在这篇文章中,我们将带领您了解通过两列订购MySQL表的全貌,同时,我们还将为您介绍有关C++操作mysql__通过mysql的capi连接mysql服务器、excel表格筛选通过mysql语句、My
在这篇文章中,我们将带领您了解通过两列订购MySQL表的全貌,同时,我们还将为您介绍有关C++操作mysql__通过mysql的c api连接mysql服务器、excel表格 筛选 通过mysql语句、MySQL - 多个 INNER JOIN、CONCAT 和 UNION ALL - 如何从不同的表/列订购、MySQL Cluster:如何通过扩展为MySQL带来2亿QPS_MySQL的知识,以帮助您更好地理解这个主题。
本文目录一览:- 通过两列订购MySQL表
- C++操作mysql__通过mysql的c api连接mysql服务器
- excel表格 筛选 通过mysql语句
- MySQL - 多个 INNER JOIN、CONCAT 和 UNION ALL - 如何从不同的表/列订购
- MySQL Cluster:如何通过扩展为MySQL带来2亿QPS_MySQL

通过两列订购MySQL表
如何按两列对MySQL表进行排序?
我想要的是文章,首先是最高评分,然后是最新日期。例如,这将是一个示例输出(左#是评分,然后是文章标题,然后是文章日期)
50 | 这篇文章令人震惊| 2009年2月4日
35 | 这篇文章相当不错| 2009年2月1日
5 | 这篇文章不是很热门| 2009年1月25日
我正在使用的相关SQL是:
ORDER BY article_rating,article_time DESC
我可以按一个或另一个排序,但不能两个都排序。

C++操作mysql__通过mysql的c api连接mysql服务器
C++通过mysql的c api连接mysql服务器
1、在连接之前,不要忘记打开mysql服务器哇(Navicat打开或者不打开都可以)
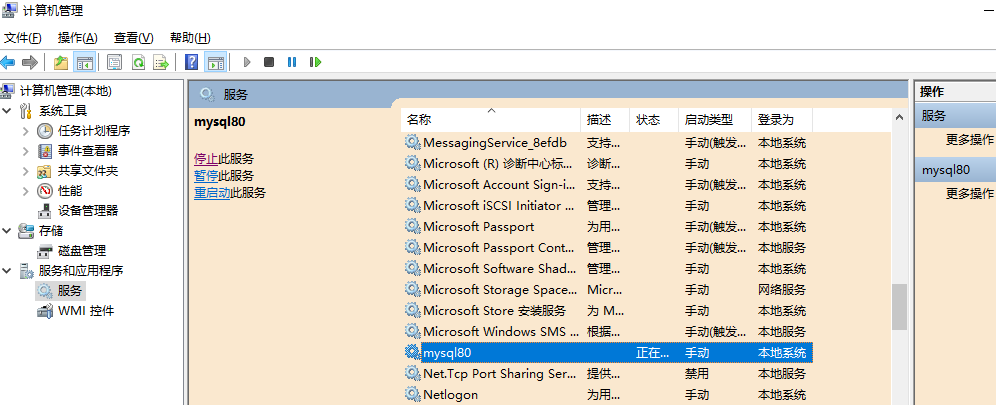
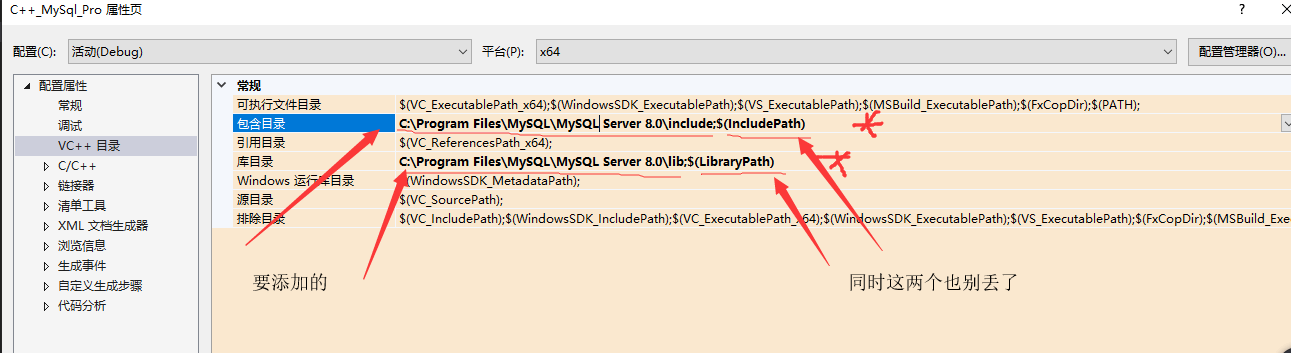
2、添加包含目录
3、添加libmysql.lib到附属依赖中
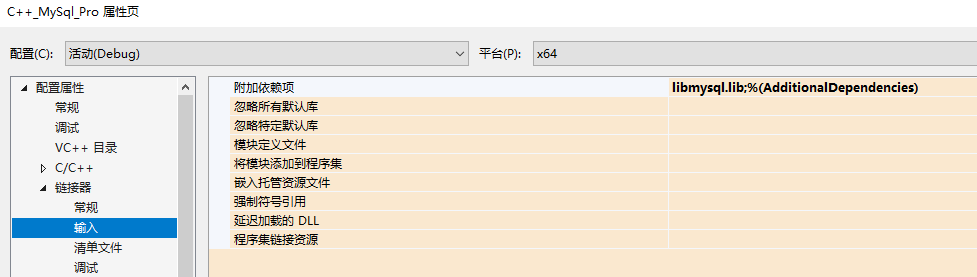
上一步中也也可以在程序代码的开始处加上#pragma comment(lib,"D:\\Program Files\\MySQL\\MySQL Server 5.6\\lib\\libmysql.lib") 来导入libmysql.lib)
4、如果使用的mysql是64位的,还需要将项目的解决方案平台由win32改成x64
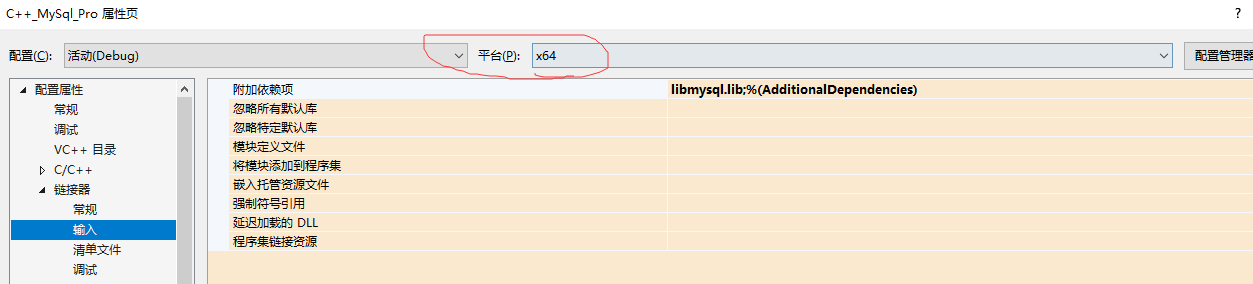
5、将D:\Program Files\MySQL\MySQL Server 5.6\lib(根据具体路径而定)下的libmysql.dll复制到项目中去,和.cpp,.h文件位于同一路径下
实例代码:


1 #include <stdio.h>
2 #include <mysql.h> // 如果配置ok就可以直接包含这个文件
3 int main(void)
4 {
5 MYSQL mysql; //一个数据库结构体
6 MYSQL_RES* res; //一个结果集结构体
7 MYSQL_ROW row; //char** 二维数组,存放一条条记录
8
9 mysql_init(&mysql);//初始化数据库
10 //设置编码方式
11 mysql_options(&mysql, MYSQL_SET_CHARSET_NAME, "gbk");
12 //连接数据库
13 //判断如果连接失败就输出连接失败。
14 if (mysql_real_connect(&mysql, "localhost", "root", "123456", "mysql", 3306, NULL, 0) == NULL) //mysql是一个数据库
15 printf("连接失败!\\n");
16 //查询数据
17 mysql_query(&mysql, "select * from db"); //db是数据库下的一个表
18 //获取结果集
19 res = mysql_store_result(&mysql);
20
21 //给ROW赋值,判断ROW是否为空,不为空就打印数据。
