关于如何从scikit-learn决策树中提取决策规则?和sklearn决策树规则导出的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Python-如何从scikit-learn决策树中提
关于如何从 scikit-learn 决策树中提取决策规则?和sklearn决策树规则导出的问题就给大家分享到这里,感谢你花时间阅读本站内容,更多关于Python-如何从scikit-learn决策树中提取决策规则?、python在Scikit-learn中用决策树和随机森林预测NBA获胜者、Python在Scikit-Learn可视化随机森林中的决策树分析房价数据、scikit-learn 决策树 分类问题等相关知识的信息别忘了在本站进行查找喔。
本文目录一览:- 如何从 scikit-learn 决策树中提取决策规则?(sklearn决策树规则导出)
- Python-如何从scikit-learn决策树中提取决策规则?
- python在Scikit-learn中用决策树和随机森林预测NBA获胜者
- Python在Scikit-Learn可视化随机森林中的决策树分析房价数据
- scikit-learn 决策树 分类问题
")
如何从 scikit-learn 决策树中提取决策规则?(sklearn决策树规则导出)
我可以从决策树中的训练树中提取基础决策规则(或“决策路径”)作为文本列表吗?
就像是:
if A>0.4 then if B<0.2 then if C>0.8 thenX''答案1
小编典典我相信这个答案比这里的其他答案更正确:
from sklearn.tree import _treedef tree_to_code(tree, feature_names): tree_ = tree.tree_ feature_name = [ feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!" for i in tree_.feature ] print "def tree({}):".format(", ".join(feature_names)) def recurse(node, depth): indent = " " * depth if tree_.feature[node] != _tree.TREE_UNDEFINED: name = feature_name[node] threshold = tree_.threshold[node] print "{}if {} <= {}:".format(indent, name, threshold) recurse(tree_.children_left[node], depth + 1) print "{}else: # if {} > {}".format(indent, name, threshold) recurse(tree_.children_right[node], depth + 1) else: print "{}return {}".format(indent, tree_.value[node]) recurse(0, 1)这将打印出一个有效的 Python 函数。这是一个尝试返回其输入的树的示例输出,一个介于 0 和 10 之间的数字。
def tree(f0): if f0 <= 6.0: if f0 <= 1.5: return [[ 0.]] else: # if f0 > 1.5 if f0 <= 4.5: if f0 <= 3.5: return [[ 3.]] else: # if f0 > 3.5 return [[ 4.]] else: # if f0 > 4.5 return [[ 5.]] else: # if f0 > 6.0 if f0 <= 8.5: if f0 <= 7.5: return [[ 7.]] else: # if f0 > 7.5 return [[ 8.]] else: # if f0 > 8.5 return [[ 9.]]以下是我在其他答案中看到的一些绊脚石:
- 用来
tree_.threshold == -2决定一个节点是否是叶子不是一个好主意。如果它是一个阈值为 -2 的真实决策节点怎么办?相反,您应该查看tree.featureortree.children_*。 - 该行在
features = [feature_names[i] for i in tree_.feature]我的 sklearn 版本中崩溃,因为 的某些值为tree.tree_.feature-2(特别是对于叶节点)。 - 递归函数中不需要有多个 if 语句,一个就可以了。

