以上就是给各位分享NumPy分配中重复索引的处理,其中也会对numpy重复进行解释,同时本文还将给你拓展3.6Python数据处理篇之Numpy系列(六)---Numpy随机函数、3.7Python数
以上就是给各位分享NumPy分配中重复索引的处理,其中也会对numpy 重复进行解释,同时本文还将给你拓展3.6Python数据处理篇之Numpy系列(六)---Numpy随机函数、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、MySQL中冗余和重复索引的区别说明、numpy ndarray索引的含义是什么?等相关知识,如果能碰巧解决你现在面临的问题,别忘了关注本站,现在开始吧!
本文目录一览:- NumPy分配中重复索引的处理(numpy 重复)
- 3.6Python数据处理篇之Numpy系列(六)---Numpy随机函数
- 3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
- MySQL中冗余和重复索引的区别说明
- numpy ndarray索引的含义是什么?
")
NumPy分配中重复索引的处理(numpy 重复)
我正在设置2D数组中多个元素的值,但是我的数据有时包含给定索引的多个值。
似乎总是分配了“更高”的值(请参见下面的示例),但是是否可以保证此行为,或者是否有机会获得不一致的结果?我怎么知道我可以按照我在矢量化分配中想要的方式来解释“稍后”?
也就是说,在我的第一个示例中,a肯定会始终包含4该内容,而在第二个示例中,它将打印values[0]吗?
很简单的例子:
import numpy as npindices = np.zeros(5,dtype=np.int)a[indices] = np.arange(5)a # array([4])另一个例子
import numpy as npgrid = np.zeros((1000, 800))# generate indices and valuesxs = np.random.randint(0, grid.shape[0], 100)ys = np.random.randint(0, grid.shape[1], 100)values = np.random.rand(100)# make sure we have a duplicate indexprint values[0], values[5]xs[0] = xs[5]ys[0] = ys[5]grid[xs, ys] = valuesprint "output value is", grid[xs[0], ys[0]]# always prints value of values[5]答案1