22 while (row = mysql_fetch_row(res))
23 {
24 printf("%s ", row[0]);//打印ID 打印第一列
25 printf("%s ", row[1]);//打印姓名 打印第二列
26 printf("%s ", row[2]);// 打印第三列
27 printf("%s ", row[3]);
28 printf("%s ", row[4]);
29 printf("%s ", row[5]);
30 printf("%s \n", row[6]);
31 }
32 //释放结果集
33 mysql_free_result(res);
34 //关闭数据库
35 mysql_close(&mysql);
36 //停留等待
37 system("pause");
38 return 0;
39 }
Navicat中的信息:

C++通过mysql的c api连接mysql服务器,并对数据库中的内容进行增删修改操作
在上面操作的基础上,修改代码如下:


1 #include <stdio.h>
2 #include <WinSock.h> //一定要包含这个,或者winsock2.h
3 //#include "include/mysql.h" //引入mysql头文件(一种方式是在vc目录里面设置,一种是文件夹拷到工程目录,然后这样包含)
4 #include "mysql.h"
5 #include <Windows.h>
6
7 //包含附加依赖项,也可以在工程--属性里面设置
8 #pragma comment(lib,"wsock32.lib")
9 #pragma comment(lib,"libmysql.lib")
10 MYSQL mysql; //mysql连接
11 MYSQL_FIELD *fd; //字段行数组
12 char field[32][32]; //存字段名二维数组
13 MYSQL_RES *res; //这个结构代表返回行的一个查询结果集
14 MYSQL_ROW column; //一个行数据的类型安全(type-safe)的表示,表示数据行的列
15 char query[150]; //存放mysql查询语句
16
17 bool ConnectDatabase(); //函数声明
18 void FreeConnect();
19 bool QueryDatabase1(); //查询1
20 bool QueryDatabase2(); //查询2
21 bool InsertData();
22 bool ModifyData();
23 bool DeleteData();
24
25 int main(int argc, char **argv)
26 {
27 ConnectDatabase();
28 QueryDatabase1();
29 InsertData();
30 QueryDatabase2();
31 ModifyData();
32 QueryDatabase2();
33 DeleteData();
34 QueryDatabase2();
35 FreeConnect();
36 system("pause");
37 return 0;
38 }
39 //连接数据库
40 bool ConnectDatabase()
41 {
42 //初始化mysql
43 mysql_init(&mysql); //连接mysql,数据库
44
45 //返回false则连接失败,返回true则连接成功
46 if (!(mysql_real_connect(&mysql, "localhost", "root", "123456", "test", 0, NULL, 0))) //中间分别是主机,用户名,密码,数据库名,端口号(可以写默认0或者3306等),可以先写成参数再传进去
47 {
48 printf("Error connecting to database:%s\n", mysql_error(&mysql));
49 return false;
50 }
51 else
52 {
53 printf("Connected...\n");
54 return true;
55 }
56 }
57 //释放资源
58 void FreeConnect()
59 {
60 //释放资源
