这篇文章主要围绕sklearnKMeans中的KMeans.cluster_centers_的值和sklearn的kmeans算法展开,旨在为您提供一份详细的参考资料。我们将全面介绍sklearnKM
这篇文章主要围绕sklearn KMeans中的KMeans.cluster_centers_的值和sklearn的kmeans算法展开,旨在为您提供一份详细的参考资料。我们将全面介绍sklearn KMeans中的KMeans.cluster_centers_的值的优缺点,解答sklearn的kmeans算法的相关问题,同时也会为您带来2022吴恩达机器学习Deeplearning.ai课程编程作业C3_W1: KMeans_Assignment、AttributeError: 模块“sklearn.cluster”没有属性“k_means_”、cluster.k-means_._labels_inertia_precompute_dense、k-means cluster images的实用方法。
本文目录一览:- sklearn KMeans中的KMeans.cluster_centers_的值(sklearn的kmeans算法)
- 2022吴恩达机器学习Deeplearning.ai课程编程作业C3_W1: KMeans_Assignment
- AttributeError: 模块“sklearn.cluster”没有属性“k_means_”
- cluster.k-means_._labels_inertia_precompute_dense
- k-means cluster images
")
sklearn KMeans中的KMeans.cluster_centers_的值(sklearn的kmeans算法)
在做K表示适合具有3个聚类的某些矢量时,我能够获得输入数据的标签。KMeans.cluster_centers_返回中心的坐标,因此不应该有对应的向量吗?如何找到这些聚类的质心处的值?
答案1
小编典典closest, _ = pairwise_distances_argmin_min(KMeans.cluster_centers_, X)
该数组closest将包含X中最接近每个质心的点的索引。
假设三个集群的closest输出结果相同array([0,8,5])。因此,X [0]是X中最接近质心0的点,X
[8]是最接近质心1的点,依此类推。

2022吴恩达机器学习Deeplearning.ai课程编程作业C3_W1: KMeans_Assignment
K-means Clustering
In this this exercise, you will implement the K-means algorithm and use it for image compression.
- You will start with a sample dataset that will help you gain an intuition of how the K-means algorithm works.
- After that, you wil use the K-means algorithm for image compression by reducing the number of colors that occur in an image to only those that are most common in that image.
Outline
- K-means Clustering
- 1 - Implementing K-means
- 1.1 Finding closest centroids
- Exercise 1
- 1.2 Computing centroid means
- Exercise 2
- 2 - K-means on a sample dataset
- 3 - Random initialization
- 4 - Image compression with K-means
- 4.1 Dataset
- Processing data
- 4.2 K-Means on image pixels
- 4.3 Compress the image
import numpy as np
import matplotlib.pyplot as plt
from utils import *
%matplotlib inline
1 - Implementing K-means
The K-means algorithm is a method to automatically cluster similar
data points together.
-
Concretely, you are given a training set { x ( 1 ) , . . . , x ( m ) } \{x^{(1)}, ..., x^{(m)}\} {x(1),...,x(m)}, and you want
to group the data into a few cohesive “clusters”. -
K-means is an iterative procedure that
- Starts by guessing the initial centroids, and then
- Refines this guess by
- Repeatedly assigning examples to their closest centroids, and then
- Recomputing the centroids based on the assignments.
-
In pseudocode, the K-means algorithm is as follows:
# Initialize centroids # K is the number of clusters centroids = kMeans_init_centroids(X, K) for iter in range(iterations): # Cluster assignment step: # Assign each data point to the closest centroid. # idx[i] corresponds to the index of the centroid # assigned to example i idx = find_closest_centroids(X, centroids) # Move centroid step: # Compute means based on centroid assignments centroids = compute_means(X, idx, K) -
The inner-loop of the algorithm repeatedly carries out two steps:
- (i) Assigning each training example x ( i ) x^{(i)} x(i) to its closest centroid, and
- (ii) Recomputing the mean of each centroid using the points assigned to it.
-
The K K K-means algorithm will always converge to some final set of means for the centroids.
-
However, that the converged solution may not always be ideal and depends on the initial setting of the centroids.
