在本文中,我们将详细介绍初始化SparkContext时jvm错误中不存在pyspark错误的各个方面,并为您提供关于sparkobjectnotserializable的相关解答,同时,我们也将为您
在本文中,我们将详细介绍初始化SparkContext时jvm错误中不存在pyspark错误的各个方面,并为您提供关于spark object not serializable的相关解答,同时,我们也将为您带来关于3 pyspark学习---sparkContext概述、eclipse IDEA maven scala spark 搭建 成功运行 sparkContext、JVM申请的memory不够导致无法启动SparkContext、PySpark中的SparkSession和SparkContext初始化的有用知识。
本文目录一览:- 初始化SparkContext时jvm错误中不存在pyspark错误(spark object not serializable)
- 3 pyspark学习---sparkContext概述
- eclipse IDEA maven scala spark 搭建 成功运行 sparkContext
- JVM申请的memory不够导致无法启动SparkContext
- PySpark中的SparkSession和SparkContext初始化
")
初始化SparkContext时jvm错误中不存在pyspark错误(spark object not serializable)
我在EMR上使用spark并编写了pyspark脚本,尝试执行时出现错误
from pyspark import SparkContextsc = SparkContext()这是错误
File "pyex.py", line 5, in <module> sc = SparkContext() File "/usr/local/lib/python3.4/site-packages/pyspark/context.py", line 118, in __init__ conf, jsc, profiler_cls) File "/usr/local/lib/python3.4/site-packages/pyspark/context.py", line 195, in _do_init self._encryption_enabled = self._jvm.PythonUtils.getEncryptionEnabled(self._jsc) File "/usr/local/lib/python3.4/site-packages/py4j/java_gateway.py", line 1487, in __getattr__ "{0}.{1} does not exist in the JVM".format(self._fqn, name)) py4j.protocol.Py4JError: org.apache.spark.api.python.PythonUtils.getEncryptionEnabled does not exist in the JVM我发现此答案说明我需要导入sparkcontext,但这也无法正常工作。
答案1
小编典典PySpark最近发布了2.4.0,但是没有一个稳定的版本可以与此新版本同时出现。尝试降级到pyspark 2.3.2,这对我来说已解决
编辑:更清楚地说,您的PySpark版本必须与下载的Apache Spark版本相同,否则您可能会遇到兼容性问题
通过使用检查pyspark的版本
点冻结

3 pyspark学习---sparkContext概述
1 Tutorial
Spark本身是由scala语言编写,为了支持py对spark的支持呢就出现了pyspark。它依然可以通过导入Py4j进行RDDS等操作。
2 sparkContext
(1)sparkContext是spark运用的入口点,当我们运行spark的时候,驱动启动同时上下文也开始初始化。
(2)sparkContext使用py4j调用JVM然后创建javaSparkContext,默认为‘sc’,所以如果在shell下就直接用sc.方法就可以。如果你再创建上下文,将会报错cannot run multiple sparkContexts at once哦。结构如下所示
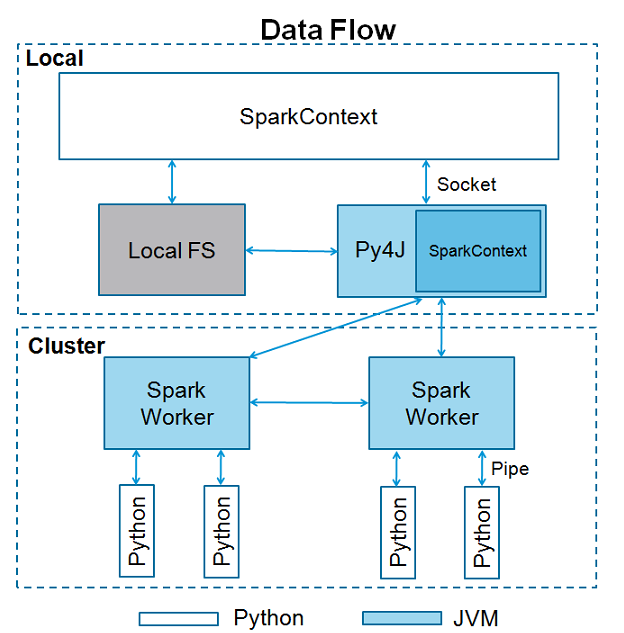
(3)那么一个sparkContext需要哪些内容呢,也就是初始化上下文的时候类有哪些参数呢。
1 class pyspark.SparkContext (
2 master = None,#我们需要连接的集群url
3 appName = None, #工作项目名称
4 sparkHome = None, #spark安装路径
5 pyFiles = None,#一般为处理文件的路径
6 environment = None, #worker节点的环境变量
7 batchSize = 0,
8 serializer = PickleSerializer(), #rdd序列化器
9 conf = None,
10 gateway = None, #要么使用已经存在的JVM要么初始化一个新的JVM
11 jsc = None, #JavaSparkContext实例
12 profiler_cls = <class ''pyspark.profiler.BasicProfiler''>
13 )尝试个例子:在pycharm中使用的哟
1 # coding:utf-8
2 from pyspark import SparkContext, SparkConf
3
4 logFile = "./files/test.txt"
5 sc = SparkContext()
6 logData = sc.textFile(logFile).cache()
7 numA = logData.filter(lambda s: ''a'' in s).count()
8 numB = logData.filter(lambda s: ''a'' in s).count()
9 print "Lines with a: %i, lines with b: %i" % (numA, numB)
加油!