61 mysql_free_result(res);
62 mysql_close(&mysql);
63 }
64 /***************************数据库操作***********************************/
65 //其实所有的数据库操作都是先写个sql语句,然后用mysql_query(&mysql,query)来完成,包括创建数据库或表,增删改查
66 //查询数据
67 //int sprintf(char* str,const char* format,...) 发送格式化输出到str所指向的字符串
68 bool QueryDatabase1()
69 {
70 sprintf(query, "select * from user"); //执行查询语句,这里是查询所有,user是表名,不用加引号,用strcpy也可以
71 mysql_query(&mysql, "set names gbk"); //设置编码格式(SET NAMES GBK也行),否则cmd下中文乱码
72 //返回0 查询成功,返回1查询失败
73 if (mysql_query(&mysql, query)) //执行SQL语句
74 {
75 printf("Query failed (%s)\n", mysql_error(&mysql));
76 return false;
77 }
78 else
79 {
80 printf("query success\n");
81 }
82 //获取结果集
83 if (!(res = mysql_store_result(&mysql))) //获得sql语句结束后返回的结果集
84 {
85 printf("Couldn''t get result from %s\n", mysql_error(&mysql));
86 return false;
87 }
88
89 //打印数据行数
90 printf("number of dataline returned: %lld\n", mysql_affected_rows(&mysql)); //此处原本是%d但是会报错,根据原因改成了%lld,lld表示长整形
91
92 //获取字段的信息
93 char *str_field[32]; //定义一个字符串数组存储字段信息
94 for (int i = 0; i < 4; i++) //在已知字段数量的情况下获取字段名
95 {
96 str_field[i] = mysql_fetch_field(res)->name;
97 }
98 for (int i = 0; i < 4; i++) //打印字段
99 printf("%10s\t", str_field[i]); //此处有个制表符\t
100 printf("\n");
101 //打印获取的数据
102 while (column = mysql_fetch_row(res)) //在已知字段数量情况下,获取并打印下一行
103 {
104 printf("%10s\t%10s\t%10s\t%10s\n", column[0], column[1], column[2], column[3]); //column是列数组 每一个数据后面都有一个制表符,cout是没有制表符的吧
105 }
106 return true;
107 }
108 bool QueryDatabase2()
109 {
110 mysql_query(&mysql, "set names gbk");
111 //返回0 查询成功,返回1查询失败
112 if (mysql_query(&mysql, "select * from user")) //执行SQL语句
113 {
114 printf("Query failed (%s)\n", mysql_error(&mysql));
115 return false;
116 }
117 else
118 {
119 printf("query success\n");
120 }
121 res = mysql_store_result(&mysql);
122 //打印数据行数
123 printf("number of dataline returned: %lld\n", mysql_affected_rows(&mysql));
