以上就是给各位分享python-有什么办法可以杀死线程吗?,其中也会对python获取线程和杀线程进行解释,同时本文还将给你拓展pythonscrapy采集百度贴吧入库mysql后。入库数据是混乱的,
以上就是给各位分享python-有什么办法可以杀死线程吗?,其中也会对python获取线程和杀线程进行解释,同时本文还将给你拓展python scrapy 采集百度贴吧入库mysql后。入库数据是混乱的,有什么办法可以按百度贴吧发贴时间入库不?、python – 从另一个进程中杀死线程、python – 有什么方法可以加速海底配对、python – 有什么方法可以让PyDrive记住用户的身份验证吗?等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- python-有什么办法可以杀死线程吗?(python获取线程和杀线程)
- python scrapy 采集百度贴吧入库mysql后。入库数据是混乱的,有什么办法可以按百度贴吧发贴时间入库不?
- python – 从另一个进程中杀死线程
- python – 有什么方法可以加速海底配对
- python – 有什么方法可以让PyDrive记住用户的身份验证吗?
")
python-有什么办法可以杀死线程吗?(python获取线程和杀线程)
是否可以在不设置/检查任何标志/信号灯/等的情况下终止正在运行的线程?
答案1
小编典典在Python和任何语言中,突然终止线程通常都是一种糟糕的模式。请考虑以下情况:
- 线程持有必须正确关闭的关键资源
- 该线程创建了其他几个必须同时终止的线程。
如果你负担得起的话(如果你要管理自己的线程),处理此问题的一种好方法是有一个exit_request标志,每个线程定期检查一次,以查看是否该退出。
例如:
import threadingclass StoppableThread(threading.Thread): """Thread class with a stop() method. The thread itself has to check regularly for the stopped() condition.""" def __init__(self, *args, **kwargs): super(StoppableThread, self).__init__(*args, **kwargs) self._stop_event = threading.Event() def stop(self): self._stop_event.set() def stopped(self): return self._stop_event.is_set()在此代码中,你应stop()在希望退出线程时调用它,然后使用来等待线程正确退出join()。线程应定期检查停止标志。
但是,在某些情况下,你确实需要杀死线程。一个示例是当你包装一个忙于长时间调用的外部库并且想要中断它时。
以下代码允许(有一些限制)在Python线程中引发Exception:
def _async_raise(tid, exctype): ''''''Raises an exception in the threads with id tid'''''' if not inspect.isclass(exctype): raise TypeError("Only types can be raised (not instances)") res = ctypes.pythonapi.PyThreadState_SetAsyncExc(ctypes.c_long(tid), ctypes.py_object(exctype)) if res == 0: raise ValueError("invalid thread id") elif res != 1: # "if it returns a number greater than one, you''re in trouble, # and you should call it again with exc=NULL to revert the effect" ctypes.pythonapi.PyThreadState_SetAsyncExc(ctypes.c_long(tid), None) raise SystemError("PyThreadState_SetAsyncExc failed")class ThreadWithExc(threading.Thread): ''''''A thread class that supports raising exception in the thread from another thread. '''''' def _get_my_tid(self): """determines this (self''s) thread id CAREFUL : this function is executed in the context of the caller thread, to get the identity of the thread represented by this instance. """ if not self.isAlive(): raise threading.ThreadError("the thread is not active") # do we have it cached? if hasattr(self, "_thread_id"): return self._thread_id # no, look for it in the _active dict for tid, tobj in threading._active.items(): if tobj is self: self._thread_id = tid return tid # TODO: in python 2.6, there''s a simpler way to do : self.ident raise AssertionError("could not determine the thread''s id") def raiseExc(self, exctype): """Raises the given exception type in the context of this thread. If the thread is busy in a system call (time.sleep(), socket.accept(), ...), the exception is simply ignored. If you are sure that your exception should terminate the thread, one way to ensure that it works is: t = ThreadWithExc( ... ) ... t.raiseExc( SomeException ) while t.isAlive(): time.sleep( 0.1 ) t.raiseExc( SomeException ) If the exception is to be caught by the thread, you need a way to check that your thread has caught it. CAREFUL : this function is executed in the context of the caller thread, to raise an excpetion in the context of the thread represented by this instance. """ _async_raise( self._get_my_tid(), exctype )(基于Tomer Filiba的Killable Threads。有关return值的引用PyThreadState_SetAsyncExc似乎来自旧版本的Python。)
如文档中所述,这不是灵丹妙药,因为如果线程在Python解释器之外很忙,它将无法捕获中断。
此代码的一个很好的用法模式是让线程捕获特定的异常并执行清理。这样,你可以中断任务并仍然进行适当的清理。

