本文将为您提供关于在SQLServer索引中搜索单词的详细介绍,我们还将为您解释sqlserver使用索引查询的相关知识,同时,我们还将为您提供关于ASP.NETC#在SQLServer数据库表中搜索
本文将为您提供关于在SQL Server索引中搜索单词的详细介绍,我们还将为您解释sqlserver使用索引查询的相关知识,同时,我们还将为您提供关于ASP.NET C#在SQL Server数据库表中搜索、SQL Server索引--(包含列和覆盖索引)、SQL Server索引原理解析、SQL Server索引哪些群集?的实用信息。
本文目录一览:- 在SQL Server索引中搜索单词(sqlserver使用索引查询)
- ASP.NET C#在SQL Server数据库表中搜索
- SQL Server索引--(包含列和覆盖索引)
- SQL Server索引原理解析
- SQL Server索引哪些群集?
")
在SQL Server索引中搜索单词(sqlserver使用索引查询)
我需要在全文搜索和索引搜索之间进行操作:
我想在表的一列中搜索文本(如果很重要的话,该列上也可能会有一个索引)。
问题是,我想搜索列中的单词,但是我不想匹配部分。
例如,我的列中可能包含公司名称:
Mighty Muck Miller and Partners Inc.
Boy&Butter Breakfast company
现在,如果我搜索“ Miller ”,我想找到第一行。但是,如果我搜索“ iller ”,我就不想找到它,因为没有以“
iller”开头的单词。但是,搜索“ Break ”应找到“ Boy&Butter Breakfast company ”,因为一个单词的开头是“
Break ”。
所以,如果我尝试使用
WHERE BusinessName LIKE %Break%
它将找到太多点击。
有什么方法可以搜索由空格 或其他定界符分隔的 单词?
(LINQ最好,普通的SQL也可以)
重要提示: 到目前为止,空格不是唯一的分隔符!斜线,冒号,圆点,所有非字母数字字符都应考虑在内才能起作用!

ASP.NET C#在SQL Server数据库表中搜索
> ID
>作者
>标签
>标题
> Markdown发布内容
这是我第一次构建这样的门户网站,我想在这些行上实现某种ASP.NET搜索,最好使用除ID之外的所有属性(列).此外,从长远来看,我正在考虑是否有可能对这些帖子进行搜索和评论,这些帖子将存储在不同的表格中.
是否有任何开源实现或在线示例代码来完成此搜索?如果没有,我该如何开始?您是否可以指向一些有关如何使用ASP.NET和C#完成此操作的示例代码的教程?此外,Google(或其他公司)是否为此创建了任何内容?
我希望我的问题不是太广泛或含糊不清.提前致谢!
解决方法
例如,这是一个查询,它将在Author,Title和PostContent字段中搜索用户输入的文本.
SELECT Author,Title FROM Posts WHERE CONTAINS((Author,Title,PostContent),@userInput);
sql Server 2008支持different search methods too,如简单令牌,加权字值,同义词,邻近和前缀搜索……它非常棒.