124 for (int i = 0; fd = mysql_fetch_field(res); i++) //获取字段名
125 strcpy(field[i], fd->name);
126 int j = mysql_num_fields(res); // 获取列数
127 for (int i = 0; i < j; i++) //打印字段
128 printf("%10s\t", field[i]);
129 printf("\n");
130 while (column = mysql_fetch_row(res))
131 {
132 for (int i = 0; i < j; i++)
133 printf("%10s\t", column[i]);
134 printf("\n");
135 }
136 return true;
137 }
138 //插入数据
139 bool InsertData()
140 {
141 sprintf(query, "insert into user values (6, ''Lilei'', ''123'',''lilei23@sina.cn'');"); //可以想办法实现手动在控制台手动输入指令
142 if (mysql_query(&mysql, query)) //执行SQL语句
143 {
144 printf("Query failed (%s)\n", mysql_error(&mysql)); //可以检查输入的信息是否有错误,比如输入的类型和字段的类型是否匹配
145 return false;
146 }
147 else
148 {
149 printf("Insert success\n");
150 return true;
151 }
152 }
153 //修改数据
154 bool ModifyData()
155 {
156 sprintf(query, "update user set email=''lilei325@163.com'' where name=''Lilei''");
157 if (mysql_query(&mysql, query)) //执行SQL语句
158 {
159 printf("Query failed (%s)\n", mysql_error(&mysql));
160 return false;
161 }
162 else
163 {
164 printf("Modify success\n");
165 return true;
166 }
167 }
168 //删除数据
169 bool DeleteData()
170 {
171 /*sprintf(query, "delete from user where id=6");*/
172 char query[100];
173 printf("please input the sql:\n");
174 gets_s(query); //这里手动输入sql语句
175 if (mysql_query(&mysql, query)) //执行SQL语句
176 {
177 printf("Query failed (%s)\n", mysql_error(&mysql));
178 return false;
179 }
180 else
181 {
182 printf("Delete success\n");
183 return true;
184 }
185 }执行结果:
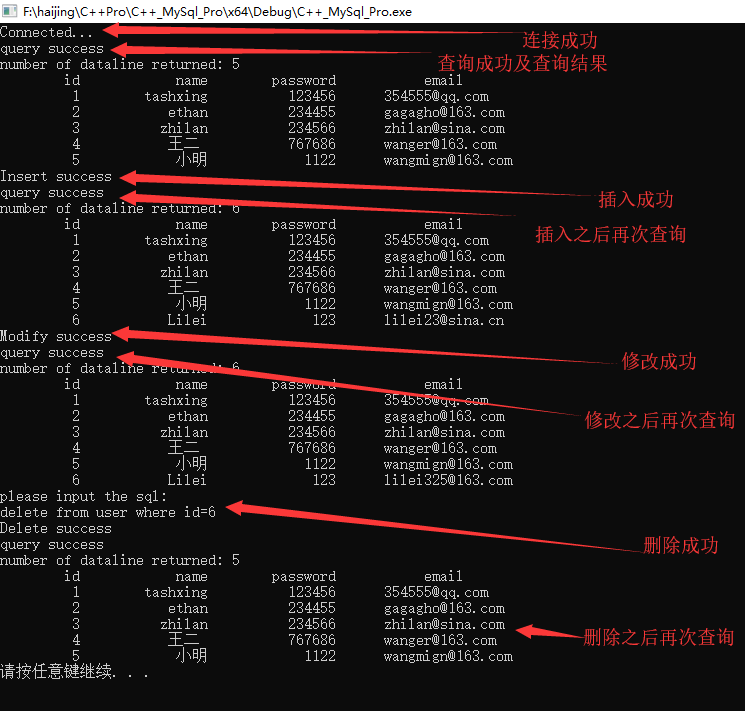
参考博客:https://www.cnblogs.com/47088845/p/5706496.html#top

excel表格 筛选 通过mysql语句
1、整理excel表格的数据
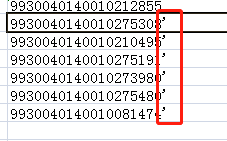
类似的 前面有其他符号的 都可以处理。


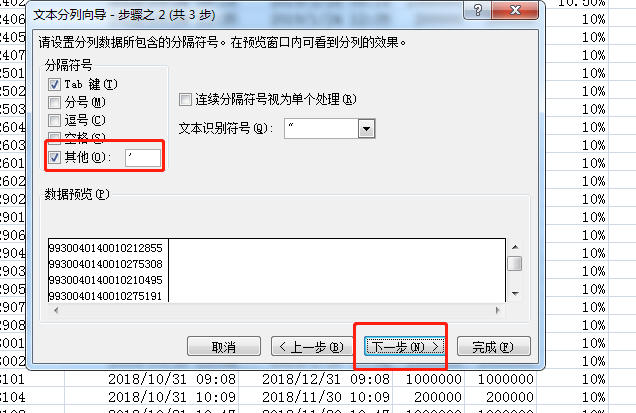
注意下一步是2个操纵:分别设置左右:
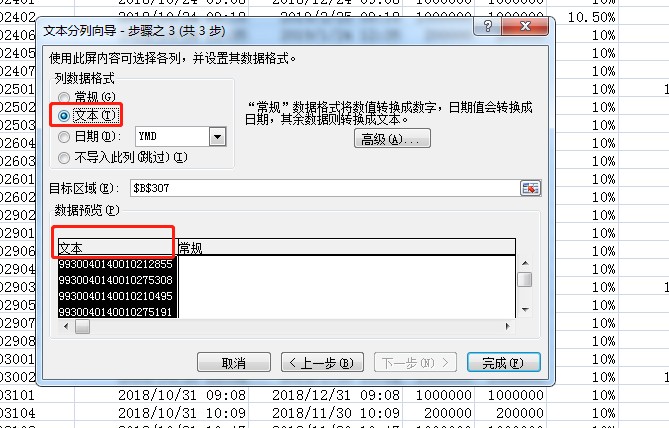
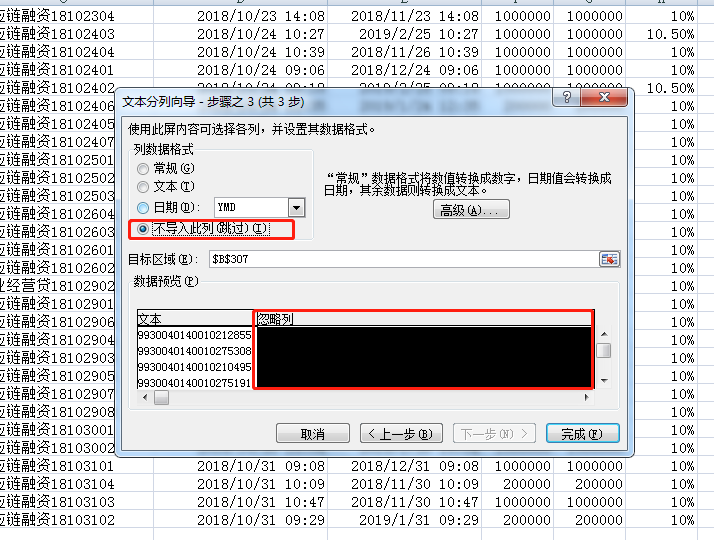
结果:
2、在复制粘贴到excel的时候,会有一些数字被设置成了科学计数法,