小编典典在NumPy 1.9和更高版本中,通常不会对此进行很好的定义。
当前实现使用单独的迭代器同时遍历所有(广播的)花式索引(和分配数组),并且这些迭代器均使用C阶。换句话说,目前可以。由于您可能想更准确地了解它。如果mapping.c在处理这些问题的NumPy中进行比较,您会看到它使用PyArray_ITER_NEXT,该文档记录为C顺序。
为了将来,我会以不同的方式描绘这幅画。我认为使用更新的迭代器将所有索引+赋值数组一起迭代将是很好的。如果这样做,则可以保留订单以供迭代器决定最快的方式。如果您对迭代器保持开放状态,很难说会发生什么,但是您不能确定您的示例是否有效(可能仍然是一维情况,但是…)。
因此,据我所知,它目前可以使用,但尚未记录(据我所知),因此,如果您确实认为应该确保这样做,则需要游说并最好编写一些测试以确保它可以得到保证。因为至少有人倾向于说:如果它使事情变得更快,就没有理由确保C阶,但是当然也许有一个很好的理由隐藏在某处…
真正的问题是:您为什么仍要这么做?;)
---Numpy随机函数")
3.6Python数据处理篇之Numpy系列(六)---Numpy随机函数
目录
[TOC]
前言
前一段日子学了numpy,觉得无趣,没有学完,不过后来看了看matplotlib,sympy等库时,频频用到numpy,
numpy才是最基础的库。
(一)基础的随机函数
(1)说明:

(2)输出效果
a = np.random.rand(3, 4, 5)
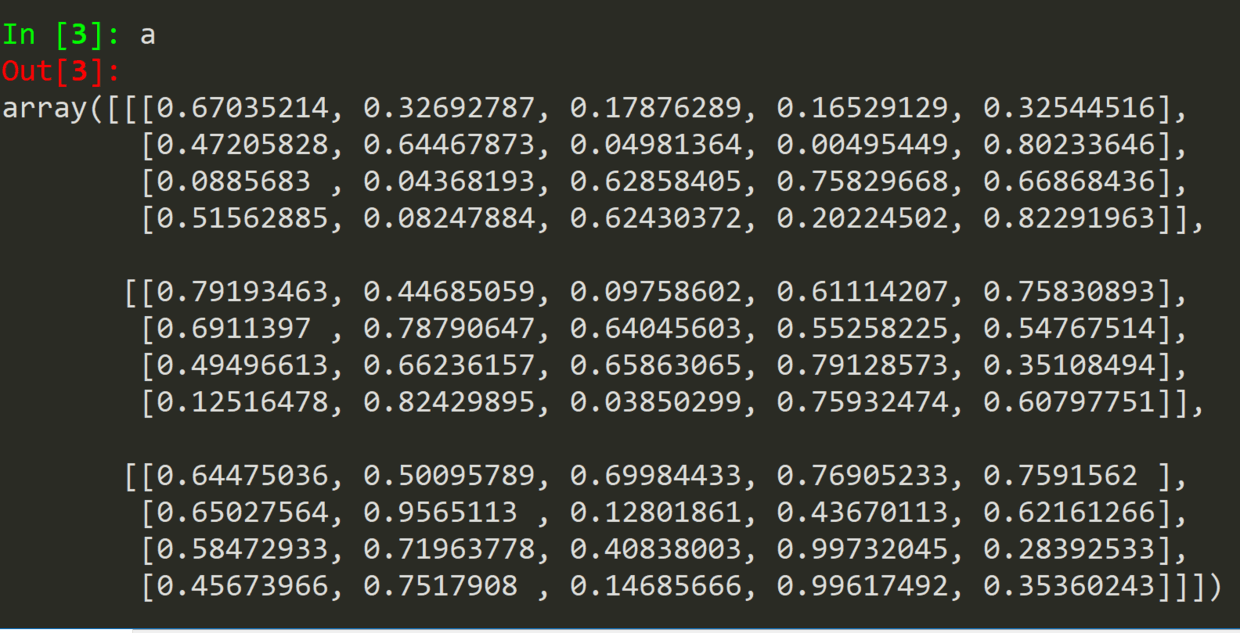
.randn(shape)
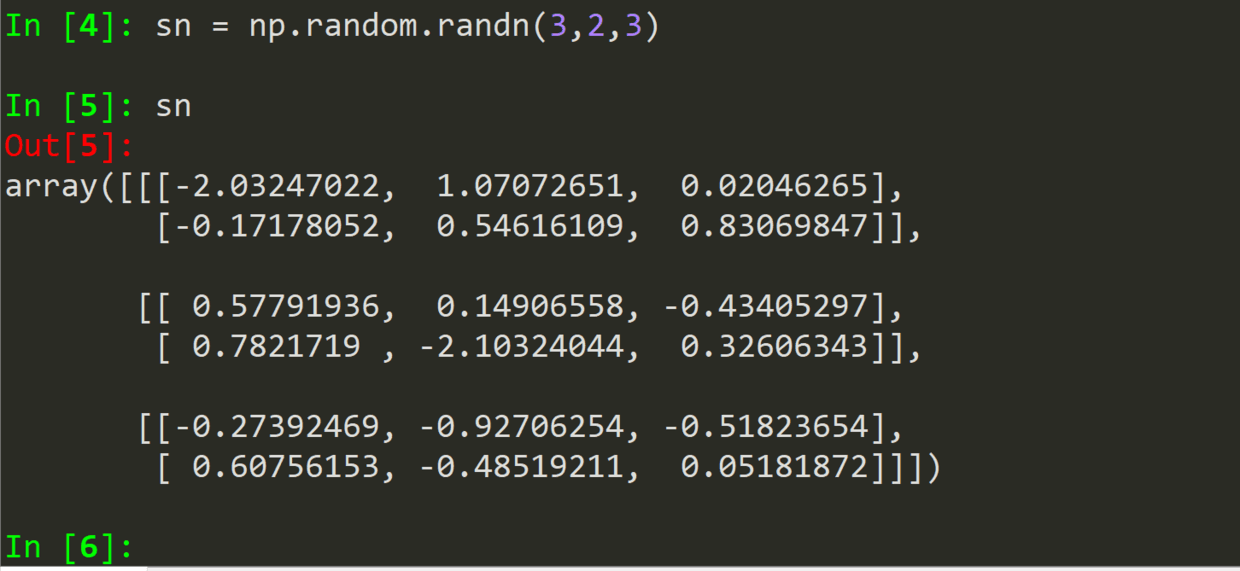
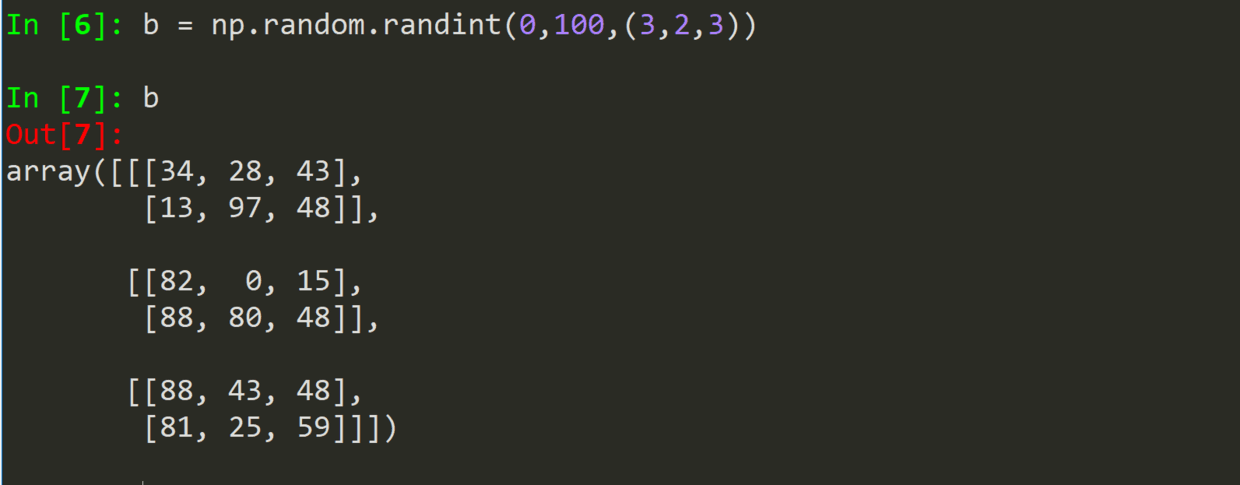
randint(low, high,shape)
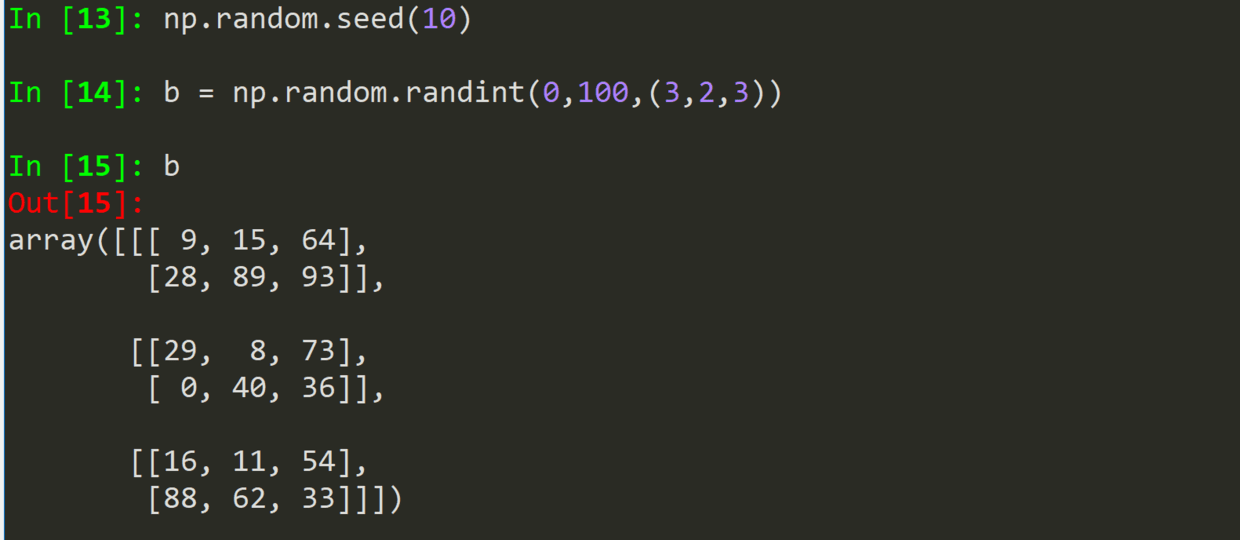
seed(num)是一个种子随机数,一种整数,就对应一种随机变量。
(二)轴的随机函数
(1)说明:

(2)输出效果
.shuffle(a)
改变原数据

.permutation(a)
不改变原数据,返回随机数组。
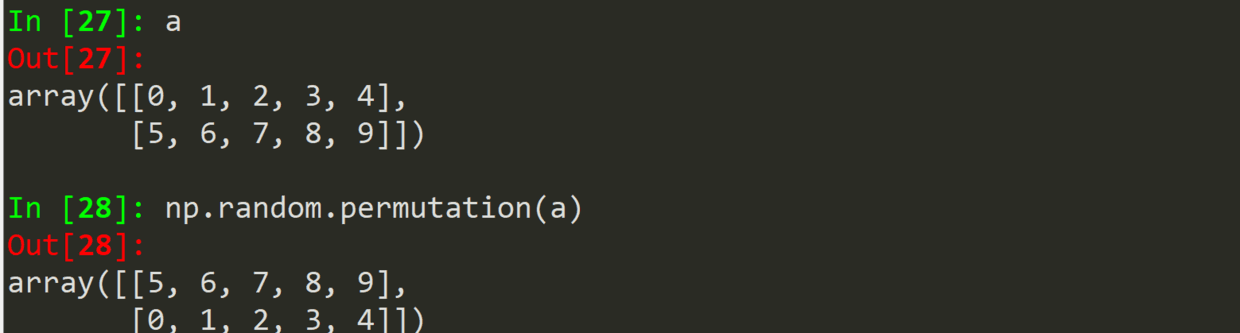
.chioce(a)

(三)概率的随机函数
(1)说明:

(2)输出效果
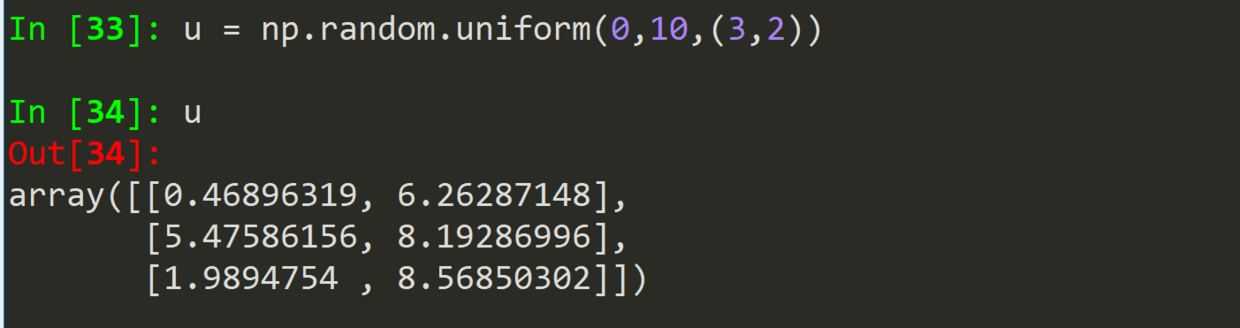
.uniform(low, high, size)
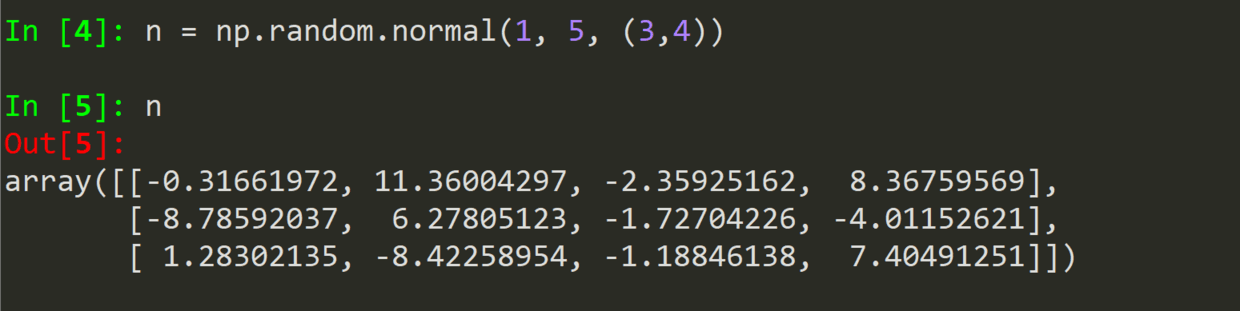
.normal(均值,标准差,size) --正态分布