- Therefore, in practice the K-means algorithm is usually run a few times with different random initializations.
- One way to choose between these different solutions from different random initializations is to choose the one with the lowest cost function value (distortion).
You will implement the two phases of the K-means algorithm separately
in the next sections.
- You will start by completing
find_closest_centroidand then proceed to completecompute_centroids.
1.1 Finding closest centroids
In the “cluster assignment” phase of the K-means algorithm, the
algorithm assigns every training example
x
(
i
)
x^{(i)}
x(i) to its closest
centroid, given the current positions of centroids.
Exercise 1
Your task is to complete the code in find_closest_centroids.
- This function takes the data matrix
Xand the locations of all
centroids insidecentroids - It should output a one-dimensional array
idx(which has the same number of elements asX) that holds the index of the closest centroid (a value in { 1 , . . . , K } \{1,...,K\} {1,...,K}, where K K K is total number of centroids) to every training example . - Specifically, for every example
x
(
i
)
x^{(i)}
x(i) we set
c ( i ) : = j t h a t m i n i m i z e s ∣ ∣ x ( i ) − μ j ∣ ∣ 2 , c^{(i)} := j \quad \mathrm{that \; minimizes} \quad ||x^{(i)} - \mu_j||^2, c(i):=jthatminimizes∣∣x(i)−μj∣∣2,
where -
c
(
i
)
c^{(i)}
c(i) is the index of the centroid that is closest to
x
(
i
)
x^{(i)}
x(i) (corresponds to
idx[i]in the starter code), and -
μ
j
\mu_j
μj is the position (value) of the
j
j
j’th centroid. (stored in
centroidsin the starter code)
If you get stuck, you can check out the hints presented after the cell below to help you with the implementation.
# UNQ_C1
# GRADED FUNCTION: find_closest_centroids
def find_closest_centroids(X, centroids):
"""
Computes the centroid memberships for every example
Args:
X (ndarray): (m, n) Input values
centroids (ndarray): k centroids
Returns:
idx (array_like): (m,) closest centroids
"""
# Set K
K = centroids.shape[0]
# You need to return the following variables correctly
idx = np.zeros(X.shape[0], dtype=int)
### START CODE HERE ###
m = X.shape[0]
for i in range(m):
mind = 1000000
ans = i
for j in range(K):
d = ((X[i, :] - centroids[j, :]) ** 2).sum()
if d < mind:
mind = d
ans = j
idx[i] = ans
### END CODE HERE ###
return idx
Now let’s check your implementation using an example dataset
# Load an example dataset that we will be using
X = load_data()
The code below prints the first five elements in the variable X and the dimensions of the variable
print("First five elements of X are:\n", X[:5])
print('The shape of X is:', X.shape)
First five elements of X are:
[[1.84207953 4.6075716 ]
[5.65858312 4.79996405]
[6.35257892 3.2908545 ]
[2.90401653 4.61220411]
[3.23197916 4.93989405]]
The shape of X is: (300, 2)
# Select an initial set of centroids (3 Centroids)
initial_centroids = np.array([[3,3], [6,2], [8,5]])
# Find closest centroids using initial_centroids
idx = find_closest_centroids(X, initial_centroids)
# Print closest centroids for the first three elements
print("First three elements in idx are:", idx[:3])
# UNIT TEST
from public_tests import *
find_closest_centroids_test(find_closest_centroids)
First three elements in idx are: [0 2 1]
All tests passed!
Expected Output:
| First three elements in idx are | [0 2 1] |
1.2 Computing centroid means
Given assignments of every point to a centroid, the second phase of the
algorithm recomputes, for each centroid, the mean of the points that
were assigned to it.
