如果您想了解为什么StanfordCoreNLPNER注释器默认加载3个模型?的相关知识,那么本文是一篇不可错过的文章,我们将对注释放在哪里进行全面详尽的解释,并且为您提供关于Eclipse下使用St
如果您想了解为什么Stanford CoreNLP NER注释器默认加载3个模型?的相关知识,那么本文是一篇不可错过的文章,我们将对注释放在哪里进行全面详尽的解释,并且为您提供关于Eclipse 下使用 Stanford CoreNLP 的方法、Eclipse 编译StanfordNLP、Java Stanford NLP:语音标签的一部分?、java – Stanford CoreNLP – 未知变量:WEEKDAY的有价值的信息。
本文目录一览:- 为什么Stanford CoreNLP NER注释器默认加载3个模型?(注释放在哪里)
- Eclipse 下使用 Stanford CoreNLP 的方法
- Eclipse 编译StanfordNLP
- Java Stanford NLP:语音标签的一部分?
- java – Stanford CoreNLP – 未知变量:WEEKDAY
")
为什么Stanford CoreNLP NER注释器默认加载3个模型?(注释放在哪里)
当我在StanfordCoreNLP对象管道中添加“ ner”注释器时,我可以看到它加载了3个模型,这需要很多时间:
Adding annotator nerLoading classifier from edu/stanford/nlp/models/ner/english.all.3class.distsim.crf.ser.gz ... done [10.3 sec].Loading classifier from edu/stanford/nlp/models/ner/english.muc.7class.distsim.crf.ser.gz ... done [10.1 sec].Loading classifier from edu/stanford/nlp/models/ner/english.conll.4class.distsim.crf.ser.gz ... done [6.5 sec].Initializing JollyDayHoliday for SUTime from classpath: edu/stanford/nlp/models/sutime/jollyday/Holidays_sutime.xml as sutime.binder.1.Reading TokensRegex rules from edu/stanford/nlp/models/sutime/defs.sutime.txtReading TokensRegex rules from edu/stanford/nlp/models/sutime/english.sutime.txtReading TokensRegex rules from edu/stanford/nlp/models/sutime/english.holidays.sutime.txt有没有一种方法可以加载同样工作的子集?特别是,我不确定为什么当它具有7级模型时为什么要加载3级和4级NER模型,并且我想知道是否不加载这两种仍然可以工作。
答案1
小编典典您可以设置以这种方式加载哪些模型:
命令行:
-ner.model model_path1,model_path2Java代码:
props.put("ner.model", "model_path1,model_path2");其中model_path1和model_path2应该类似于:
"edu/stanford/nlp/models/ner/english.all.3class.distsim.crf.ser.gz"模型是分层应用的。运行第一个模型并应用其标签。然后是第二个,第三个,依此类推。如果需要较少的模型,则可以在列表中放入1或2个模型,而不是三个默认模型,但这会改变系统的性能。
如果将“ ner.combinationMode”设置为“ HIGH_RECALL”,则将允许所有模型应用其所有标签。如果将“ ner.combinationMode”设置为“ NORMAL”,则将来的模型将无法应用以前模型设置的任何标签。
默认情况下,所有三个模型都针对不同的数据进行了训练。例如,与7类模型相比,使用3类模型训练的数据要多得多。因此,每个模型都在做不同的事情,它们的结果都被组合在一起以创建最终的标签序列。

Eclipse 下使用 Stanford CoreNLP 的方法
源码下载地址:CoreNLP 官网。
目前 release 的 CoreNLP version 3.5.0 版本仅支持 java-1.8 及以上版本,因此有时需要为 Eclipse 添加 jdk-1.8 配置,配置方法如下:
- 首先,去 oracle 官网下载 java-1.8,下载网址为:java 下载,安装完成后。
- 打开 Eclipse,选择 Window -> Preferences -> Java –> Installed JREs 进行配置:
点击窗体右边的“add”,然后添加一个“Standard VM”(应该是标准虚拟机的意思),然后点击“next”;在”JRE HOME”那一行点击右边的“Directory…”找到你java 的安装路径,比如“C:Program Files/Java/jdk1.8”
这样你的 Eclipse 就已经支持 jdk-1.8 了。
1. 新建 java 工程,注意编译环境版本选择 1.8
2. 将官网下载的源码解压到工程下,并导入所需 jar 包
如导入 stanford-corenlp-3.5.0.jar、stanford-corenlp-3.5.0-javadoc.jar、stanford-corenlp-3.5.0-models.jar、stanford-corenlp-3.5.0-sources.jar、xom.jar 等
导入 jar 包过程为:项目右击 ->Properties->Java Build Path->Libraries,点击 “Add JARs”,在路径中选取相应的 jar 包即可。

3. 新建 TestCoreNLP 类,代码如下
package Test;
import java.util.List;
import java.util.Map;
import java.util.Properties;
import edu.stanford.nlp.dcoref.CorefChain;