Python-如何从scikit-learn决策树中提取决策规则?
我可以从决策树中经过训练的树中提取出基本的决策规则(或“决策路径”)作为文本列表吗?
就像是:
if A>0.4 then if B<0.2 then if C>0.8 thenX''谢谢你的帮助。
答案1
小编典典我相信这个答案比这里的其他答案更正确:
from sklearn.tree import _treedef tree_to_code(tree, feature_names): tree_ = tree.tree_ feature_name = [ feature_names[i] if i != _tree.TREE_UNDEFINED else "undefined!" for i in tree_.feature ] print "def tree({}):".format(", ".join(feature_names)) def recurse(node, depth): indent = " " * depth if tree_.feature[node] != _tree.TREE_UNDEFINED: name = feature_name[node] threshold = tree_.threshold[node] print "{}if {} <= {}:".format(indent, name, threshold) recurse(tree_.children_left[node], depth + 1) print "{}else: # if {} > {}".format(indent, name, threshold) recurse(tree_.children_right[node], depth + 1) else: print "{}return {}".format(indent, tree_.value[node]) recurse(0, 1)这会打印出有效的Python函数。这是尝试返回其输入的树的示例输出,该数字介于0到10之间。
def tree(f0): if f0 <= 6.0: if f0 <= 1.5: return [[ 0.]] else: # if f0 > 1.5 if f0 <= 4.5: if f0 <= 3.5: return [[ 3.]] else: # if f0 > 3.5 return [[ 4.]] else: # if f0 > 4.5 return [[ 5.]] else: # if f0 > 6.0 if f0 <= 8.5: if f0 <= 7.5: return [[ 7.]] else: # if f0 > 7.5 return [[ 8.]] else: # if f0 > 8.5 return [[ 9.]]这是我在其他答案中看到的一些绊脚石:
- 使用tree_.threshold == -2来决定一个节点是否为叶是不是一个好主意。如果它是阈值为-2的真实决策节点,该怎么办?相反,你应该查看tree.feature或tree.children_*。
- 该行在features = [feature_names[i] for i in tree_.feature]我的sklearn版本中崩溃,因为某些值tree.tree_.feature是-2(特别是对于叶节点)。
- 递归函数中不需要有多个if语句,只需一个就可以了。

python在Scikit-learn中用决策树和随机森林预测NBA获胜者
原文链接:http://tecdat.cn/?p=5222
原文出处:拓端数据部落公众号

在本文中,我们将以Scikit-learn的决策树和随机森林预测NBA获胜者。美国国家篮球协会(NBA)是北美主要的男子职业篮球联赛,被广泛认为是首屈一指的男子职业篮球联赛在世界上。它有30个队(美国29个,加拿大1个)。
在 常规赛期间,每支球队打82场比赛,每场41场。一支球队每年会有四次面对对手(16场比赛)。每个小组在其四次(24场比赛)中的其他两个小组中的六个小组中进行比赛,其余四个小组三次(12场)进行比赛。最后,每个队都会在另一场比赛中两次参加所有的球队(30场比赛)。
用决策树和随机森林预测NBA获胜者
#导入数据集并解析日期
df = pd.read\_csv("NBA\_regularGames.csv",parse_dates=\["Date"\])从描述中,我们可以计算概率。在每场比赛中,主队和客队都有一半概率赢得比赛。
预测类
在下面的代码中,我们将指定我们的分类。这将帮助我们查看决策树分类的预测是否正确。如果主队获胜,我们将指定我们的等级为1,如果访客队在另一个名为“主队赢”的列中获胜,我们将指定为0。
df\["Home Team Win"\] = df\["Visitor Points"\] < df\["Home Points"\]主队胜率:58.4%
数组现在拥有scikit-learn可以读取的格式。
特征工程
我们将创建以下功能来帮助我们预测NBA的获胜者。
无论是来访者还是主队都赢得了最后一场比赛。
哪个队更好?
scikit-learn软件包实现CART(分类和回归树)算法作为其默认 决策树类
决策树实现提供了一种方法来停止构建树,以防止过度拟合:
•min\_samples\_split:可以创建任意叶子,以便在决策树中创建一个新节点。
•min\_samples\_leaf:保证从节点得到的叶子中的样本数量最少
建议使用min\_samples\_split或min\_samples\_leaf来控制叶节点处的采样数。非常小的数字通常意味着树将过度拟合,而大的数据将阻止树学习。
决策的另一个参数是创建决策的标准。基尼的不纯和信息收益是两种流行的:
•基尼:测量决策节点错误预测样本类别的频率
•信息增益:指示决策节点获得了多少额外信息
函数选择
我们通过指定我们希望使用的列并使用数据框视图的values参数,从数据集中提取要素以与我们的scikit-learn的DecisionTreeClassifier一起使用。我们使用cross\_val\_score函数来测试结果。
X\_features\_only = df \[\[ ''Home Win Streak'' ,''Visitor Win Streak'' ,''Home Team Ranks Higher'' ,''Home Team Won Last'' ,''Home Last Win'' ,''Visitor Last Win'' \]\]结果准确性:56.0%
有可能通过添加更多参数来提高准确性。
混淆矩阵显示了我们决策树的正确和不正确的分类。对角线1,295分别表示主队的真正获胜与否。左下角的1表示假阴性的数量。而右上角的195,误报的数量。我们也可以查看大约0.602的准确性分数,这表明决策树模型已经将60.2%的样本正确地归类为主队获胜与否。
导入pydotplus 图