Exercise 2
Please complete the compute_centroids below to recompute the value for each centroid
-
Specifically, for every centroid μ k \mu_k μk we set
μ k = 1 ∣ C k ∣ ∑ i ∈ C k x ( i ) \mu_k = \frac{1}{|C_k|} \sum_{i \in C_k} x^{(i)} μk=∣Ck∣1i∈Ck∑x(i)where
- C k C_k Ck is the set of examples that are assigned to centroid k k k
- ∣ C k ∣ |C_k| ∣Ck∣ is the number of examples in the set C k C_k Ck
-
Concretely, if two examples say x ( 3 ) x^{(3)} x(3) and x ( 5 ) x^{(5)} x(5) are assigned to centroid k = 2 k=2 k=2,
then you should update μ 2 = 1 2 ( x ( 3 ) + x ( 5 ) ) \mu_2 = \frac{1}{2}(x^{(3)}+x^{(5)}) μ2=21(x(3)+x(5)).
If you get stuck, you can check out the hints presented after the cell below to help you with the implementation.
# UNQ_C2
# GRADED FUNCTION: compute_centpods
def compute_centroids(X, idx, K):
"""
Returns the new centroids by computing the means of the
data points assigned to each centroid.
Args:
X (ndarray): (m, n) Data points
idx (ndarray): (m,) Array containing index of closest centroid for each
example in X. Concretely, idx[i] contains the index of
the centroid closest to example i
K (int): number of centroids
Returns:
centroids (ndarray): (K, n) New centroids computed
"""
# Useful variables
m, n = X.shape
# You need to return the following variables correctly
centroids = np.zeros((K, n))
### START CODE HERE ###
cnt = np.zeros(K)
for i in range(m):
ci = idx[i]
cnt[ci] += 1
centroids[ci] += X[i]
for k in range(K):
centroids[k] /= cnt[k]
### END CODE HERE ##
return centroids
Now check your implementation by running the cell below
K = 3
centroids = compute_centroids(X, idx, K)
print("The centroids are:", centroids)
# UNIT TEST
compute_centroids_test(compute_centroids)
The centroids are: [[2.42830111 3.15792418]
[5.81350331 2.63365645]
[7.11938687 3.6166844 ]]
All tests passed!
Expected Output:
2.42830111 3.15792418
5.81350331 2.63365645
7.11938687 3.6166844
2 - K-means on a sample dataset
After you have completed the two functions (find_closest_centroids
and compute_centroids) above, the next step is to run the
K-means algorithm on a toy 2D dataset to help you understand how
K-means works.
- We encourage you to take a look at the function (
run_kMeans) below to understand how it works. - Notice that the code calls the two functions you implemented in a loop.
When you run the code below, it will produce a
visualization that steps through the progress of the algorithm at
each iteration.
- At the end, your figure should look like the one displayed in figure 1.
Note: You do not need to implement anything for this part. Simply run the code provided below
# You do not need to implement anything for this part
def run_kMeans(X, initial_centroids, max_iters=10, plot_progress=False):
"""
Runs the K-Means algorithm on data matrix X, where each row of X
is a single example
"""
# Initialize values
m, n = X.shape
K = initial_centroids.shape[0]
centroids = initial_centroids
prevIoUs_centroids = centroids
idx = np.zeros(m)
# Run K-Means
for i in range(max_iters):
#Output progress
print("K-Means iteration %d/%d" % (i, max_iters-1))
# For each example in X, assign it to the closest centroid
idx = find_closest_centroids(X, centroids)
# Optionally plot progress
if plot_progress:
plot_progress_kMeans(X, centroids, prevIoUs_centroids, idx, K, i)
prevIoUs_centroids = centroids
# Given the memberships, compute new centroids
centroids = compute_centroids(X, idx, K)
plt.show()
return centroids, idx
# Load an example dataset
X = load_data()
# Set initial centroids
initial_centroids = np.array([[3,3],[6,2],[8,5]])
K = 3
# Number of iterations
max_iters = 10
centroids, idx = run_kMeans(X, initial_centroids, max_iters, plot_progress=True)
K-Means iteration 0/9
K-Means iteration 1/9
K-Means iteration 2/9
K-Means iteration 3/9
K-Means iteration 4/9
K-Means iteration 5/9
K-Means iteration 6/9
K-Means iteration 7/9
K-Means iteration 8/9
K-Means iteration 9/9

3 - Random initialization
The initial assignments of centroids for the example dataset was designed so that you will see the same figure as in figure 1. In practice, a good strategy for initializing the centroids is to select random examples from the
training set.
