本篇文章给大家谈谈SQL聚合函数子查询,以及sql聚合函数条件查询的知识点,同时本文还将给你拓展MySQLPHP:优化排名查询和计数子查询、MySQL分组,聚合函数,连表查询,子查询、MySQL操作之
本篇文章给大家谈谈SQL聚合函数子查询,以及sql 聚合函数条件查询的知识点,同时本文还将给你拓展MySQL PHP:优化排名查询和计数子查询、MySQL分组,聚合函数,连表查询,子查询、MySQL操作之条件,排序,分页,聚合函数,分组,连接,子查询,自连接查询总结、MySQL查询排序与查询聚合函数用法分析等相关知识,希望对各位有所帮助,不要忘了收藏本站喔。
本文目录一览:- SQL聚合函数子查询(sql 聚合函数条件查询)
- MySQL PHP:优化排名查询和计数子查询
- MySQL分组,聚合函数,连表查询,子查询
- MySQL操作之条件,排序,分页,聚合函数,分组,连接,子查询,自连接查询总结
- MySQL查询排序与查询聚合函数用法分析
")
SQL聚合函数子查询(sql 聚合函数条件查询)
我想要做的是计算子查询返回的行数,本质上如下:
select pp.prop_id, COUNT((select employee_id from employee e where e.ao1_hours > 0)) from proposal_piece pp group by pp.prop_id order by pp.prop_id这是我的错误信息:
Cannot perform an aggregate function on an expression containing an aggregate or a subquery.为什么这不起作用?如果select仅返回一堆employee_id''s具有过滤条件的行employee_id''s,为什么我不能计算行数或返回的行数?
我正在计算拥有的不同员工的数量ao1_hours > 0。按分组prop。
这是有关我的数据库的一些结构信息,作为查询的一部分。
from proposal_piece pp INNER JOIN employee e on pp.employee_id = e.employee_id谢谢!
答案1
小编典典试试这个
select pp.prop_id, (select COUNT(employee_id) from employee e where e.ao1_hours > 0 and e.employee_id = pp.employee_id) as nb_employeesfrom proposal_piece pp order by pp.prop_id或这个
select pp.prop_id, count(e.employee_id) as nb_employees from proposal_piece pp inner join employee e on pp.employee_id = e.employee_idwhere e.ao1_hours > 0group by pp.prop_idorder by pp.prop_id
MySQL PHP:优化排名查询和计数子查询
这是原始数据,并希望根据得分(count(tbl_1.id))对它们进行排名.
[tbl_1]
===========
id | name
===========
1 | peter
2 | jane
1 | peter
2 | jane
3 | harry
3 | harry
3 | harry
3 | harry
4 | ron
因此,制作临时表(tbl_2)来计算每个id的分数.
SELECT id, name, COUNT( id ) AS score
FROM tbl_1
GROUP BY id
ORDER BY score DESC;
LIMIT 0, 30;
然后结果是;
[tbl_2]
===================
id | name | score
===================
3 | harry | 4
1 | peter | 2
2 | jane | 2
4 | ron | 1
然后查询这个;
SELECT v1.id, v1.name, v1.score, COUNT( v2.score ) AS rank
FROM Votes v1
JOIN Votes v2 ON v1.score < v2.score
OR (
v1.score = v2.score
AND v1.id = v2.id
)
GROUP BY v1.id, v1.score
ORDER BY v1.rank ASC, v1.id ASC
LIMIT 0, 30;
然后结果是;
==========================
id | name | score | rank
==========================
3 | harry | 4 | 1
1 | peter | 2 | 2
2 | jane | 2 | 2
4 | ron | 1 | 4
是否可以很好地在一个事务(查询)中执行此操作?
解决方法:
是的,可以在单个查询中执行此操作.但它在MysqL中是一个完整的毛球,因为MysqL没有简单的ROWNUM操作,你需要一个用于排名计算.
这是您显示排名的投票查询. @ranka变量用于对行进行编号.
