在这篇文章中,我们将为您详细介绍NoSQL架构实践的内容,并且讨论关于三以NoSQL为缓存的相关问题。此外,我们还会涉及一些关于GaussDBNoSQL架构设计分享、N1QL为NoSQL数据库带来SQ
在这篇文章中,我们将为您详细介绍NoSQL架构实践的内容,并且讨论关于三 以NoSQL为缓存的相关问题。此外,我们还会涉及一些关于GaussDB NoSQL架构设计分享、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践、NoSQL架构实践-以NoSQL为辅的知识,以帮助您更全面地了解这个主题。
本文目录一览:- NoSQL架构实践(三) 以NoSQL为缓存(nosql采用什么方式存储)
- GaussDB NoSQL架构设计分享
- N1QL为NoSQL数据库带来SQL般的查询体验
- NoSQL架构实践
- NoSQL架构实践-以NoSQL为辅
 以NoSQL为缓存(nosql采用什么方式存储)")
NoSQL架构实践(三) 以NoSQL为缓存(nosql采用什么方式存储)
由于Nosql数据库天生具有高性能、易扩展的特点,所以我们常常结合关系数据库,存储一些高性能的、海量的数据。从另外一个角度看,根据Nosql的高性能特点,它同样适合用于缓存数据。用Nosql缓存数据可以分为内存模式和磁盘持久化模式。
AD:2014WOT全球软件技术峰会北京站 课程视频发布
在《Nosql架构实践》系列的前面两篇文章中,介绍了《以NoSQL为主》和《以NoSQL为辅》的架构。由于Nosql数据库天生具有高性能、易扩展的特点,所以我们常常结合关系数据库,存储一些高性能的、海量的数据。从另外一个角度看,根据Nosql的高性能特点,它同样适合用于缓存数据。用Nosql缓存数据可以分为内存模式和磁盘持久化模式。
内存模式
说起内存模式缓存,我们自然就会想起大名鼎鼎的Memcached。在互联网发展过程中,Memcached曾经解救了数据库的大部分压力,做出了巨大的贡献,直到今天,它依然是缓存服务器的首选。Memcached的常见使用方式类似下面的代码:

Memcached提供了相当高的读写性能,一般情况下,都足够应付应用的性能要求。但是基于内存的Memcached缓存的总数据大小受限于内存的大小。
当前如日中天、讨论得异常火热的Nosql数据库Redis又为我们提供了功能更加强大的内存存储功能。跟Memcached比,Redis的一个key的可以存储多种数据结构Strings、Hashes、Lists、Sets、Sorted sets。Redis不但功能强大,而且它的性能完全超越大名鼎鼎的Memcached。Redis支持List、hashes等多种数据结构的功能,提供了更加易于使用的api和操作性能,比如对缓存的list数据的修改。
同样,其他一些Nosql数据库也提供了内存存储的功能,所以也适合用来做内存缓存。比如Tokyo Tyrant就提供了内存hash数据库、内存tree数据库功能,内存tree数据可根据key的顺序进行遍历。你可以通过使用其提供的兼容Memcached协议或自定义的协议来使用。
持久化模式
虽然基于内存的缓存服务器具有高性能,低延迟的特点,但是内存成本高、内存数据易失却不容忽视。几十GB内存的服务器,在很多公司看来,还比较奢侈。所以,我们应该根据应用的特点,尽量的提高内存的利用率,降低成本。
大部分互联网应用的特点都是数据访问有热点,也就是说,只有一部分数据是被频繁访问的。如果全部都cache到内存中,无疑是对内存的浪费。
这时,我们可以利用Nosql来做数据的缓存。其实Nosql数据库内部也是通过内存缓存来提高性能的,通过一些比较好的算法,把热点数据进行内存cache,非热点数据存储到磁盘以节省内存占用。由于其数据库结构的简单,从磁盘获取一次数 据也比从数据库一次耗时的查询划算很多。用Nosql数据库做缓存服务器不但具有不错的性能。而且还能够Cache比内存大的数据。
使用Nosql来做缓存,由于其不受内存大小的限制,我们可以把一些不常访问、不怎么更新的数据也缓存起来。比如论坛、新闻的老数据、数据列表的靠后的页面,虽然用户访问不多,但是搜索引擎爬虫会访问,也可能导致系统负载上升。
如果Nosql持久化缓存也使用类似基于内存的memcached设置过期时间的方式,那么持久化缓存就失去了意义。所以用Nosql做缓存的过期策略最好不使用时间过期,而是数据是否被更新过,如果数据没有更新,那么就永久不过期。下面我们用代码(PHP)演示一种实现这种策略的方法:
场景:新闻站点的评论系统。用户对新闻页面的url进行评论,然后根据url进行查询展示。
我把上面代码演示的缓存使用方式称为基于版本的缓存。这种方式同样适用于基于内存的Memcached。它能实现缓存数据的实时性,让用户感觉不到延迟。只要用户一发表评论,该新闻的评论缓存就会失效。用户很少去评论一些过时的新闻,那么缓存就一直存在于Nosql中,避免了爬虫访问过时新闻的评论数据而冲击数据库。
总结
目前国内的新浪微博已经在大量的使用Redis缓存数据,赶集网也在大量的使用Redis。Redis作为一些List,Hashes等数据结构的缓存,非常适合。
把Nosql当持久化Cache使用的模式,在很多大数据量、有热点、查询非热点数据比较消耗资源的场景下比较有用。
Nosql架构实践总结
到这里,关于Nosql架构实践的三篇文章就结束了。Nosql架构并不局限于我介绍的三种模式,他们之间也可以进行组合,应该根据你具体的应用场景灵活使用。不管是什么模式,都是为了解决我们的问题而出现的,所以在系统架构的时候,要问下自己,我为什么要用Nosql;在对Nosql架构模式选型的时候,要问下自己,我为什么要这么用Nosql。
原文链接:http://www.cnblogs.com/sunli/archive/2011/03/31/nosql-architecture-practice_3.html
【编辑推荐】
NoSQL架构实践(一)以NoSQL为辅
NoSQL架构实践(二)以NoSQL为主
NoSQL理论研究:内存是新的硬盘,硬盘是新的磁带
关于NoSQL数据库你应该知道的10件事

GaussDB NoSQL架构设计分享
摘要:文章总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
本文分享自华为云社区《华为云GaussDB NoSQL云原生多模数据库的超融合实践》,作者:华为云数据库GaussDB(for Redis)团队。
数据库发展趋势
1. 行业市场
中国信通院最新研究透露出两个重要信息:
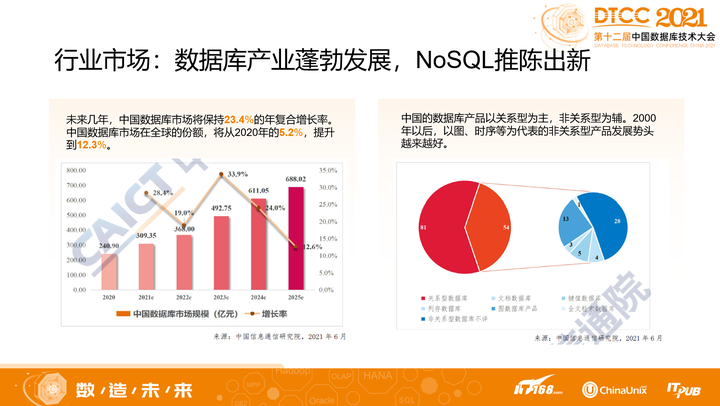
- 未来几年,中国数据库市场将保持23.4%的年复合增长率,中国数据库市场在全球的份额,将从2020年的5.2%提升到12.3%;
- 中国的国产数据库产品虽然以关系型为主,非关系型为辅,但从2000年以后,以图、时序等为代表的非关系型产品发展势头越来越好,截止2020年底,国产NoSQL数据库厂商已经占到了40%。
2. 行业趋势
受大环境的影响,国内金融、电信、政企等行业为防止潜在的供应链风险,技术层面存在国产化需求,这使得我们的国产数据库产业进入蓬勃发展的初期。
但我国数据库行业发展还面临2个核心问题:
- 如何缩小“高要求的存量数据应用”与“仍处于发展初期阶段的供给能力”之间的差距;
- 如何匹配“创新型数据应用”与“数据库技术演进”的合理映射关系。
如何回答上述两个问题,可以从中国信通院最新的趋势总结里找到答案:“多模实现一库多用,简化开发运维成本”、“云原生降低硬件依赖,更方便的享受新兴技术红利”。
因此,为了更好的兼容历史数据应用(比如原先用Redis),并支持好未来的创新应用(新增Influx),可以在多模与云原生领域提前做好相关布局。

3. 云原生数据库演进方向
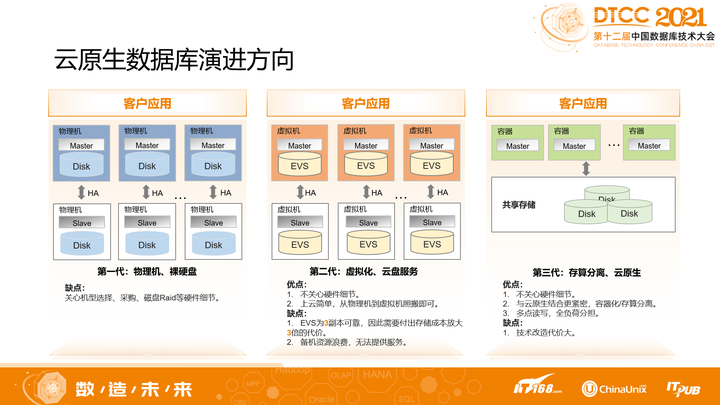
数据库的发展,按传统物理机部署到云化,大概经历了三代。
- 第一代是纯物理机、裸硬盘部署,从业人员必须关心硬件的各种细节,包括机型、系统、硬盘、组网等等;
- 第二代是云化的初级阶段,从业人员把数据库部署从物理机,迁移到虚拟机VM,把物理硬盘,换成了云盘EVS。但这一代有个明显的缺点,EVS是个3副本可靠的服务,再加上数据库自身的高可用,那么存储成本就放大了3倍;并且备机其实是资源浪费的,没有提供服务;
- 第三代是云化的高级阶段,这个阶段将数据库的资源,彻底分成存储和计算两层,其中计算资源部署在更轻量级的容器之上,而存储资源部署在分布式存储池之上。很显然,这是与云原生结合更彻底的方式,充分享受了架构的弹性、便捷,而且轻松实现了多点读写的全负荷分担能力。
4. 存算分离,分而治之
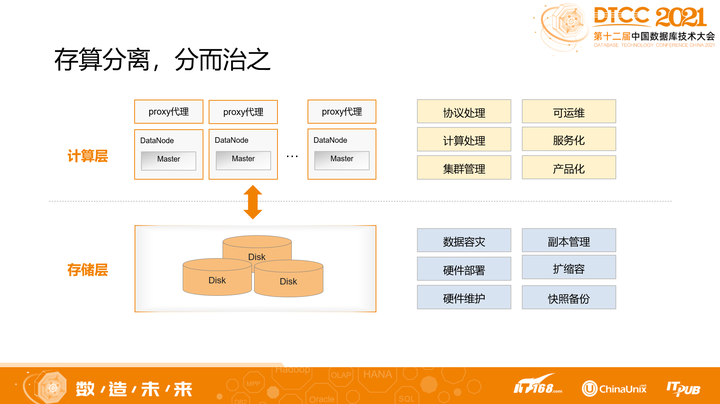
云原生数据库有两个重要的特点。首先是存算分离。
存算分离是一种分层的设计思想:
- 从逻辑到功能进行明确的划分,让计算层更聚焦服务、产品、协议处理等事件;
- 存储层更聚焦数据本身的复制、安全、扩缩容等等。
5. 多模归一,一生万物
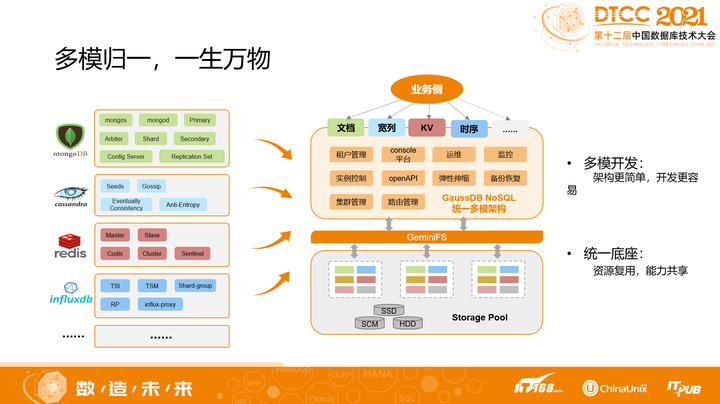
云原生数据库第二个重要的特点,是多模。
多模实际上是一种“归一”,也是一种“派生”。以大家熟悉的NoSQL为例,MongoDB是有Mongod/Mongos/Config等组件,而对应的Cassandra其实也有Coordinate Node/Data Node等组件。虽然这些组件名字不同,但背后做的事情是一样的,即:集群管理、副本管理、扩缩容管理、以及管控等功能。
其实,完全可以把这些功能抽象成统一的架构,即“多模归一”。在这套统一架构之上,我们再新增别的引擎就很容易了。可以快速复用当前的成熟架构,提供不同的协议接口即可,即“一生万物”。
6. GaussDB NoSQL概况
接下来介绍这次分享的主角——云原生多模数据库GaussDB NoSQL。
当前GaussDB NoSQL已经支持MongoDB、Cassandra、Redis、InfluxDB等4款引擎;全球客户1000+,足迹遍布金融、政府、电信、互联网等行业;总数据量超过10PB,每日新增超过10TB。
GaussDB NoSQL关键技术
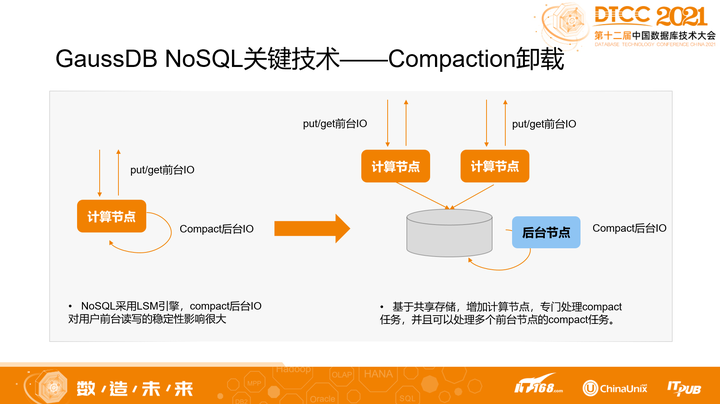
1. Compaction卸载
GaussDB NoSQL采用LSM做存储引擎,正常情况下,前台的读写会受到后台的Compaction任务的影响,从而导致时延抖动。
因此,我们设计了单独的Compaction任务节点,通过共享的方式,访问用户的数据并进行Compact,再将Compact的结果应用到用户的可见版本中。这样做的话,就将用户前台的IO和后台IO分离,解决了时延抖动问题。
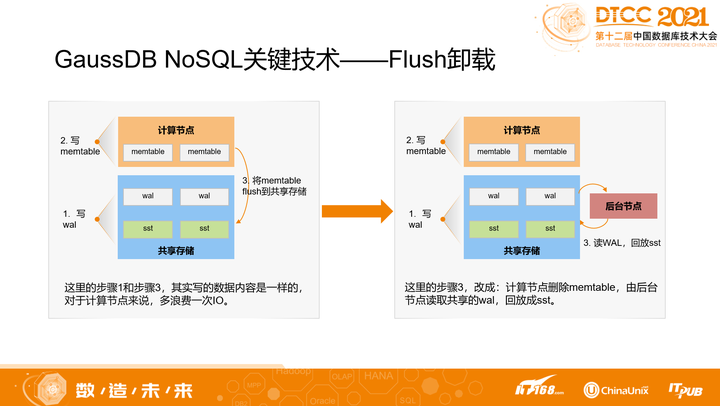
2. Flush卸载
根据LSM引擎的写入流程,可以知道,一个数据要写入DB中,需要经历两次IO:
- 写WAL
- flush memtable
而这两次IO写的其实是相同数据,完全可以省掉一次。因此,我们借助共享存储的能力,独立出一个后台任务节点。当用户前台节点需要flush memtable的时候,由后台任务节点读取WAL,并转化成L0层的SST,再应用版本,并通知前台删除memtable。这样就极大节省了用户前台的IO开销。
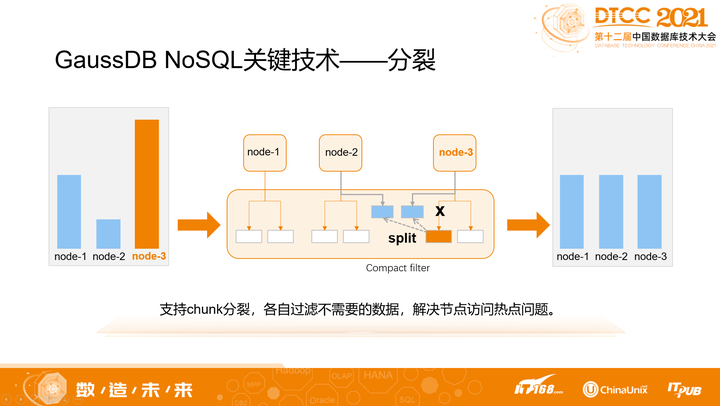
3. 分裂
GaussDB NoSQL在分片策略上,采取的是Hash + Range的结合方式,因此扩容或处理热点的时候会很灵活。
比如,当chunk数量足够多时,只需要移动chunk就可以扩容;而当某个chunk成为访问热点时,对它做分裂就可以解决局部热点问题。
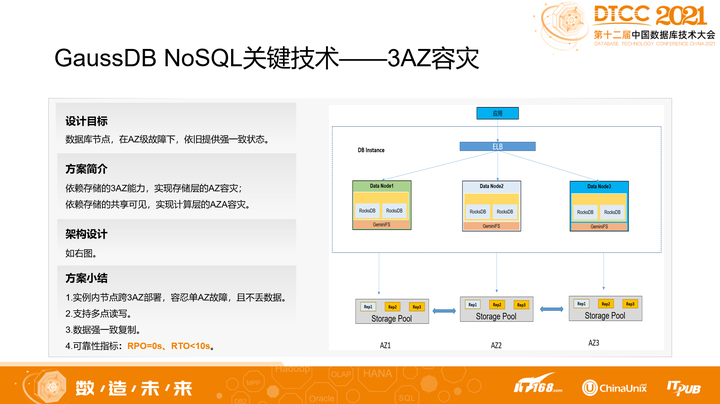
4. 3AZ容灾
作为数据库产品,容灾特性是很重要的,它可以避免极端情况给用户业务带来的灾难性损失。
GaussDB NoSQL有统一的容灾设计,即存储和计算可以实现3AZ部署,同时存储层数据实现3副本强一致复制。因此在任意时间,挂掉了任意机房的存储,都不会丢数据;而挂掉计算,也会被其他AZ的计算节点接管元数据,不会让访问完全中断。
以Redis为例看GaussDB竞争力
接下来,以使用最广泛的NoSQL引擎Redis为例,具体介绍GaussDB NoSQL的优势。
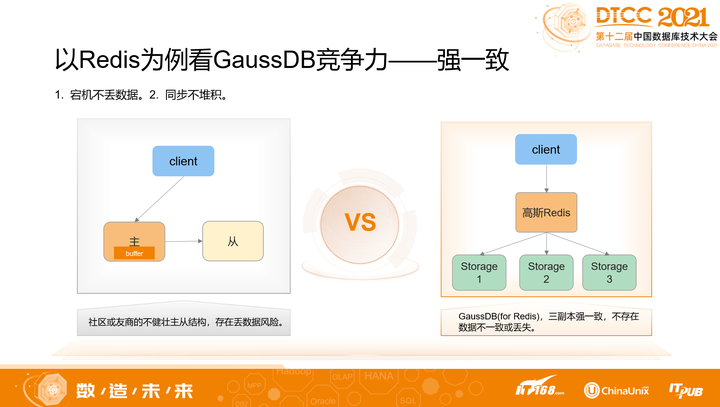
1. 强一致
社区版Redis,主从复制是异步的,容易造成数据堆积,也有宕机丢数据风险。
GaussDB(for Redis)(下文简称高斯Redis)则是采用强一致同步的,当用户的数据写入高斯Redis并收到返回OK,这意味着高斯Redis已经实现了强一致的复制,数据的安全性很高。当然,这里的复制过程采用了组提交、用户态文件系统、RDMA等技术来降低同步复制的时延。
2. 高可用
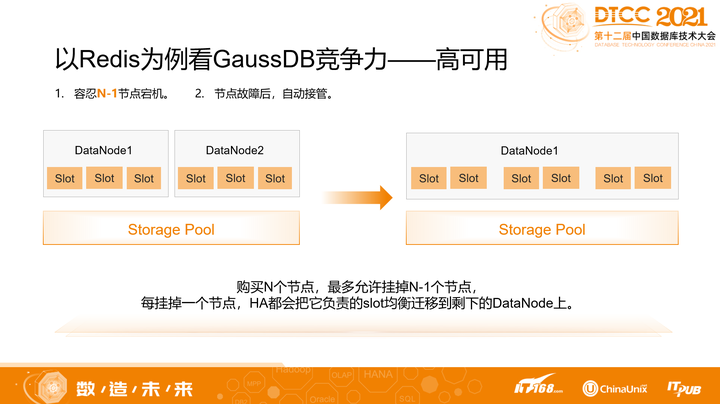
高斯Redis的数据存储是共享的,即Shared Everything,因此可以容忍最多N-1个节点故障,而不影响数据的访问。
3. 弹性伸缩
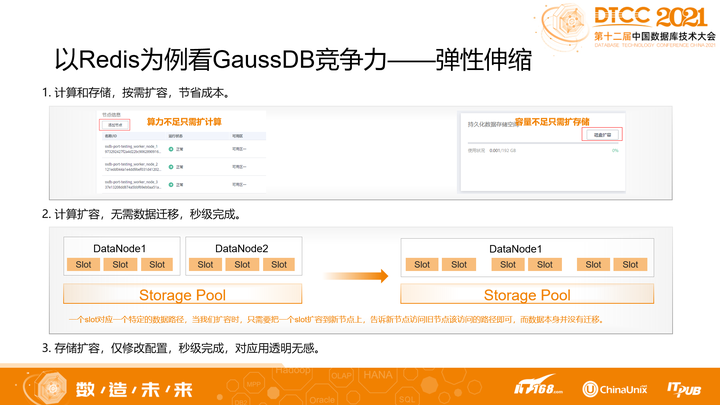
高斯Redis实现了分层弹性,将资源准确的划分成计算资源、存储资源,真正做到了按需扩容:
- 当用户的计算不足时,只需要扩展计算节点;
- 当存储空间不够时,只需要扩展存储空间即可。
同时,扩容过程也足够流畅:
- 计算扩容的过程,不需要拷贝数据,只需要修改路由映射即可,对业务侧的影响很小;
- 存储扩容更简单,只需要修改配额即可,对业务侧零影响。
所以计算、存储的扩容都足够轻量级,可极速完成且对业务干扰极小。
4. 全负荷分担
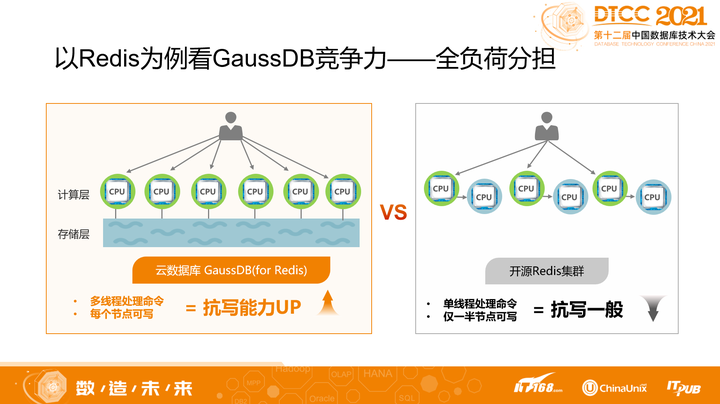
存算分离的设计,让我们把数据复制交给了存储,计算层则完全解放。
每个节点都可以承担用户的读写请求,这跟开源Redis的主上读写来比较,实现了2倍扩展。
总结
- 云原生是技术趋势
云原生是大势所趋,越来越多厂商和从业者都在提倡云原生,而华为云GaussDB NoSQL不仅仅基于云原生,还实现了多模架构,实现了多副本强一致、高可用、弹性伸缩、高性能等能力,以及具备资源复用、开发运维统一等好处。
- 华为云GaussDB NoSQL提供超融合数字化解决方案
华为云GaussDB NoSQL的多模特性,提供高并发、低时延的Redis,助力秒杀、推荐、热搜等场景;提供大容量、高频写的Cassandra,助力海量存储以及检索等场景;提供非结构化、灵活扩展的MongoDB,助力大数据分析、交易等场景;提供时序特征的InfluxDB,助力边缘计算、工业生产、实时监控等场景。
以上场景涵盖数字工业的方方面面,提供了完整的一体化解决方案,方便用户一站式使用。

本文整理自华为云数据库NoSQL架构师余汶龙的专题分享——云原生多模数据库GaussDB NoSQL架构设计,总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
点击关注,第一时间了解华为云新鲜技术~

N1QL为NoSQL数据库带来SQL般的查询体验
我们先来看看数据模型。九十年代开始随着图形界面应用和 Web 应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于 We
关系型数据库已经流行了超过 40 年,在这个过程中 sql 也成为了操作关系型数据库的标准。sql 将数据的存储方式进行了包装和抽象,使开发人员可以专注于程序逻辑。对开发人员工作的简化也是 sql 甚至关系型数据库流行的原因。
社会在发展,,数据在变化。从社交网络、科学研究、物联网等数据源产生的数据已经不局限于某个固定的结构,因此对于这些数据擅长结构化数据的关系型数据库就难以处理了。
关系型数据库最好有固定的 schema,这也使得满足现代商业要求的敏捷性和快速迭代变得困难。动态 schema 不仅仅要求我们重新思考数据模型和数据库,我们还需要一门新的查询语言来读取这些数据。
数据模型
我们先来看看数据模型。九十年代开始随着图形界面应用和 Web 应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于 Web 应用来说 JSON 是表示数据对象的标准,服务器和应用之间交换的就是一个个 JSON 文件。两千年左右 NoSQL 数据库开始流行起来,NoSQL 数据库的目的就是方便存储和管理 JSON 文件。
JSON 数据库很受开发人员的喜爱,因为它表示数据的方式和其他面向对象的程序设计语言如 Java、C++、.NET、Python 和 Ruby 等是一样的而且可以有灵活的 schema。然而文件数据库的开发人员一直以来都欠缺好用的查询语言。
文件数据库查询语言的欠缺使开发人员陷入了两难的境地:要么享受 JSON 灵活的数据模型要么享受关系型数据库的 SQL 但两者不可兼得。
查询语言
N1QL(发音是“妮叩”)是一门将 SQL 引入文件数据库的查询语言。讲得技术一点,JSON 是不符合第一范式的数据模型,而 N1QL 则对这一数据模型进行操作。N1QL 将传统 SQL 对表和行的操作拓展至 JSON (嵌套文件)。
将 SQL 引入 JSON 有点像汽车油改电,虽然引擎换了但驾驶员的操作方式保持不变。现在开发人员既可以使用熟悉的 SQL 来操作又可以动态扩展应用的 schema。
下图中是 SQL 和 N1QL 中 join 的写法的一个简单例子。想要深入学习 N1QL 的话请移步到 Couchbase 的 。

