绍到此结束,谢谢您的阅读,有关appserv的mysql和独立的php,apache,mysql的查询响应速度不一样、JDBC连接MySQL5,MySQL6,MySQL8 以及MySQL连接慢的解决办法、MySQL Charset--UTF8和UTF8MB4对比测试、MySQL 字符集utf8和utf-8的关系等更多相关知识的信息可以在本站进行查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