SELECT @ranka:=@ranka+1 AS rank, id, name, score
FROM
(
SELECT id,
name,
COUNT( id ) AS score
FROM tbl_1
GROUP BY id
ORDER BY score DESC, id
) Votes,
(SELECT @ranka:=0) r
正如您已经发现的那样,您需要自行加入此项以获得正确的排名(正确处理关系).因此,如果您接受查询并将两个引用替换为您的投票表,每个引用都有自己的子查询版本,那么您将获得所需的内容.
SELECT v1.id,
v1.name,
v1.score,
COUNT( v2.score ) AS rank
FROM (
SELECT @ranka:=@ranka+1 AS rank,
id,
name,
score
FROM
(
SELECT id,
name,
COUNT( id ) AS score
FROM tbl_1
GROUP BY id
ORDER BY score DESC, name
) Votes,
(SELECT @ranka:=0) r) v1
JOIN (
SELECT @rankb:=@rankb+1 AS rank,
id,
name,
score
FROM
(
SELECT id,
name,
COUNT( id ) AS score
FROM tbl_1
GROUP BY id
ORDER BY score DESC, name
) Votes,
(SELECT @rankb:=0) r) v2
ON (v1.score < v2.score) OR
(v1.score = v2.score AND v1.id = v2.id)
GROUP BY v1.id, v1.score
ORDER BY v1.rank ASC, v1.id ASC
LIMIT 0, 30;
告诉你这是一个毛球.请注意,在您自行加入的子查询的两个版本中需要不同的@ranka和@rankb变量,以使行编号正常工作:这些变量在MysqL中具有连接范围,而不是子查询范围.
http://sqlfiddle.com/#!2/c5350/1/0显示了这个工作.
编辑:使用Postgresql的RANK()函数更容易做到这一点.
SELECT name, Votes, rank() over (ORDER BY Votes)
FROM (
SELECT name, count(id) Votes
FROM tab
GROUP BY name
)x
http://sqlfiddle.com/#!1/94cca/18/0

MySQL分组,聚合函数,连表查询,子查询
>>>分组:
set global sql_mode="strict_trans_tables,only_full_group_by"; 更改数据库模式,在分组后,只能显示被分组字段和使用聚合函数选取出来的字段.
group by + group_concat

分组:类似于将一个班级的学生,按照性别或其他条件,分成若干个组,最终以小组为单位显示,如上图中,以post字段对表进行分组,若想在分组后,操作每个组内的数据,有两种方式,一种是通过聚合函数(max,min,avg,sum),一种是group_concat.
聚合函数(max,min,avg,sum)
max:取每个组内某个字段值的最大值
min:取每个组内某个字段值的最小值
avg:求第个组的内某个字段值的平均值
sum:求每个组内某个字段值的和
group_concat:可以提取分组中的字段,并可以将值与值进行拼接显示.