")
SQL Server索引--(包含列和覆盖索引)
一、覆盖索引
如果所构建的查询只需访问索引中的数据即可满足查询的需求,那便无需访问数据表。 一个可以满足查询全部需求的索引被称为“覆盖索引”(covering index)。
可以在一个给定的查询中使用多个索引。如果两个索引中至少有一列是相同的,则SQL Server能将两个索引联在一起以满足查询的需求。
数据库中有索引是一件好事,而覆盖索引更为查询提供了极好的值。 但是,也受限制于每个索引至多16列、900字节的约束。该限制排除了大数据类型列使用覆盖索引的可能性,否则即使针对这类值得查询也可以不从基础表中抽取数据。
当查询中的所有列都作为键列或非键列包含在索引中时,带有包含性非键列的索引可以显著提高查询性能。这样可以实现性能提升,因为查询优化器可以在索引中找到所有列值;不访问表或聚集索引数据,从而减少磁盘 I/O 操作。当索引包含查询引用的所有列时,它通常称为“覆盖查询”。
二、包含列
SQL Server 2005引入了一项新的索引特性,即所谓的包含列(included column)。包含列仅在叶节点层级上成为索引的一部分。来自包含列的值不会出现在索引的根节点或中间级内,且不计入900字节的限制。 您可以通过将非键列添加到非聚集索引的叶级,扩展非聚集索引的功能。通过包含非键列,可以创建覆盖更多查询的非聚集索引。这是因为非键列具有下列优点:
1.它们可以是不允许作为索引键列的数据类型。
2.在计算索引键列数或索引键大小时,数据库引擎不考虑它们。
三、列大小准则
1.必须至少定义一个键列。最大非键列数为 1023 列。也就是最大的表列数减 1。
2.索引键列(不包括非键)必须遵守现有索引大小的限制(最大键列数为 16,总索引键大小为 900 字节)。
3.所有非键列的总大小只受 INCLUDE 子句中所指定列的大小限制;例如,varchar(max) 列限制为 2 GB。
四、设计建议
重新设计索引键大小较大的非聚集索引,以便只有用于搜索和查找的列为键列。将覆盖查询的所有其他列设置为包含性非键列。这样,将具有覆盖查询所需的所有列,但索引键本身较小,而且效率高。例如,假设要设计覆盖下列查询的索引。
1 USE AdventureWorks;
2 GO
3 SELECT AddressLine1, AddressLine2, City, StateProvinceID, PostalCode
4 FROM Person.Address
5 WHERE PostalCode BETWEEN N''98000'' and N''99999'';PostalCode 列(长度为 30 字节),所以更好的索引设计应该将 PostalCode 定义为键列并包含作为非键列的所有其他列。
下面的语句创建了一个覆盖查询的带有包含列的索引。
1 USE AdventureWorks;
2 GO
3 CREATE INDEX IX_Address_PostalCode
4 ON Person.Address (PostalCode)
5 INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);

SQL Server索引原理解析