eclipse IDEA maven scala spark 搭建 成功运行 sparkContext
整了好几天,把eclipse弄能用.. 期间报各种错,进度也被耽误了…archetype和pom部分引用他人的,可惜调试的太多,没有记录下作者,这里歉意+感谢.
环境:
Hadoop–>2.6.4
Scala–>2.11.8
Spark–>2.2.0
IDE,
eclipseEE + scalaIDE插件–>oxygen:pom有报错,但是可用
scalaIDE–>4.7-RC:目前spark的本地/集群都可执行.
IDEA–>还有些问题,可运行,不完美.补充在最后,和eclipseEE有点像.
注意:
1,版本的一致.scala和spark的版本要对应,不然可能报class.Product$class错,报找不到类或者…错误好多,没头绪..
如:
下面pom的配置中的spark.version和scala.version和scala.binary.version还有scala Library Container中版本的匹配,
2,pom中添加scala-maven-plugin插件依赖,就不需要再添加scala的dependency,除非有特殊需求;同时要注意导入的Scala Library Container中的版本问题
3,善用maven 的update project和project 的clean还有项目右键中configure菜单中的功能
4,本方案为初级方案.有些问题还是未能解决,使用eclipse的话,就用scalaIDE版的吧.IDEA可用的话,编辑scala还是很顺手的,就是括号,引号的tab跳转不舒服
eclipse部分:
具体如下:同时适用于eclipseEE和scalaIDE,具体有说明.
创建maven Project,
next
http://repo1.maven.org/maven2/archetype-catalog.xml
remote archetype创建好后,修改
src/main/java–>src/main/scala
src/test/java–>src/test/scala修改pom.xml.使用上面远程的archetype,会自动生成指定的pom,这里不使用.


<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<spark.version>2.2.0</spark.version>
<scala.version>2.11.8</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<hadoop.version>2.6.4</hadoop.version>
</properties>
<dependencies>
<!-- ==================================spark================================-->
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core_2.11 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-streaming_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-sql_2.10 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- ==================================hadoop================================-->
<!-- https://mvnrepository.com/artifact/org.apache.hadoop/hadoop-client -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- ==================================other================================-->
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
</dependencies>
<!-- maven官方 http://repo1.maven.org/maven2/ 或 http://repo2.maven.org/maven2/
(延迟低一些) -->
<repositories>
<repository>
<id>central</id>
<name>Maven Repository Switchboard</name>
<layout>default</layout>
<url>http://repo2.maven.org/maven2</url>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<!-- MAVEN 编译使用的JDK版本 -->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.7.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.3.1</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<arg>-make:transitive</arg>
<arg>-dependencyfile</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
当当运行时出现” -make:transitive”错误时,注释掉这个<arg>.
同时在dependencies添加(可选):
<!-- https://mvnrepository.com/artifact/org.specs2/specs2-junit_2.11 -->
<dependency>
<groupId>org.specs2</groupId>
<artifactId>specs2-junit_2.11</artifactId>
<version>3.9.4</version>
<scope>test</scope>
</dependency>注意:
1. 这里在eclipseEE在市场中下载了scalaIDE插件后,依然会报错,不用管,能用.
2. pom中的依赖包的版本注意与自己的版本对应.
3. 恰当使用项目右键中maven的update Projcet功能和eclipse菜单栏projcet的clean和build Automatically.多试试.
4. 在使用maven 的update Projcet后成功识别pom中的scala插件配置后,项目右键会有scala的选项.在使用eclipseEE的maven的update Projcet后没有反应时,使用项目右键菜单中configure,有”add Scala Nature”,可给项目添加scala库容器
5. 当下载scalaIDE插件或者使用最新的scalaIDE时,默认图中的(build-in)3个版本,要添加自己的scala版本时,在Window–Perferences–>
6. 修改scala版本时,在scala Library Container 右键–> build path–> configure build path –> Libraries标签中,remove当前版本,add Library –> Scala Library–> 选择刚才添加的版本即可.
5,创建object对象,测试运行.注意eclipseEE在执行sparkjob时,我这里需要设置head memory,在的run configurations..中scala application的对应任务下