扩展 SQL 而不是完全重新创造一门语言的好处是 SQL 中经典的关键字操作符排序集合等功能都可以进行复用。这极大地降低了开发人员使用 N1QL 的门槛。
不过关系型数据库和文件数据库的模型总归是不同的,所以 N1QL 也有一些新的东西。比如 N1QL 引入了 NEST 和 UNNEST 关键字来集合或分解嵌套的对象、IS NULL 和 IS MISSING 来处理动态 schema 以及 ARRAY 函数来对数组元素进行遍历或过滤。
新型数据模型的灵活性与开发人员熟悉的查询语言的强大功能相结合为下一代更灵活更强大的应用开发打下了良好的基础。开发者们借着妮叩尽情享受文件数据库吧!
英文原文:N1QL brings SQL to NoSQL databases
译者/刘旭坤审校/朱正贵责编/仲浩
来自: CSDN
本文永久更新链接地址:

NoSQL架构实践
NoSQL架构实践
目录(?)[+]
经常有朋友遇到困惑,看到Nosql的介绍,觉得很好,但是却不知道如何正式用到自己的项目中。很大的原因就是思维固定在MysqL中了,他们问得最多的问题就是用了Nosql,我如何做关系查询。那么接下来,我们看下怎么样在我们的系统中使用Nosql。
怎么样把Nosql引入到我们的系统架构设计中,需要根据我们系统的业务场景来分析,什么样类型的数据适合存储在Nosql数据库中,什么样类型的数据必须使用关系数据库存储。明确引入的Nosql数据库带给系统的作用,它能解决什么问题,以及可能带来的新的问题。下面我们分析几种常见的Nosql架构。
(一)Nosql作为镜像
不改变原有的以MysqL作为存储的架构,使用Nosql作为辅助镜像存储,用Nosql的优势辅助提升性能。
图 1 -Nosql为镜像(代码完成模式 )
//写入数据的示例伪代码 //data为我们要存储的数据对象 data.title=”title”; data.name=”name”; data.time=”2009-12-01 10:10:01”; data.from=”1”; id=DB.Insert(data);//写入MysqL数据库 Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
如果有数据一致性要求,可以像如下的方式使用
//写入数据的示例伪代码
//data为我们要存储的数据对象
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(data);//写入MysqL数据库
if(id>0){
status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
}
if(id>0 && status==true){
DB.commit();//提交事务
}else{
DB.rollback();//不成功,进行回滚
}
上面的代码看起来可能觉得有点麻烦,但是只需要在DB类或者ORM层做一个统一的封装,就能实现重用了,其他代码都不用做任何的修改。
这种架构在原有基于MysqL数据库的架构上增加了一层辅助的Nosql存储,代码量不大,技术难度小,却在可扩展性和性能上起到了非常大的作用。只需要程序在写入MysqL数据库后,同时写入到Nosql数据库,让MysqL和Nosql拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的Nosql数据库查询,这样就节省了MysqL的查询,用Nosql的高性能来抵挡这些查询。
图 2 -Nosql为镜像(同步模式)
这种不通过程序代码,而是通过MysqL把数据同步到Nosql中,这种模式是上面一种的变体,是一种对写入透明但是具有更高技术难度一种模式。这种模式适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
MysqL到Nosql同步的实现可以使用MysqL UDF函数,MysqL binlog的解析来实现。可以利用现有的开源项目来实现,比如:
- MySQL memcached UDFs:从通过UDF操作Memcached协议。
- 国内张宴开源的mysql-udf-http:通过UDF操作http协议。
有了这两个MysqL UDF函数库,我们就能通过MysqL透明的处理Memcached或者Http协议,这样只要有兼容Memcached或者Http协议的Nosql数据库,那么我们就能通过MysqL去操作以进行同步数据。再结合lib_mysqludf_json,通过UDF和MysqL触发器功能的结合,就可以实现数据的自动同步。
(二)MysqL和Nosql组合
MysqL中只存储需要查询的小字段,Nosql存储所有数据。
图 3 -MysqL和Nosql组合
//写入数据的示例伪代码
//data为我们要存储的数据对象
data.title=”title”;
data.name=”name”;
data.time=”2009-12-01 10:10:01”;
data.from=”1”;
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(“INSERT INTO table (from) VALUES(data.from)”);//写入MysqL数据库,只写from需要where查询的字段
if(id>0){
status=Nosql.Add(id,0); clear:both; width:610px"> 把需要查询的字段,一般都是数字,时间等类型的小字段存储于MysqL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在Nosql中。在查询的时候,我们先从MysqL中查询出数据的主键,然后从Nosql中直接取出对应的数据即可。
这种架构模式把MysqL和Nosql的作用进行了融合,各司其职,让MysqL专门负责处理擅长的关系存储,Nosql作为数据的存储。它有以下优点:
- 节省MysqL的IO开销。由于MysqL只存储需要查询的小字段,不再负责存储大文本字段,这样就可以节省MysqL存储的空间开销,从而节省MysqL的磁盘IO。我们曾经通过这种优化,把MysqL一个40G的表缩减到几百M。
- 提高MysqL Query Cache缓存命中率。我们知道query cache缓存失效是表级的,在MysqL表一旦被更新就会失效,经过这种字段的分离,更新的字段如果不是存储在MysqL中,那么对query cache就没有任何影响。而Nosql的Cache往往都是行级别的,只对更新的记录的缓存失效。
- 提升MysqL主从同步效率。由于MysqL存储空间的减小,同步的数据记录也减小了,而部分数据的更新落在Nosql而不是MysqL,这样也减少了MysqL数据需要同步的次数。
- 提高MysqL数据备份和恢复的速度。由于MysqL数据库存储的数据的减小,很容易看到数据备份和恢复的速度也将极大的提高。
- 比以前更容易扩展。Nosql天生就容易扩展。经过这种优化,MysqL性能也得到提高。
比如手机凤凰网就是这种架构http://www.cnblogs.com/sunli/archive/2010/12/20/imcp.html
(三)纯Nosql架构
只使用Nosql作为数据存储。
图 4-纯Nosql架构
在一些数据结构、查询关系非常简单的系统中,我们可以只使用Nosql即可以解决存储问题。这样不但可以提高性能,还非常易于扩展。手机凤凰网的前端展示系统就使用了这种方案。
在一些数据库结构经常变化,数据结构不定的系统中,就非常适合使用Nosql来存储。比如监控系统中的监控信息的存储,可能每种类型的监控信息都不太一样。这样可以避免经常对MysqL进行表结构调整,增加字段带来的性能问题。
这种架构的缺点就是数据直接存储在Nosql中,不能做关系数据库的复杂查询,如果由于需求变更,需要进行某些查询,可能无法满足,所以采用这种架构的时候需要确认未来是否会进行复杂关系查询以及如何应对。
非常幸运的是,有些Nosql数据库已经具有部分关系数据库的关系查询特性,他们的功能介于key-value和关系数据库之间,却具有key-value数据库的性能,基本能满足绝大部分web 2.0网站的查询需求。比如:
MongoDB就带有关系查询的功能,能解决常用的关系查询,所以也是一种非常不错的选择。下面是一些MongoDB的资料:
- 《视觉中国的NoSQL之路:从MySQL到MongoDB》
- 《Choosing a non-relational database; why we migrated from MySQL to MongoDB》
- 最近的一次Mongo Beijing 开发者聚会也有一部分资料。
虽然Foursquare使用MongoDB的宕机事件的出现使人对MongoDB的自动Shard提出了质疑,但是毫无疑问,MongoDB在Nosql中,是一个优秀的数据库,其单机性能和功能确实是非常吸引人的。由于上面的例子有详细的介绍,本文就不做MongoDB的使用介绍。
Tokyo Tyrant数据库带有一个名为table的存储类型,可以对存储的数据进行关系查询和检索。一个table库类似于MysqL中的一个表。下面我们看一个小演示:
我们要存储一批用户信息,用户信息包含用户名(name),年龄(age),email,最后访问时间(lastvisit),地区(area)。下面为写入的演示代码:
<? PHP
$tt = new TokyoTyrantTable ( " 127.0.0.1 , 1978 );
-> vanish (); // 清空
$id genUid (); 获取一个自增id
//put方法提供数据写入。 put ( string $key,array $columns ); put ( array ( id => name zhangsan age 27 email zhangsan@gmail.com lastvisit strtotime ( 2011-3-5 12:30:00 ) area 北京 ) );
genUid ();
lisi 25 lisi@126.com ( 2011-3-3 14:40:44 laowang 37 laowang@yahoo.com 2011-3-5 08:30:12 成都 tom 21 tom@hotmail.com 2010-12-10 13:12:13 天津 jack jack@gmail.com 2011-02-24 20:12:55 ) );
循环打印数据库的所有数据库 $it getIterator ();
foreach ( as $k $v ) {
print_r );
}
?>
比如我们需要查询年龄为21岁的所有用户:
查询年龄为21岁的用户 addCond ( “age” TokyoTyrant :: RDBQC_NUMEQ “ ” );
search () );
查询所有在2011年3月5日之后登陆的用户:
addCond ( “lastvisit” RDBQC_NUMGE 2011-3-5 00:00:00 从上面的示例代码可以看出,使用起来是非常简单的,甚至比sql语句还要简单。Tokyo Tyrant的表类型存储还提供了给字段建立普通索引和倒排全文索引,大大增强了其检索功能和检索的性能。
所以,完全用Nosql来构建部分系统,是完全可能的。配合部分带有关系查询功能的Nosql,在开发上比MysqL数据库更加快速和高效。
(四)以Nosql为数据源的架构
数据直接写入Nosql,再通过Nosql同步协议复制到其他存储。根据应用的逻辑来决定去相应的存储获取数据。
图 5 -以Nosql为数据源
纯Nosql的架构虽然结构简单,易于开发,但是在应付需求的变更、稳定性和可靠性上,总是给开发人员一种风险难于控制的感觉。为了降低风险,系统的功能不局限在Nosql的简单功能上,我们可以使用以Nosql为数据源的架构。
在这种架构中,应用程序只负责把数据直接写入到Nosql数据库就OK,然后通过Nosql的复制协议,把Nosql数据的每次写入,更新,删除操作都复制到MysqL数据库中。同 时,也可以通过复制协议把数据同步复制到全文检索实现强大的检索功能。在海量数据下面,我们也可以根据不同的规则,把数据同步复制到设计好的分表分库的 MysqL中。这种架构:
- 非常灵活。可以非常方便的在线上系统运行过程中进行数据的调整,比如调整分库分表的规则、要添加一种新的存储类型等等。
- 操作简单。只需要写入Nosql数据库源,应用程序就不用管了。需要增加存储类型或者调整存储规则的时候,只需要增加同步的数据存储,调整同步规则即可,无需更改应用程序的代码。
- 性能高。数据的写入和更新直接操作Nosql,实现了写的高性能。而通过同步协议,把数据复制到各种适合查询类型的存储中(按照业务逻辑区分不同的存储),能实现查询的高性能,不像以前MysqL一种数据库就全包了。或者就一个表负责跟这个表相关的所有的查询,现在可以把一个表的数据复制到各种存储,让各种存储用自己的长处来对外服务。
- 易扩展。开发人员只需要关心写入Nosql数据库。数据的扩展可以方便的在后端由复制协议根据规则来完成。
这种架构需要考虑数据复制的延迟问题,这跟使用MysqL的master-salve模式的延迟问题是一样的,解决方法也一样。
在这种以Nosql为数据源的架构中,最核心的就是Nosql数据库的复制功能的实现。而当前的几乎所有的Nosql都没有提供比较易于使用的复制接口来完成这种架构,对Nosql进行复制协议的二次开发,需要更高的技术水平,所以这种架构看起来很好,但是却不是非常容易实现的。我的开源项目PHPBuffer中有个实现TokyoTyrant复制的例子,虽然是PHP版本的,但是很容易就可以翻译成其他语言。通过这个例子的代码,可以实现从Tokyo Tyrant实时的复制数据到其他系统中。
总结
以Nosql为主的架构应该算是对Nosql的一种深度应用,整个系统的架构以及代码都不是很复杂,但是却需要一定的Nosql使用经验才行
总结
以上是小编为你收集整理的NoSQL架构实践全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。

NoSQL架构实践-以NoSQL为辅
经常有朋友遇到困惑,看到Nosql的介绍,觉得很好,但是却不知道如何正式用到自己的项目中。很大的原因就是思维固定在MysqL中了,他们问得最多的问题就是用了Nosql,我如何做关系查询。那么接下来,我们看下怎么样在我们的系统中使用Nosql。
怎么样把Nosql引入到我们的系统架构设计中,需要根据我们系统的业务场景来分析,什么样类型的数据适合存储在Nosql数据库中,什么样类型的数据必须使用关系数据库存储。明确引入的Nosql数据库带给系统的作用,它能解决什么问题,以及可能带来的新的问题。下面我们分析几种常见的Nosql架构。
(一)Nosql作为镜像
不改变原有的以MysqL作为存储的架构,使用Nosql作为辅助镜像存储,用Nosql的优势辅助提升性能。
图 1 -Nosql为镜像(代码完成模式 )
//写入数据的示例伪代码 //data为我们要存储的数据对象 data.title=”title”; data.name=”name”; data.time=”2009-12-01 10:10:01”; data.from=”1”; id=DB.Insert(data);//写入MysqL数据库 Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
如果有数据一致性要求,可以像如下的方式使用
//写入数据的示例伪代码
//data为我们要存储的数据对象
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(data);//写入MysqL数据库
if(id>0){
status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
}
if(id>0 && status==true){
DB.commit();//提交事务
}else{
DB.rollback();//不成功,进行回滚
}
上面的代码看起来可能觉得有点麻烦,但是只需要在DB类或者ORM层做一个统一的封装,就能实现重用了,其他代码都不用做任何的修改。
这种架构在原有基于MysqL数据库的架构上增加了一层辅助的Nosql存储,代码量不大,技术难度小,却在可扩展性和性能上起到了非常大的作用。只需要程序在写入MysqL数据库后,同时写入到Nosql数据库,让MysqL和Nosql拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的Nosql数据库查询,这样就节省了MysqL的查询,用Nosql的高性能来抵挡这些查询。
图 2 -Nosql为镜像(同步模式)
这种不通过程序代码,而是通过MysqL把数据同步到Nosql中,这种模式是上面一种的变体,是一种对写入透明但是具有更高技术难度一种模式。这种模式适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
MysqL到Nosql同步的实现可以使用MysqL UDF函数,MysqL binlog的解析来实现。可以利用现有的开源项目来实现,比如:
- MySQL memcached UDFs:从通过UDF操作Memcached协议。
- 国内张宴开源的mysql-udf-http:通过UDF操作http协议。
有了这两个MysqL UDF函数库,我们就能通过MysqL透明的处理Memcached或者Http协议,这样只要有兼容Memcached或者Http协议的Nosql数据库,那么我们就能通过MysqL去操作以进行同步数据。再结合lib_mysqludf_json,通过UDF和MysqL触发器功能的结合,就可以实现数据的自动同步。
(二)MysqL和Nosql组合
MysqL中只存储需要查询的小字段,Nosql存储所有数据。
图 3 -MysqL和Nosql组合
//写入数据的示例伪代码
//data为我们要存储的数据对象
data.title=”title”;
data.name=”name”;
data.time=”2009-12-01 10:10:01”;
data.from=”1”;
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(“INSERT INTO table (from) VALUES(data.from)”);//写入MysqL数据库,只写from需要where查询的字段
if(id>0){
status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
}
if(id>0 && status==true){
DB.commit();//提交事务
}else{
DB.rollback();//不成功,进行回滚
把需要查询的字段,一般都是数字,时间等类型的小字段存储于MysqL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在Nosql中。在查询的时候,我们先从MysqL中查询出数据的主键,然后从Nosql中直接取出对应的数据即可。
这种架构模式把MysqL和Nosql的作用进行了融合,各司其职,让MysqL专门负责处理擅长的关系存储,Nosql作为数据的存储。它有以下优点:
节省MysqL的IO开销。由于MysqL只存储需要查询的小字段,不再负责存储大文本字段,这样就可以节省MysqL存储的空间开销,从而节省MysqL的磁盘IO。我们曾经通过这种优化,把MysqL一个40G的表缩减到几百M。
提高MysqL Query Cache缓存命中率。我们知道query cache缓存失效是表级的,在MysqL表一旦被更新就会失效,经过这种字段的分离,更新的字段如果不是存储在MysqL中,那么对query cache就没有任何影响。而Nosql的Cache往往都是行级别的,只对更新的记录的缓存失效。
提升MysqL主从同步效率。由于MysqL存储空间的减小,同步的数据记录也减小了,而部分数据的更新落在Nosql而不是MysqL,这样也减少了MysqL数据需要同步的次数。
提高MysqL数据备份和恢复的速度。由于MysqL数据库存储的数据的减小,很容易看到数据备份和恢复的速度也将极大的提高。
比以前更容易扩展。Nosql天生就容易扩展。经过这种优化,MysqL性能也得到提高。
总结
以Nosql为辅的架构还是以MysqL架构的思想为中心,只是在以前的架构上辅助增加了Nosql来提高其性能和可扩展性。这种架构实现起来比较容易,却能取得不错的效果。如果正想在项目中引入Nosql,或者你的以MysqL架构的系统目前正出现相关的瓶颈,希望本文可以为你带来帮助。
关于NoSQL架构实践和三 以NoSQL为缓存的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于GaussDB NoSQL架构设计分享、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践、NoSQL架构实践-以NoSQL为辅等相关内容,可以在本站寻找。
本文将带您了解关于NoSQL架构实践的新内容,同时我们还将为您解释二以NoSQL为主的相关知识,另外,我们还将为您提供关于GaussDB NoSQL架构设计分享、MySQL架构课程学习笔记(二)、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践的实用信息。
本文目录一览:以NoSQL为主(nosql介绍)")
NoSQL架构实践(二)以NoSQL为主(nosql介绍)
前面一篇《NoSQL架构实践(一)以NoSQL为辅》主要介绍了以Nosql为辅助的架构,这种架构实施起来比较简单,易于理解,由于其中也使用了传统的关系数据库,让开发者更容易控制Nosql带来的风险。接下来我们继续深入下去,换另外一个角度,“以Nosql为主”来架构系统。
(三)纯Nosql架构
只使用Nosql作为数据存储。
图 4-纯Nosql架构
在一些数据结构、查询关系非常简单的系统中,我们可以只使用Nosql即可以解决存储问题。这样不但可以提高性能,还非常易于扩展。手机凤凰网的前端展示系统就使用了这种方案。
在一些数据库结构经常变化,数据结构不定的系统中,就非常适合使用Nosql来存储。比如监控系统中的监控信息的存储,可能每种类型的监控信息都不太一样。这样可以避免经常对MysqL进行表结构调整,增加字段带来的性能问题。
这种架构的缺点就是数据直接存储在Nosql中,不能做关系数据库的复杂查询,如果由于需求变更,需要进行某些查询,可能无法满足,所以采用这种架构的时候需要确认未来是否会进行复杂关系查询以及如何应对。
非常幸运的是,有些Nosql数据库已经具有部分关系数据库的关系查询特性,他们的功能介于key-value和关系数据库之间,却具有key-value数据库的性能,基本能满足绝大部分web 2.0网站的查询需求。比如:
MongoDB就带有关系查询的功能,能解决常用的关系查询,所以也是一种非常不错的选择。下面是一些MongoDB的资料:
◆《视觉中国的Nosql之路:从MysqL到MongoDB》
◆《Choosing a non-relational database; why we migrated from MysqL to MongoDB》
◆最近的一次Mongo Beijing 开发者聚会也有一部分资料。
虽然Foursquare使用MongoDB的宕机事件的出现使人对MongoDB的自动Shard提出了质疑,但是毫无疑问,MongoDB在Nosql中,是一个优秀的数据库,其单机性能和功能确实是非常吸引人的。由于上面的例子有详细的介绍,本文就不做MongoDB的使用介绍。
Tokyo Tyrant数据库带有一个名为table的存储类型,可以对存储的数据进行关系查询和检索。一个table库类似于MysqL中的一个表。下面我们看一个小演示:
我们要存储一批用户信息,用户信息包含用户名(name),年龄(age),email,最后访问时间(lastvisit),地区(area)。下面为写入的演示代码:
$tt=newTokyoTyrantTable("127.0.0.1",1978);$tt->vanish();//清空$id=$tt->genUid();//获取一个自增id//put方法提供数据写入。put(string$key,array$columns);$tt->put($id,array("id"=>$id,"name"=>"zhangsan","age"=>27,"email"=>"zhangsan@gmail.com","lastvisit"=>strtotime("2011-3-512:30:00"),"area"=>"北京"));$id=$tt->genUid();$tt->put($id,"name"=>"lisi","age"=>25,"email"=>"lisi@126.com","lastvisit"=>strtotime("2011-3-314:40:44"),"name"=>"laowang","age"=>37,"email"=>"laowang@yahoo.com","lastvisit"=>strtotime("2011-3-508:30:12"),"area"=>"成都"));$id=$tt->genUid();$tt->put($id,"name"=>"tom","age"=>21,"email"=>"tom@hotmail.com","lastvisit"=>strtotime("2010-12-1013:12:13"),"area"=>"天津"));$id=$tt->genUid();$tt->put($id,"name"=>"jack","email"=>"jack@gmail.com","lastvisit"=>strtotime("2011-02-2420:12:55"),"area"=>"天津"));//循环打印数据库的所有数据库$it=$tt->getIterator();foreach($itas$k=>$v){print_r($v);}?>比如我们需要查询年龄为21岁的所有用户:$tt=newTokyoTyrantTable("127.0.0.1",1978);$query=$tt->getQuery();//查询年龄为21岁的用户$query->addCond(“age”,TokyoTyrant::RDBQC_NUMEQ,“21”);print_r($query->search());?>查询所有在2011年3月5日之后登陆的用户:$tt=newTokyoTyrantTable("127.0.0.1",1978);$query=$tt->getQuery();$query->addCond(“lastvisit”,TokyoTyrant::RDBQC_NUMGE,strtotime("2011-3-500:00:00"));print_r($query->search());?>
从上面的示例代码可以看出,使用起来是非常简单的,甚至比sql语句还要简单。Tokyo Tyrant的表类型存储还提供了给字段建立普通索引和倒排全文索引,大大增强了其检索功能和检索的性能。
所以,完全用Nosql来构建部分系统,是完全可能的。配合部分带有关系查询功能的Nosql,在开发上比MysqL数据库更加快速和高效。
(四)以Nosql为数据源的架构
数据直接写入Nosql,再通过Nosql同步协议复制到其他存储。根据应用的逻辑来决定去相应的存储获取数据。
图 5 -以Nosql为数据源
纯Nosql的架构虽然结构简单,易于开发,但是在应付需求的变更、稳定性和可靠性上,总是给开发人员一种风险难于控制的感觉。为了降低风险,系统的功能不局限在Nosql的简单功能上,我们可以使用以Nosql为数据源的架构。
在这种架构中,应用程序只负责把数据直接写入到Nosql数据库就OK,然后通过Nosql的复制协议,把Nosql数据的每次写入,更新,删除操作都复制到MysqL数据库中。同 时,也可以通过复制协议把数据同步复制到全文检索实现强大的检索功能。在海量数据下面,我们也可以根据不同的规则,把数据同步复制到设计好的分表分库的 MysqL中。这种架构:
◆非常灵活。可以非常方便的在线上系统运行过程中进行数据的调整,比如调整分库分表的规则、要添加一种新的存储类型等等。
◆操作简单。只需要写入Nosql数据库源,应用程序就不用管了。需要增加存储类型或者调整存储规则的时候,只需要增加同步的数据存储,调整同步规则即可,无需更改应用程序的代码。
◆性能高。数据的写入和更新直接操作Nosql,实现了写的高性能。而通过同步协议,把数据复制到各种适合查询类型的存储中(按照业务逻辑区分不同的存储),能实现查询的高性能,不像以前MysqL一种数据库就全包了。或者就一个表负责跟这个表相关的所有的查询,现在可以把一个表的数据复制到各种存储,让各种存储用自己的长处来对外服务。
◆易扩展。开发人员只需要关心写入Nosql数据库。数据的扩展可以方便的在后端由复制协议根据规则来完成。
这种架构需要考虑数据复制的延迟问题,这跟使用MysqL的master-salve模式的延迟问题是一样的,解决方法也一样。
在这种以Nosql为数据源的架构中,最核心的就是Nosql数据库的复制功能的实现。而当前的几乎所有的Nosql都没有提供比较易于使用的复制接口来完成这种架构,对Nosql进行复制协议的二次开发,需要更高的技术水平,所以这种架构看起来很好,但是却不是非常容易实现的。我的开源项目PHPBuffer中有个实现TokyoTyrant复制的例子,虽然是PHP版本的,但是很容易就可以翻译成其他语言。通过这个例子的代码,可以实现从Tokyo Tyrant实时的复制数据到其他系统中。
总结
以Nosql为主的架构应该算是对Nosql的一种深度应用,整个系统的架构以及代码都不是很复杂,但是却需要一定的Nosql使用经验才行。
【编辑推荐】
NoSQL理论研究:内存是新的硬盘,硬盘是新的磁带
关于NoSQL数据库你应该知道的10件事
NoSQL就业形势分析:Cassandra和MongoDB最受欢迎
用NoSQL来替代MySQL在Digg中的原因
NoSQL架构实践(一)以NoSQL为辅