import edu.stanford.nlp.dcoref.CorefCoreAnnotations.CorefChainAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.LemmaAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.NamedEntityTagAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.PartOfSpeechAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.SentencesAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TextAnnotation;
import edu.stanford.nlp.ling.CoreAnnotations.TokensAnnotation;
import edu.stanford.nlp.ling.CoreLabel;
import edu.stanford.nlp.pipeline.Annotation;
import edu.stanford.nlp.pipeline.StanfordCoreNLP;
import edu.stanford.nlp.semgraph.SemanticGraph;
import edu.stanford.nlp.semgraph.SemanticGraphCoreAnnotations.CollapsedCCProcessedDependenciesAnnotation;
import edu.stanford.nlp.sentiment.SentimentCoreAnnotations;
import edu.stanford.nlp.trees.Tree;
import edu.stanford.nlp.trees.TreeCoreAnnotations.TreeAnnotation;
import edu.stanford.nlp.util.CoreMap;
public class TestCoreNLP {
public static void main(String[] args) {
// creates a StanfordCoreNLP object, with POS tagging, lemmatization, NER, parsing, and coreference resolution
Properties props = new Properties();
props.put("annotators", "tokenize, ssplit, pos, lemma, ner, parse, dcoref");
StanfordCoreNLP pipeline = new StanfordCoreNLP(props);
// read some text in the text variable
String text = "Add your text here:Beijing sings Lenovo";
// create an empty Annotation just with the given text
Annotation document = new Annotation(text);
// run all Annotators on this text
pipeline.annotate(document);
// these are all the sentences in this document
// a CoreMap is essentially a Map that uses class objects as keys and has values with custom types
List<CoreMap> sentences = document.get(SentencesAnnotation.class);
System.out.println("word\tpos\tlemma\tner");
for(CoreMap sentence: sentences) {
// traversing the words in the current sentence
// a CoreLabel is a CoreMap with additional token-specific methods
for (CoreLabel token: sentence.get(TokensAnnotation.class)) {
// this is the text of the token
String word = token.get(TextAnnotation.class);
// this is the POS tag of the token
String pos = token.get(PartOfSpeechAnnotation.class);
// this is the NER label of the token
String ne = token.get(NamedEntityTagAnnotation.class);
String lemma = token.get(LemmaAnnotation.class);
System.out.println(word+"\t"+pos+"\t"+lemma+"\t"+ne);
}
// this is the parse tree of the current sentence
Tree tree = sentence.get(TreeAnnotation.class);
// this is the Stanford dependency graph of the current sentence
SemanticGraph dependencies = sentence.get(CollapsedCCProcessedDependenciesAnnotation.class);
}
// This is the coreference link graph
// Each chain stores a set of mentions that link to each other,
// along with a method for getting the most representative mention
// Both sentence and token offsets start at 1!