例如复制 到excel,就变成了
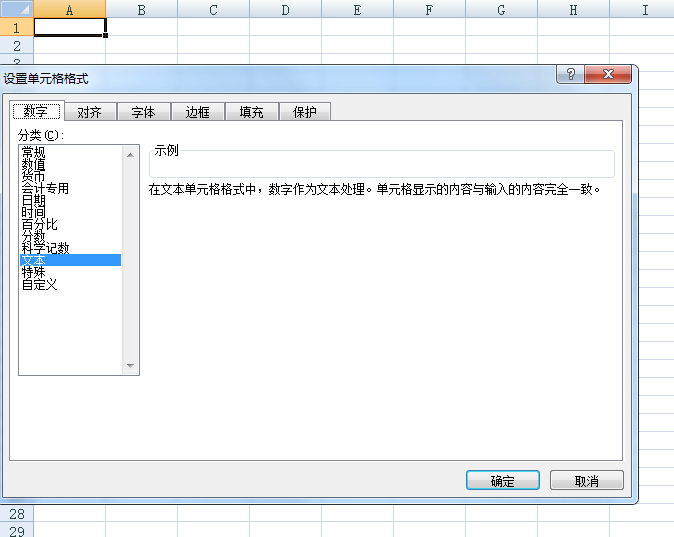
到excel,就变成了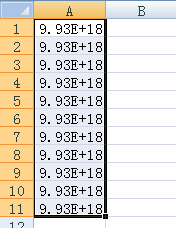 ,需要选中你要用的区域,吧这个区域提前变成文本格式,再粘贴。
,需要选中你要用的区域,吧这个区域提前变成文本格式,再粘贴。
 结果
结果 。
。
3、excel的查找 可以设置查找范围,可以查找多个sheet簿,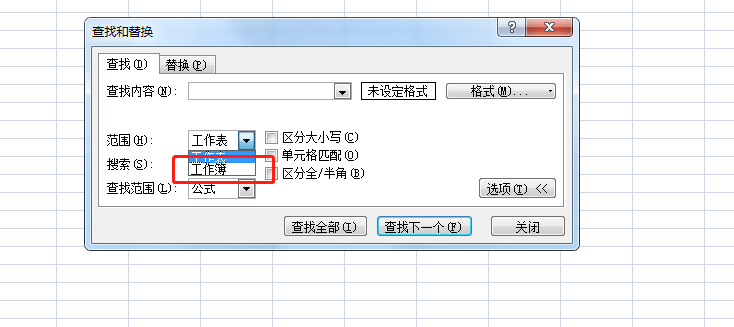 。
。
4、我们要在表1中查找数据,要查找的数据是含有表2中的id的数据。
我们整理好表1和表2的id后(格式一致)。
用mysql的 ,
,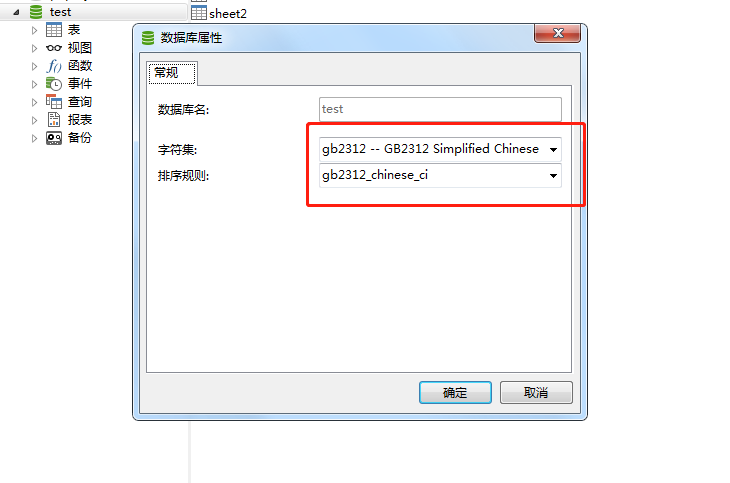 设置库的字符集,gb2312能读中文,导入
设置库的字符集,gb2312能读中文,导入 两个excel文件,执行下面的sql语句
两个excel文件,执行下面的sql语句
SELECT * from sheet2 where sheet2.id_card in(select id from sheet1)
全选 复制 找到excel 粘贴。

MySQL - 多个 INNER JOIN、CONCAT 和 UNION ALL - 如何从不同的表/列订购
如何解决MySQL - 多个 INNER JOIN、CONCAT 和 UNION ALL - 如何从不同的表/列订购?
我有以下查询,其中包含多个 INNER JOINS,CONCAT 和 UNION ALL 语句。
如何为该查询中的不同表和列添加一些 ORDER BY 语句?
例如ORDER BY unit.unit_name ASC,learning_event.learning_event_name ASC,assessment.assessment ASC
见fiddle
SELECT CONCAT(''program:'',p.program_pk) AS global_id,p.program_name AS name,NULL AS parent_global_id
FROM program p
UNION ALL
SELECT CONCAT(''program_group:'',pg.program_group_pk) AS global_id,pg.program_group AS name,CONCAT(''program:'',pg.program_fk) AS parent_global_id
FROM program_group pg
UNION ALL
SELECT CONCAT(''program_group:'',pog.program_group_fk,''program_outcome_group:'',pog.program_outcome_group) AS global_id,pog.program_outcome_group AS name,CONCAT(''program_group:'',pog.program_group_fk) AS parent_global_id
FROM program_outcome_group pog
UNION ALL
SELECT
CONCAT(''program_group:'',pog2.program_group_fk,pog2.program_outcome_group,'',program_outcome:'',po.program_outcome) AS global_id,po.program_outcome AS name,pog2.program_outcome_group) AS parent_global_id
FROM program_outcome po
INNER JOIN program_outcome_group pog2 ON po.program_outcome_group_fk = pog2.program_outcome_group_pk
UNION ALL
SELECT
CONCAT(''program_group:'',pog3.program_group_fk,pog3.program_outcome_group,po2.program_outcome,unit:'',u.unit_full_name) AS global_id,u.unit_full_name AS name,po2.program_outcome) AS parent_global_id