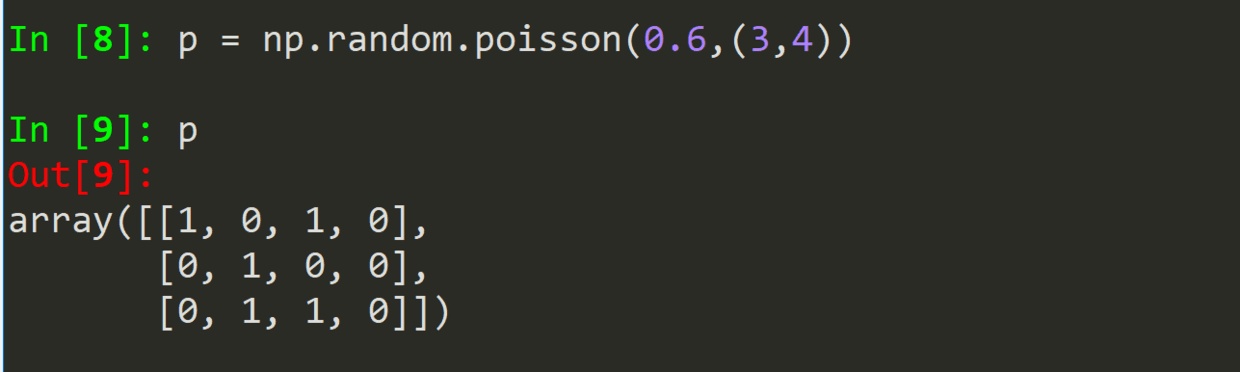
.poisson(概率,size)--泊松分布
作者:Mark
日期:2019/02/10 周日
---Numpy 的统计函数")
3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数
目录
[TOC]
前言
具体我们来学 Numpy 的统计函数
(一)函数一览表
调用方式:np.*
| .sum(a) | 对数组 a 求和 |
|---|---|
| .mean(a) | 求数学期望 |
| .average(a) | 求平均值 |
| .std(a) | 求标准差 |
| .var(a) | 求方差 |
| .ptp(a) | 求极差 |
| .median(a) | 求中值,即中位数 |
| .min(a) | 求最大值 |
| .max(a) | 求最小值 |
| .argmin(a) | 求最小值的下标,都处里为一维的下标 |
| .argmax(a) | 求最大值的下标,都处里为一维的下标 |
| .unravel_index(index, shape) | g 根据 shape, 由一维的下标生成多维的下标 |
(二)统计函数 1
(1)说明

(2)输出
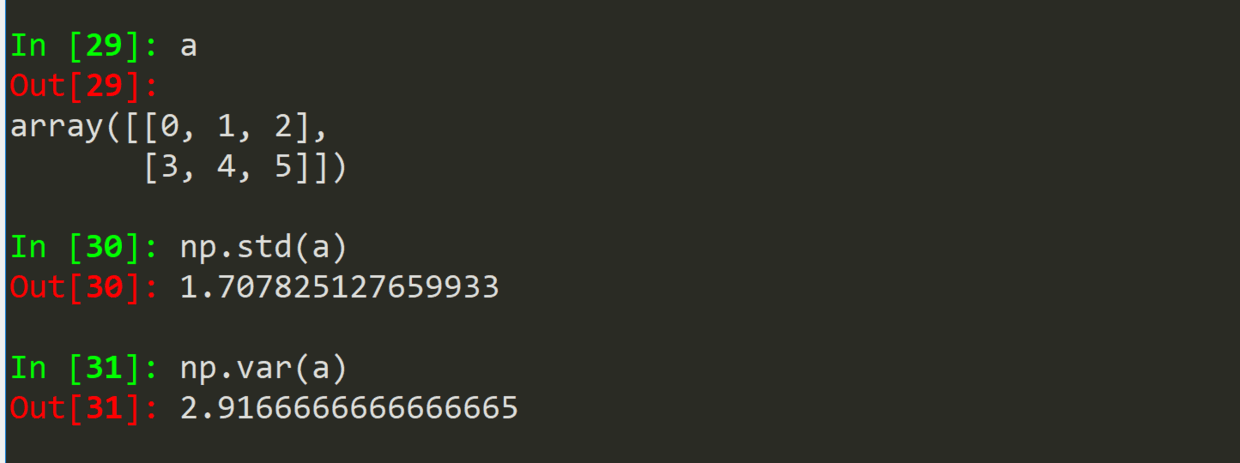
.sum(a)

.mean(a)

.average(a)

.std(a)
.var(a)
(三)统计函数 2
(1)说明

(2)输出
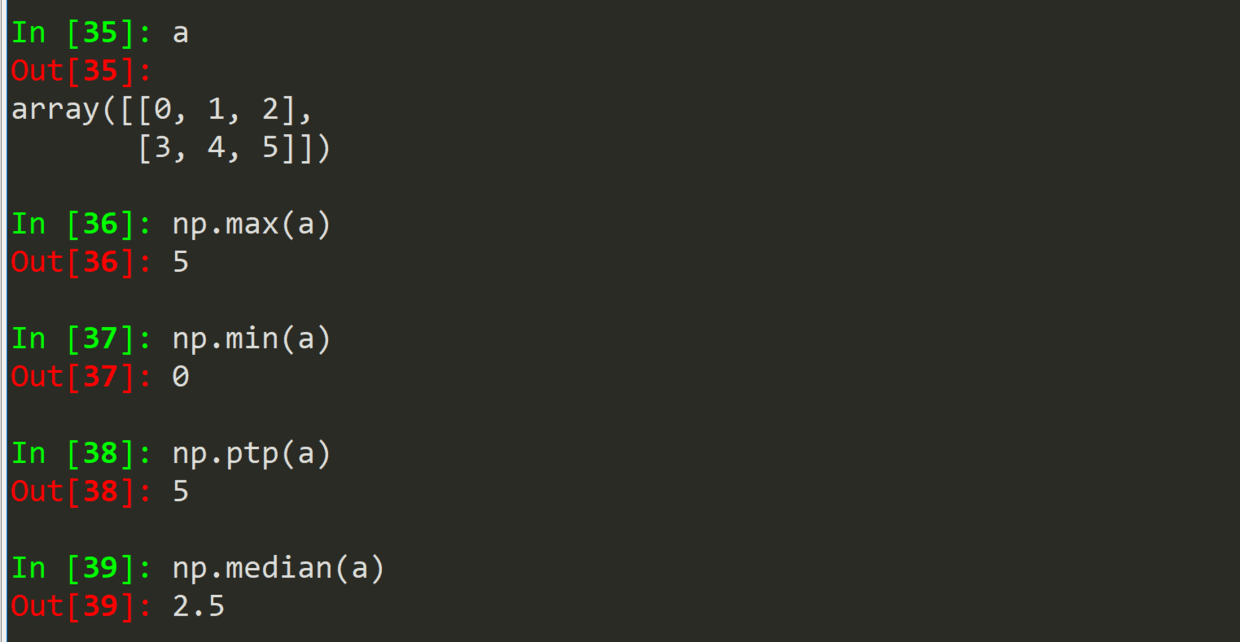
.max(a) .min(a)
.ptp(a)
.median(a)
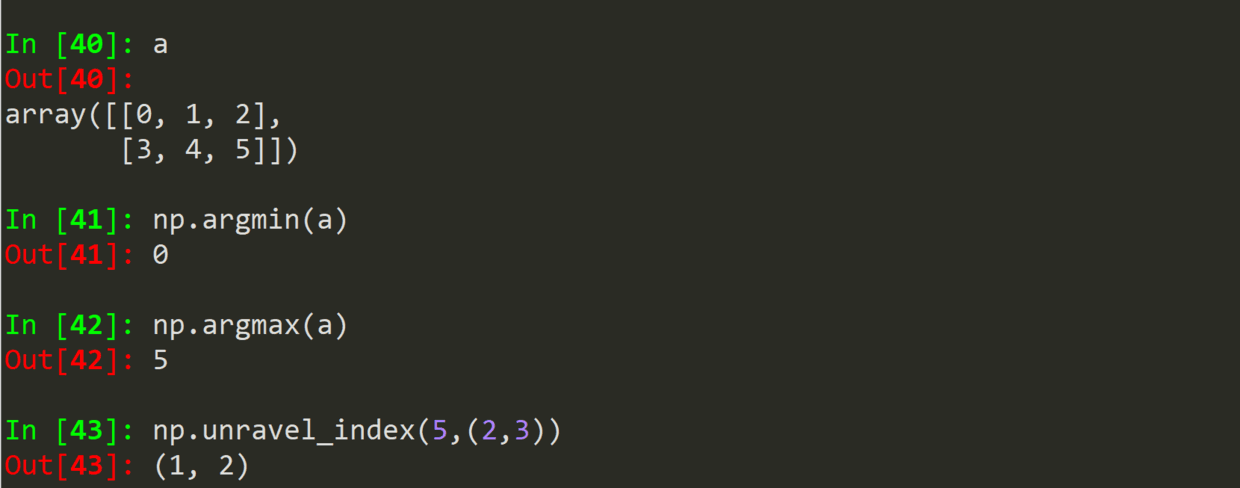
.argmin(a)
.argmax(a)
.unravel_index(index,shape)
作者:Mark
日期:2019/02/11 周一

MySQL中冗余和重复索引的区别说明
MySQL允许在单个列上创建多个索引,无论是有意还是无意,MySQL需要单独维护这些重复索引,优化器在优化查询时也需要逐个考虑这会影响MySQL的性能
概念阐述
重复索引: 在相同的列上按照相同的顺序创建的相同类型的索引。应该避免创建这样的重复索引,发现之后也应该立即移除。
冗余索引: 两个索引按照相同的顺序覆盖了相同的列。
创建的原因
一般来说,我们有时候会在不经意间创建了重复索引,例如下面的例子:
CREATE TABLE test( ID INT NOT NULL PRIMARY KEY, A INT NOT NULL, B INT NOT NULL, UNIQUE(ID), INDEX(ID) )ENGINE=InnoDB;