In this part of the exercise, you should understand how the function kMeans_init_centroids is implemented.
- The code first randomly shuffles the indices of the examples (using
np.random.permutation()). - Then, it selects the first
K
K
K examples based on the random permutation of the indices.
- This allows the examples to be selected at random without the risk of selecting the same example twice.
Note: You do not need to make implement anything for this part of the exercise.
# You do not need to modify this part
def kMeans_init_centroids(X, K):
"""
This function initializes K centroids that are to be
used in K-Means on the dataset X
Args:
X (ndarray): Data points
K (int): number of centroids/clusters
Returns:
centroids (ndarray): Initialized centroids
"""
# Randomly reorder the indices of examples
randidx = np.random.permutation(X.shape[0])
# Take the first K examples as centroids
centroids = X[randidx[:K]]
return centroids
4 - Image compression with K-means
In this exercise, you will apply K-means to image compression.
- In a straightforward 24-bit color representation of an image 2 ^{2} 2, each pixel is represented as three 8-bit unsigned integers (ranging from 0 to 255) that specify the red, green and blue intensity values. This encoding is often refered to as the RGB encoding.
- Our image contains thousands of colors, and in this part of the exercise, you will reduce the number of
colors to 16 colors. - By making this reduction, it is possible to represent (compress) the photo in an efficient way.
- Specifically, you only need to store the RGB values of the 16 selected colors, and for each pixel in the image you Now need to only store the index of the color at that location (where only 4 bits are necessary to represent 16 possibilities).
In this part, you will use the K-means algorithm to select the 16 colors that will be used to represent the compressed image.
- Concretely, you will treat every pixel in the original image as a data example and use the K-means algorithm to find the 16 colors that best group (cluster) the pixels in the 3- dimensional RGB space.
- Once you have computed the cluster centroids on the image, you will then use the 16 colors to replace the pixels in the original image.
2 ^{2} 2The provided photo used in this exercise belongs to Frank Wouters and is used with his permission.
4.1 Dataset
Load image
First, you will use matplotlib to read in the original image, as shown below.
# Load an image of a bird
original_img = plt.imread('bird_small.png')
Visualize image
You can visualize the image that was just loaded using the code below.
# Visualizing the image
plt.imshow(original_img)
<matplotlib.image.AxesImage at 0x7f4940479100>

Check the dimension of the variable
As always, you will print out the shape of your variable to get more familiar with the data.
print("Shape of original_img is:", original_img.shape)
Shape of original_img is: (128, 128, 3)
As you can see, this creates a three-dimensional matrix original_img where
- the first two indices identify a pixel position, and
- the third index represents red, green, or blue.
For example, original_img[50, 33, 2] gives the blue intensity of the pixel at row 50 and column 33.
Processing data
To call the run_kMeans, you need to first transform the matrix original_img into a two-dimensional matrix.
- The code below reshapes the matrix
original_imgto create an m × 3 m \times 3 m×3 matrix of pixel colors (where
m = 16384 = 128 × 128 m=16384 = 128\times128 m=16384=128×128)
# Divide by 255 so that all values are in the range 0 - 1
original_img = original_img / 255
# Reshape the image into an m x 3 matrix where m = number of pixels
# (in this case m = 128 x 128 = 16384)
# Each row will contain the Red, Green and Blue pixel values
# This gives us our dataset matrix X_img that we will use K-Means on.
X_img = np.reshape(original_img, (original_img.shape[0] * original_img.shape[1], 3))
4.2 K-Means on image pixels
Now, run the cell below to run K-Means on the pre-processed image.