测试代码:
import org.apache.spark.SparkConf
import org.apache.spark.SparkContext
object a {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
//conf.setMaster("spark://mini2:7077")
conf.setMaster("local[4]")
conf.setAppName("test")
val sc = new SparkContext(conf)
val a = sc.parallelize(List(1,2,3), 2)
println(a.count()) //3
sc.stop()
}
}**
IDEA部分
**
1,创建maven项目,修改
src/main/java-->src/main/scala
src/test/java-->src/test/scala2,改pom,配置内容与上面有些不同–
试了下,两个pom的部分不能互换,起码eclipse的部分不能放在IDEA这个版本里, 配置具体什么含义,会者不难.不会的人就照着这个来吧,起码能跑起来
<properties>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
<scala.version>2.11.8</scala.version>
<spark.version>2.2.0</spark.version>
<hadoop.version>2.6.4</hadoop.version>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
</dependencies>
<build>
<sourceDirectory>src/main/scala</sourceDirectory>
<testSourceDirectory>src/test/scala</testSourceDirectory>
<plugins>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.2</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
<configuration>
<args>
<!--<arg>-make:transitive</arg>-->
<arg>-dependencyfile</arg>
<arg>${project.build.directory}/.scala_dependencies</arg>
</args>
</configuration>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>3.1.0</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<filters>
<filter>
<artifact>*:*</artifact>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</filter>
</filters>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
===>这里遇到了-make:transitive问题,注释掉这行,没有添加junit依赖,也可运行…………….
3,在Projcet Structure中Global Library修改本项目的scala版本,类似eclipse添加.见eclipse部分
4,善用侧边栏的Maven Project的左上角的刷新和项目右键的build和rebuild功能
5,我这里运行时,报出和eclipseEE相同的内存不足,在run configurations…中设置,如图:
eclipse+插件版本我没找到类似的设置,只能一个obj设置一个了;
scalaIDE不存在内存问题.

6,,修改scala编译顺序,javathenscala


JVM申请的memory不够导致无法启动SparkContext
java.lang.IllegalArgumentException: System memory 259522560 must be at least 471859200. Please increase heap size using the --driver-memory option or spark.driver.memory in Spark configuration.
尝试直接在spark里运行程序的时候,遇到下面这个报错:
很明显,这是JVM申请的memory不够导致无法启动SparkContext。但是该怎么设呢?
通过查看spark源码,发现源码是这么写的:
/**
* Return the total amount of memory shared between execution and storage, in bytes.
*/
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
val minSystemMemory = reservedMemory * 1.5
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please use a larger heap size.")
}
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.75)
(usableMemory * memoryFraction).toLong
}
所以,这里主要是val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)。
conf.getLong()的定义和解释是
getLong(key: String, defaultValue: Long): Long
Get a parameter as a long, falling back to a default if not set
所以,我们应该在conf里设置一下spark.testing.memory.
通过尝试,发现可以有2个地方可以设置
1. 自己的源代码处,可以在conf之后加上:
val conf = new SparkConf().setAppName("word count")
conf.set("spark.testing.memory", "2147480000")//后面的值大于512m即可
2. 可以在Eclipse的Run Configuration处,有一栏是Arguments,下面有VMarguments,在下面添加下面一行(值也是只要大于512m即可)
-Dspark.testing.memory=1073741824
其他的参数,也可以动态地在这里设置,比如-Dspark.master=spark://hostname:7077
再运行就不会报这个错误了。

PySpark中的SparkSession和SparkContext初始化
SparkSession可以创建为http://spark.apache.org/docs/2.0.0/api/python/pyspark.sql.html
>>> from pyspark.sql import SparkSession
>>> from pyspark.conf import SparkConf
>>> SparkSession.builder.config(conf=SparkConf())
或
>>> from pyspark.sql import SparkSession
>>> spark = SparkSession.builder.appName('FirstSparkApp').getOrCreate()
非常相似。如果您已经有一个会话并想打开另一个会话,则可以使用
my_session = spark.newSession()
print(my_session)
这将产生我认为您要创建的新会话对象
<pyspark.sql.session.SparkSession object at 0x7fc3bae3f550>
spark是已在运行的会话对象,因为您正在使用数据块笔记本
关于初始化SparkContext时jvm错误中不存在pyspark错误和spark object not serializable的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于3 pyspark学习---sparkContext概述、eclipse IDEA maven scala spark 搭建 成功运行 sparkContext、JVM申请的memory不够导致无法启动SparkContext、PySpark中的SparkSession和SparkContext初始化的相关知识,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