此文是我之前的笔记整理而来,以索引为入口进行探讨相关数据库知识(又做了修改以让人更好消化)。SQL Server接触不久的朋友可以只看以下蓝色字体字,简单有用节省时间;如果是数据库基础不错的朋友,可以全看,欢迎探讨。
全文章节:
1.聚集索引和非聚集索引
1.1 聚集索引
1.2 非聚集索引
2.索引的结构
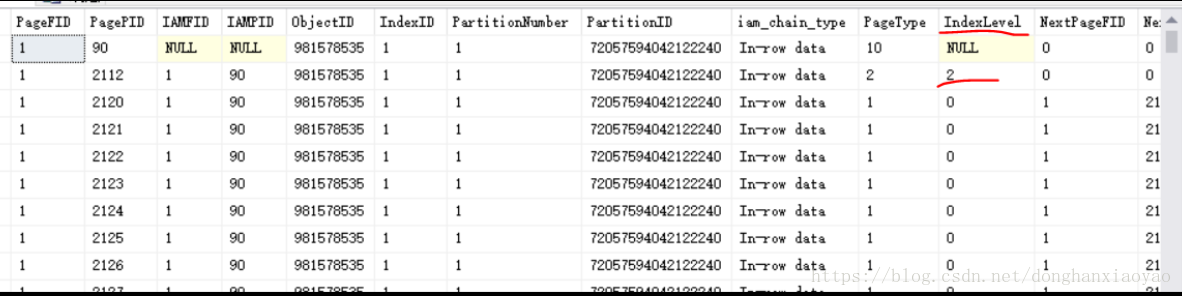
如上图,看到一个IndexLevel=2的索引页2112(这边它就是B树的根节点,IndexLevel最大的就是根节点,往下就是子级、子子级...只有一个根页作为B树结构的访问入口点),说明一定还有IndexLevel=1的索引页和IndexLevel=0的叶子页。由于这边是聚集索引,因此当IndexLevel=0的叶子页就是数据页,存储的是一笔一笔的物理数据。如上图也可以看到,IndexLevel=0的行的PageType等于1,就是代表数据页,上面1.1章节讲到聚集索引时,也有提到PageType=1;而如果是非聚集索引,IndexLevel=0的叶子页,PageType是等于 2,仍然是索引页。
-- DBCC TRACEON(3604,-1)
DBCC PAGE(Test,1,2112,3)
--根节点2112,可以查出它的两个子节点2280和2448,然后对这两个子节点再作DBCC PAGE查询
DBCC PAGE(Test,1,2280,3)
DBCC PAGE(Test,1,2448,3)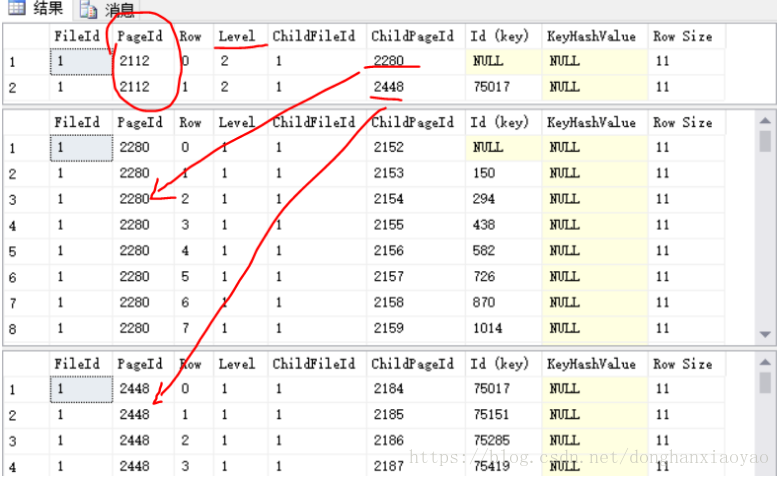
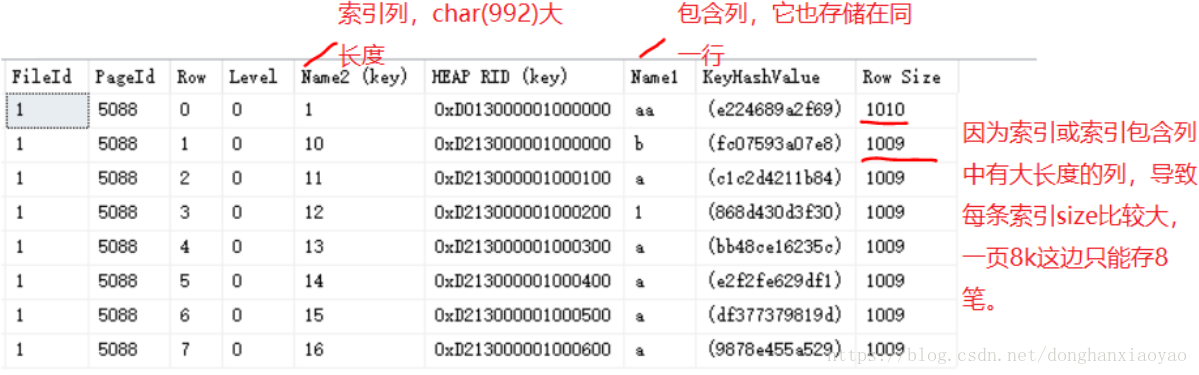
3.索引包含列和书签查找

SQL Server索引哪些群集?
我在某些表上有许多索引,它们都相似,并且我想知道聚集索引是否在正确的列上。以下是两个最活跃索引的统计信息:
Nonclustered
I3_Identity (bigint)
rows: 193,781
pages: 3821
MB: 29.85
user seeks: 463,355
user_scans: 784
user_lookups: 0
updates: 256,516
Clustered Primary Key
I3_RowId (varchar(80))
rows: 193,781
pages: 24,289
MB: 189.76
user_seeks: 2,473,413
user_scans: 958
user_lookups: 463,693
updates: 2,669,261
如您所见,经常搜索PK,但是对i3_identity列的所有搜索也正在对此PK进行关键查找,因此,我是否真的从I3_Identity的索引中受益匪浅?我应该改为使用I3_Identity作为群集吗?由于此表结构在我工作的地方重复了大约10000次,因此可能会产生巨大的影响,因此,我们将不胜感激。
今天关于在SQL Server索引中搜索单词和sqlserver使用索引查询的讲解已经结束,谢谢您的阅读,如果想了解更多关于ASP.NET C#在SQL Server数据库表中搜索、SQL Server索引--(包含列和覆盖索引)、SQL Server索引原理解析、SQL Server索引哪些群集?的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