# Run your K-Means algorithm on this data
# You should try different values of K and max_iters here
K = 16
max_iters = 10
# Using the function you have implemented above.
initial_centroids = kMeans_init_centroids(X_img, K)
# Run K-Means - this takes a couple of minutes
centroids, idx = run_kMeans(X_img, initial_centroids, max_iters)
K-Means iteration 0/9
K-Means iteration 1/9
K-Means iteration 2/9
K-Means iteration 3/9
K-Means iteration 4/9
K-Means iteration 5/9
K-Means iteration 6/9
K-Means iteration 7/9
K-Means iteration 8/9
K-Means iteration 9/9
print("Shape of idx:", idx.shape)
print("Closest centroid for the first five elements:", idx[:5])
Shape of idx: (16384,)
Closest centroid for the first five elements: [14 14 14 14 14]
4.3 Compress the image
After finding the top
K
=
16
K=16
K=16 colors to represent the image, you can Now
assign each pixel position to its closest centroid using thefind_closest_centroids function.
- This allows you to represent the original image using the centroid assignments of each pixel.
- Notice that you have significantly reduced the number of bits that are required to describe the image.
- The original image required 24 bits for each one of the 128 × 128 128\times128 128×128 pixel locations, resulting in total size of 128 × 128 × 24 = 393 , 216 128 \times 128 \times 24 = 393,216 128×128×24=393,216 bits.
- The new representation requires some overhead storage in form of a dictionary of 16 colors, each of which require 24 bits, but the image itself then only requires 4 bits per pixel location.
- The final number of bits used is therefore 16 × 24 + 128 × 128 × 4 = 65 , 920 16 \times 24 + 128 \times 128 \times 4 = 65,920 16×24+128×128×4=65,920 bits, which corresponds to compressing the original image by about a factor of 6.
# Represent image in terms of indices
X_recovered = centroids[idx, :]
# Reshape recovered image into proper dimensions
X_recovered = np.reshape(X_recovered, original_img.shape)
Finally, you can view the effects of the compression by reconstructing
the image based only on the centroid assignments.
- Specifically, you can replace each pixel location with the mean of the centroid assigned to
it. - figure 3 shows the reconstruction we obtained. Even though the resulting image retains most of the characteristics of the original, we also see some compression artifacts.
# display original image
fig, ax = plt.subplots(1,2, figsize=(8,8))
plt.axis('off')
ax[0].imshow(original_img*255)
ax[0].set_title('Original')
ax[0].set_axis_off()
# display compressed image
ax[1].imshow(X_recovered*255)
ax[1].set_title('Compressed with %d colours'%K)
ax[1].set_axis_off()


AttributeError: 模块“sklearn.cluster”没有属性“k_means_”
如何解决AttributeError: 模块“sklearn.cluster”没有属性“k_means_”?
我有一个奇怪的错误:
from sklearn.cluster import KMeans
from nose.tools import assert_equal,assert_is_instance,assert_true,assert_is_not
from numpy.testing import assert_array_equal,assert_array_almost_equal,assert_almost_equal
我的数据存储为这样的数组,只是更大:
array([[-2.65602062e+00,-1.38241098e+00,-6.04632297e-01,9.37261785e-01,-8.33086491e-01,-1.61945768e-01,1.54809554e-01,-2.62093027e-02,-2.78241107e-01,-2.42455888e-01]]
我定义了一个函数
def cluster(array,random_state,n_clusters=10):
model = KMeans(n_clusters = n_clusters,init = ''k-means++'',random_state = 0).fit(array)
clusters = model.fit_predict(array)
return model,clusters
但是当我进行单元测试时,这给了我一个错误:
AttributeError Traceback (most recent call last)
<ipython-input-47-d502eebc4ee1> in <module>
1 k_means_t,cluster_t = cluster(reduced,random_state=check_random_state(1),n_clusters=5)
2
----> 3 assert_is_instance(k_means_t,sklearn.cluster.k_means_.KMeans)
4 assert_is_instance(cluster_t,np.ndarray)
5 assert_equal(k_means_t.n_init,10)
AttributeError: module ''sklearn.cluster'' has no attribute ''k_means_''
我的代码以前工作过,不知道后来发生了什么。
我从 kmeans_ 中删除了 assert_is_instance(k_means_t,sklearn.cluster.k_means_.KMeans),错误消失了,但我认为这不是正确的解决方案。
解决方法
暂无找到可以解决该程序问题的有效方法,小编努力寻找整理中!