GaussDB NoSQL架构设计分享
摘要:文章总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
本文分享自华为云社区《华为云GaussDB NoSQL云原生多模数据库的超融合实践》,作者:华为云数据库GaussDB(for Redis)团队。
数据库发展趋势
1. 行业市场
中国信通院最新研究透露出两个重要信息:
- 未来几年,中国数据库市场将保持23.4%的年复合增长率,中国数据库市场在全球的份额,将从2020年的5.2%提升到12.3%;
- 中国的国产数据库产品虽然以关系型为主,非关系型为辅,但从2000年以后,以图、时序等为代表的非关系型产品发展势头越来越好,截止2020年底,国产NoSQL数据库厂商已经占到了40%。
2. 行业趋势
受大环境的影响,国内金融、电信、政企等行业为防止潜在的供应链风险,技术层面存在国产化需求,这使得我们的国产数据库产业进入蓬勃发展的初期。
但我国数据库行业发展还面临2个核心问题:
- 如何缩小“高要求的存量数据应用”与“仍处于发展初期阶段的供给能力”之间的差距;
- 如何匹配“创新型数据应用”与“数据库技术演进”的合理映射关系。
如何回答上述两个问题,可以从中国信通院最新的趋势总结里找到答案:“多模实现一库多用,简化开发运维成本”、“云原生降低硬件依赖,更方便的享受新兴技术红利”。
因此,为了更好的兼容历史数据应用(比如原先用Redis),并支持好未来的创新应用(新增Influx),可以在多模与云原生领域提前做好相关布局。
3. 云原生数据库演进方向
数据库的发展,按传统物理机部署到云化,大概经历了三代。
- 第一代是纯物理机、裸硬盘部署,从业人员必须关心硬件的各种细节,包括机型、系统、硬盘、组网等等;
- 第二代是云化的初级阶段,从业人员把数据库部署从物理机,迁移到虚拟机VM,把物理硬盘,换成了云盘EVS。但这一代有个明显的缺点,EVS是个3副本可靠的服务,再加上数据库自身的高可用,那么存储成本就放大了3倍;并且备机其实是资源浪费的,没有提供服务;
- 第三代是云化的高级阶段,这个阶段将数据库的资源,彻底分成存储和计算两层,其中计算资源部署在更轻量级的容器之上,而存储资源部署在分布式存储池之上。很显然,这是与云原生结合更彻底的方式,充分享受了架构的弹性、便捷,而且轻松实现了多点读写的全负荷分担能力。
4. 存算分离,分而治之
云原生数据库有两个重要的特点。首先是存算分离。
存算分离是一种分层的设计思想:
- 从逻辑到功能进行明确的划分,让计算层更聚焦服务、产品、协议处理等事件;
- 存储层更聚焦数据本身的复制、安全、扩缩容等等。
5. 多模归一,一生万物
云原生数据库第二个重要的特点,是多模。
多模实际上是一种“归一”,也是一种“派生”。以大家熟悉的NoSQL为例,MongoDB是有Mongod/Mongos/Config等组件,而对应的Cassandra其实也有Coordinate Node/Data Node等组件。虽然这些组件名字不同,但背后做的事情是一样的,即:集群管理、副本管理、扩缩容管理、以及管控等功能。
其实,完全可以把这些功能抽象成统一的架构,即“多模归一”。在这套统一架构之上,我们再新增别的引擎就很容易了。可以快速复用当前的成熟架构,提供不同的协议接口即可,即“一生万物”。
6. GaussDB NoSQL概况
接下来介绍这次分享的主角——云原生多模数据库GaussDB NoSQL。
当前GaussDB NoSQL已经支持MongoDB、Cassandra、Redis、InfluxDB等4款引擎;全球客户1000+,足迹遍布金融、政府、电信、互联网等行业;总数据量超过10PB,每日新增超过10TB。
GaussDB NoSQL关键技术
1. Compaction卸载
GaussDB NoSQL采用LSM做存储引擎,正常情况下,前台的读写会受到后台的Compaction任务的影响,从而导致时延抖动。
因此,我们设计了单独的Compaction任务节点,通过共享的方式,访问用户的数据并进行Compact,再将Compact的结果应用到用户的可见版本中。这样做的话,就将用户前台的IO和后台IO分离,解决了时延抖动问题。
2. Flush卸载
根据LSM引擎的写入流程,可以知道,一个数据要写入DB中,需要经历两次IO:
- 写WAL
- flush memtable
而这两次IO写的其实是相同数据,完全可以省掉一次。因此,我们借助共享存储的能力,独立出一个后台任务节点。当用户前台节点需要flush memtable的时候,由后台任务节点读取WAL,并转化成L0层的SST,再应用版本,并通知前台删除memtable。这样就极大节省了用户前台的IO开销。
3. 分裂
GaussDB NoSQL在分片策略上,采取的是Hash + Range的结合方式,因此扩容或处理热点的时候会很灵活。
比如,当chunk数量足够多时,只需要移动chunk就可以扩容;而当某个chunk成为访问热点时,对它做分裂就可以解决局部热点问题。
4. 3AZ容灾
作为数据库产品,容灾特性是很重要的,它可以避免极端情况给用户业务带来的灾难性损失。
GaussDB NoSQL有统一的容灾设计,即存储和计算可以实现3AZ部署,同时存储层数据实现3副本强一致复制。因此在任意时间,挂掉了任意机房的存储,都不会丢数据;而挂掉计算,也会被其他AZ的计算节点接管元数据,不会让访问完全中断。
以Redis为例看GaussDB竞争力
接下来,以使用最广泛的NoSQL引擎Redis为例,具体介绍GaussDB NoSQL的优势。
1. 强一致
社区版Redis,主从复制是异步的,容易造成数据堆积,也有宕机丢数据风险。
GaussDB(for Redis)(下文简称高斯Redis)则是采用强一致同步的,当用户的数据写入高斯Redis并收到返回OK,这意味着高斯Redis已经实现了强一致的复制,数据的安全性很高。当然,这里的复制过程采用了组提交、用户态文件系统、RDMA等技术来降低同步复制的时延。
2. 高可用
高斯Redis的数据存储是共享的,即Shared Everything,因此可以容忍最多N-1个节点故障,而不影响数据的访问。
3. 弹性伸缩
高斯Redis实现了分层弹性,将资源准确的划分成计算资源、存储资源,真正做到了按需扩容:
- 当用户的计算不足时,只需要扩展计算节点;
- 当存储空间不够时,只需要扩展存储空间即可。
同时,扩容过程也足够流畅:
- 计算扩容的过程,不需要拷贝数据,只需要修改路由映射即可,对业务侧的影响很小;
- 存储扩容更简单,只需要修改配额即可,对业务侧零影响。
所以计算、存储的扩容都足够轻量级,可极速完成且对业务干扰极小。
4. 全负荷分担
存算分离的设计,让我们把数据复制交给了存储,计算层则完全解放。
每个节点都可以承担用户的读写请求,这跟开源Redis的主上读写来比较,实现了2倍扩展。
总结
- 云原生是技术趋势
云原生是大势所趋,越来越多厂商和从业者都在提倡云原生,而华为云GaussDB NoSQL不仅仅基于云原生,还实现了多模架构,实现了多副本强一致、高可用、弹性伸缩、高性能等能力,以及具备资源复用、开发运维统一等好处。
- 华为云GaussDB NoSQL提供超融合数字化解决方案
华为云GaussDB NoSQL的多模特性,提供高并发、低时延的Redis,助力秒杀、推荐、热搜等场景;提供大容量、高频写的Cassandra,助力海量存储以及检索等场景;提供非结构化、灵活扩展的MongoDB,助力大数据分析、交易等场景;提供时序特征的InfluxDB,助力边缘计算、工业生产、实时监控等场景。
以上场景涵盖数字工业的方方面面,提供了完整的一体化解决方案,方便用户一站式使用。
本文整理自华为云数据库NoSQL架构师余汶龙的专题分享——云原生多模数据库GaussDB NoSQL架构设计,总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
点击关注,第一时间了解华为云新鲜技术~
")
MySQL架构课程学习笔记(二)
执行计划分析
explain 的使用
- 使用场景:需要知道SQL语句执行的过程,以便优化加快执行效率
- explain + SQL语句,模拟优化器执行的处理过程
执行计划字段信息含义
- id:标识查询顺序,相同,从上到下,不同,id大的优先执行
- select_type:用于分别查询类型,后面详细介绍
- table:访问的表或别名
- partitions:分区表信息
- type:访问类型,效率从高到低:system > const > eq_ref > ref > fulltext > ref_or_null > index_merge > unique_subquery > index_subquery > range > index > ALL
- possible_keys:可能用到的索引,但不一定实际会用
- key:实际使用的索引,如果为null,则没有使用到索引
- key_len:索引使用的字节数,在不损失精度的情况下,越短越好
- ref:显示索引的哪一列被使用了
- rows:估算所需读取的数据行数,越少越好
- filtered
- extra:额外信息,例如是否利用到索引排序,或是文件排序等
select_type
- SIMPLE:简单查询,不包含子查询和union查询
- PRIMARY:包含子查询,外层查询则被标记为PRIMARY
- UNION:两个select 做 union,select * from a union
- DEPENDENT UNION:标识联合查询的结果会受到外部表影响
- UNION RESULT:从union表中获取结果的select
- SUBQUERY:包含子查询
- DEPENDENT SUBQUERY:子查询会受外部表查询影响
- DERIVED:from字句出现子查询
- UNCACHEABLE SUBQUERY:子查询结果不能被缓存
- UNCACHEABLE UNION:union查询结果不能被缓存
索引优化
1. 索引的基本知识
- 索引的优点及作用
减少服务器扫描的数据量、避免临时表或排序,并将随机io变为顺序io;总体上就是为了提升查询效率;常采用的数据结构为哈希表或B+树
- 索引的分类
主键索引、唯一索引、普通索引、全文索引、组合索引
- 常用技术名词
回表、覆盖索引、最左匹配、索引下推
- 索引的匹配方式
2. 哈希索引
- 基于哈希表实现,只有memory存储引擎支持
- 哈希索引结构紧凑,查找速度快
- 索引值包含hash值和行指针,所以不能避免读取行
- 也无法利用索引进行排序,不支持部分列匹配查找,不支持范围查询
- 考虑尽量避免hash冲突,否则代价较高
3. 组合索引
- 包含多列作为索引
- 设计时需要考虑其顺序,如何更好的满足排序和分组的需求
- 遵循最左匹配原则
4. 聚簇与非聚簇索引
- 聚簇:数据行和索引紧凑存储在一起,数据访问快,可很好利用到覆盖索引机制减少回表
- 聚簇:更新索引代价大,可能导致数据行移动或数据页分裂问题
- 非聚簇:数据文件和索引文件分开存放
5. 覆盖索引
- 一个索引包含所需要的查询的字段值,则为覆盖索引
- 覆盖索引的前提是索引必须存储的是索引列的值
- 视存储引擎不同支持的情况也不同,如memory不支持覆盖索引
- 因为innodb是聚簇索引,所以索引覆盖对innodb表非常有用
6. 优化要点梳理
- 尽可能将计算逻辑放到业务层而非数据库层
- 尽量使用主键查询,因为主键查询不会触发回表
- 尽量使用前缀索引机制和利用索引进行排序
- union all in or 等都可以用到索引,推荐in
- 范围查询也可以用到索引,但范围后的列无法用到索引,但可以利用索引下推机制
- 避免强制类型转换,因为类型转换不会用到索引
- 更新频繁的字段不建议建索引
- 创建索引的列尽量不要允许为null
- 表连接尽量不要超过3张,且连接字段最好类型一致
- 能用limit尽量用,单表一般索引数量尽量控制在5个以内
- 单索引字段数量也建议控制爱爱5个以内
7. 索引监控
- show status like ''Handler_read%''; 可以查看所有使用情况
- 比较有用的参数:重要的 2个 read key、rnd_next 越大越好
查询优化总结
1. 慢查询的原因
- 涉及到服务器的网络、CPU、IO、上下文切换、系统调用、锁等待等
2. 数据访问优化
- 尽量减少访问数据量
- 排查是否取出了大量不需要记录
3. 执行过程优化
- 利用查询缓存
- 语法解析器会对SQL进行预处理
- 查询优化器会对SQL进行详细分析和优化
4. 特定查询类型的优化
- count查询,使用近似值代替,或增加汇总表、或加缓存
- 关联查询,最好关联字段应用到索引列
- 子查询:尽可能使用关联查询代替
- limit分页:尽量利用覆盖索引机制
- union查询:尽量使用union all
分区表(非重点)
1. 应用场景
- 表数据量较大
2. 存在的局限性
- 分区数有最大限制
- 不能使用外键约束
3. 底层原理
- 由多个底层表组成
- 操作分区表时,都会先锁定所有底层表,再操作
- 如果存储引擎支持行锁,在回在分区层释放对于的表锁
4. 分区类型
- 列分区(范围、列表)
- hash分区和key分区
- 子分区
5. 使用注意事项
- 分区列和索引列不匹配,则会导致查询无法进行分区过滤
- 选择分区、打开锁住底层表等操作成本可能较高
服务器参数优化
1. 常规参数
- 数据存放目录
- sock连接文件路径
- pid文件路径
- 端口
- 默认存储引擎
2. 字符集参数
- 客户端数据字符集
- 连接字符集
- 发给客户端结果数据字符集
- 数据库默认字符串
- server默认字符集
3. 连接类参数
- 最大连接数
- 用户最大连接数
- 非交互式连接最大等待时长
- 交互式连接关闭等待时长
4. 日志相关参数
- 错误日志名称
- 二进制日志名称
- 指定具体db记录二进制日志
- 忽略某些db记录二进制日志
- 指定多少次写日志后同步磁盘
- 开启查询/慢查询
- 指定查询/慢查询日志文件
- 指定慢查询时间
5. 缓存相关类参数
- 缓冲区大小
- 查询缓存大小
- 缓存数据量限制
- 缓存块大小
- 缓存类型:支持禁用,缓存所有结果,只缓存select通过指定的缓存查询
6. Innodb存储引擎相关参数
- 指定缓冲区内存大小
- 设置日志文件刷入磁盘的时间点
- 设置innodb线程并发数
- 设置日志文件使用内存大小
- 读入缓冲区大小
- 随机读缓冲区大小
MySQL中的锁与日志
1. 锁的基本知识
- 锁:是计算机协调多个进程或线程并发访问统一资源的控制机制
2. MySQL中锁的类型
- 不同存储引擎支持锁机制不同
- MyISAM及内存存储引擎,采用的是表级锁
- innodb支持行级锁和表级锁(开销小,加锁快,并发度低)
- MyISAM支持两种模式锁:共享读锁与表独占写锁,属于读写互斥
- 可通过lock table xxx write / read 来模拟
- innodb支持共享锁和排查锁,行锁是通过给索引上锁实现,可能出现死锁
3. Redo Log
- 数据发生修改,将将记录写入redo log,并更新内存
- 避免数据库服务重启导致数据丢失
- redo log 存在两阶段提交机制,保证数据的可用性
4. Undo Log
- 事务的原子性主要是利用undo log
- mvcc多版本并发控制也是基于undo log版本链实现
- 在修改数据前,先将数据备份到一个地方,然后对行数据进行修改
- 便于异常时回滚和恢复事务开始之前状态
- undo log 是逻辑日志,delete数据时就会记录insert记录,以此类推
5. Bin log
- 是server层日志,redo是innodb存储引擎特有
- binlog是所有存储引擎都可使用
- binlog记录的是语句原始操作逻辑
- binlog是追加写,redo是循环写
- 定时备份、主从复制等都是利用binlog实现

N1QL为NoSQL数据库带来SQL般的查询体验
我们先来看看数据模型。九十年代开始随着图形界面应用和 Web 应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于 We
关系型数据库已经流行了超过 40 年,在这个过程中 sql 也成为了操作关系型数据库的标准。sql 将数据的存储方式进行了包装和抽象,使开发人员可以专注于程序逻辑。对开发人员工作的简化也是 sql 甚至关系型数据库流行的原因。
社会在发展,,数据在变化。从社交网络、科学研究、物联网等数据源产生的数据已经不局限于某个固定的结构,因此对于这些数据擅长结构化数据的关系型数据库就难以处理了。
关系型数据库最好有固定的 schema,这也使得满足现代商业要求的敏捷性和快速迭代变得困难。动态 schema 不仅仅要求我们重新思考数据模型和数据库,我们还需要一门新的查询语言来读取这些数据。
数据模型
我们先来看看数据模型。九十年代开始随着图形界面应用和 Web 应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于 Web 应用来说 JSON 是表示数据对象的标准,服务器和应用之间交换的就是一个个 JSON 文件。两千年左右 NoSQL 数据库开始流行起来,NoSQL 数据库的目的就是方便存储和管理 JSON 文件。
JSON 数据库很受开发人员的喜爱,因为它表示数据的方式和其他面向对象的程序设计语言如 Java、C++、.NET、Python 和 Ruby 等是一样的而且可以有灵活的 schema。然而文件数据库的开发人员一直以来都欠缺好用的查询语言。
文件数据库查询语言的欠缺使开发人员陷入了两难的境地:要么享受 JSON 灵活的数据模型要么享受关系型数据库的 SQL 但两者不可兼得。
查询语言
N1QL(发音是“妮叩”)是一门将 SQL 引入文件数据库的查询语言。讲得技术一点,JSON 是不符合第一范式的数据模型,而 N1QL 则对这一数据模型进行操作。N1QL 将传统 SQL 对表和行的操作拓展至 JSON (嵌套文件)。
将 SQL 引入 JSON 有点像汽车油改电,虽然引擎换了但驾驶员的操作方式保持不变。现在开发人员既可以使用熟悉的 SQL 来操作又可以动态扩展应用的 schema。
下图中是 SQL 和 N1QL 中 join 的写法的一个简单例子。想要深入学习 N1QL 的话请移步到 Couchbase 的 。
扩展 SQL 而不是完全重新创造一门语言的好处是 SQL 中经典的关键字操作符排序集合等功能都可以进行复用。这极大地降低了开发人员使用 N1QL 的门槛。
不过关系型数据库和文件数据库的模型总归是不同的,所以 N1QL 也有一些新的东西。比如 N1QL 引入了 NEST 和 UNNEST 关键字来集合或分解嵌套的对象、IS NULL 和 IS MISSING 来处理动态 schema 以及 ARRAY 函数来对数组元素进行遍历或过滤。
新型数据模型的灵活性与开发人员熟悉的查询语言的强大功能相结合为下一代更灵活更强大的应用开发打下了良好的基础。开发者们借着妮叩尽情享受文件数据库吧!
英文原文:N1QL brings SQL to NoSQL databases
译者/刘旭坤审校/朱正贵责编/仲浩
来自: CSDN
本文永久更新链接地址:

NoSQL架构实践
http://www.cnblogs.com/sunli/archive/2011/02/21/1959505.html
http://www.cnblogs.com/sunli/archive/2011/03/31/nosql-architecture-practice_3.html
1. nosql为辅
(一)Nosql作为镜像
不改变原有的以MysqL作为存储的架构,使用Nosql作为辅助镜像存储,用Nosql的优势辅助提升性能。
图 1 -Nosql为镜像(代码完成模式 )
// 写入数据的示例伪代码
data为我们要存储的数据对象
data.title = ”title”;
data.name ”name”;
data.time ” 2009 - 12 01 10 : ”;
data.from 1 ”;
id DB.Insert(data); 写入MysqL数据库 Nosql.Add(id,data); 以写入MysqL产生的自增id为主键写入Nosql数据库
如果有数据一致性要求,可以像如下的方式使用
写入数据的示例伪代码
bool status false ;
DB.startTransaction(); 开始事务 id if (id > 0 ){
status 以写入MysqL产生的自增id为主键写入Nosql数据库 }
&& status == true ){
DB.commit(); 提交事务 } else {
DB.rollback(); 不成功,进行回滚 }
我们今天的关于NoSQL架构实践和二以NoSQL为主的分享就到这里,谢谢您的阅读,如果想了解更多关于GaussDB NoSQL架构设计分享、MySQL架构课程学习笔记(二)、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践的相关信息,可以在本站进行搜索。
本文将介绍NoSQL架构实践的详细情况,特别是关于一以NoSQL为辅的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于GaussDB NoSQL架构设计分享、MySQL 高级(一)MySQL架构层次结构介绍 引擎对比MyISAM和InnoDB的对比区别、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践的知识。
本文目录一览:- NoSQL架构实践(一)以NoSQL为辅(nosql介绍)
- GaussDB NoSQL架构设计分享
- MySQL 高级(一)MySQL架构层次结构介绍 引擎对比MyISAM和InnoDB的对比区别
- N1QL为NoSQL数据库带来SQL般的查询体验
- NoSQL架构实践
以NoSQL为辅(nosql介绍)")
NoSQL架构实践(一)以NoSQL为辅(nosql介绍)
很多朋友看到Nosql时总会有困惑,觉得很好,但是却不知道如何正式用到自己的项目中。下文中笔者带我们看下怎么样在我们的系统中使用Nosql。
AD:2014WOT全球软件技术峰会北京站 课程视频发布
经常有朋友遇到困惑,看到Nosql的介绍,觉得很好,但是却不知道如何正式用到自己的项目中。很大的原因就是思维固定在MysqL中了,他们问得最多的问题就是用了Nosql,我如何做关系查询。那么接下来,我们看下怎么样在我们的系统中使用Nosql。
怎么样把Nosql引入到我们的系统架构设计中,需要根据我们系统的业务场景来分析,什么样类型的数据适合存储在Nosql数据库中,什么样类型的数据必须使用关系数据库存储。明确引入的Nosql数据库带给系统的作用,它能解决什么问题,以及可能带来的新的问题。下面我们分析几种常见的Nosql架构。
(一)Nosql作为镜像
不改变原有的以MysqL作为存储的架构,使用Nosql作为辅助镜像存储,用Nosql的优势辅助提升性能。
图 1 -Nosql为镜像(代码完成模式 )
//写入数据的示例伪代码//data为我们要存储的数据对象data.title=”title”;data.name=”name”;data.time=”2009-12-0110:10:01”;data.from=”1”;id=DB.Insert(data);//写入MysqL数据库Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
如果有数据一致性要求,可以像如下的方式使用
//写入数据的示例伪代码//data为我们要存储的数据对象boolstatus=false;DB.startTransaction();//开始事务id=DB.Insert(data);//写入MysqL数据库if(id>0){status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库}if(id>0&&status==true){DB.commit();//提交事务}else{DB.rollback();//不成功,进行回滚}
上面的代码看起来可能觉得有点麻烦,但是只需要在DB类或者ORM层做一个统一的封装,就能实现重用了,其他代码都不用做任何的修改。
这种架构在原有基于MysqL数据库的架构上增加了一层辅助的Nosql存储,代码量不大,技术难度小,却在可扩展性和性能上起到了非常大的作用。只需要程序在写入MysqL数据库后,同时写入到Nosql数据库,让MysqL和Nosql拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的Nosql数据库查询,这样就节省了MysqL的查询,用Nosql的高性能来抵挡这些查询。
图 2 -Nosql为镜像(同步模式)
这种不通过程序代码,而是通过MysqL把数据同步到Nosql中,这种模式是上面一种的变体,是一种对写入透明但是具有更高技术难度一种模式。这种模式适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
MysqL到Nosql同步的实现可以使用MysqL UDF函数,MysqL binlog的解析来实现。可以利用现有的开源项目来实现,比如:
◆MysqL memcached UDFs:从通过UDF操作Memcached协议。
◆国内张宴开源的MysqL-udf-http:通过UDF操作http协议。
有了这两个MysqL UDF函数库,我们就能通过MysqL透明的处理Memcached或者Http协议,这样只要有兼容Memcached或者Http协议的Nosql数据库,那么我们就能通过MysqL去操作以进行同步数据。再结合lib_MysqLudf_json,通过UDF和MysqL触发器功能的结合,就可以实现数据的自动同步。
(二)MysqL和Nosql组合
MysqL中只存储需要查询的小字段,Nosql存储所有数据。
图 3 -MysqL和Nosql组合
//写入数据的示例伪代码//data为我们要存储的数据对象data.title=”title”;data.name=”name”;data.time=”2009-12-0110:10:01”;data.from=”1”;boolstatus=false;DB.startTransaction();//开始事务id=DB.Insert(“INSERTINTOtable(from)VALUES(data.from)”);//写入MysqL数据库,只写from需要where查询的字段if(id>0){status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库}if(id>0&&status==true){DB.commit();//提交事务}else{DB.rollback();//不成功,进行回滚}
把需要查询的字段,一般都是数字,时间等类型的小字段存储于MysqL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在Nosql中。在查询的时候,我们先从MysqL中查询出数据的主键,然后从Nosql中直接取出对应的数据即可。
这种架构模式把MysqL和Nosql的作用进行了融合,各司其职,让MysqL专门负责处理擅长的关系存储,Nosql作为数据的存储。它有以下优点:
◆节省MysqL的IO开销。由于MysqL只存储需要查询的小字段,不再负责存储大文本字段,这样就可以节省MysqL存储的空间开销,从而节省MysqL的磁盘IO。我们曾经通过这种优化,把MysqL一个40G的表缩减到几百M。
◆提高MysqL Query Cache缓存命中率。我们知道query cache缓存失效是表级的,在MysqL表一旦被更新就会失效,经过这种字段的分离,更新的字段如果不是存储在MysqL中,那么对query cache就没有任何影响。而Nosql的Cache往往都是行级别的,只对更新的记录的缓存失效。
◆提升MysqL主从同步效率。由于MysqL存储空间的减小,同步的数据记录也减小了,而部分数据的更新落在Nosql而不是MysqL,这样也减少了MysqL数据需要同步的次数。
◆提高MysqL数据备份和恢复的速度。由于MysqL数据库存储的数据的减小,很容易看到数据备份和恢复的速度也将极大的提高。
◆比以前更容易扩展。Nosql天生就容易扩展。经过这种优化,MysqL性能也得到提高。
总结
以Nosql为辅的架构还是以MysqL架构的思想为中心,只是在以前的架构上辅助增加了Nosql来提高其性能和可扩展性。这种架构实现起来比较容易,却能取得不错的效果。如果正想在项目中引入Nosql,或者你的以MysqL架构的系统目前正出现相关的瓶颈,希望本文可以为你带来帮助。
【编辑推荐】
NoSQL理论研究:内存是新的硬盘,硬盘是新的磁带
关于NoSQL数据库你应该知道的10件事
NoSQL就业形势分析:Cassandra和MongoDB最受欢迎
用NoSQL来替代MySQL在Digg中的原因
详解NoSQL数据库使用实例