FROM unit u
INNER JOIN program_outcome_unit_lookup uup ON u.unit_pk = uup.unit_fk
INNER JOIN program_outcome po2 ON po2.program_outcome_pk = uup.program_outcome_fk
INNER JOIN program_outcome_group pog3 ON po2.program_outcome_group_fk = pog3.program_outcome_group_pk
UNION ALL
SELECT
CONCAT(''program_group:'',u2.unit_full_name,unit_group:'',ug.unit_group) AS global_id,ug.unit_group AS name,u2.unit_full_name) AS parent_global_id
FROM unit_group ug
INNER JOIN unit u2 ON u2.unit_pk = ug.unit_fk
INNER JOIN program_outcome_unit_lookup uup ON u2.unit_pk = uup.unit_fk
INNER JOIN program_outcome po2 ON po2.program_outcome_pk = uup.program_outcome_fk
INNER JOIN program_outcome_group pog3 ON po2.program_outcome_group_fk = pog3.program_outcome_group_pk
UNION ALL
SELECT
CONCAT(''program_group:'',pog4.program_group_fk,pog4.program_outcome_group,po3.program_outcome,u3.unit_full_name,ug2.unit_group,learning_event:'',le.learning_event_name) AS global_id,le.learning_event_name AS name,ug2.unit_group) AS parent_global_id
FROM learning_event le
INNER JOIN unit_group ug2 ON ug2.unit_group_pk = le.unit_group_fk
INNER JOIN unit u3 ON ug2.unit_fk = u3.unit_pk
INNER JOIN program_outcome_unit_lookup uup ON u3.unit_pk = uup.unit_fk
INNER JOIN program_outcome po3 ON po3.program_outcome_pk = uup.program_outcome_fk
INNER JOIN program_outcome_group pog4 ON po3.program_outcome_group_fk = pog4.program_outcome_group_pk
JOIN learning_event_program_outcome_lookup lepol
ON lepol.learning_event_fk = le.learning_event_pk
AND lepol.program_outcome_fk = po3.program_outcome_pk
UNION ALL
SELECT
CONCAT(''program_group:'',assessment:'',t1.assessment) AS global_id,t1.assessment AS name,ug2.unit_group) AS parent_global_id
FROM assessment t1
INNER JOIN unit_group ug2 ON ug2.unit_group_pk = t1.unit_group_fk
INNER JOIN unit u3 ON ug2.unit_fk = u3.unit_pk