出于探索的目的,较少数量的变量对获得决策树输出的理解会很有帮助。我们的第一个解释变量,主队获胜概率更高。如果主队排名低于4.5,那么主队输的概率更高。
如有任何问题、意见,请留言咨询

最受欢迎的见解
1.从决策树模型看员工为什么离职
2.R语言基于树的方法:决策树,随机森林
3.python中使用scikit-learn和pandas决策树
4.机器学习:在SAS中运行随机森林数据分析报告
5.R语言用随机森林和文本挖掘提高航空公司客户满意度
6.机器学习助推快时尚精准销售时间序列
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
8.python机器学习:推荐系统实现(以矩阵分解来协同过滤)
9.python中用pytorch机器学习分类预测银行客户流失

Python在Scikit-Learn可视化随机森林中的决策树分析房价数据
原文链接:http://tecdat.cn/?p=27050
随机森林是决策树的集合。在这篇文章中,我将向您展示如何从随机森林中可视化决策树。
首先让我们在房价数据集上训练随机森林模型。
加载数据并训练随机森林。
X = pd.DataFrame(data, columns=feature_names)让我们将森林中的树数设置为 100:
RandomForestRegressor(n_estimators=100)决策树存储在 模型list 中的 estimators_ 属性中 rf 。我们可以检查列表的长度,它应该等于 n_estiamtors 值。
len(estimators_)
>>> 100我们可以从随机森林中绘制第一棵决策树( 0 列表中有索引):
plot\_tree(rf.estimators\_\[0\])
这棵树太大,无法在一个图中将其可视化。
让我们检查随机森林中第一棵树的深度:
tree_.max_depth
>>> 16我们的第一棵树有 max_depth=16. 其他树也有类似的深度。为了使可视化具有可读性,最好限制树的深度。让我们再次训练随机森林 max_depth=3。
第一个决策树的可视化图:
plot\_tree(rf.estimators\_\[0\])
我们可以可视化第一个决策树:
viz
概括
我将向您展示如何可视化随机森林中的单个决策树。可以通过 estimators_ 列表中的整数索引访问树。有时当树太深时,值得用 max_depth 超参数限制树的深度。

最受欢迎的见解
1.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像
2.R语言基于树的方法:决策树,随机森林
3.python中使用scikit-learn和pandas决策树
4.机器学习:在SAS中运行随机森林数据分析报告
5.R语言用随机森林和文本挖掘提高航空公司客户满意度
6.机器学习助推快时尚精准销售时间序列
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用
8.python机器学习:推荐系统实现(以矩阵分解来协同过滤)
9.python中用pytorch机器学习分类预测银行客户流失