GaussDB NoSQL架构设计分享
摘要:文章总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
本文分享自华为云社区《华为云GaussDB NoSQL云原生多模数据库的超融合实践》,作者:华为云数据库GaussDB(for Redis)团队。
数据库发展趋势
1. 行业市场
中国信通院最新研究透露出两个重要信息:
- 未来几年,中国数据库市场将保持23.4%的年复合增长率,中国数据库市场在全球的份额,将从2020年的5.2%提升到12.3%;
- 中国的国产数据库产品虽然以关系型为主,非关系型为辅,但从2000年以后,以图、时序等为代表的非关系型产品发展势头越来越好,截止2020年底,国产NoSQL数据库厂商已经占到了40%。
2. 行业趋势
受大环境的影响,国内金融、电信、政企等行业为防止潜在的供应链风险,技术层面存在国产化需求,这使得我们的国产数据库产业进入蓬勃发展的初期。
但我国数据库行业发展还面临2个核心问题:
- 如何缩小“高要求的存量数据应用”与“仍处于发展初期阶段的供给能力”之间的差距;
- 如何匹配“创新型数据应用”与“数据库技术演进”的合理映射关系。
如何回答上述两个问题,可以从中国信通院最新的趋势总结里找到答案:“多模实现一库多用,简化开发运维成本”、“云原生降低硬件依赖,更方便的享受新兴技术红利”。
因此,为了更好的兼容历史数据应用(比如原先用Redis),并支持好未来的创新应用(新增Influx),可以在多模与云原生领域提前做好相关布局。
3. 云原生数据库演进方向
数据库的发展,按传统物理机部署到云化,大概经历了三代。
- 第一代是纯物理机、裸硬盘部署,从业人员必须关心硬件的各种细节,包括机型、系统、硬盘、组网等等;
- 第二代是云化的初级阶段,从业人员把数据库部署从物理机,迁移到虚拟机VM,把物理硬盘,换成了云盘EVS。但这一代有个明显的缺点,EVS是个3副本可靠的服务,再加上数据库自身的高可用,那么存储成本就放大了3倍;并且备机其实是资源浪费的,没有提供服务;
- 第三代是云化的高级阶段,这个阶段将数据库的资源,彻底分成存储和计算两层,其中计算资源部署在更轻量级的容器之上,而存储资源部署在分布式存储池之上。很显然,这是与云原生结合更彻底的方式,充分享受了架构的弹性、便捷,而且轻松实现了多点读写的全负荷分担能力。
4. 存算分离,分而治之
云原生数据库有两个重要的特点。首先是存算分离。
存算分离是一种分层的设计思想:
- 从逻辑到功能进行明确的划分,让计算层更聚焦服务、产品、协议处理等事件;
- 存储层更聚焦数据本身的复制、安全、扩缩容等等。
5. 多模归一,一生万物
云原生数据库第二个重要的特点,是多模。
多模实际上是一种“归一”,也是一种“派生”。以大家熟悉的NoSQL为例,MongoDB是有Mongod/Mongos/Config等组件,而对应的Cassandra其实也有Coordinate Node/Data Node等组件。虽然这些组件名字不同,但背后做的事情是一样的,即:集群管理、副本管理、扩缩容管理、以及管控等功能。
其实,完全可以把这些功能抽象成统一的架构,即“多模归一”。在这套统一架构之上,我们再新增别的引擎就很容易了。可以快速复用当前的成熟架构,提供不同的协议接口即可,即“一生万物”。
6. GaussDB NoSQL概况
接下来介绍这次分享的主角——云原生多模数据库GaussDB NoSQL。
当前GaussDB NoSQL已经支持MongoDB、Cassandra、Redis、InfluxDB等4款引擎;全球客户1000+,足迹遍布金融、政府、电信、互联网等行业;总数据量超过10PB,每日新增超过10TB。
GaussDB NoSQL关键技术
1. Compaction卸载
GaussDB NoSQL采用LSM做存储引擎,正常情况下,前台的读写会受到后台的Compaction任务的影响,从而导致时延抖动。
因此,我们设计了单独的Compaction任务节点,通过共享的方式,访问用户的数据并进行Compact,再将Compact的结果应用到用户的可见版本中。这样做的话,就将用户前台的IO和后台IO分离,解决了时延抖动问题。
2. Flush卸载
根据LSM引擎的写入流程,可以知道,一个数据要写入DB中,需要经历两次IO:
- 写WAL
- flush memtable
而这两次IO写的其实是相同数据,完全可以省掉一次。因此,我们借助共享存储的能力,独立出一个后台任务节点。当用户前台节点需要flush memtable的时候,由后台任务节点读取WAL,并转化成L0层的SST,再应用版本,并通知前台删除memtable。这样就极大节省了用户前台的IO开销。
3. 分裂
GaussDB NoSQL在分片策略上,采取的是Hash + Range的结合方式,因此扩容或处理热点的时候会很灵活。
比如,当chunk数量足够多时,只需要移动chunk就可以扩容;而当某个chunk成为访问热点时,对它做分裂就可以解决局部热点问题。
4. 3AZ容灾
作为数据库产品,容灾特性是很重要的,它可以避免极端情况给用户业务带来的灾难性损失。
GaussDB NoSQL有统一的容灾设计,即存储和计算可以实现3AZ部署,同时存储层数据实现3副本强一致复制。因此在任意时间,挂掉了任意机房的存储,都不会丢数据;而挂掉计算,也会被其他AZ的计算节点接管元数据,不会让访问完全中断。
以Redis为例看GaussDB竞争力
接下来,以使用最广泛的NoSQL引擎Redis为例,具体介绍GaussDB NoSQL的优势。
1. 强一致
社区版Redis,主从复制是异步的,容易造成数据堆积,也有宕机丢数据风险。
GaussDB(for Redis)(下文简称高斯Redis)则是采用强一致同步的,当用户的数据写入高斯Redis并收到返回OK,这意味着高斯Redis已经实现了强一致的复制,数据的安全性很高。当然,这里的复制过程采用了组提交、用户态文件系统、RDMA等技术来降低同步复制的时延。
2. 高可用
高斯Redis的数据存储是共享的,即Shared Everything,因此可以容忍最多N-1个节点故障,而不影响数据的访问。
3. 弹性伸缩
高斯Redis实现了分层弹性,将资源准确的划分成计算资源、存储资源,真正做到了按需扩容:
- 当用户的计算不足时,只需要扩展计算节点;
- 当存储空间不够时,只需要扩展存储空间即可。
同时,扩容过程也足够流畅:
- 计算扩容的过程,不需要拷贝数据,只需要修改路由映射即可,对业务侧的影响很小;
- 存储扩容更简单,只需要修改配额即可,对业务侧零影响。
所以计算、存储的扩容都足够轻量级,可极速完成且对业务干扰极小。
4. 全负荷分担
存算分离的设计,让我们把数据复制交给了存储,计算层则完全解放。
每个节点都可以承担用户的读写请求,这跟开源Redis的主上读写来比较,实现了2倍扩展。
总结
- 云原生是技术趋势
云原生是大势所趋,越来越多厂商和从业者都在提倡云原生,而华为云GaussDB NoSQL不仅仅基于云原生,还实现了多模架构,实现了多副本强一致、高可用、弹性伸缩、高性能等能力,以及具备资源复用、开发运维统一等好处。
- 华为云GaussDB NoSQL提供超融合数字化解决方案
华为云GaussDB NoSQL的多模特性,提供高并发、低时延的Redis,助力秒杀、推荐、热搜等场景;提供大容量、高频写的Cassandra,助力海量存储以及检索等场景;提供非结构化、灵活扩展的MongoDB,助力大数据分析、交易等场景;提供时序特征的InfluxDB,助力边缘计算、工业生产、实时监控等场景。
以上场景涵盖数字工业的方方面面,提供了完整的一体化解决方案,方便用户一站式使用。
本文整理自华为云数据库NoSQL架构师余汶龙的专题分享——云原生多模数据库GaussDB NoSQL架构设计,总结了当前数据库的发展趋势、GaussDB NoSQL关键技术解密以及核心竞争力。
点击关注,第一时间了解华为云新鲜技术~
MySQL架构层次结构介绍 引擎对比MyISAM和InnoDB的对比区别")
MySQL 高级(一)MySQL架构层次结构介绍 引擎对比MyISAM和InnoDB的对比区别
MySQL 高级(一)MySQL架构层次结构介绍
mysql采用插件式的存储引擎架构将查询处理和其他的系统任务以及数据的存储提取相分离。
1.MySQL的层次结构:
在对mysql进行优化前,需要对mysql的层次结构有一定了解,当问题出现时(等待时间长,查询时间长),可以更好的定位到问题的位置。

-
连接层
最上层的连接层提供一些客户端的连接服务,包含本地sockt通信和大多数基于客户端/服务端工具实现的类似tcp/ip的通信。只要完成一些类似于连接处理、授权认证及相关的安全方案。在该层上引入了连接池的概念,为通过认证安全接入的客户提供线程。同一在该层上可以实现基于SSL的安全链接。
-
服务层
第二层架构主要完成大多数的核心服务功能,如SQL接口,并完成缓存的查询,SQL的分析和优化以及部分内置函数的执行。又有跨存储引擎的功能也在这一层实现,如过程、函数等。在该层,服务器会解析查询并创建相应的内部解析树,并对 其完成相应的优化如确定查询表的顺序、是否利用索引等,最后生成相应的执行操作。如果是select语句,服务器还会查询内部的缓存。如果缓存空间足够大,这样在解决大量读操作的环境中能很好的提示系统的性能。
-
引擎层
存储引擎层,存储引擎真正的负责了MySQL中数据的存储和提取,服务器通过API与存储引擎进行通信。不同的存储引擎具有不同的侧重点和功能,这样我们可以根据自己的实际需要进行选取。主流引擎MyISAM和InnoDB
-
存储层
数据存储层,主要是将数据存储在运行于裸设备的文件系统之上,并完成于存储引擎的交互。
2. MyISAM和InnoDB的对比区别


N1QL为NoSQL数据库带来SQL般的查询体验
关系型数据库已经流行了超过40年,在这个过程中sql也成为了操作关系型数据库的标准。sql将数据的存储方式进行了包装和抽象,使开发人员可以专注于程序逻辑。对开发人员工作的简化也是sql甚至关系型数据库流行的原因。
社会在发展,数据在变化。从社交网络、科学研究、物联网等数据源产生的数据已经不局限于某个固定的结构,因此对于这些数据擅长结构化数据的关系型数据库就难以处理了。
关系型数据库最好有固定的schema,这也使得满足现代商业要求的敏捷性和快速迭代变得困难。动态schema不仅仅要求我们重新思考数据模型和数据库,我们还需要一门新的查询语言来读取这些数据。
数据模型
我们先来看看数据模型。九十年代开始随着图形界面应用和Web应用的流行,多数商业应用的程序都使用面向对象的开发模式。对于Web应用来说JSON是表示数据对象的标准,服务器和应用之间交换的就是一个个JSON文件。两千年左右Nosql数据库开始流行起来,Nosql数据库的目的就是方便存储和管理JSON文件。
JSON数据库很受开发人员的喜爱,因为它表示数据的方式和其他面向对象的程序设计语言如Java、C++、.NET、Python和Ruby等是一样的而且可以有灵活的schema。然而文件数据库的开发人员一直以来都欠缺好用的查询语言。
文件数据库查询语言的欠缺使开发人员陷入了两难的境地:要么享受JSON灵活的数据模型要么享受关系型数据库的sql但两者不可兼得。
查询语言
N1QL(发音是“妮叩”)是一门将sql引入文件数据库的查询语言。讲得技术一点,JSON是不符合第一范式的数据模型,而N1QL则对这一数据模型进行操作。N1QL将传统sql对表和行的操作拓展至JSON (嵌套文件)。
将sql引入JSON有点像汽车油改电,虽然引擎换了但驾驶员的操作方式保持不变。现在开发人员既可以使用熟悉的sql来操作又可以动态扩展应用的schema。
下图中是sql和N1QL中join的写法的一个简单例子。想要深入学习N1QL的话请移步到Couchbase的N1QL教程。
扩展sql而不是完全重新创造一门语言的好处是sql中经典的关键字操作符排序集合等功能都可以进行复用。这极大地降低了开发人员使用N1QL的门槛。
不过关系型数据库和文件数据库的模型总归是不同的,所以N1QL也有一些新的东西。比如N1QL引入了nesT和UNnesT关键字来集合或分解嵌套的对象、ISNULL和ISMISSING来处理动态schema以及ARRAY函数来对数组元素进行遍历或过滤。
新型数据模型的灵活性与开发人员熟悉的查询语言的强大功能相结合为下一代更灵活更强大的应用开发打下了良好的基础。开发者们借着妮叩尽情享受文件数据库吧!

NoSQL架构实践
NoSQL架构实践
目录(?)[+]
经常有朋友遇到困惑,看到Nosql的介绍,觉得很好,但是却不知道如何正式用到自己的项目中。很大的原因就是思维固定在MysqL中了,他们问得最多的问题就是用了Nosql,我如何做关系查询。那么接下来,我们看下怎么样在我们的系统中使用Nosql。
怎么样把Nosql引入到我们的系统架构设计中,需要根据我们系统的业务场景来分析,什么样类型的数据适合存储在Nosql数据库中,什么样类型的数据必须使用关系数据库存储。明确引入的Nosql数据库带给系统的作用,它能解决什么问题,以及可能带来的新的问题。下面我们分析几种常见的Nosql架构。
(一)Nosql作为镜像
不改变原有的以MysqL作为存储的架构,使用Nosql作为辅助镜像存储,用Nosql的优势辅助提升性能。
图 1 -Nosql为镜像(代码完成模式 )
//写入数据的示例伪代码 //data为我们要存储的数据对象 data.title=”title”; data.name=”name”; data.time=”2009-12-01 10:10:01”; data.from=”1”; id=DB.Insert(data);//写入MysqL数据库 Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
如果有数据一致性要求,可以像如下的方式使用
//写入数据的示例伪代码
//data为我们要存储的数据对象
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(data);//写入MysqL数据库
if(id>0){
status=Nosql.Add(id,data);//以写入MysqL产生的自增id为主键写入Nosql数据库
}
if(id>0 && status==true){
DB.commit();//提交事务
}else{
DB.rollback();//不成功,进行回滚
}
上面的代码看起来可能觉得有点麻烦,但是只需要在DB类或者ORM层做一个统一的封装,就能实现重用了,其他代码都不用做任何的修改。
这种架构在原有基于MysqL数据库的架构上增加了一层辅助的Nosql存储,代码量不大,技术难度小,却在可扩展性和性能上起到了非常大的作用。只需要程序在写入MysqL数据库后,同时写入到Nosql数据库,让MysqL和Nosql拥有相同的镜像数据,在某些可以根据主键查询的地方,使用高效的Nosql数据库查询,这样就节省了MysqL的查询,用Nosql的高性能来抵挡这些查询。
图 2 -Nosql为镜像(同步模式)
这种不通过程序代码,而是通过MysqL把数据同步到Nosql中,这种模式是上面一种的变体,是一种对写入透明但是具有更高技术难度一种模式。这种模式适用于现有的比较复杂的老系统,通过修改代码不易实现,可能引起新的问题。同时也适用于需要把数据同步到多种类型的存储中。
MysqL到Nosql同步的实现可以使用MysqL UDF函数,MysqL binlog的解析来实现。可以利用现有的开源项目来实现,比如:
- MySQL memcached UDFs:从通过UDF操作Memcached协议。
- 国内张宴开源的mysql-udf-http:通过UDF操作http协议。
有了这两个MysqL UDF函数库,我们就能通过MysqL透明的处理Memcached或者Http协议,这样只要有兼容Memcached或者Http协议的Nosql数据库,那么我们就能通过MysqL去操作以进行同步数据。再结合lib_mysqludf_json,通过UDF和MysqL触发器功能的结合,就可以实现数据的自动同步。
(二)MysqL和Nosql组合
MysqL中只存储需要查询的小字段,Nosql存储所有数据。
图 3 -MysqL和Nosql组合
//写入数据的示例伪代码
//data为我们要存储的数据对象
data.title=”title”;
data.name=”name”;
data.time=”2009-12-01 10:10:01”;
data.from=”1”;
bool status=false;
DB.startTransaction();//开始事务
id=DB.Insert(“INSERT INTO table (from) VALUES(data.from)”);//写入MysqL数据库,只写from需要where查询的字段
if(id>0){
status=Nosql.Add(id,0); clear:both; width:610px"> 把需要查询的字段,一般都是数字,时间等类型的小字段存储于MysqL中,根据查询建立相应的索引,其他不需要的字段,包括大文本字段都存储在Nosql中。在查询的时候,我们先从MysqL中查询出数据的主键,然后从Nosql中直接取出对应的数据即可。
这种架构模式把MysqL和Nosql的作用进行了融合,各司其职,让MysqL专门负责处理擅长的关系存储,Nosql作为数据的存储。它有以下优点:
- 节省MysqL的IO开销。由于MysqL只存储需要查询的小字段,不再负责存储大文本字段,这样就可以节省MysqL存储的空间开销,从而节省MysqL的磁盘IO。我们曾经通过这种优化,把MysqL一个40G的表缩减到几百M。
- 提高MysqL Query Cache缓存命中率。我们知道query cache缓存失效是表级的,在MysqL表一旦被更新就会失效,经过这种字段的分离,更新的字段如果不是存储在MysqL中,那么对query cache就没有任何影响。而Nosql的Cache往往都是行级别的,只对更新的记录的缓存失效。
- 提升MysqL主从同步效率。由于MysqL存储空间的减小,同步的数据记录也减小了,而部分数据的更新落在Nosql而不是MysqL,这样也减少了MysqL数据需要同步的次数。
- 提高MysqL数据备份和恢复的速度。由于MysqL数据库存储的数据的减小,很容易看到数据备份和恢复的速度也将极大的提高。
- 比以前更容易扩展。Nosql天生就容易扩展。经过这种优化,MysqL性能也得到提高。
比如手机凤凰网就是这种架构http://www.cnblogs.com/sunli/archive/2010/12/20/imcp.html
(三)纯Nosql架构
只使用Nosql作为数据存储。
图 4-纯Nosql架构
在一些数据结构、查询关系非常简单的系统中,我们可以只使用Nosql即可以解决存储问题。这样不但可以提高性能,还非常易于扩展。手机凤凰网的前端展示系统就使用了这种方案。
在一些数据库结构经常变化,数据结构不定的系统中,就非常适合使用Nosql来存储。比如监控系统中的监控信息的存储,可能每种类型的监控信息都不太一样。这样可以避免经常对MysqL进行表结构调整,增加字段带来的性能问题。
这种架构的缺点就是数据直接存储在Nosql中,不能做关系数据库的复杂查询,如果由于需求变更,需要进行某些查询,可能无法满足,所以采用这种架构的时候需要确认未来是否会进行复杂关系查询以及如何应对。
非常幸运的是,有些Nosql数据库已经具有部分关系数据库的关系查询特性,他们的功能介于key-value和关系数据库之间,却具有key-value数据库的性能,基本能满足绝大部分web 2.0网站的查询需求。比如:
MongoDB就带有关系查询的功能,能解决常用的关系查询,所以也是一种非常不错的选择。下面是一些MongoDB的资料:
- 《视觉中国的NoSQL之路:从MySQL到MongoDB》
- 《Choosing a non-relational database; why we migrated from MySQL to MongoDB》
- 最近的一次Mongo Beijing 开发者聚会也有一部分资料。
虽然Foursquare使用MongoDB的宕机事件的出现使人对MongoDB的自动Shard提出了质疑,但是毫无疑问,MongoDB在Nosql中,是一个优秀的数据库,其单机性能和功能确实是非常吸引人的。由于上面的例子有详细的介绍,本文就不做MongoDB的使用介绍。
Tokyo Tyrant数据库带有一个名为table的存储类型,可以对存储的数据进行关系查询和检索。一个table库类似于MysqL中的一个表。下面我们看一个小演示:
我们要存储一批用户信息,用户信息包含用户名(name),年龄(age),email,最后访问时间(lastvisit),地区(area)。下面为写入的演示代码:
<? PHP
$tt = new TokyoTyrantTable ( " 127.0.0.1 , 1978 );
-> vanish (); // 清空
$id genUid (); 获取一个自增id
//put方法提供数据写入。 put ( string $key,array $columns ); put ( array ( id => name zhangsan age 27 email zhangsan@gmail.com lastvisit strtotime ( 2011-3-5 12:30:00 ) area 北京 ) );
genUid ();
lisi 25 lisi@126.com ( 2011-3-3 14:40:44 laowang 37 laowang@yahoo.com 2011-3-5 08:30:12 成都 tom 21 tom@hotmail.com 2010-12-10 13:12:13 天津 jack jack@gmail.com 2011-02-24 20:12:55 ) );
循环打印数据库的所有数据库 $it getIterator ();
foreach ( as $k $v ) {
print_r );
}
?>
比如我们需要查询年龄为21岁的所有用户:
查询年龄为21岁的用户 addCond ( “age” TokyoTyrant :: RDBQC_NUMEQ “ ” );
search () );
查询所有在2011年3月5日之后登陆的用户:
addCond ( “lastvisit” RDBQC_NUMGE 2011-3-5 00:00:00 从上面的示例代码可以看出,使用起来是非常简单的,甚至比sql语句还要简单。Tokyo Tyrant的表类型存储还提供了给字段建立普通索引和倒排全文索引,大大增强了其检索功能和检索的性能。
所以,完全用Nosql来构建部分系统,是完全可能的。配合部分带有关系查询功能的Nosql,在开发上比MysqL数据库更加快速和高效。
(四)以Nosql为数据源的架构
数据直接写入Nosql,再通过Nosql同步协议复制到其他存储。根据应用的逻辑来决定去相应的存储获取数据。
图 5 -以Nosql为数据源
纯Nosql的架构虽然结构简单,易于开发,但是在应付需求的变更、稳定性和可靠性上,总是给开发人员一种风险难于控制的感觉。为了降低风险,系统的功能不局限在Nosql的简单功能上,我们可以使用以Nosql为数据源的架构。
在这种架构中,应用程序只负责把数据直接写入到Nosql数据库就OK,然后通过Nosql的复制协议,把Nosql数据的每次写入,更新,删除操作都复制到MysqL数据库中。同 时,也可以通过复制协议把数据同步复制到全文检索实现强大的检索功能。在海量数据下面,我们也可以根据不同的规则,把数据同步复制到设计好的分表分库的 MysqL中。这种架构:
- 非常灵活。可以非常方便的在线上系统运行过程中进行数据的调整,比如调整分库分表的规则、要添加一种新的存储类型等等。
- 操作简单。只需要写入Nosql数据库源,应用程序就不用管了。需要增加存储类型或者调整存储规则的时候,只需要增加同步的数据存储,调整同步规则即可,无需更改应用程序的代码。
- 性能高。数据的写入和更新直接操作Nosql,实现了写的高性能。而通过同步协议,把数据复制到各种适合查询类型的存储中(按照业务逻辑区分不同的存储),能实现查询的高性能,不像以前MysqL一种数据库就全包了。或者就一个表负责跟这个表相关的所有的查询,现在可以把一个表的数据复制到各种存储,让各种存储用自己的长处来对外服务。
- 易扩展。开发人员只需要关心写入Nosql数据库。数据的扩展可以方便的在后端由复制协议根据规则来完成。
这种架构需要考虑数据复制的延迟问题,这跟使用MysqL的master-salve模式的延迟问题是一样的,解决方法也一样。
在这种以Nosql为数据源的架构中,最核心的就是Nosql数据库的复制功能的实现。而当前的几乎所有的Nosql都没有提供比较易于使用的复制接口来完成这种架构,对Nosql进行复制协议的二次开发,需要更高的技术水平,所以这种架构看起来很好,但是却不是非常容易实现的。我的开源项目PHPBuffer中有个实现TokyoTyrant复制的例子,虽然是PHP版本的,但是很容易就可以翻译成其他语言。通过这个例子的代码,可以实现从Tokyo Tyrant实时的复制数据到其他系统中。
总结
以Nosql为主的架构应该算是对Nosql的一种深度应用,整个系统的架构以及代码都不是很复杂,但是却需要一定的Nosql使用经验才行
总结
以上是小编为你收集整理的NoSQL架构实践全部内容。
如果觉得小编网站内容还不错,欢迎将小编网站推荐给好友。
我们今天的关于NoSQL架构实践和一以NoSQL为辅的分享已经告一段落,感谢您的关注,如果您想了解更多关于GaussDB NoSQL架构设计分享、MySQL 高级(一)MySQL架构层次结构介绍 引擎对比MyISAM和InnoDB的对比区别、N1QL为NoSQL数据库带来SQL般的查询体验、NoSQL架构实践的相关信息,请在本站查询。
对于想了解8种Nosql数据库的读者,本文将是一篇不可错过的文章,我们将详细介绍nosql数据库有那些,并且为您提供关于8种Nosql数据库系统对比的有价值信息。
本文目录一览:")
8种Nosql数据库(nosql数据库有那些)
虽然sql数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破。这只是时间问题:被迫使用关系数据库,但最终发现不能适应需求的情况不胜枚举。
但是Nosql数据库之间的不同,远超过两 sql数据库之间的差别。这意味着软件架构师更应该在项目开始时就选择好一个适合的 Nosql数据库。针对这种情况,这里对 Cassandra、Mongodb、CouchDB、Redis、 Riak、Membase、Neo4j和HBase进行了比较:
(编注1:Nosql:是一项全新的数据库革命性运动,Nosql的拥护者们提倡运用非关系型的数据存储。现今的计算机体系结构在数据存储方面要求 具 备庞大的水平扩 展性,而Nosql致力于改变这一现状。目前Google的 BigTable 和Amazon 的Dynamo使用的就是Nosql型数据库。 参见NoSQL词条。)
1. CouchDB
- 所用语言: Erlang
- 特点:DB一致性,易于使用
- 使用许可: Apache
- 协议: HTTP/REST
- 双向数据复制,
- 持续进行或临时处理,
- 处理时带冲突检查,
- 因此,采用的是master-master复制(见编注2)
- MVCC – 写操作不阻塞读操作
- 可保存文件之前的版本
- Crash-only(可靠的)设计
- 需要不时地进行数据压缩
- 视图:嵌入式 映射/减少
- 格式化视图:列表显示
- 支持进行服务器端文档验证
- 支持认证
- 根据变化实时更新
- 支持附件处理
- 因此, CouchApps(独立的 js应用程序)
- 需要 jQuery程序库
最佳应用场景:适用于数据变化较少,执行预定义查询,进行数据统计的应用程序。适用于需要提供数据版本支持的应用程序。
例如: CRM、CMS系统。 master-master复制对于多站点部署是非常有用的。
(编注2:master-master复制:是一种数据库同步方法,允许数据在一组计算机之间共享数据,并且可以通过小组中任意成员在组内进行数据更新。)
2. Redis
- 所用语言:C/C++
- 特点:运行异常快
- 使用许可: BSD
- 协议:类 Telnet
- 有硬盘存储支持的内存数据库,
- 但自2.0版本以后可以将数据交换到硬盘(注意, 2.4以后版本不支持该特性!)
- Master-slave复制(见编注3)
- 虽然采用简单数据或以键值索引的哈希表,但也支持复杂操作,例如 ZREVRANGEBYscore。
- INCR & co (适合计算极限值或统计数据)
- 支持 sets(同时也支持 union/diff/inter)
- 支持列表(同时也支持队列;阻塞式 pop操作)
- 支持哈希表(带有多个域的对象)
- 支持排序 sets(高得分表,适用于范围查询)
- Redis支持事务
- 支持将数据设置成过期数据(类似快速缓冲区设计)
- Pub/Sub允许用户实现消息机制
最佳应用场景:适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序。
例如:股票价格、数据分析、实时数据搜集、实时通讯。
(编注3:Master-slave复制:如果同一时刻只有一台服务器处理所有的复制请求,这被称为 Master-slave复制,通常应用在需要提供高可用性的服务器集群。)
3. MongoDB
- 所用语言:C++
- 特点:保留了sql一些友好的特性(查询,索引)。
- 使用许可: AGPL(发起者: Apache)
- 协议: Custom,binary( BSON)
- Master/slave复制(支持自动错误恢复,使用 sets 复制)
- 内建分片机制
- 支持 javascript表达式查询
- 可在服务器端执行任意的 javascript函数
- update-in-place支持比CouchDB更好
- 在数据存储时采用内存到文件映射
- 对性能的关注超过对功能的要求
- 建议最好打开日志功能(参数 –journal)
- 在32位操作系统上,数据库大小限制在约2.5Gb
- 空数据库大约占 192Mb
- 采用 GridFS存储大数据或元数据(不是真正的文件系统)
最佳应用场景:适用于需要动态查询支持;需要使用索引而不是 map/reduce功能;需要对大数据库有性能要求;需要使用 CouchDB但因为数据改变太频繁而占满内存的应用程序。
例如:你本打算采用 MysqL或 Postgresql,但因为它们本身自带的预定义栏让你望而却步。
4. Riak
- 所用语言:Erlang和C,以及一些Javascript
- 特点:具备容错能力
- 使用许可: Apache
- 协议: HTTP/REST或者 custom binary
- 可调节的分发及复制(N,R,W)
- 用 JavaScript or Erlang在操作前或操作后进行验证和安全支持。
- 使用JavaScript或Erlang进行 Map/reduce
- 连接及连接遍历:可作为图形数据库使用
- 索引:输入元数据进行搜索(1.0版本即将支持)
- 大数据对象支持( Luwak)
- 提供“开源”和“企业”两个版本
- 全文本搜索,索引,通过 Riak搜索服务器查询( beta版)
- 支持Masterless多站点复制及商业许可的 SNMP监控
最佳应用场景:适用于想使用类似 Cassandra(类似Dynamo)数据库但无法处理 bloat及复杂性的情况。适用于你打算做多站点复制,但又需要对单个站点的扩展性,可用性及出错处理有要求的情况。
例如:销售数据搜集,工厂控制系统;对宕机时间有严格要求;可以作为易于更新的 web服务器使用。
5. Membase
- 所用语言: Erlang和C
- 特点:兼容 Memcache,但同时兼具持久化和支持集群
- 使用许可: Apache 2.0
- 协议:分布式缓存及扩展
- 非常快速(200k+/秒),通过键值索引数据
- 可持久化存储到硬盘
- 所有节点都是唯一的( master-master复制)
- 在内存中同样支持类似分布式缓存的缓存单元
- 写数据时通过去除重复数据来减少 IO
- 提供非常好的集群管理 web界面
- 更新软件时软无需停止数据库服务
- 支持连接池和多路复用的连接代理
最佳应用场景:适用于需要低延迟数据访问,高并发支持以及高可用性的应用程序
例如:低延迟数据访问比如以广告为目标的应用,高并发的 web 应用比如网络游戏(例如 Zynga)
6. Neo4j
- 所用语言: Java
- 特点:基于关系的图形数据库
- 使用许可: GPL,其中一些特性使用 AGPL/商业许可
- 协议: HTTP/REST(或嵌入在 Java中)
- 可独立使用或嵌入到 Java应用程序
- 图形的节点和边都可以带有元数据
- 很好的自带web管理功能
- 使用多种算法支持路径搜索
- 使用键值和关系进行索引
- 为读操作进行优化
- 支持事务(用 Java api)
- 使用 Gremlin图形遍历语言
- 支持 Groovy脚本
- 支持在线备份,高级监控及高可靠性支持使用 AGPL/商业许可
最佳应用场景:适用于图形一类数据。这是 Neo4j与其他nosql数据库的最显著区别
例如:社会关系,公共交通网络,地图及网络拓谱
7. Cassandra
- 所用语言: Java
- 特点:对大型表格和 Dynamo支持得最好
- 使用许可: Apache
- 协议: Custom,binary (节约型)
- 可调节的分发及复制(N,W)
- 支持以某个范围的键值通过列查询
- 类似大表格的功能:列,某个特性的列集合
- 写操作比读操作更快
- 基于 Apache分布式平台尽可能地 Map/reduce
- 我承认对 Cassandra有偏见,一部分是因为它本身的臃肿和复杂性,也因为 Java的问题(配置,出现异常,等等)
最佳应用场景:当使用写操作多过读操作(记录日志)如果每个系统组建都必须用 Java编写(没有人因为选用 Apache的软件被解雇)
例如:银行业,金融业(虽然对于金融交易不是必须的,但这些产业对数据库的要求会比它们更大)写比读更快,所以一个自然的特性就是实时数据分析
8. HBase
(配合 ghshephard使用)
- 所用语言: Java
- 特点:支持数十亿行X上百万列
- 使用许可: Apache
- 协议:HTTP/REST (支持 Thrift,见编注4)
- 在 BigTable之后建模
- 采用分布式架构 Map/reduce
- 对实时查询进行优化
- 高性能 Thrift网关
- 通过在server端扫描及过滤实现对查询操作预判
- 支持 XML,Protobuf,和binary的HTTP
- Cascading,hive,and pig source and sink modules
- 基于 Jruby( JIRB)的shell
- 对配置改变和较小的升级都会重新回滚
- 不会出现单点故障
- 堪比MysqL的随机访问性能
最佳应用场景:适用于偏好BigTable:)并且需要对大数据进行随机、实时访问的场合。
例如: Facebook消息数据库(更多通用的用例即将出现)
编注4:Thrift 是一种接口定义语言,为多种其他语言提供定义和创建服务,由Facebook开发并开源。
当然,所有的系统都不只具有上面列出的这些特性。这里我仅仅根据自己的观点列出一些我认为的重要特性。与此同时,技术进步是飞速的,所以上述的内容肯定需要不断更新。我会尽我所能地更新这个列表。