having:必须在group by 之后,作用是,对分组后的数据,进行再次筛选
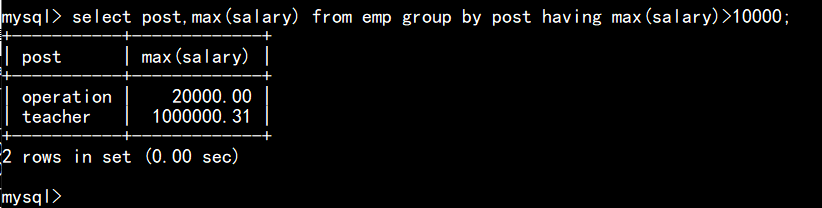
如上图:求每个部门中薪资最高的人,且只保留薪资大于10000的人
>>>连表查询
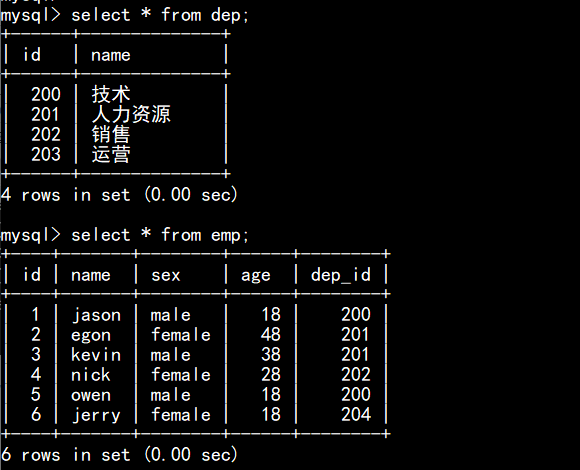
inner join:内连接:只取两张表有对应关系的记录
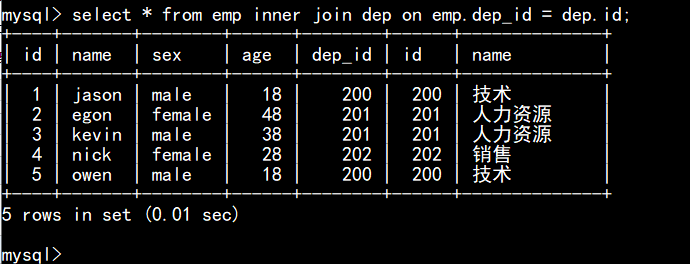
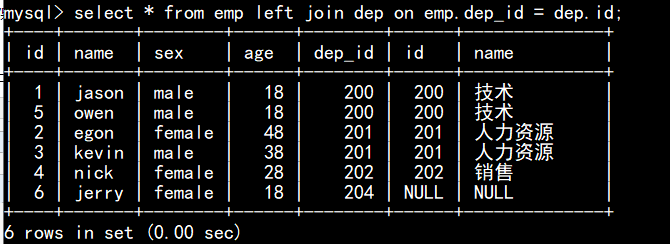
left join:左连接: 在内连接的基础上保留左表没有对应关系的记录
right join:右连接: 在内连接的基础上保留右表没有对应关系的记录
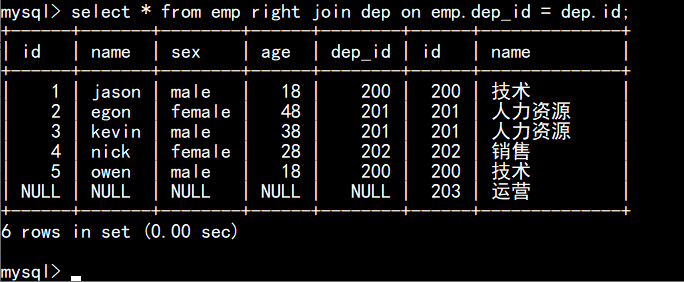
union:全连接:在内连接的基础上保留左、右面表没有对应关系的的记录
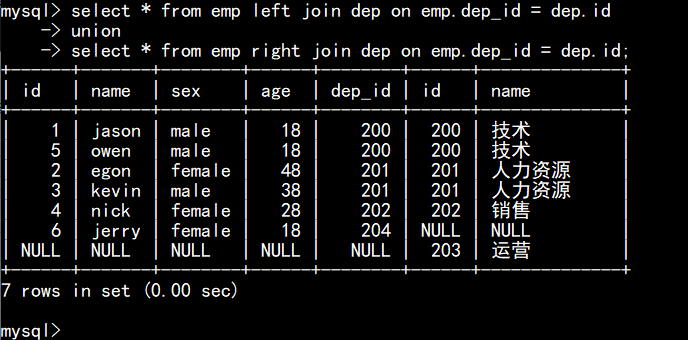
>>>子查询
将表1的查询结果,做为表2的查询条件,即为子查询.
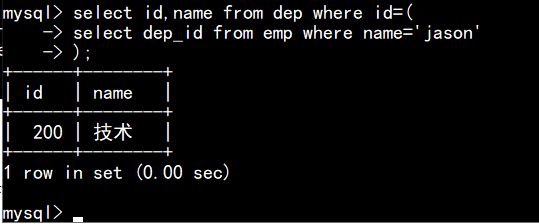
如图:查询员工jason所在的部门.