因为MySQL的唯一限制和主键限制都是通过索引实现的,所以事实上使用如上代码创建的表实际上会在ID列上创建3个索引。通常没有理由这样做,除非是在同一列上为了满足不同的查询需求创建不同类型的索引。比如KEY(col)和FULLTEXT KEY(col)两种索引。
冗余索引和重复索引有些不同。如果创建了索引(A,B),再创建索引(A)就是冗余索引,因为这只是前一个索引的前缀索引。但是如果创建了索引(B,A),则不是冗余索引,索引(B)也不是冗余索引,因为它不是索引(A,B)的最左前缀列。除此之外,不同类型的索引也不会是B树索引的冗余索引,无论覆盖的索引列是什么。
在大多数情况下都不需要使用冗余索引,应该尽可能拓展已有的索引而不是创建新的索引。但有时候出于性能的考虑,比如拓展已有的索引会使得其变得太大,从而影响其他使用该索引的查询的性能。
影响
创建冗余索引作为覆盖索引可以提高我们对于部分查询的QPS,但是存在两个索引也有缺点,即索引成本更高。
当表中的索引越来越多时,表的插入速度会变慢。一般而言,增加新索引将会导致INSERT、UPDATE、DELETE等操作的速度变慢,特别是当新增索引之后导致达到了内存的瓶颈的时候。
解决冗余索引和重复索引的方法很简单,删除这些索引就可以 ,但是首先要做的就是找出这样的索引。
补充:MySQL中重复索引和重复外键清理
MySQL允许在相同列上创建重复的索引,但这样做对数据库却是有害而无利的,需要定期检查此类重复索引以改善数据库性能。
可减少磁盘空间占用、减少磁盘IO、减少优化器优化查询时需要比较的索引个数、减少数据库维护冗余索引的各类开销、提高数据库性能(插入、更新、删除)
重复索引检测
pt-duplicate-key-checker:通过SHOW CREATE TABLE输出的表定义检测MySQL表中重复或者冗余的索引或外键
可以检测到的冗余/重复索引类型:若某个索引和另外某个索引以同样的顺序包含同样的列,或者该索引包含的列是另外某个索引的最左前缀列,则被认为是重复/冗余的索引。
默认情况下只在同类型的索引间(如BTREE索引)进行比较,不同类型的索引即使符合上述描述也不会被认为是重复/冗余,但这一行为可以通过参数改变。
除此之外,还可检测重复的外键,即引用的表和列均相同的外键。对于聚簇索引的表,在辅助索引后添加主键列的索引也被认为是冗余的,因为这种情况下,辅助索引末尾本身就包含有主键信息。
基本用法以及样例输出如下
[root@VM_8_180_centos packages]# pt-duplicate-key-checker A=utf8, F=/etc/my.cnf, h=localhost, u=root, P=3306 –ask-pass
样例输出:
# ######################################################################## # dcf.privilege # ######################################################################## # Uniqueness of UQI_IDX_1 ignored because PRIMARY is a duplicate constraint # UQI_IDX_1 is a duplicate of PRIMARY # Key definitions: # UNIQUE KEY `UQI_IDX_1` (`privilege_id`), # PRIMARY KEY (`privilege_id`), # Column types: # `privilege_id` varchar(50) collate utf8_bin not null comment ''权限id'' # To remove this duplicate index, execute: ALTER TABLE `dcf`.`privilege` DROP INDEX `UQI_IDX_1`; # ######################################################################## # dcf.t_game_config # ######################################################################## # Uniqueness of pkey ignored because PRIMARY is a duplicate constraint # pkey is a duplicate of PRIMARY # Key definitions: # UNIQUE KEY `pkey` (`pkey`) # PRIMARY KEY (`pkey`), # Column types: # `pkey` bigint(20) not null auto_increment # To remove this duplicate index, execute: ALTER TABLE `dcf`.`t_game_config` DROP INDEX `pkey`; # ######################################################################## # dcf.t_project_institution # ######################################################################## # index_1 is a left-prefix of index_2 # Key definitions: # KEY `index_1` (`project_id`), # KEY `index_2` (`project_id`,`institution_id`,`delete_flag`) # Column types: # `project_id` bigint(20) not null comment ''项目id'' # `institution_id` varchar(20) not null comment ''机构id'' # `delete_flag` tinyint(4) not null # To remove this duplicate index, execute: ALTER TABLE `dcf`.`t_project_institution` DROP INDEX `index_1`; # ######################################################################## # dcf_commons.bank_cnaps # ######################################################################## # idx is a duplicate of PRIMARY # Key definitions: # KEY `idx` (`cnaps`) # PRIMARY KEY (`cnaps`), # Column types: # `cnaps` varchar(255) not null comment ''电子联行号'' # To remove this duplicate index, execute: ALTER TABLE `dcf_commons`.`bank_cnaps` DROP INDEX `idx`; # ######################################################################## # dcf_contract.customer_bank_account # ######################################################################## # IDX_CUSTOMER_ID is a left-prefix of UQI_IDX_1 # Key definitions: # KEY `IDX_CUSTOMER_ID` (`customer_id`) # UNIQUE