python scrapy 采集百度贴吧入库mysql后。入库数据是混乱的,有什么办法可以按百度贴吧发贴时间入库不?
python scrapy 采集百度贴吧入库mysql后。入库数据是混乱的,有什么办法可以按百度贴吧发贴时间入库不?
如图:
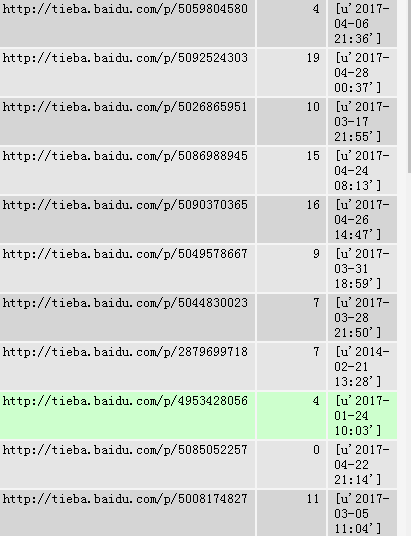
后面的这一列时间。是我采集的百度贴吧楼主发贴的时间。入库后发现这个好混乱。
如果想把百度贴吧发贴的时间顺序入库。
请问实现这个需要什么思路?

python – 从另一个进程中杀死线程
有帮助吗?
解决方法
from multiprocessing import Process
import os,time
class myThread(Process):
def __init__(self):
Process.__init__(self)
def run(self):
while True:
os.system("sleep 5")
if __name__ == ''__main__'':
p = myThread()
p.start()
print "Main thread PID:",os.getpid()
print "Launched process PID:",p.pid
os.kill(p.pid,1)
p.join()

python – 有什么方法可以加速海底配对
我知道子图的数量很大,以及绘制图表所需的时间. (我正在等待一个多小时的i5上有3,4 GHZ和32 GB RAM).
记住scikit学习允许并行构建随机森林,我正在检查这是否也可能与seaborn.
但是,我没有找到任何东西.源代码似乎为每个图像调用matplotlib绘图函数.
难道不能并行化吗?如果是的话,从这里开始的好方法是什么?
解决方法
即sns.pairplot(df.sample(1000)).

python – 有什么方法可以让PyDrive记住用户的身份验证吗?
该程序捕获图像并将其上传到Google云端硬盘上的文件夹.
这是我的身份验证和上传的基本代码:
gauth = GoogleAuth()
drive = GoogleDrive(gauth)
file_image = drive.CreateFile({"parents": [{"kind": "drive#fileLink","id": upload_folder_id}]})
file_image.SetContentFile(imageName) #Set the content to the taken image
file_image.Upload() # Upload it
任何时候我运行该程序它想要验证我.有没有办法记住身份验证?
解决方法
样品:
在脚本所在的同一文件夹中创建一个名为login.conf(或类似文件)的文件.将其放入其中:
{"user": "username","pass": "password"}
将“username”和“pasword”替换为您的真实值,但保留“.”在您的脚本中,执行以下操作:
with open("login.conf","r") as f:
content = eval(f.read())
username = content["user"]
password = content["pass"]
# Now do login using these two variables
更安全的选择是使用ConfigParser(Python 3.x中的configparser).
编辑:
登录到Google云端硬盘需要在脚本目录中使用名为client_secrets.json的文件.如果你有,请像这样登录:
gauth = GoogleAuth()
gauth.LocalWebserverAuth()
gauth.LoadCredentialsFile("credentials.txt")
if gauth.credentials is None:
gauth.LocalWebserverAuth()
elif gauth.access_token_expired:
gauth.Refresh()
else:
gauth.Authorize()
gauth.SaveCredentialsFile("credentials.txt")
drive = GoogleDrive(gauth)
希望这有帮助(问,如果事情不够清楚)!
我们今天的关于python-有什么办法可以杀死线程吗?和python获取线程和杀线程的分享就到这里,谢谢您的阅读,如果想了解更多关于python scrapy 采集百度贴吧入库mysql后。入库数据是混乱的,有什么办法可以按百度贴吧发贴时间入库不?、python – 从另一个进程中杀死线程、python – 有什么方法可以加速海底配对、python – 有什么方法可以让PyDrive记住用户的身份验证吗?的相关信息,可以在本站进行搜索。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