MySQL操作之条件,排序,分页,聚合函数,分组,连接,子查询,自连接查询总结
-- 查询练习
-- 查询所有字段
-- select * from 表名;
select * from students;
-- 查询指定字段
-- select 列1,列2,... from 表名;
select name,gender from students;
-- 使用 as 给字段起别名
-- select 字段 as 名字.... from 表名;
select name as "姓名",gender as "性别" from students;
-- select 表名.字段 .... from 表名;
select students.name,students.gender from students;
-- 可以通过 as 给表起别名
-- select 别名.字段 .... from 表名 as 别名;
select s.name,s.gender from students as s;
失败的select students.name, students.age from students as s;
-- 消除重复行(查性别)
-- distinct 字段
select distinct gender from students;
-- 条件查询
-- 比较运算符
-- select .... from 表名 where .....
-- >
-- 查询大于18岁的信息
select * from students where age > 18;
-- <
-- 查询小于18岁的信息
select * from students where age < 18;
-- >=
-- <=
-- 查询小于或者等于18岁的信息
select * from students where age <= 18;
-- =
-- 查询年龄为18岁的所有学生的名字
select name,age from students where age = 18;
-- != 或者 <>
select * from students where age != 18;
select * from students where age <> 18;
-- 逻辑运算符
-- and
-- 18和28之间的所以学生信息
select * from students where age > 18 and age < 28;
失败select * from students where age>18 and <28;
select * from students where 18<age<28;
-- 18岁以上的女性
select * from students where age > 18 and gender=2;
-- or
-- 18以上或者身高高过180(包含)以上
select * from students where age > 18 or height >= 180;
-- not
-- 不在 18岁以上的女性 这个范围内的信息
select * from students where not (age > 18 and gender = 2);
select * from students where not (age > 18 and gender = 2);(注意)
-- 模糊查询(where name like 要查询的数据)
-- like
-- % 替换任意个
-- _ 替换1个
-- 查询姓名中 以 "小" 开始的名字
select * from students where name like "小%";
-- 查询姓名中 有 "小" 所有的名字
select * from students where name like "%小%";
-- 查询有2个字的名字
select * from students where name like "__";
-- 查询有3个字的名字
select * from students where name like "___";
-- 查询至少有2个字的名字
select * from students where name like "__%";
-- 范围查询
-- in (1, 3, 8)表示在一个非连续的范围内
-- 查询 年龄为18、34的姓名
select name,age from students where age in (18,34);
-- not in 不非连续的范围之内
-- 年龄不是 18、34岁的信息
select name,age from students where age not in (18,34);
(注意)select name from students where not age in (18,34);
-- between ... and ...表示在一个连续的范围内
-- 查询 年龄在18到34之间的的信息
select * from students where age between 18 and 34;
-- not between ... and ...表示不在一个连续的范围内
-- 查询 年龄不在在18到34之间的的信息
select * from students where age not between 18 and 34;
失败的select * from students where age not (between 18 and 34);
-- 空判断
-- 判空is null
-- 查询身高为空的信息
select * from students where height is null;
-- 判非空is not null
select * from students where height is not null;
失败select * from students where height not is null;
-- 排序
-- order by 字段
-- asc从小到大排列,即升序
-- desc从大到小排序,即降序
-- 查询年龄在18到34岁之间的男性,按照年龄从小到大到排序(默认是asc升序)
select * from students where (age between 18 and 34) and gender = 1 order by age asc;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序
select * from students where (age between 18 and 34) and gender = 2 order by height desc;
-- order by 多个字段
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序
select * from students where (age between 18 and 34) and gender = 2 order by height desc,age;
-- 查询年龄在18到34岁之间的女性,身高从高到矮排序, 如果身高相同的情况下按照年龄从小到大排序,
-- 如果年龄也相同那么按照id从大到小排序
select * from students where (age between 18 and 34) and gender = 2 order by height desc,age,id desc;
-- 聚合函数
-- 总数
-- count
-- 查询男性有多少人,女性有多少人
select count(*) from students where gender=1;
select count(*) from students where gender=2;