Map<Integer, CorefChain> graph = document.get(CorefChainAnnotation.class);
}
}PS:该代码的思想是将 text 字符串交给 Stanford CoreNLP 处理,StanfordCoreNLP 的各个组件(annotator)按 “tokenize(分词), ssplit(断句), pos(词性标注), lemma(词元化), ner(命名实体识别), parse(语法分析), dcoref(同义词分辨)” 顺序进行处理。
处理完后 List<CoreMap> sentences = document.get (SentencesAnnotation.class); 中包含了所有分析结果,遍历即可获知结果。
这里简单的将单词、词性、词元、是否实体打印出来。其余的用法参见官网(如 sentiment、parse、relation 等)。
4. 执行结果:
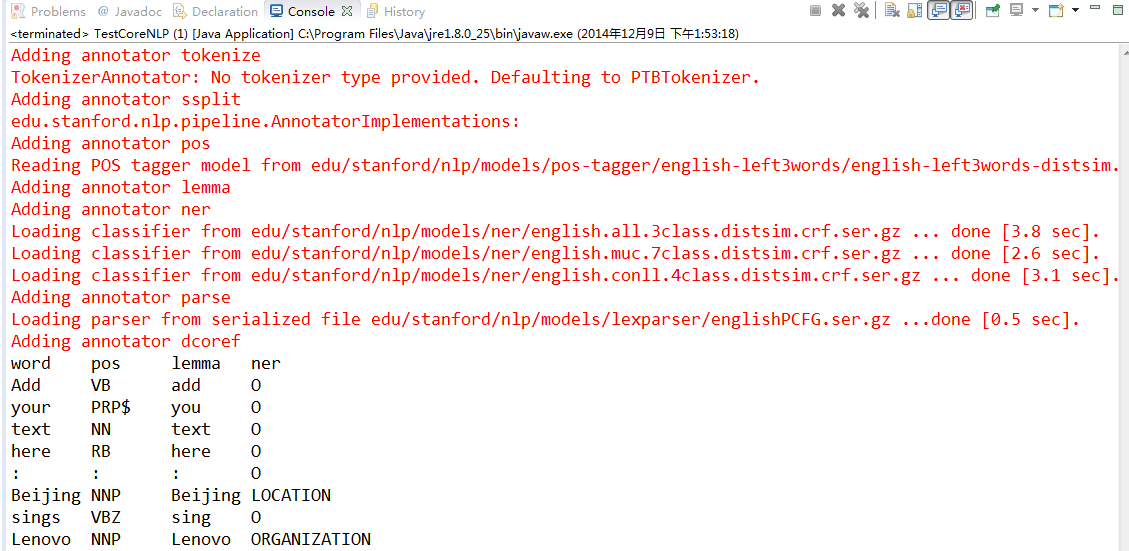
5. 关于 CoreNLP 详细内容:
http://stanfordnlp.github.io/CoreNLP/

Eclipse 编译StanfordNLP
1、源码最新下载地址:http://nlp.stanford.edu/software/index.shtml;
2、解压stanford-corenlp.zip;
3、打开Eclipse新建JAVA项目stanford-corenlp,然后在项目根目录创建文夹名"lib";
4、将步骤2解压出的*.jar复制到刚才新建lib目录中;stanford-corenlp-3.3.1-sources源代码解压至项目目录src里后,刷新项目;

5、将lib中*.jar文件添加引用;
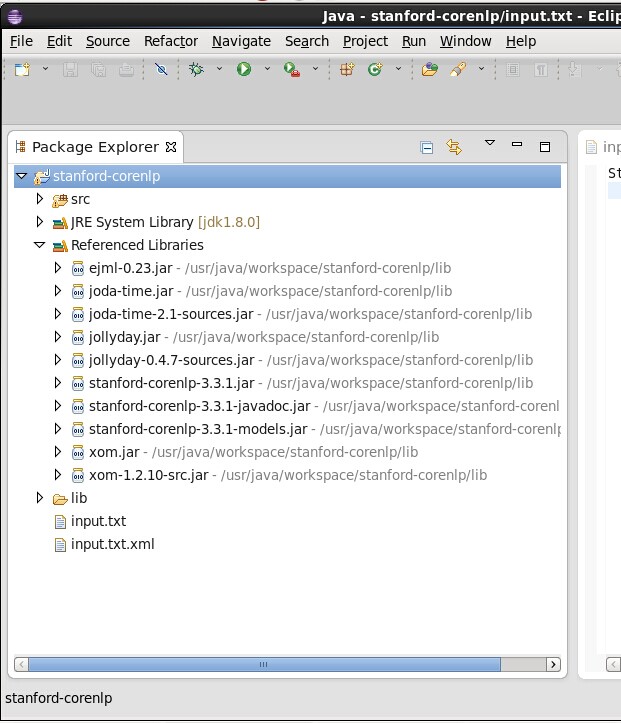
6、将步骤2解压文件中的input.txt拷贝到工程根目录下,图片参上,项目编译完成后input.txt.xml会自动产生;
7、编译器版本应该大于等于1.6否则会出错;
8、编译成功提示如下:
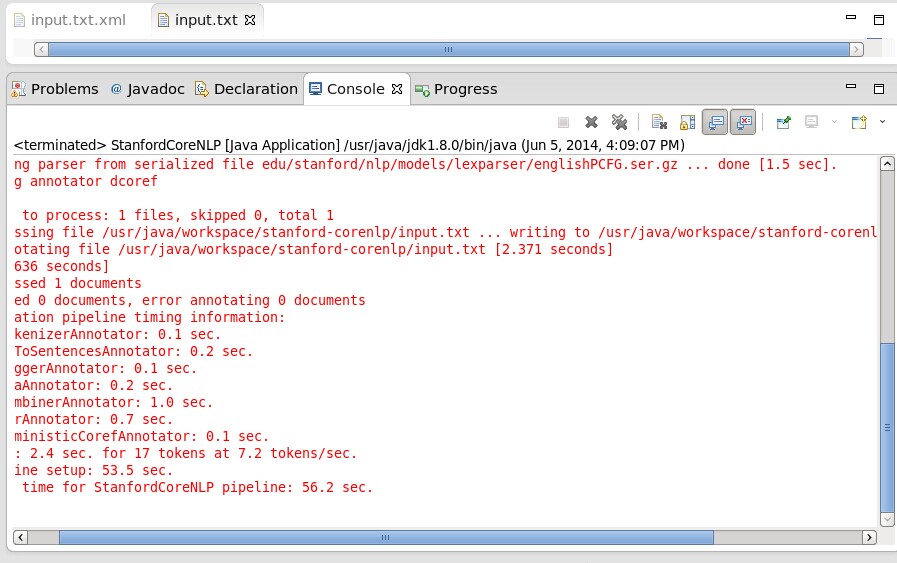
可参考地址:
http://nlp.stanford.edu/software/index.shtml
http://blog.csdn.net/jdbc/article/details/50494622

Java Stanford NLP:语音标签的一部分?
在此处演示的Stanford NLP 给出如下输出:
Colorless/JJ green/JJ ideas/NNS sleep/VBP furiously/RB ./.
词性标签是什么意思?我找不到正式名单。是斯坦福大学自己的系统,还是使用通用标签?(JJ例如,什么是?)
另外,当我遍历句子时,例如,寻找名词时,我最终会做类似检查标签是否的事情.contains('N')。这感觉很虚弱。是否有更好的方法以编程方式搜索语音的某个部分?

java – Stanford CoreNLP – 未知变量:WEEKDAY
未知变量:WEEKDAY
每次记录此消息时,内存消耗都会增加.它现在大约是23.8GB.有人知道这个问题是关于什么的吗?
我正在使用来自Github的Stanford CoreNLP 3.6.0,提交ID为4fd28dc4848616e568a2dd6eeb09b9769d1e3f4e以及以下型号stanford-english-corenlp-2016-01-10-型号.我的管道看起来像这样:“注释器”,“tokenize,ssplit,pos,lemma,ner,parse,depparse,提,coref”.
我已经知道了this的问题.但没有人回答.
解决方法
关于为什么Stanford CoreNLP NER注释器默认加载3个模型?和注释放在哪里的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Eclipse 下使用 Stanford CoreNLP 的方法、Eclipse 编译StanfordNLP、Java Stanford NLP:语音标签的一部分?、java – Stanford CoreNLP – 未知变量:WEEKDAY等相关知识的信息别忘了在本站进行查找喔。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