8种Nosql数据库系统对比
导读:Kristóf Kovács 是一位软件架构师和咨询顾问,他最近发布了一片对比各种类型nosql数据库的文章。文章由敏捷翻译 –唐尤华编译。如需转载,请参见文后声明。
虽然sql数据库是非常有用的工具,但经历了15年的一支独秀之后垄断即将被打破。这只是时间问题:被迫使用关系数据库,但最终发现不能适应需求的情况不胜枚举。
但是NoSQL数据库之间的不同,远超过两 sql数据库之间的差别。这意味着软件架构师更应该在项目开始时就选择好一个适合的 Nosql数据库。针对这种情况,这里对Cassandra、Mongodb、CouchDB、Redis、Riak、Membase、Neo4j和HBase进行了比较:
(编注1:Nosql:是一项全新的数据库革命性运动,Nosql的拥护者们提倡运用非关系型的数据存储。现今的计算机体系结构在数据存储方面要求具 备庞大的水平扩 展性,而Nosql致力于改变这一现状。目前Google的 BigTable 和Amazon 的Dynamo使用的就是Nosql型数据库。 参见NoSQL词条。)
1. CouchDB
- 所用语言: Erlang
- 特点:DB一致性,易于使用
- 使用许可: Apache
- 协议: HTTP/REST
- 双向数据复制,
- 持续进行或临时处理,
- 处理时带冲突检查,
- 因此,采用的是master-master复制(见编注2)
- MVCC – 写操作不阻塞读操作
- 可保存文件之前的版本
- Crash-only(可靠的)设计
- 需要不时地进行数据压缩
- 视图:嵌入式 映射/减少
- 格式化视图:列表显示
- 支持进行服务器端文档验证
- 支持认证
- 根据变化实时更新
- 支持附件处理
- 因此, CouchApps(独立的 js应用程序)
- 需要 jQuery程序库
最佳应用场景:适用于数据变化较少,执行预定义查询,进行数据统计的应用程序。适用于需要提供数据版本支持的应用程序。
例如:CRM、CMS系统。 master-master复制对于多站点部署是非常有用的。
(编注2:master-master复制:是一种数据库同步方法,允许数据在一组计算机之间共享数据,并且可以通过小组中任意成员在组内进行数据更新。)
2. Redis
- 所用语言:C/C++
- 特点:运行异常快
- 使用许可: BSD
- 协议:类 Telnet
- 有硬盘存储支持的内存数据库,
- 但自2.0版本以后可以将数据交换到硬盘(注意, 2.4以后版本不支持该特性!)
- Master-slave复制(见编注3)
- 虽然采用简单数据或以键值索引的哈希表,但也支持复杂操作,例如 ZREVRANGEBYscore。
- INCR & co (适合计算极限值或统计数据)
- 支持 sets(同时也支持 union/diff/inter)
- 支持列表(同时也支持队列;阻塞式 pop操作)
- 支持哈希表(带有多个域的对象)
- 支持排序 sets(高得分表,适用于范围查询)
- Redis支持事务
- 支持将数据设置成过期数据(类似快速缓冲区设计)
- Pub/Sub允许用户实现消息机制
最佳应用场景:适用于数据变化快且数据库大小可遇见(适合内存容量)的应用程序。
例如:股票价格、数据分析、实时数据搜集、实时通讯。
(编注3:Master-slave复制:如果同一时刻只有一台服务器处理所有的复制请求,这被称为 Master-slave复制,通常应用在需要提供高可用性的服务器集群。)
3. MongoDB
- 所用语言:C++
- 特点:保留了sql一些友好的特性(查询,索引)。
- 使用许可: AGPL(发起者: Apache)
- 协议: Custom,binary( BSON)
- Master/slave复制(支持自动错误恢复,使用 sets 复制)
- 内建分片机制
- 支持 javascript表达式查询
- 可在服务器端执行任意的 javascript函数
- update-in-place支持比CouchDB更好
- 在数据存储时采用内存到文件映射
- 对性能的关注超过对功能的要求
- 建议最好打开日志功能(参数 –journal)
- 在32位操作系统上,数据库大小限制在约2.5Gb
- 空数据库大约占 192Mb
- 采用 GridFS存储大数据或元数据(不是真正的文件系统)
最佳应用场景:适用于需要动态查询支持;需要使用索引而不是 map/reduce功能;需要对大数据库有性能要求;需要使用 CouchDB但因为数据改变太频繁而占满内存的应用程序。
例如:你本打算采用 MysqL或 Postgresql,但因为它们本身自带的预定义栏让你望而却步。
4. Riak
- 所用语言:Erlang和C,以及一些Javascript
- 特点:具备容错能力
- 使用许可: Apache
- 协议: HTTP/REST或者 custom binary
- 可调节的分发及复制(N,R,W)
- 用 JavaScript or Erlang在操作前或操作后进行验证和安全支持。
- 使用JavaScript或Erlang进行 Map/reduce
- 连接及连接遍历:可作为图形数据库使用
- 索引:输入元数据进行搜索(1.0版本即将支持)
- 大数据对象支持( Luwak)
- 提供“开源”和“企业”两个版本
- 全文本搜索,索引,通过 Riak搜索服务器查询( beta版)
- 支持Masterless多站点复制及商业许可的 SNMP监控
最佳应用场景:适用于想使用类似 Cassandra(类似Dynamo)数据库但无法处理 bloat及复杂性的情况。适用于你打算做多站点复制,但又需要对单个站点的扩展性,可用性及出错处理有要求的情况。
例如:销售数据搜集,工厂控制系统;对宕机时间有严格要求;可以作为易于更新的 web服务器使用。
5. Membase
- 所用语言: Erlang和C
- 特点:兼容 Memcache,但同时兼具持久化和支持集群
- 使用许可: Apache 2.0
- 协议:分布式缓存及扩展
- 非常快速(200k+/秒),通过键值索引数据
- 可持久化存储到硬盘
- 所有节点都是唯一的( master-master复制)
- 在内存中同样支持类似分布式缓存的缓存单元
- 写数据时通过去除重复数据来减少 IO
- 提供非常好的集群管理 web界面
- 更新软件时软无需停止数据库服务
- 支持连接池和多路复用的连接代理
最佳应用场景:适用于需要低延迟数据访问,高并发支持以及高可用性的应用程序
例如:低延迟数据访问比如以广告为目标的应用,高并发的 web 应用比如网络游戏(例如 Zynga)
6. Neo4j
- 所用语言: Java
- 特点:基于关系的图形数据库
- 使用许可: GPL,其中一些特性使用 AGPL/商业许可
- 协议: HTTP/REST(或嵌入在 Java中)
- 可独立使用或嵌入到 Java应用程序
- 图形的节点和边都可以带有元数据
- 很好的自带web管理功能
- 使用多种算法支持路径搜索
- 使用键值和关系进行索引
- 为读操作进行优化
- 支持事务(用 Java api)
- 使用 Gremlin图形遍历语言
- 支持 Groovy脚本
- 支持在线备份,高级监控及高可靠性支持使用 AGPL/商业许可
最佳应用场景:适用于图形一类数据。这是 Neo4j与其他nosql数据库的最显著区别
例如:社会关系,公共交通网络,地图及网络拓谱
7. Cassandra
- 所用语言: Java
- 特点:对大型表格和 Dynamo支持得最好
- 使用许可: Apache
- 协议: Custom,binary (节约型)
- 可调节的分发及复制(N,W)
- 支持以某个范围的键值通过列查询
- 类似大表格的功能:列,某个特性的列集合
- 写操作比读操作更快
- 基于 Apache分布式平台尽可能地 Map/reduce
- 我承认对 Cassandra有偏见,一部分是因为它本身的臃肿和复杂性,也因为 Java的问题(配置,出现异常,等等)
最佳应用场景:当使用写操作多过读操作(记录日志)如果每个系统组建都必须用 Java编写(没有人因为选用 Apache的软件被解雇)
例如:银行业,金融业(虽然对于金融交易不是必须的,但这些产业对数据库的要求会比它们更大)写比读更快,所以一个自然的特性就是实时数据分析
8. HBase
(配合 ghshephard使用)
- 所用语言: Java
- 特点:支持数十亿行X上百万列
- 使用许可: Apache
- 协议:HTTP/REST (支持Thrift,见编注4)
- 在 BigTable之后建模
- 采用分布式架构 Map/reduce
- 对实时查询进行优化
- 高性能 Thrift网关
- 通过在server端扫描及过滤实现对查询操作预判
- 支持 XML,Protobuf,和binary的HTTP
- Cascading,hive,and pig source and sink modules
- 基于 Jruby( JIRB)的shell
- 对配置改变和较小的升级都会重新回滚
- 不会出现单点故障
- 堪比MysqL的随机访问性能
最佳应用场景:适用于偏好BigTable:)并且需要对大数据进行随机、实时访问的场合。
例如: Facebook消息数据库(更多通用的用例即将出现)
编注4:Thrift 是一种接口定义语言,为多种其他语言提供定义和创建服务,由Facebook开发并开源。
当然,所有的系统都不只具有上面列出的这些特性。这里我仅仅根据自己的观点列出一些我认为的重要特性。与此同时,技术进步是飞速的,所以上述的内容肯定需要不断更新。我会尽我所能地更新这个列表。
今天的关于8种Nosql数据库和nosql数据库有那些的分享已经结束,谢谢您的关注,如果想了解更多关于8种Nosql数据库系统对比的相关知识,请在本站进行查询。
如果您想了解关于NoSQL的一些理论和下列关于nosql的优势正确的是的知识,那么本篇文章将是您的不二之选。我们将深入剖析关于NoSQL的一些理论的各个方面,并为您解答下列关于nosql的优势正确的是的疑在这篇文章中,我们将为您介绍关于NoSQL的一些理论的相关知识,同时也会详细的解释下列关于nosql的优势正确的是的运用方法,并给出实际的案例分析,希望能帮助到您!
本文目录一览:")
关于NoSQL的一些理论(下列关于nosql的优势正确的是)
1. The three Vs of big data
Volume: High volumes of data ranging from dozens of terabytes,and even petabytes.
Variety: Data that's organized in multiple structures,ranging from raw text (which,from a computer's perspective,has little or no discernible structure — many people call this unstructured data) to log files (commonly referred to as being semistructured) to data ordered in strongly typed rows and columns (structured data). To make things even more confusing,some data sets even include portions of all three kinds of data. (This is kNown as multistructured data.)
VeLocity: Data that enters your organization and has some kind of value for a limited window of time — a window that usually shuts well before the data has been transformed and loaded into a data warehouse for deeper analysis (for example,financial securities ticker data,which may reveal a buying opportunity,but only for a short while). The higher the volumes of data entering your organization per second,the bigger your veLocity challenge.
2. Nosql Theories
Nosql Data Stores
Nosql data stores originally subscribed to the notion "Just Say No to sql" (to paraphrase from an anti-drug advertising campaign in the 1980s),and they were a reaction to the perceived limitations of (sql-based) relational databases. It's not that these folks hated sql,but they were tired of forcing square pegs into round holes by solving problems that relational databases weren't designed for. A relational database is a powerful tool,but for some kinds of data (like key-value pairs,or graphs) and some usage patterns (like extremely large scale storage) a relational database just isn't practical. And when it comes to high-volume storage,relational database can be expensive,both in terms of database license costs and hardware costs. (Relational databases are designed to work with enterprise-grade hardware.) So,with the Nosql movement,creative programmers developed dozens of solutions for different kinds of thorny data storage and processing problems. These Nosql databases typically provide massive scalability by way of clustering,and are often designed to enable high throughput and low latency.
REMEMBER The name Nosql is somewhat misleading because many databases that fit the category do have sql support (rather than "Nosql" support). Think of its name instead as "Not Only sql."
The Nosql offerings available today can be broken down into four distinct categories,based on their design and purpose:
· Key-value stores: This offering provides a way to store any kind of data without having to use a schema. This is in contrast to relational databases,where you need to define the schema (the table structure) before any data is inserted. Since key-value stores don't require a schema,you have great flexibility to store data in many formats. In a key-value store,a row simply consists of a key (an identifier) and a value,which can be anything from an integer value to a large binary data string. Many implementations of key-value stores are based on Amazon's Dynamo paper.
· Column family stores: Here you have databases in which columns are grouped into column families and stored together on disk.
TECHNICAL STUFF Strictly speaking,many of these databases aren't column-oriented,because they're based on Google's BigTable paper,which stores data as a multidimensional sorted map. (For more on the role of Google's BigTable paper on database design,see Chapter 12.)
· Document stores: This offering relies on collections of similarly encoded and formatted documents to improve efficiencies. Document stores enable individual documents in a collection to include only a subset of fields,so only the data that's needed is stored. For sparse data sets,where many fields are often not populated,this can translate into significant space savings. By contrast,empty columns in relational database tables do take up space. Document stores also enables schema flexibility,because only the fields that are needed are stored,and new fields can be added. Again,in contrast to relational databases,table structures are defined up front before data is stored,and changing columns is a tedious task that impacts the entire data set.
· Graph databases: Here you have databases that store graph structures — representations that show collections of entities (vertices or nodes) and their relationships (edges) with each other. These structures enable graph databases to be extremely well suited for storing complex structures,like the linking relationships between all kNown web pages. (For example,individual web pages are nodes,and the edges connecting them are links from one page to another.) Google,of course,is all over graph technology,and invented a graph processing engine called pregel to power its PageRank algorithm. (And yes,there's a white paper on pregel.) In the Hadoop community,there's an Apache project called Giraph (based on the pregel paper),which is a graph processing engine designed to process graphs stored in HDFS.
REMEMBER The data storage and processing options available in Hadoop are in many cases implementations of the Nosql categories listed here. This will help you better evaluate solutions that are available to you and see how Hadoop can complement Traditional data warehouses.
ACID versus BASE Data Stores
One hallmark of relational database systems is something kNown as ACID compliance. As you might have guessed,ACID is an acronym — the individual letters,meant to describe a characteristic of individual database transactions,can be expanded as described in this list:
· Atomicity: The database transaction must completely succeed or completely fail. Partial success is not allowed.
· Consistency: During the database transaction,the RDBMS progresses from one valid state to another. The state is never invalid.
· Isolation: The client's database transaction must occur in isolation from other clients attempting to transact with the RDBMS.
· Durability: The data operation that was part of the transaction must be reflected in nonvolatile storage (computer memory that can retrieve stored information even when not powered – like a hard disk) and persist after the transaction successfully completes. Transaction failures cannot leave the data in a partially committed state.
Certain use cases for RDBMSs,like online transaction processing,depend on ACID-compliant transactions between the client and the RDBMS for the system to function properly. A great example of an ACID-compliant transaction is a transfer of funds from one bank account to another. This breaks down into two database transactions,where the originating account shows a withdrawal,and the destination account shows a deposit. ObvIoUsly,these two transactions have to be tied together in order to be valid so that if either of them fail,the whole operation must fail to ensure both balances remain valid.
Hadoop itself has no concept of transactions (or even records,for that matter),so it clearly isn't an ACID-compliant system. Thinking more specifically about data storage and processing projects in the entire Hadoop ecosystem (we tell you more about these projects later in this chapter),none of them is fully ACID-compliant,either. However,they do reflect properties that you often see in Nosql data stores,so there is some precedent to the Hadoop approach.
One key concept behind Nosql data stores is that not every application truly needs ACID-compliant transactions. Relaxing on certain ACID properties (and moving away from the relational model) has opened up a wealth of possibilities,which have enabled some Nosql data stores to achieve massive scalability and performance for their niche applications. Whereas ACID defines the key characteristics required for reliable transaction processing,the Nosql world requires different characteristics to enable flexibility and scalability. These opposing characteristics are cLeverly captured in the acronym BASE:
· Basically Available: The system is guaranteed to be available for querying by all users. (No isolation here.)
· Soft State: The values stored in the system may change because of the eventual consistency model,as described in the next bullet.
· Eventually Consistent: As data is added to the system,the system's state is gradually replicated across all nodes. For example,in Hadoop,when a file is written to the HDFS,the replicas of the data blocks are created in different data nodes after the original data blocks have been written. For the short period before the blocks are replicated,the state of the file system isn't consistent.
The acronym BASE is a bit contrived,as most Nosql data stores don't completely abandon all the ACID characteristics — it's not really the polar opposite concept that the name implies,in other words. Also,the Soft State and Eventually Consistent characteristics amount to the same thing,but the point is that by relaxing consistency,the system can horizontally scale (many nodes) and ensure availability.
CAP Theory
TECHNICAL STUFF No discussion of Nosql would be complete without mentioning the CAP theorem,which represents the three kinds of guarantees that architects aim to provide in their systems:
· Consistency: Similar to the C in ACID,all nodes in the system would have the same view of the data at any time.
· Availability: The system always responds to requests.
· Partition tolerance: The system remains online if network problems occur between system nodes.
The CAP theorem states that in distributed networked systems,architects have to choose two of these three guarantees — you can't promise your users all three. That leaves you with the three possibilities shown in figure 11-1:
· Systems using Traditional relational technologies normally aren't partition tolerant,so they can guarantee consistency and availability. In short,if one part of these Traditional relational technologies systems is offline,the whole system is offline.
· Systems where partition tolerance and availability are of primary importance can't guarantee consistency,because updates (that destroyer of consistency) can be made on either side of the partition. The key-value stores Dynamo and CouchDB and the column-family store Cassandra are popular examples of partition tolerant/availability (PA) systems.
· Systems where partition tolerance and consistency are of primary importance can't guarantee availability because the systems return errors until the partitioned state is resolved.
REMEMBER Hadoop-based data stores are considered CP systems (consistent and partition tolerant). With data stored redundantly across many slave nodes,outages to large portions (partitions) of a Hadoop cluster can be tolerated. Hadoop is considered to be consistent because it has a central Metadata store (the NameNode) which maintains a single,consistent view of data stored in the cluster. We can't say that Hadoop guarantees availability,because if the NameNode fails applications cannot access data in the cluster.

mac下关于node的一些操作
1.MAC 或者linu下 cd .. 当前目录的上一级目录 2.MAC 或者linux下 ls 显示当前目录下所有文件 3.MAC 下 开启隐藏文件夹 defaults write com.apple.finder AppleShowAllFiles -bool YES 然后killall Finder 显示的文件夹不能双击 右键在新标签里打开 4.MAC下关闭目录 (并返回上层目录) Command + 上方向键 5.MAC下开启路径拦 在Finder显示里勾上 但是路径还是右键简介里复制 6.WIN下npm命令如果报错 在安装目录roaming下新建一个npm文件夹 MAC或者linux下 安装 用 sudo npm install

NoSQL入门------关于NoSQL
转载地址:http://blog.csdn.net/testcs_dn/article/details/51225843
关于Nosql的专栏申请了可能快一年了,也没有填充一篇文章,今天看到,还是先写一篇放进去吧。现在应用Nosql的人也非常多了,大家可能都不再陌生了,中文方面的资料已经漫天飞舞了。但是查看知乎中Nosql 相关话题的回答数却寥寥无几。可能是大家都更多的去关注相关实际技术的应用了,而忽略了这一概念的本质。
什么是Nosql?
百度百科中:Nosql,泛指非关系型的数据库。中文名:非关系型数据库,外文名:Nosql=Not Only sql
看Wikipedia中:ANoSQL(originally referring to "non sql" or "non relational")database provides a mechanism forstorageandretrievalof data which is modeled in means other than the tabular relations used inrelational databases.
Nosql(最初指的"非 sql"或"非关系")数据库提供了一种机制用于存储和检索模型中的数据,不同于关系数据库中使用的表格关系的方式。
再看Wiki中参考的NoSQL终极指南(nosql-database.org)中说的:Nosql DEFinitioN:
Next Generation Databases mostly addressing some of the points: beingnon-relational,distributed,open-sourceandhorizontally scalable.
Nosql的定义:下一代数据库主要是解决一些要点:非关系型,分布式的,开放源码和支持横向扩展。
The original intention has beenmodern web-scale databases. The movement began early 2009 and is growing rapidly. Often more characteristics apply such as:schema-free,easy replication support,simple API,eventually consistent/BASE(not ACID),ahuge amount of dataand more. So the misleading term"nosql" (the community Now translates it mostly with "not only sql") should be seen as an alias to something like the deFinition above.
初衷是现代网络规模的数据库。
该运动始于2009年初,并正在迅速增长。
通常都支持的特性(共同特征),如:无架构开放架构(不需要预定义模式),易于复制,简单的API,最终一致/ 基础(不支持ACID特性),支持海量数据存储。
所以,误导性术语“的Nosql”(现在社会把它翻译大多为“不仅是sql”),应被视为类似于上面的定义的别名。
前世今生
Nosql最近几年才火起来,并且快速增长,那么它从什么时候开始有的呢?
Such databases have existed since the late 1960s,but did not obtain the "Nosql" moniker until a surge of popularity in the early twenty-first century。
早啦,从60年代后期这样的数据库已经存在,但并没有取得“Nosql”的绰号。
只是以前的应用场景更适合使用关系型的数据库,所以Nosql类型的数据库不被大多数人需要,不被大多数人所知。
Nosql一词最早出现于1998年,它是Carlo Strozzi开发的一个轻量、开源、不提供sql功能的关系型数据库(他认为,由于Nosql悖离传统关系数据库模型,因此,它应该有一个全新的名字,比如“norEL”或与之类似的名字)。
2009年,Last.fm的Johan OskaRSSon发起了一次关于分布式开源数据库的讨论,来自Rackspace的Eric Evans再次提出了Nosql的概念,这时的Nosql主要指非关系型、分布式、不提供ACID的数据库设计模式。
2009年在亚特兰大举行的“no:sql(east)”讨论会是一个里程碑,其口号是"select fun,profit from real_world where relational=false;"。因此,对Nosql最普遍的解释是“非关系型的”,强调键值存储和文档数据库的优点,而不是单纯地反对关系型数据库。
诞生的原因
随着互联网web2.0网站的兴起,传统的关系数据库在应付web2.0网站,特别是超大规模和高并发的SNS类型的web2.0纯动态网站已经显得力不从心,暴露了很多难以克服的问题,而非关系型的数据库则由于其本身的特点得到了非常迅速的发展。Nosql数据库的产生就是为了解决大规模数据集合多重数据种类带来的挑战,尤其是大数据应用难题。
键值(Key-Value)存储数据库
这一类数据库主要会使用到一个哈希表,这个表中有一个特定的键和一个指针指向特定的数据。Key/value模型对于IT系统来说的优势在于简单、易部署。但是如果DBA只对部分值进行查询或更新的时候,Key/value就显得效率低下了。[3] 举例如:Tokyo Cabinet/Tyrant,Redis,Voldemort,Oracle BDB.列存储数据库。
这部分数据库通常是用来应对分布式存储的海量数据。键仍然存在,但是它们的特点是指向了多个列。这些列是由列家族来安排的。如:Cassandra,HBase,Riak.文档型数据库
文档型数据库的灵感是来自于Lotus Notes办公软件的,而且它同第一种键值存储相类似。该类型的数据模型是版本化的文档,半结构化的文档以特定的格式存储,比如JSON。文档型数据库可 以看作是键值数据库的升级版,允许之间嵌套键值。而且文档型数据库比键值数据库的查询效率更高。如:CouchDB,MongoDb. 国内也有文档型数据库SequoiaDB,已经开源。图形(Graph)数据库
图形结构的数据库同其他行列以及刚性结构的SQL数据库不同,它是使用灵活的图形模型,并且能够扩展到多个服务器上。NoSQL数据库没有标准的查询语言(SQL),因此进行数据库查询需要制定数据模型。许多NoSQL数据库都有REST式的数据接口或者查询API。[2] 如:Neo4J,InfoGrid,Infinite Graph.因此,我们总结NoSQL数据库在以下的这几种情况下比较适用:1、数据模型比较简单;2、需要灵活性更强的IT系统;3、对数据库性能要求较高;4、不需要高度的数据一致性;5、对于给定key,比较容易映射复杂值的环境。
·简单数据模型。不同于分布式数据库,大多数NoSQL系统采用更加简单的数据模型,这种数据模型中,每个记录拥有唯一的键,而且系统只需支持单记录级别的原子性,不支持外键和跨记录的关系。这种一次操作获取单个记录的约束极大地增强了系统的可扩展性,而且数据操作就可以在单台机器中执行,没有分布式事务的开销。
·元数据和应用数据的分离。NoSQL数据管理系统需要维护两种数据:元数据和应用数据。元数据是用于系统管理的,如数据分区到集群中节点和副本的映射数据。应用数据就是用户存储在系统中的商业数据。系统之所以将这两类数据分开是因为它们有着不同的一致性要求。若要系统正常运转,元数据必须是一致且实时的,而应用数据的一致性需求则因应用场合而异。因此,为了达到可扩展性,NoSQL系统在管理两类数据上采用不同的策略。还有一些NoSQL系统没有元数据,它们通过其他方式解决数据和节点的映射问题。
·弱一致性。NoSQL系统通过复制应用数据来达到一致性。这种设计使得更新数据时副本同步的开销很大,为了减少这种同步开销,弱一致性模型如最终一致性和时间轴一致性得到广泛应用。
通过这些技术,NoSQL能够很好地应对海量数据的挑战。相对于关系型数据库,NoSQL数据存储管理系统的主要优势有:
·避免不必要的复杂性。关系型数据库提供各种各样的特性和强一致性,但是许多特性只能在某些特定的应用中使用,大部分功能很少被使用。NoSQL系统则提供较少的功能来提高性能。
·高吞吐量。一些NoSQL数据系统的吞吐量比传统关系数据管理系统要高很多,如Google使用MapReduce每天可处理20PB存储在Bigtable中的数据。
·高水平扩展能力和低端硬件集群。NoSQL数据系统能够很好地进行水平扩展,与关系型数据库集群方法不同,这种扩展不需要很大的代价。而基于低端硬件的设计理念为采用NoSQL数据系统的用户节省了很多硬件上的开销。
·避免了昂贵的对象-关系映射。许多NoSQL系统能够存储数据对象,这就避免了数据库中关系模型和程序中对象模型相互转化的代价。
主要缺点
虽然NoSQL数据库提供了高扩展性和灵活性,但是它也有自己的缺点,主要有:
·数据模型和查询语言没有经过数学验证。SQL这种基于关系代数和关系演算的查询结构有着坚实的数学保证,即使一个结构化的查询本身很复杂,但是它能够获取满足条件的所有数据。由于NoSQL系统都没有使用SQL,而使用的一些模型还未有完善的数学基础。这也是NoSQL系统较为混乱的主要原因之一。
·不支持ACID特性。这为NoSQL带来优势的同时也是其缺点,毕竟事务在很多场合下还是需要的,ACID特性使系统在中断的情况下也能够保证在线事务能够准确执行。
- ACID,指数据库事务正确执行的四个基本要素的缩写。包含:原子性(Atomicity)、一致性(Consistency)、隔离性(Isolation)、持久性(Durability)。一个支持事务(Transaction)的数据库,必需要具有这四种特性,否则在事务过程(Transactionprocessing)当中无法保证数据的正确性,交易过程极可能达不到交易方的要求。
·没有统一的查询模型。Nosql系统一般提供不同查询模型,这一定程度上增加了开发者的负担。
结束语
Nosql最初或许只是一个噱头,但随着Web 2.0的举起,对非关系型数据库的需求迅猛增加,随之相关的数据库如雨后春笋般快速成长起来,而这时做为与关系型数据库对立的或者说在它们之上的一个群体,用什么来代表呢?Nosql闪亮登场。
参考:
百度百科词条:NoSQL
Wikipedia:大数据管理系统:NoSQL数据库前世今生
)