KEY `UQI_IDX_1` (`customer_id`,`account_no`,`branch_bank`,`account_type`,`account_name`) USING BTREE, # Column types: # `customer_id` varchar(20) collate utf8_bin not null comment ''客户id'' # `account_no` varchar(40) collate utf8_bin default null comment ''银行账号'' # `branch_bank` varchar(100) collate utf8_bin default null comment ''开户支行'' # `account_type` tinyint(4) default null comment ''账户类型:比如收款账户,还款账户等\n0-收款账户\n1-还款账户'' # `account_name` varchar(100) collate utf8_bin default null comment ''银行账户户名'' # To remove this duplicate index, execute: ALTER TABLE `dcf_contract`.`customer_bank_account` DROP INDEX `IDX_CUSTOMER_ID`; # ######################################################################## # dcf_contract.t_contract_account # ######################################################################## # IDX_CONTRACT_ID is a left-prefix of t_contract_account_uq1 # Key definitions: # KEY `IDX_CONTRACT_ID` (`contract_id`) # UNIQUE KEY `t_contract_account_uq1` (`contract_id`,`account_type`), # Column types: # `contract_id` bigint(20) not null comment ''合同id'' # `account_type` tinyint(4) not null comment ''账户类 型:globalconstant.bankaccounttypec常数 \n0-收款账户\n1-还款账户 等'' # To remove this duplicate index, execute: ALTER TABLE `dcf_contract`.