-- 最大值
-- max
-- 查询最大的年龄
select max(age) from students;
-- 查询女性的最高 身高
select max(height) from students where gender=2;
-- 最小值
-- min
select min(height) from students;
-- 求和
-- sum
-- 计算所有人的年龄总和
select sum(age) from students;
-- 平均值
-- avg
-- 计算平均年龄
select avg(age) from students;
-- 计算平均年龄 sum(age)/count(*)
select sum(age)/count(*) from students;
-- 四舍五入 round(123.23 , 1) 保留1位小数
-- 计算所有人的平均年龄,保留2位小数
select round(avg(age),2) from students;
-- 计算男性的平均身高 保留2位小数
select round(avg(height),2) from students where gender=1;
-- 分组(重点)
-- group by
-- 按照性别分组,查询所有的性别
select gender from students group by gender;
select name,gender from students group by gender;错误
-- select name,gender from students group by gender;
-- 失败select * from students group by gender;
-- 计算每种性别中的人数
select count(*),gender from students group by gender;
-- group_concat(...)
-- 查询同种性别中的姓名
select gender,group_concat(name) from students group by gender;
-- 查询每组性别的平均年龄
select avg(age),gender from students group by gender;
-- 查询平均年龄超过30岁的性别,以及姓名 having avg(age) > 30(重点)
select gender,group_concat(name) from students group by gender having avg(age) > 30;
-- 查询每种性别的平均年龄和名字
select avg(age),group_concat(name) from students group by gender;
-- 查询每种性别中的人数多于2个的性别和姓名(重点)
select gender,group_concat(name) from students group by gender having count(*) > 2;
-- with rollup 汇总的作用(了解)
select gender,count(*) from students group by gender with rollup;
-- 分页
-- limit start, count
-- 限制查询出来的数据个数
-- 查询前5个数据
select * from students limit 5;
-- 每页显示2个,第1个页面
select * from students limit 0,2;
-- 每页显示2个,第2个页面
select * from students limit 2,2;
-- 每页显示2个,第3个页面
select * from students limit 4,2;
-- 每页显示2个,第4个页面
select * from students limit 6,2;
-- 每页显示2个,显示第6页的信息, 按照年龄从小到大排序
select * from students order by age asc limit 10,2;
错误1 select * from students limit 10,2 order by age asc;
-- 错误的写法
错误2 select * from students limit 2*(6-1),2;
-- limit 放在最后面(注意)
-- 连接查询(重点)
-- inner join ... on
-- select ... from 表A inner join 表B;
select * from students inner join classes;
-- 查询 有能够对应班级的学生以及班级信息
select * from students inner join classes on students.cls_id=classes.id;
-- 按照要求显示姓名、班级
select students.name,classes.name from students inner join classes on students.cls_id=classes.id;
-- 给数据表起名字
select s.name,c.name from students as s inner join classes as c on s.cls_id=c.id;
-- 查询 有能够对应班级的学生以及班级信息,显示学生的所有信息 students.*,只显示班级名称 classes.name.
select students.*,classes.name from students inner join classes on students.cls_id=classes.id;
-- 在以上的查询中,将班级姓名显示在第1列
select classes.name,students.* from students inner join classes on students.cls_id=classes.id;
-- 查询 有能够对应班级的学生以及班级信息, 按照班级进行排序
-- select c.xxx s.xxx from students as s inner join clssses as c on .... order by ....;
select classes.name,students.* from students inner join classes on students.cls_id=classes.id order by classes.name;
-- 当时同一个班级的时候,按照学生的id进行从小到大排序
select classes.name,students.* from students inner join classes on students.cls_id=classes.id order by classes.name,students.id;
-- left join
-- 查询每位学生对应的班级信息
select * from students inner join classes on students.cls_id=classes.id;
select * from students left join classes on students.cls_id=classes.id;
-- select * from students right join classes on students.cls_id = classes.id;
-- 查询没有对应班级信息的学生
-- select ... from xxx as s left join xxx as c on..... where .....