Nosql的一些疑问
couchbase,membase与memcached的关系是?
我了解memcached是什么,但是不知道前面2者与它的关系是什么?
就我的理解,好像前面2者只是提供了一个memcached的管理页面?其实还是memcahced的东西?
另外,为什么couchbase的安装包90M,而memcached只有200KB...
Membase 后来改名为 Couchbase,Couchbase 是一个 Nosql 数据库, 同时内置了 Memcached。
如果不用 Nosql,可以只把 Couchbase 当作一个 Memcached 服务器,我们现在就是这么用的。
就是说Couchbase这个包里面有2个数据?一个他自己的可能叫做CouchDB之类的, 另外还内置了一个Memcached? 其实和那个200K的memcached没区别
参考:http://q.cnblogs.com/q/46058/

NoSQL的一些碎碎念
NoSQL的一些碎碎念 NoSQL并不像字面意思那样,并不是说不再使用SQL,不再使用关系数据库,他真正的意思是Not Only SQL,他的出现是为了弥补关系数据库的不足,尤其是是在处理超大量的数据时。NoSQL并不是一个数据库的名字,而是一系列不再局限于关系型的数据
NoSQL的一些碎碎念
NoSQL并不像字面意思那样,并不是说不再使用SQL,不再使用关系数据库,他真正的意思是Not Only SQL,他的出现是为了弥补关系数据库的不足,尤其是是在处理超大量的数据时。NoSQL并不是一个数据库的名字,而是一系列不再局限于关系型的数据库的总称。
下面本文将就目前出现的一些NoSQL做一些简要的介绍,以备获悉,并且本文将不断更新,以补充一些新的NoSQL数据库的介绍,并且摒弃那些不再流行的NoSQL数据库,有关NoSQL的最新的数据库信息,可以从网站上面查阅。另外,本文的大多数Linux下面的实验是在ubuntu系统下进行的。
为了更好的了解NoSQL,这里列出了一些NoSQL常用的提升处理能力的非SQL的一些概念,这些概念会一直进行补充。
概念一:键值存储
数据的存储方式是键值对。这样的数据库处理速度一般很快,查询获取数据的方式一般为通过键或者键的正则表达式。
目前本文包含的NoSQL数据库有:memcached,
memcached
该数据库属于把数据存储在内存中的数据库,事实上,当机器断电,内存关闭的时候,memcached也就不复存在,当机器启动,内存重新加载memcached的时候,这已经是一个全新的数据库了,所以需要保存持久的数据一般是不会使用memcached数据库的。由于memcached是全部数据在内存中的,服务器空间,所以具有高速的响应速度,一般被用做高速缓存使用。
memcached数据库是基于键值存储的,并且是临时性的,一些具体的例子如下所示。该例子是使用了Ruby实现。

这个例子实现了在同一个机子中开辟3个memcached,分别对应不同的端口。Ruby访问memcached就像使用Map一样简单。
在ubuntu下面Ruby需要使用memcache-client库来支持,香港服务器,而这个需要使用gem进行安装,香港虚拟主机,所以ubuntu下面的ruby最好采用1.9以上版本。启动一个memcached的应用实例的命令如下:
memcached –d –p 11211(端口) –u nobody(用户名) –c 1024(最大连接数) –m 64(内存空间)
除此之外,repcached工具实现了memcached多个实例之间,数据的相互复制备份。
posted on
Copyright ©2012 Yakov Powered by: 博客园 模板提供:沪江博客
关于关于NoSQL的一些理论和下列关于nosql的优势正确的是的问题我们已经讲解完毕,感谢您的阅读,如果还想了解更多关于mac下关于node的一些操作、NoSQL入门------关于NoSQL、Nosql的一些疑问、NoSQL的一些碎碎念等相关内容,可以在本站寻找。
本文将介绍nosql-intro-original.pdf-Martin Fowler的详细情况,特别是关于中文翻译的相关信息。我们将通过案例分析、数据研究等多种方式,帮助您更全面地了解这个主题,同时也将涉及一些关于A Recipe for Training Neural Networks [中文翻译,part 1]、AI-Knowledge-based agents: propositional logic, propositional theorem proving, propositional mode...、Ajax-'Origin localhost不允许Access-Control-Allow-Origin'、Android NDK Application.mk(中文翻译)的知识。
本文目录一览:- nosql-intro-original.pdf-Martin Fowler(中文翻译)(nosql官网)
- A Recipe for Training Neural Networks [中文翻译,part 1]
- AI-Knowledge-based agents: propositional logic, propositional theorem proving, propositional mode...
- Ajax-'Origin localhost不允许Access-Control-Allow-Origin'
- Android NDK Application.mk(中文翻译)
(nosql官网)")
nosql-intro-original.pdf-Martin Fowler(中文翻译)(nosql官网)
第一页:未来不只是Nosql数据库,而是混合持久化
关于企业数据存储的未来-主要写给参与企业应用开发管理的人
Martin Fowler,Pramod Sadalage 2012.11.26
第二页:sql已统治了二十年
存储持久化数据
存储着大量的数据在磁盘,应用程序通过查询获取少量数据
应用程序集成
很多企业应用需要数据共享,全部的应用使用同一个数据库,我们必须保证获取的是一致的、最新的数据
主要标准
并发控制
报表
众多的报表工具是基于sql的简单数据模型和标准化而建立的第三页:但是,sql的支配地位正在崩溃
关系数据库是被设计为运行在一台机器上,所以按照数据比例,你需要买一个更大的规模的大型机器
然而,通过购买大量的并行小型机器,其实更为便宜和有效
机器在这些大型集群中,单个来说,是不可靠的;不过即使单个机器死了,整体集群可以继续保持工作,所以整个集群来说,是可靠的。“云”正是这种集群,这意味着关系数据库在云上并不能很好的运行。Web服务的兴起,提供了一个对共享数据库进行应用集成的有效选择,使得更容易为不同的应用程序选择他们各自的数据存储
谷歌和亚马逊都是在早期就开始避开关系据库而使用大集群的企业。
谷歌->Bigtable
亚马逊->Dynamo
他们的努力使得Nosql社区获得了重大的启示
第四页:于是,就有了Nosql数据库
Nosql没有一个标准的定义。这个术语诞生在2009年的一个讨论会,但是对于什么样的数据库可以正真的称为Nosql还具有争议
虽然还没有正式的定义,但是Nosql仍然有一些共同的特征:
- 它们不使用关系型数据模型,因此也不使用sql语言
- 它们往往运行在集群上
- 它们倾向于开源
- 它们没有一个固定的模式,允许你在任何记录上存储任何数据
我们应该还记得Google的Bigtable和亚马逊的SimpleDB,被尝试用于他们云机的云服务时,是必然符合一般的操作特性的
第五页:所以,这表示我们可以
减少开发阻力
我们经常遇到关系型数据库的项目,并不是因为它是最好的,而仅仅因为它是一个默认的选择而已。通常它们开发者把开发时间耗费在一些无用的功能上。
拥抱大数据
Guardian
DNC
Danish Health Care
McLaren
第六页:但这不意味关系数据库已死
关系模型依然具有重要意义
表格模型对很多类型的数据都非常适合,特别是当你需要把数据拆分再通过另一种方式重新组合。
ACID事务
为了更有效的在及集群中运行,大部分Nosql数据库对事务作了限制,一般是足够使用了,但并不总是。
工具
熟悉性
第七页:这将带领我们走向混合持久化
第八页:混合持久化是什么样的
零售商的Web应用
用户会话:Redis(快速读写,不需要持久)
财务数据:RDBMS(需要事务更新,使用表格结构来适应数据)
购物车:Riak(多location高可用性,合并不一致的写入)
客户建议:Neo4J(快速链接朋友、产品购买、评价)
产品目录:MongoDB(大量的读,极少的写)
报表:RDBMS(报表工具中sql的接口更适用)
分析系统:Cassandra(大量集群中大数据分析)
用户行为日志:Canssandra(在多个节点中大量写操作)
这只是一个假设性的例子,在没有任何调研之前我们不做任何的建议。
第九页:混合持久化为企业提供了更多的机遇与挑战
抉择
我们需要进行选择,而不是想以前一样直接使用关系型数据库
组织变革
如何把数据组织为新的技术模型
不成熟
Nosql的工具都是新出不久,还有很多缺陷。而且我们对这些工具也没有很多的使用经验,不知道如何使用,什么才是更好的使用模式,也不知道哪里有陷阱等着我们
一致性范式的处理
第十页:什么样的系统可以选择混合持久化
策略
大部分的软件项目都是实用性项目,也就是说它们并不是企业的集中竞争优势点。
快速进入市场
如果你需要快速进入市场,那么你需要让你的开发团队最大化生产力。如果适当,混合持久化可以显著的消除阻力。
数据加强
可以有多种形式:
1、大量数据
2、高可用性
3、大量读写
4、复杂的数据关系
任何一点我们建议使用非关系型数据。
第十一页:更多的信息...
网上
书
咨询
![A Recipe for Training Neural Networks [中文翻译,part 1]](http://www.gvkun.com/zb_users/upload/2025/02/3b3eb5a8-cf8b-49a1-8f62-4366914ff4701738810545882.jpg "A Recipe for Training Neural Networks [中文翻译,part 1]")
A Recipe for Training Neural Networks [中文翻译,part 1]
最近拜读大神 Karpathy 的经验之谈 A Recipe for Training Neural Networks https://karpathy.github.io/2019/04/25/recipe/,这个秘籍对很多深度学习算法训练过程中遇到的各自问题进行了总结,并提出了很多很好的建议,翻译于此,希望能够帮助更多人学到这些内容。
译文如下:
几周前,我发布了一条关于 “最常见的神经网络错误” 的推文,列出了一些与训练神经网络相关的常见问题。这条推文得到了比我预期的要多得多的认同(包括网络研讨会:))。显然,很多人个人遇到了 “卷积层是这样工作的” 和 “我们的卷积网络达到最先进结果” 之间的巨大差距。
所以我认为如果清空我尘土飞扬的博客并将这个推文扩展到这个主题应该得到的长篇形式应该是有趣的事情。然而,与其列举常见的错误或深入分析它们,我更想深入挖掘并讨论如何避免出现这些错误(或者非常快速地修复它们)。这样做的关键是遵循某个过程,据我所知,这个过程并没有文档记录下来。让我们从促使我做这个的两个重要发现开始吧。
1. 神经网络训练的困难是一种假象
据称很容易开始训练神经网络。许多图书和框架都以展示了如果采用 30 行代码解决您的数据问题,并以此而自豪。这给大家一个非常错误的印象,即这些东西是即插即用。常见的示例代码如下:
>>> your_data = # 导入数据
>>> model = SuperCrossValidator(SuperDuper.fit, your_data, ResNet50, SGDOptimizer)
# 由此征服世界这些这些库和示例激活了我们大脑里面熟悉标准软件的部分 - 通常它们认为干净和抽象的 API 是可以轻易获得的。 比如,后面的功能可以采用如下调用:
>>> r = requests.get(''https://api.github.com/user'', auth=(''user'', ''pass''))
>>> r.status_code
200这很酷! 一个勇敢的开发人员已经承担了理解查询字符串,URL,GET / POST 请求,HTTP 连接等等的负担,并且在很大程度上隐藏了几行代码背后的复杂性。 这恰恰是我们熟悉和期待的。 不幸的是,神经网不是那样的。 它们不是 “现成的” 技术,第二个与训练 ImageNet 分类器略有不同。 我试图在我的帖子 “是的你应该理解反向传播” 中通过反向传播的例子说明这一点,并将其称为 “漏洞抽象”,但不幸的是情况更加可怕。 Backprop + SGD 并没有神奇地让你的网络正常工作。 Batch Norm 也不会神奇地使其收敛得更快。RNN 不会神奇地让你 “插入” 文本。 只是因为你可以将你的问题采用增强学习来建模,并不意味着你应该如此。 如果您坚持使用该技术而不了解其工作原理,则可能会失败。 这让我想到......
2. 神经网络训练无声地失败
当您写错或错误配置代码时,您通常会遇到某种异常。你输入了一个整数,但这本来应该是一个字符串的!某函数只需要 3 个参数!导入失败!键值不存在!两个列表中的元素个数不相等。此外,通常不会为特定功能创建单元测试。
解决了这些问题,也只是训练神经网络的开始。一切都可以在语法上正确,但整个训练没有妥善安排,而且很难说清楚。 “可能的错误面” 是很大的,逻辑(与语法相反)层面的问题,并且对单元测试非常棘手。例如,在数据增强期间左右翻转图像时,您可能忘记翻转数据标签。您的网络仍然可以(令人震惊地)工作得非常好,因为您的网络可以在内部学习检测翻转的图像,然后左右翻转其预测。或许你的自回归模型会因为一个偶然错误而意外地将它想要预测的东西作为输入。或者你想要修剪你的梯度但是修剪了损失,导致在训练期间异常样本被忽略。或者您从预训练模型初始化了您的权重,但没有使用原始均值。或者你只是用错了正则化权重,学习率,衰减率,模型大小等。因此,错误设置的神经网络只有在你运气好的时候才会抛出异常;大部分时间它会训练,但默默地输出看起来有点糟糕的结果。
因此,“快速和激烈” 方法训练的神经网络并不能发挥其作用,我们只会遭受其痛苦。 现在,痛苦是让神经网络运作良好的一个非常自然的过程,但可以通过对训练过程中的所有细节了然于胸来减轻训练过程的折磨。 在我的经验中,与深度学习成功最相关的品质是耐心和对细节的关注。
秘方
鉴于上述两个事实,我已经为自己开发了一个特定的过程,使我能够将神经网络应用于新问题。稍后我会竭力描述如何做到的。 你会发现它非常重视上述两个原则。 特别是,它遵循从简单到复杂的规律,并且在每一步我们对将要发生的事情做出具体假设,然后通过实验验证它们或进行检查直到我们发现了问题。 我们试图防止的是同时引入了许多复杂 “未经验证的” 问题,这必然会导致需要花很多时间去查找的错误 / 错误配置。 如果编写您的神经网络代码就像训练一样,您需要使用非常小的学习速率并猜测,然后在每次迭代后评估整个的测试集。
1. 了解你的数据
训练神经网络的第一步是根本不是接触任何神经网络代码,而是从彻底检查数据开始。这一步至关重要。我喜欢花费大量时间(以小时为单位)扫描数千个示例,了解它们的分布并寻找模式。幸运的是,你的大脑非常擅长这一点。有一次我发现了数据中包含重复的例子。另一次我发现了错误的图像 / 标签对。我通常会寻找不均衡的数据,也会关注自己对数据的分类过程,这些过程暗示了我们最终会尝试的各种架构。例如 - 我们需要局部特征还是全局上下文?数据有多少变化,这些变化采取什么形式?什么变化是假的,是可以预处理的?空间位置是否重要,或者我们是否想要将其平均化?细节有多重要,我们可以在多大程度上对图像进行下采样?标签有多少噪声?
此外,由于神经网络实际上可以看作压缩 / 编译的数据集,因此您将能够查看网络的(错误)预测并了解它们的来源。如果你的网络给你的预测看起来与你在数据中看到的内容不一致,那么就会有所收获。
一旦获得定性的感知,编写一些简单的代码来搜索 / 过滤 / 排序也是一个好主意,无论你能想到什么(例如标签的类型、大小、数量等),并可视化它们的分布,和沿任何坐标轴的异常值。异常值尤其能揭示数据质量或预处理中的一些错误。
2. 设置端到端的训练 / 评估框架 + 获得基准
当我们了解了数据之后,我们可以采用我们超级精彩的多尺度 ASPP FPN ResNet 训练牛 X 的模型吗? 答案是不。 这是一条充满痛苦的道路。 我们的下一步是建立一个完整的训练 + 评估框架,并通过一系列实验验证其正确性。在这个阶段,最好选择一些你能正确使用的简单模型 - 例如 线性分类器,或非常小的 ConvNet。 我们希望对其进行训练,可视化损失,任何其他指标(例如准确度),模型预测,并在此过程中使用明确的假设进行一系列实验。
这个阶段的需要注意的地方和建议主要包括:
- 设置固定的随机种子。始终使用固定的随机种子,以保证当您运行两遍代码两次时,可以获得相同的结果。这消除了随机因素,并将帮助您保持理智。
- 简化。确保禁用任何不必要的尝试。例如,在此阶段肯定要关闭任何数据扩展。数据扩充是一种我们可能在以后合并的正规化策略,但是此刻它也可能引入一些愚蠢错误。
- 在评估时尽量准确。在绘制测试损失时,对整个(大)测试集进行评估。不要只是在批量上绘制测试损失,然后依靠在 Tensorboard 中平滑它们。我们追求正确,并且非常愿意放弃保持理智的时间。
- 验证初始的损失。验证您的损失函数是否以正确的损失值开始。例如。如果正确初始化最后一层,则应在初始化时查看 softmax 上的 - log(1 /n_classes),这默认值可以为 L2 回归,Huber 损失等。
- 正确初始化。正确初始化每层权重。例如,如果你正在回归一些平均值为 50 的值,那么将偏差初始化为 50。如果你有一个正负样本比例为 1:10 的不平衡数据集,请在你的数据上设置偏差,使网络初始化时就可以预测为 0.1。正确设置这些将加速收敛并消除 “曲棍球棒” 损失曲线,因为在最初的几次迭代中,您的网络基本上只是学习偏差。
- 人工评测。设置损失之外,人工可以查验和解释的的指标(例如准确性)。尽可能评估您自己(人类)的对该问题的准确性并与之进行比较。或者,对测试数据进行两次标注,并且对于每个示例,分别标注预测值和真实值。
- 指定和数据无关的标准。训练一个独立于输入数据的标准,(例如,最简单的方法是将所有输入设置为零)。这应该比实际插入数据时更糟糕,而不会将其清零。这可以吗?即你的模型是否学会从输入中提取任何信息?
- 在少量数据上过拟合。看看模型是否能够在仅仅少数几个数据(例如少至两个)上过拟合。为此,我们增加了模型的容量(例如添加层或过滤器)并验证我们可以达到可实现的最低损失(例如零)。我还想在同一个图中同时显示标签和预测,并确保一旦达到最小损失,它们就会完美重合。如果他们不这样做,那么某个地方就会出现一个错误,我们无法继续下一个阶段。
- 验证减少训练损失。在这个阶段,你希望模型在数据集上欠拟合,因为你正在使用玩具模型。尝试稍微增加容量,看看您的训练损失是否应该下降?
- 在训练模型前再次查看数据。在您 y_hat = model(x)(或 tf 中的 sess.run)之前,查看数据是否正确。也就是说 - 您希望确切地了解将要网络中的内容,将原始张量的数据和标签解码并将其可视化。这是唯一的 “事实来源”。我无法计算这个多少次节省了我的时间,并揭示了数据预处理和扩充中的问题。
- 预测过程动态可视化。我喜欢在训练过程中对固定测试数据上的预测结果进行可视化。这些预测如何动态发生的,将为您提供令人难以置信的直觉,使您能够了解训练的进展情况。很多时候,如果网络以某种方式摆动太多,显示出不稳定性,就有可能感觉网络难以拟合您的数据。学习率非常低或非常高,抖动量也很明显。
- 使用反向传递来绘制依赖关系。您的深度学习代码通常包含复杂的,矢量化的和广播的操作。我遇到的一个相对常见的错误是人们弄错了(例如他们使用视图而不是某处的转置 / 置换)并且无意中混合了 batch 的维度信息。不巧的是,您的网络通常仍然可以正常训练,因为它会学会忽略其他示例中的数据。调试此问题(以及其他相关问题)的一种方法是将某个示例的损失设置为 1.0,将反向传递一直运行到输入,并确保仅在该样本上获得非零梯度。更一般地说,梯度为您提供了网络中数据的依赖关系信息,这对调试很有用。
- 设置一个特例。这是一个更通用的编码技巧,但我经常看到人们因为贪心,从头开始编写相对一般的功能,而导入 bug。我喜欢为我现在正在做的事情编写一个专门的函数,让它工作,然后在确保我得到相同的结果再将其重构成一般功能的函数。这通常适用于矢量化代码,其中我几乎总是首先写出完全循环的版本,然后一次一个循环地将它转换为矢量化代码。

AI-Knowledge-based agents: propositional logic, propositional theorem proving, propositional mode...
Knowledge-based agents
Intelligent agents need knowledge about the world in order to reach good decisions.
Knowledge is contained in agents in the form of sentences in a knowledge representation language that are stored in a knowledge base.
Knowledge base (KB): a set of sentences, is the central component of a knowledge-based agent. Each sentence is expressed in a language called a knowledge representation language and represents some assertion about the world.
Axiom: Sometimes we dignify a sentence with the name axiom, when the sentence is taken as given without being derived from other sentences.
TELL: The operation to add new sentences to the knowledge base.
ASK: The operation to query what is known.
Inference: Both TELL and ASK may involve, deriving new sentences from old.
The outline of a knowledge-based program:

A knowledge-base agent is composed of a knowledge base and an inference mechanism. It operates by storing sentences about the world in its knowledge base, using the inference mechanism to infer new sentences, and using these sentences to decide what action to take.
The knowledge-based agent is not an arbitrary program for calculating actions, it is amenable to a description at the knowledge level, where we specify only what the agent knows and what its goals are, in order to fix its behavior, the analysis is independent of the implementation level.
Declarative approach: A knowledge-based agent can be built simply by TELLing it what it needs to know. Starting with an empty knowledge base, the gent designer can TELL sentences one by one until the agent knows how to operate in its environment.
Procedure approach: encodes desired behaviors directly as program code.
A successful agent often combines both declarative and procedural elements in its design.
A fundamental property of logical reasoning: The conclusion is guaranteed to be correct if the available information is correct.
Logic
A representation language is defined by its syntax, which specifies the structure of sentences, and its semantics, which defines the truth of each sentence in each possible world or model.
Syntax: The sentences in KB are expressed according to the syntax of the representation language, which specifies all the sentences that are well formed.
Semantics: The semantics defines the truth of each sentence with respect to each possible world.
Models: We use the term model in place of “possible world” when we need to be precise. Possible world might be thought of as (potentially) real environments that the agent might or might not be in, models are mathematical abstractions, each of which simply fixes the truth or falsehood of every relevant sentences.
If a sentence α is true in model m, we say that m satisfies α, or m is a model of α. Notation M(α) means the set of all models of α.
The relationship of entailment between sentence is crucial to our understanding of reasoning. A sentence α entails another sentence β if β is true in all world where α is true. Equivalent definitions include the validity of the sentence α⇒β and the unsatisfiability of sentence α∧¬β.
Logical entailment: The relation between a sentence and another sentence that follows from it.
Mathematical notation: α ⊨ β: αentails the sentence β.
Formal definition of entailment:
α ⊨ β if and only if M(α) ⊆ M(β)
i.e. α ⊨ β if and only if, in every model in which αis true, β is also true.
(Notice: if α ⊨ β, then α is a stronger assertion than β: it rules out more possible worlds. )
Logical inference: The definition of entailment can be applied to derive conclusions.
E.g. Apply analysis to the wupus-world.


The KB is false in models that contradict what the agent knows. (e.g. The KB is false in any model in which [1,2] contains a pit because there is no breeze in [1, 1]).
Consider 2 possible conclusions α1and α2.
We see: in every model in which KB is true,α1 is also true. Hence KB⊨α1 , so the agent can conclude that there is no pit in [1, 2].
We see: in some models in which KB is true,α2 is false. Hence KB⊭α2, so the agent cannot conclude that there is no pit in [1, 2].
The inference algorithm used is called model checking: Enumerate all possible models to check that α is true in all models in which KB is true, i.e. M(KB) ⊆ M(α).
If an inference algorithm i can derive α from KB, we write KB⊨iα,pronounced as “α is derived from KB by i” or “i derives α from KB.”
Sound/truth preserving: An inference algorithm that derives only entailed sentences. Soundness is a highly desirable property. (e.g. model checking is a sound procedure when it is applicable.)
Completeness: An inference algorithm is complete if it can derive any sentence that is entailed. Completeness is also a desirable property.
Inference is the process of deriving new sentences from old ones. Sound inference algorithms derive only sentences that are entailed; complete algorithms derive all sentences that are entailed.
If KB is true in the real world, then any sentence α derived from KB by a sound inference procedure is also true in the real world.

Grounding: The connection between logical reasoning process and the real environment in which the agent exists.
In particular, how do we know that KB is true in the real world?
Propositional logic
Propositional logic is a simple language consisting of proposition symbols and logical connectives. It can handle propositions that are known true, known false, or completely unknown.
1. Syntax
The syntax defines the allowable sentences.
Atomic sentences: consist of a single proposition symbol, each such symbol stands for a proposition that can be true or false. (e.g. W1,3 stand for the proposition that the wumpus is in [1, 3].)
Complex sentences: constructed from simpler sentences, using parentheses and logical connectives.

Semantics
The semantics defines the rules for determining the truth of a sentence with respect to a particular model.
The semantics for propositional logic must specify how to compute the truth value of any sentence, given a model.
For atomic sentences: The truth value of every other proposition symbol must be specified directly in the model.
For complex sentences:

A simple inference procedure
To decide whether KB ⊨ α for some sentence α:
Algorithm 1: Model-checking approach
Enumerate the models (assignments of true or false to every relevant proposition symbol), check that α is true in every model in which KB is true.
e.g.

TT-ENTAILS?: A general algorithm for deciding entailment in propositional logic, performs a recursive enumeration of a finite space of assignments to symbols.
Sound and complete.
Time complexity: O(2n)
Space complexity: O(n), if KB and α contain n symbols in all.

Propositional theorem proving
We can determine entailment by model checking (enumerating models, introduced above) or theorem proving.
Theorem proving: Applying rules of inference directly to the sentences in our knowledge base to construct a proof of the desired sentence without consulting models.
Inference rules are patterns of sound inference that can be used to find proofs. The resolution rule yields a complete inference algorithm for knowledge bases that are expressed in conjunctive normal form. Forward chaining and backward chaining are very natural reasoning algorithms for knowledge bases in Horn form.
Logical equivalence:
Two sentences α and β are logically equivalent if they are true in the same set of models. (write as α ≡ β).
Also: α ≡ β if and only if α ⊨ β and β ⊨ α.