如果你已经找到好的解决方法,欢迎将解决方案带上本链接一起发送给小编。
小编邮箱:dio#foxmail.com (将#修改为@)

cluster.k-means_._labels_inertia_precompute_dense
def _labels_inertia_precompute_dense(X, x_squared_norms, centers, distances):
"""Compute labels and inertia using a full distance matrix.
This will overwrite the ''distances'' array in-place.
Parameters
----------
X : numpy array, shape (n_sample, n_features)
Input data.
x_squared_norms : numpy array, shape (n_samples,)
Precomputed squared norms of X.
centers : numpy array, shape (n_clusters, n_features)
Cluster centers which data is assigned to.
distances : numpy array, shape (n_samples,)
Pre-allocated array in which distances are stored.
Returns
-------
labels : numpy array, dtype=np.int, shape (n_samples,)
Indices of clusters that samples are assigned to.
inertia : float
Sum of distances of samples to their closest cluster center.
"""
# 样本数
n_samples = X.shape[0]
# 中心点数
k = centers.shape[0]
# 计算样本点到各中心的距离。返回shape(k,n_samples)
all_distances = euclidean_distances(centers, X, x_squared_norms,
squared=True)
# 初始化labels
labels = np.empty(n_samples, dtype=np.int32)
# 赋值-1
labels.fill(-1)
# 初始化mindist,赋值inf。
mindist = np.empty(n_samples)
mindist.fill(np.infty)