-- select ... from xxx as s left join xxx as c on..... having .....
select * from students left join classes on students.cls_id=classes.id where classes.id is null;
(注意)不建议使用 select * from students left join classes on students.cls_id=classes.id having classes.id is null;
-- right join on
-- 将数据表名字互换位置,用left join完成
-- 子查询
-- 标量子查询: 子查询返回的结果是一个数据(一行一列)
-- 列子查询: 返回的结果是一列(一列多行)
-- 行子查询: 返回的结果是一行(一行多列)
-- 查询出高于平均身高的信息(height)
-- 1 查出平均身高
select avg(height) from students;
-- 2 查出高于平均身高的信息
select * from students where height > (select avg(height) from students);
-- 查询学生的班级号能够对应的 学生名字
-- select name from students where cls_id in (select id from classes);
-- 1 查出所有的班级id
select id from classes;
(1,2)
-- 2 查出能够对应上班级号的学生信息
select * from students where cls_id in (select id from classes);

MySQL查询排序与查询聚合函数用法分析
本文实例讲述了MySQL查询排序与查询聚合函数用法。分享给大家供大家参考,具体如下:
排序
为了方便查看数据,可以对数据进行排序
语法:
select * from 表名 order by 列1 asc|desc [,列2 asc|desc,...]
说明
将行数据按照列1进行排序,如果某些行列1的值相同时,则按照列2排序,以此类推
- 默认按照列值从小到大排列(asc)
- asc从小到大排列,即升序
- desc从大到小排序,即降序
例1:查询未删除男生信息,按学号降序
select * from students where gender=1 and is_delete=0 order by id desc;
例2:查询未删除学生信息,按名称升序
select * from students where is_delete=0 order by name;
例3:显示所有的学生信息,先按照年龄从大–>小排序,当年龄相同时 按照身高从高–>矮排序
select * from students order by age desc,height desc;
聚合函数
为了快速得到统计数据,经常会用到如下5个聚合函数
总数
count(*)表示计算总行数,括号中写星与列名,结果是相同的
例1:查询学生总数
select count(*) from students;
最大值
max(列)表示求此列的最大值
例2:查询女生的编号最大值
select max(id) from students where gender=2;
最小值
min(列)表示求此列的最小值
例3:查询未删除的学生最小编号
select min(id) from students where is_delete=0;
求和
sum(列)表示求此列的和
例4:查询男生的总年龄
select sum(age) from students where gender=1; -- 平均年龄 select sum(age)/count(*) from students where gender=1;
平均值
avg(列)表示求此列的平均值
例5:查询未删除女生的编号平均值
select avg(id) from students where is_delete=0 and gender=2;
更多关于MySQL相关内容感兴趣的读者可查看本站专题:《MySQL查询技巧大全》、《MySQL常用函数大汇总》、《MySQL日志操作技巧大全》、《MySQL事务操作技巧汇总》、《MySQL存储过程技巧大全》及《MySQL数据库锁相关技巧汇总》
希望本文所述对大家MySQL数据库计有所帮助。
- 深入了解MySQL中聚合函数的使用
- MySQL 聚合函数排序
- MySQL 分组查询和聚合函数
- Mysql 聚合函数嵌套使用操作
- MySQL使用聚合函数进行单表查询
- MySQL中聚合函数count的使用和性能优化技巧
- MySql 中聚合函数增加条件表达式的方法
- MySQL常用聚合函数详解
- Mysql聚合函数的使用介绍
关于SQL聚合函数子查询和sql 聚合函数条件查询的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于MySQL PHP:优化排名查询和计数子查询、MySQL分组,聚合函数,连表查询,子查询、MySQL操作之条件,排序,分页,聚合函数,分组,连接,子查询,自连接查询总结、MySQL查询排序与查询聚合函数用法分析的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