INNER JOIN program_outcome_unit_lookup uup ON u3.unit_pk = uup.unit_fk
INNER JOIN program_outcome po3 ON po3.program_outcome_pk = uup.program_outcome_fk
INNER JOIN program_outcome_group pog4 ON po3.program_outcome_group_fk = pog4.program_outcome_group_pk
JOIN assessment_program_outcome_lookup t5
ON t5.assessment_fk = t1.assessment_pk
AND t5.program_outcome_fk = po3.program_outcome_pk
解决方法
要在 ORDER BY 中使用 LIMIT/UNION [ALL],SELECT 需要在括号中。
例如:
(SELECT a FROM t1 WHERE a=10 AND B=1 ORDER BY a LIMIT 10)
UNION
(SELECT a FROM t2 WHERE a=11 AND B=2 ORDER BY a LIMIT 10);
参考:mysql manual on union / mariadb kb on union

MySQL Cluster:如何通过扩展为MySQL带来2亿QPS_MySQL

本篇文章的目的在于介绍MySQL Cluster——也就是MySQL的一套内存内、实时、可扩展且具备高可用性的版本。在解决标题中所提到的每秒2亿查询处理能力问题之前,我们先对MySQL集群的背景信息及其架构进行一番回顾,这将有助于大家理解上述目标的实现过程。
MySQL Cluster介绍
MySQL Cluster是一套具备可扩展能力、实时、内存内且符合ACID要求的事务型数据库,其将99.999%高可用性与低廉的开源总体拥有成本相结合。在设计思路方面,MySQL Cluster采用一套分布式多主架构并借此彻底消灭了单点故障问题。MySQL Cluster能够横向扩展至商用硬件之上,能够通过自动分区以承载读取与写入敏感型工作负载,并可通过SQL与NoSQL接口实现访问。
作为一套最初被设计为嵌入式电信数据库、用于实现内网应用运营商级可用性及实时性能的解决方案,MySQL Cluster已经通过众多新型功能集的强化而得到快速发展,从而将用例范围扩展到Web、移动以及企业级应用程序等部署在内部或者云环境下的实例当中,具体包括:大规模OLTP(实时分析)电子商务、库存管理、购物车、支付处理、订单追踪、在线游戏、金融交易与欺诈检测、移动与微支付、会话管理与缓存、数据流供应、分析与建议、内容管理与交付、通信与呈现服务、订阅/用户配置管理与补贴等等。
MySQL Cluster架构概述
在面向应用程序的事务流程背后,存在着三种负责将服务交付至应用程序的节点类型。下图所示为一套简单的示例型MySQL Cluster架构,其由十二套被划分为六个节点组的Data Node构成。

Data Node属于MySQL Cluster当中的主节点。它们负责提供以下功能:内存内与基于磁盘数据的存储与管理、表的自动化与用户定义型划分(即分区)、在不同数据节点间进行数据副本同步、事务与数据检查、自动故障转移以及用于实现自我修复的故障后自动重新同步。
各种表会在多个数据节点当中进行自动分区,而且每个数据节点作为一个写入操作的接收主体,这就使其能够轻松将写入敏感型工作负载分布至多个商用节点之上,同时保证应用程序的完全透明化。
通过将数据保存并分发至一套无共享架构——也就是不使用任何共享磁盘——当中,并至少为数据同步至一套副本内,MySQL Cluster能够保证在单一Data Node出现故障时、用户至少还拥有另一个存储有相同信息的Data Node。如此一来,请求与事务处理流程将以无中断方式继续提供令人满意的运作效果。任何由于Data Node故障所引发的短暂故障转移窗口(时间在秒以下)而无法正常完成的事务流程都将被回滚并重新执行。