# 对每个中心点:
for center_id in range(k):
# 取样本点到该中心点的距离,赋值dist。
dist = all_distances[center_id]
# 距离比历史距离小,则更新其labels为center_id。
labels[dist < mindist] = center_id
# 更新mindist为dist与mindist中较小的一个。
mindist = np.minimum(dist, mindist)
# 检查维度。
if n_samples == distances.shape[0]:
# distances will be changed in-place
# 更新distances
distances[:] = mindist
# 计算inertia。
inertia = mindist.sum()
return labels, inertia函数:euclidean_distances()

k-means cluster images
说明
慕课网上例子,使用 k-means 算法分类图片, 此处调试运行通过, 并添加包管理内容, 使得其他同学容易运行。
例子地址: https://github.com/fanqingsong/cluster-images
运行环境:
python3.7
包管理工具:
pipenv
参考: https://www.cnblogs.com/wuzdandz/p/9545584.html
运行:
pipenv install pipenv run ImageKmean.py
安装运行遇到问题
1、 安装依赖(numpy Pillow)很慢,
使用国内镜像替换:
http://greyli.com/set-custom-pypi-mirror-url-for-pip-pipenv-poetry-and-flit/
如果想对项目全局(per-project)设置,可以修改 Pipfile 中 [[source]] 小节:
[[source]] url = "https://pypi.doubanio.com/simple" verify_ssl = true name = "douban"
如果不用 pipenv, 使用 pip 安装
https://blog.csdn.net/lambert310/article/details/52412059
windows 下,直接在 user 目录中创建一个 pip 目录,如:C:\Users\xx\pip,新建文件 pip.ini,内容如下
[global] index-url = https://pypi.tuna.tsinghua.edu.cn/simple
运行结果
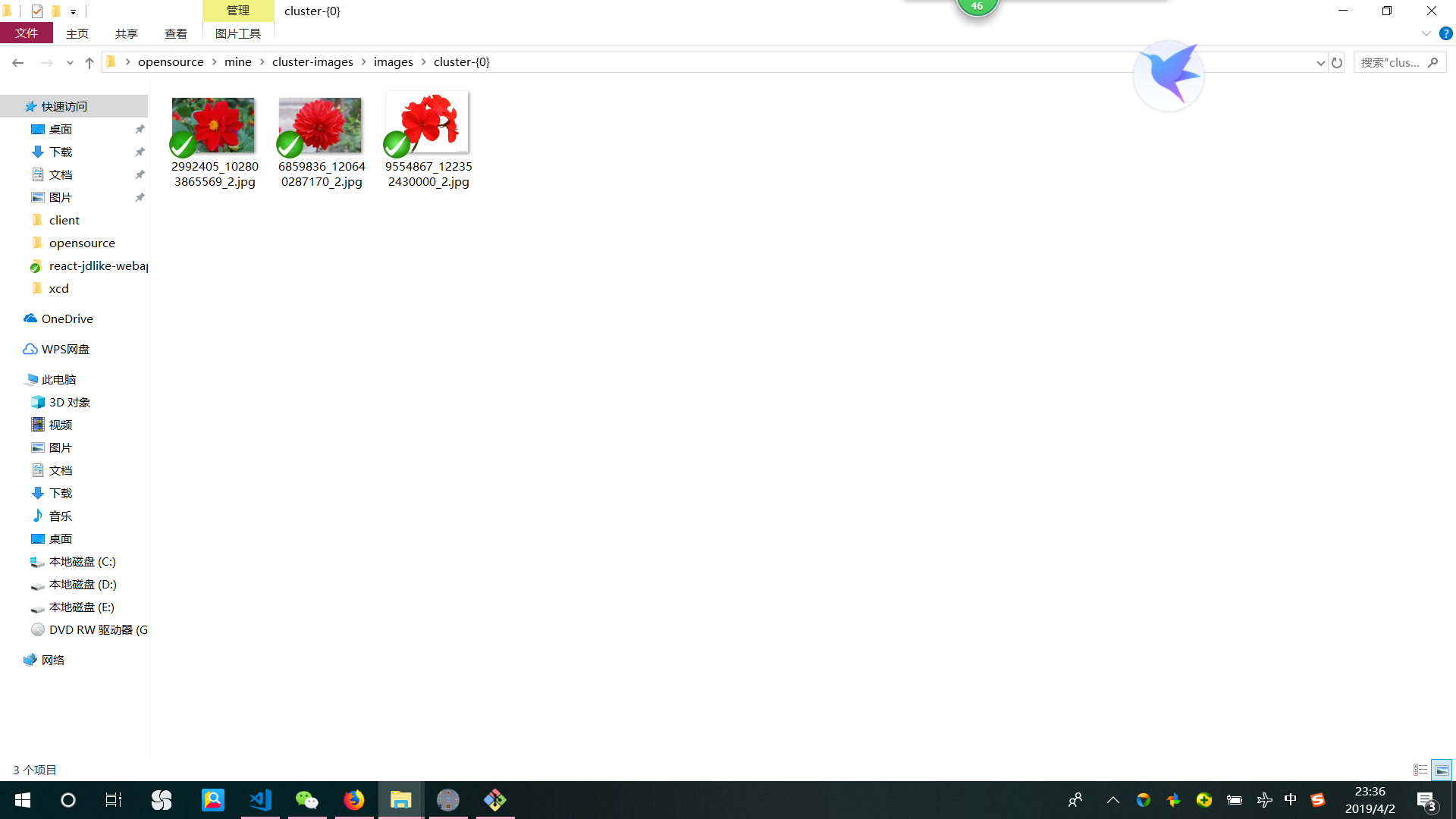