`t_contract_account` DROP INDEX `IDX_CONTRACT_ID`; ...... ...... # ######################################################################## # Summary of indexes # ######################################################################## # Size Duplicate Indexes 173317386 # Total Duplicate Indexes 18 # Total Indexes 562
会给出重复/冗余类型、索引/外键定义、索引包含的列类型、移除重复/冗余索引/外键的SQL、最后会给出有关索引的统计信息。
重复索引删除
直接执行工具输出结果中的ALTER TABLE语句即可,但是执行前一定要仔细评估可能造成的影响。比如,表非常非常大的情况下可能造成主从复制延迟,又比如SQL中若包含索引提示的话直接删除索引可能导致报SQL语法错误,最好事先查一下是不是包含此类SQL(可通过general log或者tcpdump工具获取SQL并加以分析)
以上为个人经验,希望能给大家一个参考,也希望大家多多支持。如有错误或未考虑完全的地方,望不吝赐教。
- MySQL查询冗余索引和未使用过的索引操作
- mysql重复索引与冗余索引实例分析
- 详解mysql中的冗余和重复索引

numpy ndarray索引的含义是什么?
如何解决numpy ndarray索引的含义是什么??
...在这里是什么意思?
import numpy as np
test = np.zeros((5,5,5))
print(test[...])
以上内容与
有何不同?print(test[:])
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)
我们今天的关于NumPy分配中重复索引的处理和numpy 重复的分享已经告一段落,感谢您的关注,如果您想了解更多关于3.6Python数据处理篇之Numpy系列(六)---Numpy随机函数、3.7Python 数据处理篇之 Numpy 系列 (七)---Numpy 的统计函数、MySQL中冗余和重复索引的区别说明、numpy ndarray索引的含义是什么?的相关信息,请在本站查询。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