Validity: A sentence is valid if it is true in all models.
Valid sentences are also known as tautologies—they are necessarily true. Every valid sentence is logically equivalent to True.
The deduction theorem: For any sentence αand β, α ⊨ β if and only if the sentence (α ⇒ β) is valid.
Satisfiability: A sentence is satisfiable if it is true in, or satisfied by, some model. Satisfiability can be checked by enumerating the possible models until one is found that satisfies the sentence.
The SAT problem: The problem of determining the satisfiability of sentences in propositional logic.
Validity and satisfiability are connected:
α is valid iff ¬α is unsatisfiable;
α is satisfiable iff ¬α is not valid;
α ⊨ β if and only if the sentence (α∧¬β) is unsatisfiable.
Proving β from α by checking the unsatisfiability of (α∧¬β) corresponds to proof by refutation / proof by contradiction.
Inference and proofs
Inferences rules (such as Modus Ponens and And-Elimination) can be applied to derived to a proof.
·Modus Ponens:

Whenever any sentences of the form α⇒β and α are given, then the sentence β can be inferred.
·And-Elimination:

From a conjunction, any of the conjuncts can be inferred.
·All of logical equivalence (in Figure 7.11) can be used as inference rules.

e.g. The equivalence for biconditional elimination yields 2 inference rules:

·De Morgan’s rule
We can apply any of the search algorithms in Chapter 3 to find a sequence of steps that constitutes a proof. We just need to define a proof problem as follows:
·INITIAL STATE: the initial knowledge base;
·ACTION: the set of actions consists of all the inference rules applied to all the sentences that match the top half of the inference rule.
·RESULT: the result of an action is to add the sentence in the bottom half of the inference rule.
·GOAL: the goal is a state that contains the sentence we are trying to prove.
In many practical cases, finding a proof can be more efficient than enumerating models, because the proof can ignore irrelevant propositions, no matter how many of them they are.
Monotonicity: A property of logical system, says that the set of entailed sentences can only increased as information is added to the knowledge base.
For any sentences α and β,
If KB ⊨ αthen KB ∧β ⊨ α.
Monotonicity means that inference rules can be applied whenever suitable premises are found in the knowledge base, what else in the knowledge base cannot invalidate any conclusion already inferred.
Proof by resolution
Resolution: An inference rule that yields a complete inference algorithm when coupled with any complete search algorithm.
Clause: A disjunction of literals. (e.g. A∨B). A single literal can be viewed as a unit clause (a disjunction of one literal ).
Unit resolution inference rule: Takes a clause and a literal and produces a new clause.

where each l is a literal, li and m are complementary literals (one is the negation of the other).
Full resolution rule: Takes 2 clauses and produces a new clause.

where li and mj are complementary literals.
Notice: The resulting clause should contain only one copy of each literal. The removal of multiple copies of literal is called factoring.
e.g. resolve(A∨B) with (A∨¬B), obtain(A∨A) and reduce it to just A.
The resolution rule is sound and complete.
Conjunctive normal form
Conjunctive normal form (CNF): A sentence expressed as a conjunction of clauses is said to be in CNF.
Every sentence of propositional logic is logically equivalent to a conjunction of clauses, after converting a sentence into CNF, it can be used as input to a resolution procedure.
A resolution algorithm

e.g.
KB = (B1,1⟺(P1,2∨P2,1))∧¬B1,1
α = ¬P1,2

Notice: Any clause in which two complementary literals appear can be discarded, because it is always equivalent to True.
e.g. B1,1∨¬B1,1∨P1,2 = True∨P1,2 = True.
PL-RESOLUTION is complete.
Horn clauses and definite clauses

Definite clause: A disjunction of literals of which exactly one is positive. (e.g. ¬ L1,1∨¬Breeze∨B1,1)
Every definite clause can be written as an implication, whose premise is a conjunction of positive literals and whose conclusion is a single positive literal.
Horn clause: A disjunction of literals of which at most one is positive. (All definite clauses are Horn clauses.)
In Horn form, the premise is called the body and the conclusion is called the head.
A sentence consisting of a single positive literal is called a fact, it too can be written in implication form.
Horn clause are closed under resolution: if you resolve 2 horn clauses, you get back a horn clause.
Inference with horn clauses can be done through the forward-chaining and backward-chaining algorithms.
Deciding entailment with Horn clauses can be done in time that is linear in the size of the knowledge base.
Goal clause: A clause with no positive literals.
Forward and backward chaining
forward-chaining algorithm: PL-FC-ENTAILS?(KB, q) (runs in linear time)
Forward chaining is sound and complete.

e.g. A knowledge base of horn clauses with A and B as known facts.

fixed point: The algorithm reaches a fixed point where no new inferences are possible.
Data-driven reasoning: Reasoning in which the focus of attention starts with the known data. It can be used within an agent to derive conclusions from incoming percept, often without a specific query in mind. (forward chaining is an example)
Backward-chaining algorithm: works backward rom the query.
If the query q is known to be true, no work is needed;
Otherwise the algorithm finds those implications in the KB whose conclusion is q. If all the premises of one of those implications can be proved true (by backward chaining), then q is true. (runs in linear time)
in the corresponding AND-OR graph: it works back down the graph until it reaches a set of known facts.
(Backward-chaining algorithm is essentially identical to the AND-OR-GRAPH-SEARCH algorithm.)
Backward-chaining is a form of goal-directed reasoning.
Effective propositional model checking
The set of possible models, given a fixed propositional vocabulary, is finite, so entailment can be checked by enumerating models. Efficient model-checking inference algorithms for propositional logic include backtracking and local search methods and can often solve large problems quickly.
2 families of algorithms for the SAT problem based on model checking:
a. based on backtracking
b. based on local hill-climbing search
1. A complete backtracking algorithm
David-Putnam algorithm (DPLL):

DPLL embodies 3 improvements over the scheme of TT-ENTAILS?: Early termination, pure symbol heuristic, unit clause heuristic.
Tricks that enable SAT solvers to scale up to large problems: Component analysis, variable and value ordering, intelligent backtracking, random restarts, clever indexing.
Local search algorithms
Local search algorithms can be applied directly to the SAT problem, provided that choose the right evaluation function. (We can choose an evaluation function that counts the number of unsatisfied clauses.)
These algorithms take steps in the space of complete assignments, flipping the truth value of one symbol at a time.
The space usually contains many local minima, to escape from which various forms of randomness are required.
Local search methods such as WALKSAT can be used to find solutions. Such algorithm are sound but not complete.
WALKSAT: one of the simplest and most effective algorithms.

On every iteration, the algorithm picks an unsatisfied clause, and chooses randomly between 2 ways to pick a symbol to flip:
Either a. a “min-conflicts” step that minimizes the number of unsatisfied clauses in the new state;
Or b. a “random walk” step that picks the symbol randomly.
When the algorithm returns a model, the input sentence is indeed satifiable;
When the algorithm returns failure, there are 2 possible causes:
Either a. The sentence is unsatisfiable;
Or b. We need to give the algorithm more time.
If we set max_flips=∞, p>0, the algorithm will:
Either a. eventually return a model if one exists
Or b. never terminate if the sentence is unsatifiable.
Thus WALKSAT is useful when we expect a solution to exist, but cannot always detect unsatisfiability.
The landscape of random SAT problems
Underconstrained problem: When we look at satisfiability problems in CNF, an underconstrained problem is one with relatively few clauses constraining the variables.
An overconstrained problem has many clauses relative to the number of variables and is likely to have no solutions.
The notation CNFk(m, n) denotes a k-CNF sentence with m clauses and n symbols. (with n variables and k literals per clause).
Given a source of random sentences, where the clauses are chosen uniformly, independently and without replacement from among all clauses with k different literals, which are positive or negative at random.
Hardness: problems right at the threshold > overconstrained problems > underconstrained problems

Satifiability threshold conjecture: A theory says that for every k≥3, there is a threshold ratio rk, such that as n goes to infinity, the probability that CNFk(n, rn) is satisfiable becomes 1 for all values or r below the threshold, and 0 for all values above. (remains unproven)
Agent based on propositional logic
1. The current state of the world
We can associate proposition with timestamp to avoid contradiction.
e.g. ¬Stench3, Stench4
fluent: refer an aspect of the world that changes. (E.g. Ltx,y)
atemporal variables: Symbols associated with permanent aspects of the world do not need a time superscript.
Effect axioms: specify the outcome of an action at the next time step.
Frame problem: some information lost because the effect axioms fails to state what remains unchanged as the result of an action.
Solution: add frame axioms explicity asserting all the propositions that remain the same.
Representation frame problem: The proliferation of frame axioms is inefficient, the set of frame axioms will be O(mn) in a world with m different actions and n fluents.
Solution: because the world exhibits locaility (for humans each action typically changes no more than some number k of those fluents.) Define the transition model with a set of axioms of size O(mk) rather than size O(mn).
Inferential frame problem: The problem of projecting forward the results of a t step lan of action in time O(kt) rather than O(nt).
Solution: change one’s focus from writing axioms about actions to writing axioms about fluents.
For each fluent F, we will have an axiom that defines the truth value of Ft+1 in terms of fluents at time t and the action that may have occurred at time t.
The truth value of Ft+1 can be set in one of 2 ways:
Either a. The action at time t cause F to be true at t+1
Or b. F was already true at time t and the action at time t does not cause it to be false.
An axiom of this form is called a successor-state axiom and has this schema:

Qualification problem: specifying all unusual exceptions that could cause the action to fail.
2. A hybrid agent
Hybrid agent: combines the ability to deduce various aspect of the state of the world with condition-action rules, and with problem-solving algorithms.
The agent maintains and update KB as a current plan.
The initial KB contains the atemporal axioms. (don’t depend on t)
At each time step, the new percept sentence is added along with all the axioms that depend on t (such as the successor-state axioms).
Then the agent use logical inference by ASKING questions of the KB (to work out which squares are safe and which have yet to be visited).
The main body of the agent program constructs a plan based on a decreasing priority of goals:
1. If there is a glitter, construct a plan to grab the gold, follow a route back to the initial location and climb out of the cave;
2. Otherwise if there is no current plan, plan a route (with A* search) to the closest safe square unvisited yet, making sure the route goes through only safe squares;
3. If there are no safe squares to explore, if still has an arrow, try to make a safe square by shooting at one of the possible wumpus locations.
4. If this fails, look for a square to explore that is not provably unsafe.
5. If there is no such square, the mission is impossible, then retreat to the initial location and climb out of the cave.

Weakness: The computational expense goes up as time goes by.
3. Logical state estimation
To get a constant update time, we need to cache the result of inference.
Belief state: Some representation of the set of all possible current state of the world. (used to replace the past history of percepts and all their ramifications)
e.g. 
We use a logical sentence involving the proposition symbols associated with the current time step and the temporal symbols.
Logical state estimation involves maintaining a logical sentence that describes the set of possible states consistent with the observation history. Each update step requires inference using the transition model of the environment, which is built from successor-state axioms that specify how each fluent changes.
State estimation: The process of updating the belief state as new percepts arrive.
Exact state estimation may require logical formulas whose size is exponential in the number of symbols.
One common scheme for approximate state estimation: to represent belief state as conjunctions of literals (1-CNF formulas).
The agent simply tries to prove Xt and ¬Xt for each symbol Xt, given the belief state at t-1.
The conjunction of provable literals becomes the new belief state, and the previous belief state is discarded.
(This scheme may lose some information as time goes along.)
The set of possible states represented by the 1-CNF belief state includes all states that are in fact possible given the full percept history. The 1-CNF belief state acts as a simple outer envelope, or conservative approximation.

4. Making plans by propositional inference
We can make plans by logical inference instead of A* search in Figure 7.20.
Basic idea:
1. Construct a sentence that includes:
a) Init0: a collection of assertions about the initial state;
b) Transition1, …, Transitiont: The successor-state axioms for all possible actions at each time up to some maximum time t;
c) HaveGoldt∧ClimbedOutt: The assertion that the goal is achieved at time t.
2. Present the whole sentence to a SAT solver. If the solver finds a satisfying model, the goal is achievable; else the planning is impossible.
3. Assuming a model is found, extract from the model those variables that represent actions and are assigned true.
Together they represent a plan to ahieve the goals.
Decisions within a logical agent can be made by SAT solving: finding possible models specifying future action sequences that reach the goal. This approach works only for fully observable or sensorless environment.
SATPLAN: A propositional planning. (Cannot be used in a partially observable environment)
SATPLAN finds models for a sentence containing the initial sate, the goal, the successor-state axioms, and the action exclusion axioms.
(Because the agent does not know how many steps it will take to reach the goal, the algorithm tries each possible number of steps t up to some maximum conceivable plan length Tmax.)

Precondition axioms: stating that an action occurrence requires the preconditions to be satisfied, added to avoid generating plans with illegal actions.
Action exclusion axioms: added to avoid the creation of plans with multiple simultaneous actions that interfere with each other.
Propositional logic does not scale to environments of unbounded size because it lacks the expressive power to deal concisely with time, space and universal patterns of relationshipgs among objects.

Ajax-'Origin localhost不允许Access-Control-Allow-Origin'
如何解决Ajax-''Origin localhost不允许Access-Control-Allow-Origin''?
此错误是由于跨域资源共享中强加了限制。这已作为安全功能的一部分实现,以通过跨域调用来限制资源的客户端(域)。当您将请求发送到Web服务或api或类似工具时,它会在服务器或目标(此处是api)的请求中添加Origin标头,以验证请求是否来自授权来源。理想情况下,API
/服务器应Origin在Request
header收到的信息中查找,并可能针对允许向其提供资源的一组来源(域)进行验证。如果来自允许的域,它将在响应标头中添加与"Access-
Control-Allow-
Origin"值。也可以使用通配符,但是问题是,在获得通配符许可的情况下,任何人都可以发出请求并将其送达(有一些限制,例如通过Windows
auth或cookie对api进行身份验证,不允许您发送该withCredentials值*)
)。使用通配符来源的响应标头不是一个好习惯,因为它对所有人开放。
这些是使用值设置响应头的方法:-
Access-Control-Allow-Origin: *
Access-Control-Allow-Origin: http://yourdomain.com
您甚至可以在同一响应中添加多个Access-Control-Allow-Origin标头(我相信在大多数浏览器中都可以使用)
Access-Control-Allow-Origin: http://yourdomain1.com
Access-Control-Allow-Origin: http://yourdomain2.com
Access-Control-Allow-Origin: http://yourdomain3.com
在服务器端(c#语法),您可以这样做:
var sourceDomain = Request.Headers["Origin"]; //This gives the origin domain for the request
Response.AppendHeader("Access-Control-Allow-Origin", sourceDomain ); //Set the response header with the origin value after validation (if any) .Depending on the type of application you are using Syntax may vary.
希望这可以帮助!!!
解决方法
我是Ajax的新手,只是受过此跨域调用的任务。我们的网页上有一个文本框,用户可用来执行公司名称搜索。通过单击文本框旁边的按钮,将请求Ajax调用。不幸的是,Web服务位于单独的域中,因此自然会引起问题。
以下是我使这项工作的最佳尝试。我还要注意,此调用的目的是以XML格式返回结果,该结果将success在请求的一部分中进行解析。
这又是错误消息:
Origin http://localhost:55152 is not allowed by Access-Control-Allow-Origin.
对于解决方法,我不知所措,将不胜感激任何想法。
function GetProgramDetails() {
var URL = "http://quahildy01/xRMDRMA02/xrmservices/2011/OrganizationData.svc/AccountSet?$select=AccountId,Name,neu_UniqueId&$filter=startswith(Name,\''" + $(''.searchbox'').val() + "\'')";
var request = $.ajax({
type: ''POST'',url: URL,contentType: "application/x-www-form-urlencoded",crossDomain: true,dataType: XMLHttpRequest,success: function (data) {
console.log(data);
alert(data);
},error: function (data) {
console.log(data);
alert("Unable to process your resquest at this time.");
}
});
}
")
Android NDK Application.mk(中文翻译)
前言
Application.mk 文件用来说明一款 APP 依赖于哪些本地模块。本地模块可以是静态链接库,动态链接库,或者可执行文件。
注:我们强烈建议你在阅读本文之前,先阅读 Android.mk,以便更好的理解。
概述
Application.mk 文件是一个迷你的 GNU Makefile 片段,用来定义一些编译变量。Application.mk 文件一般放在 $PROJECT/jni/ 目录下,其中 $PROJECT 代表项目目录。也可以把文件放在 $NDK/app// 目录下,其中 $NDK 为 NDK 根目录,为项目简称。例如
$NDK/apps/<myapp>/Application.mk变量
APP_PROJECT_PATH
此变量值必须是项目根目录的绝对路径。用于指定 JNI 生成的.so 文件的安装路径或拷贝路径。
注:此变量对于概述中的第一种方法是可选的,但对于第二种方法却是必须的。
APP_OPTIM
可选值为 release 或 debug。用来设置编译器的编译优化级别。
默认为 release 模式,用于生成优化过的二进制机器码。debug 模式用于生成未优化的二进制机器码,方便调试错误。
无论在哪种模式下,都可以进行调试。不同的是在 release 模式下调试器可提供的信息更少。比如,一些被优化过的变量,是无法用于检查,单步调试,或者跟踪的。
如果在项目的 manifest 文件中声明了 android:debuggable 标签,那么 Apllication.mk 文件中此变量的默认值被修改为 debug。你也可以在 Apllication.mk 文件中设置此变量来覆盖 manifest 文件中的设置。
APP_CFLAGS
此变量用来指定编译 C/C++ 代码的编译选项。当你需要修改某个指定模块的编译参数时,可以修改此变量,而不必去修改 Android.mk 文件。
此变量中涉及到的文件路径,可以使用相对路径 (相对于 NDK 根目录),或绝对路径。例如
sources/foo/Android.mk
sources/bar/Android.mk如果你想要在编译模块时把 bar 目录添加进 foo/Android.mk 文件中,可以这样做:
APP_CFLAGS += -Isources/bar或者这样:
APP_CFLAGS += -I$(LOCAL_PATH)/../bar注意,不能使用 -I../bar 这样的方式,因为它会被编译器解析为 -I$NDK_ROOT/../bar,这明显不是我们想要的结果。
注:在 android-ndk-1.5_r1 版本中,此变量只能用于 C 代码。之后的版本中 C/C++ 都是支持的。
APP_CPPFLAGS
此变量用来指定编译 C++ 代码的编译选项。
注:在 android-ndk-1.5_r1 版本中,此变量同时适用于 C 和 C++ 代码。之后的版本中只支持 C++ 代码。如果要同时支持 C/C++ 代码,可以使用 APP_CFLAGS 变量。
APP_LDFLAGS
此变量用来指定生成应用时使用到的链接选项。此选项用于编译动态链接库和可运行程序,当编译静态链接库时,此选项被忽略。
APP_BUILD_SCRIPT
此变量用来指定 NDK 编译脚本,默认为 jni/Android.mk。可以使用相对路径 (相对于 NDK 根目录),或绝对路径。
APP_ABI
默认情况下,NDK 会使用 ''armeabi'' ABI 来生成二进制机器码,这是基于 ARMv5TE 并支持浮点运算的机器码。可以使用此变量来指定不同的 ABI。下表中列出了适用于不同指令集的 ABI 选项。
表 1: 不同指令集下的 APP_ABI 设置
| 指令集 | 取值 |
|---|---|
| 支持基于 armv7 FPU 指令集的设备 | APP_ABI := armeabi-v7a |
| ARMv8 AArch64 | APP_ABI := x86 |
| IA-32 | APP_ABI := x86 |
| Intel64 | APP_ABI := x86_64 |
| MIPS32 | APP_ABI := mips |
| MIPS64 (r6) | APP_ABI := mips64 |
| 支持所有指令集 | APP_ABI := all |
注:从 NDKr7 开始支持 all 取值。
你可以同时指定多个取值,取值之间使用空格分隔。例如
APP_ABI := armeabi armeabi-v7a x86 mips有关可用的 ABI 列表,信息,及使用限制,参考这里 ABI Management。
APP_PLATFORM
此变量用来指定目标 Android 平台的名称。例如 ''android-3'' 代表了 Android 1.5 系统。完整的 Android 平台名称及系统版本参见 Android NDK Native APIs。
APP_STL
默认情况下,NDK 通过 Androoid 自带的迷你 C++ 运行库 (system/lib/libstdc++.so) 来提供标准 C++ 头文件。另外,NDK 提供了可供选择的 C++ 实现,你可以通过此变量来指定在程序内使用或链接的 C++ 库。更多有关支持的 C++ 库和特性参见这里 NDK Runtimes and Features。
APP_SHORT_COMMANDS
此变量用来给所有的模块设置 LOCAL_SHORT_COMMANDS 选项。更详细的说明查看 Android.mk 的 LOCAL_SHORT_COMMANDS 选项。
NDK_TOOLCHAIN_VERSION
此变量用来指定编译器 (默认为 GCC) 的版本。64 位 ABI 默认 GCC 版本为 4.9,32 位默认为 4.8。如果使用 Clang 编译器,可选值为 clang3.4 或 clang3.5 或 clang。clang 表示使用最新版本。
APP_PIE
安卓动态链接器,从 4.1 系统 (API 16) 开始支持基于位置的可执行程序 (PIE) 特性。从 5.0 系统 (API 21) 开始,可执行程序依赖于 PIE 特性。通过设置 - fPIE 选项来编译支持 PIE 的可执行程序。糟糕的是,这个选项会让随机代码位置引起的内存泄露的分析变得更加困难。
如果项目目标为 SDK 16 或以上版本,ndk-build 会默认启用此选项。当然你也可以设置为 false 来禁用此选项。
此选项仅对可执行程序有效。换句话说,在编译动 / 静态库时使用无任何效果。
注:此选项不支持安卓 4.1 以前的系统。
APP_THIN_ARCHIVE
此选项用来给所有的模块设置 LOCAL_THIN_ARCHIVE 默认值。更多信息请查看 Android.mk 的 LOCAL_THIN_ARCHIVE 选项。
我们今天的关于nosql-intro-original.pdf-Martin Fowler和中文翻译的分享就到这里,谢谢您的阅读,如果想了解更多关于A Recipe for Training Neural Networks [中文翻译,part 1]、AI-Knowledge-based agents: propositional logic, propositional theorem proving, propositional mode...、Ajax-'Origin localhost不允许Access-Control-Allow-Origin'、Android NDK Application.mk(中文翻译)的相关信息,可以在本站进行搜索。
对于MapR提供免费NoSQL数据库(英文)感兴趣的读者,本文将会是一篇不错的选择,我们将详细介绍on primary数据库,并为您提供关于12个最好的免费和开源的NoSQL数据库、12款免费与开源的NoSQL数据库、12款免费与开源的NoSQL数据库介绍、12款免费与开源的NoSQL数据库介绍_MySQL的有用信息。
本文目录一览:- MapR提供免费NoSQL数据库(英文)(on primary数据库)
- 12个最好的免费和开源的NoSQL数据库
- 12款免费与开源的NoSQL数据库
- 12款免费与开源的NoSQL数据库介绍
- 12款免费与开源的NoSQL数据库介绍_MySQL
(on primary数据库)")
MapR提供免费NoSQL数据库(英文)(on primary数据库)

12个最好的免费和开源的NoSQL数据库
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类json的bjson式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类于面向
MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。他支持的数据结构非常松散,是类似json的bjson格式,因此可以存储比较复杂的数据类型。Mongo最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。

它的特点是高性能、易部署、易使用,存储数据非常方便。主要功能特性有:
- 面向集合存储,易存储对象类型的数据。
- 模式自由。
- 支持动态查询。
- 支持完全索引,包含内部对象。
- 支持查询。
- 支持复制和故障恢复。
- 使用高效的二进制数据存储,包括大型对象(如视频等)。
- 自动处理碎片,以支持云计算层次的扩展性
- 支持RUBY,PYTHON,JAVA,C++,PHP等多种语言。
- 文件存储格式为BSON(一种JSON的扩展)
- 可通过网络访问
所谓“面向集合”(Collenction-Orented),意思是数据被分组存储在数据集中,被称为一个集合(Collenction)。每个 集合在数据库中都有一个唯一的标识名,并且可以包含无限数目的文档。集合的概念类似关系型数据库(RDBMS)里的表(table),不同的是它不需要定 义任何模式(schema)。
模式自由(schema-free),意味着对于存储在
存储在集合中的文档,被存储为键-值对的形式。键用于唯一标识一个文档,为字符串类型,而值则可以是各中复杂的文件类型。我们称这种存储形式为BSON(Binary Serialized dOcument Format)。
MongoDB服务端可运行在Linux、Windows或OS X平台,支持32位和64位应用,默认端口为27017。推荐运行在64位平台,因为MongoDB
在32位模式运行时支持的最大文件尺寸为2GB。
MongoDB把数据存储在文件中(默认路径为:/data/db),为提高效率使用内存映射文件进行管理。

12款免费与开源的NoSQL数据库
naresh kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,naresh撰文谈到了12款知名的免费、开源nosql数据库,并对这些数据库的特点进行了分析。 现在,NoSQL数据库变得越来越流
naresh kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,naresh撰文谈到了12款知名的免费、开源nosql数据库,并对这些数据库的特点进行了分析。
现在,NoSQL数据库变得越来越流行,我在这里总结出了一些非常棒的、免费且开源的NoSQL数据库。在这些数据库中,MongoDB独占鳌头,拥有相当大的使用量。这些免费且开源的NoSQL数据库具有很好的可伸缩性与灵活性,非常适合于大数据存储与处理。相较于传统的关系型数据库,这些NoSQL数据库在性能上具有很大的优势。然而,这些NoSQL数据库未必最适合你。大多数常见的应用仍然可以使用传统的关系型数据库进行开发。NoSQL数据库依然不太适合于那些任务关键型的事务要求。我对这些数据库进行了一些简单介绍,下面就来看看。
1. MongoDB
MongoDB是个面向文档的数据库,使用JSON风格的数据格式。它非常适合于网站的数据存储、内容管理与缓存应用,并且通过配置可以实现复制与高可用性功能。
MongoDB具有很强的可伸缩性,性能表现优异。它使用C++编写,基于文档存储。此外,MongoDB还支持全文检索、跨WAN与LAN的高可用性、易于实现的复制、水平扩展、基于文档的丰富查询、在数据处理与聚合等方面具有很强的灵活性。
2. Cassandra
这是个Apache软件基金会的项目,Cassandra是个分布式数据库,支持分散的数据存储,可以实现容错以及无单点故障等。换句话说,“Cassandra非常适合于那些无法忍受数据丢失的应用”。
3. CouchDB
这也是Apache软件基金会的一个项目,CouchDB是另一个面向文档的数据库,以JSON格式存储数据。它兼容于ACID,像MongoDB一样,CouchDB也可以用于存储网站的数据与内容,以及提供缓存等。你可以通过JavaScript在CouchDB上运行MapReduce查询。此外,CouchDB还提供了一个非常方便的基于Web的管理控制台。它非常适合于Web应用。
4. Hypertable
Hypertable模仿的是Google的BigTable数据库系统。Hypertable的创建者将“成为高可用、PB规模的数据库开源标准”作为Hypertable的目标。换言之,Hypertable的设计目标是跨越多个廉价的服务器可靠地存储大量数据。
5. Redis
这是个开源、高级的键值存储。由于在键中使用了hash、set、string、sorted set及list,因此Redis也称作数据结构服务器。这个系统可以帮助你执行原子操作,比如说增加hash中的值、集合的交集运算、字符串拼接、差集与并集等。Redis通过内存中的数据集实现了高性能。此外,该数据库还兼容于大多数编程语言。
6. Riak
Riak是最为强大的分布式数据库之一,它提供了轻松且可预测的伸缩能力,向用户提供了快速测试、原型与应用部署能力,从而简化应用的开发过程。
7. Neo4j
Neo4j是一款NoSQL图型数据库,具有非常高的性能。它拥有一个健壮且成熟的系统的所有特性,向程序员提供了灵活且面向对象的网络结构,可以让开发者充分享受到拥有完整事务特性的数据库的所有好处。相较于RDBMS,Neo4j还对某些应用提供了不少性能改进。
8. Hadoop HBase
HBase是一款可伸缩、分布式的大数据存储。它可以用在数据的实时与随机访问的场景下。HBase拥有模块化与线性的可伸缩性,并且能够保证读写的严格一致性。HBase提供了一个Java API,可以实现轻松的客户端访问;提供了可配置且自动化的表分区功能;还有Bloom过滤器以及block缓存等特性。
9. Couchbase
虽然Couchbase是CouchDB的派生,不过它已经成为了一款功能完善的数据库产品。它向文档数据库转移的趋势会让MongoDB感到压力。每个节点上它都是多线程的,这是个非常主要的可伸缩性优势,特别是当托管在自定义或是Bare-Metal硬件上时更是如此。借助于一些非常棒的集成特性,诸如与Hadoop的集成,Couchbase对于数据存储来说是个非常不错的选择。
10. MemcacheDB
这是个分布式的键值存储系统,我们不应该将其与缓存解决方案搞混;相反,它是个持久化存储引擎,用于数据存储并以非常快速且可靠的方式检索数据。它遵循memcache协议。其存储后端用于Berkeley DB中,支持诸如复制与事务等特性。
11. REVENDB
RAVENDB是第二代开源数据库,它面向文档存储并且无模式,这样就可以轻松将对象存储到其中了。它提供了非常灵活且快速的查询,通过对复制、多租与分片提供开箱即用的支持使得我们可以非常轻松地实现伸缩功能。它对ACID事务提供了完整的支持,同时又能保证数据的安全性。除了高性能之外,它还通过bundle提供了轻松的可扩展性。
12. Voldemort
这是个自动复制的分布式存储系统。它提供了自动化的数据分区功能,透明的服务器失败处理、可插拔的序列化功能、独立的节点、数据版本化以及跨越各种数据中心的数据分发功能。
各位InfoQ读者,不知在你的项目中曾经、现在或是未来使用了哪些NoSQL数据库。现今的NoSQL世界纷繁复杂,NoSQL数据库也多如牛毛,而且有一些数据库提供了相似的特性,本文所列出的只是其中比较有代表性的12款NoSQL产品。你是否使用过他们呢?是否使用了本文没有介绍的产品呢?他们有哪些特性打动了你,让你决定使用他们呢?非常欢迎将你的经历与看法与我们一起分享。