scikit-learn 决策树 分类问题
1.Demo
from sklearn import tree
import pydotplus
import numpy as np
#李航p59表数据
#年龄,有工作,有自己房子,信贷情况,类别
#青年0 中年1 老年2
#否0 是1
#一般0 好1 非常好2
datasets = np.array([[''0'', ''0'', ''0'', ''0'', ''0''],
[''0'', ''0'', ''0'', ''1'', ''0''],
[''0'', ''1'', ''0'', ''1'', ''1''],
[''0'', ''1'', ''1'', ''0'', ''1''],
[''0'', ''0'', ''0'', ''0'', ''0''],
[''1'', ''0'', ''0'', ''0'', ''0''],
[''1'', ''0'', ''0'', ''1'', ''0''],
[''1'', ''1'', ''1'', ''1'', ''1''],
[''1'', ''0'', ''1'', ''2'', ''1''],
[''1'', ''0'', ''1'', ''2'', ''1''],
[''2'', ''0'', ''1'', ''2'', ''1''],
[''2'', ''0'', ''1'', ''1'', ''1''],
[''2'', ''1'', ''0'', ''1'', ''1''],
[''2'', ''1'', ''0'', ''2'', ''1''],
[''2'', ''0'', ''0'', ''0'', ''0'']])
X = datasets[:,:4]
Y = datasets[:,4:5]
clf = tree.DecisionTreeClassifier()
clf.fit(X,Y)
dot_data = tree.export_graphviz(clf,out_file=None)
graph = pydotplus.graph_from_dot_data(dot_data)
graph.write_pdf("Tree.pdf")生成的可视化的决策树
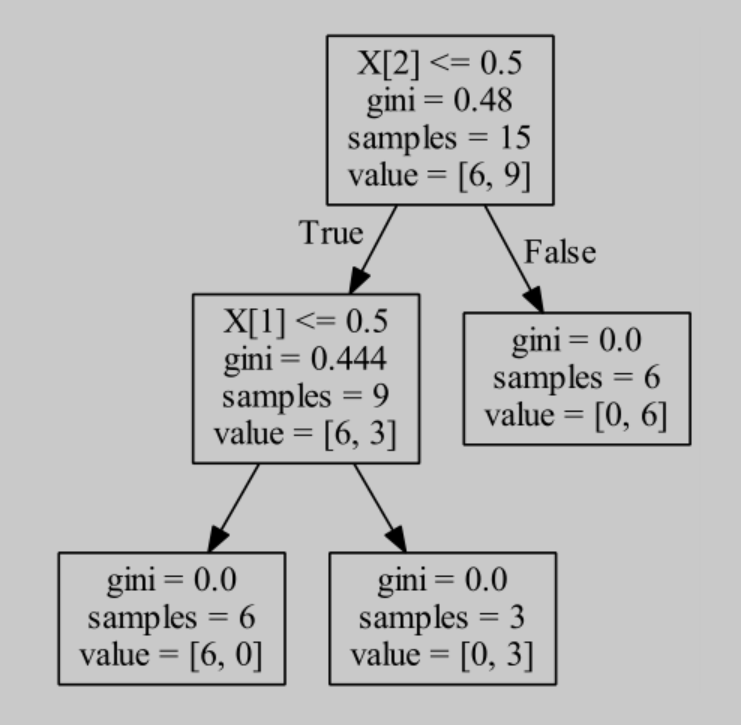
2.DecisionTreeClassifier
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, splitter=’best’, max_depth=None, min_samples_split=2, min_samples_leaf=1, min_weight_fraction_leaf=0.0, max_features=None, random_state=None, max_leaf_nodes=None, min_impurity_decrease=0.0, min_impurity_split=None, class_weight=None, presort=False)
重要参数
criterion : string, optional (default=”gini”)
用来指定特征选择的方法,有"entropy"和"gini"两个选择
entropy指定用信息增益,使用ID3、C4.5算法
gini指定用基尼不纯度,使用CART决策树算法
splitter : string, optional (default=”best”)
用来指定怎么寻找最优划分点,有"best"和"random"两个选择
best指定在所有特征中找最优划分点
random指定在随机部分划分中找最优划分点
默认的"best"适合样本量不大的时候,而如果样本数据量非常大,此时决策树构建推荐"random"
max_depth : int or None, optional (default=None)
用来指定决策树的最大深度
通常将max_depth=3作为初始值,将数据可视化查看下拟合情况,在调整树的深度
通常用来解决过拟合问题
min_samples_split : int, float, optional (default=2)
用来指定子树划分条件
默认是2,当只有一个样本的时候,不在划分子树
当样本数很大时,才会考虑增加这个值
限制决策树增长,避免过拟合
min_samples_leaf : int, float, optional (default=1)
用来指定叶子节点包含的最少样本
当样本数很大时,才会考虑增加这个值
限制决策树增长,避免过拟合
关于如何从 scikit-learn 决策树中提取决策规则?和sklearn决策树规则导出的介绍已经告一段落,感谢您的耐心阅读,如果想了解更多关于Python-如何从scikit-learn决策树中提取决策规则?、python在Scikit-learn中用决策树和随机森林预测NBA获胜者、Python在Scikit-Learn可视化随机森林中的决策树分析房价数据、scikit-learn 决策树 分类问题的相关信息,请在本站寻找。
本文标签:


![[转帖]Ubuntu 安装 Wine方法(ubuntu如何安装wine)](https://www.gvkun.com/zb_users/cache/thumbs/4c83df0e2303284d68480d1b1378581d-180-120-1.jpg)