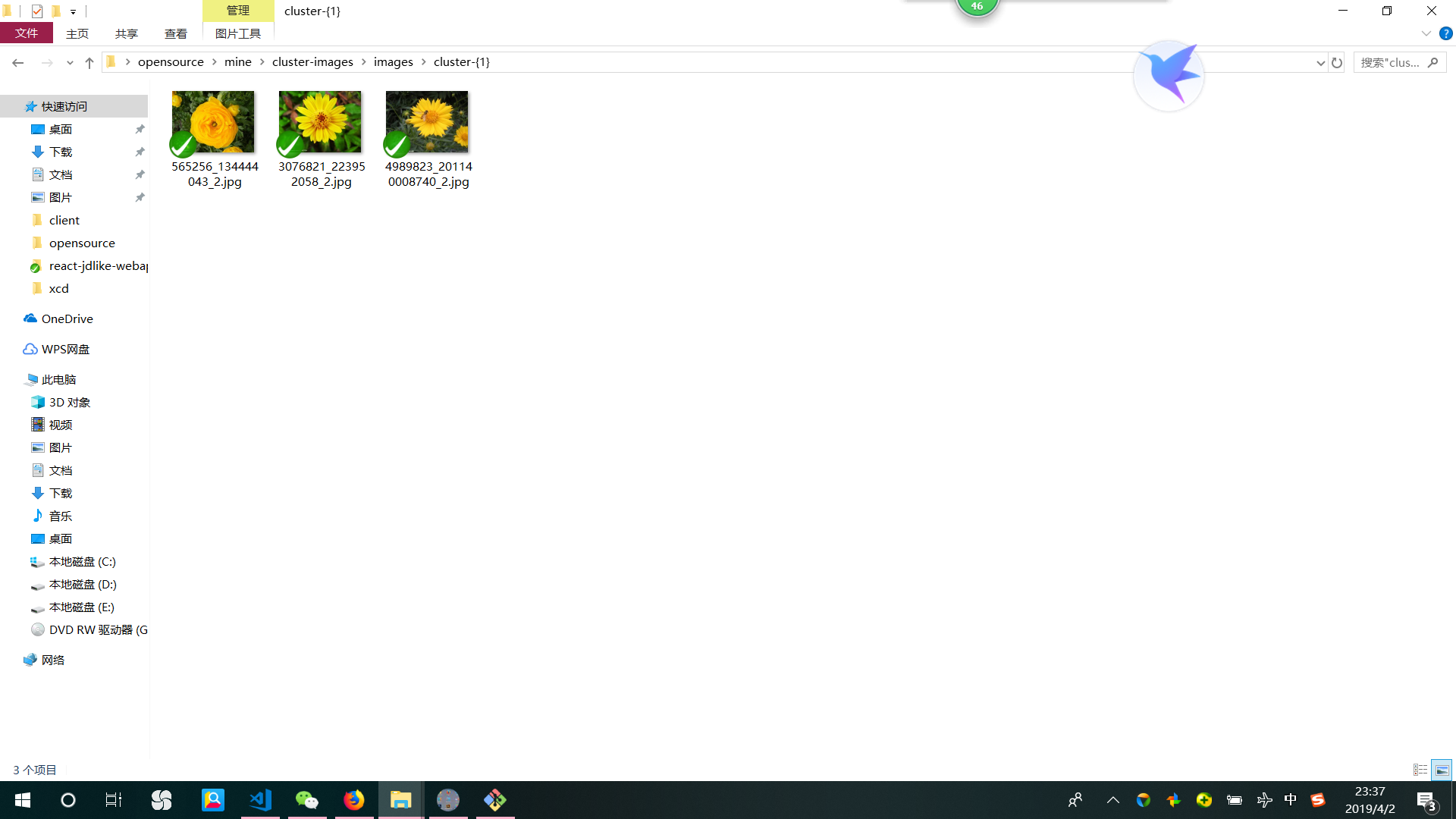
输入为 三张红花 和 三张黄花
聚类输入参数为 2 类
分类结果为 黄花一类 红花一类
类一
类二
运行报错: ModuleNotFoundError: No module named ''PIL''
https://blog.csdn.net/qq_37721412/article/details/79159544
pip install Pillow
Pillow 库
https://pillow.readthedocs.io/en/stable/handbook/overview.html
he Python Imaging Library adds image processing capabilities to your Python interpreter.
This library provides extensive file format support, an efficient internal representation, and fairly powerful image processing capabilities.
The core image library is designed for fast access to data stored in a few basic pixel formats. It should provide a solid foundation for a general image processing tool.
Let’s look at a few possible uses of this library.
参考
https://github.com/jump1003/ImageKmeans
https://scikit-learn.org/stable/auto_examples/index.html#general-examples
关于sklearn KMeans中的KMeans.cluster_centers_的值和sklearn的kmeans算法的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于2022吴恩达机器学习Deeplearning.ai课程编程作业C3_W1: KMeans_Assignment、AttributeError: 模块“sklearn.cluster”没有属性“k_means_”、cluster.k-means_._labels_inertia_precompute_dense、k-means cluster images的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