12款免费与开源的NoSQL数据库介绍
本文来源于我在InfoQ中文站原创的文章,原文地址是:http://www.infoq.com/cn/news/2014/01/12-free-and-open-source-nosql
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,Naresh撰文谈到了12款知名的免费、开源Nosql数据库,并对这些数据库的特点进行了分析。
现在,Nosql数据库变得越来越流行,我在这里总结出了一些非常棒的、免费且开源的Nosql数据库。在这些数据库中,MongoDB独占鳌头,拥有相当大的使用量。这些免费且开源的Nosql数据库具有很好的可伸缩性与灵活性,非常适合于大数据存储与处理。相较于传统的关系型数据库,这些Nosql数据库在性能上具有很大的优势。然而,这些Nosql数据库未必最适合你。大多数常见的应用仍然可以使用传统的关系型数据库进行开发。Nosql数据库依然不太适合于那些任务关键型的事务要求。我对这些数据库进行了一些简单介绍,下面就来看看。
1. MongoDB
MongoDB是个面向文档的数据库,使用JSON风格的数据格式。它非常适合于网站的数据存储、内容管理与缓存应用,并且通过配置可以实现复制与高可用性功能。
MongoDB具有很强的可伸缩性,性能表现优异。它使用C++编写,基于文档存储。此外,MongoDB还支持全文检索、跨WAN与LAN的高可用性、易于实现的复制、水平扩展、基于文档的丰富查询、在数据处理与聚合等方面具有很强的灵活性。
2. Cassandra
这是个Apache软件基金会的项目,Cassandra是个分布式数据库,支持分散的数据存储,可以实现容错以及无单点故障等。换句话说,“Cassandra非常适合于那些无法忍受数据丢失的应用”。
3. CouchDB
这也是Apache软件基金会的一个项目,CouchDB是另一个面向文档的数据库,以JSON格式存储数据。它兼容于ACID,像MongoDB一样,CouchDB也可以用于存储网站的数据与内容,以及提供缓存等。你可以通过JavaScript在CouchDB上运行MapReduce查询。此外,CouchDB还提供了一个非常方便的基于Web的管理控制台。它非常适合于Web应用。
4. Hypertable
Hypertable模仿的是Google的BigTable数据库系统。Hypertable的创建者将“成为高可用、PB规模的数据库开源标准”作为Hypertable的目标。换言之,Hypertable的设计目标是跨越多个廉价的服务器可靠地存储大量数据。
5. Redis
这是个开源、高级的键值存储。由于在键中使用了hash、set、string、sorted set及list,因此Redis也称作数据结构服务器。这个系统可以帮助你执行原子操作,比如说增加hash中的值、集合的交集运算、字符串拼接、差集与并集等。Redis通过内存中的数据集实现了高性能。此外,该数据库还兼容于大多数编程语言。
6. Riak
Riak是最为强大的分布式数据库之一,它提供了轻松且可预测的伸缩能力,向用户提供了快速测试、原型与应用部署能力,从而简化应用的开发过程。
7. Neo4j
Neo4j是一款Nosql图型数据库,具有非常高的性能。它拥有一个健壮且成熟的系统的所有特性,向程序员提供了灵活且面向对象的网络结构,可以让开发者充分享受到拥有完整事务特性的数据库的所有好处。相较于RDBMS,Neo4j还对某些应用提供了不少性能改进。
8. Hadoop HBase
HBase是一款可伸缩、分布式的大数据存储。它可以用在数据的实时与随机访问的场景下。HBase拥有模块化与线性的可伸缩性,并且能够保证读写的严格一致性。HBase提供了一个Java API,可以实现轻松的客户端访问;提供了可配置且自动化的表分区功能;还有Bloom过滤器以及block缓存等特性。
9. Couchbase
虽然Couchbase是CouchDB的派生,不过它已经成为了一款功能完善的数据库产品。它向文档数据库转移的趋势会让MongoDB感到压力。每个节点上它都是多线程的,这是个非常主要的可伸缩性优势,特别是当托管在自定义或是Bare-Metal硬件上时更是如此。借助于一些非常棒的集成特性,诸如与Hadoop的集成,Couchbase对于数据存储来说是个非常不错的选择。
10. MemcacheDB
这是个分布式的键值存储系统,我们不应该将其与缓存解决方案搞混;相反,它是个持久化存储引擎,用于数据存储并以非常快速且可靠的方式检索数据。它遵循memcache协议。其存储后端用于Berkeley DB中,支持诸如复制与事务等特性。
11. REvendB
RAvendB是第二代开源数据库,它面向文档存储并且无模式,这样就可以轻松将对象存储到其中了。它提供了非常灵活且快速的查询,通过对复制、多租与分片提供开箱即用的支持使得我们可以非常轻松地实现伸缩功能。它对ACID事务提供了完整的支持,同时又能保证数据的安全性。除了高性能之外,它还通过bundle提供了轻松的可扩展性。
12. Voldemort
这是个自动复制的分布式存储系统。它提供了自动化的数据分区功能,透明的服务器失败处理、可插拔的序列化功能、独立的节点、数据版本化以及跨越各种数据中心的数据分发功能。
各位InfoQ读者,不知在你的项目中曾经、现在或是未来使用了哪些Nosql数据库。现今的Nosql世界纷繁复杂,Nosql数据库也多如牛毛,而且有一些数据库提供了相似的特性,本文所列出的只是其中比较有代表性的12款Nosql产品。你是否使用过他们呢?是否使用了本文没有介绍的产品呢?他们有哪些特性打动了你,让你决定使用他们呢?非常欢迎将你的经历与看法与我们一起分享。

12款免费与开源的NoSQL数据库介绍_MySQL
NoSQL
Naresh Kumar是位软件工程师与热情的博主,对于编程与新事物拥有极大的兴趣,非常乐于与其他开发者和程序员分享技术上的研究成果。近日,Naresh撰文谈到了12款知名的免费、开源NoSQL数据库,并对这些数据库的特点进行了分析。

现在,NoSQL数据库变得越来越流行,我在这里总结出了一些非常棒的、免费且开源的NoSQL数据库。在这些数据库中,MongoDB独占鳌头,拥有相当大的使用量。这些免费且开源的NoSQL数据库具有很好的可伸缩性与灵活性,非常适合于大数据存储与处理。相较于传统的关系型数据库,这些NoSQL数据库在性能上具有很大的优势。然而,这些NoSQL数据库未必最适合你。大多数常见的应用仍然可以使用传统的关系型数据库进行开发。NoSQL数据库依然不太适合于那些任务关键型的事务要求。我对这些数据库进行了一些简单介绍,下面就来看看。
1. MongoDB
MongoDB是个面向文档的数据库,使用JSON风格的数据格式。它非常适合于网站的数据存储、内容管理与缓存应用,并且通过配置可以实现复制与高可用性功能。
MongoDB具有很强的可伸缩性,性能表现优异。它使用C++编写,基于文档存储。此外,MongoDB还支持全文检索、跨WAN与LAN的高可用性、易于实现的复制、水平扩展、基于文档的丰富查询、在数据处理与聚合等方面具有很强的灵活性。
2. Cassandra
这是个Apache软件基金会的项目,Cassandra是个分布式数据库,支持分散的数据存储,可以实现容错以及无单点故障等。换句话说,“Cassandra非常适合于那些无法忍受数据丢失的应用”。
3. CouchDB
这也是Apache软件基金会的一个项目,CouchDB是另一个面向文档的数据库,以JSON格式存储数据。它兼容于ACID,像MongoDB一样,CouchDB也可以用于存储网站的数据与内容,以及提供缓存等。你可以通过JavaScript在CouchDB上运行MapReduce查询。此外,CouchDB还提供了一个非常方便的基于Web的管理控制台。它非常适合于Web应用。
4. Hypertable
Hypertable模仿的是Google的BigTable数据库系统。Hypertable的创建者将“成为高可用、PB规模的数据库开源标准”作为Hypertable的目标。换言之,Hypertable的设计目标是跨越多个廉价的服务器可靠地存储大量数据。
5. Redis
这是个开源、高级的键值存储。由于在键中使用了hash、set、string、sorted set及list,因此Redis也称作数据结构服务器。这个系统可以帮助你执行原子操作,比如说增加hash中的值、集合的交集运算、字符串拼接、差集与并集等。Redis通过内存中的数据集实现了高性能。此外,该数据库还兼容于大多数编程语言。
6. Riak
Riak是最为强大的分布式数据库之一,它提供了轻松且可预测的伸缩能力,向用户提供了快速测试、原型与应用部署能力,从而简化应用的开发过程。
7. Neo4j
Neo4j是一款NoSQL图型数据库,具有非常高的性能。它拥有一个健壮且成熟的系统的所有特性,向程序员提供了灵活且面向对象的网络结构,可以让开发者充分享受到拥有完整事务特性的数据库的所有好处。相较于RDBMS,Neo4j还对某些应用提供了不少性能改进。
8. Hadoop HBase
HBase是一款可伸缩、分布式的大数据存储。它可以用在数据的实时与随机访问的场景下。HBase拥有模块化与线性的可伸缩性,并且能够保证读写的严格一致性。HBase提供了一个Java API,可以实现轻松的客户端访问;提供了可配置且自动化的表分区功能;还有Bloom过滤器以及block缓存等特性。
9. Couchbase
虽然Couchbase是CouchDB的派生,不过它已经成为了一款功能完善的数据库产品。它向文档数据库转移的趋势会让MongoDB感到压力。每个节点上它都是多线程的,这是个非常主要的可伸缩性优势,特别是当托管在自定义或是Bare-Metal硬件上时更是如此。借助于一些非常棒的集成特性,诸如与Hadoop的集成,Couchbase对于数据存储来说是个非常不错的选择。
10. MemcacheDB
这是个分布式的键值存储系统,我们不应该将其与缓存解决方案搞混;相反,它是个持久化存储引擎,用于数据存储并以非常快速且可靠的方式检索数据。它遵循memcache协议。其存储后端用于Berkeley DB中,支持诸如复制与事务等特性。
11. REVENDB
RAVENDB是第二代开源数据库,它面向文档存储并且无模式,这样就可以轻松将对象存储到其中了。它提供了非常灵活且快速的查询,通过对复制、多租与分片提供开箱即用的支持使得我们可以非常轻松地实现伸缩功能。它对ACID事务提供了完整的支持,同时又能保证数据的安全性。除了高性能之外,它还通过bundle提供了轻松的可扩展性。
12. Voldemort
这是个自动复制的分布式存储系统。它提供了自动化的数据分区功能,透明的服务器失败处理、可插拔的序列化功能、独立的节点、数据版本化以及跨越各种数据中心的数据分发功能。
各位读者,不知在你的项目中曾经、现在或是未来使用了哪些NoSQL数据库。现今的NoSQL世界纷繁复杂,NoSQL数据库也多如牛毛,而且有一些数据库提供了相似的特性,本文所列出的只是其中比较有代表性的12款NoSQL产品。你是否使用过他们呢?是否使用了本文没有介绍的产品呢?他们有哪些特性打动了你,让你决定使用他们呢?非常欢迎将你的经历与看法与我们一起分享。
今天关于MapR提供免费NoSQL数据库(英文)和on primary数据库的分享就到这里,希望大家有所收获,若想了解更多关于12个最好的免费和开源的NoSQL数据库、12款免费与开源的NoSQL数据库、12款免费与开源的NoSQL数据库介绍、12款免费与开源的NoSQL数据库介绍_MySQL等相关知识,可以在本站进行查询。
在本文中,我们将给您介绍关于《NoSQL精粹》读后感的详细内容,并且为您解答一的相关问题,此外,我们还将为您提供关于
(nosql入门)")
《NoSQL精粹》读后感(一)(nosql入门)
《Nosql精粹》是Martin Fowler和他的同事两年前合写的,看过《重构》等书的应该都对Fowler的能力和写作无可挑剔。
大家都在沸沸扬扬的讨论Nosql,那究竟什么是Nosql?作者给出了一种观点(Fowler给出的观点我认为还是比较权威的),首先Nosql现有没有一个明确的定义,以后也不可能有;但是它具有一些共同的特征:
1、正如其名,它不应该使用sql,虽然可以类似于sql,那是为了习惯大家的操作;
2、应该是开源的,虽然确实有一些非开源的,但至少至今,大家都认为它应该开源;像HBase、Redis、mongoDB不都是开源的吗
3、它应该允许在集群上,因为它产生的原因就是由于关系型数据与集群间的矛盾,当然,也有一些不能很好支持集群,比如图数据库;
4、无模式,也就是没有固定的字段,可以随时随意增减;
5、最后作者认为它具有时代性,特指21世纪出产生的数据,那是因为不加这个时代特征,光凭上述几个特点总有一些80、90年代的数据库恰好中奖,而从我们现在讨论的范围来看,那些确实不应该称之为Nosql。
总体而言,一句话粗略来说就是21世纪初诞生的为了解决大数据运行在集群上的数据库。
另外,作者还表述了一种观点,这个观点应该是全书的一个基调,那就是关系型数据库和Nosql的生存问题。首先,作者认为关系数据库不会灭亡,而且还是很好的生存、发展下去;但是,它的绝对统治地位是保不住了,Nosql不会是昙花一现,我们作为开发人员,今后将从过去的“选择哪个关系数据库”变为“选择关系数据库or Nosql”。关于这点,有一个常用词叫polyglot persistence,直译是多种(数据库)语言持久化,译者称为“混合持久化”。
为什么关系数据库不会消失?它在诞生之初,就具有四个极具创新的优点:数据持久化、事务、共享数据和标准得无可挑剔的sql。这四个优点使得它在当时打败了其它的竞争对手,存活了40多年(从1970关系模型提出开始计算的话),大家已经使用的熟悉不能再熟悉了,就好比你用了c++多年,又没出现什么大问题,你会轻易换你的编程语言吗?不要小看这个熟悉性,90年代其实出现过对象数据库,但是遗憾的是我现在真的听都没听过。(如果把关系型数据库看作一个产品的话,我觉得他就是微信,虽然有很多缺点,但是它做得确实挺好用,如果不是为了泡妞,你也不会换用陌陌,更别提来往和米聊)
然而,关系型数据又具有两个一直为人诟病并不可解决的大问题:第一个是与面向对象模型毫不匹配,译者使用了一个词叫做“阻抗失谐”,原文是mismatch,翻译为失谐我觉得还是不错的;第二是它并不能很好运行在集群上,而如今的数据量已经不同往日,不然阿里为何突然要花大力气去IOE。(其实我觉得,Nosql真正流行可能是第二个原因更为重要)
后面,作者把Nosql总结性的归为四类:键值对数据库(比如Redis)、文档数据库(如mongoDB)、列族数据库(如HBase)、图数据库(如OrientDB)。然后后面章节逐一详细介绍。
PS:里面掺杂了一些我的个人看法,如果不对或者与原作者有出入的,请原谅勿喷。

---sadalage/fowler
主要讲了nosql各个框架的优缺点,特别与RDBMS做了比较,简略说明了哪些东西适合哪个框架以及nosql的ACID问题
第一章
关系型数据库确实提供了很多好的机制,在持久化和控制并发以及事务上有很好的处理但是从根本的角度,关系模型和内存中的数据结构(键值对)生来就不匹配,或者称为"阻抗失谐".虽然后期出现了ORM框架来改善这种阻抗失谐,但是高并发查询/修改多关系的表时,就遇到了数据库的瓶颈.此时nosql就能改善这个问题(当然要基于良好的框架选择和优良的"存储模式"),特别是在集群中,nosql更好
第二章
面向关系和面向聚合.在集群中,key是采集数据时所需节点数降至最小,nosql在此时就非常强大了,因为可以把聚合包含的信息弄大一点,包含很多东西(具体看业务需求).键值数据模型(redis)查询时获取整个聚合,文档数据模型(MongoDB)可以只获取部分聚合,还可以创建聚合内容的索引.为保证事务,最好以聚合为最小数据单位操作.所以如果数据交互大多在同一聚合内执行的,可以用面向聚合的数据库(nosql大多都是).
第三章
物化视图/映射化简,就像索引一样,预先准备好业务上要查询的数据,执行时直接拿.nosql这点上比rdbms好,因为它已经持久化了一份.面向聚合的数据库在处理聚合之间的关系时,显得有点棘手.
第六章
不用事务,用版本戳代替,实现离线的并发实现,很好的解决了锁带来的性能问题.
第八章
键值数据库适合存放 会话信息 用户配置信息 购物车数据.不适合数据间关系,含有多项关键操作的事务.查询键值对的某部分值来搜寻关键字(可用lucene等)
nosql目前还是属于年轻的东西,如果目前能忍受的情况下,尽量用RDBMS,因为20多年的积累,相关问题肯定有专家的解决方案
")
Mysql实例Mysql精粹系列(精粹)
《MysqL实例MysqL精粹系列(精粹)》要点:
本文介绍了MysqL实例MysqL精粹系列(精粹),希望对您有用。如果有疑问,可以联系我们。
MysqL实例关于MysqL整理的需要记忆和熟练掌握的内容
MysqL实例1. /* 查看操作 */ ------------------------------------------------------------------------------------------------------- 1. /* 查看操作 */
MysqL实例
SHOW PROCESSLIST -- 显示哪些线程正在运行
SHOW VARIABLES -- 查看变量
MysqL实例2. /* 数据库操作 */ ------------------------------------------------------------------------------------------------------ 2. /* 数据库操作 */
MysqL实例
-- 查看当前数据库
select database();
-- 显示当前时间、用户名、数据库版本
select Now(),user(),version();
-- 复制表结构
CREATE TABLE 表名 LIKE 要复制的表名
-- 复制表结构和数据
CREATE TABLE 表名 [AS] SELECT * FROM 要复制的表名
MysqL实例3. /* 字符集编码 */ --------------------------------------------------------------------------------------------------------- 3. /* 字符集编码 */
MysqL实例
字符编码
-- MysqL、数据库、表、字段均可设置编码
-- 数据编码与客户端编码不需一致
SHOW VARIABLES LIKE 'character_set_%' -- 查看所有字符集编码项
character_set_client 客户端向服务器发送数据时使用的编码
character_set_results 服务器端将结果返回给客户端所使用的编码
character_set_connection 连接层编码
SET 变量名 = 变量值
set character_set_client = gbk;
set character_set_results = gbk;
set character_set_connection = gbk;
SET NAMES GBK; -- 相当于完成以上三个设置
MysqL实例4./* 数据类型(列类型) */ ---------------------------------------------------------------------------------------------------4. /* 数据类型(列类型) */
MysqL实例
1) 数值类型
int 4字节
bigint 8字节
int(M) M表示总位数
- 默认存在符号位,unsigned 属性修改
- 显示宽度,如果某个数不够定义字段时设置的位数,则前面以0补填,zerofill 属性修改
例:int(5) 插入一个数'123',补填后为'00123'
- 在满足要求的情况下,越小越好.
- 1表示bool值真,0表示bool值假.MysqL没有布尔类型,通过整型0和1表示.常用tinyint(1)表示布尔型.
2) 字符串类型
-- a. char,varchar ----------
char 定长字符串,速度快,但浪费空间
varchar 变长字符串,速度慢,但节省空间
M表示能存储的最大长度,此长度是字符数,非字节数.
不同的编码,所占用的空间不同.
char,最多255个字符,与编码无关.
varchar,最多65535字符,与编码有关.
一条有效记录最大不能超过65535个字节.
utf8 最大为21844个字符,gbk 最大为32766个字符,latin1 最大为65532个字符
varchar 是变长的,需要利用存储空间保存 varchar 的长度,如果数据小于255个字节,则采用一个字节来保存长度,反之需要两个字节来保存.
varchar 的最大有效长度由最大行大小和使用的字符集确定.
最大有效长度是65532字节,因为在varchar存字符串时,第一个字节是空的,不存在任何数据,然后还需两个字节来存放字符串的长度,所以有效长度是64432-1-2=65532字节.
例:若一个表定义为 CREATE TABLE tb(c1 int,c2 char(30),c3 varchar(N)) charset=utf8; 问N的最大值是多少? 答:(65535-1-2-4-30*3)/3
MysqL实例5./* 建表规范 */ ------------------------------------------------------------------------------------------------------------------ 5./* 建表规范 */
MysqL实例
-- normal Format,NF
- 每个表保存一个实体信息
- 每个具有一个ID字段作为主键
- ID主键 + 原子表
-- 1NF,第一范式
字段不能再分,就满足第一范式.
-- 2NF,第二范式
满足第一范式的前提下,不能出现部分依赖.
消除符合主键就可以避免部分依赖.增加单列关键字.
-- 3NF,第三范式
满足第二范式的前提下,不能出现传递依赖.
某个字段依赖于主键,而有其他字段依赖于该字段.这就是传递依赖.
将一个实体信息的数据放在一个表内实现.
MysqL实例6./* select 查询语句*/ -------------------------------------------------------------------------------------------------------- 6./* select 查询语句*/
MysqL实例
1) having 子句,条件子句
与 where 功能、用法相同,执行时机不同.
where 在开始时执行检测数据,对原数据进行过滤.
having 对筛选出的结果再次进行过滤.
having 字段必须是查询出来的,where 字段必须是数据表存在的.
where 不可以使用字段的别名,having 可以.因为执行WHERE代码时,可能尚未确定列值.
where 不可以使用合计函数.一般需用合计函数才会用 having
sql标准要求HAVING必须引用GROUP BY子句中的列或用于合计函数中的列.
MysqL实例7./* 备份与还原 */ ------------------------------------------------------------------------------------------------------------- 7./* 备份与还原 */
MysqL实例
备份,将数据的结构与表内数据保存起来.
利用 MysqLdump 指令完成.
-- 导出
1) 导出一张表
MysqLdump -u用户名 -p暗码 库名 表名 > 文件名(D:/a.sql)
2)导出多张表
MysqLdump -u用户名 -p暗码 库名 表1 表2 表3 > 文件名(D:/a.sql)
3)导出所有表
MysqLdump -u用户名 -p暗码 库名 > 文件名(D:/a.sql)
4)导出一个库
MysqLdump -u用户名 -p暗码 -B 库名 > 文件名(D:/a.sql)
可以-w携带备份条件
-- 导入
1)在登录MysqL的情况下:
source 备份文件
2)在不登录的情况下
MysqL -u用户名 -p暗码 库名 < 备份文
MysqL实例8./* 锁表 */ ------------------------------------------------------------------------------------------------------------------ 8./* 锁表 */
MysqL实例
表锁定只用于防止其它客户端进行不正当地读取和写入
MyISAM 支持表锁,InnoDB 支持行锁
-- 锁定
LOCK TABLES tbl_name [AS alias]
-- 解锁
UNLOCK TABLES
MysqL实例9./* 用户和权限管理 */ -------------------------------------------------------------------------------------------------------- 9./* 用户和权限管理 */
MysqL实例
用户信息表:MysqL.user
-- 刷新权限
FLUSH PRIVILEGES
-- 增加用户
CREATE USER 用户名 IDENTIFIED BY [PASSWORD] 暗码(字符串)
- 必须拥有MysqL数据库的全局CREATE USER权限,或拥有INSERT权限.
- 只能创建用户,不能赋予权限.
- 用户名,注意引号:如 'user_name'@'192.168.1.1'
- 暗码也需引号,纯数字暗码也要加引号
- 要在纯文本中指定暗码,需忽略PASSWORD关键词.要把暗码指定为由PASSWORD()函数返回的混编值,需包含关键字PASSWORD
-- 重命名用户
RENAME USER old_user TO new_user
-- 设置暗码
SET PASSWORD = PASSWORD('暗码') -- 为当前用户设置暗码
SET PASSWORD FOR 用户名 = PASSWORD('暗码') -- 为指定用户设置暗码
-- 删除用户
DROP USER 用户名
-- 分配权限/添加用户
GRANT 权限列表 ON 表名 TO 用户名 [IDENTIFIED BY [PASSWORD] 'password']
- all privileges 表示所有权限
- *.* 表示所有库的所有表
- 库名.表名 表示某库下面的某表
-- 查看权限
SHOW GRANTS FOR 用户名
-- 查看当前用户权限
SHOW GRANTS; 或 SHOW GRANTS FOR CURRENT_USER; 或 SHOW GRANTS FOR CURRENT_USER();
-- 撤消权限
REVOKE 权限列表 ON 表名 FROM 用户名
REVOKE ALL PRIVILEGES,GRANT OPTION FROM 用户名 -- 撤销所有权限
-- 权限层级
-- 要使用GRANT或REVOKE,您必须拥有GRANT OPTION权限,并且您必须用于您正在授予或撤销的权限.
全局层级:全局权限适用于一个给定服务器中的所有数据库,MysqL.user
GRANT ALL ON *.*和 REVOKE ALL ON *.*只授予和撤销全局权限.
数据库层级:数据库权限适用于一个给定数据库中的所有目标,MysqL.db,MysqL.host
GRANT ALL ON db_name.*和REVOKE ALL ON db_name.*只授予和撤销数据库权限.
表层级:表权限适用于一个给定表中的所有列,MysqL.talbes_priv
GRANT ALL ON db_name.tbl_name和REVOKE ALL ON db_name.tbl_name只授予和撤销表权限.
列层级:列权限适用于一个给定表中的单一列,MysqL.columns_priv
当使用REVOKE时,您必须指定与被授权列相同的列.
MysqL实例以上所述是小编给大家介绍的MysqL精粹系列(精粹),希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对小编PHP网站的支持!
《MysqL实例MysqL精粹系列(精粹)》是否对您有启发,欢迎查看更多与《MysqL实例MysqL精粹系列(精粹)》相关教程,学精学透。小编 jb51.cc为您提供精彩教程。
")
MySQL精讲与实战(一)
MySQL逻辑架构


NoSQL精粹_中文完整版
关于《NoSQL精粹》读后感和一的介绍现已完结,谢谢您的耐心阅读,如果想了解更多关于
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