我们可以为数据选择存储方式,包括全部保存在内存内或者将一部分数据只在在磁盘之上(仅限于非索引数据)。内存内存储对于那些需要经常进行变更的数据(也就是活跃工作组)而言意义重大。保存在内存内的数据会定期进行指向本地磁盘的检查,并与全部Data Node进行协调,这样MySQL Cluster就能够在整体系统发生故障时——例如供电中断——得以全面恢复。基于磁盘的数据能够被用于存储对性能要求较低的数据,而这类数据集往往大于可用内存空间。正如其它大部分数据库服务器一样,MySQL Cluster会利用页面缓存机制将基于磁盘且访问频率较高的数据缓存在Data Node的内存当中,从而增加其实际性能表现。
Application Node负责提供由应用程序逻辑到数据节点的连接。应用程序可以利用SQL访问该数据库,具体而言通过一台或者多台MySQL服务器向处于同一套MySQL Cluster内的存储数据执行SQL接口功能。在MySQL Server当中,我们可以使用任何一种标准化MySQL连接机制,这意味着大家拥有非常丰富的访问技术可供选择。另外,一套名为NDB API的高性能(基于C++)接口可被用于实现附加控制、改善实时行为并带来更理想的吞吐能力。NDB API的层能够帮助额外NoSQL接口绕过SQL层而直接访问该集群,如此一来不仅延迟有所降低、开发人员也有获得更理想的灵活性水平。现有接口包括Java、JPA、Memcached、JavaScript with Node.js以及HTTP/REST(通过一套Apache Module实现)。所有Application Node都能够访问到来自任意Data Node的数据,所以即使出现故障、它们也不会导致任何服务丢失——因为各应用程序能够继续使用其它尚能正常运转的节点。
Management Node的职责在于该集群的配置方案发布到集群内的所有节点当中以实现节点管理。Management Node的起效时间点分别为集群启动时、某个节点希望加入集群时以及系统进行重新配置时。Management Node能够在不影响到当前正在进行的Data及Application Node执行操作的前提下进行中止以及重启。在默认情况下,Management Node同时提供裁定服务,例如某种网络故障引发“裂脑(即split-brain)”或者某信集群开始进行网络划分的情况。
通过透明化划分实现可扩展性

来自任何给定表的行都会以透明化方式被拆分成多个分区/片段。在每个片段中会包含一个单独数据节点,负责保留全部数据内容并处理指向该数据的所有读取及写入操作。每个数据节点还拥有一套搭档体系,二者共同构成一个节点组; 搭档节点中保存有该数据片段的辅助副本,但同时也拥有着自己的主片段。MySQL Cluster利用两步式提交协议实现数据同步,从而确保当某项事务被提交之后、所引发的变更将被同时存储在两个数据节点当中。
在默认情况下,表的主键会被作为分片键使用,而MySQL Cluster将对该分片键执行MD5散列处理、从而选择需要保存哪个片段/分区。如果某一事务或者查询需要访问来自多个数据节点的数据,那么其中一个数据节点会充当事务协调方的角色,并将具体工作分配给其它相关数据节点; 接下来访问结果会得到整合,并最终提供给应用程序。请注意,我们同样可以让多个事务或者查询访问来自多个分区及表的数据——相较于利用分片机制保存数据的典型NoSQL,这无疑成为MySQL Cluster的一大显著比较优势。

要实现最理想的(线性)规模缩放效果,我们需要确保将高强度查询/事务只需运行在单独一套数据节点之上(因为这能够大大降低由数据节点间通信所带来的网络延迟)。为了实现这个目标,我们可以让应用程序获得分布识别能力——具体而言,这意味着由管理员定义的规划能够涵盖分片键所需要使用的任意列。举例来讲,上图所示为一套配备有由用户ID与服务名称组成的复合主键的表; 通过将用户ID选定为分片键,表内与给定用户相关的所有行将始终被容纳在同一片段当中。更为强大的是,如果我们在其它表中使用同样的用户ID列并将其设定为分片键,那么该给定用户在所有表内的全部数据都会被容纳在同一片段之内——换言之,指向该用户的查询/事务都将在单一数据节点内进行处理。
今天关于通过两列订购MySQL表的讲解已经结束,谢谢您的阅读,如果想了解更多关于C++操作mysql__通过mysql的c api连接mysql服务器、excel表格 筛选 通过mysql语句、MySQL - 多个 INNER JOIN、CONCAT 和 UNION ALL - 如何从不同的表/列订购、MySQL Cluster:如何通过扩展为MySQL带来2亿QPS_MySQL的相关知识,请在本站搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

